Как работать с данными киберразведки: учимся собирать и выявлять индикаторы компрометации систем
Время на прочтение
8 мин
Количество просмотров 15K
В течение всего прошедшего года в гонке кибервооружений между атакующими и защитниками все большую популярность набирала тема киберразведки или Threat Intelligence. Очевидно, что превентивное получение информации о киберугрозах — очень полезная штука, однако само по себе оно инфраструктуру не обезопасит. Необходимо выстроить процесс, который поможет грамотно распоряжаться как информацией о способе возможной атаки, так и имеющимся временем для подготовки к ней. И ключевым условием для формирования такого процесса является полнота информации о киберугрозе.

Первичные данные Threat Intelligence можно получать из самых разных источников. Это могут быть бесплатные подписки, информация от партнеров, группа технического расследования компании и пр.
Существует три основных этапа работы с информацией, полученной в рамках процесса Threat Intelligence (хотя у нас, как центра мониторинга и реагирования на кибератаки, есть и четвертый этап — оповещение заказчиков об угрозе):
- Получение информации, первичная обработка.
- Детектирование индикаторов компрометации (Indicator of Compromise, IOC).
- Ретроспективная проверка.
Получение информации, первичная обработка
Первый этап можно назвать наиболее творческим. Правильно понять описание новой угрозы, выделить релевантные индикаторы, определить их применимость к конкретной организации, отсеять лишнюю информацию об атаках (например, узконаправленных на определенные регионы) — все это зачастую непростая задача. В то же время есть источники, предоставляющие исключительно проверенные и релевантные данные, которые можно добавлять в базу автоматически.
Для системности подхода к обработке информации мы рекомендуем делить индикаторы, получаемые в рамках Threat Intelligence, на две крупных группы — хостовые и сетевые. Детектирование сетевых индикаторов еще не говорит об однозначной компрометации системы, а вот детектирование хостовых индикаторов, как правило, достоверно сигнализирует об успешности атаки.
К сетевым индикаторам относятся домены, URL, почтовые адреса, совокупность IP-адресов и портов. Хостовые индикаторы — это запущенные процессы, изменения веток реестра и файлов, хэш-суммы.
Индикаторы, полученные в рамках одного оповещения об угрозе, имеет смысл объединять в одну группу. В случае обнаружения индикаторов это сильно облегчает определение типа атаки, а также позволяет легко проверить потенциально скомпрометированную систему на все возможные индикаторы из конкретного отчета об угрозе.
Однако часто приходится иметь дело с индикаторами, обнаружение которых не позволяет однозначно говорить о компрометации системы. Это могут быть IP-адреса, принадлежащие к крупным сетям корпораций и хостингов, почтовые домены сервисов рекламных рассылок, имена и хэш-суммы легитимных исполняемых файлов. Самый простые примеры — IP-адреса Microsoft, Amazon, CloudFlare, которые часто оказываются в списках, или легитимные процессы, появляющиеся в системе после установки программных пакетов, например, pageant.exe — агента для хранения ключей. Во избежание большого количества ложноположительных срабатываний такие индикаторы лучше отсеивать, но, скажем так, не выбрасывать — большинство из них не совсем бесполезны. Если есть подозрения на компрометацию системы, производится полная проверка по всем индикаторам, и обнаружение даже косвенного индикатора эти подозрения может подтвердить.
Поскольку не все индикаторы одинаково полезны, мы в Solar JSOC используем так называемый вес индикатора. Условно, обнаружение запуска файла, хэш-сумма которого совпадает с хэш-суммой исполняемого файла вредоноса, имеет пороговый вес. Детектирование такого индикатора мгновенно приводит к возникновению события информационной безопасности. Однократное же обращение к IP-адресу потенциально опасного хоста по не специфичному порту не приведет к возникновению события ИБ, но попадет в специальный профиль, накапливающий статистику, а детектирование дальнейших обращений в итоге также приведет к расследованию.
В то же время, есть механизмы, казавшиеся нам разумными в момент создания, но в итоге признанные неэффективными. Например, изначально закладывалось, что определенные виды индикаторов будут иметь ограниченный срок жизни, по истечении которого будут деактивированы. Однако, как показала практика, при подключении новой инфраструктуры иногда обнаруживаются хосты, которые годами были заражены различными видами вредоносов. Например, однажды при подключении заказчика на машине руководителя службы ИБ был обнаружен вирус Corkow (на тот момент индикаторам было больше пяти лет), а дальнейшее расследование выявило на хосте эксплуатируемый бэкдор и кейлоггер.
Детектирование индикаторов компрометации
Мы работаем со множеством инсталляций различных SIEM-систем, тем не менее, общая структура записей, попадающих в базу индикаторов, стандартизована и выглядит следующим образом:

Например, отсортировав индикаторы по TIReportID, можно найти все индикаторы, фигурировавшие в описании конкретной угрозы, а перейдя по URLlink, можно получить ее развернутое описание.
При построении процесса Threat Intelligence очень важно проанализировать информационные системы, подключенные к SIEM, с точки зрения их пользы для выявления индикаторов компрометации.
Дело в том, что описание атаки обычно включает индикаторы компрометации различного типа — например, хэш-сумму вредоноса, IP-адрес СС-сервера, на который он стучится, и так далее. Но если IP-адреса, к которым обращается хост, отслеживаются многими средствами защиты, то информацию о хэш-суммах получить гораздо труднее. Поэтому все системы, которые могут служить источником каких-либо логов, мы рассматриваем с точки зрения того, какие индикаторы они способны отследить:
| Indicator Type | SourceType |
| Domain | Прокси серверы, NGFW, DNS серверы |
| URL | |
| Socket | Прокси серверы, NGFW, FW |
| Почтовые серверы, Антиспам, DLP | |
| Process | Логи с хоста, БД АВПО, Sysmon |
| Registry | Логи с хоста |
| Hash Sum | Логи с хоста, БД АВПО, Sysmon, Песочницы CMDB |
Схематично процесс обнаружения индикаторов компрометации можно представить в следующем виде:

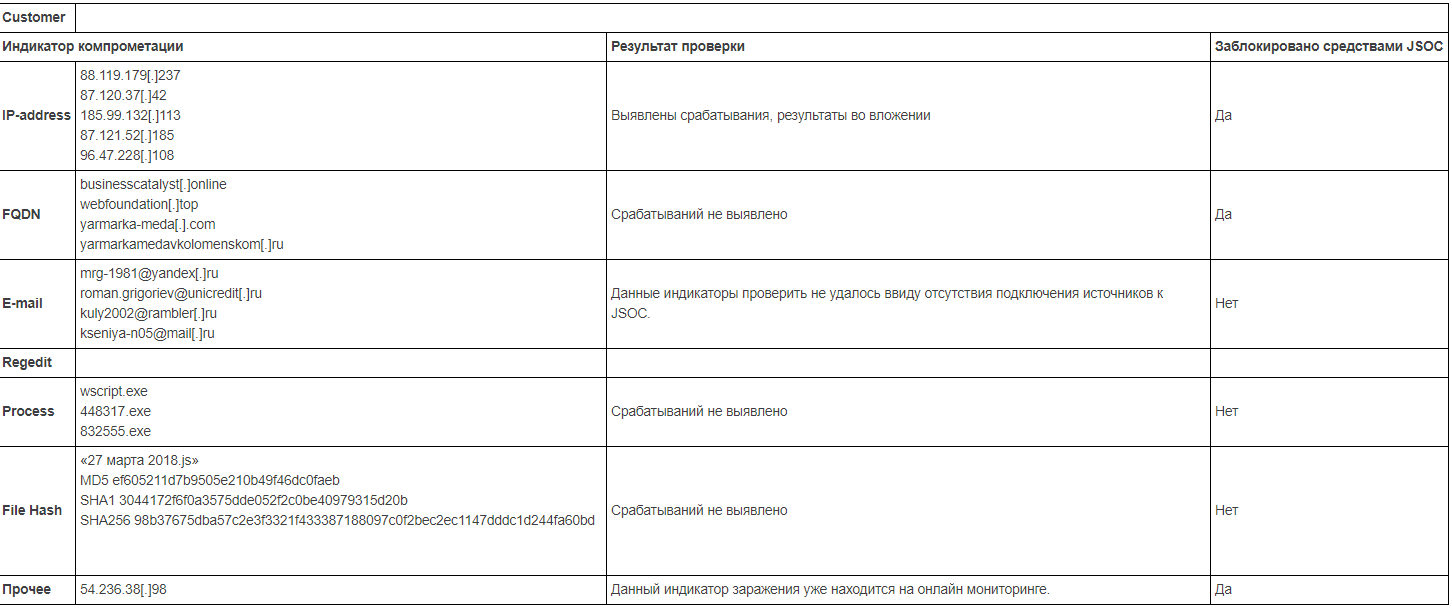
О первых двух пунктах я уже рассказал выше, теперь чуть подробнее про проверку по базе IOC. Для примера возьмем события, содержащие информацию об IP-адресах. Правило корреляции для каждого события осуществляет четыре возможных проверки по базе индикаторов:

Поиск ведется по релевантным индикаторам типа Socket, при этом на соответствие индикатору проверяется совокупная конструкция из IP-адреса и соответствующего порта. Т.к. в информации об угрозе далеко не всегда указан конкретный порт, конструкцией IP:any проверяется нахождение в базе адреса с неопределенным портом.
Похожая конструкция реализована в правиле, детектирующем индикаторы компрометации в событиях изменения реестра. В поступающей информации часто отсутствуют данные о конкретном ключе или значении, поэтому при занесении индикатора в базу неизвестные или не имеющие точного значения данные заменяются на ‘any’. Итоговые варианты поиска выглядят следующим образом:

Обнаружив в логах индикатор компрометации, правило корреляции создает корреляционное событие, помеченное той категорией, которую обрабатывает инцидентное правило (об этом мы подробно рассказывали в статье «ПРАВИЛьная кухня»).
Кроме категории корреляционное событие будет дополнено информацией о том, в каком оповещении или отчете фигурировал этот индикатор, его весе, данными об угрозе и ссылкой на источник. Дальнейшую обработку событий обнаружения индикаторов всех типов производит инцидентное правило. Его работу схематично можно представить следующим образом:

Но, конечно, следует помнить об исключениях: практически в любой инфраструктуре есть устройства, действия которых легитимны, несмотря на то, что формально содержат признаки компрометации системы. К таким устройствам чаще всего относятся песочницы, различные сканеры и пр.
Необходимость корреляции событий обнаружения индикаторов разных типов также вызвана тем, что в информации об угрозах чаще всего присутствуют разнотипные индикаторы.
Соответственно группировка событий обнаружения индикаторов может позволить увидеть всю цепочку атаки от момента проникновения до эксплуатации.
Событием информационной безопасности мы предлагаем считать реализацию одного из следующих сценариев:
- Обнаружение высокорелевантного индикатора компрометации.
- Обнаружение двух различных индикаторов из одного отчета.
- Достижение порога срабатывания.
С первыми двумя вариантами все понятно, а третий необходим в том случае, когда у нас нет иных данных, кроме сетевой активности системы.
Ретроспективная проверка индикаторов компрометации
После получения информации об угрозе, выделении индикаторов и организации их выявления, возникает необходимость в ретроспективной проверке, которая позволяет обнаружить уже произошедшую компрометацию.
Если немного углубиться в то, как это устроено в SOC, могу сказать, что этот процесс требует по-настоящему колоссального количества времени и ресурсов. Поиск индикаторов компрометации в логах за полгода вынуждает хранить внушительный их объем доступным для онлайн проверок. При этом результатом проверки должна быть не просто информация о присутствии индикаторов, но и общие данные о развитии атаки. При подключении новых информационных систем заказчика данные с них также необходимо проверять на наличие индикаторов. Для этого надо постоянно дорабатывать так называемый «контент» SOC — правила корреляции и индикаторы компрометации.
Для SIEM-системы ArcSight выполнение такого поиска даже за пару прошедших недель может сильно затянуться. Поэтому было принято решение воспользоваться трендами.
«A trend is an ESM resource that defines how and over what time period data will be aggregated and evaluated for prevailing tendencies or currents. A trend executes a specified query on a defined schedule and time duration.»
ESM_101_Guide
После нескольких тестов на нагруженных системах был выработан следующий алгоритм использования трендов:
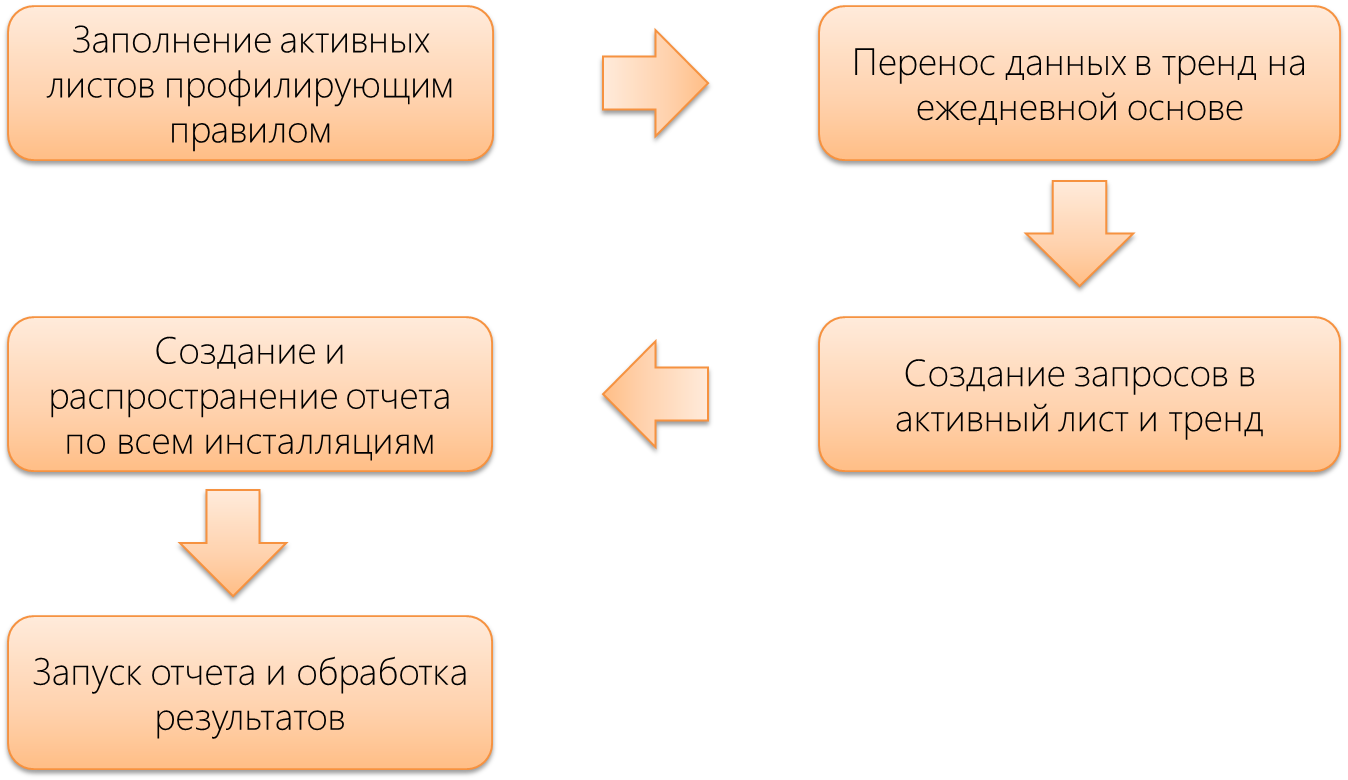
Профилирующие правила, заполняющие соответствующие активные листы полезными данными, позволяют распределить общую нагрузку на SIEM. После получения индикаторов создаются запросы в соответствующие листы и тренды, на базе которых будут сделаны отчеты, которые в свою очередь будут распространены по всем инсталляциям. Фактически остается лишь запустить отчеты и обработать результаты.
Стоит отметить, что процесс обработки можно непрерывно улучшать и автоматизировать. Например, у нас внедрена платформа для хранения и обработки индикаторов компрометации MISP, на текущий момент отвечающая нашим требованиям по гибкости и функционалу. Её аналоги широко представлены на рынке open source — YETI, зарубежные — Anomali ThreatStream, ThreatConnect, ThreatQuotinet, EclecticIQ, российские — TI.Platform, R-Vision Threat Intelligence Platform. Сейчас мы проводим финальные тесты автоматизированных выгрузок событий непосредственно из базы данных SIEM. Это значительно ускорит получение отчетов о наличии индикаторов компрометации.
Главный элемент киберразведки
Тем не менее, финальным звеном в обработке как самих индикаторов, так и отчетов являются инженеры и аналитики, а перечисленные инструменты только помогают в принятии решений. У нас за добавление индикаторов отвечает группа реагирования, а за корректность отчетов — группа мониторинга.
Без людей система не будет работать достаточно адекватно, нельзя заранее предусмотреть все мелочи и исключения. Например, мы отмечаем обращения к IP-адресам TOR-нод, но в отчетах для заказчика разделяем активность скомпрометированного хоста и хоста, на котором просто установили TOR Browser. Автоматизировать это можно, но вот заранее продумать все подобные моменты при настройке правил достаточно трудно. Так и получается, что группа реагирования по самым различным признакам отсеивает индикаторы, которые будут создавать большое число ложных срабатываний. И наоборот — может добавить специфичный индикатор, высокорелевантный для некоторых заказчиков (например, финансового сектора).
Группа мониторинга может убрать из финального отчета активность песочницы, проверку администраторов на успешную блокировку вредоносного ресурса, но добавить активность о неуспешном внешнем сканировании, показывая заказчику, что его инфраструктуру проверяют злоумышленники. Машина таких решений не примет.
Вместо вывода
Почему мы рекомендуем именно такой метод работы с Threat Intelligence? Прежде всего — он позволяет уйти от схемы, когда под каждую новую атаку надо создавать отдельное правило корреляции. Это отнимает непозволительно много времени и позволяет выявить разве что ведущуюся атаку.
Описанный метод максимально задействует возможности TI — надо просто добавить индикаторы, а это максимум 20 минут с момента их появления, и затем провести полную ретроспективную проверку логов. Так вы и сократите время реагирования, и получите более полные результаты проверки.
Если остались вопросы, добро пожаловать в комментарии.

