Существует миф:
PostgreSQL на ОС Linux, запущенной в виртуальной машине на Windows, работает быстрее, чем PostgreSQL на той же Windows
Оригинальная статья
Несколько раз слышал такое, в том числе от Антона Дорошкевича в одном из выступлений.
Сравним на одной Windows 10 машине тест гилева(без настройки postgresql.conf)
с PostgreSQL, версия 10.5-24.1C
на Windows
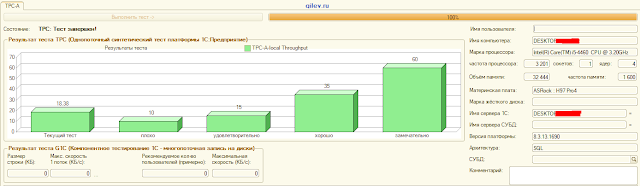
с PostgreSQL, версия 10.5-24.1C на Linux на виртуальной машине vbox сервер 1с на Windows

На той же Windows машине 1C и PostgreSQL под Linux на vbox guest host на Windows

Тест расчета зарплаты на 3000 сотрудников (с оптимизацией postgresql.conf):
с PostgreSQL, версия 10.5-24.1C на Windows
Заполнить 317
Провести 215
с PostgreSQL, версия 10.5-24.1C на Linux на виртуальной машине vbox сервер 1с на Windows
Заполнить 465
Провести 371
На той же Windows машине 1C и PostgreSQL под Linux на vbox guest host на Windows
3. Заполнить 740
Провести 647
Тест под Windows на другом подобном железе I5
PostgreSQL, версия 10.5-24.1C windows 10 postgresql.conf
Заполнить: 285
Провести и закрыть: 215
Короче миф не нашел подтверждения.
Посокольку не ставил целью сравнивать работу из под windows с нативным линуксом, не подготовил стенд, сравним с тем что было измерено ранее:
Тот же тест Ubuntu 16.04
Установка сервера 1с на бюджетном CPU
Более слабое железо, ниже частота процессора, SATA2
G2020
с настройкой postgresql.conf и без тж
Заполнить: 229 с
Провести: 222 с
1cfresh.com
Заполнить: 225 с
Провести: 260 с
i7-6700
1. Без настройки postgresql.conf и без тж
Заполнить: 156 с
Провести: 114 с
Для i7-6700:
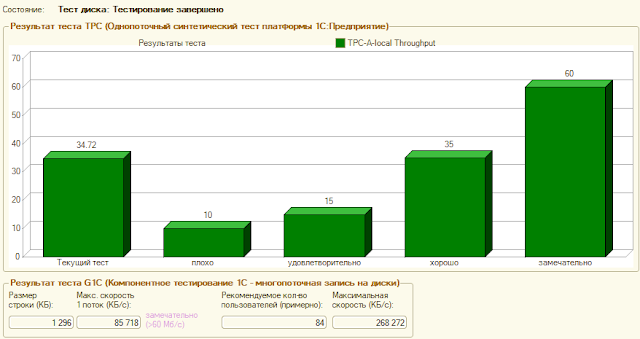
Вывод (сравниваем с G2020 более слабое железо):
1. под Linux (при установке Linux непосредственно на железо) система 1С + PostgreSQL работает минимум в 1,5 раза быстрее (скорее в 2), чем аналогичная на Windows.
2. Linux установленный поверх Windows на виртуальной машине (VirtualBox), даёт замедление работы 1С + PostgreSQL на Linux по сравнению с 1С + PostgreSQL установленной на Windows.
3. PostgreSQL установленный на Linux установленный поверх Windows (cредства виртуализации VirtualBox под Windows) даёт замедление работы 1С (Windows)+ PostgreSQL (Linux) по сравнению с 1С + PostgreSQL установленной на Windows.
PostgreSQL will definitely run faster on Linux than on Windows (and I say this as one of the guys who wrote the windows port of it..) It is designed for a Unix style architecture, and implements this same architecture on Windows, which means it does a number of things that Windows isn’t designed to do well. It works fine, but it doesn’t perform as well.
For example, PostgreSQL uses a process-per-connection model, not threading. Windows is designed to do threading. If your application does lots of connect and disconnects, it will definitely run significantly slower on Windows, for example.
There is also some assumptions around the filesystem which don’t exactly favor NTFS.
The one thing you really need to think about — if you are on Windows, most antivirus products will bug out when used with PostgreSQL, because they are not used to this type of workload (such as 1000 different processes reading and writing to the same file through different handles). That means that the strong recommendation is to always uninstall any antivirus if possible (just disabling it or excluding the PostgreSQL processes/files is often not enough). And this is not just for performance reasons, but also stability under load.
In September, I was in Paris for the Postgresql Sessions, invited there by Dalibo.
Thanks again ! It was definitely a life-changing event for me !
While discussing with some of Dalibo’s employees, one of them made a remark that triggered my internal challenge instinct.
He said that postgresql in Linux in a VM in Windows is faster than PostgreSQL on the same Windows.
As I’m new in the postgresql/linux world, I was baffled by this information but when I requested numbers for it, he had none.
I understood that it’s was just a boutade (I’m quick to understand when one explains it multiple times) and that he just meant that PostgreSQL on Linux was faster than on Windows.
Linux architecture vs Windows architecture.
To understand his speed claim, one has to understand the main difference regarding architectural design between Windows and Linux.
Linux can fork while Windows can’t !
But WTF is a fork ?
With a quick summary, a fork is a system call that allows a process to create child processes of itself and both new processes keep on their businesses.
They can both share their memory and communicate together.
This is a standard development technique in the Unix/Linux environment, but this is not standard at all for windows… as fork doesn’t exist in windows.
It doesn’t exist and you shouldn’t try to do it, this is not standard architecture for windows application.
If you’re building an application with this kind of architecture on windows, it should be based on thread instead, or even better, if you’re building it in .NET, you should build it with async !
But if fork doesn’t exist on windows but the postgresql code is the same for linux and windows, and that it forks in linux, what does it do ?
Well the brilliant PostgreSQL developer created a system for windows that emulates the fork … with threads !
Kudos to them for that, because now we have postgresql on Windows !
But let’s come back to the boutade, it is supposed that because of this custom «fork», PostgreSQL on Windows is slower than on Linux.
As with the popular «Pics or it didn’t happen», I was craving for numbers to have a proof for that.
The only benchmark I could find is one from RedHat, found on the developpez.net forum.
Some may say that it’s not entirely impartial due to the fact that it was made by RedHat.
The Situation.
The client I’m currently working for as a FULL Windows infrastructure and they are planning to have more and more PostgreSQL because .. $ORACLE$ !
So before going further with PostgreSQL on Windows for our new apps, I wanted to be sure that it was the best option because :
