I’m trying to work out how to convert a file to UTF-8, but I really can’t find much useful info on google other than to use iconv. I downloaded that, but when I ran it via the CLI it told me that I hadn’t installed it properly. The file I’m trying to handle is a rather large file (5M lines).
![]()
asked May 30, 2011 at 15:13
![]()
Notepad++ provides an easy (manual) way to do it. Open your file, choose «Encoding > Convert to UTF-8», and save. I think the size limit is 2 GB.
answered May 30, 2011 at 15:41
![]()
user775598user775598
4263 silver badges5 bronze badges
6
Well, you can just use iconv. You can for example download a Setup.exe from GnuWin32, that should just work (TM).
Also see the question Batch-convert files for encoding or line ending which describes how to convert using the command line on Windows.
![]()
answered May 30, 2011 at 15:38
![]()
sleskesleske
22.7k10 gold badges70 silver badges93 bronze badges
3
One option is to download Cygwin. Cygwin lets you use the Linux command line from within Windows. One advantage of using Cygwin is you don’t have to worry about adding a program to the PATH as you would if you used the Windows command line. So download Cygwin and be sure to search for and select the iconv tool in your download. Then you can follow the example at this StackOverflow question. For instance it says,
iconv -f UTF-8 -t ISO-8859-15 in.txt > out.txt
where UTF-8 is the starting encoding of in.txt and ISO-8859-15 is the output you’d like out.txt to be.
answered May 22, 2017 at 13:56
![]()
0
You must log in to answer this question.
Not the answer you’re looking for? Browse other questions tagged
.
Not the answer you’re looking for? Browse other questions tagged
.
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
-
Общие сведения о кодировке текста
-
Выбор кодировки при открытии файла
-
Выбор кодировки при сохранении файла
-
Поиск кодировок, доступных в Word
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
К началу страницы
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
-
Откройте вкладку Файл.
-
Нажмите кнопку Параметры.
-
Нажмите кнопку Дополнительно.
-
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
-
Закройте, а затем снова откройте файл.
-
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
-
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
-
Нажмите кнопку Пуск и выберите пункт Панель управления.
-
Выполните одно из указанных ниже действий.
В Windows 7
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
-
На панели управления щелкните элемент Установка и удаление программ.
-
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
-
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
-
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
-
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
К началу страницы
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
-
Откройте вкладку Файл.
-
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
-
В поле Имя файла введите имя нового файла.
-
В поле Тип файла выберите Обычный текст.
-
Нажмите кнопку Сохранить.
-
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
-
В диалоговом окне Преобразование файла выберите подходящую кодировку.
-
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
-
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
-
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
-
-
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
-
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
К началу страницы
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
Courier New |
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
SimSun |
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
MingLiU |
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
Courier New |
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
Courier New |
|
Греческая |
Windows 1253 |
Courier New |
|
Иврит |
Windows 1255 |
Courier New |
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
MS Mincho |
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
Malgun Gothic |
|
Тайская |
Windows 874 |
Tahoma |
|
Вьетнамская |
Windows 1258 |
Courier New |
|
Индийские: тамильская |
ISCII 57004 |
Latha |
|
Индийские: непальская |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: конкани |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: хинди |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: ассамская |
ISCII 57006 |
|
|
Индийские: бенгальская |
ISCII 57003 |
|
|
Индийские: гуджарати |
ISCII 57010 |
|
|
Индийские: каннада |
ISCII 57008 |
|
|
Индийские: малаялам |
ISCII 57009 |
|
|
Индийские: ория |
ISCII 57007 |
|
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
ISCII 57011 |
|
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
ISCII 57005 |
-
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
-
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
К началу страницы
I’m trying to work out how to convert a file to UTF-8, but I really can’t find much useful info on google other than to use iconv. I downloaded that, but when I ran it via the CLI it told me that I hadn’t installed it properly. The file I’m trying to handle is a rather large file (5M lines).
![]()
asked May 30, 2011 at 15:13
![]()
Notepad++ provides an easy (manual) way to do it. Open your file, choose «Encoding > Convert to UTF-8», and save. I think the size limit is 2 GB.
answered May 30, 2011 at 15:41
![]()
user775598user775598
4263 silver badges5 bronze badges
6
Well, you can just use iconv. You can for example download a Setup.exe from GnuWin32, that should just work (TM).
