На одной из встреч питерского сообщества .Net разработчиков SpbDotNet Community мы пошли на эксперимент и решили рассказать о том, как можно применять подходы, давно ставшие стандартом в мире Linux, для автоматизации Windows-инфраструктур. Но дабы не доводить всё до голословного размахивания флагом Ansible, было принято решение показать это на примере развёртывания ASP.Net приложения.
Быть спикером вызвался Алексей Чернов, Senior Developer команды, разрабатывающей библиотеки UI-компонентов для наших проектов. И да, вам не показалось: выступать перед .Net аудиторией пошёл JavaScript разработчик.
Кто заинтересовался итогом такого эксперимента, милости просим под кат за расшифровкой.
Привет) Тут уже немного заспойлерили и сказали, что я фронтендер, так что можете уже расходиться =) Меня зовут Алексей, я занимаюсь всяким-разным про веб разработку довольно давно. Начинал с Perl, потом был PHP, немного RoR, немного того, чуть-чуть этого. А потом в мою жизнь ворвался JavaScript, и с тех пор я занимаюсь практически только этим.
Помимо JS, последнее время я пишу довольно много автотестов (причём на том же JS), и поэтому приходится заниматься автоматизацией деплоя тестовых стендов и самой инфраструктуры для них.
Предыстория
Два года назад я оказался в Veeam, где разрабатывают продукты под Windows. В тот момент я очень удивился, но оказалось, что и так бывает =). Но больше всего меня удивил непривычно низкий уровень автоматизации всего, что связано с деплоем, с разворачиванием приложений, с тестированием и т.д.
Мы — те, кто разрабатывает под Linux — уже давно привыкли, что всё должно быть в Docker, есть Kubernetes, и всё разворачивается по одному клику. И когда я оказался в среде, где всего этого нет, это шокировало. А когда я начал заниматься автотестами, я понял, что это всего лишь 20% успеха, а всё остальное это подготовка инфраструктуры для них.

Мои ощущения в начале
Текущие условия
Немного расскажу про то, как у нас всё устроено, что нам приходится автоматизировать и чем мы занимаемся.
У нас есть куча разных продуктов, большинство из них под Windows, есть несколько под Linux и даже что-то под Solaris имеется. Ежедневно собирается довольно много билдов для всех продуктов. Соответственно, надо это всё раскатывать в тестовых лабах, как для QA, так и для самих разработчиков, чтобы они могли проверять интеграцию приложений. Всё это требует огромной инфраструктуры из множества железных серверов и виртуальных машин. А ещё иногда мы проводим тестирование производительности, когда надо поднимать сразу по тысяче виртуалок и смотреть, насколько быстро наши приложения будут работать.
Проблемы
Конечно же, на первых этапах (читай, давно) при попытке автоматизировать всё в лоб был использован PowerShell. Инструмент мощный, но скрипты деплоя получаются крайне переусложнёнными. Другая проблема заключалась в отсутствии централизованного управления этим процессом. Какие-то скрипты запускались локально у разработчиков, какие-то на виртуалках, созданных ещё в эпоху мамонтов, и т.д. Как итог: трудно был получить единый результат и понять, что работает, а что нет. Ты приходишь на работу, открываешь браузер — сервер недоступен. Почему недоступен, что случилось, где сломалось — было совершенно не понятно. Не было единой точки входа, и приходилось искать правду по рабочим чатикам, и хорошо, если кто-то отвечал.
Другая проблема, не такая очевидная — это новички. Им было сложно. Первую неделю работы они просто вникали в происходящее. Мы по привычке жили с этим, успокаивая себя тем, что жизнь — штука сложная и надо смириться. Понять и простить, так сказать.
Но в какой-то момент нашли внутренние силы перебороть это и посмотреть по сторонам. Вероятно, как-то с этим можно справиться.

Первый шаг на пути решения проблемы — её принятие
Подбор решения
Когда не знаешь, что делать, посмотри, что делают другие.
И для начала мы составили свой список требований к тому, что мы хотим получить в конце.
- Единая кодовая база. Все скрипты деплоя должны лежать в одном месте. Хочешь что-то развернуть или посмотреть, как оно разворачивается: вот тебе репозиторий, иди туда.
- Все знают, как это работает. Должны исчезнуть вопросы а-ля «Я не понимаю, как это развернуть, поэтому второй день не могу закрыть багу».
- Возможность запуска по кнопке. Нам нужно иметь возможность контроля деплоев. Например, какой-то веб интерфейс, куда заходишь, нажимаешь кнопку, и разворачивается нужный продукт на нужном хосте.
Убедившись, что данный список покрывает минимум необходимых и достаточных требований для нашего счастья, мы начали пробовать. Традиционно, первым делом попытались решать проблемы методом лобовой атаки. У нас много PowerShell скриптов? Так давайте объединим их в один репозиторий. Но проблема не в том, что скриптов было слишком много, а в том, что разные команды делали одно и тоже разными скриптами. Я походил по разным командам, послушал их требования, собрал одинаковые скрипты, попытался их как-то более-менее причесать и параметризировать, а потом сложил в единый репозиторий.
Fail: Попытка провалилась. Во-первых, мы стали очень много спорить, почему мы делаем так, а не этак. Почему был использован это метод, а не какой-то другой и т.д. И как следствие, появилось много желающих переделать всё «как надо», по принципу «Я сейчас форкнусь и всё за вас перепишу». А объединить ветки с таким подходом, конечно, не удастся.
Попытка номер два: предполагалось взять наш CI-сервер (TeamCity), сделать на нём некие шаблоны и с помощью наследования закрыть основную проблему из первой попытки. Но, как вы могли сразу догадаться, тут нас тоже ждал Fail: Можно использовать шаблон только последней версии, а значит, мы не добьёмся необходимой версионности. И следствие большого количества команд — шаблонов становилось очень много, управлять ими становилось всё сложнее, а на горизонте отчётливо виднелось новое болото.

