На чтение 7 мин Просмотров 16.5к.

Кристина Горбунова
Высшее образование по специальности “Информационные системы”. В сфере более 7 лет, занимается разработкой сайтов на WordPress и Tilda.
Большинство интернет-провайдеров предоставляет пользователям услугу IPTV. Цифровое телевидение выстраивается в форме мультивещания. Для многоадресной передачи данных применяется протокол IGMP Proxy. Рассмотрим, что такое мультикаст и как технология Multicast реализована в роутере.
Содержание
- Что значит Multicast
- Как работает функция IGMP Proxy в роутере
- IGMP V2 или V3: в чем разница
- Как включить эту функцию на роутере
Что значит Multicast
Существуют три основных формы передачи трафика в сетях: unicast, broadcast, multicast. У каждого из этих методов разный тип назначения IP-адресов. Мультикаст – многоадресное вещание. Эта технология применяется для доставки видеоконтента неограниченному количеству пользователей. В отличие от юникаста и бродкаста, этот метод не создает серьезной дополнительной нагрузки на сеть.
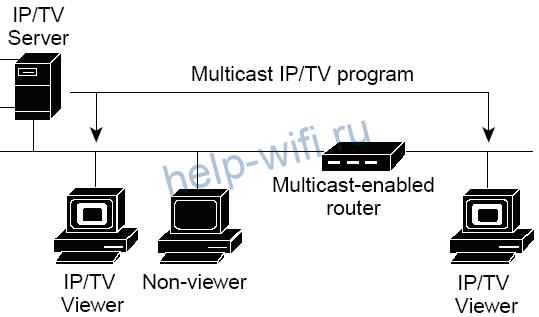
Основные принципы мультикастинга:
- Один отправитель посылает только одну копию трафика, независимо от количества конечных получателей.
- Трафик получают пользователи, которые действительно в нем нуждаются.
С многоадресными передачами могут работать маршрутизаторы, поддерживающие IGMP. Благодаря этому протоколу устройства отслеживают текущее состояние группы рассылки и получают только нужный трафик.
В IPv6 для мультикастинга используется протокол MLD. Функционирует он точно так же, как и IGMP.
Как работает функция IGMP Proxy в роутере
Протокол IGMP позволяет пользователю быстро подключиться к маршрутизатору. Он организует несколько близко расположенных устройств в группы для более эффективного распределения сетевых ресурсов. Для понимания работы протокола нужно разобрать особенности передачи многоадресных пакетов в ЛВС.
При прохождении через коммутаторы второго уровня многоадресные пакеты данных транслируются всем хостам в домене, включая не входящих в группы рассылки. Это связано с тем, что коммутатор второго уровня не способен распознавать многоадресные MAC-адреса. В результате пропускная способность ЛВС сильно падает.
Если в роутере присутствует поддержка IGMP, снижения скорости сети можно избежать. После активации этой функции устройство сможет прослушивать и анализировать сообщения протокола управления групповой передачей данных. Пакеты многоадресной рассылки будут отправлены только конкретным получателям, а не всем хостам.
Для передачи мультикаста между маршрутизаторами внутри сети используется протокол PIM. Он имеет два режима функционирования: Dense Mode (DM) и Sparse Mode (SM). Если активен DM, то сеть заполняется многоадресным трафиком. Его применяют, когда к сети подключено много клиентов разных мультикастовых групп.
В большинство случаев для передачи мультикаста используют PIM SM. В этом режиме заинтересованные в трафике узлы подают запросы на подключение. Если подобного запроса не было, мультикастовые данные маршрутизатору отправляться не будут.
Рассмотрим, как работает IGMP протокол на примере подключения к каналу 227.1.1.6.
- Клиентское ПО отправляет ближайшему маршрутизатору запрос на получение данных канала 227.1.1.6.
- Если дерево канала проходит через это устройство, пользователь получает изображение.
- После смены канала на маршрутизатор поступает сообщение о выходе из группы. Отправка трафика прекращается.
- Параллельно каждые 60 секунд маршрутизатор автоматически отправляет подключенным клиентам сигналы для проверки получения трафика. Если клиент не ответил, то его автоматически отключают от этой рассылки. Процедура полностью автоматическая.
Активируя или отключая IGMP прокси, пользователь позволяет роутеру принимать или отклонять пакеты данных IPTV. Если компьютер или телевизор не подключен к интерактивному телевидению, эту опцию можно деактивировать.
IGMP V2 или V3: в чем разница
Разница между IGMP Proxy V2 и V3 в качестве фильтрации трафика. IGMPv3 поддерживает чистый SSM. Клиент сможет указать в запросе список источников, от которых он хочет или не желает получать трафик. При использовании второй версии протокола осуществляется запрос всего трафика без разделения на источники.
Еще одно отличие V3 от V2 заключается в отправке сообщения Report на мультикастовый служебный адрес вместо группового. Адреса запрашиваемой группы находятся непосредственно внутри пакета. Это изменение упрощает IGMP Snooping.
Провайдеры часто рекомендуют использовать для мультикаста вторую версию протокола. Она является самой распространенной и поддерживается большинством роутеров.
Как включить эту функцию на роутере
Эта функция нужна для работы IPTV. В большинстве роутеров мультикаст уже включен, и менять его настройки не нужно. Рассмотрим алгоритм включения IGMP Proxy в роутерах разных производителей.
В бирюзовом интерфейсе TP-Link нужные настройки находятся в разделе «Сеть» на вкладке «IPTV». Нужно убедиться, что напротив IGMP Snooping и IGMP Proxy установлены галочки. Также нужно поставить галочку рядом с «Включить IPTV» и сохранить настройки.


Аналогичным образом включают IGMP Proxy в голубом интерфейсе TP-Link.
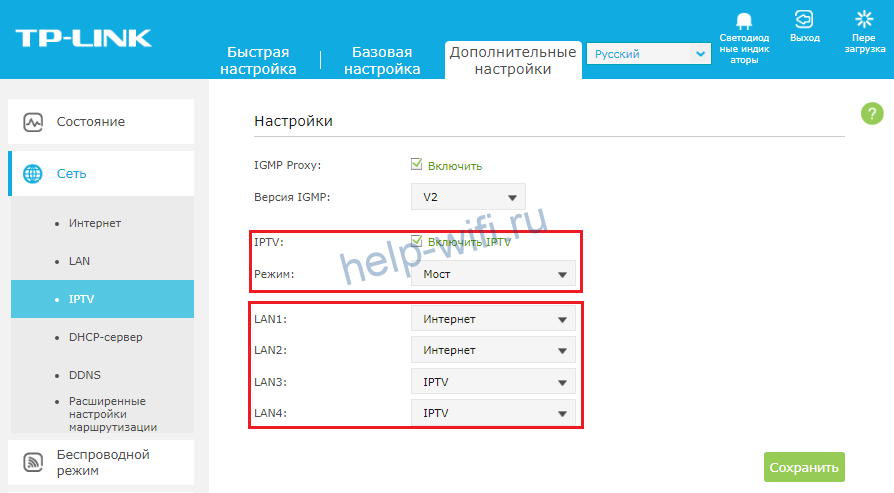
Чтобы настроить IPTV в зеленом интерфейсе TP-Link, необходимо переключить режим в «Мост» и выбрать порт для подключения приставки.

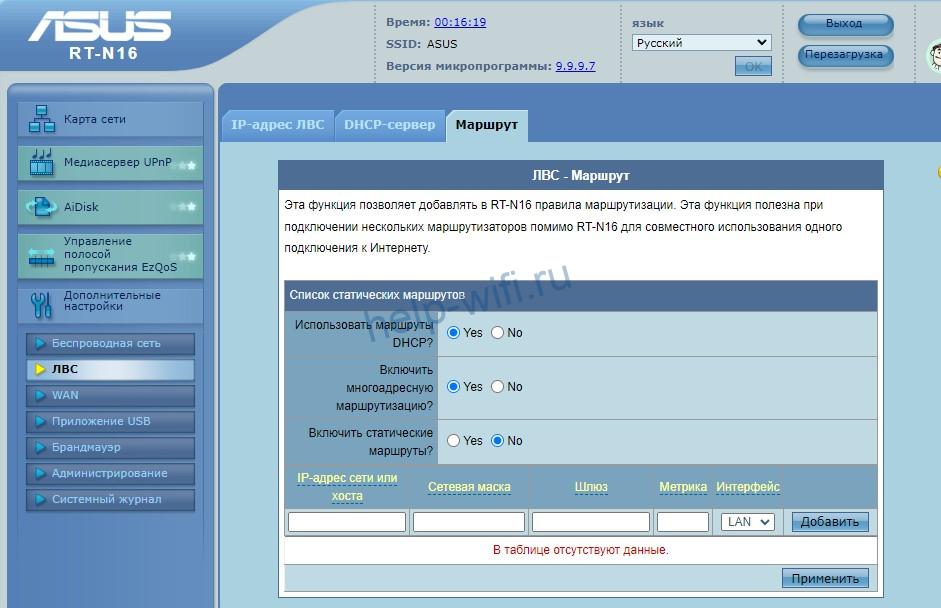
В роутере Asus со старой голубой прошивкой функция IGMP Proxy активируется во разделе «ЛВС» дополнительных настроек. Нужно перейти во вкладку «Маршрут» и установить галочку напротив пункта «Включить многоадресную маршрутизацию», а затем кликнуть на кнопку «Применить». После этого можно приступать к дальнейшей настройке IPTV в разделе WAN.
В моделях Asus с современной черной прошивкой функция активируется в разделе «Локальная сеть» на вкладке IPTV.
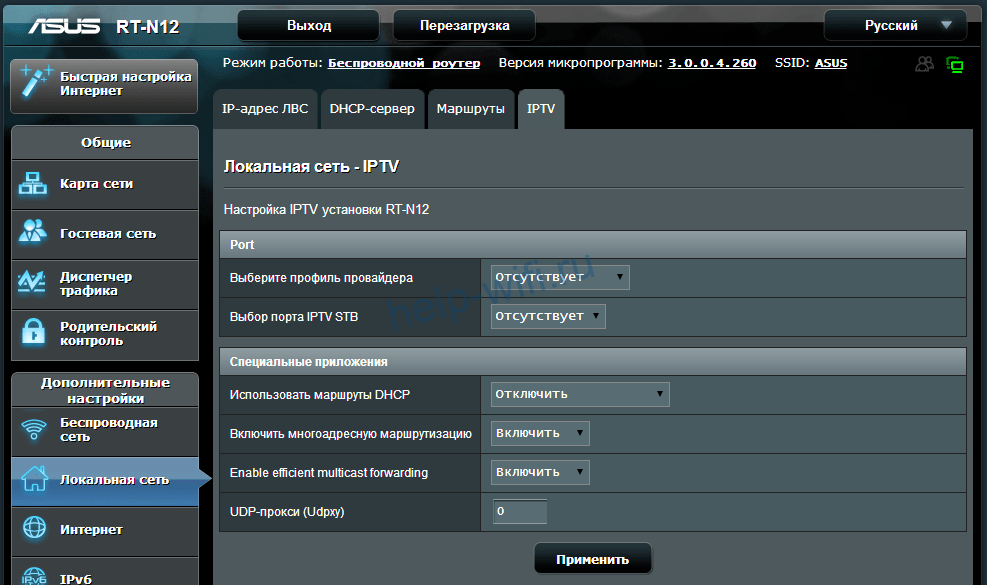
В старой прошивке роутеров Zyxel по умолчанию активирован сервис IGMP proxy. Его можно отключить в модуле «Приложения». Для этого откройте вкладку «Сервер udpxy» и нажмите на кнопку «Остановить IGMP proxy».
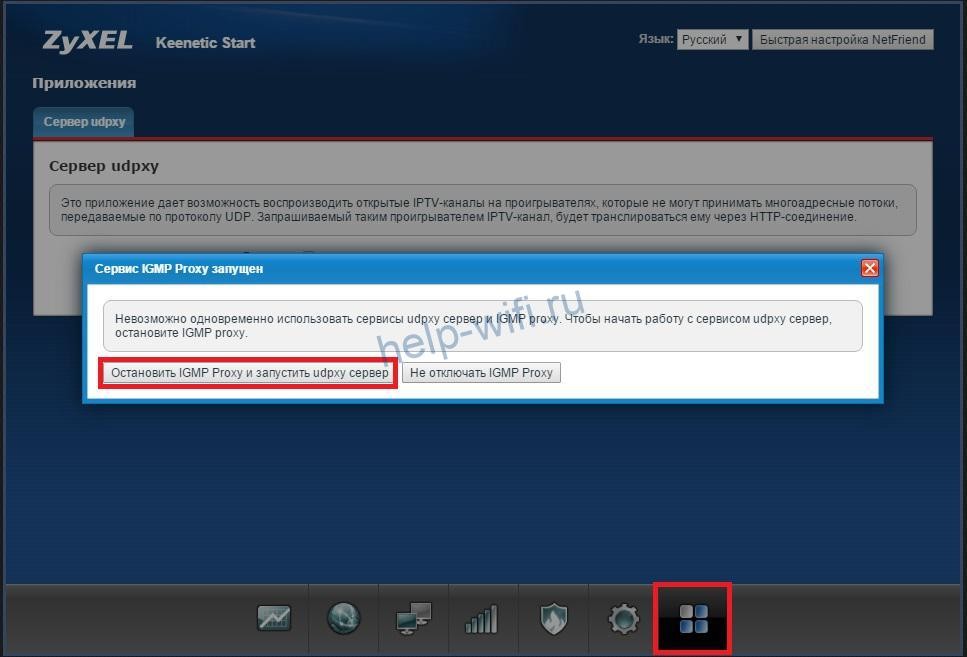
Роутеры Keenetic поддерживают одновременную работу сразу с обеими этими функциями. Активация протокола IGMP Proxy осуществляется в разделе «Домашняя сеть». Нужно промотать страницу до одноименного раздела и поставить галочку напротив «Включить».

У роутеров Tenda функция IGMP Proxy включена по умолчанию. В настройках ее нельзя активировать отдельно.
В роутерах D-Link эта опция тоже включена по умолчанию. Если же приставка не может установить соединение, можно исправить это вручную. Для этого перейдите в раздел «Настройка соединений» и выберите «WAN». Проверьте, чтобы возле параметра IGMP стоял переключатель напротив WAN.

В старых сериях устройств D-Link (DI-524, DI-808HV) можно активировать IGMP вручную. Для этого загрузите последнюю версию прошивки, а затем перейдите в раздел «WAN». Возле нужного параметра переключатель должен стоять у Enabled. Не забудьте кликнуть на кнопку «Apply».
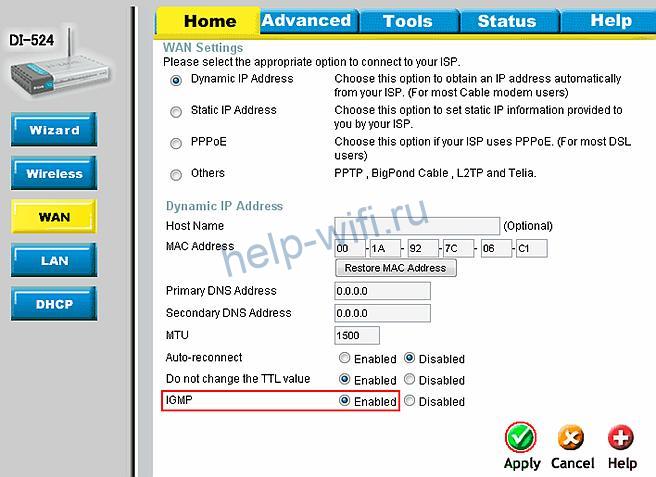
В моделях серии DI-524UP, DI-624S нужно перейти во вкладку «Tools» и в меню выбрать «Misc». Далее потребуется пролистать до «Multicast streaming», установить регулятор около «Enabled» и нажать на «Apply».

В роутерах DIR-300, DIR-400 настройки меняются в разделе «Advanced». Нужно перейти во вкладку «Advanced Network» и установить галочку рядом с «Enable Multicast Stream». Чтобы настройки вступили в силу, кликните на «Save Settings».
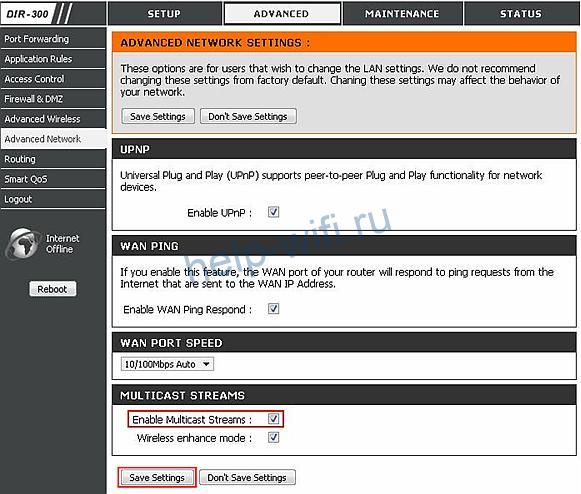
У роутеров Netis функция активации IGMP находится в расширенных настройках. После перевода протокола во включенное состояние нужно кликнуть на кнопку «Сохранить».
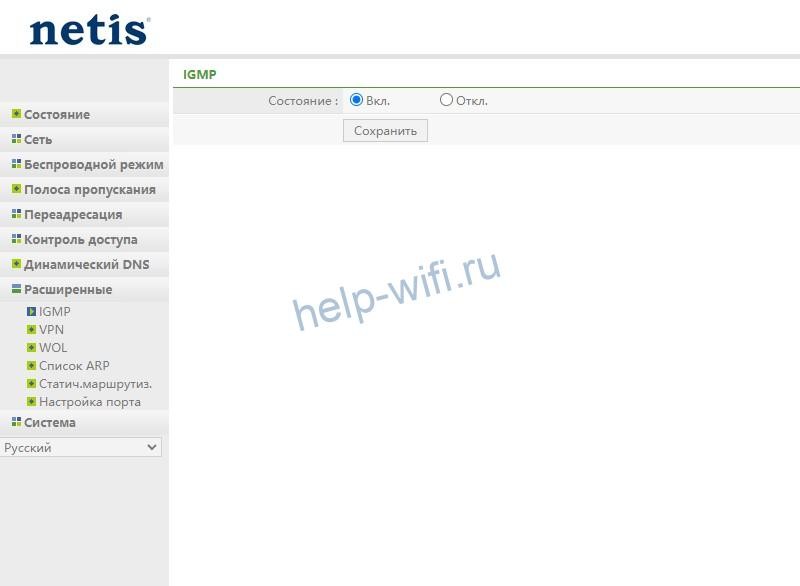
В устройствах Upvel активирован протокол IGMP по умолчанию. Проверить это можно в настройках интерфейса WAN. Напротив «Разрешить IGMP-прокси» должна быть установлена галочка.

Читайте подробную статью, как подключить телевизор у интернету для просмотра IPTV, серфинга и других задач.
И так, чтобы раскрыть тему IGMP Proxy, PIM и мультикаста полностью – давайте начнём с самого начала. Вы, наверное, уже знаете, как передаётся эфирное телевидение. То есть у нас есть телевизионная вышка, которая путём радиоволн передаёт закодированный сигнал. А клиент в свою очередь принимает этот сигнал с антенны и видит картинку на телевизоре. Аналогично все происходит и путём кабельного ТВ. Только разница в том, что в кабельном идёт сигнал непосредственно по проложенному проводу к каждому приёмнику.
Но общее все же есть – сигнал одновременно поступает к всем клиентам. Когда вы включите телевизор, то вы увидите сигнал, который отправляется всем. Но если вы включите, например тот же самый YouTube, то там все по-другому. Каждому пользователю предоставляется свой пакет трафика.
И вот мы подошли к вопросу – что же такое мультикаст? Это технология, которая объединяет два этих подхода передачи трафикав. На первом уровне, пакет отправляется только в одном экземпляре, но только тому клиенту, который сделал на него запрос. Приёмников на самом деле может быть несколько.
Самый яркий пример мультикаста — это использования IPTV. Не все провайдеры предоставляют данную возможность, но щас она набирает обороты и возможно, кто-то уже пользуется этой услугой. Представим, что у нас есть два пользователя: Вася и Петя, который подключены к одному провайдеру. Так вот сервер IPTV, отправляет сигналы не всем пользователям, а только тем, кто в данный момент подключен.
Но самое главное, что Вася и Петя будут получать сигнал и пакеты только того канала, который в данный момент включен. Например, Вася смотрит «Первый канал», а Петя «СТС». Сервер четко отправляет пакеты информации только по тому каналу, который активен. Ещё один пример — это онлайн конференция, которой часто пользуются крупные компании. Ведь нет смысла раскидываться трафиком и отправлять всем, можно просто от одного разливать информацию к каждому клиенту.
Содержание
- Реализация
- Куда идёт пакет
- Как включить на роутере
- Задать вопрос автору статьи
Реализация
А теперь встаём следующая проблема – как это организовать. Представьте себе, что в сети у провайдера очень много узлов, коммутаторов, маршутизаторов, серверов и есть центральный сервер того же IPTV. Задача сервера отправить трафик таким образом, чтобы он максимально быстро через минимальное количество узлов дошёл до пользователя.
При этом нужно это сделать так, чтобы не образовалось кольцо – когда трафик начинает ходить по кругу и бесконечно. Поэтому путь пакетов будет выглядеть как дерево, да и топология будет использоваться подобная. То есть выходя пакет от сервера он подходит к одному из узлов. Дальше узел должен определить куда дальше отправлять пакет.
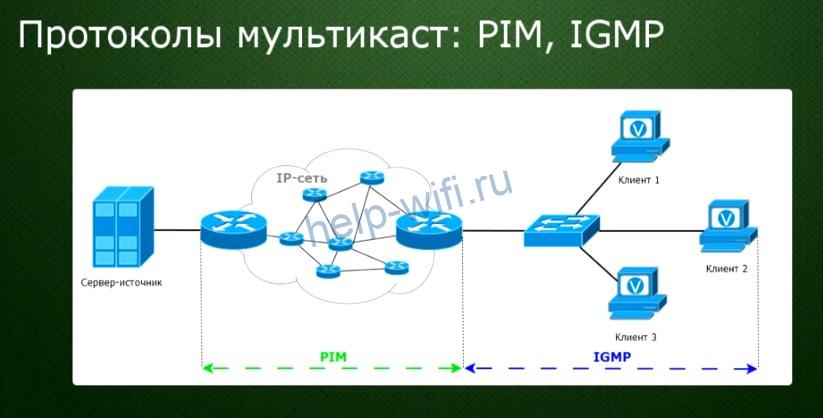
А теперь мы подобрались к протоколу IGMP (Internet Group Management Protocol) — это такой протокол, который позволяет быстро подключаться клиенту к ближайшему маршрутизатору. Он сообщает ему, что нужен трафик по тому или иному каналу. Если же запроса к маршрутизатору нет, то он просто простаивает и тем самым высвобождает ресурсы сети.
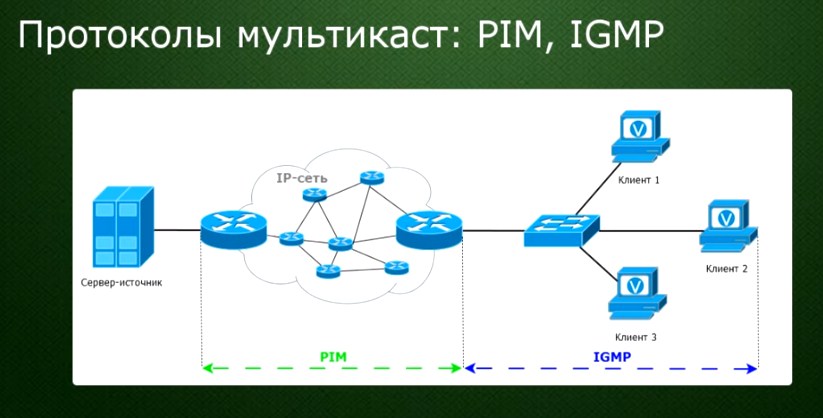
Также используется PIM (Protocol Independent Multicast) протокол – эта такая система, которая выстраивает адрес от сервера к конечному получателю через одну ветвь дерева. При этом система постоянно мониторит путь, чтобы менять его, если какой-то сегмент выключен или был перемещён.
Проще говоря, сервер транслирует только один сигнал каждого телевизионного канала. И пользователи получают только сигнал того канала, который запросили. Одновременно один сигнал могут получать и несколько приёмников. Именно для этого и нужен протокол IGMP.
Куда идёт пакет
Рассмотрим на примере. Вообще данная технология использует IP адреса 224.0.0.0-239.255.255.255 диапазона. Например, сервер отправляет один канал с адресом 224.2.2.4. Это канал «СТС». IGMP протокол, использующийся только в отрезке между клиентом и ближайшим маршрутизатором, который к нему подключен.
- Так вот, пользовательская программа отправляет запрос на просмотр канала 224.2.2.4 ближайшему маршрутизатору.
- Если в маршрутизаторе уже есть поток и через него идёт дерево канала, который запросил клиент – то пакеты сразу же отправляются пользователю, и он видит изображение.
- Как только клиент выключит программу на маршрутизатор отправляется сигнал, о выходе из группы и сигнал более туда не идёт.
- Но также маршрутизатор постоянно отправляет сигнал на ближайших включенных клиентов, чтобы удостовериться, что они ещё принимают трафик. Происходит это каждые 60 секунд. Клиент, который получил такой запрос, обязан отправить ответ или его отключат. Все это происходит в автономном режиме.
Как включить на роутере
В роутере данная функция чаще всего нужна для нормального просмотра IPTV. По умолчанию эта функция уже включена, но можно проверить. Теперь я покажу как включить эту функцию на примере модели TP-Link.
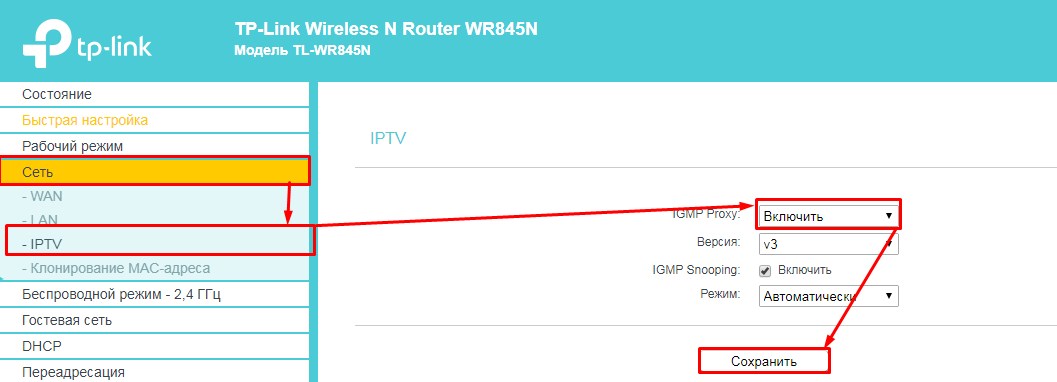
Заходим в «Сеть» – «IPTV» и включаем «IGMP Прокси». Также не забываем поставить галочку «IGMP Snooping» – функция, исключающая получение трафика от группы, к которой не принадлежит клиент. На новых прошивках данный пункт находится там же, только изначально надо нажать на вкладку «Дополнительные настройки». Обязательно нажмите на кнопку «Сохранить» в само конце.
Наш умозрительный провайдер linkmeup взрослеет и обрастает по-тихоньку всеми услугами обычных операторов связи. Теперь мы доросли до IPTV.
Отсюда вытекает необходимость настройки мультикастовой маршрутизации и в первую очередь понимание того, что вообще такое мультикаст.
Это первое отклонение от привычных нам принципов работы IP-сетей. Всё-таки парадигма многоадресной рассылки в корне отличается от тёплого лампового юникаста.
Можно даже сказать, это в некоторой степени бросает вызов гибкости вашего разума в понимании новых подходов.
В этой статье сосредоточимся на следующем:
- Общее понимание Multicast
- Протокол IGMP
- Протокол PIM
- >>>PIM Dense Mode
- >>>Pim Sparse Mode
- >>>SPT Switchover — переключение RPT-SPT
- >>>DR, Assert, Forwarder
- >>>Автоматический выбор RP
- >>>SSM
- >>>BIDIR PIM
- Мультикаст на канальном уровне
- >>>IGMP-Snooping
- >>>MVR

Традиционный видеоурок:
На заре моего становления, как инженера, тема мультикаста меня неимоверно пугала, и я связываю это с психотравмой моего первого опыта с ним.
«Так, Марат, срочно, до полудня нужно пробросить видеопоток до нашего нового здания в центре города — провайдер отдаст его нам тут на втором этаже» — услышал я одним чудесным утром. Всё, что я тогда знал о мультикасте, так это то, что отправитель один, получателей много, ну и, кажется, протокол IGMP там как-то задействован.В итоге до полудня мы пытались всё это дело запустить — я пробросил самый обычный VLAN от точки входа до точки выхода. Но сигнал был нестабильным — картинка замерзала, разваливалась, прерывалась. Я в панике пытался разобраться, что вообще можно сделать с IGMP, тыркался, тыркался, включал мультикаст роутинг, IGMP-snooping, проверял по тысяче раз задержки и потери — ничего не помогало. А потом вдруг всё заработало. Само собой, стабильно, безотказно.
Это послужило мне прививкой против мультикаста, и долгое время я не проявлял к нему никакого интереса.
Уже гораздо позже я пришёл в к следующему правилу:
И теперь с высоты оттраблшученных кейсов я понимаю, что там не могло быть никаких проблем с настройкой сетевой части — глючило конечное оборудование.

