You can use tr to convert from DOS to Unix; however, you can only do this safely if CR appears in your file only as the first byte of a CRLF byte pair. This is usually the case. You then use:
tr -d '\015' <DOS-file >UNIX-file
Note that the name DOS-file is different from the name UNIX-file; if you try to use the same name twice, you will end up with no data in the file.
You can’t do it the other way round (with standard ‘tr’).
If you know how to enter carriage return into a script (control-V, control-M to enter control-M), then:
sed 's/^M$//' # DOS to Unix
sed 's/$/^M/' # Unix to DOS
where the ‘^M’ is the control-M character. You can also use the bash ANSI-C Quoting mechanism to specify the carriage return:
sed $'s/\r$//' # DOS to Unix
sed $'s/$/\r/' # Unix to DOS
However, if you’re going to have to do this very often (more than once, roughly speaking), it is far more sensible to install the conversion programs (e.g. dos2unix and unix2dos, or perhaps dtou and utod) and use them.
If you need to process entire directories and subdirectories, you can use zip:
zip -r -ll zipfile.zip somedir/
unzip zipfile.zip
This will create a zip archive with line endings changed from CRLF to CR. unzip will then put the converted files back in place (and ask you file by file — you can answer: Yes-to-all). Credits to @vmsnomad for pointing this out.
I’m a Java developer and I’m using Ubuntu to develop. The project was created in Windows with Eclipse and it’s using the Windows-1252 encoding.
To convert to UTF-8 I’ve used the recode program:
find Web -iname \*.java | xargs recode CP1252...UTF-8
This command gives this error:
recode: Web/src/br/cits/projeto/geral/presentation/GravacaoMessageHelper.java failed: Ambiguous output in step `CR-LF..data
I’ve searched about it and get the solution in Bash and Windows, Recode: Ambiguous output in step `data..CR-LF’ and it says:
Convert line endings from CR/LF to a
single LF: Edit the file with Vim,
give the command:set ff=unixand save
the file. Recode now should run
without errors.
Nice, but I’ve many files to remove the CR/LF character from, and I can’t open each to do it. Vi doesn’t provide any option to command line for Bash operations.
Can sed be used to do this? How?
![]()
asked Oct 8, 2010 at 13:37
![]()
4
There should be a program called dos2unix that will fix line endings for you. If it’s not already on your Linux box, it should be available via the package manager.
![]()
Tomas
57.7k49 gold badges239 silver badges373 bronze badges
answered Oct 8, 2010 at 13:40
![]()
cHaocHao
85.1k20 gold badges145 silver badges172 bronze badges
6
sed cannot match \n because the trailing newline is removed before the line is put into the pattern space, but it can match \r, so you can convert \r\n (DOS) to \n (Unix) by removing \r:
sed -i 's/\r//g' file
Warning: this will change the original file
However, you cannot change from Unix EOL to DOS or old Mac (\r) by this. More readings here:
How can I replace a newline (\n) using sed?
![]()
answered Oct 9, 2013 at 21:51
![]()
JichaoJichao
1,7531 gold badge14 silver badges11 bronze badges
4
Actually, Vim does allow what you’re looking for. Enter Vim, and type the following commands:
:args **/*.java
:argdo set ff=unix | update | next
The first of these commands sets the argument list to every file matching **/*.java, which is all Java files, recursively. The second of these commands does the following to each file in the argument list, in turn:
- Sets the line-endings to Unix style (you already know this)
- Writes the file out iff it’s been changed
- Proceeds to the next file
![]()
answered Aug 19, 2014 at 13:59
![]()
ArandurArandur
7276 silver badges19 bronze badges
2
I’ll take a little exception to jichao’s answer. You can actually do everything he just talked about fairly easily. Instead of looking for a \n, just look for carriage return at the end of the line.
sed -i 's/\r$//' "${FILE_NAME}"
To change from Unix back to DOS, simply look for the last character on the line and add a form feed to it. (I’ll add -r to make this easier with grep regular expressions.)
sed -ri 's/(.)$/\1\r/' "${FILE_NAME}"
Theoretically, the file could be changed to Mac style by adding code to the last example that also appends the next line of input to the first line until all lines have been processed. I won’t try to make that example here, though.
