Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню «Файл – Сохранить как».

В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку «Сохранить».

К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню «Кодировки – Кириллица» и выбрать нужный вариант.

После открытия текста можно изменить его кодировку. Для этого нужно открыть меню «Кодировки» и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.

После преобразования файл нужно сохранить с помощью меню «Файл – Сохранить» или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню «Файл – Открыть».

В открывшемся окне нужно выделить текстовый файл, снять отметку «Автовыбор» и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.

Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню «Файл – Сохранить как» и сохранить документ с указанием новой схемы кодирования.

В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Посмотрите также:
- Чем открыть PDF файл в Windows 7 или Windows 10
- Как перевернуть страницу в Word
- Как копировать текст с помощью клавиатуры
- Как сделать рамку в Word
- Как сделать буклет в Word
Автор
Александр Степушин
Создатель сайта comp-security.net, автор более 2000 статей о ремонте компьютеров, работе с программами, настройке операционных систем.
Остались вопросы?
Задайте вопрос в комментариях под статьей или на странице
«Задать вопрос»
и вы обязательно получите ответ.
![]()
Не каждый человек обладает большими познаниями в компьютерной технике.
Что такое windows-1251 кодировка и какую роль играет в работе компьютера предстоит узнать.

Содержание:
Что это такое?
Кодировка 1251 представляет собой совокупность символов, которая составляет восьми-битную систему Windows для русифицированных устройств.
Стоит отметить, что довольное широкое применение она нашла на территории Европы.
Считается одной из самых выгодных кодировок, поскольку в ней присутствует все необходимые символы, которые используются в российской типографии. Все кириллические символы имею алфавитную последовательность.
к содержанию ↑
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.
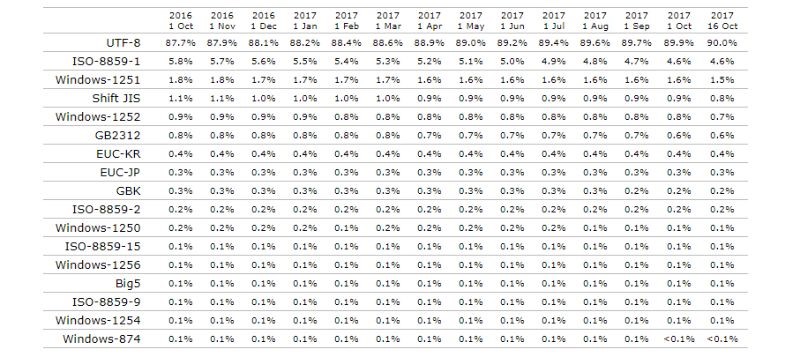
Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
к содержанию ↑
UTF-8 против 1251
Вся информация, которая хранится на компьютере, имеет кодированный вид.
Можно предположить, что символ имеет вес порядком 1 байт. 1251 – это разновидность кодировки однобайтовой, а UTF-8 – восьмибайтная.
Отсюда можно сделать вывод, что первый вариант способен к программированию 256 знаков.
Что касается второго варианта, то он представляет большее количество. Кроме того, для этого выделяют большой размер.
Можно сделать вывод, что оба варианта имеют следующие отличия:
- В верхней части необходимо указывать кодировку, которая необходима для использования. В противном случае, вместо обыкновенных символов появляются нечитаемые иероглифы. Используя UTF-8 (которая считается более универсальной кодировкой), все переводы и расшифровки осуществляются в автоматическом режиме
- Вне зависимости от того, на территории какой страны будет загружаться страница, символика останется без изменения. Важно отметить, что местоположение в данном случае не играет абсолютно никакой роли. Главное обращать внимание на языковые серверы, используемые пользователем. Каждый человек обращается к программному обеспечению на родном языке. Для жителей Европы, 1251 будет недоступна в силу использования латиницы. Соответственно можно сделать вывод о том, что русскоязычные сайты не будут открывать в корректном формате. Что касается юникода, то он присутствует в любой ОС
- Второй вид имеет возможность кодировки большего количества символов. На сегодняшний день стоит отметить 6 и 8 байт. Что касается кириллицы, то для ее кодировки достаточно двух байт.
В связи с выше перечисленными отличиями можно сделать вывод о том, что универсальная кодировка более актуальна для использования, чем 1251, поскольку она подойдет только для славянской группы языков.
Для профессиональных программистов и технических специалистов, знание кодировки 1251 является обязательным условием для осуществления полноценной работы.