Сохраняйте спокойствие и доверьтесь мне. После этой статьи такие вещи вас пугать не будут.
Общее понимание Multicast
Как известно, существуют следующие типы трафика:
Unicast — одноадресная рассылка — один отправитель, один получатель. (Пример: запрос HTTP-странички у WEB-сервера).
Broadcast — широковещательная рассылка — один отправитель, получатели — все устройства в широковещательном сегменте. (Пример: ARP-запрос).
Multicast — многоадресная рассылка — один отправитель, много получателей. (Пример: IPTV).
Anycast — одноадресная рассылка ближайшему узлу — один отправитель, вообще получателей много, но фактически данные отправляются только одному. (Пример: Anycast DNS).
Раз уж мы решили поговорить о мультикасте, то, пожалуй, начнём этот параграф с вопроса, где и как он используется.
Первое, что приходит на ум, — это телевидение (IPTV) — один сервер-источник отправляет трафик, который хочет получать сразу много клиентов. Это и определяет сам термин — multicast — многоадресное вещание. То есть, если уже известный вам Broadcast означает вещание всем, мультикаст означает вещание определённой группе.
Второе применение — это, например, репликация операционной системы на множество компьютеров разом. Это подразумевает загрузку больших объёмов данных с одного сервера.
Возможные сценарии: аудио и видеоконференции (один говорит — все слушают), электронная коммерция, аукционы, биржи. Но это в теории, а на практике редко тут всё-таки используется мультикаст.
Ещё одно применение — это служебные сообщения протоколов. Например, OSPF в своём широковещательном домене рассылает свои сообщения на адреса 224.0.0.5 и 224.0.0.6. И обрабатывать их будут только те узлы, на которых запущен OSPF.
Сформулируем два основных принципа мультикастовой рассылки:
- Отправитель посылает только одну копию трафика, независимо от количества получателей.
- Трафик получают только те, кто действительно заинтересован в нём.
В данной статье для практики мы возьмём IPTV, как наиболее наглядный пример.
Пример I
Начнём с самого простого случая:
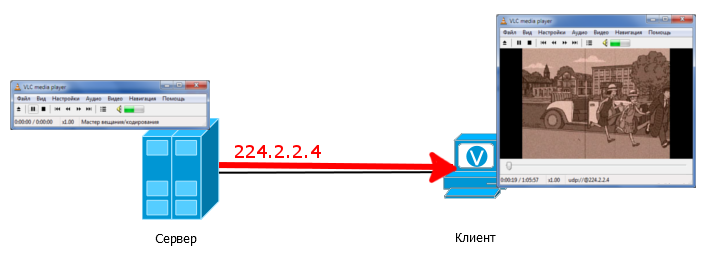
На сервере-источнике настроено вещание в группу 224.2.2.4 — это означает, что сервер отправляет трафик на IP-адрес 224.2.2.4. На клиенте видеоплеер настроен принимать поток группы 224.2.2.4.
При этом, заметьте, клиент и сервер не обязательно должны иметь адреса из одной подсети и пинговать друг друга — достаточно, чтобы они были в одном широковещательном домене.
Мультикастовый поток просто льётся с сервера, а клиент его просто принимает. Вы можете попробовать это прямо у себя на рабочем месте, соединив патчкордом два компьютера и запустив, например, VLC.
Надо заметить, что в мультикасте нет никакой сигнализации от источника, мол, «Здрасьте, я Источник, не надо немного мультикаста?».
Сервер-источник просто начинает вещать в свой интерфейс мультикастовые пакеты. В нашем примере они напрямую попадают клиенту и тот, собственно, сразу же их и принимает.
Если на этом линке отловить пакеты, то вы увидите, что мультикастовый трафик — это ни что иное, как море UDP-пакетов.

Мультикаст не привязан к какому-то конкретному протоколу. По сути, всё, что его определяет — адреса. Однако, если говорить о его применении, то в абсолютном большинстве случаев используется именно UDP. Это легко объясняется тем, что обычно с помощью многоадресной рассылки передаются данные, которые нужны здесь и сейчас. Например, видео. Если кусочек кадра потеряется, и отправитель будет пытаться его послать повторно, как это происходит в TCP, то, скорее всего, этот кусочек опоздает, и где его тогда показывать? Поезд ушёл. Ровно то же самое со звуком.
Соответственно не нужно и устанавливать соединение, поэтому TCP здесь ни к чему.
Чем же так разительно отличается мультикаст от юникаста? Думаю, у вас есть уже предположение. И вы, наверняка, правы.
В обычной ситуации у нас 1 получатель и 1 отправитель — у каждого из них один уникальный IP-адрес. Отправитель точно знает, куда надо слать пакет и ставит этот адрес в заголовок IP. Каждый промежуточный узел благодаря своей таблице маршрутизации точно знает, куда переслать пакет. Юникастовый трафик между двумя узлами беспрепятственно проходит сквозь сеть. Но проблема в том, что в обычном пакете указывается только один IP-адрес получателя.
Что делать, если у одного и того же трафика несколько получателей? В принципе можно расширить одноадресный подход и на такую ситуацию — отправлять каждому клиенту свой экземпляр пакета. Клиенты не заметят разницы — хоть он один, хоть их тысяча, но разница будет отчётливо различима на ваших каналах передачи данных.

Предположим у нас идёт передача одного SD-канала с мультикаст-сервера. Пусть, он использует 2 Мб/с. Всего таких каналов 30, а смотрит каждый канал по 20 человек одновременно. Итого получается 2 Мб/с * 30 каналов * 20 человек = 1200 Мб/с или 1,2 Гб/с только на телевидение в случае одноадресной рассылки. А есть ведь ещё HD каналы, где можно смело умножать эту цифру на 2. И где тут место для торрентов?
Вот почему в IPv4 был заложен блок адресов класса D: 224.0.0.0/4 (224.0.0.0-239.255.255.255). Адреса этого диапазона определяют мультикастовую группу. Один адрес — это одна группа, обычно она обозначается буквой «G».
То есть, говоря, что клиент подключен к группе 224.2.2.4, мы имеем ввиду, что он получает мультикастовый трафик с адресом назначения 224.2.2.4.
Пример II
Добавим в схему коммутатор и ещё несколько клиентов:

Мультикастовый сервер по-прежнему вещает для группы 224.2.2.4. На коммутаторе все 4 порта должны быть в одном VLAN. Трафик приходит на коммутатор и по умолчанию рассылается во все порты одного VLAN’а. Значит все клиенты получают этот трафик. На них на всех в видеопроигрывателе так же указан групповой адрес 224.2.2.4.
Собственно, все эти устройства становятся членами данной мультикастовой группы. Членство в ней динамическое: кто угодно, в любой момент может войти и выйти из неё.
В данной ситуации трафик будут получать даже те, кто этого в общем-то и не хотел, то есть на нём не запущен ни плеер, ни что бы то ни было другое. Но только, если он в том же VLAN’е. Позже мы разберёмся, как с этим бороться.
Обратите внимание, что в данном случае от сервера-источника приходит только одна копия трафика на коммутатор, а не по отдельной копии на каждого клиента. И в нашем примере с SD каналами загрузка порта между источником и коммутатором будет не 1,2 Гб/с, а всего 60 Мб/с (2Мб/с * 30 каналов).
Собственно говоря, весь этот огромный диапазон (224.0.0.0-239.255.255.255) можно использовать.
Ну, почти весь — первые адреса (диапазон 224.0.0.0/23) всё-таки зарезервированы под известные протоколы.
Список зарезервированных IP-адресов
Диапазон 224.0.0.0/24 зарезервирован под link-local коммуникации. Мультикастовые пакеты с такими адресами назначения не могут выходить за пределы одного широковещательного сегмента.
Диапазон 224.0.1.0/24 зарезервирован под протоколы, которым необходимо передавать мультикаст по всей сети, то есть проходить через маршрутизаторы.
Вот, собственно, самые базисные вещи касательно мультикаста.
Мы рассмотрели простую ситуацию, когда источник и получатель находятся в одном сегменте сети. Трафик, полученный коммутатором, просто рассылается им во все порты — никакой магии.
Но пока совсем непонятно, как трафик от сервера достигает клиентов, когда между ними огромная провайдерская сеть линкмиап? Да и откуда, собственно, будет известно, кто клиент? Мы же не можем вручную прописать маршруты, просто потому что не знаем, где могут оказаться клиенты. Не ответят на этот вопрос и обычные протоколы маршрутизации. Так мы приходим к пониманию, что доставка мультикаст — это нечто совершенно новое для нас.
Вообще, чтобы доставить мультикаст от источника до получателя на данный момент существует много протоколов — IGMP/MLD, PIM, MSDP, MBGP, MOSPF, DVMRP.
Мы остановимся на двух из них, которые используются в настоящее время: PIM и IGMP.
С помощью IGMP конечные получатели-клиенты сообщают ближайшим маршрутизаторам о том, что хотят получать трафик. А PIM строит путь движения мультикастового трафика от источника до получателей через маршрутизаторы.

IGMP
Снова вернёмся к дампу. Видите вот этот верхний пакет, после которого полился мультикастовый поток?

Это сообщение протокола IGMP, которое отправил клиент, когда мы на нём нажали Play. Именно так он сообщает о том, что хочет получать трафик для группы 224.2.2.4.
IGMP — Internet Group Management Protocol — это сетевой протокол взаимодействия клиентов мультикастового трафика и ближайшего к ним маршрутизатора.
В IPv6 используется MLD (Multicast Listener Discovery) вместо IGMP. Принцип работы у них абсолютно одинаковый, поэтому далее везде вы смело можете менять IGMP на MLD, а IP на IPv6.
Как же именно работает IGMP?
Пожалуй, начать нужно с того, что версий у протокола сейчас три: IGMPv1, IGMPv2, IGMPv3. Наиболее используемая — вторая, первая уже практически забыта, поэтому про неё говорить не будем, третья очень похожа на вторую.
Акцентируемся пока на второй, как на самой показательной, и рассмотрим все события от подключения клиента к группе до его выхода из неё.
Клиент будет также запрашивать группу 224.2.2.4 через проигрыватель VLC.
Роль IGMP очень проста: если клиентов нет — передавать мультикастовый трафик в сегмент не надо. Если появился клиент, он уведомляет маршрутизаторы с помощью IGMP о том, что хочет получать трафик.
Для того, чтобы понять, как всё происходит, возьмём такую сеть:

Предположим, что маршрутизатор уже настроен на получение и обработку мультикастового трафика.

1. Как только мы запустили приложение на клиенте и задали группу 224.2.2.4, в сеть будет отправлен пакет IGMP Membership Report — узел «рапортует» о том, что хочет получать трафик этой группы.

В IGMPv2 Report отправляется на адрес желаемой группы, и параллельно он же указывается в самом пакете. Данные сообщения должны жить только в пределах своего сегмента и не пересылаться никуда маршрутизаторами, поэтому и TTL у них 1.
Часто в литературе вы можете встретить упоминание о IGMP Join. Не пугайтесь — это альтернативное название для IGMP Membership Report.
2. Маршрутизатор получает IGMP-Report и, понимая, что за данным интерфейсом теперь есть клиенты, заносит информацию в свои таблицы

Это вывод информации по IGMP. Первая группа запрошена клиентом. Третья и четвёртая — это служебные группы протокола SSDP, встроенного в Windows. Вторая — специальная группа, которая всегда присутствует на маршрутизаторах Cisco — она используется для протокола Auto-RP, который по умолчанию активирован на маршрутизаторах.
Интерфейс FE0/0 становится нисходящим для трафика группы 224.2.2.4 — в него нужно будет отправлять полученный трафик.
Наряду с обычной юникастовой таблицей маршрутизации существует ещё и мультикастовая:

О наличии клиентов говорит первая запись (*, 224.2.2.4). А запись (172.16.0.5, 224.2.2.4) означает, что маршрутизатор знает об источнике мультикастового потока для этой группы.
Из вывода видно, что трафик для группы 224.2.2.4 приходит через FE0/1, а передавать его надо на порт FE0/0.
Интерфейсы, в которые нужно передавать трафик, входят в список нисходящих интерфейсов — OIL — Outbound Interface List.
Более подробно вывод команды show ip mroute мы разберём позже.
Выше на дампе вы видите, что как только клиент отправил IGMP-Report, сразу после него полетели UDP — это видеопоток.
3. Клиент начал получать трафик. Теперь маршрутизатор должен иногда проверять, что получатели до сих пор у него есть, чтобы зазря не вещать, если вдруг клиентов не осталось. Для этого он периодически отправляет во все свои нисходящие интерфейсы запрос IGMP Query.
*Дамп отфильтрован по IGMP*.

По умолчанию это происходит каждые 60 секунд. TTL таких пакетов тоже равен 1. Они отправляются на адрес 224.0.0.1 — все узлы в этом сегменте — без указания конкретной группы. Такие сообщений Query называются General Query — общие. Таким образом маршрутизатор спрашивает: «Ребят, а кто и что ещё хочет получать?».
Получив IGMP General Query, любой хост, который слушает любую группу, должен отправить IGMP Report, как он это делал при подключении. В Report, естественно, должен быть указан адрес интересующей его группы.
*Дамп отфильтрован по IGMP*.

Если в ответ на Query на маршрутизатор пришёл хотя бы один Report для группы, значит есть ещё клиенты, он продолжает вещать в тот интерфейс, откуда пришёл этот Report, трафик этой самой группы.
Если на 3 подряд Query не было с интерфейса ответа для какой-то группы, маршрутизатор удаляет этот интерфейс из своей таблицы мультикастовой маршрутизации для данной группы — перестаёт туда посылать трафик.
По своей инициативе клиент обычно посылает Report только при подключении, потом — просто отвечает на Query от маршрутизатора.
Интересная деталь в поведении клиента: получив Query, он не торопится сразу же ответить Report’ом. Узел берёт тайм-аут длиной от 0 до Max Response Time, который указан в пришедшем Query:
При отладке или в дампе, кстати, можно видеть, что между получением различных Report может пройти несколько секунд.
Сделано это для того, чтобы сотни клиентов все скопом не наводнили сеть своими пакетам Report, получив General Query. Более того, только один клиент обычно отправляет Report.
Дело в том, что Report отсылается на адрес группы, а следовательно доходит и до всех клиентов. Получив Report от другого клиента для этой же группы, узел не будет отправлять свой. Логика простая: маршрутизатор и так уже получил этот самый Report и знает, что клиенты есть, больше ему не надо.
Этот механизм называется Report Suppression.Далее в статье мы расскажем о том, почему этот механизм на деле очень редко реально работает.

4. Так продолжается веками, пока клиент не захочет выйти из группы (например, выключит плеер/телевизор). В этом случае он отправляет IGMP Leave на адрес группы.

Маршрутизатор получает его и по идее должен отключить. Но он ведь не может отключить одного конкретного клиента — маршрутизатор их не различает — у него просто есть нисходящий интерфейс. А за интерфейсом может быть несколько клиентов. То есть, если маршрутизатор удалит этот интерфейс из своего списка OIL (Outgoing Interface List) для этой группы, видео выключится у всех.
Но и не удалять его совсем тоже нельзя — вдруг это был последний клиент — зачем тогда впустую вещать?
Если вы посмотрите в дамп, то увидите, что после получения Leave маршрутизатор ещё некоторое время продолжает слать поток. Дело в том, что маршрутизатор в ответ на Leave высылает IGMP Query на адрес группы, для которой этот Leave пришёл в тот интерфейс, откуда он пришёл. Такой пакет называется Group Specific Query. На него отвечают только те клиенты, которые подключены к данной конкретной группе.

Если маршрутизатор получил ответный Report для группы, он продолжает вещать в интерфейс, если не получил — удаляет по истечении таймера.
Всего после получения Leave отправляется два Group Specific Query — один обязательный, второй контрольный.
*Дамп отфильтрован по IGMP*.

Далее маршрутизатор останавливает поток.
Querier
Рассмотрим чуть более сложный случай:

В клиентский сегмент подключено два (или больше) маршрутизатора, которые могут вещать трафик. Если ничего не сделать, мультикастовый трафик будет дублироваться — оба маршрутизатора ведь будут получать Report от клиентов. Во избежание этого существует механизм выбора Querier — опрашивателя. Тот кто победит, будет посылать Query, мониторить Report и реагировать на Leave, ну и, соответственно, он будет отправлять и трафик в сегмент. Проигравший же будет только слушать Report и держать руку на пульсе.
Выборы происходят довольно просто и интуитивно понятно.
Рассмотрим ситуацию с момента включения маршрутизаторов R1 и R2.
1) Активировали IGMP на интерфейсах.
2) Сначала по умолчанию каждый из них считает себя Querier.
3) Каждый отправляет IGMP General Query в сеть. Главная цель — узнать, есть ли клиенты, а параллельно — заявить другим маршрутизаторам в сегменте, если они есть, о своём желании участвовать в выборах.
4) General Query получают все устройства в сегменте, в том числе и другие IGMP-маршрутизаторы.
5) Получив такое сообщение от соседа, каждый маршрутизатор оценивает, кто достойнее.
6) Побеждает маршрутизатор с меньшим IP (указан в поле Source IP пакета IGMP Query). Он становится Querier, все другие — Non-Querier.
7) Non-Querier запускает таймер, который обнуляется каждый раз, как приходит Query с меньшим IP-адресом. Если до истечения таймера (больше 100 секунд: 105-107) маршрутизатор не получит Query с меньшим адресом, он объявляет себя Querier и берёт на себя все соответствующие функции.
 Если Querier получает Query с меньшим адресом, он складывает с себя эти обязанности. Querier’ом становится другой маршрутизатор, у которого IP меньше.
Если Querier получает Query с меньшим адресом, он складывает с себя эти обязанности. Querier’ом становится другой маршрутизатор, у которого IP меньше.
Тот редкий случай, когда меряются, у кого меньше.
Выборы Querier очень важная процедура в мультикасте, но некоторые коварные производители, не придерживающиеся RFC, могут вставить крепкую палку в колёса. Я сейчас говорю о IGMP Query с адресом источника 0.0.0.0, которые могут генерироваться коммутатором. Такие сообщения не должны участвовать в выборе Querier, но надо быть готовыми ко всему. Вот пример весьма сложной долгоиграющей проблемы.
Ещё пара слов о других версиях IGMP
Версия 1 отличается по сути только тем, что в ней нет сообщения Leave. Если клиент не хочет больше получать трафик данной группы, он просто перестаёт посылать Report в ответ на Query. Когда не останется ни одного клиента, маршрутизатор по таймауту перестанет слать трафик.
Кроме того, не поддерживаются выборы Querier. За избежание дублирования трафика отвечает вышестоящий протокол, например, PIM, о котором мы будем говорить далее.
Версия 3 поддерживает всё то, что поддерживает IGMPv2, но есть и ряд изменений. Во-первых, Report отправляется уже не на адрес группы, а на мультикастовый служебный адрес 224.0.0.22. А адрес запрашиваемой группы указан только внутри пакета. Делается это для упрощения работы IGMP Snooping, о котором мы поговорим дальше.
Во-вторых, что более важно, IGMPv3 стал поддерживать SSM в чистом виде. Это так называемый Source Specific Multicast. В этом случае клиент может не просто запросить группу, но также указать список источников, от которых он хотел бы получать трафик или наоборот не хотел бы. В IGMPv2 клиент просто запрашивает и получает трафик группы, не заботясь об источнике.

Итак, IGMP предназначен для взаимодействия клиентов и маршрутизатора. Поэтому, возвращаясь к Примеру II, где нет маршрутизатора, мы можем авторитетно заявить — IGMP там — не более, чем формальность. Маршрутизатора нет, и клиенту не у кого запрашивать мультикастовый поток. А заработает видео по той простой причине, что поток и так льётся от коммутатора — надо только подхватить его.
Напомним, что IGMP не работает для IPv6. Там существует протокол MLD.
Повторим ещё раз
*Дамп отфильтрован по IGMP*.

1. Первым делом маршрутизатор отправил свой IGMP General Query после включения IGMP на его интерфейсе, чтобы узнать, есть ли получатели и заявить о своём желании быть Querier. На тот момент никого не было в этой группе.
2. Далее появился клиент, который захотел получать трафик группы 224.2.2.4 и он отправил свой IGMP Report. После этого пошёл трафик на него, но он отфильтрован из дампа.
3. Потом маршрутизатор решил зачем-то проверить — а нет ли ещё клиентов и отправил IGMP General Query ещё раз, на который клиент вынужден ответить (4).
5. Периодически (раз в минуту) маршрутизатор проверяет, что получатели по-прежнему есть, с помощью IGMP General Query, а узел подтверждает это с помощью IGMP Report.
6. Потом он передумал и отказался от группы, отправив IGMP Leave.
7. Маршрутизатор получил Leave и, желая убедиться, что больше никаких других получателей нет, посылает IGMP Group Specific Query… дважды. И по истечении таймера перестаёт передавать трафик сюда.
8. Однако передавать IGMP Query в сеть он по-прежнему продолжает. Например, на тот случай, если вы плеер не отключали, а просто где-то со связью проблемы. Потом связь восстанавливается, но клиент-то Report не посылает сам по себе. А вот на Query отвечает. Таким образом поток может восстановиться без участия человека.
И ещё раз
IGMP — протокол, с помощью которого маршрутизатор узнаёт о наличии получателей мультикастового трафика и об их отключении.
IGMP Report — посылается клиентом при подключении и в ответ на IGMP Query. Означает, что клиент хочет получать трафик конкретной группы.
IGMP General Query — посылается маршрутизатором периодически, чтобы проверить какие группы сейчас нужны. В качестве адреса получателя указывается 224.0.0.1.
IGMP Group Sepcific Query — посылается маршрутизатором в ответ на сообщение Leave, чтобы узнать есть ли другие получатели в этой группе. В качестве адреса получателя указывается адрес мультикастовой группы.
IGMP Leave — посылается клиентом, когда тот хочет покинуть группу.
Querier — если в одном широковещательном сегменте несколько маршрутизаторов, который могут вещать, среди них выбирается один главный — Querier. Он и будет периодически рассылать Query и передавать трафик.
Подробное описание всех терминов IGMP.
PIM
Итак, мы разобрались, как клиенты сообщают ближайшему маршрутизатору о своих намерениях. Теперь неплохо было бы передать трафик от источника получателю через большую сеть.
Если вдуматься, то мы стоим перед довольной сложной проблемой — источник только вещает на группу, он ничего не знает о том, где находятся получатели и сколько их.
Получатели и ближайшие к ним маршрутизаторы знают только, что им нужен трафик конкретной группы, но понятия не имеют, где находится источник и какой у него адрес.
Как в такой ситуации доставить трафик?
Существует несколько протоколов маршрутизации мультикастового трафика: DVMRP, MOSPF, CBT — все они по-разному решают такую задачу. Но стандартом де факто стал PIM — Protocol Independent Multicast.
Другие подходы настолько нежизнеспособны, что порой даже их разработчики практически признают это. Вот, например, выдержка из RFC по протоколу CBT:
CBT version 2 is not, and was not, intended to be backwards compatible with version 1; we do not expect this to cause extensive compatibility problems because we do not believe CBT is at all widely deployed at this stage.
PIM имеет две версии, которые можно даже назвать двумя различными протоколами в принципе, уж сильно они разные:
- PIM Dense Mode (DM)
- PIM Sparse Mode (SM)
Independent он потому, что не привязан к какому-то конкретному протоколу маршрутизации юникастового трафика, и позже вы увидите почему.
PIM Dense Mode
PIM DM пытается решить проблему доставки мультиакста в лоб. Он заведомо предполагает, что получатели есть везде, во всех уголках сети. Поэтому изначально он наводняет всю сеть мультикастовым трафиком, то есть рассылает его во все порты, кроме того, откуда он пришёл. Если потом оказывается, что где-то он не нужен, то эта ветка «отрезается» с помощью специального сообщения PIM Prune — трафик туда больше не отправляется.
Но через некоторое время в эту же ветку маршрутизатор снова пытается отправить мультикаст — вдруг там появились получатели. Если не появились, ветка снова отрезается на определённый период. Если клиент на маршрутизаторе появился в промежутке между этими двумя событиями, отправляется сообщение Graft — маршрутизатор запрашивает отрезанную ветку обратно, чтобы не ждать, пока ему что-то перепадёт.
Как видите, здесь не стоит вопрос определения пути к получателям — трафик достигнет их просто потому, что он везде.
После «обрезания» ненужных ветвей остаётся дерево, вдоль которого передаётся мультикастовый трафик. Это дерево называется SPT — Shortest Path Tree.
Оно лишено петель и использует кратчайший путь от получателя до источника. По сути оно очень похоже на Spanning Tree в STP, где корнем является источник.
SPT — это конкретный вид дерева — дерево кратчайшего пути. А вообще любое мультикастовое дерево называется MDT — Multicast Distribution Tree.
Предполагается, что PIM DM должен использоваться в сетях с высокой плотностью мультикастовых клиентов, что и объясняет его название (Dense). Но реальность такова, что эта ситуация — скорее, исключение, и зачастую PIM DM нецелесообразен.
Что нам действительно важно сейчас — это механизм избежания петель.
Представим такую сеть:

Один источник, один получатель и простейшая IP-сеть между ними. На всех маршрутизаторах запущен PIM DM.
Что произошло бы, если бы не было специального механизма избежания петель?
Источник отправляет мультикастовый трафик. R1 его получает и в соответствии с принципами PIM DM отправляет во все интерфейсы, кроме того, откуда он пришёл — то есть на R2 и R3.
R2 поступает точно так же, то есть отправляет трафик в сторону R3. R3 не может определить, что это тот же самый трафик, который он уже получил от R1, поэтому пересылает его во все свои интерфейсы. R1 получит копию трафика от R3 и так далее. Вот она — петля.
Что же предлагает PIM в такой ситуации? RPF — Reverse Path Forwarding. Это главный принцип передачи мультикастового трафика в PIM (любого вида: и DM и SM) — трафик от источника должен приходить по кратчайшему пути.
То есть для каждого полученного мультикастового пакета производится проверка на основе таблицы маршрутизации, оттуда ли он пришёл.
1) Маршрутизатор смотрит на адрес источника мультикастового пакета.
2) Проверяет таблицу маршрутизации, через какой интерфейс доступен адрес источника.
3) Проверяет интерфейс, через который пришёл мультикастовый пакет.
4) Если интерфейсы совпадают — всё отлично, мультикастовый пакет пропускается, если же данные приходят с другого интерфейса — они будут отброшены.
В нашем примере R3 знает, что кратчайший путь до источника лежит через R1 (статический или динамический маршрут). Поэтому мультикастовые пакеты, пришедшие от R1, проходят проверку и принимаются R3, а те, что пришли от R2, отбрасываются.

