Windows
- 09.06.2020
- 84 969
- 6
- 195
- 191
- 4

- Содержание статьи
- Исправляем проблему с кодировкой с помощью смены шрифта
- Исправляем проблему с кодировкой с помощью смены кодировки
- Комментарии к статье ( 6 шт )
- Добавить комментарий
В некоторых случаях, когда используется неверная кодировка, могут возникать так называемые кракозябры или иероглифы, т.е. не читаемые символы, которые невозможно разобрать при работе с командной строкой. Эти проблемы могут также возникать и при запуске различных BAT-файлов. В данной статье мы расскажем о том, как можно сменить шрифт или кодировку, чтобы избавиться от этой проблемы. Пример таких не читаемых символов можно видеть на картинке ниже:
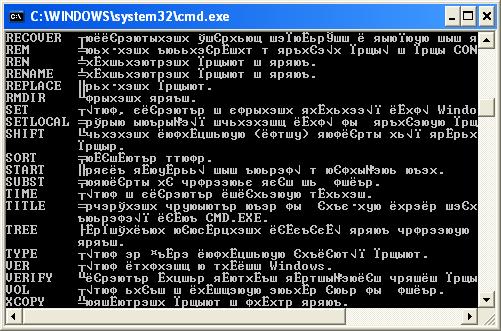
Исправляем проблему с кодировкой с помощью смены шрифта
Первым делом нужно зайти в свойства окна: Правой кнопкой щелкнуть по верхней части окна -> Свойства -> в открывшемся окне в поле Шрифт выбрать Lucida Console и нажать кнопку ОК.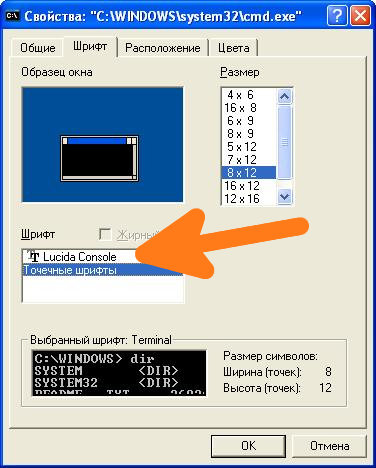
После этого не читаемые символы должны исчезнуть, а текст должен выводиться на русском языке.
Исправляем проблему с кодировкой с помощью смены кодировки
Вместо смены шрифта, можно сменить кодировку, которая используется при работе cmd.exe.
Узнать текущую кодировку можно введя в командной строке команду chcp, после ввода данной команды необходимо нажать Enter.
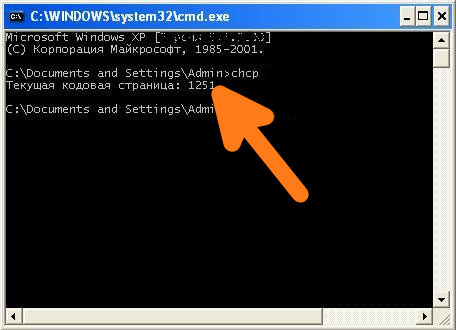
Как видно на скриншоте, текущая используемая кодировка Windows-1251
Для изменения кодировки нам необходимо воспользоваться командой chcp <код_новой_кодировки>, где <код_новой_кодировки> — это сам код кодировки, на которую мы хотим переключиться. Возможные значения:
- 1251 — Windows-кодировка (Кириллица);
- 866 — DOS-кодировка;
- 65001 — Кодировка UTF-8;
Т.е. для смены кодировки на DOS, команда примет следующий вид:
chcp 866Для смены кодировки на UTF-8, команда примет следующий вид:
chcp 65001Для смены кодировки на Windows-1251, команда примет следующий вид:
chcp 1251
Добавил(а) microsin
Иногда по неизвестным причинам некоторые команды русскоязычной версии Windows выводят русский текст в нечитаемой кодировке, кракозябрами.
Например, команда help выводит нормальный текст:

Но при этом подсказка telnet выводит в ответ кракозябры.

Так может происходить, к примеру, если текущая кодировка консоли 866, а утилита telnet.exe почему-то выводит текст в кодировке 1251. Вывести текст в нужной кодировке поможет команда chcp, которая устанавливает нужную кодировку.