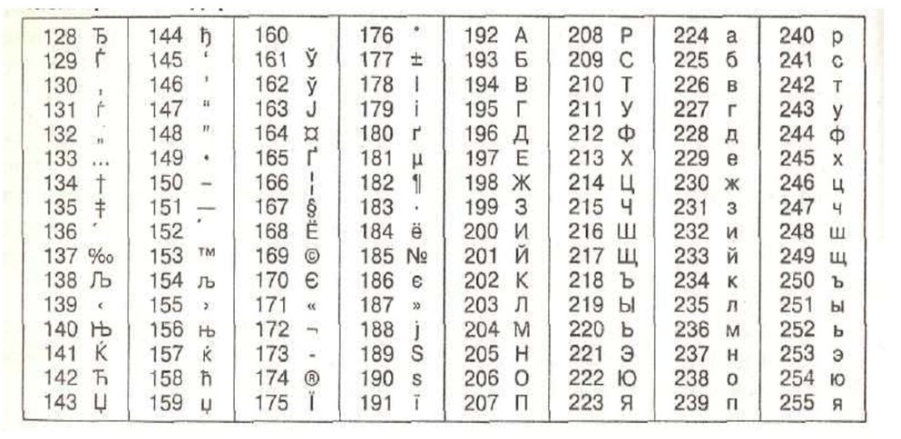
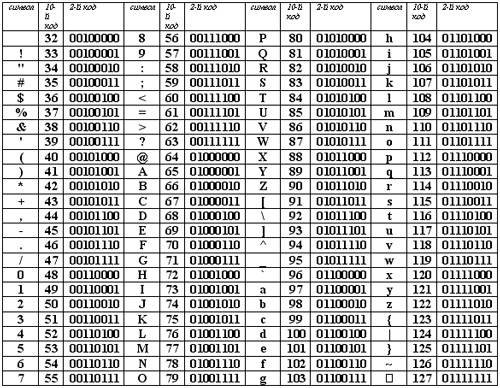
Чтобы символы можно было запомнить быстро и просто, чаще всего используют следующую таблицу:
к содержанию ↑
Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:
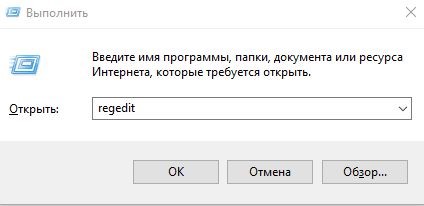
- Чтобы вызвать командную строку, нажимаем сочетание клавиш Win и R. Пишем regedit, при помощи которого открывается специальный реестр
- Как показано на рисунке, находим соответствующую папку HKEY_CURRENT_USER далее выбираем Console. Далее смотрим какой код задан для страниц (Code Page). В том случае, если там стоит число не 866, что скорее всего так и будет, значит проблема была определена верно
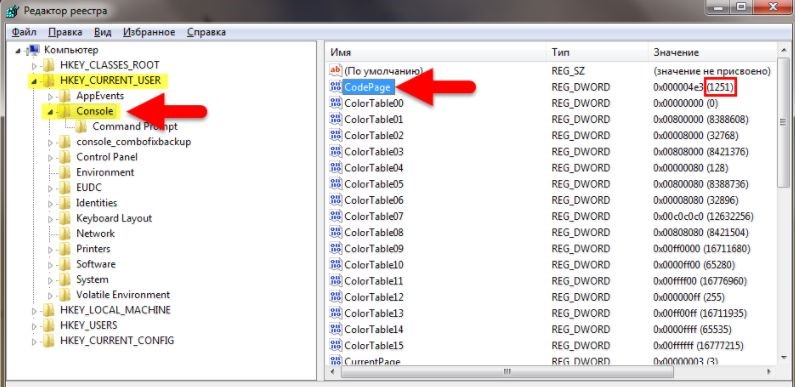
- Исправляем в строке на десятичное значение
- Чтобы править, произошли ли изменения, достаточно открыть и снова вызвать командную строчку.
к содержанию ↑
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
Существуют и другие аргументы, активно выступающие «ЗА» использование данной системы:
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251.
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием.
Windows 1251 — это одна из наиболее популярных кодировок, используемых в операционной системе Windows. Она представляет собой 8-битный набор символов, который позволяет отображать текст на русском языке и некоторых других славянских языках.
Как правило, кодировка Windows 1251 используется для работы с текстовыми файлами, веб-страницами и электронными письмами. Она может быть полезна, если вам нужно сохранить или открыть файл, содержащий текст на русском языке, в программе, которая поддерживает только эту кодировку.
