Раскрывать тему параллельного или асинхронного программирования непросто. Во-первых, она перегружена терминологией и трудна для понимания. Как правило, тонкости и особенности работы с языками усваиваются, лишь когда столкнешься с ними на практике. Во-вторых, в контексте Python тоже много своих подводных камней. Но сегодня почти любой современный web-сервис сталкивается с необходимостью многопоточности или асинхронности. Поскольку это многопользовательская среда, мы хотим направить всю процессорную мощность не на ожидание, а на решение прикладных задач бизнеса, чтобы все пользователи вовремя получили необходимые данные.
Эта статья будет полезна тем разработчикам, которые хотят выполнять больше работы за одно и то же время, и задействовать все ресурсы своего железа. Проще говоря, делать больше, и при этом обходиться меньшими ресурсами. Пусть железо работает, а не простаивает.

Давайте возьмем за отправную точку ситуацию, когда у нас есть приложение, которое работает по стандартной схеме клиент – сервер:
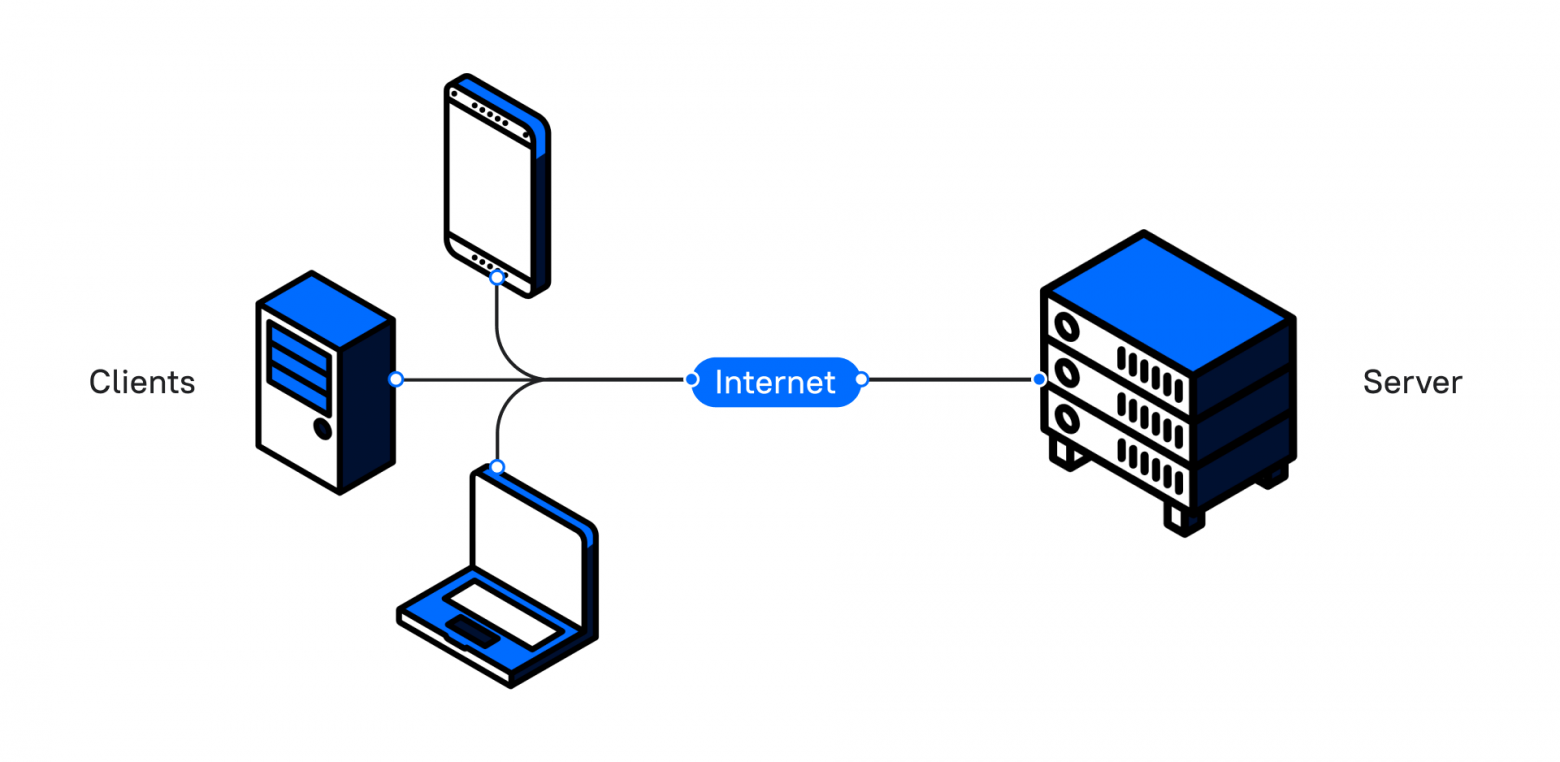
Клиент посылает запрос и получает ответ. А теперь представьте, что в нашем приложении есть кнопка, которая формирует большой отчет. Когда пользователь нажимает на нее, программа долго обрабатывает запрос. Клиент ждет ответа, и пока отчет не будет сформирован, он не сможет пользоваться интерфейсом приложения.
Как мы можем помочь пользователю продолжить взаимодействие с нашим приложением, пока формируется отчет? Мы можем создать отдельный процесс, отдельный поток, и выполнять код асинхронно.
Рассмотрим каждое понятие отдельно.
Процессы
Процессы являются контейнерами. Их основная задача – изолировать программы друг от друга, чтобы одна не могла получить доступ к памяти другой.
В контексте Python каждому процессу выделен свой интерпретатор. Когда мы запускаем несколько процессов из кода, то мы обнаруживаем такое же количество процессов в мониторинге системы.
Небольшой пример создания процессов:
from multiprocessing import Process
def print_word(word):
print('hello,', word)
if __name__ == '__main__':
p1 = Process(target=print_word, args=('bob',), daemon=True)
p2 = Process(target=print_word, args=('alice',), daemon=True)
p1.start()
p2.start()
p1.join()
p2.join()Процессы представлены как экземпляр класса Process из встроенной библиотеки multiprocessing.
У нас есть функция, которая принимает 1 параметр и печатает приветствие с переданным параметром. Внутри конструкции if мы создаем два процесса p1 и p2 в качестве параметров, то есть мы передаем:
target – с названием выполняемой функции,
args – параметры для функции, которую мы будем вызывать,
daemon – с флагом True, который говорит нам, что процесс будет являться «демоном» – об этом чуть позже.
Для того чтобы процесс стартовал, мы вызываем у каждого метод .start().
Но ниже мы вызываем еще и метод .join().
Для чего нужен join() и что такое daemon? Или основные и фоновые процессы
У нас есть основной (главный) процесс, который содержит весь код нашей программы, и два дополнительных (фоновых) p1, p2. Их мы создаем, когда мы прописываем параметр daemon=True. Так мы как раз и указываем, что эти два процесса будут второстепенными. Если мы не вызовем метод join у фонового процесса, то наша программа завершит свое выполнение, не дожидаясь выполнения p1 и p2.
Немного теории о процессах
Процессы не могут работать параллельно на одноядерной машине.
Параллельное вычисление – выполнение двух и более задач одновременно, когда каждое ядро процессора берет задачу и выполняет ее. На многоядерной машине параллельное вычисление – нормальная практика. Однако количество ядер у нас ограничено, причем весьма сильно, а процессов в системе работает много.
Познакомимся с еще одним термином — вытесняющая многозадачность.
Вытесняющая многозадачность — это такой способ управления задачами, при котором решение о переключении процессора с выполнения одного процесса на выполнение другого принимается планировщиком операционной системы.
Предположим, что у нас одноядерный процессор и ему приходится выполнять работу множества программ одновременно. Как он это делает?
В этом случае каждой программе выделяется небольшой промежуток времени, то есть программы конкурируют за доступ к ядру. Процессор сам переключает контекст выполнения, и таким образом создается впечатление, что программы работают одновременно. Но это не совсем так.
Проще говоря, одна программа поработала какое-то время, и процессор переключает контекст на другую, чтобы она выполнила запланированные действия, передала обратно и так далее.
Когда количество процессов превышает количество ядер, на помощь приходит конкурентное вычисление.
Потоки
Первое, о чем хотим сказать про потоки — интерфейсы работы с процессами и потоками в Python очень похожи.
Потоки живут внутри процессов, потребляют меньше ресурсов и разделяют общую память внутри процесса. Во многих языках программирования потоки создавались именно для того, чтобы выполнять задачи параллельно, но не в Python. А виноват в этом GIL.
GIL (Global interpreter lock) следит за тем, чтобы в один момент времени работал лишь один поток. Механизм похож на то, как процессы конкурируют за ядро. Но в отличие от процессов GIL освобождается при вызове блокирующей функции операций ввода/вывода. Другой механизм его освобождения – time.sleep(). Об этом позже.
import threading
def greet(name):
print('hello: ', name)
if __name__ == '__main__':
t1 = threading.Thread(target=greet, args=('bob',), daemon=True)
t2 = threading.Thread(target=greet, args=('alice',), daemon=True)
t1.start()
t2.start()
t1.join()
t2.join()Как видно, процесс создания потоков идентичен алгоритму формирования процессов.
Теперь, когда мы познакомились с основными понятиями, продемонстрируем несколько проблем, которые встречаются в многопоточном программировании.
Первая проблема – Race Condition или состояние гонки.
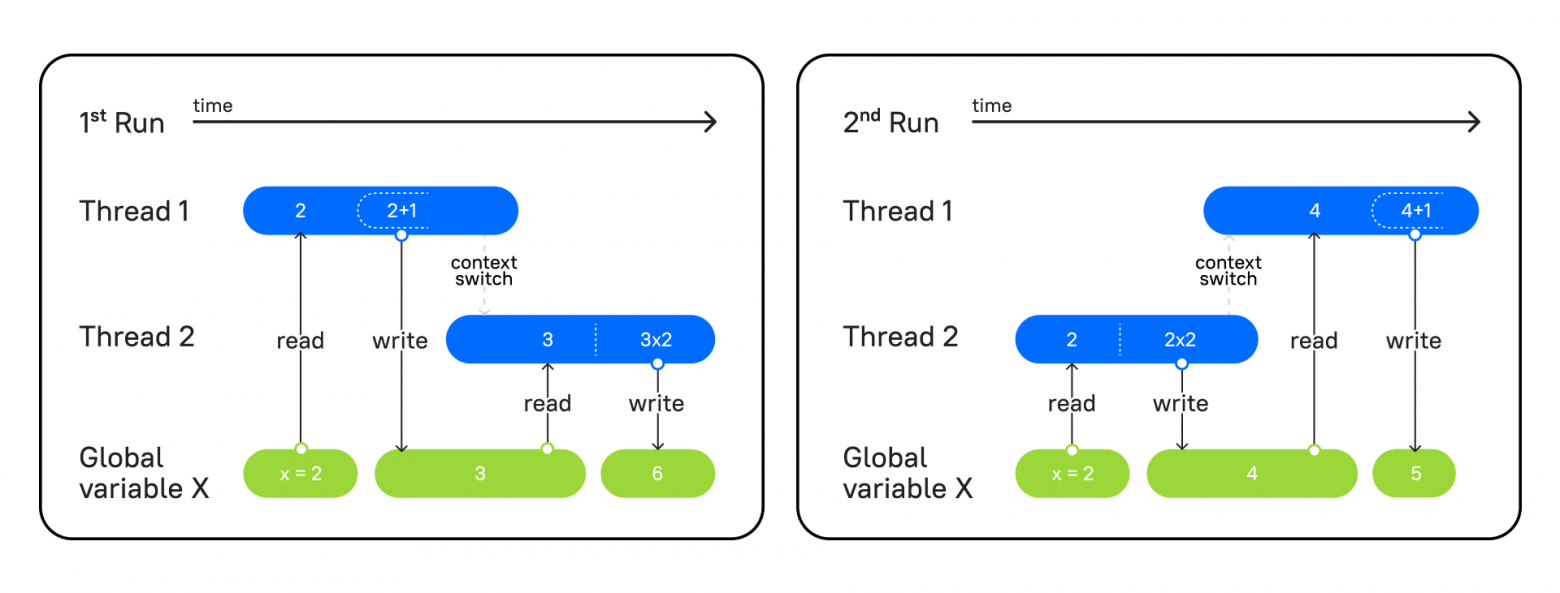
На изображении мы видим два запуска одной и той же программы, в которой есть два потока: в первом функция увеличивает переданное число на единицу, а во втором — мы умножаем число на 2.
Слева вы видите первый запуск программы. Первый поток берет значение из глобальной переменной x, прибавляет 1 и записывает в x результат = 3. Затем второй поток начинает работу. Он берет из переменной x значение 3, умножает на 2 и записывает результат = 6.
На правой схеме – второй запуск программы, где сперва в работу вступает поток 2, он выполняет те же операции, берет x = 2, умножает на 2 и фиксирует результат 4. Затем вступает поток 1, читает 4 из x, увеличивает на единицу и записывает 5.
Так как оба потока меняли порядок работы программы, но выполняли ее по очереди, у нас не возникало никакого конфликта, и мы получали ожидаемый результат.
Но давайте посмотрим на такой поток выполнения:
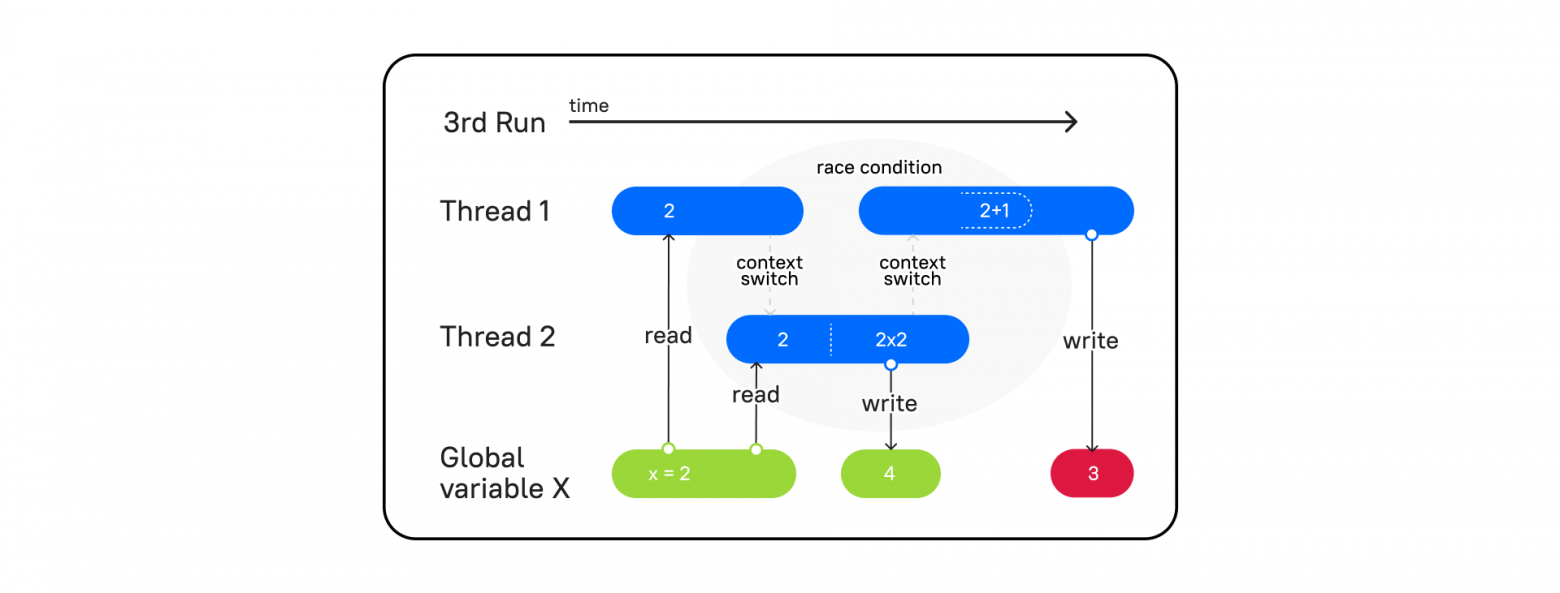
Поток 1 вступает в работу, читает переменную x и переключает контекст на поток 2 (context switch). Затем поток 2 берет значение из x = 2, умножает на 2 и записывает в x = 4. Процессор переключает контекст на поток 1, а в потоке 1, как мы помним, сохранено значение x = 2. В итоге он увеличивает значение на единицу и записывает в x = 3, а значит, на выходе мы получаем 3.
