Connecting to a Database
psql is a regular PostgreSQL client application. In order to connect to a database you need to know the name of your target database, the host name and port number of the server, and what database user name you want to connect as. psql can be told about those parameters via command line options, namely -d, -h, -p, and -U respectively. If an argument is found that does not belong to any option it will be interpreted as the database name (or the database user name, if the database name is already given). Not all of these options are required; there are useful defaults. If you omit the host name, psql will connect via a Unix-domain socket to a server on the local host, or via TCP/IP to localhost on Windows. The default port number is determined at compile time. Since the database server uses the same default, you will not have to specify the port in most cases. The default database user name is your operating-system user name. Once the database user name is determined, it is used as the default database name. Note that you cannot just connect to any database under any database user name. Your database administrator should have informed you about your access rights.
When the defaults aren’t quite right, you can save yourself some typing by setting the environment variables PGDATABASE, PGHOST, PGPORT and/or PGUSER to appropriate values. (For additional environment variables, see Section 34.15.) It is also convenient to have a ~/.pgpass file to avoid regularly having to type in passwords. See Section 34.16 for more information.
An alternative way to specify connection parameters is in a conninfo string or a URI, which is used instead of a database name. This mechanism give you very wide control over the connection. For example:
$psql "service=myservice sslmode=require"$psql postgresql://dbmaster:5433/mydb?sslmode=require
This way you can also use LDAP for connection parameter lookup as described in Section 34.18. See Section 34.1.2 for more information on all the available connection options.
If the connection could not be made for any reason (e.g., insufficient privileges, server is not running on the targeted host, etc.), psql will return an error and terminate.
If both standard input and standard output are a terminal, then psql sets the client encoding to “auto”, which will detect the appropriate client encoding from the locale settings (LC_CTYPE environment variable on Unix systems). If this doesn’t work out as expected, the client encoding can be overridden using the environment variable PGCLIENTENCODING.
Entering SQL Commands
In normal operation, psql provides a prompt with the name of the database to which psql is currently connected, followed by the string =>. For example:
$ psql testdb
psql (16.0)
Type "help" for help.
testdb=>
At the prompt, the user can type in SQL commands. Ordinarily, input lines are sent to the server when a command-terminating semicolon is reached. An end of line does not terminate a command. Thus commands can be spread over several lines for clarity. If the command was sent and executed without error, the results of the command are displayed on the screen.
If untrusted users have access to a database that has not adopted a secure schema usage pattern, begin your session by removing publicly-writable schemas from search_path. One can add options=-csearch_path= to the connection string or issue SELECT pg_catalog.set_config('search_path', '', false) before other SQL commands. This consideration is not specific to psql; it applies to every interface for executing arbitrary SQL commands.
Whenever a command is executed, psql also polls for asynchronous notification events generated by LISTEN and NOTIFY.
While C-style block comments are passed to the server for processing and removal, SQL-standard comments are removed by psql.
Advanced Features
Variables
psql provides variable substitution features similar to common Unix command shells. Variables are simply name/value pairs, where the value can be any string of any length. The name must consist of letters (including non-Latin letters), digits, and underscores.
To set a variable, use the psql meta-command \set. For example,
testdb=> \set foo bar
sets the variable foo to the value bar. To retrieve the content of the variable, precede the name with a colon, for example:
testdb=> \echo :foo
bar
This works in both regular SQL commands and meta-commands; there is more detail in SQL Interpolation, below.
If you call \set without a second argument, the variable is set to an empty-string value. To unset (i.e., delete) a variable, use the command \unset. To show the values of all variables, call \set without any argument.
Note
The arguments of \set are subject to the same substitution rules as with other commands. Thus you can construct interesting references such as \set :foo 'something' and get “soft links” or “variable variables” of Perl or PHP fame, respectively. Unfortunately (or fortunately?), there is no way to do anything useful with these constructs. On the other hand, \set bar :foo is a perfectly valid way to copy a variable.
A number of these variables are treated specially by psql. They represent certain option settings that can be changed at run time by altering the value of the variable, or in some cases represent changeable state of psql. By convention, all specially treated variables’ names consist of all upper-case ASCII letters (and possibly digits and underscores). To ensure maximum compatibility in the future, avoid using such variable names for your own purposes.
Variables that control psql‘s behavior generally cannot be unset or set to invalid values. An \unset command is allowed but is interpreted as setting the variable to its default value. A \set command without a second argument is interpreted as setting the variable to on, for control variables that accept that value, and is rejected for others. Also, control variables that accept the values on and off will also accept other common spellings of Boolean values, such as true and false.
The specially treated variables are:
AUTOCOMMIT#-
When
on(the default), each SQL command is automatically committed upon successful completion. To postpone commit in this mode, you must enter aBEGINorSTART TRANSACTIONSQL command. Whenoffor unset, SQL commands are not committed until you explicitly issueCOMMITorEND. The autocommit-off mode works by issuing an implicitBEGINfor you, just before any command that is not already in a transaction block and is not itself aBEGINor other transaction-control command, nor a command that cannot be executed inside a transaction block (such asVACUUM).Note
In autocommit-off mode, you must explicitly abandon any failed transaction by entering
ABORTorROLLBACK. Also keep in mind that if you exit the session without committing, your work will be lost.Note
The autocommit-on mode is PostgreSQL‘s traditional behavior, but autocommit-off is closer to the SQL spec. If you prefer autocommit-off, you might wish to set it in the system-wide
psqlrcfile or your~/.psqlrcfile. COMP_KEYWORD_CASE#-
Determines which letter case to use when completing an SQL key word. If set to
lowerorupper, the completed word will be in lower or upper case, respectively. If set topreserve-lowerorpreserve-upper(the default), the completed word will be in the case of the word already entered, but words being completed without anything entered will be in lower or upper case, respectively. DBNAME#-
The name of the database you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
ECHO#-
If set to
all, all nonempty input lines are printed to standard output as they are read. (This does not apply to lines read interactively.) To select this behavior on program start-up, use the switch-a. If set toqueries, psql prints each query to standard output as it is sent to the server. The switch to select this behavior is-e. If set toerrors, then only failed queries are displayed on standard error output. The switch for this behavior is-b. If set tonone(the default), then no queries are displayed. ECHO_HIDDEN#-
When this variable is set to
onand a backslash command queries the database, the query is first shown. This feature helps you to study PostgreSQL internals and provide similar functionality in your own programs. (To select this behavior on program start-up, use the switch-E.) If you set this variable to the valuenoexec, the queries are just shown but are not actually sent to the server and executed. The default value isoff. ENCODING#-
The current client character set encoding. This is set every time you connect to a database (including program start-up), and when you change the encoding with
\encoding, but it can be changed or unset. ERROR#-
trueif the last SQL query failed,falseif it succeeded. See alsoSQLSTATE. FETCH_COUNT#-
If this variable is set to an integer value greater than zero, the results of
SELECTqueries are fetched and displayed in groups of that many rows, rather than the default behavior of collecting the entire result set before display. Therefore only a limited amount of memory is used, regardless of the size of the result set. Settings of 100 to 1000 are commonly used when enabling this feature. Keep in mind that when using this feature, a query might fail after having already displayed some rows.Tip
Although you can use any output format with this feature, the default
alignedformat tends to look bad because each group ofFETCH_COUNTrows will be formatted separately, leading to varying column widths across the row groups. The other output formats work better. HIDE_TABLEAM#-
If this variable is set to
true, a table’s access method details are not displayed. This is mainly useful for regression tests. HIDE_TOAST_COMPRESSION#-
If this variable is set to
true, column compression method details are not displayed. This is mainly useful for regression tests. HISTCONTROL#-
If this variable is set to
ignorespace, lines which begin with a space are not entered into the history list. If set to a value ofignoredups, lines matching the previous history line are not entered. A value ofignorebothcombines the two options. If set tonone(the default), all lines read in interactive mode are saved on the history list.Note
This feature was shamelessly plagiarized from Bash.
HISTFILE#-
The file name that will be used to store the history list. If unset, the file name is taken from the
PSQL_HISTORYenvironment variable. If that is not set either, the default is~/.psql_history, or%APPDATA%\postgresql\psql_historyon Windows. For example, putting:\set HISTFILE ~/.psql_history-:DBNAME
in
~/.psqlrcwill cause psql to maintain a separate history for each database.Note
This feature was shamelessly plagiarized from Bash.
HISTSIZE#-
The maximum number of commands to store in the command history (default 500). If set to a negative value, no limit is applied.
Note
This feature was shamelessly plagiarized from Bash.
