Список из 256 символов и их коды в ASCII.
1
Управляющие символы
| DEC | OCT | HEX | BIN | Символ | Escape послед. | HTML код | Описание |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL | \0 | � | Нулевой байт |
| 1 | 001 | 0x01 | 00000001 | SOH |  | Начало заголовка | |
| 2 | 002 | 0x02 | 00000010 | STX |  | Начало текста | |
| 3 | 003 | 0x03 | 00000011 | ETX |  | Конец «текста» | |
| 4 | 004 | 0x04 | 00000100 | EOT |  | конец передачи | |
| 5 | 005 | 0x05 | 00000101 | ENQ |  | «Прошу подтверждения!» | |
| 6 | 006 | 0x06 | 00000110 | ACK |  | «Подтверждаю!» | |
| 7 | 007 | 0x07 | 00000111 | BEL | \a |  | Звуковой сигнал – звонок |
| 8 | 010 | 0x08 | 00001000 | BS | \b |  | Возврат на один символ (BACKSPACE) |
| 9 | 011 | 0x09 | 00001001 | TAB | \t | 	 | Табуляция |
| 10 | 012 | 0x0A | 00001010 | LF | \n | 
 | Перевод строки |
| 11 | 013 | 0x0B | 00001011 | VT | \v |  | Вертикальная табуляция |
| 12 | 014 | 0x0C | 00001100 | FF | \f |  | Прогон страницы, новая страница |
| 13 | 015 | 0x0D | 00001101 | CR | \r | 
 | Возврат каретки |
| 14 | 016 | 0x0E | 00001110 | SO |  | Переключиться на другую ленту (кодировку) | |
| 15 | 017 | 0x0F | 00001111 | SI |  | Переключиться на исходную ленту (кодировку) | |
| 16 | 020 | 0x10 | 00010000 | DLE |  | Экранирование канала данных | |
| 17 | 021 | 0x11 | 00010001 | DC1 |  | 1-й символ управления устройством | |
| 18 | 022 | 0x12 | 00010010 | DC2 |  | 2-й символ управления устройством | |
| 19 | 023 | 0x13 | 00010011 | DC3 |  | 3-й символ управления устройством | |
| 20 | 024 | 0x14 | 00010100 | DC4 |  | 4-й символ управления устройством | |
| 21 | 025 | 0x15 | 00010101 | NAK |  | «Не подтверждаю!» | |
| 22 | 026 | 0x16 | 00010110 | SYN |  | Символ для синхронизации | |
| 23 | 027 | 0x17 | 00010111 | ETB |  | Конец текстового блока | |
| 24 | 030 | 0x18 | 00011000 | CAN |  | Отмена | |
| 25 | 031 | 0x19 | 00011001 | EM |  | Конец носителя | |
| 26 | 032 | 0x1A | 00011010 | SUB |  | Подставить | |
| 27 | 033 | 0x1B | 00011011 | ESC | \e |  | Escape (Расширение) |
| 28 | 034 | 0x1C | 00011100 | FS |  | Разделитель файлов | |
| 29 | 035 | 0x1D | 00011101 | GS |  | Разделитель групп | |
| 30 | 036 | 0x1E | 00011110 | RS |  | Разделитель записей | |
| 31 | 037 | 0x1F | 00011111 | US |  | Разделитель юнитов | |
| 127 | 177 | 0x7F | 01111111 | Delete |  | Символ для удаления (на перфолентах) |
2
Печатные символы
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | Пробел |   | |
| 33 | 041 | 0x21 | 00100001 | ! | ! | |
| 34 | 042 | 0x22 | 00100010 | « | " | " |
| 35 | 043 | 0x23 | 00100011 | # | # | |
| 36 | 044 | 0x24 | 00100100 | $ | $ | |
| 37 | 045 | 0x25 | 00100101 | % | % | |
| 38 | 046 | 0x26 | 00100110 | & | & | & |
| 39 | 047 | 0x27 | 00100111 | ‘ | ' | ' |
| 40 | 050 | 0x28 | 00101000 | ( | ( | |
| 41 | 051 | 0x29 | 00101001 | ) | ) | |
| 42 | 052 | 0x2A | 00101010 | * | * | |
| 43 | 053 | 0x2B | 00101011 | + | + | |
| 44 | 054 | 0x2C | 00101100 | , | , | |
| 45 | 055 | 0x2D | 00101101 | — | - | |
| 46 | 056 | 0x2E | 00101110 | . | . | |
| 47 | 057 | 0x2F | 00101111 | / | / | |
| 48 | 060 | 0x30 | 00110000 | 0 | 0 | |
| 49 | 061 | 0x31 | 00110001 | 1 | 1 | |
| 50 | 062 | 0x32 | 00110010 | 2 | 2 | |
| 51 | 063 | 0x33 | 00110011 | 3 | 3 | |
| 52 | 064 | 0x34 | 00110100 | 4 | 4 | |
| 53 | 065 | 0x35 | 00110101 | 5 | 5 | |
| 54 | 066 | 0x36 | 00110110 | 6 | 6 | |
| 55 | 067 | 0x37 | 00110111 | 7 | 7 | |
| 56 | 070 | 0x38 | 00111000 | 8 | 8 | |
| 57 | 071 | 0x39 | 00111001 | 9 | 9 | |
| 58 | 072 | 0x3A | 00111010 | : | : | |
| 59 | 073 | 0x3B | 00111011 | ; | ; | |
| 60 | 074 | 0x3C | 00111100 | < | < | < |
| 61 | 075 | 0x3D | 00111101 | = | = | |
| 62 | 076 | 0x3E | 00111110 | > | > | > |
| 63 | 077 | 0x3F | 00111111 | ? | ? | |
| 64 | 100 | 0x40 | 01000000 | @ | @ | |
| 65 | 101 | 0x41 | 01000001 | A | A | |
| 66 | 102 | 0x42 | 01000010 | B | B | |
| 67 | 103 | 0x43 | 01000011 | C | C | |
| 68 | 104 | 0x44 | 01000100 | D | D | |
| 69 | 105 | 0x45 | 01000101 | E | E | |
| 70 | 106 | 0x46 | 01000110 | F | F | |
| 71 | 107 | 0x47 | 01000111 | G | G | |
| 72 | 110 | 0x48 | 01001000 | H | H | |
| 73 | 111 | 0x49 | 01001001 | I | I | |
| 74 | 112 | 0x4A | 01001010 | J | J | |
| 75 | 113 | 0x4B | 01001011 | K | K | |
| 76 | 114 | 0x4C | 01001100 | L | L | |
