Исторически так сложилось, что кириллическая кодировка существует в нескольких видах.
Windows-1251
Кодировка Windows-1251 (cp1251) является стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. У неё существуют разновидности: казахская, чувашская и т.д. Первая часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Вторая часть (под символами указаны шестнадцатеричные коды Unicode) приводится ниже:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | Ђ 0402 |
Ѓ 0403 |
‚ 201A |
ѓ 0453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 0409 |
‹ 2039 |
Њ 040A |
Ќ 040C |
Ћ 040B |
Џ 040F |
| 9 | ђ 0452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 0459 |
› 203A |
њ 045A |
ќ 045C |
ћ 045B |
џ 045F |
|
| A | 00A0 |
Ў 040E |
ў 045E |
Ј 0408 |
¤ 00A4 |
Ґ 0490 |
¦ 00A6 |
§ 00A7 |
Ё 0401 |
© 00A9 |
Є 0404 |
« 00AB |
¬ 00AC |
00AD |
® 00AE |
Ї 0407 |
| B | ° 00B0 |
± 00B1 |
І 0406 |
і 0456 |
ґ 0491 |
µ 00B5 |
¶ 00B6 |
· 00B7 |
ё 0451 |
№ 2116 |
є 0454 |
» 00BB |
ј 0458 |
Ѕ 0405 |
ѕ 0455 |
ї 0457 |
| C | А 0410 |
Б 0411 |
В 0412 |
Г 0413 |
Д 0414 |
Е 0415 |
Ж 0416 |
З 0417 |
И 0418 |
Й 0419 |
К 041A |
Л 041B |
М 041C |
Н 041D |
О 041E |
П 041F |
| D | Р 0420 |
С 0421 |
Т 0422 |
У 0423 |
Ф 0424 |
Х 0425 |
Ц 0426 |
Ч 0427 |
Ш 0428 |
Щ 0429 |
Ъ 042A |
Ы 042B |
Ь 042C |
Э 042D |
Ю 042E |
Я 042F |
| E | а 0430 |
б 0431 |
в 0432 |
г 0433 |
д 0434 |
е 0435 |
ж 0436 |
з 0437 |
и 0438 |
й 0439 |
к 043A |
л 043B |
м 043C |
н 043D |
о 043E |
п 043F |
| F | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
cp866
В консоли русифицированных систем семейства Windows NT используется кодировка cp866. Первая часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Вторая часть (под символами указаны шестнадцатеричные коды Unicode):
Для кодировки cp866 существуют разновидности (чувашская, ГОСТ 19768-87 и т.д.).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | А 0410 |
Б 0411 |
В 0412 |
Г 0413 |
Д 0414 |
Е 0415 |
Ж 0416 |
З 0417 |
И 0418 |
Й 0419 |
К 041A |
Л 041B |
М 041C |
Н 041D |
О 041E |
П 041F |
| 9 | Р 0420 |
С 0421 |
Т 0422 |
У 0423 |
Ф 0424 |
Х 0425 |
Ц 0426 |
Ч 0427 |
Ш 0428 |
Щ 0429 |
Ъ 042A |
Ы 042B |
Ь 042C |
Э 042D |
Ю 042E |
Я 042F |
| A | а 0430 |
б 0431 |
в 0432 |
г 0433 |
д 0434 |
е 0435 |
ж 0436 |
з 0437 |
и 0438 |
й 0439 |
к 043A |
л 043B |
м 043C |
н 043D |
о 043E |
п 043F |
| B | ░ 2591 |
▒ 2592 |
▓ 2593 |
│ 2502 |
┤ 2524 |
╡ 2561 |
╢ 2562 |
╖ 2556 |
╕ 2555 |
╣ 2563 |
║ 2551 |
╗ 2557 |
╝ 255D |
╜ 255C |
╛ 255B |
┐ 2510 |
| C | └ 2514 |
┴ 2534 |
┬ 252C |
├ 251C |
─ 2500 |
┼ 253C |
╞ 255E |
╟ 255F |
╚ 255A |
╔ 2554 |
╩ 2569 |
╦ 2566 |
╠ 2560 |
═ 2550 |
╬ 256C |
╧ 2567 |
| D | ╨ 2568 |
╤ 2564 |
╥ 2565 |
╙ 2559 |
╘ 2558 |
╒ 2552 |
╓ 2553 |
╫ 256B |
╪ 256A |
┘ 2518 |
┌ 250C |
█ 2588 |
▄ 2584 |
▌ 258C |
▐ 2590 |
▀ 2580 |
| E | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
| F | Ё 0401 |
ё 0451 |
Є 0404 |
є 0454 |
Ї 0407 |
ї 0457 |
Ў 040E |
ў 045E |
° 00B0 |
∙ 2219 |
· 00B7 |
√ 221A |
№ 2116 |
¤ 00A4 |
■ 25A0 |
00A0 |
KOI8
Стандартом для русской кириллицы в юникс-подобных операционных системах является кодировка КОИ-8 (код обмена информацией, 8 битов), или KOI8. Существует несколько вариантов кодировки КОИ-8 для различных кириллических алфавитов. Русский алфавит описывается в кодировке KOI8-R, украинский — в KOI8-U, существуют также кодировки KOI8-RU (русско-белорусско-украинская), KOI8-T (таджикская) и т.д.