HOST#-
The database server host you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
IGNOREEOF#-
If set to 1 or less, sending an EOF character (usually Control+D) to an interactive session of psql will terminate the application. If set to a larger numeric value, that many consecutive EOF characters must be typed to make an interactive session terminate. If the variable is set to a non-numeric value, it is interpreted as 10. The default is 0.
Note
This feature was shamelessly plagiarized from Bash.
LASTOID#-
The value of the last affected OID, as returned from an
INSERTor\lo_importcommand. This variable is only guaranteed to be valid until after the result of the next SQL command has been displayed. PostgreSQL servers since version 12 do not support OID system columns anymore, thus LASTOID will always be 0 followingINSERTwhen targeting such servers. LAST_ERROR_MESSAGELAST_ERROR_SQLSTATE#-
The primary error message and associated SQLSTATE code for the most recent failed query in the current psql session, or an empty string and
00000if no error has occurred in the current session. ON_ERROR_ROLLBACK#-
When set to
on, if a statement in a transaction block generates an error, the error is ignored and the transaction continues. When set tointeractive, such errors are only ignored in interactive sessions, and not when reading script files. When set tooff(the default), a statement in a transaction block that generates an error aborts the entire transaction. The error rollback mode works by issuing an implicitSAVEPOINTfor you, just before each command that is in a transaction block, and then rolling back to the savepoint if the command fails. ON_ERROR_STOP#-
By default, command processing continues after an error. When this variable is set to
on, processing will instead stop immediately. In interactive mode, psql will return to the command prompt; otherwise, psql will exit, returning error code 3 to distinguish this case from fatal error conditions, which are reported using error code 1. In either case, any currently running scripts (the top-level script, if any, and any other scripts which it may have in invoked) will be terminated immediately. If the top-level command string contained multiple SQL commands, processing will stop with the current command. PORT#-
The database server port to which you are currently connected. This is set every time you connect to a database (including program start-up), but can be changed or unset.
PROMPT1PROMPT2PROMPT3#-
These specify what the prompts psql issues should look like. See Prompting below.
QUIET#-
Setting this variable to
onis equivalent to the command line option-q. It is probably not too useful in interactive mode. ROW_COUNT#-
The number of rows returned or affected by the last SQL query, or 0 if the query failed or did not report a row count.
SERVER_VERSION_NAMESERVER_VERSION_NUM#-
The server’s version number as a string, for example
9.6.2,10.1or11beta1, and in numeric form, for example90602or100001. These are set every time you connect to a database (including program start-up), but can be changed or unset. SHELL_ERROR#-
trueif the last shell command failed,falseif it succeeded. This applies to shell commands invoked via the\!,\g,\o,\w, and\copymeta-commands, as well as backquote (`) expansion. Note that for\o, this variable is updated when the output pipe is closed by the next\ocommand. See alsoSHELL_EXIT_CODE. SHELL_EXIT_CODE#-
The exit status returned by the last shell command. 0–127 represent program exit codes, 128–255 indicate termination by a signal, and -1 indicates failure to launch a program or to collect its exit status. This applies to shell commands invoked via the
\!,\g,\o,\w, and\copymeta-commands, as well as backquote (`) expansion. Note that for\o, this variable is updated when the output pipe is closed by the next\ocommand. See alsoSHELL_ERROR. SHOW_ALL_RESULTS#-
When this variable is set to
off, only the last result of a combined query (\;) is shown instead of all of them. The default ison. The off behavior is for compatibility with older versions of psql. SHOW_CONTEXT#-
This variable can be set to the values
never,errors, oralwaysto control whetherCONTEXTfields are displayed in messages from the server. The default iserrors(meaning that context will be shown in error messages, but not in notice or warning messages). This setting has no effect whenVERBOSITYis set toterseorsqlstate. (See also\errverbose, for use when you want a verbose version of the error you just got.) SINGLELINE#-
Setting this variable to
onis equivalent to the command line option-S. SINGLESTEP#-
Setting this variable to
onis equivalent to the command line option-s. SQLSTATE#-
The error code (see Appendix A) associated with the last SQL query’s failure, or
00000if it succeeded. USER#-
The database user you are currently connected as. This is set every time you connect to a database (including program start-up), but can be changed or unset.
VERBOSITY#-
This variable can be set to the values
default,verbose,terse, orsqlstateto control the verbosity of error reports. (See also\errverbose, for use when you want a verbose version of the error you just got.) VERSIONVERSION_NAMEVERSION_NUM#-
These variables are set at program start-up to reflect psql‘s version, respectively as a verbose string, a short string (e.g.,
9.6.2,10.1, or11beta1), and a number (e.g.,90602or100001). They can be changed or unset.
SQL Interpolation
A key feature of psql variables is that you can substitute (“interpolate”) them into regular SQL statements, as well as the arguments of meta-commands. Furthermore, psql provides facilities for ensuring that variable values used as SQL literals and identifiers are properly quoted. The syntax for interpolating a value without any quoting is to prepend the variable name with a colon (:). For example,
testdb=>\set foo 'my_table'testdb=>SELECT * FROM :foo;
would query the table my_table. Note that this may be unsafe: the value of the variable is copied literally, so it can contain unbalanced quotes, or even backslash commands. You must make sure that it makes sense where you put it.
When a value is to be used as an SQL literal or identifier, it is safest to arrange for it to be quoted. To quote the value of a variable as an SQL literal, write a colon followed by the variable name in single quotes. To quote the value as an SQL identifier, write a colon followed by the variable name in double quotes. These constructs deal correctly with quotes and other special characters embedded within the variable value. The previous example would be more safely written this way:
testdb=>\set foo 'my_table'testdb=>SELECT * FROM :"foo";
Variable interpolation will not be performed within quoted SQL literals and identifiers. Therefore, a construction such as ':foo' doesn’t work to produce a quoted literal from a variable’s value (and it would be unsafe if it did work, since it wouldn’t correctly handle quotes embedded in the value).
One example use of this mechanism is to copy the contents of a file into a table column. First load the file into a variable and then interpolate the variable’s value as a quoted string:
testdb=>\set content `cat my_file.txt`testdb=>INSERT INTO my_table VALUES (:'content');
(Note that this still won’t work if my_file.txt contains NUL bytes. psql does not support embedded NUL bytes in variable values.)
Since colons can legally appear in SQL commands, an apparent attempt at interpolation (that is, :name, :'name', or :"name") is not replaced unless the named variable is currently set. In any case, you can escape a colon with a backslash to protect it from substitution.
The :{? special syntax returns TRUE or FALSE depending on whether the variable exists or not, and is thus always substituted, unless the colon is backslash-escaped.name}
The colon syntax for variables is standard SQL for embedded query languages, such as ECPG. The colon syntaxes for array slices and type casts are PostgreSQL extensions, which can sometimes conflict with the standard usage. The colon-quote syntax for escaping a variable’s value as an SQL literal or identifier is a psql extension.
Prompting
The prompts psql issues can be customized to your preference. The three variables PROMPT1, PROMPT2, and PROMPT3 contain strings and special escape sequences that describe the appearance of the prompt. Prompt 1 is the normal prompt that is issued when psql requests a new command. Prompt 2 is issued when more input is expected during command entry, for example because the command was not terminated with a semicolon or a quote was not closed. Prompt 3 is issued when you are running an SQL COPY FROM STDIN command and you need to type in a row value on the terminal.
The value of the selected prompt variable is printed literally, except where a percent sign (%) is encountered. Depending on the next character, certain other text is substituted instead. Defined substitutions are:
%M#-
The full host name (with domain name) of the database server, or
[local]if the connection is over a Unix domain socket, or[local:, if the Unix domain socket is not at the compiled in default location./dir/name] %m#-
The host name of the database server, truncated at the first dot, or
[local]if the connection is over a Unix domain socket. %>#-
The port number at which the database server is listening.
%n#-
The database session user name. (The expansion of this value might change during a database session as the result of the command
SET SESSION AUTHORIZATION.) %/#-
The name of the current database.
%~#-
Like
%/, but the output is~(tilde) if the database is your default database. %##-
If the session user is a database superuser, then a
#, otherwise a>. (The expansion of this value might change during a database session as the result of the commandSET SESSION AUTHORIZATION.) %p#-
The process ID of the backend currently connected to.