| 77 | 115 | 0x4D | 01001101 | M | M | |
| 78 | 116 | 0x4E | 01001110 | N | N | |
| 79 | 117 | 0x4F | 01001111 | O | O | |
| 80 | 120 | 0x50 | 01010000 | P | P | |
| 81 | 121 | 0x51 | 01010001 | Q | Q | |
| 82 | 122 | 0x52 | 01010010 | R | R | |
| 83 | 123 | 0x53 | 01010011 | S | S | |
| 84 | 124 | 0x54 | 01010100 | T | T | |
| 85 | 125 | 0x55 | 01010101 | U | U | |
| 86 | 126 | 0x56 | 01010110 | V | V | |
| 87 | 127 | 0x57 | 01010111 | W | W | |
| 88 | 130 | 0x58 | 01011000 | X | X | |
| 89 | 131 | 0x59 | 01011001 | Y | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | [ | |
| 92 | 134 | 0x5C | 01011100 | \ | \ | |
| 93 | 135 | 0x5D | 01011101 | ] | ] | |
| 94 | 136 | 0x5E | 01011110 | ^ | ^ | |
| 95 | 137 | 0x5F | 01011111 | _ | _ | |
| 96 | 140 | 0x60 | 01100000 | ` | ` | |
| 97 | 141 | 0x61 | 01100001 | a | a | |
| 98 | 142 | 0x62 | 01100010 | b | b | |
| 99 | 143 | 0x63 | 01100011 | c | c | |
| 100 | 144 | 0x64 | 01100100 | d | d | |
| 101 | 145 | 0x65 | 01100101 | e | e | |
| 102 | 146 | 0x66 | 01100110 | f | f | |
| 103 | 147 | 0x67 | 01100111 | g | g | |
| 104 | 150 | 0x68 | 01101000 | h | h | |
| 105 | 151 | 0x69 | 01101001 | i | i | |
| 106 | 152 | 0x6A | 01101010 | j | j | |
| 107 | 153 | 0x6B | 01101011 | k | k | |
| 108 | 154 | 0x6C | 01101100 | l | l | |
| 109 | 155 | 0x6D | 01101101 | m | m | |
| 110 | 156 | 0x6E | 01101110 | n | n | |
| 111 | 157 | 0x6F | 01101111 | o | o | |
| 112 | 160 | 0x70 | 01110000 | p | p | |
| 113 | 161 | 0x71 | 01110001 | q | q | |
| 114 | 162 | 0x72 | 01110010 | r | r | |
| 115 | 163 | 0x73 | 01110011 | s | s | |
| 116 | 164 | 0x74 | 01110100 | t | t | |
| 117 | 165 | 0x75 | 01110101 | u | u | |
| 118 | 166 | 0x76 | 01110110 | v | v | |
| 119 | 167 | 0x77 | 01110111 | w | w | |
| 120 | 170 | 0x78 | 01111000 | x | x | |
| 121 | 171 | 0x79 | 01111001 | y | y | |
| 122 | 172 | 0x7A | 01111010 | z | z | |
| 123 | 173 | 0x7B | 01111011 | { | { | |
| 124 | 174 | 0x7C | 01111100 | | | | | |
| 125 | 175 | 0x7D | 01111101 | } | } | |
| 126 | 176 | 0x7E | 01111110 | ~ | ~ |
3
Расширенные символы ASCII Win-1251 кириллица
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ | € | |
| 129 | 201 | 0x81 | 10000001 | Ѓ |  | |
| 130 | 202 | 0x82 | 10000010 | ‚ | ‚ | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ | ƒ | |
| 132 | 204 | 0x84 | 10000100 | „ | „ | „ |
| 133 | 205 | 0x85 | 10000101 | … | … | … |
| 134 | 206 | 0x86 | 10000110 | † | † | † |
| 135 | 207 | 0x87 | 10000111 | ‡ | ‡ | ‡ |
| 136 | 210 | 0x88 | 10001000 | € | ˆ | € |
| 137 | 211 | 0x89 | 10001001 | ‰ | ‰ | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ | Š | |
| 139 | 213 | 0x8B | 10001011 | ‹ | ‹ | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ | Œ | |
| 141 | 215 | 0x8D | 10001101 | Ќ |  | |
| 142 | 216 | 0x8E | 10001110 | Ћ | Ž | |
| 143 | 217 | 0x8F | 10001111 | Џ |  | |
| 144 | 220 | 0x90 | 10010000 | Ђ |  | |
| 145 | 221 | 0x91 | 10010001 | ‘ | ‘ | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ | ’ | ’ |
| 147 | 223 | 0x93 | 10010011 | “ | “ | “ |
| 148 | 224 | 0x94 | 10010100 | ” | ” | ” |
| 149 | 225 | 0x95 | 10010101 | • | • | • |
| 150 | 226 | 0x96 | 10010110 | – | – | – |
| 151 | 227 | 0x97 | 10010111 | — | — | — |
| 152 | 230 | 0x98 | 10011000 | Начало строки | ˜ | |
| 153 | 231 | 0x99 | 10011001 | ™ | ™ | ™ |
| 154 | 232 | 0x9A | 10011010 | љ | š | |
| 155 | 233 | 0x9B | 10011011 | › | › | › |
| 156 | 234 | 0x9C | 10011100 | њ | œ | |
| 157 | 235 | 0x9D | 10011101 | ќ |  | |
| 158 | 236 | 0x9E | 10011110 | ћ | ž | |
| 159 | 237 | 0x9F | 10011111 | џ | Ÿ | |
| 160 | 240 | 0xA0 | 10100000 | Неразрывный пробел |   | |
| 161 | 241 | 0xA1 | 10100001 | Ў | ¡ | |
| 162 | 242 | 0xA2 | 10100010 | ў | ¢ | |
| 163 | 243 | 0xA3 | 10100011 | Ј | £ | |
| 164 | 244 | 0xA4 | 10100100 | ¤ | ¤ | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ | ¥ | |
| 166 | 246 | 0xA6 | 10100110 | ¦ | ¦ | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § | § | § |
| 168 | 250 | 0xA8 | 10101000 | Ё | ¨ | |
| 169 | 251 | 0xA9 | 10101001 | © | © | © |
| 170 | 252 | 0xAA | 10101010 | Є | ª | |
| 171 | 253 | 0xAB | 10101011 | « | « | « |
| 172 | 254 | 0xAC | 10101100 | ¬ | ¬ | ¬ |
| 173 | 255 | 0xAD | 10101101 | Мягкий перенос | ­ | ­ |
| 174 | 256 | 0xAE | 10101110 | ® | ® | ® |
