
- Описание
- Дальнейшие действия
- Заключение
Приветствую друзья. Данный материал расскажет о неизвестном процессе в диспетчере задач, который может нагружать процессор, использовать много оперативной памяти.
Анализируя интернет, выяснил: данный процесс принадлежит программе Flock, которая предположительно является вирусом.

Можно попробовать убрать из автозагрузки:
- Откройте диспетчер задач.
- Активируйте вкладку Автозагрузка.
- Правый клик по GREP > Отключить.
РЕКЛАМА
При использовании Windows 7 — зажмите кнопки Win + R > вставьте команду msconfig > активируйте вкладку Автозагрузка > снимите галочку с GREP.
Один пользователь предложил следующее решение:

Можно сделать следующий вывод:
- Утилита поиска строк (GREP) запускается из-за неизвестной программы Flock.
- Приложение Flock расположено в папке C:\ProgramData\Flock.
- Данную папку можно попробовать удалить, при проблемах используйте утилиту Unlocker.
Способ удаления папки:
- Откройте диспетчер задач.
- Нажмите правой кнопкой по Утилита поиска строк (GREP), выберите пункт открыть расположение.
- Откроется директория, откуда запускается процесс, который грузит ПК.
- Вам нужно перейти на уровень вверх. Должна появиться выделенная папка, предположительно это будет Flock.
- Теперь нажимаем в диспетчере задач правой кнопкой по Утилита поиска строк (GREP) > выбираем пункт завершить процесс.
- Далее нажимаем правой кнопкой по директории > выбираем Удалить, при проблемах используем бесплатную утилиту Unclocker (создана специально чтобы удалять неудаляемые папки/файлы).
Дальнейшие действия
При наличии данного процесса — на компьютере могут быть вирусы. Настоятельно рекомендуется просканировать ПК на наличие рекламных модулей, опасных вирусов используя лучшие инструменты:
- Dr.Web CureIT — лучшая утилита против опасных вирусов, например трояны, майнеры, руткиты и прочие. Скачивается уже с антивирусными базами и под кодовым названием. Длительность проверки зависит от количества файлов на диске.
- AdwCleaner, HitmanPro — утилиты против рекламного ПО, рекламных тулбаров, левых расширений. Проверяют автозагрузку, реестр, планировщик задач и многое другое. Программы используют немного разный алгоритм работы, поэтому рекомендуется проверить ПК обоими.
При отсутствии качественного антивируса советую установить бесплатную версию Каспера — Kaspersky Security Cloud Free.
Заключение
Выяснили:
- Утилита поиска строк (GREP) — неизвестный процесс, предположительно вирусный, запускается программой Flock, которая также возможно является вирусом.
- Убрать нагрузку можно путем удаления папки, а также проверкой компьютера антивирусными утилитами.
Удачи.
From Wikipedia, the free encyclopedia
Example of |
|
| Original author(s) | Ken Thompson[1][2] |
|---|---|
| Developer(s) | AT&T Bell Laboratories |
| Initial release | November 1973; 49 years ago[1] |
| Written in | C |
| Operating system | Unix, Unix-like, Plan 9, Inferno, OS-9, MSX-DOS, IBM i |
| Platform | Cross-platform |
| Type | Command |
grep is a command-line utility for searching plain-text data sets for lines that match a regular expression. Its name comes from the ed command g/re/p (global / regular expression search / and print), which has the same effect.[3][4] grep was originally developed for the Unix operating system, but later available for all Unix-like systems and some others such as OS-9.[5]
History[edit]
Before it was named, grep was a private utility written by Ken Thompson to search files for certain patterns. Doug McIlroy, unaware of its existence, asked Thompson to write such a program. Responding that he would think about such a utility overnight, Thompson actually corrected bugs and made improvements for about an hour on his own program called s (short for «search»). The next day he presented the program to McIlroy, who said it was exactly what he wanted. Thompson’s account may explain the belief that grep was written overnight.[6]
Thompson wrote the first version in PDP-11 assembly language to help Lee E. McMahon analyze the text of The Federalist Papers to determine authorship of the individual papers.[7] The ed text editor (also authored by Thompson) had regular expression support but could not be used to search through such a large amount of text, as it loaded the entire file into memory to enable random access editing, so Thompson excerpted that regexp code into a standalone tool which would instead process arbitrarily long files sequentially without buffering too much into memory.[1] He chose the name because in ed, the command g/re/p would print all lines featuring a specified pattern match.[8][9] grep was first included in Version 4 Unix. Stating that it is «generally cited as the prototypical software tool», McIlroy credited grep with «irrevocably ingraining» Thompson’s tools philosophy in Unix.[10]
Implementations[edit]
A variety of grep implementations are available in many operating systems and software development environments.[11] Early variants included egrep and fgrep, introduced in Version 7 Unix.[10] The «egrep» variant supports an extended regular expression syntax added by Alfred Aho after Ken Thompson’s original regular expression implementation.[12] The «fgrep» variant searches for any of a list of fixed strings using the Aho–Corasick string matching algorithm.[13] Binaries of these variants exist in modern systems, usually linking to grep or calling grep as a shell script with the appropriate flag added, e.g. exec grep -E "$@". egrep and fgrep, while commonly deployed on POSIX systems, to the point the POSIX specification mentions their widespread existence, are actually not part of POSIX.[14]
Other commands contain the word «grep» to indicate they are search tools, typically ones that rely on regular expression matches. The pgrep utility, for instance, displays the processes whose names match a given regular expression.[15]
In the Perl programming language, grep is the name of the built-in function that finds elements in a list that satisfy a certain property.[16] This higher-order function is typically named filter or where in other languages.
The pcregrep command is an implementation of grep that uses Perl regular expression syntax.[17] Similar functionality can be invoked in the GNU version of grep with the -P flag.[18]
Ports of grep (within Cygwin and GnuWin32, for example) also run under Microsoft Windows. Some versions of Windows feature the similar qgrep or findstr command.[19]
A grep command is also part of ASCII’s MSX-DOS2 Tools for MSX-DOS version 2.[20]
The grep, egrep, and fgrep commands have also been ported to the IBM i operating system.[21]
The software Adobe InDesign has functions GREP (since CS3 version (2007)[22]), in the find/change dialog box[23] «GREP» tab, and introduced with InDesign CS4[24] in paragraph styles[25] «GREP styles».
agrep[edit]
agrep (approximate grep) matches even when the text only approximately fits the search pattern.[26]
This following invocation finds netmasks in file myfile, but also any other word that can be derived from it, given no more than two substitutions.
agrep -2 netmasks myfile
This example generates a list of matches with the closest, that is those with the fewest, substitutions listed first. The command flag B means best:
agrep -B netmasks myfile
Usage as a verb[edit]
In December 2003, the Oxford English Dictionary Online added «grep» as both a noun and a verb.[27]
A common verb usage is the phrase «You can’t grep dead trees»—meaning one can more easily search through digital media, using tools such as grep, than one could with a hard copy (i.e. one made from «dead trees», which in this context is a dysphemism for paper).[28]
See also[edit]
- Boyer–Moore string-search algorithm
- agrep, an approximate string-matching command
- find (Windows) or Findstr, a DOS and Windows command that performs text searches, similar to a simple
grep - find (Unix), a Unix command that finds files by attribute, very different from
grep - List of Unix commands
- vgrep, or «visual
grep« - ngrep, the network grep
References[edit]
- ^ a b c Kernighan, Brian (1984). The Unix Programming Environment. Prentice Hall. pp. 102. ISBN 0-13-937681-X.
- ^ “grep was a private command of mine for quite a while before i made it public.” -Ken Thompson Archived 2015-05-26 at the Wayback Machine, By Benjamin Rualthanzauva, Published on Feb 5, 2014, Medium
- ^ Hauben et al. 1997, Ch. 9
- ^ Raymond, Eric. «grep». Jargon File. Archived from the original on 2006-06-17. Retrieved 2006-06-29.
- ^ Paul S. Dayan (1992). The OS-9 Guru — 1 : The Facts. Galactic Industrial Limited. ISBN 0-9519228-0-7.
- ^ VCF East 2019 — Brian Kernighan interviews Ken Thompson (video). YouTube. 6 May 2019. Archived from the original on 2021-12-11. (35 mins)
- ^ Computerphile, Where GREP Came From, interview with Brian Kernighan
- ^ «ed regexes». perl.plover.com. Archived from the original on 20 October 2017. Retrieved 24 April 2018.
- ^ «How Grep Got its Name». robots.thoughtbot.com. Archived from the original on 9 August 2017. Retrieved 24 April 2018.
- ^ a b McIlroy, M. D. (1987). A Research Unix reader: annotated excerpts from the Programmer’s Manual, 1971–1986 (PDF) (Technical report). CSTR. Bell Labs. 139. Archived (PDF) from the original on 2017-11-11.
- ^ Abou-Assaleh, Tony; Wei Ai (March 2004). Survey of Global Regular Expression Print (GREP) Tools (Technical report). Dalhousie University.
- ^ Hume, Andrew (1988). «A Tale of Two Greps». Software: Practice and Experience. 18 (11): 1063. doi:10.1002/spe.4380181105. S2CID 6395770.