%R#-
In prompt 1 normally
=, but@if the session is in an inactive branch of a conditional block, or^if in single-line mode, or!if the session is disconnected from the database (which can happen if\connectfails). In prompt 2%Ris replaced by a character that depends on why psql expects more input:-if the command simply wasn’t terminated yet, but*if there is an unfinished/* ... */comment, a single quote if there is an unfinished quoted string, a double quote if there is an unfinished quoted identifier, a dollar sign if there is an unfinished dollar-quoted string, or(if there is an unmatched left parenthesis. In prompt 3%Rdoesn’t produce anything. %x#-
Transaction status: an empty string when not in a transaction block, or
*when in a transaction block, or!when in a failed transaction block, or?when the transaction state is indeterminate (for example, because there is no connection). %l#-
The line number inside the current statement, starting from
1. %digits#-
The character with the indicated octal code is substituted.
%:name:#-
The value of the psql variable
name. See Variables, above, for details. %`command`#-
The output of
command, similar to ordinary “back-tick” substitution. %[…%]#-
Prompts can contain terminal control characters which, for example, change the color, background, or style of the prompt text, or change the title of the terminal window. In order for the line editing features of Readline to work properly, these non-printing control characters must be designated as invisible by surrounding them with
%[and%]. Multiple pairs of these can occur within the prompt. For example:testdb=> \set PROMPT1 '%[%033[1;33;40m%]%n@%/%R%[%033[0m%]%# '
results in a boldfaced (
1;) yellow-on-black (33;40) prompt on VT100-compatible, color-capable terminals. %w#-
Whitespace of the same width as the most recent output of
PROMPT1. This can be used as aPROMPT2setting, so that multi-line statements are aligned with the first line, but there is no visible secondary prompt.
To insert a percent sign into your prompt, write %%. The default prompts are '%/%R%x%# ' for prompts 1 and 2, and '>> ' for prompt 3.
Note
This feature was shamelessly plagiarized from tcsh.
Command-Line Editing
psql uses the Readline or libedit library, if available, for convenient line editing and retrieval. The command history is automatically saved when psql exits and is reloaded when psql starts up. Type up-arrow or control-P to retrieve previous lines.
You can also use tab completion to fill in partially-typed keywords and SQL object names in many (by no means all) contexts. For example, at the start of a command, typing ins and pressing TAB will fill in insert into . Then, typing a few characters of a table or schema name and pressing TAB will fill in the unfinished name, or offer a menu of possible completions when there’s more than one. (Depending on the library in use, you may need to press TAB more than once to get a menu.)
Tab completion for SQL object names requires sending queries to the server to find possible matches. In some contexts this can interfere with other operations. For example, after BEGIN it will be too late to issue SET TRANSACTION ISOLATION LEVEL if a tab-completion query is issued in between. If you do not want tab completion at all, you can turn it off permanently by putting this in a file named .inputrc in your home directory:
$if psql set disable-completion on $endif
(This is not a psql but a Readline feature. Read its documentation for further details.)
The -n (--no-readline) command line option can also be useful to disable use of Readline for a single run of psql. This prevents tab completion, use or recording of command line history, and editing of multi-line commands. It is particularly useful when you need to copy-and-paste text that contains TAB characters.
PostgreSQL — это бесплатная объектно-реляционная СУБД с мощным функционалом, который позволяет конкурировать с платными базами данных, такими как Microsoft SQL, Oracle. PostgreSQL поддерживает пользовательские данные, функции, операции, домены и индексы. В данной статье мы рассмотрим установку и краткий обзор по управлению базой данных PostgreSQL. Мы установим СУБД PostgreSQL в Windows 10, создадим новую базу, добавим в неё таблицы и настроим доступа для пользователей. Также мы рассмотрим основы управления PostgreSQL с помощью SQL shell и визуальной системы управления PgAdmin. Надеюсь эта статья станет хорошей отправной точкой для обучения работы с PostgreSQL и использованию ее в разработке и тестовых проектах.
Содержание:
- Установка PostgreSQL 11 в Windows 10
- Доступ к PostgreSQL по сети, правила файерволла
- Утилиты управления PostgreSQL через командную строку
- PgAdmin: Визуальный редактор для PostgresSQL
- Query Tool: использование SQL запросов в PostgreSQL
Установка PostgreSQL 11 в Windows 10
Для установки PostgreSQL перейдите на сайт https://www.postgresql.org и скачайте последнюю версию дистрибутива для Windows, на сегодняшний день это версия PostgreSQL 11 (в 11 версии PostgreSQL поддерживаются только 64-х битные редакции Windows). После загрузки запустите инсталлятор.
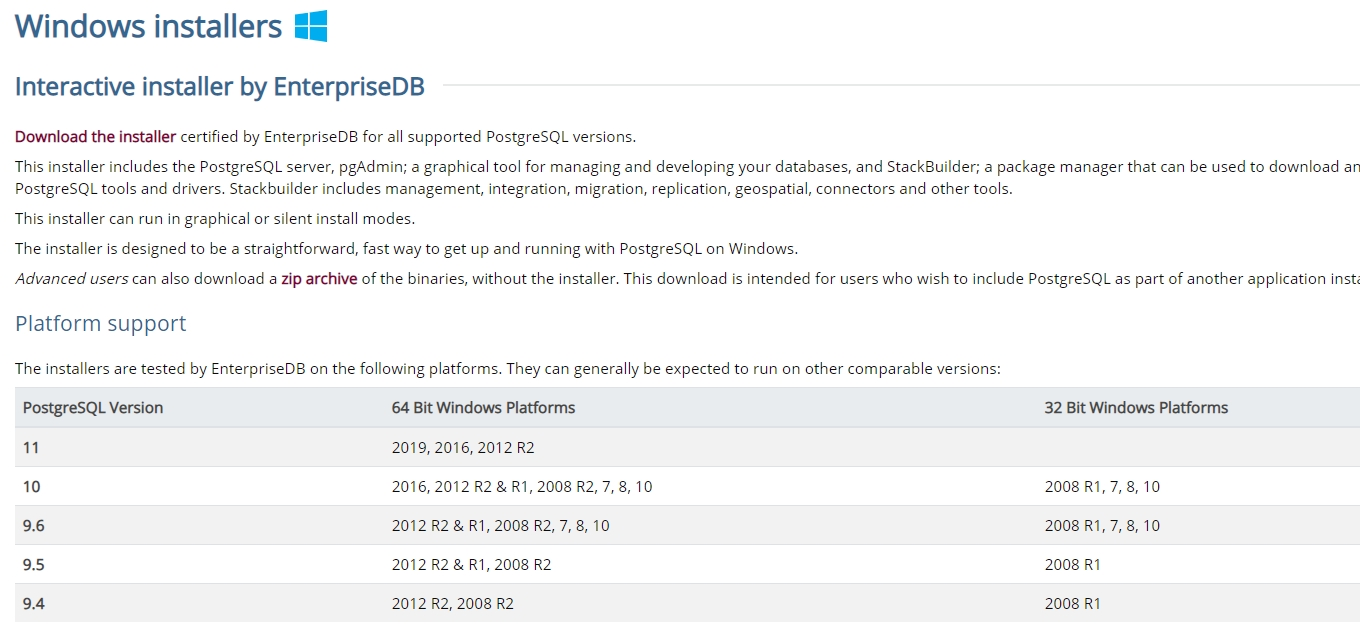
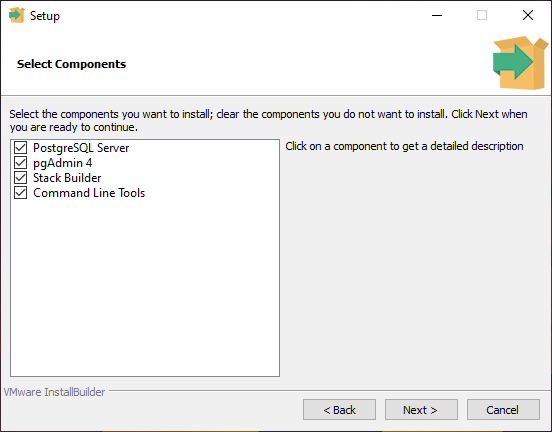
В процессе установки установите галочки на пунктах:
- PostgreSQL Server – сам сервер СУБД
- PgAdmin 4 – визуальный редактор SQL
- Stack Builder – дополнительные инструменты для разработки (возможно вам они понадобятся в будущем)
- Command Line Tools – инструменты командной строки
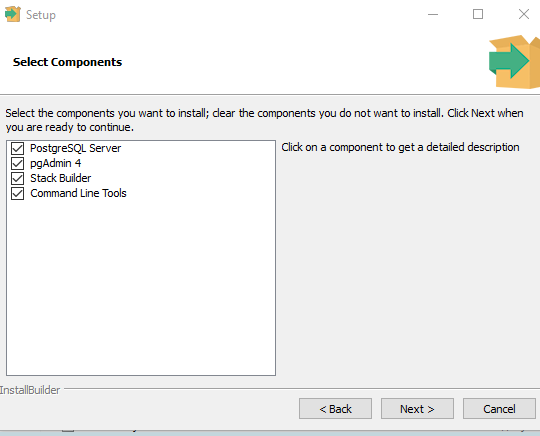
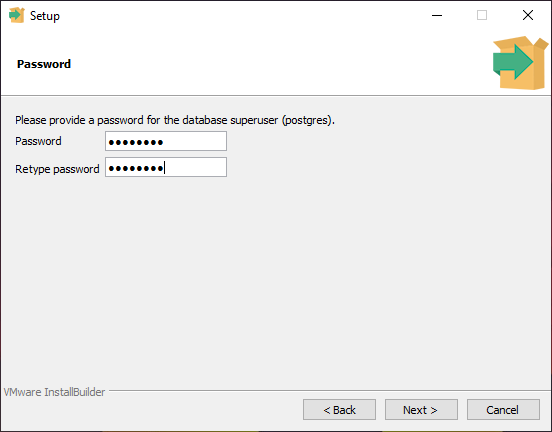
Установите пароль для пользователя postgres (он создается по умолчанию и имеет права суперпользователя).