| 175 | 257 | 0xAF | 10101111 | Ї | ¯ | |
| 176 | 260 | 0xB0 | 10110000 | ° | ° | ° |
| 177 | 261 | 0xB1 | 10110001 | ± | ± | ± |
| 178 | 262 | 0xB2 | 10110010 | І | ² | |
| 179 | 263 | 0xB3 | 10110011 | і | ³ | |
| 180 | 264 | 0xB4 | 10110100 | ґ | ´ | |
| 181 | 265 | 0xB5 | 10110101 | µ | µ | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ | ¶ | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · | · | · |
| 184 | 270 | 0xB8 | 10111000 | ё | ¸ | |
| 185 | 271 | 0xB9 | 10111001 | № | ¹ | |
| 186 | 272 | 0xBA | 10111010 | є | º | |
| 187 | 273 | 0xBB | 10111011 | » | » | » |
| 188 | 274 | 0xBC | 10111100 | ј | ¼ | |
| 189 | 275 | 0xBD | 10111101 | Ѕ | ½ | |
| 190 | 276 | 0xBE | 10111110 | ѕ | ¾ | |
| 191 | 277 | 0xBF | 10111111 | ї | ¿ | |
| 192 | 300 | 0xC0 | 11000000 | А | À | |
| 193 | 301 | 0xC1 | 11000001 | Б | Á | |
| 194 | 302 | 0xC2 | 11000010 | В | Â | |
| 195 | 303 | 0xC3 | 11000011 | Г | Ã | |
| 196 | 304 | 0xC4 | 11000100 | Д | Ä | |
| 197 | 305 | 0xC5 | 11000101 | Е | Å | |
| 198 | 306 | 0xC6 | 11000110 | Ж | Æ | |
| 199 | 307 | 0xC7 | 11000111 | З | Ç | |
| 200 | 310 | 0xC8 | 11001000 | И | È | |
| 201 | 311 | 0xC9 | 11001001 | Й | É | |
| 202 | 312 | 0xCA | 11001010 | К | Ê | |
| 203 | 313 | 0xCB | 11001011 | Л | Ë | |
| 204 | 314 | 0xCC | 11001100 | М | Ì | |
| 205 | 315 | 0xCD | 11001101 | Н | Í | |
| 206 | 316 | 0xCE | 11001110 | О | Î | |
| 207 | 317 | 0xCF | 11001111 | П | Ï | |
| 208 | 320 | 0xD0 | 11010000 | Р | Ð | |
| 209 | 321 | 0xD1 | 11010001 | С | Ñ | |
| 210 | 322 | 0xD2 | 11010010 | Т | Ò | |
| 211 | 323 | 0xD3 | 11010011 | У | Ó | |
| 212 | 324 | 0xD4 | 11010100 | Ф | Ô | |
| 213 | 325 | 0xD5 | 11010101 | Х | Õ | |
| 214 | 326 | 0xD6 | 11010110 | Ц | Ö | |
| 215 | 327 | 0xD7 | 11010111 | Ч | × | |
| 216 | 330 | 0xD8 | 11011000 | Ш | Ø | |
| 217 | 331 | 0xD9 | 11011001 | Щ | Ù | |
| 218 | 332 | 0xDA | 11011010 | Ъ | Ú | |
| 219 | 333 | 0xDB | 11011011 | Ы | Û | |
| 220 | 334 | 0xDC | 11011100 | Ь | Ü | |
| 221 | 335 | 0xDD | 11011101 | Э | Ý | |
| 222 | 336 | 0xDE | 11011110 | Ю | Þ | |
| 223 | 337 | 0xDF | 11011111 | Я | ß | |
| 224 | 340 | 0xE0 | 11100000 | а | à | |
| 225 | 341 | 0xE1 | 11100001 | б | á | |
| 226 | 342 | 0xE2 | 11100010 | в | â | |
| 227 | 343 | 0xE3 | 11100011 | г | ã | |
| 228 | 344 | 0xE4 | 11100100 | д | ä | |
| 229 | 345 | 0xE5 | 11100101 | е | å | |
| 230 | 346 | 0xE6 | 11100110 | ж | æ | |
| 231 | 347 | 0xE7 | 11100111 | з | ç | |
| 232 | 350 | 0xE8 | 11101000 | и | è | |
| 233 | 351 | 0xE9 | 11101001 | й | é | |
| 234 | 352 | 0xEA | 11101010 | к | ê | |
| 235 | 353 | 0xEB | 11101011 | л | ë | |
| 236 | 354 | 0xEC | 11101100 | м | ì | |
| 237 | 355 | 0xED | 11101101 | н | í | |
| 238 | 356 | 0xEE | 11101110 | о | î | |
| 239 | 357 | 0xEF | 11101111 | п | ï | |
| 240 | 360 | 0xF0 | 11110000 | р | ð | |
| 241 | 361 | 0xF1 | 11110001 | с | ñ | |
| 242 | 362 | 0xF2 | 11110010 | т | ò | |
| 243 | 363 | 0xF3 | 11110011 | у | ó | |
| 244 | 364 | 0xF4 | 11110100 | ф | ô | |
| 245 | 365 | 0xF5 | 11110101 | х | õ | |
| 246 | 366 | 0xF6 | 11110110 | ц | ö | |
| 247 | 367 | 0xF7 | 11110111 | ч | ÷ | |
| 248 | 370 | 0xF8 | 11111000 | ш | ø | |
| 249 | 371 | 0xF9 | 11111001 | щ | ù | |
| 250 | 372 | 0xFA | 11111010 | ъ | ú | |
| 251 | 373 | 0xFB | 11111011 | ы | û | |
| 252 | 374 | 0xFC | 11111100 | ь | ü | |
| 253 | 375 | 0xFD | 11111101 | э | ý | |
| 254 | 376 | 0xFE | 11111110 | ю | þ | |
| 255 | 377 | 0xFF | 11111111 | я | ÿ |
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
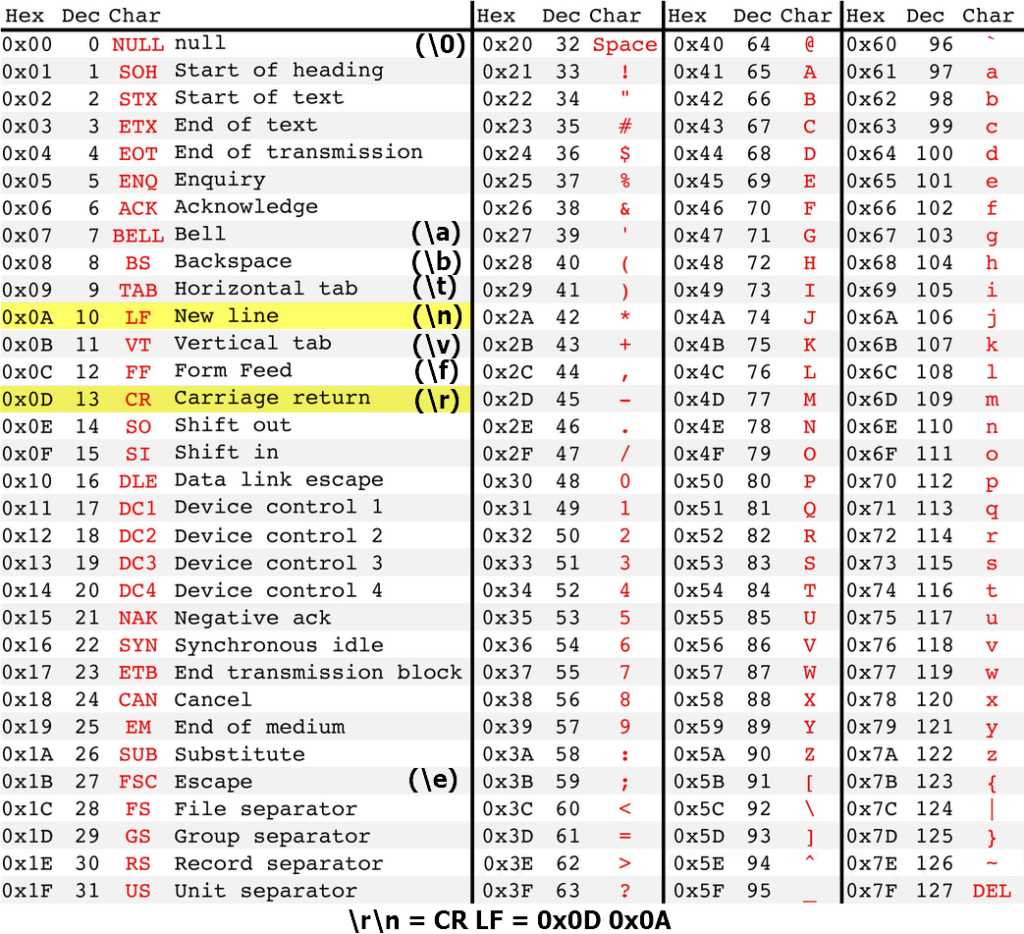
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.

Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.

Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 3 сентября 2014;
проверки требуют 9 правок.

Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»).
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Windows-1251 имеет два недостатка:
- строчная буква «я» имеет код 0XFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 — ÿ, оба варианта практически не используются; число же
-1, в дополнительном коде длиной 8 бит представляющееся числом255, часто используется в программировании как специальное значение). - отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Содержание
- 1 Таблицы
- 1.1 Кодировка Windows-1251 (синоним CP1251)