Устав падать лицом о землю при всякой попытке взлететь, было решено ещё раз сесть и крепко подумать. Итак, у нас есть большая куча ps-скриптов с одной стороны и огромное количество виртуалок с другой. Но мы ошибались, т.к. корень проблемы был совершенно не в этом. Проблема была в том, что между этими вещами всегда был человек. Неважно, будь то разработчик, тестировщик или ещё кто-то, в голове всегда происходила примерно такая логическая цепочка:
- Так, мне нужна виртуалка для тестов
- Ага, вот у нас есть пул хостов
- А вот нужный мне скрипт, сейчас запущу его, и всё случится
С осознанием такой вроде бы простой вещи общая проблема заиграла новыми красками. Оказалось, что все наши боли от отсутствия единого описания нашей инфраструктуры. Она была в головах людей, её создававших, они сидели в разных отделах, не стремились как-то её документировать, и вообще каждый жил в своём отдельном государстве.
В этот момент мы пришли к тому, что ответ на все наши проблемы это:
Infrastructure as a Code
Это именно о том, что вся наша инфраструктура должна быть описана в коде и лежать в репозитории. Все виртуалки, все их параметры, всё, что туда устанавливается — всё надо описать в коде.
Возникает законный вопрос — зачем?
Отвечаем: такой подход даст нам возможность применять лучшие практики из мира разработки, к которым мы все так привыкли:
- Version control. Мы всегда сможем понимать, что и когда поменялось. Больше никаких пришедших из ниоткуда или пропавших в никуда хостов. Всегда будет понятно, кто внёс изменения.
- Code Review. Мы сможем контролировать процессы деплоя, чтобы одни не ущемляли других.
- Continuous Integration.
Выбор инструмента
Как все мы знаем, инструментов для управления конфигурациями довольно много. Мы свой выбор остановили на Ansible, поскольку он содержит набор фич, необходимых именно нам.
Прежде всего, от системы автоматизации мы хотим, не чтобы запускались какие-то инсталляторы, что-то куда-то мигрировало и т.д. Прежде всего от такой системы мы хотим, чтобы после нажатия одной кнопки мы видели UI необходимого нам приложения.
Поэтому ключевая для нас фишка — идемпотентность. Ansible не важно, что было с системой «до». После запуска нужного плейбука мы всегда получаем один и тот же результат. Это очень важно, когда ты говоришь не «Установи IIS», а «Тут должен быть IIS», и тебе не надо думать, был он там до этого, или нет. Скриптами такого достичь очень сложно, а плейбуки Ansible дают такую возможность.
Также надо упомянуть безагентность Ansible. Большинство систем автоматизации работает через агентов. В этом есть много своих плюсов — например, лучший перфоманс — но нам было важно отсутствие агента, чтобы систему не приходилось дополнительно как-то подготавливать.
PowerShell:
$url = "http://buildserver/build.msi"
$output = "$PSSscriptRoot\build.msi"
Invoke-WebRequest -Uri $url -OutFile $outputAnsible:
name: Download build
hosts: all
tasks:
name: Download installer
win_get_url:
url: "http://buildserver/build.msi"
dest: "build.msi"
force: noТут мы видим, что в базовом примере ps-скрипт будет даже лаконичнее, чем Ansible плейбук. 3 строчки скрипта против 7 строчек плейбука ради того, чтобы скачать файл.
Но, Петька, есть нюанс (с). Как только мы захотим соблюсти принцип идемпотентности и, например, быть уверенным, что файл на сервере не изменился и его не надо качать, в скрипте придётся реализовать HEAD-запрос, что добавляет примерно 200 строчек. А в плейбук — одну. Модуль Ansible win_get_url, который делает за вас все проверки, содержит 257 строк кода, которые не придётся вставлять в каждый скрипт.
А это только один пример очень простой задачи.

И если задуматься, идемпотентность нужна нам везде:
- Проверить существование виртуальной машины. В случае скриптов мы рискуем или плодить бесконечное их множество, или скрипт будет падать в самом начале.
- Какие msi пакеты есть на машине? В лучшем случае тут ничего не упадёт, в худшем машина перестанет адекватно работать.
- Надо ли заново качать билд-артефакты? Хорошо, если ваши билды весят десяток мегабайт. А что делать тем, у кого пару гигабайт?
И другие примеры, где выход из ситуации — это раздувать скрипты бесконечными ветвлениями if’ов, которые невозможно будет адекватно отлаживать и невозможно управлять.
Среди прочих важных для нас вещей можно отметить, что Ansible не использует агентов для управления вашими хостами и машинами. На Linux, понятное дело, он ходит по ssh, а для Windows используется WinRM. Отсюда очевидное следствие: Ansible кроссплатформенный. Он поддерживает какое-то фантастическое количество платформ, вплоть до сетевого оборудования.
И последний, но не менее важный — это YAML формат записи конфигов. Все к нему привыкли, он легко читается, и не составляет труда разобраться, что там происходит.
Но не всё так сладко, есть и проблемы:
- Проблема сомнительная: для запуска плейбуков вам всё равно понадобится Linux-машина, даже если вся ваша инфраструктура исключительно Windows. Хотя это не такая большая проблема в современном мире, т.к. на Windows 10 теперь имеется WSL, где можно запустить Ubuntu, под которой гонять плейбуки.
- Иногда плейбуки действительно сложно отлаживать. Ansible написан на python, и последнее, что хочется увидеть, это простыню питоновского стек-трейса на пять экранов. А виной всему может послужить опечатка в названии модуля
Как это работает?
Для начала нам нужна машина c Linux. В терминологии Ansible это называется Control Machine.
С неё будут запускаться плейбуки, и на ней происходит вся магия.
На этой машине нам понадобятся:
- Python и питоновский пакетный менеджер pip. На многих дистрибутивах есть из коробки, так что тут без сюрпризов.
- Устанавливаем Ansible через pip, как наиболее универсальный способ: pip install ansible
- Добавляем winrm модуль, чтобы ходить на Windows машины: pip install pywinrm[credssp]
- И на машинах, которыми хотим управлять, надо winrm включить, т.к. по умолчанию он выключен. Есть много способов, как это сделать, и все они описаны в документации Ansible. Но простейший — это взять готовый скрипт из репозитория Ansible и запустить его с требуемым вариантом авторизации: ConfigureRemotingForAnsible.ps1 -EnableCredSSP
Самая важная часть, которую нам надо было получить, чтобы перестать страдать с ps-скриптами — это Inventory. YAML файл (в нашем случае), в котором описана наша инфраструктура и куда можно всегда заглянуть, чтобы понять, где что деплоится. И, конечно же, сами плейбуки. В дальнейшем работа выглядит как запуск плейбука с необходимым инвентори-файлом и дополнительными параметрами.
all:
children:
webservers:
hosts:
spbdotnet-test-host.dev.local:
dbservers:
hosts:
spbdotnet-test-host.dev.local:
vars:
ansible_connection: winrm
ansible_winrm_transport: credssp
ansible_winrm_server_cert_validation: ignore
ansible_user: administrator
ansible_password: 123qweASDЗдесь всё просто: корневая группа all и две подгруппы, webserves и dbservers. Всё остальное интуитивно понятно, только заострю ваше внимание, что Ansible по умолчанию считает, что везде Linux, поэтому для Windows надо обязательно указать winrm и тип авторизации.
Пароль в открытом виде, конечно, в плейбуке хранить не надо, здесь просто пример. Хранить пароли можно, например, в Ansible-Vault. Мы для этого используем TeamCity, который передаёт секреты через переменные окружения и ничего не палит.
Модули
Всё что делает Ansible, он делает с помощью модулей. Модули для Linux написаны на python, для Windows на PowerShell. И реверанс в сторону идемпотентности: результат работы модуля всегда приходит в виде json-файла, где указывается, были изменения на хосте или нет.
В общем случае мы будем запускать конструкцию вида ansible группа хостов инвентори файл список модулей:

Плейбуки
Плейбук это описание того, как и где мы будем выполнять модули Ansible.
- name: Install AWS CLI
hosts: all
vars:
aws_cli_download_dir: c:\downloads
aws_cli_msi_url: https://s3.amazonaws.com/aws-cli/AWSCLI32PY3.msi
tasks:
- name: Ensure target directory exists
win_file:
path: "{{ aws_cli_download_dir }}"
state: directory
- name: Download installer
win_get_url:
url: "{{ aws_cli_msi_url }}"
dest: "{{ aws_cli_download_dir }}\\awscli.msi"
force: no
- name: Install AWS CLI
win_package:
path: "{{ aws_cli_download_dir }}\\awscli.msi"
state: presentВ этом примере у нас три таски. Каждая таска — это вызов модуля. В этом плейбуке мы сначала создаём директорию (убеждаемся, что она есть), затем скачиваем туда AWS CLI и с помощью модуля win_packge устанавливаем его.
Запустив этот плейбук, мы получим такой результат.

В отчёте видно, что было успешно выполнено четыре таски и три из четырёх произвели какие-то изменения на хосте.
Но что будет, если запустить этот плейбук ещё раз? У нас нигде не написано, что мы должны именно создавать директорию, скачать файл-установщик и запустить его. Мы просто проверяем наличие каждого из пунктов и пропускаем при наличии.