Сегодня Microsoft предупредила клиентов, что необходимо исправить два недостатка безопасности, связанных с повышением привилегий службы домена Active Directory, которые в совокупности позволяют злоумышленникам легко захватывать домены Windows.
Компания выпустила обновления безопасности для устранения двух уязвимостей (отслеживаемых как CVE-2021-42287 и CVE-2021-42278 и сообщенных Эндрю Бартлеттом из Catalyst IT) во вторник ноября 2021 года.
Предупреждение Редмонда о необходимости немедленно исправить две ошибки — обе позволяют злоумышленникам выдавать себя за контроллеры домена — появилось после того, как 11 декабря в Twitter и GitHub был опубликован инструмент PoC, который может использовать эти уязвимости.
«Объединив эти две уязвимости, злоумышленник может создать прямой путь к пользователю-администратору домена в среде Active Directory, которая не применила эти новые обновления», — поясняет Microsoft в опубликованном сегодня сообщении.
«Эта эскалационная атака позволяет злоумышленникам легко повысить свои привилегии до привилегий администратора домена, как только они скомпрометируют обычного пользователя в домене.
«Как всегда, мы настоятельно рекомендуем как можно скорее развернуть последние исправления на контроллерах домена».
Администраторам Windows настоятельно рекомендуется обновлять устройства, подверженные атакам, используя действия и информацию, подробно описанные в следующих статьях базы знаний: KB5008102, KB5008380, KB5008602.
Исследователи, которые тестировали PoC, заявили, что они смогли легко использовать инструмент для повышения привилегий от стандартного пользователя Active Directory до администратора домена в конфигурациях по умолчанию.
Как выявить эксплуатацию, признаки компрометации
Microsoft также поделилась подробным руководством по обнаружению признаков эксплуатации в вашей среде и выявлению потенциально скомпрометированных серверов с помощью расширенного запроса Defender for Identity, который ищет аномальные изменения имени устройства.
Пошаговое руководство требует от защитников:
- Изменение sAMAccountName основано на событии 4662. Убедитесь, что он включен на контроллере домена, чтобы отслеживать такие действия. Узнайте больше о том, как это сделать, здесь
- Откройте Microsoft 365 Defender и перейдите в Advanced Hunting .
- Скопируйте следующий запрос (который также доступен в запросе расширенной охоты на GitHub в Microsoft 365 Defender):
IdentityDirectoryEvents | where Timestamp > ago(1d) | where ActionType == "SAM Account Name changed" | extend FROMSAM = parse_json(AdditionalFields)['FROM SAM Account Name'] | extend TOSAM = parse_json(AdditionalFields)['TO SAM Account Name'] | where (FROMSAM has "$" and TOSAM !has "$") or TOSAM in ("DC1", "DC2", "DC3", "DC4") // DC Names in the org | project Timestamp, Application, ActionType, TargetDeviceName, FROMSAM, TOSAM, ReportId, AdditionalFields - Замените отмеченную область соглашением об именах контроллеров домена.
- Запустите запрос и проанализируйте результаты, которые содержат затронутые устройства. Вы можете использовать событие Windows 4741, чтобы найти создателя этих машин, если они были созданы заново.
- Мы рекомендуем исследовать эти скомпрометированные компьютеры и убедиться, что они не использовались в качестве оружия.
«Наша исследовательская группа продолжает свои усилия по созданию большего количества способов обнаружения этих уязвимостей с помощью запросов или нестандартных методов обнаружения», — добавила Microsoft.
Последнее обновление 05.01.2023
Индикатор компрометации (Indicator of Compromise, IoC) — в сфере компьютерной безопасности наблюдаемый в сети или на конкретном устройстве объект (или активность), который с большой долей вероятности указывает на несанкционированный доступ к системе (то есть ее компрометацию). Такие индикаторы используются для обнаружения вредоносной активности на ранней стадии, а также для предотвращения известных угроз.
Что может быть индикатором компрометации
В качестве индикатора компрометации могут выступать:
- Необычные DNS-запросы.
- Подозрительные файлы, приложения и процессы.
- IP-адреса и домены, принадлежащие ботнетам или командным серверам вредоносного ПО.
- Значительное количество обращений к одному файлу.
- Подозрительная активность в учетных записях администраторов или привилегированных пользователей.
- Неожиданное обновление программных продуктов.
- Передача данных через редко используемые порты.
- Нетипичное для человека поведение на веб-сайте.
- Сигнатура или хеш-сумма вредоносной программы.
- Необычный размер HTML-ответов.
- Несанкционированное изменение конфигурационных файлов, реестров или настроек устройства.
- Большое количество неудачных попыток входа в систему.
Выявление и применение индикаторов компрометации
Индикаторы компрометации, связанные с конкретной угрозой, выделяются при анализе этой угрозы. Например, если киберразведка обнаружила новое вредоносное ПО, в отчете о нем будут приведены такие IoC, как хеши файлов, адреса командных серверов и так далее.
В дальнейшем индикаторы компрометации используются для активного поиска угроз в инфраструктуре организации. Обнаружение IoC в системе указывает на то, что, вероятно, на нее уже ведется кибератака и необходимо принять меры реагирования.
Индикаторы компрометации также добавляют в базы данных пассивных средств мониторинга и антивирусного ПО, чтобы своевременно выявлять и блокировать попытки проникновения. Например, с помощью сигнатур вредоносной программы защитное решение распознает ее и запрещает ей запускаться на устройстве.
Хотя чаще всего понятие индикаторов компрометации используется в контексте защиты корпоративных инфраструктур, с ними могут сталкиваться и обычные пользователи. Например, многие интернет-сервисы предупреждают владельцев аккаунтов об авторизации с необычного устройства или IP-адреса в другой стране. К таким сообщениям необходимо относиться серьезно, проверять приведенную в них информацию и, если какие-то из перечисленных действий выглядят подозрительно, оперативно менять пароль.
Публикации на схожие темы
Автор: Mike Pilkington
Сотрудникам группы реагирования на инциденты информационной безопасности (ГРИИБ) часто нужно ответить не только на вопросы о том, как, когда, где, по чьей вине произошел инцидент, но и на то, как организация может защитить себя от подобных инцидентов в будущем. Другими словами, нужно понять, какой урок был извлечен из инцидента, и какие можно дать рекомендации, основываясь на обнаруженных проблемах.
Новый документ от Microsoft, который называется «Практические указания по защите Active Directory» («Best Practices for Securing Active Directory»), содержит большое количество информации и инструкций, которые сотрудники службы безопасности могут использовать для ответа на вышеперечисленные вопросы. Документ можно скачать по следующей ссылке:http://blogs.technet.com/b/security/archive/2013/06/03/microsoft-releases-new-mitigation-guidance-for-active-directory.aspx.
Я ознакомился с этим документом и считаю его содержание блестящим. Как говорит во вступлении руководитель отдела информационной безопасности Microsoft, этот документ «содержит набор практических методов, которые помогут руководителям IT-отделов (и системным архитекторам) защитить корпоративную среду Active Directory». Он основан на опыте команды Microsoft по информационной безопасности и управлению рисками, которая консультирует как внутренних (MS IT), так и внешних потребителей компании, входящих в список Global Fortune 500.
Для сотрудников ГРИИБ документ может быть полезен по двум причинам:
- Он может быть взят на вооружение при составлении собственных рекомендаций на случай компрометации системы.
- Его можно проактивно использовать для улучшения профилактики и возможностей обнаружения проблем в вашей среде, а также при планировании восстановления системы после ее значительной компрометации.
Не будет преувеличением сказать, что многие организации платят тысячи долларов за оценку безопасности внешними аудиторами, и в результате получают отчет, который не более подробен и эффективен, чем данный набор рекомендаций, выложенный Microsoft в свободный доступ. Более того, поскольку организации высоко ценят рекомендации Microsoft, данный документ имеет больше веса чем такой же документ, созданный внутренним персоналом или любой другой внешней организацией.
Учитывая все сказанное, я рекомендую прочитать этот документ целиком. Однако, в нем более 120 страниц, и быстро ознакомиться с ним не получится. Так что, если вы не располагаете достаточным временем, я советую просмотреть, по меньшей мере, 5 страниц «Основных положений» (Executive Summary), которые включают таблицу с 22 практическими указаниями, грубо упорядоченными в приблизительном порядке убывания приоритета. Основные положения представлены в такой форме, что могут использоваться в вашей организации в качестве отдельного документа.
Далее следует краткий обзор, в котором укажу дополнительную информацию по тем рекомендациям, которые не вошли в Основные положения, но показались мне особенно интересными.
Мои выдержки из «Практических указаний по защите Active Directory»
Следующие подразделы названы так же, как соответствующие разделы документа.
Пути компрометации системы
В данном разделе обсуждается много распространенных проблем, приводящих к первоначальной компрометации и, как правило, быстрому повышению привилегий в домене Active Directory: от невовремя накладываемых патчей на систему и приложения и недостатков антивирусов до кражи личности и повышения привилегий. О многих из них вы уже наверняка хорошо осведомлены. Данный раздел также отмечен в Основных положениях, поэтому я не буду более на нем останавливаться.
Уменьшение поверхности атаки Active Directory
В данном перечислено большое количество полезных идей. Вот краткое описание тех, что меня заинтересовали:
Уменьшение количества административных учетных записей и членов в группе администраторов
- Уменьшите количество учетных записей в наиболее привилегированных группах. Стандартные привилегированные группы включают в себя администраторов всей корпоративной сети, администраторов домена и локальных администраторов. В идеале нужно добиться того, чтобы в данных группах отсутствовали постоянные члены. При этом пользователи добавляются в эти группы только при необходимости и удаляются после того, как ими выполнена соответствующая задача. Этого можно добиться с помощью пары решений для управления привилегированными учетными записями от Cyber-Ark и Lieberman (существуют и другие).
Создание выделенных административных хостов
- Значительный акцент делается на создании выделенных, защищенных административных систем для доступа к наиболее доверенным хостам. Идея здесь заключается в том, чтобы пользователи с привилегированными учетными записями использовали свои аккаунты только в данных выделенных заблокированных защищенных системах (то есть, без использования RunAs на своих машинах). Предложенные решения включают использование выделенных физических рабочих станций, использование ВМ и/или использование выделенных серверов типа «jump point» (как правило, через удаленный рабочий стол).
Борьба с физическими атаками на контроллер домена
- Не стоит недооценивать возможность физической компрометации, в том числе, контроллеров домена. При усилении компьютерной безопасности самым слабым звеном может стать физическая безопасность, особенно это касается офисов, находящихся на большом расстоянии. Одно из предложенных решений состоит в использовании для таких контроллеров домена режима «только чтение» (сам контроллер при этом называется read only domain controller – RODC). «Режим только чтение – это способ более безопасного развертывания контроллера домена в местах, где требуется быстрая и надежная аутентификация сервисов, но где физическая безопасность недостаточна для выдачи контроллеру права записи.»
- Возможности RODC включают:
- По умолчанию RODC не хранит учетные данные пользователя или компьютера. Чтобы настроить на RODC аутентификацию, администратор задает репликацию учетных записей определенных пользователей на определенные RODC. Так что, например, если вы хотите, чтобы все пользователи пекинского офиса могли аутентифицироваться на своих локальных RODC, вы можете указать, что на эти локальные RODC должны реплицироваться только учетные данные пекинских пользователей. Для любого другого пользователя, пришедшего в пекинский офис, запрос аутентификации будет перенаправляться локальным RODC на DC с правом записи.
- За исключением учетных записей, по умолчанию RODC содержит все те же объекты и атрибуты Active Directory, что и контроллер с правом записи. Это поведение, однако, можно изменить, поскольку некоторые приложения хранят свои специальные учетные данные или другую конфиденциальную информацию в виде атрибутов AD. При необходимости эти важные атрибуты можно фильтровать.
- Как следует из названия, в базу данных, хранящуюся на RODC, нельзя записывать изменения. Изменения должны производиться на доменном контроллере с правом записи и реплицироваться на RODC.
- Ссылка для более подробной информации по RODC: http://blogs.technet.com/b/askds/archive/2008/01/18/understanding-read-only-domain-controller-authentication.aspx.
Создание белого списка приложений
- Фильтрация приложений по белому списку – эффективный инструмент для борьбы с вредоносными программами. Bit9 – крупный игрок на рынке подобных решений и, возможно, лучший выбор для корпоративных сред (так думаю я, а не Microsoft). Однако, AppLocker от Microsoft может также неплохо подойти для некоторых организаций, включая компании, которые предпочитают медленный старт, изначально применяя решение только к критичным серверам.
Использование контроля механизма аутентификации смарт-карт
- Двухфакторная аутентификация должна быть нормой, а не исключением, особенно для привилегированных пользователей. В данном разделе обсуждаются некоторые преимущества смарт-карт. Мои собственные исследования подтверждают, что смарт-карты не могу решить всех вашех проблем, в особенности потому что учетные данные пользователя хранятся в виде обычного парольного хэша, и этот хэш может использоваться в некоторых атаках. Тем не менее, смарт-карты во многих ситуациях являются гораздо большим препятствием для злоумышленников, чем другие средства аутентификации.
- «Authentication Mechanism Assurance» (контроль механизма аутентификации) – относительно новая возможность, о которой я до этого не слышал,– может стать еще большим препятствием на пути злоумышленника. Эта возможность, появившаяся в Windows Server 2008 R2, позволяет фиксировать для маркера доступа пользователя факт аутентификации на основе сертификата. «Это позволяет администраторам сетевых ресурсов контролировать доступ к таким ресурсам как файлы, папки и принтеры, учитывая, вошел ли пользователь, воспользовавшись сертификатом, и тип этого сертификата. Например, пользователь, зашедший с помощью смарт-карты, может иметь иные права доступа к сети, нежели пользователь, зашедший другим способом (то есть, путем ввода логина и пароля)».
Использование шаблонов для безопасных настроек
- Для систем, требующих повышенной безопасности, вроде системы доменного контроллера или рабочих станций для привилегированных аккаунтов, воспользуйтесь Microsoft Security Compliance Manager (диспетчер соответствия требованиям безопасности). Это свободно распространяемая утилита, которая включает в себя шаблоны настроек безопасности, рекомендованные Microsoft. Шаблоны доступны для всех основных версий ОС и сервис-паков, а также для Exchange, IE и офисного пакета. Доступные шаблоны перечислены здесь: http://technet.microsoft.com/en-us/library/cc677002.aspx. Более того, для применения этих шаблонов можно использовать групповые политики.
- От себя я также советую вам подумать о развертывании EMET по меньшей мере на критичных рабочих станциях и, возможно, на серверах. Брайан Кребс написал неплохой обзорпоследней версии (4.0) EMET в своем блоге.
Примите меры в отношении плохо написанных программ
- Не пропустите содержащееся в данном документе обсуждение плохо написанных приложений и их влияния на безопасность системы. Здесь предлагается включать эффективный аудит безопасности в цикл разработки ПО (Software Development Lifecycle, SDL). В противном случае, либо ваши программы будут уязвимыми, либо вам придется делать дорогостоящие исправления.
- К вопросу стоимости: «По оценкам некоторых организаций полная стоимость исправления одной проблемы безопасности в релизной версии составляет порядка $10.000, и приложения, разработанные вне эффективного цикла разработки, могут иметь в среднем более 10 серьезных проблем на каждые 100 тысяч строк кода. С увеличением масштаба приложения стоимость ошибок разработки стремительно нарастает.»
Сделайте концепцию безопасности понятной для конечных пользователей
- Упрощение понимания безопасности для конечных пользователей всегда должно быть в приоритете. В качестве примера в документе рассматривается реализация доступа привилегированных пользователей к важным файлам только из специально выделенных систем. Это позволяет одновременно дать привилегированным пользователям доступ к требуемым файлам, а аналитикам – хорошую возможность обнаруживать неправомочный доступ из прочих систем. Для пользователей такое решение может быть не слишком удобным, но зато простым для понимания.
Отслеживание признаков компрометации Active Directory
Данный раздел начинается с обсуждения различных категорий аудита, доступных в системах до Windows Vista и новых подкатегорий, доступных, начиная с Vista. Если у вас Windows версии Vista и выше, вы можете просмотреть конфигурацию подкатегорий аудита, открыв командную строку от имени администратора и запустив каманду «auditpol.exe /get /category:*«.
Далее документ предлагает способы реализации выбранных настроек аудита, как правило, через групповую политику безопасности или команду auditpol.exe. Здесь возникают определенные сложности, так как вы можете включить либо девять основных категорий, либо новые подкатегории, но не то и другое. Другими словами, вам нужно продумать, как сконфигурировать подкатегории на системах начиная с Vista, но при этом выбрать подходящие настройки для старых категорий на старых системах.
Документ включает в себя подробную таблицу, содержащую рекомендации для каждой из подкатегорий аудита и типа ОС (то есть, набор рекомендаций для Windows 7 и 8 отличаетя от набора рекомендаций для Windows Server 2008, 2008 R2, и 2012). Таблица включает настройки по умолчанию, набор базовых рекомендаций по аудиту (которые, я полагаю, перекочевали из Windows Security Resource Kit), а также набор новых, «сильных» рекомендаций.
Хотел бы я сказать «Вперед, реализуйте наиболее сильные рекомендации Microsoft по аудиту и все будет замечательно!». К сожалению, это был бы плохой совет. Суровая правда в том, что вам нужно тестировать совместимость рекомендаций с вашей собственной средой. Я бы предложил использовать наиболее сильные рекомендации как отправную точку, а затем ослаблять их там, где этого требуют ограничения ресурсов. Не забывайте, что для поддержки высоких уровней аудита вам понадобится не только надежное оборудование (особенно быстрые диски для поддержки увеличенного объема ввода-вывода), но также больше дискового пространства, чтобы события не перезаписывались слишком быстро. События серверов в идеале будут перенаправляться на централизированный сервер логирования, и в данном случае дисковое пространство не будет помехой. Для рабочих станций и ноутбуков, с другой стороны, перенаправление журнала становится логистически трудной задачей, требующей более дорогой реализации, так что придется найти золотую середину между подробным журналом событий и ограничениями локального хранилища данных.
За таблицей рекомендаций следует обсуждение типов событий, подлежащих отслеживанию. Это довольно короткое обсуждение всего с парой примеров. Советую просмотреть подробное приложение L: «События для отслеживания», содержащее сотни индивидуальных идентификаторов, которые стоит включить в список.
