Connecting to a Database
psql is a regular PostgreSQL client application. In order to connect to a database you need to know the name of your target database, the host name and port number of the server, and what database user name you want to connect as. psql can be told about those parameters via command line options, namely -d, -h, -p, and -U respectively. If an argument is found that does not belong to any option it will be interpreted as the database name (or the database user name, if the database name is already given). Not all of these options are required; there are useful defaults. If you omit the host name, psql will connect via a Unix-domain socket to a server on the local host, or via TCP/IP to localhost on Windows. The default port number is determined at compile time. Since the database server uses the same default, you will not have to specify the port in most cases. The default database user name is your operating-system user name. Once the database user name is determined, it is used as the default database name. Note that you cannot just connect to any database under any database user name. Your database administrator should have informed you about your access rights.
When the defaults aren’t quite right, you can save yourself some typing by setting the environment variables PGDATABASE, PGHOST, PGPORT and/or PGUSER to appropriate values. (For additional environment variables, see Section 34.15.) It is also convenient to have a ~/.pgpass file to avoid regularly having to type in passwords. See Section 34.16 for more information.
An alternative way to specify connection parameters is in a conninfo string or a URI, which is used instead of a database name. This mechanism give you very wide control over the connection. For example:
$psql "service=myservice sslmode=require"$psql postgresql://dbmaster:5433/mydb?sslmode=require
This way you can also use LDAP for connection parameter lookup as described in Section 34.18. See Section 34.1.2 for more information on all the available connection options.
If the connection could not be made for any reason (e.g., insufficient privileges, server is not running on the targeted host, etc.), psql will return an error and terminate.
If both standard input and standard output are a terminal, then psql sets the client encoding to “auto”, which will detect the appropriate client encoding from the locale settings (LC_CTYPE environment variable on Unix systems). If this doesn’t work out as expected, the client encoding can be overridden using the environment variable PGCLIENTENCODING.
Entering SQL Commands
In normal operation, psql provides a prompt with the name of the database to which psql is currently connected, followed by the string =>. For example:
$ psql testdb
psql (16.0)
Type "help" for help.
testdb=>
At the prompt, the user can type in SQL commands. Ordinarily, input lines are sent to the server when a command-terminating semicolon is reached. An end of line does not terminate a command. Thus commands can be spread over several lines for clarity. If the command was sent and executed without error, the results of the command are displayed on the screen.
If untrusted users have access to a database that has not adopted a secure schema usage pattern, begin your session by removing publicly-writable schemas from search_path. One can add options=-csearch_path= to the connection string or issue SELECT pg_catalog.set_config('search_path', '', false) before other SQL commands. This consideration is not specific to psql; it applies to every interface for executing arbitrary SQL commands.
Whenever a command is executed, psql also polls for asynchronous notification events generated by LISTEN and NOTIFY.
While C-style block comments are passed to the server for processing and removal, SQL-standard comments are removed by psql.
Advanced Features
Variables
psql provides variable substitution features similar to common Unix command shells. Variables are simply name/value pairs, where the value can be any string of any length. The name must consist of letters (including non-Latin letters), digits, and underscores.
To set a variable, use the psql meta-command \set. For example,
testdb=> \set foo bar
sets the variable foo to the value bar. To retrieve the content of the variable, precede the name with a colon, for example:
testdb=> \echo :foo
bar
This works in both regular SQL commands and meta-commands; there is more detail in SQL Interpolation, below.
If you call \set without a second argument, the variable is set to an empty-string value. To unset (i.e., delete) a variable, use the command \unset. To show the values of all variables, call \set without any argument.
Note
The arguments of \set are subject to the same substitution rules as with other commands. Thus you can construct interesting references such as \set :foo 'something' and get “soft links” or “variable variables” of Perl or PHP fame, respectively. Unfortunately (or fortunately?), there is no way to do anything useful with these constructs. On the other hand, \set bar :foo is a perfectly valid way to copy a variable.
A number of these variables are treated specially by psql. They represent certain option settings that can be changed at run time by altering the value of the variable, or in some cases represent changeable state of psql. By convention, all specially treated variables’ names consist of all upper-case ASCII letters (and possibly digits and underscores). To ensure maximum compatibility in the future, avoid using such variable names for your own purposes.
Variables that control psql‘s behavior generally cannot be unset or set to invalid values. An \unset command is allowed but is interpreted as setting the variable to its default value. A \set command without a second argument is interpreted as setting the variable to on, for control variables that accept that value, and is rejected for others. Also, control variables that accept the values on and off will also accept other common spellings of Boolean values, such as true and false.
The specially treated variables are:
AUTOCOMMIT#-
When
on(the default), each SQL command is automatically committed upon successful completion. To postpone commit in this mode, you must enter aBEGINorSTART TRANSACTIONSQL command. Whenoffor unset, SQL commands are not committed until you explicitly issueCOMMITorEND. The autocommit-off mode works by issuing an implicitBEGINfor you, just before any command that is not already in a transaction block and is not itself aBEGINor other transaction-control command, nor a command that cannot be executed inside a transaction block (such asVACUUM).Note
In autocommit-off mode, you must explicitly abandon any failed transaction by entering
ABORTorROLLBACK. Also keep in mind that if you exit the session without committing, your work will be lost.Note
The autocommit-on mode is PostgreSQL‘s traditional behavior, but autocommit-off is closer to the SQL spec. If you prefer autocommit-off, you might wish to set it in the system-wide
psqlrcfile or your~/.psqlrcfile. COMP_KEYWORD_CASE#-
Determines which letter case to use when completing an SQL key word. If set to
lowerorupper, the completed word will be in lower or upper case, respectively. If set topreserve-lowerorpreserve-upper(the default), the completed word will be in the case of the word already entered, but words being completed without anything entered will be in lower or upper case, respectively. DBNAME#-
The name of the database you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
ECHO#-
If set to
all, all nonempty input lines are printed to standard output as they are read. (This does not apply to lines read interactively.) To select this behavior on program start-up, use the switch-a. If set toqueries, psql prints each query to standard output as it is sent to the server. The switch to select this behavior is-e. If set toerrors, then only failed queries are displayed on standard error output. The switch for this behavior is-b. If set tonone(the default), then no queries are displayed. ECHO_HIDDEN#-
When this variable is set to
onand a backslash command queries the database, the query is first shown. This feature helps you to study PostgreSQL internals and provide similar functionality in your own programs. (To select this behavior on program start-up, use the switch-E.) If you set this variable to the valuenoexec, the queries are just shown but are not actually sent to the server and executed. The default value isoff. ENCODING#-
The current client character set encoding. This is set every time you connect to a database (including program start-up), and when you change the encoding with
\encoding, but it can be changed or unset. ERROR#-
trueif the last SQL query failed,falseif it succeeded. See alsoSQLSTATE. FETCH_COUNT#-
If this variable is set to an integer value greater than zero, the results of
SELECTqueries are fetched and displayed in groups of that many rows, rather than the default behavior of collecting the entire result set before display. Therefore only a limited amount of memory is used, regardless of the size of the result set. Settings of 100 to 1000 are commonly used when enabling this feature. Keep in mind that when using this feature, a query might fail after having already displayed some rows.Tip
Although you can use any output format with this feature, the default
alignedformat tends to look bad because each group ofFETCH_COUNTrows will be formatted separately, leading to varying column widths across the row groups. The other output formats work better. HIDE_TABLEAM#-
If this variable is set to
true, a table’s access method details are not displayed. This is mainly useful for regression tests. HIDE_TOAST_COMPRESSION#-
If this variable is set to
true, column compression method details are not displayed. This is mainly useful for regression tests. HISTCONTROL#-
If this variable is set to
ignorespace, lines which begin with a space are not entered into the history list. If set to a value ofignoredups, lines matching the previous history line are not entered. A value ofignorebothcombines the two options. If set tonone(the default), all lines read in interactive mode are saved on the history list.Note
This feature was shamelessly plagiarized from Bash.
HISTFILE#-
The file name that will be used to store the history list. If unset, the file name is taken from the
PSQL_HISTORYenvironment variable. If that is not set either, the default is~/.psql_history, or%APPDATA%\postgresql\psql_historyon Windows. For example, putting:\set HISTFILE ~/.psql_history-:DBNAME
in
~/.psqlrcwill cause psql to maintain a separate history for each database.Note
This feature was shamelessly plagiarized from Bash.
HISTSIZE#-
The maximum number of commands to store in the command history (default 500). If set to a negative value, no limit is applied.
Note
This feature was shamelessly plagiarized from Bash.
HOST#-
The database server host you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
IGNOREEOF#-
If set to 1 or less, sending an EOF character (usually Control+D) to an interactive session of psql will terminate the application. If set to a larger numeric value, that many consecutive EOF characters must be typed to make an interactive session terminate. If the variable is set to a non-numeric value, it is interpreted as 10. The default is 0.
Note
This feature was shamelessly plagiarized from Bash.
LASTOID#-
The value of the last affected OID, as returned from an
INSERTor\lo_importcommand. This variable is only guaranteed to be valid until after the result of the next SQL command has been displayed. PostgreSQL servers since version 12 do not support OID system columns anymore, thus LASTOID will always be 0 followingINSERTwhen targeting such servers. LAST_ERROR_MESSAGELAST_ERROR_SQLSTATE#-
The primary error message and associated SQLSTATE code for the most recent failed query in the current psql session, or an empty string and
00000if no error has occurred in the current session. ON_ERROR_ROLLBACK#-
When set to
on, if a statement in a transaction block generates an error, the error is ignored and the transaction continues. When set tointeractive, such errors are only ignored in interactive sessions, and not when reading script files. When set tooff(the default), a statement in a transaction block that generates an error aborts the entire transaction. The error rollback mode works by issuing an implicitSAVEPOINTfor you, just before each command that is in a transaction block, and then rolling back to the savepoint if the command fails. ON_ERROR_STOP#-
By default, command processing continues after an error. When this variable is set to
on, processing will instead stop immediately. In interactive mode, psql will return to the command prompt; otherwise, psql will exit, returning error code 3 to distinguish this case from fatal error conditions, which are reported using error code 1. In either case, any currently running scripts (the top-level script, if any, and any other scripts which it may have in invoked) will be terminated immediately. If the top-level command string contained multiple SQL commands, processing will stop with the current command. PORT#-
The database server port to which you are currently connected. This is set every time you connect to a database (including program start-up), but can be changed or unset.
PROMPT1PROMPT2PROMPT3#-
These specify what the prompts psql issues should look like. See Prompting below.
QUIET#-
Setting this variable to
onis equivalent to the command line option-q. It is probably not too useful in interactive mode. ROW_COUNT#-
The number of rows returned or affected by the last SQL query, or 0 if the query failed or did not report a row count.
SERVER_VERSION_NAMESERVER_VERSION_NUM#-
The server’s version number as a string, for example
9.6.2,10.1or11beta1, and in numeric form, for example90602or100001. These are set every time you connect to a database (including program start-up), but can be changed or unset. SHELL_ERROR#-
trueif the last shell command failed,falseif it succeeded. This applies to shell commands invoked via the\!,\g,\o,\w, and\copymeta-commands, as well as backquote (`) expansion. Note that for\o, this variable is updated when the output pipe is closed by the next\ocommand. See alsoSHELL_EXIT_CODE. SHELL_EXIT_CODE#-
The exit status returned by the last shell command. 0–127 represent program exit codes, 128–255 indicate termination by a signal, and -1 indicates failure to launch a program or to collect its exit status. This applies to shell commands invoked via the
\!,\g,\o,\w, and\copymeta-commands, as well as backquote (`) expansion. Note that for\o, this variable is updated when the output pipe is closed by the next\ocommand. See alsoSHELL_ERROR. SHOW_ALL_RESULTS#-
When this variable is set to
off, only the last result of a combined query (\;) is shown instead of all of them. The default ison. The off behavior is for compatibility with older versions of psql. SHOW_CONTEXT#-
This variable can be set to the values
never,errors, oralwaysto control whetherCONTEXTfields are displayed in messages from the server. The default iserrors(meaning that context will be shown in error messages, but not in notice or warning messages). This setting has no effect whenVERBOSITYis set toterseorsqlstate. (See also\errverbose, for use when you want a verbose version of the error you just got.) SINGLELINE#-
Setting this variable to
onis equivalent to the command line option-S. SINGLESTEP#-
Setting this variable to
onis equivalent to the command line option-s. SQLSTATE#-
The error code (see Appendix A) associated with the last SQL query’s failure, or
00000if it succeeded. USER#-
The database user you are currently connected as. This is set every time you connect to a database (including program start-up), but can be changed or unset.
VERBOSITY#-
This variable can be set to the values
default,verbose,terse, orsqlstateto control the verbosity of error reports. (See also\errverbose, for use when you want a verbose version of the error you just got.) VERSIONVERSION_NAMEVERSION_NUM#-
These variables are set at program start-up to reflect psql‘s version, respectively as a verbose string, a short string (e.g.,
9.6.2,10.1, or11beta1), and a number (e.g.,90602or100001). They can be changed or unset.
SQL Interpolation
A key feature of psql variables is that you can substitute (“interpolate”) them into regular SQL statements, as well as the arguments of meta-commands. Furthermore, psql provides facilities for ensuring that variable values used as SQL literals and identifiers are properly quoted. The syntax for interpolating a value without any quoting is to prepend the variable name with a colon (:). For example,
testdb=>\set foo 'my_table'testdb=>SELECT * FROM :foo;
would query the table my_table. Note that this may be unsafe: the value of the variable is copied literally, so it can contain unbalanced quotes, or even backslash commands. You must make sure that it makes sense where you put it.
When a value is to be used as an SQL literal or identifier, it is safest to arrange for it to be quoted. To quote the value of a variable as an SQL literal, write a colon followed by the variable name in single quotes. To quote the value as an SQL identifier, write a colon followed by the variable name in double quotes. These constructs deal correctly with quotes and other special characters embedded within the variable value. The previous example would be more safely written this way:
testdb=>\set foo 'my_table'testdb=>SELECT * FROM :"foo";
Variable interpolation will not be performed within quoted SQL literals and identifiers. Therefore, a construction such as ':foo' doesn’t work to produce a quoted literal from a variable’s value (and it would be unsafe if it did work, since it wouldn’t correctly handle quotes embedded in the value).
One example use of this mechanism is to copy the contents of a file into a table column. First load the file into a variable and then interpolate the variable’s value as a quoted string:
testdb=>\set content `cat my_file.txt`testdb=>INSERT INTO my_table VALUES (:'content');
(Note that this still won’t work if my_file.txt contains NUL bytes. psql does not support embedded NUL bytes in variable values.)
Since colons can legally appear in SQL commands, an apparent attempt at interpolation (that is, :name, :'name', or :"name") is not replaced unless the named variable is currently set. In any case, you can escape a colon with a backslash to protect it from substitution.
The :{? special syntax returns TRUE or FALSE depending on whether the variable exists or not, and is thus always substituted, unless the colon is backslash-escaped.name}
The colon syntax for variables is standard SQL for embedded query languages, such as ECPG. The colon syntaxes for array slices and type casts are PostgreSQL extensions, which can sometimes conflict with the standard usage. The colon-quote syntax for escaping a variable’s value as an SQL literal or identifier is a psql extension.
Prompting
The prompts psql issues can be customized to your preference. The three variables PROMPT1, PROMPT2, and PROMPT3 contain strings and special escape sequences that describe the appearance of the prompt. Prompt 1 is the normal prompt that is issued when psql requests a new command. Prompt 2 is issued when more input is expected during command entry, for example because the command was not terminated with a semicolon or a quote was not closed. Prompt 3 is issued when you are running an SQL COPY FROM STDIN command and you need to type in a row value on the terminal.
The value of the selected prompt variable is printed literally, except where a percent sign (%) is encountered. Depending on the next character, certain other text is substituted instead. Defined substitutions are:
%M#-
The full host name (with domain name) of the database server, or
[local]if the connection is over a Unix domain socket, or[local:, if the Unix domain socket is not at the compiled in default location./dir/name] %m#-
The host name of the database server, truncated at the first dot, or
[local]if the connection is over a Unix domain socket. %>#-
The port number at which the database server is listening.
%n#-
The database session user name. (The expansion of this value might change during a database session as the result of the command
SET SESSION AUTHORIZATION.) %/#-
The name of the current database.
%~#-
Like
%/, but the output is~(tilde) if the database is your default database. %##-
If the session user is a database superuser, then a
#, otherwise a>. (The expansion of this value might change during a database session as the result of the commandSET SESSION AUTHORIZATION.) %p#-
The process ID of the backend currently connected to.
%R#-
In prompt 1 normally
=, but@if the session is in an inactive branch of a conditional block, or^if in single-line mode, or!if the session is disconnected from the database (which can happen if\connectfails). In prompt 2%Ris replaced by a character that depends on why psql expects more input:-if the command simply wasn’t terminated yet, but*if there is an unfinished/* ... */comment, a single quote if there is an unfinished quoted string, a double quote if there is an unfinished quoted identifier, a dollar sign if there is an unfinished dollar-quoted string, or(if there is an unmatched left parenthesis. In prompt 3%Rdoesn’t produce anything. %x#-
Transaction status: an empty string when not in a transaction block, or
*when in a transaction block, or!when in a failed transaction block, or?when the transaction state is indeterminate (for example, because there is no connection). %l#-
The line number inside the current statement, starting from
1. %digits#-
The character with the indicated octal code is substituted.
%:name:#-
The value of the psql variable
name. See Variables, above, for details. %`command`#-
The output of
command, similar to ordinary “back-tick” substitution. %[…%]#-
Prompts can contain terminal control characters which, for example, change the color, background, or style of the prompt text, or change the title of the terminal window. In order for the line editing features of Readline to work properly, these non-printing control characters must be designated as invisible by surrounding them with
%[and%]. Multiple pairs of these can occur within the prompt. For example:testdb=> \set PROMPT1 '%[%033[1;33;40m%]%n@%/%R%[%033[0m%]%# '
results in a boldfaced (
1;) yellow-on-black (33;40) prompt on VT100-compatible, color-capable terminals. %w#-
Whitespace of the same width as the most recent output of
PROMPT1. This can be used as aPROMPT2setting, so that multi-line statements are aligned with the first line, but there is no visible secondary prompt.
To insert a percent sign into your prompt, write %%. The default prompts are '%/%R%x%# ' for prompts 1 and 2, and '>> ' for prompt 3.
Note
This feature was shamelessly plagiarized from tcsh.
Command-Line Editing
psql uses the Readline or libedit library, if available, for convenient line editing and retrieval. The command history is automatically saved when psql exits and is reloaded when psql starts up. Type up-arrow or control-P to retrieve previous lines.
You can also use tab completion to fill in partially-typed keywords and SQL object names in many (by no means all) contexts. For example, at the start of a command, typing ins and pressing TAB will fill in insert into . Then, typing a few characters of a table or schema name and pressing TAB will fill in the unfinished name, or offer a menu of possible completions when there’s more than one. (Depending on the library in use, you may need to press TAB more than once to get a menu.)
Tab completion for SQL object names requires sending queries to the server to find possible matches. In some contexts this can interfere with other operations. For example, after BEGIN it will be too late to issue SET TRANSACTION ISOLATION LEVEL if a tab-completion query is issued in between. If you do not want tab completion at all, you can turn it off permanently by putting this in a file named .inputrc in your home directory:
$if psql set disable-completion on $endif
(This is not a psql but a Readline feature. Read its documentation for further details.)
The -n (--no-readline) command line option can also be useful to disable use of Readline for a single run of psql. This prevents tab completion, use or recording of command line history, and editing of multi-line commands. It is particularly useful when you need to copy-and-paste text that contains TAB characters.
Материал из Кафедра ИУ5 МГТУ им. Н.Э.Баумана — студенческое сообщество
![]()
В статье пойдёт речь о том, как добиться корректного вывода кириллицы в «консоли» Windows (cmd.exe).
Содержание
- 1 Описание проблемы
- 2 Решение проблемы
- 2.1 Суть
- 2.2 Конкретные действия
- 2.2.1 Супер быстро и просто
- 2.2.2 Быстро и просто
- 2.2.3 Посложнее и подольше
Описание проблемы
В дистрибутив PostgreSQL, помимо всего прочего, для работы с СУБД входит:
- приложение с графическим интерфейсом
pgAdmin; - консольная утилита
psql.
При работе с psql в среде Windows пользователи всегда довольно часто сталкиваются с проблемой вывода кириллицы. Например, при отображении результатов запроса к таблице, в полях которых хранятся строковые данные на русском языке.