Если вы хотите использовать кодировку Windows 1251, вам потребуется правильно указать ее при открытии или сохранении файла. В большинстве текстовых редакторов и IDE есть возможность выбрать кодировку при открытии или создании нового файла.
Примечание: При использовании кодировки Windows 1251, необходимо учитывать, что она не поддерживает некоторые символы, которые могут встречаться в тексте на других языках. Если вам нужно работать с международными символами или символами, отличными от славянского алфавита, вам следует выбрать другую кодировку.
Содержание
- Что такое кодировка файла windows 1251 и зачем она нужна?
- Описание и назначение
- Преимущества кодировки windows 1251 перед другими
- Как использовать кодировку windows 1251 в различных программах и приложениях
Что такое кодировка файла windows 1251 и зачем она нужна?
Кодировка windows 1251 преобразует символы в двоичные числа, которые затем могут быть сохранены в файле. Каждому символу соответствует свое численное значение, именуемое кодом символа. Для русских символов, таких как буквы А, Б, В и т.д., используются значения от 128 до 255.
Использование кодировки windows 1251 позволяет записывать и отображать текст на русском языке без искажений. Кодировка windows 1251 поддерживает полный набор символов, используемых в русском алфавите, включая заглавные и строчные буквы, цифры, знаки препинания и специальные символы.
Кроме того, кодировка windows 1251 совместима с широким спектром программ и приложений, что позволяет легко обмениваться данными и файлами на русском языке между различными системами и программами, работающими под управлением операционной системы Windows.
Важно отметить, что кодировка windows 1251 может вызывать проблемы при взаимодействии с другими кодировками, особенно при работе на разных операционных системах. Поэтому перед обменом файлами или текстом, следует убедиться в том, что все участники процесса используют одну и ту же кодировку.
Описание и назначение
Windows 1251 кодировка работает на базе однобайтного символьного набора, где каждый символ занимает 8 бит. В результате, данная кодировка поддерживает восемь битовых символов, что позволяет корректно отображать и обрабатывать символы кириллицы, знаки препинания и другие специальные символы, используемые в русском языке.
Основным назначением кодировки windows 1251 является обмен информацией на компьютерах и устройствах, работающих под управлением операционных систем Windows. Данная кодировка используется в файлах текстовых документов, веб-страниц, электронных письмах и других типах данных, где требуется корректное отображение кириллического текста.
Кодировка windows 1251 стала стандартом для русскоязычного веба, поскольку она позволяет обмениваться текстовой информацией между разными операционными системами, сохраняя при этом правильное отображение символов кириллицы. Это делает ее неотъемлемой частью разработки веб-сайтов и других русскоязычных программных приложений.
Важно помнить: при работе с файлами в кодировке windows 1251, необходимо убедиться, что используемые программы и редакторы поддерживают данную кодировку, чтобы избежать ошибок в отображении текста.
Преимущества кодировки windows 1251 перед другими
Вот некоторые преимущества кодировки windows 1251:
| Преимущество | Описание |
|---|---|
| Поддержка русского языка | Кодировка windows 1251 включает в себя полную поддержку русского языка, включая все его буквы, символы и знаки препинания. |
| Совместимость с разными системами | Кодировка windows 1251 широко используется на различных платформах, что обеспечивает высокую совместимость и возможность обмена данными между разными системами. |
| Небольшой размер файлов | Кодировка windows 1251 обладает небольшим размером файлов по сравнению с некоторыми другими кодировками, что позволяет экономить дискретное пространство. |
| Легкость использования и чтения | Кодировка windows 1251 очень легко читается и понимается разными программами и пользователем, что облегчает работу с текстом и его интерпретацию. |
В целом, кодировка windows 1251 является удобным и широко используемым способом представления текста на русском языке, обеспечивая надежность и совместимость при обмене данными.
Как использовать кодировку windows 1251 в различных программах и приложениях
Ниже приведены примеры того, как можно использовать кодировку windows 1251 в различных программах и приложениях:
- Текстовые редакторы: В большинстве текстовых редакторов, таких как Notepad, Sublime Text, Visual Studio Code и других, можно выбрать кодировку windows 1251 при сохранении файла. Обычно это можно сделать через меню «Сохранить как» или «Кодировка файла» в настройках.
- Офисные приложения: В программах Microsoft Office, таких как Word, Excel и PowerPoint, также можно выбрать кодировку windows 1251 при сохранении файла. Для этого нужно выбрать «Сохранить как», затем выбрать формат файла (например, .doc или .xls) и указать кодировку в дополнительных настройках.
