Вы узнаете, как архивировать практически любой богатый информацией сайт для создания автономной версии для себя. Бесплатная, кроссплатформенная утилита командной строки wget может загрузить весь веб-сайт. Статья проведет вас через весь процесс. Я начну с нуля, а затем перейду к подробным примерам выбранных настроек, чтобы получить превосходный архив после обработки. После прочтения этого урока он станет намного менее пугающим, чем кажется.
Почему вы хотите это сделать?
Вопреки распространенному мнению, не все в Интернете существует всегда. Сайты закрываются, подвергаются цензуре, приобретаются, перепроектируются или просто теряются. Эта идея исходит от сообщества накопителей данных в Reddit, где процесс создания архивов для развлечения не является чем-то новым. Хотя мы не можем предсказать или предотвратить катастрофическое событие на нашем любимом веб-сайте, мы, несомненно, можем сохранить его в нынешнем виде .
Есть много возможных применений и причин, по которым можно скачать весь сайт. Неважно, является ли целевой сайт вашим или нет. На заметку, будьте осторожны с тем, что вы загружаете Возможно, вы хотите сохранить эпоху сайта с особым дизайном. Может быть, вы хотите взять информативный веб-сайт с собой в место без интернета. Этот метод может гарантировать, что сайт останется с вами.
Как это работает?
Wget будет начинать с определенного URL и посещать каждую ссылку, возвращаясь к бесконечной глубине. В конечном итоге он может сканировать весь сайт. То, как я его настроил, гарантирует, что он будет загружать только весь сайт, а не весь интернет – случайно . Другими словами, он не будет бродить по внешним сайтам и ничего не загружать с них. Вы получите все активы, такие как JS, CSS и изображения. Конечно, и все внутренние ссылки будут преобразованы в относительные ссылки. Последнее имеет жизненно важное значение для просмотра в автономном режиме копии, а исключенные или внешние ссылки остаются неизменными.
Обратите внимание, что архив не является резервной копией, и вы не можете восстановить свой сайт из него. Описанный метод использует обход контента, как и поисковая система. Он найдет только те страницы, на которые ссылаются другие. Как побочный эффект, вы увидите важность использования внутренних ссылок на сайте для соединения фрагментов контента, чтобы помочь роботам сканировать ваш сайт.
Я знаю, что это не относится строго к WordPress, но работает исключительно хорошо с блогами, использующими эту платформу. Тот факт, что блоггер использует некоторые стандартные виджеты WordPress на боковой панели (например, ежемесячный архив или облако тегов), очень помогает ботам.
Настройка wget в Windows
В то время как субкультура, использующая wget ежедневно, сильно ориентирована на Unix, использование wget в Windows немного более необычно. Если вы попытаетесь найти его и вслепую загрузить с официального сайта, вы получите кучу исходных файлов, а не файл .exe. Средний пользователь Windows хочет двоичные файлы , поэтому:
- Получите последнюю версию wget для Windows, выберите zip-версию последней версии и распакуйте ее куда-нибудь. Я использую папку для переносимого программного обеспечения, так как это не требует установки.
Если вы попытаетесь открыть файл .exe, скорее всего, ничего не произойдет, просто вспышка командной строки. Я хочу получить доступ к этому wget.exe, имея открытую командную строку в папке, в которую я буду загружать весь архив веб-сайта. Нецелесообразно перемещать .exe туда и копировать его в любую другую папку архива в будущем, поэтому я хочу, чтобы он был доступен для всей системы . Поэтому я «регистрирую» его, добавляя в переменные среды Windows.
"C:Windowssystem32rundll32.exe" sysdm.cpl,EditEnvironmentVariables- Нажмите Windows + R, вставьте указанную выше строку и нажмите Enter
- Под Пользовательскими переменными найдите Путь и нажмите Редактировать…
- Нажмите New и добавьте полный путь к тому месту, куда вы извлекли wget.exe
- Нажмите ОК, ОК, чтобы закрыть все
Чтобы убедиться, что он работает, снова нажмите Windows+ Rи вставьте cmd /k "wget -V"– он не должен сказать, что «wget» не распознан

Настройка wget для загрузки всего сайта
Большинство настроек имеют короткую версию, но я не собираюсь их запоминать или вводить. Более длинное имя, вероятно, более значимое и узнаваемое. Я выбрал эти конкретные настройки из подробного руководства по wget, так что вам не нужно погружаться слишком глубоко, так как это относительно длинное чтение. Проверьте официальное описание этих настроек, если хотите, так как здесь я только разделяю свое мнение и почему я их выбрал. В порядке важности, вот они.
Настройки для использования
--mirror
Это набор других специфических настроек, все, что вам нужно знать, это волшебное слово, которое позволяет бесконечное сканирование рекурсии. Звучит необычно? Потому что это! Без этого вы не сможете скачать весь сайт, потому что у вас, вероятно, нет списка каждой статьи.
--page-requisites
При этом wget загружает все ресурсы, на которые ссылаются страницы, такие как CSS, JS и изображения. Это важно использовать, иначе ваш архив будет очень поврежден.
--convert-links
Это позволяет просматривать ваш архив локально. Это влияет на каждую ссылку, которая указывает на страницу, которая будет загружена.
--adjust-extension
Представьте, что вы сделали все возможное, чтобы загрузить весь веб-сайт, чтобы получить неиспользуемые данные. Если файлы не заканчиваются в своих естественных расширениях, вы или ваш браузер не сможете их открыть. В настоящее время большинство ссылок не содержат суффикс .html, хотя они должны быть .html файлами при загрузке. Этот параметр помогает вам открывать страницы, не размещая архив на сервере. Небольшое предостережение в том, что оно пытается быть умным, чтобы определить, какое расширение использовать, и оно не идеально. Если вы не используете следующую настройку, контент, отправляемый через gzip, может закончиться довольно непригодным расширением .gz.
--compression=auto
Я обнаружил, что при работе с ресурсами, сжатыми gzip, такими как изображение SVG, отправленное сервером, это исключает возможность загрузки, такого контента как logo.svg.gz, который практически невозможно загрузить локально. Объединить с предыдущей настройкой. Обратите внимание, что если вы используете Unix, этот переключатель может отсутствовать в вашем wget, даже если вы используете последнюю версию. Подробнее на Как может отсутствовать сжатие в моем wget?
--reject-regex "/search|/rss"
Боты могут сойти с ума, когда они достигают интерактивных частей веб-сайтов и находят странные запросы для поиска. Вы можете отклонить любой URL, содержащий определенные слова, чтобы предотвратить загрузку определенных частей сайта . Скорее всего, вы обнаружите только то, что должны были удалить после того, как wget потерпит неудачу хотя бы один раз. Для меня это породило слишком длинные имена файлов, и все это застыло. Хотя статьи на сайте имеют хорошие короткие URL-адреса, длинная строка запроса в URL-адресе может привести к длинным именам файлов. Регулярное выражение здесь является «основным» регулярным выражением POSIX.так что я бы не стал зацикливаться на правилах. Кроме того, это довольно сложно проверить методом проб и ошибок. Одна хитрость заключается в том, что шаблон / поиск будет даже соответствовать законной статье с URL yoursite.com/search-for-extraterrestrial-life или аналогичным. Если это проблема, то будьте более конкретны.
Дополнительные настройки
--no-if-modified-since
Я включаю его только когда сталкиваюсь с сервером, на котором wget жаловался на то, что мне следует использовать это. Я не собираюсь перезапускать процесс позже в той же папке, чтобы догнать текущий сайт. Следовательно, не имеет большого значения, как wget проверяет, изменились ли файлы на сервере.
--no-check-certificate
Проверка сертификатов SSL не является критически важной задачей . Это предотвращает некоторые головные боли, когда вы заботитесь только о загрузке всего сайта без входа в систему.
--user-agent
--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"Некоторые хосты могут обнаружить, что вы используете wget для загрузки всего сайта и полностью блокируете вас. Спуфинг агента пользователя приятно замаскировать эту процедуру как обычного пользователя Chrome. Если сайт блокирует ваш IP, следующим шагом будет продолжение работы через VPN и использование нескольких виртуальных машин для загрузки стратифицированных частей целевого сайта (ой). Возможно, вы захотите проверить --waitи --random-waitварианты, если ваш сервер умный, и вам нужно замедлить и задержать запросы.
--restrict-file-names=windows
В Windows это автоматически используется для ограничения символов файлов архива безопасными для Windows. Однако, если вы работаете в Unix, но планируете просмотреть позже в Windows, то вы хотите явно использовать этот параметр. Unix более простителен для специальных символов в именах файлов .