Один поток обогнал другой при переключении контекста, и мы получили непредсказуемый результат. Такое событие называется Race condition. Как тогда быть уверенным в том, что поток, взявший в работу какие-то данные, выполнит свою работу, перед тем как переключит свой контекст на другой потоку?
Вот пример:
```
from threading import Thread
from time import sleep
counter = 0
def increase(by):
global counter
local_counter = counter
local_counter += by
sleep(0.1)
counter = local_counter
print(f'{counter=}')
t1 = Thread(target=increase, args=(10,))
t2 = Thread(target=increase, args=(20,))
t1.start()
t2.start()
t1.join()
t2.join()
```Посмотрим на результат:
```
counter=10
counter=20
```Вместо 30 получаем 20.
На помощь нам может прийти такое понятие как Lock.
Lock (замок) – объект, который захватывает поток, и пока поток не освободит (release) Lock, другие потоки не смогут ничего сделать с этими данными, захваченными при помощи замка.
```
from threading import Thread, Lock
from time import sleep
counter = 0
def increase(by, lock: Lock):
global counter
lock.acquire()
local_counter = counter
local_counter += by
sleep(0.1)
counter = local_counter
print(f'{counter=}')
lock.release()
lock = Lock()
t1 = Thread(target=increase, args=(10, lock,))
t2 = Thread(target=increase, args=(20, lock,))
t1.start()
t2.start()
t1.join()
t2.join()
```Вот теперь как и должно быть:
```
counter=10
counter=30
```Несмотря на то, что Lock помогает решить проблему с Race condition, он может привести к другой сложной ситуации, когда один поток ждет освобождение одного замка, а другой ждет освобождение от первого. Такое ожидание приводит к ситуации взаимного тупика, известного как Deadlock.
```
from threading import Thread, Lock
from time import sleep
a = 5
b = 10
a_lock = Lock()
b_lock = Lock()
def function_a():
global a
global b
a_lock.acquire()
print('Функция a, a_lock = заблокирован')
sleep(1)
b_lock.acquire()
print('Функция a, b_lock = заблокирован')
sleep(1)
a_lock.release()
print('Функция a, a_lock = разблокирован')
b_lock.release()
print('Функция a, b_lock = разблокирован')
def function_b():
global a
global b
b_lock.acquire()
print('Функция b, b_lock = заблокирован')
a_lock.acquire()
print('Функция b, a_lock = заблокирован')
sleep(1)
b_lock.release()
print('Функция b, b_lock = разблокирован')
a_lock.release()
print('Функция b, a_lock = разблокирован')
t1 = Thread(target=function_a)
t2 = Thread(target=function_b)
t1.start()
t2.start()
t1.join()
t2.join()
print('Готово')
```И теперь посмотрим результат:
```
Функция a, a_lock = заблокирован
Функция b, b_lock = заблокирован
```Наша программа зависает в ожидании разблокировки, которая никогда не произойдет. Так же Deadlock произойдет при попытке заблокировать наш Lock повторно в том же потоке.
Решить проблему с Deadlock могут помочь различные механизмы синхронизации потоков. Разберем один из таких примеров – Semaphore (Семафор).
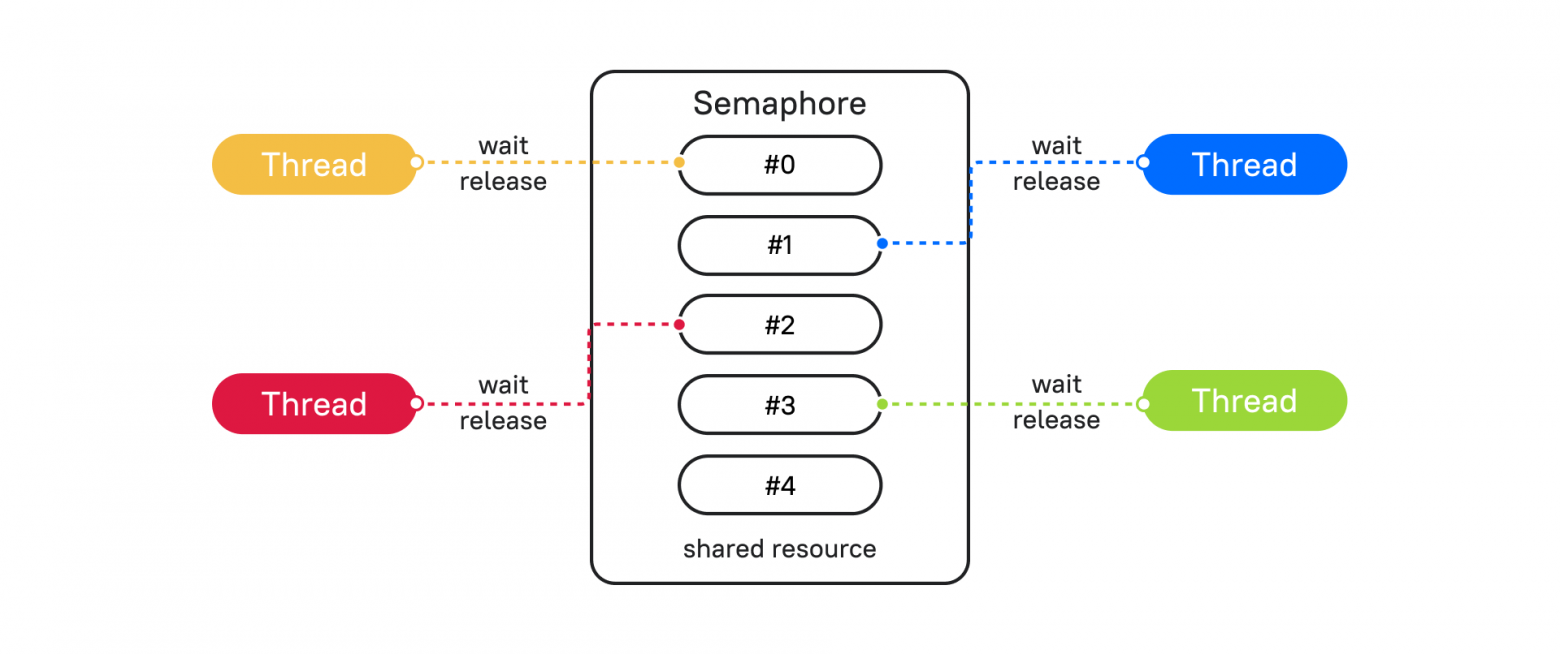
Semaphore прост в понимании, если его представить в виде объекта, который ограничивает выполнение блока кода установленным количеством, по умолчанию это 1. При каждом вхождении в блок кода Semaphore счетчик уменьшается. Если счетчик дошел до 0, все потоки блокируются, и пока поток не освободит семафор, другие будут ждать разрешения подключиться.
Посмотрим Semaphore на примере реализации очереди из реального кейса.
```
import datetime
from threading import Semaphore, Thread
from time import sleep
s = Semaphore(3)
def semaphore_func(payload: int):
s.acquire()
now = datetime.datetime.now().strftime('%H:%M:%S')
print(f'{now=}, {payload=}')
sleep(2)
s.release()
threads = [Thread(target=semaphore_func, args=(i,)) for i in range(7)]
for t in threads:
t.start()
for t in threads:
t.join()
```
В результате увидим, что функция выполнялась группами по 3 потока. То есть одновременно не может выполняться кусок кода с блокировкой через Semaphore больше, чем указан в инициализации класса Semaphore. Видим паузы в 2 секунды между блокировками.
```
now='00:49:51', payload=0
now='00:49:51', payload=1
now='00:49:51', payload=2
now='00:49:53', payload=3
now='00:49:53', payload=5
now='00:49:53', payload=4
now='00:49:55', payload=6
```Это удобно использовать, например, в таком виде: если база данных может держать не более 30 соединений, то инстанциируем Semaphore со значением 30. Блокируем, когда поднимаем соединение и разблокируем, когда освобождаем.
Есть несколько способов синхронизации потоков, которые подходят для тех или иных ситуации. Примеры можно посмотреть в документации.
Теперь поговорим об освобождении GIL.
CPython управляет памятью с помощью подсчета ссылок. То есть для каждого объекта Python подсчитывается, сколько на него указывается ссылок с других объектов, использующих его в данный момент. При добавлении ссылки счетчик увеличивается, при удалении ссылки счетчик уменьшается. А когда счетчик ссылок становится 0 — это означает, что объект больше не нужен, и его можно удалить из памяти.
Следовательно, если не будет GIL, который запрещает Python процессу выполнять более одной команды байт-кода в каждый момент времени, то при подсчете ссылок может случиться Race-condition, с подсчетом ссылок на объекты, как это было в примере с переменными выше.
Итак, раз GIL запрещает одновременное выполнение Python кода, из этого следует, что он высвобождается, когда Python код не выполняется. Когда мы ждем, например, пока считается файл с диска или придет ответ на запрос к сайту. Так как в этом случае низкоуровневые системные вызовы работают за пределами Python кода и среды выполнения, и код операционной системы не взаимодействует напрямую с объектами Python, соответственно, они не увеличивают и не уменьшают счетчик ссылок. GIL захватывается снова, когда данные переносятся в объект Python.
Стало быть, если мы сделаем библиотеку, даже с CPU-bound нагрузкой, где мы не взаимодействуем с объектами Python (словарями, списками, целыми числами и т. д.) или большая часть библиотеки не взаимодействует, то мы можем освободить GIL. Например, библиотеки hashlib и NumPy выполняют расчеты на чистом C и освобождают GIL.
time.sleep() — реализация этой функции освобождает GIL и выполняется на уровне системы и работает вне кода Python.
Как видите, в многопоточности существует огромное количество нюансов и проблем. В реальных больших программах будет непросто понять, где происходит ошибка. Рассмотрим, как можно распараллелить выполнение программ. В этом поможет асинхронность.
Асинхронность
Для того чтобы лучше понять асинхронность, окунемся в далекий 1992 год. Тогда была выпущена операционная система Windows 3.1 которая использовала кооперативную многозадачность.
Кооперативная многозадачность — это тип многозадачности, при котором фоновые задачи выполняются только во время простоя основного процесса и только в том случае, если на это получено разрешение основного процесса.
То есть время, когда исполняемая программа управляет передачей управления другому процессу и передачей процессорного времени.
Недостатком такого исполнения является то, что если одна задача зависла. Зависает вся система.
А вот преимущества такого решения: разработчик программы отдает управление тогда, когда он посчитает это нужным.
Теперь мы подобрались к понятию асинхронного программирования.
Асинхронное программирование — выполнение программы в неблокирующем режиме системного вызова, что позволяет потоку программы продолжить работу.
Благодаря асинхронному программированию в одном процессе и даже потоке мы можем выполнять сразу множество задач. Как же это происходит?
В реальном программировании, а особенно в web-разработке мы очень часто чего-то ждём и не делаем полезной работы. Вот несколько примеров:
-
Отправили запрос на сторонний ресурс и ждем ответа.
-
Отправили запрос в базу данных и ждем результата запроса.
-
Читаем или записываем файл на диск.
-
И так далее.
Получается что мы ждем, ждем и ждем. А в это время наша программа могла бы выполнить множество полезной нагрузки. И мы как разработчики ПО точно знаем, где мы будем ожидать. Ничего не напоминает? Да! Похоже на кооперативную многозадачность, но только не на уровне операционной системы, а на уровне процесса.
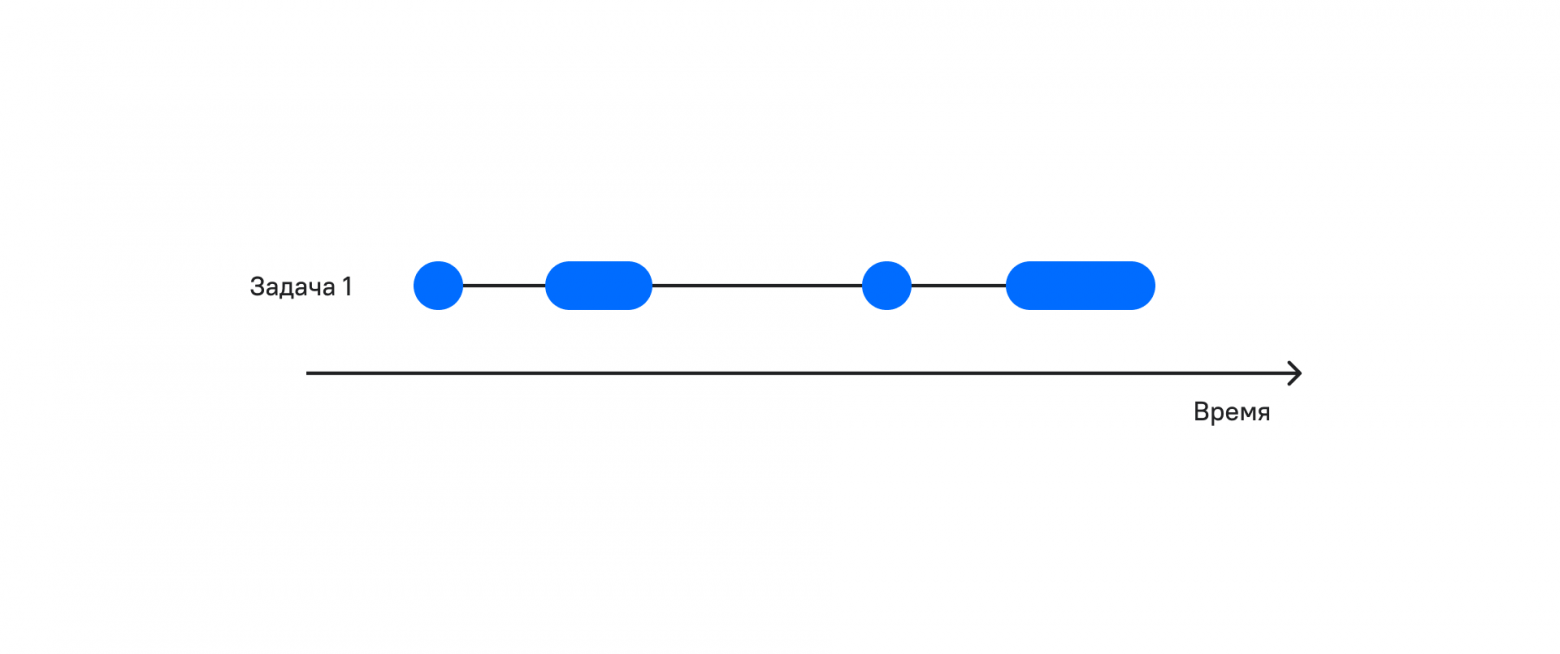
На рисунке видно, что периодов ожидания много. А что будет если во время ожидания мы будем выполнять полезную работу?
