Если вы пользователь домашней сети или офисной сети, то наверняка сталкивались с термином «шторм от роутера». Это неприятное явление, которое может серьезно затруднить работу сети и вызвать множество проблем. Чтобы понять, что такое шторм от роутера и как с ним бороться, необходимо разобраться в его причинах и последствиях.
Шторм от роутера – это ситуация, когда сеть перегружается из-за большого количества пакетов данных, которые пересылаются по ней. Это может произойти, например, при массовом отправлении одного сообщения сразу на несколько устройств. Роутер не успевает обработать все пакеты данных и начинает работать с перебоями. При этом происходят сбои в работе сети, возникают задержки и потери данных, а интернет-соединение становится ненадежным.
Шторм от роутера может быть вызван разными факторами, например, неправильной настройкой роутера или использованием устаревшего оборудования. Также шторм от роутера может быть следствием вирусов или вредоносных программ, которые перегружают сеть. В некоторых случаях, шторм от роутера может быть вызван неправильной работой приложений или компьютеров, подключенных к сети.
Итак, как же бороться с штормом от роутера? Существует несколько способов решить эту проблему. Во-первых, необходимо проверить настройки роутера и убедиться, что они корректны. Если есть подозрение на наличие вирусов или вредоносных программ, следует просканировать компьютеры в сети. Также рекомендуется обновить программное обеспечение роутера и проверить работу приложений, которые могут перегружать сеть.
Важной составляющей борьбы с штормом от роутера является правильная организация работы сети. Рекомендуется разделить сеть на зоны или виртуальные локальные сети и установить на них ограничения по использованию ресурсов. Также рекомендуется использовать специальное программное обеспечение, которое умеет оптимизировать загрузку сети и предотвращать штормы от роутера.
Наконец, необходимо обратиться к специалистам или к сетевому администратору, если проблема шторма от роутера имеет серьезный характер и не удается ее решить самостоятельно. Они смогут провести более глубокую диагностику проблемы, определить ее причины и предложить наиболее эффективные способы решения.
Содержание
- Что такое шторм от роутера?
- Причины возникновения шторма от роутера
- Как распознать шторм от роутера?
- Потенциальные проблемы, вызванные штормом от роутера
- Как предотвратить шторм от роутера?
- Как бороться с штормом от роутера?
- Рекомендации по использованию роутера для избежания шторма
Что такое шторм от роутера?
Шторм от роутера может произойти по разным причинам. Одной из них является ошибочная конфигурация роутера или его программного обеспечения. Например, если на роутере настроен виртуальный локальный узел (VLAN), но маршрут не настроен корректно, роутер может начать передавать пакеты в бесконечном цикле.
Другой причиной шторма от роутера может быть неправильно настроенный протокол Spanning Tree Protocol (STP). STP предотвращает появление петель в сетях Ethernet, однако неправильная настройка этого протокола может привести к перегрузкам и штормам от роутера.
Важно отметить, что шторм от роутера может вызвать серьезные проблемы в работе сети, вплоть до полного отказа ее работы. Поэтому важно своевременно обнаружить и устранить данный дефект.
Причины возникновения шторма от роутера
Основной причиной возникновения шторма от роутера является неправильное настроенные фильтры и таблицы маршрутизации. Если эти настройки не оптимизированы, то роутер может начать отправлять одни и те же пакеты по кругу, создавая тем самым шторм из сетевого трафика.
Еще одной причиной может быть наличие бесконечного цикла маршрутизации. Это происходит, когда два роутера пытаются передать пакеты друг другу, но из-за неправильной настройки они не могут сделать это корректно. В результате возникают коллизии и пакеты начинают ходить по кругу по сети.
Также шторм от роутера может быть вызван атакой на сеть, такой как DDoS. В этом случае злоумышленники отправляют огромное количество запросов на роутер, создавая перегрузку и приводя к его отказу.
Для предотвращения возникновения шторма от роутера необходимо правильно настроить фильтры и таблицы маршрутизации, а также использовать защитные механизмы, такие как фронтальные атаки и механизмы блокировки нежелательного трафика. Также рекомендуется использовать сетевые устройства с высокой пропускной способностью, чтобы сеть могла справиться с большим объемом трафика.
Как распознать шторм от роутера?
Один из основных признаков шторма от роутера — это резкое увеличение количества передаваемых и принимаемых пакетов данных в сети. Если обычно количество пакетов в сети было стабильным, а затем оно начинает расти экспоненциальным образом, это может указывать на наличие шторма от роутера.
Также можно заметить повышенную нагрузку на сетевое оборудование, например, загрузку процессора роутера или увеличение времени отклика сервера. Возможно, пользователи будут жаловаться на сбои в работе сети или замедленную скорость передачи данных.
Еще одним признаком шторма от роутера может быть постоянная активность светодиодов на сетевом оборудовании. Если лампочки на роутере или коммутаторе все время мигают или горят ярко, это может свидетельствовать о шторме от роутера.
Для определения шторма от роутера можно использовать сетевые инструменты мониторинга, которые позволяют отслеживать активность сетевого трафика и выявить аномалии. Также можно провести анализ журналов событий на роутере или коммутаторе для выявления нештатных ситуаций.
Если вы подозреваете наличие шторма от роутера, рекомендуется обратиться к специалистам по сетям, которые смогут провести более подробную диагностику и принять меры по устранению проблемы. Борьба с штормом от роутера может включать разные меры, например, настройку Spanning Tree Protocol (STP) или установку фильтров на коммутаторах.
Потенциальные проблемы, вызванные штормом от роутера
Шторм от роутера может привести к нескольким потенциальным проблемам, которые могут серьезно повлиять на работу и производительность вашей сети. Вот некоторые из них:
1. Перегрузка сети: Шторм от роутера может вызвать большой объем трафика в сети, что может привести к перегрузке сетевых устройств и серверов. Это может привести к падению производительности сети или даже полной неработоспособности.
2. Потеря данных: Шторм от роутера может привести к потере данных из-за большого объема трафика или нестабильной работы сети. Это может быть особенно проблематично, если вы храните ценные данные, такие как бизнес-документы или личные файлы.
3. Недоступность ресурсов: Шторм от роутера может привести к недоступности ресурсов, таких как веб-сайты или приложения. Если ваша компания зависит от этих ресурсов для работы, их недоступность может серьезно повлиять на ваш бизнес.
4. Проблемы со стабильностью сети: Шторм от роутера может вызвать проблемы со стабильностью сети, такие как отключение или снижение скорости интернет-соединения. Это может замедлить работу и вызвать раздражение у пользователей, особенно если они зависят от быстрого и стабильного интернета для своей работы или развлечений.
5. Проблемы с безопасностью: Шторм от роутера может стать источником уязвимости, через которую злоумышленники могут получить доступ к вашей сети и скомпрометировать конфиденциальные данные. Это может привести к серьезным финансовым и репутационным потерям.
Чтобы минимизировать риск таких проблем, важно принять соответствующие меры по предотвращению и защите вашей сети от шторма от роутера.
Как предотвратить шторм от роутера?
Для предотвращения шторма от роутера рекомендуется регулярно обновлять прошивку роутера. Производители постоянно выпускают новые версии прошивок, которые исправляют уязвимости и улучшают работу устройства.
Также, следует проверить список подключенных устройств и отключить те, которые не используются, чтобы уменьшить количество широковещательных пакетов.
Настройка QoS (Quality of Service) также может помочь в предотвращении шторма от роутера. Эта функция позволяет приоритезировать определенные типы трафика и ограничивать пропускную способность для других, что может снизить нагрузку на роутер.
Если производится замена или добавление нового устройства в сеть, рекомендуется внимательно проверить настройки сетевых интерфейсов и обновить их при необходимости. Также стоит убедиться, что все устройства в сети используют правильные IP-адреса и не происходит конфликтов.
Дополнительно, рекомендуется выключать роутер надлежащим образом, вместо простого отключения питания. Это позволит избежать возможных проблем и улучшить стабильность работы устройства.
Как бороться с штормом от роутера?
Чтобы эффективно справиться со штормом от роутера, следует принять несколько мер предосторожности и провести необходимые действия:
- Обновите прошивку роутера: Проверьте, не доступны ли обновления для прошивки вашего роутера. Установка новой версии может устранить возможные уязвимости и проблемы, которые могут вызвать шторм.
- Измените канал Wi-Fi: Если ваш роутер работает на перегруженном канале Wi-Fi, это может вызывать шторм. Попробуйте изменить канал на менее загруженный или автоматический режим, чтобы улучшить качество сигнала.
- Перезагрузите роутер: Простая перезагрузка роутера может привести к временному устранению проблемы шторма. Выключите роутер на несколько секунд, а затем включите его снова.
- Измените расположение роутера: Размещение роутера в определенных местах со множеством преград или между другими электронными устройствами может привести к шторму. Попробуйте переместить роутер в другое место или подключить его ближе к устройству, которое испытывает проблему со связью.
- Установите усилитель Wi-Fi сигнала: Если ваш роутер не может обеспечить достаточно сильный сигнал Wi-Fi, то установка усилителя сигнала может помочь устранить шторм и улучшить качество сети.
- Отключите другие устройства: Если множество устройств подключено к вашей Wi-Fi сети, это может нагрузить роутер и вызвать шторм. Попробуйте отключить или выключить ненужные устройства, чтобы снизить нагрузку на роутер.
Если все вышеперечисленные меры не помогли, стоит связаться с технической поддержкой провайдера интернет-услуг и сообщить им о проблеме. Они смогут провести дополнительную диагностику и предоставить решение для устранения шторма от роутера.
