-

Natalia Novoselova
- Гуру
- Сообщения: 3020
- Зарегистрирован: 15 янв 2013, 20:14
- Репутация: 69
- Ваше звание: Лиса
- Откуда: **
- Контактная информация:

Как поставить кодировку UTF-8 в Windows-8
Есть скрипт для R, где комментарии написаны на русском языке в кодировке UTF-8. При открытии скрипта у меня крякозябы, несмотря на то, что в систем на компе язык «для приложений не использующих Unicode» стоит русский. То есть — надо поставить еще кодировку UTF-8. Как это сделать для всей ОС (Windows-8)? Нигде не могу найти таких настроек. В самом R тоже.
-

Игорь Белов
- Гуру
- Сообщения: 2216
- Зарегистрирован: 04 янв 2011, 22:00
- Статьи: 12
- Проекты: 1
- Репутация: 1499
- Откуда: Казань

Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
Игорь Белов » 27 окт 2018, 21:24
Проще всего перекодировать файл в CP1251. Это можно сделать в большинстве текстовых редакторов. Или погуглите онлайн-конвертеры.
The purpose of computing is insight, not numbers
-

rhot
- Гуру
- Сообщения: 1727
- Зарегистрирован: 25 янв 2011, 17:50
- Статьи: 1
- Репутация: 194
- Ваше звание: доктор
- Откуда: Архангельск

Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
rhot » 27 окт 2018, 21:26
В RStudio кодировка выбирается через File —> Reopen with encoding
___________(¯`·.¸(¯`·.¸ Scientia potentia est _/ {SILVA}:::{FOSS}:::{GIS} \_ Знание сила ¸.·´¯)¸.·´¯)___________
-
Natalia Novoselova
- Гуру
- Сообщения: 3020
- Зарегистрирован: 15 янв 2013, 20:14
- Репутация: 69
- Ваше звание: Лиса
- Откуда: **
- Контактная информация:
Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
Natalia Novoselova » 30 окт 2018, 22:09
Игорь Белов писал(а): ↑
27 окт 2018, 21:24
Проще всего перекодировать файл в CP1251. Это можно сделать в большинстве текстовых редакторов. Или погуглите онлайн-конвертеры.
Почему-то на моем компе такая перезапись скрипта тоже дала крякозябы.
В RStudio кодировка выбирается через File —> Reopen with encoding
Я пользуюсь обычной R консолью, там такого нет. Попробую перейти в RStudio.
-
rhot
- Гуру
- Сообщения: 1727
- Зарегистрирован: 25 янв 2011, 17:50
- Статьи: 1
- Репутация: 194
- Ваше звание: доктор
- Откуда: Архангельск
Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
rhot » 31 окт 2018, 10:25
Natalia Novoselova писал(а): ↑
30 окт 2018, 22:09
Я пользуюсь обычной R консолью, там такого нет. Попробую перейти в RStudio.
Тогда не знаю как. Могу предложить последовать примеру редактирования реестра. Правда это для семёрки…
___________(¯`·.¸(¯`·.¸ Scientia potentia est _/ {SILVA}:::{FOSS}:::{GIS} \_ Знание сила ¸.·´¯)¸.·´¯)___________
-
gamm
- Гуру
- Сообщения: 3979
- Зарегистрирован: 15 окт 2010, 08:33
- Репутация: 1035
- Ваше звание: программист
- Откуда: Казань
Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
gamm » 31 окт 2018, 14:05
Поставьте FAR (он бесплатный), откройте файл во встроенном редакторе, выберите исходную кодировку (если не распознает), выделите все (Ctrl/a), уберите в буфер (ctrl/x), выберите новую кодировку, и вставьте (ctrl/v).
Выбор кодировки типа ctrl/F8 или alt/F8 или около. Если нужной кодировки нет, установите, в папке, где far стоит, есть скрипты.
-
nplatonov
- Интересующийся
- Сообщения: 25
- Зарегистрирован: 07 фев 2012, 12:00
- Репутация: 20
Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
nplatonov » 04 ноя 2018, 20:42
Можно попробовать задавать кодировку следующим образом:
path_to_R_bin\Rterm —encoding UTF-8 —file=test.R —args pi 3.1415
-
nkljdubin
- Новоприбывший
- Сообщения: 0
- Зарегистрирован: 13 мар 2021, 05:44
- Репутация: 0
- Откуда: Санкт-Петербу́рг
- Контактная информация:
Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
nkljdubin » 13 мар 2021, 05:49
Тоже интересовался данным вопросом, спасибо за советы.
-
AlexTim
- Интересующийся
- Сообщения: 35
- Зарегистрирован: 25 ноя 2021, 14:11
- Репутация: 9
- Откуда: Оренбург
Re: Как поставить кодировку UTF-8 в Windows-8
Сообщение
AlexTim » 22 дек 2021, 13:36

