From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This subsequently led to much confusion. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but additionally supports UTF-8 (aka CP_UTF8) since Windows 10 version 1803.[5]
UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder).
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
| Standard | Unicode Standard |
|---|---|
| Classification | Unicode Transformation Format, extended ASCII, variable-length encoding |
| Extends | ASCII |
| Transforms / Encodes | ISO/IEC 10646 (Unicode) |
| Preceded by | UTF-1 |
|
UTF-8 is a variable-length character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode (or Universal Coded Character Set) Transformation Format – 8-bit.[1]
UTF-8 is capable of encoding all 1,112,064[a] valid character code points in Unicode using one to four one-byte (8-bit) code units. Code points with lower numerical values, which tend to occur more frequently, are encoded using fewer bytes. It was designed for backward compatibility with ASCII: the first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single byte with the same binary value as ASCII, so that valid ASCII text is valid UTF-8-encoded Unicode as well.
UTF-8 was designed as a superior alternative to UTF-1, a proposed variable-length encoding with partial ASCII compatibility which lacked some features including self-synchronization and fully ASCII-compatible handling of characters such as slashes. Ken Thompson and Rob Pike produced the first implementation for the Plan 9 operating system in September 1992.[2][3] This led to its adoption by X/Open as its specification for FSS-UTF,[4] which would first be officially presented at USENIX in January 1993[5] and subsequently adopted by the Internet Engineering Task Force (IETF) in RFC 2277 (BCP 18)[6] for future internet standards work, replacing Single Byte Character Sets such as Latin-1 in older RFCs.
UTF-8 results in fewer internationalization issues[7][8] than any alternative text encoding, and it has been implemented in all modern operating systems, including Microsoft Windows, and standards such as JSON, where, as is increasingly the case, it is the only allowed form of Unicode.
UTF-8 is the dominant encoding for the World Wide Web (and internet technologies), accounting for 98.0% of all web pages, 99.0% of the top 10,000 pages, and up to 100% for many languages, as of 2023.[9] Virtually all countries and languages have 95% or more use of UTF-8 encodings on the web.
Naming[edit]
The official name for the encoding is UTF-8, the spelling used in all Unicode Consortium documents. Most standards officially list it in upper case as well, but all that do are also case-insensitive and utf-8 is often used in code.[citation needed]
Some other spellings may also be accepted by standards, e.g. web standards (which include CSS, HTML, XML, and HTTP headers) explicitly allow utf8 (and disallow «unicode») and many aliases for encodings.[10] Spellings with a space e.g. «UTF 8» should not be used. The official Internet Assigned Numbers Authority also lists csUTF8 as the only alias,[11] which is rarely used.
In Windows, UTF-8 is codepage 65001[12] (i.e. CP_UTF8 in source code).
In MySQL, UTF-8 is called utf8mb4[13] (with utf8mb3, and its alias utf8, being a subset encoding for characters in the Basic Multilingual Plane[14]). In HP PCL, the Symbol-ID for UTF-8 is 18N.[15]
In Oracle Database (since version 9.0), AL32UTF8[16] means UTF-8. See also CESU-8 for an almost synonym with UTF-8 that rarely should be used.
UTF-8-BOM and UTF-8-NOBOM are sometimes used for text files which contain or do not contain a byte order mark (BOM), respectively.[citation needed] In Japan especially, UTF-8 encoding without a BOM is sometimes called UTF-8N.[17][18]
Encoding[edit]
UTF-8 encodes code points in one to four bytes, depending on the value of the code point. In the following table, the x characters are replaced by the bits of the code point:
| First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0xxxxxxx | |||
| U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| U+10000 | [b]U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
The first 128 code points (ASCII) need one byte. The next 1,920 code points need two bytes to encode, which covers the remainder of almost all Latin-script alphabets, and also IPA extensions, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac, Thaana and N’Ko alphabets, as well as Combining Diacritical Marks. Three bytes are needed for the remaining 61,440 code points of the Basic Multilingual Plane (BMP), including most Chinese, Japanese and Korean characters. Four bytes are needed for the 1,048,576 code points in the other planes of Unicode, which include emoji (pictographic symbols), less common CJK characters, various historic scripts, and mathematical symbols.
A «character» can take more than 4 bytes because it is made of more than one code point. For instance a national flag character takes 8 bytes since it is «constructed from a pair of Unicode scalar values» both from outside the BMP.[19][c]
Encoding process[edit]
In these examples, red, green, and blue digits indicate how bits from the code point are distributed among the UTF-8 bytes. Additional bits added by the UTF-8 encoding process are shown in black.
- The Unicode code point for the euro sign € is U+20AC.
- As this code point lies between U+0800 and U+FFFF, this will take three bytes to encode.
- Hexadecimal 20AC is binary 0010 0000 1010 1100. The two leading zeros are added because a three-byte encoding needs exactly sixteen bits from the code point.
- Because the encoding will be three bytes long, its leading byte starts with three 1s, then a 0 (1110…)
- The four most significant bits of the code point are stored in the remaining low order four bits of this byte (11100010), leaving 12 bits of the code point yet to be encoded (…0000 1010 1100).
- All continuation bytes contain exactly six bits from the code point. So the next six bits of the code point are stored in the low order six bits of the next byte, and 10 is stored in the high order two bits to mark it as a continuation byte (so 10000010).
- Finally the last six bits of the code point are stored in the low order six bits of the final byte, and again 10 is stored in the high order two bits (10101100).
The three bytes 11100010 10000010 10101100 can be more concisely written in hexadecimal, as E2 82 AC.
The following table summarizes this conversion, as well as others with different lengths in UTF-8.
| Character | Binary code point | Binary UTF-8 | Hex UTF-8 | |
|---|---|---|---|---|
| $ | U+0024 | 010 0100 | 00100100 | 24 |
| £ | U+00A3 | 000 1010 0011 | 11000010 10100011 | C2 A3 |
| И | U+0418 | 100 0001 1000 | 11010000 10011000 | D0 98 |
| ह | U+0939 | 0000 1001 0011 1001 | 11100000 10100100 10111001 | E0 A4 B9 |
| € | U+20AC | 0010 0000 1010 1100 | 11100010 10000010 10101100 | E2 82 AC |
| 한 | U+D55C | 1101 0101 0101 1100 | 11101101 10010101 10011100 | ED 95 9C |
| 𐍈 | U+10348 | 0 0001 0000 0011 0100 1000 | 11110000 10010000 10001101 10001000 | F0 90 8D 88 |
Example[edit]
In these examples, colored digits indicate multi-byte sequences used to encode characters beyond ASCII, while digits in black are ASCII.
