В этом сообщение я представлю вам BackupPC, программный кросс-платформенный бэкап сервер, который через сеть может вытянуть резервное копирование клиентов Linux, Windows и MacOS. В BackupPC добавлено ряд функций, которые делают резервное копированиче чуть ли не приятной вещью.
BackupPC поставляется с надёжным веб-интерфейсом, который позволяет вам собирать и управлять централизованным образом резервными копированиями других удалённых хостов. Используя веб-интерфейс, вы можете изучить файлы журналов и конфигурационные файлы, запустить/отменить/настроить расписания резервных копирований удалённых хостов и визуализировать текущий статус задач резервного копирования. Вы также можете просматривать архивные файлы и очень просто восстанавливать отдельные файлы или всё полностью из архивов бэкапов. Для восстановления индивидуальных отдельных файлов, вы можете загружать их из предыдущих бэкапов прямо в веб-интерфейсе. Если этого недостаточно, не требуется специальной программы на стороне клиента для клиентских хостов. На Windows клиентах используется родной протокол SMB, в то время как на *nix клиентах вы будете использовать rsync или tar через SSH, RSH или NFS.
Установка BackupPC
На Debian, Ubuntu, Mint и их производных запустите следующую команду.
# aptitude install backuppc
На Fedora используйте команду yum command. Обратите внимание, что имя пакета регистрозависимое.
# yum install BackupPC
На CentOS/RHEL 6 сначала включите репозиторий EPEL. На CentOS/RHEL 7 включите вместо репозиторий Nux Dextop. Затем продолжайте с командой yum:
# yum install BackupPC
Далее команды на разных дистрибутивах Linux идентичны, пользователи Debian, Ubuntu, Mint и их производных не забывайте ставить sudo перед каждой командой.
Как обычно, обе системы управления пакетами будут заботиться об автоматическом разрешении зависимостей. В дополнение как часть установочного процесса, вас могут спросить настроить почтовый сервер, настроить или перенастроить веб-сервер, который будет использован для графического пользовательского интерфейса. Я не стал ничего настраивать в почтовом сервере (чтобы не удлинять инструкцию). Следующие скриншоты из системы Debian:
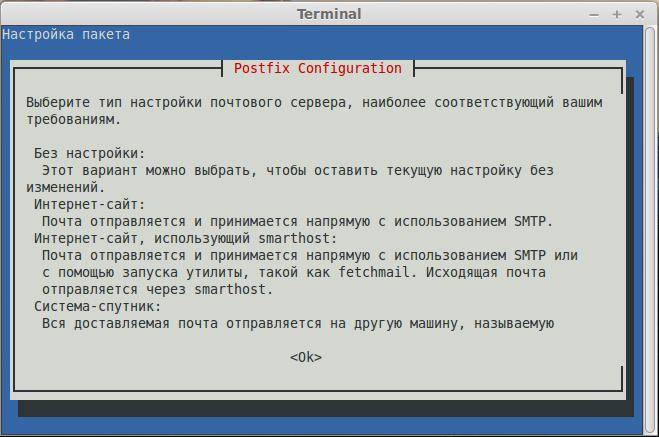
![]()
Сделайте ваш выбор нажав на пробел и затем перейдите к Ок, используя кнопку [Tab], и нажмите [Enter].
Вам будет представлена следующий экран, информирующий вас, что администраторский пользовательский аккаунт ‘backuppc’ с соответствующим ему паролем (который, по желанию, может быть изменён), был создан для управления BackupPC. Обратите внимание, что пользовательский аккаунт HTTP и обычный Linux аккаунт с одинаковым именем ‘backuppc’ будут созданы с идентичным паролем. Первый нужен для получения доступа в защищённый веб-интерфейс BackupPC, в то время как второй нужен для выполнения резервного копирования используя rsync через SSH.
![]()
Вы можете изменить пароль по умолчанию для HTTP пользователя ‘backuppc’ следующей командой:
htpasswd /etc/backuppc/htpasswd backuppc
Для изменения обычного ‘backuppc’ пользовательского аккаунта Linux, используйте команду passwd.
# passwd backuppc
Обратите внимание, что установочный процесс автоматически создаст веб и программный конфигурационные файлы.
Запуск BackupPC и настройка Backups
Чтобы начать, откройте окно браузера по адресу http://<доменное имя или IP адрес сервера>/backuppc/. Когда появится окно запроса, введите данные HTTP пользователя, которые были предоставлены вам ранее. Если авторизация успешна, вас перекинет на главную страницу веб-интерфейса.

Наиболее вероятно, первое, что вам нужно сделать, это добавить хосты клиентов для резервного копирования. Перейдите в «Edit Hosts» (редактирвоание хостов) в панеле задач. Мы добавим два клиентских хоста:
- Host #1: CentOS 7 [IP 192.168.0.17]
- Host #2: Windows 7 [IP 192.168.0.103]
Мы будем делать резервное копирование CentOS, используя rsync через SSH, и хоста Windows, используя SMB. До выполнения резервного копирования, нам нужно настроить основанную на ключе аутентификацию на наш хост CentOS и сделать доступной по сети (расшарить) каталог на Windows машине.
Вот инструкция для настройки аутентификации, основанной на ключе, для удалённого хоста CentOS. Мы создаём пользователю ‘backuppc’ пару ключей RSA и переносим публичный ключ в аккаунт рута хоста CentOS.
# usermod -s /bin/bash backuppc # su - backuppc # ssh-keygen -t rsa # ssh-copy-id [email protected]
Когда спросят, напечатайте yes и введите пароль рута для 192.168.0.17.
Вам понадобиться рут доступ для удалённого хоста CentOS для получения доступа записи на всю файловую систему в случае восстановления бэкапа файлов или каталогов, собственником которых является рут.
Когда хосты CentOS и Windows готовы, добавьте их в BackupPC используя веб-интерфейс:
Следующий шаг состоит из изменения настроек резервного копирования каждого хоста:
Следующее изображение показывает настройку для резервного копирования на Windows машине:
А следующий скриншот показывает настройку резервного копирования для CentOS:
Запуск резервного копирования
Для запуска каждого резервного копирования, перейдите к настройкам каждого хоста, а затем кликните «Start Full Backup»:
В любое время, вы можете просмотреть статус процесса, кликнув на home хоста, как показано в изображении выше. Если это по каким-либо причинам не получилось, также появится ссылка на страницу с сообщением ошибки (ошибок) в меню хоста. Когда резервное копирвоание завершено успешно, на сервере создаётся каталог с названием хоста или IP адресом в /var/lib/backuppc/pc:
Вы можете переходить по каталогам в поисках файлов, используя командную строку, но есть и более простой способ обозревать эти файлы и восстанавливать их.
Восстановление резервных копий
Для просмотра сохранённых файлов, переходите в раздел «Browse backups», что находится в главном меню хоста. Вы можете визуализировать каталоги и файлы с первого взгляда и выбрать те, которые вы хотите восстановить. Как вариант, вы можете кликнуть по файлу и открыть его, используя программу по умолчанию, или кликните правой кнопкой и выберете Сохранить ссылку, для его загрузки на машину, где вы работаете в данный момент:
Если хотите, то можете загрузить файлы zip или tar, заключающие содержание резеврных копий или просто восстановите файл (файлы) на прежнее место:
Заключение
Говорят «Чем проще — тем лучше», и именно это предлагает BackupPC. В BackupPC вы найдёте не только инструмент для резервного копирования, но также разносторонний интерфейс для управления вашими резервными копиями нескольких операционных систем без необходимости приложения на стороне клиента. Я уверен, что более чем достаточная причина, чтобы хотя бы попробовать.
Оставляйте ваши комментарии и вопросы, если они у вас есть, используя форму внизу. Я всегда счастлив услышать, что говорят читатели!
|
Рубрика: Администрирование / Продукты и решения |
Мой мир Вконтакте Одноклассники Google+ |
 АНДРЕЙ МАРКЕЛОВ
АНДРЕЙ МАРКЕЛОВ
Linux на страже Windows
Обзор и установка системы резервного копирования BackupPC
Думаю, в настоящее время никто уже не станет спорить с утверждением, что процесс вхождения Linux в корпоративный мир стал необратимым, а процент установок этой операционной системы на серверах в различных организациях постоянно возрастает.
Можно бесконечно спорить о преимуществах одних операционных систем над другими, но когда у меня возникло желание сделать единое хранилище для ежедневных архивов информации с более десяти серверов своей организации, работающих под управлением нескольких различных ОС, я свой выбор остановил на платформе Linux. До сих пор каждый сервер с помощью уникальных для него скриптов в назначенное время сбрасывал по сети на сервер резервного копирования или stand by-сервер какие-то свои данные, например, пользовательские файлы с сетевых дисков, или дампы базы данных. Для этого использовались различные протоколы: ftp, SMB или штатные средства СУБД. При этом приходилось следить за уникальным для каждого сервера лог-файлом, и в случае каких-либо изменений в стратегии резервного копирования править скрипты на каждой машине.
Чтобы как-то упростить администрирование и сократить время, затрачиваемое на поддержку и мониторинг всего этого «зоопарка», я начал искать систему, которая бы поддерживала копирование информации по сети, умела делать инкрементальные бэкапы, поддерживала бы удаленное администрирование и не требовала установки клиентского программного обеспечения. Кроме того, было важно, чтобы система умела работать по протоколу SMB, так как часть серверов, в частности основной файл-сервер, работали под управлением ОС Windows.
Спустя непродолжительное время такая система была найдена. Ею оказалась открытая, распространяющаяся по лицензии GNU система архивирования данных масштаба предприятия BackupPC. Сайт расположен по адресу http://backuppc.sourceforge.net.
Основные особенности рассматриваемой программы:
- Язык программирования, на котором написана система, – Perl.
- Минимизация хранимой информации за счет того, что идентичные файлы из разных резервных копий хранятся только в одном экземпляре.
- Настраиваемая степень сжатия данных.
- Поддержка работы по протоколам smb/ssh/rsh/nfs.
- Мощный CGI-интерфейс, позволяющий управлять сервером по сети посредством веб-браузера.
- Поддержка архивирования информации с машин, получающих настройки сети через DHCP, разрешая имена при помощи nmblookup.
- Гибкие настройки планирования архивации данных.
- Оповещения о выполненных действиях администратора и пользователей посредством электронной почты.
- Поддержка клиентов, работающих под управлением Linux, Freenix, Solaris Win95, Win98, Win2000 и WinXP. Сервер тестировался на Linux, Freenix и Solaris.
- Очень подробная документация.
В данной статье я хочу обобщить свой опыт установки, настройки и эксплуатации этой системы, а также поделиться решением нескольких проблем, которые возникли в процессе установки.
Я проверял работу BackupPC версии 2.1.0, последней на момент написания статьи, при помощи тестовой машины под управлением Fedora Core 2, и на «боевых» серверах, работающих на Red Hat Linux 9 и White Box Enterprise Linux 3. Операционная система, стоящая на тестовом сервере фактически является альфа-версией будущего Red Hat Enterprise Linux 4, а White Box Enterprise Linux 3 перекомпиляцией из свободно доступных исходных текстов текущей, третьей версии коммерческого Linux-дистрибутива от Red Hat.
Необходимость использовать не поддерживающуюся более «девятку» возникла при установке RAID-контроллера Promise SuperTRAX SX6000, для которого существовали драйвера только под эту операционную систему.
Требования к установке
Прежде чем приступить непосредственно к инсталляции и настройке самой системы резервного копирования BackupPC, необходимо определиться с требованиями к программному окружению, в котором должен работать сервер.
Во-первых, как я уже писал, это операционная система, в роли которой может выступать Linux, Solaris либо другая UNIX-подобная система. Во-вторых, необходимо предусмотреть наличие вместительного RAID-массива, или использовать LVM. Кроме того: Perl версии 5.6.0 или выше, Samba- и Apache-сервер.
В этой статье я не буду касаться настройки клиента Samba, в частности, работы в составе Active Directory. Я предполагаю само собой разумеющимся, что если вы планируете производить архивацию информации с Windows-серверов, работающих в составе домена, то и должны обеспечить к ним доступ вашей Linux-машины. Отсутствие описания процесса конфигурирования Samba-сервера в данной статье, думаю, компенсируется многочисленными материалами на эту тему в Интернете.
Также предполагается, что вы используете кодировку KOI-8 вместо установленной по умолчанию в большинстве современных дистрибутивов UTF-8. Red Hat, в частности, перешла на ее использование с версии 8.0 своего продукта. Но дело в том, что поддержка русского языка при помощи UTF-8 во многих приложениях далека от совершенства. Безусловно, лучшим решением была бы работа с UTF-8, но в данном случае я предпочел пойти по пути «наименьшего сопротивления» и воспользоваться уже существующими у меня наработками.
Соответственно должен быть настроен и веб-сервер, у которого в качестве кодировки по умолчанию должно быть указано KOI8-R.
Приступая к установке BackupPC, в системе необходимо иметь следующие perl-модули: Compress::Zlib, Archive::Zip и File:RsyncP. Проверить наличие установленных модулей можно, дав команду:
perldoc <имя модуля>
Если в ответ будет получено сообщение вида:
No documentation found for «Compress::Zlib»
следовательно, в вашей системе данный модуль еще не установлен. Оба дистрибутива, в которых я устанавливал BackupPC, по умолчанию этих модулей не содержат.
Процедура установки модулей, которые можно скачать с www.cpan.org, следующая:
#tar zxvf имя_архива.tar.gz // разархивируем исходники
#perl Makefile.PL // формируем makefile
#make // компилируем исходники
#make test // после выполнения этой команды мы должны получить сообщение, что все тесты пройдены успешно
#make install
Имеющие опыт общения с оболочкой cpan, могут поступить проще – для установки модулей воспользоваться ею.
В случае RHEL3 для успешной компиляции модуля Archive::Zip пришлось дать команду:
export LANG=en_US
без которой он отказался «собираться».
Кроме того, мне пришлось установить отсутствующую в дистрибутивах от Red Hat утилиту par2, которая создает «избыточную информацию» для файлов с использованием кодов Рида-Соломона, и позволяет восстанавливать файлы, повреждённые до определённой степени. Скачиваем с сайта http://parchive.sourceforge.net исходники в виде файла par2cmdline-0.4.tar.gz, и выполняем команды:
#tar zxvf par2cmdline-0.4.tar.gz
#cd par2cmdline-0.4
#./configure
#make
#make check
#make install
В принципе установка par2cmdline не обязательна, так как по умолчанию BackupPC работает и без нее. Но все же я рекомендовал бы ее установить, особенно при отсутствии RAID-массива на сервере.
Также для корректной работы CGI-интерфейса при стандартной установке системы, когда веб-сервер запускается из-под специально выделенного для этих целей пользователя (httpd или apache), требуется Suid Perl. В Red Hat дистрибутивах соответствующий пакет называется perl-suidperl.
Ну и, наконец, добавим пользователя, из-под которого будет выполняться запуск системы резервного копирования:
#useradd backuppc
После окончания тестирования системы нелишним будет убрать для пользователя backuppc возможность интерактивного входа.
Установка BackupPC
Теперь можно приступить непосредственно к установке BackupPC. Развернем архив и запустим конфигурационный скрипт:
#tar zxvf BackupPC-x.x.x.tar.gz
#cd BackupPC-x.x.x
#perl configure.pl

В ходе установки вам потребуется ответить на ряд вопросов. На первый – просьбу указать полный путь к уже установленной старой версии – можно ответить, просто нажав «Enter», поскольку выполняется первоначальная установка. После вам будут показаны пути к утилитам, требуемым BackupPC, которые скрипт определил самостоятельно, с просьбой подтвердить их расположение. Затем необходимо проверить, правильно ли скрипт определил имя хоста и имя пользователя, которого мы создали ранее, а также директорию для установки исполнимых файлов и директорию для хранения данных.
В зависимости от быстродействия сервера вам необходимо будет выбрать уровень компрессии резервируемых данных. Уровень можно менять от 1 до 9. По умолчанию предлагается третий уровень. По заявлениям разработчиков, при увеличении c «умолчальной» тройки до пятерки, например, загрузка процессора увеличивается на 20%, а данные занимают на 2-3% меньше места. По этим данным видно, что особого смысла увеличивать степень сжатия нет. При первоначальной установке я бы порекомендовал оставить тройку. Позднее можно попробовать поэкспериментировать с этим значением, поменяв его в конфигурационном файле.
Следующий вопрос касается пути к cgi-bin директории вашего веб-сервера (в Red Hat-подобных дистрибутивах это /var/www/cgi-bin/) и пути к директории с устанавливаемыми иконками для CGI-интерфейса (/var/www/html/BackupPC). Кроме того, будет предложено ввести часть URL, указывающего на иконки, а именно расположение относительно корневого каталога веб-сервера. Обратите внимание, что путь должен начинаться со слэша. В нашем случае он будет выглядеть как /BackupPC.
Настройка BackupPC
Как и большинство программ, работающих под управлением UNIX-подобных систем, настройка и изменение параметров сервера BackupPC производится правкой конфигурационных файлов. К чему мы и приступим.
Интересующий нас файл config.pl расположен в подкаталоге /conf, который был создан внутри директории, предназначенной для хранения данных. На самом деле этот файл очень хорошо документирован, поэтому я пройдусь лишь по основным параметрам. Config.pl состоит из четырех групп настроечных значений, содержащих:
- основные параметры сервера;
- описание тех машин, информацию с которых нужно архивировать;
- указания, как часто это надо делать;
- параметры CGI-интерфейса.
- $Conf{WakeupShedule} – как часто сервис должен проверять, были ли изменения на подлежащих архивированию компьютерах, и в случае изменений выполнять резервирование данных. По умолчанию – каждый час, кроме полуночи.
- $Conf{MaxBackups} – максимальное число одновременных процессов архивирования.
- $Conf{DfMaxUsagePct} – при заполнении указанного в процентах объема диска, заданного для хранения данных, архивирование не производится. По умолчанию 95%.
- $Conf{SmbShareName} – имя расшаренного ресурса на Windows-машине. По умолчанию – это диск C:, который в Win2000/XP доступен через SMB по имени «С$».
- $Conf{SmbShareUserName} – имя пользователя на Windows-машине, которому даны права на ресурс общего доступа .
- $Conf{SmbSharePasswd} – его пароль. В настоящее время он приводится в открытом виде. В следующих версиях планируется хранение в зашифрованном виде.
- $Conf{FullPeriod} – период в днях между полными резервными копиями.
- $Conf{IncrPeriod} – период в днях между инкрементальными резервными копиями.
- $Conf{FullKeepCnt} – максимальное число сохраняемых полных резервных копий. $Conf{BackupFilesOnly} – список директорий, которые необходимо архивировать. По умолчанию – не определено.
- $Conf{BackupFilesExclude} – то же самое, но для директорий-исключений.
- $Conf{ArchivePar} – при использовании par2cmdline процент избыточных данных в архиве. По умолчанию – 0.
- $Conf{EmailAdminUserName} – почтовый адрес администратора, на который будут приходить сообщения об ошибках и предупреждениях.
- $Conf{CgiAdminUserGroup} и $Conf{CgiAdminUsers} – пользователи и группы, которым доступен CGI-интерфейс.
Обратите внимание, что параметры, относящиеся к конкретной машине, могут быть переопределены машинно-зависимым файлом Config.pl, который хранится в поддиректории каталога с данными /BackupPC/pc/<имя_компьютера>/. Действительно, на каждой машине могут быть свои конкретные папки общего доступа, списки исключений, свой локальный пользователь с паролем, для которого установлены свои разрешения.
Теперь настроим список компьютеров, данные с которых необходимо архивировать. Файл с настройками находится в том же каталоге, где и основной конфигурационный файл, и называется hosts. Собственно, синтаксис файла максимально прост. Каждая строчка содержит три параметра: имя машины, имя (e-mail) ее хозяина и признак, получает ли данный компьютер сетевые настройки по DHCP или нет.
Теперь осталось скопировать скрипт старта и остановки сервиса из дистрибутива /init.d/linux-backuppc в /etc/rc.d/init.d/backuppc, в случае Red Hat дистрибутива, а затем можно попробовать стартовать BackupPC командой:
#service backuppc start
Кроме того, нелишне добавить автоматический старт при загрузке сервера в консоль и в X-Window:
#chkconfig — -add backuppc
#chkconfig — -level 35 backuppc on
К сожалению, данные действия приходится делать вручную, так как разработчики не включили эти операции в установочный скрипт.
В лог-файле messages вашего сервера должно появиться сообщение об успешном старте сервиса, а в директории с данными /BackupPC/log будет создан подробный лог самого сервиса. После успешного старта можно попробовать запустить браузер, и обратиться по адресу http://имя_сервера/cgi-bin/BackupPC_Admin. Если вы сделали все правильно, то должны получить нечто подобное тому, что изображено на рисунках. В случае проблем с доступом к CGI-интерфейсу рекомендую обратиться к FAQ на сайте http://backuppc.sourceforge.net. В большинстве случаев в первую очередь необходимо проверить права доступа к файлам и директориям BackupPC. Однако, если вы следовали приведенному порядку установки, таких проблем возникнуть не должно.
Русификация
Еще одной проблемой при работе с CGI-интерфейсом, решение которой, однако, пришлось искать самому, может стать некорректное отображение русских имен файлов и папок. Для исправления этой ситуации придется внести небольшие изменения в файл Lib.pm, расположенный в подкаталоге /CGI директории с исполняемыми файлами программы. Данный файл содержит системные процедуры BackupPC.
Во-первых, найдите в теле процедуры Header строчку:
print $Cgi->header();
и замените ее на:
print $Cgi->header(-charset=>»koi8-r»);
Ну а во-вторых, в процедуре EscHTML закомментируйте предпоследнюю строчку, стоящую перед «return»:
$s=~s{([^[:print:]])}{sprintf(«%02X;», ord($1));}eg;
Теперь все имена будут отображаться в нормальном виде, используя кодировку KOI-8.
Кроме того, рекомендую обратить внимание на папку /lib/BackupPC/Lang, которая находится в директории с исполнимыми файлами. Там находятся файлы с локализованными сообщениями, выводимыми CGI-интерфейсом. В комплект поставки русский язык не входит, но вам ничего не мешает создать свой файл по образцу существующих, переведя сообщения с английского на русский язык. Часть этой работы я уже проделал для своего «внутреннего» использования. Перевод, не претендующий на полноту и высокое литературное качество, я выложил на своем сайте. Скачать архив можно по ссылке http://www.markelov.net/program/bpcrus.tgz.
Интерфейс
Интерфейс системы достаточно прост и нагляден. Обратившись по адресу: http://имя_сервера/cgi-bin/BackupPC_ Admin, вы попадаете в окно с общей информацией по серверу BackupPC. В левой части окна присутствует меню с ссылками на более подробную информацию по работе всего сервера, а также выпадающее меню с возможностью выбора информации по конкретному архивируемому хосту.
Зайдя в меню по конкретному хосту, можно получить всю информацию касательно выполненных операций резервирования данных, просмотреть списки архивных копий, а также «провалиться» в любой из них и восстановить файлы и каталоги полностью или частично. Также имеется возможность скопировать любой из файлов средствами браузера на ту машину, с которой вы зашли на сервер.
Заходя в инкрементальную резервную копию, вы видите полную картину сохраненной файловой системы, то есть полную резервную копию плюс наложенную на нее инкрементальную копию. А для всех измененных файлов можно просмотреть список версий и восстановить нужную из них.
Кроме того, все операции по работе с архивами можно выполнять из командной строки, но я не вижу смысла приводить здесь синтаксис команд, поскольку он подробно описан в документации, идущей в составе дистрибутива.
В конце мне хотелось бы поблагодарить Павла Шера за ряд ценных советов, которые мне пригодились при написании статьи.



Мой мир
Вконтакте
Одноклассники
Google+
- BackupPC Introduction
- Overview
- BackupPC 4.0
- Backup basics
- Resources
- Road map
- You can help
- Installing BackupPC
- Requirements
- What type of storage space do I need?
- How much disk space do I need?
- Step 1: Getting BackupPC
- Step 2: Installing the distribution
- Step 3: Setting up config.pl
- Step 4: Setting up the hosts file
- Step 5: Client Setup
- Step 6: Running BackupPC
- Step 7: Talking to BackupPC
- Step 8: Checking email delivery
- Step 9: CGI interface
- How BackupPC Finds Hosts
- Other installation topics
- Fixing installation problems
- Restore functions
- CGI restore options
- Command-line restore options
- Archive functions
- Configuring an Archive Host
- Starting an Archive
- Starting an Archive from the command line
- Other Command Line Utilities
- Other CGI Functions
- Configuration and Host Editor
- Metrics
- RSS
- BackupPC Design
- Some design issues
- BackupPC operation
- Storage layout
- Compressed file format
- Rsync checksum caching
- Filename mangling
- Special files
- Attribute file format
- Optimizations
- Some Limitations
- Security issues
- Configuration File
- Modifying the main configuration file
- Configuration Parameters
- General server configuration
- What to backup and when to do it
- How to backup a client
- Samba Configuration
- Tar Configuration
- Rsync/Rsyncd Configuration
- FTP Configuration
- Archive Configuration
- Email reminders, status and messages
- CGI user interface configuration settings
- Version Numbers
- Author
- Copyright
- Credits
- License
BackupPC Introduction
This documentation describes BackupPC version 4.4.0, released on 20 Jun 2020.
Overview
BackupPC is a high-performance, enterprise-grade system for backing up Unix, Linux, WinXX, and MacOSX PCs, desktops and laptops to a server’s disk. BackupPC is highly configurable and easy to install and maintain.
Given the ever decreasing cost of disks and raid systems, it is now practical and cost effective to backup a large number of machines onto a server’s local disk or network storage. For some sites this might be the complete backup solution. For other sites additional permanent archives could be created by periodically backing up the server to tape.
Features include:
-
A clever pooling scheme minimizes disk storage and disk I/O. Identical files across multiple backups of the same or different PC are stored only once, resulting in substantial savings in disk storage and disk writes.
-
Compression provides additional reductions in storage, depending on the type of data being backed up. The CPU impact of compression is low since only new files (those not already in the pool) need to be compressed.
-
A powerful http/cgi user interface allows administrators to view the current status, edit configuration, add/delete hosts, view log files, and allows users to initiate and cancel backups and browse and restore files from backups.
-
The http/cgi user interface has internationalization (i18n) support, currently providing English, French, German, Spanish, Italian, Dutch, Polish, Portuguese-Brazilian, Chinese, Polish, Czech, Japanese, Ukrainian, and Russian.
-
No client-side software is needed. On WinXX the standard smb protocol is used to extract backup data. On linux, unix or MacOSX clients, rsync, tar (over ssh/rsh/nfs) or ftp is used to extract backup data. Alternatively, rsync can also be used on WinXX (using cygwin), since rsync provides for efficient transfers and allows incremental backups to detect almost all changes.
-
Flexible restore options. Single files can be downloaded from any backup directly from the CGI interface. Zip or Tar archives for selected files or directories from any backup can also be downloaded from the CGI interface. Finally, direct restore to the client machine (using smb or tar) for selected files or directories is also supported from the CGI interface.
-
BackupPC supports mobile environments where laptops are only intermittently connected to the network and have dynamic IP addresses (DHCP). Configuration settings allow machines connected via slower WAN connections (eg: dial up, DSL, cable) to not be backed up, even if they use the same fixed or dynamic IP address as when they are connected directly to the LAN.
-
Flexible configuration parameters allow multiple backups to be performed in parallel, specification of which shares to backup, which directories to backup or not backup, various schedules for full and incremental backups, schedules for email reminders to users and so on. Configuration parameters can be set system-wide or also on a per-PC basis.
-
Users are sent periodic email reminders if their PC has not recently been backed up. Email content, timing and policies are configurable.
-
BackupPC is Open Source software hosted by GitHub.
BackupPC 4.0
This is the first release of 4.0, which is a significant rewrite of BackupPC. This section provides a short overview of the changes and features in 4.0.
Here’s a short summary of what has changed in V4:
-
No use of hardlinks (except temporarily to do atomic renames). Reference counting is handled at the application level in a batch manner (hardlinks will still remain for any legacy V3 backups).
-
Backups are stored as «reverse deltas» — the most recent backup is always filled and older backups are reconstituted by merging all the deltas starting with the nearest future filled backup and working backwards.
This is the opposite of V3 where incrementals are stored as «forward deltas» to a prior backup (typically the last full backup or prior lower-level incremental backup, or the last full in the case of rsync).
-
Since the most recent backup is filled, viewing/restoring that backup (which is the most common backup used) doesn’t require merging any deltas from other backups.
-
The concepts of incr/full backups and unfilled/filled storage are decoupled. The most recent backup is always filled. By default, for the remaining backups, full backups are filled and incremental backups are unfilled, but that is configurable.
-
Uses full-file MD5 digests, which are stored in the directory attrib files. Each backup directory only contains an empty attrib file whose name includes its own MD5 digest, which is used to look up the attrib file’s contents in the pool. In turn, that file contains the metadata for every file in that directory, including each files’s MD5 digest.
-
The Pool layout still supports chains to handle md5 collisions. While collisions can be constructed and are now well-known, they are highly unlikely in the wild. Pool files are never renamed or moved, unlike V3.
-
Any backup can be deleted (deltas are merged into next older backup if it is not filled).
-
The reverse deltas allow «infinite incrementals» — no need for a full backup if you are willing to trade speed for the risk that a file change will not be detected if the metadata (eg, mtime or size) doesn’t change.
-
An rsync «full» backup now uses —checksum (instead of —ignore-times), which is much more efficient on the server side — the server just needs to check the full-file checksum computed by the client, together with the mtime, nlinks, size attributes, to see if the file has changed. If you want a more conservative approach, you can change it back to —ignore-times, which requires the server to send block checksums to the client.
-
The use of rsync —checksum allows BackupPC to guess a potential match anywhere in the pool, even on a first-time backup. In that case, the usual rsync block checksums are still exchanged to make sure the complete file is identical.
-
Uses a modified rsync called rsync_bpc (currently based on rsync-3.0.9) on the server side (in place of File::RsyncP), with a C code interface to the BackupPC storage. So the whole data path for rsync is now in compiled C code, which is much faster than perl.
-
Due to the use of rsync-3.X, acls and xattrs are supported, and many other useful options (but not all) are supported. Rsync protocol 30 supports the efficient incremental file list, which significantly improves memory usage and startup time. It also supports MD5 full-file checksums, which match BackupPC’s new digest. That allows a full-file digest to be checked as easily as an mtime on the server side.
-
Significant portions of the BackupPC code are now compiled C code in a new module called BackupPC::XS that is dynamically linked to perl.
Here is a more detailed discussion:
-
Completely new backup storage. No hardlinks! Backups are stored as reverse deltas, with the most recent backup always filled. Prior backup «n» contains the changes relative to prior backup «n+1».
-
Since every backup is based on the last filled backup, the concept of incremental levels is removed.
-
Example: let’s assume backup #4 is the most recent, and therefore filled, and backups #0..3 are not filled.
Backups #0..3 store just the necessary reverse changes needed to reconstruct those backups, relative to the next backup.
- To view/restore backup #4, all the information is stored in backup #4. - To view/restore backup #3, backup #4 (the filled one), is merged with the deltas in #3. - To view/restore backup #2, backup #4 (the filled one), is merged with the deltas in #3 and #2 - etc.When a new backup is started (#5), we begin by renaming backup #4 to #5. At that instant, backup #4 storage is now empty (which means backups #4 and #5 are currently identical). As the backup runs, changes are made to #5 with the changed/new files in place, and the opposite changes are added to backup #4, to keep the «view» of backup #4 unchanged.
After the backup is done, #5 is now the filled version of the latest backup, and #4 contains the changes necessary to turn #5 back into the state when backup #4 was done. If there are no changes detected in the new backup, the storage tree for #4 will be empty. If just one file changed, the new file will be below #5, and the prior file will be below #4 (well, technically not quite true, since files aren’t stored below the backup trees; more correctly, the attrib file in #5 will point to the new pool file, and the attrib file in #4 will point to the old pool file).
-
The concepts of incr/full backups and unfilled/filled storage are now decoupled. The most recent backup is always filled (whether or not the last backup was a full or incr). Certain older backups can be filled for convenience to make restoring old backups faster (because fewer backups need to be merged), and are used to specify expiry schedules.
-
When a backup starts, there are several different cases that determine how the backups are stored and whether prior deltas are stored:
-
No existing backups: create a new backup #0 and do a full backup in place (ie: no prior deltas are stored).
-
V3 backups exist, but no V4 backups. The last V3 backup is duplicated into V4 format, and a full backup is done in place (ie: no prior deltas are stored).
-
Last V4 backup is a full, or more than $Conf{FillCycle} since last filled backup. The last backup is duplicated to create a new filled backup, and the new backup is done in place (ie: no prior deltas are stored).
-
There are V4 backups and it’s less than $Conf{FillCycle} since last one is filled. Renumber the last backup to #n+1, and put the reverse deltas in initially empty backup tree #n.
-
CompressLevel has toggled on/off between backups. This isn’t well tested and it’s very hard to support efficiently. We treat this as a brand new (empty) backup in place, that is therefore filled. That way we won’t need to merge between backups with compress on/off.
-
Last backup was a V4 partial. If prior V4 backup is filled (and not partial), then just do another in-place backup. Otherwise, treat as case 4. When complete (whether successful or another partial), delete the prior deltas in #n, which merges the cumulative changes into #n-1.
-
-
The treatment of a «Partial» backup has changed. Unlike in V3 where partials are removed prior to the next backup, in V4 partials are kept and are used as the starting point for the next backup. See case 6 above. If the new backup fails, if no files have been backed up, the empty backup #n is removed.
-
Backups are stored as mangled directory trees, but each directory only contains an «attrib» file. The attrib file is zero-length, and its name includes the MD5 digest so the contents can be looked up in the pool.
The attrib contents in the pool contains the directory contents: for each file, that means the metadata, xattrs and the MD5 digest of the file contents.
-
A modified rsync called rsync_bpc, based on rsync 3.0.9, is used on the server side, with a C code layer that emulates all the file-system OS calls to be compatible with the BackupPC store. That means for rsync, the data path is now fully in compiled C, which should mean a significant speedup. It also means many (but not all) of the rsync options are supported natively.
-
Significant parts of the BackupPC storage and pooling code have been written in C (the same code is used in the server rsync_bpc). BackupPC::FileZIO, BackupPC::PoolWrite, BackupPC::Attrib, BackupPC::AttribCache and BackupPC::PoolRefCnt (reference counting and storage) are all replaced with BackupPC::XS, a C-code perl extension.
-
Extended attributes (xattr) are supported. Rsync is configured to «store acls using xattr», meaning both acls and xattrs are supported.
-
infinite incrementals with rsync are supported. The most recent backup is always filled, so an incremental will still leave the most recent backup filled.
-
any V4 backup can be deleted — dependencies are merged into the next older backup if it isn’t already filled.