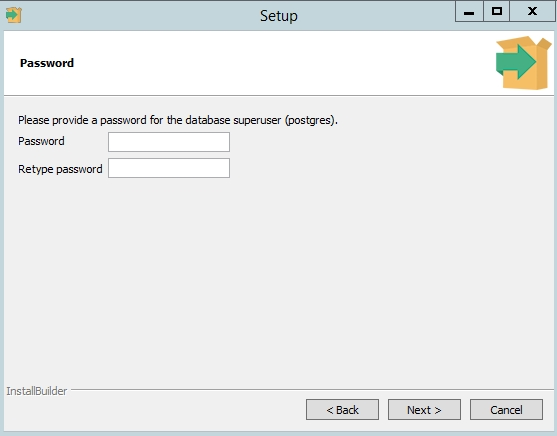
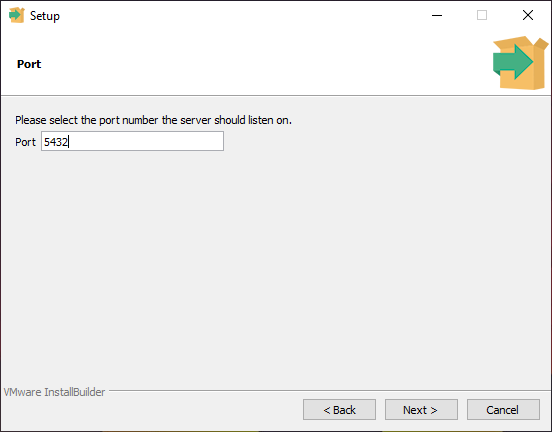
По умолчание СУБД слушает на порту 5432, который нужно будет добавить в исключения в правилах фаерволла.
Нажимаете Далее, Далее, на этом установка PostgreSQL завершена.
Доступ к PostgreSQL по сети, правила файерволла
Чтобы разрешить сетевой доступ к вашему экземпляру PostgreSQL с других компьютеров, вам нужно создать правила в файерволе. Вы можете создать правило через командную строку или PowerShell.
Запустите командную строку от имени администратора. Введите команду:
netsh advfirewall firewall add rule name="Postgre Port" dir=in action=allow protocol=TCP localport=5432
- Где rule name – имя правила
- Localport – разрешенный порт
Либо вы можете создать правило, разрешающее TCP/IP доступ к экземпляру PostgreSQL на порту 5432 с помощью PowerShell:
New-NetFirewallRule -Name 'POSTGRESQL-In-TCP' -DisplayName 'PostgreSQL (TCP-In)' -Direction Inbound -Enabled True -Protocol TCP -LocalPort 5432
После применения команды в брандмауэре Windows появится новое разрешающее правило для порта Postgres.
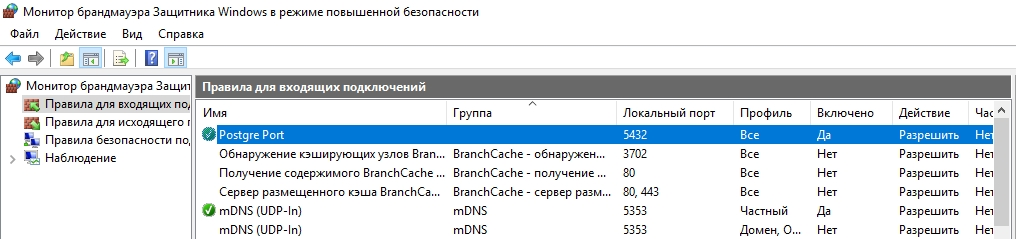
Совет. Для изменения порта в установленной PostgreSQL отредактируйте файл postgresql.conf по пути C:\Program Files\PostgreSQL\11\data.
Измените значение в пункте
port = 5432
. Перезапустите службу сервера postgresql-x64-11 после изменений. Можно перезапустить службу с помощью PowerShell:
Restart-Service -Name postgresql-x64-11

Более подробно о настройке параметров в конфигурационном файле postgresql.conf с помощью тюнеров смотрите в статье.
Утилиты управления PostgreSQL через командную строку
Рассмотрим управление и основные операции, которые можно выполнять с PostgreSQL через командную строку с помощью нескольких утилит. Основные инструменты управления PostgreSQL находятся в папке bin, потому все команды будем выполнять из данного каталога.
- Запустите командную строку.
Совет. Перед запуском СУБД, смените кодировку для нормального отображения в русской Windows 10. В командной строке выполните:
chcp 1251 - Перейдите в каталог bin выполнив команду:
CD C:\Program Files\PostgreSQL\11\bin

Основные команды PostgreSQL:

PgAdmin: Визуальный редактор для PostgresSQL
Редактор PgAdmin служит для упрощения управления базой данных PostgresSQL в понятном визуальном режиме.
По умолчанию все созданные базы хранятся в каталоге base по пути C:\Program Files\PostgreSQL\11\data\base.
Для каждой БД существует подкаталог внутри PGDATA/base, названный по OID базы данных в pg_database. Этот подкаталог по умолчанию является местом хранения файлов базы данных; в частности, там хранятся её системные каталоги. Каждая таблица и индекс хранятся в отдельном файле.
Для резервного копирования и восстановления лучше использовать инструмент Backup в панели инструментов Tools. Для автоматизации бэкапа PostgreSQL из командной строки используйте утилиту pg_dump.exe.
Query Tool: использование SQL запросов в PostgreSQL
Для написания SQL запросов в удобном графическом редакторе используется встроенный в pgAdmin инструмент Query Tool. Например, вы хотите создать новую таблицу в базе данных через инструмент Query Tool.
- Выберите базу данных, в панели Tools откройте Query Tool
- Создадим таблицу сотрудников:
CREATE TABLE employee
(
Id SERIAL PRIMARY KEY,
FirstName CHARACTER VARYING(30),
LastName CHARACTER VARYING(30),
Email CHARACTER VARYING(30),
Age INTEGER
);
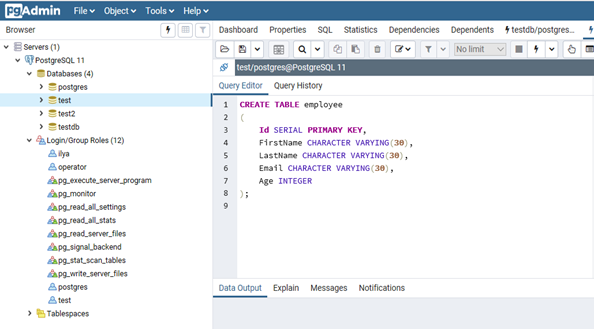
Id — номер сотрудника, которому присвоен ключ SERIAL. Данная строка будет хранить числовое значение 1, 2, 3 и т.д., которое для каждой новой строки будет автоматически увеличиваться на единицу. В следующих строках записаны имя, фамилия сотрудника и его электронный адрес, которые имеют тип CHARACTER VARYING(30), то есть представляют строку длиной не более 30 символов. В строке — Age записан возраст, имеет тип INTEGER, т.к. хранит числа.
После того, как написали код SQL запроса в Query Tool, нажмите клавишу F5 и в базе будет создана новая таблица employee.