--backup-converted
Стоит упомянуть, поскольку он будет сохранять оригинальную копию каждого файла, в который wget конвертировал ссылку . Это может почти удвоить ваш архив и требует очистки, если вы уверены, что все в порядке. Я бы не стал этим пользоваться.
Открытие командной строки в нужном месте
Вам нужно будет запустить wget из командной строки, которая работает с папкой, в которую вы собираетесь загрузить весь сайт. Для этого есть несколько способов, начиная с самого стандартного:
- Вы знаете тренировку: Windows+ Rи напишите
cmdи нажмитеEnter - Тип,
cd /d C:archive folderгде/dкоммутатор позволяет менять диски, а последний – путь к архиву.
Если вы хотите узнать, как cdработает, введите help cdзапрос. В некоторых конфигурациях необходимо заключать путь в кавычки, если он имеет пробел.
Дополнительные способы
- Чтобы сделать это за меньшее количество шагов: Windows+ R затем
cmd /k "cd /d C:archive folder" - Если вы используете Total Commander, откройте меню «Команды»> «Запустить командную оболочку».
- Получите запись «Открыть командное окно здесь» в контекстном меню проводника, используя файл .reg.
Запуск загрузки
Как только я объединю все варианты, у меня появляется этот монстр . Это можно выразить более лаконично, используя варианты с одной буквой. Тем не менее, я хотел, чтобы его было легко модифицировать, сохраняя длинные имена опций, чтобы вы могли интерпретировать, какие они есть.
wget --mirror --page-requisites --convert-links --adjust-extension --compression=auto --reject-regex "/search|/rss" --no-if-modified-since --no-check-certificate --user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36" https://yoursite.comОсталось только запустить эту команду для загрузки всего сайта. Приспособьте это к своим потребностям: по крайней мере измените URL в конце этого. Будьте готовы, что это может занять часы, даже дни – в зависимости от размера целевого сайта. И вы не видите прогресса, так как только задним числом можно понять размер архива.
Я не шучу, когда предупреждаю о множестве маленьких файлов.

На больших сайтах с десятками или даже сотнями тысяч файлов, статей, вы можете сохранить их на SSD до завершения процесса, чтобы не допустить уничтожения вашего жесткого диска. Они лучше справляются со многими небольшими файлами. Я рекомендую стабильное подключение к Интернету (желательно не беспроводное) вместе с компьютером, который может обеспечить необходимое время безотказной работы. Приближаясь к завершению, вы увидите, что wget конвертирует ссылки в файлы. Что-то вроде:
Converted links in 35862 files in 187 seconds.После этого вы должны получить обратно командную строку со строкой ввода. Если он останавливается рано, желательно изменить настройки и начать все заново в пустой папке.
Постобработка архива
К сожалению, ни одна автоматизированная система не является идеальной, особенно если ваша цель – загрузить весь сайт. Вы можете столкнуться с некоторыми небольшими проблемами. Откройте заархивированную версию страницы и сравните ее рядом с живой. Там не должно быть существенных различий. Я удовлетворен, если весь текстовый контент там с изображениями. Гораздо меньше волнует, работают ли динамические части или нет. Здесь я рассматриваю наихудший сценарий, когда изображения отсутствуют.
Современные сайты используют srcsetатрибут и тег для загрузки адаптивных изображений. Хотя wget постоянно совершенствуется, его возможности отстают от передовых технологий современного Интернета. Хотя в wget версии 1.18 добавлена поддержка, ей не нравится более экзотическая комбинация тегов. Это приводит к тому, что wget только находит запасное изображение в теге img, а не в любом из исходных тегов. Он не загружает их и не затрагивает их URL. Обходной путь для этого состоит в массовом поиске и замене (удалении) этих тегов, поэтому резервное изображение все еще может появиться.<picture> ... </picture>srcset``<picture> <source> <img> </picture>
- Получить последнюю версию grepWin – я рекомендую портативную версию.
- Добавить папку архива в Поиск в
- Выберите Regex search и Search для:
<source media=".*"> - Добавить
*.htmlв имена файлов совпадают: - Нажмите « Заменить» (вы можете проверить, что он что-то находит с помощью функции « Поиск» )
Вы можете использовать grepWin как, чтобы исправить другие повторяющиеся проблемы . Одна статья не может подготовить вас ко всему и не научит вас регулярным выражениям (подсказка: в них нет ничего регулярного ). Таким образом, этот раздел просто дает вам представление о корректировке результатов. Подход Windows не подходит для расширенной пост-обработки. В Unix-подобных системах есть более удобные инструменты для массовой обработки текста, такие как sed и оригинальный grep .
Возможная альтернатива без рекурсивной загрузки
Если вы хотите загрузить значительную часть сайта со всеми упомянутыми преимуществами, но без рекурсивного сканирования, вот другое решение. Wget может принять список ссылок для автономного использования. Как вы пришли к этому списку, зависит от вас, но вот идея.
Используйте расширенный поиск Google особым образом, чтобы определить страницы, которые вам нравятся, с целевого сайта. Примером поиска может быть site:yoursite.com "About John Doe"возвращение проиндексированных сообщений, написанных этим Автором (если на месте нет способа добраться до этого списка). Предполагается, что под статьей есть поле об этом авторе. Временно изменяя страницу результатов поиска Google, чтобы отображать до 100 результатов на страницу, в сочетании с таким расширением, как Copy Links for Chrome, вы можете быстро собрать свой список.
wget --input-file=links.txt --page-requisites --convert-links --adjust-extension --compression=auto --no-if-modified-since --no-check-certificate --user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"Я добавил --input-file=links.txtпри сбросе --mirror --reject-regexнастроек.
Заключительные мысли
Теперь, когда у вас есть некоторое представление о том, как загрузить весь веб-сайт, вы можете узнать, как обращаться с таким архивом. Множество крошечных файлов – это смерть многих систем, а это означает, что их передача, резервное копирование или проверка на вирусы будут крайне медленными , особенно если вы не храните их на SSD. Если вы не хотите активно просматривать архив, я рекомендую сжать его. Основная причина не в космических требованиях. Наличие архива в виде одного большого файла или серии больших файлов делает его более управляемым. Вы можете использовать RAR’s Store или метод Fastest Compression для быстрого создания пакета. Если контент в основном не текстовый, он может не выиграть от дополнительного сжатия. Наличие записи восстановления в архиве RAR (не добавлен по умолчанию) помогает в случае аппаратных сбоев, таких как сбойные сектора или другие повреждения данных во время хранения или передачи.
Использовать ваш архив довольно просто, просто откройте любой HTML- файл и начните просмотр сайта. Внешние ресурсы, такие как кнопки социальных сетей, будут по-прежнему загружаться из своего исходного местоположения. В случае, если вы действительно просматриваете в автономном режиме, они не смогут загрузить. Надеюсь, они не будут слишком сильно мешать вашему опыту.
Пожалуйста, поймите, что каждый сервер отличается и то, что работает на одном, может быть совершенно не так для другого. Это отправная точка. Существует еще много информации об архивации сайтов. Удачи вам в накоплении данных!
Источник записи: https://letswp.io
What does WGET Do?
Once installed, the WGET command allows you to download files over the TCP/IP protocols: FTP, HTTP and HTTPS.
If you’re a Linux or Mac user, WGET is either already included in the package you’re running or it’s a trivial case of installing from whatever repository you prefer with a single command.
Unfortunately, it’s not quite that simple in Windows (although it’s still very easy!).
To run WGET you need to download, unzip and install manually.
Install WGET in Windows 10
Download the classic 32 bit version 1.14 here or, go to this Windows binaries collection at Eternally Bored here for the later versions and the faster 64 bit builds.
Here is the downloadable zip file for version 1.2 64 bit.
If you want to be able to run WGET from any directory inside the command terminal, you’ll need to learn about path variables in Windows to work out where to copy your new executable. If you follow these steps, you’ll be able to make WGET a command you can run from any directory in Command Prompt.
Run WGET from anywhere
Firstly, we need to determine where to copy WGET.exe.
After you’d downloaded wget.exe (or unpacked the associated distribution zip files) open a command terminal by typing “cmd” in the search menu:
We’re going to move wget.exe into a Windows directory that will allow WGET to be run from anywhere.