Warning: -i changes the actual file. If you want a backup to be made, add a string of characters after -i. This will move the existing file to a file with the same name with your characters added to the end.
Update: The Unix to DOS conversion can be simplified and made more efficient by not bothering to look for the last character. This also allows us to not require using -r for it to work:
sed -i 's/$/\r/' "${FILE_NAME}"
answered May 26, 2017 at 20:51
![]()
5
The tr command can also do this:
tr -d '\15\32' < winfile.txt > unixfile.txt
and should be available to you.
You’ll need to run tr from within a script, since it cannot work with file names. For example, create a file myscript.sh:
#!/bin/bash
for f in `find -iname \*.java`; do
echo "$f"
tr -d '\15\32' < "$f" > "$f.tr"
mv "$f.tr" "$f"
recode CP1252...UTF-8 "$f"
done
Running myscript.sh would process all the java files in the current directory and its subdirectories.
![]()
tripleee
176k34 gold badges275 silver badges318 bronze badges
answered Oct 8, 2010 at 13:44
![]()
KeithLKeithL
1,15010 silver badges12 bronze badges
3
In order to overcome
Ambiguous output in step `CR-LF..data'
the simple solution might be to add the -f flag to force the conversion.
answered May 16, 2012 at 13:29
![]()
V_VV_V
6129 silver badges23 bronze badges
1
Try the Python script by Bryan Maupin found here (I’ve modified it a little bit to be more generic):
#!/usr/bin/env python
import sys
input_file_name = sys.argv[1]
output_file_name = sys.argv[2]
input_file = open(input_file_name)
output_file = open(output_file_name, 'w')
line_number = 0
for input_line in input_file:
line_number += 1
try: # first try to decode it using cp1252 (Windows, Western Europe)
output_line = input_line.decode('cp1252').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):\t%s\n' % (line_number, error)) # write to stderr
try: # then if that fails, try to decode using latin1 (ISO 8859-1)
output_line = input_line.decode('latin1').encode('utf8')
except UnicodeDecodeError, error: # if there's an error
sys.stderr.write('ERROR (line %s):\t%s\n' % (line_number, error)) # write to stderr
sys.exit(1) # and just keep going
output_file.write(output_line)
input_file.close()
output_file.close()
You can use that script with
$ ./cp1252_utf8.py file_cp1252.sql file_utf8.sql
![]()
answered Dec 8, 2010 at 15:49
![]()
Anthony O.Anthony O.
22.3k18 gold badges108 silver badges163 bronze badges
Go back to Windows, tell Eclipse to change the encoding to UTF-8, then back to Unix and run d2u on the files.
answered Oct 8, 2010 at 14:10
![]()
JonathanJonathan
13.4k4 gold badges36 silver badges33 bronze badges
3
Иногда бывает такая ситуация – получаешь от заказчика движок для его дальнейшего «допиливания». Пытаешься положить его в репозиторий Git – и получаешь кучу варнингов типа:
LF will be replaced by CRLF in index.php
Это понятно — файлы в исходнике писались/правились до меня разными людьми и на разных операционных системах. Поэтому в файлах наблюдается полная мешанина в вопросе формата окончания строк.
Небольшая справка для тех, кто не в курсе. В разных операционных системах принят разный формат символов, обозначающий перевод строк:
- Windows — \r\n или CRLF (код 0D0A)
- Unix — \n или LF (код 0A)
- Mac — \r или CR (код 0D).
Такую разносортицу в своем проекте мне держать не хочется, поэтому я предпочитаю перед началом работ приводить все окончания строк к единому виду — \n, он же LF. Почему так? Большинство серверов работают под управлением систем на базе Unix, поэтому, на мой взгляд, логично использовать nix’овые окончания строк и для файлов движка сайта.
Теперь опишу свой способ приведения конца строк к единому виду. Описывать работу буду на примере графической оболочки Git – Git GUI. Так проще и нагляднее.
- Кладу все файлы движка в папку – например, Original.
- Удаляю всякие временные файлы и прочий мусор.
- В пустые папки, которые тем не менее необходимы для работы сайта, кладу файл readme.txt. Это надо по той причине, что Git отслеживает только файлы, а не папки. Поэтому если закоммитить в Git движок с пустыми папками, то потом при выгрузке движка этих пустых, но нужных папок мы не увидим.
