Windows Server Failover Clustering (WSFC) — a feature of Microsoft Windows Server operating system for fault tolerance and high availability (HA) of applications and services — enables several computers to host a service, and if one has a fault, the remaining computers automatically take over the hosting of the service. It is included with Windows Server 2022, Windows Server 2019, Windows Server 2016 and Azure Stack HCI.
In WSFC, each individual server is called a node. The nodes can be physical computers or virtual machines, and are connected through physical connections and through software. Two or more nodes are combined to form a cluster, which hosts the service. The cluster and nodes are constantly monitored for faults. If a fault is detected, the nodes with issues are removed from the cluster and the services may be restarted or moved to another node.
Capabilities of Windows Server Failover Clustering (WSFC)
Windows Server Failover Cluster performs several functions, including:
- Unified cluster management. The configuration of the cluster and service is stored on each node within the cluster. Changes to the configuration of the service or cluster are automatically sent to each node. This allows for a single update to change the configuration on all participating nodes.
- Resource management. Each node in the cluster may have access to resources such as networking and storage. These resources can be shared by the hosted application to increase the cluster performance beyond what a single node can accomplish. The application can be configured to have startup dependencies on these resources. The nodes can work together to ensure resource consistency.
- Health monitoring. The health of each node and the overall cluster is monitored. Each node uses heartbeat and service notifications to determine health. The cluster health is voted on by the quorum of participating nodes.
- Automatic and manual failover. Resources have a primary node and one or more secondary nodes. If the primary node fails a health check or is manually triggered, ownership and use of the resource is transferred to the secondary node. Nodes and the hosted application are notified of the failover. This provides fault tolerance and allows rolling updates not to affect overall service health.
Common applications that use WSFC
A number of different applications can use WSFC, including:
- Database Server
- Windows Distributed File System (NFS) Namespace Server
- File Server
- Hyper-V
- Microsoft Exchange Server
- Microsoft SQL Server
- Namespace Server
- Windows Internet Name Server
WSFC voting, quorum and witnesses
Every cluster network must account for the possibility of individual nodes losing communication to the cluster but still being able to serve requests or access resources. If this were to happen, the service could become corrupt and serve bad responses or cause data stores to become out of sync. This is known as split-brain condition.
WSFC uses a voting system with quorum to determine failover and to prevent a split-brain condition. In the cluster, the quorum is defined as half of the total nodes. After a fault, the nodes vote to stay online. If less than the quorum amount votes yes, those nodes are removed. For example, a cluster of five nodes has a fault, causing three to stay in communication in one segment and two in the other. The group of three will have the quorum and stay online, while the other two will not have a quorum and will go offline.
In small clusters, an extra witness vote should be added. The witness is an extra vote that is added as a tiebreaker in clusters with even numbers of nodes. Without a witness, if half of the nodes go offline at one time the whole service is stopped. A witness is required in clusters with only two nodes and recommended for three and four node clusters. In clusters of five or more nodes, a witness does not provide benefits and is not needed. The witness information is stored in a witness.log file. It can be hosted as a File Share Witness, an Azure Cloud Witness or as a Disk Witness (aka custom quorum disk).
A dynamic quorum allows the number of votes to constitute a quorum to adjust as faults occur. This way, as long as more than half of the nodes don’t go offline at one time, the cluster will be able to continuously lose nodes without it going offline. This allows for a single node to run the services as the «last man standing.»
Windows Server Failover Clustering and Microsoft SQL Server Always On
SQL Server Always On is a high-availability and disaster recovery product for Microsoft SQL server that takes advantage of WSFC. SQL Server Always On has two configurations that can be used separately or in tandem. Failover Cluster Instance (FCI) is a SQL Server instance that is installed across several nodes in a WSFC. Availability Group (AG) is a one or more databases that fail over together to replicated copies. Both register components with WSFC as cluster resources.

Windows Server Failover Clustering Setup Steps
See Microsoft for full documentation on how to deploy a failover cluster using WSFC.
- Verify prerequisites
- All nodes on same Windows Server version
- All nodes using supported hardware
- All nodes are members of the same Active Directory domain
- Install the Failover Clustering feature using Windows Server Manager add Roles and Features
- Validate the failover cluster configuration
- Create the failover cluster in server manager
- Create the cluster roles and services using Microsoft Failover Cluster Manager (MSFCM)
See failover cluster quorum considerations for Windows admins, 10 top tips to maximize hyper-converged infrastructure benefits and how to build a Hyper-V home lab in Windows Server 2019.
This was last updated in March 2022
Continue Reading About Windows Server Failover Clustering (WSFC)
- How does a Hyper-V failover cluster work behind the scenes?
- Manage Windows Server HCI with Windows Admin Center
- Guest clustering achieves high availability at the VM level
- 5 skills every Hyper-V administrator needs to succeed
- How does a Hyper-V failover cluster work behind the scenes?
Dig Deeper on IT operations and infrastructure management
-

Microsoft Exchange Server
By: Nick Barney
-
Microsoft Cloud Witness
By: Katie Terrell Hanna
-
failover cluster
By: Rahul Awati
-
cluster quorum disk
By: Andrew Zola








Skip to content

Windows Server Failover Cluster Hyper-V Basics

Microsoft’s Hyper-V is a highly available and resilient hypervisor that allows enterprise datacenters to run production workloads with little downtime and tremendous flexibility. Hyper-V’s high availability and flexibility in running production workloads is made possible by the underlying clustering technology. Hyper-V clusters are built on top of Microsoft’s Windows Server Failover Clustering technology. Windows Server Failover Clustering provides the technical capabilities to allow Hyper-V to have the clustering and migration capabilities that allow production workloads to be resilient, mobile, and highly-available. It also allows for other benefits.
In this post, we will take a look at Hyper-V Failover Cluster Basics to discuss the Failover Clustering concepts that need to be understood for designing a well thought out Hyper-V cluster configuration.
Additionally, we will look at the benefits of Windows Server Failover Clustering as relates to Hyper-V environments.
What is Windows Server Failover Clustering?
Windows Server Failover Clustering is the mechanism that allows running Windows Roles, Features, and applications to be made highly available across multiple Windows Server hosts.
Why is making roles, features, and other applications across multiple hosts important?

Clustering helps to ensure that workloads are resilient in the event of a hardware failure. Especially when thinking about virtualized workloads, often multiple virtual machines are running on a single host. If a host fails, it is not simply a single workload that fails, but possibly many production workloads could be taken offline with dense configurations of virtual machines on a single host.
The Windows Server Failover Cluster in the context of Hyper-V allows bringing together multiple physical Hyper-V hosts into a “cluster” of hosts. This allows aggregating CPU/memory resources attached to shared storage which in turn allows the ability to easily migrate virtual machines between the Hyper-V hosts in the cluster. The shared storage can be in the form of the traditional SAN or in the form of Storage Spaces Direct in Windows Server 2016.
The ability to easily migrate virtual machines between shared storage allows restarting a virtual machine on a different host in the Windows Server Failover Cluster if the original physical host in which the virtual machine was running on fails. This allows business-critical workloads to be brought back up very quickly even if a host in the cluster has failed.
Windows Server Failover Clustering also has other added benefits as they relate to Hyper-V workloads that are important to consider. In addition to allowing virtual machines to be highly available when hosts fail, the Windows Server Failover Cluster also allows for planned maintenance periods such as patching Hyper-V hosts. This allows Hyper-V administrators the ability to patch hosts by migrating virtual machines off a host, applying patches, and then rehydrating the host with virtual machines. There is also Cluster Aware Updating that allows this to be done in an automated fashion. Windows Server Failover Clustering also provides the benefit of protecting against corruption if the cluster hosts become separated from one another in the classic “split-brain” scenario. If two hosts attempt to write data to the same virtual disk, corruption can occur.
