Время на прочтение
11 мин
Количество просмотров 205K
Данная статья будет полезной тем, кто только начал знакомиться с микросервисной архитектурой и с сервисом Apache Kafka. Материал не претендует на подробный туториал, но поможет быстро начать работу с данной технологией. Я расскажу о том, как установить и настроить Kafka на Windows 10. Также мы создадим проект, используя Intellij IDEA и Spring Boot.
Зачем?
Трудности в понимании тех или иных инструментов часто связаны с тем, что разработчик никогда не сталкивался с ситуациями, в которых эти инструменты могут понадобиться. С Kafka всё обстоит точно также. Опишем ситуацию, в которой данная технология будет полезной. Если у вас монолитная архитектура приложения, то разумеется, никакая Kafka вам не нужна. Всё меняется с переходом на микросервисы. По сути, каждый микросервис – это отдельная программа, выполняющая ту или иную функцию, и которая может быть запущена независимо от других микросервисов. Микросервисы можно сравнить с сотрудниками в офисе, которые сидят за отдельными столами и независимо от коллег решают свою задачу. Работа такого распределённого коллектива немыслима без централизованной координации. Сотрудники должны иметь возможность обмениваться сообщениями и результатами своей работы между собой. Именно эту проблему и призвана решить Apache Kafka для микросервисов.
Apache Kafka является брокером сообщений. С его помощью микросервисы могут взаимодействовать друг с другом, посылая и получая важную информацию. Возникает вопрос, почему не использовать для этих целей обычный POST – reqest, в теле которого можно передать нужные данные и таким же образом получить ответ? У такого подхода есть ряд очевидных минусов. Например, продюсер (сервис, отправляющий сообщение) может отправить данные только в виде response’а в ответ на запрос консьюмера (сервиса, получающего данные). Допустим, консьюмер отправляет POST – запрос, и продюсер отвечает на него. В это время консьюмер по каким-то причинам не может принять полученный ответ. Что будет с данными? Они будут потеряны. Консьюмеру снова придётся отправлять запрос и надеяться, что данные, которые он хотел получить, за это время не изменились, и продюсер всё ещё готов принять request.
Apache Kafka решает эту и многие другие проблемы, возникающие при обмене сообщениями между микросервисами. Не лишним будет напомнить, что бесперебойный и удобный обмен данными – одна из ключевых проблем, которую необходимо решить для обеспечения устойчивой работы микросервисной архитектуры.
Установка и настройка ZooKeeper и Apache Kafka на Windows 10
Первое, что надо знать для начала работы — это то, что Apache Kafka работает поверх сервиса ZooKeeper. ZooKeeper — это распределенный сервис конфигурирования и синхронизации, и это всё, что нам нужно знать о нём в данном контексте. Мы должны скачать, настроить и запустить его перед тем, как начать работу с Kafka. Прежде чем начать работу с ZooKeeper, убедитесь, что у вас установлен и настроен JRE.
Скачать свежею версию ZooKeeper можно с официального сайта.
Извлекаем из скаченного архива ZooKeeper`а файлы в какую-нибудь папку на диске.
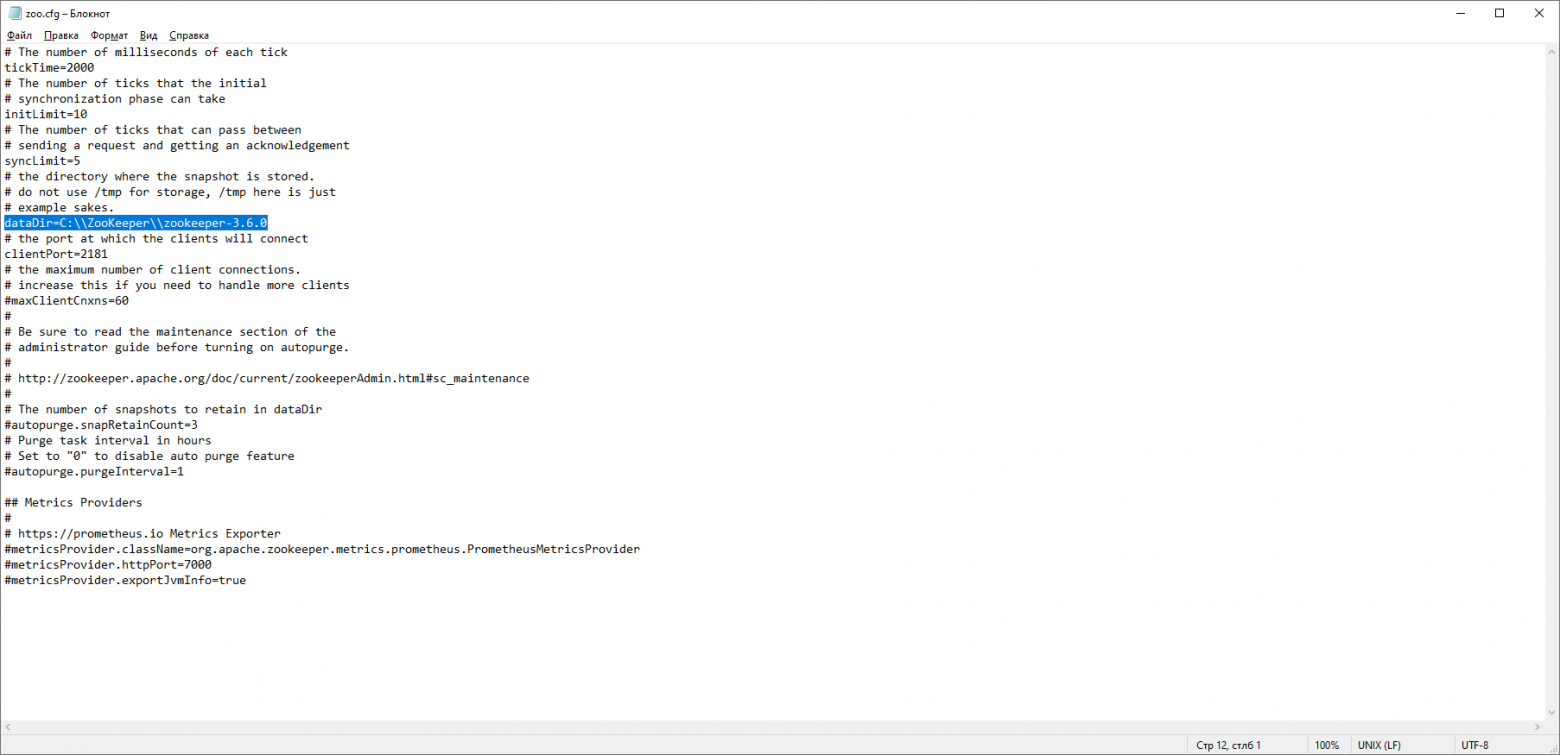
В папке zookeeper с номером версии, находим папку conf и в ней файл “zoo_sample.cfg”.

Копируем его и меняем название копии на “zoo.cfg”. Открываем файл-копию и находим в нём строчку dataDir=/tmp/zookeeper. Прописываем в данной строчке полный путь к нашей папке zookeeper-х.х.х. У меня это выглядит так: dataDir=C:\\ZooKeeper\\zookeeper-3.6.0
Теперь добавим системную переменную среды: ZOOKEEPER_HOME = C:\ ZooKeeper \zookeeper-3.4.9 и в конце системной переменной Path добавим запись: ;%ZOOKEEPER_HOME%\bin;
Запускаем командную строку и пишем команду:
zkserverЕсли всё сделано правильно, вы увидите примерно следующее.

Это означает, что ZooKeeper стартанул нормально. Переходим непосредственно к установке и настройке сервера Apache Kafka. Скачиваем свежую версию с официального сайта и извлекаем содержимое архива: kafka.apache.org/downloads
В папке с Kafka находим папку config, в ней находим файл server.properties и открываем его.
