Многие пользователи интернета сталкиваются с проблемами подключения к сети, низкой скоростью передачи данных или нестабильной работой программ. Часто причиной таких проблем является неправильная конфигурация TCP/IP на роутере. TCP (Transmission Control Protocol) — основной протокол передачи данных в Интернете, а IP (Internet Protocol) — протокол маршрутизации пакетов данных. Правильная настройка TCP/IP на роутере позволяет оптимизировать работу сети и повысить скорость передачи данных.
Первым шагом в настройке TCP на роутере является вход в его панель управления. Для этого необходимо узнать IP-адрес роутера и открыть его веб-интерфейс через браузер. Обычно адрес роутера указан на его корпусе или в документации к нему. После входа в панель управления необходимо найти раздел, ответственный за настройку TCP/IP.
Далее следует проверить текущие настройки TCP на роутере. В этом разделе можно увидеть IP-адрес роутера, DNS-сервера и другие параметры. Рекомендуется записать текущие настройки перед их изменением, чтобы в случае возникновения проблем можно было вернуться к предыдущим параметрам.
После того как текущие настройки были записаны, необходимо внести изменения. Во многих случаях достаточно изменить значения DNS-сервера на те, которые предлагает провайдер. Для этого можно воспользоваться DNS-серверами Google (8.8.8.8 и 8.8.4.4) или OpenDNS (208.67.222.222 и 208.67.220.220). Для применения изменений необходимо сохранить их и перезапустить роутер.
Таким образом, корректная настройка TCP/IP на роутере может значительно повысить производительность сети и стабильность работы программ. Следуя простым шагам этой пошаговой инструкции, даже начинающие пользователи смогут успешно настроить TCP на своем роутере.
Содержание
- Что такое TCP и зачем его настраивать на роутере?
- Принцип работы протокола TCP
- Почему важно настраивать TCP на роутере?
- Подготовка к настройке TCP на роутере
- Шаг 1: Определите модель и производителя вашего роутера
Что такое TCP и зачем его настраивать на роутере?
Настройка TCP на роутере позволяет оптимизировать работу вашей сети и улучшить ее производительность. Это особенно важно, если вы имеете проблемы с медленной или нестабильной сетью.
При настройке TCP на роутере вы можете оптимизировать параметры, такие как размер окна TCP, время ожидания подтверждений и максимальное количество одновременных соединений. Это позволяет увеличить пропускную способность сети, снизить задержки и повысить надежность передачи данных.
Настройка TCP на роутере также позволяет управлять потоком данных, определять приоритеты и ограничивать скорость передачи для различных видов трафика. Это особенно полезно, если вы хотите предоставить приоритет для определенных приложений или устройств, таких как стриминг видео или гейминг.
Важно отметить, что настройка TCP на роутере требует некоторых знаний о сетевых технологиях и может потребовать доступа к расширенным настройкам вашего роутера. Если у вас нет опыта в этой области, рекомендуется обратиться к специалисту или изучить соответствующую документацию.
Принцип работы протокола TCP
Работа протокола TCP основана на следующих принципах:
1. Установление соединения: Для начала передачи данных между двумя узлами необходимо установить соединение. Процесс установления соединения включает три фазы: установление связи, согласование параметров соединения и установление подключения.
2. Разделение данных на сегменты: Данные, которые требуется передать, разделяются на маленькие блоки, называемые сегментами. Каждый сегмент имеет свой порядковый номер, который позволяет контролировать упорядоченную доставку данных.
3. Управление потоком данных: Протокол TCP контролирует скорость передачи данных. В случае перегрузки сети, он может уменьшать скорость передачи или приостанавливать передачу до восстановления более стабильной ситуации.
4. Отслеживание доставки данных: Протокол TCP обеспечивает контроль доставки данных с помощью механизма подтверждений (acknowledgments). Получатель отправляет подтверждения о получении данных, а отправитель может повторно передавать данные, которые не были получены.
5. Завершение соединения: По окончании передачи данных происходит разрыв соединения. Процесс завершения соединения включает три фазы: завершение передачи данных, завершение подключения и закрытие соединения.
В результате, протокол TCP позволяет обеспечить надежную, упорядоченную и контролируемую доставку данных между двумя узлами в сети Интернет. Это делает TCP одним из самых широко используемых протоколов для передачи данных в сети.
Почему важно настраивать TCP на роутере?
Настройка TCP на роутере играет важную роль для обеспечения оптимальной работы сети. Вот несколько причин, почему это важно:
- Улучшение производительности сети: Правильная настройка TCP на роутере может значительно повысить производительность сети. Это может уменьшить задержки и улучшить скорость передачи данных.
- Увеличение надежности передачи данных: При правильной настройке TCP на роутере возможно улучшить надежность передачи данных. Протокол TCP обеспечивает отслеживание и повторную отправку потерянных пакетов данных, что позволяет минимизировать потери информации и обеспечить надежность передачи.
- Оптимальное использование ресурсов сети: Настройка TCP на роутере позволяет оптимизировать использование ресурсов сети. Это может включать установку оптимального размера окна TCP, активацию задержки ACK и другие параметры, которые могут повысить эффективность использования сетевых ресурсов.
- Защита от атак: Неправильная конфигурация TCP на роутере может привести к ряду уязвимостей и повысить риск атаки. Правильная настройка TCP может помочь защитить сеть от угроз безопасности и снизить вероятность успешных атак.
В целом, настройка TCP на роутере не только повышает производительность и надежность сети, но также способствует безопасности и оптимальному использованию ресурсов. Поэтому важно уделить достаточно внимания настройке TCP на роутере для оптимального функционирования сети.
Подготовка к настройке TCP на роутере
Прежде чем приступить к настройке TCP на роутере, необходимо выполнить несколько подготовительных шагов:
- Убедитесь, что у вас есть доступ к роутеру и имеются права администратора для его настройки.
- Определите IP-адрес вашего роутера и узнайте, как к нему подключиться. Обычно эту информацию можно найти в документации к роутеру или на его задней панели.
- Проверьте сетевые настройки вашего компьютера. Убедитесь, что он настроен на получение IP-адреса автоматически (через DHCP).
- Установите необходимое программное обеспечение на компьютер для доступа к роутеру. Обычно производитель роутера предоставляет программу или веб-интерфейс для настройки роутера.
- Подготовьте все необходимые данные, такие как IP-адреса, подсети и шлюза по умолчанию, которые вам нужно будет указать при настройке TCP.
После выполнения этих подготовительных шагов вы будете готовы приступить к настройке TCP на роутере и организовать стабильное и безопасное соединение к сети Интернет.
Шаг 1: Определите модель и производителя вашего роутера
Перед тем, как начать настройку TCP на вашем роутере, важно определить его модель и производителя. Эта информация необходима, так как каждый роутер имеет свой уникальный интерфейс управления.
Модель и производитель роутера обычно указаны на самом устройстве или на его задней панели. Вы можете найти название модели, такое как «TP-Link Archer C1200» или «ASUS RT-AC68U», а также информацию о производителе, такую как «NETGEAR» или «Linksys».
Если вы не можете найти информацию о модели и производителе на роутере, вы можете посмотреть на оригинальную упаковку или на поставляемый вместе с роутером документацию. Если вы все еще не можете найти информацию, вы можете воспользоваться поиском в Интернете или обратиться к службе поддержки производителя.

В сети можно найти огромное количество материала о том, как функционируют сети на базе стека протоколов TCP/IP, а также как писать компьютерные программы с сетевыми возможностями. При рассмотрении компьютерных сетей часто углубляются в описание физических основ и структур данных, передаваемых по сети, а при рассмотрении сетевого программирования основное внимание уделяют интернет-сокетам.
Но при изучении и исследовании хочется большего, например, поэкспериментировать с пакетами сетевых протоколов. Многие сетевые протоколы реализованы в ядре операционной системы, и что-либо изменить может оказаться сложной задачей, так как это требует навыков в написании драйверов для операционной системы. Но использование специализированных библиотек позволяет работать с протоколами на низком уровне из пространства пользователя.
В ходе работы над статьёй я написал небольшое приложение, которое послужит отправной точкой для понимания компьютерных сетей и семейства протоколов TCP/IP. С приложением можно экспериментировать, получая дополнительные знания.
Приложение — простое и понятное и, надеюсь, упростит изучение материалов статьи. Ведь именно радость первой победы даёт мотивацию, достаточную для того, чтобы потратить гораздо больше времени на изучение темы.
В статье изложены наиболее важные с моей точки зрения понятия, которые должен знать любой программист, хоть как-то сталкивающийся с компьютерными сетями. Так что без теоретических сведений не обошлось.
Приложение доступно на GitHub.
Содержание
- Кратко о компьютерных сетях
- Cтек протоколов TCP/IP
- Сетевое программирование и анализ сетевого трафика
- Примеры программного кода
- Заключение
Кратко о компьютерных сетях
▍ Компьютерная сеть
Компьютерная сеть — это множество вычислительных устройств, взаимодействующих между собой и совместно использующих ресурсы. Понятие сеть близко по смыслу к понятию графа. Cеть также состоит из множества узлов (nodes) и множества звеньев (links). Отличие сети от графа в том, что узлы являются чем-то осмысленным, в данном случае — это вычислительные устройства, а звенья представляют связи этих устройств. В русскоязычной литературе компьютерную сеть иногда называют вычислительной сетью.
▍ Локальные и глобальные компьютерные сети
В зависимости от охвата территории компьютерные сети бывают:
- Персональные — Personal Area Network (PAN).
- Локальные — Local Area Network (LAN).
- Городские — Metropolitan Area Network (MAN).
- Глобальные — Wide Area Network (WAN).
Различные датчики, подключённые к смартфону, образуют сеть PAN. Компьютерная сеть из устройств, подключённых к вашему домашнему роутеру, является LAN-сетью, сеть из абонентов провайдера в городе — это MAN-сеть, а весь интернет, который вам предоставляет провайдер — WAN-сеть.
▍ Сетевые модели
Под сетевой моделью понимаются концептуальные основы, которые стандартизируют сетевое взаимодействие. Это основные термины, а также назначение и функции сетевых компонентов. Сетевая модель разделяет сетевые компоненты и их функции на уровни (слои (layers)). Каждый слой сетевой модели имеет определённое назначение и функции.
Сейчас наиболее распространены две сетевых модели. Это семиуровневая OSI-модель и четырехуровневая TCP/IP-модель.
Приведу схему моделей и как они соотносятся друг с другом.

В большинстве случаев вы будете иметь дело с сетевой моделью TCP/IP, однако так исторически сложилось, что номера слоёв используются из сетевой модели OSI. Например, когда встречается термин Layer 2 или L2, подразумевается 1-й уровень (канальный уровень) из модели TCP/IP.
Разбивка по слоям позволяет технологиям каждого слоя эволюционировать независимо от всех остальных. Например, благодаря повсеместному внедрению оптоволокна скорость интернета возросла в десятки или даже сотни раз, а интернет как базировался на протоколе IP, так и продолжает базироваться.
▍ Модель TCP/IP
Большинство действующих стандартов интернета и протоколов TCP/IP регламентируются документами Request For Comments (RFC). Учебники по компьютерным сетям ставят целью объяснить модель TCP/IP, но за точной трактовкой понятий лучше обращаться к RFC.
Детально сетевая модель TCP/IP рассмотрена в RFC 1122 (Requirements for Internet Hosts — Communication Layers ) и RFC-1123 (Requirements for Internet Hosts — Application and Support). Модель объясняется и расширяется другими RFC, но для понимания основ, я думаю, достаточно этих двух.
Выделим базовые понятия из модели TCP/IP:
- хост (host);
- сообщение;
- IP-датаграмма;
- пакет;
- фрейм;
- IP-адрес;
- MAC-адрес;
- TCP-сегмент;
- UDP-датаграмма;
- MTU.
Чтобы не утомлять вас скучными определениями, я не буду приводить их, а просто расскажу принципы работы сети TCP/IP, используя вышеприведённые термины.
▍ Как работает сеть, построенная на базе TCP/IP
IP-сеть представляет собой множество связанных между собой хостов. Хосты связаны непосредственно или косвенно при помощи ретранслирующих устройств (маршрутизаторов и коммутаторов).
Для приёма сообщений из сети и отправку их в сеть хост использует интерфейсы. Физический интерфейс отправляет и принимает фреймы, а логический интерфейс отправляет и принимает IP-пакеты. Физический интерфейс идентифицируется MAC-адресом, логический интерфейс — IP-адресом.
Передаваемое сообщение представляет собой UDP-датаграмму или TCP-сегмент. Сообщение содержит заголовок и полезные данные. Чтобы передать сообщение внутри IP-сети оно помещается в IP-датаграмму. Конкретный физический интерфейс позволяет передавать данные порциями, которые имеют определённый максимально допустимый размер (MTU). Если размер IP-датаграммы превышает MTU, выполняется её фрагментация и создаётся несколько IP-пакетов, иначе создаётся только один IP-пакет для всей IP-датаграммы.
IP-пакет в соответствии с таблицей маршрутизации хоста передаётся на выбранный логический интерфейс.
Логический интерфейс сам непосредственно не может передать IP-пакет, он использует физический интерфейс. Физический интерфейс передаёт данные фреймами. Фрейм имеет заголовок и полезные данные (payload). В заголовке фрейма указывается MAC-адрес получателя, MAC-адрес отправителя и какому протоколу принадлежат данные в payload (Ethertype). Адрес отправителя известен, это МАС-адрес интерфейса отправляющего хоста. Для протокола IPv4 Ethertype=0x0800.
Адрес физического интерфейса определяется путём посылки ARP-сообщения в широковещательный домен. ARP-сообщение инкапсулируется во фрейм, у которого EtherType = 0x0806 (ARP). В сообщении указывается MAC-адрес отправителя, широковещательный MAC-адрес получателя и интересующий IP-адрес. Хост с физическим интерфейсом, которому назначен этот IP-адрес в ответном сообщении, указывает MAC-адрес этого физического интерфейса. Чтобы не отсылать ARP-сообщение каждый раз, соответствие IP-адреса MAC-адресу сохраняется в кеше хоста.
После передачи фрейма на другой сетевой интерфейс из него извлекается содержимое IP-пакета, и, если IP-адрес логического интерфейса хоста соответствует IP-адресу получателя, он собирается в IP-датаграмму. Из IP-датаграммы извлекается TCP-сегмент или UDP-датаграмма. Из них извлекаются сами данные и передаются процессу операционной системы, который уже понимает, что с ними делать дальше.
Иначе IP-пакет или отвергается или пересылается далее в соответствии с таблицей маршрутизации хоста. При отсылке он опять передаётся на логический интерфейс. Там упаковывается во фрейм и отсылается.
Это упрощённое описание, так как я не углублялся в виртуальные сетевые интерфейсы, виртуальные частные сети, PPP-соединения, как работают сетевые транспортные протоколы TCP и UDP.
▍ Адресация
Адресация позволяет указать источника и получателя данных. Для слоя L2 получатель и отправитель идентифицируются MAC-адресами, для L3 — IP-адресами, для L4 — портами.
Что касается MAC-адресации, вам достаточно знать, что в большинстве случаев физический интерфейс имеет уникальный MAC-адрес, состоящий из 6 байт.
Что касается IP-адресации, тут всё немного интереснее. Начнём с того, что всего возможно 2^32 IP-адресов, но количество допустимых IP-адресов хостов меньше, а глобальных (IP-адресов, видимых в интернете) ещё меньше. Попробую объяснить, почему так происходит.
Интернет проектировался как множество соединённых компьютерных сетей, хосты которых взаимодействуют между собой.
Для идентификации сетей используется то же адресное пространство, что и для идентификации интерфейсов хостов. Как это реализуется?
Каждый IP-адрес — это последовательность из 32 бит. Первые n-бит в IP-адресе несут информацию о том, к какой сети принадлежит IP-адрес, оставшиеся биты — это уникальный адрес внутри этой сети. Однако адреса, у которых все биты 0 или все биты 1 имеют особое значение. Если все биты 0 — это сеть, если 1 — это широковещательный адрес.
Сколько первых бит в IP-адресе несут информацию о сети определяется маской сети. Если выполнить побитовое “И” IP-адреса с маской сети, то получится идентификатор сети. Если выполнить побитовое “И” с инвертированной маской сети, то мы получим уникальный адрес внутри сети. Чтобы можно было проще представить информацию об IP-адресе, и какая его часть используется для идентификации сети, используется CIDR-нотация.
Например, запись 192.168.0.0/24 означает: сеть имеет идентификатор 192.168.0.0, 24 первых бита используются для идентификации сети. Для кодирования хостов используется 8 последних бит. Максимальное количество хостов в сети — 254 (0 — сеть, 255 — широковещательный адрес).
Но это ещё не всё. Не все сети могут быть видимыми в сети и некоторые из них используются для специальных целей.
Как мы видим, количество IP-адресов хостов в интернете не так уж и велико, поэтому выполняется переход на IPv6-адресацию, где количество IP-адресов гораздо больше.
▍ Сегмент сети, подсеть, широковещательный домен, виды адресов
Когда рассматривается сеть, нужно всегда иметь представление на каком уровне это выполняется. Если сеть рассматривается на канальном уровне, она состоит из устройств, имеющих MAC-адреса. Если она рассматривается на сетевом уровне, она состоит из хостов, имеющих IP-адреса.
С целью упрощения управления, сети на канальном уровне разделяются на сегменты, а на сетевом уровне на подсети. И сегмент сети и подсеть являются широковещательным доменом. Иногда подсети называют также сегментами, однако нужно понимать, что подразумевается сегмент сети на уровне L3.
Сетевое устройство или хост могут иметь следующие типы адресов:
- индивидуальный адрес (unicast address);
- широковещательный адрес (broadcast address);
- групповой адрес (multicast address).
Индивидуальный адрес — это уникальный адрес в сегменте сети, или локальной (глобальной) сети.
Широковещательный адрес — общий для всех сетевых устройств, имеющих MAC-адрес или для всех хостов подсети. Сообщения, посылаемые на широковещательный адрес, будут получены всеми узлами.
Можно сделать так, чтобы сообщения отсылались только тем узлам, которые в них заинтересованы. Для этого используются групповые адреса. Но это уже отдельная тема, требующая отдельного и более широкого объяснения.
▍ Маршрутизация в IP-сетях
Маршрутизация обычному пользователю сети выглядит следующим образом. Если необходимо отправить IP-пакет по определённому адресу, то каждый раз просматривается таблица маршрутизации хоста, и на основании её определяется, нужно его отправлять на хост внутри сети, которой принадлежит отправляющий хост, или нужно его перенаправить на особый хост (маршрутизатор, шлюз), который решит, что делать с ним дальше. В локальных домашних сетях часто таким шлюзом является WiFi-роутер.
WiFi-роутер обладает рядом функций и фактически состоит из нескольких устройств. Одной из важных функций WiFi-роутера является функция трансляции сетевых устройств (Network Address Translation — NAT), позволяющая устройствам из локальной сети получить доступ в интернет. Доступ этот немного ограниченный, но большинству пользователей этого достаточно.
Суть работы NAT в том, что хост, который находится за NAT, виден для глобальной сети как хост, у которого IP-адрес такой же, как и внешний адрес NAT, что позволяет более экономно расходовать глобальные IP-адреса. Подробное описание работы NAT потребует отдельной статьи, а то и книги.
▍ Расчёт контрольной суммы
При передаче данных по сети могут происходить различные ситуации, когда принятые данные могут отличаться от тех, которые были переданы. Чтобы определить такие случаи, с данными передаётся контрольная сумма, вычислив которую на принимающей стороне и сравнив с принятой, можно дать ответ, передались ли данные верно, или где-то произошла ошибка передачи данных. Как правило, сообщения с неверной контрольной суммой отвергаются, и сообщение считается потерявшимся. На различных уровнях стека используются различные варианты подсчёта контрольной суммы. Например, для Ethernet-фрейма используется CRC-32. Для вычисления контрольной суммы IP-заголовка, ICMP-сообщения, UDP-датаграммы и TCP-сегмента используется расчёт контрольной суммы с использованием обратного кода (one’s complement checksum). Чтобы не тратить процессорное время на вычисление контрольных сумм для передаваемых Ethernet-фреймов или IP-пакетов, используется механизм разгрузки (offloading), который заключается в том, что контрольные суммы вычисляются сетевым адаптером.
▍ Порядок байтов и битов
Данные в компьютере хранятся и обрабатываются в виде двоичного кода. Двоичный код подразумевает, что информация кодируется при помощи двух значений — 0 и 1. Один 0 или одна 1 содержат минимальное количество информации, которое называется бит. Процессор обычно оперирует не отдельными битами, а порциями по 8, 16, 32, 64 и т. д. Минимальная такая порция это 8 бит. 8 бит называются байтом. Можно сказать, что информация в памяти хранится в виде последовательности байт. Но байт может принимать только 256 значений, что явно недостаточно для большинства математических операций, поэтому байты группируются в слова (2 байта), двойное слово (4 байта) и т. д. Но хранить эти группы байт в памяти можно по-разному. Возьмём двойное слово 4 байта 0x12345678, оно состоит из 4 байт со значениями 0x12, 0x34, 0x56, 0x78. В памяти их можно разместить в следующем порядке 0x12, 0x34, 0x56, 0x78 или 0x78, 0x56, 0x34, 0x12. Как они будут размещены в памяти зависит от архитектуры процессора. Например в архитектуре x86 это будет порядок, при котором байт с менее значимыми битами будет храниться раньше байта с более значимыми битами.
Так исторически сложилось, что данные в пакетах, передаваемых в IP-сетях, имеют сетевой порядок байтов, который подразумевает, что байт, содержащий старшие биты, хранится первый.
Что касается порядка битов, то если не углубляться в вопросы кодирования передаваемых данных на уровне сигналов, порядок не важен, так как сетевой адаптер сделает всё без вмешательства программиста.
Cтек протоколов TCP/IP
Существует ряд протоколов, на которых всё основывается:
- Ethernet II;
- IP — Internet Protocol;
- ICMP — Internet Control Management Protocol;
- UDP — User Datagram Protocol;
- TCP — Transmission Control Protocol;
- DHCP — Dynamic Host Configuration Protocol;
- DNS — Domain Name Service.
Рассмотрим их поподробнее. Данные передаются порциями, которые называются Protocol Data Unit (PDU). PDU состоит из заголовка (header) и полезных данных (payload). PDU одного протокола в полезных данных могут содержать PDU другого протокола. Это называется инкапсуляцией. В зависимости от уровня, на котором работает сетевой протокол, PDU могут называться по-разному:
- на канальном уровне — фрейм;
- на сетевом уровне — пакет (IP, ICMP);
- на транспортном уровне — сегмент или датаграмма (TCP, UDP);
- на прикладном уровне — сообщение (DNS, DHCP).
Но в разной литературе могут не следовать правилу, например, часто можно встретить IP-датаграмму, TCP-пакеты или UDP-пакеты. А в программах по анализу трафика в сети все PDU называются пакетами. По мере приобретения опыта, вы будете лучше ориентироваться, что имелось в виду при употреблении того или иного термина.
Протокол Ethernet
Обычно при описании протокола Ethernet опускаются чуть ли не до бит, а то и сигналов, передаваемых по сети. Я не буду углубляться в такие подробности, к тому же с большой долей вероятности вы используете WiFi-соединение, поэтому различные средства для перехвата сетевого трафика, как правило, будут показывать его как IP-пакеты, инкапсулированные в Ethernet II фреймы. Эти фреймы имеют мало чего общего с фреймами WiFi, но унифицируют работу с канальным уровнем. Вообще, информация о том, как работает WiFi, заслуживает отдельной статьи.
Ethernet-фрейм, который передаётся или принимается драйвером сетевого адаптера, состоит из заголовка и полезных данных.