Also see the question Batch-convert files for encoding or line ending which describes how to convert using the command line on Windows.
![]()
answered May 30, 2011 at 15:38
![]()
sleskesleske
22.7k10 gold badges70 silver badges93 bronze badges
3
One option is to download Cygwin. Cygwin lets you use the Linux command line from within Windows. One advantage of using Cygwin is you don’t have to worry about adding a program to the PATH as you would if you used the Windows command line. So download Cygwin and be sure to search for and select the iconv tool in your download. Then you can follow the example at this StackOverflow question. For instance it says,
iconv -f UTF-8 -t ISO-8859-15 in.txt > out.txt
where UTF-8 is the starting encoding of in.txt and ISO-8859-15 is the output you’d like out.txt to be.
answered May 22, 2017 at 13:56
![]()
0
You must log in to answer this question.
Not the answer you’re looking for? Browse other questions tagged
.
Not the answer you’re looking for? Browse other questions tagged
.
Does anybody know a tool, preferably for the Explorer context menu, to recursively change the encoding of files in a project from ISO-8859-1 to UTF-8 and other encodings? Freeware or not too expensive would be great.
Edit: Thanks for the answers, +1 for all of then. But I would really like to be able to just right click a folder and say «convert all .php files to UTF-8».  Further suggestions are appreciated, starting a bounty.
Further suggestions are appreciated, starting a bounty.
![]()
thomaux
19.2k10 gold badges78 silver badges103 bronze badges
asked Nov 5, 2009 at 16:05
![]()
1
You could easily achieve something like this using Windows PowerShell. If you got the content for a file you could pipe this to the Out-File cmdlet specifying UTF8 as the encoding.
Try something like:
Get-ChildItem *.txt -Recurse | ForEach-Object {
$content = $_ | Get-Content
Set-Content -PassThru $_.Fullname $content -Encoding UTF8 -Force}
![]()
dstandish
2,32819 silver badges34 bronze badges
answered Nov 5, 2009 at 16:08
4
I don’t know about from the context menu, but notepad++ allows you to change file encodings and it has a macro option… so you could automate the process
answered Nov 5, 2009 at 16:08
![]()
MarkMark
5,44311 gold badges47 silver badges62 bronze badges
1
If you import a test.reg file having the following contain
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\Directory\shell\ConvertPHP]
@="convert all .php files to UTF-8"
[HKEY_CLASSES_ROOT\Directory\shell\ConvertPHP\command]
@="cmd.exe /c C:\\TEMP\\t.cmd php \"%1\""
After this you will receive the menu item «convert all .php files to UTF-8» in the context menu of explorer on every directory. After the choosing of the item the batch program C:\TEMP\t.cmd will be started with «php» string as the first parameter and the quoted directory name as the second parameter (of cause the first parameter «php» you can skip if it is not needed). The file t.cmd like
echo %1>C:\TEMP\t.txt
echo %2>>C:\TEMP\t.txt
can be used to prove that all this work.
So you can decode the *.php files with any tool which you prefer. For example you can use Windows PowerShell (see the answer of Alan).
If you want that the extension like PHP will be asked additionally you can write a small program which display the corresponding input dialog and then start the Windows PowerShell script.