Такая проверка называется RPF-Check и благодаря ей даже в более сложных сетях петли в MDT не возникнут.
Этот механизм важен нам, потому что он актуален и в PIM-SM и работает там точно также.
Как видите, PIM опирается на таблицу юникастовой маршрутизации, но, во-первых, сам не маршрутизирует трафик, во-вторых, ему не важно, кто и как наполнял таблицу.
Останавливаться здесь и подробно рассматривать работу PIM DM мы не будем — это устаревший протокол с массой недостатков (ну, как RIP).
Однако PIM DM может применяться в некоторых случаях. Например, в совсем небольших сетях, где поток мультикаста небольшой.

PIM Sparse Mode
Совершенно другой подход применяет PIM SM. Несмотря на название (разреженный режим), он с успехом может применяться в любой сети с эффективностью как минимум не хуже, чем у PIM DM.
Здесь отказались от идеи безусловного наводнения мультикастом сети. Заинтересованные узлы самостоятельно запрашивают подключение к дереву с помощью сообщений PIM Join.
Если маршрутизатор не посылал Join, то и трафик ему отправляться не будет.
Для того, чтобы понять, как работает PIM, начнём с уже знакомой нам простой сети с одним PIM-маршрутизатором:

Из настроек на R1 надо включить возможность маршрутизации мультикаста, PIM SM на двух интерфейсах (в сторону источника и в сторону клиента) и IGMP в сторону клиента. Помимо прочих базовых настроек, конечно (IP, IGP).
С этого момента вы можете расчехлить GNS и собирать лабораторию. Достаточно подробно о том, как собрать стенд для мультикаста я рассказал в этой статье.
R1(config)#ip multicast-routing
R1(config)#int fa0/0
R1(config-if)#ip pim sparse-mode
R1(config-if)#int fa1/0
R1(config-if)#ip pim sparse-modeCisco тут как обычно отличается своим особенным подходом: при активации PIM на интерфейсе, автоматически активируется и IGMP. На всех интерфейсах, где активирован PIM, работает и IGMP.
В то же время у других производителей два разных протокола включаются двумя разными командами: отдельно IGMP, отдельно PIM.
Простим Cisco эту странность? Вместе со всеми остальными?Плюс, возможно, потребуется настроить адрес RP (ip pim rp-address 172.16.0.1, например). Об этом позже, пока примите как данность и смиритесь.
Проверим текущее состояние таблицы мультикастовой маршрутизации для группы 224.2.2.4:

После того, как на источнике вы запустите вещание, надо проверить таблицу ещё раз.
 (S, G)")
Давайте разберём этот немногословный вывод.
Запись вида (*, 225.0.1.1) называется (*, G), /читается старкомаджи/ и сообщает нам о получателях. Причём не обязательно речь об одном клиенте-компьютере, вообще это может быть и, например, другой PIM-маршрутизатор. Важно то, в какие интерфейсы надо передавать трафик.
Если список нисходящих интерфейсов (OIL) пуст — Null, значит нет получателей — а мы их пока не запускали.
Запись (172.16.0.5, 225.0.1.1) называется (S, G), /читается эскомаджи/ и говорит о том, что известен источник. В нашем случае источник с адресом 172.16.0.5 вещает трафик для группы 224.2.2.4. Мультикастовый трафик приходит на интерфейс FE0/1 — это восходящий (Upstream) интерфейс.
Итак, нет клиентов. Трафик от источника доходит до маршрутизатора и на этом его жизнь кончается. Давайте добавим теперь получателя — настроим приём мультикаста на ПК.
ПК отсылает IGMP Report, маршрутизатор понимает, что появились клиенты и обновляет таблицу мультикастовой маршрутизации.
Теперь она выглядит так:

Появился и нисходящий интерфейс: FE0/0, что вполне ожидаемо. Причём он появился как в (*, G), так и в (S, G). Список нисходящих интерфейсов называется OIL — Outgoing Interface List.
Добавим ещё одного клиента на интерфейс FE1/0:

Если читать вывод дословно, то имеем:
(*, G): Есть получатели мультикастового трафика для группы 224.2.2.4 за интерфейсами FE0/0, FE1/0. Причём совершенно неважно, кто отправитель, о чём и говорит знак «*».
(S, G): Когда мультикастовый трафик с адресом назначения 224.2.2.4 от источника 172.16.0.5 приходит на интерфейс FE0/1, его копии нужно отправить в FE0/0 и FE1/0.
Но это был очень простой пример — один маршрутизатор сразу знает и адрес источника и где находятся получатели. Фактически даже деревьев тут никаких нет — разве что вырожденное. Но это помогло нам разобраться с тем, как взаимодействуют PIM и IGMP.
Чтобы разобраться с тем, что такое PIM, обратимся к сети гораздо более сложной

Предположим, что уже настроены все IP-адреса в соответствии со схемой. На сети запущен IGP для обычной юникастовой маршрутизации.
Клиент1, например, может пинговать Сервер-источник.

Но пока не запущен PIM, IGMP, клиенты не запрашивают каналы.
Файл начальной конфигурации.
Итак, момент времени 0.
Включаем мультикастовую маршрутизацию на всех пяти маршрутизаторах:
RX(config)#ip multicast-routingPIM включается непосредственно на всех интерфейсах всех маршрутизаторов (в том числе на интерфейсе в сторону Сервера-источника и клиентов):
RX(config)#int FEX/X
RX(config-if)#ip pim sparse-modeIGMP, по идее должен включаться на интерфейсах в сторону клиентов, но, как мы уже отметили выше, на оборудовании Cisco он включается автоматически вместе с PIM.
Первое, что делает PIM — устанавливает соседство. Для этого используются сообщения PIM Hello. При активации PIM на интерфейсе с него отправляется PIM Hello на адрес 224.0.0.13 с TTL равным 1. Это означает, что соседями могут быть только маршрутизаторы, находящиеся в одном широковещательном домене.

Как только соседи получили приветствия друг от друга:

Теперь они готовы принимать заявки на мультикастовые группы.
Если мы сейчас запустим в вольер клиентов с одной стороны и включим мультикастовый поток с сервера с другой, то R1 получит поток трафика, а R4 получит IGMP Report при попытке клиента подключиться. В итоге R1 не будет знать ничего о получателях, а R4 об источнике.


Неплохо было бы если бы информация об источнике и о клиентах группы была собрана где-то в одном месте. Но в каком?
Такая точка встречи называется Rendezvous Point — RP. Это центральное понятие PIM SM. Без неё ничего бы не работало. Здесь встречаются источник и получатели.
Все PIM-маршрутизаторы должны знать, кто является RP в домене, то есть знать её IP-адрес.
Чтобы построить дерево MDT, в сети выбирается в качестве RP некая центральная точка, которая,
- отвечает за изучение источника,
- является точкой притяжения сообщений Join от всех заинтересованных.
Существует два способа задания RP: статический и динамический. Мы рассмотрим оба в этой статье, но начнём со статического, поскольку чего уж проще статики?
Пусть пока R2 будет выполнять роль RP.
Чтобы увеличить надёжность, обычно выбирается адрес Loopback-интерфейса. Поэтому на всех маршрутизаторах выполняется команда:
RX(config)#ip pim rp-address 2.2.2.2
Естественно, этот адрес должен быть доступен по таблице маршрутизации со всех точек.
Ну и поскольку адрес 2.2.2.2 является RP, на интерфейсе Loopback 0 на R2 желательно тоже активировать PIM.
R2(config)#interface Loopback 0
RX(config-if)#ip pim sparse-modeСразу после этого R4 узнает об источнике трафика для группы 224.2.2.4:

и даже передаёт трафик:

На интерфейс FE0/1 приходит 362000 б/с, и через интерфейс FE0/0 они передаются.
Всё, что мы сделали:
Включили возможность маршрутизации мультикастового трафика (ip multicast-routing)
Активировали PIM на интерфейсах (ip pim sparse-mode)
Указали адрес RP (ip pim rp-adress X.X.X.X)
Всё, это уже рабочая конфигурация и можно приступать к разбору, ведь за кулисами скрывается гораздо больше, чем видно на сцене.
Полная конфигурация с PIM.
Разбор полётов
Ну так и как же в итоге всё работает? Как RP узнаёт где источник, где клиенты и обеспечивает связь между ними?
Поскольку всё затевается ради наших любимых клиентов, то, начав с них, рассмотрим в деталях весь процесс.
1) Клиент 1 отправляет IGMP Report для группы 224.2.2.4

2) R4 получает этот запрос, понимает, что есть клиент за интерфейсом FE0/0, добавляет этот интерфейс в OIL и формирует запись (*, G).
")
Здесь видно восходящий интерфейс FE0/1, но это не значит, что R4 получает трафик для группы 224.2.2.4. Это говорит лишь о том, что единственное место, откуда сейчас он может получать — FE0/1, потому что именно там находится RP. Кстати, здесь же указан и сосед, который прошёл RPF-Check — R2: 10.0.2.24. Ожидаемо.
R4 называется — LHR (Last Hop Router) — последний маршрутизатор на пути мультикастового трафика, если считать от источника. Иными словами — это маршрутизатор, ближайший к получателю. Для Клиента1 — это R4, для Клиента2 — это R5.
3) Поскольку на R4 пока нет мультикастового потока (он его не запрашивал прежде), он формирует сообщение PIM Join и отправляет его в сторону RP (2.2.2.2).
")
PIM Join отправляется мультикастом на адрес 224.0.0.13. «В сторону RP» означает через интерфейс, который указан в таблице маршрутизации, как outbound для того адреса, который указан внутри пакета. В нашем случае это 2.2.2.2 — адрес RP. Такой Join обозначается ещё как Join (*,G) и говорит: «Не важно, кто источник, мне нужен трафик группы 224.2.2.4».
То есть каждый маршрутизатор на пути должен обработать такой Join и при необходимости отправить новый Join в сторону RP. (Важно понимать, что если на маршрутизаторе уже есть эта группа, он не будет отправлять выше Join — он просто добавит интерфейс, с которого пришёл Join, в OIL и начнёт передавать трафик).
В нашем случае Join ушёл в FE0/1:

4) R2, получив Join, формирует запись (*, G) и добавляет интерфейс FE0/0 в OIL. Но Join отсылать уже некуда — он сам уже RP, а про источник пока ничего не известно.

Таким образом RP узнаёт о том, где находятся клиенты.
Если Клиент 2 тоже захочет получать мультикастовый трафик для той же группы, R5 отправит PIM Join в FE0/1, потому что за ним находится RP, R3, получив его, формирует новый PIM Join и отправляет в FE1/1 — туда, где находится RP.
То есть Join путешествует так узел за узлом, пока не доберётся до RP или до другого маршрутизатора, где уже есть клиенты этой группы.

Итак, R2 — наш RP — сейчас знает о том, что за FE0/0 и FE1/0 у него есть получатели для группы 224.2.2.4.
Причём неважно, сколько их там — по одному за каждым интерфейсом или по сто — поток трафика всё равно будет один на интерфейс.
Если изобразить графически то, что мы получили, то это будет выглядеть так:

Отдалённо напоминает дерево, не так ли? Поэтому оно так и называется — RPT — Rendezvous Point Tree. Это дерево с корнем в RP, а ветви которого простираются до клиентов.
Более общий термин, как мы упоминали выше, — MDT — Multicast Distribution Tree — дерево, вдоль которого распространяется мультикастовый поток. Позже вы увидите разницу между MDT и RPT.
5) Теперь врубаем сервер. Как мы уже выше обсуждали, он не волнуется о PIM, RP, IGMP — он просто вещает. А R1 получает этот поток. Его задача — доставить мультикаст до RP.
В PIM есть специальный тип сообщений — Register. Он нужен для того, чтобы зарегистрировать источник мультикаста на RP.
Итак, R1 получает мультикастовый поток группы 224.2.2.4:

")
R1 является FHR (First Hop Router) — первый маршрутизатор на пути мультикастового трафика или ближайший к источнику.
6) Далее он инкапсулирует каждый полученный от источника мультикастовый пакет в юникастовый PIM Register и отправляет его прямиком на RP.

Обратите внимание на стек протоколов. Поверх юникастового IP и заголовка PIM идёт изначальный мультикастовый IP, UDP и данные.
Теперь, в отличие от всех других, пока известных нам сообщений PIM, в адресе получателя указан 2.2.2.2, а не мультикастовый адрес.
Такой пакет доставляется до RP по стандартным правилам юникастовой маршрутизации и несёт в себе изначальный мультикастовый пакет, то есть это… это же туннелирование!
=====================
Задача № 1
Схема и начальная конфигурация.
На сервере 172.16.0.5 работает приложение, которое может передавать пакеты только на широковещательный адрес 255.255.255.255, с портом получателя UDP 10999.
Этот трафик надо доставить к клиентам 1 и 2:
Клиенту 1 в виде мультикаст трафика с адресом группы 239.9.9.9.
А в сегмент клиента 2, в виде широковещательных пакетов на адрес 255.255.255.255.Подробности задачи тут.
=====================
 Задача № 1
Задача № 1
7) RP получает PIM Register, распаковывает его и обнаруживает под обёрткой трафик для группы 224.2.2.4.
Информацию об этом он сразу заносит в свою таблицу мультикастовой маршрутизации:
")
Появилась запись (S, G) — (172.16.0.5, 224.2.2.4).
Распакованные пакеты RP дальше отправляет в RPT в интерфейсы FE0/0 и FE1/0, по которому трафик доходит до клиентов.
В принципе, на этом можно было бы и остановиться. Всё работает — клиенты получают трафик. Но есть две проблемы:
- Процессы инкапсуляции и декапсуляции — весьма затратные действия для маршрутизаторов. Кроме того, дополнительные заголовки увеличивают размер пакета, и он может просто не пролезть в MTU где-то на промежуточном узле (вспоминаем все проблемы туннелирования).
- Если вдруг где-то между источником и RP есть ещё получатели для группы, мультикастовому трафику придётся пройти один путь дважды.
Возьмём для примера вот такую топологию:

Трафик в сообщениях Register сначала дойдёт до RP по линии R1-R42-R2, затем чистый мультикаст вернётся по линии R2-R42. Таким образом на линии R42-R2 будет ходить две копии одного трафика, пусть и в противоположных направлениях.

Поэтому лучше от источника до RP тоже передавать чистый мультикаст, а для этого нужно построить дерево — Source Tree.
Поэтому RP отправляет на R1 сообщение PIM Join. Но теперь уже в нём указывается для группы адрес не RP, а источника, изученный из сообщения Register. Такое сообщение называется Join (S, G) — Source Specific Join.

Цель у него точно такая же, как у PIM Join (*, G) — построить дерево, только на этот раз от источника до RP.
Join (S, G) распространяется также узел за узлом, как обычный Join (*, G). Только Join (*, G) стремится к RP, а Join (S, G) к S — источнику. В качестве адрес получателя также служебный адрес 224.0.0.13 и TTL=1.
Если существуют промежуточные узлы, например, R42, они также формируют запись (S, G) и список нисходящих интерфейсов для данной группы и пересылают Join дальше к источнику.
Путь, по которому прошёл Join от RP до источника, превращается в Source Tree — дерево от источника. Но более распространённое название — SPT — Shortest Path Tree — ведь трафик от источника до RP пойдёт по кратчайшему пути.
9) R1 получив Join (S, G), добавляет интерфейс FE1/0, откуда пакет пришёл, в список нисходящих интерфейсов OIL и начинает туда вещать чистый мультикастовый трафик, незамутнённый инкапсуляцией. Запись (S, G) на R1 уже была, как только он получит первый мультикастовый пакет от Сервера-источник.
")
По построенному Source Tree мультикаст передаётся RP (и всем промежуточным клиентам, если они есть, например, R42).
Но надо иметь ввиду, что сообщения Register передавались всё это время и передаются до сих пор. То есть фактически R1 отправляет две копии трафика сейчас: один — чистый мультикаст по SPT, другой — инкапсулированный в юникастовый Register.

Сначала R1 отправляет мультикаст в Register — пакет 231. Потом R2 (RP) хочет подключиться к дереву, отправляет Join — пакет 232. R1 ещё какое-то время, пока обрабатывает запрос от R2, отправляет мультикаст в Register (пакеты с 233 по 238). Далее, когда нисходящий интерфейс добавлен в OIL на R1, он начинает передавать чистый мультикаст — пакеты 239 и 242, но пока не прекращает и Register — пакеты 241 и 243. А пакет 240 — это R2 не выдержал и ещё раз попросил построить дерево.
10) Итак, незамутнённый мультикаст достигает RP. Она понимает, что это тот же самый трафик, который приходит в Register, потому что одинаковый адрес группы, одинаковый адрес источника и с одного интерфейса. Чтобы не получать две копии, он отправляет на R1 юникастовый PIM Register-Stop.

Register-Stop не означает, что R2 отказывается от трафика или не признаёт больше этот источник, это говорит лишь о том, что надо прекратить посылать инкапсулированный трафик.
Далее идёт ожесточённая борьба — R1 продолжает передавать накопившийся в буфере трафик, пока обрабатывает Register-Stop, и обычным мультикастом и внутри сообщений Register:

Но, рано или поздно R1 начинает вещать только чистый мультикастовый трафик.

При подготовке у меня возник, как мне казалось, закономерный вопрос: ну и к чему все эти туннелирования, PIM Register? Почему бы не поступать с мультикастовым трафиком, как с PIM Join — отправлять хоп за хопом с TTL=1 в сторону RP — рано или поздно ведь дойдёт? Так бы и дерево построилось бы заодно без лишних телодвижений.
Тут возникает несколько нюансов.
Во-первых, нарушается главный принцип PIM SM — трафик посылать только туда, откуда он был запрошен. Нет Join — Нет дерева!
Во-вторых, если клиентов для данной группы нет, FHR не узнает об этом и будет продолжать слать трафик по «своему дереву». К чему такое бездумное использование полосы пропускания? В мире связи такой протокол просто не выжил бы, как не выжил PIM DM или DVMRP.
Таким образом мы имеем одно большое дерево MDT для группы 224.2.2.4 от Cервера-источника до Клиента 1 и Клиента 2. И это MDT составлено из двух кусков, которые строились независимо друг от друга: Source Tree от источника до RP и RPT от RP до клиентов. Вот оно отличие MDT от RPT и SPT. MDT — это довольно общий термин, означающий дерево передачи мультикаста вообще, в то время, как RPT/SPT — это его очень конкретный вид.
А что делать, если сервер уже вещает, а клиентов всё нет и нет? Мультикаст так и будет засорять участок между отправителем и RP?
Нет, в этом случае также поможет PIM Register-Stop. Если на RP начали приходить сообщения Register для какой-то группы, а для неё ещё нет получателей, то RP не заинтересован в получении этого трафика, поэтому, не отправляя PIM Join (S, G), RP сразу посылает Register-Stop на R1.
R1, получив Register-Stop и видя, что дерева для этой группы пока нет (нет клиентов), начинает отбрасывать мультикастовый трафик от сервера.
То есть сам сервер по этому поводу совершенно не беспокоится и продолжает посылать поток, но, дойдя до интерфейса маршрутизатора, поток будет отброшен.
При этом RP продолжает хранить запись (S, G). То есть трафик он не получает, но где находится источник для группы знает. Если в группе появляются получатели, RP узнаёт о них и посылает на источник Join (S, G), который строит дерево.
Кроме того, каждые 3 минуты R1 будет пытаться повторно зарегистрировать источник на RP, то есть отправлять пакеты Register. Это нужно для того, чтобы уведомить RP о том, что этот источник ещё живой.
У особо пытливых читателей обязан возникнуть вопрос — а как быть с RPF? Этот механизм ведь проверяет адрес отправителя мультикастового пакета и, если трафик идёт не с правильного интерфейса, он будет отброшен. При этом RP и источник могут находиться за разными интерфейсам. Вот и в нашем примере для R3 RP — за FE1/1, а источник — за FE1/0.
Ответ предсказуем — в таком случае проверяется не адрес источника, а RP. То есть трафик должен придти с интерфейса в сторону RP.
Но, как вы увидите далее, это тоже не нерушимое правило.
Важно понимать, что RP — это не универсальный магнит — для каждой группы может бытья своя RP. То есть в сети их может быть и две, и три, и сто — одна RP отвечает за один набор групп, другая — за другой. Более того, есть такое понятие, как Anycast RP и тогда разные RP могут обслуживать одну и ту же группу.
=====================
Схема и начальная конфигурация.
Замечание к топологии: в этой задаче только маршрутизаторы R1, R2, R3 находятся под управлением администраторов нашей сети. То есть, конфигурацию изменять можно только на них.
Сервер 172.16.0.5 передает мультикаст трафик на группы 239.1.1.1 и 239.2.2.2.
Настроить сеть таким образом, чтобы трафик группы 239.1.1.1 не передавался в сегмент между R3 и R5, и во все сегменты ниже R5.
Но при этом, трафик группы 239.2.2.2 должен передаваться без проблем.Подробности задачи тут.
=====================
Бритва Оккама или отключение ненужных ветвей
После того, как последний клиент в сегменте отказался от подписки, PIM должен отрезать лишнюю ветку RPT.
Пусть, например, единственный клиент на R4 выключил компьютер. Маршрутизатор по сообщению IGMP Leave или после трёх безответных IGMP Query понимает, что клиентов за FE0/0 больше нет, и отправляет в сторону RP сообщение PIM Prune. По формату оно точно такое же, как Join, но выполняет противоположную функцию.
Адрес назначения также 224.0.0.13, и TTL равен 1.

Но маршрутизатор, получивший PIM Prune, перед тем, как удалить подписку, ждёт некоторое время (обычно 3 секунды — Join Delay Timer).
Это сделано вот для такой ситуации:

В одном широковещательном домене 3 маршрутизатора. Один из них стоит выше и именно он передаёт в сегмент мультикастовый трафик. Это R1. Для обоих маршрутизаторов (R2 и R3) его OIL содержит только одну запись.
Если теперь R2 решит отключиться и отправит PIM Prune, то он может подставить своего коллегу R3 — R1 ведь перестанет вещать в интерфейс вообще.
Так вот, чтобы этого не произошло, R1 и даёт таймаут в 3 секунды. За это время R3 должен успеть среагировать. Учитывая широковещательность сети, он тоже получит Prune от R2 и поэтому, если хочет продолжать получать трафик, он мгновенно отправляет обычный PIM Join в сегмент, уведомляя R1, что не надо удалять интерфейс.
Этот процесс называется — Prune Override. R2 как бы объегорил R1, перехватил инициативу.
SPT Switchover — переключение RPT-SPT
До сих пор мы преимущественно рассматривали только Клиента 1. Теперь обратимся к Клиенту 2.
По началу всё для него идентично Клиенту 1 — он пользуется RPT от RP, который мы рассматривали ранее. Кстати, поскольку оба — и Клиент 1 и Клиент 2 — используют одно дерево, такое дерево называется Shared Tree — это довольно общее название. Shared tree = RPT.
Вот как выглядит таблица мультикастовой маршрутизации на R5 в самом начале, сразу после построения дерева:
 SPT Switchover")
Здесь нет записи (S, G), но это не значит, что мультикастовый трафик не передаётся. Просто R5 не заботится о том, кто отправитель.
Обратите внимание по какому пути должен идти в этом случае трафик — R1-R2-R3-R5. Хотя ведь короче путь R1-R3-R5.

А если сеть посложнее?

Как-то неаккуратненько.
Дело в том, что пока мы привязаны к RP — она корень RPT, только она поначалу знает, где кто находится. Однако если вдуматься, то после первого же мультикастового пакета все маршрутизаторы по пути трафика будут знать адрес источника, ведь он указан в заголовке IP.

Почему бы кому-нибудь не отправить самому Join в сторону источника и оптимизировать маршрут?
Зрите в корень. Такое переключение может инициировать LHR (Last Hop Router) — R5. После получения первого мультикастового пакета от R3 R5 отправляет уже знакомый нам Source Specific Join (S, G) в интерфейс FE0/1, который указан в его таблице маршрутизации, как исходящий для сети 172.16.0.0/24.

Получив такой Join, R3 отправляет его не на RP, как делал это с обычным Join (*, G), а в сторону источника (через интерфейс согласно таблице маршрутизации).
То есть в данном случае R3 отправляет Join (172.16.0.5, 224.2.2.4) в интерфейс FE1/0.

Далее этот Join попадает на R1. А R1 по большому счёту без разницы, кто его отправлял — RP или кто-то другой — он просто добавляет FE1/1 в свой OIL для группы 224.2.2.4.

В этот момент между источником и получателем два пути и R3 получает два потока.

Время сделать выбор, чтобы обрезать лишнее. Причём именно R3 его делает, потому что R5 уже не сможет различить эти два потока — они оба придут через один интерфейс.
Как только R3 зафиксировал два одинаковых потока с разных интерфейсов, он выбирает предпочтительный согласно таблице маршрутизации. В данном случае прямой, лучше, чем через RP. В этот момент R3 посылает Prune (S, G) в сторону RP, обрубая эту ветку RPT. И с этого момент остаётся только один поток напрямую от источника.

Таким образом PIM построил SPT — Shortest Path Tree. Оно же Source Tree. Это кратчайший путь от клиента до источника. Кстати, дерево от источника до RP, которое мы уже рассматривали выше, — по сути ровно то же самое SPT.
Оно характеризуется записью (S, G). Если маршрутизатор имеет такую запись, значит он знает, что S является источником для группы G и построено дерево SPT.
Корнем дерева SPT является источник и очень хочется сказать «кратчайший путь от источника до клиента». Но это технически некорректно, поскольку пути от источника до клиента и от клиента до источника могут быть разными. А именно от клиента начинает строиться ветка дерева: маршрутизатор отправляет PIM Join в сторону источника/RP и RPF также проверяет правильность интерфейса при получении трафика.
Вы помните, что вначале этого параграфа на R5 была только запись (*, G), теперь после всех этих событий их станет две: (*, G) и (S, G).
Между прочим, даже если вы посмотрите на мультикастовую таблицу маршрутизации R3 в ту же секунду, как нажали Play в VLC, то увидите, что он уже получает трафик от R1 напрямую, о чём говорит наличие записи (S, G).
То есть SPT Switchover уже произошёл — это действие по умолчанию на оборудовании многих производителей — инициировать переключение после получения первого же мультикастового пакета.
Вообще говоря, происходить такое переключение может в нескольких случаях:
- Не происходить вообще никогда (команда ip pim spt-threshold infinity).
- При достижении определённой утилизации полосы пропускания (команда ip pim spt-threshold X).
- Безусловно — сразу после получения первого пакета (действие по умолчанию или no ip pim spt-threshold X)
Как правило, решение о том, что «пора», принимает LHR.
В этом случае во второй раз изменяется правило работы RPF — он снова проверяет местонахождение источника. То есть из двух потоков мультикаста — от RP и от источника — предпочтение отдаётся трафику от источника.
DR, Assert, Forwarder
Ещё несколько важных моментов при рассмотрении PIM.
DR — Designated Router.
Это выделенный маршрутизатор, который ответственен за отправку служебных пакетов на RP.
Source DR — отвечает за принятие мультикастовых пакетов непосредственно от источника и его регистрацию на RP.
Вот пример топологии:

Здесь ни к чему, чтобы оба маршрутизатора передавали трафик на RP, пусть они резервируют друг друга, но ответственный должен быть только один.
Поскольку оба маршрутизатора подключены в одну широковещательную сеть, они получают друг от друга PIM-Hello. На основе него они и делают свой выбор.
PIM Hello несёт значение приоритета данного маршрутизатора на данном интерфейсе.

Чем больше значение, тем выше приоритет. Если они одинаковы, то выбирается узел с наибольшим IP-адресом (тоже из сообщения Hello).

Если другой маршрутизатор (не DR) в течение Holdtime (по умолчанию 105 с) не получал Hello от соседа, он автоматически берёт на себя роль DR.
По сути Source DR — это FHR — First Hop Router.
Receiver DR — то же, что Source DR, только для получателей мультикастового трафика — LHR (Last Hop Router).
Пример топологии:

Receiver DR ответственен за отправку на RP PIM Join. В вышеприведённой топологии, если оба маршрутизатора отправят Join, то оба будут получать мультикастовый трафик, но в этом нет необходимости. Только DR отправляет Join. Второй просто мониторит доступность DR.
Поскольку DR отправляет Join, то он же и будет вещать трафик в LAN. Но тут возникает закономерный вопрос — а что, если PIM DR’ом стал один, а IGMP Querier’ом другой? А ситуация-то вполне возможна, ведь для Querier чем меньше IP, тем лучше, а для DR, наоборот.
В этом случае DR’ом выбирается тот маршрутизатор, который уже является Querier и такая проблема не возникает.