Для заполнения полей в свойствах таблицы выберите таблицу employee в разделе Schemas -> Tables. Откройте меню Object инструмент View/Edit Data.
Здесь вы можете заполнить данные в таблице.
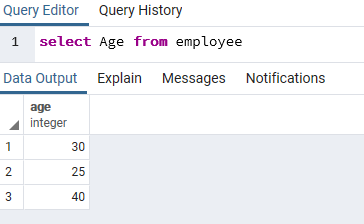
После заполнения данных выполним инструментом Query простой запрос на выборку:
select Age from employee;
В прошлый раз я познакомил тебя
с
основами реляционных баз данных и SQL.
Теперь пришло время настроить рабочую среду. Ты будешь использовать
PostgreSQL в качестве своей СУБД, поэтому для начала ее нужно скачать и установить.
PostgreSQL поддерживает все основные операционные системы. Процесс установки прост, поэтому я постараюсь рассказать
о нем как можно быстрее.
Для Windows и Mac ты можешь загрузить установщик
с
веб-сайта EDB.
EDB больше не предоставляет пакеты для систем GNU/Linux. Вместо этого они рекомендуют вам использовать диспетчер
пакетов твоего дистрибутива.
Установщики включают в себя разные компоненты.
Вот самые важные из них:
- Сервер PostgreSQL (очевидно)
- pgAdmin, графический инструмент для управления базами данных
- Менеджер пакетов для загрузки и установки дополнительных инструментов и драйверов
Windows
Скачав установщик, запусти его как любой другой исполняемый файл. Процесс довольно прямолинеен,
но некоторые вещи все же заслуживают внимания.
Диалоговое окно «Выбрать компоненты» позволяет выборочно устанавливать компоненты.
Если у тебя нет веской причины что-то менять — оставляй все как есть.
По умолчанию PostgreSQL создает суперпользователя с именем postgres (воспринимай его как учетную запись
администратора сервера базы данных).
Во время установки тебе нужно будет указать пароль для суперпользователя (root).
Позже ты сможешь создать других пользователей и назначать им отдельные доступы и роли.
Мы вернемся к этому позже, а сейчас тебе понадобится учетная запись суперпользователя, чтобы начать использовать СУБД.
Чтобы запустить сервер разработки на твоем компьютере или localhost, необходимо
назначить ему порт.
Порт по умолчанию — 5432. Если ты устанавливаешь PostgreSQL впервые, то он скорее всего свободен.
Если окажется, что этот порт уже занят другим экземпляром PostgreSQL, ты можешь указать другое значение, например 5433.
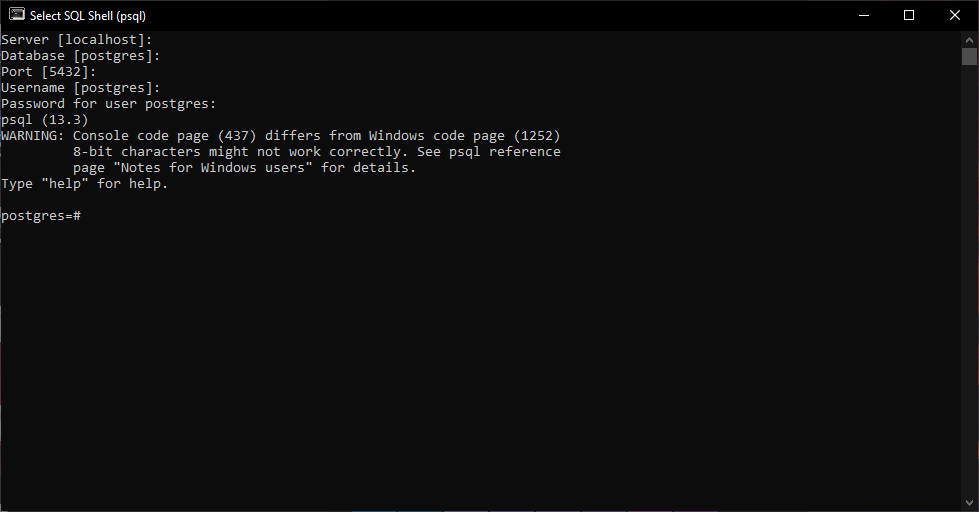
После завершения установки ты сможешь запустить SQL Shell, поставляемый с Postgres.
Шаг за шагом ты выберешь сервер, какую базу данных использовать, порт, имя пользователя и пароль.
Используй данные, которые ты вводил на предыдущих шагах.
Поздравляю! Настройка для Windows завершена, и скоро мы начнем писать первые SQL запросы.
Ниже список вариантов установки для других операционных систем.
macOS
Для macOS у тебя есть разные варианты. Можно скачать установщик с сайта EDB и запустить его.
Кроме того, можно использовать Postgres.app, простое приложение для macOS.
После запуска у тебя появится сервер PostgreSQL, готовый к использованию.
Завершить работу сервера можно просто закрыв приложение.
Кроме того, ты также можете использовать Homebrew, менеджер пакетов для macOS.
GNU/Linux
Ты можешь найти PostgreSQL в репозиториях большинства дистрибутивов Linux. Установить его можно одним щелчком мыши
из выбранного графического диспетчера пакетов.
Альтернативно, можно использовать установку через терминал.
Ты можешь обратиться к документации твоего дистрибутива для получения дополнительных сведений.
Ubuntu
sudo apt-get install postgresql
Ubuntu PostgreSQL configuration guide
Fedora
sudo yum install postgresql-server postgresql-contrib
Fedora PostgreSQL configuration guide
openSUSE
sudo zypper install postgresql postgresql-server postgresql-contrib
openSUSE PostgreSQL configuration guide
Arch
sudo pacman -S postgresql
Arch PostgreSQL configuration guide
Запуск оболочки PostgreSQL
После установки PostgreSQL, нужно запустить оболочку(shell), с помощью которой ты получишь возможность управлять базой данных.
Открой терминал и введи:
psql — это оболочка Postgres, аргумент -U используется для указания пользователя.
Поскольку ты еще не создавал других
пользователей, ты войдешь в систему как суперпользователь postgres.
После этого нужно будет ввести пароль
суперпользователя, который ты выбрал во время установки.
Как только пароль установлен, база данных PostgreSQL готова к работе!
Если сервер PostgreSQL по какой-то причине не запускается, можешь попробовать запустить его вручную.
sudo systemctl start postgres
Понимание модели клиент-сервер
Я уже упоминал PostgreSQL Server как важный компонент базы данных. Но что такое сервер в этом контексте и зачем он нам нужен?
Для начала тебе необходимо понимать модель клиент-сервер.
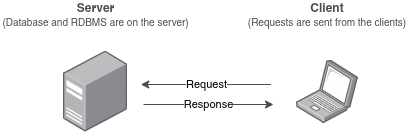
Почти все СУБД (PostgreSQL, MySQL и другие) следуют клиент-серверной модели. В ней база данных находится на сервере, и клиент
отправляет запросы на сервер, который их обрабатывает.
Под клиентом здесь подразумевается бекэнд нашего приложения, а запросы в — это SQL операции, такие как SELECT, INSERT, UPDATE и DELETE.
Для разработки любого бекэнда, тебе нужен локальный сервер для экспериментов и тестирования.
Этот локальный сервер аналогичен удаленному, но работает прямо на твоем компьютере.
С точки зрения клиента удаленный и локальный сервер идентичны. После разработки и тестирования ты можешь заставить свой
продукт взаимодействовать с удаленным сервером вместо локального, просто изменив пару параметров.
Некоторые базы данных не используют эту модель, например SQLite, которая хранит все в простом файле на диске. Это хорошо
работает для небольших приложений, но для большинства реальных приложений тебе понадобится архитектура клиент-сервер.
Мета-команды PostgreSQL
Теперь, когда ты все настроил и готов приступить к работе с базой данных, осталось разобрать несколько мета-команд.
Это не SQL запросы, а команды специфичные для PostgreSQL.
В других системах управления базами данных есть их аналоги, но их синтаксис немного отличается.
Всем мета-командам предшествует обратная косая черта \, за которой следует фактическая команда.
Список всех баз данных
Чтобы получить список всех баз данных на сервере, ты можешь использовать команду \ l.
Ввод этой мета-команды в оболочке Postgres выведет:
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-------------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
Это список всех имеющихся баз данных и служебная информация, такая как владелец базы данных, кодировка и права доступа.
На данный момент мы пока ничего не создали, а базы данных которые ты видишь на экране — создаются по умолчанию при установке Postgres.
- postgres — это просто пустая база данных.