- Открываю пункт меню «Редактировать» -> «Настройки» и указываю имя пользователя, email и кодировку файлов проекта.
- В файлах настроек Git – gitconfig — для параметра core прописываю:
- autocrlf = input
- safecrlf = warn
- $ git config —global core.autocrlf input
- $ git config —global core.safecrlf warn
- Теперь записываю все файлы движка в репозиторий. В итоге в репозитории все файлы будут иметь концы строк LF или CR (т.к. Git сконвертировал только CRLF в LF, преобразование CR->LF от не выполняет).
- Запускаю Git GUI, выбираю «Склонировать существующий репозиторий».
- В строке «Исходное положение» указываю папку Original.
- В строке «Каталог назначения» указываю полный пусть к папке, в которую я хочу скопировать репозиторий из папки Original. В данном случае я указал папку Target. Важно: папки с таким именем на диске быть не должно. Git GUI создаст ее сам.
- Выбираю «Полная копия».
- Жму «Склонировать».
или выполнить команды:
Первый параметр дает команду Git заменить все окончания строк с CRLF в LF при записи в репозиторий.
Второй – выдает предупреждения о конвертации специфических бинарников, если вдруг такие окажутся в движке.
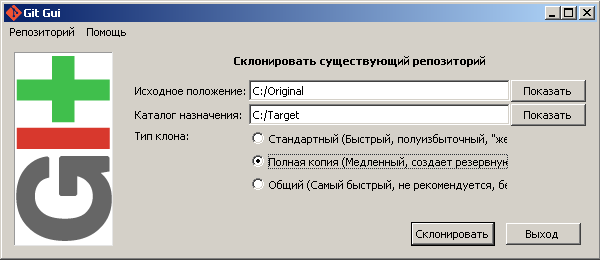
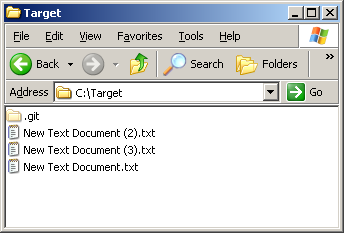
- В результате этой манипуляции у нас на диске C появилась папка Target, в которой лежат файлы из репозитория папки Original. Т.е. в папке Target все концы строк приведены к формату LF или CR.
- Заходим в папку Target, видим в ней папку .git – удаляем эту папку.
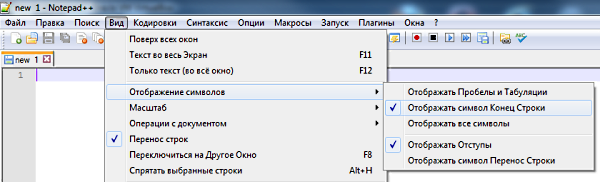
- Открываем редактор Notepad++, выбираем пункт меню «Вид» -> «Отображение символов» -> отмечаем «Отображать символ Конец строки». Теперь редактор будет нам показывать символы конца строк.
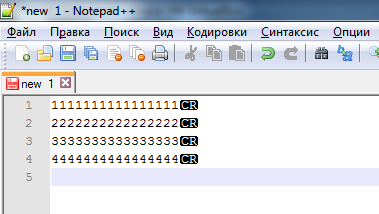
- Выбираем пункт меню «Поиск» -> «Искать в файлах». В настройках поиска выбираем:
- Режим поиска – Расширенный
- Папка – C:\Target
- Найти — \r
Жмем «Найти все»

- В итоге мы найдем все файлы, которые имеют концы строк в формате Mac, т.е.\r или CR. Вряд ли их будет много, но иногда встречаются. Открываем каждый файл по очереди в том же редакторе Notepad++. Мы сможем визуально увидеть, что у файла концы строк в формате Mac:
- Преобразуем его в Unix формат. Выбираем «Правка» -> «Формат Конца Строк» -> «Преобразовать в UNIX-формат»
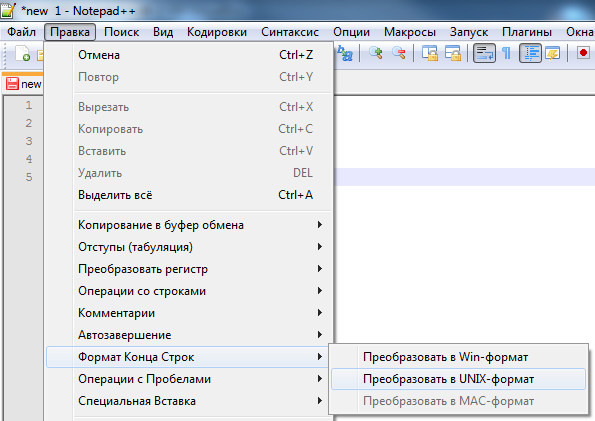
- В итоге файл преобразуется в UNIX-формат.