As an example, the Vietnamese phrase Mình nói tiếng Việt (𨉟呐㗂越, «I speak Vietnamese») is encoded as follows:
| Character | M | ì | n | h | n | ó | i | t | i | ế | n | g | V | i | ệ | t | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Code point | 4D | EC | 6E | 68 | 20 | 6E | F3 | 69 | 20 | 74 | 69 | 1EBF | 6E | 67 | 20 | 56 | 69 | 1EC7 | 74 |
| Hex UTF-8 | C3 | AC | C3 | B3 | E1 | BA | BF | E1 | BB | 87 |
| Character | 𨉟 | 呐 | 㗂 | 越 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Code point | 2825F | 5450 | 35C2 | 8D8A | |||||||||
| Hex UTF-8 | F0 | A8 | 89 | 9F | E5 | 91 | 90 | E3 | 97 | 82 | E8 | B6 | 8A |
Codepage layout[edit]
The following table summarizes usage of UTF-8 code units (individual bytes or octets) in a code page format. The upper half is for bytes used only in single-byte codes, so it looks like a normal code page; the lower half is for continuation bytes and leading bytes and is explained further in the legend below.
| UTF-8 | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | +0 | +1 | +2 | +3 | +4 | +5 | +6 | +7 | +8 | +9 | +A | +B | +C | +D | +E | +F |
| 9x | +10 | +11 | +12 | +13 | +14 | +15 | +16 | +17 | +18 | +19 | +1A | +1B | +1C | +1D | +1E | +1F |
| Ax | +20 | +21 | +22 | +23 | +24 | +25 | +26 | +27 | +28 | +29 | +2A | +2B | +2C | +2D | +2E | +2F |
| Bx | +30 | +31 | +32 | +33 | +34 | +35 | +36 | +37 | +38 | +39 | +3A | +3B | +3C | +3D | +3E | +3F |
| Cx | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Dx | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Ex | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| Fx | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 6 | 6 |
7-bit (single-byte) code points. They must not be followed by a continuation byte.[20]
Continuation bytes.[21] The cell shows in hexadecimal the value of the 6 bits they add.[d]
Leading bytes for a sequence of multiple bytes, must be followed by exactly N−1 continuation bytes.[22] The tooltip shows the code point range and the Unicode blocks encoded by sequences starting with this byte.
Leading bytes where not all arrangements of continuation bytes are valid.
E0 and
F0 could start overlong encodings.
F4 can start code points greater than U+10FFFF.
ED can start code points in the range U+D800–U+DFFF, which are invalid UTF-16 surrogate halves.[23]
Do not appear in a valid UTF-8 sequence.
C0 and
C1 could be used only for an «overlong» encoding of a 1-byte character.[24]
F5 to
FD are leading bytes of 4-byte or longer sequences that can only encode code points larger than U+10FFFF.[23]
FE and
FF were never assigned any meaning.[25]
Overlong encodings[edit]
In principle, it would be possible to inflate the number of bytes in an encoding by padding the code point with leading 0s. To encode the euro sign € from the above example in four bytes instead of three, it could be padded with leading 0s until it was 21 bits long –
000 000010 000010 101100, and encoded as 11110000 10000010 10000010 10101100 (or F0 82 82 AC in hexadecimal). This is called an overlong encoding.
The standard specifies that the correct encoding of a code point uses only the minimum number of bytes required to hold the significant bits of the code point. Longer encodings are called overlong and are not valid UTF-8 representations of the code point. This rule maintains a one-to-one correspondence between code points and their valid encodings, so that there is a unique valid encoding for each code point. This ensures that string comparisons and searches are well-defined.
Invalid sequences and error handling[edit]
Not all sequences of bytes are valid UTF-8. A UTF-8 decoder should be prepared for:
- invalid bytes
- an unexpected continuation byte
- a non-continuation byte before the end of the character
- the string ending before the end of the character (which can happen in simple string truncation)
- an overlong encoding
- a sequence that decodes to an invalid code point
Many of the first UTF-8 decoders would decode these, ignoring incorrect bits and accepting overlong results. Carefully crafted invalid UTF-8 could make them either skip or create ASCII characters such as NUL, slash, or quotes. Invalid UTF-8 has been used to bypass security validations in high-profile products including Microsoft’s IIS web server[26] and Apache’s Tomcat servlet container.[27] RFC 3629 states «Implementations of the decoding algorithm MUST protect against decoding invalid sequences.»[23] The Unicode Standard requires decoders to «…treat any ill-formed code unit sequence as an error condition. This guarantees that it will neither interpret nor emit an ill-formed code unit sequence.»
Since RFC 3629 (November 2003), the high and low surrogate halves used by UTF-16 (U+D800 through U+DFFF) and code points not encodable by UTF-16 (those after U+10FFFF) are not legal Unicode values, and their UTF-8 encoding must be treated as an invalid byte sequence. Not decoding unpaired surrogate halves makes it impossible to store invalid UTF-16 (such as Windows filenames or UTF-16 that has been split between the surrogates) as UTF-8,[28] while it is possible with WTF-8.
Some implementations of decoders throw exceptions on errors.[29] This has the disadvantage that it can turn what would otherwise be harmless errors (such as a «no such file» error) into a denial of service. For instance early versions of Python 3.0 would exit immediately if the command line or environment variables contained invalid UTF-8.[30]
Since Unicode 6[31] (October 2010), the standard (chapter 3) has recommended a «best practice» where the error is either one byte long, or ends before the first byte that is disallowed. In these decoders E1,A0,C0 is two errors (2 bytes in the first one). This means an error is no more than three bytes long and never contains the start of a valid character, and there are 21,952 different possible errors.[32] The standard also recommends replacing each error with the replacement character «�» (U+FFFD).
These recommendations are not often followed. It is common to consider each byte to be an error, in which case E1,A0,C0 is three errors (each 1 byte long). This means there are only 128 different errors, and it is also common to replace them with 128 different characters, to make the decoding «lossless».[33]
Byte order mark[edit]
If the Unicode byte order mark (BOM, U+FEFF) character is at the start of a UTF-8 file, the first three bytes will be 0xEF, 0xBB, 0xBF.
The Unicode Standard neither requires nor recommends the use of the BOM for UTF-8, but warns that it may be encountered at the start of a file trans-coded from another encoding.[34] While ASCII text encoded using UTF-8 is backward compatible with ASCII, this is not true when Unicode Standard recommendations are ignored and a BOM is added. A BOM can confuse software that isn’t prepared for it but can otherwise accept UTF-8, e.g. programming languages that permit non-ASCII bytes in string literals but not at the start of the file. Nevertheless, there was and still is software that always inserts a BOM when writing UTF-8, and refuses to correctly interpret UTF-8 unless the first character is a BOM (or the file only contains ASCII).[35]
Adoption[edit]


UTF-8 has been the most common encoding for the World Wide Web since 2008.[37] As of October 2023, UTF-8 is used by 98.0% of surveyed web sites.[9][e] Although many pages only use ASCII characters to display content, few websites now declare their encoding to only be ASCII instead of UTF-8.[38] Over 50% of the languages tracked have 100% UTF-8 use.
Many standards only support UTF-8, e.g. JSON exchange requires it (without a byte order mark (BOM)).[39] UTF-8 is also the recommendation from the WHATWG for HTML and DOM specifications, and stating «UTF-8 encoding is the most appropriate encoding for interchange of Unicode»[8] and the Internet Mail Consortium recommends that all e‑mail programs be able to display and create mail using UTF-8.[40][41] The World Wide Web Consortium recommends UTF-8 as the default encoding in XML and HTML (and not just using UTF-8, also declaring it in metadata), «even when all characters are in the ASCII range … Using non-UTF-8 encodings can have unexpected results».[42]
Lots of software has the ability to read/write UTF-8. It may though require the user to change options from the normal settings, or may require a BOM (byte order mark) as the first character to read the file. Examples of software supporting UTF-8 include Microsoft Word,[43][44][45] Microsoft Excel (2016 and later),[46][47] Google Drive, LibreOffice and most databases.