Разработчики КОИ-8 разместили символы русского алфавита таким образом, что если в тексте, написанном в КОИ-8, убирать восьмой бит каждого символа, то получается «читабельный» текст, хотя он и написан латинскими символами.
Вторая часть кодировки KOI8-R (русская), под символами указаны шестнадцатеричные коды Unicode:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | ─ 2500 |
│ 2502 |
┌ 250C |
┐ 2510 |
└ 2514 |
┘ 2518 |
├ 251C |
┤ 2524 |
┬ 252C |
┴ 2534 |
┼ 253C |
▀ 2580 |
▄ 2584 |
█ 2588 |
▌ 258C |
▐ 2590 |
| 9 | ░ 2591 |
▒ 2592 |
▓ 2593 |
⌠23 20 |
■ 25A0 |
∙ 2219 |
√ 221A |
≈ 2248 |
≤ 2264 |
≥ 2265 |
00A0 |
⌡ 2321 |
° 00B0 |
² 00B2 |
· 00B7 |
÷ 00F7 |
| A | ═ 2550 |
║ 2551 |
╒ 2552 |
ё 0451 |
╓ 2553 |
╔ 2554 |
╕ 2555 |
╖ 2556 |
╗ 2557 |
╘ 2558 |
╙ 2559 |
╚ 255A |
╛ 255B |
╜ 255C |
╝ 255D |
╞ 255E |
| B | ╟ 255F |
╠ 2560 |
╡ 2561 |
Ё 0401 |
╢ 2562 |
╣ 2563 |
╤ 2564 |
╥ 2565 |
╦ 2566 |
╧ 2567 |
╨ 2568 |
╩ 2569 |
╪ 256A |
╫ 256B |
╬ 256C |
© 00A9 |
| C | ю 044E |
а 0430 |
б 0431 |
ц 0446 |
д 0434 |
е 0435 |
ф 0444 |
г 0433 |
х 0445 |
и 0438 |
й 0439 |
к 043A |
л 043B |
м 043C |
н 043D |
о 043E |
| D | п 043F |
я 044F |
р 0440 |
с 0441 |
т 0442 |
у 0443 |
ж 0436 |
в 0432 |
ь 044C |
ы 044B |
з 0437 |
ш 0448 |
э 044D |
щ 0449 |
ч 0447 |
ъ 044A |
| C | Ю 042E |
А 0410 |
Б 0411 |
Ц 0426 |
Д 0414 |
Е 0415 |
Ф 0424 |
Г 0413 |
Х 0425 |
И 0418 |
Й 0419 |
К 041A |
Л 041B |
М 041C |
Н 041D |
О 041E |
| D | П 041F |
Я 042F |
Р 0420 |
С 0421 |
Т 0422 |
У 0423 |
Ж 0416 |
В 0412 |
Ь 042C |
Ы 042B |
З 0417 |
Ш 0428 |
Э 042D |
Щ 0429 |
Ч 0427 |
Ъ 042A |
Юникод (Unicode)
В Юникоде нет русских букв с ударением, поэтому приходится их делать составными, добавляя символ U+0301 («combining acute accent») после ударной гласной (например, ы́ э́ ю́ я́).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 400 | Ѐ | Ё | Ђ | Ѓ | Є | Ѕ | І | Ї | Ј | Љ | Њ | Ћ | Ќ | Ѝ | Ў | Џ |
| 410 | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| 420 | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| 430 | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| 440 | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
| 450 | ѐ | ё | ђ | ѓ | є | ѕ | і | ї | ј | љ | њ | ћ | ќ | ѝ | ў | џ |
| 460 | Ѡ | ѡ | Ѣ | ѣ | Ѥ | ѥ | Ѧ | ѧ | Ѩ | ѩ | Ѫ | ѫ | Ѭ | ѭ | Ѯ | ѯ |
| 470 | Ѱ | ѱ | Ѳ | ѳ | Ѵ | ѵ | Ѷ | ѷ | Ѹ | ѹ | Ѻ | ѻ | Ѽ | ѽ | Ѿ | ѿ |
| 480 | Ҁ | ҁ | ҂ | ҃ | ҄ | ҅ | ҆ | ҇ | ҈ | ҉ | Ҋ | ҋ | Ҍ | ҍ | Ҏ | ҏ |
| 490 | Ґ | ґ | Ғ | ғ | Ҕ | ҕ | Җ | җ | Ҙ | ҙ | Қ | қ | Ҝ | ҝ | Ҟ | ҟ |
| 4A0 | Ҡ | ҡ | Ң | ң | Ҥ | ҥ | Ҧ | ҧ | Ҩ | ҩ | Ҫ | ҫ | Ҭ | ҭ | Ү | ү |