Ну и зачем тогда работать с psql, кому нужно долбить клавиатурой в консольке, когда можно всё сделать красиво и быстро в pgAdmin? Ну, не всегда pgAdmin доступен, особенно если речь идёт об удалённой машине. Кроме того, выполнение SQL-запросов в текстовом режиме консоли — это +10 к хакирству.
Решение проблемы
Версии ПО:
- MS Windows 7 SP1 x64;
- PostgreSQL 8.4.12 x32.
На сервере имеется БД, созданная в кодировке UTF8.
Суть
Суть проблемы в том, что cmd.exe работает (и так будет до скончания времён) в кодировке CP866, а сама Windows — в WIN1251, о чём psql предупреждает при начале работы:
WARNING: Console code page (866) differs from Windows code page (1251)
8-bit characters might not work correctly. See psql reference
page "Notes for Windows users" for details.
Значит, надо как-то добиться, чтобы кодировка была одна.
В разных источниках встречаются разные рецепты, включая правку реестра и подмену файлов в системных папках Windows. Ничего этого делать не нужно, достаточно всего трёх шагов:
- сменить шрифт у
cmd.exe; - сменить текущую кодовую страницу
cmd.exe; - сменить кодировку на стороне клиента в
psql.
Конкретные действия
Супер быстро и просто
Запускаете cmd.exe, оттуда psql:
psql -d ВАШАБАЗА -U ВАШЛОГИН
Далее:
psql \! chcp 1251
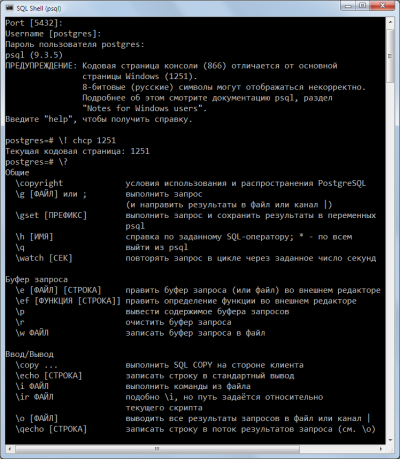
Быстро и просто
Запускаете cmd.exe, оттуда psql:
psql -d ВАШАБАЗА -U ВАШЛОГИН
Вводите пароль (если установлен) и выполняете команду:
set client_encoding='WIN866';
И всё. Теперь результаты запроса, содержащие кириллицу, будут отображаться нормально. Но есть небольшой косяк:
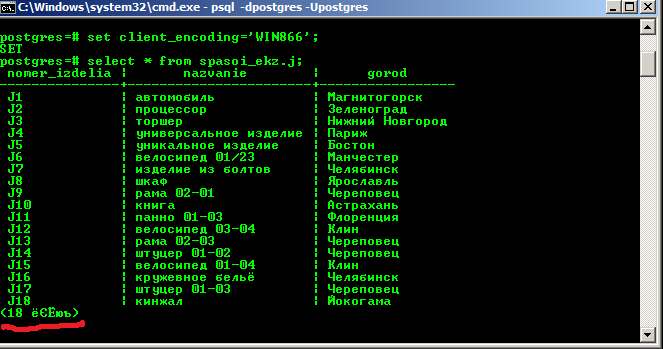
Потому предлагаем ещё способ, который этого недостатка лишён.
Посложнее и подольше
Запустить cmd.exe, нажать мышью в правом левом верхнем углу окна, там Свойства — Шрифт — выбрать Lucida Console. Нажать ОК.
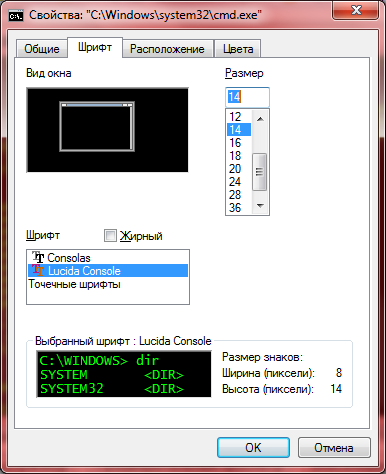
Выполнить команду:
chcp 1251
В ответ выведет:
Текущая кодовая страница: 1251
Запустить psql;
psql -d ВАШАБАЗА -U ВАШЛОГИН
Кстати, обратите внимание — теперь предупреждения о несовпадении кодировок нет.
Выполнить:
set client_encoding='win1251';
Он выведет:
SET
Всё, теперь кириллица будет нормально отображаться.
Проверяем:
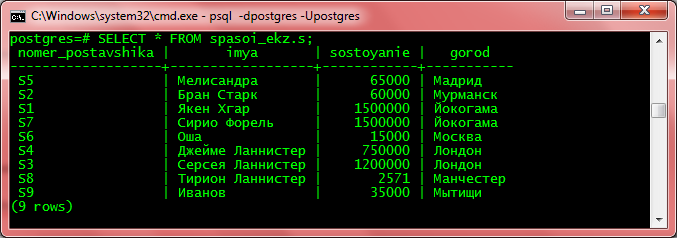
SYNOPSIS
- psql [option…] [dbname [username]]
DESCRIPTION
is a terminal-based front-end to
PostgreSQL. It enables you to type in queries interactively, issue them to
Postgres-XC, and see the query results. Alternatively, input can be from a file. In addition, it provides a number of meta-commands and various shell-like features to facilitate writing scripts and automating a wide variety of tasks.
OPTIONS
-a, —echo-all
-
Print all input lines to standard output as they are read. This is more useful for script processing than interactive mode. This is equivalent to setting the variable
ECHO
to
all.
-A, —no-align
- Switches to unaligned output mode. (The default output mode is otherwise aligned.)
-c command, —command=command
-
Specifies that
psql
is to execute one command string,
command, and then exit. This is useful in shell scripts. Start-up files (psqlrc
and
~/.psqlrc) are ignored with this option.command
must be either a command string that is completely parsable by the server (i.e., it contains no
psql-specific features), or a single backslash command. Thus you cannot mix
SQL
and
psql
meta-commands with this option. To achieve that, you could pipe the string into
psql, like this:
echo ‘\x \\ SELECT * FROM foo;’ | psql. (\\
is the separator meta-command.)If the command string contains multiple SQL commands, they are processed in a single transaction, unless there are explicit
BEGIN/COMMIT
commands included in the string to divide it into multiple transactions. This is different from the behavior when the same string is fed to
psql’s standard input. Also, only the result of the last SQL command is returned.
-d dbname, —dbname=dbname
-
Specifies the name of the database to connect to. This is equivalent to specifying
dbname
as the first non-option argument on the command line.If this parameter contains an
=
sign or starts with a valid
URI
prefix (postgresql://
or
postgres://), it is treated as a
conninfo
string. See
Section 32.1, «Database Connection Control Functions», in the documentation
for more information.
-e, —echo-queries
-
Copy all SQL commands sent to the server to standard output as well. This is equivalent to setting the variable
ECHO
to
queries.
-E, —echo-hidden
-
Echo the actual queries generated by
\d
and other backslash commands. You can use this to study
psql’s internal operations. This is equivalent to setting the variable
ECHO_HIDDEN
from within
psql.
-f filename, —file=filename
-
Use the file
filename
as the source of commands instead of reading commands interactively. After the file is processed,
psql
terminates. This is in many ways equivalent to the meta-command
\i.If
filename
is
—
(hyphen), then standard input is read.Using this option is subtly different from writing
psql < filename. In general, both will do what you expect, but using
-f
enables some nice features such as error messages with line numbers. There is also a slight chance that using this option will reduce the start-up overhead. On the other hand, the variant using the shell’s input redirection is (in theory) guaranteed to yield exactly the same output you would have received had you entered everything by hand.
-F separator, —field-separator=separator
-
Use
separator
as the field separator for unaligned output. This is equivalent to
\pset fieldsep
or
\f.
-h hostname, —host=hostname
- Specifies the host name of the machine on which the server is running. If the value begins with a slash, it is used as the directory for the Unix-domain socket.
-H, —html
-
Turn on
HTML
tabular output. This is equivalent to
\pset format html
or the
\H
command.
-l, —list
-
List all available databases, then exit. Other non-connection options are ignored. This is similar to the meta-command
\list.
-L filename, —log-file=filename
-
Write all query output into file
filename, in addition to the normal output destination.
-n, —no-readline
-
Do not use
readline
for line editing and do not use the history. This can be useful to turn off tab expansion when cutting and pasting.
-o filename, —output=filename
-
Put all query output into file
filename. This is equivalent to the command
\o.
-p port, —port=port
-
Specifies the TCP port or the local Unix-domain socket file extension on which the server is listening for connections. Defaults to the value of the
PGPORT
environment variable or, if not set, to the port specified at compile time, usually 5432.
-P assignment, —pset=assignment
-
Specifies printing options, in the style of
\pset. Note that here you have to separate name and value with an equal sign instead of a space. For example, to set the output format to
LaTeX, you could write
-P format=latex.
-q, —quiet
-
Specifies that
psql
should do its work quietly. By default, it prints welcome messages and various informational output. If this option is used, none of this happens. This is useful with the
-c
option. Within
psql
you can also set the
QUIET
variable to achieve the same effect.
-R separator, —record-separator=separator
-
Use
separator
as the record separator for unaligned output. This is equivalent to the
\pset recordsep
command.
-s, —single-step
- Run in single-step mode. That means the user is prompted before each command is sent to the server, with the option to cancel execution as well. Use this to debug scripts.
-S, —single-line
-
Runs in single-line mode where a newline terminates an SQL command, as a semicolon does.
-
Note
This mode is provided for those who insist on it, but you are not necessarily encouraged to use it. In particular, if you mix
SQL
and meta-commands on a line the order of execution might not always be clear to the inexperienced user.
-
-t, —tuples-only
-
Turn off printing of column names and result row count footers, etc. This is equivalent to the
\t
command.
-T table_options, —table-attr=table_options
-
Specifies options to be placed within the
HTMLtable
tag. See
\pset
for details.
-U username, —username=username
-
Connect to the database as the user
username
instead of the default. (You must have permission to do so, of course.)
-v assignment, —set=assignment, —variable=assignment
-
Perform a variable assignment, like the
\set
meta-command. Note that you must separate name and value, if any, by an equal sign on the command line. To unset a variable, leave off the equal sign. To set a variable with an empty value, use the equal sign but leave off the value. These assignments are done during a very early stage of start-up, so variables reserved for internal purposes might get overwritten later.
-V, —version
-
Print the
psql
version and exit.
-w, —no-password
-
Never issue a password prompt. If the server requires password authentication and a password is not available by other means such as a
.pgpass
file, the connection attempt will fail. This option can be useful in batch jobs and scripts where no user is present to enter a password.Note that this option will remain set for the entire session, and so it affects uses of the meta-command
\connect
as well as the initial connection attempt.
-W, —password
-
Force
psql
to prompt for a password before connecting to a database.This option is never essential, since
psql
will automatically prompt for a password if the server demands password authentication. However,
psql
will waste a connection attempt finding out that the server wants a password. In some cases it is worth typing
-W
to avoid the extra connection attempt.Note that this option will remain set for the entire session, and so it affects uses of the meta-command
\connect
as well as the initial connection attempt.
-x, —expanded
-
Turn on the expanded table formatting mode. This is equivalent to the
\x
command.
-X,, —no-psqlrc
-
Do not read the start-up file (neither the system-wide
psqlrc
file nor the user’s
~/.psqlrc
file).
-z, —field-separator-zero
- Set the field separator for unaligned output to a zero byte.
-0, —record-separator-zero
-
Set the record separator for unaligned output to a zero byte. This is useful for interfacing, for example, with
xargs -0.
-1, —single-transaction
-
When
psql
executes a script with the
-f
option, adding this option wraps
BEGIN/COMMIT
around the script to execute it as a single transaction. This ensures that either all the commands complete successfully, or no changes are applied.If the script itself uses
BEGIN,
COMMIT, or
ROLLBACK, this option will not have the desired effects. Also, if the script contains any command that cannot be executed inside a transaction block, specifying this option will cause that command (and hence the whole transaction) to fail.
-?, —help
-
Show help about
psql
command line arguments, and exit.
EXIT STATUS
psql
returns 0 to the shell if it finished normally, 1 if a fatal error of its own occurs (e.g. out of memory, file not found), 2 if the connection to the server went bad and the session was not interactive, and 3 if an error occurred in a script and the variable
ON_ERROR_STOP
was set.
USAGE
Connecting to a Database
psql
is a regular
Postgres-XC
client application. In order to connect to a database you need to know the name of your target database, the host name and port number of the server, and what user name you want to connect as.
psql
can be told about those parameters via command line options, namely
-d,
-h,
-p, and
-U
respectively. If an argument is found that does not belong to any option it will be interpreted as the database name (or the user name, if the database name is already given). Not all of these options are required; there are useful defaults. If you omit the host name,
psql
will connect via a Unix-domain socket to a server on the local host, or via TCP/IP to
localhost
on machines that don’t have Unix-domain sockets. The default port number is determined at compile time. Since the database server uses the same default, you will not have to specify the port in most cases. The default user name is your Unix user name, as is the default database name. Note that you cannot just connect to any database under any user name. Your database administrator should have informed you about your access rights.
When the defaults aren’t quite right, you can save yourself some typing by setting the environment variables
PGDATABASE,
PGHOST,
PGPORT
and/or
PGUSER
to appropriate values. (For additional environment variables, see
Section 32.14, «Environment Variables», in the documentation.) It is also convenient to have a
~/.pgpass
file to avoid regularly having to type in passwords. See
Section 32.15, «The Password File», in the documentation
for more information.
An alternative way to specify connection parameters is in a
conninfo
string or a
URI, which is used instead of a database name. This mechanism give you very wide control over the connection. For example:
-
$ psql "service=myservice sslmode=require" $ psql postgresql://dbmaster:5433/mydb?sslmode=require
This way you can also use
LDAP
for connection parameter lookup as described in
Section 32.17, «LDAP Lookup of Connection Parameters», in the documentation. See
Section 32.1, «Database Connection Control Functions», in the documentation
for more information on all the available connection options.
If the connection could not be made for any reason (e.g., insufficient privileges, server is not running on the targeted host, etc.),
psql
will return an error and terminate.
If at least one of standard input or standard output are a terminal, then
psql
sets the client encoding to
«auto», which will detect the appropriate client encoding from the locale settings (LC_CTYPE
environment variable on Unix systems). If this doesn’t work out as expected, the client encoding can be overridden using the environment variable
PGCLIENTENCODING.
Entering SQL Commands
In normal operation,
psql
provides a prompt with the name of the database to which
psql
is currently connected, followed by the string
=>. For example:
-
$ psql testdb psql (1.1) Type "help" for help. testdb=>
At the prompt, the user can type in
SQL
commands. Ordinarily, input lines are sent to the server when a command-terminating semicolon is reached. An end of line does not terminate a command. Thus commands can be spread over several lines for clarity. If the command was sent and executed without error, the results of the command are displayed on the screen.
Whenever a command is executed,
psql
also polls for asynchronous notification events generated by
LISTEN(7)
and
NOTIFY(7).
Meta-Commands
Anything you enter in
psql
that begins with an unquoted backslash is a
psql
meta-command that is processed by
psql
itself. These commands make
psql
more useful for administration or scripting. Meta-commands are often called slash or backslash commands.
The format of a
psql
command is the backslash, followed immediately by a command verb, then any arguments. The arguments are separated from the command verb and each other by any number of whitespace characters.
To include whitespace in an argument you can quote it with single quotes. To include a single quote in an argument, write two single quotes within single-quoted text. Anything contained in single quotes is furthermore subject to C-like substitutions for
\n
(new line),
\t
(tab),
\b
(backspace),
\r
(carriage return),
\f
(form feed),
\digits
(octal), and
\xdigits
(hexadecimal). A backslash preceding any other character within single-quoted text quotes that single character, whatever it is.
Within an argument, text that is enclosed in backquotes (`) is taken as a command line that is passed to the shell. The output of the command (with any trailing newline removed) replaces the backquoted text.
If an unquoted colon (:) followed by a
psql
variable name appears within an argument, it is replaced by the variable’s value, as described in
SQL Interpolation.
Some commands take an
SQL
identifier (such as a table name) as argument. These arguments follow the syntax rules of
SQL: Unquoted letters are forced to lowercase, while double quotes («) protect letters from case conversion and allow incorporation of whitespace into the identifier. Within double quotes, paired double quotes reduce to a single double quote in the resulting name. For example,
FOO»BAR»BAZ
is interpreted as
fooBARbaz, and
«A weird»» name»
becomes
A weird» name.
Parsing for arguments stops at the end of the line, or when another unquoted backslash is found. An unquoted backslash is taken as the beginning of a new meta-command. The special sequence
\\
(two backslashes) marks the end of arguments and continues parsing
SQL
commands, if any. That way
SQL
and
psql
commands can be freely mixed on a line. But in any case, the arguments of a meta-command cannot continue beyond the end of the line.
The following meta-commands are defined:
\a
-
If the current table output format is unaligned, it is switched to aligned. If it is not unaligned, it is set to unaligned. This command is kept for backwards compatibility. See
\pset
for a more general solution.
\c or \connect [ dbname [ username ] [ host ] [ port ] ]
-
Establishes a new connection to a
Postgres-XC
server. If the new connection is successfully made, the previous connection is closed. If any of
dbname,
username,
host
or
port
are omitted or specified as
-, the value of that parameter from the previous connection is used. If there is no previous connection, the
libpq
default for the parameter’s value is used.If the connection attempt failed (wrong user name, access denied, etc.), the previous connection will only be kept if
psql
is in interactive mode. When executing a non-interactive script, processing will immediately stop with an error. This distinction was chosen as a user convenience against typos on the one hand, and a safety mechanism that scripts are not accidentally acting on the wrong database on the other hand.
\C [ title ]
-
Sets the title of any tables being printed as the result of a query or unset any such title. This command is equivalent to
\pset title title. (The name of this command derives from
«caption», as it was previously only used to set the caption in an
HTML
table.)
\cd [ directory ]
-
Changes the current working directory to
directory. Without argument, changes to the current user’s home directory.-
Tip
To print your current working directory, use
\! pwd.
-
\conninfo
- Outputs information about the current database connection.
\copy { table [ ( column_list ) ] | ( query ) } { from | to } { filename | stdin | stdout | pstdin | pstdout } [ with ] [ binary ] [ oids ] [ delimiter [ as ] ‘character‘ ] [ null [ as ] ‘string‘ ] [ csv [ header ] [ quote [ as ] ‘character‘ ] [ escape [ as ] ‘character‘ ] [ force quote column_list | * ] [ force not null column_list ] ]
-
Performs a frontend (client) copy. This is an operation that runs an
SQLCOPY(7)
command, but instead of the server reading or writing the specified file,
psql
reads or writes the file and routes the data between the server and the local file system. This means that file accessibility and privileges are those of the local user, not the server, and no SQL superuser privileges are required.The syntax of the command is similar to that of the
SQLCOPY(7)
command. Note that, because of this, special parsing rules apply to the
\copy
command. In particular, the variable substitution rules and backslash escapes do not apply.\copy … from stdin | to stdout
reads/writes based on the command input and output respectively. All rows are read from the same source that issued the command, continuing until
\.
is read or the stream reaches
EOF. Output is sent to the same place as command output. To read/write from
psql’s standard input or output, use
pstdin
or
pstdout. This option is useful for populating tables in-line within a SQL script file.-
Tip
This operation is not as efficient as the
SQLCOPY
command because all data must pass through the client/server connection. For large amounts of data the
SQL
command might be preferable.
-
\copyright
-
Shows the copyright and distribution terms of
Postgres-XC.
\d[S+] [ pattern ]
-
For each relation (table, view, index, sequence, or foreign table) or composite type matching the
pattern, show all columns, their types, the tablespace (if not the default) and any special attributes such as
NOT NULL
or defaults. Associated indexes, constraints, rules, and triggers are also shown. For foreign tables, the associated foreign server is shown as well. («Matching the pattern»
is defined in
Patterns
below.)For some types of relation,
\d
shows additional information for each column: column values for sequences, indexed expression for indexes and foreign data wrapper options for foreign tables.The command form
\d+
is identical, except that more information is displayed: any comments associated with the columns of the table are shown, as is the presence of OIDs in the table, the view definition if the relation is a view.By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects.-
Note
If
\d
is used without a
pattern
argument, it is equivalent to
\dtvsE
which will show a list of all visible tables, views, sequences and foreign tables. This is purely a convenience measure.
-
\da[S] [ pattern ]
-
Lists aggregate functions, together with their return type and the data types they operate on. If
pattern
is specified, only aggregates whose names match the pattern are shown. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects.
\db[+] [ pattern ]
-
Lists tablespaces. If
pattern
is specified, only tablespaces whose names match the pattern are shown. If
+
is appended to the command name, each object is listed with its associated permissions.
\dc[S+] [ pattern ]
-
Lists conversions between character-set encodings. If
pattern
is specified, only conversions whose names match the pattern are listed. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects. If
+
is appended to the command name, each object is listed with its associated description.
\dC[+] [ pattern ]
-
Lists type casts. If
pattern
is specified, only casts whose source or target types match the pattern are listed. If
+
is appended to the command name, each object is listed with its associated description.
\dd[S] [ pattern ]
-
Shows the descriptions of objects of type
constraint,
operator class,
operator family,
rule, and
trigger. All other comments may be viewed by the respective backslash commands for those object types.\dd
displays descriptions for objects matching the
pattern, or of visible objects of the appropriate type if no argument is given. But in either case, only objects that have a description are listed. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects.Descriptions for objects can be created with the
COMMENT(7)SQL
command.
\ddp [ pattern ]
-
Lists default access privilege settings. An entry is shown for each role (and schema, if applicable) for which the default privilege settings have been changed from the built-in defaults. If
pattern
is specified, only entries whose role name or schema name matches the pattern are listed.The
ALTER DEFAULT PRIVILEGES (ALTER_DEFAULT_PRIVILEGES(7))
command is used to set default access privileges. The meaning of the privilege display is explained under
GRANT(7).
\dD[S+] [ pattern ]
-
Lists domains. If
pattern
is specified, only domains whose names match the pattern are shown. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects. If
+
is appended to the command name, each object is listed with its associated permissions and description.
\dE[S+] [ pattern ], \di[S+] [ pattern ], \ds[S+] [ pattern ], \dt[S+] [ pattern ], \dv[S+] [ pattern ]
-
In this group of commands, the letters
E,
i,
s,
t, and
v
stand for foreign table, index, sequence, table, and view, respectively. You can specify any or all of these letters, in any order, to obtain a listing of objects of these types. For example,
\dit
lists indexes and tables. If
+
is appended to the command name, each object is listed with its physical size on disk and its associated description, if any. If
pattern
is specified, only objects whose names match the pattern are listed. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects.
\des[+] [ pattern ]
-
Lists foreign servers (mnemonic:
«external servers»). If
pattern
is specified, only those servers whose name matches the pattern are listed. If the form
\des+
is used, a full description of each server is shown, including the server’s ACL, type, version, options, and description.
\det[+] [ pattern ]
-
Lists foreign tables (mnemonic:
«external tables»). If
pattern
is specified, only entries whose table name or schema name matches the pattern are listed. If the form
\det+
is used, generic options and the foreign table description are also displayed.
\deu[+] [ pattern ]
-
Lists user mappings (mnemonic:
«external users»). If
pattern
is specified, only those mappings whose user names match the pattern are listed. If the form
\deu+
is used, additional information about each mapping is shown.-
Caution
\deu+
might also display the user name and password of the remote user, so care should be taken not to disclose them.
-
\dew[+] [ pattern ]
-
Lists foreign-data wrappers (mnemonic:
«external wrappers»). If
pattern
is specified, only those foreign-data wrappers whose name matches the pattern are listed. If the form
\dew+
is used, the ACL, options, and description of the foreign-data wrapper are also shown.
\df[antwS+] [ pattern ]
-
Lists functions, together with their arguments, return types, and function types, which are classified as
«agg»
(aggregate),
«normal»,
«trigger», or
«window». To display only functions of specific type(s), add the corresponding letters
a,
n,
t, or
w
to the command. If
pattern
is specified, only functions whose names match the pattern are shown. If the form
\df+
is used, additional information about each function, including volatility, language, source code and description, is shown. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects.-
Tip
To look up functions taking arguments or returning values of a specific type, use your pager’s search capability to scroll through the
\df
output.
-
\dF[+] [ pattern ]
-
Lists text search configurations. If
pattern
is specified, only configurations whose names match the pattern are shown. If the form
\dF+
is used, a full description of each configuration is shown, including the underlying text search parser and the dictionary list for each parser token type.
\dFd[+] [ pattern ]
-
Lists text search dictionaries. If
pattern
is specified, only dictionaries whose names match the pattern are shown. If the form
\dFd+
is used, additional information is shown about each selected dictionary, including the underlying text search template and the option values.
\dFp[+] [ pattern ]
-
Lists text search parsers. If
pattern
is specified, only parsers whose names match the pattern are shown. If the form
\dFp+
is used, a full description of each parser is shown, including the underlying functions and the list of recognized token types.
\dFt[+] [ pattern ]
-
Lists text search templates. If
pattern
is specified, only templates whose names match the pattern are shown. If the form
\dFt+
is used, additional information is shown about each template, including the underlying function names.
\dg[+] [ pattern ]
-
Lists database roles. (Since the concepts of
«users»
and
«groups»
have been unified into
«roles», this command is now equivalent to
\du.) If
pattern
is specified, only those roles whose names match the pattern are listed. If the form
\dg+
is used, additional information is shown about each role; currently this adds the comment for each role.
\dl
-
This is an alias for
\lo_list, which shows a list of large objects.
\dL[S+] [ pattern ]
-
Lists procedural languages. If
pattern
is specified, only languages whose names match the pattern are listed. By default, only user-created languages are shown; supply the
S
modifier to include system objects. If
+
is appended to the command name, each language is listed with its call handler, validator, access privileges, and whether it is a system object.
\dn[S+] [ pattern ]
-
Lists schemas (namespaces). If
pattern
is specified, only schemas whose names match the pattern are listed. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects. If
+
is appended to the command name, each object is listed with its associated permissions and description, if any.
\do[S] [ pattern ]
-
Lists operators with their operand and return types. If
pattern
is specified, only operators whose names match the pattern are listed. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects.
\dO[S+] [ pattern ]
-
Lists collations. If
pattern
is specified, only collations whose names match the pattern are listed. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects. If
+
is appended to the command name, each collation is listed with its associated description, if any. Note that only collations usable with the current database’s encoding are shown, so the results may vary in different databases of the same installation.
\dp [ pattern ]
-
Lists tables, views and sequences with their associated access privileges. If
pattern
is specified, only tables, views and sequences whose names match the pattern are listed.The
GRANT(7)
and
REVOKE(7)
commands are used to set access privileges. The meaning of the privilege display is explained under
GRANT(7).
\drds [ role-pattern [ database-pattern ] ]
-
Lists defined configuration settings. These settings can be role-specific, database-specific, or both.
role-pattern
and
database-pattern
are used to select specific roles and databases to list, respectively. If omitted, or if
*
is specified, all settings are listed, including those not role-specific or database-specific, respectively.The
ALTER ROLE (ALTER_ROLE(7))
and
ALTER DATABASE (ALTER_DATABASE(7))
commands are used to define per-role and per-database configuration settings.
\dT[S+] [ pattern ]
-
Lists data types. If
pattern
is specified, only types whose names match the pattern are listed. If
+
is appended to the command name, each type is listed with its internal name and size, its allowed values if it is an
enum
type, and its associated permissions. By default, only user-created objects are shown; supply a pattern or the
S
modifier to include system objects.
\du[+] [ pattern ]
-
Lists database roles. (Since the concepts of
«users»
and
«groups»
have been unified into
«roles», this command is now equivalent to
\dg.) If
pattern
is specified, only those roles whose names match the pattern are listed. If the form
\du+
is used, additional information is shown about each role; currently this adds the comment for each role.
\dx[+] [ pattern ]
-
Lists installed extensions. If
pattern
is specified, only those extensions whose names match the pattern are listed. If the form
\dx+
is used, all the objects belonging to each matching extension are listed.
\e or \edit [ filename ] [ line_number ]
-
If
filename
is specified, the file is edited; after the editor exits, its content is copied back to the query buffer. If no
filename
is given, the current query buffer is copied to a temporary file which is then edited in the same fashion.The new query buffer is then re-parsed according to the normal rules of
psql, where the whole buffer is treated as a single line. (Thus you cannot make scripts this way. Use
\i
for that.) This means that if the query ends with (or contains) a semicolon, it is immediately executed. Otherwise it will merely wait in the query buffer; type semicolon or
\g
to send it, or
\r
to cancel.If a line number is specified,
psql
will position the cursor on the specified line of the file or query buffer. Note that if a single all-digits argument is given,
psql
assumes it is a line number, not a file name.-
Tip
See under
ENVIRONMENT
for how to configure and customize your editor.
-
\echo text [ … ]
-
Prints the arguments to the standard output, separated by one space and followed by a newline. This can be useful to intersperse information in the output of scripts. For example:
-
=> \echo `date` Tue Oct 26 21:40:57 CEST 1999
If the first argument is an unquoted
-n
the trailing newline is not written.-
Tip
If you use the
\o
command to redirect your query output you might wish to use
\qecho
instead of this command.
-
\ef [ function_description [ line_number ] ]
-
This command fetches and edits the definition of the named function, in the form of a
CREATE OR REPLACE FUNCTION
command. Editing is done in the same way as for
\edit. After the editor exits, the updated command waits in the query buffer; type semicolon or
\g
to send it, or
\r
to cancel.The target function can be specified by name alone, or by name and arguments, for example
foo(integer, text). The argument types must be given if there is more than one function of the same name.If no function is specified, a blank
CREATE FUNCTION
template is presented for editing.If a line number is specified,
psql
will position the cursor on the specified line of the function body. (Note that the function body typically does not begin on the first line of the file.)-
Tip
See under
ENVIRONMENT
for how to configure and customize your editor.
-
\encoding [ encoding ]
- Sets the client character set encoding. Without an argument, this command shows the current encoding.
\f [ string ]
-
Sets the field separator for unaligned query output. The default is the vertical bar (|). See also
\pset
for a generic way of setting output options.
\g [ { filename | |command } ]
-
Sends the current query input buffer to the server and optionally stores the query’s output in
filename
or pipes the output into a separate Unix shell executing
command. A bare
\g
is virtually equivalent to a semicolon. A
\g
with argument is a
«one-shot»
alternative to the
\o
command.
\h or \help [ command ]
-
Gives syntax help on the specified
SQL
command. If
command
is not specified, then
psql
will list all the commands for which syntax help is available. If
command
is an asterisk (*), then syntax help on all
SQL
commands is shown.-
Note
To simplify typing, commands that consists of several words do not have to be quoted. Thus it is fine to type
\help alter table.
-
\H
-
Turns on
HTML
query output format. If the
HTML
format is already on, it is switched back to the default aligned text format. This command is for compatibility and convenience, but see
\pset
about setting other output options.
\i filename
-
Reads input from the file
filename
and executes it as though it had been typed on the keyboard.-
Note
If you want to see the lines on the screen as they are read you must set the variable
ECHO
to
all.
-
\ir filename
-
The
\ir
command is similar to
\i, but resolves relative file names differently. When executing in interactive mode, the two commands behave identically. However, when invoked from a script,
\ir
interprets file names relative to the directory in which the script is located, rather than the current working directory.
\l (or \list), \l+ (or \list+)
-
List the names, owners, character set encodings, and access privileges of all the databases in the server. If
+
is appended to the command name, database sizes, default tablespaces, and descriptions are also displayed. (Size information is only available for databases that the current user can connect to.)
\lo_export loid filename
-
Reads the large object with
OIDloid
from the database and writes it to
filename. Note that this is subtly different from the server function
lo_export, which acts with the permissions of the user that the database server runs as and on the server’s file system.-
Tip
Use
\lo_list
to find out the large object’s
OID.
-
\lo_import filename [ comment ]
-
Stores the file into a
Postgres-XC
large object. Optionally, it associates the given comment with the object. Example:-
foo=> \lo_import '/home/peter/pictures/photo.xcf' 'a picture of me' lo_import 152801
The response indicates that the large object received object ID 152801, which can be used to access the newly-created large object in the future. For the sake of readability, it is recommended to always associate a human-readable comment with every object. Both OIDs and comments can be viewed with the
\lo_list
command.Note that this command is subtly different from the server-side
lo_import
because it acts as the local user on the local file system, rather than the server’s user and file system. -
\lo_list
-
Large object is not supported by the current
Postgres-XC.
\lo_unlink loid
-
Large object is not supported by the current
Postgres-XC.
\o [ {filename | |command} ]
-
Saves future query results to the file
filename
or pipes future results into a separate Unix shell to execute
command. If no arguments are specified, the query output will be reset to the standard output.«Query results»
includes all tables, command responses, and notices obtained from the database server, as well as output of various backslash commands that query the database (such as
\d), but not error messages.-
Tip
To intersperse text output in between query results, use
\qecho.
-
\p
- Print the current query buffer to the standard output.
\password [ username ]
-
Changes the password of the specified user (by default, the current user). This command prompts for the new password, encrypts it, and sends it to the server as an
ALTER ROLE
command. This makes sure that the new password does not appear in cleartext in the command history, the server log, or elsewhere.
\prompt [ text ] name
-
Prompts the user to supply text, which is assigned to the variable
name. An optional prompt string,
text, can be specified. (For multiword prompts, surround the text with single quotes.)By default,
\prompt
uses the terminal for input and output. However, if the
-f
command line switch was used,
\prompt
uses standard input and standard output.
\pset option [ value ]
-
This command sets options affecting the output of query result tables.
option
indicates which option is to be set. The semantics of
value
vary depending on the selected option. For some options, omitting
value
causes the option to be toggled or unset, as described under the particular option. If no such behavior is mentioned, then omitting
value
just results in the current setting being displayed.Adjustable printing options are:
border
-
The
value
must be a number. In general, the higher the number the more borders and lines the tables will have, but this depends on the particular format. In
HTML
format, this will translate directly into the
border=…
attribute; in the other formats only values 0 (no border), 1 (internal dividing lines), and 2 (table frame) make sense.
columns
-
Sets the target width for the
wrapped