However for local text files UTF-8 usage is less prevalent, where legacy single-byte (and a few CJK multi-byte) encodings remain in use. The primary cause for this are outdated text editors that refuse to read UTF-8 unless the first bytes of the file encode a byte order mark character (BOM).[48]
Some recent software can only read and write UTF-8 or at least do not require a BOM.[49] Windows Notepad, in all currently supported versions of Windows, defaults to writing UTF-8 without a BOM (a change from the outdated/unsupported Windows 7), bringing it into line with most other text editors.[50] Some system files on Windows 11 require UTF-8[51] with no requirement for a BOM, and almost all files on macOS and Linux are required to be UTF-8 without a BOM.[citation needed] Java 18 defaults to reading and writing files as UTF-8,[52] and in older versions (e.g. LTS versions) only the NIO API was changed to do so. Many other programming languages default to UTF-8 for I/O, including Ruby 3.0[53][54] and R 4.2.2.[55] All currently supported versions of Python support UTF-8 for I/O, even on Windows (where it is opt-in for the open() function[56]), and plans exist to make UTF-8 I/O the default in Python 3.15 on all platforms.[57][58] C++23 adopts UTF-8 as the only portable source code file format (surprisingly there was none before).[59]
Usage of UTF-8 in memory is much lower than in other areas, UTF-16 is often used instead. This occurs particularly in Windows, but also in JavaScript, Python,[f] Qt, and many other cross-platform software libraries. Compatibility with the Windows API is the primary reason for this, that choice was initially done due to the belief that direct indexing of the BMP would improve speed. Translating from/to external text which is in UTF-8 slows software down, and more importantly introduces bugs when different pieces of code do not do the exact same translation.
Back-compatibility is a serious impediment to changing code to use UTF-8 instead of a 16-bit encoding, but this is happening. The default string primitive in Go,[61] Julia, Rust, Swift 5,[62] and PyPy[63] uses UTF-8 internally in all cases, while Python, since Python 3.3, uses UTF-8 internally in some cases (for Python C API extensions);[60][64] a future version of Python is planned to store strings as UTF-8 by default;[65][66] and modern versions of Microsoft Visual Studio use UTF-8 internally.[67] Microsoft’s SQL Server 2019 added support for UTF-8, and using it results in a 35% speed increase, and «nearly 50% reduction in storage requirements.»[68]
All currently supported Windows versions support UTF-8 in some way (including Xbox);[7] partial support has existed since at least Windows XP. As of May 2019, Microsoft has reversed its previous position of only recommending UTF-16; the capability to set UTF-8 as the «code page» for the Windows API was introduced; and Microsoft recommends programmers use UTF-8,[69] and even states «UTF-16 [..] is a unique burden that Windows places on code that targets multiple platforms.»[7]
History[edit]
The International Organization for Standardization (ISO) set out to compose a universal multi-byte character set in 1989. The draft ISO 10646 standard contained a non-required annex called UTF-1 that provided a byte stream encoding of its 32-bit code points. This encoding was not satisfactory on performance grounds, among other problems, and the biggest problem was probably that it did not have a clear separation between ASCII and non-ASCII: new UTF-1 tools would be backward compatible with ASCII-encoded text, but UTF-1-encoded text could confuse existing code expecting ASCII (or extended ASCII), because it could contain continuation bytes in the range 0x21–0x7E that meant something else in ASCII, e.g., 0x2F for ‘/’, the Unix path directory separator, and this example is reflected in the name and introductory text of its replacement. The table below was derived from a textual description in the annex.
| Number of bytes |
First code point |
Last code point |
Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 |
|---|---|---|---|---|---|---|---|
| 1 | U+0000 | U+009F | 00–9F | ||||
| 2 | U+00A0 | U+00FF | A0 | A0–FF | |||
| 2 | U+0100 | U+4015 | A1–F5 | 21–7E, A0–FF | |||
| 3 | U+4016 | U+38E2D | F6–FB | 21–7E, A0–FF | 21–7E, A0–FF | ||
| 5 | U+38E2E | U+7FFFFFFF | FC–FF | 21–7E, A0–FF | 21–7E, A0–FF | 21–7E, A0–FF | 21–7E, A0–FF |
In July 1992, the X/Open committee XoJIG was looking for a better encoding. Dave Prosser of Unix System Laboratories submitted a proposal for one that had faster implementation characteristics and introduced the improvement that 7-bit ASCII characters would only represent themselves; all multi-byte sequences would include only bytes where the high bit was set. The name File System Safe UCS Transformation Format (FSS-UTF) and most of the text of this proposal were later preserved in the final specification.[70][71][72][73]
FSS-UTF[edit]
| Number of bytes |
First code point |
Last code point |
Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 |
|---|---|---|---|---|---|---|---|
| 1 | U+0000 | U+007F | 0xxxxxxx | ||||
| 2 | U+0080 | U+207F | 10xxxxxx | 1xxxxxxx | |||
| 3 | U+2080 | U+8207F | 110xxxxx | 1xxxxxxx | 1xxxxxxx | ||
| 4 | U+82080 | U+208207F | 1110xxxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx | |
| 5 | U+2082080 | U+7FFFFFFF | 11110xxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx | 1xxxxxxx |
In August 1992, this proposal was circulated by an IBM X/Open representative to interested parties. A modification by Ken Thompson of the Plan 9 operating system group at Bell Labs made it self-synchronizing, letting a reader start anywhere and immediately detect character boundaries, at the cost of being somewhat less bit-efficient than the previous proposal. It also abandoned the use of biases and instead added the rule that only the shortest possible encoding is allowed; the additional loss in compactness is relatively insignificant, but readers now have to look out for invalid encodings to avoid reliability and especially security issues. Thompson’s design was outlined on September 2, 1992, on a placemat in a New Jersey diner with Rob Pike. In the following days, Pike and Thompson implemented it and updated Plan 9 to use it throughout, and then communicated their success back to X/Open, which accepted it as the specification for FSS-UTF.[72]
| Number of bytes |
First code point |
Last code point |
Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|---|
| 1 | U+0000 | U+007F | 0xxxxxxx | |||||
| 2 | U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||||
| 3 | U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 4 | U+10000 | U+1FFFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 5 | U+200000 | U+3FFFFFF | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 6 | U+4000000 | U+7FFFFFFF | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
UTF-8 was first officially presented at the USENIX conference in San Diego, from January 25 to 29, 1993. The Internet Engineering Task Force adopted UTF-8 in its Policy on Character Sets and Languages in RFC 2277 (BCP 18) for future internet standards work, replacing Single Byte Character Sets such as Latin-1 in older RFCs.[6]
In November 2003, UTF-8 was restricted by RFC 3629 to match the constraints of the UTF-16 character encoding: explicitly prohibiting code points corresponding to the high and low surrogate characters removed more than 3% of the three-byte sequences, and ending at U+10FFFF removed more than 48% of the four-byte sequences and all five- and six-byte sequences.
Standards[edit]
There are several current definitions of UTF-8 in various standards documents:
- RFC 3629 / STD 63 (2003), which establishes UTF-8 as a standard internet protocol element
- RFC 5198 defines UTF-8 NFC for Network Interchange (2008)
- ISO/IEC 10646:2014 §9.1 (2014)[74]
- The Unicode Standard, Version 15.0.0 (2022)[75]
They supersede the definitions given in the following obsolete works:
- The Unicode Standard, Version 2.0, Appendix A (1996)
- ISO/IEC 10646-1:1993 Amendment 2 / Annex R (1996)
- RFC 2044 (1996)
- RFC 2279 (1998)
- The Unicode Standard, Version 3.0, §2.3 (2000) plus Corrigendum #1 : UTF-8 Shortest Form (2000)
- Unicode Standard Annex #27: Unicode 3.1 (2001)[76]
- The Unicode Standard, Version 5.0 (2006)[77]
- The Unicode Standard, Version 6.0 (2010)[78]
They are all the same in their general mechanics, with the main differences being on issues such as allowed range of code point values and safe handling of invalid input.