Часто можно встретить информацию о минимальном размере Ethernet-фрейма, преамбуле и контрольной сумме. Но это уровень реализации драйвера сетевого адаптера или аппаратной реализации самого адаптера, поэтому не буду рассматривать его в статье. Для нас Ethernet-фрейм содержит MAC-адрес получателя, MAC-адрес отправителя, тип фрейма и сами данные.
▍ Протокол IP
Оригинальное описание протокола находится в RFC 791 Internet Protocol — DARPA Internet Program Protocol Specification.
▍ Структура пакетов
Структура IP-пакета приведена ниже.

▍ IP-пакеты и IP-датаграммы
Протокол IP позволяет передавать данные порциями. В литературе можно встретить два похожих термина: IP-датаграмма и IP-пакет. Иногда их неверно употребляют. Я хочу уточнить это различие. IP-датаграмма — это те данные, которые передаются на сетевой уровень, а IP-пакет — это те данные, которые передаются в IP-сети. Размер IP-датаграммы ограничивается максимальным значением в поле Total Length. Размер IP-пакета ограничивается MTU (Maximum Transmission Unit) — максимально возможное количество данных, которые могут быть переданы одним фреймом на канальном уровне. Чтобы передать IP-датаграмму, которая содержит полезных данных больше, чем может поместиться в один IP-пакет, используется фрагментация.
▍ Фрагментация IP-датаграмм
Протокол IP поддерживает фрагментацию IP-датаграмм. Cуть фрагментации заключается в том, что максимальный размер передаваемых данных в одной IP-датаграмме составляет 65535 байт (октетов), а максимальный размер данных, который может поместиться в PDU канального уровня (MTU), гораздо меньше (обычно он составляет 1500 или около байт). Если размер IP-датаграммы больше MTU, она будет разбита на несколько IP-пакетов, каждый из которых можно будет передать в PDU канального уровня. При получении IP-пакетов они будут собраны в IP-датаграмму, и она будет разобрана на транспортном уровне.
Все IP-пакеты одной IP-датаграммы имеют одинаковое значение в поле Identification, а поле Offset содержит смещение в payload IP-датаграммы.
Хотя фрагментация позволяет соединять хосты в разнородных сетях, её желательно избегать, так как она усложняет передачу данных и увеличивает нагрузку на сеть из-за создания новых IP-пакетов и перерасчёта контрольных сумм. Поэтому желательно, чтобы TCP-сегмент или UDP-датаграмма имела размер не больше MTU по пути следования IP-пакетов.
▍ Протокол ARP
Протокол ARP используется для определения МАС-адреса физического интерфейса хоста по его IP-адресу. Описание протокола приведено в RFC 826 — An Ethernet Address Resolution Protocol. MAC-адрес не обязательно должен быть адресом в Ethernet-сети, но ниже я привожу структуру ARP-сообщения для Ethernet-сети.

▍ Протокол ICMP
Описание протокола приведено в RFC 792 (Internet Protocol DARPA Internet Program Protocol Specification) .
▍ Структура сообщений
В описании протокола приведено много различных сообщений, но нам достаточно для начала разобраться с сообщениями Echo и Reply

Хотя сообщения, используемые протоколом, инкапсулируются в IP-датаграммы, ICMP причисляют к тому же уровню, что и IP — сетевому.
▍ Протокол UDP
Описание протокола приведено в RFC 768 (User Datagram Protocol).
Протокол позволяет двум процессам обмениваться UDP-датаграммами. Каждая UDP-датаграмма содержит в себе порт отправителя (Source Port), порт получателя (Destination Port), длину дейтаграммы (Length), контрольную сумму (Checksum) и собственно сами передаваемые данные.
При расчёте контрольной суммы добавляется псевдозаголовок, который не передаётся, а только участвует в расчёте контрольной суммы.
Протокол используется в качестве транспортного протокола там, где на транспортном уровне допускается дублирование получаемых данных, пропуск данных или не важен порядок, в котором данные будут доставлены.
Как правило, обработка этих случаев возлагается на протоколы уровня приложений или не осуществляется вовсе. Например, в потоковом видео или аудио данные пропускаются, так как повторная передача данных является в этом случае бессмысленной. Но если вы хотите гарантированную доставку данных на транспортном уровне, то вам необходимо использовать протокол TCP.
▍ Структура сообщений
Структуры псевдозаголовка, используемого при вычислении контрольной суммы и UDP-датаграммы, приведены ниже.


▍ Протокол TCP
Протокол TCP — самый из сложный из всех, приведённых в статье. Назначение протокола TCP — создать надёжное виртуальное полнодуплексное соединение между процессами. На данный момент самое свежее описание протокола приведено в RFC 9293 — Transmission Control Protocol (TCP).
▍ Структура сообщений
Сообщения, используемые в протоколе TCP, называются TCP-сегментами. Просьба не путать с сегментами сети. Они с ними не имеют ничего общего. При расчёте контрольной суммы для TCP-сегмента как и в UPD используется псевдозаголовок. Но если для UDP расчёт контрольной суммы не является обязательным, то для TCP он таким не является.
Структура псевдозаголовка и TCP-сегмента приведена ниже.


Как видно из структуры заголовка, в протокол TCP, как и в протокол IP, заложены возможности для расширения и эволюции протокола при помощи поля Options.
Ключевые понятия, необходимые для понимания TCP:
- Segment;
- Sequence Number;
- Acknowledge number;
- TCP Window;
- TCP Handshake;
- MSS — Maximum Segment Size;
- TCP Flags and TCP Options;
- Window Scaling;
- Selective Acknowledgement.
Для надёжной передачи данных используются Sequence Number, Acknowledge Number и Window Size. Рассмотрим, как они работают вместе. Передаваемые данные разбиваются на TCP-сегменты.
За каждым TCP-сегментом закрепляется Sequence number.
Sequence Number может принимать значения от 0x00000000 до 0xffffffff. Если каждому передаваемому байту присвоить номер и разбить на сегменты, то Sequence Number — это номер первого байта каждого сегмента.
Sequence Number служит для упорядочивания сегментов, которые пришли не в порядке их отсылки (out of order), подтверждения полученных сегментов (acknowledgement), а также для повторной отсылки потерявшихся сегментов (retransmitting).
Каждый передаваемый по сети TCP-сегмент содержит поля Sequence Number и Acknowledge Number. Sequence Number идентифицирует отправляемый сегмент, а Acknowledge Number указывает на то, какой сегмент ожидается.
Значения Sequence Number и Acknowledge Number позволяют отслеживать прогресс передачи данных по TCP-соединению. Каждая сторона генерирует случайное число из диапазона от 0 до 2^32, которое называется ISN. Это число является началом для генерирования Sequence Numbers отсылаемых сегментов.
Сегменты отсылаются только те, которые попадают в окно. Размер этого окна сообщается отправителю при установлении соединения, но может быть изменён принимающей стороной в дальнейшем.
По мере получения подтверждений с принимающей стороны, окно сдвигается по кругу.
Перед передачей данных, необходимо установить соединение. При установке соединения стороны обмениваются параметрами будущего соединения. Любая сторона может инициировать разрыв соединения.
При установке соединения стороны обмениваются параметрами Sequence Number, Acknowledge Number, Window Size, а также параметрами, которые передаются в поле TCP Options (MSS, Window scale).
▍ Флаги TCP
Для управления TCP-соединением используются флаги в отсылаемых TCP-сегментах. Наиболее важными являются:
- SYN — используется при установлении TCP-соединения;
- ACK — означает, что сегмент был получен принимающей стороной;
- FIN — используется при нормальном (graceful) закрытии TCP-соединении;
- RST — используется при аварийном закрытии TCP-соединения.
▍ Опции TCP
Протокол TCP разработан таким образом, что его можно расширять используя механизм опций. Опции это дополнительные поля, которые передаются в заголовке. Например, при установлении соединения стороны обмениваются опциями, Window Scale, MSS. В зависимости от настроек стека в TCP-сегменте может передаваться опция TCP timestamp. Если опция не поддерживается, она игнорируется стеком.
▍ Открытие соединения, передача данных, закрытие соединения
В RFC 9293 приведено подробное описание и представлена диаграмма состояний для TCP-соединения. Я не буду её здесь приводить. При желании вы её можете разобрать. Но хочу сразу сказать, её сложно читать. Ниже представлена диаграмма последовательностей для жизненного цикла TCP соединения.

Обратите внимание, как меняются значения в полях SequenceNumber и AcknowledgeNumber предаваемых TCP сегментов.
Если при установлении TCP-соединения используется 3-way handshake, то с закрытием существует множество различных вариантов. На диаграмме приведен 4-way handshake, который будет в случае, если сервер не обработал все данные от клиента при получении TCP-сегмента FIN,ACK. В случае, если данные все обработанные, то выполняется 3-way handshake (сервер отсылает только сегмент FIN,ACK).
Чтобы вам было понятнее в механизме передачи и приёма TCP-сегментов, я нарисовал схематический рисунок.

▍ Настройка стека TCP/IP
Работу стека протоколов TCP/IP можно настраивать в операционной системе, только делать это лучше в том случае, если вы точно осознаёте, что именно вы изменяете и зачем.
В Windows стек можно настроить командой netsh, В Linux/MacOS — командой sysctl. В зависимости от операционной системы перечень и значения по умолчанию настраиваемых параметров могут отличаться. Например, в Windows tcp timestamps отключены по умолчанию. Чтобы включить, нужно выполнить команду:
netsh int tcp set global timestamps=enabledВ Linux, напротив, tcp timestamps включены, если вы хотите их отключить нужно выполнить команду:
sysctl -w net.ipv4.tcp_timestamps=0В MacOS включить/отключить tcp timestamps у вас не получится.
▍ Протокол DHCP
Для работы в сети TCP/IP хост необходимо настроить. Минимально необходимо указать его IP-адрес и маску подсети. Также может понадобиться указать адрес шлюза и адрес DNS-сервера. Протокол DHCP позволяет хосту получить эти данные автоматически из сети.
Существуют различные варианты использования данного протокола, но мы рассмотрим основной успешный сценарий получения IP-адреса хостом, который состоит из обмена 4 сообщениями.
▍ Получение конфигурации
1. Изначально хост не имеет IP-адреса и не знает, где расположен DHCP-сервер, который ему эту информацию может предоставить. Поэтому он посылает широковещательное сообщение DHCP Discover в свой сегмент сети.
2. Если в сети присутствует DHCP-сервер, он отвечает unicast-сообщением DHCP Offer, в котором содержится предлагаемая конфигурация для хоста.
3. Хост посылает unicast-сообщение DHCP Request, в котором указывает, назначенный ему IP-адрес
4. Сервер отвечает unicast-сообщением DHCP Acknowledge, которое говорит о том, что конфигурация хосту назначена.
Диаграмма последовательностей приведена ниже.

▍ Структура сообщений
Описание протокола приведено в RFC 2131 — Dynamic Host Configuration Protocol. DHCP-протокол является расширением более раннего протокола BOOTP (RFC 951 Bootstrap Protocol). Поэтому заголовок DHCP-сообщения почти полностью совпадает с BOOTP-сообщением. Поле options всегда начинается с магического числа 0x62825363, за которым следуют DHCP-опции, описанные в RFC 2132 DHCP Options and BOOTP Vendor Extensions .
Каждая опция состоит из кода, длины и одного или нескольких октетов сообщения. Исключение составляют опции с кодами 0x00 (заполнитель) и 0xff (конец опций). Размер DHCP-сообщения в октетах должен быть кратным четырём, поэтому после опции с кодом 0xff может быть одна или несколько опций с кодом 0x00.
Как выглядит DHCP-сообщение, приведено ниже:

▍ Протокол DNS
Протокол DNS регламентируется RFC 1035 DOMAIN NAMES — IMPLEMENTATION AND SPECIFICATION.
Скорее всего, вы имеете представление о службе DNS, так она используется для преобразования доменного имени хоста в его IP-адрес. Вроде бы всё просто, и для программиста всё скрывается за простым API, но этот факт затрудняет понимание сути DNS. IP-адрес хоста — это лишь часть той информации, которую может хранить DNS.
Программы типа nslookup и функции в Winsock или glibc запутывают в понимании DNS. Я бы советовал начинать изучение DNS с экспериментов с утилитой dig и анализа трафика. DNS нужно рассматривать, не привязываясь к IP. DNS — это распределённая иерархическая база данных доменов.
Чтобы убедиться, что это действительно база данных можете зайти на сайт и увидеть тому подтверждение.
▍ Домен
Что такое домен? Домен можно определить как именованную сущность, которая содержит метаинформацию о себе и находится в ведении организации или частного лица. К такой информации относятся IP-адрес, имя используемого почтового сервера, имена серверов имён, обслуживающих данный домен и др. Для упрощения управления доменами они организовываются в иерархию.
Домены не существуют сами по себе, они хранятся серверами имён. Информация, связанная с доменом, объединяется в зону, которая обслуживается конкретным сервером имён.
▍ Зона
Зона — это информация о доменах, размещённая на DNS-сервере.
Корневую зону доменов интернета можно посмотреть здесь.
Корневая зона доменов обслуживается 13 корневыми доменными серверами.
▍ Ресурсная запись
Система доменных имён позволяет структурировано хранить информацию. Доменные имена организуются в древовидную структуру, листьями которой являются ресурсные записи (Resource Record (RR)). Каждая RR имеет класс и тип. Как правило, классы могут принимать следующие значения:
- IN (Internet);
- CH (Chaos);
- HS (Hesiod).
Хотя можно встретить классы CH и HS, применение их специфическое, и с большой долей вероятности вы с ними не столкнётесь.
А вот типов RR гораздо больше, и часть из них знать обязательно:
- A (Address) — IP-адрес, закреплённый за доменным именем;
- AAAA (IPv6 Address) — IPv6-адрес, закреплённый за доменным именем;
- CNAME (Canonical Name);
- MX (Mail Exchanger);
- NS (Name Server);
- PTR (Pointer);
- SOA (Start of Authority);
- TXT (Text);
- SRV (Service).
▍ Резолвер
Domain Name Service позволяет по имени хоста получить его IP-адрес. Реализуется это при помощи распределённой базы данных, работающих на множестве хостов. Хост, как правило, взаимодействует с локальным компонентом, называемым резолвером (resolver). К резолверу можно обратиться через API операционной системы или библиотеки языка программирования.
При выполнении API-функции резолвер проверяет в своём локальном кэше IP-адрес для имени хоста. Если не находит, то пытается сделать запрос DNS-серверу, адрес которого прописан в конфигурации. Что может происходить дальше опустим, для упрощения описания. В конечном итоге DNS-сервер возвращает IP-адрес для имени хоста или ошибку, если такой хост отсутствует. Резолвер помещает эту информацию в кэш и возвращает значение вызвавшему коду. В Linux API к резолверу находится в библиотеке glibc, в Windows — в библиотеке Winsock.
Обычно в примерах по сетевому программированию приводится именно работа с API резолвера. Я же в практической части покажу, как можно послать запрос DNS-серверу на низком уровне, сформировав IP-пакет, содержащий DNS-запрос.
▍ Структура пакетов
Простой DNS-запрос выглядит следующим образом:

Пример DNS-ответа приведён ниже:

Как правило, запросы и ответы отсылаются с использованием UDP в качестве транспортного протокола. Однако если ответ слишком большой, сервер вернёт флаг TC. Это означает, что для получения полного ответа нужно использовать TCP в качестве транспорта.
Сетевое программирование и анализ сетевого трафика
▍ Стеки протоколов TCP/IP и программные интерфейсы
Практически любая современная операционная система имеет поддержку работы с семейством протоколов TCP/IP. Набор компонентов операционной системы, которые обеспечивают коммуникацию посредством семейства протоколов TCP/IP, называют стеком протоколов. Разные операционные системы предоставляют доступ к стеку, используя различные программные интерфейсы. Наиболее распространённым является интерфейс сокетов.
Хотя и существуют различия в этом интерфейсе для различных операционных систем, большинство функций схожи. Работа с сокетами подразумевает программирование на языке С. Однако для различных языков написаны обёртки, которые позволяют кроссплатформенно работать с сокетами. В зависимости от языка, обёртки могут предоставлять больше или меньше функций. Например обёртка в Python больше зависит от платформы, на которой исполняется, чем обёртка в Java.
▍ Анализ пакетов в сети
Обычно в литературе по сетевым технологиям рассматриваются основы компьютерных сетей, потом сокеты. Но то, как именно можно создать и послать пакет, структура которого подробно расписана, не приводится. Я хочу восполнить этот пробел.
Инструкции процессора в операционной системе могут исполняться в режиме ядра или режиме пользователя. Большинств кода, который пишет программист — это инструкции процессору, которые выполняются в режиме пользователя. В режиме ядра выполняется код драйверов и ядра операционной системы.
Стек TCP/IP выполняется в режиме ядра, а из режима пользователя он, как правило, доступен только через вызов АPI-сокетов. Поэтому программист только может выполнить высокоуровневые операции, такие как открыть TCP-соединение, передать данные по TCP-соединению или передать данные как UDP-датаграмму. Доступа к формируемым пакетам он не имеет.
Чтобы получить доступ к формируемым пакетам, используются так называемые Raw-сокеты. Замечу, что в Windows Raw-сокеты имеют ограниченный функционал. Например, невозможно создать Raw-сокет, который бы позволял работать с Ethernet-фреймами. Поэтому для получения доступа к формированию Ethernet-фреймов используют специальный NDIS-драйвер и библиотеку npcap. В Linux же достаточно же просто создать AF_PACKET Raw-сокет.
▍ libpcap
Библиотека предоставляет высокоуровневый, если так можно сказать, API для формирования, фильтрации и перехвата пакетов, который прячет детали реализации для разных платформ.
▍ Scapy
Для Windows существует библиотека npcap, для Unix-подобных систем — libpcap. Python-библиотека Scapy позволяет писать платформо-независимые приложения, игнорируя этот факт. Также она поддерживает многие сетевые протоколы. И содержит средства для разбора, генерации и отсылки пакетов из пространства пользователя. Например, расчёт контрольной суммы для заголовка IP-пакета, указание правильного Ethertype или Protocol при инкапсуляции пакетов. Библиотека удобна для экспериментирования и исследования сетевых протоколов.
▍ Wireshark
Программа Wireshark, можно сказать, самая распространённая программа для анализа сетевого трафика. При помощи графического интерфейса, можно записывать сетевой трафик на диск, фильтровать пакеты, рассматривать их структуру, отслеживать работу TCP-сессий и многое другое. Совместно с Scapy, это, наверное, лучший набор для изучения основ сетевых протоколов и проведения различных экспериментов.
Примеры программного кода
Далее я хочу привести фрагменты из моего приложения для упрощения понимания основ TCP/IP.
▍ Создание ARP-запроса
def create_arp_request(ip):
return Ether(dst="ff:ff:ff:ff:ff:ff")/ARP(pdst=ip)
▍ Создание сообщения Echo, используемого в протоколе ICMP
def create_ping_request(ip):
return IP(dst=ip)/ICMP()
▍ Создание сообщений DHCP Discover и DHCP Request
def create_dhcp_discover(mac):
return (Ether(src=mac, dst='ff:ff:ff:ff:ff:ff')
/ IP(src='0.0.0.0', dst='255.255.255.255')
/ UDP(dport=67, sport=68)
/ BOOTP(op=1, chaddr=mac_to_bytes(mac))
/ DHCP(options=[('message-type', 'discover'), 'end']))
def create_dhcp_request(mac, ip):
return (Ether(src=mac, dst='ff:ff:ff:ff:ff:ff')
/ IP(src='0.0.0.0', dst='255.255.255.255')
/ UDP(dport=67, sport=68)
/ BOOTP(op=1, chaddr=mac_to_bytes(mac), ciaddr=ip)
/ DHCP(options=[('message-type', 'request'), 'end']))
▍ Создание сообщения DNS на получение Resource Record типа AA
return IP(dst=dns_server)/UDP()/DNS(rd=1, qd=DNSQR(qname=host_name))
▍ Организация TCP соединения
def create_tcp_syn(src, sport, dst, dport, seq):
return IP(src=src, dst=dst)/TCP(seq=seq,sport=sport, dport=dport, flags="S")
def create_tcp_ack(src, sport, dst, dport, ack, seq):
return IP(src=src, dst=dst)/TCP(ack=ack, seq=seq, sport=sport, dport=dport, flags="A")
def create_tcp_fin_ack(src, sport, dst, dport, ack, seq):
return IP(src=src, dst=dst)/TCP(ack=ack, seq=seq, sport=sport, dport=dport, flags="F")
def create_and_close_tcp_connection(host, dport):
dst = socket.gethostbyname(host)
src = get_default_interface_ip()
sport = 12360
seq = 1000
syn = packets.create_tcp_syn(src=src, sport=sport, dst=dst, dport=dport, seq=seq)
response = send_receive_l3(syn)
ack = packets.create_tcp_ack(src=src, sport=sport, dst=dst, dport=dport, seq=response[TCP].ack, ack=response[TCP].seq+1)
send_l3(ack)
fin_ack = packets.create_tcp_fin_ack(src=src, sport=sport, dst=dst, dport=dport, seq=response[TCP].ack, ack=response[TCP].seq+1)
response = send_receive_l3(fin_ack)
ack = packets.create_tcp_ack(src=src, sport=sport, dst=dst, dport=dport, seq=response[TCP].ack, ack=response[TCP].seq+1)
send_l3(ack)
Так как мы вмешиваемся в стандартную работу стека протоколов TCP/IP, и стек не догадывается о нашем вмешательстве, то он может отсылать RST-сегменты на сегменты, которые он не ожидает. Чтобы такого не было, нам придётся временно запретить отсылку RST-сегментов. В MacOS это выполняется при помощи команды pfctl. В Linux можно использовать iptables.
echo "block drop out proto tcp from any to any flags R/R" | cat /etc/pf.conf - | sudo /sbin/pfctl -Ef -
Заключение
Изначально я хотел осветить вопросы перехвата трафика в компьютерных сетях для начинающих, но потом подумал, что было бы хорошо осветить основы компьютерных сетей с точки зрения программиста, чтобы дать начальные знания. Тема оказалась очень обширная, и, к сожалению, размер статьи не позволил включить всё. Но для понимания основ и примеров я привёл достаточно материала.
Использование Scapy позволяет экспериментировать с отсылкой кастомных пакетов из пространства пользователя, написав минимальное количество кода, не погружаясь в дебри программирования драйверов. А Wireshark удобен для анализа пакетов, передаваемых по сети и изучения их структуры.
Я написал статью о том, чего мне не хватало, когда я сам начинал изучать сетевое программирование.
Примеры, приведённые в статье, не годятся для использования в реальных приложениях, они всего лишь позволяют разобраться в основах сетевых протоколов. C большой долей вероятности, вам не понадобится собственная реализация ARP-протокола, написание DHCP-клиента, DNS-клиента или реализация команды ping. Но экспериментируя с ними можно улучшить своё понимание сетевых протоколов, а ещё, увидеть как ведут себя реализации сетевых протоколов в различных непредвиденных ситуациях.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх 🕹️

| Protocol stack | |
| Abbreviation | TCP |
|---|---|
| Developer(s) | Vint Cerf and Bob Kahn |
| Introduction | 1974 |
| Based on | Transmission Control Program |
| OSI layer | Transport layer (4) |
| RFC(s) | RFC 9293 |
The Transmission Control Protocol (TCP) is one of the main protocols of the Internet protocol suite. It originated in the initial network implementation in which it complemented the Internet Protocol (IP). Therefore, the entire suite is commonly referred to as TCP/IP. TCP provides reliable, ordered, and error-checked delivery of a stream of octets (bytes) between applications running on hosts communicating via an IP network. Major internet applications such as the World Wide Web, email, remote administration, and file transfer rely on TCP, which is part of the Transport Layer of the TCP/IP suite. SSL/TLS often runs on top of TCP.
TCP is connection-oriented, and a connection between client and server is established before data can be sent. The server must be listening (passive open) for connection requests from clients before a connection is established. Three-way handshake (active open), retransmission, and error detection adds to reliability but lengthens latency. Applications that do not require reliable data stream service may use the User Datagram Protocol (UDP) instead, which provides a connectionless datagram service that prioritizes time over reliability. TCP employs network congestion avoidance. However, there are vulnerabilities in TCP, including denial of service, connection hijacking, TCP veto, and reset attack.
Historical origin[edit]
In May 1974, Vint Cerf and Bob Kahn described an internetworking protocol for sharing resources using packet switching among network nodes.[1] The authors had been working with Gérard Le Lann to incorporate concepts from the French CYCLADES project into the new network.[2] The specification of the resulting protocol, RFC 675 (Specification of Internet Transmission Control Program), was written by Vint Cerf, Yogen Dalal, and Carl Sunshine, and published in December 1974. It contains the first attested use of the term internet, as a shorthand for internetwork.[3]
A central control component of this model was the Transmission Control Program that incorporated both connection-oriented links and datagram services between hosts. The monolithic Transmission Control Program was later divided into a modular architecture consisting of the Transmission Control Protocol and the Internet Protocol. This resulted in a networking model that became known informally as TCP/IP, although formally it was variously referred to as the Department of Defense (DOD) model, and ARPANET model, and eventually also as the Internet Protocol Suite.
In 2004, Vint Cerf and Bob Kahn received the Turing Award for their foundational work on TCP/IP.[4][5]
Network function[edit]
The Transmission Control Protocol provides a communication service at an intermediate level between an application program and the Internet Protocol. It provides host-to-host connectivity at the transport layer of the Internet model. An application does not need to know the particular mechanisms for sending data via a link to another host, such as the required IP fragmentation to accommodate the maximum transmission unit of the transmission medium. At the transport layer, TCP handles all handshaking and transmission details and presents an abstraction of the network connection to the application typically through a network socket interface.
At the lower levels of the protocol stack, due to network congestion, traffic load balancing, or unpredictable network behaviour, IP packets may be lost, duplicated, or delivered out of order. TCP detects these problems, requests re-transmission of lost data, rearranges out-of-order data and even helps minimize network congestion to reduce the occurrence of the other problems. If the data still remains undelivered, the source is notified of this failure. Once the TCP receiver has reassembled the sequence of octets originally transmitted, it passes them to the receiving application. Thus, TCP abstracts the application’s communication from the underlying networking details.
TCP is used extensively by many internet applications, including the World Wide Web (WWW), email, File Transfer Protocol, Secure Shell, peer-to-peer file sharing, and streaming media.
TCP is optimized for accurate delivery rather than timely delivery and can incur relatively long delays (on the order of seconds) while waiting for out-of-order messages or re-transmissions of lost messages. Therefore, it is not particularly suitable for real-time applications such as voice over IP. For such applications, protocols like the Real-time Transport Protocol (RTP) operating over the User Datagram Protocol (UDP) are usually recommended instead.[6]
TCP is a reliable byte stream delivery service which guarantees that all bytes received will be identical and in the same order as those sent. Since packet transfer by many networks is not reliable, TCP achieves this using a technique known as positive acknowledgement with re-transmission. This requires the receiver to respond with an acknowledgement message as it receives the data. The sender keeps a record of each packet it sends and maintains a timer from when the packet was sent. The sender re-transmits a packet if the timer expires before receiving the acknowledgement. The timer is needed in case a packet gets lost or corrupted.[6]
While IP handles actual delivery of the data, TCP keeps track of segments — the individual units of data transmission that a message is divided into for efficient routing through the network. For example, when an HTML file is sent from a web server, the TCP software layer of that server divides the file into segments and forwards them individually to the internet layer in the network stack. The internet layer software encapsulates each TCP segment into an IP packet by adding a header that includes (among other data) the destination IP address. When the client program on the destination computer receives them, the TCP software in the transport layer re-assembles the segments and ensures they are correctly ordered and error-free as it streams the file contents to the receiving application.
TCP segment structure[edit]
Transmission Control Protocol accepts data from a data stream, divides it into chunks, and adds a TCP header creating a TCP segment. The TCP segment is then encapsulated into an Internet Protocol (IP) datagram, and exchanged with peers.[7]
The term TCP packet appears in both informal and formal usage, whereas in more precise terminology segment refers to the TCP protocol data unit (PDU), datagram[8]: 5–6 to the IP PDU, and frame to the data link layer PDU:
Processes transmit data by calling on the TCP and passing buffers of data as arguments. The TCP packages the data from these buffers into segments and calls on the internet module [e.g. IP] to transmit each segment to the destination TCP.[9]
A TCP segment consists of a segment header and a data section. The segment header contains 10 mandatory fields, and an optional extension field (Options, pink background in table). The data section follows the header and is the payload data carried for the application. The length of the data section is not specified in the segment header; it can be calculated by subtracting the combined length of the segment header and IP header from the total IP datagram length specified in the IP header.
| Offsets | 0 | 1 | 2 | 3 | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 0 | 0 | Source port | Destination port | ||||||||||||||||||||||||||||||
| 4 | 32 | Sequence number | |||||||||||||||||||||||||||||||
| 8 | 64 | Acknowledgment number (if ACK set) | |||||||||||||||||||||||||||||||
| 12 | 96 | Data offset | Reserved 0 0 0 0 |
CWR | ECE | URG | ACK | PSH | RST | SYN | FIN | Window Size | |||||||||||||||||||||
| 16 | 128 | Checksum | Urgent pointer (if URG set) | ||||||||||||||||||||||||||||||
| 20 | 160 | Options (if data offset > 5. Padded at the end with «0» bits if necessary.) | |||||||||||||||||||||||||||||||
| ⋮ | ⋮ | ||||||||||||||||||||||||||||||||
| 56 | 448 |
- Source port (16 bits)
- Identifies the sending port.
- Destination port (16 bits)
- Identifies the receiving port.
- Sequence number (32 bits)
- Has a dual role:
- If the SYN flag is set (1), then this is the initial sequence number. The sequence number of the actual first data byte and the acknowledged number in the corresponding ACK are then this sequence number plus 1.
- If the SYN flag is unset (0), then this is the accumulated sequence number of the first data byte of this segment for the current session.
- Acknowledgment number (32 bits)
- If the ACK flag is set then the value of this field is the next sequence number that the sender of the ACK is expecting. This acknowledges receipt of all prior bytes (if any). The first ACK sent by each end acknowledges the other end’s initial sequence number itself, but no data.
- Data offset (4 bits)
- Specifies the size of the TCP header in 32-bit words. The minimum size header is 5 words and the maximum is 15 words thus giving the minimum size of 20 bytes and maximum of 60 bytes, allowing for up to 40 bytes of options in the header. This field gets its name from the fact that it is also the offset from the start of the TCP segment to the actual data.
- Reserved (4 bits)
- For future use and should be set to zero.
- From 2003–2017, the last bit (bit 103 of the header) was defined as the NS (Nonce Sum) flag by the experimental RFC 3540, ECN-nonce. ECN-nonce never gained widespread use and the RFC was moved to Historic status.[10]
- Flags (8 bits)
- Contains 8 1-bit flags (control bits) as follows:
- CWR (1 bit): Congestion window reduced (CWR) flag is set by the sending host to indicate that it received a TCP segment with the ECE flag set and had responded in congestion control mechanism.[a]
- ECE (1 bit): ECN-Echo has a dual role, depending on the value of the SYN flag. It indicates:
-
- If the SYN flag is set (1), the TCP peer is ECN capable.
- If the SYN flag is unset (0), a packet with the Congestion Experienced flag set (ECN=11) in its IP header was received during normal transmission.[a] This serves as an indication of network congestion (or impending congestion) to the TCP sender.
- URG (1 bit): Indicates that the Urgent pointer field is significant
- ACK (1 bit): Indicates that the Acknowledgment field is significant. All packets after the initial SYN packet sent by the client should have this flag set.
- PSH (1 bit): Push function. Asks to push the buffered data to the receiving application.
- RST (1 bit): Reset the connection
- SYN (1 bit): Synchronize sequence numbers. Only the first packet sent from each end should have this flag set. Some other flags and fields change meaning based on this flag, and some are only valid when it is set, and others when it is clear.
- FIN (1 bit): Last packet from sender
- Window size (16 bits)
- The size of the receive window, which specifies the number of window size units[b] that the sender of this segment is currently willing to receive.[c] (See § Flow control and § Window scaling.)
- Checksum (16 bits)
- The 16-bit checksum field is used for error-checking of the TCP header, the payload and an IP pseudo-header. The pseudo-header consists of the source IP address, the destination IP address, the protocol number for the TCP protocol (6) and the length of the TCP headers and payload (in bytes).
- Urgent pointer (16 bits)
- If the URG flag is set, then this 16-bit field is an offset from the sequence number indicating the last urgent data byte.
- Options (Variable 0–320 bits, in units of 32 bits)
- The length of this field is determined by the data offset field. Options have up to three fields: Option-Kind (1 byte), Option-Length (1 byte), Option-Data (variable). The Option-Kind field indicates the type of option and is the only field that is not optional. Depending on Option-Kind value, the next two fields may be set. Option-Length indicates the total length of the option, and Option-Data contains data associated with the option, if applicable. For example, an Option-Kind byte of 1 indicates that this is a no operation option used only for padding, and does not have an Option-Length or Option-Data fields following it. An Option-Kind byte of 0 marks the end of options, and is also only one byte. An Option-Kind byte of 2 is used to indicate Maximum Segment Size option, and will be followed by an Option-Length byte specifying the length of the MSS field. Option-Length is the total length of the given options field, including Option-Kind and Option-Length fields. So while the MSS value is typically expressed in two bytes, Option-Length will be 4. As an example, an MSS option field with a value of 0x05B4 is coded as (0x02 0x04 0x05B4) in the TCP options section.
- Some options may only be sent when SYN is set; they are indicated below as
[SYN]. Option-Kind and standard lengths given as (Option-Kind, Option-Length).
-
Option-Kind Option-Length Option-Data Purpose Notes 0 — — End of options list 1 — — No operation This may be used to align option fields on 32-bit boundaries for better performance. 2 4 SS Maximum segment size See § Maximum segment size for details. [SYN]3 3 S Window scale See § Window scaling for details.[11] [SYN]4 2 — Selective Acknowledgement permitted See § Selective acknowledgments for details.[12]: §2 [SYN]5 N (10, 18, 26, or 34) BBBB, EEEE, … Selective ACKnowledgement (SACK)[12]: §3 These first two bytes are followed by a list of 1–4 blocks being selectively acknowledged, specified as 32-bit begin/end pointers. 8 10 TTTT, EEEE Timestamp and echo of previous timestamp See § TCP timestamps for details.[11]
- The remaining Option-Kind values are historical, obsolete, experimental, not yet standardized, or unassigned. Option number assignments are maintained by the IANA.[13]
- Padding
- The TCP header padding is used to ensure that the TCP header ends, and data begins, on a 32-bit boundary. The padding is composed of zeros.[9]
Protocol operation[edit]
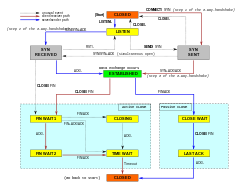
TCP protocol operations may be divided into three phases. Connection establishment is a multi-step handshake process that establishes a connection before entering the data transfer phase. After data transfer is completed, the connection termination closes the connection and releases all allocated resources.
A TCP connection is managed by an operating system through a resource that represents the local end-point for communications, the Internet socket. During the lifetime of a TCP connection, the local end-point undergoes a series of state changes:[14]
| State | Endpoint | Description |
|---|---|---|
| LISTEN | Server | Waiting for a connection request from any remote TCP end-point. |
| SYN-SENT | Client | Waiting for a matching connection request after having sent a connection request. |
| SYN-RECEIVED | Server | Waiting for a confirming connection request acknowledgment after having both received and sent a connection request. |
| ESTABLISHED | Server and client | An open connection, data received can be delivered to the user. The normal state for the data transfer phase of the connection. |
| FIN-WAIT-1 | Server and client | Waiting for a connection termination request from the remote TCP, or an acknowledgment of the connection termination request previously sent. |
| FIN-WAIT-2 | Server and client | Waiting for a connection termination request from the remote TCP. |
| CLOSE-WAIT | Server and client | Waiting for a connection termination request from the local user. |
| CLOSING | Server and client | Waiting for a connection termination request acknowledgment from the remote TCP. |
| LAST-ACK | Server and client | Waiting for an acknowledgment of the connection termination request previously sent to the remote TCP (which includes an acknowledgment of its connection termination request). |
| TIME-WAIT | Server or client | Waiting for enough time to pass to be sure that all remaining packets on the connection have expired. |
| CLOSED | Server and client | No connection state at all. |
Connection establishment[edit]
Before a client attempts to connect with a server, the server must first bind to and listen at a port to open it up for connections: this is called a passive open. Once the passive open is established, a client may establish a connection by initiating an active open using the three-way (or 3-step) handshake:
- SYN: The active open is performed by the client sending a SYN to the server. The client sets the segment’s sequence number to a random value A.
- SYN-ACK: In response, the server replies with a SYN-ACK. The acknowledgment number is set to one more than the received sequence number i.e. A+1, and the sequence number that the server chooses for the packet is another random number, B.
- ACK: Finally, the client sends an ACK back to the server. The sequence number is set to the received acknowledgment value i.e. A+1, and the acknowledgment number is set to one more than the received sequence number i.e. B+1.
Steps 1 and 2 establish and acknowledge the sequence number for one direction (client to server). Steps 2 and 3 establish and acknowledge the sequence number for the other direction (server to client). Following the completion of these steps, both the client and server have received acknowledgments and a full-duplex communication is established.
Connection termination[edit]