| 4B0 | Ұ | ұ | Ҳ | ҳ | Ҵ | ҵ | Ҷ | ҷ | Ҹ | ҹ | Һ | һ | Ҽ | ҽ | Ҿ | ҿ |
| 4C0 | Ӏ | Ӂ | ӂ | Ӄ | ӄ | Ӆ | ӆ | Ӈ | ӈ | Ӊ | ӊ | Ӌ | ӌ | Ӎ | ӎ | ӏ |
| 4D0 | Ӑ | ӑ | Ӓ | ӓ | Ӕ | ӕ | Ӗ | ӗ | Ә | ә | Ӛ | ӛ | Ӝ | ӝ | Ӟ | ӟ |
| 4E0 | Ӡ | ӡ | Ӣ | ӣ | Ӥ | ӥ | Ӧ | ӧ | Ө | ө | Ӫ | ӫ | Ӭ | ӭ | Ӯ | ӯ |
| 4F0 | Ӱ | ӱ | Ӳ | ӳ | Ӵ | ӵ | Ӷ | ӷ | Ӹ | ӹ | Ӻ | ӻ | Ӽ | ӽ | Ӿ | ӿ |
| 500 | Ԁ | ԁ | Ԃ | ԃ | Ԅ | ԅ | Ԇ | ԇ | Ԉ | ԉ | Ԋ | ԋ | Ԍ | ԍ | Ԏ | ԏ |
| 510 | Ԑ | ԑ | Ԓ | ԓ | Ԕ | ԕ | Ԗ | ԗ | Ԙ | ԙ | Ԛ | ԛ | Ԝ | ԝ | Ԟ | ԟ |
| 520 | Ԡ | ԡ | Ԣ | ԣ | Ԥ | ԥ | Ԧ | ԧ | ||||||||
| 2DE0 | ⷠ | ⷡ | ⷢ | ⷣ | ⷤ | ⷥ | ⷦ | ⷧ | ⷨ | ⷩ | ⷪ | ⷫ | ⷬ | ⷭ | ⷮ | ⷯ |
| 2DF0 | ⷰ | ⷱ | ⷲ | ⷳ | ⷴ | ⷵ | ⷶ | ⷷ | ⷸ | ⷹ | ⷺ | ⷻ | ⷼ | ⷽ | ⷾ | ⷿ |
| A640 | Ꙁ | ꙁ | Ꙃ | ꙃ | Ꙅ | ꙅ | Ꙇ | ꙇ | Ꙉ | ꙉ | Ꙋ | ꙋ | Ꙍ | ꙍ | Ꙏ | ꙏ |
| A650 | Ꙑ | ꙑ | Ꙓ | ꙓ | Ꙕ | ꙕ | Ꙗ | ꙗ | Ꙙ | ꙙ | Ꙛ | ꙛ | Ꙝ | ꙝ | Ꙟ | ꙟ |
| A660 | Ꙡ | ꙡ | Ꙣ | ꙣ | Ꙥ | ꙥ | Ꙧ | ꙧ | Ꙩ | ꙩ | Ꙫ | ꙫ | Ꙭ | ꙭ | ꙮ | ꙯ |
| A670 | ꙰ | ꙱ | ꙲ | ꙳ | ꙼ | ꙽ | ꙾ | ꙿ | ||||||||
| A680 | Ꚁ | ꚁ | Ꚃ | ꚃ | Ꚅ | ꚅ | Ꚇ | ꚇ | Ꚉ | ꚉ | Ꚋ | ꚋ | Ꚍ | ꚍ | Ꚏ | ꚏ |
| A690 | Ꚑ | ꚑ | Ꚓ | ꚓ | Ꚕ | ꚕ | Ꚗ | ꚗ |
Что один человек закодировал, то другой завсегда раскодировать сможет. Сможет ли?
А. Алешин
Рассмотрим наиболее известные и важные виды кодировок, используемые в разных
операционных системах. Особое внимание уделим, конечно, кириллическим кодировкам, а именно
WIN1251, KOI7, KOI8R и др. Ранее, в разделе 7.1, мы познакомились со
стандартными английскими кодировками типа ASCII и новейшими универсальными кодировками Unicode.
Однако исторически появлению Unicode предшествовала целая серия кириллических кодировок, которые
и сейчас еще активно и часто используются в операционных системах и Интернет.
KOI-7
Кодировка KOI-7 (KOИ-7, Код Обмена Информацией, 7-ми битный) позволяет
кодировать 27 = 128 символов, из которых 32 буквы русского алфавита, 26 букв
латинского алфавита, 10 цифр и 26 печатаемых символа, пробел, специальные символы и непечатаемые
символы. Коды непечатаемых символов находятся в диапазоне 00-20 (с ними можно ознакомиться в
разделе 7.1, в таблице ASCII).
Замечательным правилом, действующим в этой кодировке является весовой
принцип кодирования латинских символов, для которого верно правило: Веса кодов букв
латинского алфавита увеличиваются на единицу в алфавитном порядке, то есть:
Код последующего символа = Код предыдущего символа + 1, или
Код D = Код C + 1, и так далее…
Пользуясь этим правилом, можно легко располагать слова в алфавитном порядке,
поскольку эта операция сводится к простому сравнению двоичных чисел, соответствующих кодам
символов. Для русских символов этот принцип несправедлив.