Windows Server Failover Clusters have a mechanism called quorum that prevents separated Hyper-V hosts in the cluster from inadvertently corrupting data. In Windows Server 2016, a new type of quorum has been introduced that can be utilized along with the longstanding quorum mechanisms – the cloud witness.
Windows Server Failover Clustering Basics
Now that we know what Windows Server Failover Cluster is and why it is important, let’s take a look at Windows Server Failover Clustering basics to understand a bit deeper how Failover Clustering in Windows Server works.
Windows Server Failover Clustering is a feature instead of a role as Windows Server Failover clustering simply helps Windows Servers accomplish their primary role.
It is also included in the Standard Edition version of Windows Server along with the Datacenter version. There is no feature difference between the two Windows versions in the Failover Clustering features and functionality. A Windows Server Failover Cluster is compromised of two or more nodes that offer resources to the cluster as a whole. A maximum of 64 nodes per cluster is allowed with Windows Server 2016 Failover Clusters. Additionally, Windows Server 2016 Failover Clusters can run a total of 8000 virtual machines per cluster. Although in this post we are referencing Hyper-V in general, Windows Server Failover Clusters can house many different types of services including file servers, print servers, DHCP, Exchange, and SQL just to name a few.
One of the primary benefits as already mentioned with Windows Server Failover Clusters is the ability to prevent corruption when cluster nodes become isolated from the rest of the cluster. Cluster nodes communicate via the cluster network to determine if the rest of the cluster is reachable. The cluster in general then performs a voting process of sorts that determines which cluster nodes have the node majority or can reach the majority of the cluster resources.
Quorum is the mechanism that validates which cluster nodes have the majority of resources and have the winning vote when it comes to assuming ownership of resources such as in the event of a Hyper-V cluster and virtual machine data.
This becomes glaringly important when you think about the case of an even node cluster such as a cluster with (4) nodes. If a network split happens that allows two of the nodes on each side to only see its neighbor, there would be no majority. Starting with Windows Server 2012, by default, each node has a vote in the quorum voting process. A file or share witness allows a tie-breaking vote by allowing one side of the partitioned cluster to claim this resource, thus breaking the tie. The cluster hosts that claim the disk or file share witness perform a SCSI lock on the resource, which prevents the other side from obtaining the majority quorum vote. With odd numbered cluster configurations, one side of a partitioned cluster will always have a majority so the file or share witness is not needed.
Quorum received enhancements in Windows Server 2016 with the addition of the cloud witness. This allows using an Azure storage account and its reachability as the witness vote. A “0-byte” blob file is created in the Azure storage account for each cluster that utilizes the account.
Windows Server Failover Clusters Hyper-V Specific Considerations
When using Windows Server Failover Clusters for hosting the Hyper-V role, this opens up many powerful options for running production, business-critical virtual machines. There are a few technologies to be aware of that specifically pertain to Hyper-V and other workloads. These are the following
- Cluster Shared Volumes
- ReFS
- Storage Spaces Direct
Cluster Shared Volumes
Cluster Shared Volumes or CSVs provide specific benefits for Hyper-V virtual machines in allowing more than one Hyper-V host to have read/write access to the volume or LUN where virtual machines are stored. In legacy versions of Hyper-V before CSVs were implemented, only one Windows Server Failover Cluster host could have read/write access to a specific volume at a time. This created complexities when thinking about high availability and other mechanisms that are crucial to running business-critical virtual machines on a Windows Server Failover Cluster.
Cluster Shared Volumes solved this problem by allowing multiple nodes in a failover cluster to simultaneously have read/write access to the same LUN provisioned with NTFS. This allows the advantage of having all Hyper-V hosts provisioned to the various storage LUNs which can then assume compute/memory quickly in the case of a node failure in the Windows Server Failover Cluster.
ReFS
ReFS is short for “Resilient File System” and is the newest file system released from Microsoft speculated to be the replacement for NTFS by many. ReFS tout many advantages when thinking about Hyper-V environments. It is resilient by nature, meaning there is no chkdsk functionality as errors are corrected on the fly.
However, one of the most powerful features of ReFS related to Hyper-V is the block cloning technology. With block cloning, the file system merely changes metadata as opposed to moving actual blocks. This means the operation is almost instantaneous with ReFS whereas on NTFS the typical I/O intensive operations such as zeroing out a disk as well as creating and merging checkpoints take place.
ReFS should not be used with SAN/NFS configurations however as the storage operates in I/O redirected mode in this configuration where all I/O is sent to the coordinator node which can lead to severe performance issues. ReFS is recommended however with Storage Spaces Direct which does not see the performance hit that SAN/NFS configurations do with the utilization of RDMA network adapters.
Storage Spaces Direct
Storage Spaces Direct is Microsoft’s software-defined storage solution that allows creating shared storage by using locally attached drives on the Windows Server Failover Cluster nodes. It was introduced with Windows Server 2016 and allows two configurations:
- Converged
- Hyper-converged
With Storage Spaces Direct you have the ability to utilize caching, storage tiers, and erasure coding to create hardware abstracted storage constructs that allow running Hyper-V virtual machines with scale and performance more cheaply and efficiently than using traditional SAN storage.
Concluding Thoughts
Windows Server Failover Clusters provide the underlying technology that allows the Hyper-V role to be hosted with high availability and redundancy. There are basic points to note with Windows Server Failover Clustering including a need to understand the concepts of quorum which prevent corruption due to partitioned clusters or the traditional “split-brain” scenario. There are specific technologies that relate to Hyper-V workloads including Cluster Shared Volumes or CSVs, ReFS file system, and Storage Spaces Direct introduced with Windows Server 2016. Understanding and considering the basic with Windows Server Failover Clusters with Hyper-V is crucial to architecting a performant and stable Hyper-V environment.
Follow our Twitter and Facebook feeds for new releases, updates, insightful posts and more.

Windows Server Failover Clustering, commonly referred to as WSFC (historically, Microsoft Clustering Service, or MSCS) has long been a popular solution for providing a key part of a typical high availability (HA) platform for various applications in the data center. This functionally carries over to the cloud, and ensures AWS high availability.
WSFC provides a native HA platform that protects against node/server failures of many native Microsoft and third-party applications running on Windows Server instances. This is accomplished through the use of active/passive servers that access a shared storage platform. When coupled with storage HA that is typically provided by the underlying storage infrastructure, WSFC provides a complete resilience against both server nodes and storage node failures to increase application uptime.
This article takes a deep dive into the typical benefits of WSFC for enterprise organizations and how those customers can achieve the same capability when moving to cloud platforms such as AWS using NetApp Cloud Volumes ONTAP.
Windows server failover clustering (WSFC) provides native high availability and disaster recovery for applications and services running on Windows Server instances. Grouping independent server instances with a shared storage platform (typically a shared SAN storage), WSFC acts as an abstraction layer, ensuring that shared storage is accessible to all server instances (nodes) in a failover cluster group without data corruption.
WSFC uses the concept of active/passive nodes, where the active instance having write access and the passive (standby) instance only having read capabilities to the shared data volumes at a given point in time. WSFC also acts as a gatekeeper to monitor the health of the nodes. Should the health of the active node deteriorate, the passive instance is seamlessly given the write capability to the shared data volumes in use by the application or service. See these resources for more details on the WSFC architecture and using failover cluster: SQL Server Failover Introduction and this Intro to Failover Clustering.
WSFC itself guards applications against server/node failures; application use cases that require 100% uptime have typically used WSFC together with the storage high availability (which are usually available through enterprise storage solutions with redundant storage controllers or nodes).