Это и есть та самая идемпотентность, которую мы никак не могли добиться с PowerShell.
Практика
Это немного упрощённый пример, но, в принципе, это именно то, что мы делаем каждый день.
Деплоить будем приложение, состоящее из Windows сервиса и веб приложения под IIS.
- name: Setup App
hosts: webservers
tasks:
- name: Install IIS
win_feature:
name:
- Web-Server
- Web-Common-Http
include_sub_features: True
include_management_tools: True
state: present
register: win_feature
- name: reboot if installing Web-Server feature requires it
win_reboot:
when: win_feature.reboot_required Для начала нам надо посмотреть, есть ли вообще IIS на хосте, и установить его, если нет. И хорошо бы туда сразу добавить тулзы управления и все зависимые фичи. И совсем хорошо, если хост будет перезагружен при необходимости.
Первую задачу мы решаем модулем win_feature, который занимается управлением фичами Windows. И тут у нас впервые появляются переменные окружения Ansible, в пункте register. Помните, я говорил, что таски всегда возвращают json объект? Теперь, после выполнения таски Install IIS в переменной win_feature лежит вывод модуля win_feature (уж простите за тавтологию).
В следующей таске мы вызываем модуль win_reboot. Но нам не надо каждый раз перезагружать наш сервер. Мы перезагрузим его, только если модуль win_feature вернет нам это требование в виде переменной.
Следующим этапом устанавливаем SQL. Чтобы сделать это, придуман уже миллион способов. Я здесь использую модуль win_chocolatey. Это пакетный менеджер для Windows. Да, именно то самое, к чему мы так привыкли на Linux. Модули поддерживаются комьюнити, и сейчас их уже больше шести тысяч. Очень советую попробовать.
- name: SQL Server
hosts: dbservers
tasks:
- name: Install MS SQL Server 2014
win_chocolatey:
name: mssqlserver2014express
state: presentТак, хост мы подготовили к запуску приложения, давайте его деплоить!
- name: Deploy binaries
hosts: webservers
vars:
myapp_artifacts: files/MyAppService.zip
myapp_workdir: C:\myapp
tasks:
- name: Remove Service if exists
win_service:
name: MyAppService
state: absent
path: "{{ myapp_workdir }}\\MyAppService.exe"На всякий случай, первым делом мы удаляем существующий сервис.
- name: Delete old files
win_file:
path: "{{ myapp_workdir }}\\"
state: absent
- name: Copy artifacts to remote machine
win_copy:
src: "{{ myapp_artifacts }}"
dest: "{{ myapp_workdir }}\\"
- name: Unzip build artifacts
win_unzip:
src: "{{ myapp_workdir }}\\MyAppService.zip"
dest: "{{ myapp_workdir }}"Следующим шагом мы загружаем на хост новые артефакты. В этом плейбуке подразумевается, что запускается он на билд-сервере, все архивы лежат в известной папочке, а путь к ним мы указываем переменными. После копирования (win_copy) архивы распаковываются(win_unzip). Дальше мы просто регистрируем сервис, говорим путь к exe и что он должен быть запущен.
- name: Register and start the service
win_service:
name: ReporterService
start_mode: auto
state: started
path: "{{ myapp_workdir }}\\MyAppService.exe"Готово!?
Вроде наш сервис готов к труду и обороне, правда, есть одно «но» — мы не соблюли принцип идемпотентности. Мы всегда удаляем существующий код и потом деплоим новый.
И это проблема. Если мы удалили старый задеплоеный сервис, а после произошла какая-то ошибка, и плейбук не завершил свою работу, мы получим разломанный хост. Или, например, мы деплоим одновременно несколько приложений, из которых одно не изменилось, то нам не надо деплоить его тоже.
Что можно сделать? Как вариант, можно проверять контрольную сумму наших артефактов и сравнивать их с лежащими на сервере.
- name: Get arifacts checksum
stat:
path: "{{ myapp_artifacts }}"
delegate_to: localhost
register: myapp_artifacts_stat
- name: Get remote artifacts checksum
win_stat:
path: "{{ myapp_workdir }}\\MyAppService.zip"
register: myapp_remote_artifacts_stat Мы используем модуль stat, который предоставляет всякую информацию о файлах и в том числе контрольную сумму. Далее с помощью уже знакомой директивы register пишем результат в переменную. Из интересного: delegate_to указывает, что это надо выполнить на локальной машине, где запускается плейбук.
- name: Stop play if checksums match
meta: end_play
when:
- myapp_artifacts_stat.stat.checksum is defined
- myapp_remote_artifacts_stat.stat.checksum is defined
- myapp_artifacts_stat.stat.checksum == myapp_remote_artifacts_stat.stat.checksumИ с помощью модуля meta мы говорим, что надо закончить выполнение плейбука, если контрольные суммы артефактов на локальной и удалённой машине совпадают. Вот так мы соблюли принцип идемпотентности.
- name: Ensure that the WebApp application exists
win_iis_webapplication:
name: WebApp
physical_path: c:\webapp
site: Default Web Site
state: presentТеперь посмотрим на наше веб-приложение. Опускаем часть про копирование файлов, переходим сразу к сути. Наш билд-сервер сделал паблиш, загружаем всю рассыпуху файлов на хост и используем встроенный модуль для работы с IIS-приложениями. Он создаст приложение и запустит его.
Переиспользование кода
Одна из поставленных нами задач была: дать возможность любому инженеру в компании легко запустить деплой. Он пишет свой плейбук из готовых модулей, говорит, что ему надо запустить такой-то продукт на таком-то хосте.
Для этого в Ansible есть Роли. По сути, это конвенция. Мы создаём на сервере папочку /roles/ и кладём в неё наши роли. Каждая роль — это набор конфигурационных файлов: описание наших тасок, переменных, служебных файлов и т.д. Обычно ролью делают какую-то изолированную сущность. Установка IIS — отличный пример, если нам надо не просто его установить, но и как-то дополнительно сконфигурировать или проверить дополнительными тасками. Мы делаем отдельную роль и, таким образом, изолируем все относящиеся к IIS плейбуки в папке с ролями. В дальнейшем мы просто вызываем эту роль директивной include_role %role_name%.
Естественно, мы сделали роли для всех приложений, оставив возможность для инженеров, с помощью конфигурационных параметров как-то кастомизировать процесс.
- name: Run App
hosts: webservers
tasks:
- name: "Install IIS"
include_role:
name: IIS
- name: Run My App
include_role:
name: MyAppService
vars:
myapp_artifacts: ./buld.zipВ этом примере для роли Run My App заложена возможность передавать какой-то свой путь к артефактам.
Тут надо замолвить слово про Ansible Galaxy — репозиторий общедоступных типовых решений. Как заведено в приличном обществе, множество вопросов уже было решено до нас. И если возникает ощущение, что вот сейчас мы начнём изобретать велосипед, то сначала надо посмотреть список встроенных модулей, а потом покопаться в Ansible Galaxy. Вполне вероятно, что нужный вам плейбук уже был сделан кем-то другим. Модулей там лежит огромное количество, на все случаи жизни.
Больше гибкости
А что делать, если не нашлось ни встроенного модуля, ни подходящей роли в Galaxy? Тут два варианта: или мы что-то делаем не так, или у нас действительно уникальная задача.
В случае второго варианта мы всегда можем написать свой модуль. Как я показывал в начале, Ansible даёт возможность написать простейший модуль буквально за 10 минут, а когда вы углубитесь, вам на помощь приходит довольно подробная документация, покрывающая множество вопросов.
CI
В нашем отделе мы очень любим TeamCity, но тут может быть любой другой CI-сервер на ваш выбор. Для чего нам совместное их использование?
Во-первых, мы всегда можем проверить корректность синтаксиса наших плейбуков. Пока YAML считает табы синтаксической ошибкой, это очень полезная фича.
Также на CI-сервере мы запускаем ansible-lint. Это статический анализатор ansible конфигов, который выдаёт список рекомендаций.
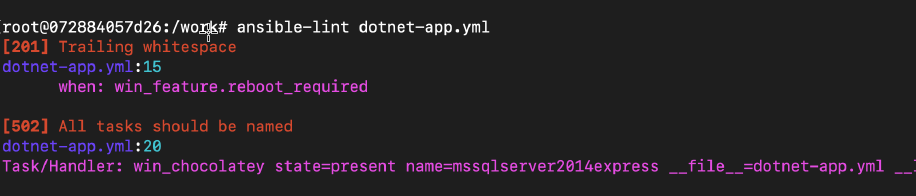
Например, здесь он говорит, что у нас лишний пробел в конце строки, и для одной таски не задано имя. Это важно, т.к. имя модуля может встречаться в одном плейбуке несколько раз, и все таски должны быть именованы.
Само собой, можно ещё писать тесты для плейбуков. Мы можем себе позволить не делать этого, т.к. мы деплоим в тестовую среду, и ничего критичного не случится. А вот если вам деплоить на прод, то лучше бы всё проверить. Благо ansible позволяет тестировать не только плейбуки, но и отдельные модули. Так что обязательно уделите ему внимание.
И вторая основная причина использовать CI-сервер — запуск плейбуков. Это и есть та самая волшебная кнопка «Сделать хорошо», которую даёт нам TeamCity. Мы просто создаём несколько простых конфигураций для разных продуктов, где говорим: ansible-playbook reporter_vm.yml -i inventory.yml -vvvv и получаем кнопку Deploy.
Бонусная удобность: можно выстраивать зависимости от билдов. Как только что-то сбилдилось, TeamCity запускает процесс редеплоя, после которого нам остаётся только глянуть логи, если вдруг что-то сломалось.
Итого
- Запутанные и разрозненные PowerShell скрипты мы заменили YAML-конфигами.
- Разные реализации одинаковых проблем мы заменили общими ролями, которые можно переиспользовать. Создан репозиторий, где лежат роли. Если роль вам подходит, вы просто её используете. Если она вам не подходит, вы просто присылаете пул-реквест, и она вам подходит =)
- Проверить успешность деплоя теперь можно в едином месте.
- Все знают, где искать логи
- Проблемы с коммуникациями тоже решились за счёт общего репозитория и TeamCity. Все заинтересованные люди знают, где лежат плейбуки и как они работают.
P.S. Все примеры из статьи можно взять на гитхабе.
В этой статье мы рассмотрим, как удаленно управлять хостами с Windows через популярную систему управления конфигурациями Ansible. Мы предполагаем, что Ansible уже установлен на вашем хосте Linux.
Содержание:
- Подготовка Windows к удаленному управления через Ansible
- Настройка Ansible для управления компьютерами Windows
- Примеры управления конфигурацией Windows из Ansible
Подготовка Windows к удаленному управления через Ansible
Ansible позволяет удаленно управлять хостами Windows со всеми поддерживаемым версиями ОС, начиная с Windows 7/Windows Server 2008 и до современных Windows 11/Windows Server 2022. В Windows должен быть установлен PowerShell 3.0 (или выше) и NET 4.0+.
Ansible использует WinRM для подключения к Windows. Поэтому вам нужно включить и настроить WinRM listener на всех управляемых хостах.
В Ansible 2.8 и выше доступна экспериментальная опция удаленного управления клиентами Windows 10 и Windows Serve 2019 через встроенный OpenSSH сервер.
- В домене AD можно централизованно настроить WinRM с помощью групповых политик;
- На отдельно стоящем хосте Windows для включения WinRM выполните команду PowerShell:
Enable-PSRemoting –Force
Если WinRM включен и настроен на хостах Windows, проверьте что с сервера Ansible на ваших серверах доступен порт TCP/5985 или TCP/5986 (если используется HTTPS).
$ nc -zv 192.168.13.122 5985