Comparison with other encodings[edit]
Some of the important features of this encoding are as follows:
- Backward compatibility: Backward compatibility with ASCII and the enormous amount of software designed to process ASCII-encoded text was the main driving force behind the design of UTF-8. In UTF-8, single bytes with values in the range of 0 to 127 map directly to Unicode code points in the ASCII range. Single bytes in this range represent characters, as they do in ASCII. Moreover, 7-bit bytes (bytes where the most significant bit is 0) never appear in a multi-byte sequence, and no valid multi-byte sequence decodes to an ASCII code-point. A sequence of 7-bit bytes is both valid ASCII and valid UTF-8, and under either interpretation represents the same sequence of characters. Therefore, the 7-bit bytes in a UTF-8 stream represent all and only the ASCII characters in the stream. Thus, many text processors, parsers, protocols, file formats, text display programs, etc., which use ASCII characters for formatting and control purposes, will continue to work as intended by treating the UTF-8 byte stream as a sequence of single-byte characters, without decoding the multi-byte sequences. ASCII characters on which the processing turns, such as punctuation, whitespace, and control characters will never be encoded as multi-byte sequences. It is therefore safe for such processors to simply ignore or pass-through the multi-byte sequences, without decoding them. For example, ASCII whitespace may be used to tokenize a UTF-8 stream into words; ASCII line-feeds may be used to split a UTF-8 stream into lines; and ASCII NUL characters can be used to split UTF-8-encoded data into null-terminated strings. Similarly, many format strings used by library functions like «printf» will correctly handle UTF-8-encoded input arguments.
- Fallback and auto-detection: Only a small subset of possible byte strings are a valid UTF-8 string: several bytes cannot appear; a byte with the high bit set cannot be alone; and further requirements mean that it is extremely unlikely that a readable text in any extended ASCII is valid UTF-8. Part of the popularity of UTF-8 is due to it providing a form of backward compatibility for these as well. A UTF-8 processor which erroneously receives extended ASCII as input can thus «auto-detect» this with very high reliability. A UTF-8 stream may simply contain errors, resulting in the auto-detection scheme producing false positives; but auto-detection is successful in the vast majority of cases, especially with longer texts, and is widely used. It also works to «fall back» or replace 8-bit bytes using the appropriate code-point for a legacy encoding when errors in the UTF-8 are detected, allowing recovery even if UTF-8 and legacy encoding is concatenated in the same file.
- Prefix code: The first byte indicates the number of bytes in the sequence. Reading from a stream can instantaneously decode each individual fully received sequence, without first having to wait for either the first byte of a next sequence or an end-of-stream indication. The length of multi-byte sequences is easily determined by humans as it is simply the number of high-order 1s in the leading byte. An incorrect character will not be decoded if a stream ends mid-sequence.
- Self-synchronization: The leading bytes and the continuation bytes do not share values (continuation bytes start with the bits 10 while single bytes start with 0 and longer lead bytes start with 11). This means a search will not accidentally find the sequence for one character starting in the middle of another character. It also means the start of a character can be found from a random position by backing up at most 3 bytes to find the leading byte. An incorrect character will not be decoded if a stream starts mid-sequence, and a shorter sequence will never appear inside a longer one.
- Sorting order: The chosen values of the leading bytes means that a list of UTF-8 strings can be sorted in code point order by sorting the corresponding byte sequences.
Single-byte[edit]
- UTF-8 can encode any Unicode character, avoiding the need to figure out and set a «code page» or otherwise indicate what character set is in use, and allowing output in multiple scripts at the same time. For many scripts there have been more than one single-byte encoding in usage, so even knowing the script was insufficient information to display it correctly.
- The bytes 0xFE and 0xFF do not appear, so a valid UTF-8 stream never matches the UTF-16 byte order mark and thus cannot be confused with it. The absence of 0xFF (0377) also eliminates the need to escape this byte in Telnet (and FTP control connection).
- UTF-8 encoded text is larger than specialized single-byte encodings except for plain ASCII characters. In the case of scripts which used 8-bit character sets with non-Latin characters encoded in the upper half (such as most Cyrillic and Greek alphabet code pages), characters in UTF-8 will be double the size. For some scripts, such as Thai and Devanagari (which is used by various South Asian languages), characters will triple in size. There are even examples where a single byte turns into a composite character in Unicode and is thus six times larger in UTF-8. This has caused objections in India and other countries.[citation needed]
- It is possible in UTF-8 (or any other multi-byte encoding) to split or truncate a string in the middle of a character. If the two pieces are not re-appended later before interpretation as characters, this can introduce an invalid sequence at both the end of the previous section and the start of the next, and some decoders will not preserve these bytes and result in data loss. Because UTF-8 is self-synchronizing this will however never introduce a different valid character, and it is also fairly easy to move the truncation point backward to the start of a character.
- If the code points are all the same size, measurements of a fixed number of them is easy. Due to ASCII-era documentation where «character» is used as a synonym for «byte» this is often considered important. However, by measuring string positions using bytes instead of «characters» most algorithms can be easily and efficiently adapted for UTF-8. Searching for a string within a long string can for example be done byte by byte; the self-synchronization property prevents false positives.
Other multi-byte[edit]
- UTF-8 can encode any Unicode character. Files in different scripts can be displayed correctly without having to choose the correct code page or font. For instance, Chinese and Arabic can be written in the same file without specialized markup or manual settings that specify an encoding.
- UTF-8 is self-synchronizing: character boundaries are easily identified by scanning for well-defined bit patterns in either direction. If bytes are lost due to error or corruption, one can always locate the next valid character and resume processing. If there is a need to shorten a string to fit a specified field, the previous valid character can easily be found. Many multi-byte encodings such as Shift JIS are much harder to resynchronize. This also means that byte-oriented string-searching algorithms can be used with UTF-8 (as a character is the same as a «word» made up of that many bytes), optimized versions of byte searches can be much faster due to hardware support and lookup tables that have only 256 entries. Self-synchronization does however require that bits be reserved for these markers in every byte, increasing the size.
- Efficient to encode using simple bitwise operations. UTF-8 does not require slower mathematical operations such as multiplication or division (unlike Shift JIS, GB 2312 and other encodings).
- UTF-8 will take more space than a multi-byte encoding designed for a specific script. East Asian legacy encodings generally used two bytes per character yet take three bytes per character in UTF-8.
UTF-16[edit]
- Byte encodings and UTF-8 are represented by byte arrays in programs, and often nothing needs to be done to a function when converting source code from a byte encoding to UTF-8. UTF-16 is represented by 16-bit word arrays, and converting to UTF-16 while maintaining compatibility with existing ASCII-based programs (such as was done with Windows) requires every API and data structure that takes a string to be duplicated, one version accepting byte strings and another version accepting UTF-16. If backward compatibility is not needed, all string handling still must be modified.
- Text encoded in UTF-8 will be smaller than the same text encoded in UTF-16 if there are more code points below U+0080 than in the range U+0800..U+FFFF. This is true for all modern European languages. It is often true even for languages like Chinese, due to the large number of spaces, newlines, digits, and HTML markup in typical files.