- ^ Meurant, Gerard (12 Sep 1990). Algorithms and Complexity. Elsevier Science. p. 278. ISBN 9780080933917. Archived from the original on 4 March 2016. Retrieved 12 December 2015.
- ^ «grep». www.pubs.opengroup.org. The Open Group. Archived from the original on 28 November 2015. Retrieved 12 December 2015.
- ^ «pgrep(1)». www.linux.die.net. Archived from the original on 22 December 2015. Retrieved 12 December 2015.
- ^ «grep». www.perldoc.perl.org. Archived from the original on 7 December 2015. Retrieved 12 December 2015.
- ^ «pcregrep man page». www.pcre.org. University of Cambridge. Archived from the original on 23 December 2015. Retrieved 12 December 2015.
- ^ «grep(1)». www.linux.die.net. Archived from the original on 10 December 2015. Retrieved 12 December 2015.
- ^ Spalding, George (2000). Windows 2000 administration. Network professional’s library. Osborne/McGraw-Hill. pp. 634. ISBN 978-0-07-882582-8. Retrieved 2010-12-10.
QGREP.EXE[:] A similar tool to grep in UNIX, this tool can be used to search for a text string
- ^ «MSX-DOS2 Tools User’s Manual by ASCII Corporation». April 1993.
- ^ IBM. «IBM System i Version 7.2 Programming Qshell» (PDF). IBM. Retrieved 2020-09-05.
- ^ «Review: Adobe InDesign CS3 — CreativePro.com». creativepro.com. 20 April 2007. Archived from the original on 5 January 2018. Retrieved 24 April 2018.
- ^ «InDesign Help: find/change». Archived from the original on 2016-08-28. Retrieved 2016-08-12.
- ^ «InDesign: GREP Styles (1) Setting text between parentheses in Italic». Archived from the original on 2017-09-24. Retrieved 2018-01-05.
- ^ «InDesign Help: GREP styles». Archived from the original on 2016-08-28. Retrieved 2016-08-12.
- ^ S. Lee Henry (June 1998). «Proper Searching». Sun Expert. pp. 35–26.
- ^ «New words list December 2003». Oxford English Dictionary. Retrieved 2021-12-06.
- ^ Jargon File, article «Documentation»
- Notes
- Alain Magloire (August 2000). Grep: Searching for a Pattern. Iuniverse Inc. ISBN 0-595-10039-2.
- Hume, Andrew Grep wars: The strategic search initiative. In Peter Collinson, editor, Proceedings of the EUUG Spring 88 Conference, pages 237–245, Buntingford, UK, 1988. European UNIX User Group.
- Michael Hauben; et al. (April 1997). Netizens: On the History and Impact of Usenet and the Internet (Perspectives). Wiley-IEEE Computer Society Press. ISBN 978-0-8186-7706-9.
External links[edit]
- GNU Grep official website
- GNU Grep manual
grep(1)– Plan 9 Programmer’s Manual, Volume 1grep(1)– Inferno General commands Manual- «why GNU grep is fast» — implementation details from GNU grep’s author.
- Command Grep – 25 practical examples
Обновлено: 08.10.2023
Кому не приходится искать в файлах определенный контент. В какой-то момент при работе с компьютерами вам захочется найти файлы, содержащие определенный текст/данные/строку/контент/информацию или любой другой термин, который вы используете. Пользователи Linux всегда хвастались возможностью использовать утилиту grep. Пользователи Windows полагались на поиск файлов с помощью простого пользовательского интерфейса и командлета Select-String. С WSL2 вы также можете использовать традиционные утилиты Linux для помощи в работе с ОС Windows. Давайте рассмотрим несколько вариантов grep, которые помогут нам в поиске нужной информации.
Для целей этой записи в блоге мы будем искать файлы на компьютере с Windows 10.
Настройка WSL2
Полные инструкции см. в официальных инструкциях по включению WSL2. Это инструкция для тех, кто не хочет читать весь документ целиком:
- Убедитесь, что вы используете правильную версию Windows 10, используя winver. Для систем x64 это должна быть версия 1903 или выше, сборка 18362 или выше. Для систем ARM64 это должна быть версия 2004 или выше со сборкой 19041 или выше.
- Откройте окно PowerShell от имени администратора и выполните приведенную ниже команду. Перезапустите при появлении запроса.
- После перезагрузки установите WSL по умолчанию на WSL2:
Установить дистрибутив Linux
Теперь вы можете установить дистрибутив Linux по вашему выбору, перейдя в Магазин Windows на панели запуска, а затем установив его. Для целей этого сообщения в блоге мы будем использовать Ubuntu 20.04 LTS. Если вы не хотите использовать Магазин Windows, выполните действия, описанные в документации WSL для ручной установки.
После установки запустите дистрибутив. В первый раз он попросит вас установить имя пользователя и пароль, как и в любом другом месте. Идите и сделайте то же самое. Давайте также продолжим и включим вход без пароля для группы %sudo:
Кроме того, давайте обновим репозитории пакетов и дистрибутив для дистрибутива. Для Ubuntu запустите ниже:
grep доступен из коробки в большинстве дистрибутивов Linux, поэтому вам не нужно его загружать и устанавливать.
Поиск заданной строки в одном файле
Очень простое использование grep включает поиск определенной строки в одном файле. Это можно просто получить с помощью grep literal_string имя файла. Вывод будет соответствовать всем строкам, содержащим строку literal_string из указанного файла, с каждым новым совпадением, присутствующим в новой строке:
Этот файл break-point.sh случайно оказался в нашем текущем каталоге. Мы могли бы указать полный путь (в unix-подобном формате), и он бы с радостью его обработал:
Поиск заданной строки в нескольких файлах
Это можно сделать, передав регулярные выражения для имени файла. Например, если вы хотите найти строку literal_string с файлами, оканчивающимися на .sh , вы можете использовать *.sh в качестве второго аргумента. Если вы хотите найти все файлы в данном каталоге, используйте подстановочный знак ( * ):
Как вы, возможно, заметили, имя каждого совпадающего файла печатается первым в выводе перед строкой, содержащей совпадающую строку.
Не все файлы, в которых вы хотите выполнить поиск, могут быть удобно расположены. Конечно, оболочке все равно, какой путь вы вводите, поэтому мы могли бы сделать что-то вроде этого:
Опять же, второй аргумент может быть более сложным регулярным выражением. Эти регулярные выражения не совпадают с сопоставлением шаблонов оболочки, хотя иногда они могут выглядеть одинаково.
Выполнить поиск без учета регистра
Поиск в оболочке с использованием grep чувствителен к регистру, так как это характерно для базовой ОС. Однако пользователи Windows привыкли выполнять поиск без учета регистра. Можно выполнить поиск без учета регистра с помощью grep -i :
Этот параметр особенно удобен для поиска слов в тексте, где может быть смешанный регистр.
Получение только имен файлов из поиска
Если вас не интересует вывод всех строк, содержащих совпадающий шаблон, а нужны только имена файлов, вы можете сделать это с помощью команды grep -l :
Это может быть весьма полезно для сценариев, поскольку позволяет нам использовать конвейер для вывода имен файлов для дальнейшей обработки. Поместите команду grep внутри $(), и эти имена файлов можно будет использовать в командной строке.
Обратите внимание, что если grep находит более одного совпадения для каждого файла, он все равно печатает имя только один раз. Если grep не находит совпадений, он ничего не выводит.
Рекурсивный поиск файлов или всех файлов в заданном каталоге
Вы можете искать все файлы по заданному пути, в папке или каталоге, включая подкаталоги, используя команду grep -r . По умолчанию поиск grep не включает поиск в подкаталогах.
Поиск в файлах содержимого, не соответствующего заданной строке
Если вы хотите отобразить строки, которые не соответствуют заданной строке, используйте параметр grep -v, как показано ниже. Вы также можете выполнить инвертированный поиск без учета регистра, смешав его с -i :
Подсчет количества совпадений
Если вы хотите подсчитать количество совпадений, данная строка присутствует в заданном наборе файлов, вы можете использовать grep -c . Вы можете смешивать и сочетать любые другие параметры, такие как -i , -v и т. д.
Показать только совпавшую строку (и пропустить всю строку)
По умолчанию grep покажет строку, которая соответствует заданному шаблону/строке, но если вы хотите, чтобы grep отображала только совпадающую строку шаблона, используйте параметр grep -o:
Это может быть не очень полезно, если вы даете строку прямо. Но это становится очень полезным, когда вы даете шаблон регулярного выражения и пытаетесь увидеть, чему он соответствует.
Проверка полных слов (а не их частей)
По умолчанию grep ищет части слов в содержимом файла. Таким образом, поиск суммы может соответствовать таким словам, как резюме, суммирование, лето, суммер, лето и т. д., которые могут не совпадать с вашими намерениями. Его легко игнорировать, когда вы выполняете поиск вручную, но это полезно, когда вы используете скрипты, так как вам нужно сделать ваши скрипты максимально точными. Для этого вы можете использовать grep -w :
Отображение линий до/после/вокруг матча
При устранении неполадок вам необходимо часто выполнять поиск в файлах журналов и проверять наличие сообщений, таких как ошибка/исключение/сбой/отказ и т. д. Может быть полезно показать несколько строк до/после/вокруг совпадающих строк. Для этого мы можем использовать -A n для отображения n строк после совпадения строки, -B n для отображения n строк до сопоставления строки и -C n для отображения n строк до и после поиска.