Рекомендации по использованию роутера для избежания шторма
Для предотвращения возникновения шторма от роутера, следуйте следующим рекомендациям:
- Обновляйте прошивку роутера регулярно. Производители регулярно выпускают обновления и исправления, которые могут предотвратить возникновение шторма и повысить общую производительность устройства.
- Оптимизируйте настройки роутера. Избегайте настройки высокой мощности передачи сигнала Wi-Fi, поскольку это может вызвать нежелательные интерференции. Используйте стандартные настройки канала и полосы частоты или выберите наилучшие значения в соответствии с вашим окружением.
- Ограничьте количество подключенных устройств. В больших домашних сетях с множеством поключенных устройств может возникнуть перегрузка роутера. Постоянно отслеживайте количество подключенных устройств и ограничьте его, если необходимо.
- Используйте безопасные пароли для доступа к роутеру. Незащищенный доступ к роутеру может стать причиной несанкционированного доступа и использования ресурсов, что приведет к перегрузке системы.
- Выключайте роутер при его длительном неиспользовании. Если у вас нет необходимости постоянного доступа к Интернету, лучше выключить роутер. Это позволит уменьшить нагрузку и повысить его производительность.
- Установите антивирусное программное обеспечение. Злонамеренное ПО на подключенных устройствах может стать причиной шторма от роутера, поэтому важно иметь антивирусную защиту на всех ваших устройствах.
Соблюдение этих рекомендаций поможет вам избежать шторма от роутера и обеспечит более стабильное и надежное функционирование вашей сети.
Роутер — это устройство, которое позволяет подключить несколько устройств к интернету одновременно. Однако, иногда роутер начинает работать нестабильно и возникает так называемый «шторм от роутера». Что это значит и как справиться с этой проблемой?
«Шторм от роутера» — это периодические сбои в работе роутера, которые проявляются в медленной загрузке страниц, неработающем Wi-Fi, перебоях в интернете и других проблемах с подключением. Это может быть вызвано разными причинами, такими как настройки роутера, проблемы со сигналом или несовместимость с другими устройствами.
Если вы столкнулись с «штормом от роутера», прежде всего, проверьте настройки роутера. Убедитесь, что у вас все правильно сконфигурировано: правильные настройки Wi-Fi, надежный пароль, актуальное программное обеспечение. Проверьте также, нет ли устройств, которые могут мешать работе роутера, например, других беспроводных устройств или микроволновой печи.
Если проблема не решается, попробуйте перезагрузить роутер и подключиться к нему заново. Иногда это помогает восстановить стабильную работу устройства. Если все это не помогает, обратитесь к специалисту, который сможет проанализировать причину проблемы и найти оптимальное решение.
Содержание
- Что такое «шторм от роутера» и как его обнаружить?
- Признаки шторма от роутера
- Причины возникновения шторма от роутера
- Как справиться с штормом от роутера?
Что такое «шторм от роутера» и как его обнаружить?
Обнаружить шторм от роутера можно по нескольким признакам:
Перегрев роутера: Если роутер нагревается сильнее обычного, это может быть признаком проблемы. Если роутер нагревается до очень высоких температур и затем выключается, это может быть признаком шторма от роутера.
Потеря пакетов: Если вы заметили, что ваша сеть стала работать медленнее, а также возникают проблемы с подключением, это может быть связано с штормом от роутера. В таких случаях сетевые пакеты могут потеряться или быть повреждены.
Нестабильное соединение: Если соединение с интернетом стало нестабильным, например, подключение постоянно пропадает и снова появляется, возможно, роутер находится в состоянии шторма.
Если вы заметили указанные признаки, рекомендуется проверить состояние роутера. Если проблему не удается решить, лучше обратиться к профессионалам или связаться с технической поддержкой производителя роутера.
Признаки шторма от роутера
Шторм от роутера может проявиться по-разному, и важно знать, какие признаки указывают на его наличие. Ниже представлена таблица, в которой указаны основные признаки шторма от роутера:
| Признак | Описание |
|---|---|
| 1. | Отключение или неправильная работа роутера. |
| 2. | Нестабильное интернет-соединение. |
| 3. | Частые сбои работы сети. |
| 4. | Низкая скорость скачивания и загрузки данных. |
| 5. | Потеря пакетов данных. |
| 6. | Появление необычных или непонятных сетевых активностей. |
Если вы заметили хотя бы несколько признаков шторма от роутера, возможно вам потребуется принять меры для его устранения или обратиться за помощью к специалисту.
Причины возникновения шторма от роутера
1. Неправильная конфигурация роутера: Неправильные настройки роутера могут привести к его перегрузке и возникновению шторма. Например, если роутер настроен на обработку большого количества соединений одновременно и не имеет достаточных ресурсов для этого, это может привести к неправильной работе и возникновению шторма.
2. Высокая нагрузка на роутер: Если на роутер поступает большое количество сетевого трафика, он может столкнуться с проблемами в обработке данных и начать перегружаться. Например, слишком много пользователей, использующих интернет одновременно или провайдер, предоставляющий недостаточно пропускной способности может вызывать высокую нагрузку на роутер.
3. Наличие ARP шторма: Шторм ARP (Address Resolution Protocol) возникает, когда на сети появляется огромное количество запросов ARP, которые роутер не может обработать. Обычно это возникает из-за наличия в сети большого числа устройств или из-за нарушений работы на уровне третьего и четвертого уровней модели OSI, что ведет к появлению ARP шторма.
4. Проблемы с оборудованием: Если роутер имеет проблемы с аппаратным обеспечением, например, неисправные сетевые карты или недостаток оперативной памяти, это может вызывать шторм. Также неисправности в программном обеспечении роутера могут привести к его неработоспособности.
5. Атаки на роутер: Возможность атаки на роутер или сеть также может быть причиной возникновения шторма. Для этого злоумышленник может использовать различные методы атаки, такие как DDoS или флуд пакетами данных, которые нагружают роутер и мешают его нормальной работе.
Обратите внимание, что причины возникновения шторма от роутера могут быть разными и требуют соответствующих мер по устранению проблемы. Регулярное обслуживание и настройка роутера, а также реализация средств защиты от атак могут помочь предотвратить возникновение шторма от роутера.
Как справиться с штормом от роутера?
1. Проверьте подключение. Убедитесь, что роутер правильно подключен к электрической сети и модему. Проверьте провода на наличие повреждений и опробуйте другие, если есть такая возможность.
2. Перезагрузите роутер. Часто перезагрузка устраняет временные сбои в работе роутера. Отключите его от электрической сети на несколько минут, затем снова включите. Дождитесь, пока все индикаторы загорятся и появится стабильное подключение.
3. Обновите прошивку. Проверьте, не требуется ли для вашего роутера обновление прошивки. Если такая возможность есть, перейдите в настройки роутера и выполните обновление. Это может помочь исправить ошибки и улучшить работу устройства.
4. Измените настройки Wi-Fi. Иногда проблемы с штормом от роутера могут быть связаны с перегруженной Wi-Fi-сетью. Попробуйте изменить канал Wi-Fi передачи данных или установить ограничение на количество подключенных устройств.
5. Проверьте наличие вирусов. Если роутер подключен к заразившемуся компьютеру или устройству, шторм от роутера может быть вызван вирусами или вредоносным программным обеспечением. Осуществите проверку всех устройств на наличие вирусов и вредоносных программ, а также убедитесь в защите вашей Wi-Fi-сети паролем.
6. Обратитесь в техническую поддержку. Если ни один из описанных выше способов не помог, обратитесь к специалистам в техническую поддержку провайдера. Они смогут провести дополнительную диагностику и помочь в решении проблемы.
Полный список способов справиться с штормом от роутера зависит от модели роутера и его настроек, поэтому рекомендуется обратиться к руководству пользователя или официальному сайту производителя для получения более подробной информации.
«Идеальный шторм» и как это лечится
Время на прочтение
7 мин
Количество просмотров 126K
Привет, Хабр!
Broadcast storm (широковещательный шторм) – это такой ночной кошмар сетевиков, когда в считанные секунды парализуется передача полезного трафика во всей сети ЦОД. Как это происходит и о чем надо было раньше думать – в нашем сегодняшнем посте.


Откуда есть пошла
Вначале была Ethernet, и не было в ней маршрутизации, и сейчас тоже нету, а посему приходится коммутатору отправлять пакеты данных во все порты – ну, чтобы наверняка. От адресата приходит ответ на определенный порт, коммутатор запоминает соответствие [порт — адресат] и следующая “посылка” отправляется уже не абы куда, а по памятным, так сказать, местам.
Если же ответа нет, а в момент отправки unknown unicast пара-тройка коммутаторов оказываются замкнуты в кольцо, посылка возвращается “отправителю”, который, понятно, снова забрасывает ее во все порты, поскольку ну а что ему еще делать. «Бесхозный» пакет данных опять возвращается и опять улетает. Каждый следующий виток “закольцованного” broadcast flood сопровождается экспоненциальным ростом количества пакетов в сегменте сети. Очень скоро эта лавина «забивает» полосу пропускания портов, на заднем плане красиво «вскипают» перегруженные процессоры коммутаторов – и ваша сеть превращается в памятник самой себе.
Причиной шторма может стать как хакерская атака, так и осечка вашего же инженера при настройке оборудования – или вовсе сбой протоколов. Иными словами, никто не застрахован.
Был такой случай
В 2009 году в сети одного из наших клиентов случился бродкастовый шторм, который мгновенно перекинулся к нам, парализовав работу всей сети передачи данных компании. Отвалились почта, телефония и интернет, система мониторинга «сошла с ума» – и стало невозможно даже локализовать «первоисточник». Полная перезагрузка коммутатора не помогла. Нам ничего не оставалось, кроме как последовательно отключать ВСЕ порты, клиентские и свои собственные… Такой вот «черный понедельник».