- 1.2 Другие варианты
- 1.2.1 Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)
- 1.2.2 Кодировка CP1251-k (KazWin, казахская кодировка)
- 1.2.3 Кодировка Windows-1251 (чувашский вариант)
- 1.2.4 Татарский вариант
- 2 Ссылки
Таблицы[править | править вики-текст]
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251 (синоним CP1251)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Ќ 40C |
Ћ 40B |
Џ 40F |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
ќ 45C |
ћ 45B |
џ 45F |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Ј 408 |
¤ A4 |
Ґ 490 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ґ 491 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
ј 458 |
Ѕ 405 |
ѕ 455 |
ї 457 |
| C. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
| D. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
| E. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
| F. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
-

Таблица основного кода ASCII
-

Таблица расширенного кода ASCII


Другие варианты[править | править вики-текст]
(Показаны только отличающиеся строки, поскольку всё остальное совпадает)
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A. |
A0 |
¡ A1 |
¢ A2 |
£ A3 |
€ 20AC |
¥ A5 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
№ 2116 |
« AB |
¬ AC |
AD |
® AE |
¯ AF |
| B. |
° B0 |
± B1 |
² B2 |
³ B3 |
´ B4 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
¹ B9 |
º BA |
» BB |
¼ BC |
½ BD |
¾ BE |
¿ BF |
Кодировка CP1251-k (KazWin, казахская кодировка)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ұ 4B0 |
Ғ 492 |
‚ 201A |
ғ 493 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ң 4A2 |
Қ 49A |
Һ 4BA |
Ү 4AE |
| 9. |
ұ 4B1 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ң 4A3 |
қ 49B |
һ 4BB |
ү 4AF |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Җ 496 |
¤ A4 |
Ҳ 4B2 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ҳ 4B3 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
җ 497 |
Ә 4D8 |
ә 4D9 |
ї 457 |
Кодировка Windows-1251 (чувашский вариант)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Ӑ 4D0 |
Ӗ 4D6 |
Ҫ 4AA |
Ӳ 4F2 |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
ӑ 4D1 |
ӗ 4D7 |
ҫ 4AB |
ӳ 4F3 |
Татарский вариант[править | править вики-текст]
Эта кодировка была официально принята в Татарстане в 1996 г.
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ә 4D8 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ү 4AE |
Җ 496 |
Ң 4A2 |
Һ 4BA |
| 9. |
ә 4D9 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ү 4AF |
җ 497 |
ң 4A3 |
һ 4BB |
Ссылки[править | править вики-текст]
- Информация о кодировке на Microsoft GlobalDev
- История создании кодировки в сообщении Игоря Семенюка в эхоконференции SU.LAN от 14 января 1996
- Юникод-коды символов на unicode.org
- 2cyr.com — универсальный декодер, конвертер кириллицы online
| Кодировки символов | ||
|---|---|---|
| Основы | алфавит • текст ( файл • данные ) • набор символов • конверсия | |
| Исторические кодировки | Докомп.: | семафорная (Макарова) • Морзе • Бодо • МТК-2 |
| Комп.: | 6-битная • УПП • RADIX-50 • EBCDIC ( ДКОИ-8 ) • КОИ-7 • ISO 646 | |
| современное 8-битное представление |
символы | ASCII ( управляющие • печатные ) • не-ASCII ( псевдографика ) |
| 8-битные код.стр. | Кириллица: КОИ-8 • ГОСТ 19768-87 • MacCyrillic | |
| ISO 8859 | 1 (лат.) • 2 • 3 • 4 • 5 (кир.) • 6 • 7 • 8 • 9 • 10 • 11 • 12 • 13 • 14 • 15 (€) • 16 | |
| Windows | 1250 • 1251 (кир.) • 1252 • 1253 • 1254 • 1255 • 1256 • 1257 • 1258 • WGL4 | |
| IBM & DOS | 437 • 850 • 852 • 855 • 866 «альт.» • МИК • НИИ ЭВМ | |
| Многобайтные | Традиционные | DBCS ( GB2312 ) • HTML |
| Unicode | UTF-32 • UTF-16 • UTF-8 • список символов ( кириллица ) | |
| Связанные темы | интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • шрифт • кракозябры • транслит • нестандартные шрифты • текст как изображение | |
| Утилиты | iconv • recode |
Reference of Extended ASCII Table for Windows-1251
The ASCII table, when defined according to the Windows-1251 character encoding (also known as Code page 1251), includes ASCII control characters and ASCII printable characters. Moreover, it also includes the extended ASCII character set unique to Windows-1251. This character set is particularly designed to support Cyrillic languages.