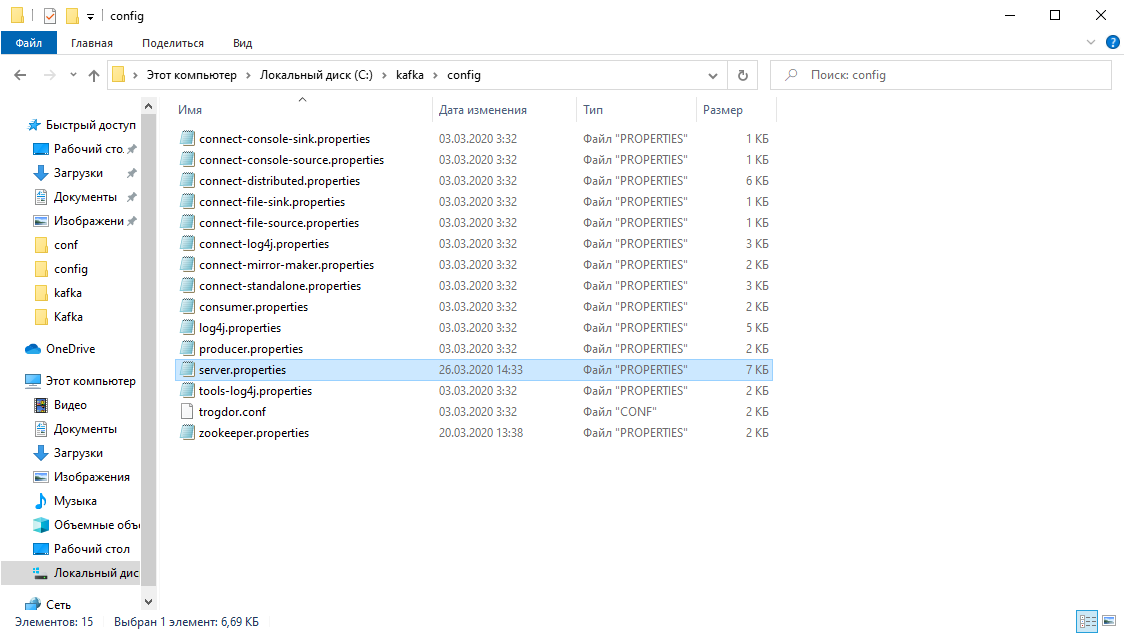
Находим строку log.dirs= /tmp/kafka-logs и указываем в ней путь, куда Kafka будет сохранять логи: log.dirs=c:/kafka/kafka-logs.
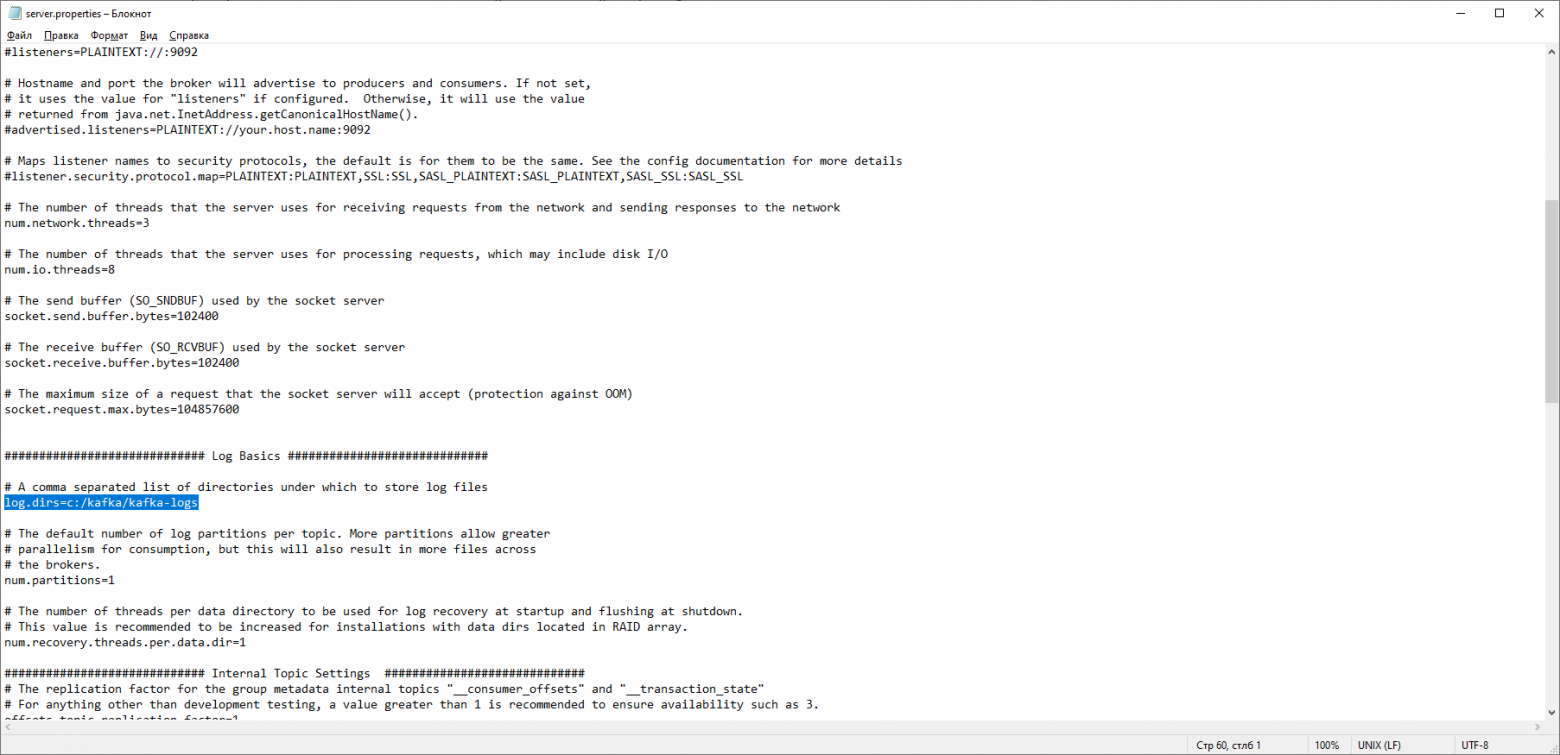
В этой же папке редактируем файл zookeeper.properties. Строчку dataDir=/tmp/zookeeper меняем на dataDir=c:/kafka/zookeeper-data, не забывая при этом, после имени диска указывать путь к своей папке с Kafka. Если вы всё сделали правильно, можно запускать ZooKeeper и Kafka.

Для кого-то может оказаться неприятной неожиданностью, что никакого GUI для управления Kafka нет. Возможно, это потому, что сервис рассчитан на суровых нёрдов, работающих исключительно с консолью. Так или иначе, для запуска кафки нам потребуется командная строка.
Сначала надо запустить ZooKeeper. В папке с кафкой находим папку bin/windows, в ней находим файл для запуска сервиса zookeeper-server-start.bat, кликаем по нему. Ничего не происходит? Так и должно быть. Открываем в этой папке консоль и пишем:
start zookeeper-server-start.batОпять не работает? Это норма. Всё потому что zookeeper-server-start.bat для своей работы требует параметры, прописанные в файле zookeeper.properties, который, как мы помним, лежит в папке config. Пишем в консоль:
start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties Теперь всё должно стартануть нормально.

Ещё раз открываем консоль в этой папке (ZooKeeper не закрывать!) и запускаем kafka:
start kafka-server-start.bat c:\kafka\config\server.propertiesДля того, чтобы не писать каждый раз команды в командной строке, можно воспользоваться старым проверенным способом и создать батник со следующим содержимым:
start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.propertiesСтрока timeout 10 нужна для того, чтобы задать паузу между запуском zookeeper и kafka. Если вы всё сделали правильно, при клике на батник должны открыться две консоли с запущенным zookeeper и kafka.Теперь мы можем прямо из командной строки создать продюсера сообщений и консьюмера с нужными параметрами. Но, на практике это может понадобиться разве что для тестирования сервиса. Гораздо больше нас будет интересовать, как работать с kafka из IDEA.