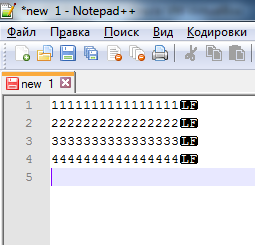
- Сохраняем файл и выполняем аналогичное преобразование для всех оставшихся файлов в формате Mac. В итоге в папке Target мы будем иметь движок, все файлы которого будут иметь конец строк Unix-формата LF.
Теперь движок можно класть в репозиторий Git. И не забудьте в редакторе, которым выпотом будете править файлы, выставить по умолчанию концовку строк LF, чтобы опять не возникла мешанина.
DOS/Windows newline(CRLF) and Unix format(LF)
The term CRLF refers to Carriage Return (ASCII 13, \r) Line Feed(ASCII 10, \n).
They’re used to note the termination of a line, however, dealt with differently in today’s popular Operation Systems.
For example: in Windows, both a CR and LF are required to note the end of a line, whereas in Linux/UNIX a LF is only required.
In the HTTP protocol, the CR-LF sequence is always used to terminate a line.
See CRLF Injection
sed command
SED command in UNIX stands for stream editor and it can perform lots of functions on file, like searching, find and replace, insertion or deletion.
Given that the conversion programs unix2dos and dos2unix are not available to every system, using sed might be a good idea.
- Replace or substitute string:
The most common use is for substitute or find and replace. The commands below replace “cat” with “dog” in the pet.txt:
$ sed 's/cat/dog/' pet.txt
$ sed -i 's/cat/dog/' pet.txt # replace the original file, "-i" option means edit files in place.
Here the “s” specifies substitute, there are some useful flags for this operation:
$ sed 's/cat/dog/2' # replace second pattern
$ sed 's/cat/dog/g' # apply the replacement to all matches to the regexp, not just the first.
$ sed 's/cat/dog/i' # case-insensitive
Replace newline
If you know how to enter the carriage return character in bash(Ctrl-V then Ctrl-M):
$ sed 's/^M$//g' # CRLF to LF
$ sed 's/$/^M/g' # LF to CRLF
Notice that “^M” represents a carriage return character, is not just “^” + character “M”.
$ sed 's/.$//g' # CRLF to LF, assumes that all lines end with CRLF
$ sed 's/$/\r/g' # LF to CRLF
Reference
- CRLF Injection
- Linux sed command
How can I programmatically (i.e., not using vi) convert DOS/Windows newlines to Unix?
The dos2unix and unix2dos commands are not available on certain systems. How can I emulate these with commands like sed/awk/tr?
This question is related to
linux
windows
bash
unix
newline
You can use tr to convert from DOS to Unix; however, you can only do this safely if CR appears in your file only as the first byte of a CRLF byte pair. This is usually the case. You then use:
tr -d '\015' <DOS-file >UNIX-file
Note that the name DOS-file is different from the name UNIX-file; if you try to use the same name twice, you will end up with no data in the file.
You can’t do it the other way round (with standard ‘tr’).
If you know how to enter carriage return into a script (control-V, control-M to enter control-M), then:
sed 's/^M$//' # DOS to Unix
sed 's/$/^M/' # Unix to DOS
where the ‘^M’ is the control-M character. You can also use the bash ANSI-C Quoting mechanism to specify the carriage return:
sed $'s/\r$//' # DOS to Unix
sed $'s/$/\r/' # Unix to DOS
However, if you’re going to have to do this very often (more than once, roughly speaking), it is far more sensible to install the conversion programs (e.g. dos2unix and unix2dos, or perhaps dtou and utod) and use them.