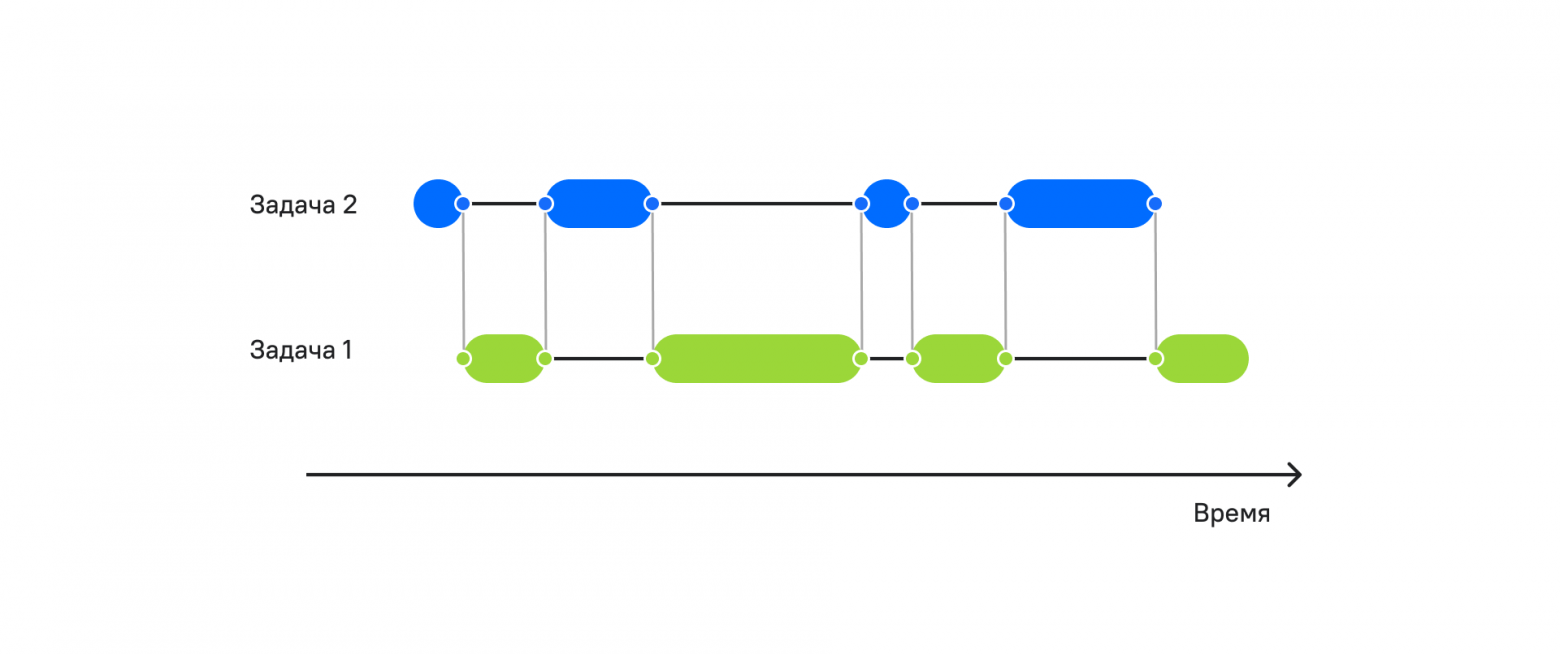
Как видно на рисунке, в моменты ожидания мы выполняем уже две задачи за то же самое время. Чем быстрее мы выполняем работу и чем дольше мы ожидаем, тем больше задач мы можем сделать за одно и то же время.
Для реализации такого поведения асинхронности есть несколько подходов:
-
Реализация на основе коллбэков.
-
Реализация на основе корутин.
Оба подхода имеют место. Например, мощный фреймворк TORNADO реализован именно на основе коллбэков.
У этого подхода есть ряд недостатков:
-
Код перестает выглядеть как синхронный, что усложняет отладку.
-
Ад коллбэков, в котором будет сложно разобраться. Просто погуглите фразу “callback hell”.
Если после этих минусов желание попробовать ещё осталось, то можно в подходе легко разобраться.
А вот подход на основе корутин мы разберем более глубоко. У него также есть ряд преимуществ и недостатков:
Плюсы:
-
Асинхронный код выглядит как синхронный.
-
Нет проблем с общей памятью, и избавляемся от синхронизаций.
-
Не нужно переключать контекст между задачами, что экономит ресурсы нашего компьютера.
-
Теперь нам не нужны коллбэки, но их также можно использовать.
Минусы:
-
Чуть более сложный подход для понимания.
В Python есть ряд библиотек, которые позволяют работать с асинхронностью:
-
asyncio — основная библиотека для работы с асинхронным программированием,
-
aiohttp — для асинхронной работы с запросами,
-
aiofiles — для работы с файловой системой.
Как вы наверное заметили, у библиотек есть префикс aio (asynchronous input output, асинхронный ввод-вывод). Тут как раз решается проблема ожидания. Такие задачи называют IO bound.
Рассмотрим термины, которые нам помогут во всём разобраться.
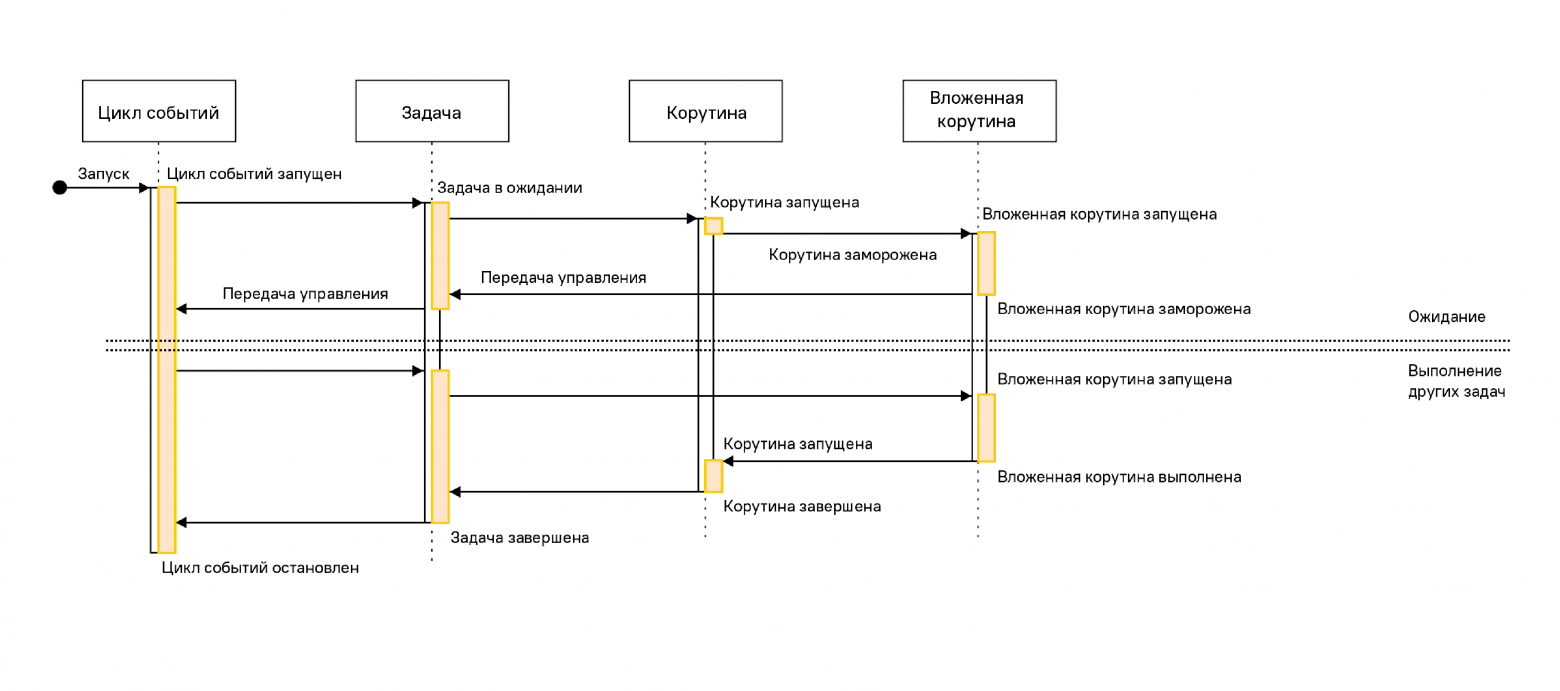
Event loop (цикл событий) — ядро каждого приложения asyncio. Циклы событий запускают асинхронные задачи и обратные вызовы, выполняют операции сетевого ввода-вывода и запускают подпроцессы. Официальную документацию можно прочесть тут.
Корутины — это специальные функции, которые запускаются, используя цикл событий. У них есть особенность — они говорят, когда они будут ждать и передают управление обратно, чтобы другая задача могла выполняться во время ожидания.
Футуры — это определение обычно воспринимается тяжелее всего, но я постараюсь объяснить как можно проще. Это объект, в котором хранится результат и состояние задачи:
+ ожидание (pending)
+ выполнение (running)
+ выполнено (done)
+ отменено (cancelled)
То есть в процессе работы мы можем управлять задачами в зависимости от футуры (статус/результат) задачи.
Корутины могут быть реализованы с использованием генераторов или async/await. Мы выбираем второй вариант как более лаконичный.
Посмотрим, как это выглядит в коде.
Создадим первую корутину:
```
import asyncio
async def hello():
print('Запуск функции hello')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждем
print('Переключение контекста в функцию hello')
```Теперь у нас есть асинхронная функция. Научимся теперь её запускать. Первое, что хочется сделать — вызвать её как обычную функцию. Давайте попробуем:
```
import asyncio
async def hello():
print('Запуск функции hello')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию hello')
hello()
```При выполнении ничего не произошло. А вот наш друг интерпретатор выдал предупреждение.
```
RuntimeWarning: coroutine 'hello' was never awaited
hello()
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
```Тут из сообщения становится понятно, что при вызове таким образом асинхронной функции она превращается в асинхронную корутину.
Как же можно запустить корутину?
-
Из другой корутины.
-
Обернуть в задачу.
-
Запустить через метод asyncio.run и run_until_complete из цикла событий.
```
import asyncio
async def hello():
print('Запуск функции hello')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию hello')
asyncio.run(hello())
```И получили результат, который ожидали.
```
Запуск функции hello
Переключение контекста в функцию hello
```Вызов метода asyncio.run(hello()) принимает корутину, которую необходимо выполнить, открывает цикл событий, выполняет корутину и закрывает цикл событий.
Что делать, если необходимо запустить две задачи конкурентно?
Это поможет нам сделать asyncio.gather, но раз функция asyncio.run принимает только одну корутину, создадим новую корутину, которая будет запускать конкурентно несколько задач.
```
import asyncio
async def hello():
print('Запуск функции hello')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию hello')
async def starter():
await asyncio.gather(hello(), hello())
asyncio.run(starter())
```И получаем тот результат, который ожидали.
```
Запуск функции hello
Запуск функции hello
Переключение контекста в функцию hello
Переключение контекста в функцию hello
```Время выполнения около 5 секунд. Если бы две функции выполнялись синхронно, то время выполнения составило около 10 секунд.
А если нам необходимо выполнить 10 тысяч раз, сколько времени это займёт? Видоизменяем код:
```
import asyncio
import time
start = time.time() ## точка отсчета времени
async def hello():
print('Запуск функции hello')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию hello')
async def starter():
await asyncio.gather(*[hello() for i in range(10000)])
asyncio.run(starter())
end = time.time() - start
print(end)
```Получаем результат. Посмотрим на вывод последних нескольких строк, которые нам говорят, сколько минут выполнялся код.
```
…
Переключение контекста в функцию hello
Переключение контекста в функцию hello
Переключение контекста в функцию hello
5.27926778793335
```Неплохо. Чуть больше тех же самых 5 секунд.
Что же это значит? Представьте, что запрос на сторонний сайт занимает порядка 5 секунд. И нам необходимо получить результат тех же самых 10000 запросов. Используя асинхронное программирование, 10 тысяч запросов сеть будут выполняться чуть больше 5 секунд. Правда, здорово?
Но мы пойдем дальше и будем уже более гибко и детально работать с асинхронным выполнением:
```
import asyncio
async def hello():
print('Запуск функции hello')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию hello')
async def bye():
print('Запуск функции bye')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию byе')
ioloop = asyncio.get_event_loop()
tasks = [ioloop.create_task(hello()), ioloop.create_task(bye())]
tasks_for_wait = asyncio.wait(tasks)
ioloop.run_until_complete(tasks_for_wait)
ioloop.close()
```В этом примере мы более гибко управляем циклом событий. Сначала получаем/создаем основной цикл событий. Затем создаем задачи и объединяем их запускаем на выполнение, пока не завершится. Затем уже закрываем цикл событий. Нужно помнить, что порядок выполнения задач при конкурентном выполнении мы не можем гарантировать, и необходимо разрабатывать приложения с учетом этой особенности.
Теперь давайте попробуем управлять выполнениями задач и рассмотрим код ниже:
```
import asyncio
async def hello():
print('Запуск функции hello')
await asyncio.sleep(5) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию hello')
return 'Выполнена функция hello'
async def bye():
print('Запуск функции bye')
await asyncio.sleep(2) # Отдаем управление обратно в Event loop пока ждём
print('Переключение контекста в функцию byе')
return 'Выполнена функция bye'
async def starter(ioloop):
tasks = [ioloop.create_task(hello()), ioloop.create_task(bye())]
done, pending = await asyncio.wait(tasks, return_when=asyncio.FIRST_COMPLETED)
result = done.pop().result()
for pending_future in pending:
pending_future.cancel()
print(result)
ioloop = asyncio.get_event_loop()
ioloop.run_until_complete(starter(ioloop))
ioloop.close()
```Результат будет таким:
```
Запуск функции hello
Запуск функции bye
Переключение контекста в функцию byе
Выполнена функция bye
```Теперь только представьте, какие возможности у нас открылись! Например, мы можем запрашивать курсы валют сразу с нескольких ресурсов, и принимать результат того, который быстрее ответит. Чувствуете, как растет скорость и устойчивость приложения?
Или ещё такой пример. Мы можем динамически добавлять новые задачи, когда одна из задач выполнена. Например, парсить сайт в 20 задач. Только в этом случае добавляем к футурам в статусе pending новую задачу.
А самое приятное — наши асинхронные задачи выглядят как синхронные:
-
Работая в один поток, можно делать больше работы;
-
Удобная отладка;
-
Нет проблем с блокировками;
-
Можем использовать обратные вызовы (коллбэки) и отложенные обратные вызовы вдобавок к нашему асинхронному коду. Для этого посмотрите на методы цикла событий call_soon, call_later, call_at.
Для работы с конкурентностью есть различные библиотеки, которые решают самые востребованные задачи IO:
-
aiohttp — работа с HTTP запросами;
-
aiofiles — работа с файлами.
Мы рассмотрели темы асинхронного и параллельного программирования. Теперь осталось дело за малым, опробовать всё это на практике.
Итого
Отдельные процессы
Плюсы:
+ Работают параллельно.
+ Используют все ресурсы ядра процессора.
+ Можно загрузить все ядра процессора.
+ Изолированная память.
+ Независимые системные процессы.
+ Подходит для CPU bound операций.
Минусы:
-
Если необходимо использовать общую память, то необходимо синхронизировать, так как нет общих переменных.
-
Требуют больших ресурсов, так как запускают отдельный интерпретатор.
Используем там, где обрабатываемые данные не зависят от других процессов и данных. Например:
+ Расчет нейронных сетей.
+ Обработка изолированных фотографий.
+ Архивирование изолированных файлов.
+ Конвертация форматов файлов.
Отдельные потоки
Плюсы:
+ Работают параллельно.
+ Используют немного памяти.
+ Общая память.
Минусы:
-
Одновременный доступ к памяти может приводить к конфликтам.
-
Сложный код.
Используем там, где код много раз ожидает, пока выполнится задача. Например:
+ Работа с сетью.
Асинхронность
Плюсы:
+ Работает в одном процессе и в одном потоке.
+ Экономное использование памяти.
+ Подходит для I/O bound операций.
+ Работает конкурентно.
Минусы:
-
Сложность отладки.
-
CPU bound операции блокируют все задачи.
Используем там, где код много раз ожидает. Например:
+ Работа с сетью.
+ Работа с файловой системой.