format, and also the width limit for determining whether output is wide enough to require the pager or switch to the vertical display in expanded auto mode. Zero (the default) causes the target width to be controlled by the environment variable
COLUMNS, or the detected screen width if
COLUMNS
is not set. In addition, if
columns
is zero then the
wrapped
format only affects screen output. If
columns
is nonzero then file and pipe output is wrapped to that width as well.
expanded (or x)
-
If
value
is specified it must be either
on
or
off, which will enable or disable expanded mode, or
auto. If
value
is omitted the command toggles between the on and off settings. When expanded mode is enabled, query results are displayed in two columns, with the column name on the left and the data on the right. This mode is useful if the data wouldn’t fit on the screen in the normal
«horizontal»
mode. In the auto setting, the expanded mode is used whenever the query output is wider than the screen, otherwise the regular mode is used. The auto setting is only effective in the aligned and wrapped formats. In other formats, it always behaves as if the expanded mode is off.
fieldsep
-
Specifies the field separator to be used in unaligned output format. That way one can create, for example, tab- or comma-separated output, which other programs might prefer. To set a tab as field separator, type
\pset fieldsep ‘\t’. The default field separator is
‘|’
(a vertical bar).
fieldsep_zero
- Sets the field separator to use in unaligned output format to a zero byte.
footer
-
If
value
is specified it must be either
on
or
off
which will enable or disable display of the table footer (the
(n rows)
count). If
value
is omitted the command toggles footer display on or off.
format
-
Sets the output format to one of
unaligned,
aligned,
wrapped,
html,
latex, or
troff-ms. Unique abbreviations are allowed. (That would mean one letter is enough.)unaligned
format writes all columns of a row on one line, separated by the currently active field separator. This is useful for creating output that might be intended to be read in by other programs (for example, tab-separated or comma-separated format).aligned
format is the standard, human-readable, nicely formatted text output; this is the default.wrapped
format is like
aligned
but wraps wide data values across lines to make the output fit in the target column width. The target width is determined as described under the
columns
option. Note that
psql
will not attempt to wrap column header titles; therefore,
wrapped
format behaves the same as
aligned
if the total width needed for column headers exceeds the target.The
html,
latex, and
troff-ms
formats put out tables that are intended to be included in documents using the respective mark-up language. They are not complete documents! (This might not be so dramatic in
HTML, but in
LaTeX
you must have a complete document wrapper.)
linestyle
-
Sets the border line drawing style to one of
ascii,
old-ascii
or
unicode. Unique abbreviations are allowed. (That would mean one letter is enough.) The default setting is
ascii. This option only affects the
aligned
and
wrapped
output formats.ascii
style uses plain
ASCII
characters. Newlines in data are shown using a
+
symbol in the right-hand margin. When the
wrapped
format wraps data from one line to the next without a newline character, a dot (.) is shown in the right-hand margin of the first line, and again in the left-hand margin of the following line.unicode
style uses Unicode box-drawing characters. Newlines in data are shown using a carriage return symbol in the right-hand margin. When the data is wrapped from one line to the next without a newline character, an ellipsis symbol is shown in the right-hand margin of the first line, and again in the left-hand margin of the following line.When the
border
setting is greater than zero, this option also determines the characters with which the border lines are drawn. Plain
ASCII
characters work everywhere, but Unicode characters look nicer on displays that recognize them.
null
-
Sets the string to be printed in place of a null value. The default is to print nothing, which can easily be mistaken for an empty string. For example, one might prefer
\pset null ‘(null)’.
numericlocale
-
If
value
is specified it must be either
on
or
off
which will enable or disable display of a locale-specific character to separate groups of digits to the left of the decimal marker. If
value
is omitted the command toggles between regular and locale-specific numeric output.
pager
-
Controls use of a pager program for query and
psql
help output. If the environment variable
PAGER
is set, the output is piped to the specified program. Otherwise a platform-dependent default (such as
more) is used.When the
pager
option is
off, the pager program is not used. When the
pager
option is
on, the pager is used when appropriate, i.e., when the output is to a terminal and will not fit on the screen. The
pager
option can also be set to
always, which causes the pager to be used for all terminal output regardless of whether it fits on the screen.
\pset pager
without a
value
toggles pager use on and off.
recordsep
- Specifies the record (line) separator to use in unaligned output format. The default is a newline character.
recordsep_zero
- Sets the record separator to use in unaligned output format to a zero byte.
tableattr (or T)
-
Specifies attributes to be placed inside the
HTMLtable
tag in
html
output format. This could for example be
cellpadding
or
bgcolor. Note that you probably don’t want to specify
border
here, as that is already taken care of by
\pset border. If no
value
is given, the table attributes are unset.
title
-
Sets the table title for any subsequently printed tables. This can be used to give your output descriptive tags. If no
value
is given, the title is unset.
tuples_only (or t)
-
If
value
is specified it must be either
on
or
off
which will enable or disable tuples-only mode. If
value
is omitted the command toggles between regular and tuples-only output. Regular output includes extra information such as column headers, titles, and various footers. In tuples-only mode, only actual table data is shown.
Illustrations of how these different formats look can be seen in the
EXAMPLES
section.-
Tip
There are various shortcut commands for
\pset. See
\a,
\C,
\H,
\t,
\T, and
\x.
-
Note
It is an error to call
\pset
without any arguments. In the future this case might show the current status of all printing options.
-
The
\q or \quit
-
Quits the
psql
program. In a script file, only execution of that script is terminated.
\qecho text [ … ]
-
This command is identical to
\echo
except that the output will be written to the query output channel, as set by
\o.
\r
- Resets (clears) the query buffer.
\s [ filename ]
-
Print or save the command line history to
filename. If
filename
is omitted, the history is written to the standard output. This option is only available if
psql
is configured to use the
GNUReadline
library.
\set [ name [ value [ … ] ] ]
-
Sets the
psql
variable
name
to
value, or if more than one value is given, to the concatenation of all of them. If only one argument is given, the variable is set with an empty value. To unset a variable, use the
\unset
command.\set
without any arguments displays the names and values of all currently-set
psql
variables.Valid variable names can contain letters, digits, and underscores. See the section
Variables
below for details. Variable names are case-sensitive.Although you are welcome to set any variable to anything you want,
psql
treats several variables as special. They are documented in the section about variables.-
Note
This command is unrelated to the
SQL
command
SET(7).
-
\setenv [ name [ value ] ]
-
Sets the environment variable
name
to
value, or if the
value
is not supplied, unsets the environment variable. Example:-
testdb=> \setenv PAGER less testdb=> \setenv LESS -imx4F
-
\sf[+] function_description
-
This command fetches and shows the definition of the named function, in the form of a
CREATE OR REPLACE FUNCTION
command. The definition is printed to the current query output channel, as set by
\o.The target function can be specified by name alone, or by name and arguments, for example
foo(integer, text). The argument types must be given if there is more than one function of the same name.If
+
is appended to the command name, then the output lines are numbered, with the first line of the function body being line 1.
\t
-
Toggles the display of output column name headings and row count footer. This command is equivalent to
\pset tuples_only
and is provided for convenience.
\T table_options
-
Specifies attributes to be placed within the
table
tag in
HTML
output format. This command is equivalent to
\pset tableattr table_options.
\timing [ on | off ]
- Without parameter, toggles a display of how long each SQL statement takes, in milliseconds. With parameter, sets same.
\unset name
-
Unsets (deletes) the
psql
variable
name.
\w filename, \w |command
-
Outputs the current query buffer to the file
filename
or pipes it to the Unix command
command.
\x [ on | off | auto ]
-
Sets or toggles expanded table formatting mode. As such it is equivalent to
\pset expanded.
\z [ pattern ]
-
Lists tables, views and sequences with their associated access privileges. If a
pattern
is specified, only tables, views and sequences whose names match the pattern are listed.This is an alias for
\dp
(«display privileges»).
\! [ command ]
-
Escapes to a separate Unix shell or executes the Unix command
command. The arguments are not further interpreted; the shell will see them as-is.
\?
- Shows help information about the backslash commands.
Patterns
-
The various
\d
commands accept a
pattern
parameter to specify the object name(s) to be displayed. In the simplest case, a pattern is just the exact name of the object. The characters within a pattern are normally folded to lower case, just as in SQL names; for example,
\dt FOO
will display the table named
foo. As in SQL names, placing double quotes around a pattern stops folding to lower case. Should you need to include an actual double quote character in a pattern, write it as a pair of double quotes within a double-quote sequence; again this is in accord with the rules for SQL quoted identifiers. For example,
\dt «FOO»»BAR»
will display the table named
FOO»BAR
(not
foo»bar). Unlike the normal rules for SQL names, you can put double quotes around just part of a pattern, for instance
\dt FOO»FOO»BAR
will display the table named
fooFOObar.Whenever the
pattern
parameter is omitted completely, the
\d
commands display all objects that are visible in the current schema search path — this is equivalent to using
*
as the pattern. (An object is said to be
visible
if its containing schema is in the search path and no object of the same kind and name appears earlier in the search path. This is equivalent to the statement that the object can be referenced by name without explicit schema qualification.) To see all objects in the database regardless of visibility, use
*.*
as the pattern.Within a pattern,
*
matches any sequence of characters (including no characters) and
?
matches any single character. (This notation is comparable to Unix shell file name patterns.) For example,
\dt int*
displays tables whose names begin with
int. But within double quotes,
*
and
?
lose these special meanings and are just matched literally.A pattern that contains a dot (.) is interpreted as a schema name pattern followed by an object name pattern. For example,
\dt foo*.*bar*
displays all tables whose table name includes
bar
that are in schemas whose schema name starts with
foo. When no dot appears, then the pattern matches only objects that are visible in the current schema search path. Again, a dot within double quotes loses its special meaning and is matched literally.Advanced users can use regular-expression notations such as character classes, for example
[0-9]
to match any digit. All regular expression special characters work as specified in
Section 9.7.3, «POSIX Regular Expressions», in the documentation, except for
.
which is taken as a separator as mentioned above,
*
which is translated to the regular-expression notation
.*,
?
which is translated to
., and
$
which is matched literally. You can emulate these pattern characters at need by writing
?
for
.,
(R+|)
for
R*, or
(R|)
for
R?.
$
is not needed as a regular-expression character since the pattern must match the whole name, unlike the usual interpretation of regular expressions (in other words,
$
is automatically appended to your pattern). Write
*
at the beginning and/or end if you don’t wish the pattern to be anchored. Note that within double quotes, all regular expression special characters lose their special meanings and are matched literally. Also, the regular expression special characters are matched literally in operator name patterns (i.e., the argument of
\do).
Advanced Features
Variables
-
psql
provides variable substitution features similar to common Unix command shells. Variables are simply name/value pairs, where the value can be any string of any length. The name must consist of letters (including non-Latin letters), digits, and underscores.To set a variable, use the
psql
meta-command
\set. For example,
testdb=> \set foo bar
sets the variable
foo
to the value
bar. To retrieve the content of the variable, precede the name with a colon, for example:
-
testdb=> \echo :foo bar
This works in both regular SQL commands and meta-commands; there is more detail in
SQL Interpolation, below.
If you call
\set
without a second argument, the variable is set, with an empty string as value. To unset (i.e., delete) a variable, use the command
\unset. To show the values of all variables, call
\set
without any argument.
-
Note
The arguments of
\set
are subject to the same substitution rules as with other commands. Thus you can construct interesting references such as
\set :foo ‘something’
and get
«soft links»
or
«variable variables»
of
Perl
or
PHP
fame, respectively. Unfortunately (or fortunately?), there is no way to do anything useful with these constructs. On the other hand,
\set bar :foo
is a perfectly valid way to copy a variable.
A number of these variables are treated specially by
psql. They represent certain option settings that can be changed at run time by altering the value of the variable, or in some cases represent changeable state of
psql. Although you can use these variables for other purposes, this is not recommended, as the program behavior might grow really strange really quickly. By convention, all specially treated variables’ names consist of all upper-case ASCII letters (and possibly digits and underscores). To ensure maximum compatibility in the future, avoid using such variable names for your own purposes. A list of all specially treated variables follows.
AUTOCOMMIT
-
When
on
(the default), each SQL command is automatically committed upon successful completion. To postpone commit in this mode, you must enter a
BEGIN
or
START TRANSACTION
SQL command. When
off
or unset, SQL commands are not committed until you explicitly issue
COMMIT
or
END. The autocommit-off mode works by issuing an implicit
BEGIN
for you, just before any command that is not already in a transaction block and is not itself a
BEGIN
or other transaction-control command, nor a command that cannot be executed inside a transaction block (such as
VACUUM).-
Note
In autocommit-off mode, you must explicitly abandon any failed transaction by entering
ABORT
or
ROLLBACK. Also keep in mind that if you exit the session without committing, your work will be lost.
-
Note
The autocommit-on mode is
Postgres-XC’s traditional behavior inherited from
PostgreSQL, but autocommit-off is closer to the SQL spec. If you prefer autocommit-off, you might wish to set it in the system-wide
psqlrc
file or your
~/.psqlrc
file.
-
COMP_KEYWORD_CASE
-
Determines which letter case to use when completing an SQL key word. If set to
lower
or
upper, the completed word will be in lower or upper case, respectively. If set to
preserve-lower
or
preserve-upper
(the default), the completed word will be in the case of the word already entered, but words being completed without anything entered will be in lower or upper case, respectively.
DBNAME
- The name of the database you are currently connected to. This is set every time you connect to a database (including program start-up), but can be unset.
ECHO
-
If set to
all, all lines entered from the keyboard or from a script are written to the standard output before they are parsed or executed. To select this behavior on program start-up, use the switch
-a. If set to
queries,
psql
merely prints all queries as they are sent to the server. The switch for this is
-e.
ECHO_HIDDEN
-
When this variable is set and a backslash command queries the database, the query is first shown. This way you can study the
Postgres-XC
internals and provide similar functionality in your own programs. (To select this behavior on program start-up, use the switch
-E.) If you set the variable to the value
noexec, the queries are just shown but are not actually sent to the server and executed.
ENCODING
- The current client character set encoding.
FETCH_COUNT
-
If this variable is set to an integer value > 0, the results of
SELECT
queries are fetched and displayed in groups of that many rows, rather than the default behavior of collecting the entire result set before display. Therefore only a limited amount of memory is used, regardless of the size of the result set. Settings of 100 to 1000 are commonly used when enabling this feature. Keep in mind that when using this feature, a query might fail after having already displayed some rows.-
Tip
Although you can use any output format with this feature, the default
aligned
format tends to look bad because each group of
FETCH_COUNT
rows will be formatted separately, leading to varying column widths across the row groups. The other output formats work better.
-
HISTCONTROL
-
If this variable is set to
ignorespace, lines which begin with a space are not entered into the history list. If set to a value of
ignoredups, lines matching the previous history line are not entered. A value of
ignoreboth
combines the two options. If unset, or if set to any other value than those above, all lines read in interactive mode are saved on the history list.-
Note
This feature was shamelessly plagiarized from
Bash.
-
HISTFILE
-
The file name that will be used to store the history list. The default value is
~/.psql_history. For example, putting:-
\set HISTFILE ~/.psql_history- :DBNAME
in
~/.psqlrc
will cause
psql
to maintain a separate history for each database.-
Note
This feature was shamelessly plagiarized from
Bash.
-
HISTSIZE
-
The number of commands to store in the command history. The default value is 500.
-
Note
This feature was shamelessly plagiarized from
Bash.
-
HOST
- The database server host you are currently connected to. This is set every time you connect to a database (including program start-up), but can be unset.
IGNOREEOF
-
If unset, sending an
EOF
character (usually
Control+D) to an interactive session of
psql
will terminate the application. If set to a numeric value, that many
EOF
characters are ignored before the application terminates. If the variable is set but has no numeric value, the default is 10.-
Note
This feature was shamelessly plagiarized from
Bash.
-
LASTOID
-
The value of the last affected OID, as returned from an
INSERT
or
\lo_import
command. This variable is only guaranteed to be valid until after the result of the next
SQL
command has been displayed.
ON_ERROR_ROLLBACK
-
When
on, if a statement in a transaction block generates an error, the error is ignored and the transaction continues. When
interactive, such errors are only ignored in interactive sessions, and not when reading script files. When
off
(the default), a statement in a transaction block that generates an error aborts the entire transaction. The on_error_rollback-on mode works by issuing an implicit
SAVEPOINT
for you, just before each command that is in a transaction block, and rolls back to the savepoint on error.
ON_ERROR_STOP
-
By default, command processing continues after an error. When this variable is set, it will instead stop immediately. In interactive mode,
psql
will return to the command prompt; otherwise,
psql
will exit, returning error code 3 to distinguish this case from fatal error conditions, which are reported using error code 1. In either case, any currently running scripts (the top-level script, if any, and any other scripts which it may have in invoked) will be terminated immediately. If the top-level command string contained multiple SQL commands, processing will stop with the current command.
PORT
- The database server port to which you are currently connected. This is set every time you connect to a database (including program start-up), but can be unset.
PROMPT1, PROMPT2, PROMPT3
-
These specify what the prompts
psql
issues should look like. See
Prompting
below.
QUIET
-
This variable is equivalent to the command line option
-q. It is probably not too useful in interactive mode.
SINGLELINE
-
This variable is equivalent to the command line option
-S.
SINGLESTEP
-
This variable is equivalent to the command line option
-s.
USER
- The database user you are currently connected as. This is set every time you connect to a database (including program start-up), but can be unset.
VERBOSITY
-
This variable can be set to the values
default,
verbose, or
terse
to control the verbosity of error reports.
SQL Interpolation
-
A key feature of
psql
variables is that you can substitute («interpolate») them into regular
SQL
statements, as well as the arguments of meta-commands. Furthermore,
psql
provides facilities for ensuring that variable values used as SQL literals and identifiers are properly quoted. The syntax for interpolating a value without any quoting is to prepend the variable name with a colon (:). For example,
testdb=> \set foo 'my_table' testdb=> SELECT * FROM :foo;
would query the table
my_table. Note that this may be unsafe: the value of the variable is copied literally, so it can contain unbalanced quotes, or even backslash commands. You must make sure that it makes sense where you put it.
When a value is to be used as an SQL literal or identifier, it is safest to arrange for it to be quoted. To quote the value of a variable as an SQL literal, write a colon followed by the variable name in single quotes. To quote the value as an SQL identifier, write a colon followed by the variable name in double quotes. These constructs deal correctly with quotes and other special characters embedded within the variable value. The previous example would be more safely written this way:
-
testdb=> \set foo 'my_table' testdb=> SELECT * FROM :"foo";
Variable interpolation will not be performed within quoted
SQL
literals and identifiers. Therefore, a construction such as
‘:foo’
doesn’t work to produce a quoted literal from a variable’s value (and it would be unsafe if it did work, since it wouldn’t correctly handle quotes embedded in the value).
One example use of this mechanism is to copy the contents of a file into a table column. First load the file into a variable and then interpolate the variable’s value as a quoted string:
-
testdb=> \set content `cat my_file.txt` testdb=> INSERT INTO my_table VALUES (:'content');
(Note that this still won’t work if
my_file.txt
contains NUL bytes.
psql
does not support embedded NUL bytes in variable values.)
Since colons can legally appear in SQL commands, an apparent attempt at interpolation (that is,
:name,
:’name’, or
:»name») is not replaced unless the named variable is currently set. In any case, you can escape a colon with a backslash to protect it from substitution.
The colon syntax for variables is standard
SQL
for embedded query languages, such as
ECPG. The colon syntaxes for array slices and type casts are
Postgres-XC
extensions, which can sometimes conflict with the standard usage. The colon-quote syntax for escaping a variable’s value as an SQL literal or identifier is a
psql
extension.
Prompting
-
The prompts
psql
issues can be customized to your preference. The three variables
PROMPT1,
PROMPT2, and
PROMPT3
contain strings and special escape sequences that describe the appearance of the prompt. Prompt 1 is the normal prompt that is issued when
psql
requests a new command. Prompt 2 is issued when more input is expected during command input because the command was not terminated with a semicolon or a quote was not closed. Prompt 3 is issued when you run an
SQLCOPY
command and you are expected to type in the row values on the terminal.The value of the selected prompt variable is printed literally, except where a percent sign (%) is encountered. Depending on the next character, certain other text is substituted instead. Defined substitutions are:
%M
-
The full host name (with domain name) of the database server, or
[local]
if the connection is over a Unix domain socket, or
[local:/dir/name], if the Unix domain socket is not at the compiled in default location.
%m
-
The host name of the database server, truncated at the first dot, or
[local]
if the connection is over a Unix domain socket.
%>
- The port number at which the database server is listening.
%n
-
The database session user name. (The expansion of this value might change during a database session as the result of the command
SET SESSION AUTHORIZATION.)
%/
- The name of the current database.
%~
-
Like
%/, but the output is
~
(tilde) if the database is your default database.
%#
-
If the session user is a database superuser, then a
#, otherwise a
>. (The expansion of this value might change during a database session as the result of the command
SET SESSION AUTHORIZATION.)
%R
-
In prompt 1 normally
=, but
^
if in single-line mode, and
!
if the session is disconnected from the database (which can happen if
\connect
fails). In prompt 2 the sequence is replaced by
-,
*, a single quote, a double quote, or a dollar sign, depending on whether
psql
expects more input because the command wasn’t terminated yet, because you are inside a
/* … */
comment, or because you are inside a quoted or dollar-escaped string. In prompt 3 the sequence doesn’t produce anything.
%x
-
Transaction status: an empty string when not in a transaction block, or
*
when in a transaction block, or
!
when in a failed transaction block, or
?
when the transaction state is indeterminate (for example, because there is no connection).
%digits
- The character with the indicated octal code is substituted.
%:name:
-
The value of the
psql
variable
name. See the section
Variables
for details.
%`command`
-
The output of
command, similar to ordinary
«back-tick»
substitution.
%[ … %]
-
Prompts can contain terminal control characters which, for example, change the color, background, or style of the prompt text, or change the title of the terminal window. In order for the line editing features of
Readline
to work properly, these non-printing control characters must be designated as invisible by surrounding them with
%[
and
%]. Multiple pairs of these can occur within the prompt. For example:
-
The full host name (with domain name) of the database server, or
testdb=> \set PROMPT1 '%[%033[1;33;40m%]%n@%/%R%[%033[0m%]%# '
results in a boldfaced (1;) yellow-on-black (33;40) prompt on VT100-compatible, color-capable terminals.
To insert a percent sign into your prompt, write
%%. The default prompts are
‘%/%R%# ‘
for prompts 1 and 2, and
‘>> ‘
for prompt 3.
-
Note
This feature was shamelessly plagiarized from
tcsh.
Command-Line Editing
-
psql
supports the
Readline
library for convenient line editing and retrieval. The command history is automatically saved when
psql
exits and is reloaded when
psql
starts up. Tab-completion is also supported, although the completion logic makes no claim to be an
SQL
parser. If for some reason you do not like the tab completion, you can turn it off by putting this in a file named
.inputrc
in your home directory:
$if psql set disable-completion on $endif
(This is not a
psql
but a
Readline
feature. Read its documentation for further details.)
ENVIRONMENT
COLUMNS
-
If
\pset columns
is zero, controls the width for the
wrapped
format and width for determining if wide output requires the pager or should be switched to the vertical format in expanded auto mode.
PAGER
-
If the query results do not fit on the screen, they are piped through this command. Typical values are
more
or
less. The default is platform-dependent. The use of the pager can be disabled by using the
\pset
command.
PGDATABASE, PGHOST, PGPORT, PGUSER
-
Default connection parameters (see
Section 32.14, «Environment Variables», in the documentation).
PSQL_EDITOR, EDITOR, VISUAL
-
Editor used by the
\e
and
\ef
commands. The variables are examined in the order listed; the first that is set is used.The built-in default editors are
vi
on Unix systems and
notepad.exe
on Windows systems.
PSQL_EDITOR_LINENUMBER_ARG
-
When
\e
or
\ef
is used with a line number argument, this variable specifies the command-line argument used to pass the starting line number to the user’s editor. For editors such as
Emacs
or
vi, this is a plus sign. Include a trailing space in the value of the variable if there needs to be space between the option name and the line number. Examples:-
PSQL_EDITOR_LINENUMBER_ARG='+' PSQL_EDITOR_LINENUMBER_ARG='--line '
The default is
+
on Unix systems (corresponding to the default editor
vi, and useful for many other common editors); but there is no default on Windows systems. -
PSQL_HISTORY
- Alternative location for the command history file. Tilde (~) expansion is performed.
PSQLRC
-
Alternative location of the user’s
.psqlrc
file. Tilde (~) expansion is performed.
SHELL
-
Command executed by the
\!
command.
TMPDIR
-
Directory for storing temporary files. The default is
/tmp.
This utility, like most other
Postgres-XC
utilities, also uses the environment variables supported by
libpq
(see
Section 32.14, «Environment Variables», in the documentation).
FILES
-
•
Unless it is passed an
-X
or
-c
option,
psql
attempts to read and execute commands from the system-wide
psqlrc
file and the user’s
~/.psqlrc
file before starting up. (On Windows, the user’s startup file is named
%APPDATA%\postgresql\psqlrc.conf.) See
PREFIX/share/psqlrc.sample
for information on setting up the system-wide file. It could be used to set up the client or the server to taste (using the
\set
and
SET
commands).The location of the user’s
~/.psqlrc
file can also be set explicitly via the
PSQLRC
environment setting.
-
•
Both the system-wide
psqlrc
file and the user’s
~/.psqlrc
file can be made
psql-version-specific by appending a dash and the
Postgres-XC
major or minor
psql
release number, for example
~/.psqlrc-9.2
or
~/.psqlrc-9.2.5. The most specific version-matching file will be read in preference to a non-version-specific file.
-
•
The command-line history is stored in the file
~/.psql_history, or
%APPDATA%\postgresql\psql_history
on Windows.The location of the history file can also be set explicitly via the
PSQL_HISTORY
environment setting.
NOTES
-
•
psql
is only guaranteed to work smoothly with servers of the same version. That does not mean other combinations will fail outright, but subtle and not-so-subtle problems might come up. Backslash commands are particularly likely to fail if the server is of a newer version than
psql
itself. However, backslash commands of the
\d
family should work.
NOTES FOR WINDOWS USERS
psql
is built as a
«console application». Since the Windows console windows use a different encoding than the rest of the system, you must take special care when using 8-bit characters within
psql. If
psql
detects a problematic console code page, it will warn you at startup. To change the console code page, two things are necessary:
-
•
Set the code page by entering
cmd.exe /c chcp 1252. (1252 is a code page that is appropriate for German; replace it with your value.) If you are using Cygwin, you can put this command in
/etc/profile.
-
•
Set the console font to
Lucida Console, because the raster font does not work with the ANSI code page.
EXAMPLES
The first example shows how to spread a command over several lines of input. Notice the changing prompt:
-
testdb=> CREATE TABLE my_table ( testdb(> first integer not null default 0, testdb(> second text) testdb-> ; CREATE TABLE
Now look at the table definition again:
-
testdb=> \d my_table Table "my_table" Attribute | Type | Modifier -----------+---------+-------------------- first | integer | not null default 0 second | text |
Now we change the prompt to something more interesting:
-
testdb=> \set PROMPT1 '%n@%m %~%R%# ' peter@localhost testdb=>
Let’s assume you have filled the table with data and want to take a look at it:
-
peter@localhost testdb=> SELECT * FROM my_table; first | second -------+-------- 1 | one 2 | two 3 | three 4 | four (4 rows)
You can display tables in different ways by using the
\pset
command:
-
peter@localhost testdb=> \pset border 2 Border style is 2. peter@localhost testdb=> SELECT * FROM my_table; +-------+--------+ | first | second | +-------+--------+ | 1 | one | | 2 | two | | 3 | three | | 4 | four | +-------+--------+ (4 rows) peter@localhost testdb=> \pset border 0 Border style is 0. peter@localhost testdb=> SELECT * FROM my_table; first second ----- ------ 1 one 2 two 3 three 4 four (4 rows) peter@localhost testdb=> \pset border 1 Border style is 1. peter@localhost testdb=> \pset format unaligned Output format is unaligned. peter@localhost testdb=> \pset fieldsep "," Field separator is ",". peter@localhost testdb=> \pset tuples_only Showing only tuples. peter@localhost testdb=> SELECT second, first FROM my_table; one,1 two,2 three,3 four,4
Alternatively, use the short commands:
-
peter@localhost testdb=> \a \t \x Output format is aligned. Tuples only is off. Expanded display is on. peter@localhost testdb=> SELECT * FROM my_table; -[ RECORD 1 ]- first | 1 second | one -[ RECORD 2 ]- first | 2 second | two -[ RECORD 3 ]- first | 3 second | three -[ RECORD 4 ]- first | 4 second | four
psql — PostgreSQL interactive terminal
Synopsis
psql [option…] [dbname [username]]
Description
psql is a terminal-based front-end to PostgreSQL. It enables you to type in queries interactively, issue them to PostgreSQL, and see the query results. Alternatively, input can be from a file or from command line arguments. In addition, psql provides a number of meta-commands and various shell-like features to facilitate writing scripts and automating a wide variety of tasks.
Options
-
-a
--echo-all -
Print all nonempty input lines to standard output as they are read. (This does not apply to lines read interactively.) This is equivalent to setting the variable
ECHOtoall. -
-A
--no-align -
Switches to unaligned output mode. (The default output mode is
aligned.) This is equivalent to\pset format unaligned. -
-b
--echo-errors -
Print failed SQL commands to standard error output. This is equivalent to setting the variable
ECHOtoerrors. -
-c command
--command=command -
Specifies that psql is to execute the given command string,
command. This option can be repeated and combined in any order with the-foption. When either-cor-fis specified, psql does not read commands from standard input; instead it terminates after processing all the-cand-foptions in sequence.commandmust be either a command string that is completely parsable by the server (i.e., it contains no psql-specific features), or a single backslash command. Thus you cannot mix SQL and psql meta-commands within a-coption. To achieve that, you could use repeated-coptions or pipe the string into psql, for example:psql -c '\x' -c 'SELECT * FROM foo;'
or
echo '\x \\ SELECT * FROM foo;' | psql
(
\\is the separator meta-command.)Each SQL command string passed to
-cis sent to the server as a single request. Because of this, the server executes it as a single transaction even if the string contains multiple SQL commands, unless there are explicitBEGIN/COMMITcommands included in the string to divide it into multiple transactions. (See Section 53.2.2.1 for more details about how the server handles multi-query strings.) Also, psql only prints the result of the last SQL command in the string. This is different from the behavior when the same string is read from a file or fed to psql’s standard input, because then psql sends each SQL command separately.Because of this behavior, putting more than one SQL command in a single
-cstring often has unexpected results. It’s better to use repeated-ccommands or feed multiple commands to psql’s standard input, either using echo as illustrated above, or via a shell here-document, for example:psql <<EOF \x SELECT * FROM foo; EOF
-
--csv -
Switches to CSV (Comma-Separated Values) output mode. This is equivalent to
\pset format csv. -
-d dbname
--dbname=dbname -
Specifies the name of the database to connect to. This is equivalent to specifying
dbnameas the first non-option argument on the command line. Thedbnamecan be a connection string. If so, connection string parameters will override any conflicting command line options. -
-e
--echo-queries -
Copy all SQL commands sent to the server to standard output as well. This is equivalent to setting the variable
ECHOtoqueries. -
-E
--echo-hidden -
Echo the actual queries generated by
\dand other backslash commands. You can use this to study psql’s internal operations. This is equivalent to setting the variableECHO_HIDDENtoon. -
-f filename
--file=filename -
Read commands from the file
filename, rather than standard input. This option can be repeated and combined in any order with the-coption. When either-cor-fis specified, psql does not read commands from standard input; instead it terminates after processing all the-cand-foptions in sequence. Except for that, this option is largely equivalent to the meta-command\i.If
filenameis-(hyphen), then standard input is read until an EOF indication or\qmeta-command. This can be used to intersperse interactive input with input from files. Note however that Readline is not used in this case (much as if-nhad been specified).Using this option is subtly different from writing
psql < filename. In general, both will do what you expect, but using-fenables some nice features such as error messages with line numbers. There is also a slight chance that using this option will reduce the start-up overhead. On the other hand, the variant using the shell’s input redirection is (in theory) guaranteed to yield exactly the same output you would have received had you entered everything by hand. -
-F separator
--field-separator=separator -