-
file digests are full-file MD5. Collisions are much more unlikely than V3, but still possible. Duplicates are implemented with an extension to the 16 byte MD5 digest (ie: 16 bytes for plain file, 17 bytes for next 255 duplicates etc).
-
V4 pool files are stored in a new hierarchy, two levels deep, with 7 bits at each level (ie: 128 directories at top-level, and each with 128 directories at next level).
-
V4 pool files are never moved or renamed.
-
Inodes for hardlinked files are stored in each backup tree. This makes backing up hardlinks accurate, compared to V3, and provides for consistent inode numbering across backups.
-
zero-sized files or empty attribute files don’t get written or pooled.
-
the elimination of hardlinks means that reference counting has to be maintained by the BackupPC code. This is one of the riskiest area in terms of development and testing. Reference counts are maintained per-backup, per-host, and for the whole pool.
Each operation that changes reference counts (eg: doing a new backup, deleting a backup, or duplicating (filling) a backup) creates one or more poolRefDelta files in that client’s backup directory (ie: TopDir/pc/HOST/NNN). These files are lists of MD5 digests, and corresponding counts deltas.
Each night, BackupPC_nightly runs BackupPC_refCountUpdate, which, for each host, updates the per-host reference count database with the new deltas. It then combines all the per-host reference count files to create the global pool reference count database.
BackupPC_refCountUpdate can run concurrently with backups. If you still have V3 backups and pool, BackupPC_nightly still needs to run and check for old V3 pool files that can be deleted. But since there are no new V3 backups happening, BackupPC_nightly can run concurrently with backups.
-
There is a new utility BackupPC_fsck that can check/fix the per-host and global reference counts. The per-host reference count database is verified by parsing all the attrib files in each backup tree. The global reference count database is verified by combing all the per-host reference count databases and comparing them.
BackupPC_fsck cannot run when BackupPC is.
-
When BackupPC_refCountUpdate updates the overall reference counts, it removes pool files that have a reference count of zero. To avoid race conditions, it uses a two-phase process. It first flags files that have zero reference counts using one of the file attributes. The next time it runs (typically 24 hours later), any flagged files that still have zero reference count are then removed. The rest of the code knows not to use flagged pool files to avoid race conditions.
-
Progress indication: a simple status that shows the number of files processed so far. It’s hard to convert that to a percentage, since the total isn’t known until the end of the backup. But knowing the number of files is quite helpful, since you can get an idea of the expected total based on the prior backups, or knowing what configuration you have changed (ie: adding a large new tree).
-
BackupPC_link is removed since it is no longer used.
-
Since files are no longer stored in backup trees, browsing the backup trees is even harder than V3 (where you just had to deal with mangling). A new utility BackupPC_ls acts like «ls -l», showing accurate directory listings of files, together with the MD5 digests.
BackupPC_ls can be given either an explicit hostname, number, and unmangled path, or can be given the full (mangled) path, which makes it easier to use directory completion. It should be possible to configure tcsh and bash, together with some new hooks in BackupPC_ls, to give a more natural file/directory completion.
BackupPC_zcat also can take just the MD5 digest (which you can paste from BackupPC_ls). Currently BackupPC_zcat doesn’t support the tree parsing that BackupPC_ls does (it can only zcat actual files), but that should be easy to rectify.
-
Configuration for expiry: since full/incr are decoupled from filled/unfilled, expiry is a bit trickier.
The convention for expiry parameters is «FullKeepPeriod/FullKeepCnt» etc refer to Filled backups, and «IncrKeepPeriod/IncrKeepCnt» refer to Unfilled backups.
-
V3 migration: nothing specific is needed. V4 can browse/view/restore V3 backups. When you install V4, no changes are made to any V3 backups. If you are upgrading from V3, be sure to set $Conf{PoolV3Enabled} to 1 so the old V3 pool is searched for matching files.
-
When you install V4, it will notice that the V3 pool exists. Running configure.pl should set $Conf{PoolV3Enabled} to 1 in that case, but you should be sure to check that.
-
When a V4 backup is first done, BackupPC_backupDuplicate is run to duplicate the most recent V3 backup to create a new V4 backup. A «filled» view of the most recent V3 backup is used to create a «filled» V4 backup tree.
This step could be time consuming, since every file needs to be read (as a V3 file) and written as a V4 file. However, the V4 pooling code knows about the V3 pool, so it will move the V3 pool file into the V4 pool. So this duplication process doesn’t burn a lot of pool storage space, but every file still needs to be read (to compute the MD5 digest) and «written» (really just matching/linking).
-
Expiry: all the V3 + V4 backups are considered on a combined basis for expiry checking.
-
On a clean new V4 install, the steps of computing and checking V3 digests is eliminated.
-
Downgrading V4->V3: Not tested and not recommended. In theory you can remove any new V4 backups, remove the V4 pool itself, and you should be able to re-install V3 and still have access to your original full working V3 store (except for any V3 backups that V4 might have routinely removed based on normal backup expiry configuration).
However, any V3 pool files moved to V4 will no longer be in the V3 pool. So subsequent V3 backups will burn more storage as files get re-added to the old V3 pool.
Hopefully downgrading isn’t necessary…
-
-
Optimizations: the C code implementation should give a significant performance advantage, as well as the more flexible.
Potential V4 optimizations that are planned, but not yet implemented, include:
-
rsync-bpc doesn’t support checksum caching.
-
rsync-bpc with —ignore-times actually reads each unchanged file three times, and writes it once (normal rsync reads twice and writes once; the extra one is due to compression). Some careful optimization can eliminate two reads and the write. The final read can be eliminated with checksum caching.
-
BackupPC_refCountUpdate, BackupPC_fsck, BackupPC_backupDuplicate, BackupPC_backupDelete are all single-threaded.
-
Backup basics
- Full Backup
-
A full backup is a complete backup of a share. BackupPC can be configured to do a full backup at a regular interval (typically weekly). BackupPC can be configured to keep a certain number of full backups. Exponential expiry is also supported, allowing full backups with various vintages to be kept (for example, a settable number of most recent weekly fulls, plus a settable number of older fulls that are 2, 4, 8, or 16 weeks apart).
- Incremental Backup
-
An incremental backup is a backup of files that have changed since the last successful backup.
Rsync is the best option for BackupPC. Any files whose attributes have changed (ie: uid, gid, mtime, modes, size) since the last full are backed up. Deleted, new files and renamed files are detected by rsync incrementals.
For SMB and tar, BackupPC uses the modification time (mtime) to determine which files have changed since the last backup. That means SMB and tar incrementals are not able to detect deleted files, renamed files or new files whose modification time is prior to the last lower-level backup.
BackupPC can also be configured to keep a certain number of incremental backups, and to keep a smaller number of very old incremental backups.
BackupPC «fills-in» incremental backups when browsing or restoring, based on the levels of each backup, giving every backup a «full» appearance. This makes browsing and restoring backups much easier: you can restore from any one backup independent of whether it was an incremental or full.
- Partial Backup
-
When a full or incremental backup fails or is canceled, the most recent backup is labeled «partial». Prior to V4, that backup was incomplete, and would be deleted when the next backup completed.
In V4 a partial backup denotes that the last backup is incomplete. However, since V4 does backup updating in place, it represents the best and latest backup. A partial backup can be browsed or used to restore files just like a successful full or incremental backup. And it will be used as the starting point for the next backup attempt.
- Identical Files
-
BackupPC pools identical files. By «identical files» we mean files with identical contents, not necessary the same permissions, ownership or modification time. Two files might have different permissions, ownership, or modification time but will still be pooled whenever the contents are identical. This is possible since BackupPC stores the file metadata (permissions, ownership, and modification time) separately from the file contents.
Prior to V4, identical files were stored using hardlinks. In V4+, hardlinks are eliminated (except for temporary atomic renames), and reference counting is done at the application level.
- Backup Policy
-
Based on your site’s requirements you need to decide what your backup policy is. BackupPC is not designed to provide exact re-imaging of failed disks. See «Some Limitations» for more information. However, with rsync and tar transports for linux/unix clients, plus full support for special file types, extended attributes etc, likely means an exact image of a linux/unix file system can be made.
BackupPC saves backups onto disk. Because of pooling you can relatively economically keep several weeks or months of old backups.
At some sites the disk-based backup will be adequate, without a secondary offsite cloud, disk or tape backup. This system is robust to any single failure: if a client disk fails or loses files, the BackupPC server can be used to restore files. If the server disk fails, BackupPC can be restarted on a fresh file system, and create new backups from the clients. The chance of the server disk failing can be made very small by spending more money on increasingly better RAID systems. However, there is still the risk of catastrophic events like fires or earthquakes that can destroy both the BackupPC server and the clients it is backing up if they are physically nearby.
Some sites might choose to do periodic backups to tape or cd/dvd. This backup can be done perhaps weekly using the archive function of BackupPC.
Other users have reported success with removable disks to rotate the BackupPC data drives, or using rsync to mirror the BackupPC data pool offsite.
In V4, since hardlinks are not used permanently, duplicating a V4 pool is much easier, allowing remote copying of the pool.
Resources
- BackupPC home page
-
The BackupPC project page is at:
https://backuppc.github.io/backuppcThis page has links to the current documentation, github project source and general information.
- Github
-
BackupPC development is hosted on github:
https://github.com/backuppcReleases for BackupPC and the required packages BackupPC-XS and rsync-bpc are available at:
https://github.com/backuppc/backuppc/releases https://github.com/backuppc/backuppc-xs/releases https://github.com/backuppc/rsync-bpc/releases - BackupPC Wiki
-
BackupPC has a Wiki at https://github.com/backuppc/backuppc/wiki. Everyone is encouraged to contribute to the Wiki. Anyone with a Github account can edit the Wiki.
- Mailing lists
-
Three BackupPC mailing lists exist for announcements (backuppc-announce), developers (backuppc-devel), and a general user list for support, asking questions or any other topic relevant to BackupPC (backuppc-users).
The lists are archived on SourceForge:
https://sourceforge.net/p/backuppc/mailman/backuppc-users/You can subscribe to these lists by visiting:
http://lists.sourceforge.net/lists/listinfo/backuppc-announce http://lists.sourceforge.net/lists/listinfo/backuppc-users http://lists.sourceforge.net/lists/listinfo/backuppc-develThe backuppc-announce list is moderated and is used only for important announcements (eg: new versions). It is low traffic. You only need to subscribe to one of backuppc-announce and backuppc-users: backuppc-users also receives any messages on backuppc-announce.
The backuppc-devel list is only for developers who are working on BackupPC. Do not post questions or support requests there. But detailed technical discussions should happen on this list.
To post a message to the backuppc-users list, send an email to
backuppc-users@lists.sourceforge.netDo not send subscription requests to this address!
- Other Programs of Interest
-
If you want to mirror linux or unix files or directories to a remote server you should use rsync, http://rsync.samba.org. BackupPC uses rsync as a transport mechanism; if you are already an rsync user you can think of BackupPC as adding efficient storage (compression and pooling) and a convenient user interface to rsync.
Two popular open source packages that do tape backup are Amanda (http://www.amanda.org) and Bacula (http://www.bacula.org). These packages can be used as complete solutions, or also as back ends to BackupPC to backup the BackupPC server data to tape.
Avery Pennarun’s bup (https://github.com/bup/bup) uses the git packfile format to do efficient incrementals and deduplication. Various programs and scripts use rsync to provide hardlinked backups. See, for example, Mike Rubel’s site (http://www.mikerubel.org/computers/rsync_snapshots), JW Schultz’s dirvish (http://www.dirvish.org/), Ben Escoto’s rdiff-backup (http://www.nongnu.org/rdiff-backup), and John Bowman’s rlbackup (http://www.math.ualberta.ca/imaging/rlbackup).
BackupPC provides many additional features, such as compressed storage, deduplicating any matching files (rather than just files with the same name), and storing special files without root privileges. But these other programs provide simple, effective and fast solutions and are definitely worthy of consideration.
Road map
The new features planned for future releases of BackupPC are on the Wiki at https://github.com/backuppc/backuppc/wiki.
Comments and suggestions are welcome.
You can help
BackupPC is free. I work on BackupPC because I enjoy doing it and I like to contribute to the open source community.
BackupPC already has more than enough features for my own needs. The main compensation for continuing to work on BackupPC is knowing that more and more people find it useful. So feedback is certainly appreciated, both positive and negative.
Also, everyone is encouraged to contribute patches, bug reports, feature and design suggestions, new code, Wiki additions (you can do those directly) and documentation corrections or improvements. Answering questions on the mailing list is a big help too.
Installing BackupPC
Requirements
BackupPC requires:
-
A linux, solaris, or unix based server with a substantial amount of free disk space (see the next section for what that means). The CPU and disk performance on this server will determine how many simultaneous backups you can run. You should be able to run 4-8 simultaneous backups on a moderately configured server.
It is also recommended you consider either an LVM or RAID setup so that you can expand the file system as necessary.
-
Perl version 5.8.0 or later. If you don’t have perl, please see http://www.cpan.org.
-
The perl modules BackupPC::XS (version >= 0.50) is required, and several others, File::Listing, Archive::Zip, XML::RSS, JSON::XS, Net::FTP, Net::FTP::RetrHandle, Net::FTP::AutoReconnect are recommended.
Try «perldoc BackupPC::XS» and «perldoc Archive::Zip» to see if you have these modules. If not, fetch them from http://www.cpan.org and see the instructions below for how to build and install them.
The CGI Perl module is required for the http/cgi user interface. CGI was a core module, but from version 5.22 Perl no longer ships with it.
-
If you are using rsync to backup linux/unix machines you should have rsync on each client machine. Version 3+ is strongly recommended, but earlier versions will work too. See http://rsync.samba.org. Use «rsync —version» to check your version.
For BackupPC to use Rsync you will also need to install rsync-bpc on the server.
-
If you are using smb to backup WinXX machines you need smbclient and nmblookup from the samba package. You will also need nmblookup if you are backing up linux/unix DHCP machines. See http://www.samba.org.
See http://www.samba.org for source and binaries. It’s pretty easy to fetch and compile samba, and just grab smbclient and nmblookup, without doing the installation. Alternatively, http://www.samba.org has binary distributions for most platforms.
-
If you are using tar to backup linux/unix machines, those machines should have version 1.13.20 or higher recommended. Use «tar —version» to check your version. Various GNU mirrors have the newest versions of tar; see http://www.gnu.org/software/tar/.
-
The Apache web server, see http://www.apache.org, preferably built with mod_perl support.
-
If rrdtool is installed on the BackupPC server, graphs of the pool usage will be maintained and displayed. To enable the graphs, point $Conf{RrdToolPath} to the rrdtool executable.
What type of storage space do I need?
Starting with 4.0.0, BackupPC no longer uses hardlinks for storage of deduplicated files. However, hardlinks are still used temporarily in a few places for doing atomic renames, with a fallback doing a file copy if the hardlink fails, and files are moved (renamed) across various paths that turn into expensive file copies if they span multiple file systems.
So ideally BackupPC’s data store (__TOPDIR__) is a single file system that supports hardlinks. It is ok to use a single symbolic link at the top-level directory (__TOPDIR__) to point the entire data store somewhere else). You can of course use any kind of RAID system or logical volume manager that combines the capacity of multiple disks into a single, larger, file system. Such approaches have the advantage that the file system can be expanded without having to copy it.
Any standard linux or unix file system supports hardlinks. NFS mounted file systems work too (provided the underlying file system supports hardlinks). But windows based FAT and NTFS file systems will not work.
In BackupPC 3.x, hardlinks are fundamental to deduplication, so a startup check is done ensure that the file system can support hardlinks, since this is a common area of configuration problems in v3. In 4.x, that check is only done if the pool still contains v3 backups and pool files.
How much disk space do I need?
Here’s one real example (circa 2002) for an environment that is backing up 65 laptops with compression off. Each full backup averages 3.2GB. Each incremental backup averages about 0.2GB. Storing one full backup and two incremental backups per laptop is around 240GB of raw data. But because of the pooling of identical files, only 87GB is used. This is without compression.
Another example, with compression on: backing up 95 laptops, where each backup averages 3.6GB and each incremental averages about 0.3GB. Keeping three weekly full backups, and six incrementals is around 1200GB of raw data. Because of pooling and compression, only 150GB is needed.
Here’s a rule of thumb. Add up the disk usage of all the machines you want to backup (210GB in the first example above). This is a rough minimum space estimate that should allow a couple of full backups and at least half a dozen incremental backups per machine. If compression is on you can reduce the storage requirements by maybe 30-40%. Add some margin in case you add more machines or decide to keep more old backups.
Your actual mileage will depend upon the types of clients, operating systems and applications you have. The more uniform the clients and applications the bigger the benefit from pooling common files.
In addition to total disk space, you should make sure you have plenty of inodes on your BackupPC data partition. Some users have reported running out of inodes on their BackupPC data partition. So even if you have plenty of disk space, BackupPC will report failures when the inodes are exhausted. This is a particular problem with ext2/ext3 file systems that have a fixed number of inodes when the file system is built. Use «df -i» to see your inode usage.
Step 1: Getting BackupPC
Many linux distributions now include BackupPC, so installing BackupPC via your package manager is the best approach.
For example, for Debian, supported by Ludovic Drolez, can be found at http://packages.debian.org/backuppc and is included in the current stable Debian release. On Debian, BackupPC can be installed with the command:
apt-get install backuppcYou should also install rsync-bpc; the BackupPC package might include it already, but if not:
apt-get install rsync-bpcIf those commands work, you can skip to Step 3.
Alternatively, manually fetching and installing BackupPC is easy. Start by downloading the latest version from
https://github.com/backuppc/backuppc/releasesStep 2: Installing the distribution
Note: most information in this step is only relevant if you build and install BackupPC yourself. If you use a package provided by a distribution, the package management system should take of installing any needed dependencies.
First off, there are several perl modules you should install. The first one, BackupPC::XS, is required. The others are optional but highly recommended. Use either your linux package manager, or the cpan command, or follow the instructions in the README files to install these packages:
- BackupPC::XS
-
Significant portions of BackupPC are implemented in C code contained in this module. You can run «perldoc BackupPC::XS» to see if this module is installed. You need to have version >= 0.50. BackupPC::XS is available from:
https://github.com/backuppc/backuppc-xs/releasesand also CPAN.
- Archive::Zip
-
To support restore via Zip archives you will need to install Archive::Zip, also from http://www.cpan.org. You can run «perldoc Archive::Zip» to see if this module is installed.
-
To support the RSS feature you will need to install XML::RSS, also from http://www.cpan.org. There is not need to install this module if you don’t plan on using RSS. You can run «perldoc XML::RSS» to see if this module is installed.
- JSON::XS
-
To support the JSON formated metrics you will need to install JSON::XS, also from http://www.cpan.org. There is not need to install this module if you don’t plan on using JSON formated metrics. You can run «perldoc JSON::XS» to see if this module is installed.
- CGI
-
The CGI Perl module is required for the http/cgi user interface. CGI was a core module, but from version 5.22 Perl no longer ships with it so you’ll need to install it if you are using a recent version of perl.
- SCGI
-
The SCGI Perl module is required to use the S/CGI protocol for the http/cgi user interface.
- File::Listing, Net::FTP, Net::FTP::RetrHandle, Net::FTP::AutoReconnect
-
To use ftp with BackupPC you will need four libraries, but actually need to install only File::Listing from http://www.cpan.org. You can run «perldoc File::Listing» to see if this module is installed. Net::FTP is a standard module. Net::FTP::RetrHandle and Net::FTP::AutoReconnect included in BackupPC distribution.
To build and install these packages you should use the cpan command. At the prompt, type
install BackupPC::XSAlternatively, if you want to install these manually, you can fetch the tarball from http://www.cpan.org and then run these commands:
tar zxvf BackupPC-XS-0.50.tar.gz
cd BackupPC-XS-0.50
perl Makefile.PL
make
make test
make installThe same sequence of commands can be used for each module.
Next, you should install rsync_bpc if you want to use rsync to backup clients (which is the recommended approach for all client types). If you don’t use your package manager, fetch the release from:
https://github.com/backuppc/rsync-bpc/releasesThen run these commands (updating the version number as appropriate):
tar zxf rsync-bpc-3.0.9.5.tar.gz
cd rsync-bpc-3.0.9.5
./configure
make
make installNow let’s move onto BackupPC itself. After fetching BackupPC-4.4.0.tar.gz, run these commands as root:
tar zxf BackupPC-4.4.0.tar.gz
cd BackupPC-4.4.0
perl configure.plThe configure.pl script also accepts command-line options if you wish to run it in a non-interactive manner. It has self-contained documentation for all the command-line options, which you can read with perldoc:
perldoc configure.plStarting with BackupPC 3.0.0, the configure.pl script by default complies with the file system hierarchy (FHS) conventions. The major difference compared to earlier versions is that by default configuration files will be stored in /etc/BackupPC rather than below the data directory, __TOPDIR__/conf, and the log files will be stored in /var/log/BackupPC rather than below the data directory, __TOPDIR__/log.
Note that distributions may choose to use different locations for BackupPC files than these defaults.
If you are upgrading from an earlier version the configure.pl script will keep the configuration files and log files in their original location.
When you run configure.pl you will be prompted for the full paths of various executables, and you will be prompted for the following information.
- BackupPC User
-
It is best if BackupPC runs as a special user, eg backuppc, that has limited privileges. It is preferred that backuppc belongs to a system administrator group so that sysadmin members can browse BackupPC files, edit the configuration files and so on. Although configurable, the default settings leave group read permission on pool files, so make sure the BackupPC user’s group is chosen restrictively.
On this installation, this is __BACKUPPCUSER__.
For security purposes you might choose to configure the BackupPC user with the shell set to /bin/false. Since you might need to run some BackupPC programs as the BackupPC user for testing purposes, you can use the -s option to su to explicitly run a shell, eg:
su -s /bin/bash __BACKUPPCUSER__Depending upon your configuration you might also need the -l option.
If the -s option is not available on your operating system, you can specify the -m option to use your login shell as invoked shell:
su -m __BACKUPPCUSER__ - Data Directory
-
You need to decide where to put the data directory, below which all the BackupPC data is stored. This needs to be a big file system.
On this installation, this is __TOPDIR__.
- Install Directory
-
You should decide where the BackupPC scripts, libraries and documentation should be installed, eg: /usr/local/BackupPC.
On this installation, this is __INSTALLDIR__.
- CGI bin Directory
-
You should decide where the BackupPC CGI script resides. This will usually be below Apache’s cgi-bin directory.
It is also possible to use a different directory and use Apache’s «<Directory>» directive to specify that location. See the Apache HTTP Server documentation for additional information.
On this installation, this is __CGIDIR__.
- Apache image Directory
-
A directory where BackupPC’s images are stored so that Apache can serve them. You should ensure this directory is readable by Apache and create a symlink to this directory from the BackupPC CGI bin Directory.
- Config and Log Directories
-
In this installation the configuration and log directories are located in the following locations:
__CONFDIR__/config.pl main config file __CONFDIR__/hosts hosts file __CONFDIR__/pc/HOST.pl per-pc config file __LOGDIR__/BackupPC log files, pid, statusThe configure.pl script doesn’t prompt for these locations but they can be set for new installations using command-line options.
Step 3: Setting up config.pl
After running configure.pl, browse through the config file, __CONFDIR__/config.pl, and make sure all the default settings are correct. In particular, you will need to decide whether to use smb, tar,or rsync or ftp transport (or whether to set it on a per-PC basis) and set the relevant parameters for that transport method. See the section «Step 5: Client Setup» for more details.
Step 4: Setting up the hosts file
The file __CONFDIR__/hosts contains the list of clients to backup. BackupPC reads this file in three cases:
-
Upon startup.
-
When BackupPC is sent a HUP (-1) signal. Assuming you installed the init.d script, you can also do this with «/etc/init.d/backuppc reload».
-
When the modification time of the hosts file changes. BackupPC checks the modification time once during each regular wakeup.
Whenever you change the hosts file (to add or remove a host) you can either do a kill -HUP BackupPC_pid or simply wait until the next regular wakeup period.
Each line in the hosts file contains three fields, separated by whitespace:
- Host name
-
This is typically the hostname or NetBios name of the client machine and should be in lowercase. The hostname can contain spaces (escape with a backslash), but it is not recommended.
Please read the section «How BackupPC Finds Hosts».
In certain cases you might want several distinct clients to refer to the same physical machine. For example, you might have a database you want to backup, and you want to bracket the backup of the database with shutdown/restart using $Conf{DumpPreUserCmd} and $Conf{DumpPostUserCmd}. But you also want to backup the rest of the machine while the database is still running. In the case you can specify two different clients in the host file, using any mnemonic name (eg: myhost_mysql and myhost), and use $Conf{ClientNameAlias} in myhost_mysql’s config.pl to specify the real hostname of the machine.
- DHCP flag
-
Starting with v2.0.0 the way hosts are discovered has changed and now in most cases you should specify 0 for the DHCP flag, even if the host has a dynamically assigned IP address. Please read the section «How BackupPC Finds Hosts» to understand whether you need to set the DHCP flag.
You only need to set DHCP to 1 if your client machine doesn’t respond to the NetBios multicast request:
nmblookup myHostbut does respond to a request directed to its IP address:
nmblookup -A W.X.Y.ZIf you do set DHCP to 1 on any client you will need to specify the range of DHCP addresses to search is specified in $Conf{DHCPAddressRanges}.
Note also that the $Conf{ClientNameAlias} feature does not work for clients with DHCP set to 1.
- User name
-
This should be the unix login/email name of the user who «owns» or uses this machine. This is the user who will be sent email about this machine, and this user will have permission to stop/start/browse/restore backups for this host. Leave this blank if no specific person should receive email or be allowed to stop/start/browse/restore backups for this host. Administrators will still have full permissions.
- More users
-
Additional usernames, separated by commas and with no whitespace, can be specified. These users will also have full permission in the CGI interface to stop/start/browse/restore backups for this host. These users will not be sent email about this host.
The first non-comment line of the hosts file is special: it contains the names of the columns and should not be edited.
Here’s a simple example of a hosts file:
host dhcp user moreUsers
farside 0 craig jim,dave
larson 1 gary andyStep 5: Client Setup
Four methods for getting backup data from a client are supported: smb, tar, rsync and ftp. Smb or rsync are the preferred methods for WinXX clients and rsync or tar are the preferred methods for linux/unix/MacOSX clients.
The transfer method is set using the $Conf{XferMethod} configuration setting. If you have a mixed environment (ie: you will use smb for some clients and tar for others), you will need to pick the most common choice for $Conf{XferMethod} for the main config.pl file, and then override it in the per-PC config file for those hosts that will use the other method. (Or you could run two completely separate instances of BackupPC, with different data directories, one for WinXX and the other for linux/unix, but then common files between the different machine types will duplicated.)
Here are some brief client setup notes:
- WinXX
-
One setup for WinXX clients is to set $Conf{XferMethod} to «smb». Actually, rsyncd is the better method for WinXX if you are prepared to run rsync/cygwin on your WinXX client.
If you want to use rsyncd for WinXX clients you can find a pre-packaged exe installer on https://github.com/backuppc/cygwin-rsyncd/releases. The package is called cygwin-rsync. It contains rsync.exe, template setup files and the minimal set of cygwin libraries for everything to run. The README file contains instructions for running rsync as a service, so it starts automatically everytime you boot your machine. If you use rsync to backup WinXX machines, be sure to set $Conf{ClientCharset} correctly (eg: ‘cp1252’) so that the WinXX filename encoding is correctly converted to utf8.
Otherwise, to use SMB, you can either create shares for the data you want to backup or your can use the existing C$ share. To create a new share, open «My Computer», right click on the drive (eg: C), and select «Sharing…» (or select «Properties» and select the «Sharing» tab). In this dialog box you can enable sharing, select the share name and permissions.
All Windows NT based OS (NT, 2000, XP Pro), are configured by default to share the entire C drive as C$. This is a special share used for various administration functions, one of which is to grant access to backup operators. All you need to do is create a new domain user, specifically for backup. Then add the new backup user to the built in «Backup Operators» group. You now have backup capability for any directory on any computer in the domain in one easy step. This avoids using administrator accounts and only grants permission to do exactly what you want for the given user, i.e.: backup. Also, for additional security, you may wish to deny the ability for this user to logon to computers in the default domain policy.
If this machine uses DHCP you will also need to make sure the NetBios name is set. Go to Control Panel|System|Network Identification (on Win2K) or Control Panel|System|Computer Name (on WinXP). Also, you should go to Control Panel|Network Connections|Local Area Connection|Properties|Internet Protocol (TCP/IP)|Properties|Advanced|WINS and verify that NetBios is not disabled.
The relevant configuration settings are $Conf{SmbShareName}, $Conf{SmbShareUserName}, $Conf{SmbSharePasswd}, $Conf{SmbClientPath}, $Conf{SmbClientFullCmd}, $Conf{SmbClientIncrCmd} and $Conf{SmbClientRestoreCmd}.
BackupPC needs to know the smb share username and password for a client machine that uses smb. The username is specified in $Conf{SmbShareUserName}. There are four ways to tell BackupPC the smb share password:
-
As an environment variable BPC_SMB_PASSWD set before BackupPC starts. If you start BackupPC manually the BPC_SMB_PASSWD variable must be set manually first. For backward compatibility for v1.5.0 and prior, the environment variable PASSWD can be used if BPC_SMB_PASSWD is not set. Warning: on some systems it is possible to see environment variables of running processes.
-
Alternatively the BPC_SMB_PASSWD setting can be included in /etc/init.d/backuppc, in which case you must make sure this file is not world (other) readable.
-
As a configuration variable $Conf{SmbSharePasswd} in __CONFDIR__/config.pl. If you put the password here you must make sure this file is not world (other) readable.
-
As a configuration variable $Conf{SmbSharePasswd} in the per-PC configuration file (__CONFDIR__/pc/$host.pl or __TOPDIR__/pc/$host/config.pl in non-FHS versions of BackupPC). You will have to use this option if the smb share password is different for each host. If you put the password here you must make sure this file is not world (other) readable.
Placement and protection of the smb share password is a significant security issue, so please double-check the file and directory permissions. In a future version there might be support for encryption of this password, but a private key will still have to be stored in a protected place. Suggestions are welcome.
As an alternative to setting $Conf{XferMethod} to «smb» (using smbclient) for WinXX clients, you can use an smb network filesystem (eg: ksmbfs or similar) on your linux/unix server to mount the share, and then set $Conf{XferMethod} to «tar» (use tar on the network mounted file system).
Also, to make sure that filenames with special characters are correctly transferred by smbclient you should make sure that the smb.conf file has (for samba 3.x):
[global] unix charset = UTF8UTF8 is the default setting, so if the parameter is missing then it is ok. With this setting $Conf{ClientCharset} should be empty, since smbclient has already converted the filenames to utf8.
-
- Linux/Unix
-
The preferred setup for linux/unix clients is to set $Conf{XferMethod} to «rsync», «rsyncd» or «tar».
You can use either rsync, smb, or tar for linux/unix machines. Smb requires that the Samba server (smbd) be run to provide the shares. Since the smb protocol can’t represent special files like symbolic links and fifos, tar and rsync are the better transport methods for linux/unix machines. (In fact, by default samba makes symbolic links look like the file or directory that they point to, so you could get an infinite loop if a symbolic link points to the current or parent directory. If you really need to use Samba shares for linux/unix backups you should turn off the «follow symlinks» samba config setting. See the smb.conf manual page.)
Important note: many linux systems use sparse files for /var/log/lastlog, and have large special files below /proc and /run. Make sure you exclude those directories and files when you configure your client.
The requirements for each Xfer Method are:
- rsync
-
To use rsync, you need rsync-bpc installed on the BackupPC server.
On the client, you should have at least rsync 3.x. Rsync is run on the remote client via ssh.
The relevant configuration settings are $Conf{RsyncClientPath}, $Conf{RsyncSshArgs}, $Conf{RsyncShareName}, $Conf{RsyncArgs}, $Conf{RsyncArgsExtra}, $Conf{RsyncFullArgsExtra}, and $Conf{RsyncRestoreArgs}.
- rsyncd
-
To use rsync, you need rsync-bpc installed on the BackupPC server.
On the client, you should have at least rsync 3.x. In this case the rsync daemon should be running on the client machine and BackupPC connects directly to it.
The relevant configuration settings are $Conf{RsyncBackupPCPath}, $Conf{RsyncdClientPort}, $Conf{RsyncdUserName}, $Conf{RsyncdPasswd}, $Conf{RsyncShareName}, $Conf{RsyncArgs}, $Conf{RsyncArgsExtra}, and $Conf{RsyncRestoreArgs}. $Conf{RsyncShareName} is the name of an rsync module (ie: the thing in square brackets in rsyncd’s conf file — see rsyncd.conf), not a file system path.
Be aware that rsyncd will remove the leading ‘/’ from path names in symbolic links if you specify «use chroot = no» in the rsynd.conf file. See the rsyncd.conf manual page for more information.
- tar
-
You must have GNU tar on the client machine. Use «tar —version» or «gtar —version» to verify. The version should be at least 1.13.20. Tar is run on the client machine via rsh or ssh.
The relevant configuration settings are $Conf{TarClientPath}, $Conf{TarShareName}, $Conf{TarClientCmd}, $Conf{TarFullArgs}, $Conf{TarIncrArgs}, and $Conf{TarClientRestoreCmd}.
- ftp
-
FTP Xfer Method is supported in V4 but not recommended since it only handles minimal metadata, it doesn’t support hardlinks or special files, and can only restore regular files (not symbolic links etc).
You need to be running an ftp server on the client machine. The relevant configuration settings are $Conf{FtpShareName}, $Conf{FtpUserName}, $Conf{FtpPasswd}, $Conf{FtpBlockSize}, $Conf{FtpPort}, $Conf{FtpTimeout}, and $Conf{FtpFollowSymlinks}.
You need to set $Conf{ClientCharset} to the client’s charset so that filenames are correctly converted to utf8. Use «locale charmap» on the client to see its charset. Note, however, that modern versions of smbclient and rsync handle this conversion automatically, so in most cases you won’t need to set $Conf{ClientCharset}.
For linux/unix machines you should not backup «/proc». This directory contains a variety of files that look like regular files but they are special files that don’t need to be backed up (eg: /proc/kcore is a regular file that contains physical memory). See $Conf{BackupFilesExclude}. It is safe to backup /dev since it contains mostly character-special and block-special files, which are correctly handed by BackupPC (eg: backing up /dev/hda5 just saves the block-special file information, not the contents of the disk). Similarly, on many linux systems, /var/log/lastlog is a sparse file, with a very large apparent size, so you should exclude that too.
Alternatively, rather than backup all the file systems as a single share («/»), it is easier to restore a single file system if you backup each file system separately. To do this you should list each file system mount point in $Conf{TarShareName} or $Conf{RsyncShareName}, and add the —one-file-system option to $Conf{TarClientCmd} or $Conf{RsyncArgs}. In this case there is no need to exclude /proc explicitly since it looks like a different file system.