Основываясь на конкретных плюсах и минусах, нам становится легче выбирать подход и грамотно использовать процессорное время и память. Хотя Python является мультипарадигменным языком общего назначения, на нем можно писать практически любые программы, используя любой подход. Но особенно приятно, когда ваш веб-сервис может держать в сотню раз больше соединений или отрабатывать запросы в 8 раз быстрее, обходясь меньшим количеством памяти.
Спасибо за внимание! Надеемся, что этот материал был полезен для вас.
Авторские материалы для разработчиков мы также публикуем в наших соцсетях – ВК и Telegram.
Introduction
Interacting with Windows shell to end process is very common,
there are many ways to do so, like through the traditional batch script
but to gain more flexibility, using python is probably a better idea.
os.systemis not the most elegant way to use, and it is meant to be replaced bysubprocesssubprocesscomes with Python standard library and allows us to spawn new processes, connect to their input/output/error pipes, and obtain their return codespsutil(python system and process utilities) is a cross-platform library for retrieving information on running processes and system utilization.
However, it is a third-party library
Bare Minimum
the bare minimum command to kill process utilizes window’s taskkill;
which doesn’t matter if we use os.system or subprocess
1 |
import os |
Using os.system
Now consider a more flexible case where we want to gather information about the processes like its PID,
and then proceed on ending the process. One of the downside of window shell command is that the output
can’t be passed on to other command, the output is just text. Therefore, we
output the text to a csv file which we will later process.
1 |
import csv |
Using subprocess
With subprocess, we no longer need to create a temp file to store the output.
Using psutil
1 |
import psutil |
we can find process start time by using
1 |
import time |
to kill process, either kill() or terminate() will work
respectfully, SIGKILL or SIGTERM
1 |
p = psutil.Process(PID) |
Bonus: Find Open Port (for socket connection)
1 |
process = psutil.Process(pid=PID) |
Bonus: Find Main Window Title
ctypes is a foreign function library for python, resulting a not-pythonic function
Reference
Microsoft Doc — tasklist
ThisPointer — Python : Check if a process is running by name and find it’s Process ID (PID)
Johannes Sasongko — Win32 Python: Getting all window titles
Stack Overflow — Obtain Active window using Python
Microsoft Docs — winuser.h header
Execute a child program in a new process. On POSIX, the class uses
os.execvp()-like behavior to execute the child program. On Windows,
the class uses the Windows CreateProcess() function. The arguments to
Popen are as follows.
args should be a sequence of program arguments or else a single string.
By default, the program to execute is the first item in args if args is
a sequence. If args is a string, the interpretation is
platform-dependent and described below. See the shell and executable
arguments for additional differences from the default behavior. Unless
otherwise stated, it is recommended to pass args as a sequence.
On POSIX, if args is a string, the string is interpreted as the name or
path of the program to execute. However, this can only be done if not
passing arguments to the program.
Note
shlex.split() can be useful when determining the correct
tokenization for args, especially in complex cases:
>>> import shlex, subprocess >>> command_line = input() /bin/vikings -input eggs.txt -output "spam spam.txt" -cmd "echo '$MONEY'" >>> args = shlex.split(command_line) >>> print(args) ['/bin/vikings', '-input', 'eggs.txt', '-output', 'spam spam.txt', '-cmd', "echo '$MONEY'"] >>> p = subprocess.Popen(args) # Success!
Note in particular that options (such as -input) and arguments (such
as eggs.txt) that are separated by whitespace in the shell go in separate
list elements, while arguments that need quoting or backslash escaping when
used in the shell (such as filenames containing spaces or the echo command
shown above) are single list elements.
On Windows, if args is a sequence, it will be converted to a string in a
manner described in Converting an argument sequence to a string on Windows. This is because
the underlying CreateProcess() operates on strings.
The shell argument (which defaults to False) specifies whether to use
the shell as the program to execute. If shell is True, it is
recommended to pass args as a string rather than as a sequence.
On POSIX with shell=True, the shell defaults to /bin/sh. If
args is a string, the string specifies the command
to execute through the shell. This means that the string must be
formatted exactly as it would be when typed at the shell prompt. This
includes, for example, quoting or backslash escaping filenames with spaces in
them. If args is a sequence, the first item specifies the command string, and
any additional items will be treated as additional arguments to the shell
itself. That is to say, Popen does the equivalent of:
Popen(['/bin/sh', '-c', args[0], args[1], ...])
On Windows with shell=True, the COMSPEC environment variable
specifies the default shell. The only time you need to specify
shell=True on Windows is when the command you wish to execute is built
into the shell (e.g. dir or copy). You do not need
shell=True to run a batch file or console-based executable.
Note
Read the Security Considerations section before using shell=True.
bufsize will be supplied as the corresponding argument to the
open() function when creating the stdin/stdout/stderr pipe
file objects:
0means unbuffered (read and write are one
system call and can return short)1means line buffered
(only usable ifuniversal_newlines=Truei.e., in a text mode)- any other positive value means use a buffer of approximately that
size - negative bufsize (the default) means the system default of
io.DEFAULT_BUFFER_SIZE will be used.
Changed in version 3.3.1: bufsize now defaults to -1 to enable buffering by default to match the
behavior that most code expects. In versions prior to Python 3.2.4 and
3.3.1 it incorrectly defaulted to 0 which was unbuffered
and allowed short reads. This was unintentional and did not match the
behavior of Python 2 as most code expected.
The executable argument specifies a replacement program to execute. It
is very seldom needed. When shell=False, executable replaces the
program to execute specified by args. However, the original args is
still passed to the program. Most programs treat the program specified
by args as the command name, which can then be different from the program
actually executed. On POSIX, the args name
becomes the display name for the executable in utilities such as
ps. If shell=True, on POSIX the executable argument
specifies a replacement shell for the default /bin/sh.
stdin, stdout and stderr specify the executed program’s standard input,
standard output and standard error file handles, respectively. Valid values
are PIPE, DEVNULL, an existing file descriptor (a positive
integer), an existing file object, and None. PIPE
indicates that a new pipe to the child should be created. DEVNULL
indicates that the special file os.devnull will be used. With the
default settings of None, no redirection will occur; the child’s file
handles will be inherited from the parent. Additionally, stderr can be
STDOUT, which indicates that the stderr data from the applications
should be captured into the same file handle as for stdout.
If preexec_fn is set to a callable object, this object will be called in the
child process just before the child is executed.
(POSIX only)
Warning
The preexec_fn parameter is not safe to use in the presence of threads
in your application. The child process could deadlock before exec is
called.
If you must use it, keep it trivial! Minimize the number of libraries
you call into.
Note
If you need to modify the environment for the child use the env
parameter rather than doing it in a preexec_fn.
The start_new_session parameter can take the place of a previously
common use of preexec_fn to call os.setsid() in the child.
If close_fds is true, all file descriptors except 0, 1 and
2 will be closed before the child process is executed. (POSIX only).
The default varies by platform: Always true on POSIX. On Windows it is
true when stdin/stdout/stderr are None, false otherwise.
On Windows, if close_fds is true then no handles will be inherited by the
child process. Note that on Windows, you cannot set close_fds to true and
also redirect the standard handles by setting stdin, stdout or stderr.
Changed in version 3.2: The default for close_fds was changed from False to
what is described above.
pass_fds is an optional sequence of file descriptors to keep open
between the parent and child. Providing any pass_fds forces
close_fds to be True. (POSIX only)
New in version 3.2: The pass_fds parameter was added.
If cwd is not None, the function changes the working directory to
cwd before executing the child. cwd can be a str and
path-like object. In particular, the function
looks for executable (or for the first item in args) relative to cwd
if the executable path is a relative path.
Changed in version 3.6: cwd parameter accepts a path-like object.
If restore_signals is true (the default) all signals that Python has set to
SIG_IGN are restored to SIG_DFL in the child process before the exec.
Currently this includes the SIGPIPE, SIGXFZ and SIGXFSZ signals.
(POSIX only)
Changed in version 3.2: restore_signals was added.
If start_new_session is true the setsid() system call will be made in the
child process prior to the execution of the subprocess. (POSIX only)
Changed in version 3.2: start_new_session was added.
If env is not None, it must be a mapping that defines the environment
variables for the new process; these are used instead of the default
behavior of inheriting the current process’ environment.
Note
If specified, env must provide any variables required for the program to
execute. On Windows, in order to run a side-by-side assembly the
specified env must include a valid SystemRoot.
If encoding or errors are specified, the file objects stdin, stdout
and stderr are opened in text mode with the specified encoding and
errors, as described above in Frequently Used Arguments. If
universal_newlines is True, they are opened in text mode with default
encoding. Otherwise, they are opened as binary streams.
New in version 3.6: encoding and errors were added.
If given, startupinfo will be a STARTUPINFO object, which is
passed to the underlying CreateProcess function.
creationflags, if given, can be CREATE_NEW_CONSOLE or
CREATE_NEW_PROCESS_GROUP. (Windows only)
Popen objects are supported as context managers via the with statement:
on exit, standard file descriptors are closed, and the process is waited for.
with Popen(["ifconfig"], stdout=PIPE) as proc: log.write(proc.stdout.read())
Changed in version 3.2: Added context manager support.
Changed in version 3.6: Popen destructor now emits a ResourceWarning warning if the child
process is still running.
В скриптах, написанных для автоматизации определенных задач, нам часто требуется запускать внешние программы и контролировать их выполнение. При работе с Python мы можем использовать модуль subprocess для создания подобных скриптов. Этот модуль является частью стандартной библиотеки языка. В данном руководстве мы кратко рассмотрим subprocess и изучим основы его использования.
Прочитав статью, вы узнаете как:
- Использовать функцию
runдля запуска внешнего процесса. - Получить стандартный вывод процесса и информацию об ошибках.
- Проверить код возврата процесса и вызвать исключение в случае сбоя.
- Запустить процесс, используя оболочку в качестве посредника.
- Установить время ожидания завершения процесса.
- Использовать класс
Popenнапрямую для создания конвейера (pipe) между двумя процессами.
Так как модуль subprocess почти всегда используют с Linux все примеры будут касаться Ubuntu. Для пользователей Windows советую скачать терминал Ubuntu 18.04 LTS.
Функция «run»
Функция run была добавлена в модуль subprocess только в относительно последних версиях Python (3.5). Теперь ее использование является рекомендуемым способом создания процессов и должно решать наиболее распространенные задачи. Прежде всего, давайте посмотрим на простейший случай применения функции run.
Предположим, мы хотим запустить команду ls -al; для этого в оболочке Python нам нужно ввести следующие инструкции:
>>> import subprocess
>>> process = subprocess.run(['ls', '-l', '-a'])
Вывод внешней команды ls отображается на экране:
total 12
drwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .
drwxr-xr-x 1 root root 4096 Apr 27 15:40 ..
-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history
-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout
-rw-r--r-- 1 cnc cnc 3771 Apr 27 15:40 .bashrcЗдесь мы просто использовали первый обязательный аргумент функции run, который может быть последовательностью, «описывающей» команду и ее аргументы (как в примере), или строкой, которая должна использоваться при запуске с аргументом shell=True (мы рассмотрим последний случай позже).
Захват вывода команды: stdout и stderr
Что, если мы не хотим, чтобы вывод процесса отображался на экране. Вместо этого, нужно чтобы он сохранялся: на него можно было ссылаться после выхода из процесса? В этом случае нам стоит установить для аргумента функции capture_output значение True:
>>> process = subprocess.run(['ls', '-l', '-a'], capture_output=True)
Как мы можем впоследствии получить вывод (stdout и stderr) процесса? Если вы посмотрите на приведенные выше примеры, то увидите, что мы использовали переменную process для ссылки на объект CompletedProcess, возвращаемый функцией run. Этот объект представляет процесс, запущенный функцией, и имеет много полезных свойств. Помимо прочих, stdout и stderr используются для «хранения» соответствующих дескрипторов команды, если, как уже было сказано, для аргумента capture_output установлено значение True. В этом случае, чтобы получить stdout, мы должны использовать:
>>> process = subprocess.run(['ls', '-l', '-a'], capture_output=True)
>>> process.stdout
b'total 12\ndrwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .\ndrwxr-xr-x 1 root root 4096 Apr 27 15:40 ..\n-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history\n-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout...По умолчанию stdout и stderr представляют собой последовательности байтов. Если мы хотим, чтобы они хранились в виде строк, мы должны установить для аргумента text функции run значение True.
Управление сбоями процесса
Команда, которую мы запускали в предыдущих примерах, была выполнена без ошибок. Однако при написании программы следует принимать во внимание все случаи. Так, что случится, если порожденный процесс даст сбой? По умолчанию ничего «особенного» не происходит. Давайте посмотрим на примере: мы снова запускаем команду ls, пытаясь вывести список содержимого каталога /root, который не доступен для чтения обычным пользователям:
>>> process = subprocess.run(['ls', '-l', '-a', '/root'])
Мы можем узнать, не завершился ли запущенный процесс ошибкой, проверив его код возврата, который хранится в свойстве returncode объекта CompletedProcess:
Видите? В этом случае returncode равен 2, подтверждая, что процесс столкнулся с ошибкой, связанной с недостаточными правами доступа, и не был успешно завершен. Мы могли бы проверять выходные данные процесса таким образом чтобы при возникновении сбоя возникало исключение. Используйте аргумент check функции run: если для него установлено значение True, то в случае, когда внешний процесс завершается ошибкой, возникает исключение CalledProcessError:
>>> process = subprocess.run(['ls', '-l', '-a', '/root'])
ls: cannot open directory '/root': Permission deniedОбработка исключений в Python довольно проста. Поэтому для управления сбоями процесса мы могли бы написать что-то вроде:
>>> try:
... process = subprocess.run(['ls', '-l', '-a', '/root'], check=True)
... except subprocess.CalledProcessError as e:
... print(f"Ошибка команды {e.cmd}!")
...
ls: cannot open directory '/root': Permission denied
['ls', '-l', '-a', '/root'] failed!
>>>Исключение CalledProcessError, как мы уже сказали, возникает, когда код возврата процесса не является 0. У данного объекта есть такие свойства, как returncode, cmd, stdout, stderr; то, что они представляют, довольно очевидно. Например, в приведенном выше примере мы просто использовали свойство cmd, чтобы отобразить последовательность, которая использовалась для запуска команды при возникновении исключения.
Выполнение процесса в оболочке
Процессы, запущенные с помощью функции run, выполняются «напрямую», это означает, что для их запуска не используется оболочка: поэтому для процесса не доступны никакие переменные среды и не выполняются раскрытие и подстановка выражений. Давайте посмотрим на пример, который включает использование переменной $HOME:
>>> process = subprocess.run(['ls', '-al', '$HOME'])
ls: cannot access '$HOME': No such file or directoryКак видите, переменная $HOME не была заменена на соответствующее значение. Такой способ выполнения процессов является рекомендованным, так как позволяет избежать потенциальные угрозы безопасности. Однако, в некоторых случаях, когда нам нужно вызвать оболочку в качестве промежуточного процесса, достаточно установить для параметра shell функции run значение True. В таких случаях желательно указать команду и ее аргументы в виде строки:
>>> process = subprocess.run('ls -al $HOME', shell=True)
total 12
drwxr-xr-x 1 cnc cnc 4096 Apr 27 16:21 .
drwxr-xr-x 1 root root 4096 Apr 27 15:40 ..
-rw------- 1 cnc cnc 2445 May 6 17:43 .bash_history
-rw-r--r-- 1 cnc cnc 220 Apr 27 15:40 .bash_logout
...Все переменные, существующие в пользовательской среде, могут использоваться при вызове оболочки в качестве промежуточного процесса. Хотя это может показаться удобным, такой подход является источником проблем. Особенно при работе с потенциально опасным вводом, который может привести к внедрению вредоносного shell-кода. Поэтому запуск процесса с shell=True не рекомендуется и должен использоваться только в безопасных случаях.