answered Nov 20, 2010 at 20:03
![]()
OlegOleg
221k34 gold badges403 silver badges798 bronze badges
Here’s a nice ASP recursive converter, you need IIS running on your computer:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<HTML>
<HEAD>
<TITLE>Charset Converter - TFI 13/02/2015</TITLE>
</HEAD>
<BODY style='font-family:arial;font-size:11px;color:white;background-color:#7790c4;font-size:15px'>
<H1 style='color:yellow'>Recursive file charset converter</H1>
by TFI 13/02/2015<BR><BR>
<%
totalconverted=0
Function transcoder( ANSIFile)
UFT8FileOut=ANSIFile&".tempfile"
Set oFS = CreateObject( "Scripting.FileSystemObject" )
Set oFrom = CreateObject( "ADODB.Stream" )
sFFSpec = oFS.GetAbsolutePathName(ANSIFile)
Set oTo = CreateObject( "ADODB.Stream" )
sTFSpec = oFS.GetAbsolutePathName(UFT8FileOut)
oFrom.Type = 2 'adTypeText
oFrom.Charset = fromchar '"Windows-1252"
oFrom.Open
oFrom.LoadFromFile sFFSpec
oTo.Type = 2 'adTypeText
oTo.Charset = tochar '"utf-8"
oTo.Open
oTo.WriteText oFrom.ReadText
oTo.SaveToFile sTFSpec,2
oFrom.Close
oTo.Close
oFS.DeleteFile sFFSpec
oFS.MoveFile sTFSpec,sFFSpec
End Function
Function ConvertFiles(objFolder, sExt, bRecursive, fromchar, tochar)
Dim objFile, objSubFolder
For each objFile in objFolder.Files
If Ucase(fso.GetExtensionName(objFile)) = ucase(sExt) Then
transcoder objFile.path
totalconverted=totalconverted+1
response.write "• Converted <B>"&fso.GetAbsolutePathName(objFile)&"</B> from <B>"&fromchar&"</B> to <B>"&tochar&"</B><BR>"
End If
Next
If bRecursive = true then
For each objSubFolder in objFolder.Subfolders
ConvertFiles objSubFolder, sExt, true, fromchar, tochar
Next
End If
End Function
sFolder=request.form("sFolder")
sExtension=request.form("sExtension")
fromchar=request.form("fromchar")
tochar=request.form("tochar")
sSubs=request.form("sSubs")
if sSubs="1" then
sub1=True
else
sub1=false
end if
if len(sExtension)=0 then sExtension="asp"
if len(sFolder)>0 and len(fromchar)>0 and len(tochar)>0 then
Dim fso, folder, files, NewsFile, sFolder, objFSO, strFileIn, strFileOut
Set fso = CreateObject("Scripting.FileSystemObject")
'sFolder = "C:\inetpub\wwwroot\naoutf8"
ConvertFiles fso.GetFolder(sFolder), sExtension, Sub1, fromchar, tochar
response.write "<hr><br>Total files converted: "&totalconverted&"<BR><BR>New conversion?<br><br>"
end if
%>
<FORM name=ndata method=post action="UTF8converter.asp">
<TABLE cellspacing=0 cellpadding=5>
<TR>
<TD>Folder to process:</TD>
<TD><INPUT name=sFolder style='width:350px' placeholder="C:\example"></TD>
</TR>
<TR>
<TD>Extension:</TD>
<TD><INPUT name=sExtension style='width:50px' value='asp'> (default is .asp)</TD>
</TR>
<TR>
<TD>Process subfolders:</TD>
<TD><INPUT type=checkbox name=sSubs value='1' checked></TD>
</TR>
<TR>
<TD>From charset:</TD>
<TD><select name=fromchar>
<option value="big5">charset=big5 - Chinese Traditional (Big5)
<option value="euc-kr">charset=euc-kr - Korean (EUC)
<option value="iso-8859-1">iso-8859-1 - Western Alphabet
<option value="iso-8859-2">iso-8859-2 - Central European Alphabet (ISO)
<option value="iso-8859-3">iso-8859-3 - Latin 3 Alphabet (ISO)
<option value="iso-8859-4">iso-8859-4 - Baltic Alphabet (ISO)
<option value="iso-8859-5">iso-8859-5 - Cyrillic Alphabet (ISO)
<option value="iso-8859-6">iso-8859-6 - Arabic Alphabet (ISO)
<option value="iso-8859-7">iso-8859-7 - Greek Alphabet (ISO)
<option value="iso-8859-8">iso-8859-8 - Hebrew Alphabet (ISO)
<option value="koi8-r">koi8-r - Cyrillic Alphabet (KOI8-R)
<option value="shift-jis">shift-jis - Japanese (Shift-JIS)
<option value="x-euc">x-euc - Japanese (EUC)
<option value="utf-8">utf-8 - Universal Alphabet (UTF-8)
<option value="windows-1250">windows-1250 - Central European Alphabet (Windows)
<option value="windows-1251">windows-1251 - Cyrillic Alphabet (Windows)
<option value="windows-1252" selected>windows-1252 - Western Alphabet (Windows)