По умолчанию grep удаляет все повторяющиеся строки при отображении вывода, что особенно полезно в данном случае.
Поиск вывода другой команды
При написании сценария чаще всего вы будете использовать конвейер, чтобы сделать свои команды более полезными. Иногда перед обработкой всего ввода, предоставленного предыдущей командой, вы можете захотеть отфильтровать его с помощью grep. Для этого вам просто нужно передать вывод команды в grep.
Например, приведенная ниже команда отфильтрует вывод ls для выбора определенного файла, затем использует awk для получения имени файла, а затем использует rm для удаления этого файла:
Если вы также хотите, чтобы grep выполнял поиск сообщений об ошибках, полученных от предыдущей команды, не забудьте перенаправить ее вывод об ошибках в стандартный вывод перед каналом:
Эта команда пытается скомпилировать некоторый гипотетический фрагмент кода. Мы перенаправляем стандартную ошибку в стандартный вывод ( 2>&1 ), прежде чем перейти к передаче ( | ) вывода в grep, где он будет искать строку error без учета регистра ( -i ).
Сокращение вывода из grep с помощью grep
Поскольку grep принимает входные данные от другой команды, вы можете комбинировать несколько команд grep в конвейере, чтобы уменьшить количество данных, которые вы хотите видеть. Например, во второй команде ниже мы удаляем строки, совпадающие со словом summary :
Поиск текстовых шаблонов, а не строк
Вы можете искать не только буквальные строки, но и шаблоны, используя регулярные выражения. За регулярным выражением может следовать один из нескольких операторов повторения:
-
<ли>? Предыдущий элемент является необязательным и соответствует не более одного раза.
- * Предыдущий элемент будет совпадать ноль или более раз.
- + Предыдущий элемент будет совпадать один или несколько раз.
- n> Предыдущий элемент соответствует точно n раз.
- n,> Предыдущий элемент соответствует n или более раз.
- m> Предыдущий элемент соответствует не более m раз. Это расширение GNU.
- n,m> Предыдущий элемент соответствует не менее n раз, но не более m раз.
Период . соответствует любому одиночному символу. Набор символов, заключенных в квадратные скобки (например, [abc] ), соответствует любому из этих символов (например, «a», «b» или «c»). Если первый символ в квадратных скобках — знак вставки, то он соответствует любому символу, которого не нет в этом наборе. Возможны многие другие комбинации и метасимволы, позволяющие смешивать и сочетать различные комбинации.
Не только это, но и расширенные регулярные выражения. Ниже дословно взяты справочные страницы для grep:
Выполнить grep для сжатых файлов
zgrep — это просто версия grep, которую можно использовать для поиска в различных типах сжатых и несжатых файлов (подразумеваемые типы различаются в зависимости от системы). Все параметры, применимые к команде grep, также применяются к команде zgrep.
grep — это большая утилита, и здесь описаны не все параметры. Если вы хотите узнать больше, просмотрите его справочные страницы.
Вывод: GREP ищет именованные входные файлы или стандартный ввод и отображает строки, соответствующие одному или нескольким шаблонам, называемым регулярными выражениями или регулярными выражениями. GREP также может искать двоичные файлы и отображать записи или буферы, содержащие совпадения.
Начните с этого краткого руководства , а затем используйте Справочное руководство GREP для получения полной информации о каждой функции, аннотированного списка всех сообщений и многого другого.
Почему GREP? Почему Этот GREP?
В командной строке Windows функция НАЙТИ полезна для поиска заданной строки в одном или нескольких файлах. Но что, если вы хотите найти слово the в верхнем или нижнем регистре, не находя при этом other, там, тогда,< /i> и так далее? Вы действительно не хотите искать конкретную строку. Скорее, то, что вы ищете, является регулярным выражением или regex, а именно the, которому предшествует и за которым следует что-то, кроме буквы. GREP спешит на помощь!
GREP принимает одно или несколько регулярных выражений, сопоставляет их с входными файлами и отображает совпадения.
- Вы получаете обширную документацию с множеством примеров — HTML-код объемом более 400 КБ по состоянию на версию 8.01, а также справочную карту на одну страницу в формате PDF.
- Вы получаете техническую поддержку непосредственно от автора программы.
- По состоянию на февраль 2019 года программа бесплатна, но приветствуются пожертвования.
- Вы можете искать несколько строк или регулярных выражений за один проход во входных файлах.
- Поддерживаются как базовые, так и расширенные регулярные выражения, а также простой поиск строк.
- Вы можете искать несколько файлов в нескольких каталогах, включая автоматический поиск в подкаталогах.
- Вы можете выполнять поиск в текстовых и двоичных файлах, и вы даже можете заставить GREP определить, что есть что. GREP отображает попадания в бинарные файлы; он не просто сообщает вам, содержит ли файл регулярное выражение.
- Вы можете читать текстовые файлы в виде строк или абзацев независимо от того, отформатированы ли они для DOS/Windows, UNIX или Macintosh.
- Вы можете выбирать файлы, используя соглашения DOS и подстановку в стиле UNIX, или предоставить GREP файл, содержащий список файлов для поиска, и вы можете указать GREP исключить определенные файлы или группы файлов.
- Вы можете отобразить любое количество контекстных строк или байтов до и после совпадающих строк.
- У вас есть широкий выбор форматов вывода: показывать имена файлов или нет; отображать ли хиты, просто подсчитывать их или просто перечислять файлы, содержащие хиты; отображать ли в шестнадцатеричном формате или в виде символов; и использовать ли формат вывода в стиле DOS FIND или UNIX grep.
- Вы можете сохранить часто используемые параметры в переменной среды вместо того, чтобы каждый раз вводить их в командной строке.
- GREP возвращает значения состояния (ERRORLEVEL), которые могут быть полезны в пакетных файлах или сценариях, и вы можете контролировать, какое условие возвращает какое значение.
Начало работы
Установка и экскурсия
Совместимость: все версии DOS и Windows, от DOS 2.0 до Windows 11.
GREP обрабатывает текст в наборах из 256 символов, таких как группа ISO-8859, ANSI и Windows-1252. Он не понимает многобайтовые символы Unicode, хотя вы можете найти то, что ищете, используя двоичный режим (параметр /R).
Нет специального процесса установки. Просто разархивируйте загруженный ZIP-файл в любой удобный каталог.
Интерактивный тур по программе включен как пакетная программа в подпапку TOUR. После распаковки архива просто введите
ZIP-файл включает 16-разрядную и 32-разрядную версии программы.
- Используйте grep32.exe в командной строке в 32-разрядной или 64-разрядной версии Windows 95–Windows 11. (Вы также можете нажать Пуск � Выполнить или одновременно нажать клавишу с логотипом Windows и клавишу R, а затем ввести cmd, затем пробел и ваша команда grep32.)
- В устаревших системах под управлением DOS 2.0–7.0 или Windows 1.0–3.11 используйте grep16.exe . Он не поддерживает длинные имена файлов, расширенные регулярные выражения и сопоставление символов, но в остальном работает так же, как grep32 .
Нет необходимости применять какие-либо параметры совместимости с Windows.
Возможно, вы захотите переименовать используемый вами исполняемый файл, grep32.exe или grep16.exe , в более простое grep.exe . Все примеры в этом кратком руководстве предполагают, что вы это сделали. В противном случае просто замените grep32 или grep16 везде, где вы видите grep в примерах.
Вы можете переместить файл программы в другое место. Он полностью автономен; вы даже можете удалить все остальные файлы, если хотите. Вы можете указать в переменной PATH каталог, в который вы поместили исполняемый файл GREP.
Точный метод установки переменных среды зависит от версии Windows. В общем, перейдите в «Свойства системы» или «Компьютер» — «Свойства», а затем выберите «Дополнительные параметры системы». В очень старой Windows или «классической» DOS установите переменную в файле AUTOEXEC.BAT.
Удалить
Специальной процедуры удаления нет; просто удалите файлы GREP. GREP не записывает секретные файлы и не изменяет реестр Windows.
Командная строка
Основная форма команды GREP
(Вы также можете выполнить GREP с рабочего стола Windows, как описано в Справочном руководстве.
Параметры перечислены далее в этом кратком руководстве и полностью описаны в справочном руководстве.
Регулярное выражение – это строка или специальная строка, соответствующая шаблону, называемая файлом . Шаблоны регулярных выражений перечислены далее в этом кратком руководстве и подробно описаны в справочном руководстве. (Регулярное выражение обычно требуется в командной строке, однако, если вы используете параметр /F, одно или несколько регулярных выражений берутся из файла или с клавиатуры, а не из командной строки.)
Вы можете указать входные файлы в командной строке; в противном случае GREP считывает стандартный ввод.
Как и в случае с любой командой, вы можете перенаправлять или направлять входные или выходные данные. GREP может возвращать полезное значение в ERRORLEVEL, как описано в Справочном руководстве.