Вот так можно посмотреть текущую кодировку консоли:
c:\Documents and Settings\user>chcp Текущая кодовая страница: 866 c:\Documents and Settings\user>
А вот так можно поменять кодировку на 1251, после чего вывод подсказки telnet будет отображаться нормально:
c:\Documents and Settings\user>chcp 1251 Текущая кодовая страница: 1251 c:\Documents and Settings\user>

К сожалению, заранее угадать, в какой кодировке выводится текст, невозможно, поэтому проще попробовать установить командой chcp разные кодировки, чтобы добиться правильного отображения русского текста. Обычно используются кодировки 866 (кодировка русского текста DOS), 1251 (кодировка русского текста Windows), 65001 (UTF-8).
[Шрифт cmd.exe]
Иногда кракозябры можно убрать, если выбрать в свойствах окна cmd.exe шрифт Lucida Console (по умолчанию там стоит «Точечные шрифты»).
[Ссылки]
1. Универсальный декодер — конвертер кириллицы.
Yes, it’s frustrating—sometimes type and other programs
print gibberish, and sometimes they do not.
First of all, Unicode characters will only display if the
current console font contains the characters. So use
a TrueType font like Lucida Console instead of the default Raster Font.
But if the console font doesn’t contain the character you’re trying to display,
you’ll see question marks instead of gibberish. When you get gibberish,
there’s more going on than just font settings.
When programs use standard C-library I/O functions like printf, the
program’s output encoding must match the console’s output encoding, or
you will get gibberish. chcp shows and sets the current codepage. All
output using standard C-library I/O functions is treated as if it is in the
codepage displayed by chcp.
Matching the program’s output encoding with the console’s output encoding
can be accomplished in two different ways:
-
A program can get the console’s current codepage using
chcpor
GetConsoleOutputCP, and configure itself to output in that encoding, or -
You or a program can set the console’s current codepage using
chcpor
SetConsoleOutputCPto match the default output encoding of the program.
However, programs that use Win32 APIs can write UTF-16LE strings directly
to the console with
WriteConsoleW.
This is the only way to get correct output without setting codepages. And
even when using that function, if a string is not in the UTF-16LE encoding
to begin with, a Win32 program must pass the correct codepage to
MultiByteToWideChar.
Also, WriteConsoleW will not work if the program’s output is redirected;
more fiddling is needed in that case.
type works some of the time because it checks the start of each file for
a UTF-16LE Byte Order Mark
(BOM), i.e. the bytes 0xFF 0xFE.
If it finds such a
mark, it displays the Unicode characters in the file using WriteConsoleW
regardless of the current codepage. But when typeing any file without a
UTF-16LE BOM, or for using non-ASCII characters with any command
that doesn’t call WriteConsoleW—you will need to set the
console codepage and program output encoding to match each other.
How can we find this out?
Here’s a test file containing Unicode characters:
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
Here’s a Java program to print out the test file in a bunch of different
Unicode encodings. It could be in any programming language; it only prints
ASCII characters or encoded bytes to stdout.
import java.io.*;
public class Foo {
private static final String BOM = "\ufeff";
private static final String TEST_STRING
= "ASCII abcde xyz\n"
+ "German äöü ÄÖÜ ß\n"
+ "Polish ąęźżńł\n"
+ "Russian абвгдеж эюя\n"
+ "CJK 你好\n";
public static void main(String[] args)
throws Exception
{
String[] encodings = new String[] {
"UTF-8", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE" };
for (String encoding: encodings) {
System.out.println("== " + encoding);
for (boolean writeBom: new Boolean[] {false, true}) {
System.out.println(writeBom ? "= bom" : "= no bom");
String output = (writeBom ? BOM : "") + TEST_STRING;
byte[] bytes = output.getBytes(encoding);
System.out.write(bytes);
FileOutputStream out = new FileOutputStream("uc-test-"
+ encoding + (writeBom ? "-bom.txt" : "-nobom.txt"));
out.write(bytes);
out.close();
}
}
}
}
The output in the default codepage? Total garbage!
Z:\andrew\projects\sx\1259084>chcp
Active code page: 850
Z:\andrew\projects\sx\1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
= bom
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
== UTF-16LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
= bom
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
== UTF-16BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
== UTF-32LE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
== UTF-32BE
= no bom
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
= bom
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
However, what if we type the files that got saved? They contain the exact
same bytes that were printed to the console.