First, we need to find out which directory that should be. Type:
path
You should see something like this:
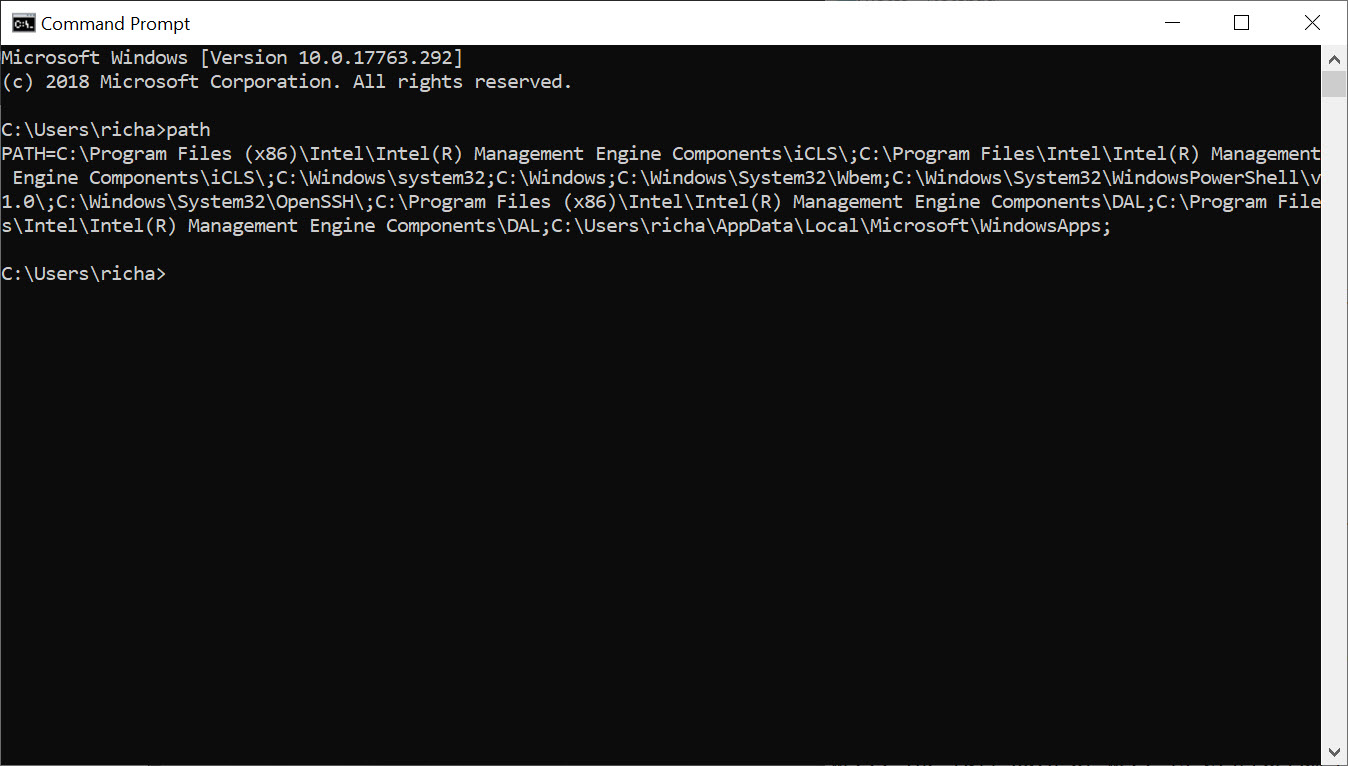
Thanks to the “Path” environment variable, we know that we need to copy wget.exe to the c:\Windows\System32 folder location.
Go ahead and copy WGET.exe to the System32 directory and restart your Command Prompt.
Restart command terminal and test WGET
If you want to test WGET is working properly, restart your terminal and type:
wget -h
If you’ve copied the file to the right place, you’ll see a help file appear with all of the available commands.
So, you should see something like this:
Now it’s time to get started.
Get started with WGET
Seeing that we’ll be working in Command Prompt, let’s create a download directory just for WGET downloads.
To create a directory, we’ll use the command md (“make directory”).
Change to the c:/ prompt and type:
md wgetdown
Then, change to your new directory and type “dir” to see the (blank) contents.
Now, you’re ready to do some downloading.
Example commands
Once you’ve got WGET installed and you’ve created a new directory, all you have to do is learn some of the finer points of WGET arguments to make sure you get what you need.
The Gnu.org WGET manual is a particularly useful resource for those inclined to really learn the details.
If you want some quick commands though, read on. I’ve listed a set of instructions to WGET to recursively mirror your site, download all the images, CSS and JavaScript, localise all of the URLs (so the site works on your local machine), and save all the pages as a .html file.
To mirror your site execute this command:
wget -r https://www.yoursite.com
To mirror the site and localise all of the urls:
wget --convert-links -r https://www.yoursite.com
To make a full offline mirror of a site:
wget --mirror --convert-links --adjust-extension --page-requisites --no-parent https://www.yoursite.com
To mirror the site and save the files as .html:
wget --html-extension -r https://www.yoursite.com
To download all jpg images from a site:
wget -A "*.jpg" -r https://www.yoursite.com
For more filetype-specific operations, check out this useful thread on Stack.
Set a different user agent:
Some web servers are set up to deny WGET’s default user agent – for obvious, bandwidth saving reasons. You could try changing your user agent to get round this. For example, by pretending to be Googlebot:
wget --user-agent="Googlebot/2.1 (+https://www.googlebot.com/bot.html)" -r https://www.yoursite.com
Wget “spider” mode:
Wget can fetch pages without saving them which can be a useful feature in case you’re looking for broken links on a website. Remember to enable recursive mode, which allows wget to scan through the document and look for links to traverse.
wget --spider -r https://www.yoursite.com
You can also save this to a log file by adding this option:
wget --spider -r https://www.yoursite.com -o wget.log
Enjoy using this powerful tool, and I hope you’ve enjoyed my tutorial. Comments welcome!
WGet — программа для загрузки файлов и
скачивания сайта целиком.
Скачать WGet для Windows можно здесь
Пришедшая из мира Linux, свободно распространяемая утилита Wget позволяет скачивать как отдельные файлы из интернета,
так и сайты целиком, следуя по ссылкам на веб-страницах.
Чтобы получить подсказку по параметрам WGet, наберите команду man wget в Linux или wget.exe —help в Windows.
Допустим, мы хотим создать полную копию сайта www.site.com на своем диске.
Для этого открываем командную строку (Wget — утилита консольная) и пишем такую команду:
wget.exe -r -l10 -k -p -E -nc http://www.site.com
WGET рекурсивно (параметр -r) обойдет каталоги и подкаталоги на удалённом сервере включая css-стили(-k)
с максимальной глубиной рекурсии равной десяти (-l), а затем заменить в загруженных HTML-документах
абсолютные ссылки на относительные (-k) и расширения на html(-E) для последующего локального просмотра скачанного сайта.
При повторном скачивании не будут лица и перезаписываться повторы(-nc).
К сожалению, внутренние стили и картинки указанные в стилях не скачиваются
Если предполагается загрузка с сайта какого-либо одного каталога (со всеми вложенными в него папками),
то логичнее будет включить в командную строку параметр -np. Он не позволит утилите при поиске файлов
подниматься по иерархии каталогов выше указанной директории:
wget.exe -r -l10 -k http://www.site.com -np
Если загрузка данных была случайно прервана, то для возобновления закачки с места останова,
необходимо в команду добавить ключ -с:
wget.exe -r -l10 -k http://www.site.com -c
По умолчанию, всё скаченное сохраняется в рабочей директории утилиты.
Определить другое месторасположение копируемых файлов поможет параметр -P:
wget.exe -r -l10 -k http://www.site.com -P c:\internet\files
Наконец, если сетевые настройки вашей сети предполагают использование прокси-сервера,
то его настройки необходимо сообщить программе. См. Конфигурирование WGET
wget -m -k -nv -np -p --user-agent="Mozilla/5.0 (compatible; Konqueror/3.0.0/10; Linux)" АДРЕС_САЙТА
Загрузка всех URL, указанных в файле FILE:
wget -i FILE
Скачивание файла в указанный каталог (-P):
wget -P /path/for/save ftp://ftp.example.org/some_file.iso
Использование имени пользователя и пароля на FTP/HTTP (вариант 1):
wget ftp://login:password@ftp.example.org/some_file.iso
Использование имени пользователя и пароля на FTP/HTTP (вариант 2):
wget --user=login --password=password ftp://ftp.example.org/some_file.iso
Скачивание в фоновом режиме (-b):
wget -b ftp://ftp.example.org/some_file.iso
Продолжить (-c continue) загрузку ранее не полностью загруженного файла:
wget -c http://example.org/file.iso
Скачать страницу с глубиной следования 10, записывая протокол в файл log:
wget -r -l 10 http://example.org/ -o log
Скачать содержимое каталога http://example.org/~luzer/my-archive/ и всех его подкаталогов,
при этом не поднимаясь по иерархии каталогов выше:
wget -r --no-parent http://example.org/~luzer/my-archive/
Для того, чтобы во всех скачанных страницах ссылки преобразовывались в относительные для локального просмотра,
необходимо использовать ключ -k:
wget -r -l 10 -k http://example.org/
Также поддерживается идентификация на сервере:
wget --save-cookies cookies.txt --post-data 'user=foo&password=bar' http://example.org/auth.php
Скопировать весь сайт целиком:
wget -r -l0 -k http://example.org/
Например, не загружать zip-архивы:
wget -r -R «*.zip» http://freeware.ru
Залогиниться и скачать файлик ключа
@echo off wget --save-cookies cookies.txt --post-data "login=ТВОЙЛОГИН&password=ТВОЙПАРОЛЬ" http://beta.drweb.com/files/ -O- wget --load-cookies cookies.txt "http://beta.drweb.com/files/?p=win%%2Fdrweb32-betatesting.key&t=f" -O drweb32-betatesting.key
Внимание! Регистр параметров WGet различен!