- IDE для разработки программного обеспечения: Многие интегрированные среды разработки (IDE), такие как Eclipse, IntelliJ IDEA и Visual Studio, позволяют выбрать кодировку windows 1251 при создании или открытии проекта. Это можно сделать в настройках проекта или в настройках самой IDE.
- Веб-разработка: При разработке веб-сайтов с использованием кодировки windows 1251, необходимо установить соответствующую кодировку в файле HTML. Для этого в теге <meta> нужно указать атрибут charset со значением windows-1251. Например: <meta charset=»windows-1251″>.
- Система управления базами данных: В системах управления базами данных, таких как MySQL и PostgreSQL, можно указать кодировку windows 1251 при создании базы данных или при импорте данных. Это позволяет хранить и обрабатывать данные, содержащие символы кириллицы, с использованием этой кодировки.
Важно помнить, что для правильного отображения и обработки данных в кодировке windows 1251, необходимо, чтобы поддержка этой кодировки была настроена и на компьютере пользователя, и на компьютере сервера, где будут отображаться данные.
From Wikipedia, the free encyclopedia
| MIME / IANA | windows-1251 |
|---|---|
| Alias(es) | cp1251 (Code page 1251) |
| Language(s) | Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Bosnian Cyrillic, Macedonian, Rotokas, Rusyn, English |
| Created by | Microsoft |
| Standard | WHATWG Encoding Standard |
| Classification | extended ASCII, Windows-125x |
| Other related encoding(s) | Amiga-1251, KZ-1048, RFC 1345’s «ECMA-Cyrillic» |
|
Windows-1251 is an 8-bit character encoding, designed to cover languages that use the Cyrillic script such as Russian, Ukrainian, Belarusian, Bulgarian, Serbian Cyrillic, Macedonian and other languages.
On the web, it is the second most-used single-byte character encoding (or third most-used character encoding overall), and most used of the single-byte encodings supporting Cyrillic. As of November 2022, 0.4% of all websites use Windows-1251.[1][2] It’s by far mostly used for Russian, while a small minority of Russian websites use it, with 93.7% of Russian (.ru) websites using UTF-8,[3][4][5] and the legacy 8-bit encoding is distant second. In Linux, the encoding is known as cp1251.[6] IBM uses code page 1251 (CCSID 1251 and euro sign extended CCSID 5347) for Windows-1251.[7][8][9][10][11][12][13]
Windows-1251 and KOI8-R (or its Ukrainian variant KOI8-U) are much more commonly used than ISO 8859-5 (which is used by less than 0.0004% of websites).[14] In contrast to Windows-1252 and ISO 8859-1, Windows-1251 is not closely related to ISO 8859-5.
Unicode (e.g. UTF-8) is preferred to Windows-1251 or other Cyrillic encodings in modern applications, especially on the Internet, making UTF-8 the dominant encoding for web pages. (For further discussion of Unicode’s complete coverage, of 436 Cyrillic letters/code points, including for Old Cyrillic, and how single-byte character encodings, such as Windows-1251 and KOI8-R, cannot provide this, see Cyrillic script in Unicode.)
Character set[edit]
The following table shows Windows-1251. Each character is shown with its Unicode equivalent and its Alt code.