Ограничение времени работы процесса
Обычно мы не хотим, чтобы некорректно работающие процессы бесконечно исполнялись в нашей системе после их запуска. Если мы используем параметр timeout функции run, то можем указать количество времени в секундах, в течение которого процесс должен завершиться. Если он не будет завершен за это время, процесс будет остановлен сигналом SIGKILL. Который, как мы знаем, не может быть перехвачен. Давайте продемонстрируем это, запустив длительный процесс и предоставив timeout в секундах:
>>> process = subprocess.run(['ping', 'google.com'], timeout=5)
PING google.com (216.58.208.206) 56(84) bytes of data.
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=1 ttl=118 time=15.8 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=2 ttl=118 time=15.7 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=3 ttl=118 time=19.3 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=4 ttl=118 time=15.6 ms
64 bytes from par10s21-in-f206.1e100.net (216.58.208.206): icmp_seq=5 ttl=118 time=17.0 ms
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.8/subprocess.py", line 495, in run
stdout, stderr = process.communicate(input, timeout=timeout)
File "/usr/lib/python3.8/subprocess.py", line 1028, in communicate
stdout, stderr = self._communicate(input, endtime, timeout)
File "/usr/lib/python3.8/subprocess.py", line 1894, in _communicate
self.wait(timeout=self._remaining_time(endtime))
File "/usr/lib/python3.8/subprocess.py", line 1083, in wait
return self._wait(timeout=timeout)
File "/usr/lib/python3.8/subprocess.py", line 1798, in _wait
raise TimeoutExpired(self.args, timeout)
subprocess.TimeoutExpired: Command '['ping', 'google.com']' timed out after 4.999637200000052 seconds
В приведенном выше примере мы запустили команду ping без указания фиксированного числа пакетов ECHO REQUEST, поэтому она потенциально может работать вечно. Мы также установили время ожидания в 5 секунд с помощью параметра timeout. Как мы видим, ping была запущена, а по истечении 5 секунд возникло исключение TimeoutExpired и процесс был остановлен.
Функции call, check_output и check_call
Как мы уже говорили ранее, функция run является рекомендуемым способом запуска внешнего процесса. Она должна использоваться в большинстве случаев. До того, как она была представлена в Python 3.5, тремя основными функциями API высокого уровня, применяемыми для создания процессов, были call, check_output и check_call; давайте взглянем на них вкратце.
Прежде всего, функция call: она используется для выполнения команды, описанной параметром args; она ожидает завершения команды; ее результатом является соответствующий код возврата. Это примерно соответствует базовому использованию функции run.
Поведение функции check_call практически не отличается от run, когда для параметра check задано значение True: она запускает указанную команду и ожидает ее завершения. Если код возврата не равен 0, возникает исключение CalledProcessError.
Наконец, функция check_output. Она работает аналогично check_call, но возвращает вывод запущенной программы, то есть он не отображается при выполнении функции.
Работа на более низком уровне с классом Popen
До сих пор мы изучали функции API высокого уровня в модуле subprocess, особенно run. Все они под капотом используют класс Popen. Из-за этого в подавляющем большинстве случаев нам не нужно взаимодействовать с ним напрямую. Однако, когда требуется большая гибкость, без создания объектов Popen не обойтись.
Предположим, например, что мы хотим соединить два процесса, воссоздав поведение конвейера (pipe) оболочки. Как мы знаем, когда передаем две команды в оболочку, стандартный вывод той, что находится слева от пайпа «|», используется как стандартный ввод той, которая находится справа. В приведенном ниже примере результат выполнения двух связанных конвейером команд сохраняется в переменной:
$ output="$(dmesg | grep sda)"Чтобы воссоздать подобное поведение с помощью модуля subprocess без установки параметра shell в значение True, как мы видели ранее, мы должны напрямую использовать класс Popen:
dmesg = subprocess.Popen(['dmesg'], stdout=subprocess.PIPE)
grep = subprocess.Popen(['grep', 'sda'], stdin=dmesg.stdout)
dmesg.stdout.close()
output = grep.comunicate()[0]
Рассматривая данный пример, вы должны помнить, что процесс, запущенный с использованием класса Popen, не блокирует выполнение скрипта.
Первое, что мы сделали в приведенном выше фрагменте кода, — это создали объект Popen, представляющий процесс dmesg. Мы установили stdout этого процесса на subprocess.PIPE. Данное значение указывает, что пайп к указанному потоку должен быть открыт.
Затем мы создали еще один экземпляр класса Popen для процесса grep. В конструкторе Popen мы, конечно, указали команду и ее аргументы, но вот что важно, мы установили стандартный вывод процесса dmesg в качестве стандартного ввода для grep (stdin=dmesg.stdout), чтобы воссоздать поведение конвейера оболочки.
После создания объекта Popen для команды grep мы закрыли поток stdout процесса dmesg, используя метод close(). Это, как указано в документации, необходимо для того, чтобы первый процесс мог получить сигнал SIGPIPE. Дело в том, что обычно, когда два процесса соединены конвейером, если один справа от «|» (grep в нашем примере) завершается раньше, чем тот, что слева (dmesg), то последний получает сигнал SIGPIPE (пайп закрыт) и по умолчанию тоже заканчивает свою работу.
Однако при репликации пайплайна между двумя командами в Python возникает проблема. stdout первого процесса открывается как в родительском скрипте, так и в стандартном вводе другого процесса. Таким образом, даже если процесс grep завершится, пайп останется открытым в вызывающем процессе (нашем скрипте), поэтому dmesg никогда не получит сигнал SIGPIPE. Вот почему нам нужно закрыть поток stdout первого процесса в нашем основном скрипте после запуска второго.
Последнее, что мы сделали, — это вызвали метод communicate() объекта grep. Этот метод можно использовать для необязательной передачи данных в stdin процесса. Он ожидает завершения процесса и возвращает кортеж. Где первый элемент — это stdout (на который ссылается переменная output), а второй — stderr процесса.
Заключение
В этом руководстве мы увидели рекомендуемый способ создания внешних процессов в Python с помощью модуля subprocess и функции run. Использование этой функции должно быть достаточным для большинства случаев. Однако, когда требуется более высокий уровень гибкости, следует использовать класс Popen напрямую.
Как всегда, мы советуем вам взглянуть на документацию subprocess, чтобы получить полную информацию о функциях и классах, доступных в данном модуле.
If you’ve ever wanted to simplify your command-line scripting or use Python alongside command-line applications—or any applications for that matter—then the Python subprocess module can help. From running shell commands and command-line applications to launching GUI applications, the Python subprocess module can help.
By the end of this tutorial, you’ll be able to:
- Understand how the Python
subprocessmodule interacts with the operating system - Issue shell commands like
lsordir - Feed input into a process and use its output.
- Handle errors when using
subprocess - Understand the use cases for
subprocessby considering practical examples
In this tutorial, you’ll get a high-level mental model for understanding processes, subprocesses, and Python before getting stuck into the subprocess module and experimenting with an example. After that, you’ll start exploring the shell and learn how you can leverage Python’s subprocess with Windows and UNIX-based shells and systems. Specifically, you’ll cover communication with processes, pipes and error handling.
Once you have the basics down, you’ll be exploring some practical ideas for how to leverage Python’s subprocess. You’ll also dip your toes into advanced usage of Python’s subprocess by experimenting with the underlying Popen() constructor.
Processes and Subprocesses
First off, you might be wondering why there’s a sub in the Python subprocess module name. And what exactly is a process, anyway? In this section, you’ll answer these questions. You’ll come away with a high-level mental model for thinking about processes. If you’re already familiar with processes, then you might want to skip directly to basic usage of the Python subprocess module.
Processes and the Operating System
Whenever you use a computer, you’ll always be interacting with programs. A process is the operating system’s abstraction of a running program. So, using a computer always involve processes. Start menus, app bars, command-line interpreters, text editors, browsers, and more—every application comprises one or more processes.
A typical operating system will report hundreds or even thousands of running processes, which you’ll get to explore shortly. However, central processing units (CPUs) typically only have a handful of cores, which means that they can only run a handful of instructions simultaneously. So, you may wonder how thousands of processes can appear to run at the same time.
In short, the operating system is a marvelous multitasker—as it has to be. The CPU is the brain of a computer, but it operates at the nanosecond timescale. Most other components of a computer are far slower than the CPU. For instance, a magnetic hard disk read takes thousands of times longer than a typical CPU operation.
If a process needs to write something to the hard drive, or wait for a response from a remote server, then the CPU would sit idle most of the time. Multitasking keeps the CPU busy.
Part of what makes the operating system so great at multitasking is that it’s fantastically organized too. The operating system keeps track of processes in a process table or process control block. In this table, you’ll find the process’s file handles, security context, references to its address spaces, and more.
The process table allows the operating system to abandon a particular process at will, because it has all the information it needs to come back and continue with the process at a later time. A process may be interrupted many thousands of times during execution, but the operating system always finds the exact point where it left off upon returning.
An operating system doesn’t boot up with thousands of processes, though. Many of the processes you’re familiar with are started by you. In the next section, you’ll look into the lifetime of a process.
Process Lifetime
Think of how you might start a Python application from the command line. This is an instance of your command-line process starting a Python process:
The process that starts another process is referred to as the parent, and the new process is referred to as the child. The parent and child processes run mostly independently. Sometimes the child inherits specific resources or contexts from the parent.
As you learned in Processes and the Operating System, information about processes is kept in a table. Each process keeps track of its parents, which allows the process hierarchy to be represented as a tree. You’ll be exploring your system’s process tree in the next section.
The parent-child relationship between a process and its subprocess isn’t always the same. Sometimes the two processes will share specific resources, like inputs and outputs, but sometimes they won’t. Sometimes child processes live longer than the parent. A child outliving the parent can lead to orphaned or zombie processes, though more discussion about those is outside the scope of this tutorial.
When a process has finished running, it’ll usually end. Every process, on exit, should return an integer. This integer is referred to as the return code or exit status. Zero is synonymous with success, while any other value is considered a failure. Different integers can be used to indicate the reason why a process has failed.
In the same way that you can return a value from a function in Python, the operating system expects an integer return value from a process once it exits. This is why the canonical C main() function usually returns an integer:
// minimal_program.c
int main(){
return 0;
}
This example shows a minimal amount of C code necessary for the file to compile with gcc without any warnings. It has a main() function that returns an integer. When this program runs, the operating system will interpret its execution as successful since it returns zero.
So, what processes are running on your system right now? In the next section, you’ll explore some of the tools that you can use to take a peek at your system’s process tree. Being able to see what processes are running and how they’re structured will come in handy when visualizing how the subprocess module works.
Active Processes on Your System
You may be curious to see what processes are running on your system right now. To do that, you can use platform-specific utilities to track them:
- Windows
- Linux + macOS
There are many tools available for Windows, but one which is easy to get set up, is fast, and will show you the process tree without much effort is Process Hacker.
You can install Process Hacker by going to the downloads page or with Chocolatey:
PS> choco install processhacker
Open the application, and you should immediately see the process tree.
One of the native commands that you can use with PowerShell is Get-Process, which lists the active processes on the command line. tasklist is a command prompt utility that does the same.
The official Microsoft version of Process Hacker is part of the Sysinternals utilities, namely Process Monitor and Process Explorer. You also get PsList, which is a command-line utility similar to pstree on UNIX. You can install Sysinternals by going to the downloads page or by using Chocolatey:
PS> choco install sysinternals
You can also use the more basic, but classic, Task Manager—accessible by pressing Win+X and selecting the Task Manager.
For UNIX-based systems, there are many command-line utilities to choose from:
top: The classic process and resource monitor, often installed by default. Once it’s running, to see the tree view, also called the forest view, press Shift+V. The forest view may not work on the default macOStop.htop: More advanced and user-friendly version oftop.atop: Another version oftopwith more information, but more technical.bpytop: A Python implementation oftopwith nice visuals.pstree: A utility specifically to explore the process tree.
On macOS, you also have the Activity Monitor application in your utilities. In the View menu, if you select All Processes, Hierarchically, you should be able to see your process tree.
You can also explore the Python psutil library, which allows you to retrieve running process information on both Windows and UNIX-based systems.
One universal attribute of process tracking across systems is that each process has a process identification number, or PID, which is a unique integer to identify the process within the context of the operating system. You’ll see this number on most of the utilities listed above.
Along with the PID, it’s typical to see the resource usage, such as CPU percentage and amount of RAM that a particular process is using. This is the information that you look for if a program is hogging all your resources.
The resource utilization of processes can be useful for developing or debugging scripts that use the subprocess module, even though you don’t need the PID, or any information about what resources processes are using in the code itself. While playing with the examples that are coming up, consider leaving a representation of the process tree open to see the new processes pop up.
You now have a bird’s-eye view of processes. You’ll deepen your mental model throughout the tutorial, but now it’s time to see how to start your own processes with the Python subprocess module.
Overview of the Python subprocess Module
The Python subprocess module is for launching child processes. These processes can be anything from GUI applications to the shell. The parent-child relationship of processes is where the sub in the subprocess name comes from. When you use subprocess, Python is the parent that creates a new child process. What that new child process is, is up to you.
Python subprocess was originally proposed and accepted for Python 2.4 as an alternative to using the os module. Some documented changes have happened as late as 3.8. The examples in this article were tested with Python 3.10.4, but you only need 3.8+ to follow along with this tutorial.
Most of your interaction with the Python subprocess module will be via the run() function. This blocking function will start a process and wait until the new process exits before moving on.
The documentation recommends using run() for all cases that it can handle. For edge cases where you need more control, the Popen class can be used. Popen is the underlying class for the whole subprocess module. All functions in the subprocess module are convenience wrappers around the Popen() constructor and its instance methods. Near the end of this tutorial, you’ll dive into the Popen class.
You may come across other functions like call(), check_call(), and check_output(), but these belong to the older subprocess API from Python 3.5 and earlier. Everything these three functions do can be replicated with the newer run() function. The older API is mainly still there for backwards compatibility, and you won’t cover it in this tutorial.
There’s also a fair amount of redundancy in the subprocess module, meaning that there are various ways to achieve the same end goal. You won’t be exploring all variations in this tutorial. What you will find, though, are robust techniques that should keep you on the right path.
Basic Usage of the Python subprocess Module
In this section, you’ll take a look at some of the most basic examples demonstrating the usage of the subprocess module. You’ll start by exploring a bare-bones command-line timer program with the run() function.
If you want to follow along with the examples, then create a new folder. All the examples and programs can be saved in this folder. Navigate to this newly created folder on the command line in preparation for the examples coming up. All the code in this tutorial is standard library Python—with no external dependencies required—so a virtual environment isn’t necessary.
The Timer Example
To come to grips with the Python subprocess module, you’ll want a bare-bones program to run and experiment with. For this, you’ll use a program written in Python:
# timer.py
from argparse import ArgumentParser
from time import sleep
parser = ArgumentParser()
parser.add_argument("time", type=int)
args = parser.parse_args()
print(f"Starting timer of {args.time} seconds")
for _ in range(args.time):
print(".", end="", flush=True)
sleep(1)
print("Done!")
The timer program uses argparse to accept an integer as an argument. The integer represents the number of seconds that the timer should wait until exiting, which the program uses sleep() to achieve. It’ll play a small animation representing each passing second until it exits:
It’s not much, but the key is that it serves as a cross-platform process that runs for a few seconds and which you can easily tinker with. You’ll be calling it with subprocess as if it were a separate executable.
Okay, ready to get stuck in! Once you have the timer.py program ready, open a Python interactive session and call the timer with subprocess:
>>>
>>> import subprocess
>>> subprocess.run(["python", "timer.py", "5"])
Starting timer of 5 seconds
.....Done!
CompletedProcess(args=['python', 'timer.py', '5'], returncode=0)
With this code, you should’ve seen the animation playing right in the REPL. You imported subprocess and then called the run() function with a list of strings as the one and only argument. This is the args parameter of the run() function.
On executing run(), the timer process starts, and you can see its output in real time. Once it’s done, it returns an instance of the CompletedProcess class.
On the command line, you might be used to starting a program with a single string:
However, with run() you need to pass the command as a sequence, as shown in the run() example. Each item in the sequence represents a token which is used for a system call to start a new process.