Каждый символ в кодировке KOI-7 представлен восьмиразрядным двоичным числом
(фактически, это один байт). Младшие 7 знакомест предназначены для кода самого символа, а самый
старший бит называется разрядом контроля четности и очень часто используется для
контроля ошибок, особенно при передаче данных. В этот разряд вписывают такое число (0 или 1),
чтобы сумма единиц, содержащихся в коде данного символа, было четным.
| Число | Символ | Число | Символ | Число | Символ | Число | Символ | Число | Символ | Число | Символ |
|---|---|---|---|---|---|---|---|---|---|---|---|
|
20 |
пробел |
30 |
0 |
40 |
@ |
50 |
P |
60 |
Ю |
70 |
П |
|
21 |
! |
31 |
1 |
41 |
A |
51 |
Q |
61 |
А |
71 |
Я |
|
22 |
« |
32 |
2 |
42 |
B |
52 |
R |
62 |
Б |
72 |
Р |
|
23 |
# |
33 |
3 |
43 |
C |
53 |
S |
63 |
С |
73 |
С |
|
24 |
$ |
34 |
4 |
44 |
D |
54 |
T |
64 |
Д |
74 |
Т |
|
25 |
% |
35 |
5 |
45 |
E |
55 |
U |
65 |
Е |
75 |
У |
|
26 |
& |
36 |
6 |
46 |
F |
56 |
V |
66 |
Ф |
76 |
Ж |
|
27 |
‘ |
37 |
7 |
47 |
G |
57 |
W |
67 |
Г |
77 |
В |
|
28 |
( |
38 |
8 |
48 |
H |
58 |
X |
68 |
Х |
78 |
Ь |
|
29 |
) |
39 |
9 |
49 |
I |
59 |
Y |
69 |
И |
79 |
Ы |
|
2A |
* |
3A |
: |
4A |
J |
5A |
Z |
6A |
Й |
7A |
З |
|
2B |
+ |
3B |
; |
4B |
K |
5B |
[ |
6B |
К |
7B |
Ш |
|
2C |
, |
3C |
< |
4C |
L |
5C |
\ |
6C |
Л |
7C |
Э |
|
2D |
— |
3D |
= |
4D |
M |
5D |
] |
6D |
М |
7D |
Щ |
|
2E |
. |
3E |
> |
4E |
N |
5E |
^ |
6E |
Н |
7E |
Ч |
|
2F |
/ |
3F |
? |
4F |
O |
5F |
Ъ |
6F |
О |
7F |
«забой» |
KOI-8R
Кодировка KOI-8R (KOИ-8, Код Обмена Информацией, 8-ми битный) позволяет
кодировать 28 = 256 символов, в число которых входят 31 прописная и 32
строчных букв русского алфавита, 26 прописных и 26 строчных букв латинского алфавита, 10 цифр,
32 служебных знака и специальные символы, предназначенные для управления устройствами и передачи
данных. Коды в диапазоне 21-5F соответствуют одинаковым символам как для KOI-7, так и для
KOI-8R.
| Код | Символ | Код | Символ | Код | Символ | Код | Символ | Код | Символ | Код | Символ | Код | Символ | Код | Символ | Код | Символ | Код | Символ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
20 |
пробел |
30 |
0 |
40 |
@ |
50 |
P |
60 |
\ |
70 |
p |
С0 |
ю |
D0 |
п |
E0 |
Ю |
F0 |
П |
|
21 |
! |
31 |
1 |
41 |
A |
51 |
Q |
61 |
а |
71 |
q |
С1 |
а |
D1 |
я |
E1 |
А |
F1 |
Я |
|
22 |
« |
32 |
2 |
42 |
B |
52 |
R |
62 |
b |
72 |
r |
С2 |
б |
D2 |
р |
E2 |
Б |
F2 |
Р |
|
23 |
# |
33 |
3 |
43 |
C |
53 |
S |
63 |
c |
73 |
s |
С3 |
ц |
D3 |
с |
E3 |
Ц |
F3 |
С |
|
24 |
$ |
34 |
4 |
44 |
D |
54 |
T |
64 |
d |
74 |
t |
С4 |
д |
D4 |
т |
E4 |
Д |
F4 |
Т |
|
25 |
% |
35 |
5 |
45 |
E |
55 |
U |
65 |
e |
75 |
u |
С5 |
е |
D5 |
у |
E5 |
Е |
F5 |
У |
|
26 |
& |
36 |
6 |
46 |
F |
56 |
V |
66 |
f |
76 |
v |
С6 |
ф |
D6 |
ж |
E6 |
Ф |
F6 |
Ж |
|
27 |
‘ |
37 |
7 |
47 |
G |
57 |
W |
67 |
g |
77 |
w |
С7 |
г |
D7 |
в |
E7 |
Г |
F7 |
В |
|
28 |
( |
38 |
8 |
48 |
H |
58 |
X |
68 |
h |
78 |
x |
С8 |
х |
D8 |
ь |
E8 |
Х |
F8 |
Ь |
|
29 |
) |
39 |
9 |
49 |
I |
59 |
Y |
69 |
i |
79 |
y |
С9 |
и |
D9 |
ы |
E9 |
И |
F9 |
Ы |
|
2A |
* |
3A |
: |
4A |
J |
5A |
Z |
6A |
j |
7A |
z |
СA |
й |
DA |
з |
EA |
Й |
FA |
З |
|
2B |
+ |
3B |
; |
4B |
K |
5B |
[ |
6B |
k |
7B |
( |
СB |
к |
DB |
ш |
EB |
Х |
FB |
Ш |
|
2C |
, |
3C |
< |
4C |
L |
5C |
\ |
6C |
l |
7C |
| |
СС |
л |
DC |
э |
EC |
Л |
FC |
Э |
|
2D |
— |
3D |
= |
4D |
M |
5D |
] |
6D |
m |
7D |
) |
СD |
м |
DD |
щ |
ED |
М |
FD |
Щ |
|
2E |
. |
3E |
> |
4E |
N |
5E |
^ |
6E |
n |
7E |
— |
СE |
н |
DE |
ч |
EE |
Н |
FE |
Ч |
|
2F |
/ |
3F |
? |
4F |
O |
5F |
Ъ |
6F |
o |
7F |
«забой» |
CF |
о |
DF |
ъ |
EF |
О |
FF |
«забой» |
Win1251 (CP1251)
Кодировка Win1251 (CP1251, Code Page 1251, кодовая страница) сейчас является
одной из наиболее распространенных в сети Интернет и персональных компьютерах (на которых
установлена операционная система Windows. Все Windows приложения должны понимать эту кодировку
без перевода.