Попробуйте
«Панель управления» —> «Региональные стандарты» —> «Дополнительно» —> [«Изменить язык системы»] —>
(v) «Использовать Юникод (UTF-8) для поддержки языка во всем Мире».
Перезагрузка.
Время на прочтение
9 мин
Количество просмотров 29K
Введение
Консольные приложения до сих пор остаются наиболее востребованным видом приложений, большинство разработчиков оттачивают архитектуру и бизнес-логику именно в консоли. При этом они нередко сталкиваются с проблемой локализации — русский текст, который вполне адекватно отражается в исходном файле, при выводе на консоль приобретает вид т.н. «кракозябр».
В целом, локализация консоли Windows при наличии соответствующего языкового пакета не представляется сложной. Тем не менее, полное и однозначное решение этой проблемы, в сущности, до сих пор не найдено. Причина этого, главным образом, кроется в самой природе консоли, которая, являясь компонентом системы, реализованным статическим классом System.Console, предоставляет свои методы приложению через системные программы-оболочки, такие как командная строка или командный процессор (cmd.exe), PowerShell, Terminal и другие.
По сути, консоль находится под двойным управлением — приложения и оболочки, что является потенциально конфликтной ситуацией, в первую очередь в части использования кодировок.
Данный материал не предлагает строгий алгоритм действий, а направлен на описание узловых проблем, с которыми неизбежно сталкивается разработчик локализованного консольного приложения, а также некоторые возможные пути их разрешения. Предполагается, что это позволит разработчику сформировать стратегию работы с локализованной консолью и эффективно реализовать существующие технические возможности, большая часть которых хорошо описана и здесь опущена.
Виды консолей
В общем случае функции консоли таковы:
-
управление операционной системой и системным окружением приложений на основе применения стандартных системных устройств ввода-вывода (экран и клавиатура), использования команд операционной системы и/или собственно консоли;
-
запуск приложений и обеспечение их доступа к стандартным потокам ввода-вывода системы, также с помощью стандартных системных устройств ввода-вывода.
Основная консоль Windows — командная строка или иначе командный процессор (CMD). Большие возможности предоставляют оболочки PowerShell (PS), Windows PowerShell (WPS) и Terminal. По умолчанию Windows устанавливает Windows Power Shell мажорной версией до 5, однако предлагает перейти на новую версию — 7-ку, имеющую принципиальное отличие (вероятно, начинающееся с 6-ки) — кроссплатформенность. Terminal — также отдельно уставливаемое приложение, по сути интегратор всех ранее установленных оболочек PowerShell и командной строки.
Отдельным видом консоли можно считать консоль отладки Visual Studio (CMD-D).
Конфликт кодировок
Полностью локализованная консоль в идеале должна поддерживать все мыслимые и немыслимые кодировки приложений, включая свои собственные команды и команды Windows, меняя «на лету» кодовые страницы потоков ввода и вывода. Задача нетривиальная, а иногда и невозможная — кодовые страницы DOS (CP437, CP866) плохо совмещаются с кодовыми страницами Windows и Unicode.
История кодировок здесь: О кодировках и кодовых страницах / Хабр (habr.com)
Исторически кодовой страницей Windows является CP1251 (Windows-1251, ANSI, Windows-Cyr), уверенно вытесняемая 8-битной кодировкой Юникода CP65001 (UTF-8, Unicode Transformation Format), в которой выполняется большинство современных приложений, особенно кроссплатформенных. Между тем, в целях совместимости с устаревшими файловыми системами, именно в консоли Windows сохраняет базовые кодировки DOS — CP437 (DOSLatinUS, OEM) и русифицированную CP866 (AltDOS, OEM).
Совет 1. Выполнять разработку текстовых файлов (программных кодов, текстовых данных и др.) исключительно в кодировке UTF-8. Мир любит Юникод, а кроссплатформенность без него вообще невозможна.
Совет 2. Периодически проверять кодировку, например в текстовом редакторе Notepad++. Visual Studio может сбивать кодировку, особенно при редактировании за пределами VS.
Поскольку в консоли постоянно происходит передача управления от приложений к собственно командному процессору и обратно, регулярно возникает «конфликт кодировок», наглядно иллюстрируемый таблица 1 и 2, сформированных следующим образом:
Были запущены три консоли — CMD, PS и WPS. В каждой консоли менялась кодовая страница с помощью команды CHCP, выполнялась команда Echo c двуязычной строкой в качестве параметра (табл. 1), а затем в консоли запускалось тестовое приложение, исходные файлы которого были созданы в кодировке UTF-8 (CP65001): первая строка формируется и направляется в поток главным модулем, вторая вызывается им же, формируется в подключаемой библиотеке классов и направляется в поток опять главным модулем, третья строка полностью формируется и направляется в поток подключаемой библиотекой.
Команды и код приложения под катом
команды консоли:
-
> Echo ffffff фффффф // в командной строке
-
PS> Echo ffffff фффффф // в PowerShell
-
PS> Echo ffffff ?????? // так выглядит та же команда в Windows PowerShell
код тестового приложения:
using System;
using ova.common.logging.LogConsole;
using Microsoft.Extensions.Logging;
using ova.common.logging.LogConsole.Colors;
namespace LoggingConsole.Test
{
partial class Program
{
static void Main2(string[] args)
{
ColorLevels.ColorsDictionaryCreate();
Console.WriteLine("Hello World! Привет, мир!"); //вывод строки приветствия на двух языках
LogConsole.Write("Лог из стартового проекта", LogLevel.Information);
Console.WriteLine($"8. Active codepage: input {Console.InputEncoding.CodePage}, output {Console.OutputEncoding.CodePage}");
Console.ReadKey();
}
}
}Командную часть задания все консоли локализовали практически без сбоев во всех кодировках, за исключением: в WPS неверно отображена русскоязычная часть команды во всех кодировках.

Вывод тестового приложения локализован лишь в 50% испытаний, как показано в табл.2.