Базовые ключи запуска
-V
—version
Отображает версию Wget.
-h
—help
Выводит помощь с описанием всех ключей командной строки Wget.
-b
—background
Переход в фоновый режим сразу после запуска. Если выходной файл не задан -o, выход перенаправляется в wget-log.
-e command
—execute command
Выполнить command, как если бы она была частью файла .wgetrc.
Команда, запущенная таким образом, будет выполнена после команд в .wgetrc, получая приоритет над ними.
Для задания более чем одной команды wgetrc используйте несколько ключей -e.
Протоколирование и ключи входного файла
-o logfile
—output-file=logfile
Протоколировать все сообщения в logfile. Обычно сообщения выводятся в standard error.
-a logfile
—append-output=logfile
Дописывать в logfile. То же, что -o, только logfile не перезаписывается, а дописывается.
Если logfile не существует, будет создан новый файл.
-d
—debug
Включает вывод отладочной информации, т.е. различной информации, полезной для разработчиков Wget при некорректной работе.
Системный администратор мог выбрать сборку Wget без поддержки отладки, в этом случае -d работать не будет.
Помните, что сборка с поддержкой отладки всегда безопасна — Wget не будет выводить отладочной информации,
пока она явно не затребована через -d.
-q
—quiet
Выключает вывод Wget.
-v
—verbose
Включает подробный вывод со всей возможной информацией. Задано по умолчанию.
-nv
—non-verbose
Неподробный вывод — отключает подробности, но не замолкает совсем (используйте -q для этого),
отображаются сообщения об ошибках и основная информация.
-i file
—input-file=file
Читать URL из входного файла file, в этом случае URL не обязательно указывать в командной строке.
Если адреса URL указаны в командной строке и во входном файле, первыми будут запрошены адреса из командной строки.
Файл не должен (но может) быть документом HTML — достаточно последовательного списка адресов URL.
Однако, при указании —force-html входной файл будет считаться html.
В этом случае могут возникнуть проблемы с относительными ссылками,
которые можно решить указанием <base href=»url»> внутри входного файла или —base=url в командной строке.
-F
—force-html
При чтении списка адресов из файла устанавливает формат файла как HTML.
Это позволяет организовать закачку по относительным ссылкам в локальном HTML-файле при указании <base href=»url»>
внутри входного файла или —base=url в командной строке.
-B URL
—base=URL
Используется совместно c -F для добавления URL к началу относительных ссылок во входном файле, заданном через -i.
Ключи скачивания
—bind-address=ADDRESS
При открытии клиентских TCP/IP соединений bind() на ADDRESS локальной машины. ADDRESS может указываться в виде имени хоста или IP-адреса.
Этот ключ может быть полезен, если машине выделено несколько адресов IP.
-t number
—tries=number
Устанавливает количество попыток в number. Задание 0 или inf соответствует бесконечному числу попыток. По умолчанию равно 20,
за исключением критических ошибок типа «в соединении отказано» или «файл не найден» (404), при которых попытки не возобновляются.
-O file
—output-document=file
Документы сохраняются не в соответствующие файлы, а конкатенируются в файл с именем file.
Если file уже существует, то он будет перезаписан. Если в качестве file задано -, документы будут выведены в стандартный вывод (отменяя -k).
Помните, что комбинация с -k нормально определена только для скачивания одного документа.
-nc
—no-clobber
Если файл скачивается более одного раза в один и тот же каталог, то поведение Wget определяется несколькими ключами, включая -nc.
В некоторых случаях локальный файл будет затёрт или перезаписан при повторном скачивании, в других — сохранён.
При запуске Wget без -N, -nc или -r скачивание того же файла в тот же каталог приводит к тому, что исходная копия файла сохраняется,
а новая копия записывается с именем file.1. Если файл скачивается вновь, то третья копия будет названа file.2 и т.д.
Если указан ключ -nc, такое поведение подавляется, Wget откажется скачивать новые копии файла.
Таким образом, «no-clobber» неверное употребление термина в данном режиме — предотвращается не затирание файлов
(цифровые суффиксы уже предотвращали затирание), а создание множественных копий.
При запуске Wget с ключом -r, но без -N или -nc, перезакачка файла приводит к перезаписыванию на место старого.
Добавление -nc предотвращает такое поведение, сохраняя исходные версии файлов и игнорируя любые новые версии на сервере.
При запуске Wget с ключом -N, с или без -r, решение о скачивании новой версии файла зависит от локальной
и удалённой временных отметок и размера файла. -nc не может быть указан вместе с -N.
При указании -nc файлы с расширениями .html и .htm будут загружаться с локального диска и обрабатываться так,
как если бы они были скачаны из сети.
-c
—continue
Продолжение закачки частично скачанного файла. Это полезно при необходимости завершить закачку,
начатую другим процессом Wget или другой программой. Например:
wget -c ftp://htmlweb.ru/ls-lR.Z
Если в текущем каталоге имеется файл ls-lR.Z, то Wget будет считать его первой частью удалённого файла и запросит сервер
о продолжении закачки с отступом от начала, равному длине локального файла.
Нет необходимости указывать этот ключ, чтобы текущий процесс Wget продолжил закачку при пи потере связи на полпути.
Это изначальное поведение. -c влияет только на закачки, начатые до текущего процесса Wget, если локальные файлы уже существуют.
Без -c предыдущий пример сохранит удалённый файл в ls-lR.Z.1, оставив ls-lR.Z без изменения.
Начиная с версии Wget 1.7, при использовании -c с непустым файлом, Wget откажется начинать закачку сначала,
если сервер не поддерживает закачку, т.к. это привело бы к потере скачанных данных. Удалите файл, если вы хотите начать закачку заново.
Также начиная с версии Wget 1.7, при использовании -c для файла равной длины файлу на сервере Wget откажется
скачивать и выведет поясняющее сообщение. То же происходит, если удалённый файл меньше локального
(возможно, он был изменён на сервере с момента предыдущей попытки) — т.к. «продолжение» в данном случае бессмысленно,
скачивание не производится.
С другой стороны, при использовании -c локальный файл будет считаться недокачанным, если длина удалённого файла больше длины локального.
В этом случае (длина(удалённая) — длина(локальная)) байт будет скачано и приклеено в конец локального файла.
Это ожидаемое поведение в некоторых случаях: например, можно использовать -c для скачивания новой порции собранных данных или лог-файла.
Однако, если файл на сервере был изменён, а не просто дописан, то вы получите испорченный файл. Wget не обладает механизмами проверки,
является ли локальный файл начальной частью удалённого файла. Следует быть особенно внимательным при использовании -c совместно с -r,
т.к. каждый файл будет считаться недокачанным.
Испорченный файл также можно получить при использовании -c с кривым HTTP прокси, который добавляет строку тима «закачка прервана».
В будущих версиях возможно добавление ключа «откат» для исправления таких случаев.
Ключ -c можно использовать только с FTP и HTTP серверами, которые поддерживают заголовок Range.
—progress=type
Выбор типа индикатора хода закачки. Возможные значения: «dot» и «bar».
Индикатор типа «bar» используется по умолчанию. Он отображает ASCII полосу хода загрузки (т.н. «термометр»).
Если вывод не в TTY, то по умолчанию используется индикатор типа «dot».
Для переключения в режим «dot» укажите —progress=dot. Ход закачки отслеживается и выводится на экран в виде точек,
где каждая точка представляет фиксированный размер скачанных данных.
При точечной закачке можно изменить стиль вывода, указав dot:style. Различные стили определяют различное значение для одной точки.
По умолчанию одна точка представляет 1K, 10 точек образуют кластер, 50 точек в строке.