CP866
Кодировка CP866 (Code Page 866, кодовая страница) в настоящее время можно
назвать реликтом, поскольку ее используют компьютеры, работающие под операционной системой MS
DOS и OS/2. Её же использует сеть ФИДО.
СЕМЕЙСТВО КОДИРОВОК 8859
Восьмибитное семейство кодировок 8859, созданное International Standorts
Organization, ISO, для наведения порядка в восьмибитных кодировках, расширило таблицу ASCII для
латинских букв с диакритикой и лигатур (кодировка ISO 8859-1), славянских языков с латинским
алфавитом, например, чешский, польский, венгерский, (ISO 8859-2), турецкого, мальтийского,
эсперанто, галисийского языков (ISO 8859-3), кириллицы (ISO 8859-5), арабского (ISO 8859-6),
греческого (ISO 8859-7), иврита (ISO 8859-8) и других языков. Кириллическая кодировка этого
семейства не получила широкого распространения, зато стандарт ISO 8859-1 (так называемая
Latin-1) стала стандартом для «расширенной» латиницы и содержит практически все символы
западноевропейских языков. Так, многие шрифты для Windows соответствуют кодировке ISO 8859-1
начиная с позиции 160 до конца таблицы, а в диапазоне 128-159 содержат дополнительные символы
(длинное тире или «торговая марка», например). Именно в этом семействе появилось понятие
«кодовая страница» (набор из 256 символов для каждого определённого языка или группы
языков). Крупным недостатком такого подхода является невозможность смешивания языков в одном
документе и отсутствие представления для китайского и японского языков.
<< Предыдущий
раздел Оглавление Следующий раздел >>
Одесский национальный университет им. И.И. Мечникова
Кафедра компьютерных и информационных технологий
Все права защищены © 
Web-страница автора
Алексей Алешин
![]()
Приложение
Таблица I
Базовая таблица кодировки ascii
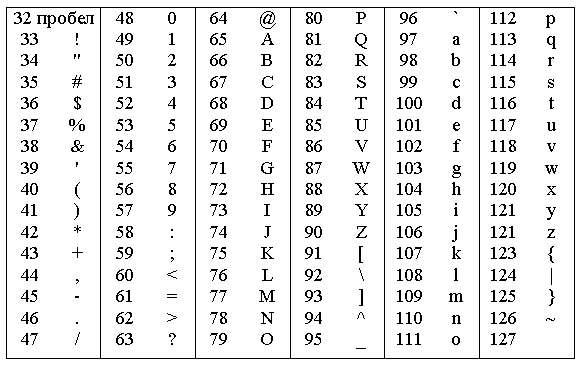
Таблица II
Кодировка Windows 1251

Таблица III
Кодировка кои-8

1
Федеральный
закон от 20 февраля 1995 г № 24-ФЗ. Собрание
законодательства Российской Федерации,
1995. №8.
2
Федеральный
закон от 4 июля1996 г № 85-ФЗ. Собрание
законодательства Российской Федерации,
1996. №28
3Аскеров
Т. М. Персональные ЭВМ и оргтехника. М.:
Изд-во РАГС, 1999.
4Cм.:
Гречишников А.В., Данчул А.Н., Павлов
А.Н. Алгоритмизация и визуальное
программирование управленческих задач.
— М.: Изд-во РАГС, 2000.
5
См.:
Юсупов Р.М., Заболотский В.П.
Научно-методологическите основы
информатизации. — СПб.: Наука, 2000,; Колин
К.К. Фундаментальные основы информатики:
социальная информатика. — М.: Академический
проект; Екатеринбург: Деловая книга,
2000; Сетевой журнал, 11, 1002, с. 76 и др.
6
См.:Совершенствование
государственного управления на основе
его реорганизации и информатизации.
Мировой опыт. Под ред. В.И. Дрожжинова.
— М.: Эко-трендз, 2002.
7Сетевой
журнал, 11, 1002, с. 45.
8
Известия,
5 марта 2002 г.
9
См.:
Юсупов Р.М., Заболотский В.П.
