From Wikipedia, the free encyclopedia
«Page size» redirects here. For information on paper, see Paper size.
A page, memory page, or virtual page is a fixed-length contiguous block of virtual memory, described by a single entry in the page table. It is the smallest unit of data for memory management in a virtual memory operating system. Similarly, a page frame is the smallest fixed-length contiguous block of physical memory into which memory pages are mapped by the operating system.[1][2][3]
A transfer of pages between main memory and an auxiliary store, such as a hard disk drive, is referred to as paging or swapping.[4]
Explanation[edit]
Computer memory is divided into pages so that information can be found more quickly.
The concept is named by analogy to the pages of a printed book. If a reader wanted to find, for example, the 5,000th word in the book, they could count from the first word. This would be time-consuming. It would be much faster if the reader had a listing of how many words are on each page. From this listing they could determine which page the 5,000th word appears on, and how many words to count on that page. This listing of the words per page of the book is analogous to a page table of a computer file system.[5]
Page size[edit]
Page size trade-off[edit]
Page size is usually determined by the processor architecture. Traditionally, pages in a system had uniform size, such as 4,096 bytes. However, processor designs often allow two or more, sometimes simultaneous, page sizes due to its benefits. There are several points that can factor into choosing the best page size.[6]
Page table size[edit]
A system with a smaller page size uses more pages, requiring a page table that occupies more space. For example, if a 232 virtual address space is mapped to 4 KiB (212 bytes) pages, the number of virtual pages is 220 = (232 / 212). However, if the page size is increased to 32 KiB (215 bytes), only 217 pages are required. A multi-level paging algorithm can decrease the memory cost of allocating a large page table for each process by further dividing the page table up into smaller tables, effectively paging the page table.
TLB usage[edit]
Since every access to memory must be mapped from virtual to physical address, reading the page table every time can be quite costly. Therefore, a very fast kind of cache, the translation lookaside buffer (TLB), is often used. The TLB is of limited size, and when it cannot satisfy a given request (a TLB miss) the page tables must be searched manually (either in hardware or software, depending on the architecture) for the correct mapping. Larger page sizes mean that a TLB cache of the same size can keep track of larger amounts of memory, which avoids the costly TLB misses.
Internal fragmentation[edit]
Rarely do processes require the use of an exact number of pages. As a result, the last page will likely only be partially full, wasting some amount of memory. Larger page sizes lead to a large amount of wasted memory, as more potentially unused portions of memory are loaded into the main memory. Smaller page sizes ensure a closer match to the actual amount of memory required in an allocation.
As an example, assume the page size is 1024 KiB. If a process allocates 1025 KiB, two pages must be used, resulting in 1023 KiB of unused space (where one page fully consumes 1024 KiB and the other only 1 KiB).
Disk access[edit]
When transferring from a rotational disk, much of the delay is caused by seek time, the time it takes to correctly position the read/write heads above the disk platters. Because of this, large sequential transfers are more efficient than several smaller transfers. Transferring the same amount of data from disk to memory often requires less time with larger pages than with smaller pages.
Getting page size programmatically[edit]
Most operating systems allow programs to discover the page size at runtime. This allows programs to use memory more efficiently by aligning allocations to this size and reducing overall internal fragmentation of pages.
Unix and POSIX-based operating systems[edit]
Unix and POSIX-based systems may use the system function sysconf(),[7][8][9][10][11] as illustrated in the following example written in the C programming language.
#include <stdio.h> #include <unistd.h> /* sysconf(3) */ int main(void) { printf("The page size for this system is %ld bytes.\n", sysconf(_SC_PAGESIZE)); /* _SC_PAGE_SIZE is OK too. */ return 0; }
In many Unix systems, the command-line utility getconf can be used.[12][13][14]
For example, getconf PAGESIZE will return the page size in bytes.
Windows-based operating systems[edit]
Win32-based operating systems, such as those in the Windows 9x and Windows NT families, may use the system function GetSystemInfo()[15][16] from kernel32.dll.
#include <stdio.h> #include <windows.h> int main(void) { SYSTEM_INFO si; GetSystemInfo(&si); printf("The page size for this system is %u bytes.\n", si.dwPageSize); return 0; }
Multiple page sizes[edit]
Some instruction set architectures can support multiple page sizes, including pages significantly larger than the standard page size. The available page sizes depend on the instruction set architecture, processor type, and operating (addressing) mode. The operating system selects one or more sizes from the sizes supported by the architecture. Note that not all processors implement all defined larger page sizes. This support for larger pages (known as «huge pages» in Linux, «superpages» in FreeBSD, and «large pages» in Microsoft Windows and IBM AIX terminology) allows for «the best of both worlds», reducing the pressure on the TLB cache (sometimes increasing speed by as much as 15%) for large allocations while still keeping memory usage at a reasonable level for small allocations.
| Architecture | Smallest page size | Larger page sizes |
|---|---|---|
| 32-bit x86[18] | 4 KiB | 4 MiB in PSE mode, 2 MiB in PAE mode[19] |
| x86-64[18] | 4 KiB | 2 MiB, 1 GiB (only when the CPU has PDPE1GB flag)
|
| IA-64 (Itanium)[20] | 4 KiB | 8 KiB, 64 KiB, 256 KiB, 1 MiB, 4 MiB, 16 MiB, 256 MiB[19] |
| Power ISA[21] | 4 KiB | 64 KiB, 16 MiB, 16 GiB |
| SPARC v8 with SPARC Reference MMU[22] | 4 KiB | 256 KiB, 16 MiB |
| UltraSPARC Architecture 2007[23] | 8 KiB | 64 KiB, 512 KiB (optional), 4 MiB, 32 MiB (optional), 256 MiB (optional), 2 GiB (optional), 16 GiB (optional) |
| ARMv7[24] | 4 KiB | 64 KiB, 1 MiB («section»), 16 MiB («supersection») (defined by a particular implementation) |
| AArch64[25] | 4 KiB | 16 KiB, 64 KiB, 2 MiB, 32 MiB, 512 MiB, 1 GiB |
| RISCV32[26] | 4 KiB | 4 MiB («megapage») |
| RISCV64[26] | 4 KiB | 2 MiB («megapage»), 1 GiB («gigapage»), 512 GiB («terapage», only for CPUs with 43-bit address space or more), 256 TiB («petapage», only for CPUs with 57-bit address space or more), |
Starting with the Pentium Pro, and the AMD Athlon, x86 processors support 4 MiB pages (called Page Size Extension) (2 MiB pages if using PAE) in addition to their standard 4 KiB pages; newer x86-64 processors, such as AMD’s newer AMD64 processors and Intel’s Westmere[27] and later Xeon processors can use 1 GiB pages in long mode. IA-64 supports as many as eight different page sizes, from 4 KiB up to 256 MiB, and some other architectures have similar features.[specify]
Larger pages, despite being available in the processors used in most contemporary personal computers, are not in common use except in large-scale applications, the applications typically found in large servers and in computational clusters, and in the operating system itself. Commonly, their use requires elevated privileges, cooperation from the application making the large allocation (usually setting a flag to ask the operating system for huge pages), or manual administrator configuration; operating systems commonly, sometimes by design, cannot page them out to disk.
However, SGI IRIX has general-purpose support for multiple page sizes. Each individual process can provide hints and the operating system will automatically use the largest page size possible for a given region of address space.[28] Later work proposed transparent operating system support for using a mix of page sizes for unmodified applications through preemptible reservations, opportunistic promotions, speculative demotions, and fragmentation control.[29]
Linux has supported huge pages on several architectures since the 2.6 series via the hugetlbfs filesystem[30] and without hugetlbfs since 2.6.38.[31] Windows Server 2003 (SP1 and newer), Windows Vista and Windows Server 2008 support huge pages under the name of large pages.[32] Windows 2000 and Windows XP support large pages internally, but do not expose them to applications.[33] Beginning with version 9, Solaris supports large pages on SPARC and x86.[34][35]
FreeBSD 7.2-RELEASE features superpages.[36] Note that until recently in Linux, applications needed to be modified in order to use huge pages. The 2.6.38 kernel introduced support for transparent use of huge pages.[31] On Linux kernels supporting transparent huge pages, as well as FreeBSD and Solaris, applications take advantage of huge pages automatically, without the need for modification.[36]
See also[edit]
- Page fault
- Page table
- Memory paging
- Virtual memory
- Zero page — a (often 256-bytes large[37][38]) memory area at the very start of a processor’s address room
- Zero page (CP/M) — a 256-byte[38] data structure at the start of a program
References[edit]
- ^ Christopher Kruegel (2012-12-03). «Operating Systems (CS170-08 course)» (PDF). cs.ucsb.edu. Archived (PDF) from the original on 2016-08-10. Retrieved 2016-06-13.
- ^ Martin C. Rinard (1998-08-22). «Operating Systems Lecture Notes, Lecture 9. Introduction to Paging». people.csail.mit.edu. Archived from the original on 2016-06-01. Retrieved 2016-06-13.
- ^ «Virtual Memory: pages and page frames». cs.miami.edu. 2012-10-31. Archived from the original on 2016-06-11. Retrieved 2016-06-13.
- ^ Belzer, Jack; Holzman, Albert G.; Kent, Allen, eds. (1981), «Virtual memory systems», Encyclopedia of computer science and technology, vol. 14, CRC Press, p. 32, ISBN 0-8247-2214-0
- ^ Kazemi, Darius (2019-01-11). «RFC-11». 365 RFCs.