Стиль binary является более «компьютер»-ориентированным — 8K на точку, 16 точек на кластер и 48 точек на строку (384K в строке).
Стиль mega наиболее подходит для скачивания очень больших файлов — каждой точке соответствует 64K, 8 точек на кластер и 48 точек в строке
(строка соответствует 3M).
Стиль по умолчанию можно задать через .wgetrc. Эта установка может быть переопределена в командной строке.
Исключением является приоритет «dot» над «bar», если вывод не в TTY. Для непременного использования bar укажите —progress=bar:force.
-N
—timestamping
Включает использование временных отметок.
-S
—server-response
Вывод заголовков HTTP серверов и ответов FTP серверов.
—spider
При запуске с этим ключом Wget ведёт себя как сетевой паук, он не скачивает страницы, а лишь проверяет их наличие.
Например, с помощью Wget можно проверить закладки:
wget --spider --force-html -i bookmarks.html
Эта функция требует большой доработки, чтобы Wget достиг функциональности реальных сетевых пауков.
-T seconds
—timeout=seconds
Устанавливает сетевое время ожидания в seconds секунд. Эквивалентно одновременному указанию —dns-timeout,
—connect-timeout и —read-timeout.
Когда Wget соединяется или читает с удалённого хоста, он проверяет время ожидания и прерывает операцию при его истечении.
Это предотвращает возникновение аномалий, таких как повисшее чтение или бесконечные попытки соединения.
Единственное время ожидания, установленное по умолчанию, — это время ожидания чтения в 900 секунд.
Установка времени ожидания в 0 отменяет проверки.
Если вы не знаете точно, что вы делаете, лучше не устанавливать никаких значений для ключей времени ожидания.
—dns-timeout=seconds
Устанавливает время ожидания для запросов DNS в seconds секунд. Незавершённые в указанное время запросы DNS будут неуспешны.
По умолчанию никакое время ожидания для запросов DNS не устанавливается, кроме значений, определённых системными библиотеками.
—connect-timeout=seconds
Устанавливает время ожидания соединения в seconds секунд. TCP соединения, требующие большего времени на установку, будут отменены.
По умолчанию никакое время ожидания соединения не устанавливается, кроме значений, определённых системными библиотеками.
—read-timeout=seconds
Устанавливает время ожидания чтения (и записи) в seconds секунд. Чтение, требующее большего времени, будет неуспешным.
Значение по умолчанию равно 900 секунд.
—limit-rate=amount
Устанавливает ограничение скорости скачивания в amount байт в секунду. Значение может быть выражено в байтах,
килобайтах с суффиксом k или мегабайтах с суффиксом m. Например, —limit-rate=20k установит ограничение скорости скачивания в 20KB/s.
Такое ограничение полезно, если по какой-либо причине вы не хотите, чтобы Wget не утилизировал всю доступную полосу пропускания.
Wget реализует ограничение через sleep на необходимое время после сетевого чтения, которое заняло меньше времени,
чем указанное в ограничении. В итоге такая стратегия приводит к замедлению скорости TCP передачи приблизительно до указанного ограничения.
Однако, для установления баланса требуется определённое время, поэтому не удивляйтесь, если ограничение будет плохо работать
для небольших файлов.
-w seconds
—wait=seconds
Ждать указанное количество seconds секунд между закачками. Использование этой функции рекомендуется для снижения нагрузки на сервер
уменьшением частоты запросов. Вместо секунд время может быть указано в минутах с суффиксом m, в часах с суффиксом h или днях с суффиксом d.
Указание большого значения полезно, если сеть или хост назначения недоступны, так чтобы Wget ждал достаточное время для исправления
неполадок сети до следующей попытки.
—waitretry=seconds
Если вы не хотите, чтобы Wget ждал между различными закачками, а только между попытками для сорванных закачек,
можно использовать этот ключ. Wget будет линейно наращивать паузу, ожидая 1 секунду после первого сбоя для данного файла,
2 секунды после второго сбоя и так далее до максимального значения seconds.
Таким образом, значение 10 заставит Wget ждать до (1 + 2 + … + 10) = 55 секунд на файл.
Этот ключ включён по умолчанию в глобальном файле wgetrc.
—random-wait
Некоторые веб-сайты могут анализировать логи для идентификации качалок, таких как Wget,
изучая статистические похожести в паузах между запросами. Данный ключ устанавливает случайные паузы в диапазоне от 0 до 2 * wait секунд,
где значение wait указывается ключом —wait. Это позволяет исключить Wget из такого анализа.
В недавней статье на тему разработки популярных пользовательских платформ был представлен код,
позволяющий проводить такой анализ на лету. Автор предлагал блокирование подсетей класса C для
блокирования программ автоматического скачивания, несмотря на возможную смену адреса, назначенного DHCP.
На создание ключа —random-wait подвигла эта больная рекомендация блокировать множество невиновных пользователей по вине одного.
-Y on/off
—proxy=on/off
Включает или выключает поддержку прокси. Если соответствующая переменная окружения установлена, то поддержка прокси включена по умолчанию.
-Q quota
—quota=quota
Устанавливает квоту для автоматических скачиваний. Значение указывается в байтах (по умолчанию),
килобайтах (с суффиксом k) или мегабайтах (с суффиксом m).
Квота не влияет на скачивание одного файла. Так если указать wget -Q10k ftp://htmlweb.ru/ls-lR.gz,
файл ls-lR.gz будет скачан целиком. То же происходит при указании нескольких URL в командной строке.
Квота имеет значение при рекурсивном скачивании или при указании адресов во входном файле.
Т.о. можно спокойно указать wget -Q2m -i sites — закачка будет прервана при достижении квоты.
Установка значений 0 или inf отменяет ограничения.
—dns-cache=off
Отключает кеширование запросов DNS. Обычно Wget запоминает адреса, запрошенные в DNS,
так что не приходится постоянно запрашивать DNS сервер об одном и том же (обычно небольшом) наборе адресов.
Этот кэш существует только в памяти. Новый процесс Wget будет запрашивать DNS снова.
Однако, в некоторых случаях кеширование адресов не желательно даже на короткий период запуска такого приложения как Wget.
Например, секоторые серверы HTTP имеют динамически выделяемые адреса IP, которые изменяются время от времени.
Их записи DNS обновляются при каждом изменении. Если закачка Wget с такого хоста прерывается из-за смены адреса IP,
Wget повторяет попытку скачивания, но (из-за кеширования DNS) пытается соединиться по старому адресу.
При отключенном кешировании DNS Wget будет производить DNS-запросы при каждом соединении и, таким образом,
получать всякий раз правильный динамический адрес.
Если вам не понятно приведённое выше описание, данный ключ вам, скорее всего, не понадобится.
—restrict-file-names=mode
Устанавливает, какие наборы символов могут использоваться при создании локального имени файла из адреса удалённого URL.
Символы, запрещённые с помощью этого ключа, экранируются, т.е. заменяются на %HH, где HH — шестнадцатиричный код соответствующего символа.
По умолчанию Wget экранирует символы, которые не богут быть частью имени файла в вашей операционной системе,
а также управляющие символы, как правило непечатные. Этот ключ полезен для смены умолчания,
если вы сохраняете файл на неродном разделе или хотите отменить экранирование управляющих символов.
Когда mode установлен в «unix», Wget экранирует символ / и управляющие символы в диапазонах 0-31 и 128-159. Это умолчание для Ос типа Unix.
Когда mode установлен в «windows», Wget экранирует символы \, |, /, :, ?, «, *, <, > и управляющие символы в диапазонах 0-31 и 128-159.
Дополнительно Wget в Windows режиме использует + вместо : для разделения хоста и порта в локальных именах файлов и @ вместо ?
для отделения запросной части имени файла от остального. Таким образом, адрес URL, сохраняемый в Unix режиме как
www.htmlweb.ru:4300/search.pl?input=blah, в режиме Windows будет сохранён как www.htmlweb.ru+4300/search.pl@input=blah.
Этот режим используется по умолчанию в Windows.
Если к mode добавить, nocontrol, например, unix,nocontrol, экранирование управляющих символов отключается.
Можно использовать —restrict-file-names=nocontrol для отключения экранирования управляющих символов без влияния
на выбор ОС-зависимого режима экранирования служебных символов.
Ключи каталогов
-nd
—no-directories
Не создавать структуру каталогов при рекурсивном скачивании. С этим ключом все файлы сохраняются в текущий каталог
без затирания (если имя встречается больше одного раза, имена получат суффикс .n).
-x
—force-directories
Обратное -nd — создаёт структуру каталогов, даже если она не создавалась бы в противном случае.
Например, wget -x http://htmlweb.ru/robots.txt сохранит файл в htmlweb.ru/robots.txt.