Microsoft Exchange Server and Microsoft SQL Server are examples of two popular applications that are often deployed on WSFC due to their criticality to many organizations. In addition to other Microsoft solutions such as Scale-Out and Clustered Windows File Servers, a number of third-party applications such as Oracle GoldenGate and SAP ASCS/SCS on Windows have also been popular deployments on WSFC in order to achieve high availability. Besides applications, a number of Microsoft Windows and third-party services such as Windows Message Queue (aka, MSMQ) and IBM Message Queue (IBM MQ) have historically also relied on the underlying use of WSFC in order to deploy in a highly available manner.
WSFC has been popular mainly due to its accessibility for the masses. Being natively available within Windows Server itself, any Microsoft customer could easily configure and implement clustering for their supported applications to increase the application uptime. This has reduced the need for additional costs involved with having to utilize third-party clustering solutions, something that also makes WSFC popular within the small- to medium-sized corporate customers around the world.
WSFC on AWS Cloud
Challenges with Windows Server Failover Clustering in AWS
Despite its popularity, deploying clustered applications such as WSFC that typically requires an underlying shared disk storage (such as SAN storage), have not always been possible to be implemented in the AWS cloud. This was mainly due to the lack of such shared storage solutions on AWS, especially if you needed to deploy resilient HA across multiple Availability Zones (AZ). This native platform limitation has presented some challenges, mainly for deployments that require enterprise-grade application node high availability within an AWS region. Such deployments are prevented from being able to deploy or migrate their existing WSFC applications to AWS without re-architecting or incorporating additional data replication software on top of the native AWS EBS storage assigned to individual Amazon EC2 nodes.
In order to address these limitations, AWS recently announced the AWS Multi-Attach EBS storage type. Multi-Attach EBS is intended to provide an AWS-native, shared, block storage solution where provisioned EBS disks can be accessed by multiple AWS EC2 instances at the same time. However, Multi-Attach EBS volumes are subject to a number of limitations today which impacts their use for most common enterprise clustered applications such as those utilizing WSFC. Some of the key limitations to Multi-Attach EBS include limited regional availability, restrictions on the type and number of disks per instance, and the limited compatibility with various EC2 instance types.
Windows Server Failover Clusters with NetApp Cloud Volumes ONTAP
NetApp ONTAP has been behind many enterprise WSFC deployments in the data center for almost three decades as the shared storage platform of choice. NetApp Cloud Volumes ONTAP is a fully fledged version of the same ONTAP software running natively in AWS (as well as in Azure and GCP).
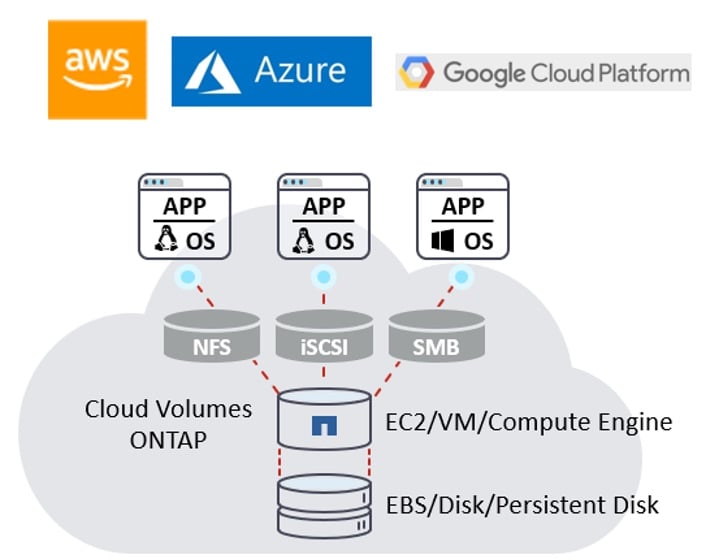
Cloud Volumes ONTAP on AWS runs on native EBS storage volumes and presents that storage as highly available, shared accessible storage in both file (NFS, SMB) as well as block (iSCSI) format to be consumed by various EC2 instances. By design, it delivers extreme performance and advanced data management services to satisfy even the most demanding applications on the cloud. Cloud Volumes ONTAP also enables enterprise customers to provision a unified data storage and management platform spanning multiple AZ’s for enterprise grade storage high availability.
WSFC on AWS with NetApp Cloud Volumes ONTAP iSCSI LUNs
Cloud Volumes ONTAP addresses the challenges customers encounter when planning to deploy or migrate highly available application clusters built on WSFC. iSCSI LUNs provisioned via Cloud Volumes ONTAP offer shared storage volumes that can be presented directly to the guest operating system running inside an AWS EC2 instance. These can then be attached to the Microsoft iSCSI initiator as shared SAN storage for the purpose of deploying a WSFC cluster. These iSCSI LUNs can be used by any EC2 instance of your choice to design and deploy WSFC cluster nodes of any size supporting various deployment choices for SQL, Exchange, SAP, Oracle, and other applications on AWS.
Cloud Volumes ONTAP Multi-AZ High Availability Configuration
Cloud Volumes ONTAP can be deployed in a standalone (inside a single AZ) as well as a HA configuration mode on AWS. The HA deployment can span multiple AZ’s within a region which ensures that the storage platform itself is resilient to data center failures on AWS. Coupled with the ability within WSFC to deploy cluster nodes across multiple AZs within a region, customers can now design extremely highly available enterprise deployments of their critical applications spanning multiple AWS data centers.
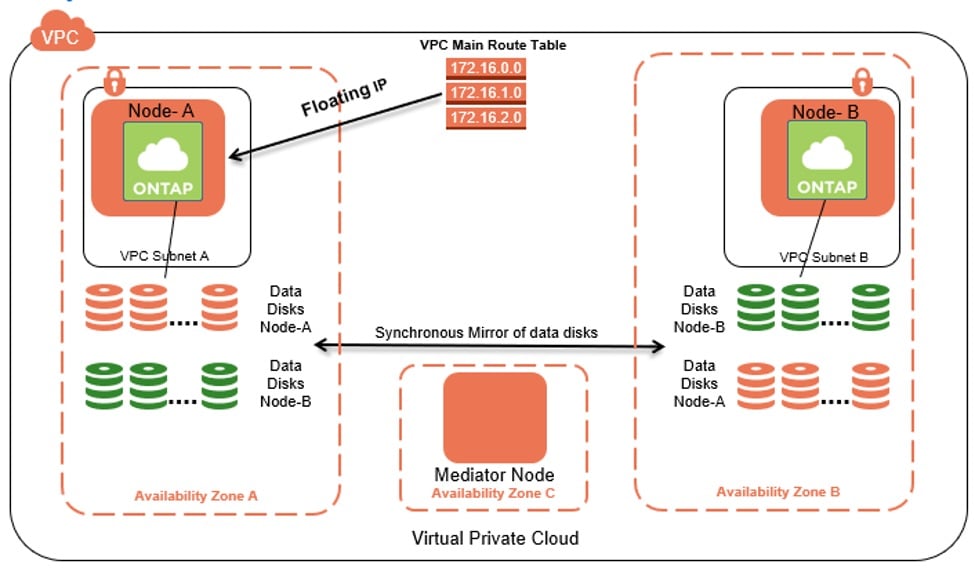
Furthermore, given the enterprise grade availability and data management features natively available within Cloud Volumes ONTAP, WSFC customers on AWS can also benefit from additional capabilities such as low-latency performance, cost effective data protection via built-in NetApp Snapshot™ technology, instant cloning via ONTAP FlexClone®, built in data replication to other regions via ONTAP SnapMirror® for disaster recovery and built in data tiering to Amazon S3 for infrequently used active data.