Вот два простых примера. Во-первых,
просматривает каждый исходный файл COBOL в корневом каталоге PROJ и отображает каждую строку, содержащую графическое предложение («pic», за которым следует «t» или пробел) в верхнем или нижнем регистре (параметр /I). Добавление параметра /S
просматривает каждый исходный файл COBOL во всех каталогах на текущем диске.
Чтобы получить сводку инструкций по эксплуатации, введите
Поскольку текст справки имеет длину более 150 строк, вы можете предпочесть перенаправить его в файл для просмотра:
Входные данные
GREP сканирует либо именованные входные файлы, либо стандартный ввод. Стандартный ввод может быть именованным файлом, каналом или клавиатурой.
Именованные входные файлы
Именованные входные файлы обеспечивают наибольшую гибкость. Их можно читать в виде текста или двоичных файлов, и вы можете выполнять поиск по деревьям подкаталогов.
GREP32 может использовать длинные имена файлов; GREP16 требует коротких (8.3) имен файлов.
GREP расширяет любые подстановочные знаки в именованных входных файлах. Не только в стиле DOS * и ? , но можно использовать [�] в стиле UNIX. Например, «c:\My Documents\[abc]*doc» указывает GREP прочитать каждый файл в указанном каталоге, имя которого начинается с A, B или C и заканчивается на DOC (включая «.DOC»). Полные правила см. в разделе «Именованные входные файлы» в Справочном руководстве.
Вы можете использовать параметр /X, чтобы исключить некоторые файлы или группы файлов из рассмотрения. Например, если вам нужны все отчеты за 2001 год, кроме декабря, вы можете указать что-то вроде
Если у вас много именованных входных файлов, вы можете сохранить список в файле; см. параметр /@.
Поиск в подкаталогах
Если вы установите параметр /S, GREP будет искать не только файлы, указанные в командной строке, но и файлы с одинаковыми именами в подкаталогах вплоть до нижней части дерева папок.
Например, командой
GREP проверяет все файлы на всем текущем диске, имена которых начинаются с «hazax». затем он просматривает все исходные файлы C в текущем каталоге и во всех его подкаталогах; наконец, он просматривает все файлы .htm в каталоге «g:\mumble» и во всех его подкаталогах.
Возможно, более реалистичный пример: у вас где-то на диске есть документ о Vandelay Industries, но вы не можете вспомнить, где именно. Вы можете найти его следующим образом:
(Как *, так и *.* выбирают все файлы; см. Расширение подстановочных знаков в Справочном руководстве.) Возможно, вы захотите добавить параметр /I, если не помните, как слово «Vandelay» пишется с заглавной буквы.
Стандартный ввод и перенаправление
Если вы не укажете какие-либо именованные входные файлы, GREP использует стандартный ввод. Это может означать любой из этих трех источников:
Ввод перенаправлен из одного файла (Windows не поддерживает подстановочные знаки):
Вывод другой команды передается в GREP для дальнейшей обработки:
Ввод с клавиатуры (запрос GREP):
указывает GREP прочитать вывод команды tracert и отобразить все строки, содержащие строку «123».
Двоичные файлы и текстовые файлы
Первоначально GREP был написан для файлов с простым текстом, но вы также можете использовать его с двоичными файлами, такими как текстовые файлы, базы данных и исполняемые программы. GREP не только по-разному читает двоичные файлы, но и настраивает формат отображения для совпадений.
Windows не помечает файл как текстовый или двоичный; программа, которая читает файл, просто должна знать. GREP «знает», что файлы являются двоичными, когда вы сообщаете об этом с помощью параметра /R2 или /R3; в противном случае он обрабатывает входные файлы как текст. Используйте параметр /R3, если вы не знаете никаких деталей внутренней структуры двоичного файла; дополнительную информацию о двоичных файлах см. в разделе «Двоичные файлы и текстовые файлы» в Справочном руководстве.
Вы также можете использовать параметр /R-1 или /R-2, чтобы GREP проверил каждый файл и решил, является ли он текстовым или двоичным; подробнее см. параметр /R в Справочном руководстве. Я рекомендую /R-1 .
Результаты
Обычно GREP отображает обращения на вашем экране. �� — это текстовые строки, двоичные записи или двоичные буферы, содержащие совпадения для регулярных выражений. Как часть вывода, GREP отображает путь и имя файла в виде заголовка над группой совпадений из этого файла.Вы можете использовать различные параметры, чтобы отображать сокращенные или расширенные формы обращений или отключать эти заголовки, перемещать их в строки с обращениями или отображать заголовки даже для файлов, в которых не было обращений.
Вы также можете перенаправить вывод GREP в файл или направить вывод GREP в другую команду (даже в другую команду GREP). Чтобы перенаправить вывод GREP, следуйте обычным правилам и поместите одно из них в конец командной строки GREP:
>> reportfile добавляет вывод GREP к существующему файлу или создает файл и записывает в него данные, если он не существует.
> reportfile перезаписывает существующий файл выходными данными GREP или создает файл и записывает в него данные, если он не существует.
| other-command направляет вывод GREP в стандартный поток ввода другой команды.
Вы можете передать или перенаправить вывод независимо от того, был ли ввод передан или перенаправлен.
Только попадания (и заголовки пути\имени файла, если они есть) перенаправляются в соответствии с приведенным выше синтаксисом. Ошибки и предупреждающие сообщения по-прежнему отправляются в стандартный поток ошибок. Обычно это ваш экран, хотя некоторые операционные системы или замены оболочки позволяют перенаправлять вывод ошибок. Например, в 4DOS, 4NT и TCC введите help piping или help redirection для получения информации.
Параметр /D позволяет создавать дополнительные выходные данные отладки и отправлять их в именованный файл или стандартный вывод ошибок.
Параметры
Список параметров
Каждое описание снабжено гиперссылкой на полное описание в Справочном руководстве.
< tr> < td>/N < td>Сканировать файлы и в подкаталогах.
| Параметры и эффекты | UNIX grep* |
Windows НАЙТИ* |
|
|---|---|---|---|
| ? | Показать справку по файлам, регулярным выражениям и параметрам. | —help | /? |
| @ | Взять имена входных файлов с клавиатуры или из файла. | ||
| A | Включить скрытые и системные файлы при раскрытии подстановочных знаков. | ||
| B | Отображать заголовок для каждого файла, даже если он не содержит совпадений. | ||
| C | Отображать количество совпадений, а не фактические совпадения. | -c | /C |
| D | Показать вывод отладки. | ||
| E | Выбор расширенных регулярных выражений или строк или поиск слова. | ( -E ), ( -w ) | |
| F | Чтение регулярных выражений с клавиатуры или из файла. | ( -f ) | |
| G | Чтение строк или абзацев текста переменной длины. | ||
| H | Не отображать его aders (имена файлов) в выводе. | -h | |
| I | Игнорировать регистр при сопоставлении. | -i | /I |
| J | Отобразить только ту часть каждой строки, которая соответствует регулярному выражению. | -o | |
| K | Сообщать только о первых нескольких совпадениях. | ||
| L< /td> | Вывести список файлов, содержащих совпадения, а не фактические совпадения. | -l | |
| M | Указать сопоставление символов и определить «слово». | ||
| N | Показать номера строк с совпадениями. | -n | |
| O | Установить выходной формат. | ||
| P | Показать строки контекста вокруг совпадающих строк. | ( -A , -B , -C ) | |
| Q | Подавить логотип программы и некоторые или все предупреждения. | ( -s ) | |
| R< /td> | Чтение и отображение входных файлов в двоичном или текстовом виде. | -U , ( -a ) | |
| S | -r | ||
| U | Вывод в стиле UNIX: показывать спецификацию файла при каждом попадании. | (подразумевается) | |
| V | Отобразить строки, которые не содержат совпадения.< /td> | -v | /V |
| W | Указать ширину строки или длину двоичного блока. | ||
| X | Исключить указанные файлы из сканирования. | -x | |
| Y< /td> | Несколько регулярных выражений должны совпадать. | ||
| Z | Сбросить все параметры (рекомендуется для пакетных файлов). | ||
| 0 | Установите для ERRORLEVEL значение 0, если были найдены совпадения. | ||
| 1 | Установите ERRORLEVEL до 1, если есть h оно было найдено. | ( -v ) | |
| 3 | Установите для ERRORLEVEL значение 3, если отображались предупреждения. | ||
| * Параметры UNIX grep чувствительны к регистру; Опции GREP и FIND — нет. (Параметр показан в скобках, если эффект параметра GREP похож, но не идентичен.) |
Как указать параметры
В командной строке параметры могут появляться где угодно, до или после регулярного выражения и входных файлов. Все параметры обрабатываются до того, как какие-либо файлы будут прочитаны.
Вы можете свободно вводить параметры: используйте начальный дефис или косую черту, используйте прописные или строчные буквы, оставляйте пробелы между параметрами или комбинируйте их. Например, ниже приведены лишь некоторые из различных способов включения параметров /P3 и /B:
В этом кратком руководстве для параметров всегда используются заглавные буквы, чтобы было легче различать букву l и цифру 1.