Правила выбора Receiver DR точно такие же, как и Source DR.
Assert и PIM Forwarder
Проблема двух одновременно передающих маршрутизаторов может возникнуть и в середине сети, где нет ни конечных клиентов, ни источников — только маршрутизаторы.
Очень остро этот вопрос стоял в PIM DM, где это была совершенно рядовая ситуация из-за механизма Flood and Prune.
Но и в PIM SM она не исключена.
Рассмотрим такую сеть:

Здесь три маршрутизатора находятся в одном сегменте сети и, соответственно, являются соседями по PIM. R1 выступает в роли RP.
R4 отправляет PIM Join в сторону RP. Поскольку этот пакет мультикастовый он попадает и на R2 и на R3, и оба они обработав его, добавляют нисходящий интерфейс в OIL.
Тут бы должен сработать механизм выбора DR, но и на R2 и на R3 есть другие клиенты этой группы, и обоим маршрутизаторам так или иначе придётся отправлять PIM Join.
Когда мультикастовый трафик приходит от источника на R2 и R3, в сегмент он передаётся обоими маршрутизаторами и задваивается там. PIM не пытается предотвратить такую ситуацию — тут он действует по факту свершившегося преступления — как только в свой нисходящий интерфейс для определённой группы (из списка OIL) маршрутизатор получает мультикастовый трафик этой самой группы, он понимает: что-то не так — другой отправитель уже есть в этом сегменте.

Тогда маршрутизатор отправляет специальное сообщение PIM Assert.
Такое сообщение помогает выбрать PIM Forwarder — тот маршрутизатор, который вправе вещать в данном сегменте.

Не надо его путать с PIM DR. Во-первых, PIM DR отвечает за отправку сообщений PIM Join и Prune, а PIM Forwarder — за отправку трафика. Второе отличие — PIM DR выбирается всегда и в любых сетях при установлении соседства, А PIM Forwrder только при необходимости — когда получен мультикастовый трафик с интерфейса из списка OIL.
Выбор RP
Выше мы для простоты задавали RP вручную командой ip pim rp-address X.X.X.X.
И вот как выглядела команда show ip pim rp:

Но представим совершенно невозможную в современных сетях ситуацию — R2 вышел из строя. Это всё — финиш. Клиент 2 ещё будет работать, поскольку произошёл SPT Switchover, а вот всё новое и всё, что шло через RP сломается, даже если есть альтернативный путь.
Ну и нагрузка на администратора домена. Представьте себе: на 50 маршрутизаторах перебить вручную как минимум одну команду (а для разных групп ведь могут быть разные RP).
Динамический выбор RP позволяет и избежать ручной работы и обеспечить надёжность — если одна RP станет недоступна, в бой вступит сразу же другая.
В данный момент существует один общепризнанный протокол, позволяющий это сделать — Bootstrap. Циска в прежние времена продвигала несколько неуклюжий Auto-RP, но сейчас он почти не используется, хотя циска этого не признаёт, и в show ip mroute мы имеем раздражающий рудимент в виде группы 224.0.1.40.
Надо на самом деле отдать должное протоколу Auto-RP. Он был спасением в прежние времена. Но с появлением открытого и гибкого Bootstrap, он закономерно уступил свои позиции.
Итак, предположим, что в нашей сети мы хотим, чтобы R3 подхватывал функции RP в случае выхода из строя R2.
R2 и R3 определяются как кандидаты на роль RP — так они и называются C-RP. На этих маршрутизаторах настраиваем:
RX(config)interface Loopback 0
RX(config-if)ip pim sparse-mode
RX(config-if)exit
RX(config)#ip pim rp-candidate loopback 0 Но пока ничего не происходит — кандидаты пока не знают, как уведомить всех о себе.
Чтобы информировать все мультикастовые маршрутизаторы домена о существующих RP вводится механизм BSR — BootStrap Router. Претендентов может быть несколько, как и C-RP. Они называются соответственно C-BSR. Настраиваются они похожим образом.
Пусть BSR у нас будет один и для теста (исключительно) это будет R1.
R1(config)interface Loopback 0
R1(config-if)ip pim sparse-mode
R1(config-if)exit
R1(config)#ip pim bsr-candidate loopback 0 Сначала из всех C-BSR выбирается один главный BSR, который и будет всем заправлять. Для этого каждый C-BSR отправляет в сеть мультикастовый BootStrap Message (BSM) на адрес 224.0.0.13 — это тоже пакет протокола PIM. Его должны принять и обработать все мультикастовые маршрутизаторы и после разослать во все порты, где активирован PIM. BSM передаётся не в сторону чего-то (RP или источника), в отличии, от PIM Join, а во все стороны. Такая веерная рассылка помогает достигнуть BSM всех уголков сети, в том числе всех C-BSR и всех C-RP. Для того, чтобы BSM не блуждали по сети бесконечно, применяется всё тот же механизм RPF — если BSM пришёл не с того интерфейса, за которым находится сеть отправителя этого сообщения, такое сообщение отбрасывается.

С помощью этих BSM все мультикастовые маршрутизаторы определяют самого достойного кандидата на основе приоритетов. Как только C-BSR получает BSM от другого маршрутизатора с бОльшим приоритетом, он прекращает рассылать свои сообщения. В результате все обладают одинаковой информацией.

На этом этапе, когда выбран BSR, благодаря тому, что его BSM разошлись уже по всей сети, C-RP знают его адрес и юникастом отправляют на него сообщения Candidte-RP-Advertisement, в которых они несут список групп, которые они обслуживают — это называется group-to-RP mapping. BSR все эти сообщения агрегирует и создаёт RP-Set — информационную таблицу: какие RP каждую группу обслуживают.

Далее BSR в прежней веерной манере рассылает те же BootStrap Message, которые на этот раз содержат RP-Set. Эти сообщения успешно достигают всех мультикастовых маршрутизаторов, каждый из которых самостоятельно делает выбор, какую RP нужно использовать для каждой конкретной группы.

BSR периодически делает такие рассылки, чтобы с одной стороны все знали, что информация по RP ещё актуальна, а с другой C-BSR были в курсе, что сам главный BSR ещё жив.
RP, кстати, тоже периодически шлют на BSR свои анонсы Candidate-RP-Advertisement.
Фактически всё, что нужно сделать для настройки автоматического выбора RP — указать C-RP и указать C-BSR — не так уж много работы, всё остальное за вас сделает PIM.
Как всегда, в целях повышения надёжности рекомендуется указывать интерфейсы Loopback в качестве кандидатов.
Завершая главу PIM SM, давайте ещё раз отметим важнейшие моменты
- Должна быть обеспечена обычная юникастовая связность с помощью IGP или статических маршрутов. Это лежит в основе алгоритма RPF.
- Дерево строится только после появления клиента. Именно клиент инициирует построение дерева. Нет клиента — нет дерева.
- RPF помогает избежать петель.
- Все маршрутизаторы должны знать о том, кто является RP — только с её помощью можно построить дерево.
- Точка RP может быть указана статически, а может выбираться автоматически с помощью протокола BootStrap.
- В первой фазе строится RPT — дерево от клиентов до RP — и Source Tree — дерево от источника до RP. Во второй фазе происходит переключение с построенного RPT на SPT — кратчайший путь от получателя до источника.
Ещё перечислим все типы деревьев и сообщений, которые нам теперь известны.
MDT — Multicast Distribution Tree. Общий термин, описывающий любое дерево передачи мультикаста.
SPT — Shortest Path Tree. Дерево с кратчайшим путём от клиента или RP до источника. В PIM DM есть только SPT. В PIM SM SPT может быть от источника до RP или от источника до получателя после того, как произошёл SPT Switchover. Обозначается записью (S, G) — известен источник для группы.
Source Tree — то же самое, что SPT.
RPT — Rendezvous Point Tree. Дерево от RP до получателей. Используется только в PIM SM. Обозначается записью (*, G).
Shared Tree — то же, что RPT. Называется так потому, что все клиенты подключены к одному общему дереву с корнем в RP.
Типы сообщений PIM Sparse Mode:
Hello — для установления соседства и поддержания этих отношений. Также необходимы для выбора DR.
Join (*, G) — запрос на подключение к дереву группы G. Не важно кто источник. Отправляется в сторону RP. С их помощью строится дерево RPT.
Join (S, G) — Source Specific Join. Это запрос на подключение к дереву группы G с определённым источником — S. Отправляется в сторону источника — S. С их помощью строится дерево SPT.
Prune (*, G) — запрос на отключение от дерева группы G, какие бы источники для неё не были. Отправляется в сторону RP. Так обрезается ветвь RPT.
Prune (S, G) — запрос на отключение от дерева группы G, корнем которого является источник S. Отправляется в сторону источника. Так обрезается ветвь SPT.
Register — специальное сообщение, внутри которого передаётся мультикаст на RP, пока не будет построено SPT от источника до RP. Передаётся юникастом от FHR на RP.
Register-Stop — отправляется юникастом с RP на FHR, приказывая прекратить посылать мультикастовый трафик, инкапсулированный в Register.
Bootstrap — пакеты механизма BSR, которые позволяют выбрать маршрутизатор на роль BSR, а также передают информацию о существующих RP и группах.
Assert — сообщение для выбора PIM Forwarder, чтобы в один сегмент не передавали трафик два маршрутизатора.
Candidate-RP-Advertisement — сообщение, в котором RP отсылает на BSR информацию о том, какие группы он обслуживает.
RP-Reachable — сообщение от RP, которым она уведомляет всех о своей доступности.
*Есть и другие типы сообщений в PIM, но это уже детали*
А давайте теперь попытаемся абстрагироваться от деталей протокола? И тогда становится очевидной его сложность.
1) Определение RP,
2) Регистрация источника на RP,
3) Переключение на дерево SPT.
Много состояний протокола, много записей в таблице мультикастовой маршрутизации. Можно ли что-то с этим сделать?
На сегодняшний день существует два диаметрально противоположных подхода к упрощению PIM: SSM и BIDIR PIM.
SSM
Всё, что мы описывали до сих пор — это ASM — Any Source Multicast. Клиентам безразлично, кто является источником трафика для группы — главное, что они его получают. Как вы помните в сообщении IGMPv2 Report запрашивается просто подключение к группе.
SSM — Source Specific Multicast — альтернативный подход. В этом случае клиенты при подключении указывают группу и источник.
Что же это даёт? Ни много ни мало: возможность полностью избавиться от RP. LHR сразу знает адрес источника — нет необходимости слать Join на RP, маршрутизатор может сразу же отправить Join (S, G) в направлении источника и построить SPT.
Таким образом мы избавляемся от
- Поиска RP (протоколы Bootstrap и Auto-RP),
- Регистрации источника на мультикасте (а это лишнее время, двойное использование полосы пропускания и туннелирование)
- Переключения на SPT.
Поскольку нет RP, то нет и RPT, соответственно ни на одном маршрутизаторе уже не будет записей (*, G) — только (S, G).
Ещё одна проблема, которая решается с помощью SSM — наличие нескольких источников. В ASM рекомендуется, чтобы адрес мультикастовой группы был уникален и только один источник вещал на него, поскольку в дереве RPT несколько потоков сольются, а клиент, получая два потока от разных источников, вероятно, не сможет их разобрать.
В SSM трафик от различных источников распространяется независимо, каждый по своему дереву SPT, и это уже становится не проблемой, а преимуществом — несколько серверов могут вещать одновременно. Если вдруг клиент начал фиксировать потери от основного источника, он может переключиться на резервный, даже не перезапрашивая его — он и так получал два потока.
Кроме того, возможный вектор атаки в сети с активированной мультикастовой маршрутизацией — подключение злоумышленником своего источника и генерирование большого объёма мультикастового трафика, который перегрузит сеть. В SSM такое практически исключено.
Для SSM выделен специальный диапазон IP-адресов: 232.0.0.0/8.
На маршрутизаторах для поддержки SSM включается режим PIM SSM.
Router(config)# ip pim ssm IGMPv3 и MLDv2 поддерживают SSM в чистом виде.
При их использовании клиент может
- Запрашивать подключение к просто группе, без указания источников. То есть работает как типичный ASM.
- Запрашивать подключение к группе с определённым источником. Источников можно указать несколько — до каждого из них будет построено дерево.
- Запрашивать подключение к группе и указать список источников, от которых клиент не хотел бы получать трафик
IGMPv1/v2, MLDv1 не поддерживают SSM, но имеет место такое понятие, как SSM Mapping. На ближайшем к клиенту маршрутизаторе (LHR) каждой группе ставится в соответствие адрес источника (или несколько). Поэтому если в сети есть клиенты, не поддерживающие IGMPv3/MLDv2, для них также будет построено SPT, а не RPT, благодаря тому, что адрес источника всё равно известен.
SSM Mapping может быть реализован как статической настройкой на LHR, так и посредством обращения к DNS-серверу.
Проблема SSM в том, что клиенты должны заранее знать адреса источников — никакой сигнализацией они им не сообщаются.
Поэтому SSM хорош в тех ситуациях, когда в сети определённый набор источников, их адреса заведомо известны и не будут меняться. А клиентские терминалы или приложения жёстко привязаны к ним.
Иными словами IPTV — весьма пригодная среда для внедрения SSM. Это хорошо описывает концепцию One-to-Many — один источник, много получателей.
BIDIR PIM
А что если в сети источники могут появляться спонтанно то там, то тут, вещать на одинаковые группы, быстро прекращать передачу и исчезать?
Например, такая ситуация возможна в сетевых играх или в ЦОД, где происходит репликация данных между различными серверами. Это концепция Many-to-Many — много источников, много клиентов.
Как на это смотрит обычный PIM SM? Понятное дело, что инертный PIM SSM здесь совсем не подходит?
Вы только подумайте, какой хаос начнётся: бесконечные регистрации источников, перестроение деревьев, огромное количество записей (S, G) живущих по несколько минут из-за таймеров протокола.
На выручку идёт двунаправленный PIM (Bidirectional PIM, BIDIR PIM). В отличие от SSM в нём напротив полностью отказываются от SPT и записей (S,G) — остаются только Shared Tree с корнем в RP.
И если в обычном PIM, дерево является односторонним — трафик всегда передаётся от источника вниз по SPT и от RP вниз по RPT — есть чёткое деление, где источник, где клиенты, то в двунаправленном от источника трафик к RP передаётся также вверх по Shared Tree — по тому же самому, по которому трафик течёт вниз к клиентам.
Это позволяет отказаться от регистрации источника на RP — трафик передаётся безусловно, без какой бы то ни было сигнализации и изменения состояний. Поскольку деревьев SPT нет вообще, то и SPT Switchover тоже не происходит.
Вот например:

Источник1 начал передавать в сеть трафик группы 224.2.2.4 одновременно с Источником2. Потоки от них просто полились в сторону RP. Часть клиентов, которые находятся рядом начали получать трафик сразу, потому что на маршрутизаторах есть запись (*, G) (есть клиенты). Другая часть получает трафик по Shared Tree от RP. Причём получают они трафик от обоих источников одновременно.
То есть, если взять для примера умозрительную сетевую игру, Источник1 это первый игрок в стрелялке, который сделал выстрел, а Источник2 — это другой игрок, который сделал шаг в сторону. Информация об этих двух событиях распространилась по всей сети. И каждый другой игрок (Получатель) должен узнать об обоих этих событиях.
Если помните, то чуть раньше мы объяснили, зачем нужен процесс регистрации источника на RP — чтобы трафик не занимал канал, когда нет клиентов, то есть RP просто отказывался от него. Почему над этой проблемой мы не задумываемся сейчас? Причина проста: BIDIR PIM для ситуаций, когда источников много, но они вещают не постоянно, а периодически, относительно небольшими кусками данных. То есть канал от источника до RP не будет утилизироваться понапрасну.
Обратите внимание, что на изображении выше между R5 и R7 есть прямая линия, гораздо более короткая, чем путь через RP, но она не была использована, потому что Join идут в сторону RP согласно таблице маршрутизации, в которой данный путь не является оптимальным.
Выглядит довольно просто — нужно отправлять мультикастовые пакеты в направлении RP и всё, но есть один нюанс, который всё портит — RPF. В дереве RPT он требует, чтобы трафик приходил от RP и не иначе. А у нас он может приходить откуда угодно. Взять и отказаться от RPF мы, конечно, не можем — это единственный механизм, который позволяет избежать образования петель.
Поэтому в BIDIR PIM вводится понятие DF — Designated Forwarder. В каждом сегменте сети, на каждой линии на эту роль выбирается тот маршрутизатор, чей маршрут до RP лучше.
В том числе это делается и на тех линиях, куда непосредственно подключены клиенты. В BIDIR PIM DF автоматически является DR.

Список OIL формируется только из тех интерфейсов, на которых маршрутизатор был выбран на роль DF.
Правила довольно прозрачны:
- Если запрос PIM Join/Leave приходит на тот интерфейс, который в данном сегменте является DF, он передаётся в сторону RP по стандартным правилам.
Вот, например, R3. Если запросы пришли в DF интерфейсы, что помечены красным кругом, он их передаёт на RP (через R1 или R2, в зависимости от таблицы маршрутизации). - Если запрос PIM Join/Leave пришёл на не DF интерфейс, он будет проигнорирован.
Допустим, что клиент, находящийся между R1 и R3, решил подключиться и отправил IGMP Report. R1 получает его через интерфейс, где он выбран DF (помечен красным кругом), и мы возвращаемся к предыдущему сценарию. А R3 получает запрос на интерфейс, который не является DF. R3 видит, что тут он не лучший, и игнорирует запрос. - Если мультикастовый трафик пришёл на DF интерфейс, он будет отправлен в интерфейсы из списка OIL и в сторону RP.
Например, Источник1 начал передавать трафик. R4 получает его в свой DF интерфейс и передаёт его и в другой DF-интерфейс — в сторону клиента и в сторону RP, — это важно, потому что трафик должен попасть на RP и распространиться по всем получателям. Также поступает и R3 — одна копия в интерфейсы из списка OIL — то есть на R5, где он будет отброшен из-за проверки RPF, и другая — в сторону RP. - Если мультикастовый трафик пришёл на не DF интерфейс, он должен быть отправлен в интерфейсы из списка OIL, но не будет отправлен в сторону RP.
К примеру, Источник2 начал вещать, трафик дошёл до RP и начал распространяться вниз по RPT. R3 получает трафик от R1, и он не передаст его на R2 — только вниз на R4 и на R5.
Таким образом DF гарантирует, что на RP в итоге будет отправлена только одна копия мультикастового пакета и образование петель исключено. При этом то общее дерево, в котором находится источник, естественно, получит этот трафик ещё до попадания на RP. RP, согласно обычным правилам разошлёт трафик во все порты OIL, кроме того, откуда пришёл трафик.
Кстати, нет нужды более и в сообщениях Assert, ведь DF выбирается в каждом сегменте. В отличие от DR он отвечает не только за отправку Join к RP, но и за передачу трафика в сегмент, то есть ситуация, когда два маршрутизатора передают в одну подсеть трафик, исключена в BIDIR PIM.
Пожалуй, последнее, что нужно сказать о двунаправленном PIM, это особенности работы RP. Если в PIM SM RP выполнял вполне конкретную функцию — регистрация источника, то в BIDIR PIM RP — это некая весьма условная точка, к которой стремится трафик с одной стороны и Join от клиентов с другой. Никто не должен выполнять декапсуляцию, запрашивать построение дерева SPT. Просто на каком-то маршрутизаторе вдруг трафик от источников начинает передаваться в Shared Tree. Почему я говорю «на каком-то»? Дело в том, что в BIDIR PIM RP — абстрактная точка, а не конкретный маршрутизатор, в качестве адреса RP вообще может выступать несуществующий IP-адрес — главное, чтобы он был маршрутизируемый (такая RP называется Phantom RP).
Все термины, касающиеся PIM, можно найти в глоссарии.
Мультикаст на канальном уровне
Итак, позади долгая трудовая неделя с недосыпами, переработками, тестами — вы успешно внедрили мультикаст и удовлетворили клиентов, директора и отдел продаж.
Пятница — не самый плохой день, чтобы обозреть творение и позволить себе приятный отдых.
Но ваш послеобеденный сон вдруг потревожил звонок техподдержки, потом ещё один и ещё — ничего не работает, всё сломалось. Проверяете — идут потери, разрывы. Всё сходится на одном сегменте из нескольких коммутаторов.
Расчехлили SSH, проверили CPU, проверили утилизацию интерфейсов и волосы дыбом — загрузка почти под 100% на всех интерфейсах одного VLAN’а. Петля! Но откуда ей взяться, если никаких работ не проводилось? Минут 10 проверки и вы заметили, что на восходящем интерфейсе к ядру у вас много входящего трафика, а на всех нисходящих к клиентам — исходящего. Для петли это тоже характерно, но как-то подозрительно: внедрили мультикаст, никаких работ по переключению не делали и скачок только в одном направлении.
Проверили список мультикастовых групп на маршрутизаторе — а там подписка на все возможные каналы и все на один порт — естественно, тот, который ведёт в этот сегмент.
Дотошное расследование показало, что компьютер клиента заражён и рассылает IGMP Query на все мультикастовые адреса подряд.
Потери пакетов начались, потому что коммутаторам пришлось пропускать через себя огромный объём трафика. Это вызвало переполнение буферов интерфейсов.
Главный вопрос — почему трафик одного клиента начал копироваться во все порты?
Причина этого кроется в природе мультикастовых MAC-адресов. Дело в том, пространство мультикастовых IP-адресов специальным образом отображается в пространство мультикастовых MAC-адресов. И загвоздка в том, что они никогда не будут использоваться в качестве MAC-адреса источника, а следовательно, не будут изучены коммутатором и занесены в таблицу MAC-адресов. А как поступает коммутатор с кадрами, адрес назначения которых не изучен? Он их рассылает во все порты. Что и произошло.
Это действие по умолчанию.

Мультикастовые MAC-адреса
Так какие же MAC-адреса получателей подставляются в заголовок Ethernet таких пакетов? Широковещательные? Нет. Существует специальный диапазон MAC-адресов, в которые отображаются мультикастовые IP-адреса.
Эти специальные адреса начинаются так: 0x01005e и следующий 25-й бит должен быть 0 (попробуйте ответить, почему так). Остальные 23 бита (напомню, всего их в МАС-адресе 48) переносятся из IP-адреса.
Здесь кроется некоторая не очень серьёзная, но проблема. Диапазон мультикастовых адресов определяется маской 224.0.0.0/4, это означает, что первые 4 бита зарезервированы: 1110, а оставшиеся 28 бит могут меняться. То есть у нас 2^28 мультикастовых IP-адресов и только 2^23 MAC-адресов — для отображения 1 в 1 не хватает 5 бит. Поэтому берутся просто последние 23 бита IP-адреса и один в один переносятся в MAC-адрес, остальные 5 отбрасываются.

Фактически это означает, что в один мультикастовый MAC-адрес будет отображаться 2^5=32 IP-адреса. Например, группы 224.0.0.1, 224.128.0.1, 225.0.0.1 и так до 239.128.0.1 все будут отображаться в один MAC-адрес 0100:5e00:0001.
Если взять в пример дамп потокового видео, то можно увидеть:

IP адрес — 224.2.2.4, MAC-адрес: 01:00:5E:02:02:04.
Есть также другие мультикастовые MAC-адреса, которые никак не относятся к IPv4-мультикаст (клик). Все они, кстати, характеризуются тем, что последний бит первого октета равен 1.
Естественно, ни на одной сетевой карте, не может быть настроен такой MAC-адрес, поэтому он никогда не будет в поле Source MAC Ethernet-кадра и никогда не попадёт в таблицу MAC-адресов. Значит такие кадры должны рассылаться как любой Unknown Unicast во все порты VLAN’а.
Всего, что мы рассматривали прежде, вполне достаточно для полноценной передачи любого мультикастового трафика от потокового видео до биржевых котировок. Но неужели мы в своём почти совершенном мире будем мирится с таким безобразием, как широковещательная передача того, что можно было бы передать избранным?
Вовсе нет. Специально для перфекционистов придуман механизм IGMP-Snooping.
IGMP-Snooping
Идея очень простая — коммутатор «слушает» проходящие через него IGMP-пакеты.
Для каждой группы отдельно он ведёт таблицу восходящих и нисходящих портов.
Если с порта пришёл IGMP Report для группы, значит там клиент, коммутатор добавляет его в список нисходящих для этой группы.
Если с порта пришёл IGMP Query для группы, значит там маршрутизатор, коммутатор добавляет его в список восходящих.
Таким образом формируется таблица передачи мультикастового трафика на канальном уровне.
В итоге, когда сверху приходит мультикастовый поток, он копируется только в нисходящие интерфейсы. Если на 16-портовом коммутаторе только два клиента, только им и будет доставлен трафик.

Гениальность этой идеи заканчивается тогда, когда мы задумываемся о её природе. Механизм предполагает, что коммутатор должен прослушивать трафик на 3-м уровне.
Впрочем, IGMP-Snooping ни в какое сравнение не идёт с NAT по степени игнорирования принципов сетевого взаимодействия. Тем более, кроме экономии в ресурсах, он несёт в себе массу менее очевидных возможностей. Да и в общем-то в современном мире, коммутатор, который умеет заглядывать внутрь IP — явление не исключительное.
=====================
Схема и начальная конфигурация.
Сервер 172.16.0.5 передает мультикаст трафик на группы 239.1.1.1, 239.2.2.2 и 239.0.0.x.
Настроить сеть таким образом, чтобы:
— клиент 1 не мог присоединиться к группе 239.2.2.2. Но при этом мог присоединиться к группе 239.0.0.x.
— клиент 2 не мог присоединиться к группе 239.1.1.1. Но при этом мог присоединиться к группе 239.0.0.x.Подробности задачи тут.
=====================
IGMP Snooping Proxy
У пытливого читателя может возникнуть вопрос по тому, как IGMP Snooping узнаёт все клиентские порты, учитывая, что на IGMP Query отвечает только один самый быстрый клиент, как мы говорили выше. А очень просто: IGMP-Snooping не позволяет сообщениям Report ходить между клиентами. Они отправляются только в восходящие порты к маршрутизаторам. Не видя Report от других получателей этой группы, клиент обязан ответить на Query в течение Max Response Time, указанном в этом Query.
В итоге в сети на 1000 узлов на один IGMP Query в течение секунд 10 (обычное значение Max Response Time) придёт 1000 Report’ов маршрутизатору. Хотя ему достаточно было бы и одного для каждой группы.
И происходит это каждую минуту.
В этом случае можно настроить проксирование IGMP-запросов. Тогда коммутатор не просто «слушает» проходящие пакеты, он их перехватывает.
Правила работы IGMP-Snooping могут отличаться для разных производителей. Поэтому рассмотрим их концептуально:
1) Если на коммутатор приходит самый первый запрос Report на группу, он отправляется вверх к маршрутизатору, а интерфейс вносится в список нисходящих. Если же такая группа уже есть, интерфейс просто добавляется в список нисходящих, а Report уничтожается.
2) Если на коммутатор приходит самый последний Leave, то есть других клиентов нет, этот Leave будет отправлен на маршрутизатор, а интерфейс удаляется из списка нисходящих. В противном случае просто удаляется интерфейс, Leave уничтожается.
3) Если IGMP Query приходит от маршрутизатора, коммутатор перехватывает его, отправляет в ответ IGMP Report для всех групп, которые в данный момент имеют получателей.
А дальше, в зависимости от настроек и производителя, либо этот же самый Query рассылается во все клиентские порты, либо коммутатор блокирует запрос от маршрутизатора и сам выступает в роли Querier, периодически опрашивая всех получателей.
Таким образом снижается и доля лишнего служебного трафика в сети и нагрузка на маршрутизатор.
Multicast VLAN Replication
Сокращённо MVR. Это механизм для тех провайдеров, кто практикует VLAN-per-user, например.
Вот типичный пример сети, где MVR жизненно необходим:

5 клиентов в разных VLAN’ах, и все хотят получать мультикастовый трафик одной группы 224.2.2.4. При этом клиенты должны оставаться изолированными друг от друга.
IGMP-Snooping учитывает, разумеется и VLAN’ы. Если пять клиентов в разных VLAN’ах запрашивают одну группу — это будет пять разных таблиц. Соответственно и к маршрутизатору идут 5 запросов на подключение к группе. И каждый сабинтерфейс из этих пяти на маршрутизаторе будет добавлен отдельно в OIL. То есть получив 1 поток для группы 224.2.2.4 он отправит 5 копий, несмотря на то, что все они идут в один сегмент.