Действия в случае компрометации
Если в результате атаки ваша AD была полностью скомпрометирована, вам не останется ничего другого, как заменить ее полностью. Как говорится в документе, если только «у вас нету записей о каждом изменении, сделанном злоумышленником, или доверенной резервной копии, вы не сможете восстановить содержимое AD до полностью доверенного состояния».
Более того, «даже восстановление доверенного состояния не устраняет тех изъянов среды, которые позволили скомпрометировать ее в первый раз.»
«Вместо попыток исправить среду, заполненную устаревшими, плохо настроенными системами и приложениями, задумайтесь над созданием новой небольшой безопасной среды, на которую вы можете гарантированно перевести пользователей, системы и информацию, наиболее критичную для вашего бизнеса.»
В документе рассмотрены следующие руководящие принципы для создания нового леса AD, который выступает в роли «безопасной ячейки» для основной инфраструктуры бизнеса.
- Принципы сегрегации и защиты критических ресурсов:
- Настройки не должны позволять новому лесу AD доверять старому лесу. Это означает, что старые учетные записи не должны иметь возможность входить в новый лес. Однако, в документе сказано, что вы можете настроить доверие в обратную сторону: старый лес может доверять новому. Я бы поспорил с такой рекомендацией, поскольку в результате ваши новые учетные записи смогут заходить в скомпрометированный домен и, если в это время в нем будут функционировать вредоносные программы, учетные записи окажутся под угрозой. Новые аккаунты будут подвержены особому риску, если в старый домен разрешены интерактивные входы.
- Используйте «немиграционные» подходы, предотвращающие копирование истории SID. (Подробнее об этом в пункте 3).
- Устанавливайте ОС и приложения заново, не перемещайте системы из старого леса в новый.
- Не разрешайте в использование старых версий ОС и программ в новом лесу. Для улучшения защиты используйте новейшие версии ОС и приложений.
- Разработайте ограниченный, основанный на анализе рисков, план миграции:
- Определитесь со стратегией. Хотите ли вы на первом этапе перенести лишь привилегированные аккаунты, определенный регион, отдел или всех пользователей разом?
- Выделите то, что действительно является критичным для бизнеса и должно естественным образом определять расстановку приоритетов в вашем плане миграции.
- Используйте «немиграционные» миграции там, где необходимо.
- Не поддерживайте историю SID из старых доменов. Используйте инструменты, которые задают соответствие между новыми аккаунтами и аккаунтами из старого леса.
- «Приложение J: Сторонние производители средств RBAC» (ролевого разграничения доступа) и «Приложение K: Сторонние производители PIM» (решений для управления привилегированными аккаунтами) перечисляют некоторые продукты, которые могут производить «немиграционные» миграции.
- Реализуйте «креативное избавление»:
- Избавляйтесь от старых программ и систем не путем их обновления, а путем создания новых защищенных приложений и систем, замещающих прежние. Переносите данные, но не устаревшие приложения.
- Изолируйте старые системы и приложения:
- Для поддержки тех старых приложений и систем, которые не могут быть заменены новыми версиями, используйте небольшой выделенный домен.
- Не разрешайте новому домену доверять старому домену приложений. В идеале доверие в обратную сторону также должно быть исключено, хоть возможно вам все же понадобится разрешить старому домену приложений доверять новому чистому домену. В таком случае не разрешайте интерактивных входов новых учетных записей в старый домен (мой совет).
- Упростите безопасность для конечных пользователей.
- Используйте простые методы вроде выделенных защищенных систем для доступа к важным файлам.
- Подумайте об альтернативных методах аутентификации вроде смарт-карт, биометрии или даже «аутентификационных данных, защищенных TPM-чипами в компьютерах пользователей».
Создание бизнес-центрированных реализаций защиты Active Directory
Данный раздел обосновывает необходимость кооперации бизнеса и ИТ в сфере защиты информационного имущества. Это одна из тех областей, которые сложно взять под свой контроль, и потому технические специалисты часто занимаются ей в последнюю очередь. Однако, в последних двух параграфах высказана вполне ясная мысль:
«В прошлом отделы информационных технологий во многих организациях рассматривались как поддерживающая структура и центры издержек. Они часто отделялись от пользователей, и взаимодействие с ними ограничивалось моделью запрос-ответ, в которой пользователи запрашивали ресурсы, а IT-специалисты отвечали на запросы.»
«По мере того, как технологии развивались и распространялись, мечта о ‘компьютере на каждом рабочем столе’ стала реальностью для большей части мира, а сегодня мы можем говорить о гораздо большем. В наши дни информационные технологии перестали играть лишь поддерживающую роль и перешли из инфраструктуры в ядро бизнеса. Если ваша организация не может продолжать функционировать в случае недоступности всех ИТ-сервисов, то ваш бизнес, по меньшей мере частично, принадлежит к сфере ИТ.»
Вот несколько более существенных пунктов из данного раздела:
- Помимо определения уровня сервиса в зависимости от аптайма (относительной доли рабочего времени) системы, вам следует подумать об определении уровней контроля безопасности и отслеживании на основе важности информационного ресурса.
- Выработайте четкие процессы определения владельцев данных, приложений, учетных записей пользователей и компьютерных аккаунтов.
- Чем более рутинной для владельца бизнеса является проверка достоверности данных в Active Directory, тем проще вам будет выявлять аномальности, говорящие о сбоях или о компрометации системы.
- Классифицируйте не только данные, но и сервера, на которых эти данные располагаются. Отслеживайте сервера в зависимости от классов расположенных на них данных. То же касается и приложений.
- Для большинства организаций попросту невозможно непрерывно отслеживать всех пользователей. Классифицируйте учетные записи пользователей и тщательно отслеживайте лишь наиболее важные аккаунты.
Сводка практических рекомендаций
Заключительная часть содержит те же 22 практические рекомендации, что и «Основные положения». Для каждой рекомендации она включает ссылку на раздел, где та рассматривается подробно. Рекомендации упорядочены в приблизительном порядке уменьшения важности.
Надеюсь, данный обзор был вам полезен, и вы найдете время, чтобы ознакомиться со всем содержимым документа. Я считаю, что «Практические указания по защите Active Directory» предоставляют солидную дорожную карту и набор рекомендаций, которые могут быть использованы во многих организациях для предотвращения, обнаружения атак и устранения их последствий.
Платформы киберразведки (Threat Intelligence, TI) работают со знаниями об угрозах информационной безопасности: атаках, атакующих, целях, мотивации, инструментах, вредоносном ПО, уязвимостях, индикаторах компрометации. Эти знания должны быть основаны на фактах — проверенных, своевременных и достаточных для принятия решений об адекватных мерах защиты.
Индикатор компрометации (Indicator of Compromise, IoC) в общем смысле — это цифровой артефакт, который явно указывает на потенциальную вредоносность описываемого объекта и/или факт компрометации информационной системы.
В процессе работы с данными TI могут использоваться такие типы индикаторов как:
- ip-адреса
- домены
- файлы
- ссылки
- хэш-суммы файлов
- e-mail адреса
- банковские карты
- учетные записи
Жизненный цикл индикатора компрометации
Каждый индикатор имеет свой жизненный цикл, то есть время, на протяжении которого с высокой долей вероятности он сохраняет свою вредоносную активность. Какие-то индикаторы могут быть «опасны» несколько дней, какие-то — месяцами. По истечении времени жизни индикатор становится неактуальным, иными словами — устаревает.
Жизненный цикл индикатора начинается с обнаружения угрозы ИБ-аналитиком или средствами защиты. Признаки вредоносной активности, то есть любые объекты и данные, связанные с обнаруженной угрозой, говорят о компрометации системы и считаются индикаторами компрометации. Собранные потоки данных вместе с дополнительным контекстом, а иногда и без него, собираются в так называемые фиды и регулярно распространяются различными поставщиками данных Threat Intelligence.
Сложность состоит в том, что источники не всегда предоставляют уникальные данные киберразведки, но могут также дополнять и частично дублировать данные друг друга. При этом важно вовремя обрабатывать поступающие потоки данных и следить за всеми изменениями, чтобы аналитик работал только с действительно актуальной информацией. Для упрощения процесса работы с данными Threat Intelligence можно использовать специализированные платформы, например, R-Vision Threat Intelligence Platform (R-Vision TIP). Такие платформы позволяют осуществить автоматический сбор, нормализацию и хранение данных из различных источников в единой базе.
При использовании R-Vision TIP индикатор проходит следующие этапы обработки:
- Получение индикатора в R-Vision TIP от поставщиков данных Threat Intelligence;
- Обогащение индикатора дополнительным контекстом. С помощью сервисов обогащения можно получить дополнительную информацию об индикаторах, например, ASN, привязку к геолокации, список поддоменов для вредоносного домена, историю изменений DNS и т.д;
- Потеря индикатором актуальности (устаревание).
IoC может проходить все эти стадии полностью или частично несколько раз.
Важно учитывать, что индикаторы компрометации не существуют в вакууме, каждый из них связан с какой-либо вредоносной активностью. В частности, IP-адреса и домены могут принадлежать ботнетам или C&C-серверам.
В процессе расследования инцидента индикаторы компрометации рассматриваются в связке с другими сущностями — вредоносным ПО, уязвимостями, группировками злоумышленников и т.д. Например, если аналитики обнаруживают новый экземпляр вредоносного ПО и делают отчет об его активности, то в отчете должны быть связанные с этим ПО индикаторы компрометации, такие как хэш-суммы вредоносных файлов, вредоносные URL и тд. Если с отчетом все понятно, то зачем нужны индикаторы компрометации конкретной организации? Для ответа на этот вопрос обратимся к известной «пирамиде боли», предложенной аналитиком Дэвидом Бианко.
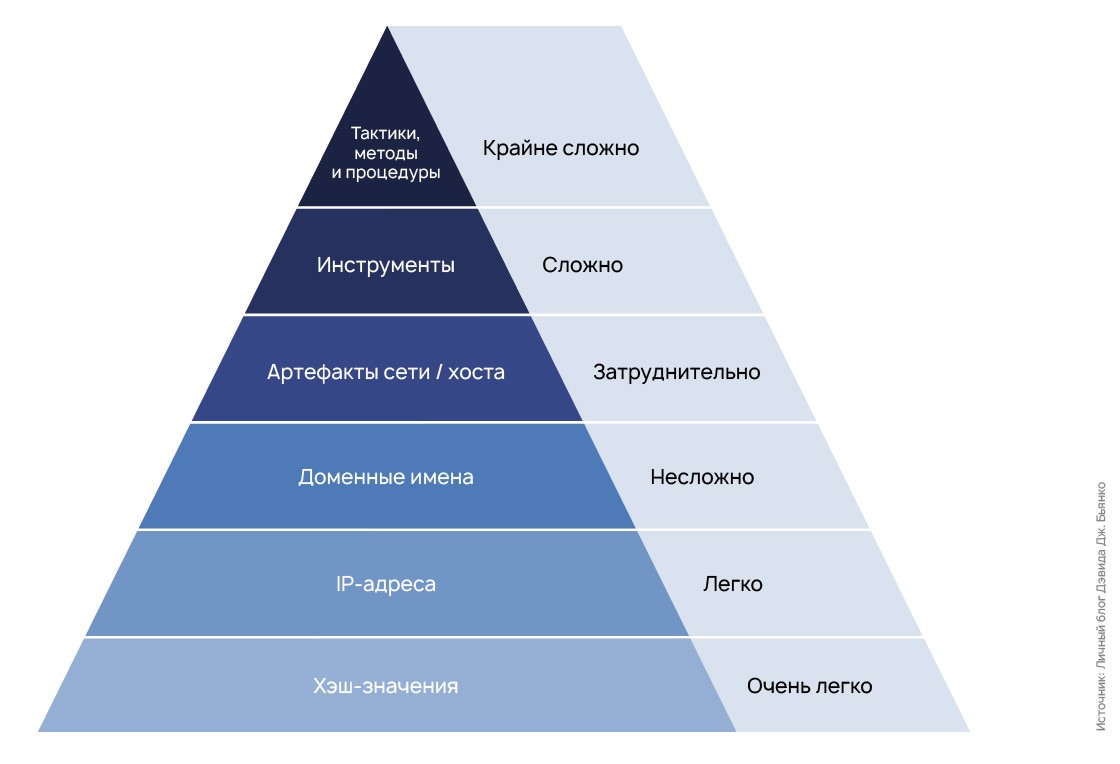
Пирамида описывает уровни сложности обнаружения различных типов индикаторов компрометации и иллюстрирует сколько «боли» их обнаружение может принести атакующему. Знания об отдельных индикаторах компрометации относительно легко применить, например, обнаружить и заблокировать вредоносный IP-адрес. Но блокировка IP-адреса не нанесет значительного ущерба киберпреступнику — он просто может начать использовать другой. В то же время установить, какими инструментами пользуется злоумышленник затруднительно, но и для самого злоумышленника достаточно «болезненно». При этом обнаружение индикаторов в инфраструктуре указывает на то, что, вероятно, против нее уже ведется вредоносная активность.
С помощью механизма обнаружений R-Vision TIP можно выполнить реактивный и ретроспективный поиск индикаторов в инфраструктуре, за счет чего время присутствия злоумышленника в сети организации сократится. Наиболее эффективно решить эту задачу можно, используя платформу имитации ИТ-инфраструктуры для обнаружения кибератак R-Vision TDP, которая также может передавать индикаторы компрометации в R-Vision TIP. Кроме того, в случае, когда инфраструктура уже подверглась вредоносной активности, пользователи R-Vision TIP могут автоматизировать процесс создания и реагирования на инциденты информационной безопасности благодаря бесшовной интеграции с системой R-Vision SOAR.
Наконец, используя интеграции со средствами защиты информации, можно предпринимать активные действия против вредоносной активности на уровне самих средств защиты, например, блокировать вредоносные url. Таким образом, работа с индикаторами компрометации позволяет выстроить эффективную систему противодействия кибератакам, как превентивно, так и на этапе, когда инфраструктура уже скомпрометирована.
Устаревание индикаторов компрометации
С течением времени индикатор компрометации теряет свою актуальность, то есть устаревает. В платформе R-Vision TIP есть механизм, позволяющий применить различные подходы к устареванию индикаторов компрометации, чтобы анализу и последующей обработке подвергались только актуальные индикаторы. Значение механизма устаревания настраивается для всех индикаторов, полученных из соответствующего источника.
В системе существует 2 варианта настроек:
1. Автоматический механизм устаревания.
Как только индикатор более не упоминается ни в одном из источников, такой индикатор начинает считаться устаревшим. В то же время, если какой-либо источник при очередном обновлении присылает данные об устаревшем ранее индикаторе, то такой индикатор становится актуальным.
2. Пользовательская настройка.
Пользователь может самостоятельно задать время устаревания IoC от даты создания этого индикатора или от даты его последнего изменения.
Вредоносность индикатора или его потенциальную опасность для системы отражает такое понятие, как рейтинг индикатора. В основе расчета рейтинга индикатора также лежит концепция устаревания индикатора. Через настройки системы пользователь R-Vision TIP может указать время, в течение которого индикатор теряет вредоносность, и, следовательно, снижается как его рейтинг, так и скорость снижения рейтинга.
Таким образом, можно выделить два подхода к потере индикаторами их вредоносности, которые предоставляет R-Vision TIP. Пользователь может напрямую повлиять на устаревание индикаторов через настройку политики устаревания, а также через настройку параметров, участвующих в расчете рейтинга. Кроме того, управляя процессом устаревания, можно значительно сократить количество индикаторов, с которыми предстоит работать пользователям системы, сэкономив тем самым время и ресурсы как специалистов, так и компании в целом.
В процессе реагирования на инциденты информационной безопасности управление жизненным циклом индикаторов компрометации представляет собой очень важную часть работ. Ведь это будет напрямую влиять на действия и решения, направленные против вредоносной активности. Ответственное отношение к управлению жизненным циклом будет гарантией того, что вся используемая в работе информация, с высокой долей вероятности является достоверной и актуальной.
Едва ли преувеличением будет сказать, что словосочетание «индикаторы компрометации» (или аббревиатура IOC, Indicators of compromise) встречается во всех отчетах на сайте Securelist. Как правило, после него перечисляются хэши MD5[1], IP-адреса и другие технические данные, которые помогают специалистам по информационной безопасности бороться с конкретными угрозами. Но как именно они используют индикаторы компрометации в ежедневной работе? Этот вопрос мы задали трем экспертам «Лаборатории Касперского»: Пьеру Дельшеру, старшему исследователю безопасности в Глобальном центре исследования и анализа угроз (GReAT), Роману Назарову, главе направления консультационных услуг для центров мониторинга и реагирования (SOC), и Константину Сапронову, руководителю отдела оперативного решения компьютерных инцидентов (GERT).
Что такое данные о киберугрозах и как мы используем их в GReAT?
Команда GReAT занимается обнаружением, анализом и описанием существующих и прогнозируемых угроз (стараясь уделять больше внимания ранее неизвестным угрозам), чтобы обеспечивать клиентов «Лаборатории Касперского» подробными отчетами, техническими данными и защитными решениями. Эту сложную работу мы называем сбором данных о киберугрозах. Она требует от нас больших временных затрат, междисциплинарных навыков, инновационных решений и самоотдачи. Кроме того, мы не можем обойтись без накопленных за продолжительное время обширных комплексных знаний о кибератаках, злоумышленниках и используемых ими инструментах. Сбором данных о киберугрозах мы занимаемся с 2008 года, и в этом нам помогают многолетний опыт и уникальные технологии «Лаборатории Касперского». Но зачем вообще этим заниматься?
Данные, которые мы предлагаем клиентам, содержат контекстную информацию — такую как типы атакуемых организаций, TTP (тактики, техники и процедуры) злоумышленников и признаки, позволяющие провести атрибуцию атаки, — а также подробный анализ используемых вредоносных инструментов, индикаторы компрометации и методы обнаружения. Они помогают организациям определять угрозы, прогнозировать возможные атаки и достигать глобальных целей в современном постоянно развивающемся ландшафте угроз на трех уровнях:
- Стратегический уровень: принятие решений об объеме ресурсов, выделяемых на кибербезопасность. Для этого используется предоставленная нами контекстная информация, которая позволяет предсказывать вероятность атак и возможности киберпреступников.
- Операционный уровень: принятие решений о приоритетных направлениях киберзащиты. Ни одна организация в мире не может похвастать безграничными ресурсами и способностью остановить или предотвратить любую киберугрозу. Детальные знания о киберпреступниках и их методах позволяют сконцентрировать ресурсы для защиты от атак, их обнаружения и реагирования на них на тех участках, которые являются целью злоумышленников сейчас или могут стать ей в обозримом будущем.
- Тактический уровень: принятие решений о технических процессах обнаружения, сортировки и активного поиска актуальных угроз, что позволяет своевременно предотвратить угрозу или остановить ее распространение. Для этого мы предоставляем полученные на основе анализа стандартизованные описания методов атак и детальные индикаторы компрометации.
В практическом смысле индикаторы компрометации представляют собой технические данные, которые можно использовать для идентификации действий или инструментов атакующих, например вредоносной инфраструктуры (имена хостов, доменные имена, IP-адреса), коммуникаций (URL-адреса, схемы обмена данными) или имплантов (хэши, пути к файлам, разделы и значения реестра Windows, артефакты, записанные вредоносными процессами в память, и др.). Хотя в большинстве своем IOC являются хэшами файлов, позволяющими определить вредоносные импланты, и доменными именами, указывающими на вредоносную инфраструктуру (например, командные серверы), в целом их происхождение, формат и способы представления могут быть любыми. Для обмена IOC используются специальные стандарты, например STIX.
Как уже было сказано, индикаторы компрометации — один из результатов действий по сбору данных о киберугрозах. Их используют на операционном и тактическом уровнях для выявления вредоносных объектов и их привязки к известным угрозам. Клиенты получают IOC в отчетах об угрозах и потоках технических данных (которые могут использоваться автоматическими системами). Также IOC интегрированы в продукты и сервисы «Лаборатории Касперского» (песочницы, Kaspersky Security Network, решения для обнаружения угроз на рабочих местах и в сети, а также в Kaspersky Threat Intelligence Portal).
Как GReAT определяет IOC?
В процессе активного поиска угроз (одного из видов деятельности по сбору данных об угрозах — см. рисунок ниже) GReAT старается получить как можно больше индикаторов компрометации, связанных с конкретной угрозой или группой злоумышленников, чтобы дать своим клиентам возможность уверенно определять или находить угрозы, используя доступные ресурсы и инструменты. Но как мы находим и собираем индикаторы компрометации? Как показывает практика, единого рецепта для активного поиска и сбора вредоносных артефактов нет: в каждом конкретном случае используется комбинация нескольких источников и методов. Чем более полно мы исследуем эти различные источники, тем глубже можем проанализировать данные и тем больше индикаторов компрометации получим. Эффективно координировать эту исследовательскую работу могут только опытные аналитики, использующие обширный спектр источников данных и надежные технологии.