ASCII control characters (character code 0-31)
The first 32 characters in the ASCII-table are unprintable control codes and are used to control peripherals such as printers.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 0 | 000 | 00 | 00000000 | ␀ | � | Null character | ||
| 1 | 001 | 01 | 00000001 | ␁ |  | Start of Heading | ||
| 2 | 002 | 02 | 00000010 | ␂ |  | Start of Text | ||
| 3 | 003 | 03 | 00000011 | ␃ |  | End of Text | ||
| 4 | 004 | 04 | 00000100 | ␄ |  | End of Transmission | ||
| 5 | 005 | 05 | 00000101 | ␅ |  | Enquiry | ||
| 6 | 006 | 06 | 00000110 | ␆ |  | Acknowledge | ||
| 7 | 007 | 07 | 00000111 | ␇ |  | Bell, Alert | ||
| 8 | 010 | 08 | 00001000 | ␈ |  | Backspace | ||
| 9 | 011 | 09 | 00001001 | ␉ | 	 | Horizontal Tab | ||
| 10 | 012 | 0A | 00001010 | ␊ | | Line Feed | ||
| 11 | 013 | 0B | 00001011 | ␋ |  | Vertical Tabulation | ||
| 12 | 014 | 0C | 00001100 | ␌ |  | Form Feed | ||
| 13 | 015 | 0D | 00001101 | ␍ | | Carriage Return | ||
| 14 | 016 | 0E | 00001110 | ␎ |  | Shift Out | ||
| 15 | 017 | 0F | 00001111 | ␏ |  | Shift In | ||
| 16 | 020 | 10 | 00010000 | ␐ |  | Data Link Escape | ||
| 17 | 021 | 11 | 00010001 | ␑ |  | Device Control One (XON) | ||
| 18 | 022 | 12 | 00010010 | ␒ |  | Device Control Two | ||
| 19 | 023 | 13 | 00010011 | ␓ |  | Device Control Three (XOFF) | ||
| 20 | 024 | 14 | 00010100 | ␔ |  | Device Control Four | ||
| 21 | 025 | 15 | 00010101 | ␕ |  | Negative Acknowledge | ||
| 22 | 026 | 16 | 00010110 | ␖ |  | Synchronous Idle | ||
| 23 | 027 | 17 | 00010111 | ␗ |  | End of Transmission Block | ||
| 24 | 030 | 18 | 00011000 | ␘ |  | Cancel | ||
| 25 | 031 | 19 | 00011001 | ␙ |  | End of medium | ||
| 26 | 032 | 1A | 00011010 | ␚ |  | Substitute | ||
| 27 | 033 | 1B | 00011011 | ␛ |  | Escape | ||
| 28 | 034 | 1C | 00011100 | ␜ |  | File Separator | ||
| 29 | 035 | 1D | 00011101 | ␝ |  | Group Separator | ||
| 30 | 036 | 1E | 00011110 | ␞ |  | Record Separator | ||
| 31 | 037 | 1F | 00011111 | ␟ |  | Unit Separator |
ASCII printable characters (character code 32-127)
Codes 32-127 are common for all the different variations of the ASCII table, they are called printable characters, represent letters, digits, punctuation marks, and a few miscellaneous symbols. You will find almost every character on your keyboard. Character 127 represents the command DEL.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 32 | 040 | 20 | 00100000 | ␠ |   | Space | ||
| 33 | 041 | 21 | 00100001 | ! | ! | ! | Exclamation mark | |
| 34 | 042 | 22 | 00100010 | « | " | " | Double quotes (or speech marks) | |
| 35 | 043 | 23 | 00100011 | # | # | # | Number sign | |
| 36 | 044 | 24 | 00100100 | $ | $ | $ | Dollar | |
| 37 | 045 | 25 | 00100101 | % | % | % | Per cent sign | |
| 38 | 046 | 26 | 00100110 | & | & | & | Ampersand | |
| 39 | 047 | 27 | 00100111 | ‘ | ' | ' | Single quote | |
| 40 | 050 | 28 | 00101000 | ( | ( | &lparen; | Open parenthesis (or open bracket) | |
| 41 | 051 | 29 | 00101001 | ) | ) | &rparen; | Close parenthesis (or close bracket) | |
| 42 | 052 | 2A | 00101010 | * | * | * | Asterisk | |
| 43 | 053 | 2B | 00101011 | + | + | + | Plus | |
| 44 | 054 | 2C | 00101100 | , | , | , | Comma | |
| 45 | 055 | 2D | 00101101 | — | - | Hyphen-minus | ||
| 46 | 056 | 2E | 00101110 | . | . | . | Period, dot or full stop | |
| 47 | 057 | 2F | 00101111 | / | / | / | Slash or divide | |
| 48 | 060 | 30 | 00110000 | 0 | 0 | Zero | ||
| 49 | 061 | 31 | 00110001 | 1 | 1 | One | ||
| 50 | 062 | 32 | 00110010 | 2 | 2 | Two | ||
| 51 | 063 | 33 | 00110011 | 3 | 3 | Three | ||
| 52 | 064 | 34 | 00110100 | 4 | 4 | Four | ||
| 53 | 065 | 35 | 00110101 | 5 | 5 | Five | ||
| 54 | 066 | 36 | 00110110 | 6 | 6 | Six | ||
| 55 | 067 | 37 | 00110111 | 7 | 7 | Seven | ||
| 56 | 070 | 38 | 00111000 | 8 | 8 | Eight | ||
| 57 | 071 | 39 | 00111001 | 9 | 9 | Nine | ||
| 58 | 072 | 3A | 00111010 | : | : | : | Colon | |
| 59 | 073 | 3B | 00111011 | ; | ; | ; | Semicolon | |
| 60 | 074 | 3C | 00111100 | < | < | < | Less than (or open angled bracket) | |
| 61 | 075 | 3D | 00111101 | = | = | = | Equals | |