- ^ Weisberg, P.; Wiseman, Y. (2009-08-10). Using 4KB Page Size for Virtual Memory is Obsolete. 2009 IEEE International Conference on Information Reuse & Integration. CiteSeerX 10.1.1.154.2023. doi:10.1109/IRI.2009.5211562.
- ^
limits.h– Base Definitions Reference, The Single UNIX Specification, Version 4 from The Open Group - ^
sysconf– System Interfaces Reference, The Single UNIX Specification, Version 4 from The Open Group - ^
sysconf(3)– Linux Library Functions Manual - ^
sysconf(3)– Darwin and macOS Library Functions Manual - ^
sysconf(3C)– Solaris 11.4 Basic Library Functions Reference Manual - ^
getconf– Shell and Utilities Reference, The Single UNIX Specification, Version 4 from The Open Group - ^
getconf(1)– Linux User Commands Manual - ^
getconf(1)– Darwin and macOS General Commands Manual - ^ «GetSystemInfo function». Microsoft. 2021-10-13.
- ^ «SYSTEM_INFO structure». Microsoft. 2022-09-23.
- ^ «Hugepages — Debian Wiki». Wiki.debian.org. 2011-06-21. Retrieved 2014-02-06.
- ^ a b «Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C & 3D): System Programming Guide» (PDF). December 2016. p. 4-2.
- ^ a b «Documentation/vm/hugetlbpage.txt». Linux kernel documentation. kernel.org. Retrieved 2014-02-06.
- ^ «Intel Itanium Architecture Software Developer’s Manual Volume 2: System Architecture» (PDF). May 2010. p. 2:58.
- ^ IBM Power Systems Performance Guide: Implementing and Optimizing. IBM Redbooks. February 2013. ISBN 978-0-7384-3766-8. Retrieved 2014-03-17.
- ^ «The SPARC Architecture Manual, Version 8». 1992. p. 249.
- ^ «UltraSPARC Architecture 2007» (PDF). 2010-09-27. p. 427.
- ^ «ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition». Arm. 2014-05-20. p. B3-1324.
- ^ «Translation granule». Learn the architecture — AArch64 memory management. Arm. Retrieved 2022-08-19.
- ^ a b Waterman, Andrew; Asanović, Krste; Hauser, John (2021). The RISC-V Instruction Set Manual Volume II: Privileged Architecture (PDF). pp. 79–87.
- ^ «The Intel Xeon 5670: Six Improved Cores». AnandTech. Retrieved 2012-11-03.
- ^ «General Purpose Operating System Support for Multiple Page Sizes» (PDF). static.usenix.org. Retrieved 2012-11-02.
- ^ Navarro, Juan; Iyer, Sitararn; Druschel, Peter; Cox, Alan (December 2002). Practical, Transparent Operating System Support for Superpages (PDF). 5th Usenix Symposium on Operating Systems Design and Implementation.
- ^ «Pages — dankwiki, the wiki of nick black». Retrieved 2023-06-17.
- ^ a b Corbet, Jonathan. «Transparent huge pages in 2.6.38». LWN. Retrieved 2011-03-02.
- ^ «Large-Page Support». Microsoft Docs. 2018-05-08.
- ^ «AGP program may hang when using page size extension on Athlon processor». Support.microsoft.com. 2007-01-27. Retrieved 2012-11-03.
- ^ «Supporting Multiple Page Sizes in the Solaris Operating System» (PDF). Sun BluePrints Online. Sun Microsystems. Archived from the original (PDF) on 2006-03-12. Retrieved 2008-01-19.
- ^ «Supporting Multiple Page Sizes in the Solaris Operating System Appendix» (PDF). Sun BluePrints Online. Sun Microsystems. Archived from the original (PDF) on 2007-01-01. Retrieved 2008-01-19.
- ^ a b «FreeBSD 7.2-RELEASE Release Notes». FreeBSD Foundation. Retrieved 2009-05-03.
- ^ «2.3.1 Read-Only Memory / 2.3.2 Program Random Access Memory». MCS-4 Assembly Language Programming Manual — The INTELLEC 4 Microcomputer System Programming Manual (PDF) (Preliminary ed.). Santa Clara, California, USA: Intel Corporation. December 1973. pp. 2-3–2-4. MCS-030-1273-1. Archived (PDF) from the original on 2020-03-01. Retrieved 2020-03-02.
[…] ROM is further divided into pages, each of which contains 256 bytes. Thus locations 0 through 255 comprise page 0 of ROM, location 256 through 511 comprise page 1 and so on. […] Program random access memory (RAM) is organized exactly like ROM. […]
- ^ a b «1. Introduction: Segment Alignment». 8086 Family Utilities — User’s Guide for 8080/8085-Based Development Systems (PDF). Revision E (A620/5821 6K DD ed.). Santa Clara, California, USA: Intel Corporation. May 1982 [1980, 1978]. p. 1-6. Order Number: 9800639-04. Archived (PDF) from the original on 2020-02-29. Retrieved 2020-02-29.
Further reading[edit]
- Dandamudi, Sivarama P. (2003). Fundamentals of Computer Organization and Design (1st ed.). Springer. pp. 740–741. ISBN 0-387-95211-X.
В этом уроке я вам расскажу про страницы памяти. Вся память используемая процессами для работы делится на маленькие кусочки — страницы (page).
Страницы памяти
Вы уже знаете что память, потребляемая процессами, состоит из оперативной памяти и файла подкачки. При этом процессы работают с виртуальной памятью и не задумываются, где физически находятся страницы памяти.
Преобразование виртуальной памяти в физическую происходит на уровне страниц. То есть виртуальная страница должна ссылаться на страницу физической памяти. Так как страница памяти это неделимая единица, то не может получиться так, чтобы часть страницы была в оперативной памяти, а другая часть в файле подкачки.
Размер страниц бывает разным, они бывают малые = 4 КБ и большие = 2 МБ. Номера страниц памяти записываются в особую таблицу. При этом малые помещаются в в одну таблицу, а большие в другую.
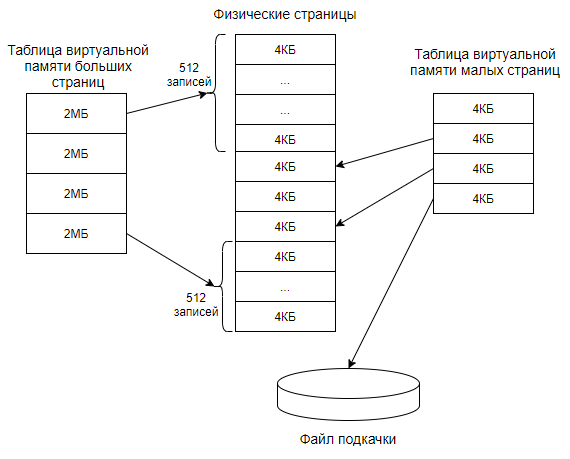
Особенности больших страниц
Преимущество больших страниц в следующем. Скорость преобразования адресов при обращениях к данным. Так как число больших страниц меньше, то таблица страниц состоит из меньшего числа элементов, что увеличивает скорость.
А недостатки такие. Большая страница занимает 512 смежных малых страниц. Из-за фрагментации памяти может возникнуть ситуация, когда в системе просто не останется столько смежных свободных страниц. И попытка выделения одной большой страницы завершится неудачей. А для малых страниц таких проблем нет. Еще одним недостатком является то, что в одной большой странице памяти может быть записан и код и данные. Обычно код доступен только на чтение, а данные на чтение и запись. Но так как права назначаются на страницу целиком, то код тоже станет доступен на запись.
Также существует некоторая особенность больших страниц. Файл подкачки не поддерживает такие страницы. Из этого следует что они всегда находятся в оперативной памяти.
Существуют также огромные страницы (huge page) = 1 ГБ. В Windows 10 большие страницы превращаются в огромные, если нужно выделить сразу большой блок памяти, а именно больше 1 ГБ. Например, выделение блока размером 1040 Мбайт приведет к использованию одной огромной (1024 МБ) и 8 больших страниц (по 2 МБ).
Вернуться к оглавлению
Сводка

Имя статьи
Страницы памяти
Описание
В этом уроке я вам расскажу про страницы памяти. Вся память используемая процессами для работы делится на маленькие кусочки — страницы (page)
Организация виртуальной памяти
Время на прочтение
14 мин
Количество просмотров 69K
 Привет, Хабрахабр!
Привет, Хабрахабр!
В предыдущей статье я рассказал про vfork() и пообещал рассказать о реализации вызова fork() как с поддержкой MMU, так и без неё (последняя, само собой, со значительными ограничениями). Но прежде, чем перейти к подробностям, будет логичнее начать с устройства виртуальной памяти.
Конечно, многие слышали про MMU, страничные таблицы и TLB. К сожалению, материалы на эту тему обычно рассматривают аппаратную сторону этого механизма, упоминая механизмы ОС только в общих чертах. Я же хочу разобрать конкретную программную реализацию в проекте Embox. Это лишь один из возможных подходов, и он достаточно лёгок для понимания. Кроме того, это не музейный экспонат, и при желании можно залезть “под капот” ОС и попробовать что-нибудь поменять.
Введение
Любая программная система имеет логическую модель памяти. Самая простая из них — совпадающая с физической, когда все программы имеют прямой доступ ко всему адресному пространству.