- Most communication (e.g. HTML and IP) and storage (e.g. for Unix) was designed for a stream of bytes. A UTF-16 string must use a pair of bytes for each code unit:
- The order of those two bytes becomes an issue and must be specified in the UTF-16 protocol, such as with a byte order mark.
- If an odd number of bytes is missing from UTF-16, the whole rest of the string will be meaningless text. Any bytes missing from UTF-8 will still allow the text to be recovered accurately starting with the next character after the missing bytes.
Derivatives[edit]
The following implementations show slight differences from the UTF-8 specification. They are incompatible with the UTF-8 specification and may be rejected by conforming UTF-8 applications.
CESU-8[edit]
Unicode Technical Report #26[79] assigns the name CESU-8 to a nonstandard variant of UTF-8, in which Unicode characters in supplementary planes are encoded using six bytes, rather than the four bytes required by UTF-8. CESU-8 encoding treats each half of a four-byte UTF-16 surrogate pair as a two-byte UCS-2 character, yielding two three-byte UTF-8 characters, which together represent the original supplementary character. Unicode characters within the Basic Multilingual Plane appear as they would normally in UTF-8. The Report was written to acknowledge and formalize the existence of data encoded as CESU-8, despite the Unicode Consortium discouraging its use, and notes that a possible intentional reason for CESU-8 encoding is preservation of UTF-16 binary collation.
CESU-8 encoding can result from converting UTF-16 data with supplementary characters to UTF-8, using conversion methods that assume UCS-2 data, meaning they are unaware of four-byte UTF-16 supplementary characters. It is primarily an issue on operating systems which extensively use UTF-16 internally, such as Microsoft Windows.[citation needed]
In Oracle Database, the UTF8 character set uses CESU-8 encoding, and is deprecated. The AL32UTF8 character set uses standards-compliant UTF-8 encoding, and is preferred.[80][81]
CESU-8 is prohibited for use in HTML5 documents.[82][83][84]
MySQL utf8mb3[edit]
In MySQL, the utf8mb3 character set is defined to be UTF-8 encoded data with a maximum of three bytes per character, meaning only Unicode characters in the Basic Multilingual Plane (i.e. from UCS-2) are supported. Unicode characters in supplementary planes are explicitly not supported. utf8mb3 is deprecated in favor of the utf8mb4 character set, which uses standards-compliant UTF-8 encoding. utf8 is an alias for utf8mb3, but is intended to become an alias to utf8mb4 in a future release of MySQL.[14] It is possible, though unsupported, to store CESU-8 encoded data in utf8mb3, by handling UTF-16 data with supplementary characters as though it is UCS-2.
Modified UTF-8[edit]
Modified UTF-8 (MUTF-8) originated in the Java programming language. In Modified UTF-8, the null character (U+0000) uses the two-byte overlong encoding 11000000 10000000 (hexadecimal C0 80), instead of 00000000 (hexadecimal 00).[85] Modified UTF-8 strings never contain any actual null bytes but can contain all Unicode code points including U+0000,[86] which allows such strings (with a null byte appended) to be processed by traditional null-terminated string functions. All known Modified UTF-8 implementations also treat the surrogate pairs as in CESU-8.
In normal usage, the language supports standard UTF-8 when reading and writing strings through InputStreamReader and OutputStreamWriter (if it is the platform’s default character set or as requested by the program). However it uses Modified UTF-8 for object serialization[87] among other applications of DataInput and DataOutput, for the Java Native Interface,[88] and for embedding constant strings in class files.[89]
The dex format defined by Dalvik also uses the same modified UTF-8 to represent string values.[90] Tcl also uses the same modified UTF-8[91] as Java for internal representation of Unicode data, but uses strict CESU-8 for external data.
WTF-8[edit]
In WTF-8 (Wobbly Transformation Format, 8-bit) unpaired surrogate halves (U+D800 through U+DFFF) are allowed.[92] This is necessary to store possibly-invalid UTF-16, such as Windows filenames. Many systems that deal with UTF-8 work this way without considering it a different encoding, as it is simpler.[93]
The term «WTF-8» has also been used humorously to refer to erroneously doubly-encoded UTF-8[94][95] sometimes with the implication that CP1252 bytes are the only ones encoded.[96]
PEP 383[edit]
Version 3 of the Python programming language treats each byte of an invalid UTF-8 bytestream as an error (see also changes with new UTF-8 mode in Python 3.7[97]); this gives 128 different possible errors. Extensions have been created to allow any byte sequence that is assumed to be UTF-8 to be losslessly transformed to UTF-16 or UTF-32, by translating the 128 possible error bytes to reserved code points, and transforming those code points back to error bytes to output UTF-8. The most common approach is to translate the codes to U+DC80…U+DCFF which are low (trailing) surrogate values and thus «invalid» UTF-16, as used by Python’s PEP 383 (or «surrogateescape») approach.[33] Another encoding called MirBSD OPTU-8/16 converts them to U+EF80…U+EFFF in a Private Use Area.[98] In either approach, the byte value is encoded in the low eight bits of the output code point.
These encodings are very useful because they avoid the need to deal with «invalid» byte strings until much later, if at all, and allow «text» and «data» byte arrays to be the same object. If a program wants to use UTF-16 internally these are required to preserve and use filenames that can use invalid UTF-8;[99] as the Windows filesystem API uses UTF-16, the need to support invalid UTF-8 is less there.[33]
For the encoding to be reversible, the standard UTF-8 encodings of the code points used for erroneous bytes must be considered invalid. This makes the encoding incompatible with WTF-8 or CESU-8 (though only for 128 code points). When re-encoding it is necessary to be careful of sequences of error code points which convert back to valid UTF-8, which may be used by malicious software to get unexpected characters in the output, though this cannot produce ASCII characters so it is considered comparatively safe, since malicious sequences (such as cross-site scripting) usually rely on ASCII characters.[99]
See also[edit]
- Alt code
- Comparison of email clients § Features
- Comparison of Unicode encodings
- GB 18030, a Chinese encoding that fully supports Unicode
- UTF-EBCDIC, a rarely used encoding, even for mainframes it was made for
- Iconv
- Percent-encoding § Current standard
- Specials (Unicode block)
- Unicode and email
- Unicode and HTML
- Character encodings in HTML
Notes[edit]
- ^ 17 planes times 216 code points per plane, minus 211 technically-invalid surrogates.
- ^ There are enough x bits to encode up to 0x1FFFFF, but the current RFC 3629 §3 limits UTF-8 encoding to code point U+10FFFF, to match the limits of UTF-16. The obsolete RFC 2279 allowed UTF-8 encoding up to (then legal) code point U+7FFFFFF.
- ^ Some complex emoji characters can take even more than this; the transgender flag emoji (🏳️⚧️), which consists of the five-codepoint sequence U+1F3F3 U+FE0F U+200D U+26A7 U+FE0F, requires sixteen bytes to encode, while that for the flag of Scotland (🏴) requires a total of twenty-eight bytes for the seven-codepoint sequence U+1F3F4 U+E0067 U+E0062 U+E0073 U+E0063 U+E0074 U+E007F.
- ^ For example, cell 9D says +1D. The hexadecimal number 9D in binary is 10011101, and since the 2 highest bits (10) are reserved for marking this as a continuation byte, the remaining 6 bits (011101) have a hexadecimal value of 1D.