Ssh allows BackupPC to run as a privileged user on the client (eg: root), since it needs sufficient permissions to read all the backup files. Ssh is setup so that BackupPC on the server (an otherwise low privileged user) can ssh as root on the client, without being prompted for a password. However, directly enabled ssh root logins is not good practice. A better approach is the ssh as a regular user, and then configure sudo to allow just rsync to be executed.
There are two common versions of ssh: v1 and v2. Here are some instructions for one way to setup ssh. (Check which version of SSH you have by typing «ssh» or «man ssh».)
- MacOSX
-
In general this should be similar to Linux/Unix machines. In versions 10.4 and later, the native MacOSX tar works, and also supports resource forks. xtar is another option, and rsync works too (although the MacOSX-supplied rsync has an extension for extended attributes that is not compatible with standard rsync).
- SSH Setup
-
SSH is a secure way to run tar or rsync on a backup client to extract the data. SSH provides strong authentication and encryption of the network data.
Note that if you run rsyncd (rsync daemon), ssh is not used. In this case, rsyncd provides its own authentication, but there is no encryption of network data. If you want encryption of network data you can use ssh to create a tunnel, or use a program like stunnel.
Setup instructions for ssh can be found on the Wiki at https://github.com/backuppc/backuppc/wiki.
- Clients that use DHCP
-
If a client machine uses DHCP BackupPC needs some way to find the IP address given the hostname. One alternative is to set dhcp to 1 in the hosts file, and BackupPC will search a pool of IP addresses looking for hosts. More efficiently, it is better to set dhcp = 0 and provide a mechanism for BackupPC to find the IP address given the hostname.
For WinXX machines BackupPC uses the NetBios name server to determine the IP address given the hostname. For unix machines you can run nmbd (the NetBios name server) from the Samba distribution so that the machine responds to a NetBios name request. See the manual page and Samba documentation for more information.
Alternatively, you can set $Conf{NmbLookupFindHostCmd} to any command that returns the IP address given the hostname.
Please read the section «How BackupPC Finds Hosts» for more details.
Step 6: Running BackupPC
The installation contains an init.d backuppc script that can be copied to /etc/init.d so that BackupPC can auto-start on boot. See init.d/README for further instructions.
BackupPC should be ready to start. If you installed the init.d script, then you should be able to run BackupPC with:
/etc/init.d/backuppc start(This script can also be invoked with «stop» to stop BackupPC and «reload» to tell BackupPC to reload config.pl and the hosts file.)
Otherwise, just run
__INSTALLDIR__/bin/BackupPC -das user __BACKUPPCUSER__. The -d option tells BackupPC to run as a daemon (ie: it does an additional fork).
Any immediate errors will be printed to stderr and BackupPC will quit. Otherwise, look in __LOGDIR__/LOG and verify that BackupPC reports it has started and all is ok.
Step 7: Talking to BackupPC
You should verify that BackupPC is running by using BackupPC_serverMesg. This sends a message to BackupPC via the unix (or TCP) socket and prints the response. Like all BackupPC programs, BackupPC_serverMesg should be run as the BackupPC user (__BACKUPPCUSER__), so you should
su __BACKUPPCUSER__before running BackupPC_serverMesg. If the BackupPC user is configured with /bin/false as the shell, you can use the -s option to su to explicitly run a shell, eg:
su -s /bin/bash __BACKUPPCUSER__Depending upon your configuration you might also need the -l option.
If the -s option is not available on your operating system, you can specify the -m option to use your login shell as invoked shell:
su -m __BACKUPPCUSER__You can request status information and start and stop backups using this interface. This socket interface is mainly provided for the CGI interface (and some of the BackupPC subprograms use it too). But right now we just want to make sure BackupPC is happy. Each of these commands should produce some status output:
__INSTALLDIR__/bin/BackupPC_serverMesg status info
__INSTALLDIR__/bin/BackupPC_serverMesg status jobs
__INSTALLDIR__/bin/BackupPC_serverMesg status hostsThe output should be some hashes printed with Data::Dumper. If it looks cryptic and confusing, and doesn’t look like an error message, then all is ok.
The hosts status should produce a list of every host you have listed in __CONFDIR__/hosts as part of a big cryptic output line.
You can also request that all hosts be queued:
__INSTALLDIR__/bin/BackupPC_serverMesg backup allAt this point you should make sure the CGI interface works since it will be much easier to see what is going on. We’ll get to that shortly.
Step 8: Checking email delivery
The script BackupPC_sendEmail sends status and error emails to the administrator and users. It is usually run each night by BackupPC_nightly.
To verify that it can run sendmail and deliver email correctly you should ask it to send a test email to you:
su __BACKUPPCUSER__
__INSTALLDIR__/bin/BackupPC_sendEmail -u MYNAME@MYDOMAIN.COMBackupPC_sendEmail also takes a -c option that checks if BackupPC is running, and it sends an email to $Conf{EMailAdminUserName} if it is not. That can be used as a keep-alive check by adding
__INSTALLDIR__/bin/BackupPC_sendEmail -cto __BACKUPPCUSER__’s cron.
The -t option to BackupPC_sendEmail causes it to print the email message instead of invoking sendmail to deliver the message.
Step 9: CGI interface
The CGI interface script, BackupPC_Admin, is a powerful and flexible way to see and control what BackupPC is doing. It is written for an Apache server. If you don’t have Apache, see http://www.apache.org.
There are three options for setting up the CGI interface:
- SCGI
-
New to 4.x, SCGI uses the SCGI interface to Apache, which requires the mod_scgi.so module to be installed and loaded by Apache. This allows Apache to run as any unprivileged user. The actual SCGI server runs as the as the BackupPC user (__BACKUPPCUSER__), and handles the requests from Apache via a TCP socket.
- mod_perl
-
Mod_perl required the mod_perl module to be loaded by Apache. This allows BackupPC_Admin to be run from inside Apache. Unlike SCGI, using mod_perl with BackupPC_Admin requires a dedicated Apache to be run as the BackupPC user (__BACKUPPCUSER__). This is because BackupPC_Admin needs permission to access various files in BackupPC’s data directories.
- standard
-
The standard mode, which is significantly slower than SCGI or mod_perl, is where Apache runs BackupPC_Admin as a separate process for every request. This adds significant startup overhead for every request, and also requires that BackupPC_Admin be run as setuid to the BackupPC user (__BACKUPPCUSER__), if Apache isn’t being run as that user. Setuid scripts are discouraged, so the preference is to use SCGI or mod_perl.
Here are some specifics for each setup:
- SCGI Setup
-
First you need to install mod_scgi. If you can’t find a pre-built package, the source is available at http://python.ca/scgi. The release has subdirectories for apache1 and apache2. Pick your matching version (nowadays most likely apache2). You’ll need apxs, the Apache Extension Tool, installed to build from source. Once compiled, the module mod_scgi.so should be installed via the Makefile.
To enable the SCGI server, set $Conf{SCGIServerPort} to an available non-privileged TCP port number, eg: 10268. The matching port number has to appear in the Apache configuration file. Typical Apache configuration entries will look like this:
LoadModule scgi_module modules/mod_scgi.so SCGIMount /BackupPC_Admin 127.0.0.1:10268 <Location /BackupPC_Admin> AuthUserFile /etc/httpd/conf/passwd AuthType basic AuthName "access" require valid-user </Location>Or a typical Nginx configuration file:
server { listen 80; server_name yourBackupPCServerHost; root /var/www/backuppc; access_log /var/log/nginx/backuppc.access.log; error_log /var/log/nginx/backuppc.error.log; location /BackupPC_Admin { auth_basic "BackupPC"; auth_basic_user_file conf.d/backuppc.users; include scgi_params; scgi_pass 127.0.0.1:10268; scgi_param REMOTE_USER $remote_user; scgi_param SCRIPT_NAME $document_uri; } }This allows the SCGI interface to be accessed with a URL:
http://yourBackupPCServerHost/BackupPC_AdminYou can use a different path or name if you prefer a different URL. Unlike traditional CGI, there is no need to specify a valid path to a CGI script.
Important security warning!! The SCGIServerPort must not be accessible by anyone untrusted. That means you can’t allow untrusted users access to the BackupPC server, and you should block the SCGIServerPort TCP port on the BackupPC server. If you don’t understand what that means, or can’t confirm you have configured SCGI securely, then don’t enable SCGI — use one of the following two methods!!
- Mod_perl Setup
-
The advantage of the mod_perl setup is that no setuid script is needed (like in the standard method below), and there is a significant performance advantage. Not only does all the perl code need to be parsed just once, the config.pl and hosts files, plus the connection to the BackupPC server are cached between requests. The typical speedup is around 10-15x.
To use mod_perl you need to run Apache as user __BACKUPPCUSER__. If you need to run multiple Apaches for different services then you need to create multiple top-level Apache directories, each with their own config file. You can make copies of /etc/init.d/httpd and use the -d option to httpd to point each http to a different top-level directory. Or you can use the -f option to explicitly point to the config file. Multiple Apache’s will run on different Ports (eg: 80 is standard, 8080 is a typical alternative port accessed via http://yourhost.com:8080).
Inside BackupPC’s Apache http.conf file you should check the settings for ServerRoot, DocumentRoot, User, Group, and Port. See http://httpd.apache.org/docs/server-wide.html for more details.
For mod_perl, BackupPC_Admin should not have setuid permission, so you should turn it off:
chmod u-s __CGIDIR__/BackupPC_AdminTo tell Apache to use mod_perl to execute BackupPC_Admin, add this to Apache’s 1.x httpd.conf file:
<IfModule mod_perl.c> PerlModule Apache::Registry PerlTaintCheck On <Location /cgi-bin/BackupPC/BackupPC_Admin> # <--- change path as needed SetHandler perl-script PerlHandler Apache::Registry Options ExecCGI PerlSendHeader On </Location> </IfModule>Apache 2.0.44 with Perl 5.8.0 on RedHat 7.1, Don Silvia reports that this works (with tweaks from Michael Tuzi):
LoadModule perl_module modules/mod_perl.so PerlModule Apache2 <Directory /path/to/cgi/> SetHandler perl-script PerlResponseHandler ModPerl::Registry PerlOptions +ParseHeaders Options +ExecCGI Order deny,allow Deny from all Allow from 192.168.0 AuthName "Backup Admin" AuthType Basic AuthUserFile /path/to/user_file Require valid-user </Directory>There are other optimizations and options with mod_perl. For example, you can tell mod_perl to preload various perl modules, which saves memory compared to loading separate copies in every Apache process after they are forked. See Stas’s definitive mod_perl guide at http://perl.apache.org/guide.
- Standard Setup
-
The CGI interface should have been installed by the configure.pl script in __CGIDIR__/BackupPC_Admin. BackupPC_Admin should have been installed as setuid to the BackupPC user (__BACKUPPCUSER__), in addition to user and group execute permission.
You should be very careful about permissions on BackupPC_Admin and the directory __CGIDIR__: it is important that normal users cannot directly execute or change BackupPC_Admin, otherwise they can access backup files for any PC. You might need to change the group ownership of BackupPC_Admin to a group that Apache belongs to so that Apache can execute it (don’t add «other» execute permission!). The permissions should look like this:
ls -l __CGIDIR__/BackupPC_Admin -swxr-x--- 1 __BACKUPPCUSER__ web 82406 Jun 17 22:58 __CGIDIR__/BackupPC_AdminThe setuid script won’t work unless perl on your machine was installed with setuid emulation. This is likely the problem if you get an error saying such as «Wrong user: my userid is 25, instead of 150», meaning the script is running as the httpd user, not the BackupPC user. This is because setuid scripts are disabled by the kernel in most flavors of unix and linux.
To see if your perl has setuid emulation, see if there is a program called sperl5.8.0 (or sperl5.8.2 etc, based on your perl version) in the place where perl is installed. If you can’t find this program, then you have two options: rebuild and reinstall perl with the setuid emulation turned on (answer «y» to the question «Do you want to do setuid/setgid emulation?» when you run perl’s configure script), or switch to the mod_perl alternative for the CGI script (which doesn’t need setuid to work).
BackupPC_Admin requires that users are authenticated by Apache. Specifically, it expects that Apache sets the REMOTE_USER environment variable when it runs. There are several ways to do this. One way is to create a .htaccess file in the cgi-bin directory that looks like:
AuthGroupFile /etc/httpd/conf/group # <--- change path as needed
AuthUserFile /etc/http/conf/passwd # <--- change path as needed
AuthType basic
AuthName "access"
require valid-userYou will also need «AllowOverride Indexes AuthConfig» in the Apache httpd.conf file to enable the .htaccess file. Alternatively, everything can go in the Apache httpd.conf file inside a Location directive. The list of users and password file above can be extracted from the NIS passwd file.
One alternative is to use LDAP. In Apache’s http.conf add these lines:
LoadModule auth_ldap_module modules/auth_ldap.so
AddModule auth_ldap.c
# cgi-bin - auth via LDAP (for BackupPC)
<Location /cgi-bin/BackupPC/BackupPC_Admin> # <--- change path as needed
AuthType Basic
AuthName "BackupPC login"
# replace MYDOMAIN, PORT, ORG and CO as needed
AuthLDAPURL ldap://ldap.MYDOMAIN.com:PORT/o=ORG,c=CO?uid?sub?(objectClass=*)
require valid-user
</Location>If you want to disable the user authentication you can set $Conf{CgiAdminUsers} to ‘*’, which allows any user to have full access to all hosts and backups. In this case the REMOTE_USER environment variable does not have to be set by Apache.
Alternatively, you can force a particular username by getting Apache to set REMOTE_USER, eg, to hard code the user to www you could add this to Apache’s httpd.conf:
<Location /cgi-bin/BackupPC/BackupPC_Admin> # <--- change path as needed
Setenv REMOTE_USER www
</Location>Finally, you should also edit the config.pl file and adjust, as necessary, the CGI-specific settings. They’re near the end of the config file. In particular, you should specify which users or groups have administrator (privileged) access: see the config settings $Conf{CgiAdminUserGroup} and $Conf{CgiAdminUsers}. Also, the configure.pl script placed various images into $Conf{CgiImageDir} that BackupPC_Admin needs to serve up. You should make sure that $Conf{CgiImageDirURL} is the correct URL for the image directory.
See the section «Fixing installation problems» for suggestions on debugging the Apache authentication setup.
How BackupPC Finds Hosts
Starting with v2.0.0 the way hosts are discovered has changed. In most cases you should specify 0 for the DHCP flag in the conf/hosts file, even if the host has a dynamically assigned IP address.
BackupPC (starting with v2.0.0) looks up hosts with DHCP = 0 in this manner:
-
First DNS is used to lookup the IP address given the client’s name using perl’s gethostbyname() function. This should succeed for machines that have fixed IP addresses that are known via DNS. You can manually see whether a given host have a DNS entry according to perl’s gethostbyname function with this command:
perl -e 'print(gethostbyname("myhost") ? "okn" : "not foundn");' -
If gethostbyname() fails, BackupPC then attempts a NetBios multicast to find the host. Provided your client machine is configured properly, it should respond to this NetBios multicast request. Specifically, BackupPC runs a command of this form:
nmblookup myhostIf this fails you will see output like:
querying myhost on 10.10.255.255 name_query failed to find name myhostIf it is successful you will see output like:
querying myhost on 10.10.255.255 10.10.1.73 myhost<00>Depending on your netmask you might need to specify the -B option to nmblookup. For example:
nmblookup -B 10.10.1.255 myhostIf necessary, experiment with the nmblookup command which will return the IP address of the client given its name. Then update $Conf{NmbLookupFindHostCmd} with any necessary options to nmblookup.
For hosts that have the DHCP flag set to 1, these machines are discovered as follows:
-
A DHCP address pool ($Conf{DHCPAddressRanges}) needs to be specified. BackupPC will check the NetBIOS name of each machine in the range using a command of the form:
nmblookup -A W.X.Y.Zwhere W.X.Y.Z is each candidate address from $Conf{DHCPAddressRanges}. Any host that has a valid NetBIOS name returned by this command (ie: matching an entry in the hosts file) will be backed up. You can modify the specific nmblookup command if necessary via $Conf{NmbLookupCmd}.
-
You only need to use this DHCP feature if your client machine doesn’t respond to the NetBios multicast request:
nmblookup myHostbut does respond to a request directed to its IP address:
nmblookup -A W.X.Y.Z
Other installation topics
- Removing a client
-
If there is a machine that no longer needs to be backed up (eg: a retired machine) you have two choices. First, you can keep the backups accessible and browsable, but disable all new backups. Alternatively, you can completely remove the client and all its backups.
To disable backups for a client $Conf{BackupsDisable} can be set to two different values in that client’s per-PC config.pl file:
-
Don’t do any regular backups on this machine. Manually requested backups (via the CGI interface) will still occur.
-
Don’t do any backups on this machine. Manually requested backups (via the CGI interface) will be ignored.
This will still allow the client’s old backups to be browsable and restorable.
To completely remove a client and all its backups, you should remove its entry in the conf/hosts file, and then delete the __TOPDIR__/pc/$host directory. Whenever you change the hosts file, you should send BackupPC a HUP (-1) signal so that it re-reads the hosts file. If you don’t do this, BackupPC will automatically re-read the hosts file at the next regular wakeup.
Note that when you remove a client’s backups you won’t initially recover much disk space. That’s because the client’s files are still in the pool. Overnight, when BackupPC_nightly next runs, all the unused pool files will be deleted and this will recover the disk space used by the client’s backups.
-
- Copying the pool
-
If the pool disk requirements grow you might need to copy the entire data directory to a new (bigger) file system. Hopefully you are lucky enough to avoid this by having the data directory on a RAID file system or LVM that allows the capacity to be grown in place by adding disks.
Backups prior to V4 make extensive use of hardlinks. So unless you have a virgin V4 installation, your file system will contain large numbers of hardlinks. This makes it hard to copy.
Prior to V4 (or a V4 upgrade to a V3 installation), the backup data directories contain large numbers of hardlinks. If you try to copy the pool the target directory will occupy a lot more space if the hardlinks aren’t re-established.
Unless you have a pure V4 installation, the best way to copy a pool file system, if possible, is by copying the raw device at the block level (eg: using dd). Application level programs that understand hardlinks include the GNU cp program with the -a option and rsync -H. However, the large number of hardlinks in the pool will make the memory usage large and the copy very slow. Don’t forget to stop BackupPC while the copy runs.
If you have a pure V4 installation, copying the pool and PC backup directories should be quite easy. Rsync 3.x should work well.
Fixing installation problems
If you find a solution to your problem that could help other users please add it to the Wiki at https://github.com/backuppc/backuppc/wiki.
Restore functions
BackupPC supports several different methods for restoring files. The most convenient restore options are provided via the CGI interface. Alternatively, backup files can be restored using manual commands.
CGI restore options
By selecting a host in the CGI interface, a list of all the backups for that machine will be displayed. By selecting the backup number you can navigate the shares and directory tree for that backup.
BackupPC’s CGI interface automatically fills incremental backups with the corresponding full backup, which means each backup has a filled appearance. Therefore, there is no need to do multiple restores from the incremental and full backups: BackupPC does all the hard work for you. You simply select the files and directories you want from the correct backup vintage in one step.
You can download a single backup file at any time simply by selecting it. Your browser should prompt you with the filename and ask you whether to open the file or save it to disk.
Alternatively, you can select one or more files or directories in the currently selected directory and select «Restore selected files». (If you need to restore selected files and directories from several different parent directories you will need to do that in multiple steps.)
If you select all the files in a directory, BackupPC will replace the list of files with the parent directory. You will be presented with a screen that has three options:
- Option 1: Direct Restore
-
With this option the selected files and directories are restored directly back onto the host, by default in their original location. Any old files with the same name will be overwritten, so use caution. You can optionally change the target hostname, target share name, and target path prefix for the restore, allowing you to restore the files to a different location.
Once you select «Start Restore» you will be prompted one last time with a summary of the exact source and target files and directories before you commit. When you give the final go ahead the restore operation will be queued like a normal backup job, meaning that it will be deferred if there is a backup currently running for that host. When the restore job is run, smbclient, tar, rsync or rsyncd is used (depending upon $Conf{XferMethod}) to actually restore the files. Sorry, there is currently no option to cancel a restore that has been started. Currently ftp restores are not fully implemented.
A record of the restore request, including the result and list of files and directories, is kept. It can be browsed from the host’s home page. $Conf{RestoreInfoKeepCnt} specifies how many old restore status files to keep.
Note that for direct restore to work, the $Conf{XferMethod} must be able to write to the client. For example, that means an SMB share for smbclient needs to be writable, and the rsyncd module needs «read only» set to «false». This creates additional security risks. If you only create read-only SMB shares (which is a good idea), then the direct restore will fail. You can disable the direct restore option by setting $Conf{SmbClientRestoreCmd}, $Conf{TarClientRestoreCmd} and $Conf{RsyncRestoreArgs} to undef.
- Option 2: Download Zip archive
-
With this option a zip file containing the selected files and directories is downloaded. The zip file can then be unpacked or individual files extracted as necessary on the host machine. The compression level can be specified. A value of 0 turns off compression.
When you select «Download Zip File» you should be prompted where to save the restore.zip file.
BackupPC does not consider downloading a zip file as an actual restore operation, so the details are not saved for later browsing as in the first case. However, a mention that a zip file was downloaded by a particular user, and a list of the files, does appear in BackupPC’s log file.
- Option 3: Download Tar archive
-
This is identical to the previous option, except a tar file is downloaded rather than a zip file (and there is currently no compression option).
Command-line restore options
Apart from the CGI interface, BackupPC allows you to restore files and directories from the command line. The following programs can be used:
- BackupPC_zcat
-
For each filename argument it inflates (uncompresses) the file and writes it to stdout. To use BackupPC_zcat you could give it the full filename, eg:
__INSTALLDIR__/bin/BackupPC_zcat __TOPDIR__/pc/host/5/fc/fcraig/fexample.txt > example.txtIt’s your responsibility to make sure the file is really compressed: BackupPC_zcat doesn’t check which backup the requested file is from. BackupPC_zcat returns a nonzero status if it fails to uncompress a file.
In V4, BackupPC_zcat can be invoked in several other ways:
BackupPC_zcat file... BackupPC_zcat MD5_digest... BackupPC_zcat $TopDir/pc/host/num/share/mangledPath... BackupPC_zcat [-h host] [-n num] [-s share] clientPath...For example, you can do this:
BackupPC_zcat d73955e08410dfc5ea8069b05d2f43b2That digest can be pasted from the output of BackupPC_ls.
The last form uses unmangled paths, so you can do this:
BackupPC_zcat -h HOST -n 10 -s / /home/craig/fileYou can also mix real paths with unmangled paths. Both of these versions work:
BackupPC_zcat /data/BackupPC/pc/HOST/10/fhome/fcraig/ffile BackupPC_zcat /data/BackupPC/pc/HOST/10/home/craig/file - BackupPC_tarCreate
-
BackupPC_tarCreate creates a tar file for any files or directories in a particular backup. Merging of incrementals is done automatically, so you don’t need to worry about whether certain files appear in the incremental or full backup.
The usage is:
BackupPC_tarCreate [options] files/directories... Required options: -h host host from which the tar archive is created -n dumpNum dump number from which the tar archive is created A negative number means relative to the end (eg -1 means the most recent dump, -2 2nd most recent etc). -s shareName share name from which the tar archive is created; can be "*" to mean all shares. Other options: -t print summary totals -r pathRemove path prefix that will be replaced with pathAdd -p pathAdd new path prefix -b BLOCKS BLOCKS x 512 bytes per record (default 20; same as tar) -w writeBufSz write buffer size (default 1048576 = 1MB) -e charset charset for encoding filenames (default: value of $Conf{ClientCharset} when backup was done) -l just print a file listing; don't generate an archive -L just print a detailed file listing; don't generate an archiveThe command-line files and directories are relative to the specified shareName. The tar file is written to stdout.
The -h, -n and -s options specify which dump is used to generate the tar archive. The -r and -p options can be used to relocate the paths in the tar archive so extracted files can be placed in a location different from their original location.
- BackupPC_zipCreate
-
BackupPC_zipCreate creates a zip file for any files or directories in a particular backup. Merging of incrementals is done automatically, so you don’t need to worry about whether certain files appear in the incremental or full backup.
The usage is:
BackupPC_zipCreate [options] files/directories... Required options: -h host host from which the zip archive is created -n dumpNum dump number from which the tar archive is created A negative number means relative to the end (eg -1 means the most recent dump, -2 2nd most recent etc). -s shareName share name from which the zip archive is created Other options: -t print summary totals -r pathRemove path prefix that will be replaced with pathAdd -p pathAdd new path prefix -c level compression level (default is 0, no compression) -e charset charset for encoding filenames (default: utf8)The command-line files and directories are relative to the specified shareName. The zip file is written to stdout. The -h, -n and -s options specify which dump is used to generate the zip archive. The -r and -p options can be used to relocate the paths in the zip archive so extracted files can be placed in a location different from their original location.
- BackupPC_ls
-
In V3, a full (or filled) backup tree contains all the files, albeit with «mangled» names, and the file contents are compressed. Some users found it convenient to directly navigate a PC’s backup tree to check for files.
In V4 that is not possible, since only a single attrib file is stored per directory in the PC backup tree, so the directory contents aren’t visible without looking in the attrib file.
A new utility BackupPC_ls (like «ls») can be used to view PC backup trees. It shows file digests, which can be pasted to BackupPC_zcat if you want to view the file contents. The arguments are similar to BackupPC_zcat. The usage is:
BackupPC_ls [-iR] [-h host] [-n bkupNum] [-s shareName] dirs/files...The -i option will show inodes (inode number and number of links). The -R option recurses into directories.
If you don’t specify -h, -n and -s, then you can specify the real file system path instead. For example, the following three commands are equivalent:
BackupPC_ls -h HOST -n 10 -s cDrive /home/craig/file BackupPC_ls /data/BackupPC/pc/HOST/10/fcDrive/fhome/fcraig/ffile BackupPC_ls /data/BackupPC/pc/HOST/10/cDrive/home/craig/fileAs you can see, the portion of the full path after the backup number can be either mangled or not. Note that using the mangled form allows directory-name completion via the shell, since those directories actually exist.
It would be great if someone would like to volunteer to add features to BackupPC_ls to make file and directory completion work with unmangled names via the shell. In tcsh you can specify a completion program to run — BackupPC_ls could be given special arguments to spit out the potential (unmangled) completions. I’m not sure how bash does this.
Each of these programs reside in __INSTALLDIR__/bin.
Archive functions
BackupPC supports archiving to removable media. For users that require offsite backups, BackupPC can create archives that stream to tape devices, or create files of specified sizes to fit onto cd or dvd media.
Each archive type is specified by a BackupPC host with its XferMethod set to ‘archive’. This allows for multiple configurations at sites where there might be a combination of tape and cd/dvd backups being made.
BackupPC provides a menu that allows one or more hosts to be archived. The most recent backup of each host is archived using BackupPC_tarCreate, and the output is optionally compressed and split into fixed-sized files (eg: 650MB).
The archive for each host is done by default using __INSTALLDIR__/bin/BackupPC_archiveHost. This script can be copied and customized as needed.
Configuring an Archive Host
To create an Archive Host, add it to the hosts file just as any other host and call it a name that best describes the type of archive, e.g. ArchiveDLT
To tell BackupPC that the Host is for Archives, create a config.pl file in the Archive Hosts’s pc directory, adding the following line:
$Conf{XferMethod} = ‘archive’;
To further customise the archive’s parameters you can add the changed parameters in the host’s config.pl file. The parameters are explained in the config.pl file. Parameters may be fixed or the user can be allowed to change them (eg: output device).
The per-host archive command is $Conf{ArchiveClientCmd}. By default this invokes
__INSTALLDIR__/bin/BackupPC_archiveHostwhich you can copy and customize as necessary.
Starting an Archive
In the web interface, click on the Archive Host you wish to use. You will see a list of previous archives and a summary on each. By clicking the «Start Archive» button you are presented with the list of hosts and the approximate backup size (note this is raw size, not projected compressed size) Select the hosts you wish to archive and press the «Archive Selected Hosts» button.
The next screen allows you to adjust the parameters for this archive run. Press the «Start the Archive» to start archiving the selected hosts with the parameters displayed.
Starting an Archive from the command line
The script BackupPC_archiveStart can be used to start an archive from the command line (or cron etc). The usage is:
BackupPC_archiveStart archiveHost userName hosts...This creates an archive of the most recent backup of each of the specified hosts. The first two arguments are the archive host and the username making the request.
Other Command Line Utilities
These utilities are automatically run by BackupPC when needed. You don’t need to manually run these utilities.
- BackupPC_attribPrint
-
BackupPC_attribPrint prints the contents of an attrib file. Usage:
BackupPC_attribPrint attribPath BackupPC_attribPrint inodePath/inodeNum - BackupPC_backupDelete
-
BackupPC_backupDelete deletes an entire backup, or a directory path within a backup. Usage:
BackupPC_backupDelete -h host -n num [-p] [-l] [-r] [-s shareName [dirs...]] Options: -h host hostname -n num backup number to delete -s shareName don't delete the backup; delete just this share (or only dirs below this share if specified) -p don't print progress information -l don't remove XferLOG files -r do a ref count update (default: none) If a shareName is specified, just that share (or share/dirs) are deleted. The backup itself is not deleted, nor is the log file removed. - BackupPC_backupDuplicate
-
BackupPC_backupDuplicate duplicates the last backup, which is used to create a filled backup copy, and also to convert a V3 backup to a new V4 starting point. Usage:
BackupPC_backupDuplicate -h host [-p] Options: -h host hostname -p don't print progress information - BackupPC_fixupBackupSummary
-
BackupPC_fixupBackupSummary is used to re-create the backups file for all the hosts if it is damaged or deleted. Usage:
BackupPC_fixupBackupSummary [-l] Options: -l legacy mode: try to reconstruct backups from LOG files for backups prior to BackupPC v3.0. - BackupPC_fsck
-
BackupPC_fsck can only be run manually, and only while BackupPC isn’t running. It updates the host reference counts, the overall pool reference counts and stats. Usage:
BackupPC_fsck [options] Options: -f force regeneration of per-host reference counts -n don't remove zero count pool files - print only -s recompute pool stats - BackupPC_migrateV3toV4
-
If you upgraded an existing 3.x installation, BackupPC 4.x is backward compatible with 3.x backups: it can browse, view and restore files. However, the existing 3.x backups will still use hardlinks for storage, and until those 3.x backups eventually expire, hardlinks will still be used for 3.x backups.
BackupPC_migrateV3toV4 is an optional utility that can migrate existing 3.x backups to 4.x stoage format, eliminating hardlinks. This allows you to eliminate the old V3 pool and you can then set $Conf{PoolV3Enabled} to 0.
BackupPC_migrateV3toV4 -a [-m] [-p] [-v] BackupPC_migrateV3toV4 -h host [-n V3backupNum] [-m] [-p] [-v] Options: -a migrate all hosts and all backups -h host migrate just a specific host -n V3backupNum migrate specific host backup; does all V3 backups for that host if not specified -m don't migrate anything; just print what would be done -p don't print progress information -v verboseThe BackupPC server should not be running when you run BackupPC_migrateV3toV4. It will check and exit if the BackupPC server is running.
If you want to test BackupPC_migrateV3toV4, a cautious approach is to make backup copies of the V3 backups, allowing you to restore them if there is any issue. For example, if exampleHost has three 3.x backups numbered 5, 6, 7, you can use cp -prl (preserving hardlinks) to make copies:
cd /data/BackupPC/pc/exampleHost mv 5 5.orig ; cp -prl 5.orig 5 mv 6 6.orig ; cp -prl 6.orig 6 mv 7 7.orig ; cp -prl 7.orig 7 cp backups backups.save BackupPC_migrateV3toV4 -h exampleHost -n 5 BackupPC_migrateV3toV4 -h exampleHost -n 6 BackupPC_migrateV3toV4 -h exampleHost -n 7If you want to put things back the way they were:
rm -rf 5 ; mv 5.orig 5 rm -rf 6 ; mv 6.orig 6 rm -rf 7 ; mv 7.orig 7 # copy the [567] lines from backups.save into backups; # only do "cp backups.save backups" if you are sure no # new backups have been doneTwo important things to note with BackupPC_migrateV3toV4. First, V4 storage does use more filesystem inodes than V3 (that’s the small cost of getting rid of hardlinks). In particular, each directory in a backup tree uses two inodes in V4 (one for the directory, and one for the (empty) attrib file), and only one inode in V3 (one for the directory, and the attrib and all other files are hardlinked to the pool). So before you run BackupPC_migrateV3toV4, make sure you have enough inodes in __TOPDIR__; use df -i to make sure you are under 45% inode usage.
Secondly, if you run BackupPC_migrateV3toV4 on all your backups, the old V3 pool should be empty, except for old-style attrib files, which should all have only one link since no backups should reference them any longer. Before you turn off the V3 pool by setting $Conf{PoolV3Enabled} to 0, make sure BackupPC_nightly has run enough times (specifically, $Conf{PoolSizeNightlyUpdatePeriod} times) so that the V3 pool can be emptied. You could do this manually, but only if you are very careful to check that the remaining files only have one link.
- BackupPC_poolCntPrint
-
BackupPC_poolCntPrint is used to print reference count information, either per-backup, per-host or for the entire pool depending on the file path you use.
If you provide a hex md5 digest, the entire pool count for that digest is printed. Usage:
BackupPC_poolCntPrint [poolCntFilePath|hexDigest]... - BackupPC_refCountUpdate
-
BackupPC_refCountUpdate is used to either update the per-backup and per-host reference counts, or the system-wide reference counts. It is used by BackupPC_dump, BackupPC_nightly, BackupPC_backupDelete, BackupPC_backupDuplicate and BackupPC_fsck. Usage:
BackupPC_refCountUpdate -h HOST [-c] [-f] [-F] [-o N] [-p] [-v] With no other args, updates count db on backups with poolCntDelta files and computers the host's total reference counts. Also builds refCnt for any >=4.0 backups without refCnts. -f - do an fsck on this HOST, which involves a rebuild of the last two backup refCnts. poolCntDelta files are ignored. Also forces fsck if requested by needFsck flag files in TopDir/pc/HOST/refCnt. Equivalent to -o 2. -F - rebuild all the >=4.0 per-backup refCnt files for this host. Equivalent to -o 3. -c - compare current count db to new db before replacing -o N - override $Conf{RefCntFsck}. -p - don't show progress -v - verbose Notes: in case there are legacy (ie: <=4.0.0alpha3) unapplied poolCntDelta files in TopDir/pc/HOST/refCnt then the -f flag is turned on. BackupPC_refCountUpdate -m [-f] [-p] [-c] [-r N-M] [-s] [-v] [-P phase] -m Updates main count db, based on each HOST -f - do an fsck on all the hosts, ignoring poolCntDelta files, and replacing each host's count db. Will wait for backups to finish if any are running. -F - rebuild all the >=4.0 per-backup refCnt files. -p - don't show progress -c - clean pool files -r N-M - process a subset of the main count db, 0 <= N <= M <= 255 -s - prints stats -v - verbose -P phase Phase from 0..15 each time we run BackupPC_nightly. Used to compute exact pool size for portions of the pool based on the phase and $Conf{PoolSizeNightlyUpdatePeriod}.