As a mature, enterprise grade data storage and management solution, Cloud Volumes ONTAP also does not have the sale limitation of AWS multi-attach disks when implementing WSFC. Unlike multi-attach EBS disks, Cloud Volumes ONTAP is not subject to AWS Nitro-based instance limitation and is generally available across most of the AWS regions providing more choice and scalability options to customers. Unlike multi-attach EBS, Cloud Volumes ONTAP iSCSI volumes are also not restricted to Provisioned IOPS SSD (io1) type only and instead can support various AWS storage types including HDD as well as General Purpose SSD (gp2) enabling broader range of TCO optimized use cases with WSFC such as scale-out Windows file servers without the need for expensive EBS storage types. In addition to these, NetApp Cloud Volumes ONTAP also introduces the built in storage efficiency features such as data deduplication and compression, significantly reducing the consumed size of the underlying EBS storage volumes, thereby significantly reducing the TCO for WSFC deployments.
WSFC with Cloud Volumes ONTAP in an AWS High Availability Configuration: An Enterprise Customer Case Study
One company that was able to leverage WSFC with Cloud Volumes ONTAP in AWS is a large business and financial software company that develops and sells financial, accounting, and tax preparation software and has up to 40% of the market share in the US. This company managed to get around the native limitations of implementing WSFC on AWS through the use of NetApp Cloud Volumes ONTAP. This solution succeeded in meeting their cloud migration agenda set out by the executive board.
The customer leveraged iSCSI data LUNs from several Cloud Volumes ONTAP high availability instances with over 1 PB of data to design and deploy a number of clustered Oracle Goldengate instances on AWS with nodes spread across multiple AZ’s for cross site HA. These Oracle Goldengate instances are being used by the organization to replicate data from their on-premises Oracle to AWS RDS as well as to replicate Oracle RDS between different AWS regions.
In addition to these, NetApp Cloud Volumes ONTAP has also provided them with the ability to deploy a number of internal, custom made applications used for various critical internal operations within the organization to AWS cloud in a highly available manner using Microsoft failover clusters. The ability to migrate these applications without application transformation has saved them significant cloud migration costs and meet vital project deadlines.
The SVP for the company wrote:
“This is an amazing cross-functional, and complex infrastructure engineering accomplishment, enabling our aggressive goals of migration of all systems by solving problems where AWS is not ready. Moving to AWS would not have been possible if we didn’t have Cloud Volumes ONTAP iSCSI.”
Conclusion
NetApp Cloud Volumes ONTAP brings decades of storage innovation and experience along with a rich set of data services on to AWS so that technologies such as Windows Server Failover Clustering can be implemented on AWS seamlessly for critical enterprise applications.
Customers can also benefit from a number of additional benefits such as cloud data storage cost efficiency and data management services inherent to Cloud Volumes ONTAP ensuring customers meet their enterprise data availability requirements without the need to sacrifice the TCO efficiency.

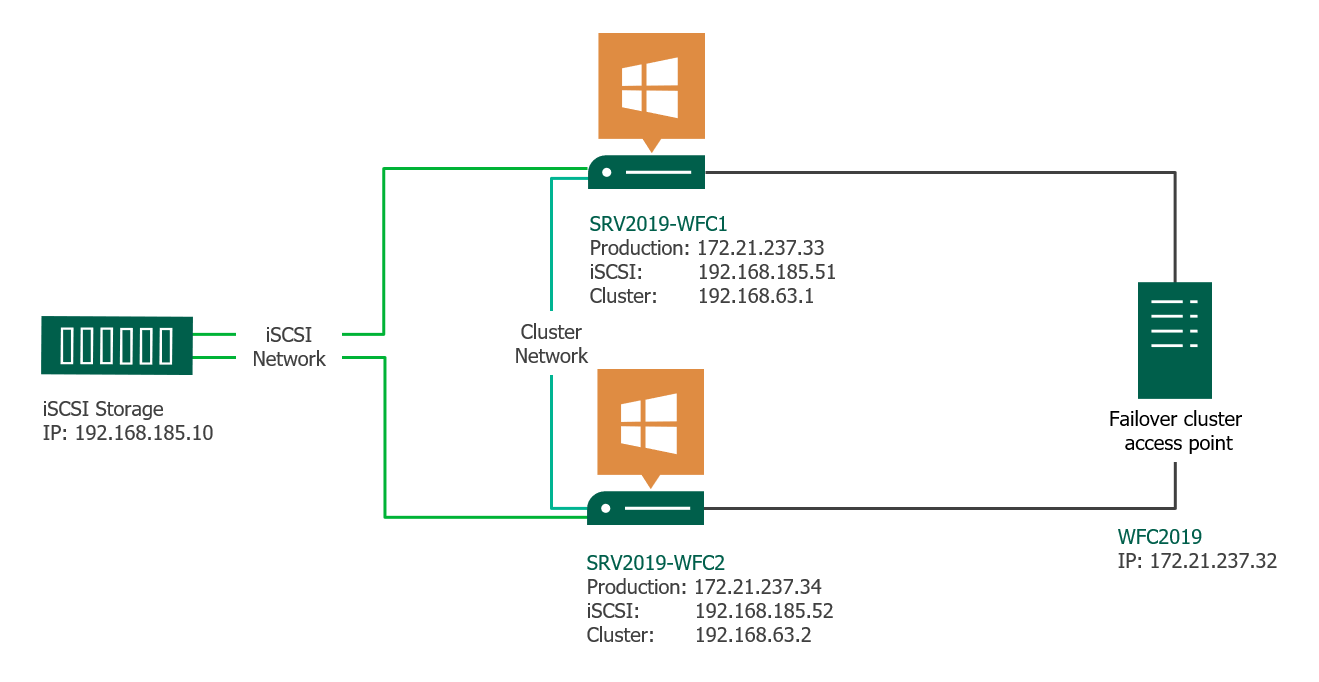
This article gives a short overview of how to create a Microsoft Windows Failover Cluster (WFC) with Windows Server 2019 or 2016. The result will be a two-node cluster with one shared disk and a cluster compute resource (computer object in Active Directory).
Preparation
It does not matter whether you use physical or virtual machines, just make sure your technology is suitable for Windows clusters. Before you start, make sure you meet the following prerequisites:
Two Windows 2019 machines with the latest updates installed. The machines have at least two network interfaces: one for production traffic, one for cluster traffic. In my example, there are three network interfaces (one additional for iSCSI traffic). I prefer static IP addresses, but you can also use DHCP.
Join both servers to your Microsoft Active Directory domain and make sure that both servers see the shared storage device available in disk management. Don’t bring the disk online yet.