- It has to withstand time ! (We are currently working with a system that was written in 1993, the year the mosaic browser and the first Pentium cpu were released !Therefore, with a little extrapolation, the new apps we’re building now will still be working in 2037).
- It has to be reliable.
- It has to be efficient.
If we had to move to Linux, maybe the best time is at the start, not the end…
So, for each point, I came to the conclusion that :
- Windows and Linux where there in 1993 and are still here, so that’s fine for me. (Windows NT and Slackware both started in 1993)
- PostgreSQL started in 1995 and a lot of users are using it now without issues and recently Gartner has put them in the leader quadrant, so this is also fine for me.
- That’s the missing link, I don’t know for sure that it’s better on Linux or Windows.
So what can I do to find the missing link ??? Do a benchmark myself !
The benchmark
For this benchmark, I want :
- A very simple scenario
- To isolate the benchmarked components.
- To see if PostgreSQL on Linux is faster/slower than on Windows with the same client. (Because I want to test the server !)
- To be the closest possible to a «real life» scenario.
- To be in the cloud. Why ? Because a lot of future apps will be built in the cloud… and I don’t have a sufficient infrastructure at home to test it.
«The database»
Remember KISS ? (Not that KISS)
create table table_a( thread_id int, a_value int);
create index on table_a(thread_id);
insert into table_a(thread_id,a_value)
select * from generate_series(1,10) as thread_id ,generate_series(1,100000) as a_value;
«The Client »
Windows 2012 R2 server on amazon, m4.xlarge type, with all the default settings.
The client «application» is composed of 3 console apps that launches 5000 tasks each, available on github https://github.com/jmguazzo/TestPostgresqlPerf.
Each task does 1 select and 1 update of a random record on the table_a.
The output of the application is composed of the following resultsApplicationId RunningTasks TaskDuration EndTime
7fef1…c1 31 9530868 03:46:01
The tasks duration value is in Ticks but I took the liberty to convert it to seconds while analyzing the results.
The console application is in C# and uses NPGSQL 3.0.3.
«The Windows Postgresql Server » aka WS
Windows 2012 R2 server on amazon, m4.xlarge type, with all the default settings.
Postgresql 9.4.5 installed with the wizard.
I changed the max_connections to 300, listen_addresses to * and the required changes to pg_hba.conf for the connection to work.
«The Linux Postgresql Server » aka LS
Amazon Linux AMI, m4.xlarge type, with all the default settings.
Postgresql 9.4.5 installed with yum.(I had to google that part a little as this was quite new for me!)
I made the same changes for postgresql.conf and pg_hba.conf as the one I made for Windows.
Results
For a simple «mise en bouche», here are the execution time for the creation of the table
My laptop
Query returned successfully: 1000000 rows affected, 14624 ms execution time.
WS
Query returned successfully: 1000000 rows affected, 9374 ms execution time.
LS
Query returned successfully: 1000000 rows affected, 3859 ms execution time.
From there, I’m baffled, Linux is definitely faster.
(And now that we know that my laptop’s quite slow, I won’t include it in other results…)
Total Executions
As explained before, the test consist of 15.000 executions of 1 SELECT and 1 UPDATE.
While running the test on LS, I had 8 «Timeout while getting a connection from pool» errors.
And to be honest, I expected to have more errors with Windows than Linux, so I guess that’s another flabbergasting based on assumptions…
When an error occurs during an execution, my projects output a -1 for duration as shown hereunder :
7fef1…c1 31 541229671 03:47:09
7fef1…c1 31 -1 00:00:00
Therefore,
I have to remove those 8 executions from my statistical analysis, and I
will remove 8 executions from the WS results.
I was quite puzzled for deciding which one to remove so I removed them around the median value.
Durations
| Server | Minimum | Maximum | Average | Median |
|---|---|---|---|---|
| WS | 0,1093749 sec | 121,6842917 sec | 1,0363515 sec | 0,8280406 sec |
| LS | 0,1249964 sec | 108,2615642 sec | 1,0234334 sec | 0,9374624 sec |
So what can we assume from this ?
On the Minimum duration, WS was almost 15% faster but on the Maximum, it was 10% slower than LS.
For the average duration, WS was 1% slower than LS. But as the saying goes, if my head is in the oven and my feet in the fridge, on average I’m good !
Due to the median being at the half of the results and the fact that we have 14992 valid results (15000 — 8 errors), the median is at result n° 7496.
WS is 10% faster if we look at the time
only; but if we look at the full results, I had
to get to the WS execution n° 8543 to have a duration of 0,93746 sec.
So more than 1000 executions on WS ran faster than the median on LS.
Response Time vs Throughput
I didn’t want to analyze traffic/throughput because most of the time, it’s useless, especially regarding the application I made and the fact that I’m using the cloud.
I find it always difficult to measure hardware precisely as, for me, analyzing it while using it is close to Schrödinger’s Cat !
I was more obsessed with response time as my memory was always ringing this research from Jakob Nielsen that give the following limits for response time :
- 0.1 second is about the limit for having the user feel that the system is reacting instantaneously, meaning that no special feedback is necessary except to display the result.
-
1.0 second is about the limit for the user’s flow of thought
to stay uninterrupted, even though the user will notice the delay.
Normally, no special feedback is necessary during delays of more than
0.1 but less than 1.0 second, but the user does lose the feeling of
operating directly on the data. -
10 seconds is about the limit for keeping the user’s attention
focused on the dialogue. For longer delays, users will want to perform