Other CGI Functions
Configuration and Host Editor
The CGI interface has a complete configuration and host editor. Only the administrator can edit the main configuration settings and hosts. The edit links are in the left navigation bar.
When changes are made to any parameter a «Save» button appears at the top of the page. If you are editing a text box you will need to click outside of the text box to make the Save button appear. If you don’t select Save then the changes won’t be saved.
The host-specific configuration can be edited from the host summary page using the link in the left navigation bar. The administrator can edit any of the host-specific configuration settings.
When editing the host-specific configuration, each parameter has an «override» setting that denotes the value is host-specific, meaning that it overrides the setting in the main configuration. If you deselect «override» then the setting is removed from the host-specific configuration, and the main configuration file is displayed.
User’s can edit their host-specific configuration if enabled via $Conf{CgiUserConfigEditEnable}. The specific subset of configuration settings that a user can edit is specified with $Conf{CgiUserConfigEdit}. It is recommended to make this list short as possible (you probably don’t want your users saving dozens of backups) and it is essential that they can’t edit any of the Cmd configuration settings, otherwise they can specify an arbitrary command that will be executed as the BackupPC user.
Metrics
BackupPC supports a metrics endpoint that expose common information in a digest format. Allowed metrics formats are json (default), prometheus and rss. Format should be specified using format query parameter, a URL similar to this will provide metrics information:
http://localhost/cgi-bin/BackupPC/BackupPC_Admin?action=metrics
http://localhost/cgi-bin/BackupPC/BackupPC_Admin?action=metrics&format=json
http://localhost/cgi-bin/BackupPC/BackupPC_Admin?action=metrics&format=prometheus
http://localhost/cgi-bin/BackupPC/BackupPC_Admin?action=metrics&format=rssJSON format requires the JSON::XS module to be installed. RSS format requires the XML::RSS module to be installed.
This feature is experimental. The information included will probably change.
The RSS feed has been merged in the metrics endpoint (see section above). Please use the metrics endpoint to access the RSS feed, as the old endpoint will be deprecated.
BackupPC supports a very basic RSS feed. Provided you have the XML::RSS perl module installed, a URL similar to this will provide RSS information:
http://localhost/cgi-bin/BackupPC/BackupPC_Admin?action=rssThis feature is experimental. The information included will probably change.
BackupPC Design
Some design issues
- Pooling common files
-
To see if a file is already in the pool, an MD5 digest of the file contents is used. This can’t guarantee a file is identical: it just reduces the search to often a single file or handful of files.
Depending on the Xfer method and settings, a complete file comparison is done to verify if two files are really the same.
Prior to V4, identical files on multiples backups are represented by hard links. Hardlinks are used so that identical files all refer to the same physical file on the server’s disk. Also, hard links maintain reference counts so that BackupPC knows when to delete unused files from the pool.
In V4+, hardlinks are not used and reference counting is done at the application level. It is done in a batch manner, which simplifies the implementation.
For the computer-science majors among you, you can think of the pooling system used by BackupPC as just a chained hash table stored on a (big) file system.
- The hashing function
-
In V4+, the file digest is the MD5 digest of the complete file. While MD5 collisions are now well known, and can be easily constructed, in real use collisions will be extremely unlikely.
Prior to V4, just a portion of all but the smallest files was used for the digest. That decision was made long ago when CPUs were a lot slower. For files less than 256K, the digest is the MD5 digest of the file size and the full file. For files up to 1MB, the first and last 128K of the file, and for over 1MB, the first and eighth 128K chunks are used, together with the file size.
- Compression
-
BackupPC supports compression. It uses the deflate and inflate methods in the Compress::Zlib module, which is based on the zlib compression library (see http://www.gzip.org/zlib/).
The $Conf{CompressLevel} setting specifies the compression level to use. Zero (0) means no compression. Compression levels can be from 1 (least cpu time, slightly worse compression) to 9 (most cpu time, slightly better compression). The recommended value is 3. Changing it to 5, for example, will take maybe 20% more cpu time and will get another 2-3% additional compression. Diminishing returns set in above 5. See the zlib documentation for more information about compression levels.
BackupPC implements compression with minimal CPU load. Rather than compressing every incoming backup file and then trying to match it against the pool, BackupPC computes the MD5 digest based on the uncompressed file, and matches against the candidate pool files by comparing each uncompressed pool file against the incoming backup file. Since inflating a file takes roughly a factor of 10 less CPU time than deflating there is a big saving in CPU time.
The combination of pooling common files and compression can yield a factor of 8 or more overall saving in backup storage.
Note that you should not turn compression on and off are you have started running BackupPC. It will result in double the storage needs, since all the files will be stored in both the compressed and uncompressed pools.
BackupPC operation
BackupPC reads the configuration information from __CONFDIR__/config.pl. It then runs and manages all the backup activity. It maintains queues of pending backup requests, user backup requests and administrative commands. Based on the configuration various requests will be executed simultaneously.
As specified by $Conf{WakeupSchedule}, BackupPC wakes up periodically to queue backups on all the PCs. This is a four step process:
-
For each host and DHCP address backup requests are queued on the background command queue.
-
For each PC, BackupPC_dump is forked. Several of these may be run in parallel, based on the configuration. First a ping is done to see if the machine is alive. If this is a DHCP address, nmblookup is run to get the netbios name, which is used as the hostname. If DNS lookup fails, $Conf{NmbLookupFindHostCmd} is run to find the IP address from the hostname. The file __TOPDIR__/pc/$host/backups is read to decide whether a full or incremental backup needs to be run. If no backup is scheduled, or the ping to $host fails, then BackupPC_dump exits.
The backup is done using the specified XferMethod. Either samba’s smbclient or tar over ssh/rsh/nfs piped into BackupPC_tarExtract, or rsync over ssh/rsh is run, or rsyncd is connected to, with the incoming data extracted to __TOPDIR__/pc/$host/new. The XferMethod output is put into __TOPDIR__/pc/$host/XferLOG.
The letter in the XferLOG file shows the type of object, similar to the first letter of the modes displayed by ls -l:
d -> directory l -> symbolic link b -> block special file c -> character special file p -> pipe file (fifo) nothing -> regular fileThe words mean:
- create
-
new for this backup (ie: directory or file not in pool)
- pool
-
found a match in the pool
- same
-
file is identical to previous backup (contents were checksummed and verified during full dump).
- skip
-
file skipped in incremental because attributes are the same (only displayed if $Conf{XferLogLevel} >= 2).
As BackupPC_tarExtract extracts the files from smbclient or tar, or as rsync or ftp runs, it checks each file in the backup to see if it is identical to an existing file from any previous backup of any PC. It does this without needed to write the file to disk. If the file matches an existing file, a hardlink is created to the existing file in the pool. If the file does not match any existing files, the file is written to disk and inserted into the pool.
BackupPC_tarExtract and rsync can handle arbitrarily large files and multiple candidate matching files without needing to write the file to disk in the case of a match. This significantly reduces disk writes (and also reads, since the pool file comparison is done disk to memory, rather than disk to disk).
Based on the configuration settings, BackupPC_dump checks each old backup to see if any should be removed.
-
Once each night, BackupPC_nightly is run to complete some additional administrative tasks, such as cleaning the pool. This involves removing any files in the pool that only have a single hard link (meaning no backups are using that file).
If BackupPC_nightly takes too long to run, the settings $Conf{MaxBackupPCNightlyJobs} and $Conf{BackupPCNightlyPeriod} can be used to run several BackupPC_nightly processes in parallel, and to split its job over several nights.
BackupPC also listens for TCP connections on $Conf{ServerPort}, which is used by the CGI script BackupPC_Admin for status reporting and user-initiated backup or backup cancel requests.
Storage layout
BackupPC resides in several directories:
- __INSTALLDIR__
-
Perl scripts comprising BackupPC reside in __INSTALLDIR__/bin, libraries are in __INSTALLDIR__/lib and documentation is in __INSTALLDIR__/doc.
- __CGIDIR__
-
The CGI script BackupPC_Admin resides in this cgi binary directory.
- __CONFDIR__
-
All the configuration information resides below __CONFDIR__. This directory contains:
The directory __CONFDIR__ contains:
- config.pl
-
Configuration file. See «Configuration File» below for more details.
- hosts
-
Hosts file, which lists all the PCs to backup.
- pc
-
The directory __CONFDIR__/pc contains per-client configuration files that override settings in the main configuration file. Each file is named __CONFDIR__/pc/HOST.pl, where HOST is the hostname.
In pre-FHS versions of BackupPC these files were located in __TOPDIR__/pc/HOST/config.pl.
- __LOGDIR__
-
The directory __LOGDIR__ (__TOPDIR__/log on pre-FHS versions of BackupPC) contains:
- LOG
-
Current (today’s) log file output from BackupPC.
- LOG.0 or LOG.0.z
-
Yesterday’s log file output. Log files are aged daily and compressed (if compression is enabled), and old LOG files are deleted.
- status.pl
-
A summary of BackupPC’s status written periodically by BackupPC so that certain state information can be maintained if BackupPC is restarted. Should not be edited.
- UserEmailInfo.pl
-
A summary of what email was last sent to each user, and when the last email was sent. Should not be edited.
- __RUNDIR__
-
The directory __RUNDIR__ (__TOPDIR__/log on pre-FHS versions of BackupPC) contains:
- BackupPC.pid
-
Contains BackupPC’s process id.
- BackupPC.sock
-
A unix domain socket for communicating to the BackupPC server.
- __TOPDIR__
-
All of BackupPC’s data (PC backup images, logs, configuration information) is stored below this directory.
Below __TOPDIR__ are several directories:
- __TOPDIR__/pool
-
All uncompressed files from PC backups are stored below __TOPDIR__/pool. Each file’s name is based on the MD5 hex digest of the file contents.
For V4+, the digest is the MD5 digest of the full file contents (the length is not used). For V4+ the pool files are stored in a 2 level tree, using 7 bits from the top of the first two bytes of the digest. So there are 128 directories are each level, numbered evenly in hex from 0x00, 0x02, to 0xfe.
For example, if a file has an MD5 digest of 123456789abcdef0123456789abcdef0, the uncompressed file is stored in __TOPDIR__/pool/12/34/123456789abcdef0123456789abcdef0.
Duplicates digest are represented with one (or more) hex byte extensions. So three colliding files would be stored as
__TOPDIR__/pool/12/34/123456789abcdef0123456789abcdef0 __TOPDIR__/pool/12/34/123456789abcdef0123456789abcdef000 __TOPDIR__/pool/12/34/123456789abcdef0123456789abcdef001The rest of this section describes the old pool layout. Note that both V3 and V4 pools can exist together, since they use different names for their directory trees.
As exampled earlier, prior to V4 the digest is computed as follows. For files less than 256K, the file length and the entire file is used. For files up to 1MB, the file length and the first and last 128K are used. Finally, for files longer than 1MB, the file length, and the first and eighth 128K chunks for the file are used.
Both BackupPC_dump (actually, BackupPC_tarExtract or rsync_bpc) are responsible for checking newly backed up files against the pool. For each file, the MD5 digest is used to generate a filename in the pool directory.
If the file exists in the pool, the contents are compared. If there is no match, additional files in the chain are checked (if any). (Actually, multiple candidate files are compared in parallel.)
If $Conf{PoolV3Enabled} is set, then the V3 pool is checked if there are no matches in the V4 pool. If a V3 file matches, it is simply moved (renamed) the the V4 pool with it’s new filename based on the V4 digest. That still allows the V3 backups to be browsed etc, since those backups are still based on hardlinks.
If the file contents exactly match, a reference count is incremented. Otherwise, the file is added to the pool by using an atomic link operation, followed by unlinking the temporary file.
One other issue: zero length files are not pooled, since there are a lot of these files and on most file systems it doesn’t save any disk space to turn these files into hard links.
Prior to V4, each pool file is stored in a subdirectory X/Y/Z, where X, Y, Z are the first 3 hex digits of the MD5 digest.
For example, if a file has an MD5 digest of 123456789abcdef0123456789abcdef0, the file is stored in __TOPDIR__/pool/1/2/3/123456789abcdef0123456789abcdef0.
The MD5 digest might not be unique (especially since not all the file’s contents are used for files bigger than 256K). Different files that have the same MD5 digest are stored with a trailing suffix «_n» where n is an incrementing number starting at 0. So, for example, if two additional files were identical to the first, except the last byte was different, and assuming the file was larger than 1MB (so the MD5 digests are the same but the files are actually different), the three files would be stored as:
__TOPDIR__/pool/1/2/3/123456789abcdef0123456789abcdef0 __TOPDIR__/pool/1/2/3/123456789abcdef0123456789abcdef0_0 __TOPDIR__/pool/1/2/3/123456789abcdef0123456789abcdef0_1 - __TOPDIR__/cpool
-
All compressed files from PC backups are stored below __TOPDIR__/cpool. Its layout is the same as __TOPDIR__/pool, and the hashing function is the same (and, importantly, based on the uncompressed file, not the compressed file).
- __TOPDIR__/pc/$host
-
For each PC $host, all the backups for that PC are stored below the directory __TOPDIR__/pc/$host. This directory contains the following files:
- LOG
-
Current log file for this PC from BackupPC_dump.
- LOG.MMYYYY or LOG.MMYYYY.z
-
Last month’s log file. Log files are aged monthly and compressed (if compression is enabled), and old LOG files are deleted. In earlier versions of BackupPC these files used to have a suffix of 0, 1, ….
- XferERR or XferERR.z
-
Output from the transport program (ie: smbclient, tar, rsync or ftp) for the most recent failed backup.
- XferLOG or XferLOG.z
-
Output from the transport program (ie: smbclient, tar, rsync or ftp) for the current backup.
- nnn (an integer)
-
Backups are in directories numbered sequentially starting at 0. Below each backup directory are the inodes (in nnn/inode) and the reference counts for this backup are in nnn/refCnt.
- refCnt
-
The host’s reference count database is stored below the refCnt directory.
- XferLOG.nnn or XferLOG.nnn.z
-
Output from the transport program (ie: smbclient, tar, rsync or ftp) corresponding to backup number nnn.
- RestoreInfo.nnn
-
Information about restore request #nnn including who, what, when, and why. This file is in Data::Dumper format. (Note that the restore numbers are not related to the backup number.)
- RestoreLOG.nnn.z
-
Output from smbclient, tar or rsync during restore #nnn. (Note that the restore numbers are not related to the backup number.)
- ArchiveInfo.nnn
-
Information about archive request #nnn including who, what, when, and why. This file is in Data::Dumper format. (Note that the archive numbers are not related to the restore or backup number.)
- ArchiveLOG.nnn.z
-
Output from archive #nnn. (Note that the archive numbers are not related to the backup or restore number.)
- config.pl
-
Old location of optional configuration settings specific to this host. Settings in this file override the main configuration file. In new versions of BackupPC the per-host configuration files are stored in __CONFDIR__/pc/HOST.pl.
- backups
-
A tab-delimited ascii table listing information about each successful backup, one per row. The columns are:
- num
-
The backup number, an integer that starts at 0 and increments for each successive backup. The corresponding backup is stored in the directory num (eg: if this field is 5, then the backup is stored in __TOPDIR__/pc/$host/5).
- type
-
Set to «full» or «incr» for full or incremental backup.
- startTime
-
Start time of the backup in unix seconds.
- endTime
-
Stop time of the backup in unix seconds.
- nFiles
-
Number of files backed up (as reported by smbclient, tar, rsync or ftp).
- size
-
Total file size backed up (as reported by smbclient, tar, rsync or ftp).
- nFilesExist
-
Number of files that were already in the pool (as determined by BackupPC_dump).
- sizeExist
-
Total size of files that were already in the pool (as determined by BackupPC_dump).
- nFilesNew
-
Number of files that were not in the pool (as determined by BackupPC_dump).
- sizeNew
-
Total size of files that were not in the pool (as determined by BackupPC_dump).
- xferErrs
-
Number of errors or warnings from smbclient, tar, rsync or ftp.
- xferBadFile
-
Number of errors from smbclient that were bad file errors (zero otherwise).
- xferBadShare
-
Number of errors from smbclient that were bad share errors (zero otherwise).
- tarErrs
-
Number of errors from BackupPC_tarExtract.
- compress
-
The compression level used on this backup. Zero or empty means no compression.
- sizeExistComp
-
Total compressed size of files that were already in the pool (as determined by BackupPC_dump).
- sizeNewComp
-
Total compressed size of files that were not in the pool (as determined by BackupPC_dump).
- noFill
-
Set if this backup has not been filled — it just includes the deltas from the next backup necessary to reconstruct this backup.
- fillFromNum
-
If this backup was filled (ie: noFill is 0) then this is the number of the backup that it was filled from
- mangle
-
Set if this backup has mangled filenames and attributes. Always true for backups in v1.4.0 and above. False for all backups prior to v1.4.0.
- xferMethod
-
Set to the value of $Conf{XferMethod} when this dump was done.
- level
-
The level of this dump. A full dump is level 0. Currently incrementals are 1. In V4+ multi-level incrementals are no longer supported, so this is just a 0 or 1.
- charset
-
The client charset when this backup was made.
- version
-
The BackupPC version when this backup was made.
- inodeLast
-
The last inode number used in this backup.
- keep
-
If set this backup won’t be deleted.
- share2path
-
Saves the value of $Conf{ClientShareName2Path} via Data::Dumper (with some tabs, newlines and % characters replaced with %xx) so that the actual client path for each share can be displayed when browsing.
- restores
-
A tab-delimited ascii table listing information about each requested restore, one per row. The columns are:
- num
-
Restore number (matches the suffix of the RestoreInfo.nnn and RestoreLOG.nnn.z file), unrelated to the backup number.
- startTime
-
Start time of the restore in unix seconds.
- endTime
-
End time of the restore in unix seconds.
- result
-
Result (ok or failed).
- errorMsg
-
Error message if restore failed.
- nFiles
-
Number of files restored.
- size
-
Size in bytes of the restored files.
- tarCreateErrs
-
Number of errors from BackupPC_tarCreate during restore.
- xferErrs
-
Number of errors from smbclient, tar, rsync or ftp during restore.
- archives
-
A tab-delimited ascii table listing information about each requested archive, one per row. The columns are:
- num
-
Archive number (matches the suffix of the ArchiveInfo.nnn and ArchiveLOG.nnn.z file), unrelated to the backup or restore number.
- startTime
-
Start time of the restore in unix seconds.
- endTime
-
End time of the restore in unix seconds.
- result
-
Result (ok or failed).
- errorMsg
-
Error message if archive failed.
Compressed file format
The compressed file format is as generated by Compress::Zlib::deflate with one minor, but important, tweak. Since Compress::Zlib::inflate fully inflates its argument in memory, it could take large amounts of memory if it was inflating a highly compressed file. For example, a 200MB file of 0x0 bytes compresses to around 200K bytes. If Compress::Zlib::inflate was called with this single 200K buffer, it would need to allocate 200MB of memory to return the result.
BackupPC watches how efficiently a file is compressing. If a big file has very high compression (meaning it will use too much memory when it is inflated), BackupPC calls the flush() method, which gracefully completes the current compression. BackupPC then starts another deflate and simply appends the output file. So the BackupPC compressed file format is one or more concatenated deflations/flushes. The specific ratios that BackupPC uses is that if a 6MB chunk compresses to less than 64K then a flush will be done.
Back to the example of the 200MB file of 0x0 bytes. Adding flushes every 6MB adds only 200 or so bytes to the 200K output. So the storage cost of flushing is negligible.
To easily decompress a BackupPC compressed file, the script BackupPC_zcat can be found in __INSTALLDIR__/bin. For each filename argument it inflates the file and writes it to stdout.
Rsync checksum caching
Rsync checksum caching is not implemented in V4. That’s because a full backup with rsync in V4 uses client-side whole-file checksums during a full backup, meaning that the server doesn’t need to send block-level digests on every full backup.
The rest of this section applies to V3.
An incremental backup with rsync compares attributes on the client with the last full backup. Any files with identical attributes are skipped. In V3, a full backup with rsync sets the —ignore-times option, which causes every file to be examined independent of attributes.
Each file is examined by generating block checksums (default 2K blocks) on the receiving side (that’s the BackupPC side), sending those checksums to the client, where the remote rsync matches those checksums with the corresponding file. The matching blocks and new data is sent back, allowing the client file to be reassembled. A checksum for the entire file is sent to as an extra check the the reconstructed file is correct.
This results in significant disk IO and computation for BackupPC: every file in a full backup, or any file with non-matching attributes in an incremental backup, needs to be uncompressed, block checksums computed and sent. Then the receiving side reassembles the file and has to verify the whole-file checksum. Even if the file is identical, prior to 2.1.0, BackupPC had to read and uncompress the file twice, once to compute the block checksums and later to verify the whole-file checksum.
Filename mangling
Backup filenames are stored in «mangled» form. Each node of a path is preceded by «f» (mnemonic: file), and special characters (n, r, % and /) are URI-encoded as «%xx», where xx is the ascii character’s hex value. So c:/craig/example.txt is now stored as fc/fcraig/fexample.txt.
This was done mainly so metadata could be stored alongside the backup files without name collisions. In particular, the attributes for the files in a directory are stored in a file called «attrib», and mangling avoids filename collisions (I discarded the idea of having a duplicate directory tree for every backup just to store the attributes). Other metadata (eg: rsync checksums) could be stored in filenames preceded by, eg, «c». There are two other benefits to mangling: the share name might contain «/» (eg: «/home/craig» for tar transport), and I wanted that represented as a single level in the storage tree.
The CGI script undoes the mangling, so it is invisible to the user.
Special files
Linux/unix file systems support several special file types: symbolic links, character and block device files, fifos (pipes) and unix-domain sockets. All except unix-domain sockets are supported by BackupPC (there’s no point in backing up or restoring unix-domain sockets since they only have meaning after a process creates them). Symbolic links are stored as a plain file whose contents are the contents of the link (not the file it points to). This file is compressed and pooled like any normal file. Character and block device files are also stored as plain files, whose contents are two integers separated by a comma; the numbers are the major and minor device number. These files are compressed and pooled like any normal file. Fifo files are stored as empty plain files (which are not pooled since they have zero size). In all cases, the original file type is stored in the attrib file so it can be correctly restored.
Hardlinks are supported. In V4, file metadata include an inode number and a link count. Any file with more than one link points at the inode information stored below the backup directory in the inode directory. That directory contains a tree of up to 16K attrib files based on bits 10-23 of the inode number. In particular, the directory name uses bits 17-23, and the attrib filename includes bits 10-16. The key (index) in the attrib file is the hex inode number. The original file metadata’s link count might not be accurate; it’s more a flag (>1) for when to look up the inode information. The correct link count is stored in the inode.
In V3, hardlinks are stored in a similar manner to symlinks. When GNU tar first encounters a file with more than one link (ie: hardlinks) it dumps it as a regular file. When it sees the second and subsequent hardlinks to the same file, it dumps just the hardlink information. BackupPC correctly recognizes these hardlinks and stores them just like symlinks: a regular text file whose contents is the path of the file linked to. The CGI script will download the original file when you click on a hardlink.
Also, BackupPC_tarCreate has enough magic to re-create the hardlinks dynamically based on whether or not the original file and hardlinks are both included in the tar file. For example, imagine a/b/x is a hardlink to a/c/y. If you use BackupPC_tarCreate to restore directory a, then the tar file will include a/b/x as the original file and a/c/y will be a hardlink to a/b/x. If, instead you restore a/c, then the tar file will include a/c/y as the original file, not a hardlink.
Attribute file format
- V4 attrib files
-
The attribute file format is new in V4. Every backup directory contains an attrib file, which is zero length and its name includes the MD5 pool digest, eg:
attrib_33fe8f9ae2f5cedbea63b9d3ea767ac0The digest is used to look up the contents in the V4 cpool, eg:
__TOPDIR__/cpool/32/fe/33fe8f9ae2f5cedbea63b9d3ea767ac0For inode attrib files, bits 17-23 (XX in hex) of the inode number are used for the directory name, and the attrib filename includes bits 10-16 (YY in hex), so relative to the backup directory:
inode/XX/attribYY_33fe8f9ae2f5cedbea63b9d3ea767ac0An empty attrib file has the name «attrib_0» (or «attribYY_0» for inodes).
The attrib file starts with a magic number, followed by the concatenation of the following information for each file (all integers are stored in perl’s pack «w» format (variable length base 128)):
-
Filename length, followed by the filename
-
Count of extended attributes
-
The unix file type, mtime, mode, uid, gid, size, inode number, compress, number of links
-
MD5 digest length, followed by the digest contents
-
Each extended attribute (length of xattr name, length of xattr value, name, value)
-
- V3 attrib files
-
The unix attributes for the contents of a directory (all the files and directories in that directory) are stored in a file called attrib. There is a single attrib file for each directory in a backup. For example, if c:/craig contains a single file c:/craig/example.txt, that file would be stored as fc/fcraig/fexample.txt and there would be an attribute file in fc/fcraig/attrib (and also fc/attrib and ./attrib). The file fc/fcraig/attrib would contain a single entry containing the attributes for fc/fcraig/fexample.txt.
The attrib file starts with a magic number, followed by the concatenation of the following information for each file:
-
Filename length in perl’s pack «w» format (variable length base 128).
-
Filename.
-
The unix file type, mode, uid, gid and file size divided by 4GB and file size modulo 4GB (type mode uid gid sizeDiv4GB sizeMod4GB), in perl’s pack «w» format (variable length base 128).
-
The unix mtime (unix seconds) in perl’s pack «N» format (32 bit integer).
The attrib file is also compressed if compression is enabled. See the lib/BackupPC/Attrib.pm module for full details.
Attribute files are pooled just like normal backup files. This saves space if all the files in a directory have the same attributes across multiple backups, which is common.
-
Optimizations
BackupPC doesn’t care about the access time of files in the pool since it saves attribute metadata separate from the files. Since BackupPC mostly does reads from disk, maintaining the access time of files generates a lot of unnecessary disk writes. So, provided BackupPC has a dedicated data disk, you should consider mounting BackupPC’s data directory with the noatime (or, with Linux kernels >=2.6.20, relatime) attribute (see mount(1)).
Some Limitations
BackupPC isn’t perfect (but it is getting better). Please see http://backuppc.sourceforge.net/faq/limitations.html for a discussion of some of BackupPC’s limitations. (Note, this is old and we should move this to the Github Wiki.)
Security issues
Please see http://backuppc.sourceforge.net/faq/security.html for a discussion of some of various security issues. (Note, this is old and we should move this to the Github Wiki.)
Configuration File
The BackupPC configuration file resides in __CONFDIR__/config.pl. Optional per-PC configuration files reside in __CONFDIR__/pc/$host.pl (or __TOPDIR__/pc/$host/config.pl in non-FHS versions of BackupPC). This file can be used to override settings just for a particular PC.
Modifying the main configuration file
The configuration file is a perl script that is executed by BackupPC, so you should be careful to preserve the file syntax (punctuation, quotes etc) when you edit it. Specifically, preserving quotes means you should never use undef for configuration parameters that expect string values. An empty string (») should be used in this case. It is recommended that you use CVS, RCS or some other method of source control for changing config.pl.
BackupPC reads or re-reads the main configuration file and the hosts file in three cases:
-
Upon startup.
-
When BackupPC is sent a HUP (-1) signal. Assuming you installed the init.d script, you can also do this with «/etc/init.d/backuppc reload».
-
When the modification time of config.pl file changes. BackupPC checks the modification time once during each regular wakeup.
Whenever you change the configuration file you can either do a kill -HUP BackupPC_pid or simply wait until the next regular wakeup period.
Each time the configuration file is re-read a message is reported in the LOG file, so you can tail it (or view it via the CGI interface) to make sure your kill -HUP worked. Errors in parsing the configuration file are also reported in the LOG file.
The optional per-PC configuration file (__CONFDIR__/pc/$host.pl or __TOPDIR__/pc/$host/config.pl in non-FHS versions of BackupPC) is read whenever it is needed by BackupPC_dump, BackupPC_restore and others.
Configuration Parameters
The configuration parameters are divided into five general groups. The first group (general server configuration) provides general configuration for BackupPC. The next two groups describe what to backup, when to do it, and how long to keep it. The fourth group are settings for email reminders, and the final group contains settings for the CGI interface.
All configuration settings in the second through fifth groups can be overridden by the per-PC config.pl file.
General server configuration
- $Conf{ServerHost} = »;
-
Host name on which the BackupPC server is running.
- $Conf{ServerPort} = -1;
-
TCP port number on which the BackupPC server listens for and accepts connections. Normally this should be disabled (set to -1). The TCP port is only needed if apache runs on a different machine from BackupPC. In that case, set this to any spare port number over 1024 (eg: 2359). If you enable the TCP port, make sure you set $Conf{ServerMesgSecret} too!
- $Conf{ServerMesgSecret} = »;
-
Shared secret to make the TCP port secure. Set this to a hard to guess string if you enable the TCP port (ie: $Conf{ServerPort} > 0).
To avoid possible attacks via the TCP socket interface, every client message is protected by an MD5 digest. The MD5 digest includes four items: — a seed that is sent to the client when the connection opens — a sequence number that increments for each message — a shared secret that is stored in $Conf{ServerMesgSecret} — the message itself.
The message is sent in plain text preceded by the MD5 digest. A snooper can see the plain-text seed sent by BackupPC and plain-text message from the client, but cannot construct a valid MD5 digest since the secret $Conf{ServerMesgSecret} is unknown. A replay attack is not possible since the seed changes on a per-connection and per-message basis.
- $Conf{MyPath} = ‘/bin’;
-
PATH setting for BackupPC. An explicit value is necessary for taint mode. Value shouldn’t matter too much since all execs use explicit paths. However, taint mode in perl will complain if this directory is world writable.
- $Conf{UmaskMode} = 027;
-
Permission mask for directories and files created by BackupPC. Default value prevents any access from group other, and prevents group write.
- $Conf{WakeupSchedule} = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23];
-
Times at which we wake up, check all the PCs, and schedule necessary backups. Times are measured in hours since midnight local time. Can be fractional if necessary (eg: 4.25 means 4:15am).
If the hosts you are backing up are always connected to the network you might have only one or two wakeups each night. This will keep the backup activity after hours. On the other hand, if you are backing up laptops that are only intermittently connected to the network you will want to have frequent wakeups (eg: hourly) to maximize the chance that each laptop is backed up.
Examples:
$Conf{WakeupSchedule} = [22.5]; # once per day at 10:30 pm. $Conf{WakeupSchedule} = [2,4,6,8,10,12,14,16,18,20,22]; # every 2 hoursThe default value is every hour except midnight.
The first entry of $Conf{WakeupSchedule} is when BackupPC_nightly is run. You might want to re-arrange the entries in $Conf{WakeupSchedule} (they don’t have to be ascending) so that the first entry is when you want BackupPC_nightly to run (eg: when you don’t expect a lot of regular backups to run).
- $Conf{PoolV3Enabled} = 0;
-
If a V3 pool exists (ie: an upgrade) set this to 1. This causes the V3 pool to be checked for matches if there are no matches in the V4 pool.
For new installations, this should be set to 0.
- $Conf{MaxBackups} = 4;
-
Maximum number of simultaneous backups to run. If there are no user backup requests then this is the maximum number of simultaneous backups.
- $Conf{MaxUserBackups} = 4;
-
Additional number of simultaneous backups that users can run. As many as $Conf{MaxBackups} + $Conf{MaxUserBackups} requests can run at the same time.
- $Conf{MaxPendingCmds} = 15;
-
Maximum number of pending link commands. New backups will only be started if there are no more than $Conf{MaxPendingCmds} plus $Conf{MaxBackups} number of pending link commands, plus running jobs. This limit is to make sure BackupPC doesn’t fall too far behind in running BackupPC_link commands.
- $Conf{CmdQueueNice} = 10;
-
Nice level at which CmdQueue commands (eg: BackupPC_link and BackupPC_nightly) are run at.
- $Conf{MaxBackupPCNightlyJobs} = 2;
-
How many BackupPC_nightly processes to run in parallel.
Each night, at the first wakeup listed in $Conf{WakeupSchedule}, BackupPC_nightly is run. Its job is to remove unneeded files in the pool, ie: files that only have one link. To avoid race conditions, BackupPC_nightly and BackupPC_link cannot run at the same time. Starting in v3.0.0, BackupPC_nightly can run concurrently with backups (BackupPC_dump).
So to reduce the elapsed time, you might want to increase this setting to run several BackupPC_nightly processes in parallel (eg: 4, or even 8).
- $Conf{BackupPCNightlyPeriod} = 1;
-
How many days (runs) it takes BackupPC_nightly to traverse the entire pool. Normally this is 1, which means every night it runs, it does traverse the entire pool removing unused pool files.
Other valid values are 2, 4, 8, 16. This causes BackupPC_nightly to traverse 1/2, 1/4, 1/8 or 1/16th of the pool each night, meaning it takes 2, 4, 8 or 16 days to completely traverse the pool. The advantage is that each night the running time of BackupPC_nightly is reduced roughly in proportion, since the total job is split over multiple days. The disadvantage is that unused pool files take longer to get deleted, which will slightly increase disk usage.
Note that even when $Conf{BackupPCNightlyPeriod} > 1, BackupPC_nightly still runs every night. It just does less work each time it runs.
Examples:
$Conf{BackupPCNightlyPeriod} = 1; # entire pool is checked every night $Conf{BackupPCNightlyPeriod} = 2; # two days to complete pool check # (different half each night) $Conf{BackupPCNightlyPeriod} = 4; # four days to complete pool check # (different quarter each night) - $Conf{PoolSizeNightlyUpdatePeriod} = 16;
-
The total size of the files in the new V4 pool is updated every night when BackupPC_nightly runs BackupPC_refCountUpdate. Instead of adding up the size of every pool file, it just updates the pool size total when files are added to or removed from the pool.
To make sure these cumulative pool file sizes stay accurate, we recompute the V4 pool size for a portion of the pool each night from scratch, ie: by checking every file in that portion of the pool.
$Conf{PoolSizeNightlyUpdatePeriod} sets how many nights it takes to completely update the V4 pool size. It can be set to: 0: never do a full refresh; simply maintain the cumulative sizes when files are added or deleted (fastest option) 1: recompute all the V4 pool size every night (slowest option) 2: recompute 1/2 the V4 pool size every night 4: recompute 1/4 the V4 pool size every night 8: recompute 1/8 the V4 pool size every night 16: recompute 1/16 the V4 pool size every night (2nd fastest option; ensures the pool files sizes stay accurate after a few day, in case the relative upgrades miss a file)
- $Conf{PoolNightlyDigestCheckPercent} = 1;
-
Integrity check the pool files by confirming the md5 digest of the contents matches their file name. Because the pool is very large, only check a small random percentage of the pool files each night.