If you need to process entire directories and subdirectories, you can use zip:
zip -r -ll zipfile.zip somedir/
unzip zipfile.zip
This will create a zip archive with line endings changed from CRLF to CR. unzip will then put the converted files back in place (and ask you file by file — you can answer: Yes-to-all). Credits to @vmsnomad for pointing this out.
tr -d "\r" < file
take a look here for examples using sed:
# IN UNIX ENVIRONMENT: convert DOS newlines (CR/LF) to Unix format.
sed 's/.$//' # assumes that all lines end with CR/LF
sed 's/^M$//' # in bash/tcsh, press Ctrl-V then Ctrl-M
sed 's/\x0D$//' # works on ssed, gsed 3.02.80 or higher
# IN UNIX ENVIRONMENT: convert Unix newlines (LF) to DOS format.
sed "s/$/`echo -e \\\r`/" # command line under ksh
sed 's/$'"/`echo \\\r`/" # command line under bash
sed "s/$/`echo \\\r`/" # command line under zsh
sed 's/$/\r/' # gsed 3.02.80 or higher
Use sed -i for in-place conversion e.g. sed -i 's/..../' file.
You can use vim programmatically with the option -c {command} :
Dos to Unix:
vim file.txt -c "set ff=unix" -c ":wq"
Unix to dos:
vim file.txt -c "set ff=dos" -c ":wq"
«set ff=unix/dos» means change fileformat (ff) of the file to Unix/DOS end of line format
«:wq» means write file to disk and quit the editor (allowing to use the command in a loop)
Doing this with POSIX is tricky:
-
POSIX Sed does not support
\ror\15. Even if it did, the in place
option-iis not POSIX -
POSIX Awk does support
\rand\15, however the-i inplaceoption
is not POSIX -
d2u and dos2unix are not POSIX utilities, but ex is
-
POSIX ex does not support
\r,\15,\nor\12
To remove carriage returns:
ex -bsc '%!awk "{sub(/\r/,\"\")}1"' -cx file
To add carriage returns:
ex -bsc '%!awk "{sub(/$/,\"\r\")}1"' -cx file
Just install dos2unix then to convert a file in place use
dos2unix <filename>
To output converted text to a different file use
dos2unix -n <input-file> <output-file>
You can install it on Ubuntu or Debian with
sudo apt install dos2unix
or on macOS using homebrew
brew install dos2unix
Using AWK you can do:
awk '{ sub("\r$", ""); print }' dos.txt > unix.txt
Using Perl you can do:
perl -pe 's/\r$//' < dos.txt > unix.txt
This problem can be solved with standard tools, but there are sufficiently many traps for the unwary that I recommend you install the flip command, which was written over 20 years ago by Rahul Dhesi, the author of zoo.
It does an excellent job converting file formats while, for example, avoiding the inadvertant destruction of binary files, which is a little too easy if you just race around altering every CRLF you see…
If you don’t have access to dos2unix, but can read this page, then you can copy/paste dos2unix.py from here.
#!/usr/bin/env python
"""\
convert dos linefeeds (crlf) to unix (lf)
usage: dos2unix.py <input> <output>
"""
import sys
if len(sys.argv[1:]) != 2:
sys.exit(__doc__)
content = ''
outsize = 0
with open(sys.argv[1], 'rb') as infile:
content = infile.read()
with open(sys.argv[2], 'wb') as output:
for line in content.splitlines():
outsize += len(line) + 1
output.write(line + '\n')
print("Done. Saved %s bytes." % (len(content)-outsize))
Cross-posted from superuser.
The solutions posted so far only deal with part of the problem, converting DOS/Windows’ CRLF into Unix’s LF; the part they’re missing is that DOS use CRLF as a line separator, while Unix uses LF as a line terminator. The difference is that a DOS file (usually) won’t have anything after the last line in the file, while Unix will. To do the conversion properly, you need to add that final LF (unless the file is zero-length, i.e. has no lines in it at all). My favorite incantation for this (with a little added logic to handle Mac-style CR-separated files, and not molest files that’re already in unix format) is a bit of perl:
perl -pe 'if ( s/\r\n?/\n/g ) { $f=1 }; if ( $f || ! $m ) { s/([^\n])\z/$1\n/ }; $m=1' PCfile.txt
Note that this sends the Unixified version of the file to stdout. If you want to replace the file with a Unixified version, add perl’s -i flag.