Shells typically do their own tokenization, which is why you just write the commands as one long string on the command line. With the Python subprocess module, though, you have to break up the command into tokens manually. For instance, executable names, flags, and arguments will each be one token.
Now that you’re familiar with some of the very basics of starting new processes with the Python subprocess module, coming up you’ll see that you can run any kind of process, not just Python or text-based programs.
The Use of subprocess to Run Any App
With subprocess, you aren’t limited to text-based applications like the shell. You can call any application that you can with the Start menu or app bar, as long as you know the precise name or path of the program that you want to run:
- Windows
- Linux
- macOS
>>>
>>> subprocess.run(["notepad"])
CompletedProcess(args=['notepad'], returncode=0)
>>>
>>> subprocess.run(["gedit"])
CompletedProcess(args=['gedit'], returncode=0)
Depending on your Linux distribution, you may have a different text editor, such as kate, leafpad, kwrite, or enki.
>>>
>>> subprocess.run(["open", "-e"])
CompletedProcess(args=['open', '-e'], returncode=0)
These commands should open up a text editor window. Usually CompletedProcess won’t get returned until you close the editor window. Yet in the case of macOS, since you need to run the launcher process open to launch TextEdit, the CompletedProcess gets returned straight away.
Launcher processes are in charge of launching a specific process and then ending. Sometimes programs, such as web browsers, have them built in. The mechanics of launcher processes is out of the scope of this tutorial, but suffice to say that they’re able to manipulate the operating system’s process tree to reassign parent-child relationships.
You’ve successfully started new processes using Python! That’s subprocess at its most basic. Next up, you’ll take a closer look at the CompletedProcess object that’s returned from run().
The CompletedProcess Object
When you use run(), the return value is an instance of the CompletedProcess class. As the name suggests, run() returns the object only once the child process has ended. It has various attributes that can be helpful, such as the args that were used for the process and the returncode.
To see this clearly, you can assign the result of run() to a variable, and then access its attributes such as .returncode:
>>>
>>> import subprocess
>>> completed_process = subprocess.run(["python", "timer.py"])
usage: timer.py [-h] time
timer.py: error: the following arguments are required: time
>>> completed_process.returncode
2
The process has a return code that indicates failure, but it doesn’t raise an exception. Typically, when a subprocess process fails, you’ll always want an exception to be raised, which you can do by passing in a check=True argument:
>>>
>>> completed_process = subprocess.run(
... ["python", "timer.py"],
... check=True
... )
...
usage: timer.py [-h] time
timer.py: error: the following arguments are required: time
Traceback (most recent call last):
...
subprocess.CalledProcessError: Command '['python', 'timer.py']' returned
non-zero exit status 2.
There are various ways to deal with failures, some of which will be covered in the next section. The important point to note for now is that run() won’t necessarily raise an exception if the process fails unless you’ve passed in a check=True argument.
The CompletedProcess also has a few attributes relating to input/output (I/O), which you’ll cover in more detail in the communicating with processes section. Before communicating with processes, though, you’ll learn how to handle errors when coding with subprocess.
subprocess Exceptions
As you saw earlier, even if a process exits with a return code that represents failure, Python won’t raise an exception. For most use cases of the subprocess module, this isn’t ideal. If a process fails, you’ll usually want to handle it somehow, not just carry on.
A lot of subprocess use cases involve short personal scripts that you might not spend much time on, or at least shouldn’t spend much time on. If you’re tinkering with a script like this, then you’ll want subprocess to fail early and loudly.
CalledProcessError for Non-Zero Exit Code
If a process returns an exit code that isn’t zero, you should interpret that as a failed process. Contrary to what you might expect, the Python subprocess module does not automatically raise an exception on a non-zero exit code. A failing process is typically not something you want your program to pass over silently, so you can pass a check=True argument to run() to raise an exception:
>>>
>>> completed_process = subprocess.run(
... ["python", "timer.py"],
... check=True
... )
...
usage: timer.py [-h] time
timer.py: error: the following arguments are required: time
Traceback (most recent call last):
...
subprocess.CalledProcessError: Command '['python', 'timer.py']' returned
non-zero exit status 2.
The CalledProcessError is raised as soon as the subprocess runs into a non-zero return code. If you’re developing a short personal script, then perhaps this is good enough for you. If you want to handle errors more gracefully, then read on to the section on exception handling.
One thing to bear in mind is that the CalledProcessError does not apply to processes that may hang and block your execution indefinitely. To guard against that, you’d want to take advantage of the timeout parameter.
TimeoutExpired for Processes That Take Too Long
Sometimes processes aren’t well behaved, and they might take too long or just hang indefinitely. To handle those situations, it’s always a good idea to use the timeout parameter of the run() function.
Passing a timeout=1 argument to run() will cause the function to shut down the process and raise a TimeoutExpired error after one second:
>>>
>>> import subprocess
>>> subprocess.run(["python", "timer.py", "5"], timeout=1)
Starting timer of 5 seconds
.Traceback (most recent call last):
...
subprocess.TimeoutExpired: Command '['python', 'timer.py', '5']' timed out
after 1.0 seconds
In this example, the first dot of the timer animation was output, but the subprocess was shut down before being able to complete.
The other type of error that might happen is if the program doesn’t exist on that particular system, which raises one final type of error.
FileNotFoundError for Programs That Don’t Exist
The final type of exception you’ll be looking at is the FileNotFoundError, which is raised if you try and call a program that doesn’t exist on the target system:
>>>
>>> import subprocess
>>> subprocess.run(["now_you_see_me"])
Traceback (most recent call last):
...
FileNotFoundError: The system cannot find the file specified
This type of error is raised no matter what, so you don’t need to pass in any arguments for the FileNotFoundError.
Those are the main exceptions that you’ll run into when using the Python subprocess module. For many use cases, knowing the exceptions and making sure that you use timeout and check arguments will be enough. That’s because if the subprocess fails, then that usually means that your script has failed.
However, if you have a more complex program, then you may want to handle errors more gracefully. For instance, you may need to call many processes over a long period of time. For this, you can use the try … except construct.
An Example of Exception Handling
Here’s a code snippet that shows the main exceptions that you’ll want to handle when using subprocess:
import subprocess
try:
subprocess.run(
["python", "timer.py", "5"], timeout=10, check=True
)
except FileNotFoundError as exc:
print(f"Process failed because the executable could not be found.\n{exc}")
except subprocess.CalledProcessError as exc:
print(
f"Process failed because did not return a successful return code. "
f"Returned {exc.returncode}\n{exc}"
)
except subprocess.TimeoutExpired as exc:
print(f"Process timed out.\n{exc}")
This snippet shows you an example of how you might handle the three main exceptions raised by the subprocess module.
Now that you’ve used subprocess in its basic form and handled some exceptions, it’s time to get familiar with what it takes to interact with the shell.
Introduction to the Shell and Text-Based Programs With subprocess
Some of the most popular use cases of the subprocess module are to interact with text-based programs, typically available on the shell. That’s why in this section, you’ll start to explore all the moving parts involved when interacting with text-based programs, and perhaps question if you need the shell at all!
The shell is typically synonymous with the command-line interface or CLI, but this terminology isn’t entirely accurate. There are actually two separate processes that make up the typical command-line experience:
- The interpreter, which is typically thought of as the whole CLI. Common interpreters are Bash on Linux, Zsh on macOS, or PowerShell on Windows. In this tutorial, the interpreter will be referred to as the shell.
- The interface, which displays the output of the interpreter in a window and sends user keystrokes to the interpreter. The interface is a separate process from the shell, sometimes called a terminal emulator.
When on the command line, it’s common to think that you’re interacting directly with the shell, but you’re really interacting with the interface. The interface takes care of sending your commands to the shell and displaying the shell’s output back to you.
With this important distinction in mind, it’s time to turn your attention to what run() is actually doing. It’s common to think that calling run() is somehow the same as typing a command in a terminal interface, but there are important differences.
While all new process are created with the same system calls, the context from which the system call is made is different. The run() function can make a system call directly and doesn’t need to go through the shell to do so:
In fact, many programs that are thought of as shell programs, such as Git, are really just text-based programs that don’t need a shell to run. This is especially true of UNIX environments, where all of the familiar utilities like ls, rm, grep, and cat are actually separate executables that can be called directly:
>>>
>>> # Linux or macOS
>>> import subprocess
>>> subprocess.run(["ls"])
timer.py
CompletedProcess(args=['ls'], returncode=0)
There are some tools that are specific to shells, though. Finding tools embedded within the shell is far more common on Windows shells like PowerShell, where commands like ls are part of the shell itself and not separate executables like they are in a UNIX environment:
>>>
>>> # Windows
>>> import subprocess
>>> subprocess.run(["ls"])
Traceback (most recent call last):
...
FileNotFoundError: [WinError 2] The system cannot find the file specified
In PowerShell, ls is the default alias for Get-ChildItem, but calling that won’t work either because Get-ChildItem isn’t a separate executable—it’s part of PowerShell itself.
The fact that many text-based programs can operate independently from the shell may make you wonder if you can cut out the middle process—namely, the shell—and use subprocess directly with the text-based programs typically associated with the shell.
Use Cases for the Shell and subprocess
There are a few common reasons why you might want to call the shell with the Python subprocess module:
- When you know certain commands are only available via the shell, which is more common in Windows
- When you’re experienced in writing shell scripts with a particular shell, so you want to leverage your ability there to do certain tasks while still working primarily in Python
- When you’ve inherited a large shell script that might do nothing that Python couldn’t do, but would take a long time to reimplement in Python
This isn’t an exhaustive list!
You might use the shell to wrap programs or to do some text processing. However, the syntax can be very cryptic when compared to Python. With Python, text processing workflows are easier to write, easier to maintain, generally more performant, and cross-platform to boot. So it’s well worth considering going without the shell.
What often happens, though, is that you just don’t have the time or it’s not worth the effort to reimplement existing shell scripts in Python. In those cases, using subprocess for some sloppy Python isn’t a bad thing!
Common reasons for using subprocess itself are similar in nature to using the shell with subprocess:
- When you have to use or analyze a black box, or even a white box
- When you want a wrapper for an application
- When you need to launch another application
- As an alternative to basic shell scripts
Often you’ll find that for subprocess use cases, there will be a dedicated library for that task. Later in the tutorial, you’ll examine a script that creates a Python project, complete with a virtual environment and a fully initialized Git repository. However, the Cookiecutter and Copier libraries already exist for that purpose.
Even though specific libraries might be able to do your task, it may still be worth doing things with subprocess. For one, it might be much faster for you to execute what you already know how to do, rather than learning a new library.
Additionally, if you’re sharing this script with friends or colleagues, it’s convenient if your script is pure Python without any other dependencies, especially if your script needs to go on minimal environments like servers or embedded systems.
However, if you’re using subprocess instead of pathlib to read and write a few files with Bash, you might want to consider learning how to read and write with Python. Learning how to read and write files doesn’t take long, and it’ll definitely be worth it for such a common task.
With that out of the way, it’s time to get familiar with the shell environments on both Windows and UNIX-based systems.
Basic Usage of subprocess With UNIX-Based Shells
To run a shell command using run(), the args should contain the shell that you want to use, the flag to indicate that you want it to run a specific command, and the command that you’re passing in:
>>>
>>> import subprocess
>>> subprocess.run(["bash", "-c", "ls /usr/bin | grep pycode"])
pycodestyle
pycodestyle-3
pycodestyle-3.10
CompletedProcess(args=['bash', '-c', 'ls /usr/bin | grep pycode'], returncode=0)
Here a common shell command is demonstrated. It uses ls piped into grep to filter some of the entries. The shell is handy for this kind of operation because you can take advantage of the pipe operator (|). You’ll cover pipes in more detail later.
You can replace bash with the shell of your choice. The -c flag stands for command, but may be different depending on the shell that you’re using. This is almost the exact equivalent of what happens when you add the shell=True argument:
>>>
>>> subprocess.run(["ls /usr/bin | grep pycode"], shell=True)
pycodestyle
pycodestyle-3
pycodestyle-3.10
CompletedProcess(args=['ls /usr/bin | grep pycode'], returncode=0)
The shell=True argument uses ["sh", "-c", ...] behind the scenes, so it’s almost the equivalent of the previous example.
You’ll note that the token after "-c" should be one single token, with all the spaces included. Here you’re giving control to the shell to parse the command. If you were to include more tokens, this would be interpreted as more options to pass to the shell executable, not as additional commands to run inside the shell.
Basic Usage of subprocess With Windows Shells
In this section, you’ll cover basic use of the shell with subprocess in a Windows environment.
To run a shell command using run(), the args should contain the shell that you want to use, the flag to indicate that you want it to run a specific command, and the command that you’re passing in:
>>>
>>> import subprocess
>>> subprocess.run(["pwsh", "-Command", "ls C:\RealPython"])
Directory: C:\RealPython
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 09/05/22 10:41 237 basics.py
-a--- 18/05/22 17:28 486 hello_world.py
CompletedProcess(args=['pwsh', '-Command', 'ls'], returncode=0)
Note that pwsh and pwsh.exe both work. If you don’t have PowerShell Core, then you can call powershell or powershell.exe.
You’ll note that the token after "-Command" should be one single token, with all the spaces included. Here you’re giving control to the shell to parse the command. If you were to include more tokens, this would be interpreted as more options to pass to the shell executable, not as additional commands to run inside the shell.
If you need the Command Prompt, then the executable is cmd or cmd.exe, and the flag to indicate that the following token is a command is /c:
>>>
>>> import subprocess
>>> subprocess.run(["cmd", "/c", "dir C:\RealPython"])
Volume in drive C has no label.
Volume Serial Number is 0000-0000
Directory of C:\RealPython
30/03/22 23:01 <DIR> .
30/03/22 23:01 <DIR> ..
09/05/22 10:41 237 basics.py
18/05/22 17:28 486 hello_world.py
This last example is the exact equivalent of calling run() with shell=True. Said in another way, using the shell=True argument is like prepending "cmd" and "/c" to your argument list.
At this point, you should know about an important security concern that you’ll want to be aware of if you have user-facing elements in your Python program, regardless of the operating system. It’s a vulnerability that’s not confined to subprocess. Rather, it can be exploited in many different areas.
A Security Warning
If at any point you plan to get user input and somehow translate that to a call to subprocess, then you have to be very careful of injection attacks. That is, take into account potential malicious actors. There are many ways to cause havoc if you just let people run code on your machine.
To use a very simplistic example, where you take user input and send it, unfiltered, to subprocess to run on the shell:
- Windows
- Linux + macOS
# unsafe_program.py
import subprocess
# ...
subprocess.run(["pwsh", "-Command", f"ls {input()}"])
# ...
# unsafe_program.py
import subprocess
# ...
subprocess.run(["bash", "-c", f"ls {input()}"])
# ...
You can imagine the intended use case is to wrap ls and add something to it. So the expected user behavior is to provide a path like "/home/realpython/". However, if a malicious actor realized what was happening, they could execute almost any code they wanted. Take the following, for instance, but be careful with this:
- Windows
- Linux + macOS
C:\RealPython; echo 'You could've been hacked: rm -Recurse -Force C:\'
/home/realpython/; echo 'You could've been hacked: rm -rf /*'
Again, beware! These innocent-looking lines could try and delete everything on the system! In this case the malicious part is in quotes, so it won’t run, but if the quotes were not there, you’d be in trouble. The key part that does this is the call to rm with the relevant flags to recursively delete all files, folders, and subfolders, and it’ll work to force the deletion through. It can run the echo and potentially the rm as entirely separate commands by adding semicolons, which act as command separators allowing what would usually be multiple lines of code to run on one line.
Running these malicious commands would cause irreparable damage to the file system, and would require reinstalling the operating system. So, beware!
Luckily, the operating system wouldn’t let you do this to some particularly important files. The rm command would need to use sudo in UNIX-based systems, or be run as an administrator in Windows to be completely successful in its mayhem. The command would probably delete a lot of important stuff before stopping, though.