Как позже выяснилось, один из сотрудников клиента перепутал порты оборудования – и закольцевал свою топологию на уровне бродкастового домена. Бывает.
Понятно, что в группе риска здесь, в первую очередь, коммерческие ЦОДы: резервированное подключение для каждого клиента само по себе уже означает избыточность соединений между коммутаторами. Однако сетевикам корпоративных дата-центров я бы также не рекомендовал расслабляться: замкнуть по рассеянности пару коммутаторов друг на друга можно и в серверной.
Хорошая новость заключается в том, что при грамотной подготовке вы можете отделаться легким испугом там, где в противном случае получили бы простой сервиса.
С чего начать
Начните с сегментирования сети посредством VLAN: когда сеть разбита на мелкие изолированные сегменты (fault domain), шторм, “накрывший” один из участков, этим участком и ограничивается. Ну, в идеале. В действительности мощный шторм, увы, способен “вбрасывать” пакеты и в так называемые независимые виртуальные сети тоже.
По-хорошему здесь нужно отказаться от “закольцованных” VLAN как внутри собственной инфраструктуры, так и при подключении клиентов к сети (если речь о коммерческом ЦОД). Например, использовать протоколы FHRP и U-образную топологию на уровне доступа.
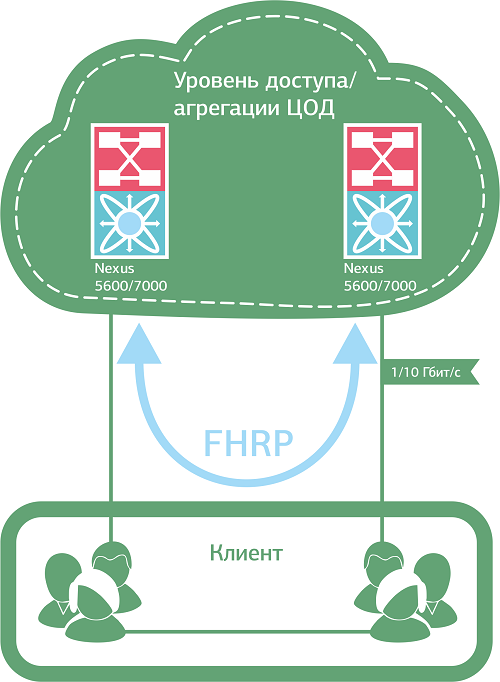
U-образная топология позволяет избежать закольцованности
В ряде случаев, впрочем, от «закольцованности» при всем желании никуда не деться. Скажем, необходимо развернуть отказоустойчивую (2N) инфраструктуру для заказчика с подключением к нашему облаку. Клиентские VLAN’ы здесь приходится «пробрасывать» внутри облачной инфраструктуры между всеми ESXi хостами кластера виртуализации, – то есть само решение подразумевает полное дублирование всех сетевых элементов.
Смотрим в картинку – видим кольцо.
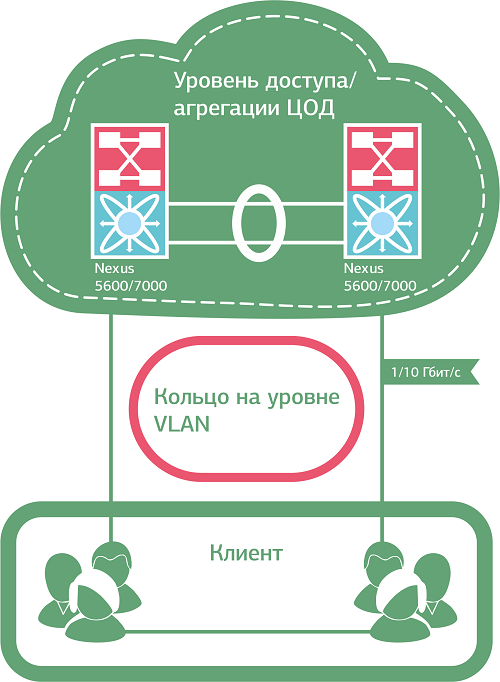
Кольцевая топология возникает при полном резервировании каналов связи и инфраструктуры заказчика
Что делать, если вы – «властелин колец»
Делать можно разное, и у каждого варианта, как водится, — свои преимущества и издержки.
Вот, например, протокол RSTP (модификация SpanningTreeProtocol) умеет быстро – в пределах 6 секунд – находить и «разбивать» бродкастовые петли. Находит он их посредством обмена BPDU (Bridge Protocol Data Unit) сообщениями между коммутаторами, а “разбивает” блокировкой резервных линков. В случае проблем с основным каналом RTSP перестраивает топологию, используя резервный порт.
Хорошая в целом штука, но есть нюанс. Под каждый VLAN выделяется один RSTP-процесс, при этом количество процессов, в отличие от VLAN, сильно ограничено, и при резком росте числа VLAN’ов в рамках одной сетки процессов RSTP может банально не хватить. То есть для корпоративного дата-центра пойдет, а для коммерческого – с постоянно растущим числом клиентов (VLAN) – уже не очень.
На этот случай имеется MSTP – улучшенное и дополненное издание RSTP. Умеет объединять несколько VLAN в один STP процесс (instance), что в хорошем смысле слова сказывается на масштабируемости сети: “потолок” здесь составляет 4096 клиентов (максимальное число VLAN). MSTP также позволяет управлять трафиком, распределяя MST процессы между основным линком и резервным, и дает возможность при необходимости разгружать “загнавшиеся” коммутаторы. Однако с MST нужно уметь работать, то есть это плюс как минимум один недешевый умник в штат (что доступно не всем).
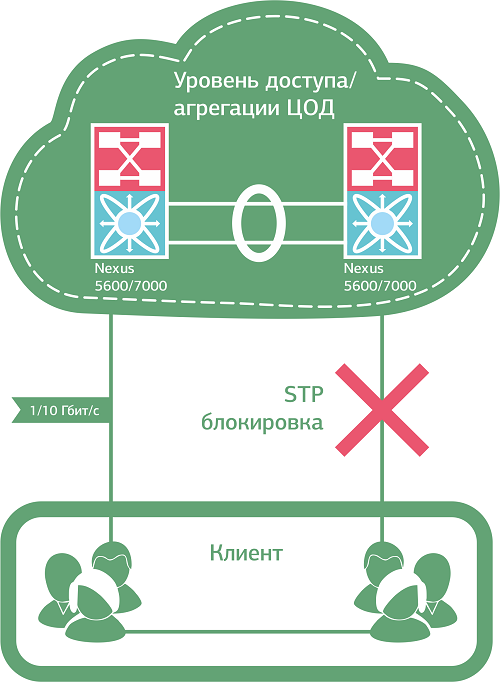
Протоколы RSTP и MST «разрывают» петлю, блокируя трафик по одному из каналов
Из проверенных альтернатив MSTP можем посоветовать FlexLinks от Cisco, который мы используем, когда на стороне клиента находится один коммутатор или стек под единым управлением. FlexLinks умеет резервировать линки коммутатора без применения STP, “назначая” в каждой паре портов основной и резервный. Используется на уровне доступа (access) при подключении оборудования разных компаний по принципу Looped Triangle в коммерческом ЦОД. Очень простой в плане настройки инструмент, что и само по себе приятно, и позволяет рассчитывать на бОльшую стабильность сервиса (по сравнению, например, с STP). Вы полюбите FlexLinks за мгновенное переключение на резервные линки и балансировку нагрузки по VLAN – а потом, возможно, разлюбите за возможность применять его исключительно в топологии Looped Triangle.
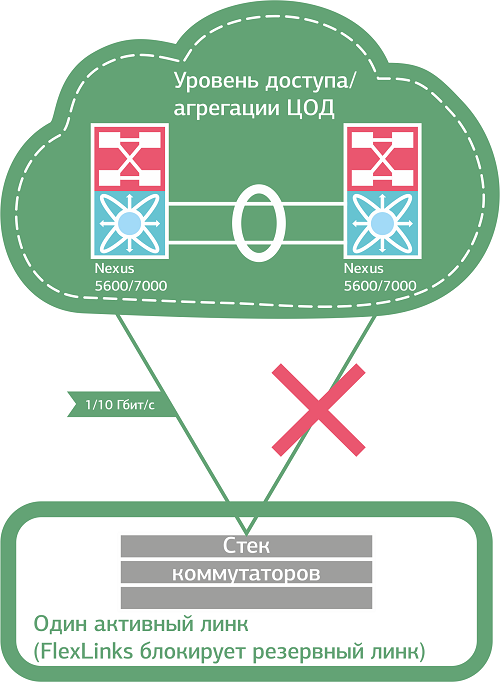
В топологии Looped Triangle можно добиться мгновенного переключения трафика между каналами в случае сбоя
Теперь отвлечемся от техники. Любите ли вы экономическую эффективность так же, как люблю ее я? Тогда вам будет интересно узнать, что и MST \ RSTP, и FlexLinks, блокируя резервные линки, фактически исключают половину портов из круговорота трафика в природе.