Use
separatoras the field separator for unaligned output. This is equivalent to\pset fieldsepor\f. -
-h hostname
--host=hostname -
Specifies the host name of the machine on which the server is running. If the value begins with a slash, it is used as the directory for the Unix-domain socket.
-
-H
--html -
Switches to HTML output mode. This is equivalent to
\pset format htmlor the\Hcommand. -
-l
--list -
List all available databases, then exit. Other non-connection options are ignored. This is similar to the meta-command
\list.When this option is used, psql will connect to the database
postgres, unless a different database is named on the command line (option-dor non-option argument, possibly via a service entry, but not via an environment variable). -
-L filename
--log-file=filename -
Write all query output into file
filename, in addition to the normal output destination. -
-n
--no-readline -
Do not use Readline for line editing and do not use the command history. This can be useful to turn off tab expansion when cutting and pasting.
-
-o filename
--output=filename -
Put all query output into file
filename. This is equivalent to the command\o. -
-p port
--port=port -
Specifies the TCP port or the local Unix-domain socket file extension on which the server is listening for connections. Defaults to the value of the
PGPORTenvironment variable or, if not set, to the port specified at compile time, usually 5432. -
-P assignment
--pset=assignment -
Specifies printing options, in the style of
\pset. Note that here you have to separate name and value with an equal sign instead of a space. For example, to set the output format to LaTeX, you could write-P format=latex. -
-q
--quiet -
Specifies that psql should do its work quietly. By default, it prints welcome messages and various informational output. If this option is used, none of this happens. This is useful with the
-coption. This is equivalent to setting the variableQUIETtoon. -
-R separator
--record-separator=separator -
Use
separatoras the record separator for unaligned output. This is equivalent to\pset recordsep. -
-s
--single-step -
Run in single-step mode. That means the user is prompted before each command is sent to the server, with the option to cancel execution as well. Use this to debug scripts.
-
-S
--single-line -
Runs in single-line mode where a newline terminates an SQL command, as a semicolon does.
Note
This mode is provided for those who insist on it, but you are not necessarily encouraged to use it. In particular, if you mix SQL and meta-commands on a line the order of execution might not always be clear to the inexperienced user.
-
-t
--tuples-only -
Turn off printing of column names and result row count footers, etc. This is equivalent to
\tor\pset tuples_only. -
-T table_options
--table-attr=table_options -
Specifies options to be placed within the HTML
tabletag. See\pset tableattrfor details. -
-U username
--username=username -
Connect to the database as the user
usernameinstead of the default. (You must have permission to do so, of course.) -
-v assignment
--set=assignment
--variable=assignment -
Perform a variable assignment, like the
\setmeta-command. Note that you must separate name and value, if any, by an equal sign on the command line. To unset a variable, leave off the equal sign. To set a variable with an empty value, use the equal sign but leave off the value. These assignments are done during command line processing, so variables that reflect connection state will get overwritten later. -
-V
--version -
Print the psql version and exit.
-
-w
--no-password -
Never issue a password prompt. If the server requires password authentication and a password is not available from other sources such as a
.pgpassfile, the connection attempt will fail. This option can be useful in batch jobs and scripts where no user is present to enter a password.Note that this option will remain set for the entire session, and so it affects uses of the meta-command
\connectas well as the initial connection attempt. -
-W
--password -
Force psql to prompt for a password before connecting to a database, even if the password will not be used.
If the server requires password authentication and a password is not available from other sources such as a
.pgpassfile, psql will prompt for a password in any case. However, psql will waste a connection attempt finding out that the server wants a password. In some cases it is worth typing-Wto avoid the extra connection attempt.Note that this option will remain set for the entire session, and so it affects uses of the meta-command
\connectas well as the initial connection attempt. -
-x
--expanded -
Turn on the expanded table formatting mode. This is equivalent to
\xor\pset expanded. -
-X,
--no-psqlrc -
Do not read the start-up file (neither the system-wide
psqlrcfile nor the user’s~/.psqlrcfile). -
-z
--field-separator-zero -
Set the field separator for unaligned output to a zero byte. This is equivalent to
\pset fieldsep_zero. -
-0
--record-separator-zero -
Set the record separator for unaligned output to a zero byte. This is useful for interfacing, for example, with
xargs -0. This is equivalent to\pset recordsep_zero. -
-1
--single-transaction -
This option can only be used in combination with one or more
-cand/or-foptions. It causes psql to issue aBEGINcommand before the first such option and aCOMMITcommand after the last one, thereby wrapping all the commands into a single transaction. This ensures that either all the commands complete successfully, or no changes are applied.If the commands themselves contain
BEGIN,COMMIT, orROLLBACK, this option will not have the desired effects. Also, if an individual command cannot be executed inside a transaction block, specifying this option will cause the whole transaction to fail. -
-?
--help[=topic] -
Show help about psql and exit. The optional
topicparameter (defaulting tooptions) selects which part of psql is explained:commandsdescribes psql’s backslash commands;optionsdescribes the command-line options that can be passed to psql; andvariablesshows help about psql configuration variables.
Exit Status
psql returns 0 to the shell if it finished normally, 1 if a fatal error of its own occurs (e.g., out of memory, file not found), 2 if the connection to the server went bad and the session was not interactive, and 3 if an error occurred in a script and the variable ON_ERROR_STOP was set.
Usage
Connecting to a Database
psql is a regular PostgreSQL client application. In order to connect to a database you need to know the name of your target database, the host name and port number of the server, and what user name you want to connect as. psql can be told about those parameters via command line options, namely -d, -h, -p, and -U respectively. If an argument is found that does not belong to any option it will be interpreted as the database name (or the user name, if the database name is already given). Not all of these options are required; there are useful defaults. If you omit the host name, psql will connect via a Unix-domain socket to a server on the local host, or via TCP/IP to localhost on machines that don’t have Unix-domain sockets. The default port number is determined at compile time. Since the database server uses the same default, you will not have to specify the port in most cases. The default user name is your operating-system user name, as is the default database name. Note that you cannot just connect to any database under any user name. Your database administrator should have informed you about your access rights.
When the defaults aren’t quite right, you can save yourself some typing by setting the environment variables PGDATABASE, PGHOST, PGPORT and/or PGUSER to appropriate values. (For additional environment variables, see Section 34.15.) It is also convenient to have a ~/.pgpass file to avoid regularly having to type in passwords. See Section 34.16 for more information.
An alternative way to specify connection parameters is in a conninfo string or a URI, which is used instead of a database name. This mechanism give you very wide control over the connection. For example:
$ psql "service=myservice sslmode=require" $ psql postgresql://dbmaster:5433/mydb?sslmode=require
This way you can also use LDAP for connection parameter lookup as described in Section 34.18. See Section 34.1.2 for more information on all the available connection options.
If the connection could not be made for any reason (e.g., insufficient privileges, server is not running on the targeted host, etc.), psql will return an error and terminate.
If both standard input and standard output are a terminal, then psql sets the client encoding to “auto”, which will detect the appropriate client encoding from the locale settings (LC_CTYPE environment variable on Unix systems). If this doesn’t work out as expected, the client encoding can be overridden using the environment variable PGCLIENTENCODING.
Entering SQL Commands
In normal operation, psql provides a prompt with the name of the database to which psql is currently connected, followed by the string =>. For example:
$ psql testdb psql (14.3) Type "help" for help. testdb=>
At the prompt, the user can type in SQL commands. Ordinarily, input lines are sent to the server when a command-terminating semicolon is reached. An end of line does not terminate a command. Thus commands can be spread over several lines for clarity. If the command was sent and executed without error, the results of the command are displayed on the screen.
If untrusted users have access to a database that has not adopted a secure schema usage pattern, begin your session by removing publicly-writable schemas from search_path. One can add options=-csearch_path= to the connection string or issue SELECT pg_catalog.set_config('search_path', '', false) before other SQL commands. This consideration is not specific to psql; it applies to every interface for executing arbitrary SQL commands.
Whenever a command is executed, psql also polls for asynchronous notification events generated by LISTEN and NOTIFY.
While C-style block comments are passed to the server for processing and removal, SQL-standard comments are removed by psql.
Advanced Features
Variables
psql provides variable substitution features similar to common Unix command shells. Variables are simply name/value pairs, where the value can be any string of any length. The name must consist of letters (including non-Latin letters), digits, and underscores.
To set a variable, use the psql meta-command \set. For example,
testdb=> \set foo bar
sets the variable foo to the value bar. To retrieve the content of the variable, precede the name with a colon, for example:
testdb=> \echo :foo bar
This works in both regular SQL commands and meta-commands; there is more detail in SQL Interpolation, below.
If you call \set without a second argument, the variable is set to an empty-string value. To unset (i.e., delete) a variable, use the command \unset. To show the values of all variables, call \set without any argument.
Note
The arguments of
\setare subject to the same substitution rules as with other commands. Thus you can construct interesting references such as\set :foo 'something'and get “soft links” or “variable variables” of Perl or PHP fame, respectively. Unfortunately (or fortunately?), there is no way to do anything useful with these constructs. On the other hand,\set bar :foois a perfectly valid way to copy a variable.
A number of these variables are treated specially by psql. They represent certain option settings that can be changed at run time by altering the value of the variable, or in some cases represent changeable state of psql. By convention, all specially treated variables’ names consist of all upper-case ASCII letters (and possibly digits and underscores). To ensure maximum compatibility in the future, avoid using such variable names for your own purposes.
Variables that control psql’s behavior generally cannot be unset or set to invalid values. An \unset command is allowed but is interpreted as setting the variable to its default value. A \set command without a second argument is interpreted as setting the variable to on, for control variables that accept that value, and is rejected for others. Also, control variables that accept the values on and off will also accept other common spellings of Boolean values, such as true and false.
The specially treated variables are:
-
AUTOCOMMIT -
When
on(the default), each SQL command is automatically committed upon successful completion. To postpone commit in this mode, you must enter aBEGINorSTART TRANSACTIONSQL command. Whenoffor unset, SQL commands are not committed until you explicitly issueCOMMITorEND. The autocommit-off mode works by issuing an implicitBEGINfor you, just before any command that is not already in a transaction block and is not itself aBEGINor other transaction-control command, nor a command that cannot be executed inside a transaction block (such asVACUUM).Note
In autocommit-off mode, you must explicitly abandon any failed transaction by entering
ABORTorROLLBACK. Also keep in mind that if you exit the session without committing, your work will be lost.Note
The autocommit-on mode is PostgreSQL’s traditional behavior, but autocommit-off is closer to the SQL spec. If you prefer autocommit-off, you might wish to set it in the system-wide
psqlrcfile or your~/.psqlrcfile. -
COMP_KEYWORD_CASE -
Determines which letter case to use when completing an SQL key word. If set to
lowerorupper, the completed word will be in lower or upper case, respectively. If set topreserve-lowerorpreserve-upper(the default), the completed word will be in the case of the word already entered, but words being completed without anything entered will be in lower or upper case, respectively. -
DBNAME -
The name of the database you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
-
ECHO -
If set to
all, all nonempty input lines are printed to standard output as they are read. (This does not apply to lines read interactively.) To select this behavior on program start-up, use the switch-a. If set toqueries, psql prints each query to standard output as it is sent to the server. The switch to select this behavior is-e. If set toerrors, then only failed queries are displayed on standard error output. The switch for this behavior is-b. If set tonone(the default), then no queries are displayed. -
ECHO_HIDDEN -
When this variable is set to
onand a backslash command queries the database, the query is first shown. This feature helps you to study PostgreSQL internals and provide similar functionality in your own programs. (To select this behavior on program start-up, use the switch-E.) If you set this variable to the valuenoexec, the queries are just shown but are not actually sent to the server and executed. The default value isoff. -
ENCODING -
The current client character set encoding. This is set every time you connect to a database (including program start-up), and when you change the encoding with
\encoding, but it can be changed or unset. -
ERROR -
trueif the last SQL query failed,falseif it succeeded. See alsoSQLSTATE. -
FETCH_COUNT -
If this variable is set to an integer value greater than zero, the results of
SELECTqueries are fetched and displayed in groups of that many rows, rather than the default behavior of collecting the entire result set before display. Therefore only a limited amount of memory is used, regardless of the size of the result set. Settings of 100 to 1000 are commonly used when enabling this feature. Keep in mind that when using this feature, a query might fail after having already displayed some rows.Tip
Although you can use any output format with this feature, the default
alignedformat tends to look bad because each group ofFETCH_COUNTrows will be formatted separately, leading to varying column widths across the row groups. The other output formats work better. -
HIDE_TABLEAM -
If this variable is set to
true, a table’s access method details are not displayed. This is mainly useful for regression tests. -
HIDE_TOAST_COMPRESSION -
If this variable is set to
true, column compression method details are not displayed. This is mainly useful for regression tests. -
HISTCONTROL -
If this variable is set to
ignorespace, lines which begin with a space are not entered into the history list. If set to a value ofignoredups, lines matching the previous history line are not entered. A value ofignorebothcombines the two options. If set tonone(the default), all lines read in interactive mode are saved on the history list.Note
This feature was shamelessly plagiarized from Bash.
-
HISTFILE -
The file name that will be used to store the history list. If unset, the file name is taken from the
PSQL_HISTORYenvironment variable. If that is not set either, the default is~/.psql_history, or%APPDATA%\postgresql\psql_historyon Windows. For example, putting:\set HISTFILE ~/.psql_history-:DBNAME
in
~/.psqlrcwill cause psql to maintain a separate history for each database.Note
This feature was shamelessly plagiarized from Bash.
-
HISTSIZE -
The maximum number of commands to store in the command history (default 500). If set to a negative value, no limit is applied.
Note
This feature was shamelessly plagiarized from Bash.
-
HOST -
The database server host you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
-
IGNOREEOF -
If set to 1 or less, sending an EOF character (usually Control+D) to an interactive session of psql will terminate the application. If set to a larger numeric value, that many consecutive EOF characters must be typed to make an interactive session terminate. If the variable is set to a non-numeric value, it is interpreted as 10. The default is 0.
Note
This feature was shamelessly plagiarized from Bash.
-
LASTOID -
The value of the last affected OID, as returned from an
INSERTor\lo_importcommand. This variable is only guaranteed to be valid until after the result of the next SQL command has been displayed. PostgreSQL servers since version 12 do not support OID system columns anymore, thus LASTOID will always be 0 followingINSERTwhen targeting such servers. -
LAST_ERROR_MESSAGE
LAST_ERROR_SQLSTATE -
The primary error message and associated SQLSTATE code for the most recent failed query in the current psql session, or an empty string and
00000if no error has occurred in the current session. -
ON_ERROR_ROLLBACK -
When set to
on, if a statement in a transaction block generates an error, the error is ignored and the transaction continues. When set tointeractive, such errors are only ignored in interactive sessions, and not when reading script files. When set tooff(the default), a statement in a transaction block that generates an error aborts the entire transaction. The error rollback mode works by issuing an implicitSAVEPOINTfor you, just before each command that is in a transaction block, and then rolling back to the savepoint if the command fails. -
ON_ERROR_STOP -
By default, command processing continues after an error. When this variable is set to
on, processing will instead stop immediately. In interactive mode, psql will return to the command prompt; otherwise, psql will exit, returning error code 3 to distinguish this case from fatal error conditions, which are reported using error code 1. In either case, any currently running scripts (the top-level script, if any, and any other scripts which it may have in invoked) will be terminated immediately. If the top-level command string contained multiple SQL commands, processing will stop with the current command. -
PORT -
The database server port to which you are currently connected. This is set every time you connect to a database (including program start-up), but can be changed or unset.
-
PROMPT1
PROMPT2
PROMPT3 -
These specify what the prompts psql issues should look like. See Prompting below.
-
QUIET -
Setting this variable to
onis equivalent to the command line option-q. It is probably not too useful in interactive mode. -
ROW_COUNT -
The number of rows returned or affected by the last SQL query, or 0 if the query failed or did not report a row count.
-
SERVER_VERSION_NAME
SERVER_VERSION_NUM -
The server’s version number as a string, for example
9.6.2,10.1or11beta1, and in numeric form, for example90602or100001. These are set every time you connect to a database (including program start-up), but can be changed or unset. -
SHOW_CONTEXT -
This variable can be set to the values
never,errors, oralwaysto control whetherCONTEXTfields are displayed in messages from the server. The default iserrors(meaning that context will be shown in error messages, but not in notice or warning messages). This setting has no effect whenVERBOSITYis set toterseorsqlstate. (See also\errverbose, for use when you want a verbose version of the error you just got.) -
SINGLELINE -
Setting this variable to
onis equivalent to the command line option-S. -
SINGLESTEP -
Setting this variable to
onis equivalent to the command line option-s. -
SQLSTATE -
The error code (see Appendix A) associated with the last SQL query’s failure, or
00000if it succeeded. -
USER -
The database user you are currently connected as. This is set every time you connect to a database (including program start-up), but can be changed or unset.
-
VERBOSITY -
This variable can be set to the values
default,verbose,terse, orsqlstateto control the verbosity of error reports. (See also\errverbose, for use when you want a verbose version of the error you just got.) -
VERSION
VERSION_NAME
VERSION_NUM -
These variables are set at program start-up to reflect psql’s version, respectively as a verbose string, a short string (e.g.,
9.6.2,10.1, or11beta1), and a number (e.g.,90602or100001). They can be changed or unset.
SQL Interpolation
A key feature of psql variables is that you can substitute (“interpolate”) them into regular SQL statements, as well as the arguments of meta-commands. Furthermore, psql provides facilities for ensuring that variable values used as SQL literals and identifiers are properly quoted. The syntax for interpolating a value without any quoting is to prepend the variable name with a colon (:). For example,
testdb=> \set foo 'my_table' testdb=> SELECT * FROM :foo;
would query the table my_table. Note that this may be unsafe: the value of the variable is copied literally, so it can contain unbalanced quotes, or even backslash commands. You must make sure that it makes sense where you put it.
When a value is to be used as an SQL literal or identifier, it is safest to arrange for it to be quoted. To quote the value of a variable as an SQL literal, write a colon followed by the variable name in single quotes. To quote the value as an SQL identifier, write a colon followed by the variable name in double quotes. These constructs deal correctly with quotes and other special characters embedded within the variable value. The previous example would be more safely written this way:
testdb=> \set foo 'my_table' testdb=> SELECT * FROM :"foo";
Variable interpolation will not be performed within quoted SQL literals and identifiers. Therefore, a construction such as ':foo' doesn’t work to produce a quoted literal from a variable’s value (and it would be unsafe if it did work, since it wouldn’t correctly handle quotes embedded in the value).
One example use of this mechanism is to copy the contents of a file into a table column. First load the file into a variable and then interpolate the variable’s value as a quoted string:
testdb=> \set content `cat my_file.txt` testdb=> INSERT INTO my_table VALUES (:'content');
(Note that this still won’t work if my_file.txt contains NUL bytes. psql does not support embedded NUL bytes in variable values.)
Since colons can legally appear in SQL commands, an apparent attempt at interpolation (that is, :name, :'name', or :"name") is not replaced unless the named variable is currently set. In any case, you can escape a colon with a backslash to protect it from substitution.
The :{?name} special syntax returns TRUE or FALSE depending on whether the variable exists or not, and is thus always substituted, unless the colon is backslash-escaped.
The colon syntax for variables is standard SQL for embedded query languages, such as ECPG. The colon syntaxes for array slices and type casts are PostgreSQL extensions, which can sometimes conflict with the standard usage. The colon-quote syntax for escaping a variable’s value as an SQL literal or identifier is a psql extension.
Prompting
The prompts psql issues can be customized to your preference. The three variables PROMPT1, PROMPT2, and PROMPT3 contain strings and special escape sequences that describe the appearance of the prompt. Prompt 1 is the normal prompt that is issued when psql requests a new command. Prompt 2 is issued when more input is expected during command entry, for example because the command was not terminated with a semicolon or a quote was not closed. Prompt 3 is issued when you are running an SQL COPY FROM STDIN command and you need to type in a row value on the terminal.
The value of the selected prompt variable is printed literally, except where a percent sign (%) is encountered. Depending on the next character, certain other text is substituted instead. Defined substitutions are:
-
%M -
The full host name (with domain name) of the database server, or
[local]if the connection is over a Unix domain socket, or[local:/dir/name], if the Unix domain socket is not at the compiled in default location. -
%m -
The host name of the database server, truncated at the first dot, or
[local]if the connection is over a Unix domain socket. -
%> -
The port number at which the database server is listening.
-
%n -
The database session user name. (The expansion of this value might change during a database session as the result of the command
SET SESSION AUTHORIZATION.) -
%/ -
The name of the current database.
-
%~ -
Like
%/, but the output is~(tilde) if the database is your default database. -
%# -
If the session user is a database superuser, then a
#, otherwise a>. (The expansion of this value might change during a database session as the result of the commandSET SESSION AUTHORIZATION.) -
%p -
The process ID of the backend currently connected to.
-
%R -
In prompt 1 normally
=, but@if the session is in an inactive branch of a conditional block, or^if in single-line mode, or!if the session is disconnected from the database (which can happen if\connectfails). In prompt 2%Ris replaced by a character that depends on why psql expects more input:-if the command simply wasn’t terminated yet, but*if there is an unfinished/* ... */comment, a single quote if there is an unfinished quoted string, a double quote if there is an unfinished quoted identifier, a dollar sign if there is an unfinished dollar-quoted string, or(if there is an unmatched left parenthesis. In prompt 3%Rdoesn’t produce anything. -
%x -
Transaction status: an empty string when not in a transaction block, or
*when in a transaction block, or!when in a failed transaction block, or?when the transaction state is indeterminate (for example, because there is no connection). -
%l -
The line number inside the current statement, starting from
1. -
%
digits -
The character with the indicated octal code is substituted.
-
%:
name
: -
The value of the psql variable
name. See Variables, above, for details. -
%`
command
` -
The output of
command, similar to ordinary “back-tick” substitution. -
%[…
%] -
Prompts can contain terminal control characters which, for example, change the color, background, or style of the prompt text, or change the title of the terminal window. In order for the line editing features of Readline to work properly, these non-printing control characters must be designated as invisible by surrounding them with
%[and%]. Multiple pairs of these can occur within the prompt. For example:testdb=> \set PROMPT1 '%[%033[1;33;40m%]%n@%/%R%[%033[0m%]%# '
results in a boldfaced (
1;) yellow-on-black (33;40) prompt on VT100-compatible, color-capable terminals. -
%w -
Whitespace of the same width as the most recent output of
PROMPT1. This can be used as aPROMPT2setting, so that multi-line statements are aligned with the first line, but there is no visible secondary prompt.
To insert a percent sign into your prompt, write %%. The default prompts are '%/%R%x%# ' for prompts 1 and 2, and '>> ' for prompt 3.
Note
This feature was shamelessly plagiarized from tcsh.
Command-Line Editing
psql supports the Readline library for convenient line editing and retrieval. The command history is automatically saved when psql exits and is reloaded when psql starts up. Tab-completion is also supported, although the completion logic makes no claim to be an SQL parser. The queries generated by tab-completion can also interfere with other SQL commands, e.g., SET TRANSACTION ISOLATION LEVEL. If for some reason you do not like the tab completion, you can turn it off by putting this in a file named .inputrc in your home directory:
$if psql set disable-completion on $endif
(This is not a psql but a Readline feature. Read its documentation for further details.)
Environment
-
COLUMNS -
If
\pset columnsis zero, controls the width for thewrappedformat and width for determining if wide output requires the pager or should be switched to the vertical format in expanded auto mode. -
PGDATABASE
PGHOST
PGPORT
PGUSER -
Default connection parameters (see Section 34.15).
-
PG_COLOR -
Specifies whether to use color in diagnostic messages. Possible values are
always,autoandnever. -
PSQL_EDITOR
EDITOR
VISUAL -
Editor used by the
\e,\ef, and\evcommands. These variables are examined in the order listed; the first that is set is used. If none of them is set, the default is to usevion Unix systems ornotepad.exeon Windows systems. -
PSQL_EDITOR_LINENUMBER_ARG -
When
\e,\ef, or\evis used with a line number argument, this variable specifies the command-line argument used to pass the starting line number to the user’s editor. For editors such as Emacs or vi, this is a plus sign. Include a trailing space in the value of the variable if there needs to be space between the option name and the line number. Examples:PSQL_EDITOR_LINENUMBER_ARG='+' PSQL_EDITOR_LINENUMBER_ARG='--line '
The default is
+on Unix systems (corresponding to the default editorvi, and useful for many other common editors); but there is no default on Windows systems. -
PSQL_HISTORY -
Alternative location for the command history file. Tilde (
~) expansion is performed. -
PSQL_PAGER
PAGER -
If a query’s results do not fit on the screen, they are piped through this command. Typical values are
moreorless. Use of the pager can be disabled by settingPSQL_PAGERorPAGERto an empty string, or by adjusting the pager-related options of the\psetcommand. These variables are examined in the order listed; the first that is set is used. If none of them is set, the default is to usemoreon most platforms, butlesson Cygwin. -
PSQLRC -
Alternative location of the user’s
.psqlrcfile. Tilde (~) expansion is performed. -
SHELL -
Command executed by the
\!command. -
TMPDIR -
Directory for storing temporary files. The default is
/tmp.
This utility, like most other PostgreSQL utilities, also uses the environment variables supported by libpq (see Section 34.15).
Files
-
psqlrcand
~/.psqlrc -
Unless it is passed an
-Xoption, psql attempts to read and execute commands from the system-wide startup file (psqlrc) and then the user’s personal startup file (~/.psqlrc), after connecting to the database but before accepting normal commands. These files can be used to set up the client and/or the server to taste, typically with\setandSETcommands.The system-wide startup file is named
psqlrcand is sought in the installation’s “system configuration” directory, which is most reliably identified by runningpg_config --sysconfdir. By default this directory will be../etc/relative to the directory containing the PostgreSQL executables. The name of this directory can be set explicitly via thePGSYSCONFDIRenvironment variable.The user’s personal startup file is named
.psqlrcand is sought in the invoking user’s home directory. On Windows, which lacks such a concept, the personal startup file is named%APPDATA%\postgresql\psqlrc.conf. The location of the user’s startup file can be set explicitly via thePSQLRCenvironment variable.Both the system-wide startup file and the user’s personal startup file can be made psql-version-specific by appending a dash and the PostgreSQL major or minor release number to the file name, for example
~/.psqlrc-9.2or~/.psqlrc-9.2.5. The most specific version-matching file will be read in preference to a non-version-specific file. -
.psql_history -
The command-line history is stored in the file
~/.psql_history, or%APPDATA%\postgresql\psql_historyon Windows.The location of the history file can be set explicitly via the
HISTFILEpsql variable or thePSQL_HISTORYenvironment variable.
Notes
-
psql works best with servers of the same or an older major version. Backslash commands are particularly likely to fail if the server is of a newer version than psql itself. However, backslash commands of the
\dfamily should work with servers of versions back to 7.4, though not necessarily with servers newer than psql itself. The general functionality of running SQL commands and displaying query results should also work with servers of a newer major version, but this cannot be guaranteed in all cases.If you want to use psql to connect to several servers of different major versions, it is recommended that you use the newest version of psql. Alternatively, you can keep around a copy of psql from each major version and be sure to use the version that matches the respective server. But in practice, this additional complication should not be necessary.
-
Before PostgreSQL 9.6, the
-coption implied-X(--no-psqlrc); this is no longer the case. -
Before PostgreSQL 8.4, psql allowed the first argument of a single-letter backslash command to start directly after the command, without intervening whitespace. Now, some whitespace is required.
Notes for Windows Users
psql is built as a “console application”. Since the Windows console windows use a different encoding than the rest of the system, you must take special care when using 8-bit characters within psql. If psql detects a problematic console code page, it will warn you at startup. To change the console code page, two things are necessary:
-
Set the code page by entering
cmd.exe /c chcp 1252. (1252 is a code page that is appropriate for German; replace it with your value.) If you are using Cygwin, you can put this command in/etc/profile. -
Set the console font to
Lucida Console, because the raster font does not work with the ANSI code page.
Examples
The first example shows how to spread a command over several lines of input. Notice the changing prompt:
testdb=> CREATE TABLE my_table ( testdb(> first integer not null default 0, testdb(> second text) testdb-> ; CREATE TABLE
Now look at the table definition again:
testdb=> \d my_table
Table "public.my_table"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
first | integer | | not null | 0
second | text | | |
Now we change the prompt to something more interesting:
testdb=> \set PROMPT1 '%n@%m %~%R%# ' peter@localhost testdb=>
Let’s assume you have filled the table with data and want to take a look at it:
peter@localhost testdb=> SELECT * FROM my_table;
first | second
-------+--------
1 | one
2 | two
3 | three
4 | four
(4 rows)
You can display tables in different ways by using the \pset command:
peter@localhost testdb=> \pset border 2
Border style is 2.
peter@localhost testdb=> SELECT * FROM my_table;
+-------+--------+
| first | second |
+-------+--------+
| 1 | one |
| 2 | two |
| 3 | three |
| 4 | four |
+-------+--------+
(4 rows)
peter@localhost testdb=> \pset border 0
Border style is 0.
peter@localhost testdb=> SELECT * FROM my_table;
first second
----- ------
1 one
2 two
3 three
4 four
(4 rows)
peter@localhost testdb=> \pset border 1
Border style is 1.
peter@localhost testdb=> \pset format csv
Output format is csv.
peter@localhost testdb=> \pset tuples_only
Tuples only is on.
peter@localhost testdb=> SELECT second, first FROM my_table;
one,1
two,2
three,3
four,4
peter@localhost testdb=> \pset format unaligned
Output format is unaligned.
peter@localhost testdb=> \pset fieldsep '\t'
Field separator is " ".
peter@localhost testdb=> SELECT second, first FROM my_table;
one 1
two 2
three 3
four 4
Alternatively, use the short commands:
peter@localhost testdb=> \a \t \x Output format is aligned. Tuples only is off. Expanded display is on. peter@localhost testdb=> SELECT * FROM my_table; -[ RECORD 1 ]- first | 1 second | one -[ RECORD 2 ]- first | 2 second | two -[ RECORD 3 ]- first | 3 second | three -[ RECORD 4 ]- first | 4 second | four
Also, these output format options can be set for just one query by using \g:
peter@localhost testdb=> SELECT * FROM my_table peter@localhost testdb-> \g (format=aligned tuples_only=off expanded=on) -[ RECORD 1 ]- first | 1 second | one -[ RECORD 2 ]- first | 2 second | two -[ RECORD 3 ]- first | 3 second | three -[ RECORD 4 ]- first | 4 second | four
Here is an example of using the \df command to find only functions with names matching int*pl and whose second argument is of type bigint:
testdb=> \df int*pl * bigint
List of functions
Schema | Name | Result data type | Argument data types | Type
------------+---------+------------------+---------------------+------
pg_catalog | int28pl | bigint | smallint, bigint | func
pg_catalog | int48pl | bigint | integer, bigint | func
pg_catalog | int8pl | bigint | bigint, bigint | func
(3 rows)
When suitable, query results can be shown in a crosstab representation with the \crosstabview command:
testdb=> SELECT first, second, first > 2 AS gt2 FROM my_table;
first | second | gt2
-------+--------+-----
1 | one | f
2 | two | f
3 | three | t
4 | four | t
(4 rows)
testdb=> \crosstabview first second
first | one | two | three | four
-------+-----+-----+-------+------
1 | f | | |
2 | | f | |
3 | | | t |
4 | | | | t
(4 rows)
This second example shows a multiplication table with rows sorted in reverse numerical order and columns with an independent, ascending numerical order.
testdb=> SELECT t1.first as "A", t2.first+100 AS "B", t1.first*(t2.first+100) as "AxB", testdb(> row_number() over(order by t2.first) AS ord testdb(> FROM my_table t1 CROSS JOIN my_table t2 ORDER BY 1 DESC testdb(> \crosstabview "A" "B" "AxB" ord A | 101 | 102 | 103 | 104 ---+-----+-----+-----+----- 4 | 404 | 408 | 412 | 416 3 | 303 | 306 | 309 | 312 2 | 202 | 204 | 206 | 208 1 | 101 | 102 | 103 | 104 (4 rows)