other tasks while waiting for the computer to finish, so they should be
given feedback indicating when the computer expects to be done. Feedback
during the delay is especially important if the response time is likely
to be highly variable, since users will then not know what to expect.
I took the hypothesis that if your DB + your Web
Server must respond in less than 10 sec, I’d give half the time to the
DB and therefore :
| Server | Quantity of execution faster than 5 sec |
| WS | 14913 |
| LS | 14926 |
There’s only a 0.001% difference between WS executions and LS.
And for both systems, more than 99% of executions took less than 5 sec.
Let’s put it all together
| Windows | Linux | Winner | |
| Number of executions | 15.000 | 15.000 | Both ! |
| Number of errors | 0 | 8 | Windows |
| Minimum duration | 0,1093749 sec | 0,1249964 sec | Windows |
| Maximum duration | 121,6842917 sec | 108,2615642 sec | Linux |
| Average duration | 1,0363515 sec | 1,0234334 sec | Linux |
| Median duration | 0,8280406 sec | 0,9374624 sec | Windows |
| Quantity of execution faster than 5 sec | 14913 | 14926 | Linux |
The infrastructure I used was on Amazon and
my results may have been impacted by some actions outside of my
control… which, by the way, will always be the case when you’re using the cloud.
Moreover, the differences aren’t statistically significant IMHO, but you could always debate.
With those results, I won’t say that PostgreSQL on one OS is faster than on the other.
And, to answer my own request, I won’t advise my client to migrate to Linux because of PostgreSQL performance. (You could argue that there are more tools for PostgreSQL on Linux than on Windows but that was not the point here)
For me, PostgreSQL performance on Windows is not better nor worst, it’s at par with Linux !
All the results are available on my github.
- Главная
- Карьера
- Блог о жизни франчайзи
Про 1С от наших сотрудников
24 Декабря 2018
Предыстория
MS SQL – наш давний друг. И около 15 предыдущих лет мы жили с полной уверенностью, что для 1С нет лучшего выбора, чем MS SQL. Oracle — сильно дорого, IBM никто в живую не видел, а про Postgres на тот момент совсем ничего не было слышно.
Примерно пять лет назад в мире 1С начал появляться Postgres, за что большое спасибо команде Postgres Pro: Олегу Бартунову и Федору Сигаеву, которые продвинули эту СУБД. Как раз в это время у руководства нашей компании появилась задача резко вырасти в масштабах ИТ-инфраструктуры 1С. При этом была поставлена задача максимально сэкономить бюджет. Мой хороший друг, а по совместительству эксперт по техвопросам 1С сказал: «Антоха, кто не рискует, тот потом на Инфостарте не выступает!». И мы рискнули. И я выступаю на Инфостарте.
Первый опыт работы с PostgreSQL на Windows
С чего мы начали? В 2014 году рискнули перевести 5 баз 1С общим объемом порядка 100 гигабайт на Postgres. Не сразу стали перепрыгивать бездну нашего незнания между Windows и Linux, а мир 1С, мне кажется, до сих пор на 80% это мир Windows. Поэтому сначала решили перепрыгнуть пропасть незнания между двумя базами данных: MS SQL и PostgreSQL.
Мы запустили Postgres на Windows. Сначала сильно удивились, что оно заработало. В целом все завелось, заработало, даже база открылась. Правда, потом начались бессонные ночи и дни без обеденного перерыва в попытках настроить Postgres так, чтобы он работал хорошо.
На момент 2014 года информации никакой нет. Есть английская документация, а в мире 1С английский язык не в почете: вы даже код пишете на русском. Поэтому читать тяжело, понимать еще тяжелее. И по сравнению с дружественным интерфейсным MS SQL, где вся настройка – это 5 галочек и 2 цифры, настройки в Postgres – это сотни параметров, слишком непонятно, как и на что отреагирует система, отреагирует ли вообще. Менять приходилось по одному параметру, потому что иначе вообще не поймешь, на что была реакция. А очень часто смена одного параметра не давала никакой реакции. Вот так мы и жили примерно полгода до момента обнаружения той самой ошибки, которая сейчас уже исправлена. О ней рассказывал Олег Бартунов.
Это была фантастика. Я на прошлой конференции по Postgres в Москве рассказывал об этом отдельно. Мы долго не верили своим глазам, будучи уверенными, что это мы неопытные и неправильно настроили систему. Потому что не может так база данных себя вести.
Там происходило очень чудесная вещь: у Postgres есть много файлов статистики. Один из них на весь сервер, и он переименовывается несколько десятков, может быть, сотен, может быть, тысяч раз в секунду. Так построена система: она создает рядом новый файл статистики, переименовывая его в действующий. А наша любимая Windows не дает так работать с файлами в своей файловой системе. Если файл кто-то читает, переименовать его нельзя. Postgres по-честному пишет, что у него нет доступа к статистике, поэтому он будет использовать старые файлы. Ладно, используй. Но нет, происходило 15-ти секундное торможение всего сервера, просто на 15 секунд останавливались все транзакции.
Мы долго не верили своим глазам, мы боялись рассказать это разработчикам. Что они бы подумали? Что какие-то дураки взялись за систему, и теперь непонятно, что от нас хотят. В итоге мы боролись-боролись, но не побороли. И все-таки написали письмо в Postgres Pro. Там тоже долго удивлялись, не верили, что такое может быть. Потом подтвердили, что, действительно, есть косяк. Пообещали исправить.
Отказ от Windows
Но у нас время поджимало. И мы решили прыгать через пропасть незнания в Linux. Это вообще кошмар. То есть система Linux – хорошая, но кошмар для админов, которые всю жизнь жили на Windows. Ни красивых окошек, ни мышек, ни кликов, даже диспетчера задач нет. Есть какие-то черные окна с белыми буковками. Когда разберешься, буковки станут цветными. Но это все, что ожидает админа в Linux. Какие службы работают, как что куда поставить – ничего не понятно. Там уже бессонные ночи начались не только у 1С-ников, но и у админов. Но примерно на 20-ой инсталляции CentOS все, вроде, стало хорошо.