В зависимости от того. в какой среде вы будете использовать Ansible, вам нужно выбрать способ аутентификации.
- Для отдельно-стоящего компьютера или рабочей группы можно использовать HTTPS для WinRM с самоподписанными сертификатами с аутентификацией под локальной учетной записью Windows с правами администратора. Для быстрой настройки хоста Windows можно использовать готовый скрипт ConfigureRemotingForAnsible.ps1 (https://github.com/ansible/ansible/blob/devel/examples/scripts/ConfigureRemotingForAnsible.ps1);
- В моем случае все хосты Windows находятся в домене Active Directory, поэтому я буду использовать учетную запись AD для аутентификации через Ansible. В этом случае нужно настроить Kerberos аутентификацию на сервере Ansible (рассмотрено далее).
Установите необходимые пакеты для Kerberos аутентификации:
- В RHEL/Rocky Linux/CentOS через менеджер пакетов yum/dnf:
$ sudo yum -y install python-devel krb5-devel krb5-libs krb5-workstation - В Ubuntu/Debian:
$ sudo apt-get -y install python-dev libkrb5-dev krb5-user
Теперь установите пакет для python через pip:
$ sudo pip3 install requests-kerberos
Укажите настройки подключения к вашему домену в файле:
$ sudo mcedit /etc/krb5.conf
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
default_realm = WINITPRO.LOC
[realms]
WINITPRO.LOC = {
admin_server = dc02.winitpro.loc
kdc = dc02.winitpro.loc
}
[domain_realm]
winitpro.loc = WINITPRO.LOC
.WINITPRO.LOC = WINITPRO.LOC
Проверьте, что вы можете выполнить аутентификацию в вашем домене AD и получите тикет Kerberos:
kinit -C [email protected]
Введите пароль пользователя AD, проверьте что получен тикет.
klist

Настройка Ansible для управления компьютерами Windows
Теперь добавьте все ваши хосты Windows в инвентаризационный файл ansible:
$ sudo mcedit /etc/ansible/hosts
msk-rds2.winitpro.loc msk-rds3.winitpro.loc wks-t1122h2.winitpro.loc [windows_all:vars] ansible_port=5985 [email protected] ansible_connection=winrm ansible_winrm_transport=kerberos ansible_winrm_scheme=http ansible_winrm_server_cert_validation=ignore
Проверьте, что все ваши Windows хосты (в моем списке два Windows Server 2019 и один компьютер Windows 11) доступны из Ansible:
$ ansible windows_all -m win_ping
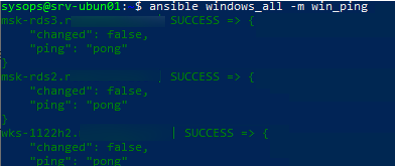
В моем случае все хосты вернули ошибку:
"msg": "kerberos: Bad HTTP response returned from server. Code 500", "unreachable": true