Общая схема деятельности GReAT по сбору данных о киберугрозах
Аналитики команды GReAT используют перечисленные ниже источники и методы анализа для сбора данных, в том числе индикаторов компрометации, — здесь представлены самые распространенные варианты, но на практике их значительно больше, и ограничены они только изобретательностью исследователей и фактической доступностью.
- Собственные технические данные «Лаборатории Касперского». Статистика обнаружений (мы часто называем эти данные телеметрией[2]), проприетарные файлы, журналы и коллекции данных, собранные за длительный период, а также специализированные системы и инструменты для запроса данных из этих систем. Это наиболее ценные источники, которые предоставляют уникальные надежные данные, собранные доверенными системами и технологиями. В таких проприетарных данных аналитики могут найти вместе с известным индикатором компрометации (например, хэшем файла или IP-адресом) связанные с ним тактики кибератак, признаки вредоносного поведения, файлы и информацию о коммуникациях, которые напрямую указывают на дополнительные индикаторы компрометации или позволяют получить их в результате анализа. Портал «Лаборатории Касперского» Kaspersky Threat Intelligence Portal (TIP), доступный клиентам как сервис, предлагает ограниченный доступ к таким техническим данным.
- Открытые и коммерческие источники. К ним относятся различные сервисы и коллекции данных о файлах, доступные бесплатно или продаваемые сторонними компаниями: онлайн-сервисы сканирования файлов (например, VirusTotal), сетевые поисковые системы (например, Onyphe), базы данных Passive DNS, открытые отчеты об обнаружении угроз в песочницах и т. д. Аналитики могут использовать эти данные наряду с проприетарными. Хотя часть этих данных открыта для всех, в них часто отсутствует информация о контексте получения или выполнения, первичном источнике или способах обработки. Из-за этого аналитики GReAT не могут доверять им в той же степени, что и данным «Лаборатории Касперского».
- Сотрудничество. Предоставляя данные об угрозах надежным партнерам (поставщикам защитного ПО и цифровых сервисов, командам реагирования на киберинциденты, некоммерческим организациям, правительственным агентствам кибербезопасности и даже некоторым клиентам «Лаборатории Касперского»), аналитики команды GReAT налаживают отношения с ними и иногда также получают взамен дополнительную полезную информацию. Обмен информацией — важный аспект сбора данных об угрозах, позволяющий организовывать реагирование в международных масштабах, дополнять сведения о злоумышленниках и проводить дальнейшие исследования, которые в противном случае были бы невозможны.
- Анализ. Выполняется автоматизированными средствами и вручную. Состоит в тщательном изучении вредоносных артефактов, таких как сэмплы или дампы памяти, с целью получения дополнительных данных. Также включает в себя реверс-инжиниринг и выполнение вредоносных имплантов в контролируемой среде. Выполняя эти действия, аналитики часто обнаруживают скрытые (обфусцированные или зашифрованные) индикаторы: инфраструктуру командных серверов вредоносного ПО, уникальные методы разработки, применяемые авторами вредоносного ПО, или вредоносные инструменты, внедрение которых является дополнительным этапом атаки.
- Активные исследования. Специальные процедуры с использованием инструментов или систем (иногда их называют роботами) для активного поиска угроз, которые аналитики создают для непрерывного отслеживания вредоносных действий в среде клиента, применяя общий и эвристический подходы. Сюда относятся использование ханипотов[3], sinkholing[4], сканирование интернета и некоторые методы поведенческого анализа, применяемые в продуктах для обнаружения угроз на рабочих местах и в сети.
Как GReAT использует IOC?
Итак, GReAT предоставляет индикаторы компрометации клиентам и даже раскрывает их в общедоступных публикациях. Однако команда также использует их в своей деятельности. IOC позволяют аналитикам GReAT в ходе анализа вредоносного импланта обнаруживать дополнительные файлы и переходить от одного источника данных к другому. Таким образом они служат общим элементом для всех исследовательских процессов. Например, предположим, что один из наших эвристических методов активного поиска выявил прежде неизвестное вредоносное ПО в системе клиента. Поиск по хэшу файла в телеметрии «Лаборатории Касперского» помогает обнаружить дополнительные попытки его выполнения и вредоносные инструменты, использованные атакующими еще до первой зарегистрированной попытки выполнения. Реверс-инжиниринг найденных вредоносных инструментов позволяет получить дополнительные индикаторы компрометации сети: схемы вредоносных коммуникаций или IP-адреса командных серверов. Проверяя эти IP-адреса в нашей телеметрии, мы можем найти дополнительные файлы и использовать их хэши для дальнейшего поиска. IOC обеспечивают непрерывность цикла исследований — команда GReAT запускает его, а клиент продолжает с использованием индикаторов компрометации, предоставленных среди прочих данных об угрозах.
IOC используются не только сами по себе, они также тщательно классифицируются и связываются с известными вредоносными кампаниями или группами злоумышленников, и GReAT применяет их в собственных инструментах для расследования. Такой процесс управления IOC позволяет осуществлять два важных и тесно связанных вида деятельности:
- Отслеживание угроз. Связывая известные IOC (а также расширенные сигнатуры и методы обнаружения) с вредоносными кампаниями и группами злоумышленников, мы можем организовать автоматический мониторинг и сортировку обнаруженных вредоносных операций. Это упрощает дальнейший поиск угроз и их расследование, так как существующие IOC с их связями можно использовать как точку отчета для исследования большинства новых обнаружений.
- Атрибуция угроз. Сравнивая новые IOC с используемыми, мы можем быстро установить связи между неизвестными угрозами и вредоносными кампаниями или группами злоумышленников. Хотя общий индикатор компрометации между известной кампанией и только что обнаруженной угрозой не может служить достаточным основанием для атрибуции, он всегда будет полезной зацепкой.
Сценарии использования IOC в центрах мониторинга и реагирования
Каждый центр мониторинга и реагирования (SOC) так или иначе использует известные индикаторы компрометации в своей деятельности. Но прежде чем говорить о сценариях их использования, примем, что IOC является признаком известной атаки.
«Лаборатория Касперского» разрабатывает и сопровождает операции SOC в различных форматах для компаний из различных отраслей, и в структуру SOC, которую мы предлагаем для внедрения своим клиентам, всегда входит использование и управление IOC. Теперь подробнее рассмотрим некоторые сценарии использования индикаторов компрометации в SOC.
Предотвращение
Как правило, современные практики SOC направлены на предотвращение потенциальных угроз на как можно более ранних этапах атаки. Зная точные индикаторы атаки, мы сможем ее блокировать, предпочтительно на нескольких уровнях (и сети, и рабочих мест) защищаемой среды. Это концепция многоуровневой безопасности. Любые попытки подключиться к вредоносному IP-адресу, обращения к доменному имени C2 или запуск ВПО с известным хэшем блокируются — это помогает предотвратить или, по крайней мере, затруднить атаку. Это также экономит время аналитиков SOC и сокращает количество ложноположительных уведомлений, поступающих в SOC. Однако для такой блокировки необходимо использовать только IOC, в которых вы полностью уверены. В противном случае чрезмерное количество правил для блокирования ложноположительных уведомлений повлияет на бизнес-процессы в защищаемой среде.
Обнаружение
Наиболее популярный сценарий использования IOC в центре мониторинга и реагирования — автоматическое сопоставление телеметрии инфраструктуры с огромной коллекцией всевозможных IOC. Чаще всего для этого используются системы SIEM. Сценарий обнаружения широко используется по ряду причин:
- SIEM ведет журналы различных типов. Мы можем сопоставить один и тот же IOC с разными журналами — например, доменное имя с журналом DNS-запросов, полученных от корпоративных DNS-серверов, и журналом запрашиваемых URL, полученных от прокси-сервера.
- Сопоставление в системе SIEM позволяет получить расширенный контекст анализируемых событий. Дополнительная информация об инциденте может рассказать аналитику, почему сработало уведомление на базе IOC, какой тип угрозы обнаружен, каков уровень достоверности и т. д.
- Доступ ко всем данным на одной платформе позволяет команде SOC тратить меньше усилий на обслуживание инфраструктуры и устраняет необходимость организовывать дополнительную маршрутизацию событий (как в следующем случае).
Еще одно популярное решение для сопоставления индикаторов — платформа обработки данных об угрозах (Threat Intelligence Platform, TIP). Как правило, она поддерживает более эффективные сценарии сопоставления (например, с использованием подстановочных символов) и оказывает меньшую нагрузку на процессы, чем SIEM. Еще одно огромное преимущество TIP — решения такого типа изначально разрабатываются для работы с IOC. Они поддерживают соответствующую схему данных и позволяют управлять IOC, обладают более гибкими функциями для настройки логики обнаружения на базе конкретных индикаторов.
При использовании детектирования в TIP требования к уровню достоверности в IOC ниже, чем при блокировании, так как ложноположительные уведомления, хотя и нежелательные, в процессе обнаружения генерируются довольно часто.
Расследование
Еще один сценарий использования индикаторов компрометации — расследование инцидента. В этом случае мы обычно ограничены теми индикаторами компрометации, которые были обнаружены в ходе конкретного инцидента. Эти IOC требуются для определения дополнительных скомпрометированных хостов в нашей среде и оценки реального масштаба инцидента. В ходе расследования команда SOC выполняет цикл переиспользования IOC:
- Определение IOC, связанного с инцидентом.
- Поиск IOC на других хостах.
- Определение дополнительных IOC на выявленных целях, повторение шага 2.
Сдерживание, устранение и восстановление
Индикаторы компрометации используются и на последующих шагах устранения инцидента. Команда SOC применяет индикаторы компрометации, собранные во время анализа инцидента, в следующих целях:
- Сдерживание — найденные IOC блокируются, чтобы ограничить возможности киберпреступников.
- Устранение угрозы и восстановление систем — отслеживается поведение, связанное с IOC, после восстановления систем. Такой контроль позволяет, вместе с остальными мерами, убедиться что угроза была успешно устранена.
Активный поиск угроз (Threat Hunting)
Активным поиском угроз мы называем действия по выявлению угроз, способных обойти инструменты предотвращения и обнаружения SOC. В основе активного поиска угроз лежит «презумпция нарушения» — она предполагает, что, несмотря на все действия по предотвращению и обнаружению угроз, мы пропустили атаку и должны проанализировать инфраструктуру как скомпрометированную, чтобы найти признаки взлома.
Здесь мы снова используем индикаторы компрометации. Команда SOC анализирует информацию, связанную с атакой, и оценивает применимость угрозы к защищаемой среде. Если угроза может быть реализована, исследователь пытается найти индикатор компрометации в прошедших событиях (DNS-запросах, попытках подключения к определенным IP-адресам и выполняемых процессах) или в самой инфраструктуре — индикатором может быть присутствие определенного файла в системе, конкретное значение в реестре и т. д. Как правило, для этого используются решения SIEM, EDR и TIP. Для активного поиска угроз подходят индикаторы компрометации, полученные из отчетов об APT-угрозах или собранные исследователями из других компаний.
Рассказывая о сценариях использования IOC, мы говорили о разных типах индикаторов компрометации в зависимости от происхождения. Давайте подытожим информацию о них:
- Потоки данных от поставщиков. Поставщики защитных решений предоставляют по подписке индикаторы компрометации в виде потоков данных. Как правило, они содержат огромное количество IOC, наблюдаемых в различных атаках. Уровень надежности индикаторов у поставщиков различается, поэтому команда SOC должна учитывать специализацию и региональные характеристики поставщика, чтобы выбирать актуальные IOC. Использование потоков данных для предотвращения и активного поиска угроз не слишком эффективно из-за потенциально большого количества ложноположительных срабатываний.
- IOC инцидентов. Эти индикаторы компрометации получает команда SOC при анализе инцидентов безопасности. Как правило, это самый надежный тип IOC.
- IOC из данных о киберугрозах. Огромное семейство IOC, получаемых специалистами по сбору данных об угрозах. Качество этих индикаторов напрямую зависит от уровня квалификации аналитиков. Использование таких IOC для предотвращения атак во многом зависит от качества данных об угрозах. Они могут вызвать слишком много ложноположительных срабатываний и помешать выполнению бизнес-процессов.
- IOC других организаций и открытых источников. Этими индикаторами компрометации делятся другие компании, государственные организации и профессиональные сообщества. Их, как правило, считают подмножеством IOC из данных о киберугрозах или из инцидентов, в зависимости от того, кто их предоставил.
Обобщив рассмотренные сценарии, источники IOC и их применимость и сопоставив эти сведения с этапами устранения инцидентов, описанными NIST[5], мы составили следующую таблицу.