Запустили Postgres, и он тоже заработал. А мы к тому времени уже были крутые чуваки в настройке Postgres, и мы его сразу настроили: и статистику внесли в оперативную память, и все параметры включили как надо.
На текущий момент мы пришли к такой ситуации: у нас 400 с лишним баз, 15 терабайт данных, все это крутится на Postgres на Linux, все сервера Postgres имеют реплики, кто-то имеет каскадные реплики, кто-то имеет несколько реплик на один мастер. То есть это не просто какая-то одноранговая система баз данных. Мы там снимаем бэкапы (backup) с реплик, мы можем восстановить бэкап с рабочей базы в тестовую или базу разработчиков одной строчкой, сохраняя транзакционную целостность данных, при этом не создавая файла бэкапа.

Самое удивительное – все есть в документации! Ты на грабли наступил уже 15 раз, все попробовал, думаешь, что «открыл Америку». Заходишь в документацию, а там прямым текстом написано все то, что ты открывал до этого три дня. Понимать эту документацию ты начинаешь только тогда, когда несколько раз уже окунулся в саму практику.
Так мы счастливо живём до сих пор.
Тестирование
В какой-то момент задумались, а может, нам страсть к Postgres на Linux застила глаза, и нам только кажется, что все хорошо работает. Решили попробовать подтвердить, что работает как минимум не хуже чем с MS SQL, а может быть, если и хуже-то, то совсем чуть-чуть.
На самом деле, когда приступали к нагрузочному тестированию, вся моя команда, скрестив пальчики думала, ладно, пусть Postgres проиграет, но проиграет не сильно. Все-таки он еще новенький, может быть, нами еще не до конца изученный, но очень активно развивается, и как рассказывал Олег Бартунов, будет очень много крутых фишек в версиях 10 в 11.