Сoвет 3. Про PowerShell забываем раз и навсегда. Ну может не навсегда, а до следующей мажорной версии…
По умолчанию Windows устанавливает для консоли кодовые страницы DOS. Чаще всего CP437, иногда CP866. Актуальные версии командной строки cmd.exe способны локализовать приложения на основе русифицированной кодовой страницы 866, но не 437, отсюда и изначальный конфликт кодировок консоли и приложения. Поэтому
Совет 4. Перед запуском приложения необходимо проверить кодовую страницу консоли командой CHCP и ей же изменить кодировку на совместимую — 866, 1251, 65001.
Совет 5. Можно установить кодовую страницу консоли по умолчанию. Кратко: в разделе реестра \HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Command Processor добавить или изменить значение параметра Autorun на: chcp <номер кодовой страницы>. Очень подробно здесь: Изменить кодовую страницу консоли Windows по умолчанию на UTF-8 (qastack.ru), оригинал на английском здесь: Change default code page of Windows console to UTF-8.
Проблемы консолей Visual Studio
В Visual Studio имеется возможность подключения консолей, по умолчанию подключены командная строка для разработчика и Windows PowerShell для разработчика. К достоинствам можно отнести возможности определения собственных параметров консоли, отдельных от общесистемных, а также запуск консоли непосредственно в директории разработки. В остальном — это обычные стандартные консоли Windows, включая, как показано ранее, установленную кодовую страницу по умолчанию.
Отдельной опцией Visual Studio является встроенная односеансная консоль отладки, которая перехватывает команду Visual Studio на запуск приложения, запускается сама, ожидает компиляцию приложения, запускает его и отдает ему управление. Таким образом, отладочная консоль в течение всего рабочего сеанса находится под управлением приложения и возможность использования команд Windows или самой консоли, включая команду CHCP, не предусмотрена. Более того, отладочная консоль не воспринимает кодовую страницу по умолчанию, определенную в реестре, и всегда запускается в кодировке 437 или 866.
Совет 6. Тестирование приложения целесообразно выполнять во внешних консолях, более дружелюбных к локализации.
Анализ проблем консолей был бы не полон без ответа на вопрос — можно ли запустить консольное приложение без консоли? Можно — любой файл «.exe» запустится двойным кликом, и даже откроется окно приложения. Однако консольное приложение, по крайней мере однопоточное, по двойному клику запустится, но консольный режим не поддержит — все консольные вводы-выводы будут проигнорированы, и приложение завершится
Локализация отладочной консоли Visual Studio
Отладочная консоль — наиболее востребованная консоль разработчика, гораздо более удобная, чем внешняя консоль, поэтому резонно приложить максимум усилий для ее локализации.
На самом деле, правильнее говорить о локализации приложения в консоли — это важное уточнение. Microsoft по этому поводу высказывается недвусмысленно: «Programs that you start after you assign a new code page use the new code page. However, programs (except Cmd.exe) that you started before assigning the new code page will continue to use the original code page». Иными словами, консоль можно локализовать когда угодно и как угодно, но приложение будет локализовано в момент стабилизации взаимодействия с консолью в соответствии с текущей локализацией консоли, и эта локализация сохранится до завершения работы приложения. В связи с этим возникает вопрос — в какой момент окончательно устанавливается связь консоли и приложения?