Причина в том, что в этом примере для WinRM подключения используется протокол HTTP вместо HTTPS. Чтобы игнорировать ошибку, нужно разрешить незашифрованный трафик на хостах Windows:
Set-Item -Path WSMan:\localhost\Service\AllowUnencrypted -Value true
Теперь через Ansible вы можете выполнить произвольную команду на всех хостах. Например, я хочу сбросить DNS кеш на всех хостах Windows:
$ ansible windows_all -m win_shell -a "ipconfig /flushdns"
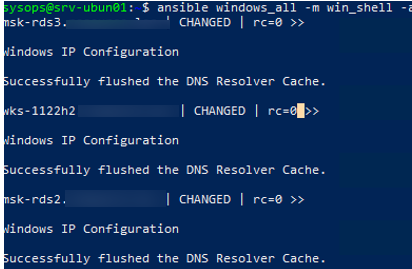
Команда успешно отработала везде.
Примеры управления конфигурацией Windows из Ansible
Теперь вы можете запускать плейбуки Ansible на ваших хостах Windows.
Например, вам нужно через Ansible выполнить PowerShell скрипт на всех хостах (в этом примере мы с помощью PowerShell получим текущие настройки DNS на хостах). Создайте файл плейбука:
$ sudo mcedit /etc/ansible/playbooks/win-exec-powershell.yml
---
- name: win_powershell_exec
hosts: windows_all
tasks:
- name: check DNS
win_shell: |
Get-DnsClientServerAddress -InterfaceIndex (Get-NetAdapter|where Status -eq "Up").ifindex -ErrorAction SilentlyContinue
register: command_output
- name: command output
ansible.builtin.debug:
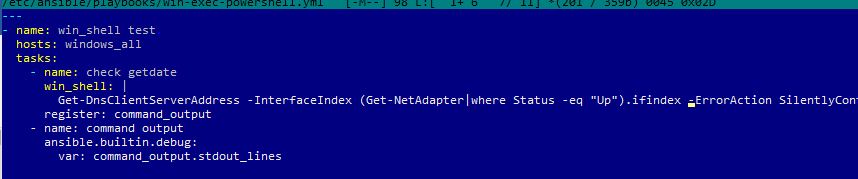
Выполните плейбук:
$ ansible-playbook /etc/ansible/playbooks/win-exec-powershell.yml
В данном примере плейбук отработал на всех Windows хостах и вернул текущие настройки DNS.
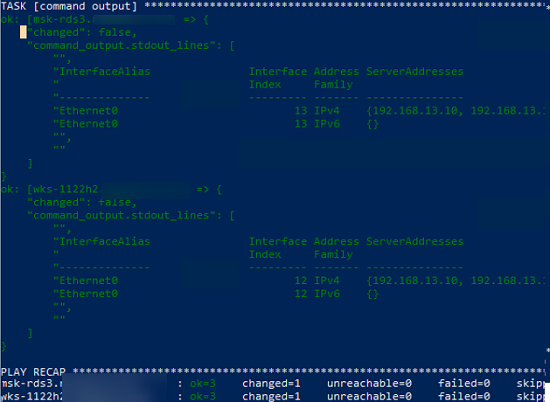
Далее рассмотрим несколько типовых плейбуков Absible, для стандартных задач управления хостами Windows.
Скопировать файл:
- name: Copy a single file
win_copy:
src: /home/sysops/files/test.ps1"
dest: C:\Temp\test.ps1
Создать файл:
- name: Create file
win_file:
path: C:\Temp\file.txt
state: touch
Удалить файл:
- name: Delete file
win_file:
path: C:\Temp\file.txt
state: absent
Создать параметр реестра:
- name: Create reg dword
win_regedit:
path: HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\DataCollection
name: AllowTelemetry
data: 0
type: dword
Установить программу из MSI:
Установить программу из MSI:
- name: Install MSI package
win_package:
path: C:\Distr\adobereader.msi
arguments:
- /install
- /passive
- /norestart
Запустить службу Windows:
- name: Run Windows Service
win_service:
name: wuauserv
state: started
Установить роль Windows Server:
- name: Install Windows Feature
win_feature:
name: SNMP-Service
state: present
Открыть порт в файерволе:
- name: Open SMTP Port п
win_firewall_rule:
name: port 25
localport: 25
action: allow
direction: in
protocol: tcp
state: present
enabled: yes
Выполнить PowerShell скрипт:
- name: Run PowerShell Script win_command: powershell.exe -ExecutionPolicy ByPass -File C:/temp/powershellscript.ps1
В этой статье мы рассмотрели, как управлять конфигурацией компьютеров Windows через Ansible. Если ваши хосты Windows не добавлены в домен Active Directory (находятся в рабочей группе), то удаленное управление конфигурацией хостов Windows через Ansible может быть неплохой альтернативной настройке с помощью доменных групповых политик.
Можно установить Ansible в подсистеме WSL на Windows. Это позволит запускать плейбуки без развертывания отдельного Linux хоста под ansible.
При наличии большого количества сотрудников, а также парка серверов и клиентских машин возникает необходимость систематизации и автоматизации процессов управления заявками пользователей, управлением конфигурацией клиентских и серверных машин, наблюдением за состоянием здоровья серверов, сетевого оборудования и сервисов, резервного копирования критически важной информации, сервисов и другие не менее важные процессы.
В арсенале программного обеспечения Microsoft есть набор продуктов под названием System Center, которые как раз могут управлять указанными выше процессами. System Center включает в себя следующие продукты (ниже мы чуть более подробно рассмотрим каждый из них):
- Service Manager (SCSM) – система хелп-деск, позволяющая управлять заявками сотрудников.
- Endpoint Configuration Manager (ECM) (ранее Configuration Manager, он же SCCM) – позволяет управлять конфигурацией серверов и клиентских машин.
- Operations Manager (SCOM) – система мониторинга за состоянием здоровья серверов и сервисов.
- Orchestrator – система оркестрации, которая позволяет автоматизировать процессы внутри самого System Center. Я бы охарактеризовал его, как систему консолидации скриптов и рабочих процессов.
- Data Protection Manager (DPM) – система резервного копирования.
- Virtual Machine Manager (VMM) – система управления виртуальными машинами, гипервизорами и сервисами для них. Что-то похожее на vCenter от VMWare.
- Service Provider Foundation (SPF) – в основном предназначен для провайдеров и для тех ситуацией, когда необходимо предоставлять инфраструктуру как сервис (infrastructure as a service (IaaS)) для конечных клиентов.
- Service Management Automation (SMA) – более “прокаченный” Orchestrator, который позволяет интегрироваться в том числе и с Windows Azure Pack. В своей сущности по большей части использует Windows PowerShell.
Скажу честно – последние два продукта в моей практике встречались крайне редко (и я пока не планирую на них подробно останавливаться), но первые шесть довольно распространенные.

Вы можете вопросить (или даже возразить) – зачем нужен, например, тот же SCOM, если есть, например, Zabbix. Тут, коллеги, прошу принять тот факт, что статья обзорная, а не холиварная 🙂 Не исключаю, что когда-нибудь и выйдет статья со сравнением этих продуктов, но мое мнение таково – нужно выбирать систему мониторинга исходя из условий и специфики применения: тип объектов наблюдения, целевая аудитория администраторов и операторов, наличие развернутых других продуктов, с которым придется интегрироваться (в т.ч. System Center), наличие REST API, бюджет и т.д. Если под ваши задачи лучше подходит Zabbix – то использовать его. Если для каких-то задач лучше подходит SCOM, то использовать его. В последних версиях SCOM очень сильно прибавил по части визуализации данных – можно рисовать любые дашборды используя HTML5, CSS и JavaScript.
Продукты System Center очень тесно интегрируются друг с другом. Например, SCSM может автоматически завести заявку при возникновении какого-то критичного алерта в SCOM, SCOM может подтягивать данные по описанию оборудования из SCCM. В Orchestrator можно настраивать довольно сложную логику процесса при возникновении каких-то событий в SCSM, SCOM и т.д.
Далее рассмотрим возможности основных продуктов линейки System Center. По каждому из этих продуктов написана не одна книжка (и есть относительно вменяемая документация), но постараюсь отметить основные моменты.
System Center Service Manager (SCSM)
Service Manager представляет собой хелп-деск от компании Microsoft, который вобрал в себя практики Microsoft Operations Framework (MOF) и Information Technology Infrastructure Library (ITIL). Основная задача SCSM – регистрация обращений от сотрудников по возникшим проблемам. Так же SCSM позволяет вести учет активов оборудования, поддерживает импорт объектов из Active Directory и т.д.
В основе архитектуры SCSM лежат следующие компоненты:
- Сервер управления (или несколько серверов) – является ядром системы и хранит оперативные накопленные данные.
- Сервер хранения данных – используется для подсистемы отчетов и хранит данные в усечённом и преобразованном виде, необходимом для построения отчетов.
- Сервер баз данных – хранит оперативную базу и базы сервера хранения данных.
- Сервер с порталом самообслуживания – HTML5 портал, через который сотрудники могут регистрировать заявки на основе тех категорий, которые вы настроите в системе.
Перечень основных возможностей Service Manager 2019:
- Регистрация и учет заявок сотрудников (инциденты, запросы на обслуживание, проблемы, запросы на изменения, ручные действия).
- Настройка утверждений заявок кураторами (при необходимости).
- Отслеживание изменений в заявках.
- Отслеживание SLA заявок.
- База знаний, в которую можно добавлять ваши наработки. Эти статьи базы знаний могут быть доступны конечным сотрудникам.
- Подсистема уведомлений (инициатора заявки, непосредственным исполнителям по заявке и т.д.).
- Интеграция “из коробки” со следующими продуктами Microsoft: Active Directory, Configuration Manager, Operation Manager, Orchestrator, Virtual Machine Manager.
- Управление ИТ-активами. Правда, из коробки это довольно небольшой набор, но можно либо доработать самому, либо найти сторонее коммерческое решение для SCSM.
- Подсистема отчетов.
- HTML5 портал самообслуживания для конечных пользователей, через который они могут регистрировать заявки. Портал можно доработать под брендбук компании, т.к. он поддерживает HTML5, CSS и JavaScript.
- SCSM так же поддерживает разработку дополнительных классов, форм, рабочих процессов и т.д. – для адаптации к конечной инфраструктуре и требованиям.
Пример консоли Service Manager приведен ниже.