На момент организации нашего батла была версия 9. И мы решили, что площадкой для батла будет Windows 2012 R2. Почему Windows? Это для того чтобы соревнование было совсем честным, не учитывая операционные системы, просто проверка двух баз данных.
Итак, в красном углу ринга – заслуженный чемпион, обладатель всех поясов производительности 1С, имеющий любые регалии в мире 1С – Microsoft SQL server версия 2016, последняя поддерживаемая на данный момент.
В синем углу ринга – наш новичок, претендент, PostgreSQL. Он выступает сразу двумя бойцами, каждый бьется по очереди. Это Postgres 9.6 и Postgres 10. Обе версии на данный момент поддерживаются 1С.
Платформа взята последняя релизная на момент тестирования. Все сервера баз данных располагаются на одном и том же железе, это прямо одна и та же коробочка. Все настроено оптимально: и дисковые подсистемы, и процессор, и сервера баз данных (оптимально, согласно требованиям фирмы 1С и нашему опыту). Плюс к этому все настроено на многопользовательскую нагрузку, в том числе параллелизм отключен: и на MS SQL, и на Postgres стоят единички.
Первый раунд
В первом раунде тяжелая операция – загрузка DT 40 с лишним гигабайт, итоговая база почти 2 терабайта. Сразу оговорюсь, если заглянуть в интернет, там будет много информации о том, что в DT не выгружается база, потому что она более 100 гигабайт, и ничего не работает. Все работает, надо только правильно настраивать сервер 1С, надо понимать, куда сервер 1С выгружает DT. Подтверждаю на своем опыте: база до 5 терабайт (больше не приходилось выгружать) из DT загружается и в DT выгружается. Все остальное – это неумение настраивать сервера 1С.
Первые результаты. С явным преимуществом побеждает MS SQL. Он в 2 раза быстрее загрузил данные в DT. Оба загружали очень долго, Postgres – почти двое суток, а MS SQL – почти сутки.

В то время как раз был шум про мельдоний (скандал в СМИ), и мы тоже решили обратиться к допингу. Решили использовать топ вредных советов из интернета на запрос «1С + Postgres тормозит». Первый совет – отключить fsync. Отключили. Получили другой результат – на 10% быстрее, чем с включенным, но риски несоизмеримы. Потому что такое отключение приведет к потере всего сервера баз данных. Вы не сможете ничего восстановить при аварийном завершении. Никогда так не делайте! Это самый вредный совет, который только может быть. Если вдруг вам действительно помогло отключение fsync, и все заработало в 10 раз быстрее, Это значит что у вас сервер неправильно настроен, начиная с самого низкого уровня – с железа, с дисками.
Fsync отключать нельзя никогда!
Но что такое есть в Postgres, что он загружает данные в DT в 2 раза дольше? Наши исследования показали, что это «create index». Он создает индексы намного медленнее MS. В начале 2018 года разработчики обещали, что в версии 12 эта ситуация улучшится. Ждем с нетерпением, думаю, тогда даже в этом раунде мы будем близки к MS SQL.

Второй раунд
Тут уже практически пользовательская нагрузка. Операция, на которой проводится тестирование, – восстановление последовательности партионного
учета управленческих партий. Это последняя УПП на момент тестирования, код типовой. Также типовой клиент, у которого итоги рассчитаны на полгода назад. Я не знаю, почему у клиентов такая амнезия по поводу этой регламентной операции, но никто не хочет следить за итогами. Почему, никто объяснить тоже не может. Поэтому берем типовой код, типового клиента, в самих партиях за месяц 150 тысяч документов, а строк в документах около 2 миллионов.
Все это делаем в 10 потоков. Это уже чуть-чуть не типовой этап, сделана определенная обработка, но внутри все запросы типовые.
В результате у нас получилось, что Postgres всего на 4% лучше. Делалось все очень долго – порядка 18 часов. И бухгалтеры будут вынуждены весь день не работать, чтобы дождаться результатов.