-nH
—no-host-directories
Отключает создание хост-каталога. По умолчания запуск Wget -r http://htmlweb.ru/ создаст структуру каталогов,
начиная с htmlweb.ru/. Данный ключ отменяет такое поведение.
—protocol-directories
Использовать название протокола как компонент каталога для локальный файлов.
Например, с этим ключом wget -r http://host сохранит в http/host/… вместо host/….
—cut-dirs=number
Игнорировать number уровней вложенности каталогов. Это полезный ключ для чёткого управления каталогом для
сохранения рекурсивно скачанного содержимого.
Например, требуется скачать каталог ftp://htmlweb.ru/pub/xxx/. При скачивании с -r локальная копия будет сохранена
в ftp.htmlweb.ru/pub/xxx/. Если ключ -nH может убрать ftp.htmlweb.ru/ часть, остаётся ненужная pub/xemacs.
Здесь на помощь приходит —cut-dirs; он заставляет Wget закрывать глаза на number удалённых подкаталогов.
Ниже приведены несколько рабочих примеров —cut-dirs.
No options -> ftp.htmlweb.ru/pub/xxx/ -nH -> pub/xxx/ -nH --cut-dirs=1 -> xxx/ -nH --cut-dirs=2 -> . --cut-dirs=1 -> ftp.htmlweb.ru/xxx/
Если вам нужно лишь избавиться от структуры каталогов, то этот ключ может быть заменён комбинацией -nd и -P.
Однако, в отличии от -nd, —cut-dirs не теряет подкаталоги — например, с -nH —cut-dirs=1,
подкаталог beta/ будет сохранён как xxx/beta, как и ожидается.
-P prefix
—directory-prefix=prefix
Устанавливает корневой каталог в prefix. Корневой каталог — это каталог, куда будут сохранены все файлы и подкаталоги,
т.е. вершина скачиваемого дерева. По умолчанию . (текущий каталог).
Ключи HTTP
-E
—html-extension
Данный ключ добавляет к имени локального файла расширение .html, если скачиваемый URL имеет тип application/xhtml+xml или text/html,
а его окончание не соответствует регулярному выражению \.[Hh][Tt][Mm][Ll]?. Это полезно, например, при зеркалировании сайтов,
использующих .asp страницы, когда вы хотите, чтобы зеркало работало на обычном сервере Apache.
Также полезно при скачивании динамически-генерируемого содержимого. URL типа http://site.com/article.cgi?25
будет сохранён как article.cgi?25.html.
Сохраняемые таким образом страницы будут скачиваться и перезаписываться при каждом последующем зеркалировании,
т.к. Wget не может сопоставить локальный файл X.html удалённому адресу URL X
(он ещё не знает, что URL возвращает ответ типа text/html или application/xhtml+xml).
Для предотвращения перезакачивания используйте ключи -k и -K, так чтобы оригинальная версия сохранялась как X.orig.
—http-user=user
—http-passwd=password
Указывает имя пользователя user и пароль password для доступа к HTTP серверу. В зависимости от типа запроса Wget закодирует их,
используя обычную (незащищённую) или дайджест схему авторизации.
Другой способ указания имени пользователя и пароля — в самом URL. Любой из способов раскрывает ваш пароль каждому,
кто запустит ps. Во избежание раскрытия паролей, храните их в файлах .wgetrc или .netrc и убедитесь в недоступности
этих файлов для чтения другими пользователями с помощью chmod. Особо важные пароли не рекомендуется хранить даже в этих файлах.
Вписывайте пароли в файлы, а затем удаляйте сразу после запуска Wget.
—no-cache
Отключает кеширование на стороне сервера. В этой ситуации Wget посылает удалённому серверу соответствующую директиву
(Pragma: no-cache) для получения обновлённой, а не кешированной версии файла. Это особенно полезно для стирания устаревших
документов на прокси серверах.
Кеширование разрешено по умолчанию.
—no-cookies
Отключает использование cookies. Cookies являются механизмом поддержки состояния сервера.
Сервер посылает клиенту cookie с помощью заголовка Set-Cookie, клиент включает эту cookie во все последующие запросы.
Т.к. cookies позволяют владельцам серверов отслеживать посетителей и обмениваться этой информацией между сайтами,
некоторые считают их нарушением конфиденциальности. По умолчанию cookies используются;
однако сохранение cookies по умолчанию не производится.
—load-cookies file
Загрузка cookies из файла file до первого запроса HTTP. file — текстовый файл в формате,
изначально использовавшемся для файла cookies.txt Netscape.
Обычно эта опция требуется для зеркалирования сайтов, требующих авторизации для части или всего содержания.
Авторизация обычно производится с выдачей сервером HTTP cookie после получения и проверки регистрационной информации.
В дальнейшем cookie посылается обозревателем при просмотре этой части сайта и обеспечивает идентификацию.
Зеркалирование такого сайта требует от Wget подачи таких же cookies, что и обозреватель.
Это достигается через —load-cookies — просто укажите Wget расположение вашего cookies.txt, и он отправит идентичные обозревателю cookies.
Разные обозреватели хранят файлы cookie в разных местах:
Netscape 4.x. ~/.netscape/cookies.txt.
Mozilla and Netscape 6.x. Файл cookie в Mozilla тоже называется cookies.txt, располагается где-то внутри ~/.mozilla в директории вашего профиля.
Полный путь обычно выглядит как ~/.mozilla/default/some-weird-string/cookies.txt.
Internet Explorer. Файл cookie для Wget может быть получен через меню File, Import and Export, Export Cookies.
Протестировано на Internet Explorer 5; работа с более ранними версиями не гарантируется.
Other browsers. Если вы используете другой обозреватель, —load-cookies будет работать только в том случае,
если формат файла будет соответствовать формату Netscape, т.е. то, что ожидает Wget.
Если вы не можете использовать —load-cookies, может быть другая альтернатива.
Если обозреватель имеет «cookie manager», то вы можете просмотреть cookies, необходимые для зеркалирования.
Запишите имя и значение cookie, и вручную укажите их Wget в обход «официальной» поддержки:
wget --cookies=off --header "Cookie: name=value"
—save-cookies file
Сохранение cookies в file перед выходом. Эта опция не сохраняет истекшие cookies и cookies
без определённого времени истечения (так называемые «сессионные cookies»).
См. также —keep-session-cookies.
—keep-session-cookies
При указании —save-cookies сохраняет сессионные cookies. Обычно сессионные cookies не сохраняются,
т.к подразумевается, что они будут забыты после закрытия обозревателя. Их сохранение полезно для сайтов,
требующих авторизации для доступа к страницам. При использовании этой опции разные процессы Wget для сайта будут выглядеть
как один обозреватель.
Т.к. обычно формат файла cookie file не содержит сессионных cookies, Wget отмечает их временной отметкой истечения 0.
—load-cookies воспринимает их как сессионные cookies, но это может вызвать проблемы у других обозревателей
Загруженные таким образом cookies интерпретируются как сессионные cookies, то есть для их сохранения с
—save-cookies необходимо снова указывать —keep-session-cookies.
—ignore-length
К сожалению, некоторые серверы HTTP (CGI программы, если точнее) посылают некорректный заголовок Content-Length,
что сводит Wget с ума, т.к. он думает, что документ был скачан не полностью.
Этот синдром можно заметить, если Wget снова и снова пытается скачать один и тот же документ,
каждый раз указывая обрыв связи на том же байте.
С этим ключом Wget игнорирует заголовок Content-Length, как будто его никогда не было.
—header=additional-header
Укажите дополнительный заголовок additional-header для передачи HTTP серверу. Заголовки должны содержать «:»
после одного или более непустых символов и недолжны содержать перевода строки.
Вы можете указать несколько дополнительных заголовков, используя ключ —header многократно.
wget --header='Accept-Charset: iso-8859-2' --header='Accept-Language: hr' http://aaa.hr/
Указание в качестве заголовка пустой строки очищает все ранее указанные пользовательские заголовки.
—proxy-user=user
—proxy-passwd=password
Указывает имя пользователя user и пароль password для авторизации на прокси сервере. Wget кодирует их, использую базовую схему авторизации.
Здесь действуют те же соображения безопасности, что и для ключа —http-passwd.
—referer=url
Включает в запрос заголовок `Referer: url’. Полезен, если при выдаче документа сервер считает, что общается с интерактивным обозревателем,
и проверяет, чтобы поле Referer содержало страницу, указывающую на запрашиваемый документ.
—save-headers
Сохраняет заголовки ответа HTTP в файл непосредственно перед содержанием, в качестве разделителя используется пустая строка.