Для решения этой проблемы и был разработан механизм Multicast VLAN Replication.
Вводится дополнительный VLAN — Multicast VLAN — в нём, соответственно, будет передаваться мультикастовый поток. Он «проброшен» непосредственно до последнего коммутатора, где трафик из него копируется во все клиентские интерфейсы, которые хотят получать этот трафик — это и есть репликация.
В зависимости от реализации репликация из Multicast VLAN может производиться в User-VLAN или в определённые физические интерфейсы.

А что с IGMP-сообщениями? Query от маршрутизатора, естественно, приходит по мультикастовому VLAN’у. Коммутатор их рассылает в клиентские порты. Когда Report или Leave приходит от клиента, коммутатор проверяет откуда именно (VLAN, интерфейс) и, если необходимо, перенаправляет в мультикастовый VLAN.
Таким образом обычный трафик изолирован и по-прежнему ходит до маршрутизатора в пользовательском VLAN’е. А мультикастовый трафик и IGMP-пакеты передаются в Multicast VLAN.
На оборудовании Cisco MVR и IGMP-Snooping настраиваются независимо. То есть можно отключить один и второй будет работать. Вообще же MVR основан на IGMP-Snooping и на коммутаторах других производителей для работы MVR может быть обязательным включение IGMP-Snooping.
Кроме того, IGMP-Snooping позволяет осуществлять на коммутаторах фильтрацию трафика, ограничивать количество групп, доступных пользователю, включение IGMP Querier, статическую настройку восходящих портов, перманентное подключение к какой-либо группе (этот сценарий есть в сопутствующем видео), быструю реакцию на изменение топологии путём рассылки дополнительных Query, SSM-Mapping для IGMPv2 итд.
Заканчивая разговор об IGMP-Snooping, хочется повторить — это необязательный функционал — всё и без него будет работать. Но это сделает сеть более предсказуемой, а жизнь инженера спокойнее.
Однако все плюсы IGMP Snooping можно обернуть и против себя. Один такой выдающийся случай можно почитать по ссылке.
К слову у той же Cisco есть протокол CGMP — аналог IGMP, который не нарушает принципы работы коммутатора, но он проприетарный и не сказать, что широко распространённый.
Итак, мой неутомимый читатель, мы приближаемся к концу выпуска и напоследок хочется показать, как может быть реализована услуга IPTV на стороне клиента.
Самый простой способ, к которому мы уже не раз обращались в этой статье — запустить плеер, который может принять мультикастовый поток из сети. На нём можно вручную задать IP-адрес группы и наслаждаться видео.
Другой программный вариант, который часто используют провайдеры — специальное приложение, обычно весьма кастомное, в котором зашит набор каналов, используемых в сети провайдера. Нет необходимости что-то задавать вручную — нужно просто переключать каналы кнопками.
Оба эти способа дают возможность смотреть потоковое видео только на компьютере.
Третий же вариант позволяет использовать телевизор, причём как правило, любой. Для этого в доме клиента ставит так называемый Set-Top-Box (STB) — коробочка, устанавливаемая на телевизор. Это шелезяка, которая включается в абонентскую линию и разделяет трафик: обычный юникаст она отдаёт в Ethernet или WiFi, чтобы клиенты имели доступ в Интернет, а мультикастовый поток передаётся на телевизор через кабель (DVI, RGB, антенный итд.).
Часто вы, кстати, можете увидеть рекламу, где провайдер предлагает свои приставки для подключения телевидения — это и есть те самые STB
=====================
Напоследок нетривиальная задачка по мультикасту (авторы не мы, в ответах будет ссылка на оригинал).
Самая простая схема:
С одной стороны сервер-источник, с дугой — компьютер, который готов принимать трафик.
Адрес мультикастового потока вы можете устанавливать сами.
И соответственно, два вопроса:
1. Что нужно сделать, чтобы компьютер мог получать поток и при этом не прибегать к мультикастовой маршрутизации?
2. Допустим, вы вообще не знаете, что такое мультикаст и не можете его настраивать, как передать поток от сервера к компьютеру?Задача легко ищется в поисковике, но попробуйте решить её сами.
Подробности задачи тут.
=====================

Незатронутыми в статье остались междоменная маршрутизация мультикастового трафика (MSDP, MBGP, BGMP), балансировка нагрузки между RP (Anycast RP), PGM, проприетарные протоколы. Но, я думаю, имея как точку старта эту статью, разобраться в остальном не составит труда.
Все термины, касающиеся мультикаста, вы можете найти в телекоммуникационном глоссарии lookmeup.
За помощь в подготовке статьи спасибо JDima…
За техническую поддержку спасибо Наташе Самойленко.
КДПВ нарисована Ниной Долгополовой — замечательным художником и другом проекта.
В пуле статей СДСМ ещё много интересного до окончания, поэтому не нужно хоронить цикл из-за долгого отсутствия выпуска — с каждой новой статьёй сложность значительно возрастает. Впереди почти весь MPLS, IPv6, QoS и дизайн сетей.
Как вы уже, наверно, заметили, у linkmeup появился новый проект — Глоссарий lookmeup (да, недалеко у нас ушла фантазия). Мы надеемся, что этот глоссарий станет самым полным справочником терминов в области связи, поэтому мы будем рады любой помощи в его заполнении. Пишите нам на info@linkmeup.ru
Оставайтесь с нами.
Содержание
- Понимание мультикаста и его значимость для сетевых технологий
- Особенности настройки мультикаста на роутере
- Преимущества и недостатки использования мультикаста на роутере
- Как улучшить производительность мультикаста на роутере
- Сравнение мультикаста и широковещательной рассылки на роутере
Понимание мультикаста и его значимость для сетевых технологий
Мультикаст – это метод передачи данных на одновременное вещание информации на несколько устройств. Это позволяет сократить нагрузку на сеть и оптимизировать ее работу.Значимость мультикаста для сетевых технологий заключается в том, что он позволяет передавать данные на большое количество устройств, не создавая лишней нагрузки на сеть. Это особенно актуально для трансляции видео и аудио, когда необходимо передавать информацию одновременно на множество устройств.Для работы с мультикастом необходимо использовать соответствующее оборудование, такое как маршрутизаторы и коммутаторы. Они должны поддерживать протоколы мультикаста, такие как IGMP и PIM.В целом, понимание мультикаста и его значимость для сетевых технологий позволяет оптимизировать работу сети и повысить ее эффективность при передаче данных на большое количество устройств. Какие услуги используют мультикаст на роутере
Мультикаст – это технология, которая позволяет передавать данные одновременно нескольким пользователям. Она используется в различных услугах, которые требуют массовой передачи информации. На роутере мультикаст используется для следующих услуг:
1. IPTV. Мультикаст позволяет передавать телевизионные каналы одновременно нескольким абонентам, что существенно экономит пропускную способность сети. Благодаря этому пользователи могут смотреть различные телеканалы в одно и то же время без задержек и тормозов.
2. Радиовещание. Мультикаст используется для передачи радиостанций в сети Интернет. Это позволяет слушателям получать радио в режиме реального времени без задержек.
3. Видеоконференции. Мультикаст позволяет передавать видео и аудио одновременно нескольким пользователям, что особенно важно для организации видеоконференций с большим количеством участников.
4. Онлайн-игры. Мультикаст используется для передачи игровых данных, что позволяет игрокам получать информацию о действиях других игроков в режиме реального времени.
Использование мультикаста на роутере позволяет значительно улучшить качество услуг, которые требуют передачи информации многим пользователям одновременно.
Особенности настройки мультикаста на роутере
Настройка мультикаста на роутере – это процесс, который позволяет передавать один и тот же поток данных на несколько устройств. Это особенно полезно для тех, кто хочет смотреть один телевизионный канал на нескольких телевизорах одновременно.
Для настройки мультикаста на роутере необходимо установить IP-адреса и порты мультикаст-группы. Это можно сделать с помощью специального программного обеспечения или веб-интерфейса роутера.
При настройке мультикаста на роутере необходимо учитывать ряд особенностей, таких как наличие поддержки мультикаста на устройствах в сети, настройка IGMP-сервера и IGMP-фильтров на роутере, а также оптимизация настроек сети для передачи мультикаст-трафика.
Важно помнить, что настройка мультикаста на роутере может повлиять на производительность сети, поэтому необходимо тщательно подходить к выбору настроек и следить за их оптимизацией.
Для проверки работы мультикаста на роутере необходимо выполнить несколько простых действий. Во-первых, убедитесь, что мультикаст включен на вашем роутере. Для этого зайдите в настройки роутера и найдите соответствующую опцию.
Во-вторых, проверьте, что ваше устройство подключено к сети, которая поддерживает мультикаст. Обычно это локальная сеть, в которой находится ваш роутер.
В-третьих, можно проверить работу мультикаста, отправив запрос на определенный адрес группы мультикаста. Для этого можно использовать утилиту ping с указанием адреса группы мультикаста.
Если запрос успешно отправлен и получен, то мультикаст на вашем роутере работает корректно. Если же возникают ошибки или запрос не получен, можно попробовать настроить роутер или проверить настройки на устройстве.
В любом случае, проверка работы мультикаста на роутере не займет много времени и поможет убедиться в правильной работе вашей сети.
Преимущества и недостатки использования мультикаста на роутере
Мультикаст на роутере – это технология, которая позволяет передавать данные с одного источника на несколько приемников одновременно. Она используется в различных приложениях, таких как IPTV, видеоконференции и другие.
Преимущества использования мультикаста на роутере включают:
– Экономия пропускной способности: при использовании мультикаста данные передаются только один раз, что позволяет снизить нагрузку на сеть и уменьшить затраты на трафик.
– Высокая эффективность: мультикаст обеспечивает быстрое распространение данных на несколько приемников, что позволяет сократить время передачи информации.
– Простота управления: использование мультикаста позволяет сократить количество устройств, которые необходимо настроить для передачи данных на несколько приемников.
Однако, использование мультикаста на роутере имеет и недостатки:
– Сложность настройки: настройка мультикаста на роутере может быть сложной задачей, особенно для пользователей, которые не имеют достаточного опыта в администрировании сетей.
– Необходимость использования специального оборудования: для работы с мультикастом на роутере необходимо использовать специальное оборудование, что может стать дополнительной нагрузкой на бюджет компании или организации.
В целом, использование мультикаста на роутере имеет свои преимущества и недостатки. Однако, при правильной настройке и использовании, эта технология может значительно улучшить производительность и эффективность работы сети.
Как улучшить производительность мультикаста на роутере
Мультикаст на роутере – это технология передачи данных, которая позволяет передавать один и тот же поток информации на несколько устройств одновременно. Она используется для передачи мультимедийных данных, например, видео и аудио, в сетях с большим количеством устройств.
Однако использование мультикаста может повлиять на производительность сети и привести к сбоям в ее работе. Чтобы избежать этого, рекомендуется применять следующие меры:
1. Оптимизация настроек роутера. Для улучшения производительности мультикаста на роутере необходимо настроить соответствующие параметры, например, IGMP Snooping и Multicast Routing. Это позволит оптимизировать передачу данных и снизить нагрузку на сеть.
2. Использование маршрутизации по протоколу PIM. Данный протокол позволяет оптимизировать передачу мультимедийных данных в сетях с большим количеством устройств. Он позволяет выбирать оптимальный путь для передачи потока данных и снижает нагрузку на сеть.
3. Использование кэширования мультимедийных данных на устройствах. Кэширование позволяет сохранять мультимедийные данные на устройствах, что позволяет снизить количество запросов на передачу данных в сети и увеличить производительность.
Все вышеперечисленные меры помогут улучшить производительность мультикаста на роутере и снизить нагрузку на сеть. При правильной настройке роутера и использовании соответствующих протоколов можно обеспечить стабильную работу сети при передаче мультимедийных данных.
Сравнение мультикаста и широковещательной рассылки на роутере
Мультикаст и широковещательная рассылка являются двумя основными методами передачи данных на роутере. Оба метода используются для доставки информации к нескольким устройствам одновременно, но имеют свои уникальные особенности.
Широковещательная рассылка (broadcast) используется для передачи информации всем устройствам в локальной сети. Каждое устройство в сети получает копию передаваемого сообщения. Этот метод эффективен для передачи информации, которая должна быть получена всеми устройствами в сети, например, для обнаружения новых устройств в сети.
Мультикаст (multicast) используется для передачи информации нескольким устройствам в локальной сети, которые являются частью определенной группы. Только устройства, которые являются членами группы, получают копию передаваемого сообщения. Этот метод более эффективен, чем широковещательная рассылка, потому что он уменьшает количество передаваемых данных в сети.
В целом, использование мультикаста на роутере может существенно улучшить производительность и эффективность сети. Он позволяет передавать информацию только тем устройствам, которые ее нуждаются, и уменьшает количество передаваемых данных в сети. Однако, использование широковещательной рассылки также необходимо в некоторых случаях, например, для обнаружения новых устройств в сети.
В итоге, выбор между мультикастом и широковещательной рассылкой на роутере зависит от конкретной задачи и требований к сети. Важно понимать разницу между этими методами передачи данных и выбирать тот, который наилучшим образом подходит для конкретной ситуации. Мультикаст – это технология передачи данных, которая позволяет одновременно доставлять одинаковую информацию нескольким устройствам в сети. Например, при просмотре видео онлайн, вместо того, чтобы каждый раз отправлять видео на каждое устройство в сети, используется мультикаст, чтобы доставить видео одновременно всем устройствам в группе.
В бизнесе мультикаст используется для передачи видеоконференций, онлайн-трансляций и других медиа-контента внутри организации. Это позволяет экономить пропускную способность сети и снижать нагрузку на серверы.
В домашней сети мультикаст может использоваться для стриминга медиа-контента на несколько устройств одновременно, а также для игр в режиме мультиплеера.
Для того, чтобы использовать мультикаст на роутере, необходимо включить эту функцию в настройках роутера. Не все модели роутеров поддерживают мультикаст, поэтому перед покупкой необходимо проверить технические характеристики.
В целом, мультикаст – это удобная технология для передачи медиа-контента в сети, которая позволяет снизить нагрузку на серверы и экономить пропускную способность. Однако, для использования мультикаста необходимо иметь подходящий роутер и правильно настроить его на работу с этой технологией.
Table Of Contents
Configuring IP Multicast Routing
Understanding Cisco’s Implementation of IP Multicast Routing
Understanding IGMP
IGMP Version 1
IGMP Version 2
Understanding PIM
PIM Versions
PIM Modes
PIM Stub Routing
IGMP Helper
Auto-RP
Bootstrap Router
Multicast Forwarding and Reverse Path Check
Configuring IP Multicast Routing
Default Multicast Routing Configuration
Multicast Routing Configuration Guidelines
PIMv1 and PIMv2 Interoperability
Auto-RP and BSR Configuration Guidelines
Configuring Basic Multicast Routing
Configuring PIM Stub Routing
PIM Stub Routing Configuration Guidelines
Enabling PIM Stub Routing
Configuring Source-Specific Multicast
SSM Components Overview
How SSM Differs from Internet Standard Multicast
SSM IP Address Range
SSM Operations
IGMPv3 Host Signalling
Configuration Guidelines
Configuring SSM
Monitoring SSM
Configuring Source Specific Multicast Mapping
Configuration Guidelines and Restrictions
SSM Mapping Overview
Configuring SSM Mapping
Monitoring SSM Mapping
Configuring a Rendezvous Point
Manually Assigning an RP to Multicast Groups
Configuring Auto-RP
Configuring PIMv2 BSR
Using Auto-RP and a BSR
Monitoring the RP Mapping Information
Troubleshooting PIMv1 and PIMv2 Interoperability Problems
Configuring Advanced PIM Features
Understanding PIM Shared Tree and Source Tree
Delaying the Use of PIM Shortest-Path Tree
Modifying the PIM Router-Query Message Interval
Configuring Optional IGMP Features
Default IGMP Configuration
Configuring the Switch as a Member of a Group
Controlling Access to IP Multicast Groups
Changing the IGMP Version
Modifying the IGMP Host-Query Message Interval
Changing the IGMP Query Timeout for IGMPv2
Changing the Maximum Query Response Time for IGMPv2
Configuring the Switch as a Statically Connected Member
Configuring Optional Multicast Routing Features
Configuring sdr Listener Support
Enabling sdr Listener Support
Limiting How Long an sdr Cache Entry Exists
Configuring an IP Multicast Boundary
Monitoring and Maintaining IP Multicast Routing
Clearing Caches, Tables, and Databases
Displaying System and Network Statistics
Monitoring IP Multicast Routing
Configuring IP Multicast Routing
This chapter describes how to configure IP multicast routing on the Cisco ME 3800X and ME 3600X switch. IP multicasting is a more efficient way to use network resources, especially for bandwidth-intensive services such as audio and video. IP multicast routing enables a host (source) to send packets to a group of hosts (receivers) anywhere within the IP network by using a special form of IP address called the IP multicast group address. The sending host inserts the multicast group address into the IP destination address field of the packet, and IP multicast routers and multilayer switches forward incoming IP multicast packets out all interfaces that lead to members of the multicast group. Any host, regardless of whether it is a member of a group, can sent to a group. However, only the members of a group receive the message.