The connection termination phase uses a four-way handshake, with each side of the connection terminating independently. When an endpoint wishes to stop its half of the connection, it transmits a FIN packet, which the other end acknowledges with an ACK. Therefore, a typical tear-down requires a pair of FIN and ACK segments from each TCP endpoint. After the side that sent the first FIN has responded with the final ACK, it waits for a timeout before finally closing the connection, during which time the local port is unavailable for new connections; this state lets the TCP client resend the final acknowledgement to the server in case the ACK is lost in transit. The time duration is implementation-dependent, but some common values are 30 seconds, 1 minute, and 2 minutes. After the timeout, the client enters the CLOSED state and the local port becomes available for new connections.[15]
It is also possible to terminate the connection by a 3-way handshake, when host A sends a FIN and host B replies with a FIN & ACK (combining two steps into one) and host A replies with an ACK.[16]
Some operating systems, such as Linux and HP-UX,[citation needed] implement a half-duplex close sequence. If the host actively closes a connection, while still having unread incoming data available, the host sends the signal RST (losing any received data) instead of FIN. This assures that a TCP application is aware there was a data loss.[17]
A connection can be in a half-open state, in which case one side has terminated the connection, but the other has not. The side that has terminated can no longer send any data into the connection, but the other side can. The terminating side should continue reading the data until the other side terminates as well.[citation needed]
Resource usage[edit]
Most implementations allocate an entry in a table that maps a session to a running operating system process. Because TCP packets do not include a session identifier, both endpoints identify the session using the client’s address and port. Whenever a packet is received, the TCP implementation must perform a lookup on this table to find the destination process. Each entry in the table is known as a Transmission Control Block or TCB. It contains information about the endpoints (IP and port), status of the connection, running data about the packets that are being exchanged and buffers for sending and receiving data.
The number of sessions in the server side is limited only by memory and can grow as new connections arrive, but the client must allocate an ephemeral port before sending the first SYN to the server. This port remains allocated during the whole conversation and effectively limits the number of outgoing connections from each of the client’s IP addresses. If an application fails to properly close unrequired connections, a client can run out of resources and become unable to establish new TCP connections, even from other applications.
Both endpoints must also allocate space for unacknowledged packets and received (but unread) data.
Data transfer[edit]
The Transmission Control Protocol differs in several key features compared to the User Datagram Protocol:
- Ordered data transfer: the destination host rearranges segments according to a sequence number[6]
- Retransmission of lost packets: any cumulative stream not acknowledged is retransmitted[6]
- Error-free data transfer: corrupted packets are treated as lost and are retransmitted[18]
- Flow control: limits the rate a sender transfers data to guarantee reliable delivery. The receiver continually hints the sender on how much data can be received. When the receiving host’s buffer fills, the next acknowledgment suspends the transfer and allows the data in the buffer to be processed.[6]
- Congestion control: lost packets (presumed due to congestion) trigger a reduction in data delivery rate[6]
Reliable transmission[edit]
TCP uses a sequence number to identify each byte of data. The sequence number identifies the order of the bytes sent from each computer so that the data can be reconstructed in order, regardless of any out-of-order delivery that may occur. The sequence number of the first byte is chosen by the transmitter for the first packet, which is flagged SYN. This number can be arbitrary, and should, in fact, be unpredictable to defend against TCP sequence prediction attacks.
Acknowledgements (ACKs) are sent with a sequence number by the receiver of data to tell the sender that data has been received to the specified byte. ACKs do not imply that the data has been delivered to the application, they merely signify that it is now the receiver’s responsibility to deliver the data.
Reliability is achieved by the sender detecting lost data and retransmitting it. TCP uses two primary techniques to identify loss. Retransmission timeout (RTO) and duplicate cumulative acknowledgements (DupAcks).
When a TCP segment is retransmitted, it retains the same sequence number as the original delivery attempt. This conflation of delivery and logical data ordering means that, when acknowledgement is received after a retransmission, the sender cannot tell whether the original transmission or the retransmission is being acknowledged, the so-called retransmission ambiguity.[19] TCP incurs complexity due to retransmission ambiguity.[20]
Dupack-based retransmission[edit]
If a single segment (say segment number 100) in a stream is lost, then the receiver cannot acknowledge packets above that segment number (100) because it uses cumulative ACKs. Hence the receiver acknowledges packet 99 again on the receipt of another data packet. This duplicate acknowledgement is used as a signal for packet loss. That is, if the sender receives three duplicate acknowledgements, it retransmits the last unacknowledged packet. A threshold of three is used because the network may reorder segments causing duplicate acknowledgements. This threshold has been demonstrated to avoid spurious retransmissions due to reordering.[21] Some TCP implementations use selective acknowledgements (SACKs) to provide explicit feedback about the segments that have been received. This greatly improves TCP’s ability to retransmit the right segments.
Retransmission ambiguity can cause spurious fast retransmissions and congestion avoidance if there is reordering beyond the duplicate acknowledgement threshold.[22]
Timeout-based retransmission[edit]
When a sender transmits a segment, it initializes a timer with a conservative estimate of the arrival time of the acknowledgement. The segment is retransmitted if the timer expires, with a new timeout threshold of twice the previous value, resulting in exponential backoff behavior. Typically, the initial timer value is  , where
, where  is the clock granularity.[23]: 2 This guards against excessive transmission traffic due to faulty or malicious actors, such as man-in-the-middle denial of service attackers.
is the clock granularity.[23]: 2 This guards against excessive transmission traffic due to faulty or malicious actors, such as man-in-the-middle denial of service attackers.
Accurate RTT estimates are important for loss recovery, as it allows a sender to assume an unacknowledged packet to be lost after sufficient time elapses (i.e., determining the RTO time).[24] Retransmission ambiguity can lead a sender’s estimate of RTT to be imprecise.[24] In an environment with variable RTTs, spurious timeouts can occur:[25] if the RTT is under-estimated, then the RTO fires and triggers a needless retransmit and slow-start. After a spurious retransmission, when the acknowledgements for the original transmissions arrive, the sender may believe them to be acknowledging the retransmission and conclude, incorrectly, that segments sent between the original transmission and retransmission have been lost, causing further needless retransmissions to the extent that the link truly becomes congested;[26][27] selective acknowlegement can reduce this effect.[28] RFC 6298 specifies that implementations must not use retransmitted segments when estimating RTT.[29] Karn’s algorithm ensures that a good RTT estimate will be produced—eventually—by waiting until there is an unambiguous acknowledgement before adjusting the RTO.[30] After spurious retransmissions, however, it may take significant time before such an unambiguous acknowledgement arrives, degrading performance in the interim.[31] TCP timestamps also resolve the retransmission ambiguity problem in setting the RTO,[29] though they do not necessarily improve the RTT estimate.[32]
Error detection[edit]
Sequence numbers allow receivers to discard duplicate packets and properly sequence out-of-order packets. Acknowledgments allow senders to determine when to retransmit lost packets.
To assure correctness a checksum field is included; see § Checksum computation for details. The TCP checksum is a weak check by modern standards and is normally paired with a CRC integrity check at layer 2, below both TCP and IP, such as is used in PPP or the Ethernet frame. However, introduction of errors in packets between CRC-protected hops is common and the 16-bit TCP checksum catches most of these.[33]
Flow control[edit]
TCP uses an end-to-end flow control protocol to avoid having the sender send data too fast for the TCP receiver to receive and process it reliably. Having a mechanism for flow control is essential in an environment where machines of diverse network speeds communicate. For example, if a PC sends data to a smartphone that is slowly processing received data, the smartphone must be able to regulate the data flow so as not to be overwhelmed.[6]
TCP uses a sliding window flow control protocol. In each TCP segment, the receiver specifies in the receive window field the amount of additionally received data (in bytes) that it is willing to buffer for the connection. The sending host can send only up to that amount of data before it must wait for an acknowledgement and receive window update from the receiving host.