Поскольку результат получился не очень большой, плюс 4%, решили вместо
мельдония использовать что-нибудь похлеще. Второй в рейтинге вредных советов интернета на запрос «1С + Postgres тормозит» оказалась рекомендация отключить autovacuum. Отключили.
Результат получился еще хуже – примерно на 5%. То есть если бы мы изначально настроили систему с помощью этого вредного совета, мы бы вообще раунд полностью проиграли, было бы минус 0,6%.
На этом хочу остановиться чуть подробнее. Что за зверь такой autovacuum, зачем он нужен. И почему разработчики Postgres на каждой конференции твердят: «Не отключайте autovacuum!», но народ упорно его отключает. Попытаюсь объяснить, как говорят, на пальцах.
Чтобы понять, для чего нужен autovacuum, нужно понять, как Postgres работает с данными. Операция insert – записали строчку. Помимо строчки, пишется еще два служебных параметры x min и x max. В x min записывается номер транзакции, которая выполнила этот insert. Операция delete на самом деле ничего не удаляет, она просто в служебное поле строки x max записывает номер транзакции, которая ее удалила. Потом идет самая прикольная операция update. На самом деле нет такой операции, это просто delete + insert.

А в мире 1С, к сожалению, просто обожают работать задним числом: для пользователей не вопрос перевести месяц или год. То есть апдейтов миллионы. У нас не столько растут данные с помощью insert, сколько с помощью update, мы постоянно что-то обновляем. Из-за этого база имеет эффект распухания. Ладно, пусть раздувается, скажем админам, что это их проблемы, пусть увеличивают диски. Они увеличат. Но если было бы все так просто, никто не заморачивался бы. Проблема в том, что данные хранятся не где-то в сферическом вакууме, они хранятся в страницах. И когда у вас в страницах хранится куча мертвых данных, а в Postgres есть такое страшное понятие, как мертвые строчки, и когда вы делаете запрос базе данных, движок вынужден поднять все страницы с данными, отфильтровать данные, в которых x max пустой, и только с ними потом работать. Вы каждый раз заставляете Postgres ставить олимпийские рекорды по поднятию данных с дисков, чтобы выдать вам выборку.

Что делает autovacuum? Autovacuum – это своеобразный пылесос, он циклически и периодически идёт к каждой таблице вашей базы данных и делает выборку всех данных, где x max не пустой и чистит их физически. Теперь туда insert возможен, у вас на страницах будет больше живых данных, чем мертвых. Эффект – вам проще поднимать страницы. Это первое.
Второе. Помимо чистого autovacuum, есть еще такой фоновый процесс autovacuum analyze. Это аналог фонового обновления статистики в MS SQL. Без него планировщик никогда не узнает, что вы в таблицу добавили данные. Было в таблице 100 записей, добавили вы миллион записей, но планировщик свято уверен, что там их 100. И при любом запросе не парится и не ищет никакие индексы. Он просит TableScan, ему его дают, а там миллион записей. И вы сидите и ждете несколько минут.
Поэтому никогда не выключайте autovacuum. Надо его правильно настраивать, но ни в коем случае не отключать. Он имеет кучу настроек, и если у вас autovacuum настроен достаточно агрессивно, то есть он срабатывает на очень маленьком проценте изменения данных в таблицах, то вам не нужны даже ночные и недельные регламенты над базой данных, которые имеются у MS SQL. Ничего не надо делать, просто ничего. Кое-что делают только админы, если точно знают, что в этой таблице недавно удалили огромный массив данных, и ее нужно, грубо говоря, сжать. Тогда делается autovacuum full – это реструктуризация таблицы в понятиях 1С. Рядом создается табличка, куда и копируются данные.
В других случаях вам никакие регламенты, ни ночные, ни недельные, не нужны. Autovacuum все сделает за вас. Только настраивайте его правильно.
Третий раунд
Та же самая операция, но бойцам меняем тренера. Приглашаем эксперта по техвопросам, он месяц чешет затылок, два часа кодит, меняет пару запросов. Особо большой эффект дал запрос, где поменяли получение остатков на момент документа. Клиент остается типовой с амнезией по поводу пересчета итогов. Запускаем!
В этом раунде Postgres выигрывает с явным преимуществом.

Гораздо благодарнее отнесся к более правильному коду, код правильный в той части, что поднимает гораздо меньше данных, намного меньше данных. Postgres выиграл почти в 2 раза, а по сравнению с изначальным временем выполнения процедура целиком стала выполняться в 3 раза быстрее. И это после вмешательства компетентного специалиста 1С, который понимает, что делать. Я даже думаю, что, обновив весь сервер за космические деньги, вы вряд ли добьетесь большего ускорения, если будут неправильные запросы.
Ничего бы этого не произошло, и этого бы доклада не было, и Postgres бы у меня не было, если бы в свое время Фёдор Сигаев – ведущий разработчик команды Postgres Pro, а также один из всего лишь двух коммитеров во всей России не создали патч OnlineAnalyze для 1С.