-U agent-string
—user-agent=agent-string
Идентифицируется как обозреватель agent-string для сервера HTTP.
HTTP протокол допускает идентификацию клиентов, используя поле заголовка User-Agent. Это позволяет различать программное обеспечение,
обычно для статистики или отслеживания нарушений протокола. Wget обычно идентифицируется как Wget/version, где version — текущая версия Wget.
Однако, некоторые сайты проводят политику адаптации вывода для обозревателя на основании поля User-Agent.
В принципе это не плохая идея, но некоторые серверы отказывают в доступе клиентам кроме Mozilla и Microsoft Internet Explorer.
Этот ключ позволяет изменить значение User-Agent, выдаваемое Wget. Использование этого ключа не рекомендуется,
если вы не уверены в том, что вы делаете.
—post-data=string
—post-file=file
Использует метод POST для всех запросов HTTP и отправляет указанные данные в запросе. —post-data отправляет в качестве данных строку string,
а —post-file — содержимое файла file. В остальном они работают одинаково.
Пожалуйста, имейте в виду, что Wget должен изначально знать длину запроса POST. Аргументом ключа —post-file должен быть обычный файл;
указание FIFO в виде /dev/stdin работать не будет. Не совсем понятно, как можно обойти это ограничение в HTTP/1.0.
Хотя HTTP/1.1 вводит порционную передачу, для которой не требуется изначальное знание длины, клиент не может её использовать,
если не уверен, что общается с HTTP/1.1 сервером. А он не может этого знать, пока не получит ответ, который, в свою очередь,
приходит на полноценный запрос. Проблема яйца и курицы.
Note: если Wget получает перенаправление в ответ на запрос POST, он не отправит данные POST на URL перенаправления.
Часто URL адреса, обрабатывающие POST, выдают перенаправление на обычную страницу (хотя технически это запрещено),
которая не хочет принимать POST. Пока не ясно, является ли такое поведение оптимальным; если это не будет работать, то будет изменено.
Пример ниже демонстрирует, как авторизоваться на сервере, используя POST, и затем скачать желаемые страницы,
доступные только для авторизованных пользователей:
wget --save-cookies cookies.txt --post-data 'user=foo&password=bar' http://htmlweb.ru/auth.php
wget --load-cookies cookies.txt -p http://server.com/interesting/article.php
Конфигурирование WGET
Основные настроки, которые необходимо писать каждый раз, можно указать в конфигурационном файле программы.
Для этого зайдите в рабочую директорию Wget, найдите там файл sample.wgetrc,
переименуйте его в .wgetrc и редакторе пропишите необходимые конфигурационные параметры.
user-agent = "Mozilla/5.0" tries = 5 количество попыток скачать wait = 0 не делать паузы continue = on нужно докачивать dir_prefix = ~/Downloads/ куда складывать скачаное use_proxy=on - использовать прокси http_proxy - характеристики вашего прокси-сервера.
Как под Windows заставить WGET читать настройки из wgetrc файла:
- Задать переменную окружения WGETRC, указав в ней полный путь к файлу.
- Задать переменную HOME, в которой указать путь к домашней папке пользователя (c:\Documents and settings\jonh).
Тогда wget будет искать файл «wgetrc» в этой папке. - Кроме этого можно создать файл wget.ini в той же папке, где находится wget.exe,
и задать там дополнительные параметры командной строки wget.
Полезную информацию по WGET можно почерпнуть здесь:
- http://mydebianblog.blogspot.com/2007/09/wget.html
- http://forum.ru-board.com/topic.cgi?forum=5&topic=10066
- PhantomJS — Используйте, если вам нужно скачать сайт, часть данных на котором загружается с помощью JavaScript
Очень часто возникает необходимость в копировании стороннего сайта. В то время, как копирование с помощью встроенной функции браузера «сохранить как», не работает должным образом, можно воспользоваться программой wget.
В этой статье будут рассмотрены основные команды wget, на примере будет показано, как скачать страницу с помощью wget для локального просмотра, а так же, как скачать https сайт.
- Скачивание страниц по списку из файла
- Как задать папку для скачивания
- Рекурсивное скачивание подкаталогов
- Выкачивание всего сайта
- Скачивание страницы с локальным сохранением клиентских файлов
- Скачивание http-страниц
- Резюме
В этой статье я не буду рассматривать установку wget на компьютер. Я воспользуюсь сборкой Open Server, в которой эта программа уже включена. Open Server — это сборка локального веб-сервера. Потому, если вы не программируете на php, то смысла устанавливать Open Server не много. Для вас лучший вариант — это отдельная установка wget.
Wget — это консольная программа для загрузки файлов. Это программа чем-то похожа на CURL, однако, они решают совсем разные задачи. Wget позволяет скачивать страницы сайта, вместе с полным содержанием страницы (css, js, картинки) к себе на компьютер. Что позволяет открыть этот сайт у себя, без интернета, абсолютно не искажая его исходное отображение. Так же, эта программа включает в себе возможность рекурсивного скачивания страниц, что позволит с помощью wget скачать весь сайт целиком, и отображать его локально.
Скачивание всех страниц по списку из файла
wget -i YOURFILE, где YOURFILE — путь к файлу, с URL-адресами
Например, у меня есть файл links.txt:

Теперь, запустив команду wget -i links.txt (у меня links.txt находится в той папке, относительно которой запущена консоль)
И в результате получим 3 файла, как и было в списке:

Скачивание в указанную папку
Для того, чтобы скачать в нужную нам папку, нужно выполнить:
wget -P /path http://example.com, где /path — папка для сохранения, http://example.com — url-сайта, который нужно скачать
-P — путь сохранения (указывается -P /path)
Например, скачаем содержимое главной страницы http://badcode.ru в папку files
Выполним:
wget -P files http://badcode.ru
И wget создаст папку с названием files, и куда сохранит содержимое нашего сайта
Рекурсивное скачивание каталога и вложенных подкаталогов
wget -r --no-parent http://example.com/catalog
Проверим это на примере скачивания всех статей одного из тегов: http://badcode.ru/tag/parsery/
Выполнив:
wget -r --no-parent http://badcode.ru/tag/parsery/
Скачивание всего сайта
wget -r -l 5 -k -p http://example.com
Каждая из опций значит:
-r — рекурсивно открывает новые найденные страницы
-l — глубина рекурсии -l 5, что значит, что максимально рекурсивно будет открыто 5 ссылок
-k — конвертирование ссылок на локальные, загружая файлы (css, js, картинки) к себе в папку
-p — скачать в папку все нужные файлы для отображения страницы без интернета
Выполнив:
wget -r -l 5 -k -p http://badcode.ru
Получим результат в виде всех скачанных статей, которые без проблем можно читать без интернета:
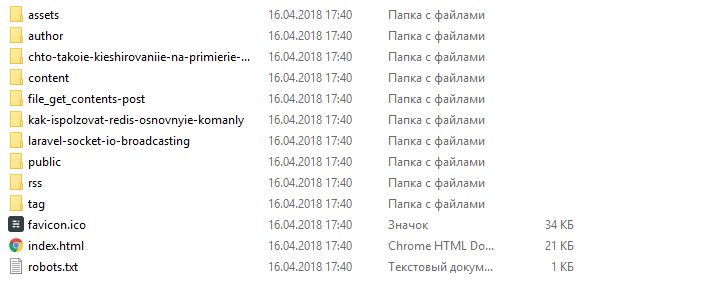
Скачивание одной страницы со всеми файлами
Эта команда будет симбиозом того, что мы уже рассмотрели.
wget -k -p http://example.com
А ключи -k и -p нам уже известны: это значит, что мы говорим wget скачать все файлы, и проставить пути так, чтобы можно было открыть эти страницы локально, без интернета.
Скачивание https-страницы
Для того, чтобы скачать https-страницы, просто нужно добавить опцию --no-check-certificate
На прошлом примере, что будет иметь вид:
wget -k -p https://example.com --no-check-certificate
Резюме
Цель этой статьи — показать, с какой простотой и удобством можно пользоваться Wget. Я постарался ответить на то, как сохранять страницы, или даже целые сайты к себе локально, и просматривать их без интернета. В этой статье были описаны основные команды Wget, если вы хотите более продвинутого пользования этим инструментом, то этой информации будет недостаточно.
Ранее, для того, чтобы скопировать какую-то страницу, я прибегал к использованию сторонних сервисов, которые, зачастую, являются обёрткой над Wget. Потому, изучив основные команды Wget, необходимость в других сервисах отпадает сама собой.
К слову, моя «история фриланса», как раз и началась, с того, что я копировал лендинги, и тут мне очень помогали знания, связанные с Wget.