Сценарии использования индикаторов компрометации в SOC
Во всех этих сценариях предъявляются разные требования к качеству индикаторов компрометации. Как правило, в нашем SOC не возникает проблем с IOC из инцидентов, но качество остальных индикаторов мы должны отслеживать и каким-то образом контролировать. Чтобы контроль качества был более эффективным, для каждого типа источников IOC необходимо использовать метрики, позволяющие оценить источник, а не полученные из него индикаторы. Вот несколько базовых метрик, определенных нашей командой консультирования SOC, которые можно использовать для оценки качества IOC:
- Конверсия — доля IOC, срабатывания по которым выявили реальный инцидент. Применяется в сценариях обнаружения.
- Доля ложноположительных уведомлений, генерируемых IOC. Используется для сценариев обнаружения и предотвращения.
- Уникальность — эта метрика применяется к источнику IOC и показывает, насколько набор предоставленных IOC отличается от наборов других поставщиков.
- Устаревание — актуальность IOC из данного источника.
- Количество IOC из данного источника.
- Контекстная информация — применимость и полнота контекста, предоставленного вместе с IOC.
Чтобы получить эти метрики, команда SOC должна тщательно отслеживать для каждого IOC его источник, сценарий использования и результат применения.
Как команда GERT использует IOC в своей работе?
GERT специализируется на расследовании инцидентов, и основными источниками информации для нас являются цифровые артефакты. Эксперты анализируют их и находят информацию о действиях, напрямую связанных с расследуемым инцидентом. Таким образом индикаторы компрометации позволяют установить связь между исследуемым объектом и инцидентом.
Мы используем различные IOC на разных этапах цикла реагирования на инциденты информационной безопасности. Как правило, когда мы связываемся с жертвой инцидента, мы получаем индикаторы компрометации, которые могут помочь подтвердить инцидент, приписать инцидент конкретной группе злоумышленников и принять решение о начальных мерах реагирования. Возьмем один из самых типичных инцидентов — атаку с использованием шифровальщика. В этом случае исходным артефактом будут файлы. Индикаторами компрометации в таком случае являются имена или расширения файлов, а также их хэш-суммы. Такие первичные индикаторы позволяют определить тип шифровальщика, атакующую группу и присущие ей методы, тактики и процедуры. Кроме того, они помогают сформулировать рекомендации по начальному реагированию.
Следующий набор IOC — индикаторы, полученные в процессе анализа данных собранных на этапе классификации инцидента. Как правило, они показывают продвижение атакующих в сети и позволяют определить дополнительные системы, затронутые инцидентом. В большинстве своем это имена скомпрометированных пользователей, хэш-суммы вредоносных файлов, IP-адреса и URL-адреса. Здесь следует отметить возникающие трудности. Злоумышленники часто используют легитимные программы, уже установленные в атакуемых системах (так называемые LOLBins). Вредоносное выполнение такой программы трудно отличить от легитимного. Например, только тот факт, что интерпретатор PowerShell запущен, не может указывать на атаку, если неизвестны контекст и полезная нагрузка. В таких случаях необходимо использовать дополнительные индикаторы, например временные метки, имя пользователя, связи между событиями.
Наконец, все найденные IOC используются для поиска скомпрометированных сетевых ресурсов и блокирования действий атакующих. Кроме того, на их основе создаются индикаторы атаки, которые используются для превентивного обнаружения злоумышленников. На последнем этапе реагирования найденные индикаторы используются для проверки отсутствия атакующих в сети.
После каждого расследования составляется отчет, содержащий все индикаторы компрометации и основанные на них индикаторы атаки. Команды мониторинга должны добавлять эти индикаторы в свои системы и использовать их для проактивного поиска угроз.
[1] Хэш — сравнительно короткая, но достаточно уникальная битовая последовательность фиксированной длины, получаемая в результате применения алгоритма хэширования (математической функции, например, MD5 или SHA-256) к произвольному набору данных. Восстановить набор данных по хэшу нельзя, однако он обладает полезным свойством: применив к двум идентичным файлам один и тот же алгоритм хэширования, мы получим один и тот же хэш, однако если файлы отличаются незначительно, хэши будут совершенно разными. Так как хэш — краткое представление данных, его удобнее использовать для обозначения и поиска файла, чем полное содержимое.
[2] Телеметрия — статистика детектирования и сведения о вредоносных файлах, которые продукты для обнаружения угроз отправляют в Kaspersky Security Network с согласия клиентов.
[3] Слабые, уязвимые и (или) привлекательные для злоумышленников системы, которые исследователи подключают к интернету и намеренно оставляют незащищенными в качестве приманки для киберпреступников. В случае атаки используются специальные методы мониторинга для определения новых угроз, методов эксплуатации или инструментов атакующих.
[4] Перехват трафика известных вредоносных командных серверов для нейтрализации вредоносных действий, отслеживания коммуникаций и определения возможных жертв, которых исследователи могут предупредить об угрозе. Sinkholing часто проводится при содействии поставщиков услуг интернет-хостинга, исследователи также могут использовать ошибки киберпреступников и перехватывать брошенную ими инфраструктуру.
[5] NIST. Computer Security Incident Handling Guide. Special Publication 800-61 Revision 2 («NIST. Руководство по устранению инцидентов компьютерной безопасности. Специальное издание 800-61, редакция 2»)
Блог 11.09.2020 18:57:00 2020-09-11 18:57:00