This is check if there has been any server file system corruption.
The default value of 1% means approximately 30% of the pool files will be checked each month, although the actual number will be a bit less since some files might be checked more than once in that time. If BackupPC_nightly takes too long, you could reduce this value.
- $Conf{RefCntFsck} = 1;
-
Reference counts of pool files are computed per backup by accumulating the relative changes. That means, however, that any error will never be corrected. To be more conservative, we do a periodic full-redo of the backup reference counts (called an «fsck»). $Conf{RefCntFsck} controls how often this is done:
0: no additional fsck 1: do an fsck on the last backup if it is from a full backup 2: do an fsck on the last two backups always 3: do a full fsck on all the backups$Conf{RefCntFsck} = 1 is the recommended setting.
- $Conf{MaxOldLogFiles} = 14;
-
Maximum number of log files we keep around in log directory. These files are aged nightly. A setting of 14 means the log directory will contain about 2 weeks of old log files, in particular at most the files LOG, LOG.0, LOG.1, … LOG.13 (except today’s LOG, these files will have a .z extension if compression is on).
If you decrease this number after BackupPC has been running for a while you will have to manually remove the older log files.
- $Conf{DfPath} = »;
-
Full path to the df command. Security caution: normal users should not allowed to write to this file or directory.
- $Conf{DfCmd} = ‘$dfPath $topDir’;
-
Command to run df. The following variables are substituted at run-time:
$dfPath path to df ($Conf{DfPath}) $topDir top-level BackupPC data directoryNote: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{DfInodeUsageCmd} = ‘$dfPath -i $topDir’;
-
Command to run df to get inode % usage. The following variables are substituted at run-time:
$dfPath path to df ($Conf{DfPath}) $topDir top-level BackupPC data directoryNote: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{SplitPath} = »;
- $Conf{ParPath} = »;
- $Conf{CatPath} = »;
- $Conf{GzipPath} = »;
- $Conf{Bzip2Path} = »;
-
Full path to various commands for archiving
- $Conf{DfMaxUsagePct} = 95;
-
Maximum threshold for disk utilization on the __TOPDIR__ filesystem. If the output from $Conf{DfCmd} reports a percentage larger than this number then no new regularly scheduled backups will be run. However, user requested backups (which are usually incremental and tend to be small) are still performed, independent of disk usage. Also, currently running backups will not be terminated when the disk usage exceeds this number.
- $Conf{DfMaxInodeUsagePct} = 95;
-
Maximum threshold for inode utilization on the __TOPDIR__ filesystem. If the output from $Conf{DfInodeUsageCmd} reports a percentage larger than this number then no new regularly scheduled backups will be run. However, user requested backups (which are usually incremental and tend to be small) are still performed, independent of disk usage. Also, currently running backups will not be terminated when the disk inode usage exceeds this number.
- $Conf{DHCPAddressRanges} = [];
-
List of DHCP address ranges we search looking for PCs to backup. This is an array of hashes for each class C address range. This is only needed if hosts in the conf/hosts file have the dhcp flag set.
Examples:
# to specify 192.10.10.20 to 192.10.10.250 as the DHCP address pool $Conf{DHCPAddressRanges} = [ { ipAddrBase => '192.10.10', first => 20, last => 250, }, ]; # to specify two pools (192.10.10.20-250 and 192.10.11.10-50) $Conf{DHCPAddressRanges} = [ { ipAddrBase => '192.10.10', first => 20, last => 250, }, { ipAddrBase => '192.10.11', first => 10, last => 50, }, ]; - $Conf{BackupPCUser} = »;
-
The BackupPC user.
- $Conf{TopDir} = »;
- $Conf{ConfDir} = »;
- $Conf{LogDir} = »;
- $Conf{RunDir} = »;
- $Conf{InstallDir} = »;
- $Conf{CgiDir} = »;
-
Important installation directories:
TopDir - where all the backup data is stored ConfDir - where the main config and hosts files resides LogDir - where log files and other transient information resides RunDir - where pid and sock files reside InstallDir - where the bin, lib and doc installation dirs reside. Note: you cannot change this value since all the perl scripts include this path. You must reinstall with configure.pl to change InstallDir. CgiDir - Apache CGI directory for BackupPC_AdminNote: it is STRONGLY recommended that you don’t change the values here. These are set at installation time and are here for reference and are used during upgrades.
Instead of changing TopDir here it is recommended that you use a symbolic link to the new location, or mount the new BackupPC store at the existing $Conf{TopDir} setting.
- $Conf{BackupPCUserVerify} = 1;
-
Whether BackupPC and the CGI script BackupPC_Admin verify that they are really running as user $Conf{BackupPCUser}. If this flag is set and the effective user id (euid) differs from $Conf{BackupPCUser} then both scripts exit with an error. This catches cases where BackupPC might be accidentally started as root or the wrong user, or if the CGI script is not installed correctly.
- $Conf{HardLinkMax} = 31999;
-
Maximum number of hardlinks supported by the $TopDir file system that BackupPC uses. Most linux or unix file systems should support at least 32000 hardlinks per file, or 64000 in other cases. If a pool file already has this number of hardlinks, a new pool file is created so that new hardlinks can be accommodated. This limit will only be hit if an identical file appears at least this number of times across all the backups.
- $Conf{PerlModuleLoad} = undef;
-
Advanced option for asking BackupPC to load additional perl modules. Can be a list (arrayref) of module names to load at startup.
- $Conf{ServerInitdPath} = »;
- $Conf{ServerInitdStartCmd} = »;
-
Path to init.d script and command to use that script to start the server from the CGI interface. The following variables are substituted at run-time:
$sshPath path to ssh ($Conf{SshPath}) $serverHost same as $Conf{ServerHost} $serverInitdPath path to init.d script ($Conf{ServerInitdPath})Example:
$Conf{ServerInitdPath} = ‘/etc/init.d/backuppc’; $Conf{ServerInitdStartCmd} = ‘$sshPath -q -x -l root $serverHost’ . ‘ $serverInitdPath start’ . ‘ < /dev/null >& /dev/null’;
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
What to backup and when to do it
- $Conf{FullPeriod} = 6.97;
-
Minimum period in days between full backups. A full dump will only be done if at least this much time has elapsed since the last full dump, and at least $Conf{IncrPeriod} days has elapsed since the last successful dump.
Typically this is set slightly less than an integer number of days. The time taken for the backup, plus the granularity of $Conf{WakeupSchedule} will make the actual backup interval a bit longer.
- $Conf{IncrPeriod} = 0.97;
-
Minimum period in days between incremental backups (a user requested incremental backup will be done anytime on demand).
Typically this is set slightly less than an integer number of days. The time taken for the backup, plus the granularity of $Conf{WakeupSchedule} will make the actual backup interval a bit longer.
- $Conf{FillCycle} = 0;
-
In V4+, full/incremental backups are decoupled from whether the stored backup is filled/unfilled.
To mimic V3 behaviour, if $Conf{FillCycle} is set to zero then fill/unfilled will continue to match full/incremental: full backups will remained filled, and incremental backups will be unfilled. (However, the most recent backup is always filled, whether it is full or incremental.) This is the recommended setting to keep things simple: since the backup expiry is actually done based on filled/unfilled (not full/incremental), keeping them synched makes it easier to understand the expiry settings.
If you plan to do incremental-only backups (ie: set FullPeriod to a very large value), then you should set $Conf{FillCycle} to how often you want a stored backup to be filled. For example, if $Conf{FillCycle} is set to 7, then every 7th backup will be filled (whether or not the corresponding backup was a full or not).
There are two reasons you will want a non-zero $Conf{FillCycle} setting when you are only doing incrementals:
- a filled backup is a starting point for merging deltas when you restore or view backups. So having periodic filled backups makes it more efficient to view or restore older backups. - more importantly, in V4+, deleting backups is done based on Fill/Unfilled, not whether the original backup was full/incremental. If there aren't any filled backups (other than the most recent), then the $Conf{FullKeepCnt} and related settings won't have any effect. - $Conf{FullKeepCnt} = 1;
-
Number of filled backups to keep. Must be >= 1.
The most recent backup (which is always filled) doesn’t count when checking $Conf{FullKeepCnt}. So if you specify $Conf{FullKeepCnt} = 1 then that means keep one full backup in addition to the most recent backup (which might be a filled incr or full).
Note: Starting in V4+, deleting backups is done based on Fill/Unfilled, not whether the original backup was full/incremental. For backward compatibility, these parameters continue to be called FullKeepCnt, rather than FilledKeepCnt. If $Conf{FillCycle} is 0, then full backups continue to be filled, so the terms are interchangeable. For V3 backups, the expiry settings have their original meanings.
In the steady state, each time a full backup completes successfully the oldest one is removed. If this number is decreased, the extra old backups will be removed.
Exponential backup expiry is also supported. This allows you to specify:
- num fulls to keep at intervals of 1 * $Conf{FillCycle}, followed by - num fulls to keep at intervals of 2 * $Conf{FillCycle}, - num fulls to keep at intervals of 4 * $Conf{FillCycle}, - num fulls to keep at intervals of 8 * $Conf{FillCycle}, - num fulls to keep at intervals of 16 * $Conf{FillCycle},and so on. This works by deleting every other full as each expiry boundary is crossed. Note: if $Conf{FillCycle} is 0, then $Conf{FullPeriod} is used instead in these calculations.
Exponential expiry is specified using an array for $Conf{FullKeepCnt}:
$Conf{FullKeepCnt} = [4, 2, 3];Entry #n specifies how many fulls to keep at an interval of 2^n * $Conf{FillCycle} (ie: 1, 2, 4, 8, 16, 32, …).
The example above specifies keeping 4 of the most recent full backups (1 week interval) two full backups at 2 week intervals, and 3 full backups at 4 week intervals, eg:
full 0 19 weeks old full 1 15 weeks old >--- 3 backups at 4 * $Conf{FillCycle} full 2 11 weeks old / full 3 7 weeks old ____ 2 backups at 2 * $Conf{FillCycle} full 4 5 weeks old / full 5 3 weeks old full 6 2 weeks old ___ 4 backups at 1 * $Conf{FillCycle} full 7 1 week old / full 8 current /On a given week the spacing might be less than shown as each backup ages through each expiry period. For example, one week later, a new full is completed and the oldest is deleted, giving:
full 0 16 weeks old full 1 12 weeks old >--- 3 backups at 4 * $Conf{FillCycle} full 2 8 weeks old / full 3 6 weeks old ____ 2 backups at 2 * $Conf{FillCycle} full 4 4 weeks old / full 5 3 weeks old full 6 2 weeks old ___ 4 backups at 1 * $Conf{FillCycle} full 7 1 week old / full 8 current /You can specify 0 as a count (except in the first entry), and the array can be as long as you wish. For example:
$Conf{FullKeepCnt} = [4, 0, 4, 0, 0, 2];This will keep 10 full dumps, 4 most recent at 1 * $Conf{FillCycle}, followed by 4 at an interval of 4 * $Conf{FillCycle} (approx 1 month apart), and then 2 at an interval of 32 * $Conf{FillCycle} (approx 7-8 months apart).
Example: these two settings are equivalent and both keep just the four most recent full dumps:
$Conf{FullKeepCnt} = 4; $Conf{FullKeepCnt} = [4]; - $Conf{FullKeepCntMin} = 1;
- $Conf{FullAgeMax} = 180;
-
Very old full backups are removed after $Conf{FullAgeMax} days. However, we keep at least $Conf{FullKeepCntMin} full backups no matter how old they are.
Note that $Conf{FullAgeMax} will be increased to $Conf{FullKeepCnt} times $Conf{FillCycle} if $Conf{FullKeepCnt} specifies enough full backups to exceed $Conf{FullAgeMax}.
- $Conf{IncrKeepCnt} = 6;
-
Number of incremental backups to keep. Must be >= 1.
Note: Starting in V4+, deleting backups is done based on Fill/Unfilled, not whether the original backup was full/incremental. For historical reasons these parameters continue to be called IncrKeepCnt, rather than UnfilledKeepCnt. If $Conf{FillCycle} is 0, then incremental backups continue to be unfilled, so the terms are interchangeable. For V3 backups, the expiry settings have their original meanings.
In the steady state, each time an incr backup completes successfully the oldest one is removed. If this number is decreased, the extra old backups will be removed.
- $Conf{IncrKeepCntMin} = 1;
- $Conf{IncrAgeMax} = 30;
-
Very old incremental backups are removed after $Conf{IncrAgeMax} days. However, we keep at least $Conf{IncrKeepCntMin} incremental backups no matter how old they are.
- $Conf{BackupsDisable} = 0;
-
Disable all full and incremental backups. These settings are useful for a client that is no longer being backed up (eg: a retired machine), but you wish to keep the last backups available for browsing or restoring to other machines.
There are three values for $Conf{BackupsDisable}:
0 Backups are enabled. 1 Don't do any regular backups on this client. Manually requested backups (via the CGI interface) will still occur. 2 Don't do any backups on this client. Manually requested backups (via the CGI interface) will be ignored.In versions prior to 3.0 Backups were disabled by setting $Conf{FullPeriod} to -1 or -2.
- $Conf{RestoreInfoKeepCnt} = 10;
-
Number of restore logs to keep. BackupPC remembers information about each restore request. This number per client will be kept around before the oldest ones are pruned.
Note: files/dirs delivered via Zip or Tar downloads don’t count as restores. Only the first restore option (where the files and dirs are written to the host) count as restores that are logged.
- $Conf{ArchiveInfoKeepCnt} = 10;
-
Number of archive logs to keep. BackupPC remembers information about each archive request. This number per archive client will be kept around before the oldest ones are pruned.
- $Conf{BackupFilesOnly} = undef;
-
List of directories or files to backup. If this is defined, only these directories or files will be backed up.
For Smb, only one of $Conf{BackupFilesExclude} and $Conf{BackupFilesOnly} can be specified per share. If both are set for a particular share, then $Conf{BackupFilesOnly} takes precedence and $Conf{BackupFilesExclude} is ignored.
This can be set to a string, an array of strings, or, in the case of multiple shares, a hash of strings or arrays. A hash is used to give a list of directories or files to backup for each share (the share name is the key). If this is set to just a string or array, and $Conf{SmbShareName} contains multiple share names, then the setting is assumed to apply all shares.
If a hash is used, a special key «*» means it applies to all shares that don’t have a specific entry.
Examples:
$Conf{BackupFilesOnly} = '/myFiles'; $Conf{BackupFilesOnly} = ['/myFiles']; # same as first example $Conf{BackupFilesOnly} = ['/myFiles', '/important']; $Conf{BackupFilesOnly} = { 'c' => ['/myFiles', '/important'], # these are for 'c' share 'd' => ['/moreFiles', '/archive'], # these are for 'd' share }; $Conf{BackupFilesOnly} = { 'c' => ['/myFiles', '/important'], # these are for 'c' share '*' => ['/myFiles', '/important'], # these are other shares }; - $Conf{BackupFilesExclude} = undef;
-
List of directories or files to exclude from the backup. For Smb, only one of $Conf{BackupFilesExclude} and $Conf{BackupFilesOnly} can be specified per share. If both are set for a particular share, then $Conf{BackupFilesOnly} takes precedence and $Conf{BackupFilesExclude} is ignored.
This can be set to a string, an array of strings, or, in the case of multiple shares, a hash of strings or arrays. A hash is used to give a list of directories or files to exclude for each share (the share name is the key). If this is set to just a string or array, and $Conf{SmbShareName} contains multiple share names, then the setting is assumed to apply to all shares.
The exact behavior is determined by the underlying transport program, smbclient or tar. For smbclient the exclude file list is passed into the X option. Simple shell wild-cards using «*» or «?» are allowed.
For tar, if the exclude file contains a «/» it is assumed to be anchored at the start of the string. Since all the tar paths start with «./», BackupPC prepends a «.» if the exclude file starts with a «/». Note that GNU tar version >= 1.13.7 is required for the exclude option to work correctly. For linux or unix machines you should add «/proc» to $Conf{BackupFilesExclude} unless you have specified —one-file-system in $Conf{TarClientCmd} or —one-file-system in $Conf{RsyncArgs}. Also, for tar, do not use a trailing «/» in the directory name: a trailing «/» causes the name to not match and the directory will not be excluded.
Users report that for smbclient you should specify a directory followed by «/*», eg: «/proc/*», instead of just «/proc».
FTP servers are traversed recursively so excluding directories will also exclude its contents. You can use the wildcard characters «*» and «?» to define files for inclusion and exclusion. Both attributes $Conf{BackupFilesOnly} and $Conf{BackupFilesExclude} can be defined for the same share.
If a hash is used, a special key «*» means it applies to all shares that don’t have a specific entry.
Examples:
$Conf{BackupFilesExclude} = '/temp'; $Conf{BackupFilesExclude} = ['/temp']; # same as first example $Conf{BackupFilesExclude} = ['/temp', '/winnt/tmp']; $Conf{BackupFilesExclude} = { 'c' => ['/temp', '/winnt/tmp'], # these are for 'c' share 'd' => ['/junk', '/dont_back_this_up'], # these are for 'd' share }; $Conf{BackupFilesExclude} = { 'c' => ['/temp', '/winnt/tmp'], # these are for 'c' share '*' => ['/junk', '/dont_back_this_up'], # these are for other shares }; - $Conf{BlackoutBadPingLimit} = 3;
- $Conf{BlackoutGoodCnt} = 7;
-
PCs that are always or often on the network can be backed up after hours, to reduce PC, network and server load during working hours. For each PC a count of consecutive good pings is maintained. Once a PC has at least $Conf{BlackoutGoodCnt} consecutive good pings it is subject to «blackout» and not backed up during hours and days specified by $Conf{BlackoutPeriods}.
To allow for periodic rebooting of a PC or other brief periods when a PC is not on the network, a number of consecutive bad pings is allowed before the good ping count is reset. This parameter is $Conf{BlackoutBadPingLimit}.
Note that bad and good pings don’t occur with the same interval. If a machine is always on the network, it will only be pinged roughly once every $Conf{IncrPeriod} (eg: once per day). So a setting for $Conf{BlackoutGoodCnt} of 7 means it will take around 7 days for a machine to be subject to blackout. On the other hand, if a ping is failed, it will be retried roughly every time BackupPC wakes up, eg, every one or two hours. So a setting for $Conf{BlackoutBadPingLimit} of 3 means that the PC will lose its blackout status after 3-6 hours of unavailability.
To disable the blackout feature set $Conf{BlackoutGoodCnt} to a negative value. A value of 0 will make all machines subject to blackout. But if you don’t want to do any backups during the day it would be easier to just set $Conf{WakeupSchedule} to a restricted schedule.
- $Conf{BlackoutPeriods} = [ … ];
-
One or more blackout periods can be specified. If a client is subject to blackout then no regular (non-manual) backups will be started during any of these periods. hourBegin and hourEnd specify hours from midnight and weekDays is a list of days of the week where 0 is Sunday, 1 is Monday etc.
For example:
$Conf{BlackoutPeriods} = [ { hourBegin => 7.0, hourEnd => 19.5, weekDays => [1, 2, 3, 4, 5], }, ];specifies one blackout period from 7:00am to 7:30pm local time on Mon-Fri.
The blackout period can also span midnight by setting hourBegin > hourEnd, eg:
$Conf{BlackoutPeriods} = [ { hourBegin => 7.0, hourEnd => 19.5, weekDays => [1, 2, 3, 4, 5], }, { hourBegin => 23, hourEnd => 5, weekDays => [5, 6], }, ];This specifies one blackout period from 7:00am to 7:30pm local time on Mon-Fri, and a second period from 11pm to 5am on Friday and Saturday night.
- $Conf{BackupZeroFilesIsFatal} = 1;
-
A backup of a share that has zero files is considered fatal. This is used to catch miscellaneous Xfer errors that result in no files being backed up. If you have shares that might be empty (and therefore an empty backup is valid) you should set this flag to 0.
How to backup a client
- $Conf{XferMethod} = ‘smb’;
-
What transport method to use to backup each host. If you have a mixed set of WinXX and linux/unix hosts you will need to override this in the per-PC config.pl.
The valid values are:
- 'smb': backup and restore via smbclient and the SMB protocol. Easiest choice for WinXX. - 'rsync': backup and restore via rsync (via rsh or ssh). Best choice for linux/unix. Good choice also for WinXX. - 'rsyncd': backup and restore via rsync daemon on the client. Best choice for linux/unix if you have rsyncd running on the client. Good choice also for WinXX. - 'tar': backup and restore via tar, tar over ssh, rsh or nfs. Good choice for linux/unix. - 'archive': host is a special archive host. Backups are not done. An archive host is used to archive other host's backups to permanent media, such as tape, CDR or DVD. - $Conf{XferLogLevel} = 1;
-
Level of verbosity in Xfer log files. 0 means be quiet, 1 will give one line per file, 2 will also show skipped files on incrementals, higher values give more output.
- $Conf{ClientCharset} = »;
-
Filename charset encoding on the client. BackupPC uses utf8 on the server for filename encoding. If this is empty, then utf8 is assumed and client filenames will not be modified. If set to a different encoding then filenames will converted to/from utf8 automatically during backup and restore.
If the filenames displayed in the browser (eg: accents or special characters) don’t look right then it is likely you haven’t set $Conf{ClientCharset} correctly.
If you are using smbclient on a WinXX machine, smbclient will convert to the «unix charset» setting in smb.conf. The default is utf8, in which case leave $Conf{ClientCharset} empty since smbclient does the right conversion.
If you are using rsync on a WinXX machine then it does no conversion. A typical WinXX encoding for latin1/western europe is ‘cp1252’, so in this case set $Conf{ClientCharset} to ‘cp1252’.
On a linux or unix client, run «locale charmap» to see the client’s charset. Set $Conf{ClientCharset} to this value. A typical value for english/US is ‘ISO-8859-1’.
Do «perldoc Encode::Supported» to see the list of possible charset values. The FAQ at http://www.cl.cam.ac.uk/~mgk25/unicode.html is excellent, and http://czyborra.com/charsets/iso8859.html provides more information on the iso-8859 charsets.
- $Conf{ClientCharsetLegacy} = ‘iso-8859-1’;
-
Prior to 3.x no charset conversion was done by BackupPC. Backups were stored in whatever charset the XferMethod provided — typically utf8 for smbclient and the client’s locale settings for rsync and tar (eg: cp1252 for rsync on WinXX and perhaps iso-8859-1 with rsync on linux). This setting tells BackupPC the charset that was used to store filenames in old backups taken with BackupPC 2.x, so that non-ascii filenames in old backups can be viewed and restored.
- $Conf{ClientShareName2Path} = {};
-
Optionally map the share name to a different path on the client when the xfer program is run. This can be used if you create a snapshot on the client, which has a different path to the real share name. Or you could use simpler names for the share instead of a path (eg: root, home, usr) and map them to the real paths here.
This should be a hash whose key is the share name used in $Conf{SmbShareName}, $Conf{TarShareName}, $Conf{RsyncShareName}, $Conf{FtpShareName}, and the value is the string path name on the client. When a backup or restore is done, if there is no matching entry in $Conf{ClientShareName2Path}, or the entry is empty, then the share name is not modified (so the default behavior is unchanged).
If you are using the rsyncd xfer method, then there is no need to use this configuration setting (since rsyncd already supports mapping of share names to paths in the client’s rsyncd.conf).
Samba Configuration
- $Conf{SmbShareName} = ‘C$’;
-
Name of the host share that is backed up when using SMB. This can be a string or an array of strings if there are multiple shares per host. Examples:
$Conf{SmbShareName} = 'c'; # backup 'c' share $Conf{SmbShareName} = ['c', 'd']; # backup 'c' and 'd' sharesThis setting only matters if $Conf{XferMethod} = ‘smb’.
- $Conf{SmbShareUserName} = »;
-
Smbclient share username. This is passed to smbclient’s -U argument.
This setting only matters if $Conf{XferMethod} = ‘smb’.
- $Conf{SmbSharePasswd} = »;
-
Smbclient share password. This is passed to smbclient via its PASSWD environment variable. There are several ways you can tell BackupPC the smb share password. In each case you should be very careful about security. If you put the password here, make sure that this file is not readable by regular users! See the «Setting up config.pl» section in the documentation for more information.
This setting only matters if $Conf{XferMethod} = ‘smb’.
- $Conf{SmbClientPath} = »;
-
Full path for smbclient. Security caution: normal users should not allowed to write to this file or directory.
smbclient is from the Samba distribution. smbclient is used to actually extract the incremental or full dump of the share filesystem from the PC.
This setting only matters if $Conf{XferMethod} = ‘smb’.
- $Conf{SmbClientFullCmd} = …
-
Command to run smbclient for a full dump. This setting only matters if $Conf{XferMethod} = ‘smb’.
The following variables are substituted at run-time:
$smbClientPath same as $Conf{SmbClientPath} $host host to backup/restore $hostIP host IP address $shareName share name $userName username $fileList list of files to backup (based on exclude/include) $I_option optional -I option to smbclient $X_option exclude option (if $fileList is an exclude list) $timeStampFile start time for incremental dumpNote: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{SmbClientIncrCmd} = …
-
Command to run smbclient for an incremental dump. This setting only matters if $Conf{XferMethod} = ‘smb’.
Same variable substitutions are applied as $Conf{SmbClientFullCmd}.
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{SmbClientRestoreCmd} = …
-
Command to run smbclient for a restore. This setting only matters if $Conf{XferMethod} = ‘smb’.
Same variable substitutions are applied as $Conf{SmbClientFullCmd}.
If your smb share is read-only then direct restores will fail. You should set $Conf{SmbClientRestoreCmd} to undef and the corresponding CGI restore option will be removed.
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
Tar Configuration
- $Conf{TarShareName} = ‘/’;
-
Which host directories to backup when using tar transport. This can be a string or an array of strings if there are multiple directories to backup per host. Examples:
$Conf{TarShareName} = '/'; # backup everything $Conf{TarShareName} = '/home'; # only backup /home $Conf{TarShareName} = ['/home', '/src']; # backup /home and /srcThe fact this parameter is called ‘TarShareName’ is for historical consistency with the Smb transport options. You can use any valid directory on the client: there is no need for it to correspond to any Smb share or device mount point.
Note also that you can also use $Conf{BackupFilesOnly} to specify a specific list of directories to backup. It’s more efficient to use this option instead of $Conf{TarShareName} since a new tar is run for each entry in $Conf{TarShareName}.
On the other hand, if you add —one-file-system to $Conf{TarClientCmd} you can backup each file system separately, which makes restoring one bad file system easier. In this case you would list all of the mount points here, since you can’t get the same result with $Conf{BackupFilesOnly}:
$Conf{TarShareName} = ['/', '/var', '/data', '/boot'];This setting only matters if $Conf{XferMethod} = ‘tar’.
- $Conf{TarClientCmd} = ‘$sshPath -q -x -n -l root $host env LC_ALL=C $tarPath -c -v -f — -C $shareName+ —totals’;
-
Command to run tar on the client. GNU tar is required. You will need to fill in the correct paths for ssh2 on the local host (server) and GNU tar on the client. Security caution: normal users should not allowed to write to these executable files or directories.
$Conf{TarClientCmd} is appended with with either $Conf{TarFullArgs} or $Conf{TarIncrArgs} to create the final command that is run.
See the documentation for more information about setting up ssh2 keys.
If you plan to use NFS then tar just runs locally and ssh2 is not needed. For example, assuming the client filesystem is mounted below /mnt/hostName, you could use something like:
$Conf{TarClientCmd} = '$tarPath -c -v -f - -C /mnt/$host/$shareName' . ' --totals';In the case of NFS or rsh you need to make sure BackupPC’s privileges are sufficient to read all the files you want to backup. Also, you will probably want to add «/proc» to $Conf{BackupFilesExclude}.
The following variables are substituted at run-time:
$host hostname $hostIP host's IP address $incrDate newer-than date for incremental backups $shareName share name to backup (ie: top-level directory path) $fileList specific files to backup or exclude $tarPath same as $Conf{TarClientPath} $sshPath same as $Conf{SshPath}If a variable is followed by a «+» it is shell escaped. This is necessary for the command part of ssh or rsh, since it ends up getting passed through the shell.
This setting only matters if $Conf{XferMethod} = ‘tar’.
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{TarFullArgs} = ‘$fileList+’;
-
Extra tar arguments for full backups. Several variables are substituted at run-time. See $Conf{TarClientCmd} for the list of variable substitutions.
If you are running tar locally (ie: without rsh or ssh) then remove the «+» so that the argument is no longer shell escaped.
This setting only matters if $Conf{XferMethod} = ‘tar’.
- $Conf{TarIncrArgs} = ‘—newer=$incrDate+ $fileList+’;
-
Extra tar arguments for incr backups. Several variables are substituted at run-time. See $Conf{TarClientCmd} for the list of variable substitutions.
Note that GNU tar has several methods for specifying incremental backups, including:
--newer-mtime $incrDate+ This causes a file to be included if the modification time is later than $incrDate (meaning its contents might have changed). But changes in the ownership or modes will not qualify the file to be included in an incremental. --newer=$incrDate+ This causes the file to be included if any attribute of the file is later than $incrDate, meaning either attributes or the modification time. This is the default method. Do not use --atime-preserve in $Conf{TarClientCmd} above, otherwise resetting the atime (access time) counts as an attribute change, meaning the file will always be included in each new incremental dump.If you are running tar locally (ie: without rsh or ssh) then remove the «+» so that the argument is no longer shell escaped.
This setting only matters if $Conf{XferMethod} = ‘tar’.
- $Conf{TarClientRestoreCmd} = …
-
Full command to run tar for restore on the client. GNU tar is required. This can be the same as $Conf{TarClientCmd}, with tar’s -c replaced by -x and ssh’s -n removed.
See $Conf{TarClientCmd} for full details.
This setting only matters if $Conf{XferMethod} = «tar».
If you want to disable direct restores using tar, you should set $Conf{TarClientRestoreCmd} to undef and the corresponding CGI restore option will be removed.
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{TarClientPath} = »;
-
Full path for tar on the client. Security caution: normal users should not allowed to write to this file or directory.
This setting only matters if $Conf{XferMethod} = ‘tar’.
Rsync/Rsyncd Configuration
- $Conf{RsyncClientPath} = »;
-
Path to rsync executable on the client. If it is set, it is passed to to rsync_bpc using the —rsync-path option. You can also add sudo, for example:
$Conf{RsyncClientPath} = 'sudo /usr/bin/rsync';For OSX laptop clients, you can use caffeinate to make sure the laptop stays awake during the backup, eg:
$Conf{RsyncClientPath} = '/usr/bin/sudo /usr/bin/caffeinate -ism /usr/bin/rsync';This setting only matters if $Conf{XferMethod} = ‘rsync’.
- $Conf{RsyncBackupPCPath} = «»;
-
Full path to rsync_bpc on the server. Rsync_bpc is the customized version of rsync that is used on the server for rsync and rsyncd transfers.
- $Conf{RsyncSshArgs} = [‘-e’, ‘$sshPath -l root’];
-
Ssh arguments for rsync to run ssh to connect to the client. Rather than permit root ssh on the client, it is more secure to just allow ssh via a low-privileged user, and use sudo in $Conf{RsyncClientPath}.
The setting should only have two entries: «-e» and everything else; don’t add additional array elements.
This setting only matters if $Conf{XferMethod} = ‘rsync’.
- $Conf{RsyncShareName} = ‘/’;
-
Share name to backup. For $Conf{XferMethod} = «rsync» this should be a file system path, eg ‘/’ or ‘/home’.
For $Conf{XferMethod} = «rsyncd» this should be the name of the module to backup (ie: the name from /etc/rsynd.conf).
This can also be a list of multiple file system paths or modules. For example, by adding —one-file-system to $Conf{RsyncArgs} you can backup each file system separately, which makes restoring one bad file system easier. In this case you would list all of the mount points:
$Conf{RsyncShareName} = ['/', '/var', '/data', '/boot']; - $Conf{RsyncdClientPort} = 873;
-
Rsync daemon port on the client, for $Conf{XferMethod} = «rsyncd».
- $Conf{RsyncdUserName} = »;
-
Rsync daemon username on client, for $Conf{XferMethod} = «rsyncd». The username and password are stored on the client in whatever file the «secrets file» parameter in rsyncd.conf points to (eg: /etc/rsyncd.secrets).
- $Conf{RsyncdPasswd} = »;
-
Rsync daemon username on client, for $Conf{XferMethod} = «rsyncd». The username and password are stored on the client in whatever file the «secrets file» parameter in rsyncd.conf points to (eg: /etc/rsyncd.secrets).
- $Conf{RsyncArgs} = [ … ];
-
Arguments to rsync for backup. Do not edit the first set unless you have a good understanding of rsync options.
-
Additional arguments added to RsyncArgs. This can be used in combination with $Conf{RsyncArgs} to allow customization of the rsync arguments on a part-client basis. The standard arguments go in $Conf{RsyncArgs} and $Conf{RsyncArgsExtra} can be set on a per-client basis.
Examples of additional arguments that should work are —exclude/—include, eg:
$Conf{RsyncArgsExtra} = [ '--exclude', '/proc', '--exclude', '*.tmp', '--acls', '--xattrs', ];Both $Conf{RsyncArgs} and $Conf{RsyncArgsExtra} are subject to the following variable substitutions:
$client client name being backed up $host hostname (could be different from client name if $Conf{ClientNameAlias} is set) $hostIP IP address of host $confDir configuration directory path $shareName share name being backed upThis allows settings of the form:
$Conf{RsyncArgsExtra} = [ '--exclude-from=$confDir/pc/$host.exclude', ]; -
Additional arguments for a full rsync or rsyncd backup.
The —checksum argument causes the client to send full-file checksum for every file (meaning the client reads every file and computes the checksum, which is sent with the file list). On the server, rsync_bpc will skip any files that have a matching full-file checksum, and size, mtime and number of hardlinks. Any file that has different attributes will be updating using the block rsync algorithm.
In V3, full backups applied the block rsync algorithm to every file, which is a lot slower but a bit more conservative. To get that behavior, replace —checksum with —ignore-times.
-
Additional arguments for an incremental rsync or rsyncd backup.
- $Conf{RsyncRestoreArgs} = [ … ];
-
Arguments to rsync for restore. Do not edit the first set unless you have a thorough understanding of how File::RsyncP works.
If you want to disable direct restores using rsync (eg: is the module is read-only), you should set $Conf{RsyncRestoreArgs} to undef and the corresponding CGI restore option will be removed.
$Conf{RsyncRestoreArgs} is subject to the following variable substitutions:
$client client name being backed up $host hostname (could be different from client name if $Conf{ClientNameAlias} is set) $hostIP IP address of host $confDir configuration directory pathNote: $Conf{RsyncArgsExtra} doesn’t apply to $Conf{RsyncRestoreArgs}.