А вот решения, которые так не делают: Cisco VSS (Virtual Switch System), Nexus vPC (virtual port-channel), Juniper virtual router и другие mLAG-подобные (multichassis link aggregation) технологии. Хороши тем, что задействует все доступные линки, объединяя их в один логический канал EtherChannel. Получается своего рода коммутирующий кластер, в котором модуль управления одного из коммутаторов (Control-plane) “рулит” всеми линками кластера (Data-Plane). В случае выхода текущего Control-plane из строя его полномочия автоматически передаются “оставшемуся в живых”. Мы используем Cisco Nexus vPC для балансировки нагрузки между линками клиентов, у которых по одному коммутатору или стеку. Если же на стороне клиента два отдельных коммутатора, связанных общим VLAN, добавляем в схему STP.
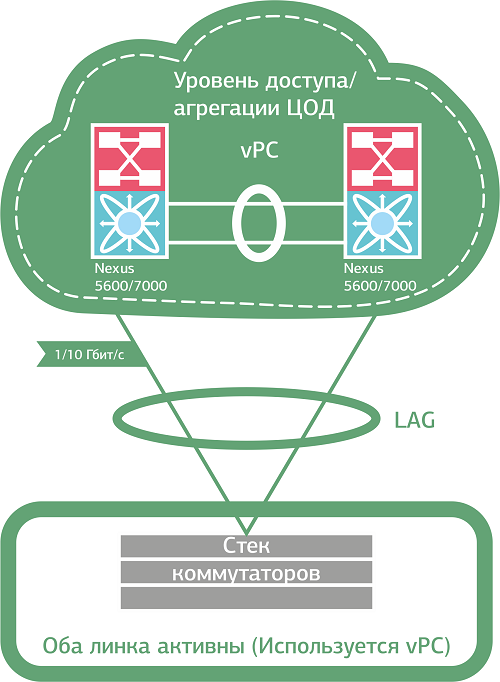
Объединение линков в один логический канал решает проблему со штормами и не сказывается на производительности
Если у вас облака
Виртуализация, катастрофоустойчивые облачные сервисы, распределенные между дата-центрами, и прочие кластерные решения – все это требует несколько иного подхода к организации Layer 2 сети. Убираем STP на антресоли – достаем TRILL.
TRILL использует механизм маршрутизации на Ethernet-уровне и сама строит свободный от петель путь для бродкастового трафика, тем самым предотвращая возникновение штормов. Ну не чудо ли?:) Еще TRILL позволяет равномерно распределять нагрузку между линками (до 16 линков), объединять распределенные дата-центры в единую L2-сеть и гибко управлять трафиком. TRILL – общепринятый стандарт, у которого быстро появились вендорские варианты: FabricPath от Cisco (который используем мы) и VCS от Brocade. Juniper разработал собственную технологию Qfabric, позволяющую создавать единую Ethernet фабрику.
Контрольный выстрел
Какой протокол даст вам 100% защиту от шторма? Правильно, никакой. Поэтому, возможно, вас заинтересуют следующие два инструмента:
• Storm-control
Позволяет установить посекундную “квоту” на количество бродкастовых пакетов, проходящих через один порт. Все, что сверх «квоты», – отбрасывается, и таким образом контролируется нагрузка. Некоторый нюанс заключается в том, что Storm-control не отличает полезный трафик от мусора.
• Control—plane policing (CoPP)
Этакий storm-control для процессора коммутатора. При бродкастовом шторме, помимо прочего, резко возрастает количество ARP-запросов. Когда это количество зашкаливает, процессор загружается на 100% – и сеть, понятно, говорит вам “до свиданья”. CoPP умеет “дозировать” количество ARP-запросов и таким образом управлять нагрузкой на процессор. Неплохо справляется и с броадкастовыми штормами со стороны точек обмена трафиком, и с различными DDoS-атаками — проверено.
Как построить death proof сеть
Итак, какие из возможных вариантов мы проверили на себе и используем в зависимости от вводных:
1. U, V и П-образные топологии + RSTP (MST) + storm control + CoPP.
Базовый набор, в первую очередь, для коммерческого ЦОД, в котором приходится подключать к собственной сети большое количество внешних (неконтролируемых) сетей – и потому крайне желательно не допускать возникновения «петель» вообще.
Если U, V и П-образные топологии не ваш случай, «сокращенный» вариант RSTP (MST) + storm control + CoPP тоже подойдет.
2. Если есть задача максимально использовать возможности оборудования и каналов, присмотритесь к варианту mLAG (VSS, vPC) + storm control + CoPP.
3. Если у вас уже имеется оборудование Cisco или Juniper и нет противопоказаний по топологии, попробуйте комбинацию Flex Links/RTG + storm control + CoPP.
4. Если у вас сложносочиненный случай с распределенными площадками и прочими изысками виртуализации и отказоустойчивости, ваш вариант TRILL + storm control + CoPP.
5. Если вы не знаете, какой у вас случай, – мы можем поговорить об этом:).
Главное – начать делать хоть что-то уже сейчас, даже если вам искренне кажется, что бродкастовый шторм это то, что бывает с другими. В реальности штормы «накрывают» сети самых разных масштабов, а нелепые ошибки совершают даже люди, которые, что называется, двадцать лет в искусстве. «И пусть это вдохновит вас на подвиг» (с).
From Wikipedia, the free encyclopedia
A broadcast storm or broadcast radiation is the accumulation of broadcast and multicast traffic on a computer network. Extreme amounts of broadcast traffic constitute a broadcast storm. It can consume sufficient network resources so as to render the network unable to transport normal traffic.[1] A packet that induces such a storm is occasionally nicknamed a Chernobyl packet.[2]
Causes[edit]
Most commonly the cause is a switching loop in the Ethernet network topology (i.e. two or more paths exist between switches). A simple example is both ends of a single Ethernet patch cable connected to a switch. As broadcasts and multicasts are forwarded by switches out of every port, the switch or switches will repeatedly rebroadcast broadcast messages and flood the network. Since the layer-2 header does not support a time to live (TTL) value, if a frame is sent into a looped topology, it can loop forever.
In some cases, a broadcast storm can be instigated for the purpose of a denial of service (DOS) using one of the packet amplification attacks, such as the smurf attack or fraggle attack, where an attacker sends a large amount of ICMP Echo Requests (ping) traffic to a broadcast address, with each ICMP Echo packet containing the spoof source address of the victim host. When the spoofed packet arrives at the destination network, all hosts on the network reply to the spoofed address. The initial Echo Request is multiplied by the number of hosts on the network. This generates a storm of replies to the victim host tying up network bandwidth, using up CPU resources or possibly crashing the victim.[3]
In wireless networks a disassociation packet spoofed with the source to that of the wireless access point and sent to the broadcast address can generate a disassociation broadcast DOS attack.[4]
Prevention[edit]
- Switching loops are largely addressed through link aggregation, shortest path bridging or spanning tree protocol. In Metro Ethernet rings it is prevented using the Ethernet Ring Protection Switching (ERPS) or Ethernet Automatic Protection System (EAPS) protocols.
- Filtering broadcasts by Layer 3 equipment, typically routers (and even switches that employ advanced filtering called brouters).
- Physically segmenting the broadcast domains using routers at Layer 3 (or logically with VLANs at Layer 2) in the same fashion switches decrease the size of collision domains at Layer 2.
- Routers and firewalls can be configured to detect and prevent maliciously inducted broadcast storms (e.g. due to a magnification attack).
- Broadcast storm control is a feature of many managed switches in which the switch intentionally ceases to forward all broadcast traffic if the bandwidth consumed by incoming broadcast frames exceeds a designated threshold. Although this does not resolve the root broadcast storm problem, it limits broadcast storm intensity and thus allows a network manager to communicate with network equipment to diagnose and resolve the root problem.
MANET broadcast storms[edit]
In a mobile ad hoc network (MANET), route request (RREQ) packets are usually broadcast to discover new routes.
These RREQ packets may cause broadcast storms and compete over the channel with data packets.
One approach to alleviate the broadcast storm problem is to inhibit some hosts from rebroadcasting to reduce the redundancy, and thus contention and collision.[5]
References[edit]
- ^ «Internetwork Design Guide — Broadcasts in Switched LAN Internetworks». DocWiki. Cisco. 1999. Archived from the original on 10 April 2018.
- ^ Chernobyl packet. Free On-line Dictionary of Computing. 17 February 2004. Retrieved 30 August 2013.
- ^ Chau, Hang (17 September 2004). «Defense Against the DoS/DDoS Attacks on Cisco Routers». SecurityDocs. Archived from the original on 11 December 2006.
- ^ «Disassociation Broadcast Attack Using ESSID Jack». ManageEngine. Archived from the original on 11 December 2006.
- ^ Ni, Sze-Yao; Tseng, Yu-Chee; Chen, Yuh-Shyan; Sheu, Jang-Ping (15–19 August 1999). The Broadcast Storm Problem in a Mobile Ad Hoc Network (PDF). MobiCom ’99: The Fifth International Conference on Mobile Computing and Networking. Seattle, Washington, USA. pp. 151–162. ISBN 978-1-58113-142-0. Archived (PDF) from the original on 14 November 2019 – via the University of California, Berkeley.

3 ноября 2012, 17:06

19

599370

80



I think that I shall never see
A graph more lovely than a tree.
A tree whose crucial propertеу
Is loop-free connectivity.
A tree that must be sure to span
So packets can reach every LAN.
First, the root must be selected.
By ID, it is elected.
Least-cost paths from root are traced.
In the tree, these paths are placed.
A mesh is made by folks like me,
Then bridges find a spanning tree.
— Radia Joy Perlman
В прошлом выпуске мы остановились на статической маршрутизации. Теперь надо сделать шаг в сторону и обсудить вопрос стабильности нашей сети.