При таком подходе программы имеют доступ ко всему адресному пространству, не только могут “мешать” друг другу, но и способны привести к сбою работы всей системы — для этого достаточно, например, затереть кусок памяти, в котором располагается код ОС. Кроме того, иногда физической памяти может просто не хватить для того, чтобы все нужные процессы могли работать одновременно. Виртуальная память — один из механизмов, позволяющих решить эти проблемы. В данной статье рассматривается работа с этим механизмом со стороны операционной системы на примере ОС Embox. Все функции и типы данных, упомянутые в статье, вы можете найти в исходном коде нашего проекта.
Будет приведён ряд листингов, и некоторые из них слишком громоздки для размещения в статье в оригинальном виде, поэтому по возможности они будут сокращены и адаптированы. Также в тексте будут возникать отсылки к функциям и структурам, не имеющим прямого отношения к тематике статьи. Для них будет дано краткое описание, а более полную информацию о реализации можно найти на вики проекта.
Общие идеи
Виртуальная память — это концепция, которая позволяет уйти от использования физических адресов, используя вместо них виртуальные, и это даёт ряд преимуществ:
- Расширение реального адресного пространства. Часть виртуальной памяти может быть вытеснена на жёсткий диск, и это позволяет программам использовать больше оперативной памяти, чем есть на самом деле.
- Создание изолированных адресных пространств для различных процессов, что повышает безопасность системы, а также решает проблему привязанности программы к определённым адресам памяти.
- Задание различных свойств для разных участков участков памяти. Например, может существовать неизменяемый участок памяти, видный нескольким процессам.
При этом вся виртуальная память делится на участки памяти постоянного размера, называемые страницами.
Аппаратная поддержка
MMU — это компонент аппаратного обеспечения компьютера, через который “проходят” все запросы к памяти, совершаемые процессором. Задача этого устройства — трансляция адресов, управление кэшированием памяти и её защита.
Обращение к памяти хорошо описанно в этой хабростатье. Происходит оно следующим образом:
Процессор подаёт на вход MMU виртуальный адрес
Если MMU выключено или если виртуальный адрес попал в нетранслируемую область, то физический адрес просто приравнивается к виртуальному
Если MMU включено и виртуальный адрес попал в транслируемую область, производится трансляция адреса, то есть замена номера виртуальной страницы на номер соответствующей ей физической страницы (смещение внутри страницы одинаковое):
Если запись с нужным номером виртуальной страницы есть в TLB [Translation Lookaside Buffer], то номер физической страницы берётся из нее же
Если нужной записи в TLB нет, то приходится искать ее в таблицах страниц, которые операционная система размещает в нетранслируемой области ОЗУ (чтобы не было промаха TLB при обработке предыдущего промаха). Поиск может быть реализован как аппаратно, так и программно — через обработчик исключения, называемого страничной ошибкой (page fault). Найденная запись добавляется в TLB, после чего команда, вызвавшая промах TLB, выполняется снова.
Таким образом, при обращении программы к тому или иному участку памяти трансляция адресов производится аппаратно. Программная часть работы с MMU — формирование таблиц страниц и работа с ними, распределение участков памяти, установка тех или иных флагов для страниц, а также обработка page fault, ошибки, которая происходит при отсутствии страницы в отображении.
В тексте статьи в основном будет рассматриваться трёхуровневая модель памяти, но это не является принципиальным ограничением: для получения модели с бóльшим количеством уровней можно действовать аналогичным образом, а особенности работы с меньшим количеством уровней (как, например, в архитектуре x86 — там всего два уровня) будут рассмотрены отдельно.
Программная поддержка
Для приложений работа с виртуальной памятью незаметна. Это прозрачность обеспечивается наличием в ядре ОС соответствующей подсистемы, осуществляющей следующие действия:
- Выделение физических страниц из некоторого зарезервированного участка памяти
- Внесение соответствующих изменений в таблицы виртуальной памяти
- Сопоставление участков виртуальной памяти с процессами, выделившими их
- Проецирование региона физической памяти на виртуальный адрес
Данные механизмы будут рассмотрены подробно ниже, после введения нескольких базовых определений.
Виртуальный адрес
Page Global Directory (далее — PGD) — таблица (здесь и далее — то же самое, что директория) самого высокого уровня, каждая запись в ней — ссылка на Page Middle Directory (PMD), записи которой, в свою очередь, ссылаются на таблицу Page Table Entry (PTE). Записи в PTE ссылаются на реальные физические адреса, а также хранят флаги состояния страницы.
То есть, при трёхуровневой иерархии памяти виртуальный адрес будет выглядеть так:

Значения полей PGD, PMD и PTE — это индексы в соответствующих таблицах (то есть сдвиги от начала этих таблиц), а offset — это смещение адреса от начала страницы.
В зависимости от архитектуры и режима страничной адресации, количество битов, выделяемых для каждого из полей, может отличаться. Кроме того, сама страничная иерархия может иметь число уровней, отличное от трёх: например, на x86 нет PMD.
Для обеспечения переносимости мы задали границы этих полей с помощью констант: MMU_PGD_SHIFT, MMU_PMD_SHIFT, MMU_PTE_SHIFT, которые в приведённой выше схеме равны 24, 18 и 12 соответственно их определение дано в заголовочном файле src/include/hal/mmu.h. В дальнейшем будет рассматриваться именно этот пример.
На основании сдвигов PGD, PMD и PTE вычисляются соответствующие маски адресов.
#define MMU_PTE_ENTRIES (1UL << (MMU_PMD_SHIFT - MMU_PTE_SHIFT))
#define MMU_PTE_MASK ((MMU_PTE_ENTRIES - 1) << MMU_PTE_SHIFT)
#define MMU_PTE_SIZE (1UL << MMU_PTE_SHIFT)
#define MMU_PAGE_SIZE (1UL << MMU_PTE_SHIFT)
#define MMU_PAGE_MASK (MMU_PAGE_SIZE - 1)Эти макросы даны в том же заголовочном файле.
Для работы с виртуальной таблицами виртуальной памяти в некоторой области памяти хранятся указатели на все PGD. При этом каждая задача хранит в себе контекст struct mmu_context, который, по сути, является индексом в этой таблице. Таким образом, к каждой задаче относится одна таблица PGD, которую можно определить с помощью mmu_get_root(ctx).
Страницы и работа с ними
Размер страницы
В реальных (то есть не в учебных) системах используются страницы от 512 байт до 64 килобайт. Чаще всего размер страницы определяется архитектурой и является фиксированным для всей системы, например — 4 KiB.
С одной стороны, при меньшем размере страницы память меньше фрагментируется. Ведь наименьшая единица виртуальной памяти, которая может быть выделена процессу — это одна страница, а программам очень редко требуется целое число страниц. А значит, в последней странице, которую запросил процесс, скорее всего останется неиспользуемая память, которая, тем не менее, будет выделена, а значит — использована неэффективно.
С другой стороны, чем меньше размер страницы, тем больше размер страничных таблиц. Более того, при отгрузке на HDD и при чтении страниц с HDD быстрее получится записать несколько больших страниц, чем много маленьких такого же суммарного размера.
Отдельного внимания заслуживают так называемые большие страницы: huge pages и large pages[вики].
| Платформа | Размер обычной страницы | Размер страницы максимально возможного размера |
| x86 | 4KB | 4MB |
| x86_64 | 4KB | 1GB |
| IA-64 | 4KB | 256MB |
| PPC | 4KB | 16GB |
| SPARC | 8KB | 2GB |
| ARMv7 | 4KB | 16MB |
Действительно, при использовании таких страниц накладные расходы памяти повышаются. Тем не менее, прирост производительности программ в некоторых случаях может доходить до 10%[ссылка], что объясняется меньшим размером страничных директорий и более эффективной работой TLB.
В дальнейшем речь пойдёт о страницах обычного размера.
Устройство Page Table Entry
В реализации проекта Embox тип mmu_pte_t — это указатель.
Каждая запись PTE должна ссылаться на некоторую физическую страницу, а каждая физическая страница должна быть адресована какой-то записью PTE. Таким образом, в mmu_pte_t незанятыми остаются MMU_PTE_SHIFT бит, которые можно использовать для сохранения состояния страницы. Конкретный адрес бита, отвечающего за тот или иной флаг, как и набор флагов в целом, зависит от архитектуры.
Вот некоторые из флагов:
- MMU_PAGE_WRITABLE — Можно ли менять страницу
- MMU_PAGE_SUPERVISOR — Пространство супер-пользователя/пользователя
- MMU_PAGE_CACHEABLE — Нужно ли кэшировать
- MMU_PAGE_PRESENT — Используется ли данная запись директории
Снимать и устанавливать эти флаги можно с помощью следующих функций:
mmu_pte_set_writable(), mmu_pte_set_usermode(), mmu_pte_set_cacheable(), mmu_pte_set_executable()
Например: mmu_pte_set_writable(pte_pointer, 0)
Можно установить сразу несколько флагов:
void vmem_set_pte_flags(mmu_pte_t *pte, vmem_page_flags_t flags)Здесь vmem_page_flags_t — 32-битное значение, и соответствующие флаги берутся из первых MMU_PTE_SHIFT бит.
Трансляция виртуального адреса в физический
Как уже писалось выше, при обращении к памяти трансляция адресов производится аппаратно, однако, явный доступ к физическим адресам может быть полезен в ряде случаев. Принцип поиска нужного участка памяти, конечно, такой же, как и в MMU.