Научно-методологическите основы
информатизации.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- 1 Представление символов в вычислительных машинах
- 2 Таблицы кодировок
- 3 Кодировки стандарта ASCII
- 3.1 Структурные свойства таблицы
- 4 Кодировки стандарта UNICODE
- 4.1 Кодовое пространство
- 4.2 Модифицирующие символы
- 4.3 Способы представления
- 4.4 UTF-8
- 4.4.1 Принцип кодирования
- 4.4.1.1 Правила записи кода одного символа в UTF-8
- 4.4.1.2 Определение длины кода в UTF-8
- 4.4.1 Принцип кодирования
- 4.5 UTF-16
- 4.5.1 UTF-16LE и UTF-16BE
- 4.6 UTF-32
- 4.7 Порядок байт
- 4.7.1 Варианты записи
- 4.7.1.1 Порядок от старшего к младшему
- 4.7.1.2 Порядок от младшего к старшему
- 4.7.1.3 Переключаемый порядок
- 4.7.1.4 Смешанный порядок
- 4.7.1.5 Различия
- 4.7.2 Маркер последовательности байт
- 4.7.1 Варианты записи
- 4.8 Проблемы Юникода
- 5 Примеры
- 5.1 Код на python
- 5.2 hex-дамп файла exampleBOM
- 6 См. также
- 7 Источники информации
Представление символов в вычислительных машинах
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины , задается простой формулой . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов.
Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания.
Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение символов: основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до кодовых позиций, было принято решение использовать лишь для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее кодовых позиций ( графических и прочих символов).
Кодовое пространство разбито на плоскостей (англ. planes) по символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости и выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов ) или «U+xxxxx» (для кодов ) или «U+xxxxxx» (для кодов ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
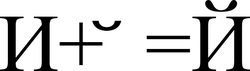
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими -битные символы. Текст, состоящий только из символов с номером меньше , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид , а остальные — .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
111111xx |
служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = байт
- Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 байт (то есть от до ):
- 2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления;
2 — 11 3 — 111 4 — 1111 5 — 1111 1 6 — 1111 11
- 2.2 «0» — бит терминатор, означающий завершение кода размера
- 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
(1 байт) 0aaa aaaa (2 байта) 110x xxxx 10xx xxxx (3 байта) 1110 xxxx 10xx xxxx 10xx xxxx (4 байта) 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx (5 байт) 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx (6 байт) 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
В общем случае количество значащих бит , кодируемых байтами UTF-8, определяется по формуле:
при
при
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством ), причем -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от до ). При этом можно кодировать символы Unicode в диапазонах и . Исключенный отсюда диапазон используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя -битными словами. Символы Unicode до включительно (исключая диапазон для суррогатов) записываются как есть -битным словом. Символы же в диапазоне (больше бит) уже кодируются парой -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число ). В результате получится значение от нуля до , которое занимает до бит. Старшие бит этого значения идут в лидирующее (первое) слово, а младшие бит — в последующее (второе). При этом в обоих словах старшие бит используются для обозначения суррогата. Биты с по имеют значения , а -й бит содержит у лидирующего слова и — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа , большего (здесь — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число записывается в позиционной системе счисления по основанию :
Набор целых чисел , каждое из которых лежит в интервале от до , является последовательностью байт, составляющих . При этом называется младшим байтом, а — старшим байтом числа .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление -байтных целых чисел на -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия

Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число , то прочитав его как int16 (два байта) мы получим число , прочитав один байт — число . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
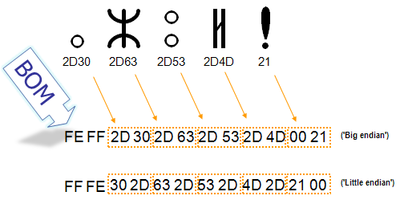
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF
|
| UTF-16 (BE) | FE FF
|
| UTF-16 (LE) | FF FE
|
| UTF-32 (BE) | 00 00 FE FF
|
| UTF-32 (LE) | FF FE 00 00
|
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его или байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на python
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOM
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
См. также
- Представление целых чисел: прямой код, код со сдвигом, дополнительный код
- Представление вещественных чисел
Источники информации
- Wikipedia — таблица ASCII
- Wikipedia — стандарт UNICODE
- Wikipedia — Byte order mark
- Wikipedia — Порядок байтов
- Wikipedia — Юникод
- Wikipedia — Windows-1251
- Wikipedia — UTF-8
- Wikipedia — UTF-16
- Wikipedia — UTF-32
Кодировка (или кодирование) – это процедура преобразования данных и сигналов из формы представления, удобной для восприятия человеком, в форму, которую распознает электронное устройство. Прием, позволяющий подготовить информацию для обработки, передачи, а также дальнейшего хранения.
Получаемые данные будут обрабатываться в виде логических единиц и нулей – в двоичной системе. Если числовые символы можно перевести в такую форму представления без проблем, то с кириллицей и другими буквами ситуация обстоит иначе. Буквы не поддерживают перевод в двоичный код. Вместо этого записи сначала преобразовываются в числа по специальной таблице символов. Далее компьютер считывает полученные данные и выдает результат.
В истории сложилось так, что были созданы несколько таблиц символов. Связано это с большим количеством национальных алфавитов, а также разными позициями относительно их написания.