Linux wget: ваш загрузчик командной строки
Wget — это открыто распостраняемая утилита для загрузки файлов из интернет. 
Он поддерживает HTTP, FTP, HTTPS и другие протоколы, а также средство аутентификации и множество других опций.
Если вы пользователь Linux или Mac, WGET либо уже включен в пакет, который вы используете, либо это простой случай установки из любого репозитория, который вы предпочитаете, с помощью одной команды.
Как установить команду wget в Linux
Используйте команду apt / apt-get, если вы работаете в Ubuntu / Debian / Mint Linux:
$ sudo apt install wget
Пользователь Fedora Linux должен ввести команду dnf
$ sudo dnf install wget
Пользователь RHEL / CentOS / Oracle Linux должен ввести команду yum :
$ sudo yum install wget
Пользователь SUSE / OpenSUSE Linux должен ввести команду zypper:
$ zypper install wget
Пользователь Arch Linux должен ввести команду pacman:
$ sudo pacman -S wget
К сожалению, в Windows все не так просто (хотя не так сложно!).
Для запуска WGET вам необходимо скачать, распаковать и установить утилиту вручную.
Установите WGET в Windows 10
Загрузите классическую 32-разрядную версию 1.14 здесь или перейдите в эту коллекцию двоичных файлов Windows на сайте Eternal Bored здесь, чтобы получить более поздние версии и более быстрые 64-разрядные сборки.
Вот загружаемый zip-файл для 64-разрядной версии 1.2.
Если вы хотите иметь возможность запускать WGET из любого каталога в терминале, вам нужно будет узнать о переменных пути в Windows, чтобы решить, куда копировать новый исполняемый файл. Если вы это сделаете, то сможете сделать WGET командой, которую можно запускать из любого каталога в командной строке, это отдельная тема по настройке Windows.
Запуск WGET из любого места
Во-первых, нам нужно определить, куда копировать WGET.exe.
Мы собираемся переместить wget.exe в каталог Windows, который позволит запускать WGET из любого места.
После того, как вы загрузили wget.exe (или распаковали связанные с ним zip-файлы дистрибутива), откройте командный терминал, набрав «cmd» в меню поиска и запустите командную строку.
Во-первых, нам нужно выяснить, в каком каталоге это должно быть. В командную строку введите:
path
Вы должны увидеть что-то вроде этого:

Благодаря переменной окружения “Path” мы знаем, что нам нужно скопировать wget.exe в папку c:\Windows\System32.
Скопируйте WGET.exe в каталог System32 и перезапустите командную строку.
Если вы хотите проверить правильность работы WGET, перезапустите терминал и введите:
wget -h
Если вы скопировали файл в нужное место, вы увидите файл справки со всеми доступными командами.
Итак, вы должны увидеть что-то вроде этого:

Начнем работать с WGET
Мы будем работать в командной строке, поэтому давайте создадим каталог загрузок только для загрузок WGET.
Чтобы создать каталог, воспользуемся командой md («создать каталог»).
Перейдите в корневой каталог c: / и введите команду:
md wgetdown
Затем перейдите в новый каталог и введите «dir», и вы увидите (пустое) содержимое.

После того, как вы установили WGET и создали новый каталог, все, что вам нужно сделать, это изучить некоторые тонкости аргументов WGET, чтобы убедиться, что вы получаете то, что вам нужно.
Руководство Gnu.org WGET — особенно полезный ресурс для тех, кто действительно хочет узнать подробности.
Вот несколько советов, как извлечь из этого максимум пользы:
Linux wget примеры команд
Синтаксис:
wget url
wget [options] url
Давайте посмотрим на некоторые распространенные примеры команд Linux wget, синтаксис и использование.
WGET можно использовать для:
Скачать один файл с помощью wget
$ wget https://cyberciti.biz/here/lsst.tar.gz
Загрузить несколько файлов с помощью wget
$ wget https://cyberciti.biz/download/lsst.tar.gz ftp://ftp.freebsd.org/pub/sys.tar.gz ftp://ftp.redhat.com/pub/xyz-1rc-i386.rpm
Можно прочитать URL из файла
Вы можете поместить все URL в текстовый файл и использовать опцию -i, чтобы wget загрузил все файлы. Сначала создайте текстовый файл:
$ xed /temp/download.txt
Добавить список URL:
https://cyberciti.biz/download/lsst.tar.gz
ftp://ftp.freebsd.org/pub/sys.tar.gz
ftp://ftp.redhat.com/pub/xyz-1rc-i386.rpm
Введите команду wget следующим образом:
$ wget -i /temp/download.txt
Можно ограничить скорость загрузки
$ wget -c -o /temp/susedvd.log —limit-rate=50k ftp://ftp.novell.com/pub/suse/dvd1.iso
Используйте wget с сайтами, защищенными паролем
Вы можете указать http имя пользователя / пароль на сервере следующим образом:
$ wget —http-user=vivek —http-password=Secrete http://cyberciti.biz/vivek/csits.tar.gz
Другой способ указать имя пользователя и пароль — в самом URL.
$ wget ‘http://username:password@cyberciti.biz/file.tar.gz
Скачать все mp3 или pdf файлы с удаленного FTP сервера
$ wget ftp://somedom-url/pub/downloads/*.mp3
$ wget ftp://somedom-url/pub/downloads/*.pdf
Скачать сайт целиком
$ wget -r -k -l 7 -p -E -nc https://site.com/
Рассмотрим используемые параметры:
-r — указывает на то, что нужно рекурсивно переходить по ссылкам на сайте, чтобы скачивать страницы.
-k — используется для того, чтобы wget преобразовал все ссылки в скаченных файлах таким образом, чтобы по ним можно было переходить на локальном компьютере (в автономном режиме).
-p — указывает на то, что нужно загрузить все файлы, которые требуются для отображения страниц (изображения, css и т.д.).
-l — определяет максимальную глубину вложенности страниц, которые wget должен скачать (по умолчанию значение равно 5, в примере мы установили 7). В большинстве случаев сайты имеют страницы с большой степенью вложенности и wget может просто «закопаться», скачивая новые страницы. Чтобы этого не произошло можно использовать параметр -l.
-E — добавлять к загруженным файлам расширение .html.
-nc — при использовании данного параметра существующие файлы не будут перезаписаны. Это удобно, когда нужно продолжить загрузку сайта, прерванную в предыдущий раз.
По умолчанию wget загружает файл и сохраняет его с оригинальным именем в URL — в текущем каталоге.
Здесь я перечислил набор инструкций для WGET для рекурсивного зеркалирования вашего сайта, загрузки всех изображений, CSS и JavaScript, локализации всех URL-адресов (чтобы сайт работал на вашем локальном компьютере) и сохранения всех страниц как .html файл.
Чтобы скачать ваш сайт, выполните эту команду:
wget -r https://www.yoursite.com
Чтобы скачать сайт и локализовать все URL:
wget —convert-links -r https://www.yoursite.com
Чтобы создать полноценное оффлайн зеркало сайта:
wget —mirror —convert-links —adjust-extension —page-requisites —no-parent https://www.yoursite.com
Чтобы скачать сайт и сохранить файлы как .html:
wget —html-extension -r https://www.yoursite.com
Чтобы скачать все изображения в формате jpg с сайта:
wget -A «*.jpg» -r https://www.yoursite.com
Дополнительные сведения об операциях, связанных с конкретным типом файлов, можно найти в этой полезной ветке на Stack .
Установите другой пользовательский агент:
Некоторые веб-серверы настроены так, чтобы запрещать пользовательский агент WGET по умолчанию — по очевидным причинам экономии полосы пропускания. Вы можете попробовать изменить свой пользовательский агент, чтобы обойти это. Например, притворившись роботом Google:
wget —user-agent=»Googlebot/2.1 (+https://www.googlebot.com/bot.html)» -r https://www.yoursite.com
Wget режим «паук»:
Wget может получать страницы без их сохранения, что может быть полезной функцией, если вы ищете неработающие ссылки на веб-сайте. Не забудьте включить рекурсивный режим, который позволяет wget сканировать документ и искать ссылки для перехода.
wget —spider -r https://www.yoursite.com
Вы также можете сохранить это в файл журнала, добавив эту опцию:
wget —spider -r https://www.yoursite.com -o wget.log
wget -m -l 10 -e robots=off -p -k -E —reject-regex «wp» —no-check-certificate -U=«Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36» site-addr.com
Как найти неработающие ссылки на вашем сайте
wget —spider -r -nd -nv -H -l 2 -w 2 -o run1.log https://site.by
Наслаждайтесь использованием этого мощного инструмента, и я надеюсь, что вам понравился мой урок.