Важно! Приложение окончательно стабилизирует взаимодействие с консолью в момент начала ввода-вывода в консоль, благодаря чему и появляется возможность программного управления локализацией приложения в консоли — до первого оператора ввода-вывода.
Ниже приведен пример вывода тестового приложения в консоль, иллюстрирующий изложенное. Метод Write получает номера текущих страниц, устанавливает новые кодовые страницы вводного и выводного потоков, выполняет чтение с консоли и записывает выводную строку, содержащий русский текст, в том числе считанный с консоли, обратно в консоль. Операция повторяется несколько раз для всех основных кодовых страниц, упомянутых ранее.
F:\LoggingConsole.Test\bin\Release\net5.0>chcp
Active code page: 1251
F:\LoggingConsole.Test\bin\Release\net5.0>loggingconsole.test
Codepages: current 1251:1251, setted 437:437, ΓΓεΣΦ∞ 5 ±Φ∞ΓεδεΓ ∩ε-≡≤±±ΩΦ: Θ÷≤Ωσ=Θ÷≤Ωσ
Codepages: current 437:437, setted 65001:65001, 5 -: =
Codepages: current 65001:65001, setted 1252:1252, ââîäèì 5 ñèìâîëîâ ïî-ðóññêè: éöóêå=éöóêå
Codepages: current 1252:1252, setted 1251:1251, вводим 5 символов по-русски: йцуке=йцуке
Codepages: current 1251:1251, setted 866:866, ттюфшь 5 ёшьтюыют яю-Ёєёёъш: щЎєъх=щЎєъх
Codepages: current 866:866, setted 1251:1251, вводим 5 символов по-русски: йцуке=йцуке
Codepages: current 1251:1251, setted 1252:1252, ââîäèì 5 ñèìâîëîâ ïî-ðóññêè: éöóêå=éöóêå
F:\LoggingConsole.Test\bin\Release\net5.0>chcp
Active code page: 1252-
приложение запущено в консоли с кодовыми страницами 1251 (строка 2);
-
приложение меняет кодовые страницы консоли (current, setted);
-
приложение остановлено в консоли с кодовыми страницами 1252 (строка 11, setted);
-
по окончании работы приложения изменения консоли сохраняются (строка 14 — Active codepage 1252);
-
Приложение адекватно локализовано только в случае совпадения текущих кодовых страниц консоли (setted 1251:1251) с начальными кодовыми страницами (строки 8 и 10).
Код тестового приложения под катом
using System;
using System.Runtime.InteropServices;
namespace LoggingConsole.Test
{
partial class Program
{
[DllImport("kernel32.dll")] static extern uint GetConsoleCP();
[DllImport("kernel32.dll")] static extern bool SetConsoleCP(uint pagenum);
[DllImport("kernel32.dll")] static extern uint GetConsoleOutputCP();
[DllImport("kernel32.dll")] static extern bool SetConsoleOutputCP(uint pagenum);
static void Main(string[] args)
{
Write(437);
Write(65001);
Write(1252);
Write(1251);
Write(866);
Write(1251);
Write(1252);
}
static internal void Write(uint WantedIn, uint WantedOut)
{
uint CurrentIn = GetConsoleCP();
uint CurrentOut = GetConsoleOutputCP();
Console.Write($"current {CurrentIn}:{CurrentOut} - текущая кодировка, "); /*wanted {WantedIn}:{WantedOut},*/
SetConsoleCP(WantedIn);
SetConsoleOutputCP(WantedOut);
Console.Write($"setted {GetConsoleCP()}:{GetConsoleOutputCP()} - новая кодировка, ");
Console.Write($"вводим 3 символа по-русски: ");
string str = "" + Console.ReadKey().KeyChar.ToString();
str += Console.ReadKey().KeyChar.ToString();
str += Console.ReadKey().KeyChar.ToString();
Console.WriteLine($"={str}");
}
static internal void Write(uint ChangeTo)
{
Write(ChangeTo, ChangeTo);
}
}
}
Программное управление кодировками консоли — это единственный способ гарантированной адекватной локализацией приложения в консоли. Языки .Net такой возможности не предоставляют, однако предоставляют функции WinAPI: SetConsoleCP(uint numcp) и SetConsoleOutputCP(uint numcp), где numcp — номер кодовой страницы потоков ввода и вывода соответственно. Подробнее здесь: Console Functions — Windows Console | Microsoft Docs. Пример применения консольных функций WInAPI можно посмотреть в тестовом приложении под катом выше.