Для того, чтобы получить из виртуального адреса физический, необходимо пройти по цепочке таблиц PGD, PMD и PTE. Функция vmem_translate() и производит эти шаги.
Сначала проверяется, есть ли в PGD указатель на директорию PMD. Если это так, то вычисляется адрес PMD, а затем аналогичным образом находится PTE. После выделения физического адреса страницы из PTE необходимо добавить смещение, и после этого будет получен искомый физический адрес.
Исходный код функции vmem_translate
mmu_paddr_t vmem_translate(mmu_ctx_t ctx, mmu_vaddr_t virt_addr) {
size_t pgd_idx, pmd_idx, pte_idx;
mmu_pgd_t *pgd;
mmu_pmd_t *pmd;
mmu_pte_t *pte;
pgd = mmu_get_root(ctx);
vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx);
if (!mmu_pgd_present(pgd + pgd_idx)) {
return 0;
}
pmd = mmu_pgd_value(pgd + pgd_idx);
if (!mmu_pmd_present(pmd + pmd_idx)) {
return 0;
}
pte = mmu_pmd_value(pmd + pmd_idx);
if (!mmu_pte_present(pte + pte_idx)) {
return 0;
}
return mmu_pte_value(pte + pte_idx) + (virt_addr & MMU_PAGE_MASK);
}
Пояснения к коду функции.
mmu_paddr_t — это физический адрес страницы, назначение mmu_ctx_t уже обсуждалось выше в разделе “Виртуальный адрес”.
С помощью функции vmem_get_idx_from_vaddr() находятся сдвиги в таблицах PGD, PMD и PTE.
void vmem_get_idx_from_vaddr(mmu_vaddr_t virt_addr, size_t *pgd_idx, size_t *pmd_idx, size_t *pte_idx) {
*pgd_idx = ((uint32_t) virt_addr & MMU_PGD_MASK) >> MMU_PGD_SHIFT;
*pmd_idx = ((uint32_t) virt_addr & MMU_PMD_MASK) >> MMU_PMD_SHIFT;
*pte_idx = ((uint32_t) virt_addr & MMU_PTE_MASK) >> MMU_PTE_SHIFT;
}
Работа с Page Table Entry
Для работы с записей в таблице страниц, а так же с самими таблицами, есть ряд функций:
Эти функции возвращают 1, если у соответствующей структуры установлен бит MMU_PAGE_PRESENT
int mmu_pgd_present(mmu_pgd_t *pgd);
int mmu_pmd_present(mmu_pmd_t *pmd);
int mmu_pte_present(mmu_pte_t *pte);Page Fault
Page fault — это исключение, возникающее при обращении к странице, которая не загружена в физическую память — или потому, что она была вытеснена, или потому, что не была выделена.
В операционных системах общего назначения при обработке этого исключения происходит поиск нужной странице на внешнем носителе (жёстком диске, к примеру).
В нашей системе все страницы, к которым процесс имеет доступ, считаются присутствующими в оперативной памяти. Так, например, соответствующие сегменты .text, .data, .bss; куча; и так далее отображаются в таблицы при инициализации процесса. Данные, связанные с потоками (например, стэк), отображаются в таблицы процесса при создании потоков.
Выталкивание страниц во внешнюю память и их чтение в случае page fault не реализовано. С одной стороны, это лишает возможности использовать больше физической памяти, чем имеется на самом деле, а с другой — не является актуальной проблемой для встраиваемых систем. Нет никаких ограничений, делающих невозможной реализацию данного механизма, и при желании читатель может попробовать себя в этом деле 
Выделение памяти
Для виртуальных страниц и для физических страниц, которые могут быть использованы при работе с виртуальной памятью, статически резервируется некоторое место в оперативной памяти. Тогда при выделении новых страниц и директорий они будут браться именно из этого места.
Исключением является набор указателей на PGD для каждого процесса (MMU-контексты процессов): этот массив хранится отдельно и используется при создании и разрушении процесса.
Выделение страниц
Итак, выделить физическую страницу можно с помощью vmem_alloc_page
void *vmem_alloc_page() {
return page_alloc(virt_page_allocator, 1);
}
Функция page_alloc() ищет участок памяти из N незанятых страниц и возвращает физический адрес начала этого участка, помечая его как занятый. В приведённом коде virt_page_allocator ссылается на участок памяти, резервированной для выделения физических страниц, а 1 — количество необходимых страниц.
Выделение таблиц
Тип таблицы (PGD, PMD, PTE) не имеет значения при аллокации. Более того, выделение таблиц производится также с помощью функции page_alloc(), только с другим аллокатором (virt_table_allocator).
Участки памяти (Memory Area)
После добавления страниц в соответствующие таблицы нужно уметь сопоставлять участки памяти с процессами, к которым они относятся. У нас в системе процесс представлен структурой task, содержащей всю необходимую информацию для работы ОС с процессом. Все физически доступные участки адресного пространства процесса записываются в специальный репозиторий: task_mmap. Он представляет из себя список дескрипторов этих участков (регионов), которые могут быть отображены на виртуальную память, если включена соответствующая поддержка.
struct emmap {
void *brk;
mmu_ctx_t ctx;
struct dlist_head marea_list;
};brk — это самый большой из всех физических адресов репозитория, данное значение необходимо для ряда системных вызовов, которые не будут рассматриваться в данной статье.
ctx — это контекст задачи, использование которого обсуждалось в разделе “Виртуальный адрес”.
struct dlist_head — это указатель на начало двусвязного списка, организация которого аналогична организации Linux Linked List.
За каждый выделенный участок памяти отвечает структура marea
struct marea {
uintptr_t start;
uintptr_t end;
uint32_t flags;
uint32_t is_allocated;
struct dlist_head mmap_link;
};Поля данной структуры имеют говорящие имена: адреса начала и конца данного участка памяти, флаги региона памяти. Поле mmap_link нужно для поддержания двусвязного списка, о котором говорилось выше.
void mmap_add_marea(struct emmap *mmap, struct marea *marea) {
struct marea *ma_err;
if ((ma_err = mmap_find_marea(mmap, marea->start))
|| (ma_err = mmap_find_marea(mmap, marea->end))) {
/* Обработка ошибки */
}
dlist_add_prev(&marea->mmap_link, &mmap->marea_list);
}Отображение виртуальных участков памяти на физические (Mapping)
Ранее уже рассказывалось о том, как происходит выделение физических страниц, какие данные о виртуальной памяти относятся к задаче, и теперь всё готово для того, чтобы говорить о непосредственном отображении виртуальных участков памяти на физические.
Отображение виртуальных участков памяти на физическую память подразумевает внесение соответствующих изменений в иерархию страничных директорий.
Подразумевается, что некоторый участок физической памяти уже выделен. Для того, чтобы выделить соответствующие виртуальные страницы и привязать их к физическим, используется функция vmem_map_region()
int vmem_map_region(mmu_ctx_t ctx, mmu_paddr_t phy_addr, mmu_vaddr_t virt_addr, size_t reg_size, vmem_page_flags_t flags) {
int res = do_map_region(ctx, phy_addr, virt_addr, reg_size, flags);
if (res) {
vmem_unmap_region(ctx, virt_addr, reg_size, 0);
}
return res;
}В качестве параметров передаётся контекст задачи, адрес начала физического участка памяти, а также адрес начала виртуального участка. Переменная flags содержит флаги, которые будут установлены у соответствующих записей в PTE.
Основную работу на себя берёт do_map_region(). Она возвращает 0 при удачном выполнении и код ошибки — в ином случае. Если во время маппирования произошла ошибка, то часть страниц, которые успели выделиться, нужно откатить сделанные изменения с помощью функции vmem_unmap_region(), которая будет рассмотрена позднее.
Рассмотрим функцию do_map_region() подробнее.
Исходный код функции do_map_region()
static int do_map_region(mmu_ctx_t ctx, mmu_paddr_t phy_addr, mmu_vaddr_t virt_addr, size_t reg_size, vmem_page_flags_t flags) {
mmu_pgd_t *pgd;
mmu_pmd_t *pmd;
mmu_pte_t *pte;
mmu_paddr_t p_end = phy_addr + reg_size;
size_t pgd_idx, pmd_idx, pte_idx;
/* Considering that all boundaries are already aligned */
assert(!(virt_addr & MMU_PAGE_MASK));
assert(!(phy_addr & MMU_PAGE_MASK));
assert(!(reg_size & MMU_PAGE_MASK));
pgd = mmu_get_root(ctx);
vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx);
for ( ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) {
GET_PMD(pmd, pgd + pgd_idx);
for ( ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) {
GET_PTE(pte, pmd + pmd_idx);
for ( ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) {
/* Considering that address has not mapped yet */
assert(!mmu_pte_present(pte + pte_idx));
mmu_pte_set(pte + pte_idx, phy_addr);
vmem_set_pte_flags(pte + pte_idx, flags);
phy_addr += MMU_PAGE_SIZE;
if (phy_addr >= p_end) {
return ENOERR;
}
}
pte_idx = 0;
}
pmd_idx = 0;
}
return -EINVAL;
}Вспомогательные макросы
#define GET_PMD(pmd, pgd) \
if (!mmu_pgd_present(pgd)) { \
pmd = vmem_alloc_pmd_table(); \
if (pmd == NULL) { \
return -ENOMEM; \
} \
mmu_pgd_set(pgd, pmd); \
} else { \
pmd = mmu_pgd_value(pgd); \
}
#define GET_PTE(pte, pmd) \
if (!mmu_pmd_present(pmd)) { \
pte = vmem_alloc_pte_table(); \
if (pte == NULL) { \
return -ENOMEM; \
} \
mmu_pmd_set(pmd, pte); \
} else { \
pte = mmu_pmd_value(pmd); \
}
Макросы GET_PTE и GET_PMD нужны для лучшей читаемости кода. Они делают следующее: если в таблице памяти нужный нам указатель не ссылается на существующую запись, нужно выделить её, если нет — то просто перейти по указателю к следующей записи.