Для ясности всегда следует использовать дефис или косую черту перед числовым параметром /0, параметром /1 или параметром /3. Пример: /E0 означает параметр /E со значением 0, а /E/0 означает параметр /E без указания значения, за которым следует параметр /0.
Справочное руководство содержит дополнительную информацию о переменной среды, включая инструкции по переопределению определенного сохраненного параметра в командной строке.
Регулярные выражения (регулярные выражения)
Регулярное выражение или представляет собой шаблон символов для сравнения со строками, записями или буферами из одного или нескольких входных файлов. GREP сообщает о попадании, если входные данные содержат совпадение с шаблоном в регулярном выражении.
Регулярное выражение может быть простой текстовой строкой, например mother , или чем-то более сложным. (Если вы хотите искать только простые строки, используйте параметр /E0 и игнорируйте все эти регулярные выражения.)
Регулярные выражения на примере
Пример 1. Если вам нужны варианты написания слова «grey/grey» как в английском, так и в американском, используйте
в качестве регулярного выражения. (См. пример 5 для «цвета/цвета».)
Пример 2. Базовое регулярное выражение для любого слова, начинающегося с «мотылек», это
это буквы «мотылек», за которыми следует любое количество букв от a до z. Да, это регулярное выражение соответствует самому «мотыльку»: см. * или + для повторения в Справочном руководстве .
Пример 3. Слово в двойных кавычках будет соответствовать
Прочитайте это регулярное выражение как «двойную кавычку, за которой следуют одна или несколько букв, за которыми следует еще одна двойная кавычка». (Вам нужна обратная косая черта \, чтобы указать командной строке Windows передать кавычки вперед в GREP. См. Цитаты в регулярном выражении в Справочном руководстве .)
Пример 4. Местный номер телефона в США имеет базовое регулярное выражение
Это означает три цифры, за которыми следует дефис, а затем четыре цифры. (Вы можете выразить это проще с помощью расширенного регулярного выражения: 4-4 или даже \d-\d .)
Пример 5. Чтобы получить американское и английское написание «color/color», с помощью GREP32 легко: укажите расширенное регулярное выражение (с параметром /E2)
GREP16 не поддерживает расширенные регулярные выражения, поэтому вы можете либо использовать colou*r (что также будет соответствовать цветам, не являющимся словами, colouur, colouuuuur и т. д.), либо использовать параметр /F- и ввести цвет и цвет как два регулярных выражения.
Обзор языка регулярных выражений
Из примеров видно, что регулярное выражение — это, по сути, строка символов с набором операторов, добавленных для выражения таких возможностей, как «любой из этих символов» и «повторяется». Вот краткий обзор символов, которые имеют особое значение в регулярном выражении; обратите внимание, что некоторые работают в любом регулярном выражении, а другие только в расширенном регулярном выражении (параметр /E2). Каждый из них связан гиперссылкой с разделом Справочного руководства, где вы найдете полное описание.
Хотя все функции PowerGREP также доступны из командной строки, основным преимуществом PowerGREP по сравнению с традиционным grep является гибкий и удобный графический интерфейс. Вместо того, чтобы просто перечислить совпадающие строки, PowerGREP также выделит фактические совпадения и сделает их кликабельными. Когда вы щелкнете по совпадению, PowerGREP загрузит файл с подсветкой синтаксиса, что позволит вам легко проверить контекст совпадения.
PowerGREP также предоставляет полнофункциональный многострочный текстовый редактор для составления регулярного выражения, которое вы хотите использовать в своем поиске.

< /p>
Лучший поиск и замена
Если у вас уже есть некоторый опыт работы с регулярными выражениями, то вы уже знаете, что поиск и замена с помощью регулярных выражений и обратных ссылок — это эффективный способ обслуживания всех типов текстовых файлов. Если нет, я предлагаю вам загрузить копию PowerGREP и взглянуть на примеры в файле справки.
Одним из преимуществ использования PowerGREP для таких задач является возможность предварительного просмотра замен и проверки контекста замен, как и в случае с функцией поиска, описанной выше. Заменить или отменить все совпадения или все совпадения в файле после предварительного просмотра или выполнения поиска и замены. Замените или отмените отдельные или выбранные совпадения в полнофункциональном файловом редакторе PowerGREP. Естественно, также доступна функция отмены.
Еще одним преимуществом является возможность PowerGREP работать со списками регулярных выражений. Вы можете указать любое количество операций поиска и замены, которые будут выполняться вместе, одна за другой, над одними и теми же файлами. Сохранение списков, которые вы регулярно используете, в файл действий PowerGREP сэкономит вам много времени.
Сбор информации и статистики
Функция «сбора» PowerGREP — это уникальная и полезная разновидность традиционного поиска по регулярным выражениям.Вместо того, чтобы выводить строку, в которой было найдено совпадение, он выводит само совпадение с регулярным выражением или его вариант. Этот вариант представляет собой фрагмент текста, который вы можете составить с помощью обратных ссылок, точно так же, как заменяющий текст для поиска и замены. Вы можете отсортировать собранные совпадения и сгруппировать идентичные совпадения. Таким образом, вы можете вычислить простую статистику. Функция «сбор» наиболее полезна, если вы хотите извлечь информацию из файлов журналов, для которых не существует специализированного программного обеспечения для анализа.
Переименовывать, копировать, объединять и разделять файлы
PowerGREP может делать гораздо больше с помощью регулярных выражений, чем традиционные задания поиска и поиска и замены. Переименовывайте или копируйте файлы или целые папки, выполняя поиск и замену в именах файлов, именах папок или полных путях. Вы даже можете сжимать и распаковывать файлы таким образом, добавляя или удаляя расширение .gz или .bzip2, или изменяя путь так, чтобы он находился внутри архива .zip или .7z, или нет. Объединяйте или разделяйте содержимое файлов на новые файлы, выполняя поиск по регулярному выражению и используя текст замены для построения пути к целевому файлу или файлам.
Фильтрация файлов, секционирование файлов, дополнительная обработка и контекст
Большинство инструментов grep могут одновременно работать только с одним регулярным выражением. С PowerGREP вы можете использовать до пяти списков любого количества регулярных выражений. Один список — это основной поиск, поиск и замена, сбор, переименование, объединение или разделение. Другие списки используются для фильтрации файлов, секционирования файлов, дополнительной обработки и контекста. Используйте фильтрацию файлов, чтобы пропустить определенные файлы на основе совпадения с регулярным выражением или его отсутствия. Используйте секционирование файлов, чтобы ограничить основное действие только определенными частями каждого файла. Используйте дополнительную обработку, чтобы применить дополнительный поиск и замену к каждому отдельному совпадению поиска. Используйте регулярные выражения для сопоставления блоков контекста, чтобы результаты отображались более четко, если ваши файлы не основаны на строках.
Если это звучит сложно, это не так. Часто с PowerGREP можно использовать гораздо более простые регулярные выражения. Вместо создания сложного регулярного выражения для сопоставления адреса электронной почты внутри тега привязки HTML используйте стандартное регулярное выражение, соответствующее адресу электронной почты, в качестве действия поиска и стандартное регулярное выражение, соответствующее тегу привязки HTML, для разделения файла.
Представьте, что у вас есть файл (или группа файлов), и вы хотите найти определенную строку или параметр конфигурации в этих файлах. Открывать каждый файл по отдельности и пытаться найти конкретную строку было бы утомительно и, вероятно, не является правильным подходом. Так что же мы можем использовать?
Дополнительные ресурсы по Linux
Существует множество инструментов, которые мы можем использовать в системах на основе *nix для поиска и обработки текста. В этой статье мы рассмотрим команду grep для поиска шаблонов, найденных в файлах или поступающих из потока (файл или ввод, полученный из канала, или | ). В следующей статье мы также увидим, как использовать sed (редактор потоков) для управления потоком.
Лучший способ понять, как работает программа или утилита, — просмотреть ее справочную страницу. Многие (если не все) инструменты Unix предоставляют man-страницы во время установки. В системах на базе Red Hat Enterprise Linux мы можем запустить следующее, чтобы получить список файлов документации grep:
Имея в нашем распоряжении справочные страницы, мы теперь можем использовать grep и исследовать его возможности.
основы grep
В этой части статьи мы используем файл Words, который вы можете найти по следующему адресу:
Этот файл содержит 479 826 слов и предоставляется пакетом words. В моей системе Fedora этот пакет Words-3.0-33.fc30.noarch. Когда мы перечисляем содержимое файла Words, мы видим следующий вывод:
Хорошо, мы сказали, что файл Word содержит 479 826 строк, но откуда мы это знаем? Помните, мы говорили о справочных страницах ранее. Давайте посмотрим, предлагает ли grep возможность подсчета строк в заданном файле.
Как ни странно, мы будем использовать grep для выбора опции следующим образом:

Итак, нам, очевидно, нужна опция -c или длинная опция —count для подсчета количества строк в заданном файле. Подсчет строк в /usr/share/dict/words дает:
‘.’ означает, что мы будем считать все строки, содержащие хотя бы один символ, пробел, пробел, табуляцию и т. д.