Совет 7. Обязательный и повторный! Функции SetConsoleCP должны размещаться в коде до первого оператора ввода-вывода в консоль.
Стратегия локализации приложения в консоли
-
Удалить приложение PowerShell (если установлено), сохранив Windows PowerShell;
-
Установить в качестве кодовую страницу консоли по умолчанию CP65001 (utf-8 Unicode) или CP1251 (Windows-1251-Cyr), см. совет 5;
-
Разработку приложений выполнять в кодировке utf-8 Unicode;
-
Контролировать кодировку файлов исходных кодов, текстовых файлов данных, например с помощью Notepad++;
-
Реализовать программное управление локализацией приложения в консоли, пример ниже под катом:
Пример программной установки кодовой страницы и локализации приложения в консоли
using System;
using System.Runtime.InteropServices;
namespace LoggingConsole.Test
{
partial class Program
{
static void Main(string[] args)
{
[DllImport("kernel32.dll")] static extern bool SetConsoleCP(uint pagenum);
[DllImport("kernel32.dll")] static extern bool SetConsoleOutputCP(uint pagenum);
SetConsoleCP(65001); //установка кодовой страницы utf-8 (Unicode) для вводного потока
SetConsoleOutputCP(65001); //установка кодовой страницы utf-8 (Unicode) для выводного потока
Console.WriteLine($"Hello, World!");
}
}
}
Всех приветствую на портале WiFiGiD.RU. Сегодня мы рассмотрим еще одну достаточно популярную проблему, когда в Windows вместо букв отображаются кракозябры, иероглифы, знаки вопроса и какие-то непонятные символы. Проблема встречается на всех версиях Windows 10, 11, 7 и 8, и решается она одинаково. Причем кракозябры могут быть как в отдельных программах (например, в блокноте или Word) или системных окнах (в проводнике, компьютере или панели управления). В статье я расскажу вам, как можно исправить кодировку и вернуть все на свои места.
Содержание
- Способ 1: Изменение системного языка
- Способ 2: Изменение кодовой таблицы
- Способ 3: Подмена файлов
- Способ 4: Дополнительные советы
- Задать вопрос автору статьи
Способ 1: Изменение системного языка
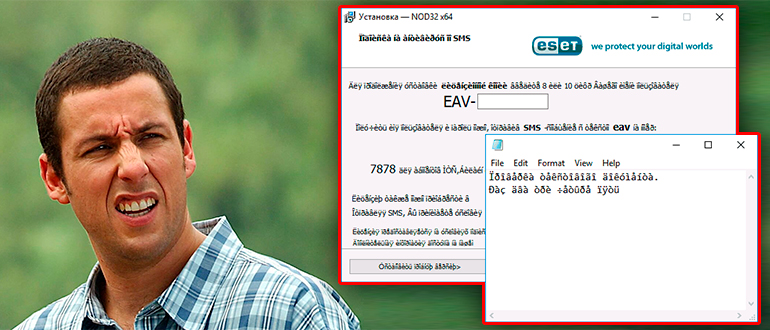
Итак, у нас вместо русских букв отображаются знаки вопроса или другие непонятные символы в Windows – давайте разбираться вместе. После установки английской или любой другой версии, есть вероятность, что язык, который установлен в системе, установился неправильно. Второй вариант – когда региональные стандарты языка были сбиты или установлены не так как нужно. Давайте это исправим.
- Зажимаем на клавиатуре две клавиши:
+ R
- Теперь используем команду:
control
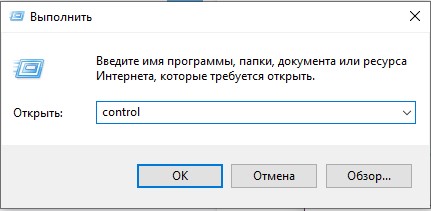
- В панели управления найдите пункт «Региональные стандарты» – ориентируйтесь на значок. Если вы видите, что пунктов не так много как у меня, измените режим «Просмотра».
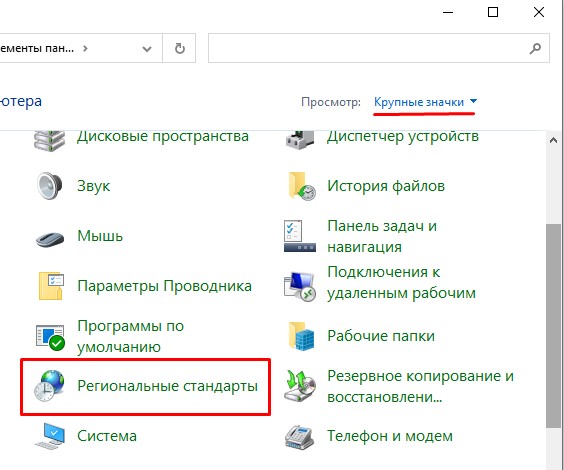
- На второй вкладке нажмите по кнопке «Изменить язык…».
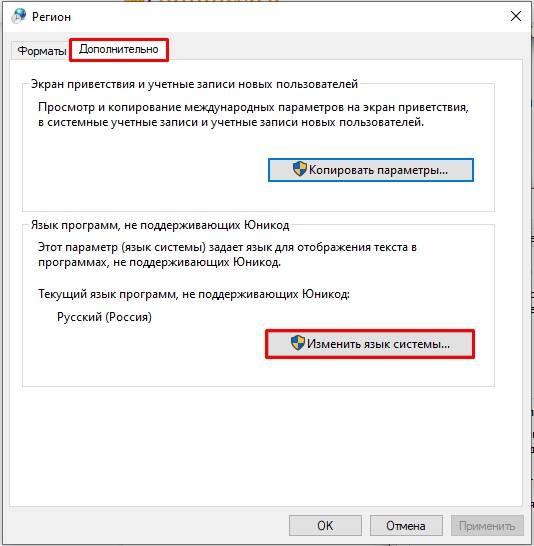
- Сначала в первом пункте установите «Русский» язык. Ниже есть настройка использования Юникода (UTF-8). Если эта галочка стоит, значит попробуйте её убрать. Если эта конфигурация, наоборот, выключена – активируйте. Нажмите «ОК».
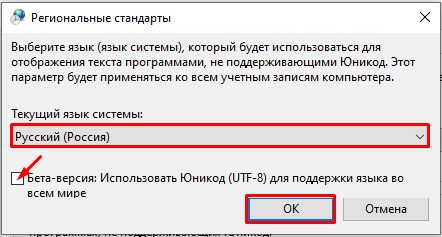
- Вас попросят перезагрузиться – сделайте это.
Способ 2: Изменение кодовой таблицы
Смотрите, каждому символу кириллицы соответствует свое отображение. Также у каждого такого символа есть специальный байтовый код. Чтобы все это работало нормально, для каждого символа и байта есть таблица соответствия. Если таблица выбрана неправильно, код байта будет показывать иероглифы – вопросительные знаки или еще какие кракозябры.