В самом начале необходимо проверить, выровнены ли под размер страницы размер региона, физический и виртуальный адреса. После этого определяется PGD, соответствующая указанному контексту, и извлекаются сдвиги из виртуального адреса (более подробно это уже обсуждалось выше).
Затем последовательно перебираются виртуальные адреса, и в соответствующих записях PTE к ним привязывается нужный физический адрес. Если в таблицах отсутствуют какие-то записи, то они будут автоматически сгенерированы при вызове вышеупомянутых макросов GET_PTE и GET_PMD.
Освобождение виртуального участка памяти (Unmapping)
После того, как участок виртуальной памяти был отображён на физическую, рано или поздно её придётся освободить: либо в случае ошибки, либо в случае завершения работы процесса.
Изменения, которые при этом необходимо внести в структуру страничной иерархии памяти, производятся с помощью функции vmem_unmap_region().
Исходный код функции vmem_unmap_region()
void vmem_unmap_region(mmu_ctx_t ctx, mmu_vaddr_t virt_addr, size_t reg_size, int free_pages) {
mmu_pgd_t *pgd;
mmu_pmd_t *pmd;
mmu_pte_t *pte;
mmu_paddr_t v_end = virt_addr + reg_size;
size_t pgd_idx, pmd_idx, pte_idx;
void *addr;
/* Considering that all boundaries are already aligned */
assert(!(virt_addr & MMU_PAGE_MASK));
assert(!(reg_size & MMU_PAGE_MASK));
pgd = mmu_get_root(ctx);
vmem_get_idx_from_vaddr(virt_addr, &pgd_idx, &pmd_idx, &pte_idx);
for ( ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) {
if (!mmu_pgd_present(pgd + pgd_idx)) {
virt_addr = binalign_bound(virt_addr, MMU_PGD_SIZE);
pte_idx = pmd_idx = 0;
continue;
}
pmd = mmu_pgd_value(pgd + pgd_idx);
for ( ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) {
if (!mmu_pmd_present(pmd + pmd_idx)) {
virt_addr = binalign_bound(virt_addr, MMU_PMD_SIZE);
pte_idx = 0;
continue;
}
pte = mmu_pmd_value(pmd + pmd_idx);
for ( ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) {
if (virt_addr >= v_end) {
// Try to free pte, pmd, pgd
if (try_free_pte(pte, pmd + pmd_idx) && try_free_pmd(pmd, pgd + pgd_idx)) {
try_free_pgd(pgd, ctx);
}
return;
}
if (mmu_pte_present(pte + pte_idx)) {
if (free_pages && mmu_pte_present(pte + pte_idx)) {
addr = (void *) mmu_pte_value(pte + pte_idx);
vmem_free_page(addr);
}
mmu_pte_unset(pte + pte_idx);
}
virt_addr += VMEM_PAGE_SIZE;
}
try_free_pte(pte, pmd + pmd_idx);
pte_idx = 0;
}
try_free_pmd(pmd, pgd + pgd_idx);
pmd_idx = 0;
}
try_free_pgd(pgd, ctx);
}Все параметры функции, кроме последнего, должны быть уже знакомы. free_pages отвечает за то, должны ли быть удалены страничные записи из таблиц.
try_free_pte, try_free_pmd, try_free_pgd — это вспомогательные функции. При удалении очередной страницы может выясниться, что директория, её содержащая, могла стать пустой, а значит, её нужно удалить из памяти.
Исходный код функций try_free_pte, try_free_pmd, try_free_pgd
static inline int try_free_pte(mmu_pte_t *pte, mmu_pmd_t *pmd) {
for (int pte_idx = 0 ; pte_idx < MMU_PTE_ENTRIES; pte_idx++) {
if (mmu_pte_present(pte + pte_idx)) {
return 0;
}
}
#if MMU_PTE_SHIFT != MMU_PMD_SHIFT
mmu_pmd_unset(pmd);
vmem_free_pte_table(pte);
#endif
return 1;
}
static inline int try_free_pmd(mmu_pmd_t *pmd, mmu_pgd_t *pgd) {
for (int pmd_idx = 0 ; pmd_idx < MMU_PMD_ENTRIES; pmd_idx++) {
if (mmu_pmd_present(pmd + pmd_idx)) {
return 0;
}
}
#if MMU_PMD_SHIFT != MMU_PGD_SHIFT
mmu_pgd_unset(pgd);
vmem_free_pmd_table(pmd);
#endif
return 1;
}
static inline int try_free_pgd(mmu_pgd_t *pgd, mmu_ctx_t ctx) {
for (int pgd_idx = 0 ; pgd_idx < MMU_PGD_ENTRIES; pgd_idx++) {
if (mmu_pgd_present(pgd + pgd_idx)) {
return 0;
}
}
// Something missing
vmem_free_pgd_table(pgd);
return 1;
}Макросы вида
#if MMU_PTE_SHIFT != MMU_PMD_SHIFT
...
#endifнужны как раз для случая двухуровневой иерархии памяти.
Заключение
Конечно, данной статьи не достаточно, чтобы с нуля организовать работу с MMU, но, я надеюсь, она хоть немного поможет погрузиться в OSDev тем, кому он кажется слишком сложным.
P.S. Всех с началом недели Мат-Меха
Аннотация: Виртуальная память. Реализация виртуальной памяти в Windows. Структура виртуального адресного пространства. Выделение памяти процессам. Дескрипторы виртуальных адресов. Трансляция адресов. Ошибки страниц. Пределы памяти.
Виртуальная память
Всем процессам в операционной системе Windows предоставляется важнейший ресурс – виртуальная память (virtual memory). Все данные, с которыми процессы непосредственно работают, хранятся именно в виртуальной памяти.
Название «виртуальная» произошло из-за того что процессу неизвестно реальное (физическое) расположение памяти – она может находиться как в оперативной памяти (ОЗУ), так и на диске. Операционная система предоставляет процессу виртуальное адресное пространство (ВАП, virtual address space) определенного размера и процесс может работать с ячейками памяти по любым виртуальным адресам этого пространства, не «задумываясь» о том, где реально хранятся данные.
Размер виртуальной памяти теоретически ограничивается разрядностью операционной системы. На практике в конкретной реализации операционной системы устанавливаются ограничения ниже теоретического предела. Например, для 32-разрядных систем (x86), которые используют для адресации 32 разрядные регистры и переменные, теоретический максимум составляет 4 ГБ (232 байт = 4 294 967 296 байт = 4 ГБ). Однако для процессов доступна только половина этой памяти – 2 ГБ, другая половина отдается системным компонентам. В 64 разрядных системах (x64) теоретический предел равен 16 экзабайт (264 байт = 16 777 216 ТБ = 16 ЭБ). При этом процессам выделяется 8 ТБ, ещё столько же отдается системе, остальное адресное пространство в нынешних версиях Windows не используется.
Введение виртуальной памяти, во-первых, позволяет прикладным программистам не заниматься сложными вопросами реального размещения данных в памяти, во-вторых, дает возможность операционной системе запускать несколько процессов одновременно, поскольку вместо дорогого ограниченного ресурса – оперативной памяти, используется дешевая и большая по емкости внешняя память.
Реализация виртуальной памяти в Windows
Схема реализации виртуальной памяти в 32-разрядной операционной системе Windows представлена на рис.11.1. Как уже отмечалось, процессу предоставляется виртуальное адресное пространство размером 4 ГБ, из которых 2 ГБ, расположенных по младшим адресам (0000 0000 – 7FFF FFFF), процесс может использовать по своему усмотрению (пользовательское ВАП), а оставшиеся два гигабайта (8000 0000 – FFFF FFFF) выделяются под системные структуры данных и компоненты (системное ВАП)1Специальный ключ /3GB в файле boot.ini увеличивает пользовательское ВАП до 3 ГБ, соответственно, уменьшая системное ВАП до 1 ГБ. Начиная с Windows Vista вместо файла boot.ini используется утилита BCDEDIT. Чтобы увеличить пользовательское ВАП, нужно выполнить следующую команду: bcdedit /Set IncreaseUserVa 3072. При этом, чтобы приложение могло использовать увеличенное ВАП, оно должно компилироваться с ключом /LARGEADDRESSAWARE.. Отметим, что каждый процесс имеет свое собственное пользовательское ВАП, а системное ВАП для всех процессов одно и то же.

Рис.
11.1.
Реализация виртуальной памяти в 32-разрядных Windows
Виртуальная память делится на блоки одинакового размера – виртуальные страницы. В Windows страницы бывают большие (x86 – 4 МБ, x64 – 2 МБ) и малые (4 КБ). Физическая память (ОЗУ) также делится на страницы точно такого же размера, как и виртуальная память. Общее количество малых виртуальных страниц процесса в 32 разрядных системах равно 1 048 576 (4 ГБ / 4 КБ = 1 048 576).