Основные регулярные выражения grep
Команда grep становится более мощной, когда мы используем регулярные выражения (регулярные выражения). Итак, сосредоточившись на самой команде grep, мы также коснемся основного синтаксиса регулярных выражений.
Предположим, что нас интересуют только слова, начинающиеся с Z . В этой ситуации на помощь приходят регулярные выражения.Мы используем карат (^) для поиска шаблонов, начинающихся с определенного символа, обозначающего начало строки:

Для поиска шаблонов, оканчивающихся на определенный символ, мы используем знак доллара ( $ ) для обозначения конца строки. См. пример ниже, где мы ищем строки, оканчивающиеся на шляпу:

Чтобы напечатать все строки, содержащие шляпу, независимо от ее положения, будь то в начале строки или в конце строки, мы должны использовать что-то вроде:

Пример: удаление комментариев
Теперь, когда мы коснулись поверхности grep , давайте поработаем над некоторыми реальными сценариями. Многие конфигурационные файлы в *nix содержат комментарии, описывающие различные настройки в конфигурационном файле. Например, файл /etc/fstab имеет:
Тем не менее, здесь вам не нужен кот (избегайте бесполезного использования кота). Команда grep отлично умеет читать файлы, поэтому вместо этого вы можете использовать что-то вроде этого, чтобы игнорировать строки, содержащие комментарии:
Если вы хотите вместо этого отправить вывод (без комментариев) в другой файл, используйте:
Хотя grep может форматировать вывод на экран, эта команда не может изменить файл на месте. Для этого нам понадобится редактор файлов, например ed. В следующей статье мы будем использовать sed, чтобы добиться того же, что мы сделали здесь с grep .
Пример: удалить комментарии и пустые строки
Пока мы все еще работаем с grep , давайте изучим файл /etc/sudoers. Этот файл содержит много комментариев, но нас интересуют только строки без комментариев, а также мы хотим избавиться от пустых строк.
Итак, сначала давайте удалим строки, содержащие комментарии. Получается следующий вывод:
Теперь мы хотим избавиться от пустых (пустых) строк. Ну, это легко, просто запустите другую команду grep:
Можем ли мы сделать лучше? Можем ли мы запустить нашу команду grep, чтобы быть более ресурсоемкими, а не разветвлять grep дважды? Мы, конечно, можем:
Здесь мы ввели еще один параметр grep, -E (или —extended-regexp )
является расширенным регулярным выражением.
Пример: Печатать только пользователей /etc/passwd
Очевидно, что grep эффективен при использовании с регулярными выражениями. В этой статье рассматривается лишь небольшая часть того, на что действительно способен grep. Чтобы продемонстрировать возможности grep и использование регулярных выражений, мы проанализируем файл /etc/passwd и выведем только имена пользователей.
Формат файла /etc/passwd следующий:
Вышеуказанные поля имеют следующее значение:
Дополнительную информацию о файле /etc/passwd см. в man 5 passwd. Чтобы напечатать только имена пользователей, мы могли бы использовать что-то вроде следующего:
В приведенной выше команде grep мы ввели еще один параметр: -o (или —only-matching ), чтобы показать только часть совпадающей строки
<р>. Затем мы объединили -Eo, чтобы получить желаемый результат.
Теперь мы разделим приведенную выше команду, чтобы лучше понять, что происходит на самом деле. Слева направо:
- ^ соответствует началу строки.
- [a-zA-Z_-] называется классом символов и соответствует одному символу, соответствующему включенному списку.
- + – это квантификатор, который соответствует от одного до неограниченного числа раз.
Приведенное выше регулярное выражение будет повторяться до тех пор, пока не будет достигнут несоответствующий символ. Первая строка файла:
Он обрабатывается следующим образом:
- Первый символ — это r , поэтому он соответствует [a-z].
- + перемещает к следующему символу.
- Второй символ — буква o, и ему соответствует [a-z].
- + перемещает к следующему символу.
Эта последовательность повторяется до тех пор, пока мы не нажмем двоеточие ( : ). Класс символов [a-zA-Z_-] не соответствует символу :, поэтому grep переходит на следующую строку.
Поскольку все имена пользователей в файле passwd написаны строчными буквами, мы также можем упростить наш класс символов следующим образом и получить желаемый результат:
Пример: найти процесс
При использовании ps для grep для процесса мы часто используем что-то вроде:
Но команда ps выведет не только список процессов Thunderbird. В нем также указана команда grep, которую мы только что запустили, поскольку grep также выполняется после канала и отображается в списке процессов:
С этим можно справиться, добавив grep -v grep, чтобы исключить grep из вывода:
Хотя использование grep -v grep сделает то, что мы хотели, существуют более эффективные способы достижения того же результата без создания нового процесса grep:
[t]hunderbird здесь совпадает с литералом t и чувствителен к регистру. Он не будет соответствовать grep , и поэтому теперь мы видим в выводе только Thunderbird.
Этот пример — просто демонстрация гибкости grep, он не поможет вам устранить неполадки в дереве процессов. Для этой цели подходят более подходящие инструменты, например pgrep .
Подведение итогов
Используйте grep, если вы хотите рекурсивно искать шаблон в файле или нескольких каталогах. Попытайтесь понять, как работают регулярные выражения, когда grep , поскольку регулярные выражения могут быть мощными.
[Хотите попробовать Red Hat Enterprise Linux? Загрузите его сейчас бесплатно.]
Читайте также:
- 4 ГБ оперативной памяти — это много или мало
- Замена процессора Asus X54h
- Нужно ли менять материнскую плату при замене видеокарты
- Переименовать жесткий диск mac os
- Немаркированный том 1 на локальном диске, как исправить
В настоящее время многие пользователи операционной системы Windows сталкиваются с проблемой, связанной с нагрузкой процессора при использовании утилиты поиска строк Grep. Что именно приводит к такому поведению программы и как можно справиться с этой проблемой?
Grep — это мощная и эффективная утилита поиска и фильтрации строк в текстовых файлах. Благодаря своей гибкости и широкому набору параметров, она стала популярным инструментом для программистов, системных администраторов и других специалистов, работающих с текстовыми данными.
Однако, в отличие от других операционных систем, в Windows Grep работает неоптимально и может вызывать высокую нагрузку на процессор. В основе этой проблемы лежит алгоритм, который Grep использует для поиска строк — он неэффективно обрабатывает большие текстовые файлы и может требовать значительных ресурсов системы.
Счастью, есть несколько способов справиться с проблемой загрузки процессора. Один из них — использование более эффективных алгоритмов поиска, таких как agrep или ripgrep, которые работают на подобных принципах, но имеют более оптимизированный код и меньшее потребление ресурсов.
Содержание
- Почему Grep windows грузит процессор
- Утилита поиска строк
- Эффективность и проблемы
- Искажающая нагрузка
- Влияние на производительность
- Недостатки в работе
Почему Grep windows грузит процессор
Одной из причин, почему Grep может грузить процессор, является интенсивный поиск по большому количеству файлов или объемным текстовым данным. Если файлы, в которых производится поиск, очень большие или их много, то Grep может потреблять значительное количество ресурсов, включая высокую загрузку процессора.
Кроме того, эффективность работы Grep может зависеть от специфических факторов, связанных с конфигурацией системы. Например, плохая оптимизация системы или недостаточное количество оперативной памяти может еще больше увеличить нагрузку Grep на процессор.
Также стоит упомянуть, что равномерное распределение нагрузки на несколько ядер процессора может быть вызвано некорректно настроенным параллельным выполнением Grep. Если параллельный поиск включен, но не правильно настроен, это может привести к неравномерному распределению нагрузки на процессор.
В целом, для устранения проблем с загрузкой процессора при использовании Grep на Windows, рекомендуется:
- Оптимизировать поиск, перераспределяя данные на несколько файлов, если это возможно.
- Использовать фильтры и регулярные выражения для сужения критериев поиска и исключения излишних данных.
- Обновить ОС и установить все имеющиеся обновления, чтобы устранить возможные проблемы с производительностью.
- Проверить и оптимизировать конфигурацию системы, включая добавление оперативной памяти и оптимизацию процессора.
С учетом вышеперечисленных рекомендаций, возможно улучшить производительность при использовании Grep в Windows-среде и снизить нагрузку на процессор.
Утилита поиска строк
Утилита grep в Windows – это отдельная консольная утилита, которая обладает мощными возможностями поиска и фильтрации текста. Она может обрабатывать огромные объемы данных и самостоятельно искать нужные строки по определенным критериям.
Преимущества использования grep в Windows:
- Быстрый и эффективный поиск строк в файле или выводе команд;
- Возможность использования регулярных выражений для более сложного и точного поиска;
- Гибкое настройка параметров поиска, таких как учет регистра символов;
- Возможность поиска не только в одном файле, но и в нескольких файлах одновременно;
- Поддержка различных кодировок текста;
- Простота использования и наличие подробной документации.
Утилита grep может быть полезна во многих сферах, включая программирование, администрирование системы, анализ логов и многое другое. Ее гибкость и мощные возможности делают ее незаменимым инструментом для работы с текстовыми данными.
Эффективность и проблемы
Утилита Grep в Windows предоставляет пользователю удобный и эффективный инструмент для поиска строк в файловой системе операционной системы. Однако, несмотря на свою функциональность, утилита может вызывать некоторые проблемы.