Для управления рабочими элементами и настройками системы на рабочие места администраторов и операторов устанавливает консоль, которая приведена на скриншоте выше.
Моё мнение: далеко не самый простой хелп-деск в плане настройки, конфигурирования и поддержки, но хорошо масштабируется (вплоть до 50 000 пользователей) и позволяет настроить довольно сложную логику маршрутизации заявок. В первых версиях консоль была не торопливая, но в последних версиях стало гораздо лучше. При необходимости можно донастроить под свои потребности (добавить классы, нарисовать формочки, кастомизировать портал самообслуживания и т.д.). И прям не хватает какого-то веб интерфейса управления (или хотя бы работы с заявками), т.к. сейчас для управления и работы аналитиков/операторов нужно устанавливать консоль на каждое рабочее место.
System Center Operations Manager (SCOM)
Operations Manager – система мониторинга от компании Microsoft. Очень хорошо заточена под мониторинг Windows систем, но так же поддерживает мониторинг Linux систем, сетевых устройств, веб-приложений и сервисов. По части мониторинга операционных систем SCOM работает следующим образом – на конечную машину устанавливается агент SCOM, а затем этот агент передает собранные данные серверу управления. SCOM сверяет эти данные со своими эталонными значениями (если немного конкретики, то сверяет полученные значения с пороговыми значениями монитора для каждого компонента) и, при возникновении критичного отклонения, генерирует либо предупреждение, либо ошибку. В консоли SCOM эти ошибку уже можно будет проанализировать. По части мониторинга сетевого оборудования – из коробки уже поддерживается некоторый набор устройств. Сетевые устройства можно подключать как по протоколу ICMP, так и по SNMP. По части мониторинга веб-приложений SCOM может отправлять запросы на указанный вами URL адрес и отслеживать код ответа, скорость ответа и т.д. Если какие-то значения отличаются от эталонных, то генерируется предупреждение, либо ошибка.
В основе архитектуры SCOM лежат следующие компоненты:
- Сервер управления (или несколько серверов) – является ядром системы и хранит оперативные накопленные данные.
- Агент наблюдения – устанавливается на конечные операционные системы и передает данные на сервер управления.
- Шлюз – опциональный компоненты. Устанавливается там, где нужно сжимать трафик на отрезке от шлюза до сервера управления. Второй сценарий использования – накопление данных мониторинга в период недоступности сервера управления (например, канал упал до сервера). При возобновлении связи все данные будут переданы на сервер управления.
- Сервер баз данных – содержит оперативную базу и базу для хранилища данных.
- Сервер с веб-консолью – позволяет наблюдать за данными мониторинга через веб-браузер. Роль может быть совмещена с ролью сервера управления.
Перечень основных возможностей Operations Manager Manager 2019:
- Наблюдение за состоянием здоровья операционных системы: Windows, Linux, IBM AIX, Solaris 10-11.
- Наблюдение за состоянием здоровья сетевого оборудования.
- Наблюдение за состоянием здоровья веб-приложений.
- Наблюдение за состоянием здоровья сервисов. Например, Exchange, Skype for Business, Axapta, Active Directory и т.д.
- Наблюдение за состоянием здоровья распределенных приложений. Например, вы можете настроить мониторинг своего сервиса, который состоит из множества, например, веб-сервисов. Причем вы можете четко указать иерархию компонентов – что и от чего зависит.
- Возможность расширения за счет импорта пакетов управления. Например, HP и Dell для своих серверов предоставляют готовые пакеты управления. Есть много готовых пакетов управления в галереи Microsoft.
- Возможность написать свой пакет управления, который добавит необходимые классы, мониторы, рабочие процессы и т.д.
- Наличие встроенной базы знаний, которую можно дополнять.
- Служба централизованного сбора журналов аудита (Audit Collection Services (ACS)). Позволяет централизовано собирать данные журнала аудита на сервере SCOM, а затем через подсистему отчетов осуществлять выборку необходимых событий.
- Есть обозреватель здоровья объектов, через который вы можете посмотреть какому же из компонентов наблюдаемой системы стало плохо.
- Подсистема уведомлений.
- Подсистема отчетов.
- Наличие HTML5 веб-консоли. Через веб-консоль можно только просматривать данные о состоянии здоровья и выполнять действия над объектами мониторинга. Конфигурация системы и отчеты через веб-консоль не доступны.
- С недавнего времени так же есть своей RESP API, через который можно забирать данные из системы.
Пример консоли OperationsManager приведен ниже.

Для отcлеживания состояния здоровья объектов мониторинга и настройки системы на рабочие места администраторов и операторов устанавливается консоль, которая приведена на скриншоте выше. Так же отслеживать состояние здоровья наблюдаемых объектов можно через веб-консоль.
Моё мнение: система уже довольно зрелая, к тому же обросла необходимым набором возможностей, в т.ч. и HTML5 консолью, в которой вы можете настроить количество и вид дашбордов так, как вам нужно. Позволяет собирать огромное кол-во данных с Windows устройств и сервисов. Так же позволяет собирать данные и с Linux. Есть много готовых пакетов от различных вендоров по их продуктам: Microsoft (даже есть целая галерея пакетов управления), HP, Dell, Veeam, APC и т.д. Рекомендую к рассмотрению.
System Center Endpoint Configuration Manager (ECM)
Endpoint Configuration Manager (ранее Configuration Manager) – система управлением конфигурацией клиентских ПК и серверов. Его облачный собрат (Endpoint Manager, про него, вероятнее всего тоже будут записи в этом блоге) дополнительно поддерживает управлением мобильными устройствами (Android, iOS). Между Endpoint Configuration Manager и Endpoint Manager может быть настроена интеграция при которой за часть настроек один, а за другую часть второй продукт. В текущей версии ECM по большей части поддерживаются только клиентские и серверные ОС Windows, но есть некоторая поддержка Mac OS, некоторый перечень ОС для встроенных систем. С полным перечнем поддерживаемых ОС можно ознакомится вот в документации вот тут.
В основу архитектуры Endpoint Configuration Manager лежат два ключевых фактора:
- Иерархия сайтов. Сайт может быть одного из трех типов: центральный, основной и вторичный. Центральный сайт опционален, но он может быть только один. Для минимального развертывания достаточно одного первичного сайта. Вторичные сайты так же опциональны, но их, как и первичных сайтов, может быть несколько.
- Роли системы сайтов. Серверов ECM может быть несколько. Например, по одному-два сервера для каждой географически обособленной локации. И каждый сервер несет на себе определенную роль сайта. Какие-то роли обязательные, какие-то опциональны. Примеры ролей: база данных сайта, сервер сайта, точка распространения, точка обновления приложений и т.д.
Перечень основных возможностей Endpoint Configuration Manager :
- Развертывание приложений на конечные операционные системы.
- Политики соответствия для конечных устройств.
- Развертывание образов операционных систем по сети.
- Управление параметрами конфигурации конечных ОС.
- Развертывание обновлений на конечные ОС.
- Инвентаризация установленных приложений на конечных рабочих станциях и серверах.
- Инвентаризация оборудования на конечных рабочих станциях и серверах.
- Управление параметрами Endpoint Protection.
- Подсистема отчетов.
- Интеграция с облачными сервисами Azure.
Пример консоли Endpoint Configuration Manager приведен ниже (скрин с SCCM, но отличий не много).