Статья расскажет о существующих кодировках, а также поможет понять, как выразить символы кириллицы в UTF-8 и UTF-16.
Виды кодировок
Кодировать символы можно разными способами. Ситуация напрямую зависит от того, какая кодировка используется в системе. Существуют различные ее виды. Основные:
- ASCII;
- CP866;
- KOI8-R;
- Windows 251;
- Unicode.
Чаще всего встречаются первая и последняя кодировки. Не все они распознают буквы русского алфавита. Далее каждый вариант будет рассмотрен более подробно. А еще предстоит выяснить, что делать, если при попытке закодировать кириллицу на экране появляются непонятные записи.
ASCII – базовая кодировка
ASCII – American Standard Code for Information Interchange. В русском языке произносится как «Аски». Базовая кодировка для работы устройств. Первые 128 ее символов являются наиболее используемыми. Они включают в себя:
- латинские буквы;
- цифры (арабские);
- служебные компоненты;
- знаки препинания.
Для кодировки используется один байт. Это привело к тому, что у ASCII появились расширенные версии. Изначально данные таблицы не предоставляли возможность работы с кириллицей и русскими символами. Вместо них на экране появлялись непонятные записи – «кракозябры».


Выше представлены стандартные таблицы ASCII. В них русского алфавита нет – он не предусмотрен действующими правилами.
Расширенные ASCII
ASCII положила начало развития актуальных современных таблиц кодирования информации. Изначально она содержала 128 составляющих, но в расширенной версии их стало 256. Это дало возможность добавления новых алфавитов для корректного распознавания информации и ее дальнейшего отображения на дисплее устройства.
Первая расширенная версия ASCII – это CP866. В ней реализована первая таблица кодировки русских букв. Верхняя часть CP866 полностью совпадает с базовым «Аски», а нижняя позволяет закодировать кириллицу и некоторые символы, которых нет на клавиатуре.

Выше расположена кодовая таблица CP866. Она распространялась компанией IBM и использовалась преимущественно в DOS-системах.
Кириллица с момента образования CP866 стала активно использоваться к компьютерной технике. Это привело к созданию совершенно новых кодировок с русскими символами. Пример – KOI8-R.
Здесь каждый символ тоже кодируется одним байтом. Первая часть соответствует классической ASCII. Во второй располагаются специальные записи, которых нет на клавиатуре, а также русские буквы.
KOI8-R отличается тем, что буквы в русского языка в ней располагаются не в алфавитном порядке. Они располагаются по принципу созвучия с латиницей. Данный прием предпринят для того, чтобы было удобнее переходить с кириллицы на латинские буквы, отбрасывая всего один бит.
Windows 1251
Дальнейшее развитие кодировок связано с появлением графических операционных систем. Для отображения информации на экране псевдографика стала ненужной. Так возникли группы, которые выступали в качестве расширенных версий ASCII, но являлись более совершенными. Псевдографика в них отсутствовала. Они получили название ANSI.
Наглядный и весьма распространенный вариант такой кодировки – это Windows 1251. Он отличается от предшественников следующими особенностями:
- Вместо псевдографики здесь располагаются недостающие символы кириллицы и русской типографики. Знак ударения – единственное исключение. Его там нет.
- На замену псевдографики пришли элементы, приближенные к кириллице – буквы славянских языков.
- Первые 32 элемента отведены под операции, перевод строки и пробел.
- До 127 элемента расположены интернациональные компоненты, латинский алфавит, знаки препинания и математических действий, цифры.
- Оставшееся «пространство» выделено под национальные элементы. Именно они отображают различные мировые алфавиты.

Кодовая таблица, представленная выше – часть Windows 1251, отведенная под кириллицу и иные элементы.
Unicode
Unicode – кодировка, которая пользуется наибольшим спросом в современных компьютерных устройствах. Этот стандарт включает в себя почти все знаки существующих письменных языков. Он преобладает в Интернете. Был создан в 1991 году.
Unicode является многоязычным стандартом, базирующимся на ASCII. Он включает не только кириллицу, но и азиатские иероглифы. Выступает в качестве универсальной кодировки. Включает в себя несколько стандартов.
UTF-32
Первая вариация Unicode. Для кодирования одного элемента здесь используются 32 бита или 4 байта. Данная особенность приводит к тому, что закодированный кириллический символ в UTF-32 будет иметь вес в 4 раза больше, чем в ASCII. Несмотря на соответствующий недостаток, система стала предлагать закодировать знаки в количестве 232.
Все символы в UTF-32 непосредственно индексируемы. Найти тот или иной знак по номеру его позиции в файле удается очень быстро. Это привело к быстрой обработке операций по замене символьных данных.
UTF-16
UTF-16 – новый, более совершенный стандарт Unicode. После появления стала выступать базовым пространством для всех используемых печатных элементов. Кириллическая таблица в ней тоже есть.

Коды символов в UTF-16 содержатся в 16-ричной системе счислений. Увидеть их можно, если перейти в раздел Windows «Таблица символов». Она располагается в меню «Пуск»–«Программы»–«Стандартные»–«Служебные».
При помощи UTF-16 можно закодировать 65 536 элементов. Это число стало базовым для Unicode. Расширенное пространство включает в себя миллион дополнительных символьных записей.