Z:\andrew\projects\sx\1259084>type *.txt
uc-test-UTF-16BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣☺↓☺z☺|☺D☺B
R u s s i a n ♦0♦1♦2♦3♦4♦5♦6 ♦M♦N♦O
C J K O`Y}
uc-test-UTF-16LE-bom.txt
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
uc-test-UTF-16LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
uc-test-UTF-32BE-bom.txt
■ A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32BE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ☺♣ ☺↓ ☺z ☺| ☺D ☺B
R u s s i a n ♦0 ♦1 ♦2 ♦3 ♦4 ♦5 ♦6 ♦M ♦N
♦O
C J K O` Y}
uc-test-UTF-32LE-bom.txt
A S C I I a b c d e x y z
G e r m a n ä ö ü Ä Ö Ü ß
P o l i s h ą ę ź ż ń ł
R u s s i a n а б в г д е ж э ю я
C J K 你 好
uc-test-UTF-32LE-nobom.txt
A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺ ↓☺ z☺ |☺ D☺ B☺
R u s s i a n 0♦ 1♦ 2♦ 3♦ 4♦ 5♦ 6♦ M♦ N
♦ O♦
C J K `O }Y
uc-test-UTF-8-bom.txt
´╗┐ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
uc-test-UTF-8-nobom.txt
ASCII abcde xyz
German ├ñ├Â├╝ ├ä├û├£ ├ƒ
Polish ąęźżńł
Russian ð░ð▒ð▓ð│ð┤ðÁð ÐìÐÄÐÅ
CJK õ¢áÕÑ¢
The only thing that works is UTF-16LE file, with a BOM, printed to the
console via type.
If we use anything other than type to print the file, we get garbage:
Z:\andrew\projects\sx\1259084>copy uc-test-UTF-16LE-bom.txt CON
■A S C I I a b c d e x y z
G e r m a n õ ÷ ³ ─ Í ▄ ▀
P o l i s h ♣☺↓☺z☺|☺D☺B☺
R u s s i a n 0♦1♦2♦3♦4♦5♦6♦ M♦N♦O♦
C J K `O}Y
1 file(s) copied.
From the fact that copy CON does not display Unicode correctly, we can
conclude that the type command has logic to detect a UTF-16LE BOM at the
start of the file, and use special Windows APIs to print it.
We can see this by opening cmd.exe in a debugger when it goes to type
out a file:

After type opens a file, it checks for a BOM of 0xFEFF—i.e., the bytes
0xFF 0xFE in little-endian—and if there is such a BOM, type sets an
internal fOutputUnicode flag. This flag is checked later to decide
whether to call WriteConsoleW.
But that’s the only way to get type to output Unicode, and only for files
that have BOMs and are in UTF-16LE. For all other files, and for programs
that don’t have special code to handle console output, your files will be
interpreted according to the current codepage, and will likely show up as
gibberish.
You can emulate how type outputs Unicode to the console in your own programs like so:
#include <stdio.h>
#define UNICODE
#include <windows.h>
static LPCSTR lpcsTest =
"ASCII abcde xyz\n"
"German äöü ÄÖÜ ß\n"
"Polish ąęźżńł\n"
"Russian абвгдеж эюя\n"
"CJK 你好\n";
int main() {
int n;
wchar_t buf[1024];
HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE);
n = MultiByteToWideChar(CP_UTF8, 0,
lpcsTest, strlen(lpcsTest),
buf, sizeof(buf));
WriteConsole(hConsole, buf, n, &n, NULL);
return 0;
}
This program works for printing Unicode on the Windows console using the
default codepage.
For the sample Java program, we can get a little bit of correct output by
setting the codepage manually, though the output gets messed up in weird ways:
Z:\andrew\projects\sx\1259084>chcp 65001
Active code page: 65001
Z:\andrew\projects\sx\1259084>java Foo
== UTF-8
= no bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
ж эюя
CJK 你好
你好
好
�
= bom
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
еж эюя
CJK 你好
你好
好
�
== UTF-16LE
= no bom
A S C I I a b c d e x y z
…
However, a C program that sets a Unicode UTF-8 codepage:
#include <stdio.h>
#include <windows.h>
int main() {
int c, n;
UINT oldCodePage;
char buf[1024];
oldCodePage = GetConsoleOutputCP();
if (!SetConsoleOutputCP(65001)) {
printf("error\n");
}
freopen("uc-test-UTF-8-nobom.txt", "rb", stdin);
n = fread(buf, sizeof(buf[0]), sizeof(buf), stdin);
fwrite(buf, sizeof(buf[0]), n, stdout);
SetConsoleOutputCP(oldCodePage);
return 0;
}
does have correct output:
Z:\andrew\projects\sx\1259084>.\test
ASCII abcde xyz
German äöü ÄÖÜ ß
Polish ąęźżńł
Russian абвгдеж эюя
CJK 你好
The moral of the story?
typecan print UTF-16LE files with a BOM regardless of your current codepage- Win32 programs can be programmed to output Unicode to the console, using
WriteConsoleW. - Other programs which set the codepage and adjust their output encoding accordingly can print Unicode on the console regardless of what the codepage was when the program started
- For everything else you will have to mess around with
chcp, and will probably still get weird output.