Руслан Рахметов, Security Vision
В предыдущей статье мы описали политики аудита Windows, значимые с точки зрения защиты информации, а также обсудили утилиту Sysmon. В настоящей статье мы рассмотрим несколько полезных «фич» при работе со встроенной системой журналирования Windows для того, чтобы показать, что для построения грамотной системы мониторинга событий ИБ можно воспользоваться и штатным функционалом ОС. Приступим!
Как мы уже говорили, начиная с Microsoft Windows Server 2008 и Vista в Windows используются политики расширенного аудита событий безопасности, которые настраиваются достаточно гибко и дают массу значимой с точки зрения ИБ информации, позволяя выстраивать продуманную систему мониторинга событий безопасности. Для работы с подсистемой журналирования можно не только использовать графическую оболочку, но и осуществлять администрирование и точную настройку из командной строки. Для этого в ОС Windows существует утилита wevtutil
, которая позволяет управлять свойствами конкретных журналов аудита, получать текущие настройки журналирования, искать интересующие нас данные в журналах, в том числе в событиях аудита информационной безопасности, причем как локально, так и на удаленных устройствах.
Например, для увеличения размера журнала Sysmon до 512 МБайт следует выполнить команду
wevtutil sl Microsoft-Windows-Sysmon/Operational /ms:536870912 (размер указывается в байтах).
Для установки разрешения на ротацию, т.е. перезапись старых событий в журнале более новыми, следует использовать опцию retention со значением false (значение true означает, что новые события не будут перезаписывать старые, что может привести к потере информации в случае переполнения журнала):
wevtutil sl Microsoft-Windows-Sysmon/Operational /rt:false
Для просмотра детальных свойств определенного журнала с отображением прав доступа к нему в SDDL-синтаксисе следует выполнить команду
wevtutil gl security (где Security — имя встроенного журнала безопасности).
Простой текстовый поиск по лог-файлу, в том числе и экспортированному в форматы evtx и etl , можно осуществить командой
wevtutil qe «C:pathtofile.evtx» /lf:true /f:text | find /i «some_text»
Наконец, выполнив необходимые настройки файлов журналов Windows, перейдем непосредственно к поиску интересующей информации. Заметим, что в случае включения всех рекомендованных политик аудита ИБ сами журналы событий становятся достаточно объемными, поэтому поиск по их содержимому может быть медленным (этих недостатков лишены специализированные решения, предназначенные в том числе для быстрого поиска информации — Log Management и SIEM-системы). Отметим также, что по умолчанию не все журналы Windows отображаются к графической оснастке (eventvwr.msc), поэтому в данной оснастке следует перейти в меню «Вид» и отметить check-box «Отобразить аналитический и отладочный журналы».
Итак, поиск по журналам аудита будем осуществлять с помощью встроенного редактора запросов XPath (XPath queries). Открыв интересующий нас журнал, например, журнал безопасности Windows (вкладка «Журналы Windows» -> «Безопасность» / «Security»), нажатием правой кнопки мыши на имени журнала выберем пункт «Фильтр текущего журнала». Нам откроется графический редактор поисковых запросов, при этом для наиболее продуктивной работы следует открыть вторую вкладку открывшегося окна с названием XML, отметив внизу check-box «Изменить запрос вручную». Нам будет предложено изменить XML-текст (по сути, XPath запрос) в соответствии с нашими критериями поиска. Результат запроса будет также представляться в различных формах, но для лучшего понимания и получения детального контента в конкретном событии рекомендуем переключиться на вкладку «Подробности», а там выбрать radio-button «Режим XML», в котором в формате «ключ-значение» будут представлены данные события безопасности.
Приведем несколько полезных XPath запросов с комментариями.
1. Поиск по имени учетной записи в журнале Security — возьмем для примера имя Username:
<QueryList>
<Query Id=»0″ Path=»Security»>
<Select Path=»Security»>*[EventData[Data[@Name=’TargetUserName’]=’Username’]]
</Select>
</Query>
</QueryList>
2. Поиск по значению конкретного свойства события в журнале Sysmon — возьмем для примера поиск событий, в которых фигурировал целевой порт 443:
<QueryList>
<Query Id=»0″ Path=»Microsoft-Windows-Sysmon/Operational»>
<Select Path=»Microsoft-Windows-Sysmon/Operational»>*[EventData[Data[@Name=’DestinationPort’] = ‘443’]]</Select>
</Query>
</QueryList>
3. Произведем поиск сразу по двум условиям — возьмем для примера событие входа с EventID=4624 и имя пользователя Username:
<QueryList>
<Query Id=»0″ Path=»Security»>
<Select Path=»Security»>
*[System[(EventID=4624)]]
and
*[EventData[Data[@Name=’TargetUserName’]=’Username’]]
</Select>
</Query>
</QueryList>
4. Поиск по трем условиям — дополнительно укажем Logon Type = 2, что соответствует интерактивному входу в ОС:
<QueryList>
<Query Id=»0″ Path=»Security»>
<Select Path=»Security»>
*[System[(EventID=4624)]]
and
*[EventData[Data[@Name=’TargetUserName’]=’Username’]]
and
*[EventData[Data[@Name=’LogonType’]=’2′]]
</Select>
</Query>
</QueryList>
5. Рассмотрим функционал исключения из выборки данных по определенным критериям — это осуществляется указанием оператора Suppress с условиями исключения. В данном примере мы исключим из результатов поиска по фактам успешного входа (EventID=4624) все события, которые имеют отношения к системным учетным записям (SID S-1-5-18/19/20) с нерелевантным для нас типам входа (Logon Type = 4/5), а также применим функционал задания условий поиска с логическим оператором «ИЛИ», указав не интересующие нас имя процесса входа (Advapi) и методы аутентификации (Negotiate и NTLM):
<QueryList>
<Query Id=»0″ Path=»Security»>
<Select Path=»Security»>*[System[(EventID=4624)]]</Select>
<Suppress Path=»Security»>*[EventData[(Data[@Name=’TargetUserSid’] and (Data=’S-1-5-18′ or Data=’S-1-5-19′ or Data=’S-1-5-20′) and Data[@Name=’LogonType’] and (Data=’4′ or Data=’5′))]]
or
*[EventData[(Data[@Name=’LogonProcessName’] and (Data=’Advapi’) and Data[@Name=’AuthenticationPackageName’] and (Data=’Negotiate’ or Data=’NTLM’))]]
</Suppress>
</Query>
</QueryList>
Как видим, встроенный функционал подсистемы журналирования Windows позволяет весьма гибко осуществлять поиск по зафиксированным событиям аудита ИБ, комбинируя различные условия поиска. Однако, у Windows есть еще одна интересная «фишка», которая позволяет использовать сформированные описанным выше образом правила поиска событий — мы говорим про создание задач с определенным триггером в «Планировщике заданий» Windows, что также является штатным функционалом ОС.
Как мы знаем, задачи в ОС Windows могут выполнять совершенно разные функции, от запуска диагностических и системных утилит до обновления компонент прикладного ПО. В задаче можно не только указать исполняемый файл, который будет запущен при наступлении определенных условий и триггеров, но и задать пользовательский PowerShell/VBS/Batch-скрипт, который также будет передан на обработку. В контексте применения подсистемы журналирования интерес для нас представляет функционал гибкой настройки триггеров выполнения задач. Открыв «Планировщик заданий» (taskschd.msc), мы можем создать новую задачу, в свойствах которой на вкладке «Триггеры» мы увидим возможность создать свой триггер. При нажатии на кнопку «Создать» откроется новое окно, в котором в drop-down списке следует выбрать вариант «При событии», а в открывшейся форме отображения установить radio-button «Настраиваемое». После этих действий появится кнопка «Создать фильтр события», нажав на которую, мы увидим знакомое меню фильтрации событий, на вкладке XML в котором мы сможем задать произвольное поисковое условие в синтаксисе XPath-запроса.
Например, если мы хотим выполнять некоторую команду или скрипт при каждом интерактивном входе в систему пользователя Username, мы можем задать в качестве триггера задачи следующее поисковое выражение, уже знакомое нам по примеру выше:
<QueryList>
<Query Id=»0″ Path=»Security»>
<Select Path=»Security»>
*[System[(EventID=4624)]]
and
*[EventData[Data[@Name=’TargetUserName’]=’Username’]]
and
*[EventData[Data[@Name=’LogonType’]=’2′]]
</Select>
</Query>
</QueryList>
Таким образом, при условии работоспособности системы журналирования событий Windows можно не только детально и глубоко анализировать все произошедшее на устройстве, но и выполнять произвольные действия при появлении в журнале ОС событий, отвечающих условиям XPath-запроса, что позволяет выстроить целостную систему аудита ИБ, реагирования и мониторинга событий безопасности штатными средствами ОС. Кроме того, объединив рекомендованные политики аудита информационной безопасности, утилиту Sysmon с детально проработанными конфигами, функционал XPath-запросов, пересылку и централизацию событий с помощью Windows Event Forwarding, а также настраиваемые задачи с гибкими условиями выполнения скриптов, можно получить фактически бесплатную (по цене лицензии на ОС) систему защиты конечных точек и реагирования на киберинциденты, используя лишь штатный функционал ОС.