| 62 | 076 | 3E | 00111110 | > | > | > | Greater than (or close angled bracket) | |
| 63 | 077 | 3F | 00111111 | ? | ? | ? | Question mark | |
| 64 | 100 | 40 | 01000000 | @ | @ | @ | At sign | |
| 65 | 101 | 41 | 01000001 | A | A | Uppercase A | ||
| 66 | 102 | 42 | 01000010 | B | B | Uppercase B | ||
| 67 | 103 | 43 | 01000011 | C | C | Uppercase C | ||
| 68 | 104 | 44 | 01000100 | D | D | Uppercase D | ||
| 69 | 105 | 45 | 01000101 | E | E | Uppercase E | ||
| 70 | 106 | 46 | 01000110 | F | F | Uppercase F | ||
| 71 | 107 | 47 | 01000111 | G | G | Uppercase G | ||
| 72 | 110 | 48 | 01001000 | H | H | Uppercase H | ||
| 73 | 111 | 49 | 01001001 | I | I | Uppercase I | ||
| 74 | 112 | 4A | 01001010 | J | J | Uppercase J | ||
| 75 | 113 | 4B | 01001011 | K | K | Uppercase K | ||
| 76 | 114 | 4C | 01001100 | L | L | Uppercase L | ||
| 77 | 115 | 4D | 01001101 | M | M | Uppercase M | ||
| 78 | 116 | 4E | 01001110 | N | N | Uppercase N | ||
| 79 | 117 | 4F | 01001111 | O | O | Uppercase O | ||
| 80 | 120 | 50 | 01010000 | P | P | Uppercase P | ||
| 81 | 121 | 51 | 01010001 | Q | Q | Uppercase Q | ||
| 82 | 122 | 52 | 01010010 | R | R | Uppercase R | ||
| 83 | 123 | 53 | 01010011 | S | S | Uppercase S | ||
| 84 | 124 | 54 | 01010100 | T | T | Uppercase T | ||
| 85 | 125 | 55 | 01010101 | U | U | Uppercase U | ||
| 86 | 126 | 56 | 01010110 | V | V | Uppercase V | ||
| 87 | 127 | 57 | 01010111 | W | W | Uppercase W | ||
| 88 | 130 | 58 | 01011000 | X | X | Uppercase X | ||
| 89 | 131 | 59 | 01011001 | Y | Y | Uppercase Y | ||
| 90 | 132 | 5A | 01011010 | Z | Z | Uppercase Z | ||
| 91 | 133 | 5B | 01011011 | [ | [ | [ | Opening bracket | |
| 92 | 134 | 5C | 01011100 | \ | \ | \ | Backslash | |
| 93 | 135 | 5D | 01011101 | ] | ] | ] | Closing bracket | |
| 94 | 136 | 5E | 01011110 | ^ | ^ | ^ | Caret — circumflex | |
| 95 | 137 | 5F | 01011111 | _ | _ | _ | Underscore | |
| 96 | 140 | 60 | 01100000 | ` | ` | ` | Grave accent | |
| 97 | 141 | 61 | 01100001 | a | a | Lowercase a | ||
| 98 | 142 | 62 | 01100010 | b | b | Lowercase b | ||
| 99 | 143 | 63 | 01100011 | c | c | Lowercase c | ||
| 100 | 144 | 64 | 01100100 | d | d | Lowercase d | ||
| 101 | 145 | 65 | 01100101 | e | e | Lowercase e | ||
| 102 | 146 | 66 | 01100110 | f | f | Lowercase f | ||
| 103 | 147 | 67 | 01100111 | g | g | Lowercase g | ||
| 104 | 150 | 68 | 01101000 | h | h | Lowercase h | ||
| 105 | 151 | 69 | 01101001 | i | i | Lowercase i | ||
| 106 | 152 | 6A | 01101010 | j | j | Lowercase j | ||
| 107 | 153 | 6B | 01101011 | k | k | Lowercase k | ||
| 108 | 154 | 6C | 01101100 | l | l | Lowercase l | ||
| 109 | 155 | 6D | 01101101 | m | m | Lowercase m | ||
| 110 | 156 | 6E | 01101110 | n | n | Lowercase n | ||
| 111 | 157 | 6F | 01101111 | o | o | Lowercase o | ||
| 112 | 160 | 70 | 01110000 | p | p | Lowercase p | ||
| 113 | 161 | 71 | 01110001 | q | q | Lowercase q | ||
| 114 | 162 | 72 | 01110010 | r | r | Lowercase r | ||
| 115 | 163 | 73 | 01110011 | s | s | Lowercase s | ||
| 116 | 164 | 74 | 01110100 | t | t | Lowercase t | ||
| 117 | 165 | 75 | 01110101 | u | u | Lowercase u | ||
| 118 | 166 | 76 | 01110110 | v | v | Lowercase v | ||
| 119 | 167 | 77 | 01110111 | w | w | Lowercase w | ||
| 120 | 170 | 78 | 01111000 | x | x | Lowercase x | ||
| 121 | 171 | 79 | 01111001 | y | y | Lowercase y | ||
| 122 | 172 | 7A | 01111010 | z | z | Lowercase z | ||
| 123 | 173 | 7B | 01111011 | { | { | { | Opening brace | |
| 124 | 174 | 7C | 01111100 | | | | | | | Vertical bar | |
| 125 | 175 | 7D | 01111101 | } | } | } | Closing brace | |
| 126 | 176 | 7E | 01111110 | ~ | ~ | ˜ | Equivalency sign — tilde | |
| 127 | 177 | 7F | 01111111 | ␡ |  | Delete |
The extended ASCII codes (character code 128-255)
Windows-1251 is a character encoding standard used to represent text in the Cyrillic script. It was introduced by Microsoft in the Windows operating system and is based on ISO 8859-5. Windows-1251 supports a range of characters and symbols used in the Cyrillic script, including Russian, Bulgarian, Serbian, and others.