Note ![]() For complete syntax and usage information for the commands used in this chapter, see the Cisco IOS IP Command Reference, Volume 3 of 3: Multicast, Release 12.2.
For complete syntax and usage information for the commands used in this chapter, see the Cisco IOS IP Command Reference, Volume 3 of 3: Multicast, Release 12.2.
•![]() Understanding Cisco’s Implementation of IP Multicast Routing
Understanding Cisco’s Implementation of IP Multicast Routing
•![]() Configuring IP Multicast Routing
Configuring IP Multicast Routing
•![]() Configuring Advanced PIM Features
Configuring Advanced PIM Features
•![]() Configuring Optional IGMP Features
Configuring Optional IGMP Features
•![]() Configuring Optional Multicast Routing Features
Configuring Optional Multicast Routing Features
•![]() Monitoring and Maintaining IP Multicast Routing
Monitoring and Maintaining IP Multicast Routing
Understanding Cisco’s Implementation of IP Multicast Routing
The switch supports these protocols to implement IP multicast routing:
•![]() Internet Group Management Protocol (IGMP) is used among hosts on a LAN and the routers (and multilayer switches) on that LAN to track the multicast groups of which hosts are members.
Internet Group Management Protocol (IGMP) is used among hosts on a LAN and the routers (and multilayer switches) on that LAN to track the multicast groups of which hosts are members.
•![]() Protocol-Independent Multicast (PIM) protocol is used among routers and multilayer switches to track which multicast packets to forward to each other and to their directly connected LANs.
Protocol-Independent Multicast (PIM) protocol is used among routers and multilayer switches to track which multicast packets to forward to each other and to their directly connected LANs.
According to IPv4 multicast standards, the MAC destination multicast address begins with 0100:5e and is appended by the last 23 bits of the IP address. On the Cisco ME switch, if the multicast packet does not match the switch multicast address, the packets are treated in this way:
•![]() If the packet has a multicast IP address and a unicast MAC address, the packet is forwarded in software. This can occur because some protocols on legacy devices use unicast MAC addresses with multicast IP addresses.
If the packet has a multicast IP address and a unicast MAC address, the packet is forwarded in software. This can occur because some protocols on legacy devices use unicast MAC addresses with multicast IP addresses.
•![]() If the packet has a multicast IP address and an unmatched multicast MAC address, the packet is dropped.
If the packet has a multicast IP address and an unmatched multicast MAC address, the packet is dropped.
This section contains this information:
•![]() Understanding IGMP
Understanding IGMP
•![]() Understanding PIM
Understanding PIM
Understanding IGMP
To participate in IP multicasting, multicast hosts, routers, and multilayer switches must have the IGMP operating. This protocol defines the querier and host roles:
•![]() A querier is a network device that sends query messages to discover which network devices are members of a given multicast group.
A querier is a network device that sends query messages to discover which network devices are members of a given multicast group.
•![]() A host is a receiver that sends report messages (in response to query messages) to inform a querier of a host membership.
A host is a receiver that sends report messages (in response to query messages) to inform a querier of a host membership.
A set of queriers and hosts that receive multicast data streams from the same source is called a multicast group. Queriers and hosts use IGMP messages to join and leave multicast groups.
Any host, regardless of whether it is a member of a group, can send to a group. However, only the members of a group receive the message. Membership in a multicast group is dynamic; hosts can join and leave at any time. There is no restriction on the location or number of members in a multicast group. A host can be a member of more than one multicast group at a time. How active a multicast group is and what members it has can vary from group to group and from time to time. A multicast group can be active for a long time, or it can be very short-lived. Membership in a group can constantly change. A group that has members can have no activity.
IP multicast traffic uses group addresses, which are class D addresses. The high-order bits of a Class D address are 1110. Therefore, host group addresses can be in the range 224.0.0.0 through 239.255.255.255. Multicast addresses in the range 224.0.0.0 to 24.0.0.255 are reserved for use by routing protocols and other network control traffic. The address 224.0.0.0 is guaranteed not to be assigned to any group.
IGMP packets are sent using these IP multicast group addresses:
•![]() IGMP general queries are destined to the address 224.0.0.1 (all systems on a subnet).
IGMP general queries are destined to the address 224.0.0.1 (all systems on a subnet).
•![]() IGMP group-specific queries are destined to the group IP address for which the switch is querying.
IGMP group-specific queries are destined to the group IP address for which the switch is querying.
•![]() IGMP group membership reports are destined to the group IP address for which the switch is reporting.
IGMP group membership reports are destined to the group IP address for which the switch is reporting.
•![]() IGMP Version 2 (IGMPv2) leave messages are destined to the address 224.0.0.2 (all-multicast-routers on a subnet). In some old host IP stacks, leave messages might be destined to the group IP address rather than to the all-routers address.
IGMP Version 2 (IGMPv2) leave messages are destined to the address 224.0.0.2 (all-multicast-routers on a subnet). In some old host IP stacks, leave messages might be destined to the group IP address rather than to the all-routers address.
IGMP Version 1
IGMP Version 1 (IGMPv1) primarily uses a query-response model that enables the multicast router and multilayer switch to find which multicast groups are active (have one or more hosts interested in a multicast group) on the local subnet. IGMPv1 has other processes that enable a host to join and leave a multicast group. For more information, see RFC 1112.
IGMP Version 2
IGMPv2 extends IGMP functionality by providing such features as the IGMP leave process to reduce leave latency, group-specific queries, and an explicit maximum query response time. IGMPv2 also adds the capability for routers to elect the IGMP querier without depending on the multicast protocol to perform this task. For more information, see RFC 2236.
Understanding PIM
PIM is called protocol-independent: regardless of the unicast routing protocols used to populate the unicast routing table, PIM uses this information to perform multicast forwarding instead of maintaining a separate multicast routing table.
PIM is defined in RFC 2362, Protocol-Independent Multicast-Sparse Mode (PIM-SM): Protocol Specification. PIM is defined in these Internet Engineering Task Force (IETF) Internet drafts:
•![]() Protocol Independent Multicast (PIM): Motivation and Architecture
Protocol Independent Multicast (PIM): Motivation and Architecture
•![]() Protocol Independent Multicast (PIM), Dense Mode Protocol Specification
Protocol Independent Multicast (PIM), Dense Mode Protocol Specification
•![]() Protocol Independent Multicast (PIM), Sparse Mode Protocol Specification
Protocol Independent Multicast (PIM), Sparse Mode Protocol Specification
•![]() draft-ietf-idmr-igmp-v2-06.txt, Internet Group Management Protocol, Version 2
draft-ietf-idmr-igmp-v2-06.txt, Internet Group Management Protocol, Version 2
•![]() draft-ietf-pim-v2-dm-03.txt, PIM Version 2 Dense Mode
draft-ietf-pim-v2-dm-03.txt, PIM Version 2 Dense Mode
This section includes this information about PIM:
•![]() PIM Versions
PIM Versions
•![]() PIM Modes
PIM Modes
•![]() PIM Stub Routing
PIM Stub Routing
•![]() IGMP Helper
IGMP Helper
•![]() Auto-RP
Auto-RP
•![]() Bootstrap Router
Bootstrap Router
•![]() Multicast Forwarding and Reverse Path Check
Multicast Forwarding and Reverse Path Check
PIM Versions
PIMv2 includes these improvements over PIMv1:
•![]() A single, active rendezvous point (RP) exists per multicast group, with multiple backup RPs. This single RP compares to multiple active RPs for the same group in PIMv1.
A single, active rendezvous point (RP) exists per multicast group, with multiple backup RPs. This single RP compares to multiple active RPs for the same group in PIMv1.
•![]() A bootstrap router (BSR) provides a fault-tolerant, automated RP discovery and distribution mechanism that enables routers and multilayer switches to dynamically learn the group-to-RP mappings.
A bootstrap router (BSR) provides a fault-tolerant, automated RP discovery and distribution mechanism that enables routers and multilayer switches to dynamically learn the group-to-RP mappings.
•![]() Sparse mode and dense mode are properties of a group, as opposed to an interface. We strongly recommend sparse-dense mode, as opposed to either sparse mode or dense mode only.
Sparse mode and dense mode are properties of a group, as opposed to an interface. We strongly recommend sparse-dense mode, as opposed to either sparse mode or dense mode only.
•![]() PIM join and prune messages have more flexible encoding for multiple address families.
PIM join and prune messages have more flexible encoding for multiple address families.
•![]() A more flexible hello packet format replaces the query packet to encode current and future capability options.
A more flexible hello packet format replaces the query packet to encode current and future capability options.
•![]() Register messages to an RP specify whether they are sent by a border router or a designated router.
Register messages to an RP specify whether they are sent by a border router or a designated router.
•![]() PIM packets are no longer inside IGMP packets; they are standalone packets.
PIM packets are no longer inside IGMP packets; they are standalone packets.
PIM Modes
PIM can operate in dense mode (DM), sparse mode (SM), or in sparse-dense mode (PIM DM-SM), which handles both sparse groups and dense groups at the same time.
PIM DM
PIM DM builds source-based multicast distribution trees. In dense mode, a PIM DM router or multilayer switch assumes that all other routers or multilayer switches forward multicast packets for a group. If a PIM DM device receives a multicast packet and has no directly connected members or PIM neighbors present, a prune message is sent back to the source to stop unwanted multicast traffic. Subsequent multicast packets are not flooded to this router or switch on this pruned branch because branches without receivers are pruned from the distribution tree, leaving only branches that contain receivers.
When a new receiver on a previously pruned branch of the tree joins a multicast group, the PIM DM device detects the new receiver and immediately sends a graft message up the distribution tree toward the source. When the upstream PIM DM device receives the graft message, it immediately puts the interface on which the graft was received into the forwarding state so that the multicast traffic begins flowing to the receiver.
PIM SM
PIM SM uses shared trees and shortest-path-trees (SPTs) to distribute multicast traffic to multicast receivers in the network. In PIM SM, a router or multilayer switch assumes that other routers or switches do not forward multicast packets for a group, unless there is an explicit request for the traffic (join message). When a host joins a multicast group using IGMP, its directly connected PIM SM device sends PIM join messages toward the root, also known as the RP. This join message travels router-by-router toward the root, constructing a branch of the shared tree as it goes.
The RP keeps track of multicast receivers. It also registers sources through register messages received from the source’s first-hop router (designated router [DR]) to complete the shared tree path from the source to the receiver. When using a shared tree, sources must send their traffic to the RP so that the traffic reaches all receivers.
Prune messages are sent up the distribution tree to prune multicast group traffic. This action permits branches of the shared tree or SPT that were created with explicit join messages to be torn down when they are no longer needed.
PIM Stub Routing
The PIM stub routing feature reduces resource usage by moving routed traffic closer to the end user.
In a network using PIM stub routing, the only allowable route for IP traffic to the user is through a switch that is configured with PIM stub routing. PIM passive interfaces are connected to Layer 2 access domains, such as VLANs, or to interfaces that are connected to other Layer 2 devices. Only directly connected multicast (IGMP) receivers and sources are allowed in the Layer 2 access domains. The PIM passive interfaces do not send or process any received PIM control packets.
When using PIM stub routing, you should configure the distribution and remote routers to use IP multicast routing and configure only the switch as a PIM stub router. The switch does not route transit traffic between distribution routers. You also need to configure a routed uplink port on the switch. The switch uplink port cannot be used with SVIs. If you need PIM for an SVI uplink port, you should upgrade to the IP services feature set.
You must also configure EIGRP stub routing when configuring PIM stub routing on the switch. For more information, see the «Configuring EIGRP Stub Routing» section.
The redundant PIM stub router topology is not supported. The redundant topology exists when there is more than one PIM router forwarding multicast traffic to a single access domain. PIM messages are blocked, and the PIM assert and designated router election mechanisms are not supported on the PIM passive interfaces. Only the nonredundant access router topology is supported by the PIM stub feature. By using a nonredundant topology, the PIM passive interface assumes that it is the only interface and designated router on that access domain.
In Figure 33-1, Switch A routed uplink port 25 is connected to the router and PIM stub routing is enabled on the VLAN 100 interfaces and on Host 3. This configuration allows the directly connected hosts to receive traffic from multicast source 200.1.1.3. See the «Configuring PIM Stub Routing» section for more information.
Figure 33-1 PIM Stub Router Configuration
IGMP Helper
PIM stub routing moves routed traffic closer to the end user and reduces network traffic. You can also reduce traffic by configuring a stub router (switch) with the IGMP helper feature.
You can configure a stub router (switch) with the igmp helper help-address interface configuration command to enable the switch to send reports to the next-hop interface. Hosts that are not directly connected to a downstream router can then join a multicast group sourced from an upstream network. The IGMP packets from a host wanting to join a multicast stream are forwarded upstream to the next-hop device when this feature is configured. When the upstream central router receives the helper IGMP reports or leaves, it adds or removes the interfaces from its outgoing interface list for that group.
For complete syntax and usage information for the ip igmp helper-address command, see the Cisco IOS IP Command Reference, Volume 3 Release 12.2:
http://www.cisco.com/en/US/docs/ios/12_2/ipmulti/command/reference/1rfindx3.html#LTR_I
Auto-RP
This proprietary feature eliminates the need to manually configure the RP information in every router and multilayer switch in the network. For Auto-RP to work, you configure a Cisco router or multilayer switch as the mapping agent. It uses IP multicast to learn which routers or switches in the network are possible candidate RPs to receive candidate RP announcements. Candidate RPs periodically send multicast RP-announce messages to a particular group or group range to announce their availability.
Mapping agents listen to these candidate RP announcements and use the information to create entries in their Group-to-RP mapping caches. Only one mapping cache entry is created for any Group-to-RP range received, even if multiple candidate RPs are sending RP announcements for the same range. As the RP-announce messages arrive, the mapping agent selects the router or switch with the highest IP address as the active RP and stores this RP address in the Group-to-RP mapping cache.
Mapping agents periodically multicast the contents of their Group-to-RP mapping cache. Thus, all routers and switches automatically discover which RP to use for the groups they support. If a router or switch fails to receive RP-discovery messages and the Group-to-RP mapping information expires, it switches to a statically configured RP that was defined with the ip pim rp-address global configuration command. If no statically configured RP exists, the router or switch changes the group to dense-mode operation.
Multiple RPs serve different group ranges or serve as hot backups of each other.
Bootstrap Router
PIMv2 BSR is another method to distribute group-to-RP mapping information to all PIM routers and multilayer switches in the network. It eliminates the need to manually configure RP information in every router and switch in the network. However, instead of using IP multicast to distribute group-to-RP mapping information, BSR uses hop-by-hop flooding of special BSR messages to distribute the mapping information.
The BSR is elected from a set of candidate routers and switches in the domain that have been configured to function as BSRs. The election mechanism is similar to the root-bridge election mechanism used in bridged LANs. The BSR election is based on the BSR priority of the device contained in the BSR messages that are sent hop-by-hop through the network. Each BSR device examines the message and forwards out all interfaces only the message that has either a higher BSR priority than its BSR priority or the same BSR priority, but with a higher BSR IP address. Using this method, the BSR is elected.
The elected BSR sends BSR messages with a TTL of 1. Neighboring PIMv2 routers or multilayer switches receive the BSR message and multicast it out all other interfaces (except the one on which it was received) with a TTL of 1. In this way, BSR messages travel hop-by-hop throughout the PIM domain. Because BSR messages contain the IP address of the current BSR, the flooding mechanism enables candidate RPs to automatically learn which device is the elected BSR.
Candidate RPs send candidate RP advertisements showing the group range for which they are responsible to the BSR, which stores this information in its local candidate-RP cache. The BSR periodically advertises the contents of this cache in BSR messages to all other PIM devices in the domain. These messages travel hop-by-hop through the network to all routers and switches, which store the RP information in the BSR message in their local RP cache. The routers and switches select the same RP for a given group because they all use a common RP hashing algorithm.
Multicast Forwarding and Reverse Path Check
With unicast routing, routers and multilayer switches forward traffic through the network along a single path from the source to the destination host whose IP address appears in the destination address field of the IP packet. Each router and switch along the way makes a unicast forwarding decision, using the destination IP address in the packet, by looking up the destination address in the unicast routing table and forwarding the packet through the specified interface to the next hop toward the destination.
With multicasting, the source is sending traffic to an arbitrary group of hosts represented by a multicast group address in the destination address field of the IP packet. To decide whether to forward or drop an incoming multicast packet, the router or multilayer switch uses a reverse path forwarding (RPF) check on the packet as follows and shown in Figure 33-2:
1. ![]() The router or multilayer switch examines the source address of the arriving multicast packet to decide whether the packet arrived on an interface that is on the reverse path back to the source.
The router or multilayer switch examines the source address of the arriving multicast packet to decide whether the packet arrived on an interface that is on the reverse path back to the source.
2. ![]() If the packet arrives on the interface leading back to the source, the RPF check is successful and the packet is forwarded to all interfaces in the outgoing interface list (which might not be all interfaces on the router).
If the packet arrives on the interface leading back to the source, the RPF check is successful and the packet is forwarded to all interfaces in the outgoing interface list (which might not be all interfaces on the router).
3. ![]() If the RPF check fails, the packet is discarded.
If the RPF check fails, the packet is discarded.
Some multicast routing protocols maintain a separate multicast routing table and use it for the RPF check. However, PIM uses the unicast routing table to perform the RPF check.
Note ![]() The switch does not handle RPF fail packets default; you can use the platform nl3mm rpf_fail_handling enable command to enable RPF fail packets handling.
The switch does not handle RPF fail packets default; you can use the platform nl3mm rpf_fail_handling enable command to enable RPF fail packets handling.
Figure 33-2 shows port 2 receiving a multicast packet from source 151.10.3.21. Table 33-1 shows that the port on the reverse path to the source is port 1, not port 2. Because the RPF check fails, the multilayer switch discards the packet. Another multicast packet from source 151.10.3.21 is received on port 1, and the routing table shows this port is on the reverse path to the source. Because the RPF check passes, the switch forwards the packet to all port in the outgoing port list.
Figure 33-2 RPF Check
|
Network |
Port |
|---|---|
|
151.10.0.0/16 |
Gigabit Ethernet 0/1 |
|
198.14.32.0/32 |
Fast Ethernet 0/1 |
|
204.1.16.0/24 |
Fast Ethernet 0/2 |
PIM uses both source trees and RP-rooted shared trees to forward datagrams (described in the «PIM DM» section and the «PIM SM» section). The RPF check is performed differently for each:
•![]() If a PIM router or multilayer switch has a source-tree state (that is, an (S,G) entry is present in the multicast routing table), it performs the RPF check against the IP address of the source of the multicast packet.
If a PIM router or multilayer switch has a source-tree state (that is, an (S,G) entry is present in the multicast routing table), it performs the RPF check against the IP address of the source of the multicast packet.
•![]() If a PIM router or multilayer switch has a shared-tree state (and no explicit source-tree state), it performs the RPF check on the RP address (which is known when members join the group).
If a PIM router or multilayer switch has a shared-tree state (and no explicit source-tree state), it performs the RPF check on the RP address (which is known when members join the group).
Sparse-mode PIM uses the RPF lookup function to decide where it needs to send joins and prunes:
•![]() (S,G) joins (which are source-tree states) are sent toward the source.
(S,G) joins (which are source-tree states) are sent toward the source.
•![]() (*,G) joins (which are shared-tree states) are sent toward the RP.
(*,G) joins (which are shared-tree states) are sent toward the RP.
Dense-mode PIM uses only source trees and use RPF as previously described.
Configuring IP Multicast Routing
•![]() Default Multicast Routing Configuration
Default Multicast Routing Configuration
•![]() Multicast Routing Configuration Guidelines
Multicast Routing Configuration Guidelines
•![]() Configuring Basic Multicast Routing (required)
Configuring Basic Multicast Routing (required)
•![]() Configuring PIM Stub Routing (optional)
Configuring PIM Stub Routing (optional)
•![]() Configuring Source-Specific Multicast
Configuring Source-Specific Multicast
•![]() Configuring Source Specific Multicast Mapping
Configuring Source Specific Multicast Mapping
•![]() Configuring a Rendezvous Point (required if the interface is in sparse-dense mode, and you want to treat the group as a sparse group)
Configuring a Rendezvous Point (required if the interface is in sparse-dense mode, and you want to treat the group as a sparse group)
•![]() Using Auto-RP and a BSR (required for non-Cisco PIMv2 devices to interoperate with Cisco PIM v1 devices))
Using Auto-RP and a BSR (required for non-Cisco PIMv2 devices to interoperate with Cisco PIM v1 devices))
•![]() Monitoring the RP Mapping Information (optional)
Monitoring the RP Mapping Information (optional)
•![]() Troubleshooting PIMv1 and PIMv2 Interoperability Problems (optional)
Troubleshooting PIMv1 and PIMv2 Interoperability Problems (optional)
Default Multicast Routing Configuration
Table 33-2 shows the default multicast routing configuration.
|
Feature |
Default Setting |
|---|---|
|
Multicast routing |
Disabled on all interfaces. |
|
PIM version |
Version 2. |
|
PIM mode |
No mode is defined. |
|
PIM RP address |
None configured. |
|
PIM domain border |
Disabled. |
|
PIM multicast boundary |
None. |
|
Candidate BSRs |
Disabled. |
|
Candidate RPs |
Disabled. |
|
Shortest-path tree threshold rate |
0 kbps. |
|
PIM router query message interval |
30 seconds. |
Multicast Routing Configuration Guidelines
•![]() PIMv1 and PIMv2 Interoperability
PIMv1 and PIMv2 Interoperability
•![]() Auto-RP and BSR Configuration Guidelines
Auto-RP and BSR Configuration Guidelines
PIMv1 and PIMv2 Interoperability
The Cisco PIMv2 implementation provides interoperability and transition between Version 1 and Version 2, although there might be some minor problems.
You can upgrade to PIMv2 incrementally. PIM Versions 1 and 2 can be configured on different routers and multilayer switches within one network. Internally, all routers and multilayer switches on a shared media network must run the same PIM version. Therefore, if a PIMv2 device detects a PIMv1 device, the Version 2 device downgrades itself to Version 1 until all Version 1 devices have been shut down or upgraded.
PIMv2 uses the BSR to discover and announce RP-set information for each group prefix to all the routers and multilayer switches in a PIM domain. PIMv1, together with the Auto-RP feature, can perform the same tasks as the PIMv2 BSR. However, Auto-RP is a standalone protocol, separate from PIMv1, and is a proprietary Cisco protocol. PIMv2 is a standards track protocol in the IETF. We recommend that you use PIMv2. The BSR mechanism interoperates with Auto-RP on Cisco routers and multilayer switches. For more information, see the «Auto-RP and BSR Configuration Guidelines» section.
When PIMv2 devices interoperate with PIMv1 devices, Auto-RP should have already been deployed. A PIMv2 BSR that is also an Auto-RP mapping agent automatically advertises the RP elected by Auto-RP. That is, Auto-RP sets its single RP on every router or multilayer switch in the group. Not all routers and switches in the domain use the PIMv2 hash function to select multiple RPs.
Dense-mode groups in a mixed PIMv1 and PIMv2 region need no special configuration; they automatically interoperate.
Sparse-mode groups in a mixed PIMv1 and PIMv2 region are possible because the Auto-RP feature in PIMv1 interoperates with the PIMv2 RP feature. Although all PIMv2 devices can also use PIMv1, we recommend that the RPs be upgraded to PIMv2. To ease the transition to PIMv2, we have these recommendations:
•![]() Use Auto-RP throughout the region.
Use Auto-RP throughout the region.
•![]() Configure sparse-dense mode throughout the region.
Configure sparse-dense mode throughout the region.
If Auto-RP is not already configured in the PIMv1 regions, configure Auto-RP. For more information, see the «Configuring Auto-RP» section.
Auto-RP and BSR Configuration Guidelines
There are two approaches to using PIMv2. You can use Version 2 exclusively in your network or migrate to Version 2 by employing a mixed PIM version environment.
•![]() If your network is all Cisco routers and multilayer switches, you can use either Auto-RP or BSR.
If your network is all Cisco routers and multilayer switches, you can use either Auto-RP or BSR.
•![]() If you have non-Cisco routers in your network, you must use BSR.
If you have non-Cisco routers in your network, you must use BSR.
•![]() If you have Cisco PIMv1 and PIMv2 routers and multilayer switches and non-Cisco routers, you must use both Auto-RP and BSR. If your network includes routers from other vendors, configure the Auto-RP mapping agent and the BSR on a Cisco PIMv2 device. Ensure that no PIMv1 device is located in the path a between the BSR and a non-Cisco PIMv2 device.
If you have Cisco PIMv1 and PIMv2 routers and multilayer switches and non-Cisco routers, you must use both Auto-RP and BSR. If your network includes routers from other vendors, configure the Auto-RP mapping agent and the BSR on a Cisco PIMv2 device. Ensure that no PIMv1 device is located in the path a between the BSR and a non-Cisco PIMv2 device.
•![]() Because bootstrap messages are sent hop-by-hop, a PIMv1 device prevents these messages from reaching all routers and multilayer switches in your network. Therefore, if your network has a PIMv1 device in it and only Cisco routers and multilayer switches, it is best to use Auto-RP.
Because bootstrap messages are sent hop-by-hop, a PIMv1 device prevents these messages from reaching all routers and multilayer switches in your network. Therefore, if your network has a PIMv1 device in it and only Cisco routers and multilayer switches, it is best to use Auto-RP.
•![]() If you have a network that includes non-Cisco routers, configure the Auto-RP mapping agent and the BSR on a Cisco PIMv2 router or multilayer switch. Ensure that no PIMv1 device is on the path between the BSR and a non-Cisco PIMv2 router.
If you have a network that includes non-Cisco routers, configure the Auto-RP mapping agent and the BSR on a Cisco PIMv2 router or multilayer switch. Ensure that no PIMv1 device is on the path between the BSR and a non-Cisco PIMv2 router.
•![]() If you have non-Cisco PIMv2 routers that need to interoperate with Cisco PIMv1 routers and multilayer switches, both Auto-RP and a BSR are required. We recommend that a Cisco PIMv2 device be both the Auto-RP mapping agent and the BSR. For more information, see the «Using Auto-RP and a BSR» section.
If you have non-Cisco PIMv2 routers that need to interoperate with Cisco PIMv1 routers and multilayer switches, both Auto-RP and a BSR are required. We recommend that a Cisco PIMv2 device be both the Auto-RP mapping agent and the BSR. For more information, see the «Using Auto-RP and a BSR» section.
Configuring Basic Multicast Routing
You must enable IP multicast routing and configure the PIM version and the PIM mode. Then the software can forward multicast packets, and the switch can populate its multicast routing table.
You can configure an interface to be in PIM dense mode, sparse mode, or sparse-dense mode. The switch populates its multicast routing table and forwards multicast packets it receives from its directly connected LANs according to the mode setting. You must enable PIM in one of these modes for an interface to perform IP multicast routing. Enabling PIM on an interface also enables IGMP operation on that interface.
Note ![]() If you enable PIM on multiple interfaces and most of these interfaces are not part of the outgoing interface list, when IGMP snooping is disabled the outgoing interface might not be able to sustain line rate for multicast traffic because of the extra, unnecessary replication.
If you enable PIM on multiple interfaces and most of these interfaces are not part of the outgoing interface list, when IGMP snooping is disabled the outgoing interface might not be able to sustain line rate for multicast traffic because of the extra, unnecessary replication.
In populating the multicast routing table, dense-mode interfaces are always added to the table. Sparse-mode interfaces are added to the table only when periodic join messages are received from downstream devices or when there is a directly connected member on the interface. When forwarding from a LAN, sparse-mode operation occurs if there is an RP known for the group. If so, the packets are encapsulated and sent toward the RP. When no RP is known, the packet is flooded in a dense-mode fashion. If the multicast traffic from a specific source is sufficient, the receiver’s first-hop router might send join messages toward the source to build a source-based distribution tree.
By default, multicast routing is disabled, and there is no default mode setting. This procedure is required.
Beginning in privileged EXEC mode, follow these steps to enable IP multicasting, to configure a PIM version, and to configure a PIM mode. This procedure is required.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip multicast-routing distributed |
Enable IP multicast distributed switching. |
|
Step 3 |
interface interface-id |
Specify the Layer 3 interface on which you want to enable multicast routing, and enter interface configuration mode. The specified interface must be one of the following: • • These interfaces must have IP addresses assigned to them. For more information, see the «Configuring Layer 3 Interfaces» section. |
|
Step 4 |
ip pim version [1 | 2] |
Configure the PIM version on the interface. By default, Version 2 is enabled and is the recommended setting. An interface in PIMv2 mode automatically downgrades to PIMv1 mode if that interface has a PIMv1 neighbor. The interface returns to Version 2 mode after all Version 1 neighbors are shut down or upgraded. For more information, see the «PIMv1 and PIMv2 Interoperability» section. |
|
Step 5 |
ip pim {dense-mode | sparse-mode | sparse-dense-mode} |
Enable a PIM mode on the interface. By default, no mode is configured. The keywords have these meanings: • • • |
|
Step 6 |
end |
Return to privileged EXEC mode. |
|
Step 7 |
show running-config |
Verify your entries. |
|
Step 8 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To disable multicasting, use the no ip multicast-routing distributed global configuration command. To return to the default PIM version, use the no ip pim version interface configuration command. To disable PIM on an interface, use the no ip pim interface configuration command.
Configuring PIM Stub Routing
The PIM Stub routing feature supports multicast routing between the distribution layer and the access layer. It supports two types of PIM interfaces, uplink PIM interfaces, and PIM passive interfaces. A routed interface configured with the PIM passive mode does not pass or forward PIM control traffic, it only passes and forwards IGMP traffic.
PIM Stub Routing Configuration Guidelines
•![]() Before configuring PIM stub routing, you must have IP multicast routing configured on both the stub router and the central router. You must also have PIM mode (dense-mode, sparse-mode, or dense-sparse-mode) configured on the uplink interface of the stub router.
Before configuring PIM stub routing, you must have IP multicast routing configured on both the stub router and the central router. You must also have PIM mode (dense-mode, sparse-mode, or dense-sparse-mode) configured on the uplink interface of the stub router.
•![]() The PIM stub router does not route the transit traffic between the distribution routers. Unicast (EIGRP) stub routing enforces this behavior. You must configure unicast stub routing to assist the PIM stub router behavior. For more information, see the «Configuring EIGRP Stub Routing» section.
The PIM stub router does not route the transit traffic between the distribution routers. Unicast (EIGRP) stub routing enforces this behavior. You must configure unicast stub routing to assist the PIM stub router behavior. For more information, see the «Configuring EIGRP Stub Routing» section.
•![]() Only directly connected multicast (IGMP) receivers and sources are allowed in the Layer 2 access domains. The PIM protocol is not supported in access domains.
Only directly connected multicast (IGMP) receivers and sources are allowed in the Layer 2 access domains. The PIM protocol is not supported in access domains.
•![]() The redundant PIM stub router topology is not supported.
The redundant PIM stub router topology is not supported.
Enabling PIM Stub Routing
Beginning in privileged EXEC mode, follow these steps to enable PIM stub routing on an interface. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface on which you want to enable PIM stub routing, and enter interface configuration mode. |
|
Step 3 |
ip pim passive |
Configure the PIM stub feature on the interface. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip pim interface |
Display the PIM stub that is enabled on each interface. |
|
Step 6 |
show running-config |
Verify your entries. |
|
Step 7 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To disable PIM stub routing on an interface, use the no ip pim passive interface configuration command.
In this example, IP multicast routing is enabled, Switch A PIM uplink port 25 is configured as a routed uplink port with spare-dense-mode enabled. PIM stub routing is enabled on the VLAN 100 interfaces and on Gigabit Ethernet port 20 in Figure 33-1:
Switch(config)# ip multicast-routing distributed
Switch(config)# interface GigabitEthernet0/25
Switch(config-if)# no switchport
Switch(config-if)# ip address 3.1.1.2 255.255.255.0
Switch(config-if)# ip pim sparse-dense-mode
Switch(config)# interface vlan100
Switch(config-if)# ip pim passive
Switch(config)# interface GigabitEthernet0/20
Switch(config-if)# ip pim passive
Switch(config)# interface vlan100
Switch(config-if)# ip address 100.1.1.1 255.255.255.0
Switch(config-if)# ip pim passive
Switch(config)# interface GigabitEthernet0/20
Switch(config-if)# no switchport
Switch(config-if)# ip address 10.1.1.1 255.255.255.0
Switch(config-if)# ip pim passive
To verify that PIM stub is enabled for each interface, use the show ip pim interface privileged EXEC command:
Switch# show ip pim interface
Address Interface Ver/ Nbr Query DR DR
3.1.1.2 GigabitEthernet0/25 v2/SD 1 30 1 3.1.1.2
100.1.1.1 Vlan100 v2/P 0 30 1 100.1.1.1
10.1.1.1 GigabitEthernet0/20 v2/P 0 30 1 10.1.1.1
Use these privileged EXEC commands to display information about PIM stub configuration and status:
•![]() show ip pim interface displays the PIM stub that is enabled on each interface.
show ip pim interface displays the PIM stub that is enabled on each interface.
•![]() show ip igmp detail displays the interested clients that have joined the specific multicast source group.
show ip igmp detail displays the interested clients that have joined the specific multicast source group.
•![]() show ip igmp mroute verifies that the multicast stream forwards from the source to the interested clients.
show ip igmp mroute verifies that the multicast stream forwards from the source to the interested clients.
Configuring Source-Specific Multicast
This section describes how to configure source-specific multicast (SSM). For a complete description of the SSM commands in this section, refer to the «IP Multicast Routing Commands» chapter of the Cisco IOS IP Command Reference, Volume 3 of 3: Multicast. To locate documentation for other commands that appear in this chapter, use the command reference master index, or search online.
The SSM feature is an extension of IP multicast in which datagram traffic is forwarded to receivers from only those multicast sources that the receivers have explicitly joined. For multicast groups configured for SSM, only SSM distribution trees (no shared trees) are created.
SSM Components Overview
SSM is a datagram delivery model that best supports one-to-many applications, also known as broadcast applications. SSM is a core networking technology for the Cisco implementation of IP multicast solutions targeted for audio and video broadcast application environments. The switch supports these components that support the implementation of SSM:
•![]() Protocol independent multicast source-specific mode (PIM-SSM)
Protocol independent multicast source-specific mode (PIM-SSM)
PIM-SSM is the routing protocol that supports the implementation of SSM and is derived from PIM sparse mode (PIM-SM).
•![]() Internet Group Management Protocol version 3 (IGMPv3)
Internet Group Management Protocol version 3 (IGMPv3)
To run SSM with IGMPv3, SSM must be supported in the Cisco IOS router, the host where the application is running, and the application itself.
How SSM Differs from Internet Standard Multicast
The current IP multicast infrastructure in the Internet and many enterprise intranets is based on the PIM-SM protocol and Multicast Source Discovery Protocol (MSDP). These protocols have the limitations of the Internet Standard Multicast (ISM) service model. For example, with ISM, the network must maintain knowledge about which hosts in the network are actively sending multicast traffic.
The ISM service consists of the delivery of IP datagrams from any source to a group of receivers called the multicast host group. The datagram traffic for the multicast host group consists of datagrams with an arbitrary IP unicast source address S and the multicast group address G as the IP destination address. Systems receive this traffic by becoming members of the host group.
Membership in a host group simply requires signalling the host group through IGMP version 1, 2, or 3. In SSM, delivery of datagrams is based on (S, G) channels. In both SSM and ISM, no signalling is required to become a source. However, in SSM, receivers must subscribe or unsubscribe to (S, G) channels to receive or not receive traffic from specific sources. In other words, receivers can receive traffic only from (S, G) channels to which they are subscribed, whereas in ISM, receivers need not know the IP addresses of sources from which they receive their traffic. The proposed standard approach for channel subscription signalling use IGMP include mode membership reports, which are supported only in IGMP version 3.
SSM IP Address Range
SSM can coexist with the ISM service by applying the SSM delivery model to a configured subset of the IP multicast group address range. Cisco IOS software allows SSM configuration for the IP multicast address range of 224.0.0.0 through 239.255.255.255. When an SSM range is defined, existing IP multicast receiver applications do not receive any traffic when they try to use an address in the SSM range (unless the application is modified to use an explicit (S, G) channel subscription).
SSM Operations
An established network, in which IP multicast service is based on PIM-SM, can support SSM services. SSM can also be deployed alone in a network without the full range of protocols that are required for interdomain PIM-SM (for example, MSDP, Auto-RP, or bootstrap router [BSR]) if only SSM service is needed.
If SSM is deployed in a network already configured for PIM-SM, only the last-hop routers support SSM. Routers that are not directly connected to receivers do not require support for SSM. In general, these not-last-hop routers must only run PIM-SM in the SSM range and might need additional access control configuration to suppress MSDP signalling, registering, or PIM-SM shared tree operations from occurring within the SSM range.
Use the ip pim ssm global configuration command to configure the SSM range and to enable SSM. This configuration has the following effects:
•![]() For groups within the SSM range, (S, G) channel subscriptions are accepted through IGMPv3 include-mode membership reports.
For groups within the SSM range, (S, G) channel subscriptions are accepted through IGMPv3 include-mode membership reports.
•![]() PIM operations within the SSM range of addresses change to PIM-SSM, a mode derived from PIM-SM. In this mode, only PIM (S, G) join and prune messages are generated by the router, and no (S, G) rendezvous point tree (RPT) or (*, G) RPT messages are generated. Incoming messages related to RPT operations are ignored or rejected, and incoming PIM register messages are immediately answered with register-stop messages. PIM-SSM is backward-compatible with PIM-SM unless a router is a last-hop router. Therefore, routers that are not last-hop routers can run PIM-SM for SSM groups (for example, if they do not yet support SSM).
PIM operations within the SSM range of addresses change to PIM-SSM, a mode derived from PIM-SM. In this mode, only PIM (S, G) join and prune messages are generated by the router, and no (S, G) rendezvous point tree (RPT) or (*, G) RPT messages are generated. Incoming messages related to RPT operations are ignored or rejected, and incoming PIM register messages are immediately answered with register-stop messages. PIM-SSM is backward-compatible with PIM-SM unless a router is a last-hop router. Therefore, routers that are not last-hop routers can run PIM-SM for SSM groups (for example, if they do not yet support SSM).
•![]() No MSDP source-active (SA) messages within the SSM range are accepted, generated, or forwarded.
No MSDP source-active (SA) messages within the SSM range are accepted, generated, or forwarded.
IGMPv3 Host Signalling
In IGMPv3, hosts signal membership to last hop routers of multicast groups. Hosts can signal group membership with filtering capabilities with respect to sources. A host can either signal that it wants to receive traffic from all sources sending to a group except for some specific sources (called exclude mode), or that it wants to receive traffic only from some specific sources sending to the group (called include mode).
IGMPv3 can operate with both ISM and SSM. In ISM, both exclude and include mode reports are applicable. In SSM, only include mode reports are accepted by the last-hop router. Exclude mode reports are ignored.
Configuration Guidelines
Legacy Applications Within the SSM Range Restrictions
Existing applications in a network predating SSM do not work within the SSM range unless they are modified to support (S, G) channel subscriptions. Therefore, enabling SSM in a network can cause problems for existing applications if they use addresses within the designated SSM range.
Address Management Restrictions