Интересные публикации
Спасибо, что выбрали нас!
Запрос на авторизацию проекта успешно отправлен! Мы свяжемся с Вами в ближайшее время.
Спасибо, что выбрали нас!
Мы свяжемся с Вами в ближайшее время.
Регистрация в качестве партнера
|
Мы используем файлы cookies для улучшения качества обслуживания. Оставаясь на сайте, вы соглашаетесь с использованием данных технологий. |
Согласен |
На чтение 2 мин Опубликовано 05.01.2018
Есть два типа людей: одни не знают, что такое фракталы, а другие уверены, что есть два типа людей: одни не знают, что такое фракталы, а другие уверены, что есть два типа людей: одни не знают, что такое фракталы, а другие уверены, что есть…
Аудит доступа к журналам аудита. Тем, кто озадачен внедрением PCI DSS, это вполне понятно. Ну и остальным может быть интересно, кто лазит по логам. Но! Это работает только если записи о событиях собираются в централизованное место хранения. А то при компрометации системы взломщик запросто может потереть все журналы.
Тут мы настроим аудит всего доступа к журналам Windows Application, Security и System. Через PowerShell:
$AuditUser = “Everyone”
$AuditRules = “GenericAll”
$InheritType = “ContainerInherit,ObjectInherit”
$AuditType = “Success,Failure”
$AccessRule = New-Object System.Security.AccessControl.FileSystemAuditRule($AuditUser,$AuditRules,$InheritType,”None”,$AuditType)
$path = “$env:SystemRootSystem32WinevtLogsApplication.evtx”
$ACL = Get-Acl $path
$ACL.AddAuditRule($AccessRule)
$ACL | Set-Acl $path
$path = “$env:SystemRootSystem32WinevtLogsSecurity.evtx”
$ACL = Get-Acl $path
$ACL.AddAuditRule($AccessRule)
$ACL | Set-Acl $path
$path = “$env:SystemRootSystem32WinevtLogsSystem.evtx”
$ACL = Get-Acl $path
$ACL.AddAuditRule($AccessRule)
$ACL | Set-Acl $path
Источник : https://t.me/informhardening
Пожалуйста, не спамьте и никого не оскорбляйте.
Это поле для комментариев, а не спамбокс.
Рекламные ссылки не индексируются!
Информация о работе каждого компонента Kaspersky Endpoint Security, о событиях шифрования данных, о выполнении каждой задачи поиска вредоносного ПО, задачи обновления и задачи проверки целостности, а также о работе приложения в целом сохраняется в журнале событий Kaspersky Security Center и журнале событий Windows.
Kaspersky Endpoint Security формирует события следующих типов: общие и специфические события. Специфические события создает только приложение Kaspersky Endpoint Security для Windows. Специфические события имеют простой идентификатор, например, 000000cb. Специфические события содержат следующие обязательные параметры:
Общие события, кроме Kaspersky Endpoint Security для Windows, могут создавать и другие приложения «Лаборатории Касперского» (например, Kaspersky Security для Windows Server). Общие события имеют более сложный идентификатор, например, GNRL_EV_VIRUS_FOUND. Общие события кроме обязательных параметров содержат еще дополнительные параметры.
Развернуть всё | Свернуть всё
Критические события
Нарушено Лицензионное соглашение
Срок действия лицензии почти истек
Базы повреждены или отсутствуют
Базы сильно устарели
Автозапуск приложения выключен
Ошибка активации
Обнаружена активная угроза. Требуется запуск процедуры лечения активного заражения
Серверы KSN недоступны
Недостаточно места в хранилище карантина
Объект не восстановлен из карантина
Объект не удален из карантина
Приложение установило соединение с сайтом с недоверенным сертификатом
Возникла ошибка проверки зашифрованного соединения. Домен добавлен в список исключений
Обнаружен вредоносный объект (локальные базы)
Обнаружен вредоносный объект (KSN)
Лечение невозможно
Невозможно удалить
Ошибка обработки
Процесс завершен
Невозможно завершить процесс
Заблокирована опасная ссылка
Открыта опасная ссылка
Обнаружена ранее открытая опасная ссылка
Действие процесса заблокировано
Клавиатура не авторизована
AMSI-запрос заблокирован
Сетевая активность запрещена
Обнаружена сетевая атака
Запуск приложения запрещен
Запрещенный процесс был запущен до старта Kaspersky Endpoint Security для Windows
Доступ запрещен (локальные базы)
Доступ запрещен (KSN)
Операция с устройством запрещена
Сетевое соединение заблокировано
Ошибка обновления компонента
Ошибка копирования обновлений компонента
Локальная ошибка обновления
Сетевая ошибка обновления
Невозможен запуск двух задач одновременно
Ошибка проверки баз и модулей приложения
Ошибка взаимодействия с Kaspersky Security Center
Обновлены не все компоненты
Обновление завершено успешно, а копирование обновлений завершено с ошибкой
Внутренняя ошибка задачи
Ошибка установки патча
Ошибка отката патча
Ошибка применения правил шифрования / расшифровки файлов
Ошибка шифрования / расшифровки файла
Заблокирован доступ к файлу
Ошибка активации портативного режима
Ошибка деактивации портативного режима
Ошибка создания зашифрованного архива
Ошибка шифрования / расшифровки устройства
Не удалось загрузить модуль шифрования
Задача управления учетными записями Агента аутентификации завершилась ошибкой
Политика не может быть применена
Обновление функциональности шифрования завершено с ошибкой
Откат обновления функциональности шифрования завершен с ошибкой (более подробная информация доступна в онлайн-справке для Kaspersky Endpoint Security для Windows)
Сервер Kaspersky Anti Targeted Attack Platform недоступен
Ошибка удаления объекта
Объект не помещен на карантин (Kaspersky Sandbox)
Возникла внутренняя ошибка
Сертификат сервера Kaspersky Sandbox недействителен
Узел Kaspersky Sandbox не доступен
Обработка объекта в Kaspersky Sandbox завершилась с ошибкой
Превышена допустимая нагрузка на Kaspersky Sandbox
IOC обнаружен
Возникла ошибка при проверке лицензии Kaspersky Sandbox
Запрещен запуск объекта
Запрещен запуск процесса
Запрещено выполнение скрипта
Объект не помещен на карантин (Endpoint Detection and Response)
Запуск процесса не заблокирован
Объект не заблокирован
Выполнение скрипта не заблокировано
Ошибка изменения состава компонентов приложения
Обнаружена возможная попытка взлома пароля с помощью подбора
Обнаружены признаки компрометации журналов Windows
Обнаружена подозрительная активность со стороны новой установленной службы
Обнаружена подозрительная аутентификация с явным указанием учетных данных
Обнаружены признаки атаки Kerberos forged PAC (MS14-068)
Обнаружены подозрительные изменения привилегированной группы Администраторы
Обнаружена подозрительная активность во время сетевого сеанса входа
Сработало правило Анализа журналов
Подозрительное событие повторяется слишком часто. Запущено формирование агрегированных событий
Отчет о подозрительном событии за период агрегации
Отказ функционирования
Не удалось выполнить задачу
Ошибка в настройках задачи. Настройки задачи не применены
Предупреждение
Обнаружено некорректное завершение предыдущей сессии работы приложения
Срок действия лицензии скоро истекает
Базы устарели
Автоматическое обновление выключено
Самозащита приложения выключена
Компоненты защиты выключены
Компьютер работает в безопасном режиме
Есть необработанные файлы
Применена групповая политика
Задача остановлена
Для завершения обновления необходимо перезапустить приложение
Необходима перезагрузка компьютера
Установлены не все компоненты приложения, которые позволяет использовать лицензия
Запущена процедура лечения активного заражения
Процедура лечения активного заражения завершена
Некорректный резервный ключ
Подписка скоро истекает
Запрещено
Невозможно восстановить объект из резервного хранилища
Обнаружена подозрительная сетевая активность
Защищенное соединение разорвано
Участие в KSN выключено
Обработка приложением некоторых функций ОС выключена
В хранилище карантина скоро закончится место
Сетевое соединение заблокировано
Невозможно создать резервную копию объекта
Объект не обработан
Объект зашифрован
Объект поврежден
Обнаружено легальное приложение, которое может быть использовано злоумышленниками для нанесения вреда компьютеру или данным пользователя (локальные базы)
Обнаружено легальное приложение, которое может быть использовано злоумышленниками для нанесения вреда компьютеру или данным пользователя (KSN)
Объект удален
Объект вылечен
Объект будет вылечен при перезагрузке
Объект будет удален при перезагрузке
Объект удален в соответствии с настройками
Откат выполнен
Загрузка объекта запрещена
Ошибка авторизации клавиатуры
Результат проверки объекта передан стороннему приложению
Настройки задачи успешно применены
Предупреждение о нежелательном содержимом (локальные базы)
Предупреждение о нежелательном содержимом (KSN)
Осуществлен доступ к нежелательному содержимому после предупреждения
Активирован временный доступ к устройству
Операция отменена пользователем
Пользователь отказался от политики шифрования
Прервано применение правил шифрования / расшифровки файлов
Операция шифрования / расшифровки файла прервана
Приостановка шифрования / расшифровки устройства
Не удалось установить или обновить драйверы для компонента Шифрование диска Kaspersky в образе среды восстановления Windows
Неуспешная проверка подписи модуля
Запуск приложения был заблокирован
Открытие документа было заблокировано
Процесс завершен администратором сервера Kaspersky Anti Targeted Attack Platform
Работа приложения завершена администратором сервера Kaspersky Anti Targeted Attack Platform
Файл или стрим удален администратором сервера Kaspersky Anti Targeted Attack Platform
Файл восстановлен из карантина сервера Kaspersky Anti Targeted Attack Platform администратором
Файл помещен на карантин сервера Kaspersky Anti Targeted Attack Platform администратором
Сетевая активность приложений сторонних производителей заблокирована
Сетевая активность приложений сторонних производителей разблокирована
Объект будет удален после перезагрузки (Kaspersky Sandbox)
Суммарный размер задач проверки превысил максимальное значение
Запуск объекта разрешен, событие записано в отчет
Запуск процесса разрешен, событие записано в отчет
Объект будет удален после перезагрузки (Endpoint Detection and Response)
Сетевая изоляция
Завершение сетевой изоляции
Для завершения задачи требуется перезагрузка
Сообщение администратору о запрете запуска приложения
Сообщение администратору о запрете доступа к устройству
Сообщение администратору о запрете доступа к веб-странице
Подключение устройства заблокировано
Сообщение администратору о запрете действия приложения
Файл изменен
Объект изменяется слишком часто. Запущено формирование агрегированных событий
Отчет об изменениях объекта за период агрегации
Область мониторинга содержит некорректные объекты
Информационное сообщение
Приложение запущено
Приложение остановлено
Самозащита ограничила доступ к защищаемому ресурсу
Отчет очищен
Групповая политика деактивирована
Изменены настройки приложения
Задача запущена
Задача завершена
Все компоненты приложения, которые допускает лицензия, установлены и работают в нормальном режиме
Параметры подписки были изменены
Подписка была продлена
Объект восстановлен из резервного хранилища
Ввод имени пользователя и пароля
Участие в KSN включено
Серверы KSN доступны
Приложение работает и обрабатывает данные в соответствии с местным законодательством и использует локальную инфраструктуру
Объект восстановлен из карантина
Объект удален из карантина
Создана резервная копия объекта
Объект перезаписан вылеченной ранее копией
Обнаружен защищенный паролем архив
Информация об обнаруженном объекте
Объект находится в списке разрешенных в Локальном KSN
Объект переименован
Объект обработан
Объект пропущен
Обнаружен архив
Обнаружен упакованный объект
Ссылка обработана
Запуск приложения разрешен
Выбран источник обновлений
Выбран прокси-сервер
Ссылка находится в списке разрешенных в Локальном KSN
Приложение помещено в группу доверенных приложений
Приложение помещено в группу с ограничениями
Сработал компонент Предотвращение вторжений
Файл восстановлен
Значение реестра восстановлено
Значение реестра удалено
Действие процесса пропущено
Клавиатура авторизована
Сетевая активность разрешена
Запуск приложения запрещен в тестовом режиме
Запуск приложения разрешен в тестовом режиме
Открыта разрешенная страница
Операция с устройством разрешена
Выполнена операция с файлом
Нет доступных обновлений
Копирование обновлений успешно завершено
Загрузка файла
Файл загружен
Файл установлен
Файл обновлен
Выполнен откат файла из-за ошибки обновления
Обновление файлов
Копирование обновлений
Откат файлов
Формирование списка файлов для загрузки
Загрузка патчей
Установка патча
Патч установлен
Откат патча
Откат патча выполнен
Началось применение правил шифрования / расшифровки файлов
Завершено применение правил шифрования / расшифровки файлов
Продолжено применение правил шифрования / расшифровки файлов
Запущена операция шифрования / расшифровки файла
Завершена операция шифрования / расшифровки файла
Шифрование файла не выполнено, так как файл является исключением
Активирован портативный режим
Деактивирован портативный режим
Запущена операция шифрования / расшифровки устройства
Завершена операция шифрования / расшифровки устройства
Возобновление шифрования / расшифровки устройства
Устройство не зашифровано
Процесс шифрования / расшифровки устройства переведен в активный режим
Процесс шифрования / расшифровки устройства переведен в пассивный режим
Загружен модуль шифрования
Создана новая учетная запись Агента аутентификации
Удалена учетная запись Агента аутентификации
Изменен пароль для учетной записи Агента аутентификации
Успешная аутентификация в Агенте аутентификации
Аутентификация в Агенте аутентификации завершилась с ошибкой
Получен доступ к жесткому диску с помощью процедуры запроса доступа к зашифрованным устройствам
Попытка получения доступа к жесткому диску с помощью процедуры запроса доступа к зашифрованным устройствам завершилась с ошибкой
Учетная запись не добавлена. Такая учетная запись уже существует
Учетная запись не изменена. Такая учетная запись не существует
Учетная запись не удалена. Такая учетная запись не существует
Обновление функциональности шифрования завершено успешно
Откат обновления функциональности шифрования завершен успешно
Не удалось удалить драйверы для компонента Шифрование диска Kaspersky из образа среды восстановления Windows
Ключ восстановления для BitLocker изменен
Пароль / PIN-код для BitLocker изменен
Ключ восстановления BitLocker был сохранен на съемный диск
Задачи с сервера Kaspersky Anti Targeted Attack Platform не обрабатываются
Компонент Endpoint Sensor подключен к серверу
Связь с сервером Kaspersky Anti Targeted Attack Platform восстановлена
Задачи с сервера Kaspersky Anti Targeted Attack Platform обрабатываются
Объект удален
Статистика задачи удаления
Объект помещен на карантин (Kaspersky Sandbox)
Объект удален (Kaspersky Sandbox)
Запущен поиск IOC
Завершен поиск IOC
Объект помещен на карантин (Endpoint Detection and Response)
Объект удален (Endpoint Detection and Response)
Состав компонентов приложения успешно изменен
Асинхронное обнаружение Kaspersky Sandbox
Устройство подключено
Устройство отключено
Ошибка при удалении предыдущей версии приложения
Индикаторы компрометации (Indicators of Compromise, IOC) — это данные, которые являются свидетельством потенциального вторжения в систему. Они используются специалистами в области кибербезопасности для выявления угроз в информационных системах.
IOC могут включать различные виды данных, такие как:
- IP-адреса: Подозрительные или известные вредоносные IP-адреса могут указывать на потенциальное вторжение.
- URL: Вредоносные URL, которые используются для распространения вредоносного ПО или проведения фишинговых атак.
- Хэши файлов: Хэши вредоносных файлов, которые могут быть связаны с определенным вредоносным ПО или кибератакой.
- Реестр Windows: Записи реестра, которые были изменены или добавлены вредоносным ПО.
- Подозрительные электронные письма: Подозрительные электронные письма или вложения, которые могут быть использованы для фишинговых атак или распространения вредоносного ПО.
Поиск IOC является важной частью процесса обнаружения и реагирования на инциденты информационной безопасности. Если IOC обнаружены в системе, это может указывать на потенциальное вторжение, что требует дальнейшего исследования и реагирования.
Индикаторы компрометации дают подсказки и доказательства в отношении утечки данных. Узнайте о важности их мониторинга и о четырех инструментах, которые могут помочь в этом