When a receiver advertises a window size of 0, the sender stops sending data and starts its persist timer. The persist timer is used to protect TCP from a deadlock situation that could arise if a subsequent window size update from the receiver is lost, and the sender cannot send more data until receiving a new window size update from the receiver. When the persist timer expires, the TCP sender attempts recovery by sending a small packet so that the receiver responds by sending another acknowledgement containing the new window size.
If a receiver is processing incoming data in small increments, it may repeatedly advertise a small receive window. This is referred to as the silly window syndrome, since it is inefficient to send only a few bytes of data in a TCP segment, given the relatively large overhead of the TCP header.
Congestion control[edit]
The final main aspect of TCP is congestion control. TCP uses a number of mechanisms to achieve high performance and avoid congestive collapse, a gridlock situation where network performance is severely degraded. These mechanisms control the rate of data entering the network, keeping the data flow below a rate that would trigger collapse. They also yield an approximately max-min fair allocation between flows.
Acknowledgments for data sent, or the lack of acknowledgments, are used by senders to infer network conditions between the TCP sender and receiver. Coupled with timers, TCP senders and receivers can alter the behavior of the flow of data. This is more generally referred to as congestion control or congestion avoidance.
Modern implementations of TCP contain four intertwined algorithms: slow start, congestion avoidance, fast retransmit, and fast recovery.[34]
In addition, senders employ a retransmission timeout (RTO) that is based on the estimated round-trip time (RTT) between the sender and receiver, as well as the variance in this round-trip time.[23] There are subtleties in the estimation of RTT. For example, senders must be careful when calculating RTT samples for retransmitted packets; typically they use Karn’s Algorithm or TCP timestamps.[11] These individual RTT samples are then averaged over time to create a smoothed round trip time (SRTT) using Jacobson’s algorithm. This SRTT value is what is used as the round-trip time estimate.
Enhancing TCP to reliably handle loss, minimize errors, manage congestion and go fast in very high-speed environments are ongoing areas of research and standards development. As a result, there are a number of TCP congestion avoidance algorithm variations.
Maximum segment size[edit]
The maximum segment size (MSS) is the largest amount of data, specified in bytes, that TCP is willing to receive in a single segment. For best performance, the MSS should be set small enough to avoid IP fragmentation, which can lead to packet loss and excessive retransmissions. To accomplish this, typically the MSS is announced by each side using the MSS option when the TCP connection is established. The option value is derived from the maximum transmission unit (MTU) size of the data link layer of the networks to which the sender and receiver are directly attached. TCP senders can use path MTU discovery to infer the minimum MTU along the network path between the sender and receiver, and use this to dynamically adjust the MSS to avoid IP fragmentation within the network.
MSS announcement may also be called MSS negotiation but, strictly speaking, the MSS is not negotiated. Two completely independent values of MSS are permitted for the two directions of data flow in a TCP connection,[35][9] so there is no need to agree on a common MSS configuration for a bidirectional connection.
Selective acknowledgments[edit]
Relying purely on the cumulative acknowledgment scheme employed by the original TCP can lead to inefficiencies when packets are lost. For example, suppose bytes with sequence number 1,000 to 10,999 are sent in 10 different TCP segments of equal size, and the second segment (sequence numbers 2,000 to 2,999) is lost during transmission. In a pure cumulative acknowledgment protocol, the receiver can only send a cumulative ACK value of 2,000 (the sequence number immediately following the last sequence number of the received data) and cannot say that it received bytes 3,000 to 10,999 successfully. Thus the sender may then have to resend all data starting with sequence number 2,000.
To alleviate this issue TCP employs the selective acknowledgment (SACK) option, defined in 1996 in RFC 2018, which allows the receiver to acknowledge discontinuous blocks of packets that were received correctly, in addition to the sequence number immediately following the last sequence number of the last contiguous byte received successively, as in the basic TCP acknowledgment. The acknowledgment can include a number of SACK blocks, where each SACK block is conveyed by the Left Edge of Block (the first sequence number of the block) and the Right Edge of Block (the sequence number immediately following the last sequence number of the block), with a Block being a contiguous range that the receiver correctly received. In the example above, the receiver would send an ACK segment with a cumulative ACK value of 2,000 and a SACK option header with sequence numbers 3,000 and 11,000. The sender would accordingly retransmit only the second segment with sequence numbers 2,000 to 2,999.
A TCP sender may interpret an out-of-order segment delivery as a lost segment. If it does so, the TCP sender will retransmit the segment previous to the out-of-order packet and slow its data delivery rate for that connection. The duplicate-SACK option, an extension to the SACK option that was defined in May 2000 in RFC 2883, solves this problem. The TCP receiver sends a D-ACK to indicate that no segments were lost, and the TCP sender can then reinstate the higher transmission rate.
The SACK option is not mandatory and comes into operation only if both parties support it. This is negotiated when a connection is established. SACK uses a TCP header option (see § TCP segment structure for details). The use of SACK has become widespread—all popular TCP stacks support it. Selective acknowledgment is also used in Stream Control Transmission Protocol (SCTP).
Selective acknowledgements can be ‘reneged’, where the receiver unilaterally discards the selectively acknowledged data. RFC 2018 discouraged such behaviour, but did not prohibit it to allow receivers the option of reneging if they, for example, ran out of buffer space.[36] The possibility of reneging leads to implementation complexity for both senders and receivers, and also imposes memory costs on the sender.[37]
Window scaling[edit]
For more efficient use of high-bandwidth networks, a larger TCP window size may be used. A 16-bit TCP window size field controls the flow of data and its value is limited to 65,535 bytes. Since the size field cannot be expanded beyond this limit, a scaling factor is used. The TCP window scale option, as defined in RFC 1323, is an option used to increase the maximum window size to 1 gigabyte. Scaling up to these larger window sizes is necessary for TCP tuning.
The window scale option is used only during the TCP 3-way handshake. The window scale value represents the number of bits to left-shift the 16-bit window size field when interpreting it. The window scale value can be set from 0 (no shift) to 14 for each direction independently. Both sides must send the option in their SYN segments to enable window scaling in either direction.
Some routers and packet firewalls rewrite the window scaling factor during a transmission. This causes sending and receiving sides to assume different TCP window sizes. The result is non-stable traffic that may be very slow. The problem is visible on some sites behind a defective router.[38]
TCP timestamps[edit]
TCP timestamps, defined in RFC 1323 in 1992, can help TCP determine in which order packets were sent. TCP timestamps are not normally aligned to the system clock and start at some random value. Many operating systems will increment the timestamp for every elapsed millisecond; however, the RFC only states that the ticks should be proportional.
There are two timestamp fields:
- a 4-byte sender timestamp value (my timestamp)
- a 4-byte echo reply timestamp value (the most recent timestamp received from you).
TCP timestamps are used in an algorithm known as Protection Against Wrapped Sequence numbers, or PAWS. PAWS is used when the receive window crosses the sequence number wraparound boundary. In the case where a packet was potentially retransmitted, it answers the question: «Is this sequence number in the first 4 GB or the second?» And the timestamp is used to break the tie.
Also, the Eifel detection algorithm uses TCP timestamps to determine if retransmissions are occurring because packets are lost or simply out of order.[39]
TCP timestamps are enabled by default in Linux,[40] and disabled by default in Windows Server 2008, 2012 and 2016.[41]
Recent Statistics show that the level of TCP timestamp adoption has stagnated, at ~40%, owing to Windows Server dropping support since Windows Server 2008.[42]
Out-of-band data[edit]
It is possible to interrupt or abort the queued stream instead of waiting for the stream to finish. This is done by specifying the data as urgent. This marks the transmission as out-of-band data (OOB) and tells the receiving program to process it immediately. When finished, TCP informs the application and resumes the stream queue. An example is when TCP is used for a remote login session where the user can send a keyboard sequence that interrupts or aborts the remotely-running program without waiting for the program to finish its current transfer.[6]
The urgent pointer only alters the processing on the remote host and doesn’t expedite any processing on the network itself. The capability is implemented differently or poorly on different systems or may not be supported. Where it is available, it is prudent to assume only single bytes of OOB data will be reliably handled.[43][44] Since the feature is not frequently used, it is not well tested on some platforms and has been associated with vulnerabilities, WinNuke for instance.
Forcing data delivery[edit]
Normally, TCP waits for 200 ms for a full packet of data to send (Nagle’s Algorithm tries to group small messages into a single packet). This wait creates small, but potentially serious delays if repeated constantly during a file transfer. For example, a typical send block would be 4 KB, a typical MSS is 1460, so 2 packets go out on a 10 Mbit/s Ethernet taking ~1.2 ms each followed by a third carrying the remaining 1176 after a 197 ms pause because TCP is waiting for a full buffer. In the case of telnet, each user keystroke is echoed back by the server before the user can see it on the screen. This delay would become very annoying.
Setting the socket option TCP_NODELAY overrides the default 200 ms send delay. Application programs use this socket option to force output to be sent after writing a character or line of characters.
The RFC defines the PSH push bit as «a message to the receiving TCP stack to send this data immediately up to the receiving application».[6] There is no way to indicate or control it in user space using Berkeley sockets; it is controlled by the protocol stack only.[45]
Vulnerabilities[edit]
TCP may be attacked in a variety of ways. The results of a thorough security assessment of TCP, along with possible mitigations for the identified issues, were published in 2009,[46] and was pursued within the IETF through 2012.[47] Notable vulnerabilities include denial of service, connection hijacking, TCP veto and TCP reset attack.
Denial of service[edit]
By using a spoofed IP address and repeatedly sending purposely assembled SYN packets, followed by many ACK packets, attackers can cause the server to consume large amounts of resources keeping track of the bogus connections. This is known as a SYN flood attack. Proposed solutions to this problem include SYN cookies and cryptographic puzzles, though SYN cookies come with their own set of vulnerabilities.[48] Sockstress is a similar attack, that might be mitigated with system resource management.[49] An advanced DoS attack involving the exploitation of the TCP persist timer was analyzed in Phrack #66.[50] PUSH and ACK floods are other variants.[51]
Connection hijacking[edit]
An attacker who is able to eavesdrop on a TCP session and redirect packets can hijack a TCP connection. To do so, the attacker learns the sequence number from the ongoing communication and forges a false segment that looks like the next segment in the stream. A simple hijack can result in one packet being erroneously accepted at one end. When the receiving host acknowledges the false segment, synchronization is lost.[52] Hijacking may be combined with ARP spoofing or other routing attacks that allow an attacker to take permanent control of the TCP connection.
Impersonating a different IP address was not difficult prior to RFC 1948 when the initial sequence number was easily guessable. The earlier implementations allowed an attacker to blindly send a sequence of packets that the receiver would believe came from a different IP address, without the need to intercept communication through ARP or routing attacks: it is enough to ensure that the legitimate host of the impersonated IP address is down, or bring it to that condition using denial-of-service attacks. This is why the initial sequence number is now chosen at random.
TCP veto[edit]
An attacker who can eavesdrop and predict the size of the next packet to be sent can cause the receiver to accept a malicious payload without disrupting the existing connection. The attacker injects a malicious packet with the sequence number and a payload size of the next expected packet. When the legitimate packet is ultimately received, it is found to have the same sequence number and length as a packet already received and is silently dropped as a normal duplicate packet—the legitimate packet is vetoed by the malicious packet. Unlike in connection hijacking, the connection is never desynchronized and communication continues as normal after the malicious payload is accepted. TCP veto gives the attacker less control over the communication but makes the attack particularly resistant to detection. The only evidence to the receiver that something is amiss is a single duplicate packet, a normal occurrence in an IP network. The sender of the vetoed packet never sees any evidence of an attack.[53]
TCP ports[edit]
A TCP connection is identified by a four-tuple of the source address, source port, destination address, and destination port (or, equivalently, a pair of network sockets for the source and destination, each of which is made up of an address and a port).[54][55] Port numbers are used to identify different services, and to allow multiple connections between hosts to be multiplexed.[56] TCP uses 16-bit port numbers, providing a space of 65,536 possible values for each of the source and destination ports. The dependency of connection identity on addresses means that TCP connections are bound to a single network path; TCP cannot utilise other routes that multihomed hosts have available, and connections break if an endpoint’s address changes.[58]
Port numbers are categorized into three basic categories: well-known, registered, and dynamic/private. The well-known ports are assigned by the Internet Assigned Numbers Authority (IANA) and are typically used by system-level or root processes. Well-known applications running as servers and passively listening for connections typically use these ports. Some examples include: FTP (20 and 21), SSH (22), TELNET (23), SMTP (25), HTTP over SSL/TLS (443), and HTTP (80). Note, as of the latest standard, HTTP/3, QUIC is used as a transport instead of TCP. Registered ports are typically used by end user applications as ephemeral source ports when contacting servers, but they can also identify named services that have been registered by a third party. Dynamic/private ports can also be used by end user applications, but are less commonly so. Dynamic/private ports do not contain any meaning outside of any particular TCP connection.
Network Address Translation (NAT), typically uses dynamic port numbers, on the («Internet-facing») public side, to disambiguate the flow of traffic that is passing between a public network and a private subnetwork, thereby allowing many IP addresses (and their ports) on the subnet to be serviced by a single public-facing address.
Development[edit]
TCP is a complex protocol. However, while significant enhancements have been made and proposed over the years, its most basic operation has not changed significantly since its first specification RFC 675 in 1974, and the v4 specification RFC 793, published in September 1981. RFC 1122, Host Requirements for Internet Hosts, clarified a number of TCP protocol implementation requirements. A list of the 8 required specifications and over 20 strongly encouraged enhancements is available in RFC 7414. Among this list is RFC 2581, TCP Congestion Control, one of the most important TCP-related RFCs in recent years, describes updated algorithms that avoid undue congestion. In 2001, RFC 3168 was written to describe Explicit Congestion Notification (ECN), a congestion avoidance signaling mechanism.
The original TCP congestion avoidance algorithm was known as «TCP Tahoe», but many alternative algorithms have since been proposed (including TCP Reno, TCP Vegas, FAST TCP, TCP New Reno, and TCP Hybla).
TCP Interactive (iTCP) [59] is a research effort into TCP extensions that allows applications to subscribe to TCP events and register handler components that can launch applications for various purposes, including application-assisted congestion control.
Multipath TCP (MPTCP) [60][61] is an ongoing effort within the IETF that aims at allowing a TCP connection to use multiple paths to maximize resource usage and increase redundancy. The redundancy offered by Multipath TCP in the context of wireless networks enables the simultaneous utilization of different networks, which brings higher throughput and better handover capabilities. Multipath TCP also brings performance benefits in datacenter environments.[62] The reference implementation[63] of Multipath TCP is being developed in the Linux kernel.[64] Multipath TCP is used to support the Siri voice recognition application on iPhones, iPads and Macs [65]
tcpcrypt is an extension proposed in July 2010 to provide transport-level encryption directly in TCP itself. It is designed to work transparently and not require any configuration. Unlike TLS (SSL), tcpcrypt itself does not provide authentication, but provides simple primitives down to the application to do that. As of 2010, the first tcpcrypt IETF draft has been published and implementations exist for several major platforms.
TCP Fast Open is an extension to speed up the opening of successive TCP connections between two endpoints. It works by skipping the three-way handshake using a cryptographic «cookie». It is similar to an earlier proposal called T/TCP, which was not widely adopted due to security issues.[66] TCP Fast Open was published as RFC 7413 in 2014.[67]
Proposed in May 2013, Proportional Rate Reduction (PRR) is a TCP extension developed by Google engineers. PRR ensures that the TCP window size after recovery is as close to the slow start threshold as possible.[68] The algorithm is designed to improve the speed of recovery and is the default congestion control algorithm in Linux 3.2+ kernels.[69]
Deprecated proposals[edit]
TCP Cookie Transactions (TCPCT) is an extension proposed in December 2009[70] to secure servers against denial-of-service attacks. Unlike SYN cookies, TCPCT does not conflict with other TCP extensions such as window scaling. TCPCT was designed due to necessities of DNSSEC, where servers have to handle large numbers of short-lived TCP connections. In 2016, TCPCT was deprecated in favor of TCP Fast Open. Status of the original RFC was changed to «historic».[71]
Hardware implementations[edit]
One way to overcome the processing power requirements of TCP is to build hardware implementations of it, widely known as TCP offload engines (TOE). The main problem of TOEs is that they are hard to integrate into computing systems, requiring extensive changes in the operating system of the computer or device. One company to develop such a device was Alacritech.
Wire image and ossification[edit]
The wire image of TCP provides significant information-gathering and modification opportunities to on-path observers, as the protocol metadata is transmitted in cleartext.[72][73] While this transparency is useful to network operators and researchers,[75] information gathered from protocol metadata may reduce the end-user’s privacy.[76] This visibility and malleability of metadata has led to TCP being difficult to extend—a case of protocol ossification—as any intermediate node (a ‘middlebox’) can make decisions based on that metadata or even modify it,[77][78] breaking the end-to-end principle.[79] One measurement found that a third of paths across the Internet encounter at least one intermediary that modifies TCP metadata, and 6.5% of paths encounter harmful ossifying effects from intermediaries.[80] Avoiding extensibility hazards from intermediaries placed significant constraints on the design of MPTCP,[81][82] and difficulties caused by intermediaries have hindered the deployment of TCP Fast Open in web browsers.[83] Another source of ossification is the difficulty of modification of TCP functions at the endpoints, typically in the operating system kernel[84] or in hardware with a TCP offload engine.[85]
Performance[edit]
As TCP provides applications with the abstraction of a reliable byte stream, it can suffer from head-of-line blocking: if packets are reordered or lost and need to be retransmitted (and thus arrive out-of-order), data from sequentially later parts of the stream may be received before sequentially earlier parts of the stream; however, the later data cannot typically be used until the earlier data has been received, incurring network latency. If multiple independent higher-level messages are encapsulated and multiplexed onto a single TCP connection, then head-of-line blocking can cause processing of a fully-received message that was sent later to wait for delivery of a message that was sent earlier.[86] Web browsers attempt to mitigate head-of-line blocking by opening multiple parallel connections. This incurs the cost of connection establishment repeatedly, as well as multiplying the resources needed to track those connections at the endpoints.[87] Parallel connections also have congestion control operating independently of each other, rather than being able to pool information together and respond more promptly to observed network conditions;[88] TCP’s aggressive initial sending patterns can cause congestion if multiple parallel connections are opened; and the per-connection fairness model leads to a monopolisation of resources by applications that take this approach.[89]
Connection establishment is a major contributor to latency as experienced by Web users.[90][91] TCP’s three-way handshake introduces one RTT of latency during connection establishment before data can be sent.[91] For short flows, these delays are very significant.[92] Transport Layer Security (TLS) requires a handshake of its own for key exchange at connection establishment. Because of the layered design, the TCP handshake and the TLS handshake proceed serially: the TLS handshake cannot begin until the TCP handshake has concluded.[93] Two RTTs are required for connection establishment with TLS 1.3 over TCP.[94] TLS 1.3 allows for zero RTT connection resumption in some circumstances, but, when layered over TCP, one RTT is still required for the TCP handshake, and this cannot assist the initial connection; zero RTT handshakes also present cryptographic challenges, as efficient, replay-safe and forward secure non-interactive key exchange is an open research topic.[95] TCP Fast Open allows the transmission of data in the initial (i.e, SYN and SYN-ACK) packets, removing one RTT of latency during connection establishment.[96] However, TCP Fast Open has been difficult to deploy due to protocol ossification; in 2020, no Web browsers used it by default.[83]
TCP throughput is affected by packet reordering. Reordered packets can cause duplicate acknowledgements to be sent, which, if they cross the threshold, will then trigger a spurious retransmission and congestion control. Transmission behaviour can also become less smooth and more bursty, as large ranges are acknowledged all at once when a reordered packet at the range’s start is received (in a similar manner to how head-of-line blocking affects applications).[97] Blanton & Allman (2002) found that throughput was inversely related to the amount of reordering, up to a limit where all reordering triggers spurious retransmission.[98] Mitigating reordering depends on a sender’s ability to determine that it has sent a spurious retransmission, and hence on resolving retransmission ambiguity.[99] Reducing reordering-induced spurious retransmissions trades off against speedy recovery from genuine loss.[100]
Selective acknowledgement can provide a significant benefit to throughput; Bruyeron, Hemon & Zhang (1998) measured gains of up to 45%.[101] An important factor in the improvement is that selective acknowledgement can more often avoid going into slow start after a loss and can hence better utilise available bandwidth.[102] However, TCP can only selectively acknowledge a maximum of three blocks of sequence numbers. This can limit the retransmission rate and hence loss recovery or cause needless retransmissions, especially in high-loss environments.[103][104]
TCP was originally designed for wired networks. Packet loss is considered to be the result of network congestion and the congestion window size is reduced dramatically as a precaution. However, wireless links are known to experience sporadic and usually temporary losses due to fading, shadowing, hand off, interference, and other radio effects, that are not strictly congestion. After the (erroneous) back-off of the congestion window size, due to wireless packet loss, there may be a congestion avoidance phase with a conservative decrease in window size. This causes the radio link to be underutilized. Extensive research on combating these harmful effects has been conducted. Suggested solutions can be categorized as end-to-end solutions, which require modifications at the client or server,[105] link layer solutions, such as Radio Link Protocol (RLP) in cellular networks, or proxy-based solutions which require some changes in the network without modifying end nodes.[105][106]
A number of alternative congestion control algorithms, such as Vegas, Westwood, Veno, and Santa Cruz, have been proposed to help solve the wireless problem.[citation needed]
Acceleration[edit]
The idea of a TCP accelerator is to terminate TCP connections inside the network processor and then relay the data to a second connection toward the end system. The data packets that originate from the sender are buffered at the accelerator node, which is responsible for performing local retransmissions in the event of packet loss. Thus, in case of losses, the feedback loop between the sender and the receiver is shortened to the one between the acceleration node and the receiver which guarantees a faster delivery of data to the receiver.
Since TCP is a rate-adaptive protocol, the rate at which the TCP sender injects
packets into the network is directly proportional to the prevailing load condition within the network as well as the processing capacity of the receiver. The prevalent conditions within the network are judged by the sender on the basis of the acknowledgments received by it. The acceleration node splits the feedback loop between the sender and the receiver and thus guarantees a shorter round trip time (RTT) per packet. A shorter RTT is beneficial as it ensures a quicker response time to any changes in the network and a faster adaptation by the sender to combat these changes.
Disadvantages of the method include the fact that the TCP session has to be directed through the accelerator; this means that if routing changes, so that the accelerator is no longer in the path, the connection will be broken. It also destroys the end-to-end property of the TCP ack mechanism; when the ACK is received by the sender, the packet has been stored by the accelerator, not delivered to the receiver.
Debugging[edit]
A packet sniffer, which intercepts TCP traffic on a network link, can be useful in debugging networks, network stacks, and applications that use TCP by showing the user what packets are passing through a link. Some networking stacks support the SO_DEBUG socket option, which can be enabled on the socket using setsockopt. That option dumps all the packets, TCP states, and events on that socket, which is helpful in debugging. Netstat is another utility that can be used for debugging.
Alternatives[edit]
For many applications TCP is not appropriate. One problem (at least with normal implementations) is that the application cannot access the packets coming after a lost packet until the retransmitted copy of the lost packet is received. This causes problems for real-time applications such as streaming media, real-time multiplayer games and voice over IP (VoIP) where it is generally more useful to get most of the data in a timely fashion than it is to get all of the data in order.
For historical and performance reasons, most storage area networks (SANs) use Fibre Channel Protocol (FCP) over Fibre Channel connections.