Address management is still necessary to some degree when SSM is used with Layer 2 switching mechanisms. Cisco Group Management Protocol (CGMP), IGMP snooping, or Router-Port Group Management Protocol (RGMP) support only group-specific filtering, not (S, G) channel-specific filtering. If different receivers in a switched network request different (S, G) channels sharing the same group, they do not benefit from these existing mechanisms. Instead, both receivers receive all (S, G) channel traffic and filter out the unwanted traffic on input. Because SSM can re-use the group addresses in the SSM range for many independent applications, this situation can lead to decreased traffic filtering in a switched network. For this reason, it is important to use random IP addresses from the SSM range for an application to minimize the chance for re-use of a single address within the SSM range between different applications. For example, an application service providing a set of television channels should, even with SSM, use a different group for each television (S, G) channel. This setup guarantees that multiple receivers to different channels within the same application service never experience traffic aliasing in networks that include Layer 2 switches.
IGMP Snooping and CGMP Limitations
IGMPv3 uses new membership report messages that might not be correctly recognized by older IGMP snooping switches.
For more information about switching issues related to IGMP (especially with CGMP), refer to the «Configuring IGMP Version 3» section of the «Configuring IP Multicast Routing» chapter.
State Maintenance Limitations
In PIM-SSM, the last hop router continues to periodically send (S, G) join messages if appropriate (S, G) subscriptions are on the interfaces. Therefore, as long as receivers send (S, G) subscriptions, the shortest path tree (SPT) state from the receivers to the source is maintained, even if the source does not send traffic for longer periods of time (or even never).
This case is opposite to PIM-SM, where (S, G) state is maintained only if the source is sending traffic and receivers are joining the group. If a source stops sending traffic for more than 3 minutes in PIM-SM, the (S, G) state is deleted and only re-established after packets from the source arrive again through the RPT. Because no mechanism in PIM-SSM notifies a receiver that a source is active, the network must maintain the (S, G) state in PIM-SSM as long as receivers are requesting receipt of that channel.
Configuring SSM
Beginning in privileged EXEC mode, follow these steps to configure SSM:
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
ip pim ssm [default | range access-list] |
Define the SSM range of IP multicast addresses. |
|
Step 2 |
interface type number |
Select an interface that is connected to hosts on which IGMPv3 can be enabled, and enter the interface configuration mode. |
|
Step 3 |
ip pim {sparse-mode | sparse-dense-mode} |
Enable PIM on an interface. You must use either sparse mode or sparse-dense mode. |
|
Step 4 |
ip igmp version 3 |
Enable IGMPv3 on this interface. The default version of IGMP is set to Version 2. |
Monitoring SSM
Use the commands in Table 33-3 to monitor SSM.
|
Command |
Purpose |
|---|---|
|
show ip igmp groups detail |
Display the (S, G) channel subscription through IGMPv3. |
|
show ip mroute |
Display whether a multicast group supports SSM service or whether a source-specific host report was received. |
Configuring Source Specific Multicast Mapping
The Source Specific Multicast (SSM) mapping feature supports SSM transition when supporting SSM on the end system is impossible or unwanted due to administrative or technical reasons. You can use SSM mapping to leverage SSM for video delivery to legacy STBs that do not support IGMPv3 or for applications that do not use the IGMPv3 host stack.
This section covers these topics:
•![]() Configuration Guidelines and Restrictions
Configuration Guidelines and Restrictions
•![]() SSM Mapping Overview
SSM Mapping Overview
•![]() Configuring SSM Mapping
Configuring SSM Mapping
•![]() Monitoring SSM Mapping
Monitoring SSM Mapping
Configuration Guidelines and Restrictions
SSM mapping configuration guidelines:
•![]() Before you configure SSM mapping, enable IP multicast routing, enable PIM sparse mode, and configure SSM. For information on enabling IP multicast routing and PIM sparse mode, see the «Default Multicast Routing Configuration» section.
Before you configure SSM mapping, enable IP multicast routing, enable PIM sparse mode, and configure SSM. For information on enabling IP multicast routing and PIM sparse mode, see the «Default Multicast Routing Configuration» section.
•![]() Before you configure static SSM mapping, you must configure access control lists (ACLs) that define the group ranges to be mapped to source addresses. For information on configuring an ACL, see Chapter 26 «Configuring Network Security with ACLs.»
Before you configure static SSM mapping, you must configure access control lists (ACLs) that define the group ranges to be mapped to source addresses. For information on configuring an ACL, see Chapter 26 «Configuring Network Security with ACLs.»
•![]() Before you can configure and use SSM mapping with DNS lookups, you must be able to add records to a running DNS server. If you do not already have a DNS server running, you need to install one.
Before you can configure and use SSM mapping with DNS lookups, you must be able to add records to a running DNS server. If you do not already have a DNS server running, you need to install one.
You can use a product such as Cisco Network Registrar.
SSM mapping restrictions:
•![]() The SSM mapping feature does not have all the benefits of full SSM. Because SSM mapping takes a group join from a host and identifies this group with an application associated with one or more sources, it can only support one such application per group. Full SSM applications can still share the same group as in SSM mapping.
The SSM mapping feature does not have all the benefits of full SSM. Because SSM mapping takes a group join from a host and identifies this group with an application associated with one or more sources, it can only support one such application per group. Full SSM applications can still share the same group as in SSM mapping.
•![]() Enable IGMPv3 with care on the last hop router when you rely solely on SSM mapping as a transition solution for full SSM. When you enable both SSM mapping and IGMPv3 and the hosts already support IGMPv3 (but not SSM), the hosts send IGMPv3 group reports. SSM mapping does not support these IGMPv3 group reports, and the router does not correctly associate sources with these reports.
Enable IGMPv3 with care on the last hop router when you rely solely on SSM mapping as a transition solution for full SSM. When you enable both SSM mapping and IGMPv3 and the hosts already support IGMPv3 (but not SSM), the hosts send IGMPv3 group reports. SSM mapping does not support these IGMPv3 group reports, and the router does not correctly associate sources with these reports.
SSM Mapping Overview
In a typical STB deployment, each TV channel uses one separate IP multicast group and has one active server host sending the TV channel. A single server can send multiple TV channels, but each to a different group. In this network environment, if a router receives an IGMPv1 or IGMPv2 membership report for a particular group, the report addresses the well-known TV server for the TV channel associated with the multicast group.
When SSM mapping is configured, if a router receives an IGMPv1 or IGMPv2 membership report for a particular group, the router translates this report into one or more channel memberships for the well-known sources associated with this group.
When the router receives an IGMPv1 or IGMPv2 membership report for a group, the router uses SSM mapping to determine one or more source IP addresses for the group. SSM mapping then translates the membership report as an IGMPv3 report and continues as if it had received an IGMPv3 report. The router then sends PIM joins and continues to be joined to these groups as long as it continues to receive the IGMPv1 or IGMPv2 membership reports, and the SSM mapping for the group remains the same.
SSM mapping enables the last hop router to determine the source addresses either by a statically configured table on the router or through a DNS server. When the statically configured table or the DNS mapping changes, the router leaves the current sources associated with the joined groups.
Go to this URL for additional information on SSM mapping:
http://www.cisco.com/en/US/docs/ios/12_3t/12_3t2/feature/guide/gtssmma.html
Static SSM Mapping
With static SSM mapping, you can configure the last hop router to use a static map to determine the sources that are sending to groups. Static SSM mapping requires that you configure ACLs to define group ranges. Then you can map the groups permitted by those ACLs to sources by using the ip igmp static ssm-map global configuration command.
You can configure static SSM mapping in smaller networks when a DNS is not needed or to locally override DNS mappings. When configured, static SSM mappings take precedence over DNS mappings.
DNS-Based SSM Mapping
You can use DNS-based SSM mapping to configure the last hop router to perform a reverse DNS lookup to determine sources sending to groups. When DNS-based SSM mapping is configured, the router constructs a domain name that includes the group address and performs a reverse lookup into the DNS. The router looks up IP address resource records and uses them as the source addresses associated with this group. SSM mapping supports up to 20 sources for each group. The router joins all sources configured for a group (see Figure 33-3).
Figure 33-3 DNS-Based SSM-Mapping
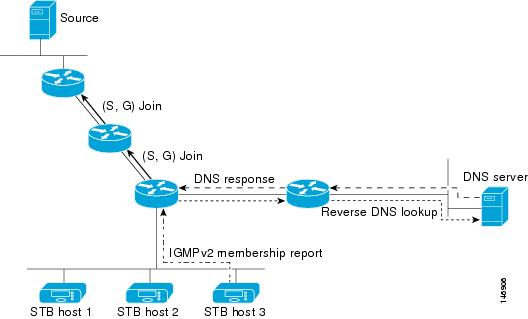
The SSM mapping mechanism that enables the last hop router to join multiple sources for a group can provide source redundancy for a TV broadcast. In this context, the last hop router provides redundancy using SSM mapping to simultaneously join two video sources for the same TV channel. However, to prevent the last hop router from duplicating the video traffic, the video sources must use a server-side switchover mechanism. One video source is active, and the other backup video source is passive. The passive source waits until an active source failure is detected before sending the video traffic for the TV channel. Thus, the server-side switchover mechanism ensures that only one of the servers is actively sending video traffic for the TV channel.
To look up one or more source addresses for a group that includes G1, G2, G3, and G4, you must configure these DNS records on the DNS server:
G4.G3.G2.G1 [multicast-domain] [timeout] IN A source-address-1 IN A source-address-2 IN A source-address-n
Refer to your DNS server documentation for more information about configuring DNS resource records, and go to this URL for additional information on SSM mapping:
http://www.cisco.com/en/US/docs/ios/12_3t/12_3t2/feature/guide/gtssmma.html
Configuring SSM Mapping
•![]() Configuring Static SSM Mapping (required)
Configuring Static SSM Mapping (required)
•![]() Configuring DNS-Based SSM Mapping (required)
Configuring DNS-Based SSM Mapping (required)
•![]() Configuring Static Traffic Forwarding with SSM Mapping (optional)
Configuring Static Traffic Forwarding with SSM Mapping (optional)
Configuring Static SSM Mapping
Beginning in privileged EXEC mode, follow these steps to configure static SSM mapping:
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip igmp ssm-map enable |
Enable SSM mapping for groups in the configured SSM range. Note |
|
Step 3 |
no ip igmp ssm-map query dns |
(Optional) Disable DNS-based SSM mapping. Note |
|
Step 4 |
ip igmp ssm-map static access-list source-address |
Configure static SSM mapping. The ACL supplied for access-list defines the groups to be mapped to the source IP address entered for the source-address. Note |
|
Step 5 |
Repeat Step 4 to configure additional static SSM mappings, if required. |
|
|
Step 6 |
end |
Return to privileged EXEC mode. |
|
Step 7 |
show running-config |
Verify your entries. |
|
Step 8 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
Go to this URL to see SSM mapping configuration examples:
http://www.cisco.com/en/US/docs/ios/12_3t/12_3t2/feature/guide/gtssmma.html
Configuring DNS-Based SSM Mapping
To configure DNS-based SSM mapping, you need to create a DNS server zone or add records to an existing zone. If the routers that are using DNS-based SSM mapping are also using DNS for other purposes, you should use a normally configured DNS server. If DNS-based SSM mapping is the only DNS implementation being used on the router, you can configure a false DNS setup with an empty root zone or a root zone that points back to itself.
Beginning in privileged EXEC mode, follow these steps to configure DNS-based SSM mapping:
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip igmp ssm-map enable |
Enable SSM mapping for groups in a configured SSM range. |
|
Step 3 |
ip igmp ssm-map query dns |
(Optional) Enable DNS-based SSM mapping. By default, the ip igmp ssm-map command enables DNS-based SSM mapping. Only the no form of this command is saved to the running configuration. Note |
|
Step 4 |
ip domain multicast domain-prefix |
(Optional) Change the domain prefix used by the switch for DNS-based SSM mapping. By default, the switch uses the ip-addr.arpa domain prefix. |
|
Step 5 |
ip name-server server-address1 [server-address2… server-address6] |
Specify the address of one or more name servers to use for name and address resolution. |
|
Step 6 |
Repeat Step 5 to configure additional DNS servers for redundancy, if required. |
— |
|
Step 7 |
end |
Return to privileged EXEC mode. |
|
Step 8 |
show running-config |
Verify your entries. |
|
Step 9 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
Configuring Static Traffic Forwarding with SSM Mapping
Use static traffic forwarding with SSM mapping to statically forward SSM traffic for certain groups.
Beginning in privileged EXEC mode, follow these steps to configure static traffic forwarding with SSM mapping:
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface type number |
Select an interface on which to statically forward traffic for a multicast group using SSM mapping, and enter interface configuration mode. Note |
|
Step 3 |
ip igmp static-group group-address source ssm-map |
Configure SSM mapping to statically forward a (S, G) channel from the interface. Use this command if you want to statically forward SSM traffic for certain groups. Use DNS-based SSM mapping to determine the source addresses of the channels. |
|
Step 4 |
show running-config |
Verify your entries. |
|
Step 5 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
Monitoring SSM Mapping
Use the privileged EXEC commands in Table 33-4 to monitor SSM mapping.
|
Command |
Purpose |
|---|---|
|
show ip igmp ssm-mapping |
Display information about SSM mapping. |
|
show ip igmp ssm-mapping group-address |
Display the sources that SSM mapping uses for a particular group. |
|
show ip igmp groups [group-name | group-address | interface-type interface-number] [detail] |
Display the multicast groups with receivers that are directly connected to the router and that were learned through IGMP. |
|
show host |
Display the default domain name, the style of name lookup service, a list of name server hosts, and the cached list of hostnames and addresses. |
|
debug ip igmp group-address |
Display the IGMP packets received and sent and IGMP host-related events. |
Go to this URL to see SSM mapping monitoring examples:
http://www.cisco.com/en/US/docs/ios/12_3t/12_3t2/feature/guide/gtssmma.html
Configuring a Rendezvous Point
You must have an RP if the interface is in sparse-dense mode and if you want to treat the group as a sparse group. You can use several methods, as described in these sections:
•![]() Manually Assigning an RP to Multicast Groups
Manually Assigning an RP to Multicast Groups
•![]() Configuring Auto-RP (a standalone, Cisco-proprietary protocol separate from PIMv1)
Configuring Auto-RP (a standalone, Cisco-proprietary protocol separate from PIMv1)
•![]() Configuring PIMv2 BSR (a standards track protocol in the Internet Engineering Task Force (IETF)
Configuring PIMv2 BSR (a standards track protocol in the Internet Engineering Task Force (IETF)
You can use Auto-RP, BSR, or a combination of both, depending on the PIM version you are running and the types of routers in your network. For more information, see the «PIMv1 and PIMv2 Interoperability» section and the «Auto-RP and BSR Configuration Guidelines» section.
Manually Assigning an RP to Multicast Groups
This section explains how to manually configure an RP. If the RP for a group is learned through a dynamic mechanism (such as Auto-RP or BSR), you need not perform this task for that RP.
Senders of multicast traffic announce their existence through register messages received from the source’s first-hop router (designated router) and forwarded to the RP. Receivers of multicast packets use RPs to join a multicast group by using explicit join messages. RPs are not members of the multicast group; rather, they serve as a meeting place for multicast sources and group members.
You can configure a single RP for multiple groups defined by an access list. If there is no RP configured for a group, the multilayer switch treats the group as dense and uses the dense-mode PIM techniques.
Beginning in privileged EXEC mode, follow these steps to manually configure the address of the RP. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip pim rp-address ip-address [access-list-number] [override] |
Configure the address of a PIM RP. By default, no PIM RP address is configured. You must configure the IP address of RPs on all routers and multilayer switches (including the RP). If there is no RP configured for a group, the switch treats the group as dense, using the dense-mode PIM techniques. A PIM device can be an RP for more than one group. Only one RP address can be used at a time within a PIM domain. The access-list conditions specify for which groups the device is an RP. • • • |
|
Step 3 |
access-list access-list-number {deny | permit} source [source-wildcard] |
Create a standard access list, repeating the command as many times as necessary. • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show running-config |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove an RP address, use the no ip pim rp-address ip-address [access-list-number] [override] global configuration command.
This example shows how to configure the address of the RP to 147.106.6.22 for multicast group 225.2.2.2 only:
Switch(config)# access-list 1 permit 225.2.2.2 0.0.0.0
Switch(config)# ip pim rp-address 147.106.6.22 1
Configuring Auto-RP
Auto-RP uses IP multicast to automate the distribution of group-to-RP mappings to all Cisco routers and multilayer switches in a PIM network. It has these benefits:
•![]() It is easy to use multiple RPs within a network to serve different group ranges.
It is easy to use multiple RPs within a network to serve different group ranges.
•![]() It provides load splitting among different RPs and arrangement of RPs according to the location of group participants.
It provides load splitting among different RPs and arrangement of RPs according to the location of group participants.
•![]() It avoids inconsistent, manual RP configurations on every router and multilayer switch in a PIM network, which can cause connectivity problems.
It avoids inconsistent, manual RP configurations on every router and multilayer switch in a PIM network, which can cause connectivity problems.
Note ![]() If you configure PIM in sparse mode or sparse-dense mode and do not configure Auto-RP, you must manually configure an RP as described in the «Manually Assigning an RP to Multicast Groups» section.
If you configure PIM in sparse mode or sparse-dense mode and do not configure Auto-RP, you must manually configure an RP as described in the «Manually Assigning an RP to Multicast Groups» section.
Note ![]() If routed interfaces are configured in sparse mode, Auto-RP can still be used if all devices are configured with a manual RP address for the Auto-RP groups.
If routed interfaces are configured in sparse mode, Auto-RP can still be used if all devices are configured with a manual RP address for the Auto-RP groups.
These sections describe how to configure Auto-RP:
•![]() Setting up Auto-RP in a New Internetwork (optional)
Setting up Auto-RP in a New Internetwork (optional)
•![]() Adding Auto-RP to an Existing Sparse-Mode Cloud (optional)
Adding Auto-RP to an Existing Sparse-Mode Cloud (optional)
•![]() Preventing Join Messages to False RPs (optional)
Preventing Join Messages to False RPs (optional)
•![]() Filtering Incoming RP Announcement Messages (optional)
Filtering Incoming RP Announcement Messages (optional)
For overview information, see the «Auto-RP» section.
Setting up Auto-RP in a New Internetwork
If you are setting up Auto-RP in a new internetwork, you do not need a default RP because you configure all the interfaces for sparse-dense mode. Follow the process described in the «Adding Auto-RP to an Existing Sparse-Mode Cloud» section. However, omit Step 3 if you want to configure a PIM router as the RP for the local group.
Adding Auto-RP to an Existing Sparse-Mode Cloud
This section contains some suggestions for the initial deployment of Auto-RP into an existing sparse-mode cloud to minimize disruption of the existing multicast infrastructure.
Beginning in privileged EXEC mode, follow these steps to deploy Auto-RP in an existing sparse-mode cloud. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
show running-config |
Verify that a default RP is already configured on all PIM devices and the RP in the sparse-mode network. It was previously configured with the ip pim rp-address global configuration command. This step is not required for spare-dense-mode environments. The selected RP should have good connectivity and be available across the network. Use this RP for the global groups (for example 224.x.x.x and other global groups). Do not reconfigure the group address range that this RP serves. RPs dynamically discovered through Auto-RP take precedence over statically configured RPs. Assume that it is desirable to use a second RP for the local groups. |
|
Step 2 |
configure terminal |
Enter global configuration mode. |
|
Step 3 |
ip pim send-rp-announce interface-id scope ttl group-list access-list-number interval seconds |
Configure another PIM device to be the candidate RP for local groups. • • • • |
|
Step 4 |
access-list access-list-number {deny | permit} source [source-wildcard] |
Create a standard access list, repeating the command as many times as necessary. • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 5 |
ip pim send-rp-discovery scope ttl |
Find a switch whose connectivity is not likely to be interrupted, and assign it the role of RP-mapping agent. For scope ttl, specify the time-to-live value in hops to limit the RP discovery packets. All devices within the hop count from the source device receive the Auto-RP discovery messages. These messages tell other devices which group-to-RP mapping to use to avoid conflicts (such as overlapping group-to-RP ranges). There is no default setting. The range is 1 to 255. |
|
Step 6 |
end |
Return to privileged EXEC mode. |
|
Step 7 |
show running-config show ip pim rp mapping show ip pim rp |
Verify your entries. Display active RPs that are cached with associated multicast routing entries. Display the information cached in the routing table. |
|
Step 8 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove the PIM device configured as the candidate RP, use the no ip pim send-rp-announce interface-id global configuration command. To remove the switch as the RP-mapping agent, use the no ip pim send-rp-discovery global configuration command.
This example shows how to send RP announcements out all PIM-enabled interfaces for a maximum of 31 hops. The IP address of port 1 is the RP. Access list 5 describes the group for which this switch serves as RP:
Switch(config)# ip pim send-rp-announce gigabitethernet0/1 scope 31 group-list 5
Switch(config)# access-list 5 permit 224.0.0.0 15.255.255.255
Preventing Join Messages to False RPs
Find whether the ip pim accept-rp command was previously configured throughout the network by using the show running-config privileged EXEC command. If the ip pim accept-rp command is not configured on any device, this problem can be addressed later. In those routers or multilayer switches already configured with the ip pim accept-rp command, you must enter the command again to accept the newly advertised RP.
To accept all RPs advertised with Auto-RP and reject all other RPs by default, use the ip pim accept-rp auto-rp global configuration command. This procedure is optional.
If all interfaces are in sparse mode, use a default-configured RP to support the two well-known groups 224.0.1.39 and 224.0.1.40. Auto-RP uses these two well-known groups to collect and distribute RP-mapping information. When this is the case and the ip pim accept-rp auto-rp command is configured, another ip pim accept-rp command accepting the RP must be configured as follows:
Switch(config)# ip pim accept-rp 172.10.20.1 1
Switch(config)# access-list 1 permit 224.0.1.39
Switch(config)# access-list 1 permit 224.0.1.40
Filtering Incoming RP Announcement Messages
You can add configuration commands to the mapping agents to prevent a maliciously configured router from masquerading as a candidate RP and causing problems.
Beginning in privileged EXEC mode, follow these steps to filter incoming RP announcement messages. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip pim rp-announce-filter rp-list access-list-number group-list access-list-number |
Filter incoming RP announcement messages. Enter this command on each mapping agent in the network. Without this command, all incoming RP-announce messages are accepted by default. For rp-list access-list-number, configure an access list of candidate RP addresses that, if permitted, is accepted for the group ranges supplied in the group-list access-list-number variable. If this variable is omitted, the filter applies to all multicast groups. If more than one mapping agent is used, the filters must be consistent across all mapping agents to ensure that no conflicts occur in the Group-to-RP mapping information. |
|
Step 3 |
access-list access-list-number {deny | permit} source [source-wildcard] |
Create a standard access list, repeating the command as many times as necessary. • • • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show running-config |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove a filter on incoming RP announcement messages, use the no ip pim rp-announce-filter rp-list access-list-number [group-list access-list-number] global configuration command.
This example shows a sample configuration on an Auto-RP mapping agent that is used to prevent candidate RP announcements from being accepted from unauthorized candidate RPs:
Switch(config)# ip pim rp-announce-filter rp-list 10 group-list 20
Switch(config)# access-list 10 permit host 172.16.5.1
Switch(config)# access-list 10 permit host 172.16.2.1
Switch(config)# access-list 20 deny 239.0.0.0 0.0.255.255
Switch(config)# access-list 20 permit 224.0.0.0 15.255.255.255
In this example, the mapping agent accepts candidate RP announcements from only two devices, 172.16.5.1 and 172.16.2.1. The mapping agent accepts candidate RP announcements from these two devices only for multicast groups that fall in the group range of 224.0.0.0 to 239.255.255.255. The mapping agent does not accept candidate RP announcements from any other devices in the network. Furthermore, the mapping agent does not accept candidate RP announcements from 172.16.5.1 or 172.16.2.1 if the announcements are for any groups in the 239.0.0.0 through 239.255.255.255 range. This range is the administratively scoped address range.
Configuring PIMv2 BSR
These sections describe how to set up BSR in your PIMv2 network:
•![]() Defining the PIM Domain Border (optional)
Defining the PIM Domain Border (optional)
•![]() Defining the IP Multicast Boundary (optional)
Defining the IP Multicast Boundary (optional)
•![]() Configuring Candidate BSRs (optional)
Configuring Candidate BSRs (optional)
•![]() Configuring Candidate RPs (optional)
Configuring Candidate RPs (optional)
For overview information, see the «Bootstrap Router» section.
Defining the PIM Domain Border
As IP multicast becomes more widespread, the chance of one PIMv2 domain bordering another PIMv2 domain is increasing. Because these two domains probably do not share the same set of RPs, BSR, candidate RPs, and candidate BSRs, you need to constrain PIMv2 BSR messages from flowing into or out of the domain. Allowing these messages to leak across the domain borders could adversely affect the normal BSR election mechanism and elect a single BSR across all bordering domains and co-mingle candidate RP advertisements, resulting in the election of RPs in the wrong domain.
Beginning in privileged EXEC mode, follow these steps to define the PIM domain border. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip pim bsr-border |
Define a PIM bootstrap message boundary for the PIM domain. Enter this command on each interface that connects to other bordering PIM domains. This command instructs the switch to neither send or receive PIMv2 BSR messages on this interface as shown in Figure 33-4. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show running-config |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove the PIM border, use the no ip pim bsr-border interface configuration command.
Figure 33-4 Constraining PIMv2 BSR Messages
Defining the IP Multicast Boundary
You define a multicast boundary to prevent Auto-RP messages from entering the PIM domain. You create an access list to deny packets destined for 224.0.1.39 and 224.0.1.40, which carry Auto-RP information.
Beginning in privileged EXEC mode, follow these steps to define a multicast boundary. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
access-list access-list-number deny source [source-wildcard] |
Create a standard access list, repeating the command as many times as necessary. • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 3 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 4 |
ip multicast boundary access-list-number |
Configure the boundary, specifying the access list you created in Step 2. |
|
Step 5 |
end |
Return to privileged EXEC mode. |
|
Step 6 |
show running-config |
Verify your entries. |
|
Step 7 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove the boundary, use the no ip multicast boundary interface configuration command.
This example shows a portion of an IP multicast boundary configuration that denies Auto-RP information:
Switch(config)# access-list 1 deny 224.0.1.39
Switch(config)# access-list 1 deny 224.0.1.40
Switch(config)# interface gigabitethernet0/1
Switch(config-if)# ip multicast boundary 1
Configuring Candidate BSRs
You can configure one or more candidate BSRs. The devices serving as candidate BSRs should have good connectivity to other devices and be in the backbone portion of the network.
Beginning in privileged EXEC mode, follow these steps to configure your switch as a candidate BSR. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip pim bsr-candidate interface-id hash-mask-length [priority] |
Configure your switch to be a candidate BSR. • • • |
|
Step 3 |
end |
Return to privileged EXEC mode. |
|
Step 4 |
show running-config |
Verify your entries. |
|
Step 5 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove this device as a candidate BSR, use the no ip pim bsr-candidate global configuration command.
This example shows how to configure a candidate BSR, which uses the IP address 172.21.24.18 on a port as the advertised BSR address, uses 30 bits as the hash-mask-length, and has a priority of 10.
Switch(config)# interface gigabitethernet0/2
Switch(config-if)# ip address 172.21.24.18 255.255.255.0
Switch(config-if)# ip pim sparse-dense-mode
Switch(config-if)# ip pim bsr-candidate gigabitethernet0/2 30 10
Configuring Candidate RPs
You can configure one or more candidate RPs. Similar to BSRs, the RPs should also have good connectivity to other devices and be in the backbone portion of the network. An RP can serve the entire IP multicast address space or a portion of it. Candidate RPs send candidate RP advertisements to the BSR. When deciding which devices should be RPs, consider these options:
•![]() In a network of Cisco routers and multilayer switches where only Auto-RP is used, any device can be configured as an RP.
In a network of Cisco routers and multilayer switches where only Auto-RP is used, any device can be configured as an RP.
•![]() In a network that includes only Cisco PIMv2 routers and multilayer switches and with routers from other vendors, any device can be used as an RP.
In a network that includes only Cisco PIMv2 routers and multilayer switches and with routers from other vendors, any device can be used as an RP.
•![]() In a network of Cisco PIMv1 routers, Cisco PIMv2 routers, and routers from other vendors, configure only Cisco PIMv2 routers and multilayer switches as RPs.
In a network of Cisco PIMv1 routers, Cisco PIMv2 routers, and routers from other vendors, configure only Cisco PIMv2 routers and multilayer switches as RPs.
Beginning in privileged EXEC mode, follow these steps to configure your switch to advertise itself as a PIMv2 candidate RP to the BSR. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip pim rp-candidate interface-id [group-list access-list-number] |
Configure your switch to be a candidate RP. • • |
|
Step 3 |
access-list access-list-number {deny | permit} source [source-wildcard] |
Create a standard access list, repeating the command as many times as necessary. • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show running-config |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove this device as a candidate RP, use the no ip pim rp-candidate interface-id global configuration command.
This example shows how to configure the switch to advertise itself as a candidate RP to the BSR in its PIM domain. Standard access list number 4 specifies the group prefix associated with the RP that has the address identified by a port. That RP is responsible for the groups with the prefix 239.
Switch(config)# ip pim rp-candidate gigabitethernet0/2 group-list 4
Switch(config)# access-list 4 permit 239.0.0.0 0.255.255.255
Using Auto-RP and a BSR
If there are only Cisco devices in you network (no routers from other vendors), there is no need to configure a BSR. Configure Auto-RP in a network that is running both PIMv1 and PIMv2.
If you have non-Cisco PIMv2 routers that need to interoperate with Cisco PIMv1 routers and multilayer switches, both Auto-RP and a BSR are required. We recommend that a Cisco PIMv2 router or multilayer switch be both the Auto-RP mapping agent and the BSR.
If you must have one or more BSRs, we have these recommendations:
•![]() Configure the candidate BSRs as the RP-mapping agents for Auto-RP. For more information, see the «Configuring Auto-RP» section and the «Configuring Candidate BSRs» section.
Configure the candidate BSRs as the RP-mapping agents for Auto-RP. For more information, see the «Configuring Auto-RP» section and the «Configuring Candidate BSRs» section.
•![]() For group prefixes advertised through Auto-RP, the PIMv2 BSR mechanism should not advertise a subrange of these group prefixes served by a different set of RPs. In a mixed PIMv1 and PIMv2 domain, have backup RPs serve the same group prefixes. This prevents the PIMv2 DRs from selecting a different RP from those PIMv1 DRs, due to the longest match lookup in the RP-mapping database.
For group prefixes advertised through Auto-RP, the PIMv2 BSR mechanism should not advertise a subrange of these group prefixes served by a different set of RPs. In a mixed PIMv1 and PIMv2 domain, have backup RPs serve the same group prefixes. This prevents the PIMv2 DRs from selecting a different RP from those PIMv1 DRs, due to the longest match lookup in the RP-mapping database.
Beginning in privileged EXEC mode, follow these steps to verify the consistency of group-to-RP mappings. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
show ip pim rp [[group-name | group-address] | mapping] |
On any Cisco device, display the available RP mappings. • • • |
|
Step 2 |
show ip pim rp-hash group |
On a PIMv2 router or multilayer switch, confirm that the same RP is the one that a PIMv1 system chooses. For group, enter the group address for which to display RP information. |
Monitoring the RP Mapping Information
To monitor the RP mapping information, use these commands in privileged EXEC mode:
•![]() show ip pim bsr displays information about the elected BSR.
show ip pim bsr displays information about the elected BSR.
•![]() show ip pim rp-hash group displays the RP that was selected for the specified group.
show ip pim rp-hash group displays the RP that was selected for the specified group.
•![]() show ip pim rp [group-name | group-address | mapping] displays how the switch learns of the RP (through the BSR or the Auto-RP mechanism).
show ip pim rp [group-name | group-address | mapping] displays how the switch learns of the RP (through the BSR or the Auto-RP mechanism).
Troubleshooting PIMv1 and PIMv2 Interoperability Problems
When debugging interoperability problems between PIMv1 and PIMv2, check these in the order shown:
1. ![]() Verify RP mapping with the show ip pim rp-hash privileged EXEC command, making sure that all systems agree on the same RP for the same group.
Verify RP mapping with the show ip pim rp-hash privileged EXEC command, making sure that all systems agree on the same RP for the same group.
2. ![]() Verify interoperability between different versions of DRs and RPs. Make sure the RPs are interacting with the DRs properly (by responding with register-stops and forwarding decapsulated data packets from registers).
Verify interoperability between different versions of DRs and RPs. Make sure the RPs are interacting with the DRs properly (by responding with register-stops and forwarding decapsulated data packets from registers).
Configuring Advanced PIM Features
•![]() Understanding PIM Shared Tree and Source Tree
Understanding PIM Shared Tree and Source Tree
•![]() Delaying the Use of PIM Shortest-Path Tree (optional)
Delaying the Use of PIM Shortest-Path Tree (optional)
•![]() Modifying the PIM Router-Query Message Interval (optional)
Modifying the PIM Router-Query Message Interval (optional)
Understanding PIM Shared Tree and Source Tree
By default, members of a group receive data from senders to the group across a single data-distribution tree rooted at the RP. Figure 33-5 shows this type of shared-distribution tree. Data from senders is delivered to the RP for distribution to group members joined to the shared tree.
Figure 33-5 Shared Tree and Source Tree (Shortest-Path Tree)
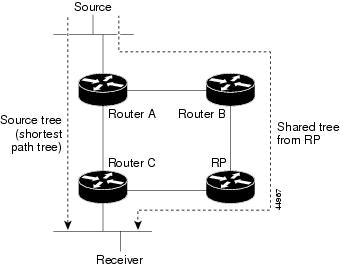
If the data rate warrants, leaf routers (routers without any downstream connections) on the shared tree can use the data distribution tree rooted at the source. This type of distribution tree is called a shortest-path tree or source tree. By default, the software switches to a source tree upon receiving the first data packet from a source.
This process describes the move from a shared tree to a source tree:
1. ![]() A receiver joins a group; leaf Router C sends a join message toward the RP.
A receiver joins a group; leaf Router C sends a join message toward the RP.
2. ![]() The RP puts a link to Router C in its outgoing interface list.
The RP puts a link to Router C in its outgoing interface list.
3. ![]() A source sends data; Router A encapsulates the data in a register message and sends it to the RP.
A source sends data; Router A encapsulates the data in a register message and sends it to the RP.
4. ![]() The RP forwards the data down the shared tree to Router C and sends a join message toward the source. At this point, data might arrive twice at Router C, once encapsulated and once natively.
The RP forwards the data down the shared tree to Router C and sends a join message toward the source. At this point, data might arrive twice at Router C, once encapsulated and once natively.
5. ![]() When data arrives natively (unencapsulated) at the RP, it sends a register-stop message to Router A.
When data arrives natively (unencapsulated) at the RP, it sends a register-stop message to Router A.
6. ![]() By default, reception of the first data packet prompts Router C to send a join message toward the source.
By default, reception of the first data packet prompts Router C to send a join message toward the source.
7. ![]() When Router C receives data on (S,G), it sends a prune message for the source up the shared tree.
When Router C receives data on (S,G), it sends a prune message for the source up the shared tree.
8. ![]() The RP deletes the link to Router C from the outgoing interface of (S,G). The RP triggers a prune message toward the source.
The RP deletes the link to Router C from the outgoing interface of (S,G). The RP triggers a prune message toward the source.
Join and prune messages are sent for sources and RPs. They are sent hop-by-hop and are processed by each PIM device along the path to the source or RP. Register and register-stop messages are not sent hop-by-hop. They are sent by the designated router that is directly connected to a source and are received by the RP for the group.
Multiple sources sending to groups use the shared tree.
You can configure the PIM device to stay on the shared tree. For more information, see the «Delaying the Use of PIM Shortest-Path Tree» section.
Delaying the Use of PIM Shortest-Path Tree
The change from shared to source tree happens when the first data packet arrives at the last-hop router (Router C in Figure 33-5). This change occurs because the ip pim spt-threshold global configuration command controls that timing.
The shortest-path tree requires more memory than the shared tree but reduces delay. You might want to postpone its use. Instead of allowing the leaf router to immediately move to the shortest-path tree, you can specify that the traffic must first reach a threshold.
You can configure when a PIM leaf router should join the shortest-path tree for a specified group. If a source sends at a rate greater than or equal to the specified kbps rate, the multilayer switch triggers a PIM join message toward the source to construct a source tree (shortest-path tree). If the traffic rate from the source drops below the threshold value, the leaf router switches back to the shared tree and sends a prune message toward the source.
You can specify to which groups the shortest-path tree threshold applies by using a group list (a standard access list). If a value of 0 is specified or if the group list is not used, the threshold applies to all groups.
Beginning in privileged EXEC mode, follow these steps to configure a traffic rate threshold that must be reached before multicast routing is switched from the source tree to the shortest-path tree. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
access-list access-list-number {deny | permit} source [source-wildcard] |
Create a standard access list. • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 3 |
ip pim spt-threshold {kbps | infinity} [group-list access-list-number] |
Specify the threshold that must be reached before moving to shortest-path tree (spt). • Note • • |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show running-config |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To return to the default setting, use the no ip pim spt-threshold {kbps | infinity} global configuration command.
Modifying the PIM Router-Query Message Interval
PIM routers and multilayer switches send PIM router-query messages to find which device will be the DR for each LAN segment (subnet). The DR is responsible for sending IGMP host-query messages to all hosts on the directly connected LAN.
With PIM DM operation, the DR has meaning only if IGMPv1 is in use. IGMPv1 does not have an IGMP querier election process, so the elected DR functions as the IGMP querier. With PIM SM operation, the DR is the device that is directly connected to the multicast source. It sends PIM register messages to notify the RP that multicast traffic from a source needs to be forwarded down the shared tree. In this case, the DR is the device with the highest IP address.
Beginning in privileged EXEC mode, follow these steps to modify the router-query message interval. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip pim query-interval seconds |
Configure the frequency at which the switch sends PIM router-query messages. The default is 30 seconds. The range is 1 to 65535. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To return to the default setting, use the no ip pim query-interval [seconds] interface configuration command.
Configuring Optional IGMP Features
•![]() Default IGMP Configuration
Default IGMP Configuration
•![]() Configuring the Switch as a Member of a Group (optional)
Configuring the Switch as a Member of a Group (optional)
•![]() Controlling Access to IP Multicast Groups (optional)
Controlling Access to IP Multicast Groups (optional)
•![]() Changing the IGMP Version (optional)
Changing the IGMP Version (optional)
•![]() Modifying the IGMP Host-Query Message Interval (optional)
Modifying the IGMP Host-Query Message Interval (optional)
•![]() Changing the IGMP Query Timeout for IGMPv2 (optional)
Changing the IGMP Query Timeout for IGMPv2 (optional)
•![]() Changing the Maximum Query Response Time for IGMPv2 (optional)
Changing the Maximum Query Response Time for IGMPv2 (optional)
•![]() Configuring the Switch as a Statically Connected Member (optional)
Configuring the Switch as a Statically Connected Member (optional)
Default IGMP Configuration
Table 33-5 shows the default IGMP configuration.
|
Feature |
Default Setting |
|---|---|
|
Multilayer switch as a member of a multicast group |
No group memberships are defined. |
|
Access to multicast groups |
All groups are allowed on an interface. |
|
IGMP version |
Version 2 on all interfaces. |
|
IGMP host-query message interval |
60 seconds on all interfaces. |
|
IGMP query timeout |
60 seconds on all interfaces. |
|
IGMP maximum query response time |
10 seconds on all interfaces. |
|
Multilayer switch as a statically connected member |
Disabled. |
Configuring the Switch as a Member of a Group
You can configure the switch as a member of a multicast group and discover multicast reachability in a network. If all the multicast-capable routers and multilayer switches that you administer are members of a multicast group, pinging that group causes all these devices to respond. The devices respond to IGMP echo-request packets addressed to a group of which they are members. Another example is the multicast trace-route tools provided in the software.