Многие скажут — в PowerShell нет таких проблем как в CMD, юникод поддерживается из коробки!
И будут правы:)
Но мне быстрее и проще что-то простое сделать с помощью batch файла.
Мы используем русский язык в Windows.
Windows же использует несколько кодировок для русского языка:
CP1251 — Windows кодировка
CP866 — используется в консольных приложениях
UTF-8 — Юникод
В консоли CMD по умолчанию используется кодировка CP866.
Поэтому для вывода русского текста в cmd, batch файлах необходимо русский текст перекодировать в CP866 кодировку.
Узнать какая кодировка установлена в консоли позволяет команда chcp:
chcp Текущая кодовая страница: 866
Попробуем вывести текст в кодировке CP1251
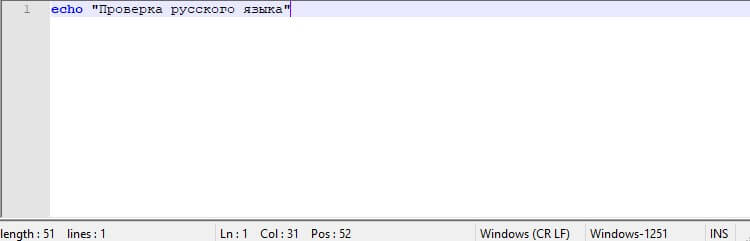
>test.bat C:\Users\vino7>echo "╧ЁютхЁър Ёєёёъюую ч√ър" "╧ЁютхЁър Ёєёёъюую ч√ър"
Изменим кодировку терминала командой:
@echo off chcp 1251 echo "Проверка русского языка"
Выполним скрипт:
test.bat Текущая кодовая страница: 1251 "Проверка русского языка"
Теперь русский выводится правильно.
Варианты установок:
- chcp 1251 — Установить кодировку в CP1251
- chcp 866 — Установить кодировку в CP866
- chcp 65001 — UTF-8
( 1 оценка, среднее 5 из 5 )
Одной из решающих проблем, с которой сталкиваются пользователи Windows, является некорректное отображение символов Unicode в консоли. При попытке работы с текстом на языках, отличных от латиницы, могут возникать непонятные символы и квадратики вместо нужных знаков.
Однако есть способ настроить Windows таким образом, чтобы она корректно отображала символы UTF-8. В этой статье мы рассмотрим несколько шагов, которые помогут вам выполнить эту настройку и наслаждаться полноценной поддержкой Unicode в консоли.
Примечание: Убедитесь, что у вас установлена последняя версия Windows, чтобы иметь доступ ко всем функциям, которые мы рассмотрим далее.
Первым шагом к настройке Windows для работы с UTF-8 в консоли является открытие окна командной строки. Для этого нажмите комбинацию клавиш Win + R, чтобы открыть окно Запуск, и введите «cmd». Нажмите клавишу Enter, и окно командной строки будет открыто.
Содержание
- Основные проблемы UTF-8 в Windows
- Windows и кодировка UTF-8 по умолчанию
- Как узнать кодировку консоли в Windows
- Установка и использование локали UTF-8
- Настройка шрифтов для поддержки UTF-8
Основные проблемы UTF-8 в Windows
При работе с UTF-8 кодировкой в Windows могут возникать некоторые проблемы, связанные с неправильным отображением символов и невозможностью корректной работы с некоторыми программами. Вот основные проблемы, с которыми можно столкнуться при использовании UTF-8 в Windows:
- Неправильное отображение символов. Windows по умолчанию использует кодировку CP1251, поэтому некоторые символы UTF-8 могут отображаться неправильно или как знаки вопроса. Это может стать проблемой при работе с файлами или приложениями, которые ожидают использование другой кодировки.
- Непонимание и несовместимость. Многие старые программы и операционные системы Windows не поддерживают UTF-8 кодировку. Это может привести к проблемам с открытием или сохранением файлов, а также с обработкой строковых данных.
- Проблемы с командной строкой. При работе с консолью Windows могут возникать проблемы с выводом и вводом текста на UTF-8. Кириллические символы могут отображаться неправильно или приводить к ошибкам при выполнении команд.
- Проблемы с поддержкой разных языков. Некоторые языки, такие как китайский или японский, используют большое количество символов, которые не могут быть полностью представлены в UTF-8. Это может привести к проблемам с отображением, поиску или редактированию текста на этих языках.