Мы просто подставим для нашей кириллицы правильную таблицу отображения символов, и после этого проблема должна решиться. Мы будем использовать редактор реестра. Сам способ не должен поломать систему, но перед этим я настоятельно рекомендую создать точку восстановления (на всякий случай!).
Читаем – как создать точку восстановления.
После этого переходим к описанным ниже шагам:
- Используем наши любимые волшебные кнопки:
+ R
- Вводим команду:
regedit
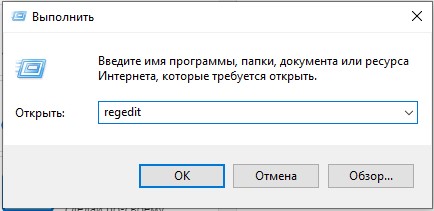
- Можете скопировать путь, который я укажу ниже, и вставить в адресную строку. Или просто пройтись по папкам и разделам вручную.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage
- В правом блоке, где находится список файлов с конфигурациями, в самом низу найдите:
ACP
- Именно этот файл отвечает за настройку соответствия таблицы символов. Два раза кликните левой кнопкой мыши и установите значение:
1251
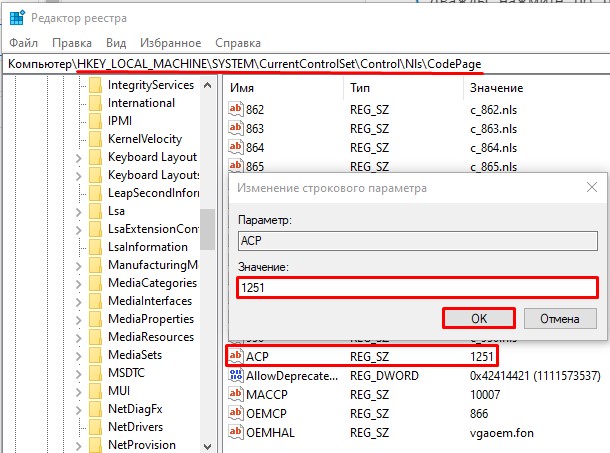
- Нажмите «ОК», закройте окно редактора реестра и перезагрузите компьютер.
Способ 3: Подмена файлов
Третий способ чуть сложнее, мы просто возьмем файл, который используется для английского языка и подменим его на русский. Я все же рекомендую использовать прошлый вариант с реестром (он все же проще). Но, на всякий пожарный, опишу и этот способ.
- Откройте проводник и пройдите по пути:
C:/Windows/System32
- Найдите файл:
C_1252.NLS
- Он используется для английского языка. Через правую кнопку заходим в «Свойства».
- Во вкладке «Безопасность» выбираем кнопку «Дополнительно». Нам нужно дать вам полные права. В противном случае вы ничего с этим файлом не сделаете.
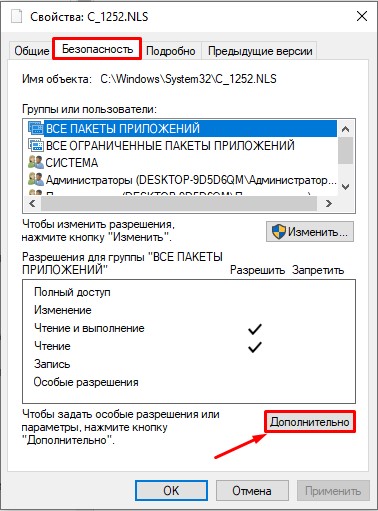
- В строке «Владелец» жмем по ссылке «Изменить».
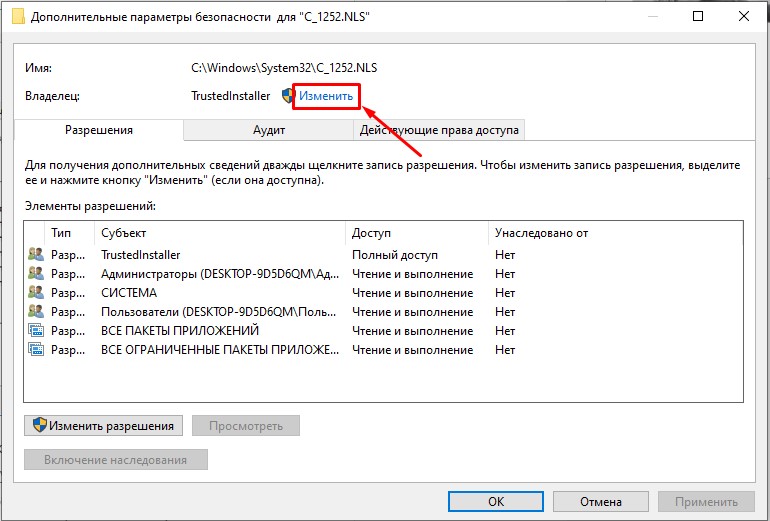
- «Дополнительно».
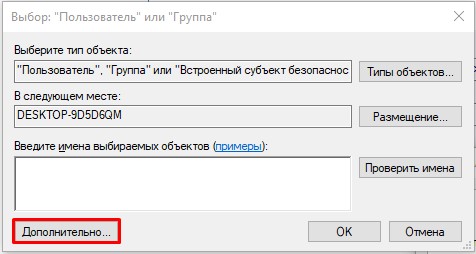
- Нажмите «Поиск». Ниже в списке кликните по той учетной записи, через которую вы сейчас сидите. Если у вас авторизация через учётку Microsoft, то указываем почту. Как только пользователь будет выбран, жмем «ОК».
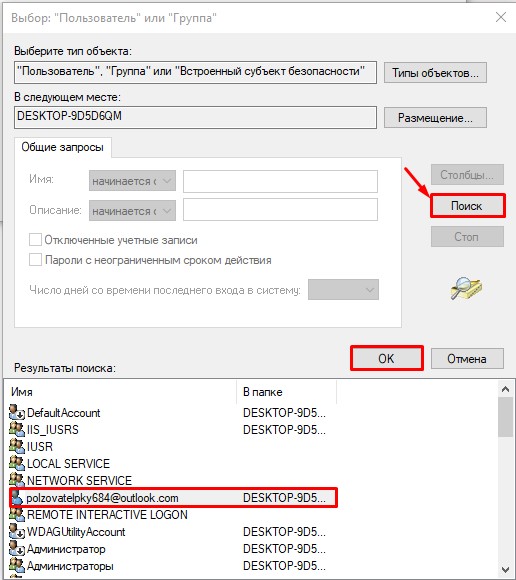
- В этом и следующем окне жмем на кнопку «ОК», чтобы применить параметры.
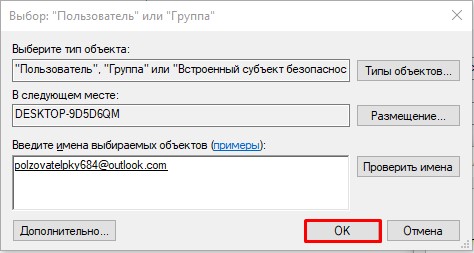
- В окне «Свойства» нажмите «Изменить».
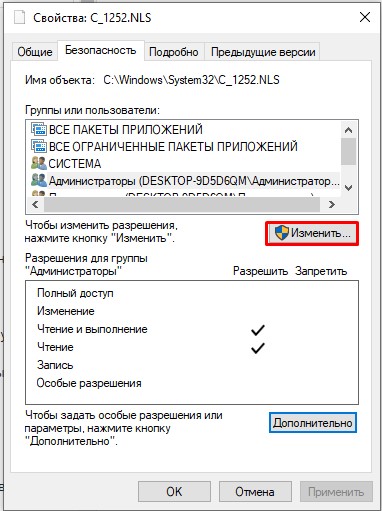
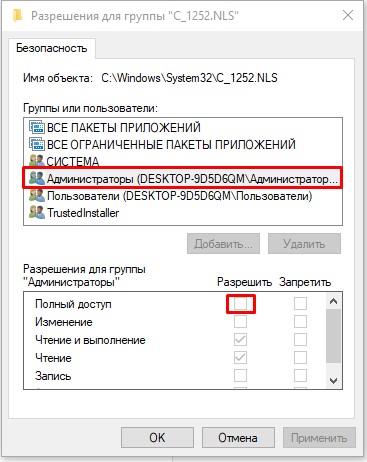
- Выберите «Администраторов» и установите «Полный доступ». Применяем настройки и закрываем оба окошка.
- Теперь установите другой формат для файла (через ПКМ и команду «Переименовать»):
c_1252.NLS
- Например:
c_1252.txt
- На клавиатуре, зажмите Ctrl и, не отпуская, перетащите в любое место в папке файл:
c_1251.NLS
- Мы создали копию файла. Теперь оригинал NLS переименуйте в:
c_1252.NLS
- Перезагрузите систему.
В случае чего у вас есть оригинал c_1251.NLS и сам файл c_1252, у которого мы изменили формат.
Способ 4: Дополнительные советы
Если вы видите иероглифы вместо русских букв в Windows 10, 11, 7 или 8, то есть вероятность, что произошла более серьезная поломка в системных файлах. Поэтому вот ряд советов:
- Если вы делали какие-то глобальные обновления в ОС, то попробуйте выполнить откат системы до самой ранней точки восстановления.
- Если вы устанавливали какую-то кривую и стороннюю сборку Windows, то советую выполнить установку оригинальной версии «Окон».
- Проверьте системные файлы на наличие ошибок.
- Можно попробовать выполнить чистку системы.
На этом все, дорогие друзья. Пишите свои вопросы в комментариях. Всем добра и берегите себя.
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню «Файл – Сохранить как».