Caution
![]() Performing this procedure might impact the CPU performance because the CPU will receive all data traffic for the group address.
Performing this procedure might impact the CPU performance because the CPU will receive all data traffic for the group address.
Beginning in privileged EXEC mode, follow these steps to configure the switch to be a member of a group. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip igmp join-group group-address |
Configure the switch to join a multicast group. By default, no group memberships are defined. For group-address, specify the multicast IP address in dotted decimal notation. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To cancel membership in a group, use the no ip igmp join-group group-address interface configuration command.
This example shows how to enable the switch to join multicast group 255.2.2.2:
Switch(config)# interface gigabitethernet0/1
Switch(config-if)# ip igmp join-group 255.2.2.2
Controlling Access to IP Multicast Groups
The switch sends IGMP host-query messages to find which multicast groups have members on attached local networks. The switch then forwards to these group members all packets addressed to the multicast group. You can place a filter on each interface to restrict the multicast groups that hosts on the subnet serviced by the interface can join.
Beginning in privileged EXEC mode, follow these steps to filter multicast groups allowed on an interface. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip igmp access-group access-list-number |
Specify the multicast groups that hosts on the subnet serviced by an interface can join. By default, all groups are allowed on an interface. For access-list-number, specify an IP standard access list number. The range is 1 to 99. |
|
Step 4 |
exit |
Return to global configuration mode. |
|
Step 5 |
access-list access-list-number {deny | permit} source [source-wildcard] |
Create a standard access list. • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 6 |
end |
Return to privileged EXEC mode. |
|
Step 7 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 8 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To disable groups on an interface, use the no ip igmp access-group interface configuration command.
This example shows how to configure hosts attached to a port as able to join only group 255.2.2.2:
Switch(config)# access-list 1 255.2.2.2 0.0.0.0
Switch(config-if)# interface gigabitethernet0/1
Switch(config-if)# ip igmp access-group 1
Changing the IGMP Version
By default, the switch uses IGMP Version 2, which provides features such as the IGMP query timeout and the maximum query response time.
All systems on the subnet must support the same version. The switch does not automatically detect Version 1 systems and switch to Version 1. You can mix Version 1 and Version 2 hosts on the subnet because Version 2 routers or switches always work correctly with IGMPv1 hosts.
Configure the switch for Version 1 if your hosts do not support Version 2.
Beginning in privileged EXEC mode, follow these steps to change the IGMP version. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip igmp version {1 | 2} |
Specify the IGMP version that the switch uses. Note |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To return to the default setting, use the no ip igmp version interface configuration command.
Modifying the IGMP Host-Query Message Interval
The switch periodically sends IGMP host-query messages to discover which multicast groups are present on attached networks. These messages are sent to the all-hosts multicast group (224.0.0.1) with a time-to-live (TTL) of 1. The switch sends host-query messages to refresh its knowledge of memberships present on the network. If, after some number of queries, the software discovers that no local hosts are members of a multicast group, the software stops forwarding multicast packets to the local network from remote origins for that group and sends a prune message upstream toward the source.
The switch elects a PIM designated router (DR) for the LAN (subnet). The DR is the router or multilayer switch with the highest IP address for IGMPv2. For IGMPv1, the DR is elected according to the multicast routing protocol that runs on the LAN. The designated router is responsible for sending IGMP host-query messages to all hosts on the LAN. In sparse mode, the designated router also sends PIM register and PIM join messages toward the RP router.
Beginning in privileged EXEC mode, follow these steps to modify the host-query interval. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip igmp query-interval seconds |
Configure the frequency at which the designated router sends IGMP host-query messages. By default, the designated router sends IGMP host-query messages every 60 seconds to keep the IGMP overhead very low on hosts and networks. The range is 1 to 65535. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To return to the default setting, use the no ip igmp query-interval interface configuration command.
Changing the IGMP Query Timeout for IGMPv2
If you are using IGMPv2, you can specify the period of time before the switch takes over as the querier for the interface. By default, the switch waits twice the query interval controlled by the ip igmp query-interval interface configuration command. After that time, if the switch has received no queries, it becomes the querier.
You can configure the query interval by entering the show ip igmp interface interface-id privileged EXEC command.
Beginning in privileged EXEC mode, follow these steps to change the IGMP query timeout. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip igmp querier-timeout seconds |
Specify the IGMP query timeout. The default is 60 seconds (twice the query interval). The range is 60 to 300. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To return to the default setting, use the no ip igmp querier-timeout interface configuration command.
Changing the Maximum Query Response Time for IGMPv2
If you are using IGMPv2, you can change the maximum query response time advertised in IGMP queries. The maximum query response time enables the switch to quickly detect that there are no more directly connected group members on a LAN. Decreasing the value enables the switch to prune groups faster.
Beginning in privileged EXEC mode, follow these steps to change the maximum query response time. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip igmp query-max-response-time seconds |
Change the maximum query response time advertised in IGMP queries. The default is 10 seconds. The range is 1 to 25. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To return to the default setting, use the no ip igmp query-max-response-time interface configuration command.
Configuring the Switch as a Statically Connected Member
Sometimes there is either no group member on a network segment or a host cannot report its group membership by using IGMP. However, you might want multicast traffic to go to that network segment. These are ways to pull multicast traffic down to a network segment:
•![]() Use the ip igmp join-group interface configuration command. With this method, the switch accepts the multicast packets in addition to forwarding them. Accepting the multicast packets prevents the switch from fast switching.
Use the ip igmp join-group interface configuration command. With this method, the switch accepts the multicast packets in addition to forwarding them. Accepting the multicast packets prevents the switch from fast switching.
•![]() Use the ip igmp static-group interface configuration command. With this method, the switch does not accept the packets itself, but only forwards them. This method enables fast switching. The outgoing interface appears in the IGMP cache, but the switch itself is not a member, as evidenced by lack of an L (local) flag in the multicast route entry.
Use the ip igmp static-group interface configuration command. With this method, the switch does not accept the packets itself, but only forwards them. This method enables fast switching. The outgoing interface appears in the IGMP cache, but the switch itself is not a member, as evidenced by lack of an L (local) flag in the multicast route entry.
Beginning in privileged EXEC mode, follow these steps to configure the switch itself to be a statically connected member of a group (and enable fast switching). This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 3 |
ip igmp static-group group-address |
Configure the switch as a statically connected member of a group. By default, this feature is disabled. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show ip igmp interface [interface-id] |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove the switch as a member of the group, use the no ip igmp static-group group-address interface configuration command.
Configuring Optional Multicast Routing Features
•![]() Configuring sdr Listener Support (optional)—for MBONE multimedia conference session and set up
Configuring sdr Listener Support (optional)—for MBONE multimedia conference session and set up
•![]() Configuring an IP Multicast Boundary (optional)—to control bandwidth utilization.
Configuring an IP Multicast Boundary (optional)—to control bandwidth utilization.
Configuring sdr Listener Support
The MBONE is the small subset of Internet routers and hosts that are interconnected and capable of forwarding IP multicast traffic. Other multimedia content is often broadcast over the MBONE. Before you can join a multimedia session, you need to know what multicast group address and port are being used for the session, when the session is going to be active, and what sort of applications (audio, video, and so forth) are required on your workstation. The MBONE Session Directory Version 2 (sdr) tool provides this information. This freeware application can be downloaded from several sites on the World Wide Web, one of which is http://www.video.ja.net/mice/index.html.
SDR is a multicast application that listens to a well-known multicast group address and port for Session Announcement Protocol (SAP) multicast packets from SAP clients, which announce their conference sessions. These SAP packets contain a session description, the time the session is active, its IP multicast group addresses, media format, contact person, and other information about the advertised multimedia session. The information in the SAP packet is displayed in the SDR Session Announcement window.
Enabling sdr Listener Support
By default, the switch does not listen to session directory advertisements.
Beginning in privileged EXEC mode, follow these steps to enable the switch to join the default session directory group (224.2.127.254) on the interface and listen to session directory advertisements. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
interface interface-id |
Specify the interface to be enabled for sdr, and enter interface configuration mode. |
|
Step 3 |
ip sdr listen |
Enable sdr listener support. |
|
Step 4 |
end |
Return to privileged EXEC mode. |
|
Step 5 |
show running-config |
Verify your entries. |
|
Step 6 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To disable sdr support, use the no ip sdr listen interface configuration command.
Limiting How Long an sdr Cache Entry Exists
By default, entries are never deleted from the sdr cache. You can limit how long the entry remains active so that if a source stops advertising SAP information, old advertisements are not needlessly kept.
Beginning in privileged EXEC mode, follow these steps to limit how long an sdr cache entry stays active in the cache. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
ip sdr cache-timeout minutes |
Limit how long an sdr cache entry stays active in the cache. By default, entries are never deleted from the cache. For minutes, the range is 1 to 4294967295. |
|
Step 3 |
end |
Return to privileged EXEC mode. |
|
Step 4 |
show running-config |
Verify your entries. |
|
Step 5 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To return to the default setting, use the no ip sdr cache-timeout global configuration command. To delete the entire cache, use the clear ip sdr privileged EXEC command.
To display the session directory cache, use the show ip sdr privileged EXEC command.
Configuring an IP Multicast Boundary
Administratively-scoped boundaries can be used to limit the forwarding of multicast traffic outside of a domain or subdomain. This approach uses a special range of multicast addresses, called administratively-scoped addresses, as the boundary mechanism. If you configure an administratively-scoped boundary on a routed interface, multicast traffic whose multicast group addresses fall in this range can not enter or exit this interface, thereby providing a firewall for multicast traffic in this address range.
Note ![]() Multicast boundaries and TTL thresholds control the scoping of multicast domains; however, TTL thresholds are not supported by the switch. You should use multicast boundaries instead of TTL thresholds to limit the forwarding of multicast traffic outside of a domain or a subdomain.
Multicast boundaries and TTL thresholds control the scoping of multicast domains; however, TTL thresholds are not supported by the switch. You should use multicast boundaries instead of TTL thresholds to limit the forwarding of multicast traffic outside of a domain or a subdomain.
Figure 33-6 shows that Company XYZ has an administratively-scoped boundary set for the multicast address range 239.0.0.0/8 on all routed interfaces at the perimeter of its network. This boundary prevents any multicast traffic in the range 239.0.0.0 through 239.255.255.255 from entering or leaving the network. Similarly, the engineering and marketing departments have an administratively-scoped boundary of 239.128.0.0/16 around the perimeter of their networks. This boundary prevents multicast traffic in the range of 239.128.0.0 through 239.128.255.255 from entering or leaving their respective networks.
Figure 33-6 Administratively-Scoped Boundaries
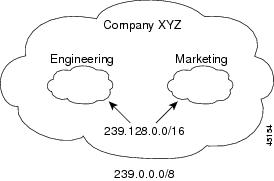
You can define an administratively-scoped boundary on a routed interface for multicast group addresses. A standard access list defines the range of addresses affected. When a boundary is defined, no multicast data packets are allowed to flow across the boundary from either direction. The boundary allows the same multicast group address to be reused in different administrative domains.
The IANA has designated the multicast address range 239.0.0.0 to 239.255.255.255 as the administratively-scoped addresses. This range of addresses can then be reused in domains administered by different organizations. The addresses would be considered local, not globally unique.
Beginning in privileged EXEC mode, follow these steps to set up an administratively-scoped boundary. This procedure is optional.
|
Command |
Purpose |
|
|---|---|---|
|
Step 1 |
configure terminal |
Enter global configuration mode. |
|
Step 2 |
access-list access-list-number {deny | permit} source [source-wildcard] |
Create a standard access list, repeating the command as many times as necessary. • • • • Recall that the access list is always terminated by an implicit deny statement for everything. |
|
Step 3 |
interface interface-id |
Specify the interface to be configured, and enter interface configuration mode. |
|
Step 4 |
ip multicast boundary access-list-number |
Configure the boundary, specifying the access list you created in Step 2. |
|
Step 5 |
end |
Return to privileged EXEC mode. |
|
Step 6 |
show running-config |
Verify your entries. |
|
Step 7 |
copy running-config startup-config |
(Optional) Save your entries in the configuration file. |
To remove the boundary, use the no ip multicast boundary interface configuration command.
This example shows how to set up a boundary for all administratively-scoped addresses:
Switch(config)# access-list 1 deny 239.0.0.0 0.255.255.255
Switch(config)# access-list 1 permit 224.0.0.0 15.255.255.255
Switch(config)# interface gigabitethernet0/1
Switch(config-if)# ip multicast boundary 1
Monitoring and Maintaining IP Multicast Routing
•![]() Clearing Caches, Tables, and Databases
Clearing Caches, Tables, and Databases
•![]() Displaying System and Network Statistics
Displaying System and Network Statistics
•![]() Monitoring IP Multicast Routing
Monitoring IP Multicast Routing
Clearing Caches, Tables, and Databases
You can remove all contents of a particular cache, table, or database. Clearing a cache, table, or database might be necessary when the contents of the particular structure are or suspected to be invalid.
You can use any of the privileged EXEC commands in Table 33-6 to clear IP multicast caches, tables, and databases:
|
Command |
Purpose |
|---|---|
|
clear ip igmp group [group-name | group-address | interface] |
Delete entries from the IGMP cache. |
|
clear ip mroute {* | group [source]} |
Delete entries from the IP multicast routing table. |
|
clear ip pim auto-rp rp-address |
Clear the Auto-RP cache. |
|
clear ip sdr [group-address | «session-name«] |
Delete the Session Directory Protocol Version 2 cache or an sdr cache entry. |
Displaying System and Network Statistics
You can display specific statistics, such as the contents of IP routing tables, caches, and databases.
Note ![]() The switch does not support per-route statistics.
The switch does not support per-route statistics.
You can display information to learn resource utilization and solve network problems. You can also display information about node reachability and discover the routing path your device’s packets are taking through the network.
You can use any of the privileged EXEC commands in Table 33-7 to display various routing statistics:
|
Command |
Purpose |
|---|---|
|
ping [group-name | group-address] |
Send an ICMP Echo Request to a multicast group address. |
|
show ip igmp groups [group-name | group-address | type number] |
Display the multicast groups that are directly connected to the switch and that were learned through IGMP. |
|
show ip igmp interface [type number] |
Display multicast-related information about an interface. |
|
show ip mcache [group [source]] |
Display the contents of the IP fast-switching cache. |
|
show ip mpacket [source-address | name] [group-address | name] [detail] |
Display the contents of the circular cache-header buffer. |
|
show ip mroute [group-name | group-address] [source] [summary] [count] [active kbps] |
Display the contents of the IP multicast routing table. |
|
show ip pim interface [type number] [count] |
Display information about interfaces configured for PIM. |
|
show ip pim neighbor [type number] |
List the PIM neighbors discovered by the switch. |
|
show ip pim rp [group-name | group-address] |
Display the RP routers associated with a sparse-mode multicast group. |
|
show ip rpf {source-address | name} |
Display how the switch is doing Reverse-Path Forwarding (that is, from the unicast routing table or static mroutes). |
|
show ip sdr [group | «session-name« | detail] |
Display the Session Directory Protocol Version 2 cache. |
Monitoring IP Multicast Routing
You can use the privileged EXEC commands in Table 33-8 to monitor IP multicast routers, packets, and paths:
|
Command |
Purpose |
|---|---|
|
mrinfo [hostname | address] [source-address | interface] |
Query a multicast router or multilayer switch about which neighboring multicast devices are peering with it. |
|
mstat source [destination] [group] |
Display IP multicast packet rate and loss information. |
|
mtrace source [destination] [group] |
Trace the path from a source to a destination branch for a multicast distribution tree for a given group. |