Одной из основных проблем, связанных с использованием Grep, является его нагрузка на процессор. При обработке больших файлов или при использовании сложных регулярных выражений, утилита может значительно увеличивать использование CPU, что может привести к замедлению работы системы в целом.
Другой проблемой может стать неправильное использование Grep пользователем. Некорректно описанные или сложные в выражениях запросы, могут привести к неправильным или неполным результатам поиска. Поэтому важно учитывать особенности синтаксиса и использования утилиты Grep.
Также стоит отметить, что Grep не поддерживает поиск в бинарных файлах, что может ограничить его применение в некоторых случаях. Например, утилита не сможет найти строки в исполняемых файлах, архивах или изображениях.
Однако, несмотря на данные проблемы, Grep остается одной из наиболее эффективных утилит поиска строк в Windows. Он обладает широкими возможностями настройки поиска, поддерживает регулярные выражения, а также предлагает удобный и интуитивно понятный интерфейс.
Искажающая нагрузка
Во-первых, поиск в больших файлах может занять значительное количество времени и уровень нагрузки на процессор будет высоким. Это связано с тем, что Grep windows должен просканировать каждую строку файла в поисках совпадений, что требует значительной вычислительной мощности.
Во-вторых, использование сложных регулярных выражений может также вызвать высокую нагрузку на процессор. При использовании сложных выражений Grep windows должен выполнить дополнительные операции для проверки совпадений, что может замедлить процесс и увеличить нагрузку на процессор.
Чтобы снизить нагрузку на процессор при использовании Grep windows, можно попробовать использовать более специфичные фильтры или регулярные выражения, чтобы уменьшить количество строк, которые необходимо проверить. Также можно разделить большие файлы на более мелкие части и выполнить поиск отдельно для каждой части, чтобы распределить нагрузку на процессор.
- Использование более специфичных фильтров или регулярных выражений
- Разделение больших файлов на мелкие части
- Выполнение поиска отдельно для каждой части файла
Принимая во внимание эти рекомендации, можно снизить нагрузку на процессор при использовании Grep windows и сделать его более эффективным инструментом поиска строк.
Влияние на производительность
Причина такого значительного использования процессора заключается в способе работы Grep windows. Утилита сканирует файлы и ищет указанные строки, применяя определенные правила и операции, такие как поиск регулярных выражений. Эти операции требуют значительных вычислительных ресурсов и могут занимать значительное время.
Более того, при выполнении поиска строк в режиме реального времени, Grep windows выполняет сканирование файлов непрерывно, что продолжает нагружать процессор постоянно. Это может вызвать замедление работы системы и привести к ухудшению производительности.
Для минимизации влияния Grep windows на производительность системы, можно использовать некоторые стратегии. Во-первых, можно ограничить поиск строк только определенными файлами или папками, чтобы снизить общую нагрузку на процессор. Во-вторых, можно использовать фильтры и исключения, чтобы исключить из поиска определенные типы файлов или папки, которые нам не интересны. Такие стратегии могут помочь снизить использование процессора и улучшить производительность системы при использовании Grep windows.
Недостатки в работе
Grep windows, несмотря на свою эффективность в поиске строк, имеет несколько недостатков, которые могут повлиять на его работу:
- Высокая нагрузка на процессор: из-за особенностей алгоритма поиска, Grep windows может потреблять большое количество ресурсов процессора, что может привести к замедлению работы системы.
- Отсутствие графического интерфейса: Grep windows является текстовым инструментом командной строки, что может быть неудобным для пользователей, не знакомых с командами и синтаксисом.
- Ограниченные возможности поиска: хотя Grep windows может быть полезным для базового поиска строк, он не предоставляет таких продвинутых функций, как поиск с использованием регулярных выражений или поиск внутри файлов различных форматов.
- Нет поддержки внедрения в пользовательские программы: Grep windows не может быть использован как библиотека в других программных приложениях, поэтому его функциональность ограничена только выполнением команды из командной строки.
В целом, несмотря на эти ограничения, Grep windows остается полезным и удобным инструментом для базового поиска строк в операционных системах Windows.
In this tutorial, we will learn how to install the grep command on the Windows operating system. We will then look at a few examples to learn how to search for text patterns with the grep command.
After you install grep on Windows, you can use it on both CMD and Windows PowerShell. You can pipe CMD and PowerShell commands to the grep to filter the output.
Install Grep on Windows
There are a couple of ways to install grep on Windows. The easiest way is to install git using the winget package manager.
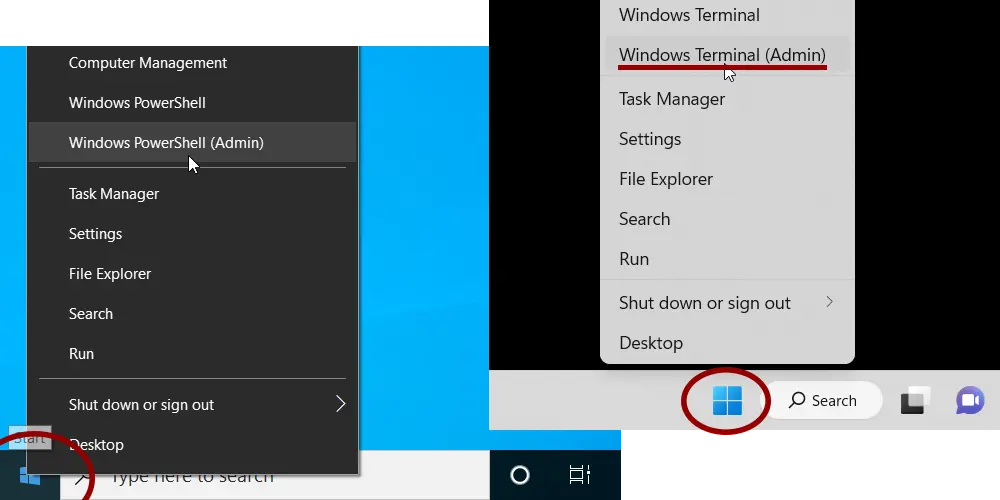
To get started, start an Administrator console: Right-click the Start button and choose Windows Terminal (Admin) if you are on Windows 11 or PowerShell (Admin) if you are on Windows 10.
Execute the following command to install Git:
winget install --id Git.Git -e --source wingetNext, run the following command to add the bin directory to the system PATH variable:
$PATH = [Environment]::GetEnvironmentVariable("PATH", "Machine"); [Environment]::SetEnvironmentVariable("PATH", "$PATH;C:\Program Files\Git\usr\bin", "Machine")After that, exit and re-open the PowerShell console. And that is it. The grep command is now available in both CMD and Windows PowerShell.
If for some reason, you don’t like to install Git Bash, there is an alternative. That is to install grep using the chocolatey package manager. You can do that by running the following two commands:
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))
choco install -y grepThis will only install the grep command. The Git Bash package installs other Linux command-line tools such as awk, sed, and find under the C:\Program Files\Git\usr\bin directory.
Grep Command Examples
There are two ways to use grep. First, grep can be used to search strings on one or more files. Second, grep can be used to filter the output of another command.
In the following section, we will go through a number of examples to learn the grep command.
Basic Text Searching
In its basic form, we use the grep command to search strings in files and grep prints lines that match.
grep 'string' filenameYou can search on multiple files at once if you want:
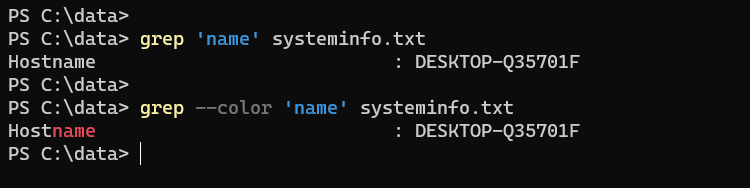
grep 'string' file1 file2 file3In the following example, we search for the string ‘name’ in the text file called systeminfo.txt:
grep 'name' systeminfo.txtThe command will display lines that contain the given string anywhere in it. You can add the --color option to colorize the matching pattern in the output.
Windows grep command is case-sensitive. Use the -i option to ignore capitalization:
grep -i 'name' systeminfo.txtThe -i option, you will use it more often than not.
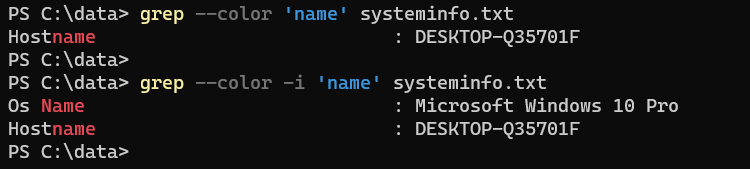
Important: Always put the search string inside quotes. Especially if there are spaces in your search.