Для работы с ECM на рабочие места администратора устанавливается консоль, которая приведена на скриншоте выше.
Моё мнение: отличный инструмент для управления конфигурацией Windows устройств. Так же отлично интегрируется из коробки со всей необходимой экосистемой ПО и сервисов от Microsoft. В версии 2012 R2 и чуть более поздних была даже поддержка части функций для Linux систем (установка ПО, инвентаризация и т.д.), но в более поздних версиях её упразднили. Так же не хватает веб-консоли. Хотя бы, например, для работы с отчетами и просмотром текущего состояниях развертывания ПО.
Промежуточный итог
В данной статье мы рассмотрели основные возможности и назначения следующих трех продуктов из линейки System Cnter – Service Manager, Operations Manager и Endpoint Configuration Manager. Делаем поправку на то, что это выдержка по основным возможностям, но детально про каждую систему можно рассказывать очень долго. Так же делаем поправку на то, что я даю свою оценку этим системам исходя из моего опыта работы с ними.
В следующей статье мы продолжим наш обзор и рассмотрим возможности следующих трех продуктов линейки System Center – Orchestaror, Data Protection Mnager и Virtual Machine Manager.
2023. Зодиак АйТиЭм — российская альтернатива Microsoft Intune
После ухода из России Microsoft и других западных вендоров, опустела ниша систем управления конечными устройствами. Основные системы в этой категории: Microsoft Intune (или SCCM), Altiris AM, Ansible, Puppet. Для их замены была быстренько создана отечественная альтернатива — Зодиак АйТиЭм. Решение внесено в Реестр отечественного ПО и подходит для администрирования смешанных парков рабочих устройств с разными операционными системами и архитектурами. Система позволяет проводить инвентаризацию аппаратного и программного обеспечения, осуществлять дистанционную установку и обновления ПО. Все это работает в гетерогенной среде различных ОС, как российских разработчиков, так и иностранных. Цены Зодиак АйТиЭм на сайте не светит.
2020. Atlassian купила разработчика ПО для учета ИТ активов

Компания Atlassian купила стартап Mindville, специализирующийся на решениях для учета компьютеров, лицензий ПО и других активов ИТ инфраструктуры. Флагманским продуктом Mindville является система Mindville Insights, которая помогает ИТ, HR-, sales- и юридическим отделам отслеживать различные активы в компании. Atlassian намерена использовать разработки стартапа для контроля технологической инфраструктуры предприятий. Помимо мониторинга физических ресурсов, Mindville Insights можно использовать для автоматического переноса облачных серверов, например, из инфраструктуры Amazon Web Services, Microsoft Azure и Google Cloud Platform. Кроме того, сервис помогает реализовывать интеграцию с сервисами других компаний, таких как Service Now и Snow Software.
2018. Okdesk разработал готовую интеграцию с 1С

В России 1С это «де-факто» стандарт для автоматизации бухгалтерского или управленческого учета, выписки счетов, актов, учета поступлений денежных средств от клиентов. Для автоматизации постпродажного и постпроектного обслуживания в сервисных компаниях стандартом стало использование Help Desk системы Okdesk. И, конечно, у большинства компаний возникают задачи «на стыке»: синхронизация контактной базы (клиенты, контактные лица и договоры, по которым обеспечивается абонентское обслуживание) + платные заявки, по которым нужно выставлять счета и прикладывать их автоматически к заявкам в Okdesk. Теперь 2 этих самых популярных сценария интеграции реализованы «из коробки». Готовая «обработка» поддерживает самые популярные конфигурации 1С и может быть самостоятельно доработана для реализации более сложных сценариев.
2015. Naumen Service Desk получила сертификат соответствия требованиям ITIL AXELOS

Система Naumen Service Desk успешно прошла сертификацию на соответствие требованиям ITIL Software Endorsement Scheme от компании AXELOS, глобального провайдера лучших практик управления (Best Management Practice). В рамках аккредитации AXELOS продукт Naumen Service Desk сертифицирован по 9 процессам ITIL: управление инцидентами, управление запросами на обслуживание, управление проблемами, управление запросами на изменение, управление событиями, управление знаниями, управление каталогом услуг, управление уровнем услуг, управление сервисными активами и конфигурациями.
2010. RemedyForce — IT Service Desk на платформе Force.com