-
Additional arguments for an rsync or rsyncd restore.
This makes it easy to have per-client arguments.
FTP Configuration
- $Conf{FtpShareName} = »;
-
Which host directories to backup when using FTP. This can be a string or an array of strings if there are multiple shares per host.
This value must be specified in one of two ways: either as a subdirectory of the ‘share root’ on the server, or as the absolute path of the directory.
In the following example, if the directory /home/username is the root share of the ftp server with the given username, the following two values will back up the same directory:
$Conf{FtpShareName} = 'www'; # www directory $Conf{FtpShareName} = '/home/username/www'; # same directoryPath resolution is not supported; i.e.; you may not have an ftp share path defined as ‘../otheruser’ or ‘~/games’.
Multiple shares may also be specified, as with other protocols: $Conf{FtpShareName} = [ 'www', 'bin', 'config' ];Note also that you can also use $Conf{BackupFilesOnly} to specify a specific list of directories to backup. It’s more efficient to use this option instead of $Conf{FtpShareName} since a new tar is run for each entry in $Conf{FtpShareName}.
This setting only matters if $Conf{XferMethod} = ‘ftp’.
- $Conf{FtpUserName} = »;
-
FTP username. This is used to log into the server.
This setting is used only if $Conf{XferMethod} = ‘ftp’.
- $Conf{FtpPasswd} = »;
-
FTP user password. This is used to log into the server.
This setting is used only if $Conf{XferMethod} = ‘ftp’.
- $Conf{FtpPassive} = 1;
-
Whether passive mode is used. The correct setting depends upon whether local or remote ports are accessible from the other machine, which is affected by any firewall or routers between the FTP server on the client and the BackupPC server.
This setting is used only if $Conf{XferMethod} = ‘ftp’.
- $Conf{FtpBlockSize} = 10240;
-
Transfer block size. This sets the size of the amounts of data in each frame. While undefined, this value takes the default value.
This setting is used only if $Conf{XferMethod} = ‘ftp’.
- $Conf{FtpPort} = 21;
-
The port of the ftp server. If undefined, 21 is used.
This setting is used only if $Conf{XferMethod} = ‘ftp’.
- $Conf{FtpTimeout} = 120;
-
Connection timeout for FTP. When undefined, the default is 120 seconds.
This setting is used only if $Conf{XferMethod} = ‘ftp’.
- $Conf{FtpFollowSymlinks} = 0;
-
Behaviour when BackupPC encounters symlinks on the FTP share.
Symlinks cannot be restored via FTP, so the desired behaviour will be different depending on the setup of the share. The default for this behavior is 1. Directory shares with more complicated directory structures should consider other protocols.
Archive Configuration
- $Conf{ArchiveDest} = ‘/tmp’;
-
Archive Destination
The Destination of the archive e.g. /tmp for file archive or /dev/nst0 for device archive
- $Conf{ArchiveComp} = ‘gzip’;
-
Archive Compression type
The valid values are:
- 'none': No Compression - 'gzip': Medium Compression. Recommended. - 'bzip2': High Compression but takes longer. - $Conf{ArchivePar} = 0;
-
Archive Parity Files
The amount of Parity data to generate, as a percentage of the archive size. Uses the command line par2 (par2cmdline) available from http://parchive.sourceforge.net
Only useful for file dumps.
Set to 0 to disable this feature.
- $Conf{ArchiveSplit} = 0;
-
Archive Size Split
Only for file archives. Splits the output into the specified size * 1,000,000. e.g. to split into 650,000,000 bytes, specify 650 below.
If the value is 0, or if $Conf{ArchiveDest} is an existing file or device (e.g. a streaming tape drive), this feature is disabled.
- $Conf{ArchiveClientCmd} = …
-
Archive Command
This is the command that is called to actually run the archive process for each host. The following variables are substituted at run-time:
$Installdir The installation directory of BackupPC $tarCreatePath The path to BackupPC_tarCreate $splitpath The path to the split program $parpath The path to the par2 program $host The host to archive $backupnumber The backup number of the host to archive $compression The path to the compression program $compext The extension assigned to the compression type $splitsize The number of bytes to split archives into $archiveloc The location to put the archive $parfile The amount of parity data to create (percentage)Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{SshPath} = »;
-
Full path for ssh. Security caution: normal users should not allowed to write to this file or directory.
- $Conf{NmbLookupPath} = »;
-
Full path for nmblookup. Security caution: normal users should not allowed to write to this file or directory.
nmblookup is from the Samba distribution. nmblookup is used to get the netbios name, necessary for DHCP hosts.
- $Conf{NmbLookupCmd} = ‘$nmbLookupPath -A $host’;
-
NmbLookup command. Given an IP address, does an nmblookup on that IP address. The following variables are substituted at run-time:
$nmbLookupPath path to nmblookup ($Conf{NmbLookupPath}) $host IP addressThis command is only used for DHCP hosts: given an IP address, this command should try to find its NetBios name.
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{NmbLookupFindHostCmd} = ‘$nmbLookupPath $host’;
-
NmbLookup command. Given a netbios name, finds that host by doing a NetBios lookup. Several variables are substituted at run-time:
$nmbLookupPath path to nmblookup ($Conf{NmbLookupPath}) $host NetBios nameIn some cases you might need to change the broadcast address, for example if nmblookup uses 192.168.255.255 by default and you find that doesn’t work, try 192.168.1.255 (or your equivalent class C address) using the -B option:
$Conf{NmbLookupFindHostCmd} = '$nmbLookupPath -B 192.168.1.255 $host';If you use a WINS server and your machines don’t respond to multicast NetBios requests you can use this (replace 1.2.3.4 with the IP address of your WINS server):
$Conf{NmbLookupFindHostCmd} = '$nmbLookupPath -R -U 1.2.3.4 $host';This is preferred over multicast since it minimizes network traffic.
Experiment manually for your site to see what form of nmblookup command works.
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{FixedIPNetBiosNameCheck} = 0;
-
For fixed IP address hosts, BackupPC_dump can also verify the netbios name to ensure it matches the hostname. An error is generated if they do not match. Typically this flag is off. But if you are going to transition a bunch of machines from fixed host addresses to DHCP, setting this flag is a great way to verify that the machines have their netbios name set correctly before turning on DHCP.
- $Conf{PingPath} = »;
-
Full path to the ping command. Security caution: normal users should not be allowed to write to this file or directory.
If you want to disable ping checking, set this to some program that exits with 0 status, eg:
$Conf{PingPath} = '/bin/echo'; - $Conf{Ping6Path} = »;
-
Like PingPath, but for IPv6. Security caution: normal users should not be allowed to write to this file or directory. In some environments, this is something like ‘/usr/bin/ping6’. In modern environments, the regular ping command can handle both IPv4 and IPv6. In the latter case, just set it to $Conf{PingPath}
If you want to disable ping checking for IPv6 hosts, set this to some program that exits with 0 status, eg:
$Conf{Ping6Path} = '/bin/echo'; - $Conf{PingCmd} = ‘$pingPath -c 1 $host’;
-
Ping command. The following variables are substituted at run-time:
$pingPath path to ping ($Conf{PingPath} or $Conf{Ping6Path}) depending on the address type of $host. $host hostnameWade Brown reports that on solaris 2.6 and 2.7 ping -s returns the wrong exit status (0 even on failure). Replace with «ping $host 1», which gets the correct exit status but we don’t get the round-trip time.
Note: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{PingMaxMsec} = 20;
-
Maximum round-trip ping time in milliseconds. This threshold is set to avoid backing up PCs that are remotely connected through WAN or dialup connections. The output from ping -s (assuming it is supported on your system) is used to check the round-trip packet time. On your local LAN round-trip times should be much less than 20msec. On most WAN or dialup connections the round-trip time will be typically more than 20msec. Tune if necessary.
- $Conf{CompressLevel} = 3;
-
Compression level to use on files. 0 means no compression. Compression levels can be from 1 (least cpu time, slightly worse compression) to 9 (most cpu time, slightly better compression). The recommended value is 3. Changing to 5, for example, will take maybe 20% more cpu time and will get another 2-3% additional compression. See the zlib documentation for more information about compression levels.
Changing compression on or off after backups have already been done will require both compressed and uncompressed pool files to be stored. This will increase the pool storage requirements, at least until all the old backups expire and are deleted.
It is ok to change the compression value (from one non-zero value to another non-zero value) after dumps are already done. Since BackupPC matches pool files by comparing the uncompressed versions, it will still correctly match new incoming files against existing pool files. The new compression level will take effect only for new files that are newly compressed and added to the pool.
If compression was off and you are enabling compression for the first time you can use the BackupPC_compressPool utility to compress the pool. This avoids having the pool grow to accommodate both compressed and uncompressed backups. See the documentation for more information.
- $Conf{ClientTimeout} = 72000;
-
Timeout in seconds when listening for the transport program’s (smbclient, tar etc) stdout. If no output is received during this time, then it is assumed that something has wedged during a backup, and the backup is terminated.
Note that stdout buffering combined with huge files being backed up could cause longish delays in the output from smbclient that BackupPC_dump sees, so in some cases you might want to increase this value.
For rsync, this is passed onto rsync_bpc using the —timeout argument, which is based on any I/O, so you could likely reduce this value.
- $Conf{MaxOldPerPCLogFiles} = 12;
-
Maximum number of log files we keep around in each PC’s directory (ie: pc/$host). These files are aged monthly. A setting of 12 means there will be at most the files LOG, LOG.0, LOG.1, … LOG.11 in the pc/$host directory (ie: about a year’s worth). (Except this month’s LOG, these files will have a .z extension if compression is on).
If you decrease this number after BackupPC has been running for a while you will have to manually remove the older log files.
- $Conf{DumpPreUserCmd} = undef;
- $Conf{DumpPostUserCmd} = undef;
- $Conf{DumpPreShareCmd} = undef;
- $Conf{DumpPostShareCmd} = undef;
- $Conf{RestorePreUserCmd} = undef;
- $Conf{RestorePostUserCmd} = undef;
- $Conf{ArchivePreUserCmd} = undef;
- $Conf{ArchivePostUserCmd} = undef;
-
Optional commands to run before and after dumps and restores, and also before and after each share of a dump.
Stdout from these commands will be written to the Xfer (or Restore) log file. One example of using these commands would be to shut down and restart a database server, dump a database to files for backup, or doing a snapshot of a share prior to a backup. Example:
$Conf{DumpPreUserCmd} = '$sshPath -q -x -l root $host /usr/bin/dumpMysql';The following variable substitutions are made at run time for $Conf{DumpPreUserCmd}, $Conf{DumpPostUserCmd}, $Conf{DumpPreShareCmd} and $Conf{DumpPostShareCmd}:
$type type of dump (incr or full) $xferOK 1 if the dump succeeded, 0 if it didn't $client client name being backed up $host hostname (could be different from client name if $Conf{ClientNameAlias} is set) $hostIP IP address of host $user username from the hosts file $moreUsers list of additional users from the hosts file $share the first share name (or current share for $Conf{DumpPreShareCmd} and $Conf{DumpPostShareCmd}) $shares list of all the share names $XferMethod value of $Conf{XferMethod} (eg: tar, rsync, smb) $sshPath value of $Conf{SshPath}, $cmdType set to DumpPreUserCmd or DumpPostUserCmdThe following variable substitutions are made at run time for $Conf{RestorePreUserCmd} and $Conf{RestorePostUserCmd}:
$client client name being backed up $xferOK 1 if the restore succeeded, 0 if it didn't $host hostname (could be different from client name if $Conf{ClientNameAlias} is set) $hostIP IP address of host $user username from the hosts file $moreUsers list of additional users from the hosts file $share the first share name $XferMethod value of $Conf{XferMethod} (eg: tar, rsync, smb) $sshPath value of $Conf{SshPath}, $type set to "restore" $bkupSrcHost hostname of the restore source $bkupSrcShare share name of the restore source $bkupSrcNum backup number of the restore source $pathHdrSrc common starting path of restore source $pathHdrDest common starting path of destination $fileList list of files being restored $cmdType set to RestorePreUserCmd or RestorePostUserCmdThe following variable substitutions are made at run time for $Conf{ArchivePreUserCmd} and $Conf{ArchivePostUserCmd}:
$client client name being backed up $xferOK 1 if the archive succeeded, 0 if it didn't $host Name of the archive host $user username from the hosts file $share the first share name $XferMethod value of $Conf{XferMethod} (eg: tar, rsync, smb) $HostList list of hosts being archived $BackupList list of backup numbers for the hosts being archived $archiveloc location where the archive is sent to $parfile amount of parity data being generated (percentage) $compression compression program being used (eg: cat, gzip, bzip2) $compext extension used for compression type (eg: raw, gz, bz2) $splitsize size of the files that the archive creates $sshPath value of $Conf{SshPath}, $type set to "archive" $cmdType set to ArchivePreUserCmd or ArchivePostUserCmdNote: all Cmds are executed directly without a shell, so the prog name needs to be a full path and you can’t include shell syntax like redirection and pipes; put that in a script if you need it.
- $Conf{UserCmdCheckStatus} = 0;
-
Whether the exit status of each PreUserCmd and PostUserCmd is checked.
If set and the Dump/Restore/Archive Pre/Post UserCmd returns a non-zero exit status then the dump/restore/archive is aborted. To maintain backward compatibility (where the exit status in early versions was always ignored), this flag defaults to 0.
If this flag is set and the Dump/Restore/Archive PreUserCmd fails then the matching Dump/Restore/Archive PostUserCmd is not executed. If DumpPreShareCmd returns a non-exit status, then DumpPostShareCmd is not executed, but the DumpPostUserCmd is still run (since DumpPreUserCmd must have previously succeeded).
An example of a DumpPreUserCmd that might fail is a script that snapshots or dumps a database which fails because of some database error.
- $Conf{ClientNameAlias} = undef;
-
Override the client’s hostname. This allows multiple clients to all refer to the same physical host. This should only be set in the per-PC config file and is only used by BackupPC at the last moment prior to checking the host is alive, and generating the command used to backup # that machine (ie: the value of $Conf{ClientNameAlias} is invisible everywhere else in BackupPC). The setting can be a hostname or IP address, eg:
$Conf{ClientNameAlias} = 'realHostName'; $Conf{ClientNameAlias} = '192.1.1.15';which will cause the relevant smb/tar/rsync backup/restore commands to be directed to realHostName or the IP address, not the client name.
It can also be an array, to allow checking (in order) of several host names or IP addresses that refer to the same host. For example, if your client has a wired and wireless connection you could set:
$Conf{ClientNameAlias} = ['hostname-lan', 'hostname-wifi'];If hostname-lan is alive, it will be used for the backup/restore. If not, the next name (hostname-wifi) is tested.
Note: this setting doesn’t work for hosts with DHCP set to 1.
-
A user-settable comment string that is displayed in this host’s status. The value is otherwise ignored by BackupPC.
Email reminders, status and messages
- $Conf{SendmailPath} = »;
-
Full path to the sendmail command. Security caution: normal users should not allowed to write to this file or directory.
- $Conf{EMailNotifyMinDays} = 2.5;
-
Minimum period between consecutive emails to a single user. This tries to keep annoying email to users to a reasonable level. Email checks are done nightly, so this number is effectively rounded up (ie: 2.5 means a user will never receive email more than once every 3 days).
- $Conf{EMailFromUserName} = »;
-
Name to use as the «from» name for email. Depending upon your mail handler this is either a plain name (eg: «admin») or a fully-qualified name (eg: «admin@mydomain.com»).
- $Conf{EMailAdminUserName} = »;
-
Destination address to an administrative user who will receive a nightly email with warnings and errors. If there are no warnings or errors then no email will be sent. Depending upon your mail handler this is either a plain name (eg: «admin») or a fully-qualified name (eg: «admin@mydomain.com»).
- $Conf{EMailAdminSubject} = »;
-
Subject for admin emails. If empty, defaults to pre-4.2.2 values.
- $Conf{EMailUserDestDomain} = »;
-
Destination domain name for email sent to users. By default this is empty, meaning email is sent to plain, unqualified addresses. Otherwise, set it to the destination domain, eg:
$Cong{EMailUserDestDomain} = '@mydomain.com';With this setting user email will be set to ‘user@mydomain.com’.
- $Conf{EMailNoBackupEverSubj} = undef;
- $Conf{EMailNoBackupEverMesg} = undef;
-
This subject and message is sent to a user if their PC has never been backed up.
These values are language-dependent. The default versions can be found in the language file (eg: lib/BackupPC/Lang/en.pm). If you need to change the message, copy it here and edit it, eg:
$Conf{EMailNoBackupEverMesg} = <<'EOF'; To: $user$domain cc: Subject: $subj Dear $userName, This is a site-specific email message. EOF - $Conf{EMailNotifyOldBackupDays} = 7.0;
-
How old the most recent backup has to be before notifying user. When there have been no backups in this number of days the user is sent an email.
- $Conf{EMailNoBackupRecentSubj} = undef;
- $Conf{EMailNoBackupRecentMesg} = undef;
-
This subject and message is sent to a user if their PC has not recently been backed up (ie: more than $Conf{EMailNotifyOldBackupDays} days ago).
These values are language-dependent. The default versions can be found in the language file (eg: lib/BackupPC/Lang/en.pm). If you need to change the message, copy it here and edit it, eg:
$Conf{EMailNoBackupRecentMesg} = <<'EOF'; To: $user$domain cc: Subject: $subj Dear $userName, This is a site-specific email message. EOF - $Conf{EMailNotifyOldOutlookDays} = 5.0;
-
How old the most recent backup of Outlook files has to be before notifying user.
- $Conf{EMailOutlookBackupSubj} = undef;
- $Conf{EMailOutlookBackupMesg} = undef;
-
This subject and message is sent to a user if their Outlook files have not recently been backed up (ie: more than $Conf{EMailNotifyOldOutlookDays} days ago).
These values are language-dependent. The default versions can be found in the language file (eg: lib/BackupPC/Lang/en.pm). If you need to change the message, copy it here and edit it, eg:
$Conf{EMailOutlookBackupMesg} = <<'EOF'; To: $user$domain cc: Subject: $subj Dear $userName, This is a site-specific email message. EOF -
Additional email headers. This sets to charset to utf8.
CGI user interface configuration settings
- $Conf{CgiAdminUserGroup} = »;
- $Conf{CgiAdminUsers} = »;
-
Normal users can only access information specific to their host. They can start/stop/browse/restore backups.
Administrative users have full access to all hosts, plus overall status and log information.
The administrative users are the union of the list of unix/linux groups, separated by spaces, in $Conf{CgiAdminUserGroup} and the list of users, separated by spaces, in $Conf{CgiAdminUsers}. If you don’t want a list of groups or users set the corresponding configuration setting to undef or an empty string.
If you want every user to have admin privileges (careful!), set $Conf{CgiAdminUsers} = ‘*’.
Examples:
$Conf{CgiAdminUserGroup} = 'admin wheel'; $Conf{CgiAdminUsers} = 'craig celia'; --> administrative users are the union of groups admin and wheel, plus craig and celia. $Conf{CgiAdminUserGroup} = ''; $Conf{CgiAdminUsers} = 'craig celia'; --> administrative users are only craig and celia'. - $Conf{SCGIServerPort} = -1;
-
TCP port number of the SCGI server. A negative value disables the SCGI server. Set to any available unprivileged TCP port number, eg: 10268. Apache needs the mod_scgi module installed, and you will need to set the same port number in the Apache configuration. Here are some typical settings you’ll need in Apache’s httpd.conf:
LoadModule scgi_module modules/mod_scgi.so SCGIMount /BackupPC_Admin 127.0.0.1:10268 <Location /BackupPC_Admin> AuthUserFile /etc/httpd/conf/passwd AuthType basic AuthName "access" require valid-user </Location>Important security warning!! The SCGIServerPort must not be accessible by anyone untrusted. That means you can’t allow untrusted users access to the BackupPC server, and you should block the SCGIServerPort TCP port on the BackupPC server. If you don’t understand what that means, or can’t confirm you have configured SCGI securely, then don’t enable it!!
- $Conf{CgiURL} = »;
-
Full URL of the BackupPC_Admin CGI script, or the configured path for SCGI. Used for links in email messages.
- $Conf{RrdToolPath} = »;
-
Full path to the rrdtool command. If available, graphs of pool usage will be generated. If empty, then the graphs will be skipped.
Security caution: normal users should not allowed to write to this file or directory.
- $Conf{Language} = ‘en’;
-
Language to use. See lib/BackupPC/Lang for the list of supported languages, which include English (en), French (fr), Spanish (es), German (de), Italian (it), Dutch (nl), Polish (pl), Portuguese Brazilian (pt_br) and Chinese (zh_CN).
Currently the Language setting applies to the CGI interface and email messages sent to users. Log files and other text are still in English.
- $Conf{CgiUserHomePageCheck} = »;
- $Conf{CgiUserUrlCreate} = ‘mailto:%s’;
-
User names that are rendered by the CGI interface can be turned into links into their home page or other information about the user. To set this up you need to create two sprintf() strings, that each contain a single ‘%s’ that will be replaced by the user name. The default is a mailto: link.
$Conf{CgiUserHomePageCheck} should be an absolute file path that is used to check (via «-f») that the user has a valid home page. Set this to undef or an empty string to turn off this check.
$Conf{CgiUserUrlCreate} should be a full URL that points to the user’s home page. Set this to undef or an empty string to turn off generation of URLs for usernames.
Example:
$Conf{CgiUserHomePageCheck} = '/var/www/html/users/%s.html'; $Conf{CgiUserUrlCreate} = 'http://myhost/users/%s.html'; --> if /var/www/html/users/craig.html exists, then 'craig' will be rendered as a link to http://myhost/users/craig.html. - $Conf{CgiDateFormatMMDD} = 2;
-
Date display format for CGI interface. A value of 1 uses US-style dates (MM/DD), a value of 2 uses full YYYY-MM-DD format, and zero for international dates (DD/MM).
- $Conf{CgiNavBarAdminAllHosts} = 1;
-
If set, the complete list of hosts appears in the left navigation bar pull-down for administrators. Otherwise, just the hosts for which the user is listed in the host file (as either the user or in moreUsers) are displayed.
- $Conf{CgiSearchBoxEnable} = 1;
-
Enable/disable the search box in the navigation bar.
- $Conf{CgiNavBarLinks} = [ … ];
-
Additional navigation bar links. These appear for both regular users and administrators. This is a list of hashes giving the link (URL) and the text (name) for the link. Specifying lname instead of name uses the language specific string (ie: $Lang->{lname}) instead of just literally displaying name.
- $Conf{CgiStatusHilightColor} = { …
-
Highlight colors based on status that are used in the PC summary page.
-
Additional CGI header text.
- $Conf{CgiImageDir} = »;
-
Directory where images are stored. This directory should be below Apache’s DocumentRoot. This value isn’t used by BackupPC but is used by configure.pl when you upgrade BackupPC.
Example:
$Conf{CgiImageDir} = '/var/www/htdocs/BackupPC'; - $Conf{CgiExt2ContentType} = {};
-
Additional mappings of filename extensions to Content-Type for individual file restore. See $Ext2ContentType in BackupPC_Admin for the default setting. You can add additional settings here, or override any default settings. Example:
$Conf{CgiExt2ContentType} = { 'pl' => 'text/plain', }; - $Conf{CgiImageDirURL} = »;
-
URL (without the leading http://host) for BackupPC’s image directory. The CGI script uses this value to serve up image files.
Example:
$Conf{CgiImageDirURL} = '/BackupPC'; - $Conf{CgiCSSFile} = ‘BackupPC_stnd.css’;
-
CSS stylesheet «skin» for the CGI interface. It is stored in the $Conf{CgiImageDir} directory and accessed via the $Conf{CgiImageDirURL} URL.
For BackupPC v3 and v2 the prior css versions are available as BackupPC_retro_v3.css and BackupPC_retro_v2.css
- $Conf{CgiUserDeleteBackupEnable} = 0;
-
Whether the user is allowed to delete backups. If set to a positive value, the user will have a delete button for each backup on any host they have permission to access. If set to 0, only administrators have access to the backup delete feature. If set to a negative value, even admins will not be able to use the delete feature.
- $Conf{CgiUserConfigEditEnable} = 1;
-
Whether the user is allowed to edit their per-PC config.
- $Conf{CgiUserConfigEdit} = { …
-
Which per-host config variables a non-admin user is allowed to edit. Admin users can edit all per-host config variables, even if disabled in this list.
SECURITY WARNING: Do not let users edit any of the Cmd config variables! That’s because a user could set a Cmd to a shell script of their choice and it will be run as the BackupPC user. That script could do all sorts of bad things.
Version Numbers
BackupPC uses a X.Y.Z version numbering system. The first digit is for major new releases, the middle digit is for significant feature releases and improvements (most of the releases have been in this category).
Craig Barratt <cbarratt@users.sourceforge.net>
See https://backuppc.github.io/backuppc/BackupPC.html.
Copyright
Copyright (C) 2001-2020 Craig Barratt
Credits
Ryan Kucera contributed the directory navigation code and images for v1.5.0. He contributed the first skeleton of BackupPC_restore. He also added a significant revision to the CGI interface, including CSS tags, in v2.1.0, and designed the BackupPC logo.
Xavier Nicollet, with additions from Guillaume Filion, added the internationalization (i18n) support to the CGI interface for v2.0.0. Xavier provided the French translation fr.pm, with additions from Guillaume.
Guillaume Filion wrote BackupPC_zipCreate and added the CGI support for zip download, in addition to some CGI cleanup, for v1.5.0. Guillaume continues to support fr.pm updates for each new version.
Josh Marshall implemented the Archive feature in v2.1.0.
Ludovic Drolez supports the BackupPC Debian package.
Javier Gonzalez provided the Spanish translation, es.pm for v2.0.0.
Manfred Herrmann provided the German translation, de.pm for v2.0.0. Manfred continues to support de.pm updates for each new version, together with some help from Ralph Paßgang.
Lorenzo Cappelletti provided the Italian translation, it.pm for v2.1.0. Giuseppe Iuculano and Vittorio Macchi updated it for 3.0.0.
Lieven Bridts provided the Dutch translation, nl.pm, for v2.1.0, with some tweaks from Guus Houtzager, and updates for 3.0.0.
Reginaldo Ferreira provided the Portuguese Brazilian translation pt_br.pm for v2.2.0.
Rich Duzenbury provided the RSS feed option to the CGI interface.
Jono Woodhouse from CapeSoft Software (www.capesoft.com) provided a new CSS skin for 3.0.0 with several layout improvements. Sean Cameron (also from CapeSoft) designed new and more compact file icons for 3.0.0.
Youlin Feng provided the Chinese translation for 3.1.0.
Karol ‘Semper’ Stelmaczonek provided the Polish translation for 3.1.0.
Jeremy Tietsort provided the host summary table sorting feature for 3.1.0.
Paul Mantz contributed the ftp Xfer method for 3.2.0.
Petr Pokorny provided the Czech translation for 3.2.1.
Rikiya Yamamoto provided the Japanese translation for 3.3.0.
Yakim provided the Ukrainian translation for 3.3.0.
Sergei Butakov provided the Russian translation for 3.3.0.
Alexander Moisseev provided the rrdtool graphing code in 4.0.0 and has provided many fixes and improvements in 3.x and 4.x.
Many people have provided user support on the mail lists, reported bugs, made useful suggestions, and helped with testing; see the ChangeLog and the mailing lists.
Your name could appear here in the next version!
License
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program. If not, see <http://www.gnu.org/licenses/>.
BackupPC is a high-performance enterprise-grade cross-platform backup software suite with a web-based frontend. It can be used for backing up Linux, Windows and Mac OSXs PCs and laptops to a server’s disk. In this guide, we are going to learn how to install and setup BackupPC Server on Ubuntu 20.04.
BackupPC provides quite a number of features;
- Provides a web interface which allows administrators to view log files, configuration, current status and allows users to initiate and cancel backups and browse and restore files from backups.
- It supports Data deduplication: Identical files across multiple backups of the same or different PCs are stored only once resulting in substantial savings in disk storage and disk I/O.
- It supports data Compression: Since only new files (not already pooled) need to be compressed, there is only a modest impact on CPU time.
- It is Open-source: BackupPC is hosted on Github, and is distributed under a GPL license.
- No client-side software is needed.
- A full set of restore options is supported, including direct restore (via smbclient, tar, or rsync/rsyncd) or downloading a zip or tar file.
Read more on About BackupPC page.
Update System packages
To begin with, ensure that your system packages are up-to-date.
apt updateapt upgradeInstall BackupPC on Ubuntu 20.04
As of this writing, BackupPC 4.3.2 is the latest stable release version. Unfortunately, the default Ubuntu 20.04 repos provides BackupPC 3.3.2;
apt show backuppcPackage: backuppc
Version: 3.3.2-3
Priority: optional
Section: utils
Origin: Ubuntu
Maintainer: Ubuntu Developers <[email protected]>
Original-Maintainer: Debian BackupPC Team <[email protected]>
Bugs: https://bugs.launchpad.net/ubuntu/+filebug
Installed-Size: 2,314 kB
...
Homepage: https://backuppc.github.io/backuppc/
Download-Size: 460 kB
APT-Sources: http://ke.archive.ubuntu.com/ubuntu focal/main amd64 PackagesAs such, we are going to build BackupPC 4 on Ubuntu 20.04 from source.
Install Required Dependencies
apt install apache2 apache2-utils libapache2-mod-perl2 par2 perl smbclient rsync tar gcc zlib1g zlib1g-dev rrdtool git make perl-doc libnss-winbind winbind libarchive-zip-perl libfile-listing-perl libxml-rss-perl libcgi-session-perl libacl1-dev curl -yCreate BackupPC User
BackupPC is usually run by a low privileged backuppc user with /var/lib/backuppc as the working directory. As such, create a backuppc system user by executing the command below;
useradd -r -m -d /var/lib/backuppc -s /bin/bash -c "BackupPC user" backuppcBuild and Install BackupPC XS
BackupPC V4+ requires BackupPC XS, a perl module that implements various BackupPC functions in a perl-callable module.
Download BackupPC XS source code;
git clone https://github.com/backuppc/backuppc-xs.gitBuild and install BackupPC XS;
cd backuppc-xs/To install this module, run the following commands:
perl Makefile.PLmakeRun the make test to verify the correctness of the compilation of the module;
make testIf everything is in order, the result should be pass;
t/BackupPC_XS.t .. ok
All tests successful.
Files=1, Tests=1, 0 wallclock secs ( 0.00 usr 0.04 sys + 0.07 cusr 0.03 csys = 0.14 CPU)
Result: PASSInstall BackupPC XS module;
make installThere are other optional but highly RECOMMENDED modules that have been installed on the requirements section above.
Install BackupPC rsync_bpc
In order to be able to backup clients using rsync command, you need rsync_bpc module installed. Rsync-bpc is a customized version of rsync that is used as part of BackupPC.
Download rsync_bpc source code;
cd ~git clone https://github.com/backuppc/rsync-bpc.gitCompile and install the rsync_bpc module;
cd rsync-bpc./configureThis configures rsync_bpc with the default options. You can check other configuration options with the command, ./configure --help.
Compile and install rsync_bpc;
makemake installInstall BackupPC on Ubuntu 20.04
Once all the above is done, you can now install BackupPC itself. Download the source code cloning the Github repository;
cd ~git clone https://github.com/backuppc/backuppc.gitNavigate to backup source directory;
cd backuppcGenerate the latest release BackupPC tarball from the source file and BackupPC build tools;
VER=`curl --silent "https://api.github.com/repos/backuppc/backuppc/releases/latest" | grep '"tag_name":' | sed -E 's/.*"([^"]+)".*/\1/'`./makeDist --nosyntaxCheck --releasedate 'date -u "+%d %b %Y"' --version $VERThis creates BackupPC tarball and store it under distr directory in the current working directory as, for example, dist/BackupPC-4.3.2.tar.gz, for the current stable release (as of this writing).
Extract the source code;
tar zxf dist/BackupPC-*.tar.gzBuild and install and setup BackupPC server on Ubuntu 20.04;
cd BackupPC-*perl configure.plThe script when executed in this way, will run interactively. Answer the prompts accordingly. Press ENTER to accept the defaults.
Is this a new installation or upgrade for BackupPC? If this is
an upgrade please tell me the full path of the existing BackupPC
configuration file (eg: /etc/BackupPC/config.pl). Otherwise, just
hit return.
--> Full path to existing main config.pl []?
I found the following locations for these programs:
bzip2 => /usr/bin/bzip2
cat => /usr/bin/cat
df => /usr/bin/df
gtar/tar => /usr/bin/tar
gzip => /usr/bin/gzip
hostname => /usr/bin/hostname
nmblookup => /usr/bin/nmblookup
par2 => /usr/bin/par2
perl => /usr/bin/perl
ping => /usr/bin/ping
ping6 => /usr/bin/ping6
rrdtool => /usr/bin/rrdtool
rsync => /usr/bin/rsync
rsync_bpc => /usr/local/bin/rsync_bpc
sendmail =>
smbclient => /usr/bin/smbclient
split => /usr/bin/split
ssh/ssh2 => /usr/bin/ssh
--> Are these paths correct? [y]? y
Please tell me the hostname of the machine that BackupPC will run on.
--> BackupPC will run on host [ubuntu20]?
BackupPC should run as a dedicated user with limited privileges. You
need to create a user. This user will need read/write permission on
the main data directory and read/execute permission on the install
directory (these directories will be setup shortly).
The primary group for this user should also be chosen carefully.
The data directories and files will have group read permission,
so group members can access backup files.
--> BackupPC should run as user [backuppc]?
Please specify an install directory for BackupPC. This is where the
BackupPC scripts, library and documentation will be installed.
--> Install directory (full path) [/usr/local/BackupPC]?
Please specify a data directory for BackupPC. This is where all the
PC backup data is stored. This file system needs to be big enough to
accommodate all the PCs you expect to backup (eg: at least several GB
per machine).
--> Data directory (full path) [/data/BackupPC]? /var/lib/backuppc
BackupPC has SCGI and CGI perl interfaces that run under Apache. You need
to pick which one to run.
...
The traditional alternative is to use CGI. In this case, an executable needs
to be installed Apache's cgi-bin directory. This executable needs to run as
set-uid backuppc, or it can be run under mod_perl with Apache
running as user backuppc.
--> SCGI port (-1 to disable) [-1]?
--> CGI bin directory (full path, or empty for no CGI) []? /var/www/cgi-bin/BackupPC
BackupPC's CGI and SCGI script need to display various PNG/GIF
images that should be stored where Apache can serve them. They
should be placed somewhere under Apache's DocumentRoot. BackupPC
also needs to know the URL to access these images. Example:
Apache image directory: /var/www/htdocs/BackupPC
URL for image directory: /BackupPC
The URL for the image directory should start with a slash.