В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку «Сохранить».

К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню «Кодировки – Кириллица» и выбрать нужный вариант.

После открытия текста можно изменить его кодировку. Для этого нужно открыть меню «Кодировки» и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.

После преобразования файл нужно сохранить с помощью меню «Файл – Сохранить» или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню «Файл – Открыть».

В открывшемся окне нужно выделить текстовый файл, снять отметку «Автовыбор» и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.

Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню «Файл – Сохранить как» и сохранить документ с указанием новой схемы кодирования.

В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Посмотрите также:
- Чем открыть PDF файл в Windows 7 или Windows 10
- Как перевернуть страницу в Word
- Как копировать текст с помощью клавиатуры
- Как сделать рамку в Word
- Как сделать буклет в Word
Автор
Александр Степушин
Создатель сайта comp-security.net, автор более 2000 статей о ремонте компьютеров, работе с программами, настройке операционных систем.
Остались вопросы?
Задайте вопрос в комментариях под статьей или на странице
«Задать вопрос»
и вы обязательно получите ответ.
-
Доступные статьи
-
PHP
-
Локали и кодировки
Локали и кодировки
- Введение
-
Работа с локалями в PHP
- Windows
- UNIX (FreeBSD)
- Кодировки в MySQL
- Кодировка HTML-страниц
- Заключение
Введение
При разработке веб-приложений есть три важных момента, связанных с кодировками: информация в файлах-сценариях, информация в базе данных и браузер пользователя. Если выставить хотя бы одну кодировку неверно, то, в лучшем случае, данные отобразятся неверно, в худшем, безвозвратно потеряются. Чтобы этого не произошло, а приложение работало корректно при любых настройках сервера, нужно правильно выставить кодировки.
Работа с локалями в PHP
Работа с локалями в PHP выглядит одинаково и в UNIX, и в Windows, и в любой другой платформе. Для установки значений локали служит всего одна функция setlocale(). Чтобы выставить локаль, нужно передать функции первым аргументом категорию, на которую эта локаль распространяется, последующими список возможных локалей. Результатом будет название первой подходящей локали, которая и была установлена.
Пример - установка и использование локали
|
<?php // Установка локали echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'); // Выведет ru_RU.CP1251 для FreeBSD // Выведет rus_RUS.CP1251 для линукса // Выведет Russian_Russia.1251 для Windows // ... // Вывод локализованных сообщений, например, даты echo '<br />', strftime('Число: %d, месяц: %B, день недели: %A'); ?> ru_RU.CP1251 Число: 10, месяц: октября, день недели: пятница или Russian_Russia.1251 Число: 10, месяц: Октябрь, день недели: пятница |
Локали в Windows
Для того, чтобы узнать, какие локали доступны в Windows, нужно зайти в панель управления, «Язык и региональные стандарты».
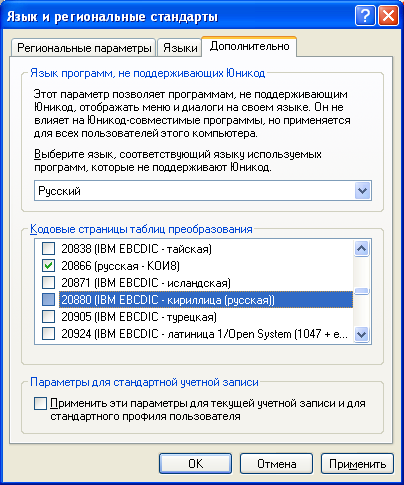
На вкладке «Дополнительно», в разделе «Кодовые страницы таблиц преобразования» показан список всех возможных локалей для Windows, которые можно использовать в PHP.
Кодовые страницы, которые отмечены в списке, из PHP могут быть использованы по их номеру.
В общем случае, использование выглядит по следующей схеме: Язык_Регион.Номер_кодовой_страницы
Для России это может выглядеть как Russian_Russia.1251 (cp1251) или Russian_Russia.20866 (KOI8-R).
Для Украины — Ukrainian_Ukraine.1251 (cp1251).
Вместо длинных названий можно использовать сокращённые russian, american, ukrainian и так далее. При этом кодовая страница выставится с учётом региональных настроек, для России и Украины — 1251, для Америки — 1252.
Единственная кодировка, с которой у меня возникли проблемы, как ни странно, оказалась UTF-8. При попытке выставить эту кодировку, выставляются все категории локалей, кроме основной. Вывод локализованных сообщений при этом идёт в cp1251.
Пример - установка локали UTF-8 на Windows
|
<? // Кодировка страницы windows-1251 header('Content-Type: text/html; charset=windows-1251'); echo '<pre>'; // Локаль устанавливаем UTF-8 echo setlocale(LC_ALL, 'Russian_Russia.65001'), PHP_EOL; // Но данные будут выводиться всё равно в cp1251 :((( echo strftime('%A'), PHP_EOL; ?> LC_COLLATE=Russian_Russia.65001;LC_CTYPE=Russian_Russia.1251; LC_MONETARY=Russian_Russia.65001;LC_NUMERIC=Russian_Russia.65001; LC_TIME=Russian_Russia.65001 пятница |
Пока это можно списать на внутренний механизм PHP работы со строками. С шестой версии PHP вся обработка строк должна будет вестись в UTF-8, но до тех пор надо просто знать об этом и делать поправку.
Ещё одной странностью при работе с локалями в PHP на Windows является неправильная работа с категориями локалей. Так, например, я выставляю локаль на функции времени KOI8-R, setlocale(LC_TIME, 'Russian_Russia.20866'), но почему-то выставляется cp1251 на все категории. Суть проблемы я так и не понял, возможно, это просто баг (проверялось на PHP 5.2.3), а возможно, что внутренний механизм Windows просто не позволяет этого делать. Хотя по мне, так это чистой воды баг.
В общем-то, на этом можно и закончить разговор о локалях на Windows. Главное, запомнить, что локали, которые портированы из UNIX, под WIndows работают только для «галочки». Шаг влево, шаг вправо и результат будет непредсказуемым. Безопасно можно использовать только cp1251 (windows-1251) и KOI8-R, и только для LC_ALL.
Код - установка локали на Windows
|
<?php // Устновка локалей для Windows // Кодировка Windows-1251 setlocale(LC_ALL, 'Russian_Russia.1251'); // Кодировка KOI8-R setlocale(LC_ALL, 'Russian_Russia.20866'); // Кодировка UTF-8 (использовать осторожно) setlocale(LC_ALL, 'Russian_Russia.65001'); ?> |
Локали в UNIX
Выше я описал работу с локалями в Windows, теперь можно заострить внимание на UNIX-like системах. Для простоты, я буду их называть UNIX, а подразумевать FreeBSD :). В контексте данной статьи это не особо важно.
Итак, дистрибутивы UNIX поставляются в одном виде для всех, и работа рассчитана на многопользовательский режим, поэтому о правильной настройке локали должен заботиться сам пользователь, например:
zg# locale LANG= LC_CTYPE="ru_RU.KOI8-R" LC_COLLATE="ru_RU.KOI8-R" LC_TIME="ru_RU.KOI8-R" LC_NUMERIC="ru_RU.KOI8-R" LC_MONETARY="ru_RU.KOI8-R" LC_MESSAGES="ru_RU.KOI8-R" LC_ALL=ru_RU.KOI8-R zg#
Так может выглядеть работа системной команды locale, которая выводит текущие настройки локали для пользователя. А так, обычно, выглядят настройки локали для пользователя, под которым работает PHP:
passthru('locale'); ================ LANG= LC_CTYPE="C" LC_COLLATE="C" LC_TIME="C" LC_NUMERIC="C" LC_MONETARY="C" LC_MESSAGES="C" LC_ALL=
Функция ucwords() должна была сделать заглавными первые буквы всех слов. А перед этим strtolower() должна была предварительно все заглавные буквы сделать строчными. Но ничего не произошло. Так же не будет работать следующий код:
echo ucwords(strtolower('привет, МИР!')); ================ привет, МИР!
Хотя \w является множеством знаков, из которых может состоять слово (алфавит, цифры и _), регулярное выражение не срабатывает. Причина как раз в том, что, работая с cp1251, мы не сказали об этом php. Чтобы исправить положение, достаточно воспользоваться функцией setlocale() и указать правильную локаль, например, так:
setlocale(LC_ALL, 'ru_RU.CP1251');