Дело в том, что однажды, когда вы — единственный сетевой админ фирмы “Лифт ми Ап” — отпросились на полдня раньше, вдруг упала связь с серверами, и директора не получили несколько важных писем. После короткой, но ощутимой взбучки вы идёте разбираться, в чём дело, а оказалось, по чьей-то неосторожности выпал из разъёма кабель, ведущий к коммутатору в серверной. Небольшая проблема, которую вы могли исправить за две минуты, и даже вообще избежать, существенно сказалась на вашем доходе в этом месяце и возможностях роста.
Итак, сегодня обсуждаем: проблему широковещательного шторма ,работу и настройку протокола STP и его модификаций (RSTP, MSTP, PVST, PVST+) ,технологию агрегации интерфейсов и перераспределения нагрузки между ними ,некоторые вопросы стабильности и безопасности, как изменить схему существующей сети, чтобы всем было хорошо.
Содержание выпуска
- Широковещательный шторм
- STP
- Роли портов
- Состояния портов
- Виды STP
- RSTP
- MSTP
- Практика
- L2 security
- Port security
- DHCP Snooping
- IP Source Guard
- Dynamic ARP Inspection
- EtherChannel/EtherTrunk/LAG
- Материалы выпуска
Оборудование, работающее на втором уровне модели OSI (коммутатор), должно выполнять 3 функции: запоминание адресов, перенаправление (коммутация) пакетов, защита от петель в сети. Разберем по пунктам каждую функцию.
Запоминание адресов и перенаправление пакетов: Как мы уже говорили ранее, у каждого свича есть таблица сопоставления MAC-адресов и портов (aka CAM-table — Content Addressable Memory Table). Когда устройство, подключенное к свичу, посылает кадр в сеть, свич смотрит MAC-адрес отправителя и порт, откуда получен кадр, и добавляет эту информацию в свою таблицу. Далее он должен передать кадр получателю, адрес которого указан в кадре.
По идее, информацию о порте, куда нужно отправить кадр, он берёт из этой же CAM-таблицы. Но, предположим, что свич только что включили (таблица пуста), и он понятия не имеет, в какой из его портов подключен получатель. В этом случае он отправляет полученный кадр во все свои порты, кроме того, откуда он был принят. Все конечные устройства, получив этот кадр, смотрят MAC-адрес получателя, и, если он адресован не им, отбрасывают его. Устройство-получатель отвечает отправителю, а в поле отправителя ставит свой адрес, и вот свич уже знает, что такой-то адрес находится на таком-то порту (вносит запись в таблицу), и в следующий раз уже будет переправлять кадры, адресованные этому устройству, только в этот порт.
Чтобы посмотреть содержимое CAM-таблицы, используется команда show mac address-table. Однажды попав в таблицу, информация не остаётся там пожизненно, содержимое постоянно обновляется и если к определенному mac-адресу не обращались 300 секунд (по умолчанию), запись о нем удаляется.
Тут всё должно быть понятно. Но зачем защита от петель? И что это вообще такое?
Широковещательный шторм
Часто, для обеспечения стабильности работы сети в случае проблем со связью между свичами (выход порта из строя, обрыв провода), используют избыточные линки (redundant links) — дополнительные соединения. Идея простая — если между свичами по какой-то причине не работает один линк, используем запасной. Вроде все правильно, но представим себе такую ситуацию: два свича соединены двумя проводами (пусть будет, что у них соединены fa0/1 и fa0/24).

Одной из их подопечных — рабочих станций (например, ПК1) вдруг приспичило послать широковещательный кадр (например, ARP-запрос). Раз широковещательный, шлем во все порты, кроме того, с которого получили.

Второй свич получает кадр в два порта, видит, что он широковещательный, и тоже шлет во все порты, но уже, получается, и обратно в те, с которых получил (кадр из fa0/24 шлет в fa0/1, и наоборот).

Первый свич поступает точно также, и в итоге мы получаем широковещательный шторм (broadcast storm), который намертво блокирует работу сети, ведь свичи теперь только и занимаются тем, что шлют друг другу один и тот же кадр.

Как можно избежать этого? Ведь мы, с одной стороны, не хотим штормов в сети, а с другой, хотим повысить ее отказоустойчивость с помощью избыточных соединений? Тут на помощь нам приходит STP (Spanning Tree Protocol)
STP
Основная задача STP — предотвратить появление петель на втором уровне. Как это сделать? Да просто отрубить все избыточные линки, пока они нам не понадобятся. Тут уже сразу возникает много вопросов: какой линк из двух (или трех-четырех) отрубить? Как определить, что основной линк упал, и пора включать запасной? Как понять, что в сети образовалась петля? Чтобы ответить на эти вопросы, нужно разобраться, как работает STP.
STP использует алгоритм STA (Spanning Tree Algorithm), результатом работы которого является граф в виде дерева (связный и без простых циклов)
Для обмена информацией между собой свичи используют специальные пакеты, так называемые BPDU (Bridge Protocol Data Units). BPDU бывают двух видов: конфигурационные (Configuration BPDU) и панические “ААА, топология поменялась!” TCN (Topology Change Notification BPDU). Первые регулярно рассылаются корневым свичом (и ретранслируются остальными) и используются для построения топологии, вторые, как понятно из названия, отсылаются в случае изменения топологии сети (проще говоря, подключении\отключении свича). Конфигурационные BPDU содержат несколько полей, остановимся на самых важных:
- Идентификатор отправителя (Bridge ID)
- Идентификатор корневого свича (Root Bridge ID)
- Идентификатор порта, из которого отправлен данный пакет (Port ID)
- Стоимость маршрута до корневого свича (Root Path Cost)
Что все это такое и зачем оно нужно, объясню чуть ниже. Так как устройства не знают и не хотят знать своих соседей, никаких отношений (смежности/соседства) они друг с другом не устанавливают. Они шлют BPDU из всех работающих портов на мультикастовый ethernet-адрес 01-80-c2-00-00-00 (по умолчанию каждые 2 секунды), который прослушивают все свичи с включенным STP.
Итак, как же формируется топология без петель?
Сначала выбирается так называемый корневой мост/свич (root bridge). Это устройство, которое STP считает точкой отсчета, центром сети; все дерево STP сходится к нему. Выбор базируется на таком понятии, как идентификатор свича (Bridge ID). Bridge ID это число длиной 8 байт, которое состоит из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768+номер vlan или инстанс MSTP, в зависимости от реализации протокола), и MAC-адреса устройства. В начале выборов каждый коммутатор считает себя корневым, о чем и заявляет всем остальным с помощью BPDU, в котором представляет свой идентификатор как ID корневого свича. При этом, если он получает BPDU с меньшим Bridge ID, он перестает хвастаться своим и покорно начинает анонсировать полученный Bridge ID в качестве корневого. В итоге, корневым оказывается тот свич, чей Bridge ID меньше всех.
Такой подход таит в себе довольно серьезную проблему.
Дело в том, что, при равных значениях Priority (а они равные, если не менять ничего) корневым выбирается самый старый свич, так как мак адреса прописываются на производстве последовательно, соответственно, чем мак меньше, тем устройство старше (естественно, если у нас все оборудование одного вендора).
Понятное дело, это ведет к падению производительности сети, так как старое устройство, как правило, имеет худшие характеристики. Подобное поведение протокола следует пресекать, выставляя значение приоритета на желаемом корневом свиче вручную, об этом в практической части.
Роли портов
После того, как коммутаторы померились айдями и выбрали root bridge, каждый из остальных свичей должен найти один, и только один порт, который будет вести к корневому свичу. Такой порт называется корневым портом (Root port). Чтобы понять, какой порт лучше использовать, каждый некорневой свич определяет стоимость маршрута от каждого своего порта до корневого свича. Эта стоимость определяется суммой стоимостей всех линков, которые нужно пройти кадру, чтобы дойти до корневого свича. В свою очередь, стоимость линка определяется просто- по его скорости (чем выше скорость, тем меньше стоимость). Процесс определения стоимости маршрута связан с полем BPDU “Root Path Cost” и происходит так:
- Корневой свич посылает BPDU с полем Root Path Cost, равным нулю
- Ближайший свич смотрит на скорость своего порта, куда BPDU пришел, и добавляет стоимость согласно таблице
Скорость порта Стоимость STP (802.1d) 10 Mbps 100 100 Mbps 19 1 Gbps 4 10 Gbps 2 - Далее этот второй свич посылает этот BPDU нижестоящим коммутаторам, но уже с новым значением Root Path Cost, и далее по цепочке вниз
Если имеют место одинаковые стоимости (как в нашем примере с двумя свичами и двумя проводами между ними — у каждого пути будет стоимость 19) — корневым выбирается меньший порт.
Далее выбираются назначенные (Designated) порты. Из каждого конкретного сегмента сети должен существовать только один путь по направлению к корневому свичу, иначе это петля. В данном случае имеем в виду физический сегмент, в современных сетях без хабов это, грубо говоря, просто провод. Назначенным портом выбирается тот, который имеет лучшую стоимость в данном сегменте. У корневого свича все порты — назначенные.
И вот уже после того, как выбраны корневые и назначенные порты, оставшиеся блокируются, таким образом разрывая петлю.  *На картинке маршрутизаторы выступают в качестве коммутаторов. В реальной жизни это можно сделать с помощью дополнительной свитчёвой платы.
*На картинке маршрутизаторы выступают в качестве коммутаторов. В реальной жизни это можно сделать с помощью дополнительной свитчёвой платы.