Now is a great time to learn relational databases and SQL. From web development to data science, they are used everywhere.
In the Stack Overflow 2021 Survey, 4 out of the top 5 database technologies used by professional developers were relational database management systems.
PostgreSQL is an excellent choice as a first relational database management system to learn.
- It’s widely used in industry, including at Uber, Netflix, Instagram, Spotify, and Twitch.
- It’s open source, so you won’t be locked into a particular vendor.
- It’s more than 25 years old, and in that time it has earned a reputation for stability and reliability.
Whether you’re learning from the freeCodeCamp Relational Database Certification or trying out PostgreSQL on your own computer, you need a way to create and manage databases, insert data into them, and query data from them.
While there are several graphical applications for interacting with PostgreSQL, using psql and the command line is probably the most direct way to communicate with your database.
What is psql?
psql is a tool that lets you interact with PostgreSQL databases through a terminal interface. When you install PostgreSQL on a machine, psql is automatically included.
psql lets you write SQL queries, send them to PostgreSQL, and view the results. It also lets you use meta-commands (which start with a backslash) for administering the databases. You can even write scripts and automate tasks relating to your databases.
Now, running a database on your local computer and using the command line can seem intimidating at first. I’m here to tell you it’s really not so bad. This guide will teach you the basics of managing PostgreSQL databases from the command line, including how to create, manage, back up, and restore databases.
Prerequisite – Install PostgreSQL
If you haven’t already installed PostgreSQL on your computer, follow the instructions for your operating system on the official PostgreSQL documentation.
When you install PostgreSQL, you will be asked for a password. Keep this in a safe place as you’ll need it to connect to any databases you create.
How to Connect to a Database
You have two options when using psql to connect to a database: you can connect via the command line or by using the psql application. Both provide pretty much the same experience.
Option 1 – Connect to a database with the command line
Open a terminal. You can make sure psql is installed by typing psql --version. You should see psql (PostgreSQL) version_number, where version_number is the version of PostgreSQL that’s installed on your machine. In my case, it’s 14.1.
The pattern for connecting to a database is:
psql -d database_name -U usernameThe -d flag is shorter alternative for --dbname while -U is an alternative for --username.
When you installed PostgreSQL, a default database and user were created, both called postgres. So enter psql -d postgres -U postgres to connect to the postgres database as the postgres superuser.
psql -d postgres -U postgresYou will be prompted for a password. Enter the password you chose when you installed PostgreSQL on your computer. Your terminal prompt will change to show that you’re now connected to the postgres database.
If you want to directly connect to a database as yourself (rather than as the postgres superuser), enter your system username as the username value.
Option 2 – Connect to a database with the psql application
Launch the psql application – it’ll be called «SQL Shell (psql)». You will be prompted for a server, a database, a port and a username. You can just press enter to select the default values, which are localhost, postgres, 5432, and postgres.
Next, you’ll be prompted for the password you chose when you installed PostgreSQL. Once you enter this, your terminal prompt will change to show that you’re connected to the postgres database.