- ^ W3Techs.com survey[9] is based on the encoding as declared in the server’s response, see https://w3techs.com/forum/topic/22994
- ^ Python uses a number of encodings for what it calls «Unicode», however none of these encodings are UTF-8. Python 2 and early version 3 used UTF-16 on Windows and UTF-32 on Unix. More recent implementations of Python 3 use three fixed-length encodings: ISO-8859-1, UCS-2, and UTF-32, depending on the maximum code point needed.[60]
References[edit]
- ^ «Chapter 2. General Structure». The Unicode Standard (6.0 ed.). Mountain View, California, US: The Unicode Consortium. ISBN 978-1-936213-01-6.
- ^ a b Pike, Rob (30 April 2003). «UTF-8 history».
- ^ Pike, Rob; Thompson, Ken (1993). «Hello World or Καλημέρα κόσμε or こんにちは 世界» (PDF). Proceedings of the Winter 1993 USENIX Conference.
- ^ «File System Safe UCS — Transformation Format (FSS-UTF) — X/Open Preliminary Specification» (PDF). unicode.org.
- ^ «USENIX Winter 1993 Conference Proceedings». usenix.org.
- ^ a b Alvestrand, Harald T. (January 1998). IETF Policy on Character Sets and Languages. IETF. doi:10.17487/RFC2277. BCP 18. RFC 2277.
- ^ a b c «UTF-8 support in the Microsoft Game Development Kit (GDK) — Microsoft Game Development Kit». learn.microsoft.com. Retrieved 2023-03-05.
By operating in UTF-8, you can ensure maximum compatibility [..] Windows operates natively in UTF-16 (or WCHAR), which requires code page conversions by using MultiByteToWideChar and WideCharToMultiByte. This is a unique burden that Windows places on code that targets multiple platforms. [..] The Microsoft Game Development Kit (GDK) and Windows in general are moving forward to support UTF-8 to remove this unique burden of Windows on code targeting or interchanging with multiple platforms and the web. Also, this results in fewer internationalization issues in apps and games and reduces the test matrix that’s required to get it right.
- ^ a b «Encoding Standard». encoding.spec.whatwg.org. Retrieved 2020-04-15.
- ^ a b c «Usage Survey of Character Encodings broken down by Ranking». w3techs.com. Retrieved 2023-10-01.
- ^ «Encoding Standard § 4.2. Names and labels». WHATWG. Retrieved 2018-04-29.
- ^ «Character Sets». Internet Assigned Numbers Authority. 2013-01-23. Retrieved 2013-02-08.
- ^ Liviu (2014-02-07). «UTF-8 codepage 65001 in Windows 7 — part I». Retrieved 2018-01-30.
Previously under XP (and, unverified, but probably Vista, too) for loops simply did not work while codepage 65001 was active
- ^ «MySQL :: MySQL 8.0 Reference Manual :: 10.9.1 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)». MySQL 8.0 Reference Manual. Oracle Corporation. Retrieved 2023-03-14.
- ^ a b «MySQL :: MySQL 8.0 Reference Manual :: 10.9.2 The utf8mb3 Character Set (3-Byte UTF-8 Unicode Encoding)». MySQL 8.0 Reference Manual. Oracle Corporation. Retrieved 2023-02-24.
- ^ «HP PCL Symbol Sets | Printer Control Language (PCL & PXL) Support Blog». 2015-02-19. Archived from the original on 2015-02-19. Retrieved 2018-01-30.
- ^ «Database Globalization Support Guide». docs.oracle.com. Retrieved 2023-03-16.
- ^ «BOM». suikawiki (in Japanese). Archived from the original on 2009-01-17.
- ^ Davis, Mark. «Forms of Unicode». IBM. Archived from the original on 2005-05-06. Retrieved 2013-09-18.
- ^ «Apple Developer Documentation». developer.apple.com. Retrieved 2021-03-15.
- ^ «Chapter 3» (PDF), The Unicode Standard, p. 54
- ^ «Chapter 3» (PDF), The Unicode Standard, p. 55
- ^ «Chapter 3» (PDF), The Unicode Standard, p. 55
- ^ a b c Yergeau, F. (November 2003). UTF-8, a transformation format of ISO 10646. IETF. doi:10.17487/RFC3629. STD 63. RFC 3629. Retrieved August 20, 2020.
- ^ «Chapter 3» (PDF), The Unicode Standard, p. 54
- ^ «Chapter 3» (PDF), The Unicode Standard, p. 55
- ^ Marin, Marvin (2000-10-17). «Web Server Folder Traversal MS00-078».
- ^ «Summary for CVE-2008-2938». National Vulnerability Database.
- ^ «PEP 529 — Change Windows filesystem encoding to UTF-8». Python.org. Retrieved 2022-05-10.
This PEP proposes changing the default filesystem encoding on Windows to utf-8, and changing all filesystem functions to use the Unicode APIs for filesystem paths. [..] can correctly round-trip all characters used in paths (on POSIX with surrogateescape handling; on Windows because str maps to the native representation). On Windows bytes cannot round-trip all characters used in paths
- ^ «DataInput (Java Platform SE 8)». docs.oracle.com. Retrieved 2021-03-24.
- ^ «Non-decodable Bytes in System Character Interfaces». python.org. 2009-04-22. Retrieved 2014-08-13.
- ^ «Unicode 6.0.0».
- ^ 128 1-byte, (16+5)×64 2-byte, and 5×64×64 3-byte. There may be somewhat fewer if more precise tests are done for each continuation byte.
- ^ a b c von Löwis, Martin (2009-04-22). «Non-decodable Bytes in System Character Interfaces». Python Software Foundation. PEP 383.
- ^ «Chapter 2» (PDF), The Unicode Standard — Version 15.0.0, p. 39
- ^ «UTF-8 and Unicode FAQ for Unix/Linux».
- ^ Davis, Mark (2012-02-03). «Unicode over 60 percent of the web». Official Google blog. Archived from the original on 2018-08-09. Retrieved 2020-07-24.
- ^ Davis, Mark (2008-05-05). «Moving to Unicode 5.1». Official Google Blog. Retrieved 2023-03-13.
- ^ «Usage statistics and market share of ASCII for websites, October 2021». w3techs.com. Retrieved 2020-10-01.
- ^ Bray, Tim (December 2017). Bray, T. (ed.). The JavaScript Object Notation (JSON) Data Interchange Format. IETF. doi:10.17487/RFC8259. RFC 8259. Retrieved 16 February 2018.
- ^ «Usage of Internet mail in the world characters». washingtonindependent.com. 1998-08-01. Retrieved 2007-11-08.
- ^ «Encoding Standard». encoding.spec.whatwg.org. Retrieved 2018-11-15.
- ^ «Specifying the document’s character encoding». HTML 5.2 (Report). World Wide Web Consortium. 14 December 2017. Retrieved 2018-06-03.
- ^ «Choose text encoding when you open and save files». support.microsoft.com. Retrieved 2021-11-01.
- ^ «utf 8 — Character encoding of Microsoft Word DOC and DOCX files?». Stack Overflow. Retrieved 2021-11-01.
- ^ «Exporting a UTF-8 .txt file from Word».
- ^ «excel — Are XLSX files UTF-8 encoded by definition?». Stack Overflow. Retrieved 2021-11-01.
- ^ «How to open UTF-8 CSV file in Excel without mis-conversion of characters in Japanese and Chinese language for both Mac and Windows?». answers.microsoft.com. Retrieved 2021-11-01.
- ^ «How can I make Notepad to save text in UTF-8 without the BOM?». Stack Overflow. Retrieved 2021-03-24.