Состояния портов
Чуть раньше мы упомянули состояние блокировки порта, теперь поговорим о том, что это значит, и о других возможных состояниях порта в STP. Итак, в обычном (802.1D) STP существует 5 различных состояний:
- Блокировка (blocking): блокированный порт не шлет ничего. Это состояние предназначено, как говорилось выше, для предотвращения петель в сети. Блокированный порт, тем не менее, слушает BPDU (чтобы быть в курсе событий, это позволяет ему, когда надо, разблокироваться и начать работать)
- Прослушивание (listening): порт слушает и начинает сам отправлять BPDU, кадры с данными не отправляет.
- Обучение (learning): порт слушает и отправляет BPDU, а также вносит изменения в CAM- таблицу, но данные не перенаправляет.
- Пересылка (forwarding): этот может все: и посылает\принимает BPDU, и с данными оперирует, и участвует в поддержании таблицы mac-адресов. То есть это обычное состояние рабочего порта.
- Отключен (disabled): состояние administratively down, отключен командой shutdown. Понятное дело, ничего делать не может вообще, пока вручную не включат.
Порядок перечисления состояний не случаен: при включении (а также при втыкании нового провода), все порты на устройстве с STP проходят вышеприведенные состояния именно в таком порядке (за исключением disabled-портов).
Возникает закономерный вопрос: а зачем такие сложности? А просто STP осторожничает. Ведь на другом конце провода, который только что воткнули в порт, может быть свич, а это потенциальная петля. Вот поэтому порт сначала 15 секунд (по умолчанию) пребывает в состоянии прослушивания — он смотрит BPDU, попадающие в него, выясняет свое положение в сети — как бы чего не вышло, потом переходит к обучению еще на 15 секунд — пытается выяснить, какие mac-адреса “в ходу” на линке, и потом, убедившись, что ничего он не поломает, начинает уже свою работу.
Итого, мы имеем целых 30 секунд простоя, прежде чем подключенное устройство сможет обмениваться информацией со своими соседями.
Современные компы грузятся быстрее, чем за 30 секунд. Вот комп загрузился, уже рвется в сеть, истерит на тему “DHCP-сервер, сволочь, ты будешь айпишник выдавать, или нет?”, и, не получив искомого, обижается и уходит в себя, извлекая из своих недр айпишник автонастройки. Естественно, после таких экзерсисов, в сети его слушать никто не будет, ибо “не местный” со своим 169.254.x.x. Понятно, что все это не дело, но как этого избежать?
Portfast
Для таких случаев используется особый режим порта — portfast. При подключении устройства к такому порту, он, минуя промежуточные стадии, сразу переходит к forwarding-состоянию. Само собой, portfast следует включать только на интерфейсах, ведущих к конечным устройствам (рабочим станциям, серверам, телефонам и т.д.), но не к другим свичам.
Есть очень удобная команда режима конфигурации интерфейса для включения нужных фич на порту, в который будут включаться конечные устройства: switchport host. Эта команда разом включает PortFast, переводит порт в режим access (аналогично switchport mode access), и отключает протокол PAgP (об этом протоколе подробнее в разделе агрегация каналов).
Виды STP
STP довольно старый протокол, он создавался для работы в одном LAN-сегменте. А что делать, если мы хотим внедрить его в нашей сети, которая имеет несколько VLANов?
Стандарт 802.1Q, о котором мы упоминали в статье о коммутации, определяет, каким образом вланы передаются внутри транка. Кроме того, он определяет один процесс STP для всех вланов. BPDU по транкам передаются нетегированными (в native VLAN). Этот вариант STP известен как CST (Common Spanning Tree). Наличие только одного процесса для всех вланов очень облегчает работу по настройке и разгружает процессор свича, но, с другой стороны, CST имеет недостатки: избыточные линки между свичами блокируются во всех вланах, что не всегда приемлемо и не дает возможности использовать их для балансировки нагрузки.
Cisco имеет свой взгляд на STP, и свою проприетарную реализацию протокола — PVST (Per-VLAN Spanning Tree) — которая предназначена для работы в сети с несколькими VLAN. В PVST для каждого влана существует свой процесс STP, что позволяет независимую и гибкую настройку под потребности каждого влана, но самое главное, позволяет использовать балансировку нагрузки за счет того, что конкретный физический линк может быть заблокирован в одном влане, но работать в другом. Минусом этой реализации является, конечно, проприетарность: для функционирования PVST требуется проприетарный же ISL транк между свичами.
Также существует вторая версия этой реализации — PVST+, которая позволяет наладить связь между свичами с CST и PVST, и работает как с ISL- транком, так и с 802.1q. PVST+ это протокол по умолчанию на коммутаторах Cisco.
RSTP
Все, о чем мы говорили ранее в этой статье, относится к первой реализация протокола STP, которая была разработана в 1985 году Радией Перлман (ее стихотворение использовано в качестве эпиграфа). В 1990 году эта реализации была включена в стандарт IEEE 802.1D. Тогда время текло медленнее, и перестройка топологии STP, занимающая 30-50 секунд (!!!), всех устраивала. Но времена меняются, и через десять лет, в 2001 году, IEEE представляет новый стандарт RSTP (он же 802.1w, он же Rapid Spanning Tree Protocol, он же Быстрый STP). Чтобы структурировать предыдущий материал и посмотреть различия между обычным STP (802.1d) и RSTP (802.1w), соберем таблицу с основными фактами:
| STP (802.1d) | RSTP (802.1w) |
| В уже сложившейся топологии только корневой свич шлет BPDU, остальные ретранслируют | Все свичи шлют BPDU в соответствии с hello-таймером (2 секунды по умолчанию) |
| Состояния портов | |
| — блокировка (blocking) — прослушивание (listening) — обучение (learning) — перенаправление\пересылка (forwarding) — отключен (disabled) | — отбрасывание (discarding), заменяет disabled, blocking и listening — learning — forwarding |
| Роли портов | |
| — корневой (root), участвует в пересылке данных, ведет к корневому свичу — назначенный (designated), тоже работает, ведет от корневого свича — неназначенный (non-designated), не участвует в пересылке данных | — корневой (root), участвует в пересылке данных — назначенный (designated), тоже работает — дополнительный (alternate), не участвует в пересылке данных — резервный (backup), тоже не участвует |
| Механизмы работы | |
| Использует таймеры: Hello (2 секунды) Max Age (20 секунд) Forward delay timer (15 секунд) | Использует процесс proposal and agreement (предложение и соглашение) |
| Свич, обнаруживший изменение топологии, извещает корневой свич, который, в свою очередь, требует от всех остальных очистить их записи о текущей топологии в течение forward delay timer | Обнаружение изменений в топологии влечет немедленную очистку записей |
| Если не-корневой свич не получает hello- пакеты от корневого в течение Max Age, он начинает новые выборы | Начинает действовать, если не получает BPDU в течение 3 hello-интервалов |
| Последовательное прохождение порта через состояния Blocking (20 сек) — Listening (15 сек) — Learning (15 сек) — Forwarding | Быстрый переход к Forwarding для p2p и Edge-портов |
Как мы видим, в RSTP остались такие роли портов, как корневой и назначенный, а роль заблокированного разделили на две новых роли: Alternate и Backup. Alternate — это резервный корневой порт, а backup — резервный назначенный порт. Как раз в этой концепции резервных портов и кроется одна из причин быстрого переключения в случае отказа. Это меняет поведение системы в целом: вместо реактивной (которая начинает искать решение проблемы только после того, как она случилась) система становится проактивной, заранее просчитывающей “пути отхода” еще до появления проблемы. Смысл простой: для того, чтобы в случае отказа основного переключится на резервный линк, RSTP не нужно заново просчитывать топологию, он просто переключится на запасной, заранее просчитанный.
Ранее, для того, чтобы убедиться, что порт может участвовать в передаче данных, требовались таймеры, т.е. свич пассивно ждал в течение означенного времени, слушая BPDU. Ключевой фичей RSTP стало введение концепции типов портов, основанных на режиме работы линка- full duplex или half duplex (типы портов p2p или shared, соответственно), а также понятия пограничный порт (тип edge p2p), для конечных устройств. Пограничные порты назначаются, как и раньше, командой spanning-tree portfast, и с ними все понятно — при включении провода сразу переходим к forwarding-состоянию и работаем. Shared-порты работают по старой схеме с прохождением через состояния BLK — LIS — LRN — FWD. А вот на p2p-портах RSTP использует процесс предложения и соглашения (proposal and agreement).
Не вдаваясь в подробности, его можно описать так: свич справедливо считает, что если линк работает в режиме полного дуплекса, и он не обозначен, как пограничный, значит, на нем только два устройства — он и другой свич. Вместо того, чтобы ждать входящих BPDU, он сам пытается связаться со свичом на том конце провода с помощью специальных proposal BPDU, в которых, конечно, есть информация о стоимости маршрута к корневому свичу. Второй свич сравнивает полученную информацию со своей текущей, и принимает решение, о чем извещает первый свич посредством agreement BPDU. Так как весь этот процесс теперь не привязан к таймерам, происходит он очень быстро — только подключили новый свич — и он практически сразу вписался в общую топологию и приступил к работе (можете сами оценить скорость переключения в сравнении с обычным STP на видео).
В Cisco-мире RSTP называется PVRST (Per-Vlan Rapid Spanning Tree).
MSTP
Чуть выше, мы упоминали о PVST, в котором для каждого влана существует свой процесс STP. Вланы довольно удобный инструмент для многих целей, и поэтому, их может быть достаточно много даже в некрупной организации. И в случае PVST, для каждого будет рассчитываться своя топология, тратиться процессорное время и память свичей.
А нужно ли нам рассчитывать STP для всех 500 вланов, когда единственное место, где он нам нужен- это резервный линк между двумя свичами?