Note: If you’re on Windows you might see a warning like “Console code page (850) differs from Windows code page (1252) 8-bit characters might not work correctly. See psql reference page ‘Notes for Windows users’ for details.” You don’t need to worry about this at this stage. If you want to read more about it, see the psql documentation.
How to Get Help in psql
To see a list of all psql meta-commands, and a brief summary of what they do, use the \? command.
\?
If you want help with a PostgreSQL command, use \h or \help and the command.
\h COMMANDThis will give you a description of the command, its syntax (with optional parts in square brackets), and a URL for the relevant part of the PostgreSQL documentation.

How to Quit a Command in psql
If you’ve run a command that’s taking a long time or printing too much information to the console, you can quit it by typing q.
qHow to Create a Database
Before you can manage any databases, you’ll need to create one.
Note: SQL commands should end with a semicolon, while meta-commands (which start with a backslash) don’t need to.
The SQL command to create a database is:
CREATE DATABASE database_name;For this guide, we’re going to be working with book data, so let’s create a database called books_db.
CREATE DATABASE books_db;You can view a list of all available databases with the list command.
\l
You should see books_db, as well as postgres, template0, and template1. (The CREATE DATABASE command actually works by copying the standard database, called template1. You can read more about this in the PostgreSQL documentation.)
Using \l+ will display additional information, such as the size of the databases and their tablespaces (the location in the filesystem where the files representing the database will be stored).
\l+
How to Switch Databases
You’re currently still connected to the default postgres database. To connect to a database or to switch between databases, use the \c command.
\c database_nameSo \c books_db will connect you to the books_db database. Note that your terminal prompt changes to reflect the database you’re currently connected to.