- ^ Galloway, Matt (October 2012). «Character encoding for iOS developers. Or, UTF-8 what now?». www.galloway.me.uk. Retrieved 2021-01-02.
in reality, you usually just assume UTF-8 since that is by far the most common encoding.
- ^ «Windows 10 Notepad is getting better UTF-8 encoding support». BleepingComputer. Retrieved 2021-03-24.
Microsoft is now defaulting to saving new text files as UTF-8 without BOM, as shown below.
- ^ «Customize the Windows 11 Start menu». docs.microsoft.com. Retrieved 2021-06-29.
Make sure your LayoutModification.json uses UTF-8 encoding.
- ^ «JEP 400: UTF-8 by default». openjdk.java.net. Retrieved 2022-03-30.
- ^ «Feature #16604: Set default for Encoding.default_external to UTF-8 on Windows». bugs.ruby-lang.org. Ruby master – Ruby Issue Tracking System. Retrieved 2022-08-01.
- ^ «Feature #12650: Use UTF-8 encoding for ENV on Windows». bugs.ruby-lang.org. Ruby master – Ruby Issue Tracking System. Retrieved 2022-08-01.
- ^ «New features in R 4.2.0». The Jumping Rivers Blog. R bloggers. 2022-04-01. Retrieved 2022-08-01.
- ^ «PEP 540 – add a new UTF-8 mode». peps.python.org. Retrieved 2022-09-23.
- ^ «PEP 686 – Make UTF-8 mode default | peps.python.org». peps.python.org. Retrieved 2023-07-26.
- ^ «PEP 597 – add optional EncodingWarning». Python.org. Retrieved 2021-08-24.
- ^ «Support for UTF-8 as a portable source file encoding» (PDF).
- ^ a b «PEP 393 – Flexible String Representation». Python.org. Retrieved 2022-05-18.
As interaction with other libraries will often require some sort of internal representation, the specification chooses UTF-8 as the recommended way of exposing strings to C code. [..] The data and utf8 pointers point to the same memory if the string uses only ASCII characters (using only Latin-1 is not sufficient). [..] The recommended way to create a Unicode object is to use the function PyUnicode_New [..] A new function PyUnicode_AsUTF8 is provided to access the UTF-8 representation.
- ^ «Source code representation». The Go Programming Language Specification. golang.org (Report). Retrieved 2021-02-10.
- ^ Tsai, Michael J. (21 March 2019). «UTF-8 string in Swift 5» (blog). Retrieved 2021-03-15.
Switching to UTF-8 fulfills one of string’s long-term goals, to enable high-performance processing, […] also lays the groundwork for providing even more performant APIs in the future.
- ^ «PyPy v7.1 released; now uses UTF-8 internally for Unicode strings». Mattip. PyPy status blog. 2019-03-24. Retrieved 2020-11-21.
- ^ «Unicode Objects and Codecs». Python documentation. Retrieved 2023-08-19.
UTF-8 representation is created on demand and cached in the Unicode object.
- ^ «PEP 623 – remove wstr from Unicode». Python.org. Retrieved 2020-11-21.
Until we drop [the] legacy Unicode object, it is very hard to try other Unicode implementation[s], like UTF-8 based implementation in PyPy.
- ^ Wouters, Thomas (2023-07-11). «Python Insider: Python 3.12.0 beta 4 released». Python Insider. Retrieved 2023-07-26.
The deprecated wstr and wstr_length members of the C implementation of unicode objects were removed, per PEP 623.
- ^ «/validate-charset (validate for compatible characters)». docs.microsoft.com. Retrieved 2021-07-19.
Visual Studio uses UTF-8 as the internal character encoding during conversion between the source character set and the execution character set.
- ^ «Introducing UTF-8 support for SQL Server». techcommunity.microsoft.com. 2019-07-02. Retrieved 2021-08-24.
For example, changing an existing column data type from NCHAR(10) to CHAR(10) using an UTF-8 enabled collation, translates into nearly 50% reduction in storage requirements. [..] In the ASCII range, when doing intensive read/write I/O on UTF-8, we measured an average 35% performance improvement over UTF-16 using clustered tables with a non-clustered index on the string column, and an average 11% performance improvement over UTF-16 using a heap.
- ^ «Use the Windows UTF-8 code page – UWP applications». docs.microsoft.com. Retrieved 2020-06-06.
As of Windows version 1903 (May 2019 update), you can use the ActiveCodePage property in the appxmanifest for packaged apps, or the fusion manifest for unpackaged apps, to force a process to use UTF-8 as the process code page. […]
CP_ACPequates toCP_UTF8only if running on Windows version 1903 (May 2019 update) or above and the ActiveCodePage property described above is set to UTF-8. Otherwise, it honors the legacy system code page. We recommend usingCP_UTF8explicitly. - ^ «Appendix F. FSS-UTF / File System Safe UCS Transformation format» (PDF). The Unicode Standard 1.1. Archived (PDF) from the original on 2016-06-07. Retrieved 2016-06-07.
- ^ Whistler, Kenneth (2001-06-12). «FSS-UTF, UTF-2, UTF-8, and UTF-16». Archived from the original on 2016-06-07. Retrieved 2006-06-07.
- ^ a b Pike, Rob (2003-04-30). «UTF-8 history». Retrieved 2012-09-07.
- ^ Pike, Rob (2012-09-06). «UTF-8 turned 20 years old yesterday». Retrieved 2012-09-07.
- ^ ISO/IEC 10646:2014 §9.1, 2014.
- ^ The Unicode Standard, Version 15.0 §3.9 D92, §3.10 D95, 2021.
- ^ Unicode Standard Annex #27: Unicode 3.1, 2001.
- ^ The Unicode Standard, Version 5.0 §3.9–§3.10 ch. 3, 2006.
- ^ The Unicode Standard, Version 6.0 §3.9 D92, §3.10 D95, 2010.
- ^ McGowan, Rick (2011-12-19). «Compatibility Encoding Scheme for UTF-16: 8-Bit (CESU-8)». Unicode Consortium. Unicode Technical Report #26.
- ^ «Character Set Support». Oracle Database 19c Documentation, SQL Language Reference. Oracle Corporation.
- ^ «Supporting Multilingual Databases with Unicode § Support for the Unicode Standard in Oracle Database». Database Globalization Support Guide. Oracle Corporation.
- ^ «8.2.2.3. Character encodings». HTML 5.1 Standard. W3C.
- ^ «8.2.2.3. Character encodings». HTML 5 Standard. W3C.
- ^ «12.2.3.3 Character encodings». HTML Living Standard. WHATWG.
- ^ «Java SE documentation for Interface java.io.DataInput, subsection on Modified UTF-8». Oracle Corporation. 2015. Retrieved 2015-10-16.
- ^ «The Java Virtual Machine Specification, section 4.4.7: «The CONSTANT_Utf8_info Structure»«. Oracle Corporation. 2015. Retrieved 2015-10-16.
- ^ «Java Object Serialization Specification, chapter 6: Object Serialization Stream Protocol, section 2: Stream Elements». Oracle Corporation. 2010. Retrieved 2015-10-16.
- ^ «Java Native Interface Specification, chapter 3: JNI Types and Data Structures, section: Modified UTF-8 Strings». Oracle Corporation. 2015. Retrieved 2015-10-16.
- ^ «The Java Virtual Machine Specification, section 4.4.7: «The CONSTANT_Utf8_info Structure»«. Oracle Corporation. 2015. Retrieved 2015-10-16.