--> Apache image directory (full path, or empty for no S/CGI) []? /var/www/html/BackupPC
--> URL for image directory (omit http://host; starts with '/', or empty for no S/CGI) []? /BackupPC
Ok, we're about to:
- install the binaries, lib and docs in /usr/local/BackupPC
- create the data directory /var/lib/backuppc
- optionally install the cgi-bin interface
- create/update the config.pl file /etc/BackupPC/config.pl
--> Do you want to continue? [y]?y
...
Ok, it looks like we are finished. There are several more things you
will need to do:
- Browse through the config file, /etc/BackupPC/config.pl,
and make sure all the settings are correct. In particular,
you will need to set $Conf{CgiAdminUsers} so you have
administration privileges in the CGI interface.
- Edit the list of hosts to backup in /etc/BackupPC/hosts.
- Read the documentation in /usr/local/BackupPC/doc/BackupPC.html.
Please pay special attention to the security section.
- Verify that the CGI script BackupPC_Admin runs correctly. You might
need to change the permissions or group ownership of BackupPC_Admin.
If this is an upgrade and you are using mod_perl, you will need
to restart Apache. Otherwise it will have stale code.
- BackupPC should be ready to start. Don't forget to run it
as user backuppc! The installation also contains
a systemd/backuppc.service script that can be installed so
that BackupPC can auto-start on boot. This will also enable
administrative users to start the server from the CGI interface.
See systemd/README.
Enjoy!If you want to run non-interactive installation;
./configure.pl --batch --cgi-dir /var/www/cgi-bin/BackupPC --data-dir /var/lib/backuppc --hostname ubuntu20 --html-dir /var/www/html/BackupPC --html-dir-url /BackupPC --install-dir /usr/local/BackupPCConfigure Apache Web Server for BackupPC
Copy the sample BackupPC Apache configuration file to Apache enabled configurations directory;
cp ~/backuppc/BackupPC-*/httpd/BackupPC.conf /etc/apache2/conf-available/Next, configure Apache to allow external access to BackupPC;
sed -i 's/Require local/Require all granted/' /etc/apache2/conf-available/BackupPC.confConfigure Apache to run as BackupPC user, backuppc.
sed -i 's/www-data/backuppc/g' /etc/apache2/envvarsRemove the set-uid from BackupPC admin CGI file;
chmod u-s /var/www/cgi-bin/BackupPC/BackupPC_AdminConfigure BackupPC Apache Basic Authentication
Change the Basic authentication file if you so wish;
sed -i 's#^AuthUserFile.*$#AuthUserFile /etc/BackupPC/.allowed#' /etc/apache2/conf-available/BackupPC.confChange the basic authentication message;
sed -i 's/^AuthName.*$/AuthName "Kifarunix-demo BackupPC Restricted Access"/' /etc/apache2/conf-available/BackupPC.confCreate the BackupPC basic authentication user and password. This information should be stored on a file specified by the value of the AuthUserFile parameter above. For example, to create web authentication user called kifarunixadmin;
htpasswd -c /etc/BackupPC/.allowed kifarunixadminYou can add another user, say kifarunixuser.
htpasswd /etc/BackupPC/.allowed kifarunixuserAdjust the ownership and permissions of the auth user file;
chmod 666 /etc/BackupPC/.allowedchown backuppc:backuppc /etc/BackupPC/.allowedConfigure BackupPC Administrative User
Default Administrative user for BackupPC is defined under CGI user interface configuration settings section. Normal users can only access information specific to their host. They can also start/stop/browse/restore backups. Administrative users have full access to all hosts, plus overall status and log information. In this demo, we set the kifarunixadmin user as BackupPC admin.
vim /etc/BackupPC/config.pl$Conf{CgiAdminUserGroup} = 'kifarunixadmin';
$Conf{CgiAdminUsers} = 'kifarunixadmin';Define BackupPC Client Backup User
By default, BackupPC uses the root user on the backup clients for backup purposes.
$Conf{RsyncSshArgs} = [
'-e', '$sshPath -l root',
];It is more secure to allow backup via a low-privileged user. In this demo, we will create a non-privileged user, backuppc, on every client to backup which is only allowed to run rsync command with sudo rights for backup purposes. Therefore, change this user accordingly.
$Conf{RsyncSshArgs} = [
'-e', '$sshPath -l backuppc',
];We will leave other Rsync settings with the default options.\
Note that all these configurations are overwritable via the per-client configuration.
Enable BackupPC Apache configuration and CGI modules;
Run the commands below to enable BackupPC Apache configuration and CGI modules;
a2enconf BackupPCa2enmod cgidDisable Apache default site and Disable directory listing;
a2dissite 000-default.confmv /var/www/html/index.html /var/www/html/index.html.oldsed -i 's/Options Indexes FollowSymLinks/Options -Indexes +FollowSymLinks/' /etc/apache2/apache2.confHide web server version on error pages;
echo -e 'ServerSignature Off\nServerTokens Prod' >> /etc/apache2/apache2.confCheck Apache for any errors;
apachectl -tSyntax OKStart and enable Apache to run on system boot;
systemctl enable --now apache2Restart Apache if it were already running;
systemctl restart apache2Running BackupPC Service
Copy BackupPC sample systemd service file from the source directory;
cp ~/backuppc/BackupPC-*/systemd/backuppc.service /etc/systemd/system/Edit the service group;
sed -i 's/^#Group/Group/' /etc/systemd/system/backuppc.servicesed -i 's#PIDFile=/var/run/#PIDFile=/run/#' /etc/systemd/system/backuppc.serviceReload systemd service configuration;
systemctl daemon-reloadStart and enable BackupPC service;
systemctl enable --now backuppcTo check the status;
systemctl status backuppc● backuppc.service - BackupPC server
Loaded: loaded (/etc/systemd/system/backuppc.service; enabled; vendor preset: enabled)
Active: active (running) since Sun 2020-05-17 19:29:38 UTC; 7s ago
Main PID: 3772 (BackupPC)
Tasks: 1 (limit: 2283)
Memory: 8.6M
CGroup: /system.slice/backuppc.service
└─3772 /usr/bin/perl /usr/local/BackupPC/bin/BackupPC
May 17 19:29:38 ubuntu20 systemd[1]: Started BackupPC server.Accessing BackupPC Web User Interface
If firewall is running, allow external access to Apache.
ufw allow 80/tcpYou can now access BackupPC via the URL http://server_IP_OR_hostname/BackupPC_Admin.
Authenticate and proceed to BackupPC web dashboard.

When you authenticate as admin user, this is the interface you get;

When you authenticate as non admin user, this is the interface you get;

BackupPC is now installed on Ubuntu 20.04. You can now go ahead and add hosts for backing up;
Backup Linux systems with BackupPC using Rsync Protocol
Backup Windows System via SMB Using BackupPC
Backup Windows System with BackupPC Using Rsyncd
That marks the end of our guide on how to install and setup BackupPC server on Ubuntu 20.04. Enjoy!
Reference
Installing BackupPC 4 from tarball or git on Ubuntu
BackupPC Documentation: Installing BackupPC
Other Related Tutorials
Install and Configure BackupPC on Debian 10
How to Install and Configure BackupPC as a Backup Server on Ubuntu 18.04
Install and Configure BackupPC on CentOS 8
|
Рубрика: Администрирование / Продукты и решения |
Мой мир Вконтакте Одноклассники Google+ |
АНДРЕЙ МАРКЕЛОВ
Linux на страже Windows
Обзор и установка системы резервного копирования BackupPC
Думаю, в настоящее время никто уже не станет спорить с утверждением, что процесс вхождения Linux в корпоративный мир стал необратимым, а процент установок этой операционной системы на серверах в различных организациях постоянно возрастает.
Можно бесконечно спорить о преимуществах одних операционных систем над другими, но когда у меня возникло желание сделать единое хранилище для ежедневных архивов информации с более десяти серверов своей организации, работающих под управлением нескольких различных ОС, я свой выбор остановил на платформе Linux. До сих пор каждый сервер с помощью уникальных для него скриптов в назначенное время сбрасывал по сети на сервер резервного копирования или stand by-сервер какие-то свои данные, например, пользовательские файлы с сетевых дисков, или дампы базы данных. Для этого использовались различные протоколы: ftp, SMB или штатные средства СУБД. При этом приходилось следить за уникальным для каждого сервера лог-файлом, и в случае каких-либо изменений в стратегии резервного копирования править скрипты на каждой машине.
Чтобы как-то упростить администрирование и сократить время, затрачиваемое на поддержку и мониторинг всего этого «зоопарка», я начал искать систему, которая бы поддерживала копирование информации по сети, умела делать инкрементальные бэкапы, поддерживала бы удаленное администрирование и не требовала установки клиентского программного обеспечения. Кроме того, было важно, чтобы система умела работать по протоколу SMB, так как часть серверов, в частности основной файл-сервер, работали под управлением ОС Windows.
Спустя непродолжительное время такая система была найдена. Ею оказалась открытая, распространяющаяся по лицензии GNU система архивирования данных масштаба предприятия BackupPC. Сайт расположен по адресу http://backuppc.sourceforge.net.
Основные особенности рассматриваемой программы:
- Язык программирования, на котором написана система, – Perl.
- Минимизация хранимой информации за счет того, что идентичные файлы из разных резервных копий хранятся только в одном экземпляре.
- Настраиваемая степень сжатия данных.
- Поддержка работы по протоколам smb/ssh/rsh/nfs.
- Мощный CGI-интерфейс, позволяющий управлять сервером по сети посредством веб-браузера.
- Поддержка архивирования информации с машин, получающих настройки сети через DHCP, разрешая имена при помощи nmblookup.
- Гибкие настройки планирования архивации данных.
- Оповещения о выполненных действиях администратора и пользователей посредством электронной почты.
- Поддержка клиентов, работающих под управлением Linux, Freenix, Solaris Win95, Win98, Win2000 и WinXP. Сервер тестировался на Linux, Freenix и Solaris.
- Очень подробная документация.
В данной статье я хочу обобщить свой опыт установки, настройки и эксплуатации этой системы, а также поделиться решением нескольких проблем, которые возникли в процессе установки.
Я проверял работу BackupPC версии 2.1.0, последней на момент написания статьи, при помощи тестовой машины под управлением Fedora Core 2, и на «боевых» серверах, работающих на Red Hat Linux 9 и White Box Enterprise Linux 3. Операционная система, стоящая на тестовом сервере фактически является альфа-версией будущего Red Hat Enterprise Linux 4, а White Box Enterprise Linux 3 перекомпиляцией из свободно доступных исходных текстов текущей, третьей версии коммерческого Linux-дистрибутива от Red Hat.
Необходимость использовать не поддерживающуюся более «девятку» возникла при установке RAID-контроллера Promise SuperTRAX SX6000, для которого существовали драйвера только под эту операционную систему.
Требования к установке
Прежде чем приступить непосредственно к инсталляции и настройке самой системы резервного копирования BackupPC, необходимо определиться с требованиями к программному окружению, в котором должен работать сервер.
Во-первых, как я уже писал, это операционная система, в роли которой может выступать Linux, Solaris либо другая UNIX-подобная система. Во-вторых, необходимо предусмотреть наличие вместительного RAID-массива, или использовать LVM. Кроме того: Perl версии 5.6.0 или выше, Samba- и Apache-сервер.
В этой статье я не буду касаться настройки клиента Samba, в частности, работы в составе Active Directory. Я предполагаю само собой разумеющимся, что если вы планируете производить архивацию информации с Windows-серверов, работающих в составе домена, то и должны обеспечить к ним доступ вашей Linux-машины. Отсутствие описания процесса конфигурирования Samba-сервера в данной статье, думаю, компенсируется многочисленными материалами на эту тему в Интернете.
Также предполагается, что вы используете кодировку KOI-8 вместо установленной по умолчанию в большинстве современных дистрибутивов UTF-8. Red Hat, в частности, перешла на ее использование с версии 8.0 своего продукта. Но дело в том, что поддержка русского языка при помощи UTF-8 во многих приложениях далека от совершенства. Безусловно, лучшим решением была бы работа с UTF-8, но в данном случае я предпочел пойти по пути «наименьшего сопротивления» и воспользоваться уже существующими у меня наработками.
Соответственно должен быть настроен и веб-сервер, у которого в качестве кодировки по умолчанию должно быть указано KOI8-R.
Приступая к установке BackupPC, в системе необходимо иметь следующие perl-модули: Compress::Zlib, Archive::Zip и File:RsyncP. Проверить наличие установленных модулей можно, дав команду:
perldoc <имя модуля>
Если в ответ будет получено сообщение вида:
No documentation found for «Compress::Zlib»
следовательно, в вашей системе данный модуль еще не установлен. Оба дистрибутива, в которых я устанавливал BackupPC, по умолчанию этих модулей не содержат.
Процедура установки модулей, которые можно скачать с www.cpan.org, следующая:
#tar zxvf имя_архива.tar.gz // разархивируем исходники
#perl Makefile.PL // формируем makefile
#make // компилируем исходники
#make test // после выполнения этой команды мы должны получить сообщение, что все тесты пройдены успешно
#make install
Имеющие опыт общения с оболочкой cpan, могут поступить проще – для установки модулей воспользоваться ею.
В случае RHEL3 для успешной компиляции модуля Archive::Zip пришлось дать команду:
export LANG=en_US
без которой он отказался «собираться».
Кроме того, мне пришлось установить отсутствующую в дистрибутивах от Red Hat утилиту par2, которая создает «избыточную информацию» для файлов с использованием кодов Рида-Соломона, и позволяет восстанавливать файлы, повреждённые до определённой степени. Скачиваем с сайта http://parchive.sourceforge.net исходники в виде файла par2cmdline-0.4.tar.gz, и выполняем команды:
#tar zxvf par2cmdline-0.4.tar.gz
#cd par2cmdline-0.4
#./configure
#make
#make check
#make install
В принципе установка par2cmdline не обязательна, так как по умолчанию BackupPC работает и без нее. Но все же я рекомендовал бы ее установить, особенно при отсутствии RAID-массива на сервере.
Также для корректной работы CGI-интерфейса при стандартной установке системы, когда веб-сервер запускается из-под специально выделенного для этих целей пользователя (httpd или apache), требуется Suid Perl. В Red Hat дистрибутивах соответствующий пакет называется perl-suidperl.
Ну и, наконец, добавим пользователя, из-под которого будет выполняться запуск системы резервного копирования:
#useradd backuppc
После окончания тестирования системы нелишним будет убрать для пользователя backuppc возможность интерактивного входа.
Установка BackupPC
Теперь можно приступить непосредственно к установке BackupPC. Развернем архив и запустим конфигурационный скрипт:
#tar zxvf BackupPC-x.x.x.tar.gz
#cd BackupPC-x.x.x
#perl configure.pl
В ходе установки вам потребуется ответить на ряд вопросов. На первый – просьбу указать полный путь к уже установленной старой версии – можно ответить, просто нажав «Enter», поскольку выполняется первоначальная установка. После вам будут показаны пути к утилитам, требуемым BackupPC, которые скрипт определил самостоятельно, с просьбой подтвердить их расположение. Затем необходимо проверить, правильно ли скрипт определил имя хоста и имя пользователя, которого мы создали ранее, а также директорию для установки исполнимых файлов и директорию для хранения данных.
В зависимости от быстродействия сервера вам необходимо будет выбрать уровень компрессии резервируемых данных. Уровень можно менять от 1 до 9. По умолчанию предлагается третий уровень. По заявлениям разработчиков, при увеличении c «умолчальной» тройки до пятерки, например, загрузка процессора увеличивается на 20%, а данные занимают на 2-3% меньше места. По этим данным видно, что особого смысла увеличивать степень сжатия нет. При первоначальной установке я бы порекомендовал оставить тройку. Позднее можно попробовать поэкспериментировать с этим значением, поменяв его в конфигурационном файле.
Следующий вопрос касается пути к cgi-bin директории вашего веб-сервера (в Red Hat-подобных дистрибутивах это /var/www/cgi-bin/) и пути к директории с устанавливаемыми иконками для CGI-интерфейса (/var/www/html/BackupPC). Кроме того, будет предложено ввести часть URL, указывающего на иконки, а именно расположение относительно корневого каталога веб-сервера. Обратите внимание, что путь должен начинаться со слэша. В нашем случае он будет выглядеть как /BackupPC.
Настройка BackupPC
Как и большинство программ, работающих под управлением UNIX-подобных систем, настройка и изменение параметров сервера BackupPC производится правкой конфигурационных файлов. К чему мы и приступим.
Интересующий нас файл config.pl расположен в подкаталоге /conf, который был создан внутри директории, предназначенной для хранения данных. На самом деле этот файл очень хорошо документирован, поэтому я пройдусь лишь по основным параметрам. Config.pl состоит из четырех групп настроечных значений, содержащих:
- основные параметры сервера;
- описание тех машин, информацию с которых нужно архивировать;
- указания, как часто это надо делать;
- параметры CGI-интерфейса.
- $Conf{WakeupShedule} – как часто сервис должен проверять, были ли изменения на подлежащих архивированию компьютерах, и в случае изменений выполнять резервирование данных. По умолчанию – каждый час, кроме полуночи.
- $Conf{MaxBackups} – максимальное число одновременных процессов архивирования.
- $Conf{DfMaxUsagePct} – при заполнении указанного в процентах объема диска, заданного для хранения данных, архивирование не производится. По умолчанию 95%.
- $Conf{SmbShareName} – имя расшаренного ресурса на Windows-машине. По умолчанию – это диск C:, который в Win2000/XP доступен через SMB по имени «С$».
- $Conf{SmbShareUserName} – имя пользователя на Windows-машине, которому даны права на ресурс общего доступа .
- $Conf{SmbSharePasswd} – его пароль. В настоящее время он приводится в открытом виде. В следующих версиях планируется хранение в зашифрованном виде.
- $Conf{FullPeriod} – период в днях между полными резервными копиями.
- $Conf{IncrPeriod} – период в днях между инкрементальными резервными копиями.
- $Conf{FullKeepCnt} – максимальное число сохраняемых полных резервных копий. $Conf{BackupFilesOnly} – список директорий, которые необходимо архивировать. По умолчанию – не определено.
- $Conf{BackupFilesExclude} – то же самое, но для директорий-исключений.
- $Conf{ArchivePar} – при использовании par2cmdline процент избыточных данных в архиве. По умолчанию – 0.
- $Conf{EmailAdminUserName} – почтовый адрес администратора, на который будут приходить сообщения об ошибках и предупреждениях.
- $Conf{CgiAdminUserGroup} и $Conf{CgiAdminUsers} – пользователи и группы, которым доступен CGI-интерфейс.
Обратите внимание, что параметры, относящиеся к конкретной машине, могут быть переопределены машинно-зависимым файлом Config.pl, который хранится в поддиректории каталога с данными /BackupPC/pc/<имя_компьютера>/. Действительно, на каждой машине могут быть свои конкретные папки общего доступа, списки исключений, свой локальный пользователь с паролем, для которого установлены свои разрешения.
Теперь настроим список компьютеров, данные с которых необходимо архивировать. Файл с настройками находится в том же каталоге, где и основной конфигурационный файл, и называется hosts. Собственно, синтаксис файла максимально прост. Каждая строчка содержит три параметра: имя машины, имя (e-mail) ее хозяина и признак, получает ли данный компьютер сетевые настройки по DHCP или нет.
Теперь осталось скопировать скрипт старта и остановки сервиса из дистрибутива /init.d/linux-backuppc в /etc/rc.d/init.d/backuppc, в случае Red Hat дистрибутива, а затем можно попробовать стартовать BackupPC командой:
#service backuppc start
Кроме того, нелишне добавить автоматический старт при загрузке сервера в консоль и в X-Window:
#chkconfig — -add backuppc
#chkconfig — -level 35 backuppc on
К сожалению, данные действия приходится делать вручную, так как разработчики не включили эти операции в установочный скрипт.
В лог-файле messages вашего сервера должно появиться сообщение об успешном старте сервиса, а в директории с данными /BackupPC/log будет создан подробный лог самого сервиса. После успешного старта можно попробовать запустить браузер, и обратиться по адресу http://имя_сервера/cgi-bin/BackupPC_Admin. Если вы сделали все правильно, то должны получить нечто подобное тому, что изображено на рисунках. В случае проблем с доступом к CGI-интерфейсу рекомендую обратиться к FAQ на сайте http://backuppc.sourceforge.net. В большинстве случаев в первую очередь необходимо проверить права доступа к файлам и директориям BackupPC. Однако, если вы следовали приведенному порядку установки, таких проблем возникнуть не должно.
Русификация
Еще одной проблемой при работе с CGI-интерфейсом, решение которой, однако, пришлось искать самому, может стать некорректное отображение русских имен файлов и папок. Для исправления этой ситуации придется внести небольшие изменения в файл Lib.pm, расположенный в подкаталоге /CGI директории с исполняемыми файлами программы. Данный файл содержит системные процедуры BackupPC.
Во-первых, найдите в теле процедуры Header строчку:
print $Cgi->header();
и замените ее на:
print $Cgi->header(-charset=>»koi8-r»);
Ну а во-вторых, в процедуре EscHTML закомментируйте предпоследнюю строчку, стоящую перед «return»:
$s=~s{([^[:print:]])}{sprintf(«%02X;», ord($1));}eg;
Теперь все имена будут отображаться в нормальном виде, используя кодировку KOI-8.
Кроме того, рекомендую обратить внимание на папку /lib/BackupPC/Lang, которая находится в директории с исполнимыми файлами. Там находятся файлы с локализованными сообщениями, выводимыми CGI-интерфейсом. В комплект поставки русский язык не входит, но вам ничего не мешает создать свой файл по образцу существующих, переведя сообщения с английского на русский язык. Часть этой работы я уже проделал для своего «внутреннего» использования. Перевод, не претендующий на полноту и высокое литературное качество, я выложил на своем сайте. Скачать архив можно по ссылке http://www.markelov.net/program/bpcrus.tgz.
Интерфейс
Интерфейс системы достаточно прост и нагляден. Обратившись по адресу: http://имя_сервера/cgi-bin/BackupPC_ Admin, вы попадаете в окно с общей информацией по серверу BackupPC. В левой части окна присутствует меню с ссылками на более подробную информацию по работе всего сервера, а также выпадающее меню с возможностью выбора информации по конкретному архивируемому хосту.
Зайдя в меню по конкретному хосту, можно получить всю информацию касательно выполненных операций резервирования данных, просмотреть списки архивных копий, а также «провалиться» в любой из них и восстановить файлы и каталоги полностью или частично. Также имеется возможность скопировать любой из файлов средствами браузера на ту машину, с которой вы зашли на сервер.
Заходя в инкрементальную резервную копию, вы видите полную картину сохраненной файловой системы, то есть полную резервную копию плюс наложенную на нее инкрементальную копию. А для всех измененных файлов можно просмотреть список версий и восстановить нужную из них.
Кроме того, все операции по работе с архивами можно выполнять из командной строки, но я не вижу смысла приводить здесь синтаксис команд, поскольку он подробно описан в документации, идущей в составе дистрибутива.
В конце мне хотелось бы поблагодарить Павла Шера за ряд ценных советов, которые мне пригодились при написании статьи.
Мой мир
Вконтакте
Одноклассники
Google+
Время на прочтение
15 мин
Количество просмотров 95K
Приветствую всех хаброжителей!
Как нетрудно догадаться, речь пойдет о бекапах.
Своевременный бекап — крайне важная часть работы системного администратора. Своевременный бекап делает сон спокойным, а нервы стальными, придает сил и оберегает здоровье.
Думаю вполне резонным будет предположение, что данная тема уже набила оскомину, но все же я рискну поделиться своим опытом. На суд читателя будет представлена клиент-серверная реализация схемы резервного копирования. В качестве инструмента я выбрал open source проект Bacula. По более чем полугодовому опыту его использования остаюсь доволен своим выбором.
Bacula состоит из нескольких демонов, каждый из которых несет свою функциональную нагрузку. На рисунке ниже схематично представлена взаимосвязь этих демонов.
Под хабракатом я опишу все демоны подробно
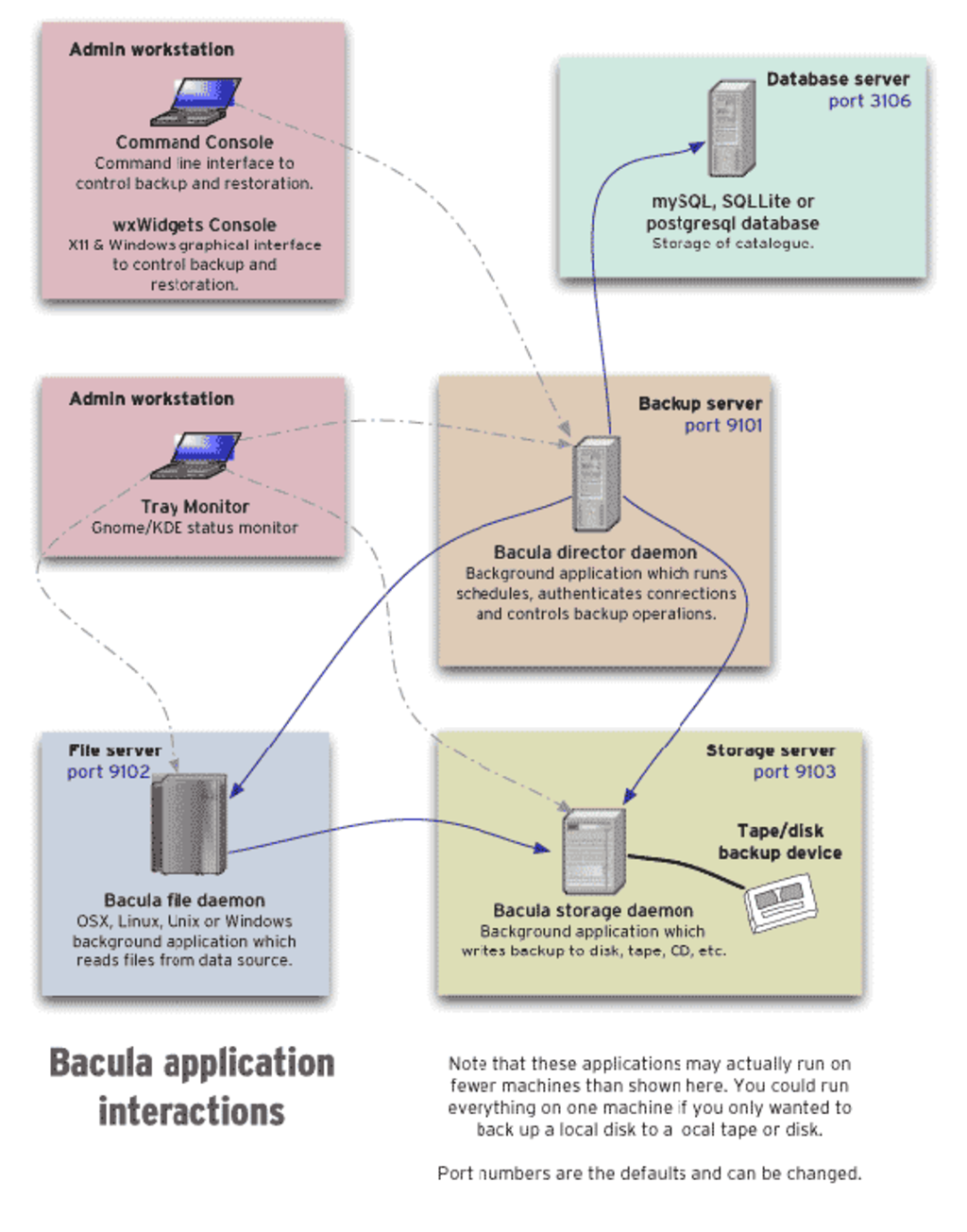
В моем случае резервному копированию подлежат:
- Конфигурационные файлы различных демонов со всех серверов.
- MySQL базы данных.
- Документооборот с файлового сервера Windows.
- Различные важные данные с nix серверов(движки сайтов/форумов, etc..)
1.Описание демонов Bacula
Система построена по технологии клиент-сервер, и для передачи данных использует протокол TCP. Резервные копии создаются в собственном, полностью открытом формате.
Система резервирования данных Bacula состоит из четырёх основных элементов: Director Daemon, Storage Daemon, File Daemon и Bacula Console. Все эти элементы реализованы в виде самостоятельных приложений.
Director Daemon (DD) – это центральный элемент системы, осуществляющий управление её остальными компонентами. В его задачи входит управление процессом резервирования/восстановления данных, обеспечение интерфейса управления для администраторов и многое другое. Говоря проще – это диспетчер, который инициирует все процессы и отслеживает ход их выполнения.
Storage Daemon (SD) – приложение, отвечающее за чтение/запись данных непосредственно на устройства хранения информации. Принимает управляющие команды от DD, а также резервируемые данные от/к File Daemon.
File Daemon (FD) – этот элемент ещё можно назвать Агентом. Ведь именно он работает в рамках операционной системы, данные которой необходимо резервировать. File Daemon выполняет всю рутину, осуществляя обращение к резервируемым файлам и их дальнейшую передачу к SD. Также на стороне FD выполняется шифрование резервных копий, если это определено конфигурацией.
Bacula Console (BC) – интерфейс администратора сиcтемы. По своей сути, это командный интерпретатор для управления Bacula. Строго говоря, Bacula Console может быть расширена с помощью графических систем управления, которые, как правило, являются всего лишь надстройкой над BC. К таким системам можно отнести Tray Monitor и Bat. Первая устанавливается на компьютере администратора системы и осуществляет наблюдение за работой системы резервирования, а вторая обеспечивает возможность управления посредством графического интерфейса.
Bacula Catalog – база данных, в которой хранятся сведения обо всех зарезервированных файлах и их местонахождении в резервных копиях. Каталог необходим для обеспечения эффективной адресации к требуемым файлам. Поддерживаются MySql, PostgreSql и SqLite.
Такое структурное деление позволяет организовать очень гибкую систему резервирования, когда Storage Daemon разворачивается на выделенном сервере с несколькими устройствами хранения данных. Также Bacula Director может управлять несколькими экземплярами SD, обеспечивая резервирование части данных на одно устройство хранения, а части – на другое.
2. ОС и железо
Теперь, когда у читателя сформировалось представление о работе демонов Bacula, я перейду к описанию того, как я реализовал всю эту красоту у себя.
В качестве аппаратного обеспечения для DD, SD и Bacula Catalog у меня выступает PC со следующими характеристиками
| Устройство | Модель | количество | Емкость/Частота |
| HDD | Hitachi HDS723020BLA642 | 3 | 2Tb |
| CPU | AMD Phenom(tm) II X4 970 Processor | 1 | 3500 Mhz |
| Motherboard | Gigabyte GA-880GA-UD3H | 1 | — |
| RAM | 3541 Mb |
О используемых на сервере ОС и версиях ПО
# lsb_release -a
LSB Version: :core-4.0-ia32:core-4.0-noarch:graphics-4.0-ia32:graphics-4.0-noarch:printing-4.0-ia32:printing-4.0-noarch
Distributor ID: CentOS
Description: CentOS release 5.7 (Final)
Release: 5.7
Codename: Final
# uname -a
Linux backupsrv.domain.ru 2.6.18-274.7.1.el5PAE #1 SMP Thu Oct 20 17:03:59 EDT 2011 i686 athlon i386 GNU/Linux
# rpm -qa |grep -E "syslog-ng|bacula|mysql-ser"
bacula-libs-5. 0.3-1
syslog-ng-2.1.4-9.el5
bacula-mysql-5. 0.3-1
mysql-server-5. 0.77-4.el5_6.6
Хранением данных занимаются несколько software(mdadm) RAID массивов.
Под систему три партиции на трех дисках, грузится можно с любого из них, под бекапы один массив из двух партиций.
| Имя массива | из каких партиций | точка монтирования | Файловая система | Уровень массива |
| md0 | /dev/sda1,/dev/sdb1,/dev/sdc1 | boot | ext2 | 1 |
| md1 | /dev/sda2,/dev/sdb2,/dev/sdc2 | / | ext3 | 1 |
| md2 | /dev/sda3,/dev/sdb3 | /backup | ext4 | 1 |
3. Описание схемы резервного копирования и настроек демонов Bacula
Всего у меня сконфигурированы 19 клиентов Bacula, но подробно я остановлюсь на описании бекапа сервера биллинга и документов с файлового сервера Windows. Фокус на эти два сервера обусловлен тем, что остальные клиенты настроены аналогично, и на примере этих серверов-клиентов можно строить свои конфигурации.
Резервное копирование сервера биллинга это, по сути, бекап базы данных mysql и конфигурационных файлов демонов.
BD позволяет выполнять локальный скрипт на клиенте как до, так и после задания.
Каждую ночь, при старте задания на бекап сервере, запускается локальный(на самом сервере биллинга) скрипт, который создает архив базы биллинга, далее этот архив забирает BD и помещает на соответствующий пул томов(на самом деле операциями с чтением/записью управляет SD, но это сейчас не важно). Сразу же после выполнения задания запускается еще один скрипт, который в свою очередь, перемещает созданный архив в отдельную папку на сервере биллинга, для пущей надежности. Таким образом архив БД будет как у Bacula, так и локально на сервере биллинга(да, я параноик). Подробнее эти механизмы и скрипты будут описаны ниже.
С файлового сервера Windows сохраняем весь необходимый документооборот. В воскресенье создается Full бекап, каждый последующий день, с понедельника по субботу, Diff бекапы.
Теперь о конфигурационных файлах демонов Bacula. Начнем с самого объемного — bacula-dir.conf.
Файлы конфигурации всех демонов Bacula состоят из описаний, так называемых, ресурсов. Каждый из ресурсов характеризует определенный функционал демона.
Я буду комментировать каждую строчку в конфиге, поэтому далее будут следовать блоки-ресурсы файлов Bacula(bacula-dir.conf, bacula-sd.conf, bacula-fd.conf), если что-то нужно объяснить более подробно укажите это в комментариях.
Ресурс Dirtector
Director {
# имя bacula director'а
Name = backupsrv.domain.ru-dir
# какой порт слушать, у нас default
DIRport = 9101
# путь к скрипту, где лежат sql запросы для работы с Bacula Catalog(mysql database)
QueryFile = "/usr/lib/bacula/query.sql"
# здесь хранятся статус файлы демона
WorkingDirectory = "/backup/bacula-work/"
# pid файл демона
PidDirectory = "/var/run"
# сколько заданий может запускаться одновременно
Maximum Concurrent Jobs = 1
# пароль для доступа в BC и управления демонами
Password = "bacula_paS$w0rD10*"
# куда слать mail'ы, описано в ресурсе Messages
Messages = Daemon
# на какой адрес биндится процессу
DirAddress = 10.1.19.2
} Ресурс catalog, описываем подключение к БД
Catalog {
Name = MyCatalog
dbname = "bacula"; dbuser = "bacula"; dbpassword = "edsfweo8vhwpe"
}Ресурс Messages
Messages {
# это имя прописано в ресурсе Director, помните?
Name = Daemon
# команда для отправки email
mailcommand = "/usr/sbin/bsmtp -f \"\(Bacula\) \<%r\>\" -s \"Bacula daemon message\" %r"
# шлем все на майл админам(root алиас на admins@domain.ru)
# высылаются только алярмы, ероры и прочую важность
mail = root@backupsrv.domain.ru = alert,error,fatal,terminate, !skipped
# что выводить на консоль
console = all, !skipped, !saved
# что в лог
append = "/var/lib/bacula/log" = alert,error,fatal,terminate, !skipped
}Для каждого клиента в заданиях указаны Pool и Storage.