Все эти проблемы могут быть решены путем правильной настройке Windows для работы с UTF-8. Для этого необходимо изменить параметры системы, установить поддержку нужных кодировок и использовать правильные инструменты для работы с текстом на UTF-8.
Windows и кодировка UTF-8 по умолчанию
Однако в операционной системе Windows по умолчанию используется кодировка ANSI, которая поддерживает только ограниченный набор символов. Это может приводить к проблемам при отображении, редактировании и обработке файлов и текста на других языках.
Чтобы настроить Windows для работы с кодировкой UTF-8 по умолчанию, необходимо выполнить следующие действия:
- Обновите Windows. Убедитесь, что у вас установлена последняя версия операционной системы Windows.
- Измените локальную настройку кодировки. Откройте панель управления, выберите «Язык и регион» и в разделе «Форматы» выберите «Русский (Россия)».
- Настройте кодировку в командной строке. Откройте командную строку (cmd.exe), щелкните правой кнопкой мыши на заголовке окна и выберите «Свойства». В разделе «Шрифт» выберите «Lucida Console» или другой шрифт, который поддерживает UTF-8.
- Настройте кодировку в редакторах текста и IDE. Если вы используете редакторы текста или интегрированные среды разработки (например, Notepad++ или Visual Studio), убедитесь, что они также используют кодировку UTF-8 по умолчанию.
После выполнения этих действий Windows будет использовать кодировку UTF-8 по умолчанию, что позволит вам свободно работать с текстом на разных языках и избежать проблем с отображением символов.
Обратите внимание, что изменение настроек системы может потребовать администраторских прав.
Как узнать кодировку консоли в Windows
Чтобы узнать текущую кодировку консоли в Windows, можно воспользоваться командой chcp в командной строке.
Для этого, откройте командную строку: нажмите Win + R, введите cmd и нажмите Enter.
Далее, введите команду chcp и нажмите Enter.
Команда chcp покажет текущую кодировку консоли в Windows.
Например, если выводится Active code page: 65001, это означает, что текущая кодировка консоли — UTF-8.
Если кодировка не установлена или не совпадает с нужной, можно изменить кодировку с помощью команды chcp с указанием нужного кода страницы.
Например, для изменения кодировки на UTF-8, введите команду chcp 65001 и нажмите Enter.
Теперь вы знаете, как узнать и изменить кодировку консоли в Windows.
Установка и использование локали UTF-8
Для корректной работы с символами Unicode в консоли Windows необходимо установить и использовать локаль UTF-8. Ниже приведены шаги, которые помогут вам настроить вашу систему.
- Откройте «Панель управления» и выберите «Часы и язык».
- В разделе «Регион и язык» выберите «Дополнительные настройки».
- В открывшемся окне выберите вкладку «Административа» и нажмите кнопку «Изменить языковые параметры системы».
- В разделе «Языки для неюникода» нажмите кнопку «Изменить» и выберите опцию «Обновить список языков в виждете».
- В появившемся списке выберите пункт «Русский (Россия)» и нажмите «OK».
- Перезагрузите компьютер для применения изменений.
После перезагрузки ваша система будет работать с локалью UTF-8, что позволит консоли корректно отображать и обрабатывать символы Unicode. Теперь вы можете использовать ваши скрипты и программы, в которых используется UTF-8 кодировка, без проблем.
Настройка шрифтов для поддержки UTF-8
Для работы с UTF-8 символами в консоли Windows необходимо настроить поддержку соответствующих шрифтов. В стандартной установке операционной системы не все шрифты предоставляют поддержку UTF-8.
Чтобы настроить шрифты, необходимо открыть настройки консоли. Для этого нажмите правой кнопкой мыши на панели задач и выберите пункт «Параметры». В открывшемся меню выберите «Свойства».
В окне «Свойства консоли» перейдите на вкладку «Шрифт». Здесь вы увидите список доступных шрифтов для консольного вывода. Найдите шрифт, который поддерживает символы UTF-8, например «Consolas» или «Lucida Console».
Выберите нужный шрифт и установите его размер в соответствии с вашими предпочтениями. Затем нажмите кнопку «OK», чтобы сохранить изменения.
После настройки шрифтов консоль Windows будет правильно отображать символы UTF-8. Теперь вы можете работать с файлами или программами, использующими эту кодировку, без проблем с отображением.
Обратите внимание, что изменение шрифтов в настройках консоли не влияет на все приложения и программы в операционной системе. Некоторые программы могут иметь собственные настройки шрифтов или будут использовать шрифты по умолчанию, установленные в системе.