<option value="windows-1253">windows-1253 - Greek Alphabet (Windows)
<option value="windows-1254">windows-1254 - Turkish Alphabet
<option value="windows-1255">windows-1255 - Hebrew Alphabet (Windows)
<option value="windows-1256">windows-1256 - Arabic Alphabet (Windows)
<option value="windows-1257">windows-1257 - Baltic Alphabet (Windows)
<option value="windows-1258">windows-1258 - Vietnamese Alphabet (Windows)
<option value="windows-874">windows-874 - Thai (Windows)
</select></TD>
</TR>
<TR>
<TD>To charset:</TD>
<TD><select name=tochar>
<option value="big5">big5 - Chinese Traditional (Big5)
<option value="euc-kr">euc-kr - Korean (EUC)
<option value="iso-8859-1">iso-8859-1 - Western Alphabet
<option value="iso-8859-2">iso-8859-2 - Central European Alphabet (ISO)
<option value="iso-8859-3">iso-8859-3 - Latin 3 Alphabet (ISO)
<option value="iso-8859-4">iso-8859-4 - Baltic Alphabet (ISO)
<option value="iso-8859-5">iso-8859-5 - Cyrillic Alphabet (ISO)
<option value="iso-8859-6">iso-8859-6 - Arabic Alphabet (ISO)
<option value="iso-8859-7">iso-8859-7 - Greek Alphabet (ISO)
<option value="iso-8859-8">iso-8859-8 - Hebrew Alphabet (ISO)
<option value="koi8-r">koi8-r - Cyrillic Alphabet (KOI8-R)
<option value="shift-jis">shift-jis - Japanese (Shift-JIS)
<option value="x-euc">x-euc - Japanese (EUC)
<option value="utf-8" selected>utf-8 - Universal Alphabet (UTF-8)
<option value="windows-1250">windows-1250 - Central European Alphabet (Windows)
<option value="windows-1251">windows-1251 - Cyrillic Alphabet (Windows)
<option value="windows-1252">windows-1252 - Western Alphabet (Windows)
<option value="windows-1253">windows-1253 - Greek Alphabet (Windows)
<option value="windows-1254">windows-1254 - Turkish Alphabet
<option value="windows-1255">windows-1255 - Hebrew Alphabet (Windows)
<option value="windows-1256">windows-1256 - Arabic Alphabet (Windows)
<option value="windows-1257">windows-1257 - Baltic Alphabet (Windows)
<option value="windows-1258">windows-1258 - Vietnamese Alphabet (Windows)
<option value="windows-874">windows-874 - Thai (Windows)
</select></TD>
</TR>
</TABLE><BR>
<INPUT TYPE=BUTTON onClick='if(document.ndata.sFolder.value.length>0)document.ndata.submit()'value='Convert folder and subfolders'>
</FORM>
</BODY>
</HTML>
answered Feb 19, 2015 at 13:21
![]()
I know this answer is late-coming, but here are two commandline apps to convert encoding. Just make a batch-file wrapper for one, and add it to your * key in the registry.
http://www.autohotkey.com/forum/topic10796.html
http://www.gbordier.com/gbtools/stringconverter.htm
I used the stringconvertor by adding it as a button in my file-manager, FreeCommanderXE. It only converts one file at a time, but I can click on one, and push the convert button, then click on the next.
answered Feb 4, 2012 at 4:04
![]()
bgmCoderbgmCoder
6,2358 gold badges58 silver badges106 bronze badges
Всем привет! Сегодня я расскажу вам, как поменять кодировку в блокноте. Я думаю, про само значение кодировки рассказывать не надо – раз вы ищите данную информацию, то знаете, что это такое. Как мы все знаем, кодировок сейчас существует огромное множество. Хочу сразу расстроить многих – изменить кодировку по умолчанию при открытии блокнота или создании нового документа нельзя. Вся проблема в том, что приложение «Блокнот» имеет небольшой функционал. В таком случае вам лучше использовать Notepad++ или стороннюю программу Штирлиц.
Но можно сменить кодировку при открытии пустого текстового документа, который создается через контекстное меню (ПКМ – создать текстовый документ). Если открыть этот документ через блокнот, то у него будет та кодировка, которую мы зададим в реестре. Начнем с самого начала.
ПРИМЕЧАНИЕ! Если у вас есть проблема с кодировкой в Windows, например, в некоторых окнах вместо букв отображаются кракозябры – читаем эту инструкцию.