Pool, извините за тавтологию, это пул томов(volume) на который размещаются резервные копии данных клиентов. У меня тома — это файлы в формате bacula, размещенные на software raid массиве. Для разных клиентов могут быть определены разные пулы томов. К примеру у меня созданы 6 пулов, для разных типов клиентов. В примере ниже описан лишь один из них, для данных биллинга.
Storage описывает какие физические устройства будут использованы в качестве томов.
(Storage BGB-ST описан в конфиге SD)
Ресурс Pool
Pool {
# имя пула, указывается в заданиях резервного копирования
Name = bgb
# тип пула, емнип этой версии только такой поддерживается
Pool Type = Backup #
# повторно использовать тома(сначала пишет в 1-ый, потом в 2-ой,
# потом 3-й, 3-й закончился - снова в 1-й)
Recycle = yes
# удалять записи из bacula catalog(из mysql базы бакулы)
# старше нижеуказанных значений
AutoPrune = yes
# период в течении которого информация о томах(volumes)
# хранится в базе данных, по истечению периода эта информация
# удаляется
Volume Retention = 90 days
# максимальный объем тома
Maximum Volume Bytes = 100G
# максимальное количество томов в пуле
Maximum Volumes = 3
# с каких символов начинается имя тома
LabelFormat = "Vol"
} Ресурс Storage
Storage {
# имя хранилища и пароль (о соответствии имен и паролей в разных конфигах
# демонов Bacula, я расскажу позже)
Name = BGB-F
Password = "StoRage_PaSSw0rD"
# fqdn имя сервера
Address = backupsrv.domain.ru
# порт оставляем стандартный
SDPort = 9103
# имя девайса описанного в конфиге SD
Device = BGB-ST
# у нас все пишется на софтовый рэйд в файлы собственного формата
# bacula(например /backup/bgbilling/Vol0001)
Media Type = File
} Задание на примере бекапа базы данных биллинга.
Ресурс Client
Client {
# имя
Name = bgbilling-fd
# ip адрес клиента
Address = 10.103.2.5
# порт, который клиент слушает
FDPort = 9102
# имя mysql базы данных Bacula
Catalog = MyCatalog
# пароль для FD
Password = "Fd_paSSw0rd"
# период в течении которого информация о файлах задания
# хранится в базе данных, по истечению периода эта информация
# удаляется(но не сами данные!!)
File Retention = 45 days
# тоже самое, только для самого задания
Job Retention = 90 days
# удалять записи из каталога(бд mysql) старше вышеуказанных значений
AutoPrune = yes
} Само задание.
Ресурс Job
Job {
# имя задания
Name = "BGBilling"
# тип(backup or restore)
Type = Backup
# уровень(полный, диференциальный или инкрементный)
Level = Full
# имя клиента
Client=bgbilling-fd
# имя файл-сета(там рассказано что бекапить, а что не бекапить)
FileSet="bgbilling-set"
# имя SD ресурса
Storage = BGB-F
# имя пула(для разных клиентов разные пулы томов(volume) куда пишутся сами
# бекапы)
Pool = bgb
# скрипт запускающийся ДО выполнения задания (путь до скрипта -
# это путь НА КЛИЕНТЕ!)
ClientRunBeforeJob = "/root/sh/before_bg_db_backup.sh"
# скрипт запускающийся ПОСЛЕ выполнения задания
ClientRunAfterJob = "/root/sh/after_bg_db_backup.sh"
# имя ресурса messages, который будет использоваться для этого задания
Messages = Standard
# имя шедулера
Schedule = "DaylyFullBGBilling"
# в этом файле содержится информация о том, какие файлы должны будут
# востанавливаться, на каком вольюме находятся файлы,
# где конкретно они находятся - это очень важные файлы, их нужно бэкапить
Write Bootstrap = "/backup/bsr-files/bgbilling.bsr"
}
Я обещал подробнее остановиться на скриптах выполняющихся до и после задания.
Скрипт до задания
$ sudo cat /root/sh/before_bg_db_backup.sh
#!/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
mysql -e "flush tables with read lock" --user=root --password="ololo" bgbilling
lvcreate -L20G -s -n backup_db /dev/BGB-LVM1/billing_db
mysql -e "unlock tables" --user=root --password="ololo" bgbilling
mount /dev/BGB-LVM1/backup_db /backup
tar -czf /usr/backups/`date +%Y-%m-%d_%H-%M`.bgb.tgz /backup/bgbilling/
umount /backup
lvremove -f /dev/BGB-LVM1/backup_db
Скрипт после задания
$ sudo cat /root/sh/after_bg_db_backup.sh
#!/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
rm /usr/backups/after_run_bacula_backup/*
mv /usr/backups/*.tgz /usr/backups/after_run_bacula_backup/
Ресурс FileSet(что бекапим, а что нет)
FileSet {
Name = "bgbilling-set"
Include {
Options {
# разработчики яро рекомендуют юзать это опцию,
# создается сигнатура забекапленных файлов в md5
signature = MD5
}
# перечисляем то, что нужно бекапить
File = /usr/backups
File = /etc
File = /root/sh
}
Exclude {
# а это бекапить нет нужды
File = /usr/backups/after_run_bacula_backup/*
File = /usr/backups/after_run_bacula_backup
}
}
Расписание запуска задания.
Ресурс Schedule
Schedule {
# имя расписания
Name = "DaylyFullBGBilling"
# когда запускать задание
Run = Full sun-sat at 1:10
} Подробно комментировать ресурсы для резервного копирования документов с сервера Windows я не буду, приведу соответствующую часть конфига bacula-dir.conf полностью
Storage {
Name = WINDOWS-F
Address = backupsrv.domain.ru # N.B. Use a fully qualified name here
SDPort = 9103
Password = "StoRage_PaSSw0rD"
Device = WINDOWS-ST
Media Type = File
}
Pool {
Name = windows
Pool Type = Backup
Recycle = yes # Bacula can automatically recycle Volumes
AutoPrune = yes # Prune expired volumes
Volume Retention = 60 days
Maximum Volume Bytes = 30G # Limit Volume size to something reasonable
Maximum Volumes = 5 # Limit number of Volumes in Pool
LabelFormat = "Vol-Windows"
}
Job {
Name = "centra-bdk"
Type = Backup
Level = Full
Client= centra-bdk-fd
FileSet="centra-bdk-fd-fs"
Storage = WINDOWS-F
Pool = windows
Messages = Standard
Schedule = "Windows_Centra-bdk"
Write Bootstrap = "/backup/bsr-files/centra-bdk.bsr"
}
FileSet {
Name = "centra-bdk-fd-fs"
Include {
Options {
signature = MD5
Compression=GZIP
}
# обратите внимание на двойной бекслэш и ковычки!
File = "D:\\Public\\!!!Абонентский\ Отдел"
File = "D:\\Public\\Отдел\ ИТ"
File = "D:\\Public\\tex\\Maps"
File = "D:\\Public\\сервис\ мены "
File = "D:\\Public\\Отдел\ продаж1"
}
Exclude {
File = "*.mp3"
File = "*.avi"
File = "*.wmv"
}
}
Client {
Name = centra-bdk-fd
Address = 10.1.19.50
FDPort = 9102
Catalog = MyCatalog
Password = "Fd_paSSw0rd" # password for FileDaemon
File Retention = 30 days # 30 days
Job Retention = 2 months # two months
AutoPrune = yes # Prune expired Jobs/Files
}
Schedule {
Name = "Windows_Centra-bdk"
Run = Level=Full on sun at 07:10
Run = Level=Differential on mon-sat at 22:15
}
Конфигурационный файл BD на этом завершен. Переходим к конфигурации SD — описанию файла bacula-sd.conf
Ресурс Storage
Storage {
# имя для SD
Name = backupsrv.domain.ru-sd
# порт стандартный
SDPort = 9103
# рабочая директория процесса(для статус файлов)
WorkingDirectory = "/var/lib/bacula"
# pid будет здесь
Pid Directory = "/var/run/bacula"
# биндится на этом ip
SDAddress = 10.1.19.2
}
Ресурс Director(связь с BD описанном в конфиге bacula-dir.conf)
Director {
# имя DD, того самого, который был описан ранее
Name = backupsrv.domain.ru-dir
# пароль
Password = "StoRage_PaSSw0rD"
} Начинается описание различных девайсов, всего у меня используется 4 разных девайса. Я приведу в качестве примера два, для биллинга и для Windows.
Ресурс Device для биллинга.
Device {
# имя, о соответствии имен и паролей будет сказано ниже
Name = BGB-ST
# тип
Media Type = File
# директория где лежат файлы этого устройства(тома, volumes)
Archive Device = /backup/bgbilling
# новые тома будут обзываться согласно настроек Pool'а(здесь Vol*) см.
# конфиг DD
LabelMedia = yes;
# для устройства типа File должно быть так
Random Access = Yes;
# если устройство открыто, использовать его
AutomaticMount = yes;
# думаю понятно =)
RemovableMedia = no;
# открывать только тогда, когда стартует соответствующие задание
AlwaysOpen = no;
}
Ресурс Device для файлового сервера Windows
Device {
Name = WINDOWS-ST
Media Type = File
Archive Device = /backup/windows
LabelMedia = yes;
Random Access = Yes;
AutomaticMount = yes;
RemovableMedia = no;
AlwaysOpen = no;
}
Ресурс Messeges.
Messages {
# имя
Name = Standard
# отправлять DD = имя директора = слать все
director = backupsrv.domain.ru-dir = all
} Конфигурационный файл bconsole.conf, доступ в консоль Bacula.
Director {
Name = backupsrv.ray-com.ru-dir
DIRport = 9101
address = 10.1.19.2
Password = "bacula_paS$w0rD10*"
}
Не забудьте создать соответствующие Storage папки и назначить bacula владельцем этих папок.
Совет из комментариев
@/usr/local/etc/bacula/client.conf
@/usr/local/etc/bacula/job.conf
@/usr/local/etc/bacula/pool.conf
@/usr/local/etc/bacula/fileset.conf
Конфиги можно разделить на разные файлы,
Options { signature = MD5 compression = GZIP }
и включить компрессию.
Конфигурирование серверной части завершено.
Конфиг клиента.
Важно отметить, что каждый из клиентов должен резолвить fqdn имя сервера в его ip адрес! Обеспечте это средствами dns или пропишите в hosts!
Ресурс Director.
Director {
# имя BD
Name = backupsrv.domain.ru-dir
# пароль для доступа к BD к клиенту(указан в ресурсе Client у BD)
Password = "Fd_paSSw0rd"
}
Ресурс FileDaemon
FileDaemon {
# имя клиента
Name = bgbilling-fd
# слушаем порт 9102
FDport = 9102
WorkingDirectory = /usr/lib/bacula
Pid Directory = /var/run/bacula
FDAddress = 10.103.2.5
}
Ресурс Messeges
Messages {
Name = Standard
director = backupsrv.domain.ru = all, !skipped, !restored
append = "/var/bacula/log" = all, !skipped
}
В комментариях конфигурационных файлов я упоминал о схеме соответствия паролей и имен демонов в различных конфирурационных файлах, так вот, если вы где-то запутались — воспользуйтесь картинкой ниже.
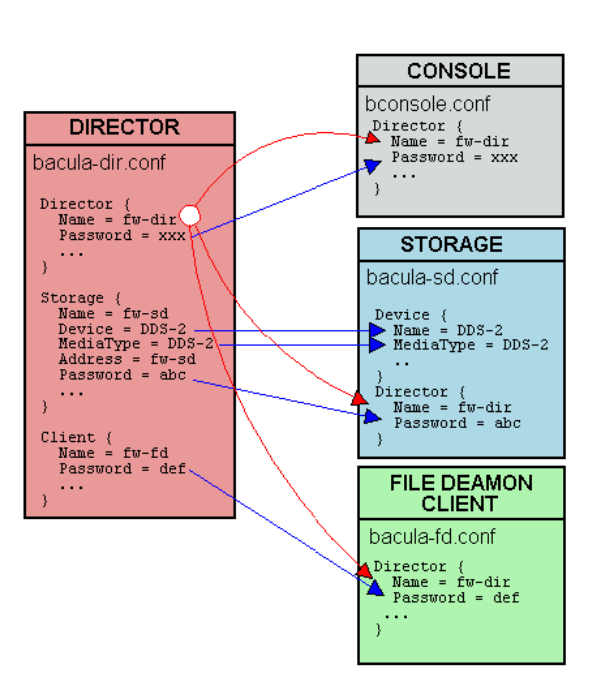
4. Пример процедуры востановления
Для мониторинга и востановления ваших резервных копий удобно использовать утилиту bat.
В Ubuntu она ставиться так
# sudo aptitude install bacula-console-qt
В портажах Gentoo я её не нашел, поэтому собирал из исходников.
Конфигурационный файл bat.conf полностью аналогичен bconsole.conf, приведенному ранее.
Итак, к примеру я хочу востановить архив базы данных биллинга за определенное число. Алгоритм, которым пользуюсь я, таков:
1. Открываем bat и находим нужное задание

2. вводим команду list files jobid=3059 для того чтобы убедиться что в задании есть нужные файлы
3. Теперь переходим в консоль(мне так удобнее просто=)). В консоли я восстановлю архив биллинга на другого клиента
$ sudo bconsole
[sudo] password for onotole:
Connecting to Director 10.1.19.2:9101
1000 OK: backupsrv.domain.ru-dir Version: 5.0.3 (30 August 2010)
Enter a period to cancel a command.
*restore
Automatically selected Catalog: MyCatalog
Using Catalog "MyCatalog"
First you select one or more JobIds that contain files
to be restored. You will be presented several methods
of specifying the JobIds. Then you will be allowed to
select which files from those JobIds are to be restored.
To select the JobIds, you have the following choices:
1: List last 20 Jobs run
2: List Jobs where a given File is saved
3: Enter list of comma separated JobIds to select
4: Enter SQL list command
5: Select the most recent backup for a client
6: Select backup for a client before a specified time
7: Enter a list of files to restore
8: Enter a list of files to restore before a specified time
9: Find the JobIds of the most recent backup for a client
10: Find the JobIds for a backup for a client before a specified time
11: Enter a list of directories to restore for found JobIds
12: Select full restore to a specified Job date
13: Cancel
Select item: (1-13): 9
Defined Clients:
1: 192.168.15.12-fd
2: 1.1.1.1-fd
3: 1.1.1.75-fd
4: ASTERISK-configs-fd
5: DHCPD-configs-fd
6: GW1-configs-fd
7: GW2-configs-fd
8: NAS-20-configs-fd
9: NAS-21-configs-fd
10: NAS-6-configs-fd
11: NAS-ololo-configs-fd
12: NS_AND_MAIL-configs-fd
13: RADIUS-ololo-configs-fd
14: VIRTSRV1-configs-fd
15: bgbilling-fd
16: configs-fd
17: domain.ru-fd
18: mydomain.ru-fd
19: tv.domain.ru-fd
20: zabbix.domain.ru-fd
Select the Client (1-20): 15
Automatically selected FileSet: bgbilling-set
+-------+-------+----------+----------------+---------------------+------------+
| JobId | Level | JobFiles | JobBytes | StartTime | VolumeName |
+-------+-------+----------+----------------+---------------------+------------+
| 3,292 | F | 1,666 | 10,874,552,420 | 2011-12-19 02:31:08 | Vol0014 |
+-------+-------+----------+----------------+---------------------+------------+
To select the JobIds, you have the following choices:
1: List last 20 Jobs run
2: List Jobs where a given File is saved
3: Enter list of comma separated JobIds to select
4: Enter SQL list command
5: Select the most recent backup for a client
6: Select backup for a client before a specified time
7: Enter a list of files to restore
8: Enter a list of files to restore before a specified time
9: Find the JobIds of the most recent backup for a client
10: Find the JobIds for a backup for a client before a specified time
11: Enter a list of directories to restore for found JobIds
12: Select full restore to a specified Job date
13: Cancel
Select item: (1-13): 12
Enter JobId to get the state to restore: 3059
Selecting jobs to build the Full state at 2011-12-06 02:28:47
You have selected the following JobId: 3059
Building directory tree for JobId(s) 3059 ... +++++++++++++++++++++++++++++++++++++++++++++
1,535 files inserted into the tree.
You are now entering file selection mode where you add (mark) and
remove (unmark) files to be restored. No files are initially added, unless
you used the "all" keyword on the command line.
Enter "done" to leave this mode.
cwd is: /
$ ls
etc/
root/
usr/
$ ls usr
usr/
$ mark usr
1,667 files marked.
$ done
Bootstrap records written to /backup/bacula-work//backupsrv.domain.ru-dir.restore.8.bsr
The job will require the following
Volume(s) Storage(s) SD Device(s)
===========================================================================
Vol0010 BGB-F BGB-ST
Volumes marked with "*" are online.
1,667 files selected to be restored.
Run Restore job
JobName: restore
Bootstrap: /backup/bacula-work//backupsrv.domain.ru-dir.restore.8.bsr
Where: /usr/restore
Replace: always
FileSet: bgbilling-set
Backup Client: bgbilling-fd
Restore Client: bgbilling-fd
Storage: BGB-F
When: 2011-12-26 15:01:38
Catalog: MyCatalog
Priority: 10
Plugin Options: *None*
OK to run? (yes/mod/no): mod
Parameters to modify:
1: Level
2: Storage
3: Job
4: FileSet
5: Restore Client
6: When
7: Priority
8: Bootstrap
9: Where
10: File Relocation
11: Replace
12: JobId
13: Plugin Options
Select parameter to modify (1-13): 5
The defined Client resources are:
1: bgbilling-fd
2: GW1-configs-fd
3: GW2-configs-fd
4: NAS-6-configs-fd
5: NAS-20-configs-fd
6: NAS-21-configs-fd
7: NAS-ololo-configs-fd
8: DHCPD-configs-fd
9: ASTERISK-configs-fd
10: NS_AND_MAIL-configs-fd
11: VIRTSRV1-configs-fd
12: mydomain.ru-fd
13: tv.domain.ru-fd
14: domain.ru-fd
15: 1.1.1.1-fd
16: 1.1.1.75-fd
17: zabbix.domain.ru-fd
18: 192.168.15.12-fd
Select Client (File daemon) resource (1-18): 2
Run Restore job
JobName: restore
Bootstrap: /backup/bacula-work//backupsrv.ray-com.ru-dir.restore.8.bsr
Where: /usr/restore
Replace: always
FileSet: bgbilling-set
Backup Client: bgbilling-fd
Restore Client: GW1-configs-fd
Storage: BGB-F
When: 2011-12-26 15:01:38
Catalog: MyCatalog
Priority: 10
Plugin Options: *None*
OK to run? (yes/mod/no): yes
Job queued. JobId=3453
You have messages.
*
4. Ждем успешного выполнения задания, статус можно отслеживать в том же bat
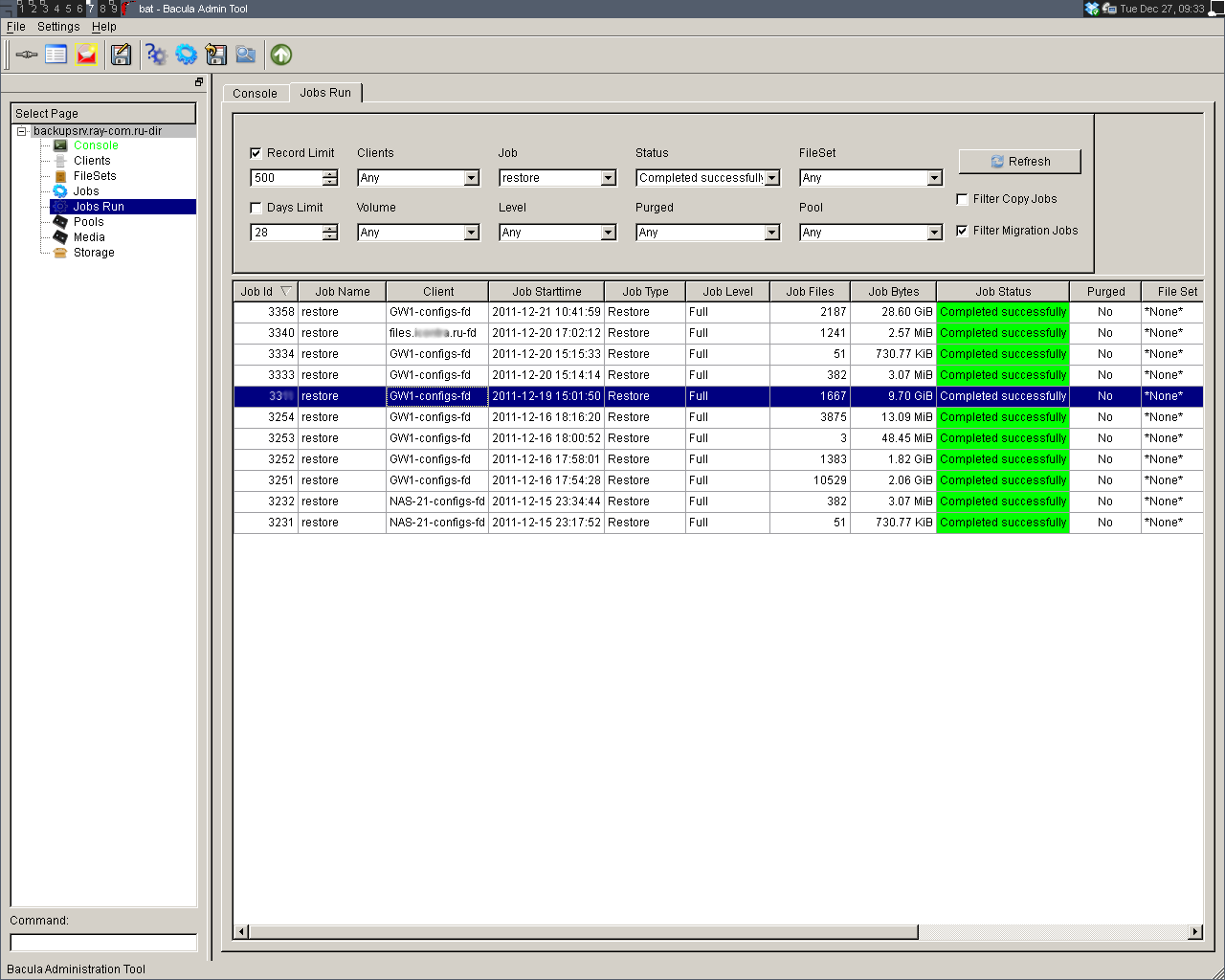
Еще несколько скриншотов
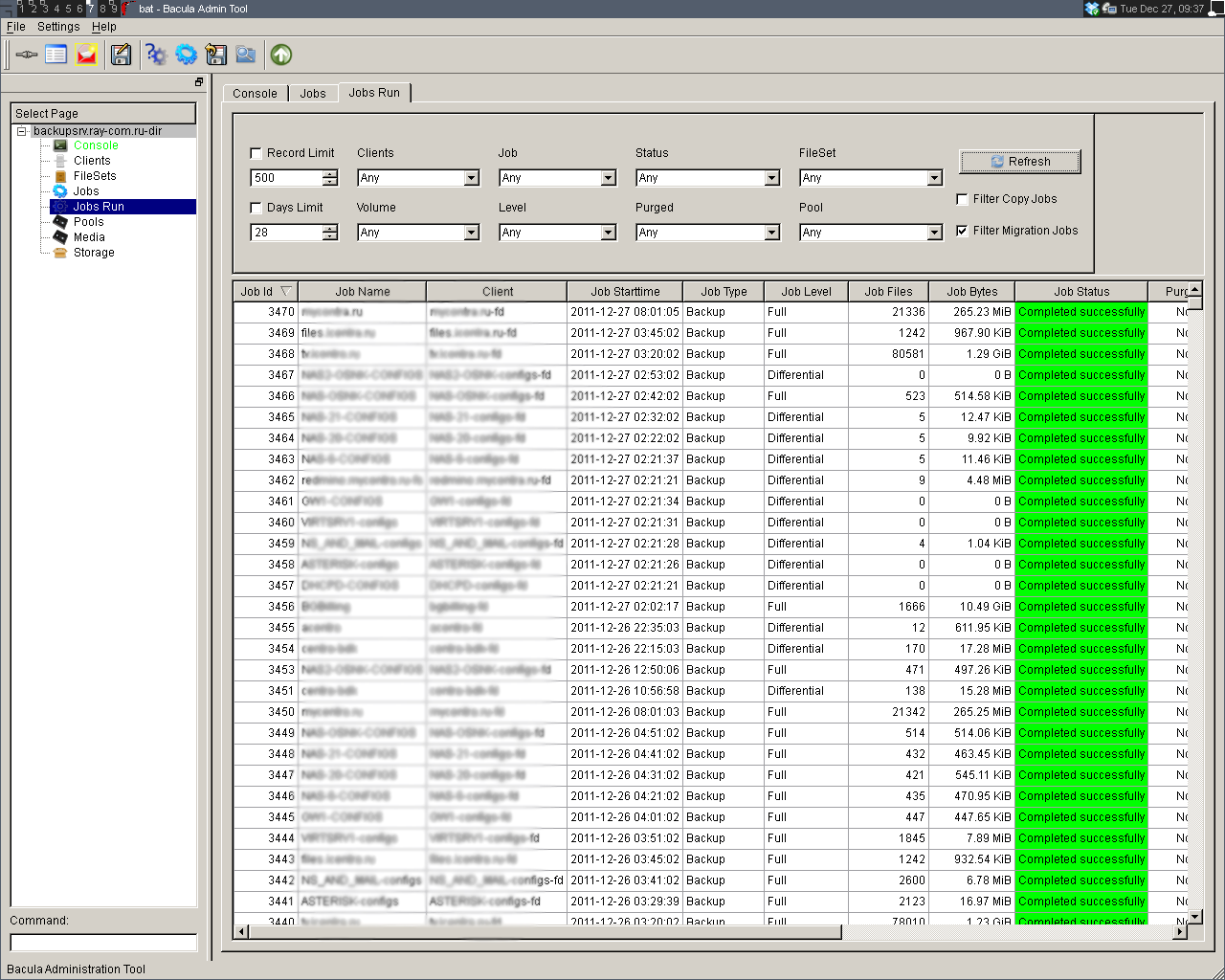
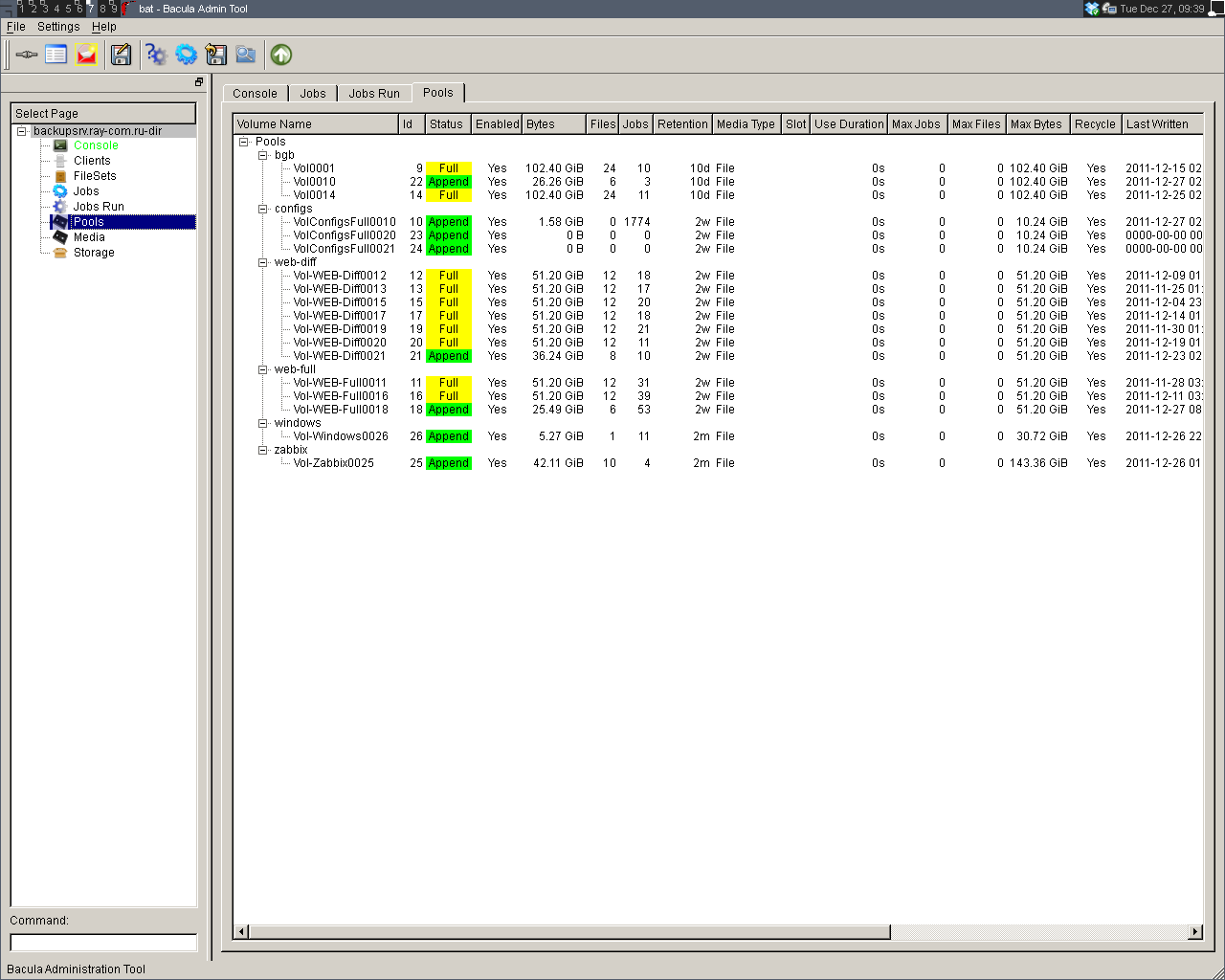
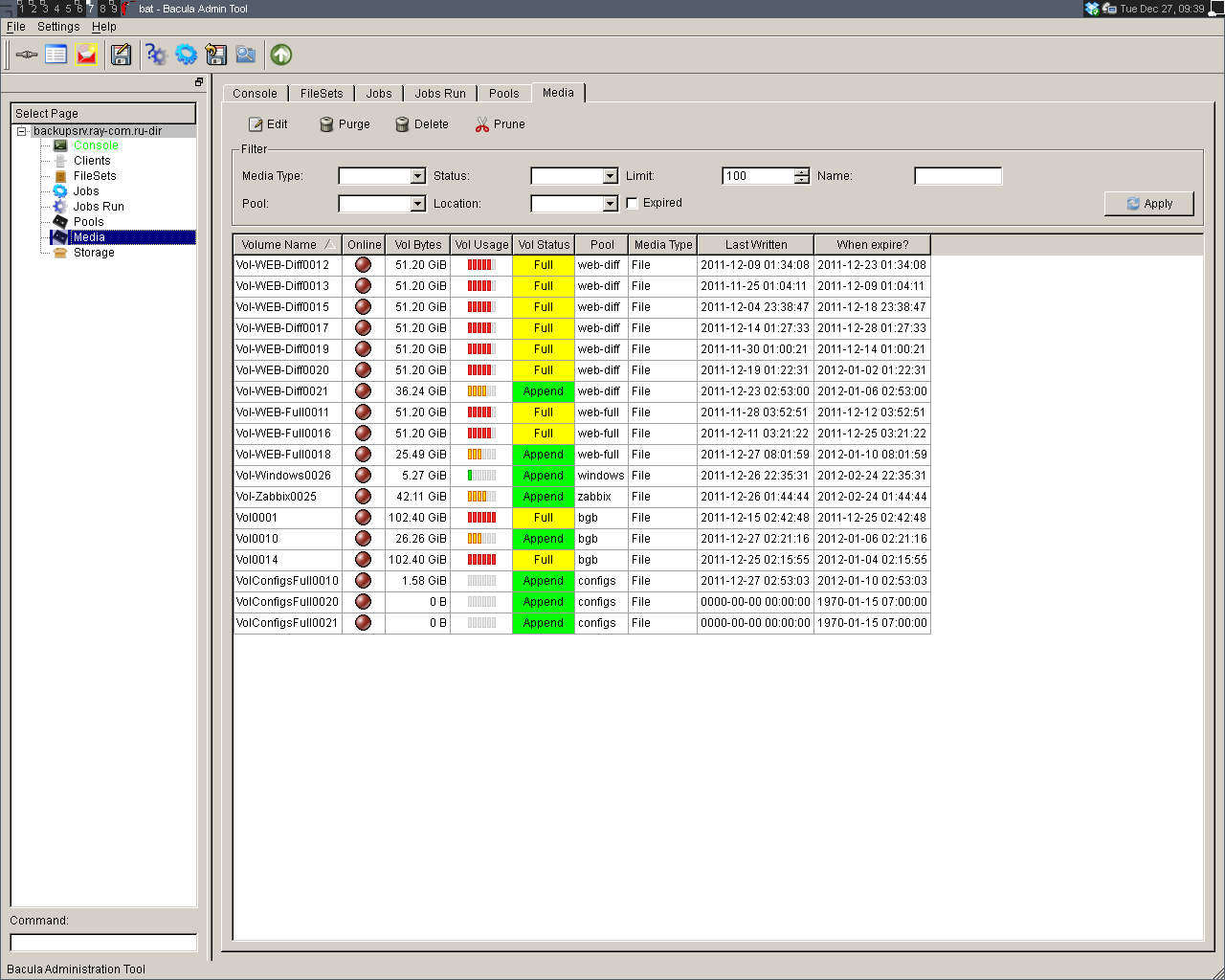
Благодарю всех кто дочитал мой опус до конца.
В качестве завершения позволю себе еще несколько советов.
Важно не только делать бекапы и отслеживать что они выполнились без ошибок, но так же и регулярно их разворачивать и проверять. Подобная практика даёт еще +100 к указанным в начале спокойствию, крепкости нервов и здоровью. Так же очень хорошей практикой является регулярное резервное копирование базы данных bacula и bsr файлов.
С наступающим Новым Годом вас!!!
Использованые источники:
1. www.ibm.com/developerworks/ru/library/l-Backup_4
2. www.bacula.org/en/?page=documentation