- ^ «ART and Dalvik». Android Open Source Project. Archived from the original on 2013-04-26. Retrieved 2013-04-09.
- ^ «UTF-8 bit by bit». Tcler’s Wiki. 2001-02-28. Retrieved 2022-09-03.
- ^ Sapin, Simon (2016-03-11) [2014-09-25]. «The WTF-8 encoding». Archived from the original on 2016-05-24. Retrieved 2016-05-24.
- ^ Sapin, Simon (2015-03-25) [2014-09-25]. «The WTF-8 encoding § Motivation». Archived from the original on 2020-08-16. Retrieved 2020-08-26.
- ^ «WTF-8.com». 2006-05-18. Retrieved 2016-06-21.
- ^ Speer, Robyn (2015-05-21). «ftfy (fixes text for you) 4.0: changing less and fixing more». Archived from the original on 2015-05-30. Retrieved 2016-06-21.
- ^ «WTF-8, a transformation format of code page 1252». Archived from the original on 2016-10-13. Retrieved 2016-10-12.
- ^ «PEP 540 — Add a new UTF-8 Mode». Python.org. Retrieved 2021-03-24.
- ^ «RTFM optu8to16(3), optu8to16vis(3)». www.mirbsd.org.
- ^ a b Davis, Mark; Suignard, Michel (2014). «3.7 Enabling Lossless Conversion». Unicode Security Considerations. Unicode Technical Report #36.
External links[edit]
- Original UTF-8 paper (or pdf) for Plan 9 from Bell Labs
- History of UTF-8 by Rob Pike
- UTF-8 test pages:
- Andreas Prilop Archived 2017-11-30 at the Wayback Machine
- Jost Gippert
- World Wide Web Consortium
- Unix/Linux: UTF-8/Unicode FAQ, Linux Unicode HOWTO, UTF-8 and Gentoo
- Characters, Symbols and the Unicode Miracle on YouTube
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
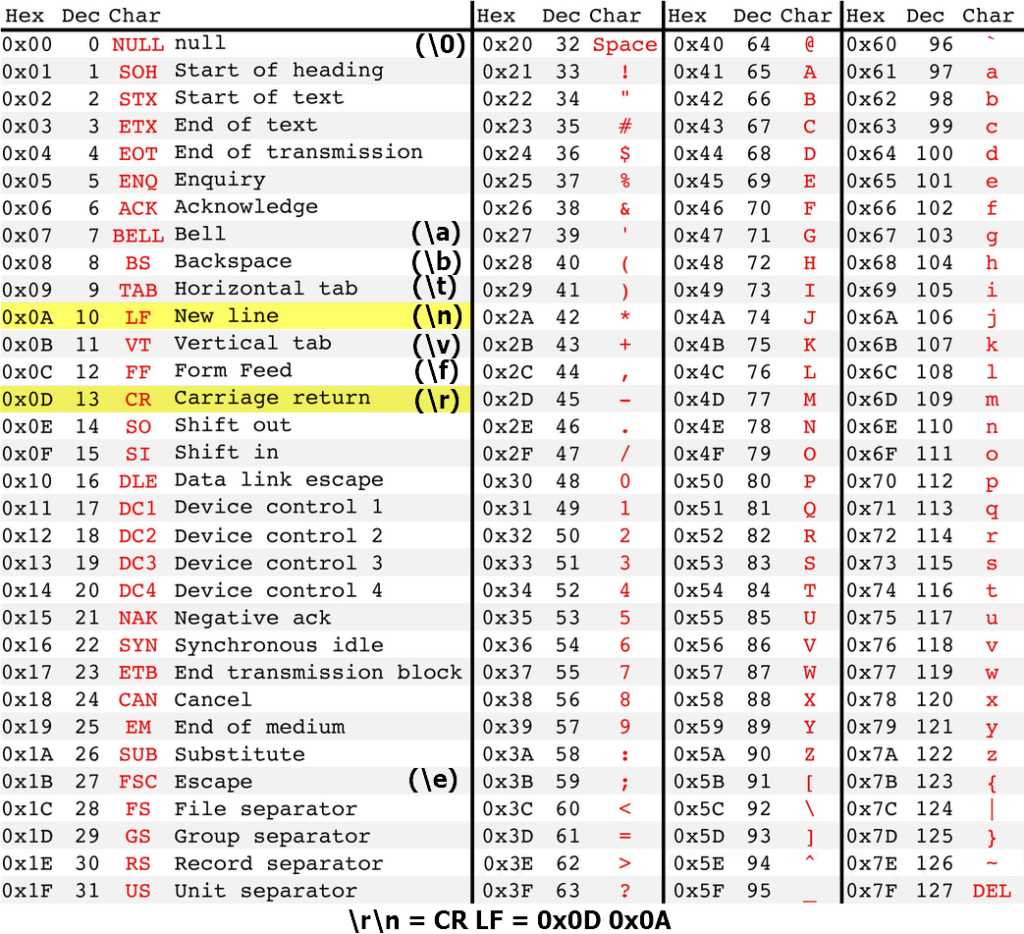
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.

Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.

Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
Когда и если вы прочитали теорию о разнице кодировок utf-8 и windows 1251 — это уже победа! 
смайлы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн! 
смайлы, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим…
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
Опять var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Марат’);
Результат:
string(10) «Марат»
И что мы здесь видим!?
Что количество элементов в строке 10… Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается…!
Поэтому, и возникают проблемы с текстом в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример…как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций…
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’);:
string(5) «Marat»
Результат var_dump(‘Марат’);:
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
И третий вариант перекодировать строку из utf-8 в windows 1251
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
(
[0] => �
[1] => �
[2] => �
[3] => �
[4] => �
[5] => �
[6] => �
[7] => �
[8] => �
[9] => �
)
print_r (mb_str_split(‘Марат’)); выдаст :

Как видим… полный отстой…
Мы далее разбирались с этим здесь.
Как перекодировать строку из utf-8 в windows 1251
Итак… есть третий вариант, борьбы с квадратиками(непонимание кодировки) — перекодировать строку из utf-8 в windows 1251:
iconv(«UTF-8», «windows-1251», $text)
После того, как вы выполнили все намеченные действия с текстом, возвращаем его в исходную кодировку :
iconv(«windows-1251», «UTF-8», $text)
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
Мы использовали var_dump, и он посчитал не правильно, поскольку просто так, на страницу вывести данные с помощью var_dump нельзя, мы использовали вот такой костыль :
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
string(5) «�����»
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
string(5) «Марат»
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить… 
смайлы
Что лучше для кириллицы utf-8 или…
Интересный поисковый запрос — «Что лучше для кириллицы utf-8 или…«…
Дело в том, что я выбрал кодировку «utf-8» уже… 14 лет(число динамическое) назад… и… уже сейчас трудно вспомнить, почему именно её… но точно вам могу заявить, что когда-то пользовался «windows-1251″… и у неё были какие-то заморочки, в виде неадекватного вывода информации, что, я волей неволей перешел на «utf-8»
Какие минусы у utf-8?
Одна из самых главных проблем «utf-8» — это многобайтовость…
Да! Это несколько неудобно в самом начале, но для всякой функции, которая не хочет работать с кириллицей, существуют замены.
В процессе создания сайта у вас может возникнуть несколько проблем, которые вы решите и «тупо» забудете об этом…
Задумывался ли я о переходе с кодировки utf-8 на другую?
Смысл задумываться о переходе с кодировки utf-8 на другую, если всё работает так, как нужно!