Also, for embedded systems, network booting, and servers that serve simple requests from huge numbers of clients (e.g. DNS servers) the complexity of TCP can be a problem. Finally, some tricks such as transmitting data between two hosts that are both behind NAT (using STUN or similar systems) are far simpler without a relatively complex protocol like TCP in the way.
Generally, where TCP is unsuitable, the User Datagram Protocol (UDP) is used. This provides the application multiplexing and checksums that TCP does, but does not handle streams or retransmission, giving the application developer the ability to code them in a way suitable for the situation, or to replace them with other methods like forward error correction or interpolation.
Stream Control Transmission Protocol (SCTP) is another protocol that provides reliable stream oriented services similar to TCP. It is newer and considerably more complex than TCP, and has not yet seen widespread deployment. However, it is especially designed to be used in situations where reliability and near-real-time considerations are important.
Venturi Transport Protocol (VTP) is a patented proprietary protocol that is designed to replace TCP transparently to overcome perceived inefficiencies related to wireless data transport.
TCP also has issues in high-bandwidth environments. The TCP congestion avoidance algorithm works very well for ad-hoc environments where the data sender is not known in advance. If the environment is predictable, a timing based protocol such as Asynchronous Transfer Mode (ATM) can avoid TCP’s retransmits overhead.
UDP-based Data Transfer Protocol (UDT) has better efficiency and fairness than TCP in networks that have high bandwidth-delay product.[107]
Multipurpose Transaction Protocol (MTP/IP) is patented proprietary software that is designed to adaptively achieve high throughput and transaction performance in a wide variety of network conditions, particularly those where TCP is perceived to be inefficient.
Checksum computation[edit]
TCP checksum for IPv4[edit]
When TCP runs over IPv4, the method used to compute the checksum is defined as follows:[9]
The checksum field is the 16-bit ones’ complement of the ones’ complement sum of all 16-bit words in the header and text. The checksum computation needs to ensure the 16-bit alignment of the data being summed. If a segment contains an odd number of header and text octets, alignment can be achieved by padding the last octet with zeros on its right to form a 16-bit word for checksum purposes. The pad is not transmitted as part of the segment. While computing the checksum, the checksum field itself is replaced with zeros.
In other words, after appropriate padding, all 16-bit words are added using ones’ complement arithmetic. The sum is then bitwise complemented and inserted as the checksum field. A pseudo-header that mimics the IPv4 packet header used in the checksum computation is shown in the table below.
| Bit offset | 0–3 | 4–7 | 8–15 | 16–31 |
|---|---|---|---|---|
| 0 | Source address | |||
| 32 | Destination address | |||
| 64 | Zeros | Protocol | TCP length | |
| 96 | Source port | Destination port | ||
| 128 | Sequence number | |||
| 160 | Acknowledgement number | |||
| 192 | Data offset | Reserved | Flags | Window |
| 224 | Checksum | Urgent pointer | ||
| 256 | Options (optional) | |||
| 256/288+ | Data |
The source and destination addresses are those of the IPv4 header. The protocol value is 6 for TCP (cf. List of IP protocol numbers). The TCP length field is the length of the TCP header and data (measured in octets).
TCP checksum for IPv6[edit]
When TCP runs over IPv6, the method used to compute the checksum is changed:[108]
Any transport or other upper-layer protocol that includes the addresses from the IP header in its checksum computation must be modified for use over IPv6, to include the 128-bit IPv6 addresses instead of 32-bit IPv4 addresses.
A pseudo-header that mimics the IPv6 header for computation of the checksum is shown below.
| Bit offset | 0–7 | 8–15 | 16–23 | 24–31 |
|---|---|---|---|---|
| 0 | Source address | |||
| 32 | ||||
| 64 | ||||
| 96 | ||||
| 128 | Destination address | |||
| 160 | ||||
| 192 | ||||
| 224 | ||||
| 256 | TCP length | |||
| 288 | Zeros | Next header = Protocol |
||
| 320 | Source port | Destination port | ||
| 352 | Sequence number | |||
| 384 | Acknowledgement number | |||
| 416 | Data offset | Reserved | Flags | Window |
| 448 | Checksum | Urgent pointer | ||
| 480 | Options (optional) | |||
| 480/512+ | Data |
- Source address: the one in the IPv6 header
- Destination address: the final destination; if the IPv6 packet doesn’t contain a Routing header, TCP uses the destination address in the IPv6 header, otherwise, at the originating node, it uses the address in the last element of the Routing header, and, at the receiving node, it uses the destination address in the IPv6 header.
- TCP length: the length of the TCP header and data
- Next Header: the protocol value for TCP
Checksum offload [edit]
Many TCP/IP software stack implementations provide options to use hardware assistance to automatically compute the checksum in the network adapter prior to transmission onto the network or upon reception from the network for validation. This may relieve the OS from using precious CPU cycles calculating the checksum. Hence, overall network performance is increased.
This feature may cause packet analyzers that are unaware or uncertain about the use of checksum offload to report invalid checksums in outbound packets that have not yet reached the network adapter.[109] This will only occur for packets that are intercepted before being transmitted by the network adapter; all packets transmitted by the network adaptor on the wire will have valid checksums.[110] This issue can also occur when monitoring packets being transmitted between virtual machines on the same host, where a virtual device driver may omit the checksum calculation (as an optimization), knowing that the checksum will be calculated later by the VM host kernel or its physical hardware.
RFC documents[edit]
- RFC 675 – Specification of Internet Transmission Control Program, December 1974 Version
- RFC 793 – TCP v4
- RFC 1122 – includes some error corrections for TCP
- RFC 1323 – TCP Extensions for High Performance [Obsoleted by RFC 7323]
- RFC 1379 – Extending TCP for Transactions—Concepts [Obsoleted by RFC 6247]
- RFC 1948 – Defending Against Sequence Number Attacks
- RFC 2018 – TCP Selective Acknowledgment Options
- RFC 5681 – TCP Congestion Control
- RFC 6247 – Moving the Undeployed TCP Extensions RFC 1072, 1106, 1110, 1145, 1146, 1379, 1644 and 1693 to Historic Status
- RFC 6298 – Computing TCP’s Retransmission Timer
- RFC 6824 – TCP Extensions for Multipath Operation with Multiple Addresses
- RFC 7323 – TCP Extensions for High Performance
- RFC 7414 – A Roadmap for TCP Specification Documents
- RFC 9293 – Transmission Control Protocol (TCP)
See also[edit]
- Connection-oriented communication
- List of TCP and UDP port numbers (a long list of ports and services)
- Micro-bursting (networking)
- T/TCP variant of TCP
- TCP global synchronization
- TCP pacing
- Transport layer § Comparison of transport layer protocols
- WTCP a proxy-based modification of TCP for wireless networks
Notes[edit]
- ^ a b Added to header by RFC 3168
- ^ Windows size units are, by default, bytes.
- ^ Window size is relative to the segment identified by the sequence number in the acknowledgment field.
References[edit]
- ^ Vinton G. Cerf; Robert E. Kahn (May 1974). «A Protocol for Packet Network Intercommunication» (PDF). IEEE Transactions on Communications. 22 (5): 637–648. doi:10.1109/tcom.1974.1092259. Archived from the original (PDF) on March 4, 2016.
- ^ Bennett, Richard (September 2009). «Designed for Change: End-to-End Arguments, Internet Innovation, and the Net Neutrality Debate» (PDF). Information Technology and Innovation Foundation. p. 11. Archived (PDF) from the original on 29 August 2019. Retrieved 11 September 2017.
- ^ V. Cerf; Y. Dalal; C. Sunshine (December 1974). SPECIFICATION OF INTERNET TRANSMISSION CONTROL PROGRAM. Network Working Group. doi:10.17487/RFC0675. RFC 675. Obsolete. Obsoleted by RFC 7805. NIC 2. INWG 72.
- ^ «Robert E Kahn — A.M. Turing Award Laureate». amturing.acm.org. Archived from the original on 2019-07-13. Retrieved 2019-07-13.
- ^ «Vinton Cerf — A.M. Turing Award Laureate». amturing.acm.org. Archived from the original on 2021-10-11. Retrieved 2019-07-13.
- ^ a b c d e f g h i Comer, Douglas E. (2006). Internetworking with TCP/IP: Principles, Protocols, and Architecture. Vol. 1 (5th ed.). Prentice Hall. ISBN 978-0-13-187671-2.
- ^ «TCP (Transmission Control Protocol)». Archived from the original on 2013-04-07. Retrieved 2019-06-26.
- ^ J. Postel, ed. (September 1981). INTERNET PROTOCOL — DARPA INTERNET PROGRAM PROTOCOL SPECIFICATION. IETF. doi:10.17487/RFC0791. STD 5. RFC 791. IEN 128, 123, 111, 80, 54, 44, 41, 28, 26. Internet Standard. Obsoletes RFC 760. Updated by RFC 1349, 2474 and 6864.
- ^ a b c d W. Eddy, ed. (August 2022). Transmission Control Protocol (TCP). Internet Engineering Task Force. doi:10.17487/RFC9293. ISSN 2070-1721. STD 7. RFC 9293. Internet Standard. Obsoletes RFC 793, 879, 2873, 6093, 6429, 6528 and 6691. Updates RFC 1011, 1122 and 5961.
- ^ «Change RFC 3540 «Robust Explicit Congestion Notification (ECN) Signaling with Nonces» to Historic». datatracker.ietf.org. Retrieved 2023-04-18.
- ^ a b c D. Borman; B. Braden; V. Jacobson (September 2014). R. Scheffenegger (ed.). TCP Extensions for High Performance. Internet Engineering Task Force. doi:10.17487/RFC7323. ISSN 2070-1721. RFC 7323. Proposed Standard. Obsoletes RFC 1323.
- ^ a b S. Floyd; J. Mahdavi; M. Mathis; A. Romanow (October 1996). TCP Selective Acknowledgment Options. IETF TCP Large Windows workgroup. doi:10.17487/RFC2018. RFC 2018. Proposed Standard. Obsoletes RFC 1072.
- ^ «Transmission Control Protocol (TCP) Parameters: TCP Option Kind Numbers». IANA. Archived from the original on 2017-10-02. Retrieved 2017-10-19.
- ^ W. Eddy, ed. (August 2022). Transmission Control Protocol (TCP). Internet Engineering Task Force. doi:10.17487/RFC9293. ISSN 2070-1721. STD 7. RFC 9293. Internet Standard. sec. 3.3.2.
- ^ Kurose, James F. (2017). Computer networking : a top-down approach. Keith W. Ross (7th ed.). Harlow, England. p. 286. ISBN 978-0-13-359414-0. OCLC 936004518.
{{cite book}}: CS1 maint: location missing publisher (link) - ^ Tanenbaum, Andrew S. (2003-03-17). Computer Networks (Fourth ed.). Prentice Hall. ISBN 978-0-13-066102-9.
- ^ R. Braden, ed. (October 1989). Requirements for Internet Hosts — Communication Layers. Network Working Group. doi:10.17487/RFC1122. STD 3. RFC 1122. Internet Standard. sec. 4.2.2.13.
- ^ «TCP Definition». Archived from the original on 2020-05-06. Retrieved 2011-03-12.
- ^ Karn & Partridge 1991, p. 364.
- ^ Iyengar & Swett 2021, 4.2. Monotonically Increasing Packet Numbers.
- ^ Mathis; Mathew; Semke; Mahdavi; Ott (1997). «The macroscopic behavior of the TCP congestion avoidance algorithm». ACM SIGCOMM Computer Communication Review. 27 (3): 67–82. CiteSeerX 10.1.1.40.7002. doi:10.1145/263932.264023. S2CID 1894993.
- ^ Ludwig & Meyer 2003, p. 4.
- ^ a b V. Paxson; M. Allman; J. Chu; M. Sargent (June 2011). Computing TCP’s Retransmission Timer. Internet Engineering Task Force. doi:10.17487/RFC6298. ISSN 2070-1721. RFC 6298. Proposed Standard. Obsoletes RFC 2988. Updates RFC 1122.
- ^ a b Zhang 1986, p. 399.
- ^ Karn & Partridge 1991, p. 365.
- ^ Ludwig & Katz 2000, p. 31-33.
- ^ Gurtov & Ludwig 2003, p. 2.
- ^ Gurtov & Floyd 2004, p. 1.
- ^ a b Paxson et al. 2011, p. 4.
- ^ Karn & Partridge 1991, p. 370-372.
- ^ Allman & Paxson 1999, p. 268.
- ^ Borman, Braden & Jacobson 2014, p. 7.
- ^ Stone; Partridge (2000). «When the CRC and TCP checksum disagree». Proceedings of the conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. pp. 309–319. CiteSeerX 10.1.1.27.7611. doi:10.1145/347059.347561. ISBN 978-1581132236. S2CID 9547018. Archived from the original on 2008-05-05. Retrieved 2008-04-28.
- ^ M. Allman; V. Paxson; E. Blanton (September 2009). TCP Congestion Control. IETF. doi:10.17487/RFC5681. RFC 5681. Draft Standard. Obsoletes RFC 2581.
- ^ R. Braden, ed. (October 1989). Requirements for Internet Hosts — Communication Layers. Network Working Group. doi:10.17487/RFC1122. STD 3. RFC 1122. Internet Standard. Updated by RFC 1349, 4379, 5884, 6093, 6298, 6633, 6864, 8029 and 9293.
- ^ Mathis et al. 1996, p. 10.
- ^ Iyengar & Swett 2021, 4.4. No Reneging.
- ^ «TCP window scaling and broken routers». LWN.net. Archived from the original on 2020-03-31. Retrieved 2016-07-21.
- ^ RFC 3522
- ^ «IP sysctl». Linux Kernel Documentation. Archived from the original on 5 March 2016. Retrieved 15 December 2018.
- ^ Wang, Eve. «TCP timestamp is disabled». Technet — Windows Server 2012 Essentials. Microsoft. Archived from the original on 2018-12-15. Retrieved 2018-12-15.
- ^ David Murray; Terry Koziniec; Sebastian Zander; Michael Dixon; Polychronis Koutsakis (2017). «An Analysis of Changing Enterprise Network Traffic Characteristics» (PDF). The 23rd Asia-Pacific Conference on Communications (APCC 2017). Archived (PDF) from the original on 3 October 2017. Retrieved 3 October 2017.
- ^ Gont, Fernando (November 2008). «On the implementation of TCP urgent data». 73rd IETF meeting. Archived from the original on 2019-05-16. Retrieved 2009-01-04.
- ^ Peterson, Larry (2003). Computer Networks. Morgan Kaufmann. p. 401. ISBN 978-1-55860-832-0.
- ^ Richard W. Stevens (November 2011). TCP/IP Illustrated. Vol. 1, The protocols. Addison-Wesley. pp. Chapter 20. ISBN 978-0-201-63346-7.
- ^ «Security Assessment of the Transmission Control Protocol (TCP)» (PDF). Archived from the original on March 6, 2009. Retrieved 2010-12-23.
{{cite web}}: CS1 maint: bot: original URL status unknown (link) - ^ Survey of Security Hardening Methods for Transmission Control Protocol (TCP) Implementations
- ^ Jakob Lell (13 August 2013). «Quick Blind TCP Connection Spoofing with SYN Cookies». Archived from the original on 2014-02-22. Retrieved 2014-02-05.
- ^ «Some insights about the recent TCP DoS (Denial of Service) vulnerabilities» (PDF). Archived from the original (PDF) on 2013-06-18. Retrieved 2010-12-23.
- ^ «Exploiting TCP and the Persist Timer Infiniteness». Archived from the original on 2010-01-22. Retrieved 2010-01-22.
- ^ «PUSH and ACK Flood». f5.com. Archived from the original on 2017-09-28. Retrieved 2017-09-27.
- ^ Laurent Joncheray (1995). «Simple Active Attack Against TCP» (PDF). Retrieved 2023-06-04.
- ^ John T. Hagen; Barry E. Mullins (2013). «TCP veto: A novel network attack and its Application to SCADA protocols». 2013 IEEE PES Innovative Smart Grid Technologies Conference (ISGT). pp. 1–6. doi:10.1109/ISGT.2013.6497785. ISBN 978-1-4673-4896-6. S2CID 25353177.
- ^ Eddy 2022, 4. Glossary.
- ^ Fairhurst, Trammell & Kuehlewind 2017, p. 6.
- ^ Eddy 2022, 2.2. Key TCP Concepts.
- ^ Paasch & Bonaventure 2014, p. 51.
- ^ «TCP Interactive». www.medianet.kent.edu. Archived from the original on 2008-08-20. Retrieved 2008-04-28.
- ^ J. Iyengar; C. Raiciu; S. Barre; M. Handley; A. Ford (March 2011). Architectural Guidelines for Multipath TCP Development. Internet Engineering Task Force (IETF). doi:10.17487/RFC6182. RFC 6182. Informational.
- ^ Alan Ford; C. Raiciu; M. Handley; O. Bonaventure (January 2013). TCP Extensions for Multipath Operation with Multiple Addresses. Internet Engineering Task Force. doi:10.17487/RFC6824. ISSN 2070-1721. RFC 6824. Experimental. Obsoleted by RFC 8624.
- ^ Raiciu; Barre; Pluntke; Greenhalgh; Wischik; Handley (2011). «Improving datacenter performance and robustness with multipath TCP». ACM SIGCOMM Computer Communication Review. 41 (4): 266. CiteSeerX 10.1.1.306.3863. doi:10.1145/2043164.2018467. Archived from the original on 2020-04-04. Retrieved 2011-06-29.
- ^ «MultiPath TCP — Linux Kernel implementation». Archived from the original on 2013-03-27. Retrieved 2013-03-24.
- ^ Raiciu; Paasch; Barre; Ford; Honda; Duchene; Bonaventure; Handley (2012). «How Hard Can It Be? Designing and Implementing a Deployable Multipath TCP». Usenix NSDI: 399–412. Archived from the original on 2013-06-03. Retrieved 2013-03-24.
- ^ Bonaventure; Seo (2016). «Multipath TCP Deployments». IETF Journal. Archived from the original on 2020-02-23. Retrieved 2017-01-03.
- ^ Michael Kerrisk (2012-08-01). «TCP Fast Open: expediting web services». LWN.net. Archived from the original on 2014-08-03. Retrieved 2014-07-21.
- ^ Yuchung Cheng; Jerry Chu; Sivasankar Radhakrishnan & Arvind Jain (December 2014). «TCP Fast Open». IETF. doi:10.17487/RFC7413. Archived from the original on 1 January 2015. Retrieved 10 January 2015.
- ^ Mathis, Matt; Dukkipati, Nandita; Cheng, Yuchung (May 2013). «RFC 6937 — Proportional Rate Reduction for TCP». doi:10.17487/RFC6937. Archived from the original on 14 July 2014. Retrieved 6 June 2014.
- ^ Grigorik, Ilya (2013). High-performance browser networking (1. ed.). Beijing: O’Reilly. ISBN 978-1449344764.
- ^ W. Simpson (January 2011). TCP Cookie Transactions (TCPCT). IETF. doi:10.17487/RFC6013. ISSN 2070-1721. RFC 6013. Obsolete. Obsoleted by RFC 7805.
- ^ A. Zimmermann; W. Eddy; L. Eggert (April 2016). Moving Outdated TCP Extensions and TCP-Related Documents to Historic or Informational Status. IETF. doi:10.17487/RFC7805. ISSN 2070-1721. RFC 7805. Informational. Obsoletes RFC 675, 721, 761, 813, 816, 879, 896 and 6013. Updates RFC 7414, 4291, 4338, 4391, 5072 and 5121.
- ^ Trammell & Kuehlewind 2019, p. 6.
- ^ Hardie 2019, p. 3.
- ^ Fairhurst & Perkins 2021, 3. Research, Development, and Deployment.
- ^ Hardie 2019, p. 8.
- ^ Thomson & Pauly 2021, 2.3. Multi-party Interactions and Middleboxes.
- ^ Thomson & Pauly 2021, A.5. TCP.
- ^ Papastergiou et al. 2017, p. 620.
- ^ Edeline & Donnet 2019, p. 175-176.
- ^ Raiciu et al. 2012, p. 1.
- ^ Hesmans et al. 2013, p. 1.
- ^ a b Rybczyńska 2020.
- ^ Papastergiou et al. 2017, p. 621.
- ^ Corbet 2015.
- ^ Briscoe et al. 2016, pp. 29–30.
- ^ Marx 2020, HOL blocking in HTTP/1.1.
- ^ Marx 2020, Bonus: Transport Congestion Control.
- ^ IETF HTTP Working Group, Why just one TCP connection?.
- ^ Corbet 2018.
- ^ a b Cheng et al. 2014, p. 3.
- ^ Sy et al. 2020, p. 271.
- ^ Chen et al. 2021, p. 8-9.
- ^ Ghedini 2018.
- ^ Chen et al. 2021, p. 3-4.
- ^ Cheng et al. 2014, p. 1.
- ^ Blanton & Allman 2002, p. 1-2.
- ^ Blanton & Allman 2002, p. 4-5.
- ^ Blanton & Allman 2002, p. 3-4.
- ^ Blanton & Allman 2002, p. 6-8.
- ^ Bruyeron, Hemon & Zhang 1998, p. 67.
- ^ Bruyeron, Hemon & Zhang 1998, p. 72.
- ^ Bhat, Rizk & Zink 2017, p. 14.
- ^ Iyengar & Swett 2021, 4.5. More ACK Ranges.
- ^ a b «TCP performance over CDMA2000 RLP». Archived from the original on 2011-05-03. Retrieved 2010-08-30.
- ^ Muhammad Adeel & Ahmad Ali Iqbal (2007). «TCP Congestion Window Optimization for CDMA2000 Packet Data Networks». Fourth International Conference on Information Technology (ITNG’07). pp. 31–35. doi:10.1109/ITNG.2007.190. ISBN 978-0-7695-2776-5. S2CID 8717768.
- ^ Yunhong Gu, Xinwei Hong, and Robert L. Grossman.
«An Analysis of AIMD Algorithm with Decreasing Increases» Archived 2016-03-05 at the Wayback Machine.
2004. - ^ S. Deering; R. Hinden (July 2017). Internet Protocol, Version 6 (IPv6) Specification. IETF. doi:10.17487/RFC8200. STD 86. RFC 8200. Internet Standard. Obsoletes RFC 2460.
- ^ «Wireshark: Offloading». Archived from the original on 2017-01-31. Retrieved 2017-02-24.
Wireshark captures packets before they are sent to the network adapter. It won’t see the correct checksum because it has not been calculated yet. Even worse, most OSes don’t bother initialize this data so you’re probably seeing little chunks of memory that you shouldn’t. New installations of Wireshark 1.2 and above disable IP, TCP, and UDP checksum validation by default. You can disable checksum validation in each of those dissectors by hand if needed.
- ^ «Wireshark: Checksums». Archived from the original on 2016-10-22. Retrieved 2017-02-24.
Checksum offloading often causes confusion as the network packets to be transmitted are handed over to Wireshark before the checksums are actually calculated. Wireshark gets these «empty» checksums and displays them as invalid, even though the packets will contain valid checksums when they leave the network hardware later.
Bibliography[edit]
- Allman, Mark; Paxson, Vern (October 1999). «On estimating end-to-end network path properties». ACM SIGCOMM Computer Communication Review. 29 (4): 263–274. doi:10.1145/316194.316230.
- Bhat, Divyashri; Rizk, Amr; Zink, Michael (June 2017). «Not so QUIC: A Performance Study of DASH over QUIC». NOSSDAV’17: Proceedings of the 27th Workshop on Network and Operating Systems Support for Digital Audio and Video. pp. 13–18. doi:10.1145/3083165.3083175. S2CID 32671949.
- Blanton, Ethan; Allman, Mark (January 2002). «On making TCP more robust to packet reordering» (PDF). ACM SIGCOMM Computer Communication Review. 32: 20–30. doi:10.1145/510726.510728. S2CID 15305731.
- Borman, David; Braden, Bob; Jacobson, Van (September 2014). Scheffenegger, Richard (ed.). TCP Extensions for High Performance. doi:10.17487/RFC7323. RFC 7323.
- Briscoe, Bob; Brunstrom, Anna; Petlund, Andreas; Hayes, David; Ros, David; Tsang, Ing-Jyh; Gjessing, Stein; Fairhurst, Gorry; Griwodz, Carsten; Welzl, Michael (2016). «Reducing Internet Latency: A Survey of Techniques and Their Merits». IEEE Communications Surveys & Tutorials. 18 (3): 2149–2196. doi:10.1109/COMST.2014.2375213. hdl:2164/8018. S2CID 206576469.
- Bruyeron, Renaud; Hemon, Bruno; Zhang, Lixa (April 1998). «Experimentations with TCP selective acknowledgment». ACM SIGCOMM Computer Communication Review. 28 (2): 54–77. doi:10.1145/279345.279350.
- Chen, Shan; Jero, Samuel; Jagielski, Matthew; Boldyreva, Alexandra; Nita-Rotaru, Cristina (2021). «Secure Communication Channel Establishment: TLS 1.3 (Over TCP Fast Open) versus QUIC». Journal of Cryptology. 34 (3). doi:10.1007/s00145-021-09389-w. S2CID 235174220.
- Cheng, Yuchung; Chu, Jerry; Radhakrishnan, Sivasankar; Jain, Arvind (December 2014). TCP Fast Open. doi:10.17487/RFC7413. RFC 7413.
- Corbet, Jonathan (8 December 2015). «Checksum offloads and protocol ossification». LWN.net.
- Corbet, Jonathan (29 January 2018). «QUIC as a solution to protocol ossification». LWN.net.
- Eddy, Wesley M., ed. (August 2022). Transmission Control Protocol (TCP). doi:10.17487/RFC9293. RFC 9293.
- Edeline, Korian; Donnet, Benoit (2019). A Bottom-Up Investigation of the Transport-Layer Ossification. 2019 Network Traffic Measurement and Analysis Conference (TMA). doi:10.23919/TMA.2019.8784690.
- Fairhurst, Gorry; Trammell, Brian; Kuehlewind, Mirja, eds. (March 2017). Services Provided by IETF Transport Protocols and Congestion Control Mechanisms. doi:10.17487/RFC8095. RFC 8095.
- Fairhurst, Gorry; Perkins, Colin (July 2021). Considerations around Transport Header Confidentiality, Network Operations, and the Evolution of Internet Transport Protocols. doi:10.17487/RFC9065. RFC 9065.
- Ghedini, Alessandro (26 July 2018). «The Road to QUIC». Cloudflare.
- Gurtov, Andrei; Floyd, Sally (February 2004). Resolving Acknowledgment Ambiguity in non-SACK TCP (PDF). Next Generation Teletraffic and Wired/Wireless Advanced Networking (NEW2AN’04).
- Gurtov, Andrei; Ludwig, Reiner (2003). Responding to Spurious Timeouts in TCP (PDF). IEEE INFOCOM 2003. Twenty-second Annual Joint Conference of the IEEE Computer and Communications Societies. doi:10.1109/INFCOM.2003.1209251.
- Hardie, Ted, ed. (April 2019). Transport Protocol Path Signals. doi:10.17487/RFC8558. RFC 8558.
- Hesmans, Benjamin; Duchene, Fabien; Paasch, Christoph; Detal, Gregory; Bonaventure, Olivier (2013). Are TCP extensions middlebox-proof?. HotMiddlebox ’13. doi:10.1145/2535828.2535830.
- Iyengar, Jana; Swett, Ian, eds. (May 2021). QUIC Loss Detection and Congestion Control. doi:10.17487/RFC9002. RFC 9002.
- IETF HTTP Working Group. «HTTP/2 Frequently Asked Questions».
- Karn, Phil; Partridge, Craig (November 1991). «Improving round-trip time estimates in reliable transport protocols». ACM Transactions on Computer Systems. 9 (4): 364–373. doi:10.1145/118544.118549.
- Ludwig, Reiner; Katz, Randy Howard (January 2000). «The Eifel algorithm: making TCP robust against spurious retransmissions». ACM SIGCOMM Computer Communication Review. doi:10.1145/505688.505692.
- Ludwig, Reiner; Meyer, Michael (April 2003). The Eifel Detection Algorithm for TCP. doi:10.17487/RFC3522. RFC 3522.
- Marx, Robin (3 December 2020). «Head-of-Line Blocking in QUIC and HTTP/3: The Details».
- Mathis, Matt; Mahdavi, Jamshid; Floyd, Sally; Romanow, Allyn (October 1996). TCP Selective Acknowledgment Options. doi:10.17487/RFC2018. RFC 2018.
- Paasch, Christoph; Bonaventure, Olivier (1 April 2014). «Multipath TCP». Communications of the ACM. 57 (4): 51–57. doi:10.1145/2578901. S2CID 17581886.
- Papastergiou, Giorgos; Fairhurst, Gorry; Ros, David; Brunstrom, Anna; Grinnemo, Karl-Johan; Hurtig, Per; Khademi, Naeem; Tüxen, Michael; Welzl, Michael; Damjanovic, Dragana; Mangiante, Simone (2017). «De-Ossifying the Internet Transport Layer: A Survey and Future Perspectives». IEEE Communications Surveys & Tutorials. 19: 619–639. doi:10.1109/COMST.2016.2626780. hdl:2164/8317. S2CID 1846371.
- Paxson, Vern; Allman, Mark; Chu, H.K. Jerry; Sargent, Matt (June 2011). Computing TCP’s Retransmission Timer. doi:10.17487/RFC6298. RFC 6298.
- Rybczyńska, Marta (13 March 2020). «A QUIC look at HTTP/3». LWN.net.
- Sy, Erik; Mueller, Tobias; Burkert, Christian; Federrath, Hannes; Fischer, Mathias (2020). «Enhanced Performance and Privacy for TLS over TCP Fast Open». Proceedings on Privacy Enhancing Technologies. 2020 (2): 271–287. arXiv:1905.03518. doi:10.2478/popets-2020-0027.
- Thomson, Martin; Pauly, Tommy (December 2021). Long-Term Viability of Protocol Extension Mechanisms. doi:10.17487/RFC9170. RFC 9170.
- Trammell, Brian; Kuehlewind, Mirja (April 2019). The Wire Image of a Network Protocol. doi:10.17487/RFC8546. RFC 8546.
- Zhang, Lixia (5 August 1986). «Why TCP timers don’t work well». ACM SIGCOMM Computer Communication Review. 16 (3): 397–405. doi:10.1145/1013812.18216.
Further reading[edit]
- Stevens, W. Richard (1994-01-10). TCP/IP Illustrated, Volume 1: The Protocols. Addison-Wesley Pub. Co. ISBN 978-0-201-63346-7.
- Stevens, W. Richard; Wright, Gary R (1994). TCP/IP Illustrated, Volume 2: The Implementation. Addison-Wesley. ISBN 978-0-201-63354-2.
- Stevens, W. Richard (1996). TCP/IP Illustrated, Volume 3: TCP for Transactions, HTTP, NNTP, and the UNIX Domain Protocols. Addison-Wesley. ISBN 978-0-201-63495-2.**
External links[edit]
- Oral history interview with Robert E. Kahn
- IANA Port Assignments
- IANA TCP Parameters
- John Kristoff’s Overview of TCP (Fundamental concepts behind TCP and how it is used to transport data between two endpoints)
- Checksum example
Cтек протоколов TCP/IP широко распространен. Он используется в качестве основы для глобальной сети интернет. Разбираемся в основных понятиях и принципах работы стека.
Основы TCP/IP
Стек протоколов TCP/IP (Transmission Control Protocol/Internet Protocol, протокол управления передачей/протокол интернета) — сетевая модель, описывающая процесс передачи цифровых данных. Она названа по двум главным протоколам, по этой модели построена глобальная сеть интернет. Сейчас это кажется невероятным, но в 1970-х информация не могла быть передана из одной сети в другую. Чтобы обеспечить такую возможность, был разработан стек интернет-протоколов, известный как TCP/IP.
Разработка сетевой модели осуществлялась при содействии Министерства обороны США, поэтому иногда модель TCP/IP называют DoD (Department of Defence) модель. Если вы знакомы с моделью OSI, то вам будет проще понять построение модели TCP/IP, потому что обе модели имеют деление на уровни, внутри которых действуют определенные протоколы и выполняются собственные функции. Мы разделили статью на смысловые части, чтобы было проще понять, как устроена модель TCP/IP:
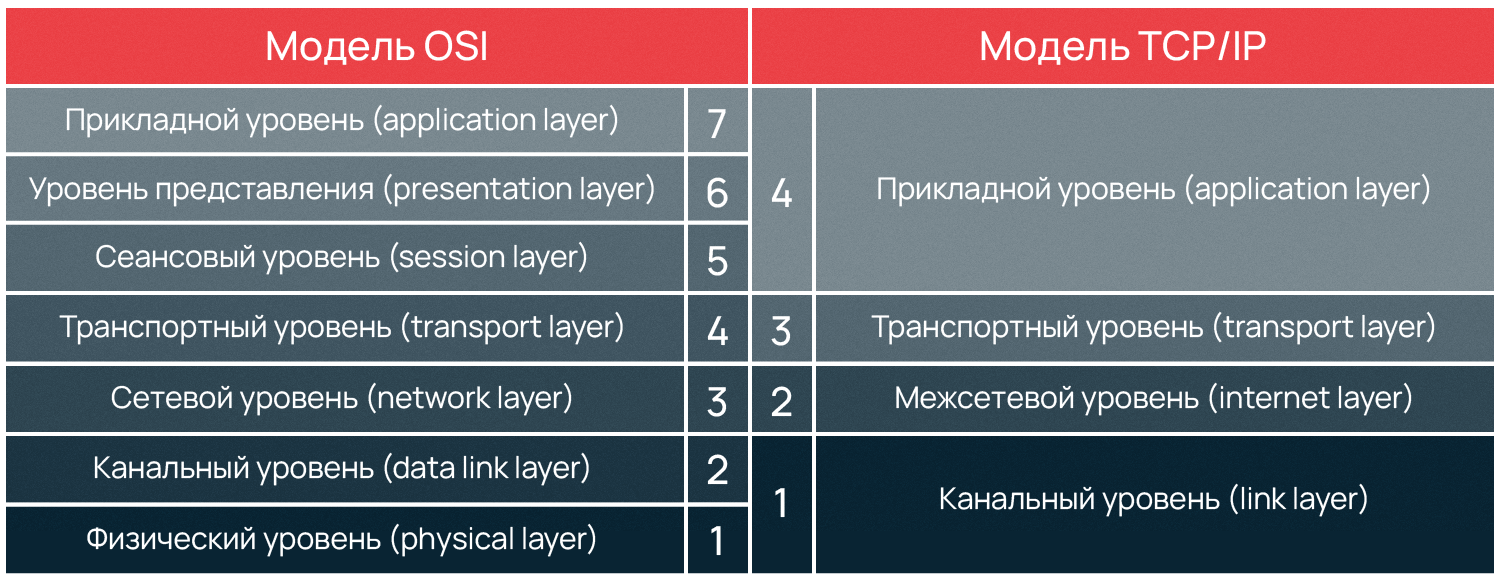
Уровневая модель TCP/IP
Выше мы уже упоминали, что модель TCP/IP разделена на уровни, как и OSI, но отличие двух моделей в количестве уровней. Документами, определяющими сертификацию модели, являются RFC 1122 и RFC1123. Эти стандарты описывают четыре уровня абстракции модели TCP/IP: прикладной, транспортный, межсетевой и канальный. Существуют и другие версии описания модели, в том числе включающие иное количество уровней и их наименований. Однако в этой статье мы придерживаемся оригинальной версии и далее рассмотрим четыре уровня модели.
Канальный уровень (link layer)
Предназначение канального уровня — дать описание тому, как происходит обмен информацией на уровне сетевых устройств, определить, как информация будет передаваться от одного устройства к другому. Информация здесь кодируется, делится на пакеты и отправляется по нужному каналу, т.е. среде передачи.
Этот уровень также вычисляет максимальное расстояние, на которое пакеты возможно передать, частоту сигнала, задержку ответа и т.д. Все это — физические свойства среды передачи информации. На канальном уровне самым распространенным протоколом является Ethernet, который мы рассмотрим в конце статьи.
Межсетевой уровень (internet layer)
Глобальная сеть интернет состоит из множества локальных сетей, взаимодействующих между собой. Межсетевой уровень используется, чтобы описать обеспечение такого взаимодействия.
Межсетевое взаимодействие — это основной принцип построения интернета. Локальные сети по всему миру объединены в глобальную, а передачу данных между этими сетями осуществляют магистральные и пограничные маршрутизаторы.
Именно на межсетевом уровне функционирует протокол IP, позволивший объединить разные сети в глобальную. Как и протокол TCP, он дал название модели, рассматриваемой в статье.
Маска подсети и IP-адреса