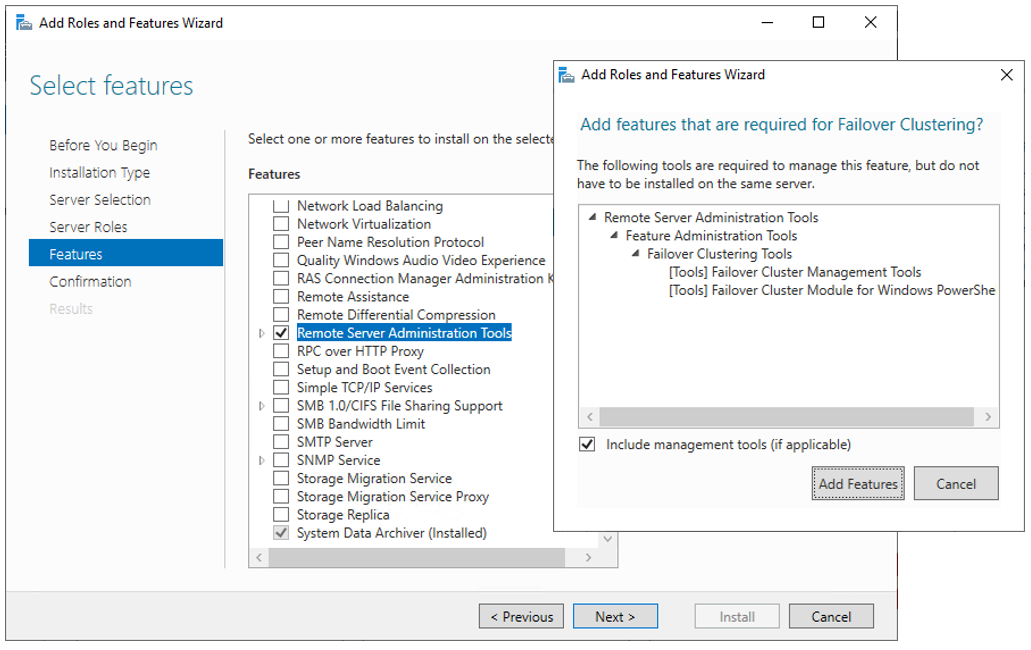
The next step before we can really start is to add the Failover clustering feature (Server Manager > add roles and features).
Reboot your server if required. As an alternative, you can also use the following PowerShell command:
Install-WindowsFeature -Name Failover-Clustering –IncludeManagementTools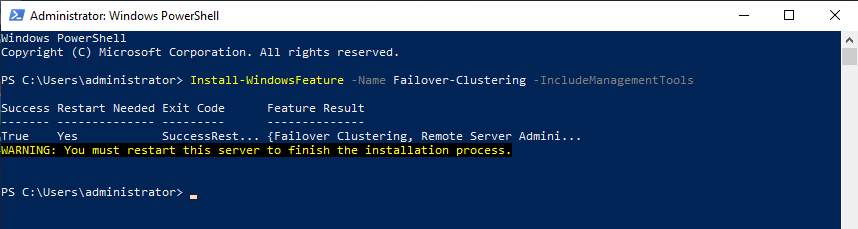
After a successful installation, the Failover Cluster Manager appears in the start menu in the Windows Administrative Tools.
After you installed the Failover-Clustering feature, you can bring the shared disk online and format it on one of the servers. Don’t change anything on the second server. On the second server, the disk stays offline.
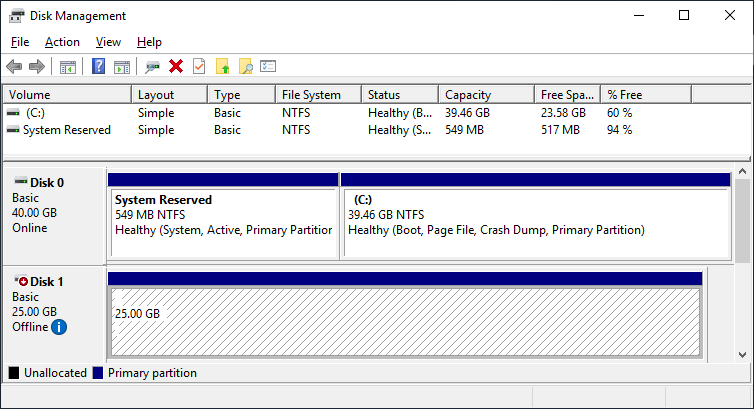
After a refresh of the disk management, you can see something similar to this:
Server 1 Disk Management (disk status online)
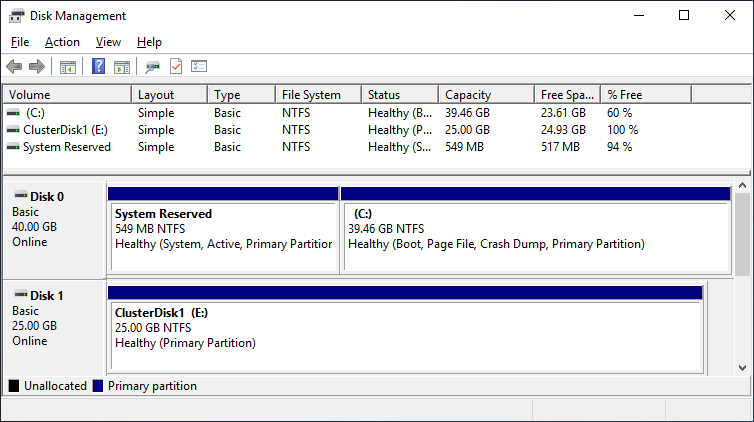
Server 2 Disk Management (disk status offline)
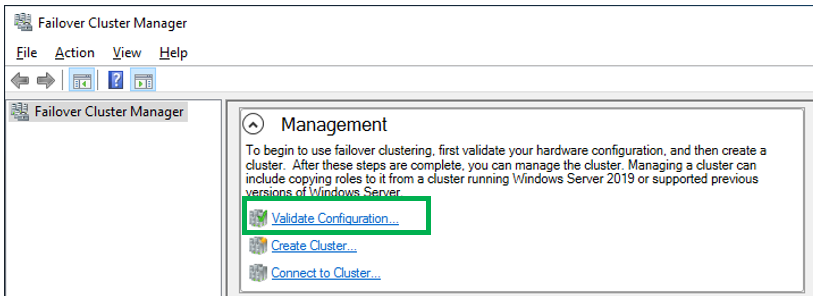
Failover Cluster readiness check
Before we create the cluster, we need to make sure that everything is set up properly. Start the Failover Cluster Manager from the start menu and scroll down to the management section and click Validate Configuration.
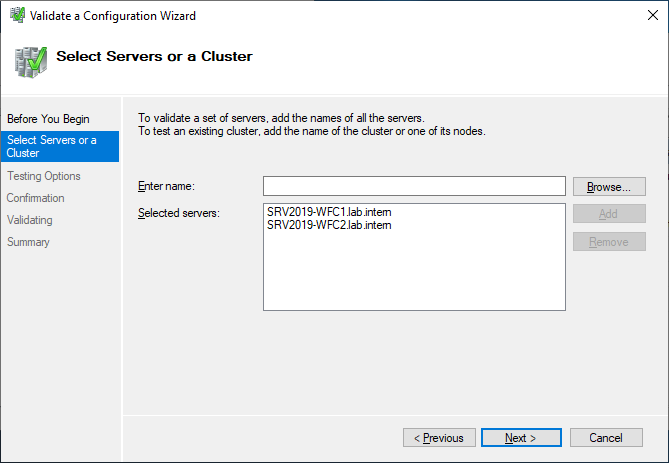
Select the two servers for validation.
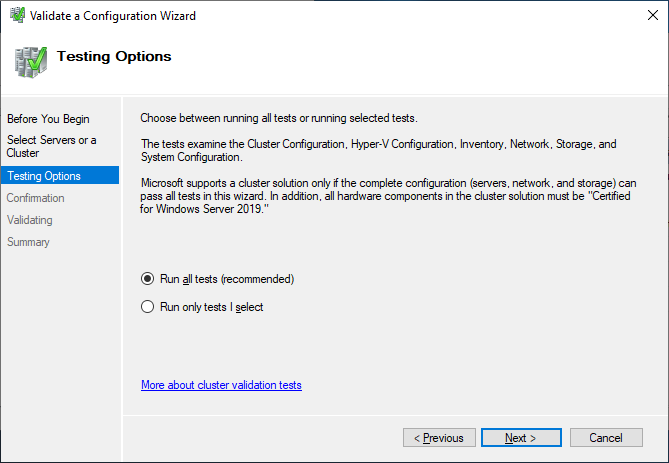
Run all tests. There is also a description of which solutions Microsoft supports.