Below you will find the most basic search options you should know about.
| -i | Ignore the case. |
| -n | Print line numbers. |
| -v | Display non-matching lines. |
| -c | Print line count. |
| -w | Match only whole words. |
| -x | The entire line should match. |
| -o | Prints only the text that matches instead of the entire line. |
| -a | Read binary files as if they are text files. |
| -f | Take search strings from a file. |
| -e | Specify multiple patterns. |
| —color | Colorize the search pattern in the output. |
Using -n to display the line number of the matching line:
grep -in 'windows' systeminfo.txtUsing the -v option to display lines that do not match:
grep -iv 'windows' systeminfo.txtIn the following example, we are using -v and -c options to count all the lines that do not contain Windows:
grep -ivc 'windows' systeminfo.txtIf you want to search more than one pattern, use the -e option as shown in the following example:
grep -i -e 'name' -e 'win' systeminfo.txt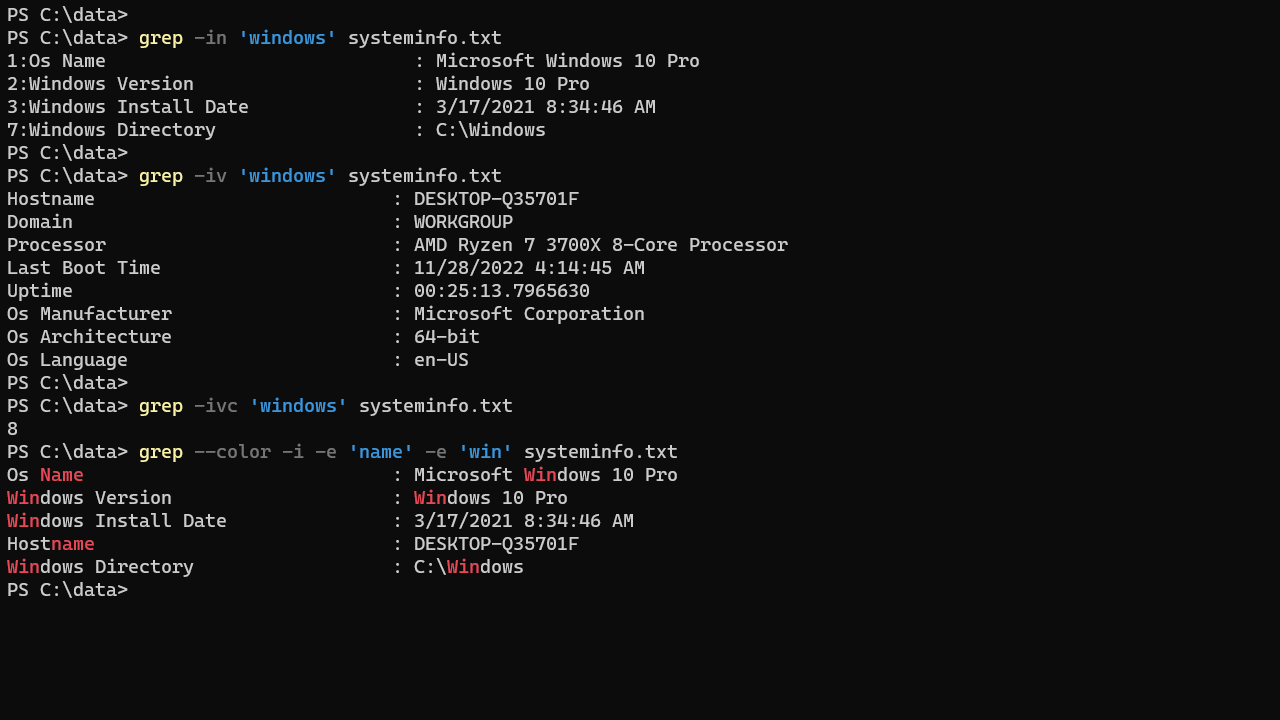
Send Output From Another Command
As a system administrator, most of the time, you will use the grep command to filter the output of another command.
tasklist | grep -i explorerIn the previous example, the output of the tasklist command is piped into the grep command, which will then display only those lines that contain the string explorer.
You can also use grep to filter PowerShell commands:
Get-ComputerInfo | grep -i 'network'It is also possible to chain grep commands together any number of times, as shown in the following example:
tasklist | grep -i 'exe' | grep -i 'service'Recursive Search
Using the -r option, we can search for a particular string throughout all files in a directory or entire filesystem.
grep -i -r 'error' C:\Windows\Logs\The preceding command finds all instances of error in all files under the C:\Windows\Logs\ and its subdirectories.
Add the -l option to the previous command, and it prints only the names of files.
grep -irl 'error' C:\Windows\Logs\The -L (uppercase) does the opposite. It prints the names of files containing no match.
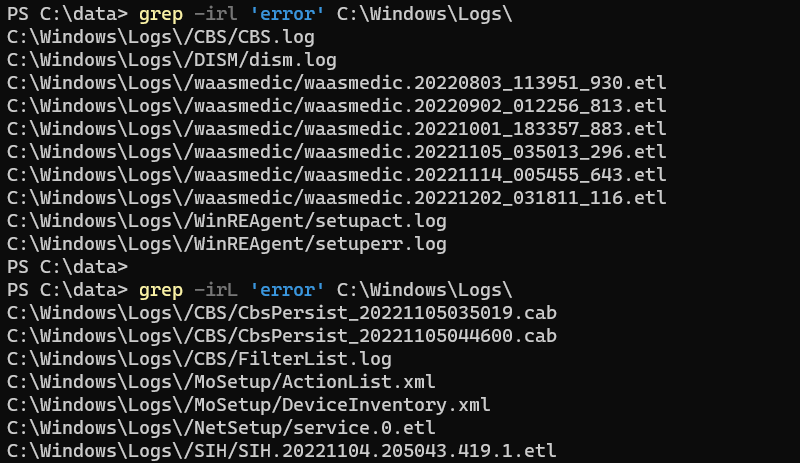
To include or exclude a file pattern, use --include or --exclude options, respectively.
grep -ir 'error' C:\Windows\Logs\ --include=*.log
grep -ir 'error' C:\Windows\Logs\ --exclude=*.logIn the above example, the first command searches the given string on all files with the .log extension, while the second command searches all files except the ones that end with the .log extension.
| -r | Search for matching files under each directory recursively. |
| -R | Search for matching files under each directory recursively. Follow all symbolic links, unlike -r. |
| -l | Display only the names of files with matching lines. |
| -L | Display only the names of files with no matching lines. |
| —include=GLOB | Search only files that match a file pattern. |
| —exclude=GLOB | Skip files that match a file pattern. |
Metacharacters
As a system administrator, you should be familiar with a few important regular expressions for advanced text searching.
The asterisk(*) is by far the most commonly used metacharacter. In the following example, we filter the output of the systeminfo command to find any occurrence of ‘pro’ followed by any number of characters.
systeminfo | grep -i 'pro*'Positional Searching
The grep command has metacharacters that we can use to search patterns at the start and end of a line and the start and end of a word.
| ^ | Find the pattern at the start of the line. |
| $ | Find the pattern at the end of the line. |
| \< | Find the pattern at the start of a word. |
| \> | Find the pattern at the end of a word. |
| \s | Any whitespace character. |
Examples
Search for the lines starting with Windows:
grep -i '^windows' systeminfo.txtSearch for the lines that end with Windows:
grep -i 'windows$' systeminfo.txtFind the lines that have words starting with the letters ‘ver’:
systeminfo | grep --color -i '\<ver'Find the lines that have words ends with the letters ‘ver’:
systeminfo | grep --color -i 'ver\>'Find Windows surrounded by whitespace:
grep -i '\swindows\s' systeminfo.txt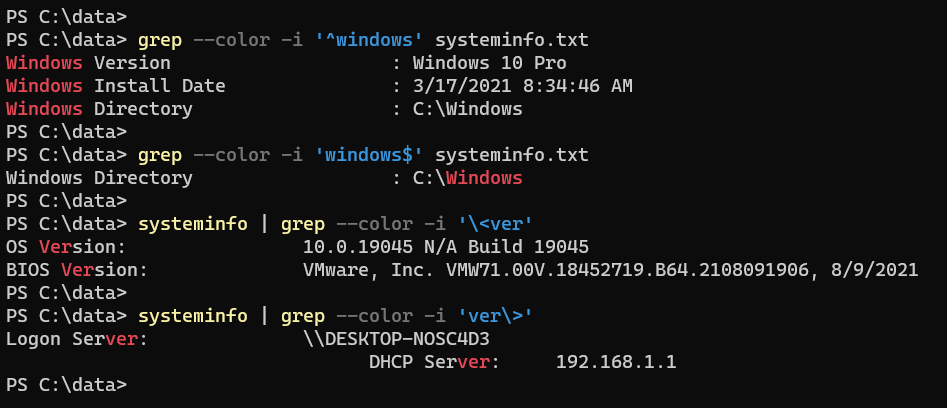
Escaping Metacharacters
If a meta character (for example, the dollar sign) is part of the string, you need to escape it with a black slash (\).
For example, let’s say you are searching for an amount that contains the dollar sign. Since the dollar sign is a metacharacter, you need to escape it with a black slash to make it part of the string:
grep '10\$' systeminfo.txtGrep comes with a handful of options that control the way it displays the results. To view information on all available options, type grep --help.
Windows Command Prompt also has a text search tool called findstr, which is very similar to the grep command.