Работа с kafka из IDEA
Мы напишем максимально простое приложение, которое одновременно будет и продюсером и консьюмером сообщения, а затем добавим в него полезные фичи. Создадим новый спринг-проект. Удобнее всего делать это с помощью спринг-инициалайзера. Добавляем зависимости org.springframework.kafka и spring-boot-starter-web


В итоге файл pom.xml должен выглядеть так:

Для того, чтобы отправлять сообщения, нам потребуется объект KafkaTemplate<K, V>. Как мы видим объект является типизированным. Первый параметр – это тип ключа, второй – самого сообщения. Пока оба параметра мы укажем как String. Объект будем создавать в классе-рестконтроллере. Объявим KafkaTemplate и попросим Spring инициализировать его, поставив аннотацию Autowired.
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;В принципе, наш продюсер готов. Всё что осталось сделать – это вызвать у него метод send(). Имеется несколько перегруженных вариантов данного метода. Мы используем в нашем проекте вариант с 3 параметрами — send(String topic, K key, V data). Так как KafkaTemplate типизирован String-ом, то ключ и данные в методе send будут являться строкой. Первым параметром указывается топик, то есть тема, в которую будут отправляться сообщения, и на которую могут подписываться консьюмеры, чтобы их получать. Если топик, указанный в методе send не существует, он будет создан автоматически. Полный текст класса выглядит так.
@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
Контроллер мапится на localhost:8080/msg, в теле запроса передаётся ключ и само сообщений.
Отправитель сообщений готов, теперь создадим слушателя. Spring так же позволяет cделать это без особых усилий. Достаточно создать метод и пометить его аннотацией @KafkaListener, в параметрах которой можно указать только топик, который будет слушаться. В нашем случае это выглядит так.
@KafkaListener(topics="msg")У самого метода, помеченного аннотацией, можно указать один принимаемый параметр, имеющий тип сообщения, передаваемого продюсером.
Класс, в котором будет создаваться консьюмер необходимо пометить аннотацией @EnableKafka.
@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}Так же в файле настроек application.property необходимо указать параметр консьюмера groupe-id. Если этого не сделать, приложение не запустится. Параметр имеет тип String и может быть любым.
spring.kafka.consumer.group-id=app.1
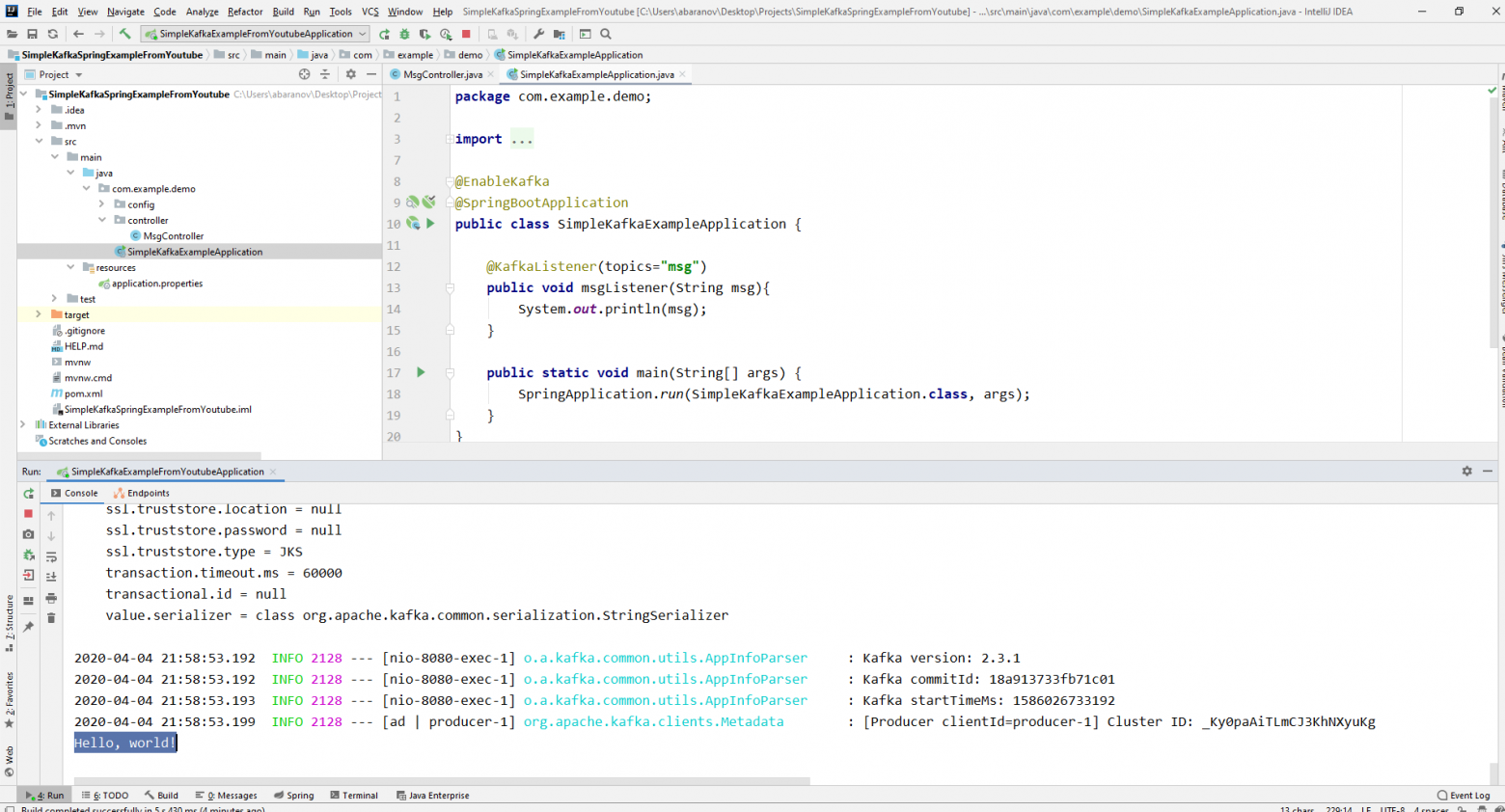
Наш простейший кафка-проект готов. У нас есть отправитель и получатель сообщений. Осталось только запустить. Для начала запускаем ZooKeeper и Kafka с помощью батника, который мы написали ранее, затем запускаем наше приложение. Отправлять запрос удобнее всего с помощью Postman. В теле запроса не забываем указывать параметры msgId и msg.
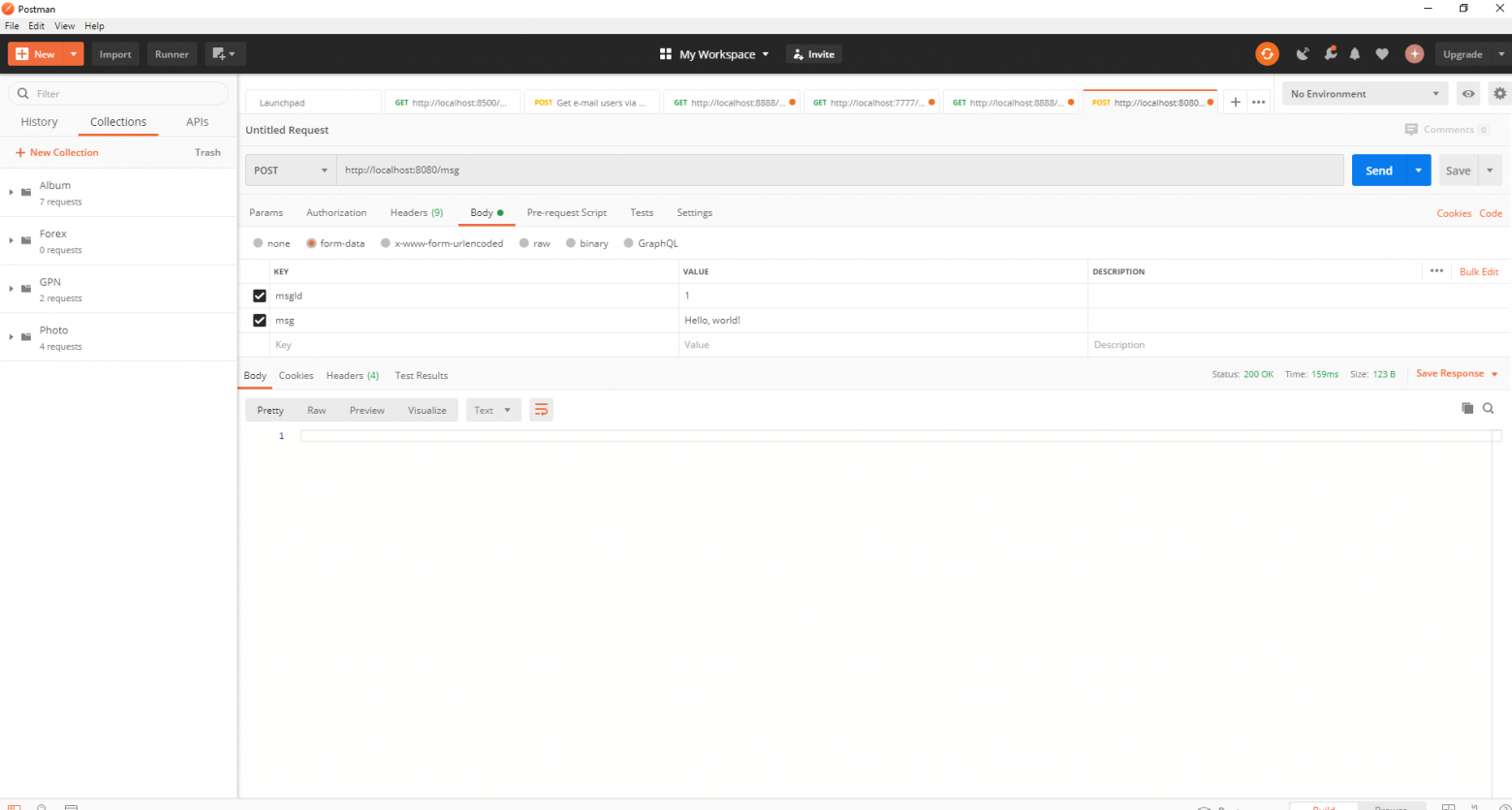
Если мы видим в IDEA такую картину, значит всё работает: продюсер отправил сообщение, консьюмер получил его и вывел в консоль.