Содержание
- Сохранение
- Изменения кодировки по умолчанию
- Задать вопрос автору статьи
Сохранение
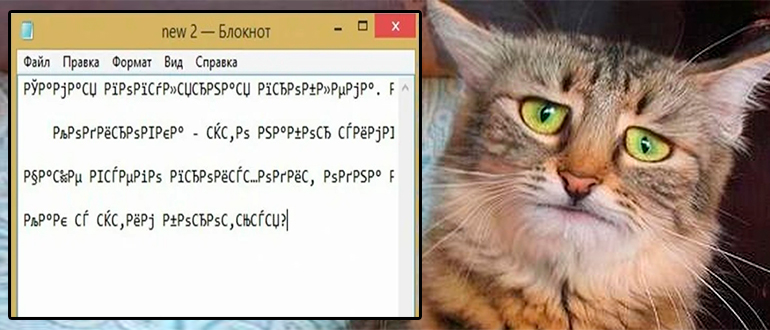
Данная глава предназначена для новичков, здесь я расскажу вам как изменить кодировку в блокноте при сохранении файла. Опять же, кому-то это может понадобиться.
- Откройте документ.
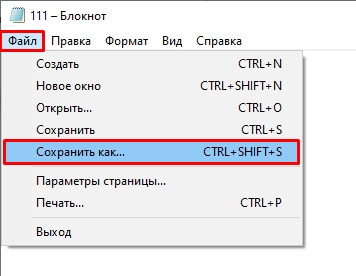
- Теперь давайте его сохраним в другой кодировке – жмем «Файл» – «Сохранить как…».
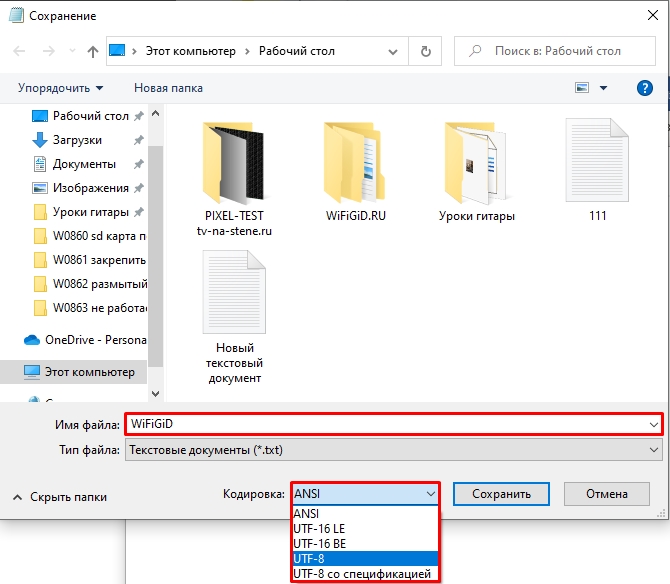
- Вводим название, ниже указываем кодировку и жмем «Сохранить». После этого файл будет иметь ту кодировку, которую вы указали. Как вы можете заметить, тут не так много вариантов. Для работы со специализированным кодом лучше использовать отдельные приложения и программы.
Изменения кодировки по умолчанию
Смотрите, когда мы создаем текстовый документ (.txt) в Windows через контекстное меню – мы создаем файл определенной кодировки, которая указана в реестре и настройках Windows. Блокнот мы используем только как инструмент и с помощью него мы открываем файлик. Проблема в том, что по умолчанию в Windows на всех последних обновлениях использовалась кодировка ANSI. Хотя с последними обновами (после 2019 года) её обновили до UTF-8. Если же вас это не устраивает, то вы можете изменить эту конфигурацию.
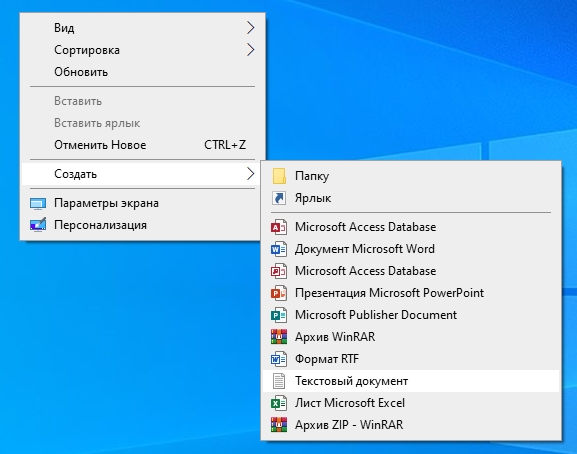
Так как мы полезем в реестр – я советую перед этим создать точку восстановления.