Что это такое? Во всем нормальном мире база данных считает, что временные таблицы – это чуть ли не ошибка проектировщика базы данных, и уж точно ошибка программиста, который просто не умеет писать правильные запросы. И считает, ну ладно, раз уж так случилось, простим, создадим этим неучам временную таблицу. Она в любом случае будет очень маленькой – на сотню, может, тысячу записей, но ни в коем случае не на миллионы и не на миллиарды, как это в 1С сделано. 1С вся построена на временных таблицах: на любой запрос мы создадим временные таблицы. И тут возник вопрос о быстродействии Postgres в связи с этим. Postgres крайне прохладно относится к временным таблицам, он их вообще «за людей не считает». Это просто какой-то артефакт, который создался. А мы же когда пишем кода в 1С, мы даже индексируем временные таблицы (прямо индексы по ним создаем). А Postgres на все плевать, потому что планировщик просто не в курсе, что это за временная таблица, сколько там записей, что в ней есть индекс. Он ничего не знает. Он всегда пользуется TableScan и все.
И был разработан патч OnlineAnalyze, который заставляет наш autovacuum analyze, грубо говоря, проверять и временную таблицу. Причем, заставляет ее проверять мгновенно во время создания и еще каждые новые тысячи записей. Он их проверяет, анализирует, и таким образом у нас планировщик запросов четко знает, сколько записей в этой таблице, что за индексы по ней, и строит запрос правильно.
Ради интереса отключили OnlineAnalyze. Получили результат тестирования в 17 раз хуже. Мы прождали несколько дней, она у нас все-таки посчитала, результаты упали в 17 раз.
К сожалению, в своей практике сталкиваюсь очень часто и даже на очень крупных предприятиях, на которых есть Postgres и которые уже поискали ответы в интернете на запрос «1С + Postgres тормозит», что люди следуют этим 2 вредным рекомендациям. А тем временем в самом конце конфигурационного файла есть строчка OnlineAnalyze.enable = off. Но если поправим настройку на on, все взлетает.
Я вас призываю, если у вас уже стоит Postgres, посмотрите свои конфигурационные файлы. И включите патч, включите! Это очень крутая вещь.
И еще один момент. В последней сборке Postgres, опубликованной на сайте 1С, к сожалению, этого патча нет. Его просто нет в строчке предкомпилированных библиотек, он в настройках есть и даже внизу включен, но его нет в строчках предкомпилируемых библиотек. Надо добавить. Внимательно отнеситесь: патч должен быть, патч должен быть включен. И будет резкий рост производительности.
Финальный раунд
На этот раз меняем нашего типового клиента на идеального, который не страдает амнезией, и пересчитываем итоги на начало расчетного месяца. Запускаем ту же самую операцию. Получаем еще раз двухкратное ускорение той же самой операции, а по сравнению с первыми результатами, когда операция длилась почти 18 часов, ускорение в 6 с лишним раз.
И тут Postgres опять выиграл. Он опять более благодарно отнесся к порядку в данных, чем MS. Выиграл не так круто, как на старых итогах, но все-таки на четверть быстрее – это очень серьезный результат.

Итоги батла
Итак, Postgres выиграл со счетом 3:1. Но хочу обратить внимание, что на пользовательских нагрузках, а именно многопоточное проведение документов, участвующих в восстановление последовательности партионного учета, Postgres выиграл вообще со счетом 3:0. Вот такие противоречивые результаты.

Postgres на Linux и Postgres на Windows: что лучше
Сами удивились, сами себя похвалили, какие мы молодцы, что 5 лет назад сделали крутой выбор. Но встречаем очень часто вопрос: стоит ли переходить на Postgres.10 на Windows.
Тот самый злополучный баг Postgres, когда система замирала на 15 секунд из-за недоступности файла статистика исправлен в версии Postgres 10.4.1. Говорю об этом отдельно, потому что эта версия на данный момент 1С не поддерживается. Она есть только на сайте Postgres Pro, мы ее поставили и запустили ради этой конференции. Что получили? При 10 потоках все почти одинаково, что на Postgres версии 9, что на Postgres версии 10. При 20 потоках Postgres.10 в 3 раза быстрее. Я бы даже сказал иначе: Postgres.9 на Windows в 3 раза медленнее, потому что возникает та самая блокировка, замирание на 15 секунд. Причем, оно рандомное, то есть вы не угадаете, это будут замирания один раз в минуту или у вас будет секунда работы, 15 секунд замирание и так тысячу раз.
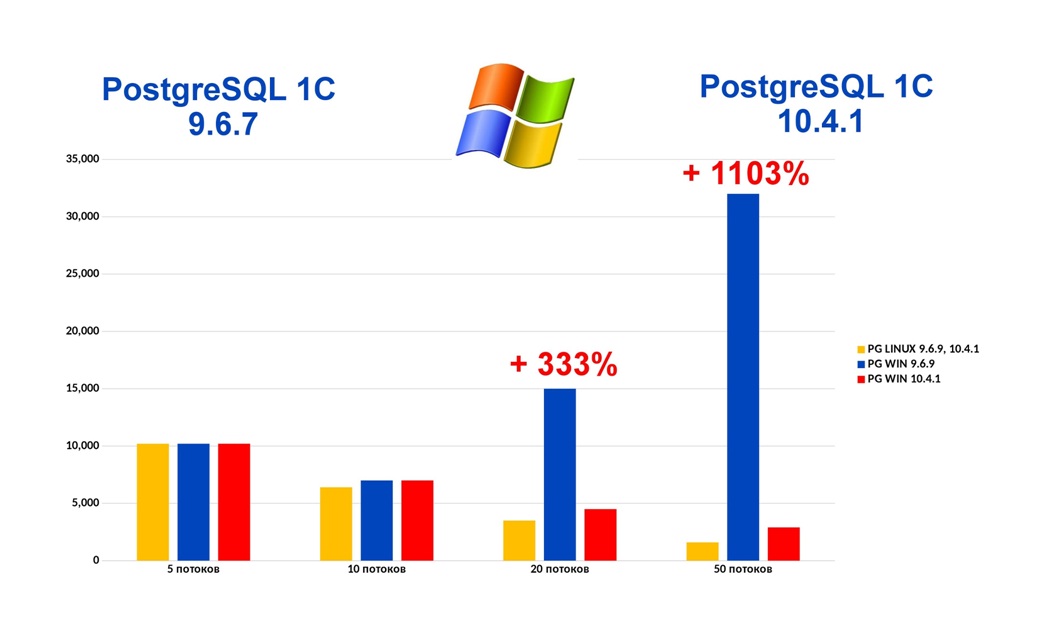
При 50 потоках Postgres.9 медленнее в 11 раз. При 100 потоках мы не дождались завершения операции. Данные я не привожу. Нам надоело: мы неделю ждали.
Второй самый популярный вопрос, стоит ли переходить на Linux? Да, стоит переходить! По нашим данным, а они у нас достаточно релевантные – 15 терабайт и 400 баз, Postgres работает почти в 2 раза быстрее.