Усложняем проект
Реальные проекты с использованием Kafka конечно же сложнее, чем тот, который мы создали. Теперь, когда мы разобрались с базовыми функциями сервиса, рассмотрим, какие дополнительные возможности он предоставляет. Для начала усовершенствуем продюсера.
Если вы открывали метод send(), то могли заметить, что у всех его вариантов есть возвращаемое значение ListenableFuture<SendResult<K, V>>. Сейчас мы не будем подробно рассматривать возможности данного интерфейса. Здесь будет достаточно сказать, что он нужен для просмотра результата отправки сообщения.
@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}Метод addCallback() принимает два параметра – SuccessCallback и FailureCallback. Оба они являются функциональными интерфейсами. Из названия можно понять, что метод первого будет вызван в результате успешной отправки сообщения, второго – в результате ошибки.Теперь, если мы запустим проект, то увидим на консоли примерно следующее:
SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]Посмотрим ещё раз внимательно на нашего продюсера. Интересно, что будет если в качестве ключа будет не String, а, допустим, Long, а в качестве передаваемого сообщения и того хуже – какая-нибудь сложная DTO? Попробуем для начала изменить ключ на числовое значение…

Если мы укажем в продюсере в качестве ключа Long, то приложение нормально запуститься, но при попытке отправить сообщение будет выброшен ClassCastException и будет сообщено, что класс Long не может быть приведён к классу String.

Если мы попробуем вручную создать объект KafkaTemplate, то увидим, что в конструктор в качестве параметра передаётся объект интерфейса ProducerFactory<K, V>, например DefaultKafkaProducerFactory<>. Для того, чтобы создать DefaultKafkaProducerFactory, нам нужно в его конструктор передать Map, содержащий настройки продюсера. Весь код по конфигурации и созданию продюсера вынесем в отдельный класс. Для этого создадим пакет config и в нём класс KafkaProducerConfig.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
В методе producerConfigs() создаём мапу с конфигурациями и в качестве сериализатора для ключа указываем LongSerializer.class. Запускаем, отправляем запрос из Postman и видим, что теперь всё работает, как надо: продюсер отправляет сообщение, а консьюмер принимает его.
Теперь изменим тип передаваемого значения. Что если у нас не стандартный класс из библиотеки Java, а какой-нибудь кастомный DTO. Допустим такой.
@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}Для отправки DTO в качестве сообщения, нужно внести некоторые изменения в конфигурацию продюсера. В качестве сериализатора значения сообщения укажем JsonSerializer.class и не забудем везде изменить тип String на UserDto.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}Отправим сообщение. В консоль будет выведена следующая строка:

Теперь займёмся усложнением консьюмера. До этого наш метод public void msgListener(String msg), помеченный аннотацией @KafkaListener(topics=«msg») в качестве параметра принимал String и выводил его на консоль. Как быть, если мы хотим получить другие параметры передаваемого сообщения, например, ключ или партицию? В этом случае тип передаваемого значения необходимо изменить.
@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}Из объекта ConsumerRecord мы можем получить все интересующие нас параметры.
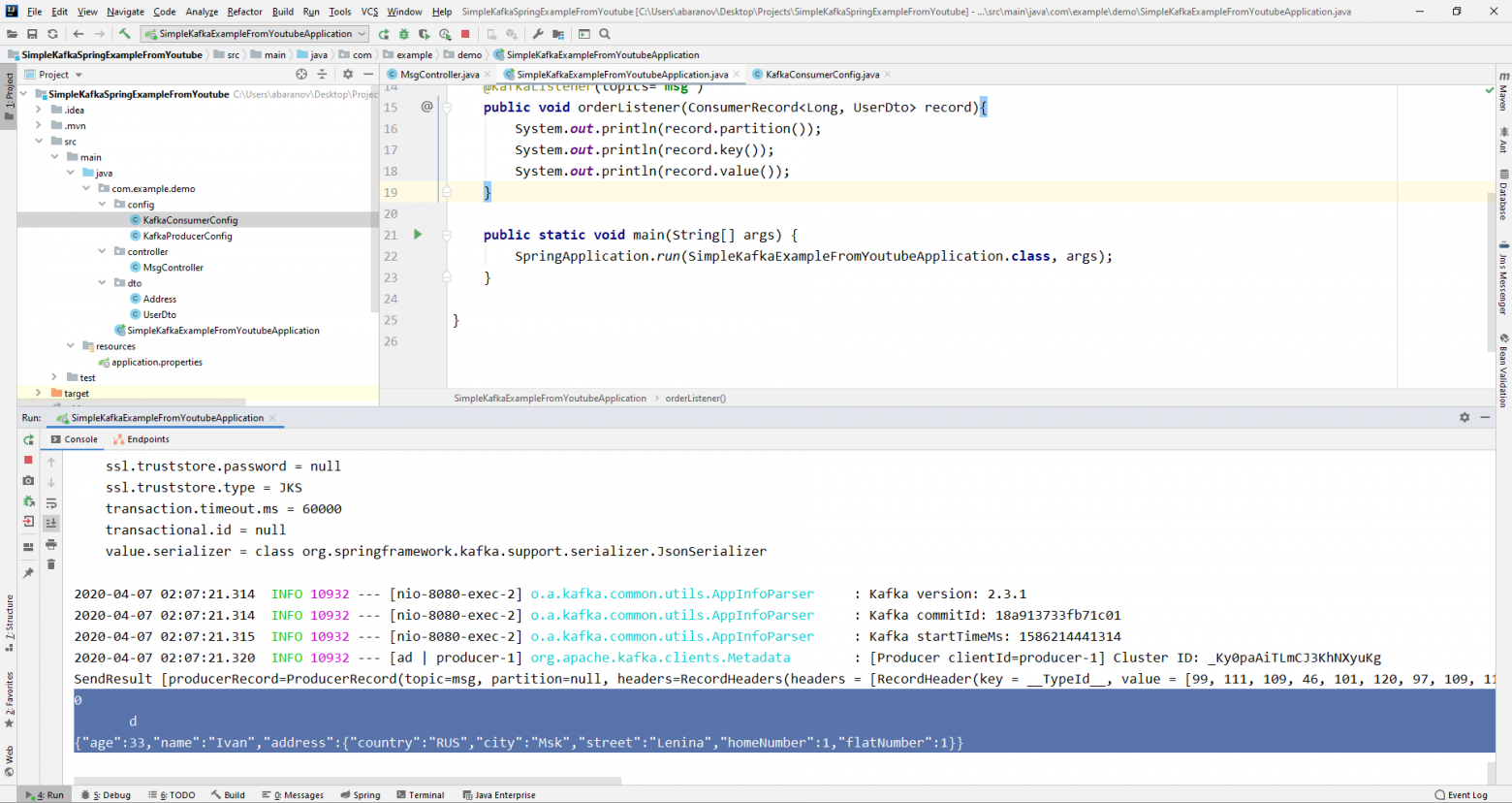
Мы видим, что вместо ключа на консоль выводятся какие-то кракозябры. Это потому, что для десериализации ключа по умолчанию используется StringDeserializer, и если мы хотим, чтобы ключ в целочисленном формате корректно отображался, мы должны изменить его на LongDeserializer. Для настройки консьюмера в пакете config создадим класс KafkaConsumerConfig.