- «template0» и «template1» — это служебные базы данных, которые служат шаблоном для создания новых баз.
Тебе пока не стоит беспокоиться о них. Если хочешь изучить все детали, то проверь официальную документацию.
Подключаемся к базе данных PostgreSQL
Некоторые команды SQL требуют, чтобы ты сначала вошел в базу данных (например, для создания новой таблицы).
Ты можешь выбрать, в какую базу данных входить, при запуске SQL Shell.
Когда ты находишься внутри оболочки (shell), то можешь использовать команду \c (или \connect), за которой следует имя
базы данных. Если бы у тебя была другая база данных под названием hello_world, то подключиться к ней можно было бы так:
Полностью в терминале у тебя получится что-то такое:
postgres=# \c hello_world
You are now connected to database "hello_world" as user "postgres".
hello_world=#
Обрати внимание, что приглашение оболочки изменилось с postgres на hello_world. Это значит, что теперь ты
подключен к базе данных hello_world, а не postgres.
Получить список всех таблиц в базе данных
Как и в случае со списком существующих баз данных, ты можешь получить список таблиц внутри конкретной базы данных
с помощью команды \dt.
Перед выполнением этой команды вам необходимо войти в базу данных.
Предположим, ты уже находишься внутри базы hello_world, и в ней есть таблица с именем my_table. Набрав \dt, ты
получишь следующее:
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | my_table | table | postgres
Ты можешь увидеть имя таблицы и некоторую другую информацию, такую как схема (мы обсудим схемы в более сложных
руководствах) и владельца.
Владелец (owner) — это пользователь, который создал таблицу.
Если ты создаешь других пользователей и используешь их для создания таблиц, то в последнем столбце будут именно они.
Список пользователей и ролей
Как ты уже знаешь, при установке Postgres создается суперпользователь с именем postgres.
Список всех пользователей базы данных можно вывести на экран используя команду \dg.
List of roles
Role name | Attributes | Member of
------------+------------------------------------------------------------+-----------
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
Обрати внимание, что первый столбец называется — роль (role name).
И весь вывод на экран называется “список ролей” (List of roles), а не список пользователей.
В PostgreSQL пользователи и роли практически
одинаковы.
У ролей есть атрибуты, которые определяют их разрешения, такие как создание баз данных или даже создание
других новых ролей.
Любая роль с атрибутом LOGIN может рассматриваться, как пользователь.
Здесь мы видим только одну роль, суперпользователя по умолчанию.
В реальном мире все будет иначе, потому что использовать только суперпользователя все время опасно.
Вместо этого создают другие роли с меньшими привилегиями.
Это гарантирует, что никто не совершит нежелательных действий по ошибке.
Если у одной из ролей есть доступ только на чтение данных, то с помощью этой роли будет невозможно удалить таблицу или поле.
Твой первый SQL оператор
Наконец, мы все настроили и готовы к работе и знаем основные мета-команды, специфичные для PostgreSQL.
Теперь приступим к изучению языка запросов SQL.
Я покажу тебе несколько базовых примеров, чтобы разобраться в структурированном языке запросов и получить представление о SQL. А более подробно мы рассмотрим операции CRUD это в следующей статье.
Создание новой базы данных
Первое, что тебе нужно узнать при изучении баз данных, — это как создать базу данных.
Создать базу можно сделать с помощью команды CREATE DATABASE, за которой следует имя базы данных:
Команды и ключевые слова SQL обычно пишутся в верхнем регистре.
На самом деле это не является обязательным требованием, и обычно они нечувствительны к регистру.
То есть ты мог бы написать
И все сработало бы нормально.
Но при написании операторов SQL обычно предпочтительнее прописные буквы. Это
хорошая практика, потому что она может помочь тебе визуально отличить ключевые слова SQL от других частей оператора,
таких как имена таблиц и столбцов.
Заметь, что все стандартные команды в PostgreSQL должны заканчиваться точкой с запятой ;. Это часть стандарта.
Для мета-команд PostgreSQL точка с запятой не нужна.
Создание таблиц
После того как ты создал новую базу данных, можно приступать к созданию таблиц.
Но, для начала, подключимся к новой базе данных с помощью команды \c, за которой следует имя базы данных:
Теперь, когда ты подключился к базе данных (обратите внимание, что приглашение оболочки SQL теперь включает имя активной
базы данных), ты готов создать свою первую таблицу.
Таблица создается с помощью команды CREATE TABLE, за которой
следует список столбцов таблицы и их типы данных в круглых скобках:
CREATE TABLE products (
id INT,
name TEXT,
quantity INT
)
Это создаст таблицу под названием products, которая содержит 3 столбца:
idтипаINT(целое число)nameтипаTEXT(строка)quantityтакже типаINT
После создания таблицы перейдем к добавлению данных.
Вставка данных в таблицы PostgreSQL
Чтобы добавить данные в таблицу, используют команду INSERT INTO следующим образом:
INSERT INTO products (id, name, quantity) VALUES (1, 'first product', 20);
Посмотрим на команду INSERT INTO подробнее:
- Команда
INSERT INTOозначает, что вы собираетесь вставить новые данные products— это имя таблицы в базе данных, в которую ты хочешь вставить данные(id, name, quantity)— это список столбцов в нашей таблице, разделенных запятыми. Тебе не нужно указывать
все столбцы (иначе какой в смысл?). В некоторых случаях вы хотите выборочно вставлять данные в некоторые
столбцы. Остальные столбцы будут автоматически заполнены значениями по умолчанию.VALUES (1, 'first product', 20)— это фактические данные, которые будут вставлены в таблицу. «1» — этоid,
«first product» — этоname, «20» — этоquantity.
Выборка данных из SQL таблицы
Теперь, когда ты добавил в таблицу первую запись, ты можешь использовать SQL для
получения содержимого таблицы.
Выборка данных осуществляется с помощью команды SELECT, и это выглядит следующим
образом:
SELECT id, name, quantity FROM products;
Мы используем команду SELECT. За ней следует список столбцов, которые мы хотим получить.
Затем мы используем команду FROM, чтобы указать, из какой таблицы брать данные. На этот раз это таблица products.
id | name | quantity
---+---------------+----------
1 | first product | 50
Для ситуаций когда ты хочешь выбрать все столбцы которые есть в таблице, ты можешь поставить звездочку вместо списка полей.
Звездочка означает: выбрать все столбцы. Результат останется прежним.
Ты должен обратить внимание на то, как команда SELECT выбирает столбцы и строки. Столбцы указываются в виде списка и
разделяются запятыми. Затем команда переходит к выбору запрошенных строк.
Если условия не указаны (как в этом случае), будут выбраны все строки в таблице.
Позже мы увидим, как использовать условия с командой WHERE для создания эффективных запросов.
Обновление данных в PostgreSQL
Представь, что ты запустил свое потрясающее приложение для магазина и получили первый заказ на один из продуктов.
Первое, что нужно сделать — это обновить доступное количество в вашем инвентаре, чтобы в дальнейшем у вас не возникли
проблемы с отсутствием товара на складе.
Для обновления данных ты можешь использовать команду UPDATE:
UPDATE products SET quantity=49 WHERE id=1;
Давайте разберемся с тем как работает UPDATE.
Начинаем мы с ключевого слова UPDATE, за которым следует имя таблицы.
Затем мы используем SET, чтобы установить новые значения для наших столбцов.
После SET — пишем имена столбцов, которые
хотим обновить.
За ними — знак равенства и новое обновленное значение.
Также ты можешь обновить сразу несколько столбцов, разделив их запятыми:
UPDATE products SET name='new name', quantity=49 WHERE id=1;
Но стоп, какие строки обновляются этой командой?
Ты уже должны были догадаться об этом. Чтобы указать, какие строки
следует обновить новыми значениями, мы используем команду WHERE, за которым следует условие.
В этом случае мы сопоставляем строки, используя их столбец id, и обновляем строку с id 1.
Удаление данных из SQL таблицы
Теперь рассмотрим случай, когда ты прекратил продажу определенного продукта и захотел полностью удалить его из своей
базы данных.
Для этого можно использовать команду DELETE:
DELETE FROM products WHERE id=1;
Как и при обновлении данных, чтобы определить, какие именно строки мы хотим удалить, нам нужно условие WHERE.
Удаление таблиц в PostgreSQL
Если вдруг ты решил изменить структуру базы и для этого нужно удалить всю таблицу, то тебе подойдет команда DROP TABLE:
Это приведет к удалению всей таблицы products из базы данных.
Будь очень осторожен с командой DELETE!