Тут нас выручает MSTP. В нем каждый влан не обязан иметь собственный процесс STP, их можно объединять. Вот у нас есть, например, 500 вланов, и мы хотим балансировать нагрузку так, чтобы половина из них работала по одному линку (второй при этом блокируется и стоит в резерве), а вторая- по другому. Это можно сделать с помощью обычного STP, назначив один корневой свич в диапазоне вланов 1-250, а другой- в диапазоне 250-500. Но процессы будут работать для каждого из пятисот вланов по отдельности (хотя действовать будут совершенно одинаково для каждой половины). Логично, что тут хватит и двух процессов.
MSTP позволяет создавать столько процесов STP, сколько у нас логических топологий (в данном примере — 2), и распределять по ним вланы.
Думаем, нет особого смысла углубляться в теорию и практику MSTP в рамках этой статьи (ибо теории там ого-го), интересующиеся могут пройти по ссылке.
Агрегация каналов
Но какой бы вариант STP мы не использовали, у нас все равно существует так или иначе неработающий линк. А возможно ли задействовать параллельные линки по полной и при этом избежать петель? Да, отвечаем мы вместе с циской, начиная рассказ о EtherChannel.
Иначе это называется link aggregation, link bundling, NIC teaming, port trunkinkg
Технологии агрегации (объединения) каналов выполняют 2 функции: с одной стороны, это объединение пропускной способности нескольких физических линков, а с другой — обеспечение отказоустойчивости соединения (в случае падения одного линка нагрузка переносится на оставшиеся). Объединение линков можно выполнить как вручную (статическое агрегирование), так и с помощью специальных протоколов: LACP (Link Aggregation Control Protocol) и PAgP (Port Aggregation Protocol). LACP, опеределяемый стандартом IEEE 802.3ad, является открытым стандартом, то есть от вендора оборудования не зависит. Соответственно, PAgP — проприетарная цисковская разработка.
В один такой канал можно объединить до восьми портов. Алгоритм балансировки нагрузки основан на таких параметрах, как IP/MAC-адреса получателей и отправителей и порты. Поэтому в случае возникновения вопроса: “Хей, а чего так плохо балансируется?” в первую очередь смотрите на алгоритм балансировки.
Практика
Наверное, большинство ошибок в Packet Tracer допущено в части кода, отвечающего за симуляцию STP, будте готовы. В случае сомнения сохранитесь, закройте PT и откройте заново
Итак, переходим к практике.
Для начала внесем некоторые изменения в топологию — добавим избыточные линки. Учитывая сказанное в самом начале, вполне логично было бы сделать это в московском офисе в районе серверов — там у нас свич msk-arbat-asw2 доступен только через asw1, что не есть гуд. Мы отбираем (пока, позже возместим эту потерю) гигабитный линк, который идет от msk-arbat-dsw1 к msk-arbat-asw3, и подключаем через него asw2. Asw3 пока подключаем в порт Fa0/2 dsw1. Перенастраиваем транки:
msk-arbat-dsw1(config)#interface gi1/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw2
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-dsw1(config-if)#int fa0/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw3
msk-arbat-dsw1(config-if)#switchport mode trunk
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,101-104
msk-arbat-asw2(config)#int gi1/2
msk-arbat-asw2(config-if)#description msk-arbat-dsw1
msk-arbat-asw2(config-if)#switchport mode trunk
msk-arbat-asw2(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-asw2(config-if)#no shutdown
Не забываем вносить все изменения в документацию! Скачать актуальную версию документа.
Скачать актуальную версию документа.
Теперь посмотрим, как в данный момент у нас самонастроился STP. Нас интересует только VLAN0003, где у нас, судя по схеме, петля.
msk-arbat-dsw1>en
msk-arbat-dsw1#show spanning-tree vlan 3
Разбираем по полочкам вывод команды  Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем- таблица состояния портов, которая состоит из следующих колонок (слева направо):
Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем- таблица состояния портов, которая состоит из следующих колонок (слева направо):
- Собственно, порт
- Его роль (Root- корневой порт, Desg- назначенный порт, Altn- дополнительный, Back- резервный)
- Его статус (FWD- работает, BLK- заблокирован, LIS- прослушивание, LRN- обучение)
- Стоимость маршрута до корневого свича
- Port ID в формате: приоритет порта.номер порта
- Тип соединения
Итак, мы видим, что Gi1/1 корневой порт, это дает некоторую вероятность того, что на другом конце линка корневой свич. Смотрим по схеме, куда ведет линк: ага, некий msk-arbat-asw1.
msk-arbat-asw1#show spanning-tree vlan 3
И что же мы видим?
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 32771
Address 0007.ECC4.09E2
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Вот он, наш корневой свич для VLAN0003.
А теперь посмотрим на схему.
Ранее, мы увидели в состоянии портов, что dsw1 блокирует порт Gi1/2, разрывая таким образом петлю. Но является ли это оптимальным решением? Нет, конечно. Сейчас наша новая сеть работает точь-в-точь как старая — трафик от asw2 идет только через asw1. Выбор корневого маршрутизатора никогда не нужно оставлять на совесть глупого STP.
Исходя из схемы, наиболее оптимальным будет выбор в качестве корневого свича dsw1 — таким образом, STP заблокирует линк между asw1 и asw2. Теперь это все надо объяснить недалекому протоколу. А для него главное что? Bridge ID. И он неслучайно складывается из двух чисел. Приоритет — это как раз то слагаемое, которое отдано на откуп сетевому инженеру, чтобы он мог повлиять на результат выбора корневого свича.
Итак, наша задача сводится к тому, чтобы уменьшить (меньше-лучше, думает STP) приоритет нужного свича, чтобы он стал Root Bridge. Есть два пути:
- Вручную установить приоритет, заведомо меньший, чем текущий:
msk-arbat-dsw1>enable msk-arbat-dsw1#configure terminal msk-arbat-dsw1(config)#spanning-tree vlan 3 priority ? <0-61440> bridge priority in increments of 4096 msk-arbat-dsw1(config)#spanning-tree vlan 3 priority 4096Теперь он стал корневым для влана 3, так как имеет меньший Bridge ID:
msk-arbat-dsw1#show spanning-tree vlan 3 VLAN0003 Spanning tree enabled protocol ieee Root ID Priority 4099 Address 000B.BE2E.392C This bridge is the root Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec - Дать умной железке решить все за тебя:
msk-arbat-dsw1(config)#spanning-tree vlan 3 root primaryПроверяем:
msk-arbat-dsw1#show spanning-tree vlan 3 VLAN0003 Spanning tree enabled protocol ieee Root ID Priority 24579 Address 000B.BE2E.392C This bridge is the root Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Мы видим, что железка поставила какой-то странный приоритет.
Откуда взялась эта круглая цифра, спросите вы? А все просто — STP смотрит минимальный приоритет (т.е. тот, который у корневого свича), и уменьшает его на два шага инкремента (который составляет 4096, т.е. в итоге 8192). Почему на два? А чтобы была возможность на другом свиче дать команду spanning-tree vlan n root secondary (назначает приоритет = приоритет корневого — 4096), что позволит нам быть уверенными, что, если с текущим корневым свичом что-то произойдет, его функции перейдут к этому, “запасному”.
Вероятно, вы уже видите на схеме, как лампочка на линке между asw2 и asw1 пожелтела? Это STP разорвал петлю. Причем именно в том месте, в котором мы хотели. Sweet! Зайдем проверим: лампочка — это лампочка, а конфиг — это факт.
msk-arbat-asw2#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 24579
Address 000B.BE2E.392C
Cost 4
Port 26(GigabitEthernet1/2)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 32771 (priority 32768 sys-id-ext 3)
Address 000A.F385.D799
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 20
Interface Role Sts Cost Prio.Nbr Type
---------------- ---- --- --------- -------- --------------------------------
Fa0/1 Desg FWD 19 128.1 P2p
Gi1/1 Altn BLK 4 128.25 P2p
Gi1/2 Root FWD 4 128.26 P2p
Теперь полюбуемся, как работает STP: заходим в командную строку на ноутбуке PTO1 и начинаем бесконечно пинговать наш почтовый сервер (172.16.0.4). Пинг сейчас идет по маршруту ноутбук-asw3-dsw1-gw1-dsw1(ну тут понятно, зачем он крюк делает — они из разных вланов)-asw2-сервер. А теперь поработаем Годзиллой из SimСity: нарушим связь между dsw1 и asw2, вырвав провод из порта (замечаем время, нужное для пересчета дерева).
Пинги пропадают, STP берется за дело, и за каких-то 30 секунд коннект восстанавливается. Годзиллу прогнали, пожары потушили, связь починили, втыкаем провод обратно. Пинги опять пропадают на 30 секунд! Мда-а-а, как-то не очень быстро, особенно если представить, что это происходит, например, в процессинговом центре какого-нибудь банка.
Но у нас есть ответ медленному PVST+! И ответ этот — Быстрый PVST+ (так и называется, это не шутка: Rapid-PVST). Посмотрим, что он нам дает. Меняем тип STP на всех свичах в москве командой конфигурационного режима: spanning-tree mode rapid-pvst
Снова запускаем пинг, вызываем Годзиллу… Эй, где пропавшие пинги? Их нет, это же Rapid-PVST. Как вы, наверное, помните из теоретической части, эта реализация STP, так сказать, “подстилает соломку” на случай падения основного линка, и переключается на дополнительный (alternate) порт очень быстро, что мы и наблюдали. Ладно, втыкаем провод обратно. Один потерянный пинг. Неплохо по сравнению с 6-8, да?