Маска подсети помогает маршрутизатору понять, как и куда передавать пакет. Подсетью может являться любая сеть со своими протоколами. Маршрутизатор передает пакет напрямую, если получатель находится в той же подсети, что и отправитель. Если же подсети получателя и отправителя различаются, пакет передается на второй маршрутизатор, со второго на третий и далее по цепочке, пока не достигнет получателя.
Протокол IP (Internet Protocol) используется маршрутизатором, чтобы определить, к какой подсети принадлежит получатель. Свой уникальный IP-адрес есть у каждого сетевого устройства, при этом в глобальной сети не может существовать два устройства с одинаковым IP. Протокол имеет две действующие версии, первая из которых — IPv4 (IP version 4, версии 4) — была описана в 1981 году.
IPv4 предусматривает назначение каждому устройству 32-битного IP-адреса, что ограничивало максимально возможное число уникальных адресов 4 миллиардами (2^32). В более привычном для человека десятичном виде IPv4 выглядит как четыре блока (октета) чисел от 0 до 255, разделенных тремя точками. Первый октет IP-адреса означает класс сети, классов всего 5: A, B, C, D, E. При этом адреса сети D являются мультикастовыми, а сети E вообще не используются.
Рассмотрим, например, IPv4 адрес класса С 223.135.100.7. Первые три октета определяют класс и номер сети, а последний означает номер конечного устройства. Например, если необходимо отправить информацию с компьютера номер 7 с IPv4 адресом 223.135.100.7 на компьютер номер 10 в той же подсети, то адрес компьютера получателя будет следующий: 223.135.100.10.
В связи с быстрым ростом сети интернет остро вставала необходимость увеличения числа возможных IP-адресов. В 1995 году впервые был описан протокол IPv6 (IP version 6, версии 6), который использует 128-битные адреса и позволяет назначить уникальные адреса для 2^128 устройств.
IPv6 имеет вид восьми блоков по четыре шестнадцатеричных значения, а каждый блок разделяется двоеточием. IPv6 выглядит следующим образом:
2dab:ffff:0000:0000:01aa:00ff:dd72:2c4a.
Так как IPv6 адреса длинные, их разрешается сокращать по определенным правилам, которые также описываются RFC:
- Для написания адреса используются строчные буквы латинского алфавита: a, b, c, d, e, f.
- Ведущие нули допускается не указывать — например, в адресе выше :00ff: можно записать как :ff:.
- Группы нулей, идущие подряд, тоже допустимо сокращать и заменять на двойное двоеточие. На примере выше это выглядит так: 2dab:аааа::01aa:00ff:dd72:2c4a. Допускается делать не больше одного подобного сокращения в адресе IPv6 на наибольшей последовательности нулей. Если одинаково длинных последовательностей несколько — на самой левой из них.
IP предназначен для определения адресата и доставки ему информации. Он предоставляет услугу для вышестоящих уровней, но не гарантирует целостность доставляемой информации.
IP способен инкапсулировать другие протоколы, предоставлять место, куда они могут быть встроены. К таким протоколам, например, относятся ICMP (межсетевой протокол управляющих сообщений) и IGMP (межсетевой протокол группового управления). Информация о том, какой протокол инкапсулируется, отражается в заголовке IP-пакета. Так, ICMP будет обозначен числом 1, а IGMP будет обозначен числом 2.
ICMP