При переходе с ASCII на UTF-16 размер исходного кода документа увеличивается уже не в 4, а в 2 раза. Связано это с использованием 2 байтов для кодирования одного и того же символа или шестнадцать бит.
UTF-8
Со временем был разработан стандарт UTF-8. В нем тоже есть кириллическая кодовая таблица. Носит название переменной длины. Несмотря на то, что в названии стандарта стоит 8, она действительно меняется. Каждый элемент может получить код длиной от 1 до 6 байт включительно. Практически стандартом используются компоненты до 4 байт. Латинские буквы здесь содержатся в одном байте, как и в ASCII.
В UTF-8 русские символы занимают по 2 байта, а грузинские – по 3. Текущий стандарт предусматривает возможность печати не только букв, но и смайликов. С UTF-8 хорошо работают даже системы, которые не ориентированы на Unicode. Связано это с тем, что базовая часть ASCII перешла в новый стандарт Юникода.
Блоки кириллицы
Unicode, начиная с версии 9.0, для кириллицы отвел пять различных блоков:
| Как называется | Диапазон кодов типа hex | Версия Unicode | |
| Cyrillic | Стандартная кириллица | От 0400 до 04FF | 1.1 |
| Cyrillic Supplement | Дополнения | От 0500 до 052F | 3.2 |
| Cyrillic Extended-A | Расширенная кириллица–А | От 2DE0 до 2DFF | 5.1 |
| Extended-B | Кириллица расширенного типа–B | От A640 до A69F | |
| Extended-C | Кириллица расширенная–C | От 1C80 до 1C8F | 9.0 |
Эти 4 раздела содержатся в кодовом пространстве Unicode 448 позиций. Из них 22 не определены.
Все символы кириллицы можно разбить на несколько групп:
- славянские алфавиты;
- исторические буквы и старославянский (церковный славянский) алфавит;
- дополнительные буквы для различных языков, использующих кириллицу;
- церковнославянские буквотипы;
- дополнительные буквы и символы для церковнославянского языка;
- элементы для старой орфографии Абхазии;
- старые формы представления кириллицы.
Несмотря на относительное совершенство Unicode, при использовании кодировок кириллицы в UTF-8 и других возникают некоторые проблемы. Пример – неоднозначность относительно кодирования некоторых букв. Для того, чтобы привести текст к единому стилю и корректному отображению, приходится определять каждым конкретным стандартом форму нормализации информации.
Непонятные символы на экране – исправление
Любая страница данных может быть закодирована не только в ASCII, но и в Unicode. Главное правильно выбрать кодировку для русского текста. Если на экране вместо нормальных текстовых данных отображаются «кракозябры» (или непонятные надписи), значит возникла проблема перекодирования.
Для редактирования и создания новых текстовых документов можно использовать различные приложения, поддерживающие работу не только с Unicode. Тогда вероятность возникновения ошибок отображения информации будет сведена к минимуму. Пример – Notepad++. Он умеет подсвечивать синтаксис сотен языков программирования и разметки, что станет особо полезным при программировании проектов.
Чтобы страница, содержащая текст, была приведена от одного стандарта к другому, потребуется:
- Выделить текст в Notepad++.
- Нажать на кнопку «Кодировка» на верхней панели инструментов.
- Выбрать подходящий вариант. Пример – «Преобразовать в UTF-8».
Желательно выбирать вариант кодировки UTF-8 без BOM для русского языка, отображаемого на странице в документе или на сайте. Этот прием поможет сохранить данные без сигнатуры (добавления лишних трех байтов в самое начало документов).
Десятичная система
При преобразовании информации из одной системы счисления (и кодировки) в другую, могут потребоваться ее десятичные значения. Такой вариант используется в ASCII и UTF-32. При помощи него можно перевести символ в удобную для восприятия компьютером форму. А еще – выполнить дальнейшую перекодировку в те или иные системы счисления.
Десятичная система помогает в Windows вводить различные символы при помощи сочетания с Alt. Для перевода кириллицы в UTF-8 format поможет таблица ниже.



В Unicode transformation символьных записей производится при помощи целых чисел без знаков. Необходимые преобразования помогут выполнить специализированные сайты-конвертеры. Самостоятельно такие операции практически не используются. Таблицы соответствия и конвертеры сильно облегчают эту задачу.
Как освоить кодирование информации
Русская кодировка может некорректно отображаться в некоторых приложениях, а также операционных системах. Связано это с тем, что не все стандарты кодирования данных имеют коды для соответствующих элементов.
Чтобы лучше разобраться в программировании, а также грамотном использовании стандартов кодирования и переводе текста из одной системы в другую, рекомендуется закончить дистанционные онлайн курсы. Они предлагают:
- постоянное кураторство;
- домашние задания и интересные практические задачи;
- возможность освоить инновационные профессии и направления в мире IT в сжатые сроки;
- помощь в формировании портфолио;
- разнообразие направлений – есть предложения как для новичков, так и для взрослых.
По завершении курса обучения ученик получит сертификат в электронной форме, подтверждающий приобретенный спектр знаний и умений.
Хотите стать профессионалом в сфере обработки данных? Добро пожаловать на курсы в Otus:
- Промышленный ML на больших данных
- Data Warehouse Analyst
- Data Engineer