Я бы не позавидовал тому, кто “случайно” удалит не ту таблицу из базы данных.
Удаление баз данных PostgreSQL
Точно так же ты можешь удалить из системы всю базу данных:
Заключение
Поздравляю, у тебя все получилось!
Ты установил и запустили PostgreSQL. Ты изучил основные команды SQL и проделали с ними несколько интересных вещей.
Эти несколько простых команд — основа, которую ты будешь использовать большую часть времени при взаимодействии с базами
данных, поэтому тебе следует пойти и потренироваться и изучить самостоятельно. В следующий раз мы погрузимся глубже и
обсудим
Базы данных, роли и таблицы в PostgreSQL
Настройка удаленного подключения к БД PostgreSQL 13 на сервере Ubuntu 18 LTS из ОС Windows 10 утилиты pgAdmin 4, двумя способами: подключение с помощью SSH туннеля и прямое подключение к серверу PostgreSQL.
? Я рекомендую использовать подключение через SSH туннель, простое в настройке и безопасное. При использовании SSH туннеля, порт PostgreSQL не открывается для внешних подключений.
Для использования SSH туннеля, необходимо настроить SSH сертификаты входа на Ubuntu.
pgAdmin — самая популярная и многофункциональная платформа для администрирования и разработки с открытым исходным кодом для PostgreSQL, самой совершенной базы данных с открытым исходным кодом в мире.
Официальный сайт pgAdmin
Узнать расположение файлов конфигурации PostgreSQL: postgresql.conf, pg_hba.conf.
ps aux | grep postgres | grep -- -DУзнать порт PostgreSQL командой:
grep -H '^port' /etc/postgresql/*/main/postgresql.conf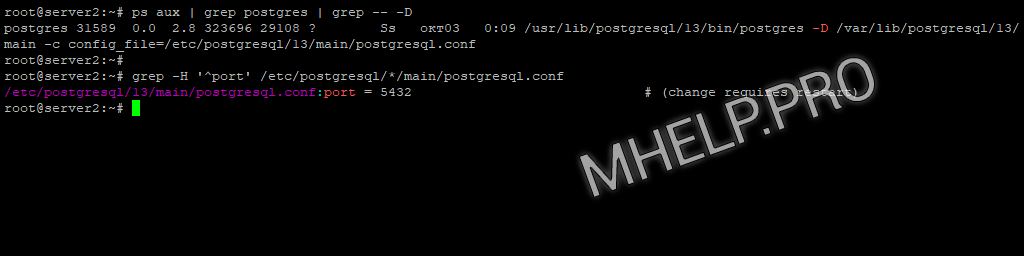
В примере, файл конфигурации PostgreSQL располагается по пути /etc/postgresql/13/main/postgresql.conf, порт подключения 5432.
Содержание
- SSH туннель к PostgreSQL
- Прямое подключение к PostgreSQL
- Частые вопросы
Статья на других языках:
?? – How to Setup Remote Access to PostgreSQL Database from Windows
?? – Cómo configurar el acceso remoto a la base datos PostgreSQL desde Windows
Подключение к серверу PostgreSQL с использованием SSH туннеля. При выборе такого типа подключения никаких дополнительных настроек на сервере PostgreSQL не требуется.
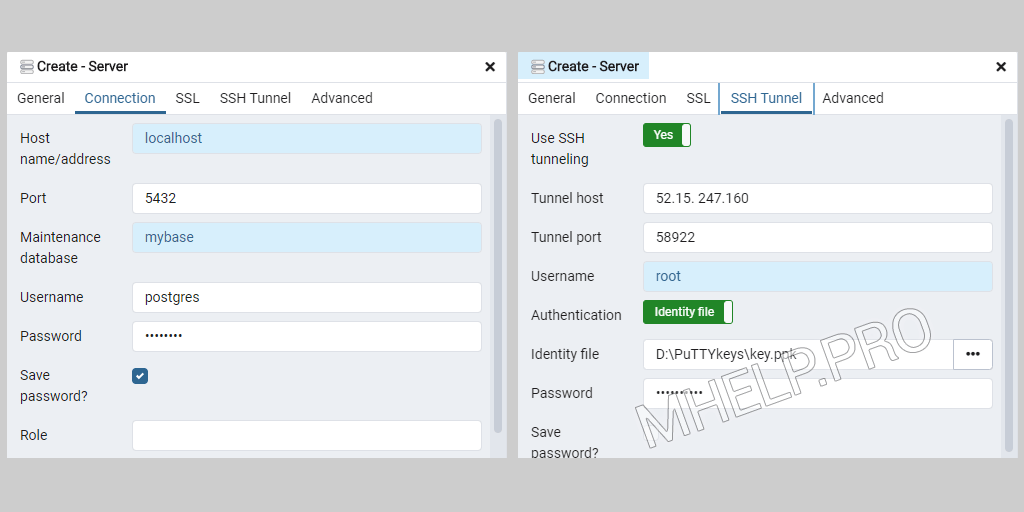
Настройка pgAdmin на Windows 10:
- Запускаем pgAdmin
- Создаем новое подключение к серверу: Object -> Create -> Server;
- Вкладка General:
- Name: название сервера (произвольное);
- Вкладка Connection:
- Host Name: localhost;
- Port: 5432;
- Maintenance database: mybase;
- Username: postgres;
- Вкладка SSH Tunnel:
- Use SSH tunneling: Yes;
- Tunnel host: myserver-IP;
- Tunnel port: 58222;
- Username: root;
- Authentication: Identity file;
- Identity file: path_key.
? В качестве ключа указываем приватный ключ id_rsa из Настройка SSH сертификатов на сервере. Как изменить порт SSH в Частые вопросы.
Прямое подключение к PostgreSQL
Для настройки прямого подключения к PostgreSQL вносим изменения в файлы конфигурации postgresql.conf и pg_hba.conf
Настройка PostgreSQL
postgresql.conf
Файл postgresql.conf находится в папке установки PostgreSQL.
sudo nano /etc/postgresql/13/main/postgresql.confРаскомментируем или добавим строку:
listen_addresses = '*'Мы разрешили прослушивание запросов от всех IP-адресов.
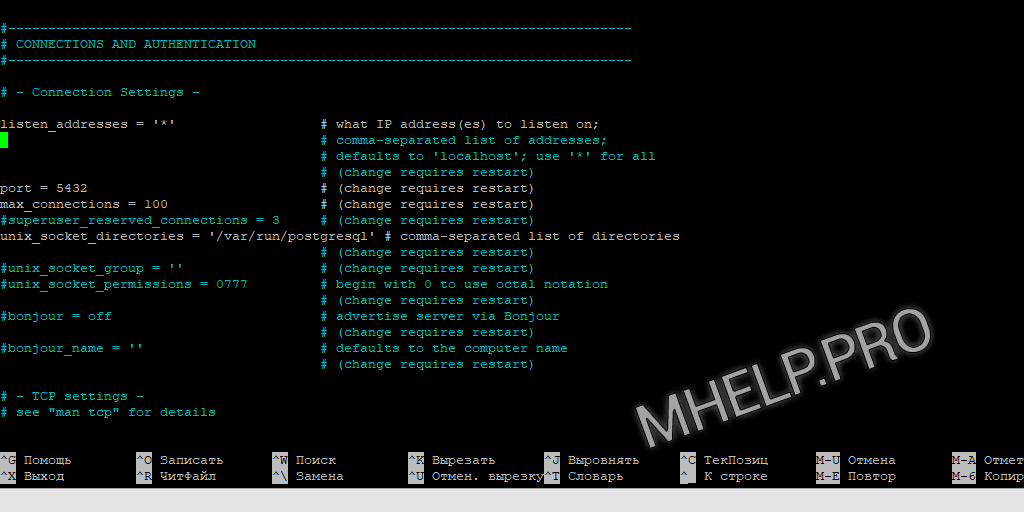
? Возможные варианты:listen_addresses = '0.0.0.0' чтобы слушать все IPv4;listen_addresses = '::' чтобы слушать все IPv6;listen_addresses = 'your.host.ip.adress' определенный адрес или список адресов через запятую.
pg_hba.conf
Файл pg_hba.conf находится в папке установки PostgreSQL.
Открываем на редактирование:
sudo nano /etc/postgresql/13/main/pg_hba.confДобавляем запись в секцию # IPv4 local connections:
host mybd postgres 41.223.232.15/32 md5Запись разрешает подключение к БД mybd пользователю postgres с IP адресом 41.223.232.15, используя пароль.