Windows-1251 is widely used in the former Soviet Union countries and other countries that use the Cyrillic script. It is commonly used in word processing software, spreadsheets, and databases. However, it is important to note that Windows-1251 may not provide full support for all of the characters used in these languages and may cause issues when dealing with text in certain scripts.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 128 | 200 | 80 | 10000000 | Ђ | Ђ | Ђ | Cyrillic capital letter Dje | |
| 129 | 201 | 81 | 10000001 | Ѓ | Ѓ | Ѓ | Cyrillic capital letter Gje | |
| 130 | 202 | 82 | 10000010 | ‚ | ‚ | ‚ | Single low-9 quotation mark | |
| 131 | 203 | 83 | 10000011 | ѓ | ѓ | ѓ | Cyrillic small letter gje | |
| 132 | 204 | 84 | 10000100 | „ | „ | „ | Double low-9 quotation mark | |
| 133 | 205 | 85 | 10000101 | … | … | … | Horizontal ellipsis | |
| 134 | 206 | 86 | 10000110 | † | † | † | Dagger | |
| 135 | 207 | 87 | 10000111 | ‡ | ‡ | ‡ | Double dagger | |
| 136 | 210 | 88 | 10001000 | € | € | € | Euro sign | |
| 137 | 211 | 89 | 10001001 | ‰ | ‰ | ‰ | Per mille sign | |
| 138 | 212 | 8A | 10001010 | Љ | Љ | Љ | Cyrillic capital letter Lje | |
| 139 | 213 | 8B | 10001011 | ‹ | ‹ | ‹ | Single left-pointing angle quotation | |
| 140 | 214 | 8C | 10001100 | Њ | Њ | Њ | Cyrillic capital letter Nje | |
| 141 | 215 | 8D | 10001101 | Ќ | Ќ | Ќ | Cyrillic capital letter Kje | |
| 142 | 216 | 8E | 10001110 | Ћ | Ћ | Ћ | Cyrillic capital letter Tshe | |
| 143 | 217 | 8F | 10001111 | Џ | Џ | Џ | Cyrillic capital letter Dzhe | |
| 144 | 220 | 90 | 10010000 | ђ | ђ | ђ | Cyrillic small letter dje | |
| 145 | 221 | 91 | 10010001 | ‘ | ‘ | ‘ | Left single quotation mark | |
| 146 | 222 | 92 | 10010010 | ’ | ’ | ’ | Right single quotation mark | |
| 147 | 223 | 93 | 10010011 | “ | “ | “ | Left double quotation mark | |
| 148 | 224 | 94 | 10010100 | ” | ” | ” | Right double quotation mark | |
| 149 | 225 | 95 | 10010101 | • | • | • | Bullet | |
| 150 | 226 | 96 | 10010110 | – | – | – | En dash | |
| 151 | 227 | 97 | 10010111 | — | — | — | Em dash | |
| 152 | 230 | 98 | 10011000 | Unused | ||||
| 153 | 231 | 99 | 10011001 | ™ | ™ | ™ | Trade mark sign | |
| 154 | 232 | 9A | 10011010 | љ | љ | љ | Cyrillic small letter lje | |
| 155 | 233 | 9B | 10011011 | › | › | › | Single right-pointing angle quotation mark | |
| 156 | 234 | 9C | 10011100 | њ | њ | њ | Cyrillic small letter nje | |
| 157 | 235 | 9D | 10011101 | ќ | ќ | ќ | Cyrillic small letter Kje | |
| 158 | 236 | 9E | 10011110 | ћ | ћ | ћ | Cyrillic small letter Tshe | |
| 159 | 237 | 9F | 10011111 | џ | џ | џ | Cyrillic small letter Dzhe | |
| 160 | 240 | A0 | 10100000 |   | | Non-breaking space | ||
| 161 | 241 | A1 | 10100001 | Ў | Ў | Ў | Cyrillic capital letter short U | |
| 162 | 242 | A2 | 10100010 | ў | ў | ў | Cyrillic small letter short u | |
| 163 | 243 | A3 | 10100011 | Ј | Ј | Ј | Cyrillic capital letter Je | |
| 164 | 244 | A4 | 10100100 | ¤ | ¤ | ¤ | Currency sign | |
| 165 | 245 | A5 | 10100101 | Ґ | Ґ | Cyrillic capital letter Ghe with upturn | ||
| 166 | 246 | A6 | 10100110 | ¦ | ¦ | ¦ | Pipe, broken vertical bar | |
| 167 | 247 | A7 | 10100111 | § | § | § | Section sign | |
| 168 | 250 | A8 | 10101000 | Ё | Ё | Ё | Cyrillic capital letter Io | |
| 169 | 251 | A9 | 10101001 | © | © | © | Copyright sign | |
| 170 | 252 | AA | 10101010 | Є | Є | Є | Cyrillic capital letter Ukrainian Ie | |
| 171 | 253 | AB | 10101011 | « | « | « | Left double angle quotes | |
| 172 | 254 | AC | 10101100 | ¬ | ¬ | ¬ | Negation | |
| 173 | 255 | AD | 10101101 | | ­ | ­ | Soft hyphen | |
| 174 | 256 | AE | 10101110 | ® | ® | ® | Registered trade mark sign | |
| 175 | 257 | AF | 10101111 | Ї | Ї | Ї | Cyrillic capital letter Yi | |
| 176 | 260 | B0 | 10110000 | ° | ° | ° | Degree sign | |
| 177 | 261 | B1 | 10110001 | ± | ± | ± | Plus-or-minus sign | |
| 178 | 262 | B2 | 10110010 | І | І | І | Cyrillic capital letter Byelorussian-Ukrainian I | |
| 179 | 263 | B3 | 10110011 | і | і | і | Cyrillic small letter Byelorussian-Ukrainian i | |
| 180 | 264 | B4 | 10110100 | ґ | ґ | Cyrillic small letter ghe with upturn | ||
| 181 | 265 | B5 | 10110101 | µ | µ | µ | Micro sign | |
| 182 | 266 | B6 | 10110110 | ¶ | ¶ | ¶ | Pilcrow sign — paragraph sign | |
| 183 | 267 | B7 | 10110111 | · | · | · | Middle dot — Georgian comma | |
| 184 | 270 | B8 | 10111000 | ё | ё | ё | Cyrillic small letter io | |
| 185 | 271 | B9 | 10111001 | № | № | № | Numero Sign | |
| 186 | 272 | BA | 10111010 | є | є | є | Cyrillic small letter Ukrainian ie | |
| 187 | 273 | BB | 10111011 | » | » | » | Right double angle quotes | |
| 188 | 274 | BC | 10111100 | ј | ј | ј | Cyrillic small letter je | |
| 189 | 275 | BD | 10111101 | Ѕ | Ѕ | Ѕ | Cyrillic capital letter Dze | |
| 190 | 276 | BE | 10111110 | ѕ | ѕ | ѕ | Cyrillic small letter dze | |
| 191 | 277 | BF | 10111111 | ї | ї | ї | Cyrillic small letter yi | |
| 192 | 300 | C0 | 11000000 | А | А | А | Cyrillic capital letter A | |