How to Delete a Database
If you want to delete a database, use the DROP DATABASE command.
DROP DATABASE database_name;You will only be allowed to delete a database if you are a superuser, such as postgres, or if you are the database’s owner.
If you try to delete a database that doesn’t exist, you will get an error. Use IF EXISTS to get a notice instead.
DROP DATABASE IF EXISTS database_name;
You can’t delete a database that has active connections. So if you want to delete the database you are currently connected to, you’ll need to switch to another database.
How to Create Tables
Before we can manage tables, we need to create a few and populate them with some sample data.
The command to create a table is:
CREATE TABLE table_name();This will create an empty table. You can also pass column values into the parentheses to create a table with columns. At the very least, a basic table should have a Primary Key (a unique identifier to tell each row apart) and a column with some data in it.
For our books_db, we’ll create a table for authors and another for books. For authors, we’ll record their first name and last name. For books, we’ll record the title and the year they were published.
We’ll make sure that the authors’ first_name and last_name and the books’ title aren’t null, since this is pretty vital information to know about them. To do this we include the NOT NULL constraint.
CREATE TABLE authors(
author_id SERIAL PRIMARY KEY,
first_name VARCHAR(100) NOT NULL,
last_name VARCHAR(100) NOT NULL
);
CREATE TABLE books(
book_id SERIAL PRIMARY KEY,
title VARCHAR(100) NOT NULL,
published_year INT
);You will see CREATE TABLE printed to the terminal if the table was created successfully.
Now let’s connect the two tables by adding a Foreign Key to books. Foreign Keys are unique identifiers that reference the Primary Key of another table. Books can, of course, have multiple authors but we’re not going to get into the complexities of many to many relationships right now.
Add a Foreign Key to books with the following command:
ALTER TABLE books ADD COLUMN author_id INT REFERENCES authors(author_id);Next, let’s insert some sample data into the tables. We’ll start with authors.
INSERT INTO authors (first_name, last_name)
VALUES (‘Tamsyn’, ‘Muir’), (‘Ann’, ‘Leckie’), (‘Zen’, ‘Cho’);Select everything from authors to make sure the insert command worked.
SELECT * FROM authors;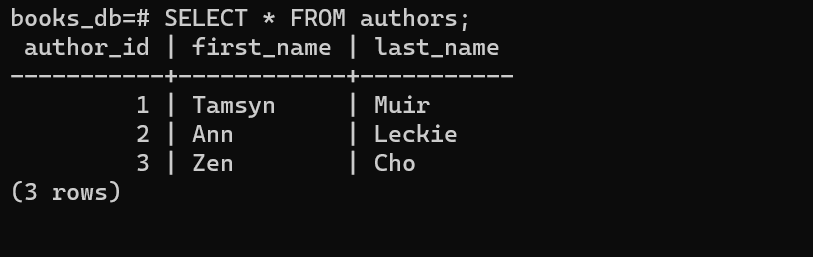
Next, we’ll insert some books data into books.
INSERT INTO books(title, published_year, author_id)
VALUES (‘Gideon the Ninth’, 2019, 1), (‘Ancillary Justice’, 2013, 2), (‘Black Water Sister’, 2021, 3);If you run SELECT * FROM books; you’ll see the book data.