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}Класс KafkaConsumerConfig очень похож на KafkaProducerConfig, который мы создавали ранее. Здесь так же присутствует Map, содержащий необходимые конфигурации, например, такие как десериализатор для ключа и значения. Созданная мапа используется при создании ConsumerFactory<>, которая в свою очередь, нужна для создания KafkaListenerContainerFactory<?>. Важная деталь: метод возвращающий KafkaListenerContainerFactory<?> должен называться kafkaListenerContainerFactory(), иначе Spring не сможет найти нужного бина и проект не скомпилируется. Запускаем.
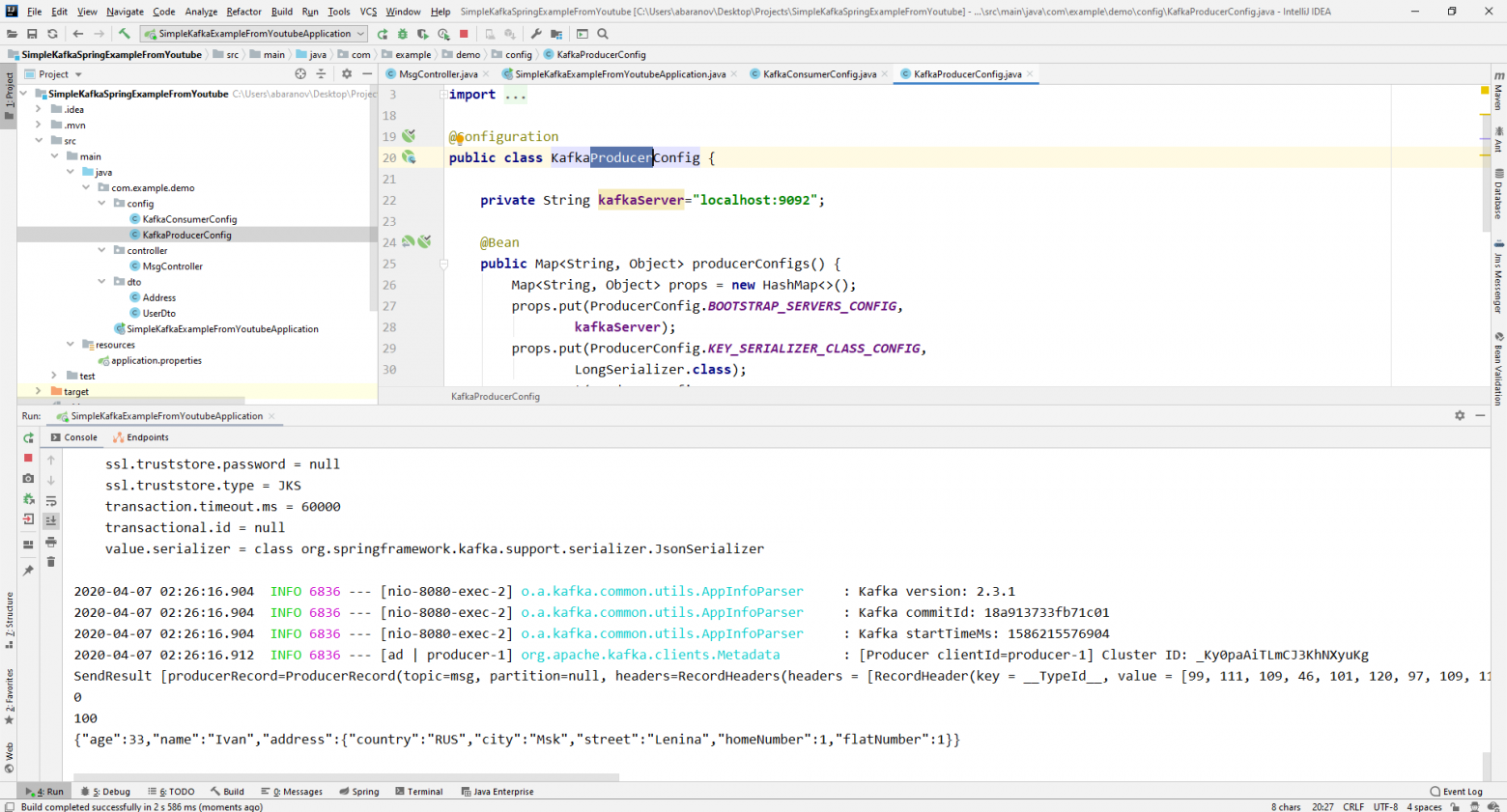
Видим, что теперь ключ отображается как надо, а это значит, что всё работает. Конечно, возможности Apache Kafka далеко выходят за пределы тех, что описаны в данной статье, однако, надеюсь, прочитав её, вы составите представление о данном сервисе и, самое главное, сможете начать работу с ним.
Мойте руки чаще, носите маски, не выходите без необходимости на улицу, и будьте здоровы.
Apache Kafka is an open-source application used for real-time streams for data in huge amount. Apache Kafka is a publish-subscribe messaging system. A messaging system lets you send messages between processes, applications, and servers. Broadly Speaking, Apache Kafka is software where topics can be defined and further processed.
Downloading and Installation
Apache Kafka can be downloaded from its official site kafka.apache.org
For the installation process, follow the steps given below:
Step 1: Go to the Downloads folder and select the downloaded Binary file.
Step 2: Extract the file and move the extracted folder to the directory where you wish to keep the files.
Step 3: Copy the path of the Kafka folder. Now go to config inside kafka folder and open zookeeper.properties file. Copy the path against the field dataDir and add /zookeeper-data to the path.
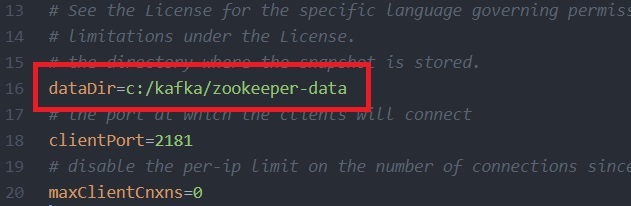
For example if the path is c:/kafka
Step 4: Now in the same folder config open server.properties and scroll down to log.dirs and paste the path. To the path add /kafka-logs
Step 5: This completes the configuration of zookeeper and kafka server. Now open command prompt and change the directory to the kafka folder. First start zookeeper using the command given below:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
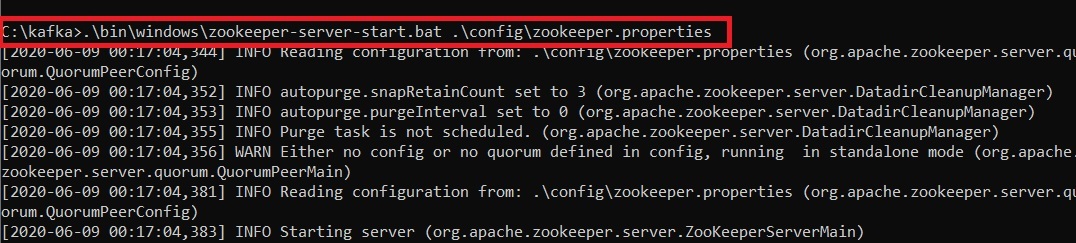
Step 6: Now open another command prompt and change the directory to the kafka folder. Run kafka server using the command:
.\bin\windows\kafka-server-start.bat .\config\server.properties

Now kafka is running and ready to stream data.