So, make sure that if you’re dynamically building user inputs to feed into a subprocess call, then you’re very careful! With that warning, coming up you’ll be covering using the outputs of commands and chaining commands together—in short, how to communicate with processes once they’ve started.
Communication With Processes
You’ve used the subprocess module to execute programs and send basic commands to the shell. But something important is still missing. For many tasks that you might want to use subprocess for, you might want to dynamically send inputs or use the outputs in your Python code later.
To communicate with your process, you first should understand a little bit about how processes communicate in general, and then you’ll take a look at two examples to come to grips with the concepts.
The Standard I/O Streams
A stream at its most basic represents a sequence of elements that aren’t available all at once. When you read characters and lines from a file, you’re working with a stream in the form of a file object, which at its most basic is a file descriptor. File descriptors are often used for streams. So, it’s not uncommon to see the terms stream, file, and file-like used interchangeably.
When processes are initialized, there are three special streams that a process makes use of. A process does the following:
- Reads
stdinfor input - Writes to
stdoutfor general output - Writes to
stderrfor error reporting
These are the standard streams—a cross-platform pattern for process communication.
Sometimes the child process inherits these streams from the parent. This is what’s happening when you use subprocess.run() in the REPL and are able to see the output of the command. The stdout of the Python interpreter is inherited by the subprocess.
When you’re in a REPL environment, you’re looking at a command-line interface process, complete with the three standard I/O streams. The interface has a shell process as a child process, which itself has a Python REPL as a child. In this situation, unless you specify otherwise, stdin comes from the keyboard, while stdout and stderr are displayed on-screen. The interface, the shell, and the REPL share the streams:
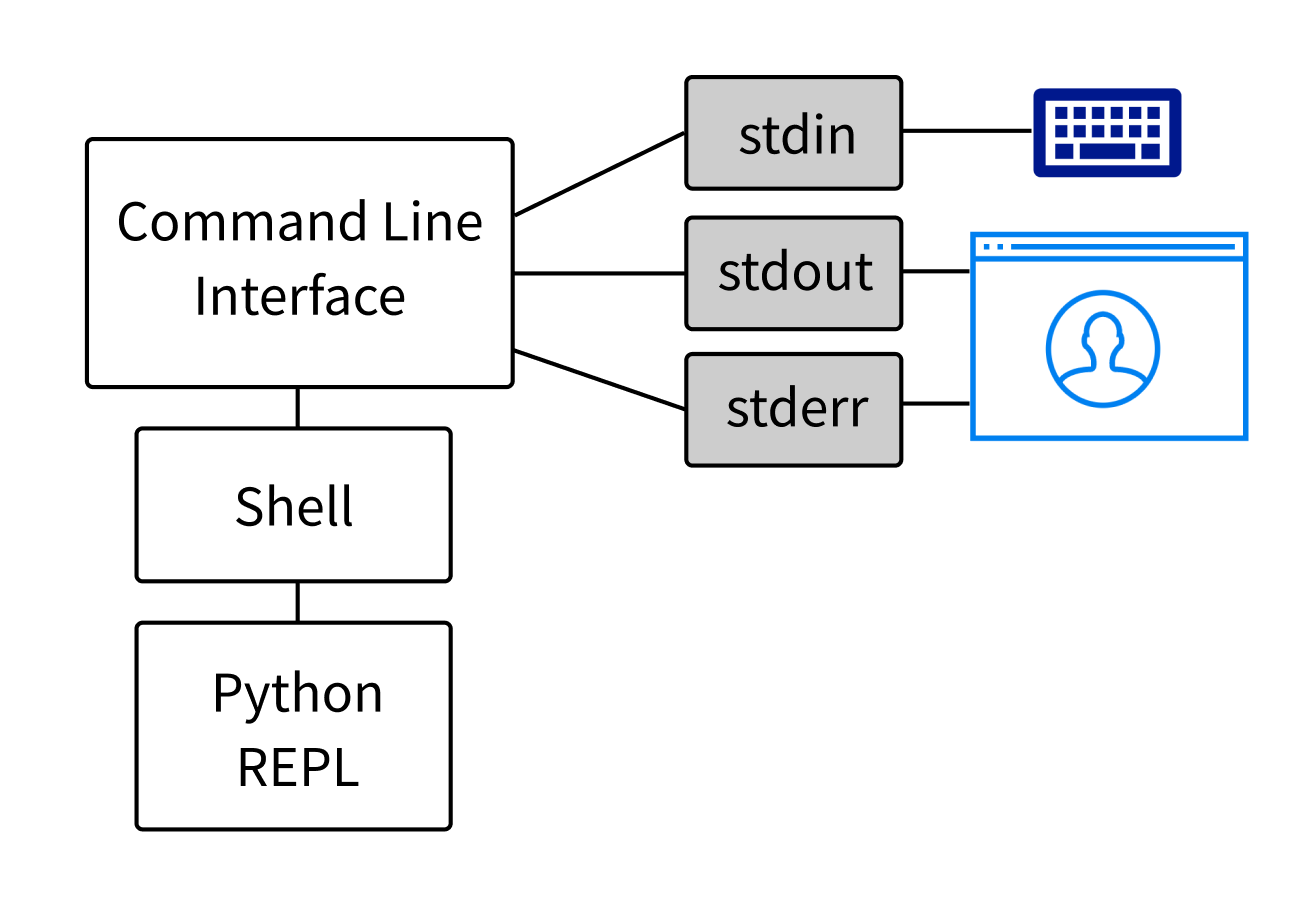
You can think of the standard I/O streams as byte dispensers. The subprocess fills up stdout and stderr, and you fill up stdin. Then you read the bytes in stdout and stderr, and the subprocess reads from stdin.
As with a dispenser, you can stock stdin before it gets linked up to a child process. The child process will then read from stdin as and when it needs to. Once a process has read from a stream, though, the bytes are dispensed. You can’t go back and read them again:
These three streams, or files, are the basis for communicating with your process. In the next section, you’ll start to see this in action by getting the output of a magic number generator program.
The Magic Number Generator Example
Often, when using the subprocess module, you’ll want to use the output for something and not just display the output as you have been doing so far. In this section, you’ll use a magic number generator that outputs, well, a magic number.
Imagine that the magic number generator is some obscure program, a black box, inherited across generations of sysadmins at your job. It outputs a magic number that you need for your secret calculations. You’ll read from the stdout of subprocess and use it in your wrapper Python program:
# magic_number.py
from random import randint
print(randint(0, 1000))
Okay, not really so magical. That said, it’s not the magic number generator that you’re interested in—it’s interacting with a hypothetical black box with subprocess that’s interesting. To grab the number generator’s output to use later, you can pass in a capture_output=True argument to run():
>>>
>>> import subprocess
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"], capture_output=True
... )
>>> magic_number_process.stdout
b'769\n'
Passing a capture_output argument of True to run() makes the output of the process available at the .stdout attribute of the completed process object. You’ll note that it’s returned as a bytes object, so you need to be mindful of encodings when reading it.
Also note that the .stdout attribute of the CompletedProcess is no longer a stream. The stream has been read, and it’s stored as a bytes object in the .stdout attribute.
With the output available, you can use more than one subprocess to grab values and operate on them in your code:
>>>
>>> import subprocess
>>> sum(
... int(
... subprocess.run(
... ["python", "magic_number.py"], capture_output=True
... ).stdout
... )
... for _ in range(2)
... )
1085
In this example, you start two magic number processes that fetch two magic numbers and then add them together. For now, you rely on the automatic decoding of the bytes object by the int() constructor. In the next section, though, you’ll learn how to decode and encode explicitly.
The Decoding of Standard Streams
Processes communicate in bytes, and you have a few different ways to deal with encoding and decoding these bytes. Beneath the surface, subprocess has a few ways of getting into text mode.
Text mode means that subprocess will try to take care of encoding itself. To do that, it needs to know what character encoding to use. Most of the options for doing this in subprocess will try to use the default encoding. However, you generally want to be explicit about what encoding to use to prevent a bug that would be hard to find in the future.
You can pass a text=True argument for Python to take care of encodings using the default encoding. But, as mentioned, it’s always safer to specify the encodings explicitly using the encoding argument, as not all systems work with the nearly universal UTF-8:
>>>
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"], capture_output=True, encoding="utf-8"
... )
...
>>> magic_number_process.stdout
'647\n'
If in text mode, the .stdout attribute on a CompletedProcess is now a string and not a bytes object.
You can also decode the bytes returned by calling the .decode() method on the stdout attribute directly, without requiring text mode at all:
>>>
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"], capture_output=True
... )
...
>>> magic_number_process.stdout.decode("utf-8")
'72\n'
There are other ways to put run() into text mode. You can also set a True value for errors or universal_newlines, which will also put run() into text mode. This may seem redundant, but much of this is kept for backwards compatibility, seeing as the subprocess module has changed over the years.
Now that you know how to read and decode the output of a process, it’s time to take a look at writing to the input of a process.
Reaction Game Example
In this section, you’ll use subprocess to interact with a command-line game. It’s a basic program that’s designed to test a human’s reaction time. With your knowledge of standard I/O streams, though, you’ll be able to hack it! The source code of the game makes use of the time and random module:
# reaction_game.py
from time import perf_counter, sleep
from random import random
print("Press enter to play")
input()
print("Ok, get ready!")
sleep(random() * 5 + 1)
print("go!")
start = perf_counter()
input()
end = perf_counter()
print(f"You reacted in {(end - start) * 1000:.0f} milliseconds!\nGoodbye!")
The program starts, asks for the user to press enter, and then after a random amount of time will ask the user to press enter again. It measures from the time the message appears to the time the user presses enter, or at least that’s what the game developer thinks:
The input() function will read from stdin until it reaches a newline, which means an Enter keystroke in this context. It returns everything it consumed from stdin except the newline. With that knowledge, you can use subprocess to interact with this game:
>>>
>>> import subprocess
>>> process = subprocess.run(
... ["python", "reaction_game.py"], input="\n\n", encoding="utf-8"
... )
...
Press enter to play
Ok, get ready!
go!
You reacted in 0 milliseconds!
Goodbye!
A reaction time of 0 milliseconds! Not bad! Considering the average human reaction time is around 270 milliseconds, your program is definitely superhuman. Note that the game rounds its output, so 0 milliseconds doesn’t mean it’s instantaneous.
The input argument passed to run() is a string consisting of two newlines. The encoding parameter is set to utf-8, which puts run() into text mode. This sets up the process for it to receive the input you that give it.
Before the program starts, stdin is stocked, waiting for the program to consume the newlines it contains. One newline is consumed to start the game, and the next newline is consumed to react to go!.
Now that you know what’s happening—namely that stdin can be stocked, as it were—you can hack the program yourself without subprocess. If you start the game and then press Enter a few times, that’ll stock up stdin with a few newlines that the program will automatically consume once it gets to the input() line. So your reaction time is really only the time it takes for the reaction game to execute start = time() and consume an input:
The game developer gets wise to this, though, and vows to release another version, which will guard against this exploit. In the meantime, you’ll peek a bit further under the hood of subprocess and learn about how it wires up the standard I/O streams.
Pipes and the Shell
To really understand subprocesses and the redirection of streams, you really need to understand pipes and what they are. This is especially true if you want to wire up two processes together, feeding one stdout into another process’s stdin, for instance. In this section, you’ll be coming to grips with pipes and how to use them with the subprocess module.
Introduction to Pipes
A pipe, or pipeline, is a special stream that, instead of having one file handle as most files do, has two. One handle is read-only, and the other is write-only. The name is very descriptive—a pipe serves to pipe a byte stream from one process to another. It’s also buffered, so a process can write to it, and it’ll hold onto those bytes until it’s read, like a dispenser.
You may be used to seeing pipes on the command line, as you did in the section on shells:
$ ls /usr/bin | grep python
This command tells the shell to create an ls process to list all the files in /usr/bin. The pipe operator (|) tells the shell to create a pipe from the stdout of the ls process and feed it into the stdin of the grep process. The grep process filters out all the lines that don’t contain the string python.
Windows doesn’t have grep, but a rough equivalent of the same command would be as follows:
PS> ls "C:\Program Files" | Out-String -stream | Select-String windows
However, on Windows PowerShell, things work very differently. As you learned in the Windows shell section of this tutorial, the different commands are not separate executables. Therefore, PowerShell is internally redirecting the output of one command into another without starting new processes.
You can use pipes for different processes on PowerShell, though getting into the intricacies of which ones is outside the scope of this tutorial. For more information on PowerShell pipes, check out the documentation. So, for the rest of the pipe examples, only UNIX-based examples will be used, as the basic mechanism is the same for both systems. They’re not nearly as common on Windows, anyway.
If you want to let the shell take care of piping processes into one another, then you can just pass the whole string as a command into subprocess:
>>>
>>> import subprocess
>>> subprocess.run(["sh" , "-c", "ls /usr/bin | grep python"])
python3
python3-config
python3.8
python3.8-config
...
CompletedProcess(...)
This way, you can let your chosen shell take care of piping one process into another, instead of trying to reimplement things in Python. This is a perfectly valid choice in certain situations.
Later in the tutorial, you’ll also come to see that you can’t pipe processes directly with run(). For that, you’ll need the more complicated Popen(). Actual piping is demonstrated in Connecting Two Porcesses Together With Pipes, near the end of the tutorial.
Whether you mean to pipe one process into another with the subprocess module or not, the subprocess module makes extensive use of pipes behind the scenes.
The Pipes of subprocess
The Python subprocess module uses pipes extensively to interact with the processes that it starts. In a previous example, you used the capture_output parameter to be able to access stdout:
>>>
>>> import subprocess
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"], capture_output=True
... )
>>> magic_number_process.stdout
b'769\n'
capture_output=True is equivalent to explicitly setting the stdout and stderr parameters to the subprocess.PIPE constant:
>>>
>>> import subprocess
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"],
... stdout=subprocess.PIPE,
... stderr=subprocess.PIPE
... )
...
>>> magic_number_process.stdout
b'769\n'
The PIPE constant is nothing special. It’s just a number that indicates to subprocess that a pipe should be created. The function then creates a pipe to link up to the stdout of the subprocess, which the function then reads into the CompletedProcess object’s stdout attribute. By the time it’s a CompletedProcess, it’s no longer a pipe, but a bytes object that can be accessed multiple times.
You can also pass a file object to any of the standard stream parameters:
>>>
>>> from tempfile import TemporaryFile
>>> with TemporaryFile() as f:
... ls_process = subprocess.run(["python", "magic_number.py"], stdout=f)
... f.seek(0)
... print(f.read().decode("utf-8"))
...
0
554
You can’t pass a bytes object or a string directly to the stdin argument, though. It needs to be something file-like.
Note that the 0 that gets returned first is from the call to seek() which returns the new stream position, which in this case is the start of the stream.
The input parameter is similar to the capture_output parameter in that it’s a shortcut. Using the input parameter will create a buffer to store the contents of input, and then link the file up to the new process to serve as its stdin.
To actually link up two processes with a pipe from within subprocess is something that you can’t do with run(). Instead, you can delegate the plumbing to the shell, as you did earlier in the Introduction to the Shell and Text Based Programs with subprocess section.
If you needed to link up different processes without delegating any of the work to the shell, then you could do that with the underlying Popen() constructor. You’ll cover Popen() in a later section. In the next section, though, you’ll be simulating a pipe with run() because in most cases, it’s not vital for processes to be linked up directly.
Pipe Simulation With run()
Though you can’t actually link up two processes together with a pipe by using the run() function, at least not without delegating it to the shell, you can simulate piping by judicious use of the stdout attribute.
If you’re on a UNIX-based system where almost all typical shell commands are separate executables, then you can just set the input of the second process to the .stdout attribute of the first CompletedProcess:
>>>
>>> import subprocess
>>> ls_process = subprocess.run(["ls", "/usr/bin"], stdout=subprocess.PIPE)
>>> grep_process = subprocess.run(
... ["grep", "python"], input=ls_process.stdout, stdout=subprocess.PIPE
... )
>>> print(grep_process.stdout.decode("utf-8"))
python3
python3-config
python3.8
python3.8-config
...