Обычно процессы задействуют не весь объем виртуальной памяти, а только небольшую его часть. Соответственно, не имеет смысла (и, часто, возможности) выделять страницу в физической памяти для каждой виртуальной страницы всех процессов. Вместо этого в ОЗУ (говорят, «резидентно») находится ограниченное количество страниц, которые непосредственно необходимы процессу. Такое подмножество виртуальных страниц процесса, расположенных в физической памяти, называется рабочим набором процесса (working set).
Те виртуальные страницы, которые пока не требуются процессу, операционная система может выгрузить на диск, в специальный файл, называемый файлом подкачки (page file).
Каким образом процесс узнает, где в данный момент находится требуемая страница? Для этого служат специальные структуры данных – таблицы страниц (page table).
Структура виртуального адресного пространства
Рассмотрим, из каких элементов состоит виртуальное адресное пространство процесса в 32 разрядных Windows (рис.11.2).
В пользовательском ВАП располагаются исполняемый образ процесса, динамически подключаемые библиотеки (DLL, dynamic-link library), куча процесса и стеки потоков.
При запуске программы создается процесс (см. лекцию 6 «Процессы и потоки»), при этом в память загружаются код и данные программы (исполняемый образ, executable image), а также необходимые программе динамически подключаемые библиотеки (DLL). Формируется куча (heap) – область, в которой процесс может выделять память динамическим структурам данных (т. е. структурам, размер которых заранее неизвестен, а определяется в ходе выполнения программы). По умолчанию размер кучи составляет 1 МБ, но при компиляции приложения или в ходе выполнения процесса может быть изменен. Кроме того, каждому потоку предоставляется стек (stack) для хранения локальных переменных и параметров функций, также по умолчанию размером 1 МБ.
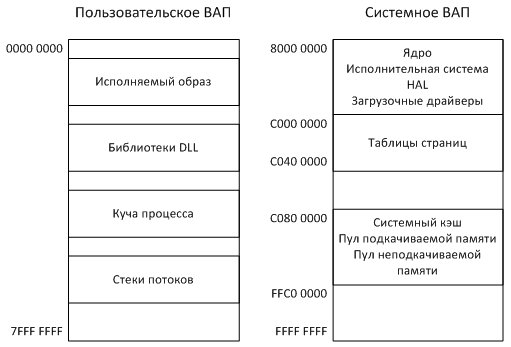
Рис.
11.2.
Структура виртуального адресного пространства
В системном ВАП расположены:
- образы ядра (ntoskrnl.exe), исполнительной системы, HAL (hal.dll), драйверов устройств, требуемых при загрузке системы;
- таблицы страниц процесса;
- системный кэш;
- пул подкачиваемой памяти (paged pool) – системная куча подкачиваемой памяти;
- пул подкачиваемой памяти (nonpaged pool) – системная куча неподкачиваемой памяти;
- другие элементы (см. [5]).
Переменные, в которых хранятся границы разделов в системном ВАП, приведены в [5, стр. 442]. Вычисляются эти переменные в функции MmInitSystem (файл base\ntos\mm\mminit.c, строка 373), отвечающей за инициализацию подсистемы памяти. В файле base\ntos\mm\i386\mi386.h приведена структура ВАП и определены константы, связанные с управлением памятью (например, стартовый адрес системного кэша MM_SYSTEM_CACHE_START, строка 199).
Выделение памяти процессам
Существует несколько способов выделения виртуальной памяти процессам при помощи Windows API2См. обзор в MSDN «Comparing Memory Allocation Methods» (http://msdn.microsoft.com/en-us/library/windows/desktop/aa366533(v=vs.85).aspx).. Рассмотрим два основных способа – с помощью функции VirtualAlloc и с использованием кучи.
1. WinAPI функция VirtualAlloc позволяет резервировать и передавать виртуальную память процессу. При резервировании запрошенный диапазон виртуального адресного пространства закрепляется за процессом (при условии наличия достаточного количества свободных страниц в пользовательском ВАП), соответствующие виртуальные страницы становятся зарезервированными (reserved), но доступа к этой памяти у процесса нет – при попытке чтения или записи возникнет исключение. Чтобы получить доступ, процесс должен передать память зарезервированным страницам, которые в этом случае становятся переданными (commit).
Отметим, что резервируются участки виртуальной памяти по адресам, кратным значению константы гранулярности выделения памяти MM_ALLOCATION_GRANULARITY (файл base\ntos\inc\mm.h, строка 54). Это значение равно 64 КБ. Кроме того, размер резервируемой области должен быть кратен размеру страницы (4 КБ).
WinAPI функция VirtualAlloc для выделения памяти использует функцию ядра NtAllocateVirtualMemory (файл base\ntos\mm\allocvm.c, строка 173).
2. Для более гибкого распределения памяти существует куча процесса, которая управляется диспетчером кучи (heap manager). Кучу используют WinAPI функция HeapAlloc, а также оператор языка C malloc и оператор C++ new. Диспетчер кучи предоставляет возможность процессу выделять память с гранулярностью 8 байтов (в 32-разрядных системах), а для обслуживания этих запросов использует те же функции ядра, что и VirtualAlloc.
Дескрипторы виртуальных адресов
Для хранения информации о зарезервированных страницах памяти используются дескрипторы виртуальных адресов (Virtual Address Descriptors, VAD). Каждый дескриптор содержит данные об одной зарезервированной области памяти и описывается структурой MMVAD (файл base\ntos\mm\mi.h, строка 3976).
Границы области определяются двумя полями – StartingVpn (начальный VPN) и EndingVpn (конечный VPN). VPN (Virtual Page Number) – это номер виртуальной страницы; страницы просто нумеруются, начиная с нулевой. Если размер страницы 4 КБ (212 байт), то VPN получается из виртуального адреса начала страницы отбрасыванием младших 12 бит (или 3 шестнадцатеричных цифр). Например, если виртуальная страница начинается с адреса 0x340000, то VPN такой страницы равен 0x340.
Дескрипторы виртуальных адресов для каждого процесса организованы в сбалансированное двоичное АВЛ дерево3АВЛ дерево – структура данных для организации эффективного поиска; двоичное дерево, сбалансированное по высоте. Названо в честь разработчиков – советских ученых Г. М. Адельсон Вельского и Е. М. Ландиса. (AVL tree). Для этого в структуре MMVAD имеются поля указатели на левого и правого потомков: LeftChild и RightChild.
Для хранения информации о состоянии области памяти, за которую отвечает дескриптор, в структуре MMVAD содержится поле флагов VadFlags.
Страничная организация памяти
В данной статье мы рассмотрим следующие вопросы:
Инструменты управления памятью:
- Страничная организация памяти (также таблицы страниц)
- Сегментная организация пямяти (таблицы сегментов)
- Страничное прерывание (page fauet) и виртуальная память
- Механизмы замещения страниц: Алгоритм Belady, FIFO Алгоритм LRU (Last recently used) – наименее используемое, Not Frequently Used (алгоритм clock – часовой)
- Рабочее множество
- Алгоритм Page Fault Frequency
Страничная организация памяти
Организация памяти в виде страниц борется с двумя проблемами:
- Внешней фрагментацией – используются блоки фиксированного размера в виртуальной и физической памяти, т.е. все запросы на выделение памяти будут кратны, не будет оставаться некратных зон.
- Внутренней фрагментацией – блоки достаточно малого размера, поэтому (К) будет мал.
С точки зрения программиста:
- Процессам виртуальное адресное пространство предоставляется непрерывным, от байта 0 до байта N;
- N зависит от аппаратной поддержки (например 32бита — адрресное пространство 4Гб), делится соответственно.
- В реальности виртуальные страницы распределены по страницам физической памяти далеко не непрерывно и не один к одному. Это два разных мира – физические страницы и виртуальные страницы. Это ключевой аспект, который надо понимать.
С точки зрения менеджера памяти:
- Эффективное использование памяти из-за очень низкой внутренней фрагментации.
- Внешняя фрагментация полностью отсутствует и не нужно дефрагментировать.
С точки зрения защиты:
- Процесс имеет доступ только к своему адресному пространству.
Допущение – все страницы виртуальной памяти всегда находятся в страницах физической памяти.
Не будем думать, что есть только виртуальные страницы, а физических – их нет, т.е. полное отображение виртуальной и физической памяти.
Предположим, что все страницы резидентно в памяти, это необходимо, чтобы понять как работает трансляция адресов.
Трансляция адресов
Трансляция виртуального адреса: Виртуальный адрес состоит из двух частей: номер виртуальной страницы (VPN) и смещение внутри страницы
Номер виртуальной страницы (VPN- virtual page number) это индекс в таблице страниц (Pagetable).
Запись в таблице страниц (PTE – page table entry) содержит номер фрейма (PFN –page frame number).
Номер фрейма – это номер физической страницы.
Фрейм – это страница физической памяти.
Смысл таблицы страниц – одна запись в таблице страниц (PTE) на одну страницу виртуального адресного пространства (VPN), отображает VPN на PFN.
Какая виртуальная страница соответствует какому фрейму физической памяти.

Трансляция адресов
Есть виртуальный адрес, состоящий из двух частей:
- №виртуальной страницы, по нему идет поиск в таблице страниц и находится № фрейма, он составляет одну часть физического адреса;
- Смещение – берется напрямую – вторая часть физического адреса.
По новому адресу осуществляется поиск уже в физической памяти и доступ к данным.
На рисунке ниже каким образом два процесса располагаются в памяти.