After you made sure that every applicable test passed with the status “successful,” you can create the cluster by using the checkbox Create the cluster now using the validated nodes, or you can do that later. If you have errors or warnings, you can use the detailed report by clicking on View Report.
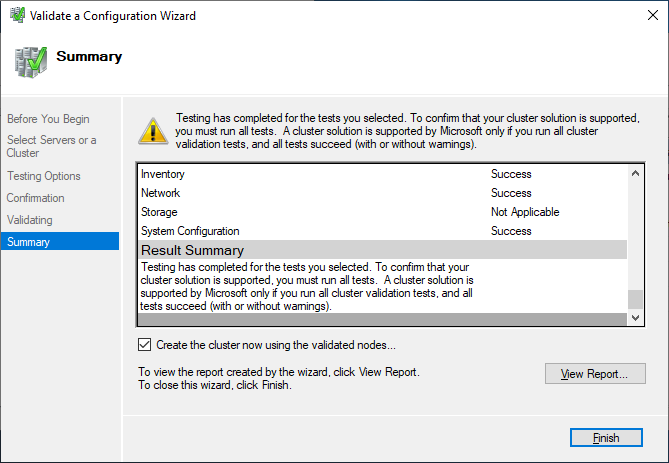
If you choose to create the cluster by clicking on Create Cluster in the Failover Cluster Manager, you will be prompted again to select the cluster nodes. If you use the Create the cluster now using the validated nodes checkbox from the cluster validation wizard, then you will skip that step. The next relevant step is to create the Access Point for Administering the Cluster. This will be the virtual object that clients will communicate with later. It is a computer object in Active Directory.
The wizard asks for the Cluster Name and IP address configuration.
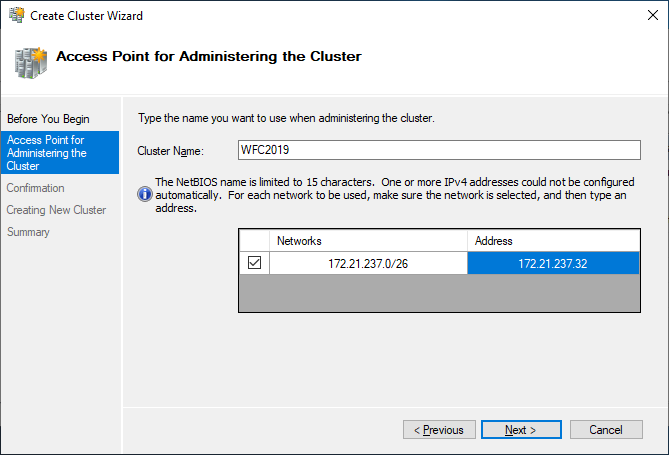
As a last step, confirm everything and wait for the cluster to be created.
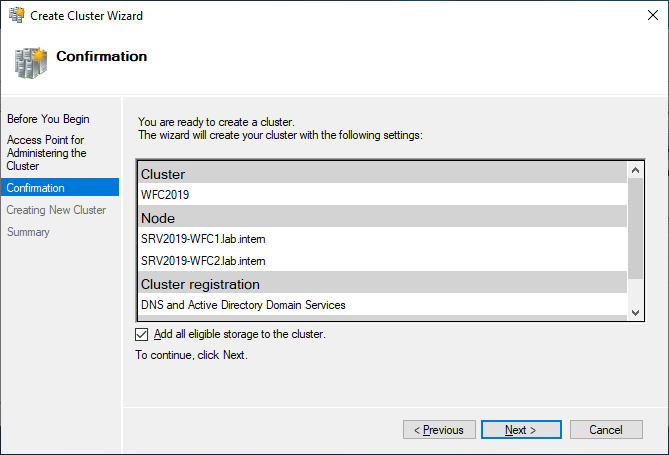
The wizard will add the shared disk automatically to the cluster per default. If you did not configure it yet, then it is also possible afterwards.
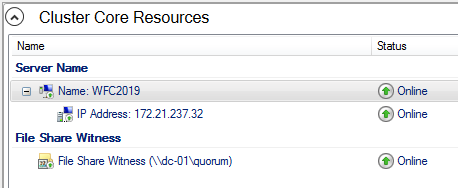
As a result, you can see a new Active Directory computer object named WFC2019.

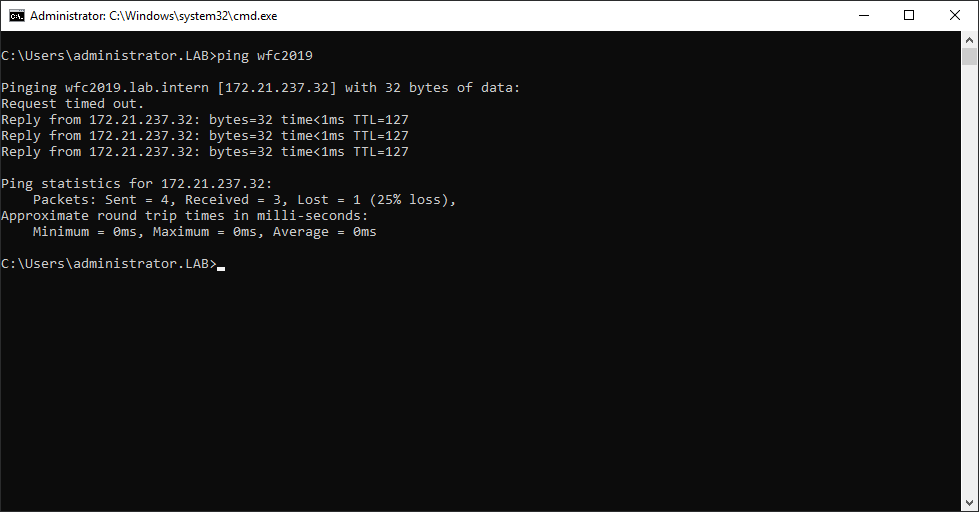
You can ping the new computer to check whether it is online (if you allow ping on the Windows firewall).
As an alternative, you can create the cluster also with PowerShell. The following command will also add all eligible storage automatically:
New-Cluster -Name WFC2019 -Node SRV2019-WFC1, SRV2019-WFC2 -StaticAddress 172.21.237.32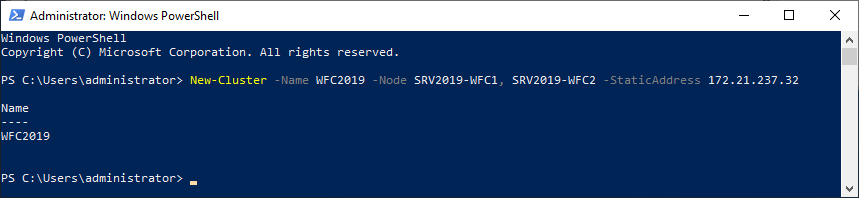
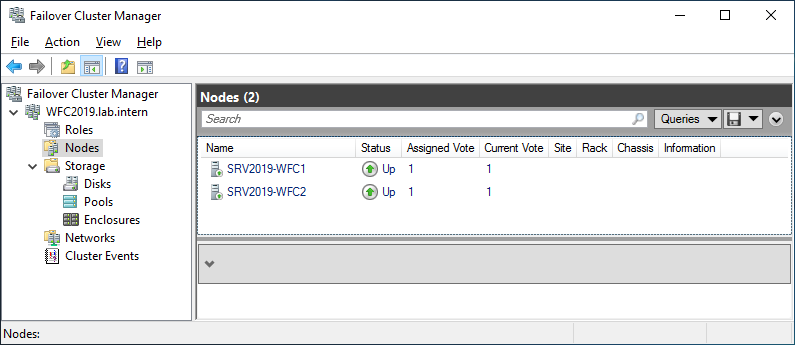
You can see the result in the Failover Cluster Manager in the Nodes and Storage > Disks sections.