Here the .stdout attribute of the CompletedProcess object of ls is set to the input of the grep_process. It’s important that it’s set to input rather than stdin. This is because the .stdout attribute isn’t a file-like object. It’s a bytes object, so it can’t be used as an argument to stdin.
As an alternative, you can operate directly with files too, setting them to the standard stream parameters. When using files, you set the file object as the argument to stdin, instead of using the input parameter:
>>>
>>> import subprocess
>>> from tempfile import TemporaryFile
>>> with TemporaryFile() as f:
... ls_process = subprocess.run(["ls", "/usr/bin"], stdout=f)
... f.seek(0)
... grep_process = subprocess.run(
... ["grep", "python"], stdin=f, stdout=subprocess.PIPE
... )
...
0 # from f.seek(0)
>>> print(grep_process.stdout.decode("utf-8"))
python3
python3-config
python3.8
python3.8-config
...
As you learned in the previous section, for Windows PowerShell, doing something like this doesn’t make a whole lot of sense because most of the time, these utilities are part of PowerShell itself. Because you aren’t dealing with separate executables, piping becomes less of a necessity. However, the pattern for piping is still the same if something like this needs to be done.
With most of the tools out the way, it’s now time to think about some practical applications for subprocess.
Practical Ideas
When you have an issue that you want to solve with Python, sometimes the subprocess module is the easiest way to go, even though it may not be the most correct.
Using subprocess is often tricky to get working across different platforms, and it has inherent dangers. But even though it may involve some sloppy Python, using subprocess can be a very quick and efficient way to solve a problem.
As mentioned, for most tasks you can imagine doing with subprocess, there’s usually a library out there that’s dedicated to that specific task. The library will almost certainly use subprocess, and the developers will have worked hard to make the code reliable and to cover all the corner cases that can make using subprocess difficult.
So, even though dedicated libraries exist, it can often be simpler to just use subprocess, especially if you’re in an environment where you need to limit your dependencies.
In the following sections, you’ll be exploring a couple of practical ideas.
Creating a New Project: An Example
Say you often need to create new local projects, each complete with a virtual environment and initialized as a Git repository. You could reach for the Cookiecutter library, which is dedicated to that task, and that wouldn’t be a bad idea.
However, using Cookiecutter would mean learning Cookiecutter. Imagine you didn’t have much time, and your environment was extremely minimal anyway—all you could really count on was Git and Python. In these cases, subprocess can quickly set up your project for you:
# create_project.py
from argparse import ArgumentParser
from pathlib import Path
import subprocess
def create_new_project(name):
project_folder = Path.cwd().absolute() / name
project_folder.mkdir()
(project_folder / "README.md").touch()
with open(project_folder / ".gitignore", mode="w") as f:
f.write("\n".join(["venv", "__pycache__"]))
commands = [
[
"python",
"-m",
"venv",
f"{project_folder}/venv",
],
["git", "-C", project_folder, "init"],
["git", "-C", project_folder, "add", "."],
["git", "-C", project_folder, "commit", "-m", "Initial commit"],
]
for command in commands:
try:
subprocess.run(command, check=True, timeout=60)
except FileNotFoundError as exc:
print(
f"Command {command} failed because the process "
f"could not be found.\n{exc}"
)
except subprocess.CalledProcessError as exc:
print(
f"Command {command} failed because the process "
f"did not return a successful return code.\n{exc}"
)
except subprocess.TimeoutExpired as exc:
print(f"Command {command} timed out.\n {exc}")
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("project_name", type=str)
args = parser.parse_args()
create_new_project(args.project_name)
This is a command-line tool that you can call to start a project. It’ll take care of creating a README.md file and a .gitignore file, and then it’ll run a few commands to create a virtual environment, initialize a git repository, and perform your first commit. It’s even cross-platform, opting to use pathlib to create the files and folders, which abstracts away the operating system differences.
Could this be done with Cookiecutter? Could you use GitPython for the git part? Could you use the venv module to create the virtual environment? Yes to all. But if you just need something quick and dirty, using commands you already know, then just using subprocess can be a great option.
Changing Extended Attributes
If you use Dropbox, you may not know that there’s a way to ignore files when syncing. For example, you can keep virtual environments in your project folder and use Dropbox to sync the code, but keep the virtual environment local.
That said, it’s not as easy as adding a .dropboxignore file. Rather, it involves adding special attributes to files, which can be done from the command line. These attributes are different between UNIX-like systems and Windows:
- Windows
- Linux
- macOS
PS> Set-Content -Path `
'C:\Users\yourname\Dropbox\YourFileName.pdf' `
-Stream com.dropbox.ignored -Value 1
$ attr -s com.dropbox.ignored -V 1 \
/home/yourname/Dropbox/YourFileName.pdf
$ xattr -w com.dropbox.ignored 1 \
/Users/yourname/Dropbox/YourFileName.pdf
There are some UNIX-based projects, like dropboxignore, that use shell scripts to make it easier to ignore files and folders. The code is relatively complex, and it won’t work on Windows.
With the subprocess module, you can wrap the different shell commands quite easily to come up with your own utility:
# dropbox_ignore.py
import platform
from pathlib import Path
from subprocess import run, DEVNULL
def init_shell():
print("initializing shell")
system = platform.system()
print(f"{system} detected")
if system == "Linux":
return Bash_shell()
elif system == "Windows":
return Pwsh_shell()
elif system == "Darwin":
raise NotImplementedError
class Pwsh_shell():
def __init__(self) -> None:
try:
run(["pwsh", "-V"], stdout=DEVNULL, stderr=DEVNULL)
self.shell = "pwsh"
except FileNotFoundError as exc:
print("Powershell Core not installed, falling back to PowerShell")
self.shell = "powershell"
@staticmethod
def _make_string_path_list(paths: list[Path]) -> str:
return "', '".join(str(path).replace("'", "`'") for path in paths)
def ignore_folders(self, paths: list[Path]) -> None:
path_list = self._make_string_path_list(paths)
command = (
f"Set-Content -Path '{path_list}' "
f"-Stream com.dropbox.ignored -Value 1"
)
run([self.shell, "-NoProfile", "-Command", command], check=True)
print("Done!")
class Bash_shell():
@staticmethod
def _make_string_path_list(paths: list[Path]) -> str:
return "' '".join(str(path).replace("'", "\\'") for path in paths)
def ignore_folders(self, paths: list[Path]) -> None:
path_list = self._make_string_path_list(paths)
command = (
f"for f in '{path_list}'\n do\n "
f"attr -s com.dropbox.ignored -V 1 $f\ndone"
)
run(["bash", "-c", command], check=True)
print("Done!")
This is a simplified snippet from the author’s dotDropboxIgnore repository. The init_shell() function detects the operating system with the platform module and returns an object that’s an abstraction around the system-specific shell. The code hasn’t implemented the behavior on macOS, so it raises a NotImplementedError if it detects it’s running on macOS.
The shell object allows you to call an .ignore_folders() method with a list of pathlib Path objects to set Dropbox to ignore those files.
On the Pwsh_shell class, the constructor tests to see if PowerShell Core is available, and if not, will fall back to the older Windows PowerShell, which is installed by default on Windows 10.
In the next section, you’ll review some of the other modules that might be interesting to keep in mind when deciding whether to use subprocess.
Python Modules Associated With subprocess
When deciding whether a certain task is a good fit for subprocess, there are some associated modules that you may want to be aware of.
Before subprocess existed, you could use os.system() to run commands. However, as with many things that os was used for before, standard library modules have come to replace os, so it’s mostly used internally. There are hardly any use cases for using os yourself.
There’s an official documentation page where you can examine some of the old ways to accomplish tasks with os and learn how you might do the same with subprocess.
It might be tempting to think that subprocess can be used for concurrency, and in simple cases, it can be. But, in line with the sloppy Python philosophy, it’s probably only going to be to hack something together quickly. If you want something more robust, then you’ll probably want to start looking at the multiprocessing module.
Depending on the task that you’re attempting, you may be able to accomplish it with the asyncio or threading modules. If everything is written in Python, then these modules are likely your best bet.
The asyncio module has a high-level API to create and manage subprocesses too, so if you want more control over non-Python parallel processes, that might be one to check out.
Now it’s time to get deep into subprocess and explore the underlying Popen class and its constructor.
The Popen Class
As mentioned, the underlying class for the whole subprocess module is the Popen class and the Popen() constructor. Each function in subprocess calls the Popen() constructor under the hood. Using the Popen() constructor gives you lots of control over the newly started subprocesses.
As a quick summary, run() is basically the Popen() class constructor, some setup, and then a call to the .communicate() method on the newly initialized Popen object. The .communicate() method is a blocking method that returns the stdout and stderr data once the process has ended.
The name of Popen comes from a similar UNIX command that stands for pipe open. The command creates a pipe and then starts a new process that invokes the shell. The subprocess module, though, doesn’t automatically invoke the shell.
The run() function is a blocking function, which means that interacting dynamically with a process isn’t possible with it. However, the Popen() constructor starts a new process and continues, leaving the process running in parallel.
The developer of the reaction game that you were hacking earlier has released a new version of their game, one in which you can’t cheat by loading stdin with newlines:
# reaction_game_v2.py
from random import choice, random
from string import ascii_lowercase
from time import perf_counter, sleep
print(
"A letter will appear on screen after a random amount of time,\n"
"when it appears, type the letter as fast as possible "
"and then press enter\n"
)
print("Press enter when you are ready")
input()
print("Ok, get ready!")
sleep(random() * 5 + 2)
target_letter = choice(ascii_lowercase)
print(f"=====\n= {target_letter} =\n=====\n")
start = perf_counter()
while True:
if input() == target_letter:
break
else:
print("Nope! Try again.")
end = perf_counter()
print(f"You reacted in {(end - start) * 1000:.0f} milliseconds!\nGoodbye!")
Now the program will display a random character, and you need to press that exact character to have the game register your reaction time:
What’s to be done? First, you’ll need to come to grips with using Popen() with basic commands, and then you’ll find another way to exploit the reaction game.
Using Popen()
Using the Popen() constructor is very similar in appearance to using run(). If there’s an argument that you can pass to run(), then you’ll generally be able to pass it to Popen(). The fundamental difference is that it’s not a blocking call—rather than waiting until the process is finished, it’ll run the process in parallel. So you need to take this non-blocking nature into account if you want to read the new process’s output:
# popen_timer.py
import subprocess
from time import sleep
with subprocess.Popen(
["python", "timer.py", "5"], stdout=subprocess.PIPE
) as process:
def poll_and_read():
print(f"Output from poll: {process.poll()}")
print(f"Output from stdout: {process.stdout.read1().decode('utf-8')}")
poll_and_read()
sleep(3)
poll_and_read()
sleep(3)
poll_and_read()
This program calls the timer process in a context manager and assigns stdout to a pipe. Then it runs the .poll() method on the Popen object and reads its stdout.
The .poll() method is a basic method to check if a process is still running. If it is, then .poll() returns None. Otherwise, it’ll return the process’s exit code.
Then the program uses .read1() to try and read as many bytes as are available at .stdout.
The output of this program first prints None because the process hasn’t yet finished. The program then prints what is available in stdout so far, which is the starting message and the first character of the animation.
After three seconds, the timer hasn’t finished, so you get None again, along with two more characters of the animation. After another three seconds, the process has ended, so .poll() produces 0, and you get the final characters of the animation and Done!:
Output from poll: None
Output from stdout: Starting timer of 5 seconds
.
Output from poll: None
Output from stdout: ..
Output from poll: 0
Output from stdout: ..Done!
In this example, you’ve seen how the Popen() constructor works very differently from run(). In most cases, you don’t need this kind of fine-grained control. That said, in the next sections, you’ll see how you can pipe one process into another, and how you can hack the new reaction game.
Connecting Two Processes Together With Pipes
As mentioned in a previous section, if you need to connect processes together with pipes, you need to use the Popen() constructor. This is mainly because run() is a blocking call, so by the time the next process starts, the first one has ended, meaning that you can’t directly link up to its stdout.
This procedure will only be demonstrated for UNIX systems, because piping in Windows is far less common, as mentioned in the simulating a pipe section:
# popen_pipe.py
import subprocess
ls_process = subprocess.Popen(["ls", "/usr/bin"], stdout=subprocess.PIPE)
grep_process = subprocess.Popen(
["grep", "python"], stdin=ls_process.stdout, stdout=subprocess.PIPE
)
for line in grep_process.stdout:
print(line.decode("utf-8").strip())
In this example, the two processes are started in parallel. They are joined with a common pipe, and the for loop takes care of reading the pipe at stdout to output the lines.
A key point to note is that in contrast to run(), which returns a CompletedProcess object, the Popen() constructor returns a Popen object. The standard stream attributes of a CompletedProcess point to bytes objects or strings, but the same attributes of a Popen object point to the actual streams. This allows you to communicate with processes as they’re running.
Whether you really need to pipe processes into one another, though, is another matter. Ask yourself if there’s much to be lost by mediating the process with Python and using run() exclusively. There are some situations in which you really need Popen, though, such as hacking the new version of the reaction time game.
Interacting Dynamically With a Process
Now that you know you can use Popen() to interact with a process dynamically as it runs, it’s time to turn that knowledge toward exploiting the reaction time game again:
# reaction_game_v2_hack.py
import subprocess
def get_char(process):
character = process.stdout.read1(1)
print(
character.decode("utf-8"),
end="",
flush=True, # Unbuffered print
)
return character.decode("utf-8")
def search_for_output(strings, process):
buffer = ""
while not any(string in buffer for string in strings):
buffer = buffer + get_char(process)
with subprocess.Popen(
[
"python",
"-u", # Unbuffered stdout and stderr
"reaction_game_v2.py",
],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
) as process:
process.stdin.write(b"\n")
process.stdin.flush()
search_for_output(["==\n= ", "==\r\n= "], process)
target_char = get_char(process)
stdout, stderr = process.communicate(
input=f"{target_char}\n".encode("utf-8"), timeout=10
)
print(stdout.decode("utf-8"))
With this script, you’re taking complete control of the buffering of a process, which is why you pass in arguments such as -u to the Python process and flush=True to print(). These arguments are to ensure that no extra buffering is taking place.
The script works by using a function that’ll search for one of a list of strings by grabbing one character at a time from the process’s stdout. As each character comes through, the script will search for the string.
After the script has found one of the target strings, which in this case is the sequence of characters before the target letter, it’ll then grab the next character and write that letter to the process’s stdin followed by a newline:
At one millisecond, it’s not quite as good as the original hack, but it’s still very much superhuman. Well done!
With all this fun aside, interacting with processes using Popen can be very tricky and is prone to errors. First, see if you can use run() exclusively before resorting to the Popen() constructor.
If you really need to interact with processes at this level, the asyncio module has a high-level API to create and manage subprocesses.
The asyncio subprocess functionality is intended for more complex uses of subprocess where you may need to orchestrate various processes. This might be the case if you’re performing complex processing of many image, video, or audio files, for example. If you’re using subprocess at this level, then you’re probably building a library.
Conclusion
You’ve completed your journey into the Python subprocess module. You should now be able to decide whether subprocess is a good fit for your problem. You should also be able to decide whether you need to invoke the shell. Aside from that, you should be able to run subprocesses and interact with their inputs and outputs.
You should also be able to start exploring the possibilities of process manipulation with the Popen() constructor.
Along the way, you’ve:
- Learned about processes in general
- Gone from basic to advanced usage of
subprocess - Understood how to raise and handle errors when using
run() - Gotten familiar with shells and their intricacies on both Windows and UNIX-like systems
- Explored the use cases for
subprocessthrough practical examples - Understood the standard I/O streams and how to interact with them
- Come to grips with pipes, both in the shell and with
subprocess - Looked at the
Popen()constructor and used it for some advanced process communication
You’re now ready to bring a variety of executables into your Pythonic sphere of influence!