Last Updated :
28 Jun, 2022
Like Article
Save Article

How To Set Up Apache Kafka on Window 10
By Chunren Lai, Dec. 12, 2020
This article lists steps to install and run Apache Kafka on Windows 10.
Table of Contents
Step 1. Introduction
Step 2. Download Files
Step 3. Install the 7zip and Notepad++
Step 4. Install the Java Runtime
Step 5. Install ZooKeeper
Step 6. Install and Set up Kafka
Step 7. Test Apache Kafka
Step 1. Introduction
To run Apache Kafka on a windows OS, you will need to download , install, and set up Java, ZooKeeper, and Apache Kakfa. After set up the Apache Kafka, we will run some commands to produce and consume some messages on a test topics on Kafka to ensure Apache Kafka is running properly.
Step 2. Download Files
-
Upzip and Text Editor tools
- If you don’t have 7-zip installed on your windows, you are recommended to download the 7-zip from (https://www.7-zip.org/download.html). If your system is 64-bit x64, you can download the exe installer from (https://www.7-zip.org/a/7z1900-x64.exe)
- You are also recommended to download the text editor Notepad++ from (https://notepad-plus-plus.org/downloads/)
-
JRE download
- You can download the Java runtime from Oracle site ( http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html) based on your CPU architecture.
-
ZooKeeper download
- You can download the ZooKeepr from Apache site ( http://zookeeper.apache.org/releases.html)
-
Kafka download
- You can download the Apache Kafka from Apache site ( http://kafka.apache.org/downloads.html)
The following is a list of my downloads.
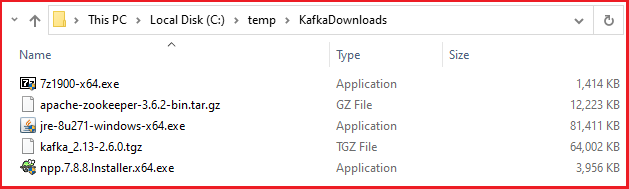
Step 3. Install the 7zip and Notepad plus plus
You can directly run the executable installer (e.g., «7z1900-x64.exe» and «npp.7.8.8.Installer.x64.exe»)
Step 4. Install the Java Runtime
You can run the JRE installer (e.g., «jre-8u271-windows-x64.exe»), and install the Java in its default installation folder (e.g., «C:\Program Files\Java\jre1.8.0_271»).
After the installation, you need to set up:
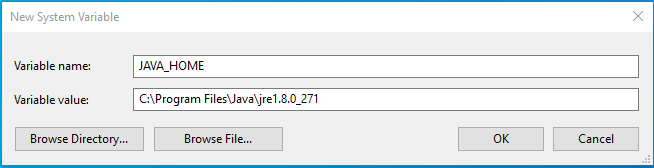
- Environment variable for JAVA_HOME
Open the «Control Panel» -> «System» -> «Advanced system settings» -> «Environment Variables» -> «System variables» («New»):
| Item | Value |
|---|---|
| Variable name | JAVA_HOME |
| Variable value | Java installation folder (e.g., «C:\Program Files\Java\jre1.8.0_271») |
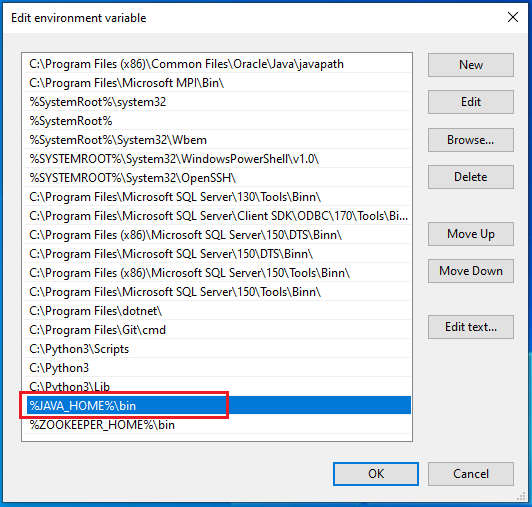
- Add Java path to the «Path» variable
Select «Path» of the «System variable» section, and the click «Edit…» button to add the java path. In the «Edit environment variable» pop up window, click the «New» button, and add:
Step 5. Install ZooKeeper
dataDir=C:/zookeeper-3.6.2/data
- Similar to the above Java installation,
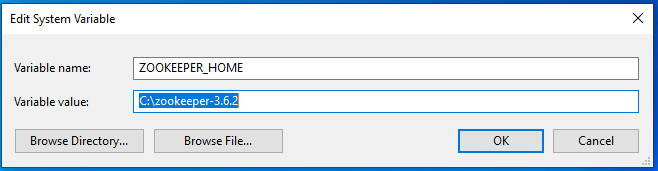
- to add a variable of «ZOOKEEPER_HOME» to the System Variables:
| Item | Value |
|---|---|
| Variable name | ZOOKEEPER_HOME |
| Variable value | C:\zookeeper-3.6.2 |
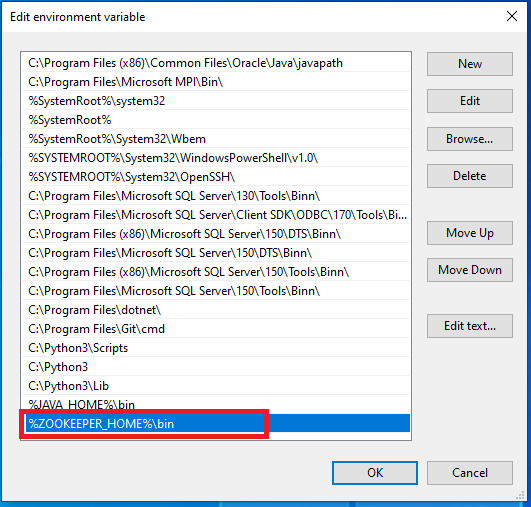
- to add «%ZOOKEEPER_HOME%\bin» new entry to the System Variable «Path»
- Start the ZooKeeper, by
- type «cmd» in the Search area (bottom left side)
- in the commond line, type
cd c:\zookeeper-3.6.2\bin
- type «zkserver», and you will see:
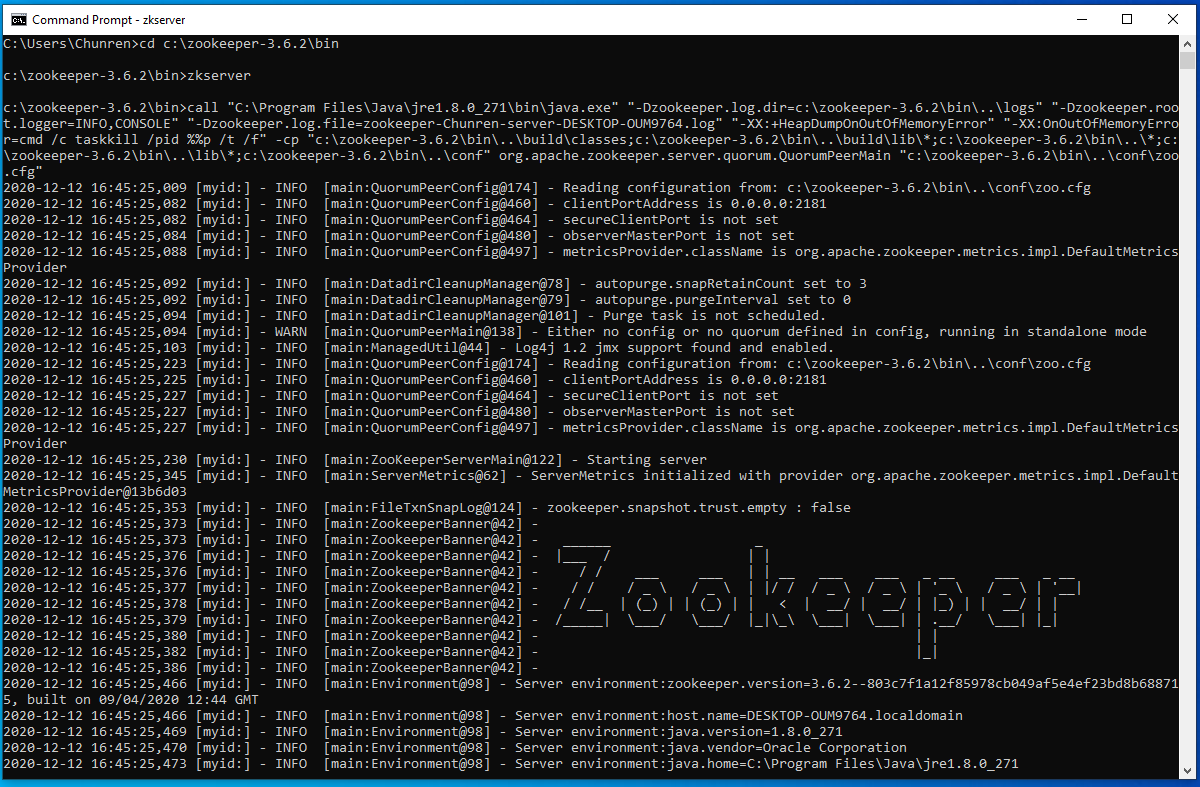
Step 6. Install and Set up Kafka
log.dirs=c:/kafka/kafka-logs
- If you plan to run Kafka on your loacal machine with other default settings, you are ready to go, otherwise you can change the following default setting:
zookeeper.connect=localhost:2181 with a proper IP address and a custom port number. - Open a new command prompt, and:
- type:
cd c:\kafka, and press enter
- then press «Enter», and type:
.\bin\windows\kafka-server-start.bat .\config\server.properties
, and press enter, you will see:

3) Now you finish installing and setting up Apache Kafka, and the Kafka server is up running.