How to List All Tables
You can use the \dt command to list all the tables in a database.
\dtFor books_db you will see books and authors. You’ll also see books_book_id_seq and authors_author_id_seq. These keep track of the sequence of integers used as ids by the tables because we used SERIAL to generate their Primary Keys.

How to Describe a Table
To see more information about a particular table, you can use the describe table command: \d table_name. This will list the columns, indexes, and any references to other tables.
\d table_name
Using \dt+ table_name will provide more information, such as about storage and compression.
How to Rename a Table
If you ever need to change the name of a table, you can rename it with the ALTER TABLE command.
ALTER TABLE table_name RENAME TO new_table_name;How to Delete a Table
If you want to delete a table, you can use the DROP TABLE command.
DROP TABLE table_name;If you try to delete a table that doesn’t exist, you will get an error. You can avoid this by including the IF EXISTS option in the statement. This way you’ll get a notice instead.
DROP TABLE IF EXISTS table_name;How to Manage Longer Commands and Queries
If you’re writing longer SQL queries, the command line isn’t the most ergonomic way to do it. It’s probably better to write your SQL in a file and then have psql execute it.
If you are working with psql and think your next query will be long, you can open a text editor from psql and write it there. If you have an existing query, or maybe want to run several queries to load sample data, you can execute commands from a file that is already written.
Option 1 – Open a text editor from psql
If you enter the \e command, psql will open a text editor. When you save and close the editor, psql will run the command you just wrote.
\e
On Windows, the default text editor for psql is Notepad, while on MacOs and Linux it’s vi. You can change this to another editor by setting the EDITOR value in your computer’s environment variables.
Option 2 – Execute commands and queries from a file
If you have particularly long commands or multiple commands that you want to run, it would be better to write the SQL in a file ahead of time and have psql execute that file once you’re ready.
The \i command lets you read input from a file as if you had typed it into the terminal.
\i path_to_file/file_name.sqlNote: If you’re executing this command on Windows, you still need to use forward slashes in the file path.
If you don’t specify a path, psql will look for the file in the last directory that you were in before you connected to PostgreSQL.

How to Time Queries
If you want to see how long your queries are taking, you can turn on query execution timing.
\timingThis will display in milliseconds the time that the query took to complete.
If you run the \timing command again, it will turn off query execution timing.

How to Import Data from a CSV File
If you have a CSV file with data and you want to load this into a PostgreSQL database, you can do this from the command line with psql.
First, create a CSV file called films.csv with the following structure (It doesn’t matter if you use Excel, Google Sheets, Numbers, or any other program).

Open psql and create a films_db database, connect to it, and create a films table.
CREATE DATABASE films_db;
\c films_db
CREATE TABLE films(
id SERIAL PRIMARY KEY,
title VARCHAR(100),
year INT,
running_time INT
);You can then use the \copy command to import the CSV file into films. You need to provide an absolute path to where the CSV file is on your computer.
\copy films(title, year, running_time) FROM 'path_to_file' DELIMITER ‘,’ CSV HEADER;The DELIMITER option specifies the character that separates the columns in each row of the file being imported, CSV specifies that it is a CSV file, and HEADER specifies that the file contains a header line with the names of the columns.
Note: The column names of the films table don’t need to match the column names of films.csv but they do need to be in the same order.
Use SELECT * FROM films; to see if the process was successful.

How to Back Up a Database with pg_dump
If you need to backup a database, pg_dump is a utility that lets you extract a database into a SQL script file or other type of archive file.
First, on the command line (not in psql), navigate to the PostgreSQL bin folder.
cd "C:\Program Files\PostgreSQL\14\bin"Then run the following command, using postgres as the username, and filling in the database and output file that you want to use.
pg_dump -U username database_name > path_to_file/filename.sqlUse postgres for the username and you will be prompted for the postgres superuser’s password. pg_dump will then create a .sql file containing the SQL commands needed to recreate the database.

If you don’t specify a path for the output file, pg_dump will save the file in the last directory that you were in before you connected to PostgreSQL.

You can pass the -v or --verbose flag to pg_dump to see what pg_dump is doing at each step.

You can also backup a database to other file formats, such as .tar (an archive format).
pg_dump -U username -F t database_name > path_to_file/filename.tarHere the -F flag tells pg_dump that you’re going to specify an output format, while t tells it it’s going to be in the .tar format.
How to Restore a Database
You can restore a database from a backup file using either psql or the pg_restore utility. Which one you choose depends on the type of file you are restoring the database from.
- If you backed up the database to a plaintext format, such as
.sql, use psql. - If you backed up the database to an archive format, such as
.tar, usepg_restore.
Option 1 – Restore a database using psql
To restore a database from a .sql file, on the command line (so not in psql), use psql -U username -d database_name -f filename.sql.
You can use the films_db database and films.sql file you used earlier, or create a new backup file.
Create an empty database for the file to restore the data into. If you’re using films.sql to restore films_db, the easiest thing might be to delete films_db and recreate it.
DROP DATABASE films_db;
CREATE DATABASE films_db;In a separate terminal (not in psql), run the following command, passing in postgres as the username, and the names of the database and backup file you are using.
psql -U username -d database_name -f path_to_file/filename.sqlThe -d flag points psql to a specific database, while the -f flag tells psql to read from the specified file.
If you don’t specify a path for the backup file, psql will look for the file in the last directory that you were in before you connected to PostgreSQL.
You will be prompted for the postgres superuser’s password and then will see a series of commands get printed to the command line while psql recreates the database.
This command ignores any errors that occur during the restore. If you want to stop restoring the database if an error occurs, pass in --set ON_ERROR_STOP=on.
psql -U username -d database_name --set ON_ERROR_STOP=on -f filename.sqlOption 2 – Restore a database using pg_restore
To restore a database using pg_restore, use pg_restore -U username -d database_name path_to_file/filename.tar.
Create an empty database for the file to restore the data into. If you’re restoring films_db from a films.tar file, the easiest thing might be to delete films_db and recreate it.
DROP DATABASE films_db;
CREATE DATABASE films_db;On the command line (not in psql), run the following command, passing in postgres as the username, and the names of the database and backup file you are using.
pg_restore -U username -d database_name path_to_file/filename.tar
You can also pass in the -v or --verbose flag to see what pg_restore is doing at each step.

How to Quit psql
If you’ve finished with psql and want to exit from it, enter quit or \q.
\qThis will close the psql application if you were using it, or return you to your regular command prompt if you were using psql from the command line.
Where to Take it from Here
There are lots more things you can do with psql, such as managing schemas, roles, and tablespaces. But this guide should be enough to get you started with managing PostgreSQL databases from the command line.
If you want to learn more about PostgreSQL and psql, you could try out freeCodeCamp’s Relational Database Certificate . The official PostgreSQL documentation is comprehensive, and PostgreSQL Tutorial offers several in-depth tutorials.
I hope you find this guide helpful as you continue to learn about PostgreSQL and relational databases.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started