ICMP в основном используется устройствами в сети для доставки сообщений об ошибках и операционной информации, сообщающей об успехе или ошибке при связи с другим устройством. Например, именно с использованием ICMP осуществляется передача отчетов о недоступности устройств в сети. Кроме того, ICMP используется при диагностике сети — к примеру, в эксплуатации утилит ping или traceroute.
ICMP не передает какие-либо данные, что отличает его от протоколов, работающих на транспортном уровне — таких как TCP и UDP. ICMP, аналогично IP, работает на межсетевом уровне и фактически является неотъемлемой частью при реализации модели TCP/IP. Стоит отметить, что для разных версий IP используются и разные версии протокола ICMP.
Транспортный уровень (transport layer)
Постоянные резиденты транспортного уровня — протоколы TCP и UDP, они занимаются доставкой информации.
TCP (протокол управления передачей) — надежный, он обеспечивает передачу информации, проверяя дошла ли она, насколько полным является объем полученной информации и т.д. TCP дает возможность двум конечным устройствам производить обмен пакетами через предварительно установленное соединение. Он предоставляет услугу для приложений, повторно запрашивает потерянную информацию, устраняет дублирующие пакеты, регулируя загруженность сети. TCP гарантирует получение и сборку информации у адресата в правильном порядке.
UDP (протокол пользовательских датаграмм) — ненадежный, он занимается передачей автономных датаграмм. UDP не гарантирует, что всех датаграммы дойдут до получателя. Датаграммы уже содержат всю необходимую информацию, чтобы дойти до получателя, но они все равно могут быть потеряны или доставлены в порядке отличном от порядка при отправлении.
UDP обычно не используется, если требуется надежная передача информации. Использовать UDP имеет смысл там, где потеря части информации не будет критичной для приложения, например, в видеоиграх или потоковой передаче видео. UDP необходим, когда делать повторный запрос сложно или неоправданно по каким-то причинам.
Протоколы транспортного уровня не интерпретируют информацию, полученную с верхнего или нижних уровней, они служат только как канал передачи, но есть исключения. RSVP (Resource Reservation Protocol, протокол резервирования сетевых ресурсов) может использоваться, например, роутерами или сетевыми экранами в целях анализа трафика и принятия решений о его передаче или отклонении в зависимости от содержимого.
Прикладной уровень (application layer)
В модели TCP/IP отсутствуют дополнительные промежуточные уровни (представления и сеансовый) в отличие от OSI. Функции форматирования и представления данных делегированы библиотекам и программным интерфейсам приложений (API) — своего рода базам знаний, содержащим сведения о том, как приложения взаимодействуют между собой. Когда службы или приложения обращаются к библиотеке или API, те в ответ предоставляют набор действий, необходимых для выполнения задачи и полную инструкцию, каким образом эти действия нужно выполнять.
Протоколы прикладного уровня действуют для большинства приложений, они предоставляют услуги пользователю или обмениваются данными с «коллегами» с нижних уровней по уже установленным соединениям. Здесь для большинства приложений созданы свои протоколы. Например, браузеры используют HTTP для передачи гипертекста по сети, почтовые клиенты — SMTP для передачи почты, FTP-клиенты — протокол FTP для передачи файлов, службы DHCP — протокол назначения IP-адресов DHCP и так далее.
Узнайте, как устроена сетевая архитектура крупного провайдера.
Зачем нужен порт и что означает термин «сокет»
Приложения прикладного уровня, общаются также с предыдущим, транспортным, но они видят его протоколы как «черные ящики». Для приема-передачи информации они могут работать, например, с TCP или UDP, но понимают только конечный адрес в виде IP и порта, а не принцип их работы.
Как говорилось ранее, IP-адрес присваивается каждому конечному устройству протоколом межсетевого уровня. Но обмен данными происходит не между конечными устройствами, а между приложениями, установленными на них. Чтобы получить доступ к тому или иному сетевому приложению недостаточно только IP-адреса, поэтому для идентификации приложений применяют также порты. Комбинация IP-адреса и порта называется сокетом, или гнездом (socket).
Кроме собственных протоколов, приложения на прикладном уровне зачастую имеют и фиксированный номер порта для обращения к сети. Администрация адресного пространства интернет (IANA), занимающаяся выделением диапазонов IP-адресов, отвечает еще за назначение сетевым приложениям портов.
Так почтовые приложения, которые общаются по SMTP-протоколу, используют порт 25, по протоколу POP3 — порт 110, браузеры при работе по HTTP — порт 80, FTP-клиенты — порт 21. Порт всегда записывается после IP и отделяется от него двоеточием, выглядит это, например, так: 192.168.1.1:80.
Что такое DNS и для чего используется эта служба
Чтобы не запоминать числовые адреса интернет-серверов была создана DNS — служба доменных имен. DNS всегда слушает на 53 порту и преобразует буквенные имена сетевых доменов в числовые IP-адреса и наоборот. Служба DNS позволяет не запоминать IP — компьютер самостоятельно посылает запрос «какой IP у selectel.ru?» на 53 порт DNS-сервера, полученного от поставщика услуг интернет.
DNS-сервер дает компьютеру ответ «IP для selectel.ru — XXX.XXX.XXX.XXX». Затем, компьютер устанавливает соединение с веб-сервером полученного IP, который слушает на порту 80 для HTTP-протокола и на порту 443 для HTTPS. В браузере порт не отображается в адресной строке, а используется по умолчанию, но, по сути, полный адрес сайта Selectel выглядит вот так: https://selectel.ru:443.
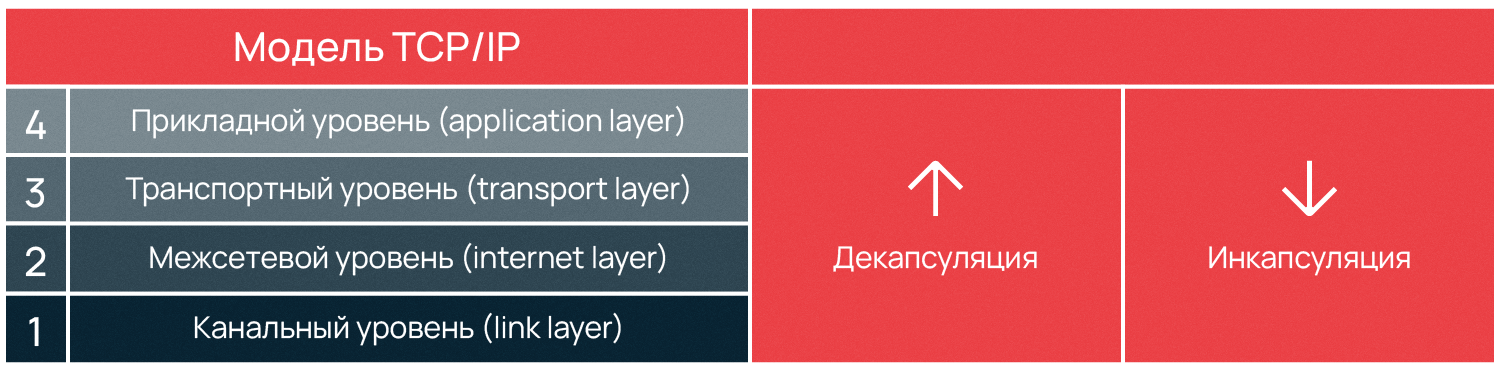
Для обеспечения корректной работы протоколов различных уровней в сетевых моделях используется специальный метод — инкапсуляция. Суть этого метода заключается в добавлении заголовка протокола текущего уровня к данным, полученным от протокола вышестоящего уровня. Процесс, обратный описанному, называется декапсуляцией. Оба процесса осуществляются на компьютерах получателя и отправителя данных попеременно, это позволяет долго не удерживать одну сторону канала занятой, оставляя время на передачу информации другому компьютеру.
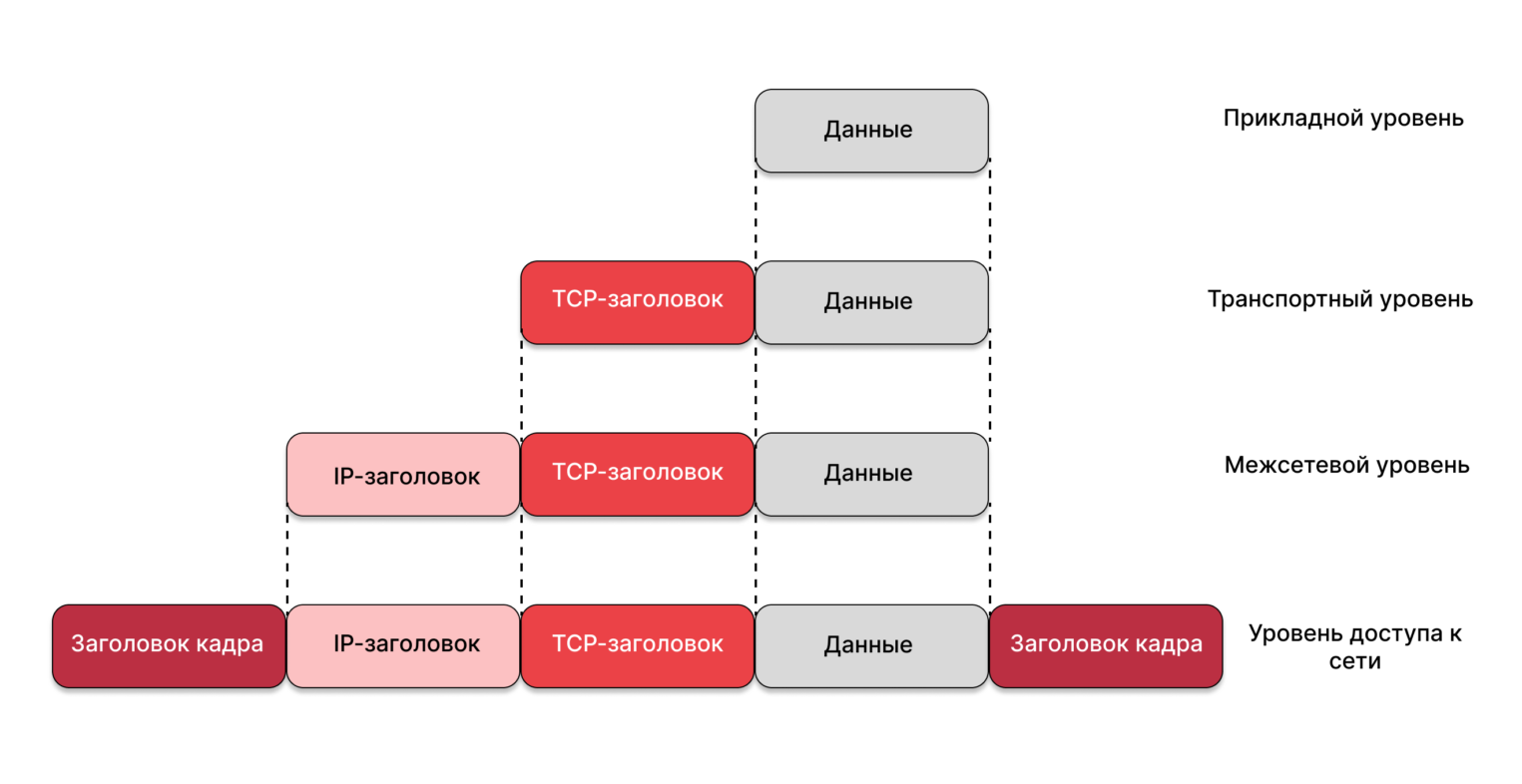
Стек протоколов, снова канальный уровень
О канальном уровне модели TCP/IP мы рассказали меньше всего. Давайте вернемся еще раз к началу, чтобы рассмотреть инкапсуляцию протоколов и что значит «стек».
Большинству пользователей знаком протокол Ethernet. В сети, по стандарту Ethernet, устройства отправителя и адресата имеют определенный MAC-адрес — идентификатор «железа». MAC-адрес инкапсулируется в Ethernet вместе с типом передаваемых данных и самими данными. Фрагмент данных, составленных в соответствии с Ethernet, называется фреймом, или кадром (frame).
MAC-адрес каждого устройства уникален, и двух «железок» с одинаковым адресом не должно существовать. Совпадение может привести к сетевым проблемам. Таким образом, при получении кадра сетевой адаптер занимается извлечением полученной информации и ее дальнейшей обработкой.
После ознакомления с уровневой структурой модели становится понятно, что информация не может передаваться между двумя компьютерами напрямую. Сначала кадры передаются на межсетевой уровень, где компьютеру отправителя и компьютеру получателя назначается уникальный IP. После чего, на транспортном уровне, информация передается в виде TCP-фреймов либо UDP-датаграмм.
На каждом этапе, подобно снежному кому, к уже имеющейся информации добавляется служебная информация, например, порт на прикладном уровне, необходимый для идентификации сетевого приложения. Добавление служебной информации к основной обеспечивают разные протоколы — сначала Ethernet, поверх него IP, еще выше TCP, над ним порт, означающий приложение с делегированным ему протоколом. Такая вложенность называется стеком, названным TCP/IP по двум главным протоколам модели.
Point-to-Point протоколы
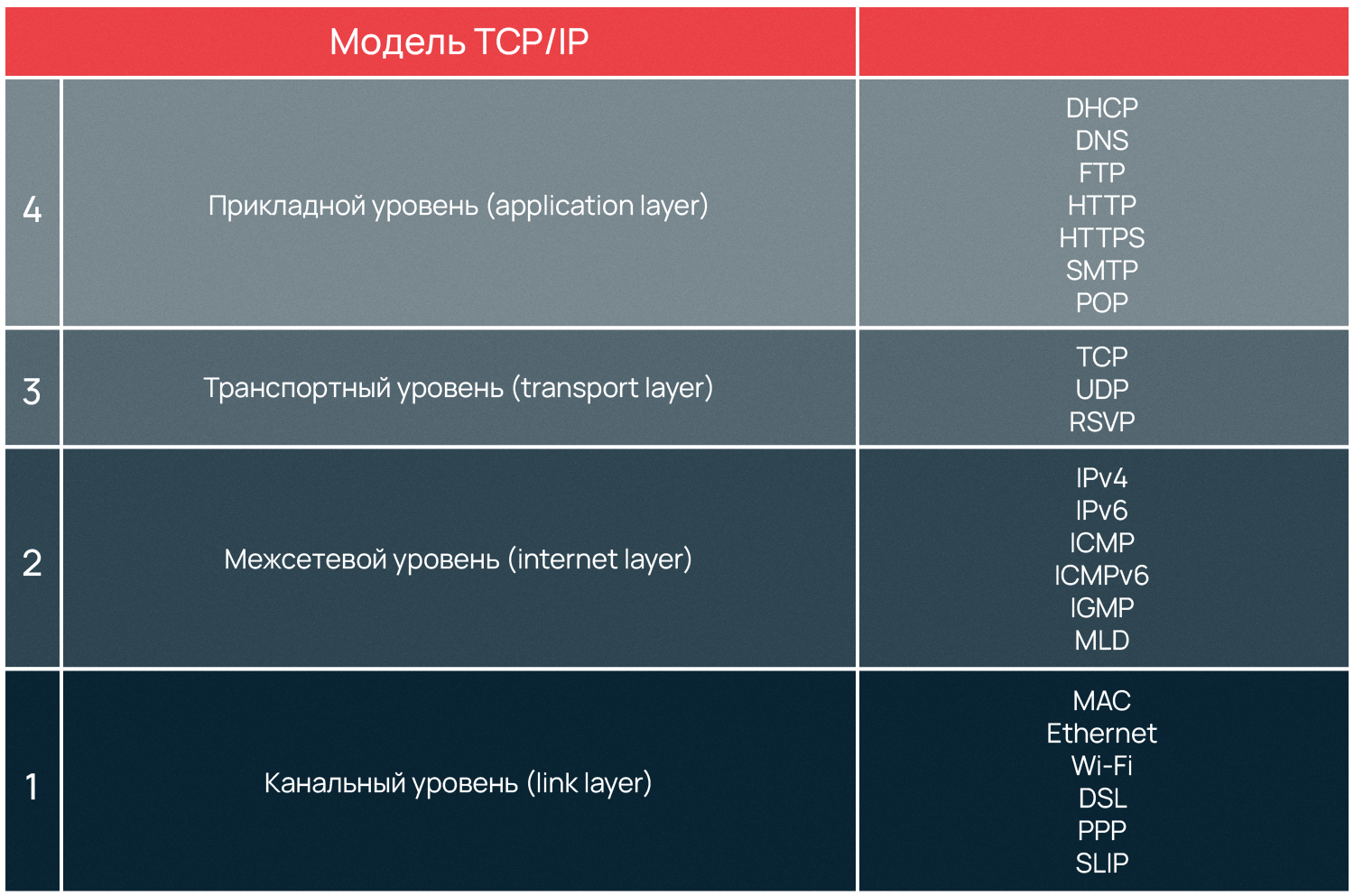
Отдельно расскажем о Point-to-Point (от точки к точке, двухточечный) протоколе, также известном как PPP. PPP уникален по своим функциям, он применяется для коммуникации между двумя маршрутизаторами без участия хоста или какой-либо сетевой структуры в промежутке. При необходимости PPP обеспечивает аутентификацию, шифрование, а также сжатие данных. Он широко используется при построении физических сетей, например, кабельных телефонных, сотовых телефонных, сетей по кабелю последовательной передачи и транк-линий (когда один маршрутизатор подключают к другому для увеличения размера сети).
У PPP есть два подвида — PPPoE (PPP по Ethernet) и PPPoA (PPP через асинхронный способ передачи данных — ATM), интернет-провайдеры часто их используют для DSL соединений.
PPP и его старший аналог SLIP (протокол последовательной межсетевой связи) формально относятся к межсетевому уровню TCP/IP, но в силу особого принципа работы, иногда выделяются в отдельную категорию. Преимущество PPP в том, что для установки соединения не требуется сетевая инфраструктура, а необходимость маршрутизаторов отпадает. Эти факторы обуславливают специфику использования PPP протоколов.
Заключение
Стек TCP/IP регламентирует взаимодействие разных уровней. Ключевым понятием здесь являются протоколы, формирующие стек, встраиваясь друг в друга с целью передать данные. Рассмотренная модель по сравнению с OSI имеет более простую архитектуру.
Сама модель остается неизменной, в то время как стандарты протоколов могут обновляться, что еще дальше упрощает работу с TCP/IP. Благодаря всем преимуществам стек TCP/IP получил широкое распространение и использовался сначала в качестве основы для создания глобальной сети, а после для описания работы интернета.
Quick Definition of TCP: Transmission Control Protocol (TCP) is a global communication standard that devices use to reliably transmit data. TCP is defined by being connection-oriented, which means that both the client and the server have to be established before the data gets sent. This means the data is reliable, ordered and error-checked in transit. It is one of the main protocols of the Internet protocol suite — and the entire suite is often referred to as TCP/IP.
Quick Definition of TCP Ports: A «port» is a logical distinction in computer networking. Ports are numbered and used as global standards to identify specific processes or types of network services.
Much like before shipping something to a foreign country, you’d agree where you’d be shipping out of and where you’d have it arriving, TCP ports allow for standardized communication between devices. One device can receive information for many different processes and services, and which port the information flows on helps to keep it organized.
An Overview of TCP Ports [VIDEO]
In this video, Tim Warner covers what TCP ports are as well as where and how TCP port numbers are used. He further describes how you can use the netstat command-line tool to find port use information. He also explains how, on Windows computers, you can use a free GUI-based tool called TCPView to better view and work with this information.
How Do TCP and TCP Ports Work?
Transmission Control Protocol is a key component of the TCP/IP protocol stack. TCP is a connection-oriented protocol that requires a connection or a circuit between the source sending computer and the destination one. TCP is one of the two main ways to transmit data in a TCP/IP network. UDP, which is a best-effort connectionless protocol, is the other one.
For devices to communicate via TCP, they use TCP ports. Generally, a TCP port represents an application or service-specific endpoint identifier.
Think of opening a web browser. When you type in «CBTNuggets.com», your browser translates that to «http://www.cbtnuggets.com». And with that, you’re specifying the hypertext transfer protocol — and hopefully, you get the page without issue. That happens because CBT Nuggets’ web server aka its HTTP server is listening for incoming connections on a particular port address.
The well-known port for HTTP is 80. By contrast, you might download some software from ftp.microsoft.com, their FTP server is going to be listening on the well-known Port 23. And so forth. Protip: If you’re planning to earn an IT certification exam, you may need to have many of the most common TCP ports memorized.
How Many TCP Ports Are There?
A TCP port is a 16-bit, unsigned value, so there’s a finite number of TCP ports available in the world. Specifically, there are 65,535 available TCP ports.
You’ve probably heard that the world is moving from IPv4 to IPv6 due to address depletion. It’s also entirely likely that the time will come when we’ll have to expand the port range to accommodate additional services.
That said, the first 1,024 TCP ports are called well-known port numbers, and they’re agreed upon among technology vendors. So if you and I were to go into business and sell a really nice FTP client software, we’d agree to work with the standard, well-known FTP port numbers.
How Do Sockets Work with TCP Connections?
A socket allows for a connection to another system that’s already running some TCP server software. A socket takes a combination of an IP address and a port number. That means a single host can host multiple instances of the same service by using different port numbers.
For instance, we can set up a web server that has «Site 1» listening on the default port of 80 and another web server. That is to say another website on the same server with the same IP address, «Site 2», but listening on Port 8080.
Where and How Do We Use Port Numbers?
One place is during server application configuration. Enterprise apps like Oracle, SQL, SharePoint, all require you to set up services on discrete port numbers. Which is also why working with your network administrator to allow for that traffic to flow on those port IDs are important. Firewalls monitor ports to keep systems secure.
Service addressing is another way to use port numbers. Once we install our enterprise application, we advertise the service using, generally speaking, a hostname and the port number. For example, «http://cbtnuggets:1988». We wouldn’t have to do that if it were a well-known port. If it’s well known, we can leave it off.
We use port numbers for troubleshooting purposes. Specifically, we can troubleshoot malware and identify rogue processes.
Firewall configuration often uses rules that denote both aspects of a socket. You might create allowances or traffic blocks based on IP addresses, port numbers, or both.
How to View TCP Connections on Your Machine
Regardless of your OS, you can always get to the netstat command line tool, although the specific parameters you use will depend on your OS. In Windows, start with a command prompt and type:
This will output a table of all current TCP connections on the system. Unfortunately, you can’t do all that much besides looking at it.
There’s another option, though, and that’s to type:
This outputs a lot more data that’s much more useful. This includes all the parameters.
What’s a Good Tool for Viewing TCP Information?
If you’re working on a Windows machine, TCPView.exe is strongly recommended. A Microsoft property now, it was originally developed by Mark Russinovich. There’s also a command line version of the tool called TCPVcon that’s also free.
What’s great about TCPView is its graphical interface. And the interface is more than just a netstat query on steroids, there’s a lot of context and information in its interface.
Running TCPView, you may discover that you have quite a lot more running on your system in terms of remote connections than you might have otherwise been aware. That’s one of the reasons TCPView is an excellent way to diagnose rogue processes. It could be a trojan horse, some sort of backdoor administrative application that phones home. You can easily identify those tools, by taking a look.
Don’t be surprised if you see many applications running with processes going like Outlook, Chrome, or Dropbox. If you right-click one of these items that’s listed, you’ll get a specific ID of the image or the executable program that’s running. You can also end the process — terminate it from there — by right-clicking and pressing «close application». You can right-click a process and do a WHOIS lookup. There’s a lot of good things to do in TCPView and you should play around with it.
The bottom line with TCPView is that by using it you can see that for each process that you have running on your system, you can see at a glance if it’s TCP or UDP. And you can see the local and remote port. You’ll see that UDP doesn’t have remote ports, that’s because UDP is a connectionless protocol and doesn’t require an end-to-end circuit like TCP does. Which is why TCP tells us on this interface where we’re connected, both locally and to a remote system.
Wrapping Up
TCP is an important concept for any network professional to understand. It’s one of the tools that has made our modern digital age possible. All this information about understanding TCP/IP lends itself to learning much more about IT professions. If you’re looking for more detail, check out our CompTIA A+ training.