страничная организация памяти
Существуют два процесса 0 и 1, у 0 есть две страницы у 1 процесса четыре страницы. И мы видим, что они могут отображаться как угодно, вплоть до того, что две виртуальные страницы могут отображаться на одной физической.
Зачастую это бывает полезно, простор для манипуляций ограниченный и в этом состоит вся прелесть виртуального адресного пространства.
Страничная организация памяти — Пример
-32битная разрядность адресов
-Размер страницы 4096байт
-VPN длиной 20бит, смещение 12бит (20+12=32бита)
-Преобразуем виртуальный адрес 0* 43456 323
— № вирт. страницы смещение внутри страницы
-VPN=43456 смещение=323
-Допустим, что в ячейке таблицы страниц по индексу 0*43456 находится значение фрейма PFN= 0*1002.
Получаем физический адрес 0*01002323
Таблица страниц (PTE)
Если есть таблица страниц, которая содержит преобразование адреса, то необходимо воспользоваться и нагрузить ее дополнительными функциями:
- Добавить защиту доступа;
- Добавить дополнительную вспомогательную информацию (например, используется эта вирт.страница или нет, был ли к ней когда-либо осуществлен доступ, была ли в нее осуществлена запись…);
Таблица страниц превращается в сложную структуру данных, которые начинает использоваться множеством всяких дополнительных полей.
Все это нужно, чтобы сохранить память для других процессов, делать все быстро и не плодить десятки новых таблиц с данными – все по возможности хранить внутри таблицы РТЕ.
Приведем пример стректуры таблицы страниц PTE.

таблица страниц PTE
Если мы посмотрим на запись в РТЕ, то мы увидим, что туда можно поместить:
- V— может ли использоваться данная запись РТЕ (valid or not) – бит валидности, бит присутствия;
- R- был ли доступ к этой странице;
- M– была ли страница модифицирована;
- P– какие операции разрешены (битовая маска операций);
- PFN– номер фрейма (как основной, как основная нагрузка).
Преимущества страничной памяти
- Легко выделять физическую память
— Списки свободных фреймов, выделить фрейм
– просто удалить из списка свободных; — Внешняя фрагментация не проблема, т.к. фреймы одного размера; - Естественный подход
— Всей программе не нужно быть резидентной – это «побочный» продукт;
— Все страницы одного размера;
— Основа – устранение внешней фрагментации.
Недостатки страничной памяти
- Внутренняя фрагментация
— Процессам может быть нужны размеры, некратные размеру страницы;
— По сравнению с размером адресного пространства, размер страницы очень мал. - Накладные расходы при обращении к памяти
– вначале к таблице страниц, а затем уже к памяти.
Решение: аппаратный КЭШ для обращений к таблице страниц (TLB translation lookaside buffer – буфер внутри процессора). - Большой объем памяти, требуемый для хранения таблиц страниц.
Один РТЕ на одну страницу в виртуальном адресном пространстве
Пример:
Архитектура х86
32-битное АП с 4КБ страницами = 2 в 20 степени РТЕ= 1048576записей РТЕ
4 байта на РТЕ = 4Мб памяти на таблицу страниц.
В ОС создаются отдельные таблицы страниц для каждого процесса.
Итого, например 25процессов * 4Мб = 100Мб
Соответственно нужны отдельные таблицы страниц для каждого процесса.
Решение: хранить таблицы страниц в страничной памяти)
Страничная организация памяти (обобщение)
- Решает разные проблемы, типа фрагментации
- Адресное пространство – линейный массив байтов
- Разделяется на страницы одинакового размера (например 4Кб)
- Использует таблицы страниц для отображения виртуальной страницы на физический фрейм
Сегментное распределение памяти (Сегментация)
Сегментация подходит к распределению памяти более «продвинуто», чем страничная — выделяются разные логические сегменты памяти: стек, код программы, куча, т.е. адресное пространство делится на логические блоки.
Блоки имеют свой размер, расположение и права доступа, например, куча – для динамической памяти программы – все это отдельные логические блоки памяти.
Их не нужно мешать в одно, поэтому следующим этапом было разделение всего названного и ввод виртуального адреса в виде пары: Сегмент, смещение.
Виртуальный адрес в виде – сегмент + смещение.
Страничная организация предполагает куски памяти, как в примере выше, 4096байт (4Кб), таких кусков можно брать сколько угодно.
Сегментация:
- Позволяет разделить разные участки памяти в соответствии с их назначением
- Динамический (изменяемый) размер у сегментов
Два варианта
- Один сегмент на процесс – переменный раздел
- Много сегментов на процесс — сегментация
Аппаратная поддержка сегментации
- Одна пара база-предел(лимит) на сегмент
- Сегменты идентифицируются №, который является индексом в таблице
- Виртуальный адрес = пара <СЕГМЕНТ, СМЕЩЕНИЕ>
- Физический адрес = база сегмента + смещение
Недостатки:
- Все недостатки, присущие организации памяти разделами переменной длины присущи и сегментной организации
- Внешняя фрагментация
Лучшим, как можно заметить является организация этих подходов в один. Давайте объединим страничную и сегментную адресацию.
Архитектура х86 поддерживает и страничную и сегментную адресацию.
- Сегменты используются для управления логическими блоками, обычно сегменты большие (помещают множество страниц).
- Сегменты разбиваются на страницы, у каждого сегмента своя таблица страниц
В современных ОС достаточно ограниченно применяются сегменты, много их не применяется. Пример ОС Linux
- Один сегмент кода ядра, Один сегмент данных ядра
- Один сегмент кода пользователя, Один сегмент данных пользователя
- Все сегменты организованы странично.
Страничная виртуальная память
Мы предполагали ранее, что вся память резидентная — не рассматривался вариант, что какой-либо страницы может не быть в физической памяти.
Сейчас, допустим, что адресное пространство может и не быть полностью резидентным. На практике так в основном и есть – память никогда не резидентна. Процессов сотни, на них выделяется много виртуальной памяти и ее не хватит на отображение в физической памяти.
Например, 100 процессов 100П*4Гб=400ГБ ОП.
Соответственно какая то часть адресного пространства находится в физической памяти, какая то часть в некоторой вторичной памяти (понимается дисковая подсистема), абстрагируется от физической реализации.
С точки зрения опрерационной системы важно, что ОС использует основную память, как КЭШ.
У ОС есть медленная память (это дисковая подсистема), она может туда загружать процессы и выгружать их оттуда, а основная память используется как ограниченный ресурс, сродни классическому кэшированию.
Принцип работы достаточно простой – нужная страница перемещается в свободный фрейм физической памяти из вторичной памяти. А если свободных фреймов нет, то какая-либо страница выгружается на диск, таким образом освобождается драгоценный фрейм физической памяти.
Важно отметить, запись во вторичной памяти происходит только тогда, когда страница в основной памяти была модифицирована, если она не была модифицирована, то соответственно и выгружать нечего.
Весь процесс происходит прозрачно для программы. Никакая программа не управляет напрямую, какую страницу ей выгрузить в основную память, какую загрузить.
Менеджер памяти операционной системы все абстрагирует и делает все прозрачным для программиста, чтобы он не «напрягался» на данную тему, это сложно реализовывать самостоятельно.
Рассмотрим понятие Страничное прерывание.
Page fault – Страничное прерывание
Процесс обращается к виртуальному адресу на выгруженной (или загруженной) странице, т.е. страница в принципе отсутствует, при этом обращении и происходит страничное прерывание. Как этот процесс весь работает:
- Когда страница выгружается, ОС устанавливает бит присутствия (valid – является ли валидной ячейка) PTE=0. И там же в РТЕ записывает куда она была соответственно выгружена.
- Когда же процесс обращается к этой странице, то происходит исключение, т.к. Valid=0,т.е. бит валидности установлен в 0 – страница не использовалась.
- После того, как произошло исключение ОС передает управление обработчику страничного прерывания
- Обработчик находит то место, куда была выгружена страница
- Считывает эту страницу в фрейм физической памяти, обновляет РТЕ, ставит бит валидности (присутствия) в 1.
- В физической памяти появляется новая страница.
Процесс достаточно простой, если страницы нет, то сама же ОС ее загрузит обратно, или выгрузит, когда ей это надо.
Загрузка по требованию
Еще один ключевой механизм работы менеджера памяти.Практически все страницы памяти загружаются по требованию.
Смысл: страницы загружаются в основную память только тогда, когда к ним происходит непосредственное обращение.
Предсказать заранее, какая страница потребуется в будущем – сложно(это как гадать на кофейной гуще).
Сегодня для этого разработано множество алгоритмов, есть разные подходы. Самый логичный из них — кластеризация страниц.
Операционная система ведет учет страниц, которые обычно загружаются вместе, даже если они расположены в различных местах виртуальной памяти или физической памяти. Если идет обращение к одной их них, то ОС загружает все страницы их этого кластера.
Это естественный подход к тому, как можно провести исходную оптимизацию этого алгоритма. Можно даже предоставить программисту возможность определять такие кластеры.
Механизм замещения страниц
Допустим у нас заняты все фреймы(страницы) физической памяти, а нам нужно еще загрузить одну страницу.
Вопрос – какую из страниц физизической памяти выгрузить? Ведь страниц много и это выбора многое зависит.
Алгоритм замещения страниц простой:
- Выбрать страницу, которую не понадобится в ближайшем бедующем
- Выбрать страницу, которая не была модифицирована, чтобы обойтись без записи ее на диск.
- Чтобы обойтись без замены в ОС есть пул свободных страниц.