- Создаем файл и сохраняем его в нужной кодировке (UTF-8 или ANSI). В качестве названия, чтобы в будущем не запутаться, используйте наименование кодировки.
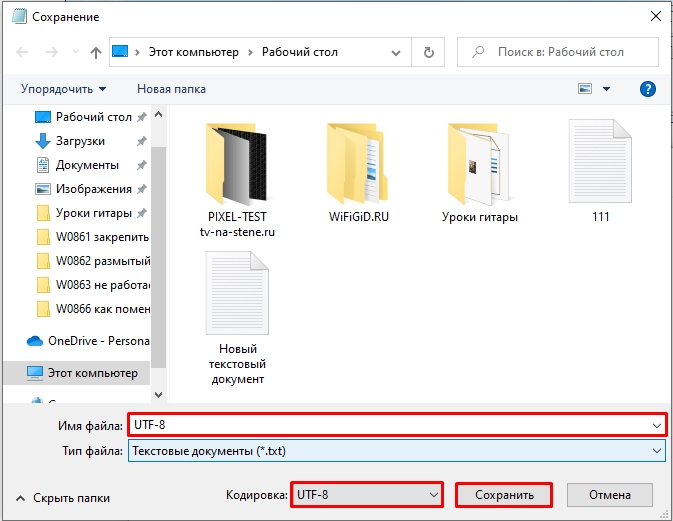
- Перекидываем файл в папку. Если папки нет, то создайте её.
C:\WindowsShellNew
- Жмем по кнопкам:
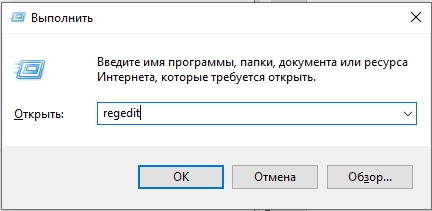
+ R
- Вводим запрос на вход в редактор реестра:
regedit
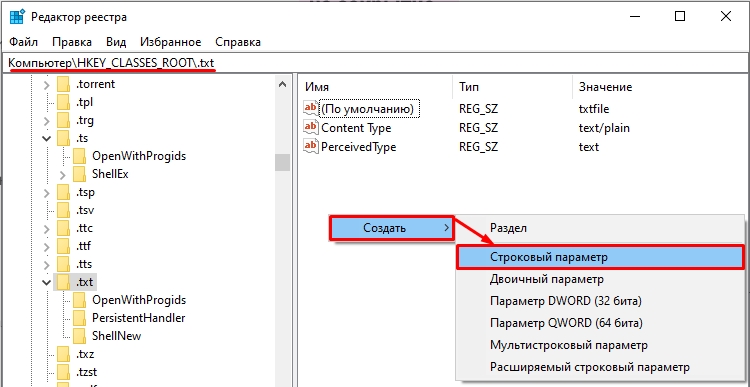
- Переходим по пути:
Компьютер\HKEY_CLASSES_ROOT\.txt
- Создаем строковый параметр.
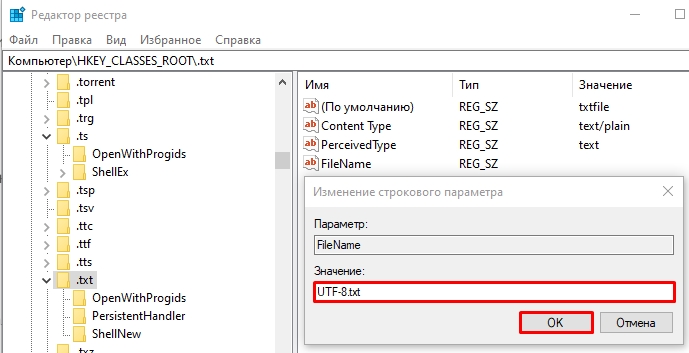
- Даём ему название:
FileName
- Указываем в значении наименование файла с форматом:
UTF-8.txt
- Перезагружаем систему. Теперь все создаваемые файлы через контекстное меню будут иметь именно эту кодировку.
Еще раз повторюсь, что для чтения других файлов с кракозябрами в какой-то «интересной» кодировке вам нужно использовать сторонний софт. Вот и все, дорогие друзья. Смена кодировки в Блокноте прошла успешна. Если у вас еще остались вопросы – пишите их в комментариях. До новых встреч на портале WiFiGiD.RU.