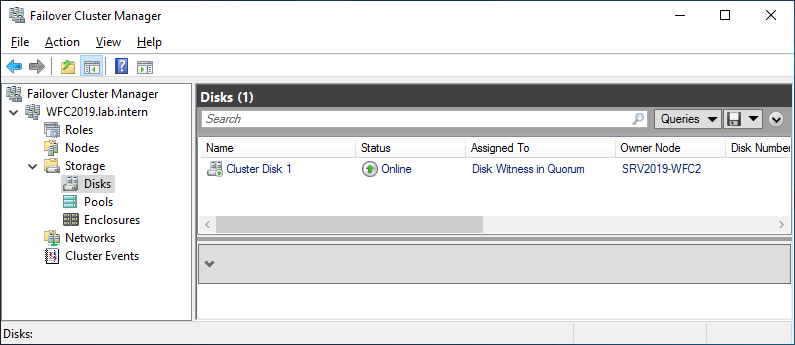
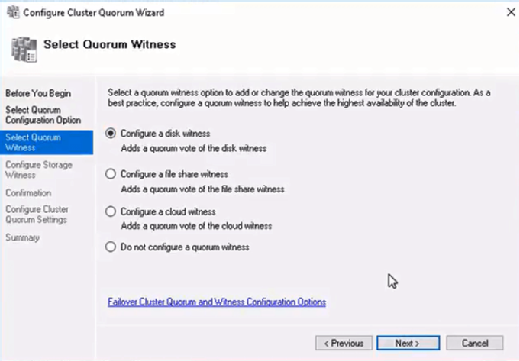
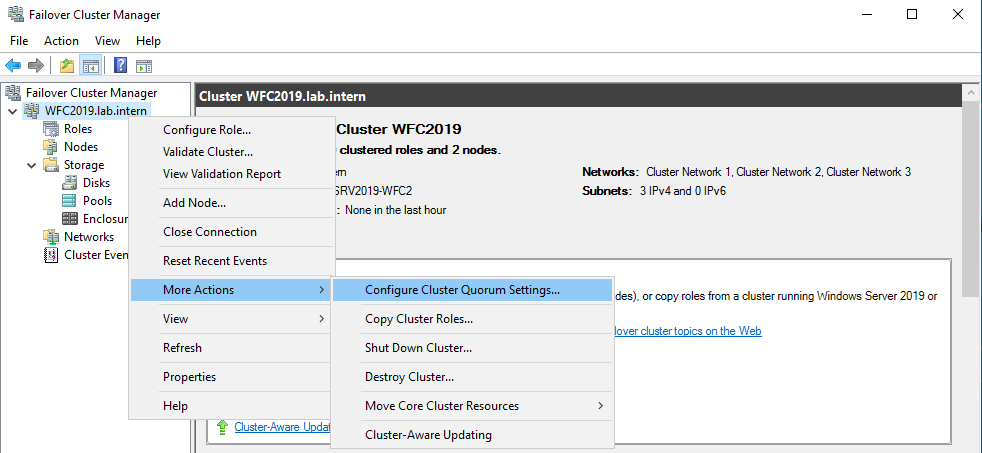
The picture shows that the disk is currently used as a quorum. As we want to use that disk for data, we need to configure the quorum manually. From the cluster context menu, choose More Actions > Configure Cluster Quorum Settings.
Here, we want to select the quorum witness manually.
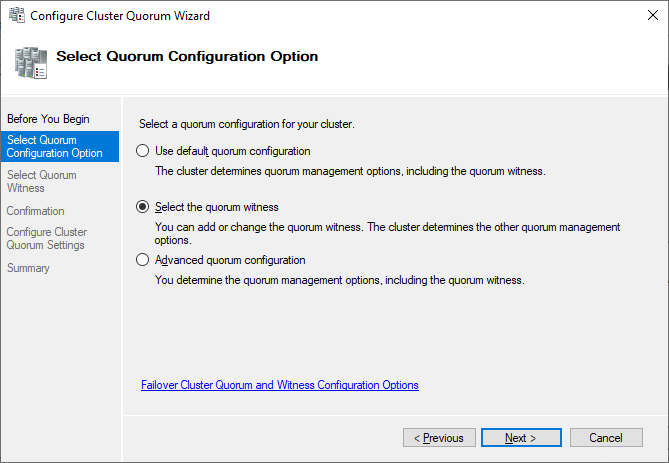
Currently, the cluster is using the disk configured earlier as a disk witness. Alternative options are the file share witness or an Azure storage account as witness. We will use the file share witness in this example. There is a step-by-step how-to on the Microsoft website for the cloud witness. I always recommend configuring a quorum witness for proper operations. So, the last option is not really an option for production.
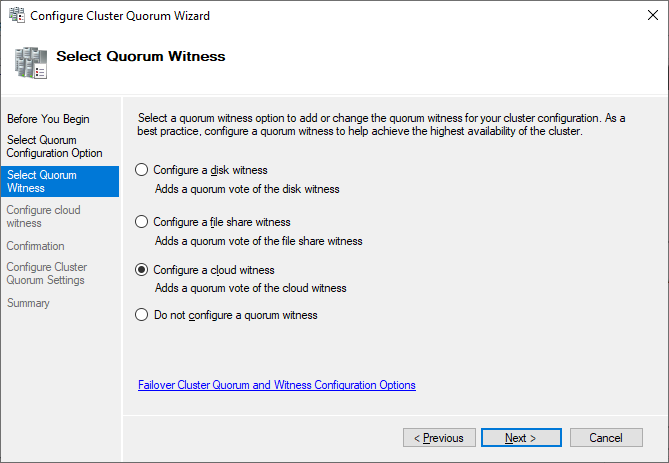
Just point to the path and finish the wizard.
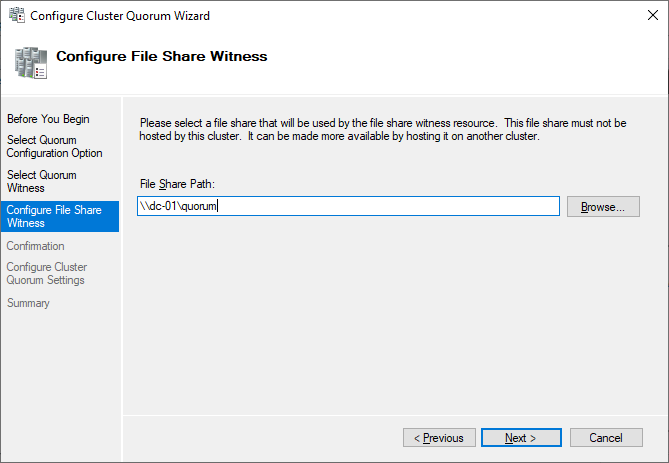
After that, the shared disk is available for use for data.
Congratulations, you have set up a Microsoft failover cluster with one shared disk.
Next steps and backup
One of the next steps would be to add a role to the cluster, which is out of scope of this article. As soon as the cluster contains data, it is also time to think about backing up the cluster. Veeam Agent for Microsoft Windows can back up Windows failover clusters with shared disks. We also recommend doing backups of the “entire system” of the cluster. This also backs up the operating systems of the cluster members. This helps to speed up restore of a failed cluster node, as you don’t need to search for drivers, etc. in case of a restore.