| Windows-1251[15] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Ќ | Ћ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | ќ | ћ | џ | |
| Ax | NBSP | Ў | ў | Ј | ¤ | Ґ | ¦ | § | Ё | © | Є | « | ¬ | SHY | ® | Ї |
| Bx | ° | ± | І | і | ґ | µ | ¶ | · | ё | № | є | » | ј | Ѕ | ѕ | ї |
| Cx | А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| Dx | Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
| Ex | а | б | в | г | д | е | ж | з | и | й | к | л | м | н | о | п |
| Fx | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
Kazakh variant[edit]
An altered version of Windows-1251 was standardised in Kazakhstan as Kazakh standard STRK1048, and is known by the label KZ-1048. It differs in the rows shown below:
| KZ-1048 (STRK1048-2002)[16] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | Ђ | Ѓ | ‚ | ѓ | „ | … | † | ‡ | € | ‰ | Љ | ‹ | Њ | Қ | Һ | Џ |
| 9x | ђ | ‘ | ’ | “ | ” | • | – | — | ™ | љ | › | њ | қ | һ | џ | |
| Ax | NBSP | Ұ | ұ | Ә | ¤ | Ө | ¦ | § | Ё | © | Ғ | « | ¬ | SHY | ® | Ү |
| Bx | ° | ± | І | і | ө | µ | ¶ | · | ё | № | ғ | » | ә | Ң | ң | ү |
Differences from Windows-1251
Amiga variant[edit]
| MIME / IANA | Amiga-1251 |
|---|---|
| Alias(es) | Ami1251 |
| Language(s) | English, Russian |
| Classification | extended ASCII |
| Based on | Windows-1251, ISO-8859-1, ISO-8859-15 |
|
Russian Amiga OS systems used a version of code page 1251 which matches Windows-1251 for the Russian subset of the Cyrillic letters, but otherwise mostly follows ISO-8859-1. This version is known as Amiga-1251,[17] under which name it is registered with the IANA.[18]
| Amiga-1251[17] | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 8x | XXX | XXX | BPH | NBH | IND | NEL | SSA | ESA | HTS | HTJ | VTS | PLD | PLU | RI | SS2 | SS3 |
| 9x | DCS | PU1 | PU2 | STS | CCH | MW | SPA | EPA | SOS | XXX | SCI | CSI | ST | OSC | PM | APC |
| Ax | NBSP | ¡ | ¢ | £ | €[a] | ¥ | ¦ | § | Ё | © | №[b] | « | ¬ | SHY | ® | ¯ |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ё | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
Different from Windows-1251 to match ISO-8859-1
Different from both Windows-1251 and ISO-8859-1
- ^ Matching ISO-8859-15; at a different location than in Windows-1251
- ^ Present in Windows-1251, but in a different location (absent from ISO-8859-1/15)
See also[edit]
- Latin script in Unicode
- Unicode
- Universal Character Set
- European Unicode subset (DIN 91379)
- UTF-8
References[edit]
- ^ «Historical trends in the usage of character encodings, November 2022». Retrieved 2022-11-28.
- ^ «Frequently Asked Questions».
- ^ «Distribution of Character Encodings among websites that use .ru». w3techs.com. Retrieved 2022-11-28.
- ^ «Distribution of Character Encodings among websites that use Russian». w3techs.com. Retrieved 2023-01-16.
- ^ «Distribution of Character Encodings among websites that use Russian Federation». w3techs.com. Retrieved 2021-11-05.
- ^ «cp1251(7) — Linux manual page». man7.org. Retrieved 2018-07-01.
- ^ «Code page 1251 information document». Archived from the original on 2016-03-03.
- ^ «CCSID 1251 information document». Archived from the original on 2014-11-29.
- ^ «CCSID 5347 information document». Archived from the original on 2014-11-29.
- ^ Code Page CPGID 01251 (pdf) (PDF), IBM
- ^ Code Page CPGID 01251 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-1251_P100-1995.ucm, 2002-12-03
- ^ International Components for Unicode (ICU), ibm-5347_P100-1998.ucm, 2002-12-03
- ^ «Usage Statistics of Character Encodings for Websites». w3techs.com. Archived from the original on 2012-05-30.
- ^ Steele, Shawn (1998). CP1251 to Unicode table. Unicode Consortium. CP1251.TXT.
- ^ Whistler, Ken (2007). KZ-1048 to Unicode. Unicode Consortium. KZ1048.TXT.
- ^ a b Malyshev, Michael (2003). «Amiga-1251 to Unicode table». Registration of new charset [Amiga-1251]. IANA.
- ^ «Character Sets». IANA.
Further reading[edit]
- Kornai, Andras; Birnbaum, David J.; da Cruz, Frank; Davis, Bur; Fowler, George; Paine, Richard B.; Paperno, Slava; Simonsen, Keld J.; Thobe, Glenn E.; Vulis, Dimitri; van Wingen, Johan W. (1993-03-13). «CYRILLIC ENCODING FAQ Version 1.3». Retrieved 2020-06-24.
External links[edit]
- Windows 1251 reference chart
- IANA Charset Name Registration
- Unicode mappings of windows 1251 with «best fit»
- Universal Cyrillic decoder, an online program that may help recovering unreadable Cyrillic texts with broken Windows-1251 or other character encodings.
Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
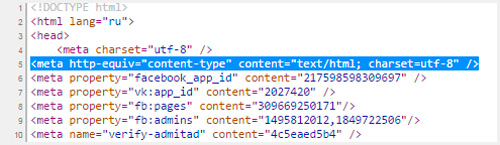
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова «Создание и Раскрутка сайта от А до Я».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова. Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset "cp1251"
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.