Step 7. Test Apache Kafka
-
Create a topic called «StudentImport»
- Open a new command prompt, and type: cd c:\kafka\bin\windows, press enter
- type:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic StudentImport
- Now the «StudentImport» has been successfully created. See below:
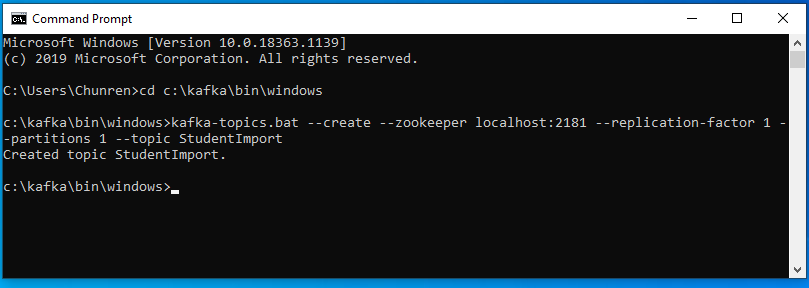
-
Create a Producer to the Kafka server
- Open a new command prompt (called producer command window «P»), and type: cd c:\kafka\bin\windows, press enter
- type:
kafka-console-producer.bat --broker-list localhost:9092 --topic StudentImport
- Now it is ready for you to enter any message in the Producer console. See below:
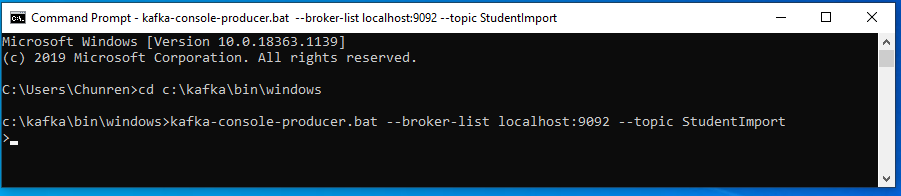
-
Create a Consumer to the Kafka server
- Open a new command prompt (called consumer command window «C»), and type: cd c:\kafka\bin\windows, press enter
- type:
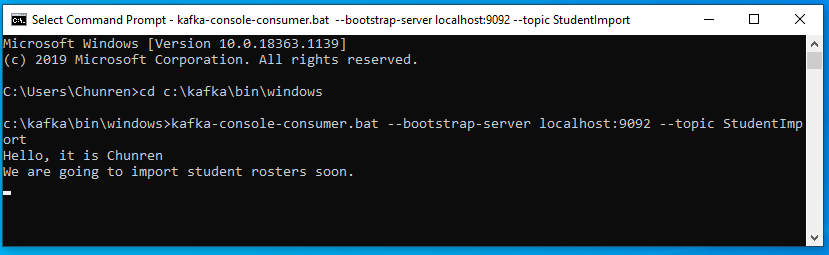
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic StudentImport
- Now it is listening any messages in the Producer console.
-
Testing message communications
- In the producer command window «P» (see above), when you type: «Hello, it is Chunren», and press enter, then in the consumer command window «C» (see above), you will see the message «Hello, It is Chunren» being displayed.
- In the producer command window «P», when you type: «We are going to import student rosters soon.», and press enter, then in the consumer command window «C», uou will see the message «We are going to import student rosters soon.» being displayed.
- See below the results:
In the producer command window «P»:
In the consumer command window «C»:
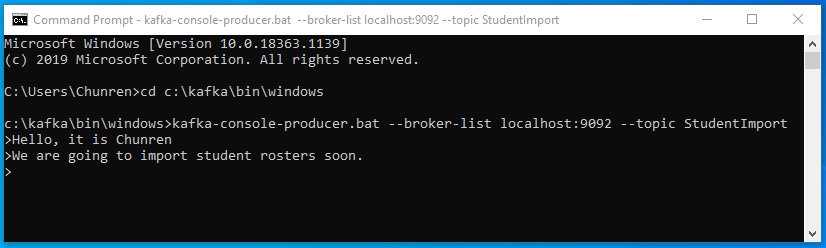
Congratulations! You have successfully set up Apache Kafka on your Windows 10.
In this tutorial, We’ll learn how to install and run Apache kafka broker in local machine running on Windows or Mac operating system.
Running kafka broker in local machine helps developer to code, debug and test kafka application in initial phase of development when Kafka infrastructure is not ready.
If you are using Windows, then you can follow these steps to install Kafka:-
Install JDK 1.8 or higher
JDK 1.8 or higher version is prerequisite for Kafka Installation. You can download and install JDK based on your OS and CPU architecture from here:-
https://www.oracle.com/sg/java/technologies/javase-downloads.html
Once your JDK installation is complete, you must configure PATH and JAVA_HOME environment variables. You can set up your environment variables using the following steps:-
- Start system settings in the control panel. You can directly start it by pressing Win + Pause/Break key.
- Click on Advanced System Settings.
- In the advanced tab, click the environment variable button.
- In the user variables section, add new
JAVA_HOMEenvironment variable as your Java installation directory. In a typical case, your Java installation directory should be something likeC:\Program Files\Java\jdk1.8.0_191. However, if you have installed JDK as per the steps defined above, you should have noted down your JDK location as advised earlier. - Now you can add a new
PATHenvironment variable and specify the path as%JAVA_HOME%\bin
The final step is to test your JDK installation. Start windows command prompt and test JDK using below command. You should see the installed version:-
C:\>java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
Thats it! Your JDK in installed successfully.
Install Kafka
-
Download and install Kafka binaries from here:-
https://kafka.apache.org/downloadsNote: At the time of writing this article, latest kafka version was kafka_2.13-2.8.0.tgz. It is recommended to use latest version available.
-
Download and install 7-zip (required to un-compress the Kafka binaries) from here:-
http://www.7-zip.org/download.html -
Un-compress the kafka_2.13-2.8.0.tgz file using 7-zip, and you may have to use it twice to extract the files correctly.
For example, after exraction, my kafka location is as follow:-C:\apache\kafka_2.13-2.8.0 -
Next, we need to change Zookeeper configuration
zookeeper.propertiesas follows:-Open the property file:-
C:\apache\kafka_2.13-2.8.0\config\zookeeper.propertiesand change the Zookeeper
dataDirlocation config to a valid windows directory location. An example value is given below.zookeeper.properties
dataDir = C:\apache\kafka_2.13-2.8.0\zookeeper_dataMake sure that
zookeeper_datadirectory exist in specified location. If not, create one. -
We also need to make some changes in the Kafka configurations
server.propertiesas follows:-Open the property file:-
C:\apache\kafka_2.13-2.8.0\config\server.propertiesand change/add following configuration properties.
server.properties
log.dirs = C:\apache\kafka_2.13-2.8.0\kafka_logs offsets.topic.num.partitions = 1 offsets.topic.replication.factor = 1 min.insync.replicas = 1 default.replication.factor = 1Make sure that
kafka_logsdirectory exist in specified location. If not, create one.