Но проблема замещения страниц существует. Посмотрим последовательность действий в ОС, когда у нас загружается программа.
Как загружается программа:
- Для создания нового процесса создается новый РСВ (процесс контрол.блок).
- Создается таблица страниц для этого процесса, которая описывает его виртуальное адресное пространство.
- Образ программы на диск размещается блоками в адресное пространство (он не копируется, а неким образом размещается).
- Строится таблица страниц, указатель на которую уже есть в РСВ. — Все РТЕ имеют бит присутствия =0 (виртуальное адресное пространство в начале процесса полностью пустое, в плане отображения на физическую память – ни одна страница не присутствует) — В эти же РТЕ заносится информация о нахождении этих физических страниц уже во вторичной памяти, т.е. на диске
- Передает управление на точку входа этого процесса – исполнение первой же инструкции приводит к страничному прерыванию (page fault).
- Обработчик прерывания загружает эти страницы из дисковой памяти.
Таким образом никто, ничего заранее не подгружает, все загружается через «page fault» по требованию. Именно так все работает.
Алгоритмы замещения страниц
Принцип локальности определяется двумя подходами:
- Одна загрузка –много обращений (локальность по времени);
- Обращение к страницам рядом с уже загруженной (локальность по расположению).
Загрузка страниц по требованию может быть частой, а может и не такой частой, зависит от:
- Локальности;
- Политики замещения страниц;
- Объема физической памяти;
- «рабочего множества» ( так называемого).
Смысл алгоритма замещения страниц – уменьшить число страничных прерываний (page fault) путем выбора лучшей страницы для выгрузки.
Лучшая – та, к которой вообще больше не будет обращений, т.е. освобождает место в памяти и решаем все вопросы, все будет работать быстро.
Далее рассмотрим разные алгоритмы, которые были предложены к решению данной проблемы (фундаментальной и основополагающей, как оказалось). Это как в алгоритмах планирования, они существенно влияют на производительность, отзывчивость системы. В менеджере памяти тоже есть ниша, которая оказывает большое влияние.
Алгоритм Belady
Оптимальность его доказана по критерию наименьшего числа страничных прерываний.
—Выгрузить страницу, которая дольше всех не будет использоваться в будующем. Проблема – предсказать будущее. Физический смысл Алгоритма Вelady(АВ) на практике реализовать сложно, а по сути нельзя. Его используют в качестве эталона для сравнения.
Если Вы реализовали какой-то другой алгоритм практически в операционной систем и он оказался ненамного хуже, чем АВ, что значит Вы сделали очень хороший алгоритм.
Но на самом деле не существует «лучшего» алгоритма, т.к. все зависит от задачи. Например, при планировании при интерактивных процессов один алгоритм, для фоновых – другой. Чаще используется объединение этих всех алгоритмов.
Не существует худшего алгоритма, но в качестве эталона «худшего» можно указать: — Случайный выбор страницы для замены, но случайный не всегда худшее.
Рассмотрев теоретический АВ первым был сделан алгоритм FIFO.
Алгоритм FIFO
Достаточно прост в реализации:
—При загрузке страницы мы помещаем ее в конец списка
—Выгружаем страницы из начала списка.
Преимущества:
- Выгружается самая старая страница, может быть и редко использованная
Недостатки :
- Выгруженная страница может все еще использоваться, хотя и давно загрузилась, нет уверенности что она редко используемая.
- Плохая производительность
Аномалия Belady
Существует понятие аномалия Belady – если дать процессу больше физической памяти, то определенные последовательности обращений к страницам приведет к увеличению числа страничных прерываний.
Есть определенная ограниченная физическая память, когда выполняется процесс он генерирует страничные прерывания. При использовании алгоритма FIFO при определенных случаях, если увеличить размер физической памяти, то этих страничных прерываний станет еще больше. Это доказал Belady и названо явление аномалией Belady.
Алгоритм LRU (Last recently used) – наименее используемое
Использует информацию об обращениях к страницам памяти для принятия решения о ее выгрузке.
Смысл: угадать будущее на основе прошлого.
При завершении выгрузить ту страницу, которая дольше всех не использовалась.
При сравнении с АВ, то АВ заглядывает в будущее, LRU в прошлое.
В идеале нужно сохранять время при каждом обращении к памяти в РТЕ, сортировать на основе этих данных. И та страница, к которой дольше всех не было обращений выбирается первым кандидатом на выгрузку.
Если каждое обращение к памяти будет сопровождаться записью значения времени последнего обращения к памяти, то система начнет тормозить. Преимущество LRU сойдет на нет, все окажется слишком долго.
На практике LRU «в чистом виде» не реализуется. Но существуют аппроксимации, спасает математический подход ко всему, можно реализовать различные приближения к алгоритму LRU.
Аппроксимации алгоритма LRU
Существует бит в РТЕ, который называется referenced (0 или 1). Вводим счетчик для каждой страницы. Алгоритм аппроксимации: регулярно для каждой страницы через какие-то равные промежутки времени смотрим:
- если бит referenced =0, то мы увеличим некий счетчик;
- если бит referenced =1, то счетчик обнулим.
И через равные промежутки времени всегда обнуляем бит referenced.
Таким образом, эта аппроксимация приводит к тому, что счетчик будет содержать количество временных интервалов с момента последнего обращения к памяти к этой странице.
В некоторых архитектурах этого бита в РТЕ нет, поэтому применяются всякие «некрасивые» ухищрения. Бит referenced устанавливается автоматически процессором, когда происходит доступ к памяти, чтобы было достаточно быстро.
Not Frequently Used — алгоритм clock – часовой

Алгоритм часов
Суть Алгоритма: он замещает достаточно старую страницу. Фреймы физической памяти организуются в виде часов. Есть часовая стрелка и по кругу фреймы физической памяти. Стрелка выбирает кандидата на выгрузку.
- Если бит ref=0, то выгружает эту страницу
- Если бит ref=1, то обнуляет его и идет дальше
- Действия происходят через регулярные промежутки времени.
Если памяти много, то ниже затраты и ниже точность.
Изначально в список «часов» помещаются только те страницы, которые используются, то есть те у которых ref=1. Стрелка идет по кругу и начинает обнулять ref и соответственно выгружать страницы при необходимости. Поэтому из круга выпадают только те, которые не были недавно использованы.
Задача: Распределение фреймов физической памяти между процессами
Существуют два подхода
- Локальный алгоритм замещения
— У каждого процесса свой лимит на число страниц, который он может использовать
— Выгружает только свои страницы - Глобальный алгоритм замещения
— Неважно, чьи страницы кому принадлежат – алгоритм замещения идет по большому кругу и выгружает независимо от владельца.
Примеры из практики:
Linux использует глобальное замещение.
Существуют гибридные алгоритмы – локальное замещение и механизм явного добавления/удаления фреймов.
Рабочее множество
Рабочее множество — Woking set– необходимо для моделирования локальности использования памяти.

Peter Denning
Рабочее множество – это множество тех страниц процесса, которые ему сейчас нужны.
Формальное определение РМ ввел Петр Деннинг в 1968г.
Эти алгоритмы используются во всех современных ОС.
WS(t,w) ={страницы Р, к которым были обращения за интервал (t-w; t) }
t- время;
w — окно рабочего множества;
«Сейчас» — в определении рабочего множества это имеет какую-то точку во времени, «когда сейчас?» и имеет некоторую длительность.
Страница находилась в рабочем множестве тогда, когда к ней обращались за последние W-единиц времени.
Рабочее множество (WS) изменяется во времени и размер WS также меняется, это плавающие величины.
Размер рабочего множества
Введем обозначение |WS(t,w)| — зависит от локальности
При плохой локальности, подгружается много страниц.
|WS(t,w)| в этот момент увеличивать
Очевидно, что WS должно быть в памяти резидентно, иначе случится «пробуксовка»(trashing), компьютер затормаживается, т.е. постоянные страничные прерывания для того, чтобы подгрузить страницу, так как процесс без нее работать не сможет, он будет к ней обращаться.
Перед тем как запустить процесс мы должны оценить размер его исходного рабочего множества.
- Оценить |WS(0,w)| для процесса;
- Запустить этот процесс только тогда, если есть столько фреймов физической памяти, чтобы туда поместилось это исходное рабочее множество;
- Используя алгоритм замещения страниц загружать нужные страницы;
- Динамически отслеживать размеры рабочего множества процессов.
Алгоритм Page Fault Frequency
Page Fault Frequency – частоты возникновения страничных прерываний.
Он в корне отличается от всех остальных, так как пытается уровнять число страничных прерываний между всеми процессами и снизить их общее число.
За счет чего он это делает?
- Следит за частотой страничных прерываний каждого процесса
- Если оно выше определенного порога – предоставляет процессу больше памяти
- Если оно меньше, то забирает у него память.
- Таким образом он перераспределяет память между процессами и регулирует число страничных прерываний.
И последнее, что мы рассмотрим это пробуксовка.
Пробуксовка (thrashung)
Она происходит, когда система проводит большую часть времени, обслуживая страничные прерывания, а не занимаясь полезной работой – вычислениями.
Из-за чего это происходит, причины:
- Из-за неправильного алгоритма замещения страниц при достаточном объеме памяти;
- Либо если объема физической памяти недостаточно, слишком много активных процессов ;
Это ненормально состояние, которое должно решаться каким-то образом.
Скачать презентацию к лекции «Управление памятью»
Скачать тест по теме «Управление памятью»