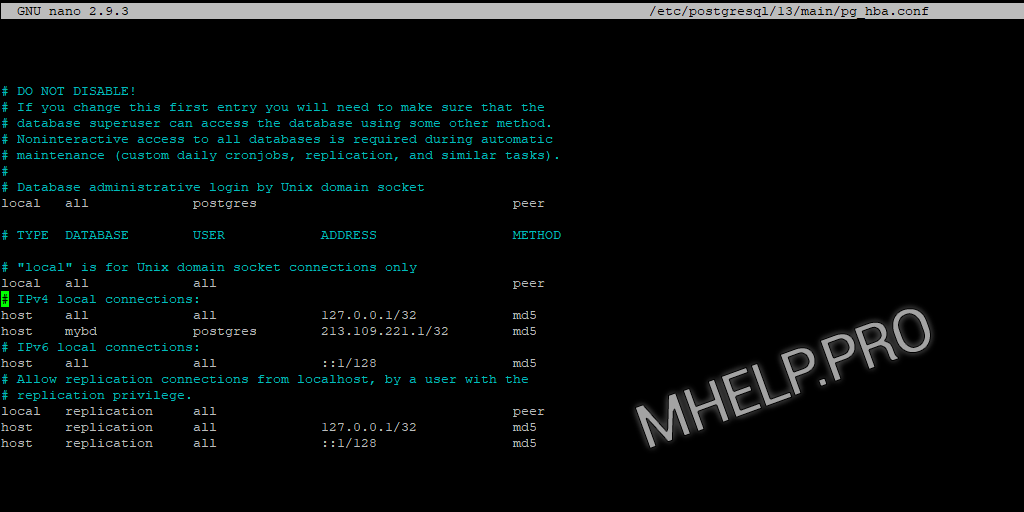
После изменения файлов конфигурации, перезапустите службу PostgreSQL.
systemctl restart postgresqlНастройка pgAdmin
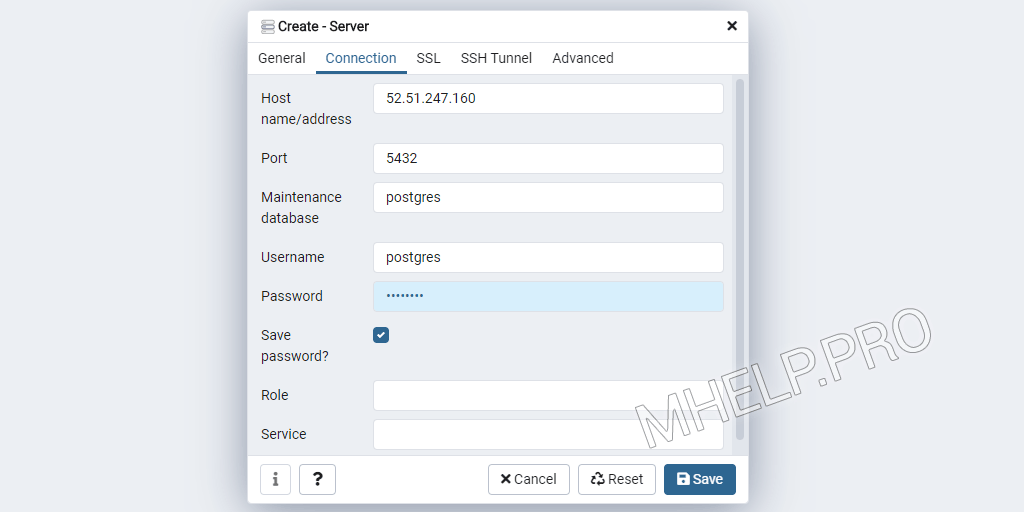
Настройка прямого подключения к базе данных PostgreSQL через интернет или локальную сеть используя pgAdmin.
- Запустите pgAdmin
- Создаем новое подключение к серверу: Object -> Create -> Server;
- Вкладка General:
- Name: название сервера (произвольное);
- Вкладка Connection:
- Host Name: RemoteServerIP;
- Port: 5432;
- Maintenance database: mybase;
- Username: postgres.
Частые вопросы
PostgreSQL как узнать расположение файлов конфигурации?
ps aux | grep postgres | grep — -D
PostgreSQL как узнать порт?
grep -H ‘^port’ /etc/postgresql/*/main/postgresql.conf
SSH как узнать или изменить порт подключения?
Файл /etc/ssh/sshd_config , строка port.
Как настроить удаленное подключение к БД PostgreSQL из Windows обсуждалось в этой статье. Я надеюсь, что теперь вы сможете настроить pgAdmin для подключения к PostgreSQL (прямое подключение или используя SSH туннель). Однако, если вы столкнетесь с каким-то проблемами при настройке сервера или pgAdmin, не стесняйтесь написать в комментариях. Я постараюсь помочь.
- Introduction
- Connect to PostgreSQL Server
- Setup ODBC
- Troubleshooting
- More Information
Introduction
This article explains how to connect to PostgreSQL with the official PostgreSQL ODBC driver psqlodbc, when using Windows 10.
It covers the following topics:
- How to connect to postrgreSQL (with code samples).
- How to setup ODBC:
- Configure ODBC using the ODBC Data Source Administrator:
We recommend using system DSNs (available to all users).
- Configure ODBC using the ODBC Data Source Administrator:
Connect to PostgreSQL Server [top]
We strongly recommend using connection objects to connect to databases, and this is what we demonstrate in the code samples.
Follow these steps to connect:
- Create a new channel to try out the code:
- Create a channel like this:
- Name: DB PostgreSQL Connection (or similar)
- Source: From Translator
- Destination: To Channel
- Alternatively use an existing channel:
Your channel will need a From/To Translator or a Filter component.
- Create a channel like this:
- Connect to a database using ODBC:
- Paste this code into the Translator:
If your script uses connection object methods
conn:query{}orconn:execute{}to connect to a remote PostgreSQL database, the location of the remote host is specified as part of the name parameter in thedb.connect{ }command. If you useconn:merge{}to connect the remote host is specified as part of the name parameter in theconn:merge{}command itself.function main() local conn = db.connect{ api=db.POSTGRES, name='your_odbc_server_name', user='your_login', password='secret', use_unicode = true, live = true } conn:execute{sql='SELECT * FROM <your table>', live=true} end - The name is the name of an ODBC source that you create using the ODBC Administrator.
- Paste this code into the Translator:
- Adapt the code to your requirements.
Setup ODBC [top]
Note: Iguana may not always support the very latest version of the PostgreSQL ODBC drivers, so you can simply download an earlier version if necessary. This is particularly true if you are not able to use the the latest version of Iguana.
If you need to know which versions of PostgreSQL are supported by the version of Iguana you are using please contact us at support@interfaceware.com.
To set up a new ODBC data source for PostgreSQL:
- Install the latest PostgreSQL ODBC drivers:
- Download the latest 64 bit driver installer (zipped msi file) from the psqlodbc download site.
- Unzip the file.
- Run the msi installer and accept the defaults.
- Open the 64 bit ODBC Administrator:
Windows 10 (64 bit version) supports 32 and 64 bit ODBC sources — always use the 64 bit ODBC Administrator.
- Open the System DSN tab and click Add:

- Choose the latest PostgreSQL ODBC driver and click Finish:

- Enter the ODBC credentials:
- Use any Data Source and Description you prefer.
- Optional: Choose your default Database.
- Enter the Network Name of the PostgreSQL Server in the Server field:
Note: If you are unsure of the name ask your DBA (database administrator). - Optional: Enter the Port number (default = 5432)
- Enter the User name and Password:
Note: If you are unsure of these ask your DBA (database administrator).

- Test the data source connection:
- If the connection does not work speak to your DBA (database administrator) about how to login to the database (user authentication).



Troubleshooting [top]
- Problems with connection settings:
Speak to your DBA (database administrator) for general connection issues like: User name and password, Database Server network name etc.
- Iguana may not always support the very latest version of the psqlodbc ODBC drivers:
Please contact us at support@interfaceware.com if you need to know the latest supported version of the psqlodbc ODBC drivers.
- Incorrect port number:
SQL Server defaults to port 5432, but a different port can be used. Speak to your database administrator (DBA) or network administrator.
- Using integrated security:
Using integrated security is the usual way to connect to a Microsoft SQL Server database. If this does not work speak to your DBA (database administrator).
If you need more help please contact us at support@interfaceware.com.
More Information [top]
- Using Database Connection Objects
- Forum thread on Windows ODBC
- Using Integrated Authentication, Microsoft SQL Server documentation (kerberos etc)
- Connect to PostgreSQL from Linux or Mac with ODBC