Здесь первый аргумент — это категория, на которую будет распространяться локаль (константа LC_*), второй — название локали. Начиная с версии 4.3.0 можно указывать несколько имён локалей в виде массива или в качестве дополнительных аргументов. После вызова функция установит первую подходящую локаль и вернёт её имя:
echo setlocale(LC_ALL, 'cp1251', 'koi8-r', 'ru_RU.KOI8-R'); ================ ru_RU.KOI8-R
С помощью команды grep я отобрал локали, которые поддерживают русский язык. Любую из них можно использовать, однако следует понимать, что данные должны быть в кодировке, на которую рассчитана локаль. Если же это правило не будет соблюдено, то результат может оказаться весьма неожиданным:
echo setlocale(LC_ALL, 'ru_RU.KOI8-R'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')); =============== ru_RU.KOI8-R пРИВЕТ, мИР!
Если учесть, что koi8-r достаточно популярная кодировка для UNIX-севреров, а windows-1251 для русскоязычных сайтов, то подобное «необычное» поведение не такая уж и редкость. Когда-то я и сам столкнулся с этой проблемой при портировании проекта на реальный хостинг.
После установки правильной локали все примеры, которые не работали выше, будут работать как нужно!
echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')), PHP_EOL; echo preg_match('/^\w+$/', 'привет') ? 'нашёл' : 'не работает', PHP_EOL; echo strftime('Сегодня: %A, %d %B, %Y года'); =============== ru_RU.CP1251 Привет, Мир! нашёл Сегодня: суббота, 12 июля, 2008 года
По-русски заговорит и функция strftime(), которая корректно работает с локалями, а также и всё остальное, что зависит от локали.
Кодировки в MySQL
Напомню, что возможность задавать кодировки появилась только в MySQL 4.1.11 и выше.
В отличие от php, проблемы с кодировками базы данных проявляют себя гораздо быстрее, чем проблемы с локалью. И связано это прежде всего с хранением и выборкой данных, поскольку от этого зависит информация на сайте. Я не буду подробно расписывать все тонкости, поскольку есть отдельная статья, остановлюсь на самых важных моментах.
Первое, чему необходимо научиться, смотреть текущие настройки соединения с mysql:
mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | cp1251 | | character_set_database | cp1251 | | character_set_filesystem | binary | | character_set_results | cp1251 | | character_set_server | cp1251 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.00 sec)
Критичными для пользователя являются character_set_client и character_set_results, которые отвечают за кодировку, в которой данные поступают в базу, и кодировку, в которой данные поступают из базы к пользователю. Если эти две кодировки отличаются от той, в которой работает клиент, в нашем случае php-скрипты, то неминуемо будут «странности», например, при сортировке выборки или внесении данных в базу.
Второе, что необходимо знать, как правильно сообщить mysql о кодировках. Самый простой и правильный способ, это использовать запрос set names:
mysql> set names 'cp1251'; Query OK, 0 rows affected (0.00 sec)
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение cp1251. Это будет означать — клиент работает в кодировке windows-1251 (cp1251).
Помимо этого можно устанавливать непосредственно серверные переменные:
mysql> set character_set_client='UTF8'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | utf8 | | character_set_connection | cp1251 | .....
Теперь данные поступают и извлекаются в разных кодировках.
Список доступных кодировок можно просмотреть так:
mysql> show charset; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | +----------+-----------------------------+---------------------+--------+ 26 rows in set (0.00 sec)
И третье, что необходимо знать, — правила создания таблиц для хранения данных в нужной кодировке. К слову, данные можно хранить в любой кодировке, а работать с ними в кодировке клиента. Однако, важно понимать, что кодировки носят национальный характер и должны соответствовать вносимым данным. Иначе будут потери. Для русского языка есть три национальных кодировки koi8r, cp866, cp1251, которые могут конвертироваться друг в друга без потерь. Также можно использовать интернациональную кодировку UTF8.
Кодировку можно выставить на базу данных, таблицу и поле таблицы. Так, например, можно создать базу данных в кодировке koi8r:
CREATE DATABASE `test` DEFAULT CHARACTER SET koi8r;
Следует отметить, что кодировка базы данных влияет только на дефолтные значения кодировок при создании таблиц. Это значит, что неважно в какой кодировке была создана база, если кодировка таблицы была задана явно. Это же правило относится и к полям таблицы.
Следующим шагом я создам таблицу в cp1251 и одним полем в utf8:
CREATE TABLE `t` ( `id` VARCHAR( 60 ) NOT NULL , `data` TEXT CHARACTER SET utf8 NOT NULL , PRIMARY KEY ( `id` ) ) TYPE = MYISAM CHARACTER SET cp1251;
После того, как таблица создана с нужными параметрами кодировки, mysql автоматически начинает переводить данные при внесении и выборке.
mysql> select * from t; +--------+-------------+ | id | data | +--------+-------------+ | привет | привет мир! | +--------+-------------+ 1 row in set (0.00 sec)
Данные хранятся в разном виде, но поступают к пользователю именно так, как надо!
Подробнее с кодировками и проблемами их использования можно ознакомиться на http://dev.mysql.com/doc/refman/5.1/en/charset.html.
Кодировка HTML-страниц
Объявить кодировку html-страницы можно двумя способами: через заголовки и мета-тег в самой странице. Мета-тег используется только в статичных страницах.
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
Я не буду его разбирать, это проблемы html. Во всех остальных случаях предпочтительней использовать HTTP-заголовок Content-Type.
PHP позволяет работать с HTTP-заголовками посредством функции header():
// Объявление типа содержимого и его кодировки header('Content-Type: text/html; charset=windows-1251');
Но браузер отобразит страницу корректно только в том случае, когда php-файлы сами были созданы в кодировке cp1251. Также нужно понимать, что заголовки должны быть отправлены до любого вывода на экран.
При необходимости перекодировать страницы «на лету», достаточно воспользоваться буферизацией и iconv:
Код - динамическая перекодировка
|
|
1 |
<?php iconv_set_encoding('internal_encoding', 'WINDOWS-1251'); // Исходная кодировка файлов iconv_set_encoding('output_encoding' , 'UTF-8'); // Конечная кодировка ob_start('ob_iconv_handler'); // буферизация header('Content-Type: text/html; charset=UTF8'); ?> Привет, мир! |
Надпись «Привет, мир!» будет выведена в юникоде, при этом браузер получит информацию о кодировке через заголовки и правильно отобразит страницу. Но важно понимать, что внутри скрипта и при соединении с базой данных надо использовать windows-1251 (cp1251), поскольку страница должна быть сформирована в одной кодировке.
Важно помнить, что функции iconv доступны не всегда, и проверка на доступность этих функций не будет лишней.
Заключение
Для безопасной разработки русскоязычных веб-проектов необходимо включать в файл с общими настройками следующие команды:
Код - файл общих настроек
|
|
1 |
<?php // Файл общих настроек ... // Вывод заголовка с данными о кодировке страницы header('Content-Type: text/html; charset=windows-1251'); // Настройка локали setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251', 'russian'); // Настройка подключения к базе данных mysql_query('SET names "cp1251"'); ?> |
Как ни странно, но эти три строчки кода значительно повышают портируемость веб-проектов.