Компании BMC и Salesforce представили совместное решение — SaaS Service Desk систему RemedyForce. Это решение основано на популярной BMC Remedy Service Desk и работает на облачной платформе Force.com. Функциональность системы, кроме базовых инструментов IT Service Desk, включает возможности для управления изменениями, управления знаниями, управления проблемами и управления конфигурациями. Благодаря размещению на платформе Force.com, RemedyForce предоставляет также социальный слой для коммуникаций и совместной работы, основанный на Salesforce Chatter, а также полноценный мобильный доступ. Напомним, что кроме RemedyForce, компания BMC предоставляет еще одну SaaS версию своей Service Desk системы — Remedy OnDemand.
2008. LANDesk Management Suite 8.8 стал выбором журнала Network World
Журнал Network World выбрал продукт LANDesk Management Suite в качестве лучшего решения для управления ИТ сетями и системами. Система получила высокие оценки за интуитивно понятный интерфейс, поддержку самых различных платформ и мобильных устройств. В дополнение, LANDesk Management Suite 8.8 получил высокие оценки за реализацию функционала по инвентаризации ресурсов, контролю над лицензированием ПО, распространению приложений и конфигурированию. Функционал решения включает в себя инвентаризацию ресурсов; развертку ОС и конфигурирование; управление виртуальными системами; распространение ПО и управление патчами; управление удаленными системами; контроль доступа к сети; анализ уязвимостей систем; защита от вторжения на уровне клиентского ПК; обнаружение вирусов и их удаление, возможности управлению антивирусными решениями других поставщиков; управление подключениями; возможности резервного копирования и восстановления систем.
2007. LANDesk Service Desk 7.2 улучшила управление конфигурациями
Компания LANDesk объявила о выходе новой версии LANDesk Service Desk 7.2, которая привнесла ряд изменений и усовершенствований и позволяет обеспечить управление системами уровня предприятия. LANDesk Service Desk может использоваться как в качестве отдельного решения, так и совместно с LANDesk Management Suite и LANDesk Security Suite. Новое решение включает встроенные процессы для организации Service Desk по ITIL, управления инцидентами, изменениями и проблемами. Новый LANDesk Service Desk включает следующие возможности: Интеграция с телефонией (CTI) — интеграция системы IP телефонии по стандартным интерфейсам непосредственно в системы Service Desk заказчика. Поддержка Vista — программный продукт поддерживает все версии Microsoft Windows Vista. Управление конфигурациями — новая версия предоставляет возможность более легкого импорта в базу данных конфигурационных единиц (CMDB) и удобное структурирование информации в ней облегчает обработку инцидентов.
2007. IT Expert внедрила ПО HP OV Service Desk в Волгателекоме
Консалтинговая компания IT Expert организовала поддержку пользователей ИТ-услуг в Нижегородском филиале ОАО “Волгателеком”. Цель проекта — формирование единого подхода к поддержке пользователей в территориально-распределенных структурах филиала, создание инструментов для обработки поступающих обращений от пользователей, а также обеспечение взаимодействия между подразделениями, поддерживающими внешних абонентов и внутренних пользователей ИТ-услуг. В ходе проекта, выполнявшегося на основе методик и стандартов ITIL, ITSM, CobiT и ISO 20000, был сформирован единый процесс ИТ-поддержки, объединяющий деятельность более 40 ИТ-подразделений Нижегородского филиала. После выполнения проекта число пользователей, удовлетворенных качеством поддержки, достигло 90%. В настоящее время на предприятии выполняется проект по реализации процессов управления конфигурациями, изменениями, и релизами.
2007. В СУАЛе автоматизировали управление конфигурациями на HP OpenView
Компании ИНЛАЙН ГРУП и IT Expert внедрили решение по управлению конфигурациями разнородных территориально распределенных вычислительных платформ, входящих в состав ИТ-ифраструктуры СУАЛ-ХОЛДИНГ, предприятия, выполняющего добычу бокситов и производство глинозема, кремния и алюминиевых полуфабрикатов. Проект, выполнявшийся на базе ПО HP OpenView Service Desk 4.5, также предполагал разработку процесса управления конфигурациями, включающего определение требований ключевых потребителей информации к структуре и содержанию CMDB (configuration management database — база управления конфигурациями), разработку модели данных и правил учета, планирование и выполнение работ по идентификации и актуализации данных, а также верификацию и аудит собранных сведений. Помимо этого, проект предусматривал внедрение системы маркировки и инвентаризации оборудования с применением как технологии штрих-кодирования, так и с помощью RFID.
Что такое программное обеспечение для базы данных управления конфигурацией (CMDB)?
Программное обеспечение для базы данных управления конфигурацией (CMDB) позволяет организациям отслеживать IТ-активы и видеть, как эти активы связаны друг с другом. Инструменты ПО для базы данных управления конфигурацией (CMDB) помогают управлять IТ-ресурсами и лицензированием программного обеспечения, рассчитывать возврат инвестиций (ROI), стандартизировать методы контроля изменений и отслеживать IT-показатели.
Преимущества программного обеспечения для базы данных управления конфигурацией (CMDB)
-
Логистический контроль: создав централизованное хранилище всех IТ-активов и их взаимосвязей, компании могут легко измерить и проанализировать влияние, которое изменение в одной системе окажет на другие связанные системы. Спецификации оборудования и программного обеспечения отслеживаются, чтобы облегчить быстрое размещение новых реализаций или обновлений системы.
-
Соответствие лицензирования: ПО для базы данных управления конфигурацией (CMDB) специально разработано для отслеживания количества и типов лицензий на программные активы в организации. При этом организации могут эффективно соблюдать структуры лицензирования для размещенных в настоящее время технологий и прогнозировать стоимость дополнительных лицензий.
-
Точные расчеты возврата инвестиций: анализируя показатели использования, программное обеспечение для базы данных управления конфигурацией (CMDB) позволяет компаниям более эффективно рассчитывать возврат инвестиций в оборудование и программное обеспечение.
Типичные особенности программного обеспечения для базы данных управления конфигурацией (CMDB)
-
Управление изменениями: обеспечивает использование стандартизированных методов и процедур для обработки изменений в IТ-инфраструктуре.
-
Управление конфигурацией: устанавливает точную конфигурацию IТ-актива на основе проектных и эксплуатационных спецификаций; обеспечивает постоянную работу IТ-активов для достижения желаемых показателей.
-
Управление активами: позволяет пользователям отслеживать и управлять IТ-ресурсами.
-
Автоматическое обнаружение устройства: периодически сканирует сеть и выполняет предопределенные действия после обнаружения.
-
Управление лицензиями: отслеживает и систематизирует количество лицензий, доступных (или потенциально необходимых) организации.
-
Мониторинг производительности: отслеживает и измеряет соответствующие показатели для оценки производительности IТ-ресурсов.
-
Управление знаниями: cистематически управляет активами знаний с целью создания ценности и удовлетворения тактических и стратегических требований.
Каталог ПО для базы данных управления конфигурацией позволяет выполнять фильтрацию по функциям, чтобы просматривать только те варианты, которые соответствуют потребностям вашего бизнеса, что может помочь вам сузить список программного обеспечения.
Соображения при покупке программного обеспечения для базы данных управления конфигурацией (CMDB)
-
Общая стоимость в сравнении с текущими операционными расходами: в то время как программное обеспечение для управления IT-активами IT (ITAM) используется для отслеживания и прогнозирования стоимости IТ-активов в течение его жизненного цикла (в основном для целей бухгалтерского учета), ПО для базы данных управления конфигурацией (CMDB) ориентировано на текущую работу IТ-конфигурации организации — главным образом, как изменения в операционной среде будут влиять на другие системы. Некоторые продукты предлагают функциональность для ПО для управления IT-активами (ITAM) и ПО для базы данных управления конфигурацией (CMDB). Четкая приоритетность долгосрочных целей в области IТ поможет вам выбрать подходящий продукт для вашей организации.
-
Автоматическое обнаружение: в то время как большинство программ для базы данных управления конфигурацией (CMDB) содержат поля для записи номеров версий программного обеспечения, используемого организацией, некоторые делают еще один шаг вперед, активно просматривая инфраструктуру организации на предмет устаревших версий, а затем автоматически выполняют обновления, чтобы убедиться, что версии соответствуют схеме желаемой конфигурации. Автоматическое обнаружение также обнаружит наличие нелегального или нелицензионного программного обеспечения в IТ-инфраструктуре организации.
Тенденции программного обеспечения для базы данных управления конфигурацией (CMDB)
-
Программное обеспечение для базы данных управления конфигурацией (CMDB) будет все больше зависеть от искусственного интеллекта (ИИ) и машинного обучения для автоматизации контроля версий: ИИ продолжит дальнейшую автоматизацию пространства CMDB. ИИ будет не только отслеживать и сравнивать информацию о IT-конфигурации в рамках всего бизнеса, но также будет использовать алгоритмы для определения и реализации оптимальной схемы конфигурации без участия пользователя. Учитывая, что 68 % малых предприятий в некоторой степени примут ИИ в течение следующих одного-двух лет, даже самым маленьким предприятиям потребуется ПО для базы данных управления конфигурацией (CMDB) с ИИ, чтобы оставаться конкурентоспособными.
-
Штрафы, наложенные за использование нелицензионного программного обеспечения, могут нанести ущерб малым предприятиям: Союз производителей программ для бизнеса (BSA) не проводит различий между малыми предприятиями и крупными предприятиями, когда речь идет о наказании за нарушение лицензий на программное обеспечение. В некоторых случаях Союз производителей программ для бизнеса (BSA) налагает штрафы в размере до 150 000 долларов за нарушение авторских прав, и эта тенденция, вероятно, сохранится. Когда вы защищаете свою организацию с помощью технологии автоматического обнаружения пакета для базы данных управления конфигурацией (CMDB), вы избегаете крупных штрафов.