В мире криминалистики данных понимание механики кибератаки не менее важно, чем разгадка тайны преступления. Индикаторы компрометации (IoCs) – это те подсказки, частицы улик, которые могут помочь раскрыть сложные утечки данных сегодняшнего дня
IoCs – это самый большой актив для экспертов по кибербезопасности, когда они пытаются раскрыть и демистифицировать сетевые атаки, вредоносные действия или утечки вредоносного ПО. Поиск в IoC позволяет выявлять нарушения данных на ранних стадиях, что помогает смягчить последствия атак
Почему важно отслеживать индикаторы компрометации?
IoC играют важную роль в анализе кибербезопасности. Они не только выявляют и подтверждают факт атаки безопасности, но и раскрывают инструменты, которые были использованы для осуществления атаки
Они также помогают определить степень ущерба, нанесенного компрометацией, и установить ориентиры для предотвращения будущих компрометаций
IoC обычно собираются с помощью обычных решений безопасности, таких как антивирусное и антиретровирусное ПО, но некоторые инструменты на основе искусственного интеллекта также могут быть использованы для сбора этих индикаторов в ходе реагирования на инциденты
Читать далее: Лучшие бесплатные программы интернет-безопасности для Windows
Примеры индикаторов компрометации

Обнаруживая нерегулярные модели и действия, IoC могут помочь определить, произойдет ли атака в ближайшее время, уже произошла, а также факторы, стоящие за атакой
Вот некоторые примеры МОК, за которыми должны следить все люди и организации:
Странные схемы входящего и исходящего трафика
Конечная цель большинства кибер-атак – завладеть конфиденциальными данными и перенести их в другое место. Поэтому необходимо следить за необычными схемами трафика, особенно за тем, что выходит из вашей сети
В то же время необходимо следить за изменениями во входящем трафике, поскольку они являются хорошими индикаторами готовящейся атаки. Наиболее эффективным подходом является постоянный мониторинг входящего и исходящего трафика на предмет аномалий
Географические несоответствия
Если вы занимаетесь бизнесом или работаете в компании, деятельность которой ограничена определенным географическим положением, но вдруг видите, что вход в систему происходит из неизвестных мест, считайте это тревожным сигналом
IP-адреса являются отличным примером IoCs, поскольку они предоставляют полезные доказательства для отслеживания географического происхождения атаки
Действия пользователя с высокими привилегиями
Привилегированные учетные записи имеют самый высокий уровень доступа в силу характера своей роли. Субъекты угроз всегда стремятся использовать эти учетные записи для получения постоянного доступа к системе. Поэтому любые необычные изменения в структуре использования учетных записей пользователей с высокими привилегиями следует отслеживать с осторожностью
Если привилегированный пользователь использует свою учетную запись в аномальном месте и в аномальное время, то это, безусловно, является признаком компрометации. Хорошей практикой безопасности всегда является применение принципа наименьшей привилегии при настройке учетных записей
Читать далее: Что такое принцип наименьших привилегий и как он может предотвратить кибератаки?
Увеличение количества чтений баз данных
Базы данных всегда являются главной мишенью для субъектов угроз, поскольку большинство персональных и организационных данных хранятся в формате баз данных
Если вы видите увеличение объема чтения базы данных, следите за этим, так как это может быть попытка злоумышленника проникнуть в вашу сеть
Высокий уровень попыток аутентификации
Большое количество попыток аутентификации, особенно неудачных, всегда должно настораживать. Если вы видите большое количество попыток входа в систему с существующей учетной записи или неудачных попыток с несуществующей учетной записи, то, скорее всего, речь идет о готовящемся компромиссе
Необычные изменения конфигурации
Если вы подозреваете большое количество изменений конфигурации ваших файлов, серверов или устройств, есть шанс, что кто-то пытается проникнуть в вашу сеть
Изменения конфигурации не только обеспечивают второй черный ход в вашу сеть для субъектов угроз, но и подвергают систему атакам вредоносного ПО
Признаки DDoS-атак

Распределенный отказ в обслуживании или DDoS-атака проводится в основном для того, чтобы нарушить нормальный поток трафика в сети, бомбардируя ее потоком интернет-трафика
Поэтому неудивительно, что частые DDoS-атаки осуществляются ботнетами для отвлечения внимания от вторичных атак и должны рассматриваться как IoC
Читать далее: Новые типы DDoS-атак и их влияние на вашу безопасность
Паттерны веб-трафика с нечеловеческим поведением
Любой веб-трафик, который не похож на нормальное поведение человека, всегда должен отслеживаться и изучаться
Инструменты, помогающие отслеживать индикаторы компрометации

Обнаружение и мониторинг IoC может быть достигнуто с помощью охоты за угрозами. Агрегаторы журналов могут использоваться для мониторинга журналов на предмет несоответствий, и если они предупреждают об аномалии, то вы должны рассматривать ее как IoC
После анализа IoC его всегда следует добавить в блок-лист, чтобы предотвратить будущие заражения от таких факторов, как IP-адреса, хэши безопасности или доменные имена
Следующие пять инструментов могут помочь в выявлении и мониторинге IoCs. Обратите внимание, что большинство из этих инструментов поставляются как в версиях для сообщества, так и в виде платных подписок
- CrowdStrike.
CrowdStrike – это компания, которая предотвращает нарушения безопасности, предоставляя первоклассные облачные варианты защиты конечных точек
Компания предлагает платформу Falcon Query API с функцией импорта, которая позволяет получать, загружать, обновлять, искать и удалять пользовательские индикаторы компрометации (IOCs), которые вы хотите, чтобы CrowdStrike отслеживал
2. Sumo Logic
Sumo Logic – это организация, занимающаяся анализом данных на основе облачных технологий и специализирующаяся на операциях безопасности. Компания предлагает услуги по управлению журналами, которые используют генерируемые машиной большие данные для анализа в режиме реального времени
Используя платформу Sumo Logic, компании и частные лица могут применять конфигурации безопасности для многооблачных и гибридных сред и быстро реагировать на угрозы путем обнаружения IoCs
3. Akamai Bot Manager
Боты хороши для автоматизации определенных задач, но они также могут использоваться для захвата аккаунтов, угроз безопасности и DDoS-атак
Akamai Technologies, Inc.это глобальная сеть доставки контента, которая также предлагает инструмент, известный как Bot Manager, который обеспечивает расширенное обнаружение ботов для поиска и предотвращения самых сложных атак ботов
Обеспечивая детальную видимость бот-трафика, входящего в вашу сеть, Bot Manager помогает вам лучше понять и отследить, кто входит или выходит из вашей сети
4. Proofpoint
Proofpoint – компания, занимающаяся корпоративной безопасностью, которая обеспечивает защиту от целевых атак наряду с надежной системой реагирования на угрозы
Их креативная система реагирования на угрозы обеспечивает автоматическую проверку IoC путем сбора криминалистических данных конечных точек из целевых систем, что упрощает обнаружение и устранение компрометации
Защита данных путем анализа ландшафта угроз

Большинство нарушений безопасности и краж данных оставляют за собой следы в виде хлебных крошек, и именно мы должны играть в детективов безопасности и находить подсказки
К счастью, внимательно анализируя наш ландшафт угроз, мы можем отслеживать и составлять список индикаторов компрометации для предотвращения всех типов текущих и будущих киберугроз
Уровень сложности
Средний
Время на прочтение
5 мин
Количество просмотров 4.8K

Журналирование событий информационной безопасности является важным элементом системы защиты информации. Нам необходимо знать какое событие когда произошло, когда какой пользователь пытался зайти в систему, с какого узла, удачно или нет, и так далее. Конечно, некоторые события ИБ сохраняются в журналах ОС при использовании настроек по умолчанию, например, не/удачные входы в систему, изменения прав доступа и т. д. Однако, настроек по умолчанию и локального хранения логов недостаточно для эффективного мониторинга и реагирования на события ИБ.
В этой статье мы посмотрим, как можно организовать эффективный аудит узлов под управлением ОС Windows, а в следующей статье настроим централизованный сбор событий с нескольких узлов и попробуем с помощью Powershell автоматизировать обработку собранных событий.
Зачем нужно централизованное хранение
Локальное хранение журналов событий имеет целый ряд недостатков, не позволяющих использовать этот механизм для мониторинга событий ИБ. С точки зрения безопасности локальные журналы хранят все события только на данной машине. Пока злоумышленник пытается получить доступ и поднять привилегии на данной машине, некоторые события обличающие его действия, возможно будут сохраняться в логах, но как только он получит необходимые права, он сможет почистить журнал событий, затем заполнить его фиктивными логами, в результате чего мы не увидим событий, связанных с компрометацией узла.
Да, при очистке лога будет создано событие ‘1102 Журнал аудита был очищен’, но от этого события тоже можно избавиться, просто заполнив лог большим количеством фиктивных событий.

Так как, обычно EventLog пишется по принципу циклической записи, более старые события удаляются, и их заменяют более новые.
Ну а создать поддельные события можно с помощью того же PowerShell, используя командлет Write-EventLog.
Таким образом, локальное хранение событий это не самый лучший вариант работы с логами с точки зрения безопасности. Ну а кроме того, нам не слишком удобно анализировать журналы событий, если они хранятся только локально. Тогда необходимо подключаться к журналам событий каждой локальной машины и работать с ними локально.
Гораздо удобнее пересылать логи на отдельный сервер, где их можно централизованно хранить и анализировать. В таком случае, в процессе выполнения атаки мы можем получать события от атакуемого узла, которые точно не будут потеряны. Кроме того, даже если злоумышленник сможет очистить лог на локальной машине, на удаленном сервере все события сохраняться. Ну и если события от нескольких узлов сохраняются централизованно на одном сервере, то с ними гораздо удобнее работать, что тоже не маловажно при анализе логов.
Эффективный аудит
Мы разобрались с необходимостью централизованного мониторинга событий. Однако, еще необходимо разобраться с тем, какие именно события должны присутствовать в наших логах. С одной стороны в логах должны присутствовать важные события с точки зрения ИБ, а с другой, в нем не должно быть слишком много неинтересных событий, например постоянных обращений к каким-либо файлам или сообщений о запуске каких-либо процессов, не представляющих никакого интереса для ИБ. Таким образом, чтоб нам не потонуть в большом объеме ненужных событий и не потерять что-то действительно важное, нам необходимо грамотно настроить политики аудита.
Для настройки откроем Политики аудита (Конфигурация компьютера / Конфигурация Windows / Параметры безопасности / Локальные политики / Политика аудита (Computer Configuration / Windows Settings / Security Settings / Local Policies / Audit Policy).

Также нам потребуются расширенные политики аудита, которые можно открыть здесь: Конфигурация компьютера / Конфигурация Windows / Параметры безопасности / Конфигурация расширенной политики аудита (Computer Configuration / Windows Settings / Security Settings / Advanced Audit Policy Configuration).

Отличием политики расширенного аудита является наличие подкатегорий и теперь мы можем управлять аудитом на уровне не только категорий, но и подкатегорий. Если сравнить Политики аудита и Расширенные политики аудита, то можно заметить, что разделы в обычных политиках в свою очередь разделены на подразделы в расширенных политиках, что позволяет нам настраивать более подробные категории аудита. Так, для группы Вход учётной записи (Account Logon) мы можем настроить четыре проверки -Аудит проверки учётных данных, Аудит службы проверки подлинности Kerberos, Аудит операций с билетами службы Kerberos, Аудит других событий входа учётных записей.
Для каждого типа аудита мы можем настроить аудит событий успеха или отказа. С событиями успеха нужно быть аккуратными. Так, для того же аудита входов в систему мы рискуем получить большое количество событий успешного входа, которые по факту не будут представлять никакой ценности. Также, не стоит включать в аудите доступа к объектам, аудит событий «платформы фильтрации Windows», потому что он генерирует крайне большое количество событий (всё сетевое взаимодействие хоста). В результате мы снова рискуем получить большое количество ненужных событий. В результате срабатывания настроек политик аудита, в журнале создаются события, каждое из которых имеет собственный код.
Для эффективного аудита нам необходим сбор следующих типов событий: 4624 (Успешный вход в систему), 4647 (Выход из системы), 4625 (Неудачный вход в систему), 4778/4779 (Соединение/разъединение по RDP), 4800/4801 (Блокировка/Разблокировка рабочей станции) и некоторые другие.
При анализе событий нам важно понимать, как именно был осуществлен вход в систему или с каким кодом мы получили событие о неудачном входе в систему.
Посмотрим типы входа в систему:
2 – интерактивный
3 – сетевой (через сетевой диск)
4 – запуск по расписанию
5 – запуск сервиса
7 – разблокировка экрана
8 – сетевой (Basic Authentication в IIS)
10 – подключение по RDP
11 – вход по закешированным учетным данным
В приведенном ниже скриншоте у нас представлен вход в систему при запуске сервиса

И посмотрим, как мы можем узнать причину неудачного входа в систему
0xC0000064 — такого пользователя не существует
0xC000006A — неверный пароль
0xC0000234 — пользователь заблокирован
0xC0000072 — пользователь отключен
0xC000006F — пользователь попытался войти в систему вне установленных для него ограничений по дням недели или времени суток
0xC0000070 — ограничение рабочей станции или нарушение изолированной политики аутентификации (найдите идентификатор события 4820 на контроллере домена)
0xC0000193 — срок действия учетной записи истек
0xC0000071 — истек пароль
0xC0000133 — часы между DC и другим компьютером слишком сильно рассинхронизированы
0xC0000224 — пользователю необходимо сменить пароль при следующем входе в систему
0xc000015b Пользователю не был предоставлен запрошенный тип входа в систему (он же право входа в систему) на этом компьютере
Таким образом, по значениям данных кодов в соответствующих событиях мы можем понять, что стало причиной неудачного входа в систему или каким образом пользователь или сервис осуществили вход.
На картинке ниже представлен неудачный интерактивный вход в систему, причиной которого стало указание неверного пароля.

В следующей статье мы посмотрим, как средствами PowerShell можно извлекать различные значения из событий и делать обработку логов более “человеко-удобной.
Заключение
В этой статье мы рассмотрели виды аудита в современных версиях ОС Windows, поговорили о том, какие именно события должны собираться в системе и что означают некоторые поля в этих событиях. В следующей статье мы настроим централизованный сбор событий с нескольких источников и попробуем с помощью PowerShell настроить автоматический анализ собираемых событий.
Напоследок приглашаю вас на бесплатный вебинар, где мы узнаем, зачем нужны бэкапы и как их организовать путем сервисов в Windows.