See More:
- On-Demand Sessions from VeeamON Virtual
ServerWatch content and product recommendations are editorially independent. We may make money when you click on links to our partners. Learn More.
A failover cluster is a set of computer servers that work together to provide either high availability (HA) or continuous availability (CA). If one of the servers goes down, another node in the cluster can assume its workload with either minimum or no downtime through a process referred to as failover.
Some failover clusters use physical servers only, whereas others involve virtual machines (VMs).
The main purpose of a failover cluster is to provide either CA or HA for applications and services. Also referred to as fault tolerant (FT) clusters, CA clusters allow end users to keep utilizing applications and services without experiencing any timeouts if a server fails. HA clusters might cause a brief interruption in service for customers, but the system will recover automatically with no data loss and minimum downtime.
A cluster is made up of two or more nodes—or servers—that transfer data and software to process the data through physical cables or a dedicated secure network. Other kinds of clustering technology can be used for load balancing, storage, and concurrent or parallel processing. Some implementations combine failover clusters with additional clustering technology.

To protect your data, a dedicated network connects the failover cluster nodes, providing essential CA or HA backup.
How Failover Clusters Work
While CA failover clusters are designed for 100 percent availability, HA clusters attempt 99.999 percent availability—also known as “five nines.” This downtime amounts to no more than 5.26 minutes yearly. CA clusters offer greater availability, but they require more hardware to run, which increases their overall cost.
High Availability Failover Clusters
In a high availability cluster, groups of independent servers share resources and data throughout the system. All nodes in a failover cluster have access to shared storage. High availability clusters also include a monitoring connection that servers use to check the “heartbeat” or health of the other servers. At any time, a least one of the nodes in a cluster is active, while at least one is passive.
In a simple two-node configuration, for example, if Node 1 fails, Node 2 uses the heartbeat connection to recognize the failure and then configures itself as the active node. Clustering software installed on every node in the cluster makes sure that clients connect to an active node.
Larger configurations may use dedicated servers to perform cluster management. A cluster management server constantly sends out heartbeat signals to determine if any of the nodes are failing, and if so, to direct another node to assume the load.
Some cluster management software provides HA for virtual machines (VMs) by pooling the machines and the physical servers they reside on into a cluster. If failure occurs, the VMs on the failed host are restarted on alternate hosts.
Shared storage does pose a risk as a potential single point of failure. However, the use of RAID 6 together with RAID 10 can help to ensure that service will continue even if two hard drives fail.
If all servers are plugged into the same power grid, electrical power can represent another single point of failure. The nodes can be safeguarded by equipping each with a separate uninterruptible power supply (UPS).
Continuous Availability Failover Clusters
In contrast to the HA model, a fault-tolerant cluster consists of multiple systems that share a single copy of a computer’s OS. Software commands issued by one system are also executed on the other systems.
CA requires the organization to use formatted computer equipment and a secondary UPS. In a CA failover cluster, the operating system (OS) has an interface where a software programmer can check critical data at predetermined points in a transaction. CA can only be achieved by using a continuously available and nearly exact copy of a physical or virtual machine running the service. This redundancy model is called 2N.
CA systems can compensate for many different sorts of failures. A fault tolerant system can automatically detect a failure of
- A hard drive
- A computer processor unit
- A I/O subsystem
- A power supply
- A network component
The failure point can be immediately identified, and a backup component or procedure can take its place instantly without interruption in service.
Clustering software can be used to group together two or more servers to act as a single virtual server, or you can create many other CA failover setups. For example, a cluster might be configured so that if one of the virtual servers fails, the others respond by temporarily removing the virtual server from the cluster. It then automatically redistributes the workload among the remaining servers until the downed server is ready to go online again.
An alternative to CA failover clusters is use of a “double” hardware server in which all physical components are duplicated. These servers perform calculations independently and simultaneously on the separate hardware systems. These “double” hardware systems perform synchronization by using a dedicated node that monitors the results coming from both physical servers. While this provides security, this option can be even more expensive than other options. Stratus, a maker of these specialized fault tolerant hardware servers, promises that system downtime won’t amount to more than 32 seconds each year. However, the cost of one Stratus server with dual CPUs for each synchronized module is estimated at approximately $160,000 per synchronized nodule.
Practical Applications of Failover Clusters
Ongoing Availability of Mission Critical Applications
Fault tolerant systems are a necessity for computers used in online transaction processing (OLTP) systems. OLTP, which demands 100 percent availability, is used in airline reservations systems, electronic stock trading, and ATM banking, for example.
Many other types of organizations also use either CA clusters or fault tolerant computers for mission critical applications, such as businesses in the fields of manufacturing, logistics, and retail. Applications include e-commerce, order management, and employee time clock systems.
For clustering applications and services requiring only “five nines” uptime, high availability clusters are generally regarded as adequate.
Disaster Recovery
Disaster recovery is another practical application for failover clusters. Of course, it’s highly advisable for failover servers to be housed at remote sites in the event that a disaster such as a fire or flood takes out all physical hardware and software in the primary data center.
In Windows Server 2016 and 2019, for example, Microsoft provides Storage Replica, a technology that replicates volumes between servers for disaster recovery. The technology includes a stretch failover feature for failover clusters spanning two geographic sites.
By stretching failover clusters, organizations can replicate among multiple data centers. If a disaster strikes at one location, all data continues to exist on failover servers at other sites.
Database Replication
According to Microsoft, the company originally introduced Windows Server Failover Cluster (WSFC) in Windows Server 2016 to protect “mission-critical” applications such as its SQL Server database and Microsoft Exchange communications server.
Other database providers offer failover cluster technology for database replication. MySQL Cluster, for example, includes a heartbeat mechanism for instant failure detection, typically within one second, to other nodes in the cluster with no service interruptions to clients. A geographic replication feature enables databases to be mirrored to remote locations.
Failover Cluster Types
VMWare Failover Clusters
Among the virtualization products available, VMware offers several virtualization tools for VM clusters. vSphere vMotion provides a CA architecture that exactly replicates a VMware virtual machine and its network between physical data center networks.
A second product, VMware vSphere HA, provides HA for VMs by pooling them and their hosts into a cluster for automatic failover. The tool also does not rely on external components like DNS, which reduces potential points of failure.
Windows Server Failover Cluster (WSFC)
You can create Hyper-V failover servers with the use of WFSC, a feature in Windows 2016 and 2019 that monitors clustered physical servers, providing failover if needed. WFSC also monitors clustered roles, formerly referred to as clustered applications and services. If a clustered role isn’t working correctly, it is either restarted or moved to another node.
WFSC includes Microsoft’s previous Cluster Shared Volume (CSV) technology to provide a consistent, distributed namespace for accessing shared storage from all nodes. In addition, WSFC supports CA file share storage for SQL Server and Microsoft Hyper-V cluster VMs. It also supports HA roles running on physical servers and Hyper-V cluster VMs.
SQL Server Failover Clusters
In SQL Server 2017, Microsoft introduced Always On, an HA solution that uses WSFC as a platform technology, registering SQL Server components as WSFC cluster resources. According to Microsoft, related resources are combined into a role which is dependent on other WSFC resources. WSFC can then identify and communicate the need to either restart a SQL Server instance or automatically fail it over to a different node.
Red Hat Linux Failover Clusters
OS makers other than Microsoft also provide their own failover cluster technologies. For example, Red Hat Enterprise Linux (RHEL) users can create HA failover clusters with the High Availability Add-On and Red Hat Global File System (GFS/GFS2). Support is provided for single-cluster stretch clusters spanning multiple sites as well as multi-site of “disaster-tolerant” clusters. The multi-site clusters generally use storage area network (SAN)-enabled data storage replication.