Super duper easy with PCRE;
As a script, or replace $@ with your files.
#!/usr/bin/env bash
perl -pi -e 's/\r\n/\n/g' -- $@
This will overwrite your files in place!
I recommend only doing this with a backup (version control or otherwise)
An even simpler awk solution w/o a program:
awk -v ORS='\r\n' '1' unix.txt > dos.txt
Technically ‘1’ is your program, b/c awk requires one when given option.
UPDATE:
After revisiting this page for the first time in a long time I realized that no one has yet posted an internal solution, so here is one:
while IFS= read -r line;
do printf '%s\n' "${line%$'\r'}";
done < dos.txt > unix.txt
interestingly in my git-bash on windows sed "" did the trick already:
$ echo -e "abc\r" >tst.txt
$ file tst.txt
tst.txt: ASCII text, with CRLF line terminators
$ sed -i "" tst.txt
$ file tst.txt
tst.txt: ASCII text
My guess is that sed ignores them when reading lines from input and always writes unix line endings on output.
Had just to ponder that same question (on Windows-side, but equally applicable to linux.)
Suprisingly nobody mentioned a very much automated way of doing CRLF<->LF conversion for text-files using good old zip -ll option (Info-ZIP):
zip -ll textfiles-lf.zip files-with-crlf-eol.*
unzip textfiles-lf.zip
NOTE: this would create a zip file preserving the original file names but converting the line endings to LF. Then unzip would extract the files as zip’ed, that is with their original names (but with LF-endings), thus prompting to overwrite the local original files if any.
Relevant excerpt from the zip --help:
zip --help
...
-l convert LF to CR LF (-ll CR LF to LF)
This worked for me
tr "\r" "\n" < sampledata.csv > sampledata2.csv
sed --expression='s/\r\n/\n/g'
Since the question mentions sed, this is the most straight forward way to use sed to achieve this. What the expression says is replace all carriage-return and line-feed with just line-feed only. That is what you need when you go from Windows to Unix. I verified it works.
On Linux it’s easy to convert ^M (ctrl-M) to *nix newlines (^J) with sed.
It will something like this on the CLI, there will actually be a line break in the text. However, the \ passes that ^J along to sed:
sed 's/^M/\
/g' < ffmpeg.log > new.log
You get this by using ^V (ctrl-V), ^M (ctrl-M) and \ (backslash) as you type:
sed 's/^V^M/\^V^J/g' < ffmpeg.log > new.log
TIMTOWTDI!
perl -pe 's/\r\n/\n/; s/([^\n])\z/$1\n/ if eof' PCfile.txt
Based on @GordonDavisson
One must consider the possibility of [noeol] …
You can use awk. Set the record separator (RS) to a regexp that matches all possible newline character, or characters. And set the output record separator (ORS) to the unix-style newline character.
awk 'BEGIN{RS="\r|\n|\r\n|\n\r";ORS="\n"}{print}' windows_or_macos.txt > unix.txt
For Mac osx if you have homebrew installed [http://brew.sh/][1]
brew install dos2unix
for csv in *.csv; do dos2unix -c mac ${csv}; done;
Make sure you have made copies of the files, as this command will modify the files in place.
The -c mac option makes the switch to be compatible with osx.
With bash 4.2 and newer you can use something like this to strip the trailing CR, which only uses bash built-ins:
if [[ "${str: -1}" == $'\r' ]]; then
str="${str:: -1}"
fi
As an extension to Jonathan Leffler’s Unix to DOS solution, to safely convert to DOS when you’re unsure of the file’s current line endings:
sed '/^M$/! s/$/^M/'
This checks that the line does not already end in CRLF before converting to CRLF.
I made a script based on the accepted answer so you can convert it directly without needing an additional file in the end and removing and renaming afterwards.
convert-crlf-to-lf() {
file="$1"
tr -d '\015' <"$file" >"$file"2
rm -rf "$file"
mv "$file"2 "$file"
}
just make sure if you have a file like «file1.txt» that «file1.txt2» doesn’t already exist or it will be overwritten, I use this as a temporary place to store the file in.