Почему? Не потому что Postgres такой плохой на Windows, а потому что файловая система Windows не способна обрабатывать такое большое количество файлов. Тут вся фишка в том, как Postgres и MS хранят файлы. Если MS хранит по умолчанию всю вашу базу данных в двух файлах (это файл данных mdf и файл журнала транзакций lgf), то Postgres хранит каждую таблицу в отдельном файле и каждый индекс в отдельном файле.
Типовая база бухгалтерии содержит 6 тысяч таблиц и 20 тысяч индексов. Значит, одна база будет в Postgres представлена 26 тысячами файлов. На наших серверах мы примерно делаем по 60 баз на один instant Postgres, это в районе 2 миллионов файлов. С таким количеством файлов Linux управляется, как мы видим, почти в 2 раза быстрее, чем Windows.
Поэтому если вы уже всерьез на Postgres, а всерьез – это наличие хотя бы 20 сессий, начинайте подумывать о переходе на Linux. Причем, не обязательно железный, можете на этой же винде, если сильно страшно, то поднимите hyper-v, поднимите виртуалку, на эту виртуалку ставьте Linux, ставьте Postgres, и получите отличный эффект. Проверено!
Два важных момента
Хочу обратить еще внимание на два небольших досадных недоразумения, которые пока есть еще в Postgres. Первое недоразумение – это такой параметр по настройке default_statistics_target. Это своеобразный множитель количества страниц, который берет Postgres для расчета статистики. Он этот множитель умножает на 300 и берет такое количество страниц. Множитель может иметь значение от 1 до 10 тысяч, по умолчанию 100. Все хорошо работает при сотке. Но как только мы ставим 10 тысяч, Postgres, действительно, берет много страниц, считает статистику, но потом запросы к базе начинают резко тормозить. К разработчикам мы еще с этим не обращались, вот-вот обратимся, думаю, победим и разберемся.

Второй момент – это репликация. Просто обращу ваше внимание. Разработчики говорят: репликации – это не бэкап. Это действительно так. Кроме того, репликация может отставать на часы и дни. Потому что она однопоточная. Все, что мастер-сервер удалил, создал, обновил в сотне своих потоков, все это придется догонять в один поток. Поэтому реплика это хорошо, мы, например, с нее бэкапы льем, но перед тем, как слить бэкап с реплики, мы проверяем какое отставание. Если отставание не больше секунды, то делаем бэкап с нее, а если больше – то с мастера.
В завершение хочу сказать, что, привлекая компетентных специалистов, вы можете зарабатывать золотые медали любых тестов 1С. Даже на таком новичке в мире 1С, как Postgres, выбирая правильную инфраструктуру.

****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.
Источник // infostart.ru
Create an account to follow your favorite communities and start taking part in conversations.
![]()
Log in or sign up to leave a comment
![]()
level 1
Why wouldn’t he use pgbench for this?
level 2
1- Didn’t knew it existed ! Thanks ! I’m knew to this and discovering great stuff everyday ! 2- Wanted to make my tests with npgsql as our apps are made in .NET
level 1
That benchmark does not adequately test the memory management issues with running postgres on Windows. If your dataset is tiny, you will not notice much of a difference.
level 2
How big should the dataset be ?
About Community

The home of the most advanced Open Source database server on the worlds largest and most active Front Page of the Internet.