| 193 | 301 | C1 | 11000001 | Б | Б | Б | Cyrillic capital letter Be | |
| 194 | 302 | C2 | 11000010 | В | В | В | Cyrillic capital letter Ve | |
| 195 | 303 | C3 | 11000011 | Г | Г | Г | Cyrillic capital letter Ghe | |
| 196 | 304 | C4 | 11000100 | Д | Д | Д | Cyrillic capital letter De | |
| 197 | 305 | C5 | 11000101 | Е | Е | Е | Cyrillic capital letter Ie | |
| 198 | 306 | C6 | 11000110 | Ж | Ж | Ж | Cyrillic capital letter Zhe | |
| 199 | 307 | C7 | 11000111 | З | З | З | Cyrillic capital letter Ze | |
| 200 | 310 | C8 | 11001000 | И | И | И | Cyrillic capital letter I | |
| 201 | 311 | C9 | 11001001 | Й | Й | Й | Cyrillic capital letter Short I | |
| 202 | 312 | CA | 11001010 | К | К | К | Cyrillic capital letter Ka | |
| 203 | 313 | CB | 11001011 | Л | Л | Л | Cyrillic capital letter El | |
| 204 | 314 | CC | 11001100 | М | М | М | Cyrillic capital letter Em | |
| 205 | 315 | CD | 11001101 | Н | Н | Н | Cyrillic capital letter En | |
| 206 | 316 | CE | 11001110 | О | О | О | Cyrillic capital letter O | |
| 207 | 317 | CF | 11001111 | П | П | П | Cyrillic capital letter Pe | |
| 208 | 320 | D0 | 11010000 | Р | Р | Р | Cyrillic capital letter Er | |
| 209 | 321 | D1 | 11010001 | С | С | С | Cyrillic capital letter Es | |
| 210 | 322 | D2 | 11010010 | Т | Т | Т | Cyrillic capital letter Te | |
| 211 | 323 | D3 | 11010011 | У | У | У | Cyrillic capital letter U | |
| 212 | 324 | D4 | 11010100 | Ф | Ф | Ф | Cyrillic capital letter Ef | |
| 213 | 325 | D5 | 11010101 | Х | Х | Х | Cyrillic capital letter Ha | |
| 214 | 326 | D6 | 11010110 | Ц | Ц | Ц | Cyrillic capital letter Tse | |
| 215 | 327 | D7 | 11010111 | Ч | Ч | Ч | Cyrillic capital letter Che | |
| 216 | 330 | D8 | 11011000 | Ш | Ш | Ш | Cyrillic capital letter Sha | |
| 217 | 331 | D9 | 11011001 | Щ | Щ | Щ | Cyrillic capital letter Shcha | |
| 218 | 332 | DA | 11011010 | Ъ | Ъ | Ъ | Cyrillic capital letter Hard Sign | |
| 219 | 333 | DB | 11011011 | Ы | Ы | Ы | Cyrillic capital letter Yeru | |
| 220 | 334 | DC | 11011100 | Ь | Ь | Ь | Cyrillic capital letter Soft Sign | |
| 221 | 335 | DD | 11011101 | Э | Э | Э | Cyrillic capital letter E | |
| 222 | 336 | DE | 11011110 | Ю | Ю | Ю | Cyrillic capital letter Yu | |
| 223 | 337 | DF | 11011111 | Я | Я | Я | Cyrillic capital letter Ya | |
| 224 | 340 | E0 | 11100000 | а | а | а | Cyrillic Small Letter A | |
| 225 | 341 | E1 | 11100001 | б | б | б | Cyrillic small letter be | |
| 226 | 342 | E2 | 11100010 | в | в | в | Cyrillic small letter ve | |
| 227 | 343 | E3 | 11100011 | г | г | г | Cyrillic small letter ghe | |
| 228 | 344 | E4 | 11100100 | д | д | д | Cyrillic small letter de | |
| 229 | 345 | E5 | 11100101 | е | е | е | Cyrillic small letter ie | |
| 230 | 346 | E6 | 11100110 | ж | ж | ж | Cyrillic small letter zhe | |
| 231 | 347 | E7 | 11100111 | з | з | з | Cyrillic small letter ze | |
| 232 | 350 | E8 | 11101000 | и | и | и | Cyrillic small letter i | |
| 233 | 351 | E9 | 11101001 | й | й | й | Cyrillic small letter short i | |
| 234 | 352 | EA | 11101010 | к | к | к | Cyrillic small letter ka | |
| 235 | 353 | EB | 11101011 | л | л | л | Cyrillic small letter el | |
| 236 | 354 | EC | 11101100 | м | м | м | Cyrillic small letter em | |
| 237 | 355 | ED | 11101101 | н | н | н | Cyrillic small letter en | |
| 238 | 356 | EE | 11101110 | о | о | о | Cyrillic small letter o | |
| 239 | 357 | EF | 11101111 | п | п | п | Cyrillic small letter pe | |
| 240 | 360 | F0 | 11110000 | р | р | р | Cyrillic small letter er | |
| 241 | 361 | F1 | 11110001 | с | с | с | Cyrillic small letter es | |
| 242 | 362 | F2 | 11110010 | т | т | т | Cyrillic small letter te | |
| 243 | 363 | F3 | 11110011 | у | у | у | Cyrillic small letter u | |
| 244 | 364 | F4 | 11110100 | ф | ф | ф | Cyrillic small letter ef | |
| 245 | 365 | F5 | 11110101 | х | х | х | Cyrillic small letter ha | |
| 246 | 366 | F6 | 11110110 | ц | ц | ц | Cyrillic small letter tse | |
| 247 | 367 | F7 | 11110111 | ч | ч | ч | Cyrillic small letter che | |
| 248 | 370 | F8 | 11111000 | ш | ш | ш | Cyrillic small letter sha | |
| 249 | 371 | F9 | 11111001 | щ | щ | щ | Cyrillic small letter shcha | |
| 250 | 372 | FA | 11111010 | ъ | ъ | ъ | Cyrillic small letter hard sign | |
| 251 | 373 | FB | 11111011 | ы | ы | ы | Cyrillic small letter yeru | |
| 252 | 374 | FC | 11111100 | ь | ь | ь | Cyrillic small letter soft sign | |
| 253 | 375 | FD | 11111101 | э | э | э | Cyrillic small letter e | |
| 254 | 376 | FE | 11111110 | ю | ю | ю | Cyrillic small letter yu | |
| 255 | 377 | FF | 11111111 | я | я | я | Cyrillic small letter ya |
From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This subsequently led to much confusion. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but additionally supports UTF-8 (aka CP_UTF8) since Windows 10 version 1803.[5]
UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder).
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»