Also note that we are setting topic defaults to 1, and that makes sense because we will be running a single node Kafka on our machine. -
Finally, add Kafka
C:\apache\kafka_2.13-2.8.0\bin\windowsdirectory to thePATHenvironment variable. This directory contains a bunch of Kafka tools for the windows platform. We will be using some of those in the next section.
Run Kafka
-
Start Zookeeper in new terminal using:
C:\apache\kafka_2.13-2.8.0>bin\windows\zookeeper-server-start.bat config\zookeeper.properties -
Start Kafka in new terminal using:
C:\apache\kafka_2.13-2.8.0>bin\windows\kafka-server-start.bat server\zookeeper.properties -
Create a test kafka topic in new terminal using:
C:\apache\kafka_2.13-2.8.0>bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test -
Publish messages to test kafka topic by initializing a producer in new terminal using:
C:\apache\kafka_2.13-2.8.0>bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test >send first message >send second message >wow it is working -
Consume messages from test kafka topic by intializing a consumer in new terminal using:
C:\apache\kafka_2.13-2.8.0>bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning send first message send second message wow it is working -
You can List the available Kafka topics using:-
C:\apache\kafka_2.13-2.8.0>bin\windows\kafka-topics.bat --list --zookeeper localhost:2181
Kafka Installation on Mac
If you are using MacOS, then you can install Homebrew package manager and run following commands from terminal:-
-
To install Java (Prerequisite for Kafka), run
brew install openjdk@11 -
To install Kafka, run
$ brew install kafkaHere are the brew logs of Kafka Installation, Note that brew also installs Zookeeper as Kafka dependency:-
==> Installing kafka dependency: zookeeper ==> Pouring zookeeper--3.7.0.catalina.bottle.tar.gz ==> Caveats To have launchd start zookeeper now and restart at login: brew services start zookeeper Or, if you don't want/need a background service you can just run: zkServer start ==> Summary 🍺 /usr/local/Cellar/zookeeper/3.7.0: 1,073 files, 42.4MB ==> Installing kafka ==> Pouring kafka--2.8.0.catalina.bottle.tar.gz ==> Caveats To have launchd start kafka now and restart at login: brew services start kafka Or, if you don't want/need a background service you can just run: zookeeper-server-start -daemon /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties ==> Summary 🍺 /usr/local/Cellar/kafka/2.8.0: 200 files, 68.2MB ==> zookeeper To have launchd start zookeeper now and restart at login: brew services start zookeeper Or, if you don't want/need a background service you can just run: zkServer start ==> kafka To have launchd start kafka now and restart at login: brew services start kafka Or, if you don't want/need a background service you can just run: zookeeper-server-start -daemon /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties -
Edit the
server.propertiesfile$ vim /usr/local/etc/kafka/server.propertiesUncomment the
listenersproperty and update the value fromlisteners=PLAINTEXT://:9092
tolisteners=PLAINTEXT://localhost:9092 -
Start Zookeeper in new terminal using:
$ zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties -
Start Kafka in new terminal using:
$ kafka-server-start /usr/local/etc/kafka/server.properties -
Create a test kafka topic in new terminal using:
$ kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test -
Publish messages to test kafka topic by initializing a producer in new terminal using:
$ kafka-console-producer --broker-list localhost:9092 --topic test >send first message >send second message >wow it is working -
Consume messages from test kafka topic by intializing a consumer in new terminal using:
$ kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning send first message send second message wow it is working -
Delete the kafka logs if there is any issue in starting Kafka server
$ rm -rf /tmp/kafka-logs
Summary
You have successfully installed and run a single-node Kafka broker on your local machine running on Windows or Mac operating system. This installation will help you to execute your Kafka application code locally and help you debug your application from the IDE.
Kafka is a distributed event streaming platform that can be used for high-performance streaming analytics, asynchronous event processing and reliable applications. This article provides step-by-step guidance about installing Kafka on Windows 10 for test and learn purposes.
Install Git Bash
Download Git Bash from https://git-scm.com/downloads and then install it. We will use it to unzip Kafka binary package. If you have 7-zip of other unzip software, this is then not required.
Install Java JDK
Java JDK is required to run Kafka. If you have not installed Java JDK, please install it.
1) You can install JDK 8 from the following page:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2) Setup environment variable
Let’s configure JAVA_HOME environment variable.
First, we need to find out the location of Java SDK. In my system, the path is: D:\Java\jdk1.8.0_161.
Your location can be different depends on where you install your JDK.
And then run the following command in PowerShell window:
SETX JAVA_HOME "D:\Java\jdk1.8.0_161"
Remember to quote the path if you have spaces in your JDK path.
3) Add Java bin folder into PATH system variable.
4) Verify java command
Once you complete the installation, please run the following command in PowerShell or Git Bash to verify:
$ java -version java version "1.8.0_161" Java(TM) SE Runtime Environment (build 1.8.0_161-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
Download Kafka binary package
1) Go to Kafka download portal and select a version. For this tutorial, version Scala 2.13 — kafka_2.13-2.6.0.tgz is downloaded.
2) Unzip the binary package to a installation folder.
Now we need to unpack the downloaded package using GUI tool (like 7 Zip) or command line. I will use git bash to unpack it.
Open git bash and change the directory to the destination folder:
cd F:/big-data
And then run the following command to unzip:
tar -xvzf kafka_2.13-2.6.0.tgz
Most of the scripts that we need to run in the following steps are located in bin/windows folder as the screenshot shows:
3) Setup Kafka environment variable.
Let’s add a environment variable KAFKA_HOME so that we can easily reference it in the following steps.
Remember to change variable value accordingly based on your environment setup.
Start Kafka environment
1) Open Command Prompt and start ZooKeeper services by running this command:
%KAFKA_HOME%/bin/windows/zookeeper-server-start.bat %KAFKA_HOME%/config/zookeeper.properties
In this version, ZooKeeper is still required.
2) Start Kafka server
Open another Command Prompt window and run the following command:
%KAFKA_HOME%/bin/windows/kafka-server-start.bat %KAFKA_HOME%/config/server.properties
Once all the services are launched, you will have a Kafka environment ready to use.
You can verify by running jps commands (if you have Hadoop installed in your environment):
Let’s run some tests about Kafka environment.
Create a Kafka topic
Open another Command Prompt window and run the following command:
%KAFKA_HOME%/bin/windows/kafka-topics.bat --create --topic kontext-events --bootstrap-server localhost:9092
The command will create a topic named kontext-events as the above screenshot shows.
Describe Kafka topic
Run the following command to describe the created topic.
%KAFKA_HOME%/bin/windows/kafka-topics.bat --describe --topic kontext-events --bootstrap-server localhost:9092
The output looks like the following:
Topic: kontext-events PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: kontext-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Write some events into the topic
Let’s start to write some events into the topic by running the following command:
%KAFKA_HOME%/bin/windows/kafka-console-producer.bat --topic kontext-events --bootstrap-server localhost:9092
Each time represents an event. Let’s type into some events:
Press Ctrl + C to terminate this Console producer client.
Read the events in the topic
Let’s read the events by running the following command:
%KAFKA_HOME%/bin/windows/kafka-console-consumer.bat --topic kontext-events --from-beginning --bootstrap-server localhost:9092
The Console consumer client prints out the following events:
Press Ctrl + C to terminate the consumer client.
Shutdown Kafka services
After finish practices, you can turn off the series by running the following commands:
%KAFKA_HOME%/bin/windows/kafka-server-stop.bat %KAFKA_HOME%/config/server.properties %KAFKA_HOME%/bin/windows/zookeeper-server-stop.bat %KAFKA_HOME%/config/zookeeper.properties
The output looks like the following screenshot:
References
- Apache Kafka Quick Start
As you can see, it is very easy to configure and run Kafka on Windows 10. Stay tuned and more articles will be published about streaming analytics with Kafka in this Column.
No comments yet.