L2 security
Port security
Теперь расскажем вкратце, как обеспечить безопасность сети на втором уровне OSI. В этой части статьи теория и практическая конфигурация совмещены. Увы, Packet Tracer не умеет ничего из упомянутых в этом разделе команд, поэтому все без иллюстраций и проверок.
Для начала, следует упомянуть команду конфигурации интерфейса switchport port-security, включающую защиту на определенном порту свича. Затем, с помощью switchport port-security maximum 1 мы можем ограничить количество mac-адресов, связанных с данным портом (т.е., в нашем примере, на данном порту может работать только один mac-адрес). Теперь указываем, какой именно адрес разрешен: его можно задать вручную switchport port-security mac-address адрес, или использовать волшебную команду switchport port-security mac-address sticky, закрепляющую за портом тот адрес, который в данный момент работает на порту. Далее, задаем поведение в случае нарушения правила switchport port-security violation {shutdown | restrict | protect}: порт либо отключается, и потом его нужно поднимать вручную (shutdown), либо отбрасывает пакеты с незарегистрированного мака и пишет об этом в консоль (restrict), либо просто отбрасывает пакеты (protect).
Помимо очевидной цели — ограничение числа устройств за портом — у этой команды есть другая, возможно, более важная: предотвращать атаки. Одна из возможных — истощение CAM-таблицы. С компьютера злодея рассылается огромное число кадров, возможно, широковещательных, с различными значениями в поле MAC-адрес отправителя. Первый же коммутатор на пути начинает их запоминать. Одну тысячу он запомнит, две, но память-то оперативная не резиновая, и среднее ограничение в 16000 записей будет довольно быстро достигнуто. При этом дальнейшее поведение коммутатора может быть различным. И самое опасное из них с точки зрения безопасности: коммутатор может начать все кадры, приходящие на него, рассылать, как широковещательные, потому что MAC-адрес получателя не известен (или уже забыт), а запомнить его уже просто некуда. В этом случае сетевая карта злодея будет получать все кадры, летающие в вашей сети.
DHCP Snooping
Другая возможная атака нацелена на DHCP сервер. Как мы знаем, DHCP обеспечивает клиентские устройства всей нужной информацией для работы в сети: ip-адресом, маской подсети, адресом шюза по умолчанию, DNS-сервера и прочим. Атакующий может поднять собственный DHCP, который в ответ на запрос клиентского устройства будет отдавать в качестве шлюза по умолчанию (а также, например, DNS-сервера) адрес подконтрольной атакующему машины. Соответственно, весь трафик, направленный за пределы подсети обманутыми устройствами, будет доступен для изучения атакующему — типичная man-in-the-middle атака. Либо такой вариант: подлый мошенник генерируют кучу DHCP-запросов с поддельными MAC-адресами и DHCP-сервер на каждый такой запрос выдаёт IP-адрес до тех пор, пока не истощится пул.
Для того, чтобы защититься от подобного вида атак, используется фича под названием DHCP snooping. Идея совсем простая: указать свичу, на каком порту подключен настоящий DHCP-сервер, и разрешить DHCP-ответы только с этого порта, запретив для остальных. Включаем глобально командой ip dhcp snooping, потом говорим, в каких вланах должно работать ip dhcp snooping vlan номер(а). Затем на конкретном порту говорим, что он может пренаправлять DHCP-ответы (такой порт называется доверенным): ip dhcp snooping trust.
IP Source Guard
После включения DHCP Snooping’а, он начинает вести у себя базу соответствия MAC и IP-адресов устройств, которую обновляет и пополняет за счет прослушивания DHCP запросов и ответов. Эта база позволяет нам противостоять еще одному виду атак — подмене IP-адреса (IP Spoofing). При включенном IP Source Guard, каждый приходящий пакет может проверяться на:
- соответствие IP-адреса источника адресу, полученному из базы DHCP Snooping (иными словами, айпишник закрепляется за портом свича)
- соответствие MAC-адреса источника адресу, полученному из базы DHCP Snooping
Включается IP Source Guard командой ip verify source на нужном интерфейсе. В таком виде проверяется только привязка IP-адреса, чтобы добавить проверку MAC, используем ip verify source port-security. Само собой, для работы IP Source Guard требуется включенный DHCP snooping, а для контроля MAC-адресов должен быть включен port security.
Dynamic ARP Inspection
Как мы уже знаем, для того, чтобы узнать MAC-адрес устройства по его IP-адресу, используется протокол ARP: посылается широковещательный запрос вида “у кого ip-адрес 172.16.1.15, ответьте 172.16.1.1”, устройство с айпишником 172.16.1.15 отвечает.
Подобная схема уязвима для атаки, называемой ARP-poisoning aka ARP-spoofing: вместо настоящего хоста с адресом 172.16.1.15 отвечает хост злоумышленника, заставляя таким образом трафик, предназначенный для 172.16.1.15, следовать через него.
Для предотвращения такого типа атак используется фича под названием Dynamic ARP Inspection. Схема работы похожа на схему DHCP-Snooping’а: порты делятся на доверенные и недоверенные, на недоверенных каждый ARP-ответ подвергаются анализу: сверяется информация, содержащаяся в этом пакете, с той, которой свич доверяет (либо статически заданные соответствия MAC-IP, либо информация из базы DHCP Snooping). Если не сходится, пакет отбрасывается и генерируется сообщение в syslog. Включаем в нужном влане (вланах): ip arp inspection vlan номер(а). По умолчанию все порты недоверенные, для доверенных портов используем ip arp inspection trust.
EtherChannel/EtherTrunk/LAG
Помните, мы отобрали у офисных работников их гигабитный линк и отдали его в пользу серверов? Сейчас они, бедняжки, сидят, на каких-то ста мегабитах, прошлый век! Попробуем расширить канал, и на помощь призовем EtherChannel.
В данный момент у нас соединение идет от fa0/2 dsw1 на Gi1/1 asw3, отключаем провод. Смотрим, какие порты можем использовать на asw3: ага, fa0/20-24 свободны, кажется. Вот их и возьмем.
Со стороны dsw1 пусть будут fa0/19-23. Соединяем порты для EtherChannel между собой. На asw3 у нас на интерфейсах что-то настроено, обычно в таких случаях используется команда конфигурационного режима default interface range fa0/20-24, сбрасывающая настройки порта (или портов, как в нашем случае) в дефолтные. Packet tracer, увы, не знает такой хорошей команды, поэтому в ручном режиме убираем каждую настройку, и тушим порты (лучше это сделать, во избежание проблем)
msk-arbat-asw3(config)#interface range fa0/20-24
msk-arbat-asw3(config-if-range)#no description
msk-arbat-asw3(config-if-range)#no switchport access vlan
msk-arbat-asw3(config-if-range)#no switchport mode
msk-arbat-asw3(config-if-range)#shutdown
ну а теперь волшебная команда
msk-arbat-asw3(config-if-range)#channel-group 1 mode on
то же самое на dsw1:
msk-arbat-dsw1(config)#interface range fa0/19-23
msk-arbat-dsw1(config-if-range)#channel-group 1 mode on
поднимаем интерфейсы asw3, и вуаля: вот он, наш EtherChannel, раскинулся аж на 5 физических линков. В конфиге он будет отражен как interface Port-channel 1. Настраиваем транк (повторить для dsw1):
msk-arbat-asw3(config)#int port-channel 1
msk-arbat-asw3(config-if)#switchport mode trunk
msk-arbat-asw3(config-if)#switchport trunk allowed vlan 2,101-104
Как и с STP, есть некая трудность при работе с etherchannel в Packet Tracer’e. Настроить-то мы, в принципе, можем по вышеописанному сценарию, но вот проверка работоспособности под большим вопросом: после отключения одного из портов в группе, трафик перетекает на следующий, но как только вы вырубаете второй порт — связь теряется и не восстанавливается даже после включения портов.
Отчасти в силу только что озвученной причины, отчасти из-за ограниченности ресурсов мы не сможем раскрыть в полной мере эти вопросы и посему оставляем бОльшую часть на самоизучение.
Материалы выпуска
- Новый план коммутации
- Файл PT с лабораторной.
- Конфигурация устройств
- STP или STP
- Безопасность канального уровня
- Агрегация каналов
Авторы
- eucariot — Марат Сибгатулин (inst, tg, in)
- Макс Gluck
Оставайтесь на связи
Пишите нам: info@linkmeup.ru
Канал в телеграме: t.me/linkmeup_podcast
Канал на youtube: youtube.com/c/linkmeup-podcast
Подкаст доступен в iTunes, Google Подкастах, Яндекс Музыке, Castbox
Сообщество в вк: vk.com/linkmeup
Группа в фб: www.facebook.com/linkmeup.sdsm
Добавить RSS в подкаст-плеер.
Пообщаться в общем чате в тг: https://t.me/linkmeup_chatПоддержите проект:





19

599370

80
80 коментариев
Ещё статьи

test
[R2]dis efm ses al Interface EFM State Loopback Timeout ———————————————————————- GigabitEthernet1/1/4 detect — GigabitEthernet1/1/6 detect — 111 111
Вебинар и лабинар по EIGRP
В четверг 18 августа в 19:30 МСК состоится очередной вебинар на тему «EIGRP», который проведёт Дмитрий Фиголь. В нём мы рассмотрим как и основы протокола EIGRP, так и продвинутые фичи. …
Анонс подкаста. Выпуск 29
Коллеги, предлагаю отдохнуть от череды технических выпусков и поговорить о том, о сём. В гостях подкаста Дмитрий Фиголь и Олег Фиксель, которые будут вещать из Германии. Работа, жизнь, образование. Если …