From Wikipedia, the free encyclopedia
Windows code pages are sets of characters or code pages (known as character encodings in other operating systems) used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows,[citation needed] although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
There are two groups of system code pages in Windows systems: OEM and Windows-native («ANSI») code pages.
(ANSI is the American National Standards Institute.) Code pages in both of these groups are extended ASCII code pages. Additional code pages are supported by standard Windows conversion routines, but not used as either type of system code page.
ANSI code page[edit]
| Alias(es) | ANSI (misnomer) |
|---|---|
| Standard | WHATWG Encoding Standard |
| Extends | US-ASCII |
| Preceded by | ISO 8859 |
| Succeeded by | Unicode UTF-16 (in Win32 API) |
|
ANSI code pages (officially called «Windows code pages» [1] after Microsoft accepted the former term being a misnomer [2]) are used for native non-Unicode (say, byte oriented) applications using a graphical user interface on Windows systems. The term «ANSI» is a misnomer because these Windows code pages do not comply with any ANSI (American National Standards Institute) standard; code page 1252 was based on an early ANSI draft that became the international standard ISO 8859-1, [2] which adds a further 32 control codes and space for 96 printable characters. Among other differences, Windows code-pages allocate printable characters to the supplementary control code space, making them at best illegible to standards-compliant operating systems.)
Most legacy «ANSI» code pages have code page numbers in the pattern 125x. However, 874 (Thai) and the East Asian multi-byte «ANSI» code pages (932, 936, 949, 950), all of which are also used as OEM code pages, are numbered to match IBM encodings, none of which are identical to the Windows encodings (although most are similar). While code page 1258 is also used as an OEM code page, it is original to Microsoft rather than an extension to an existing encoding. IBM have assigned their own, different numbers for Microsoft’s variants, these are given for reference in the lists below where applicable.
All of the 125x Windows code pages, as well as 874 and 936, are labelled by Internet Assigned Numbers Authority (IANA) as «Windows-number«, although «Windows-936» is treated as a synonym for «GBK». Windows code page 932 is instead labelled as «Windows-31J».[3]
ANSI Windows code pages, and especially the code page 1252, were so called since they were purportedly based on drafts submitted or intended for ANSI. However, ANSI and ISO have not standardized any of these code pages. Instead they are either:[2]
- Supersets of the standard sets such as those of ISO 8859 and the various national standards (like Windows-1252 vs. ISO-8859-1),
- Major modifications of these (making them incompatible to various degrees, like Windows-1250 vs. ISO-8859-2)
- Having no parallel encoding (like Windows-1257 vs. ISO-8859-4; ISO-8859-13 was introduced much later). Also, Windows-1251 follows neither the ISO-standardised ISO-8859-5 nor the then-prevailing KOI-8.
Microsoft assigned about twelve of the typography and business characters (including notably, the euro sign, €) in CP1252 to the code points 0x80–0x9F that, in ISO 8859, are assigned to C1 control codes. These assignments are also present in many other ANSI/Windows code pages at the same code-points. Windows did not use the C1 control codes, so this decision had no direct effect on Windows users. However, if included in a file transferred to a standards-compliant platform like Unix or MacOS, the information was invisible and potentially disruptive.[citation needed]
OEM code page[edit]
The OEM code pages (original equipment manufacturer) are used by Win32 console applications, and by virtual DOS, and can be considered a holdover from DOS and the original IBM PC architecture. A separate suite of code pages was implemented not only due to compatibility, but also because the fonts of VGA (and descendant) hardware suggest encoding of line-drawing characters to be compatible with code page 437. Most OEM code pages share many code points, particularly for non-letter characters, with the second (non-ASCII) half of CP437.
A typical OEM code page, in its second half, does not resemble any ANSI/Windows code page even roughly. Nevertheless, two single-byte, fixed-width code pages (874 for Thai and 1258 for Vietnamese) and four multibyte CJK code pages (932, 936, 949, 950) are used as both OEM and ANSI code pages. Code page 1258 uses combining diacritics, as Vietnamese requires more than 128 letter-diacritic combinations. This is in contrast to VISCII, which replaces some of the C0 (i.e. ASCII) control codes.
History[edit]
Initially, computer systems and system programming languages did not make a distinction between characters and bytes: for the segmental scripts used in most of Africa, the Americas, southern and south-east Asia, the Middle East and Europe, a character needs just one byte, but two or more bytes are needed for the ideographic sets used in the rest of the world. This subsequently led to much confusion. Microsoft software and systems prior to the Windows NT line are examples of this, because they use the OEM and ANSI code pages that do not make the distinction.
Since the late 1990s, software and systems have adopted Unicode as their preferred storage format; this trend has been improved by the widespread adoption of XML which default to UTF-8 but also provides a mechanism for labelling the encoding used.[4] All current Microsoft products and application program interfaces use Unicode internally,[citation needed] but some applications continue to use the default encoding of the computer’s ‘locale’ when reading and writing text data to files or standard output.[citation needed] Therefore, files may still be encountered that are legible and intelligible in one part of the world but unintelligible mojibake in another.
UTF-8, UTF-16[edit]
Microsoft adopted a Unicode encoding (first the now-obsolete UCS-2, which was then Unicode’s only encoding), i.e. UTF-16 for all its operating systems from Windows NT onwards, but additionally supports UTF-8 (aka CP_UTF8) since Windows 10 version 1803.[5]
UTF-16 uniquely encodes all Unicode characters in the Basic Multilingual Plane (BMP) using 16 bits but the remaining Unicode (e.g. emojis) is encoded with a 32-bit (four byte) code – while the rest of the industry (Unix-like systems and the web), and now Microsoft chose UTF-8 (which uses one byte for the 7-bit ASCII character set, two or three bytes for other characters in the BMP, and four bytes for the remainder).
List[edit]
The following Windows code pages exist:
Windows-125x series[edit]
These nine code pages are all extended ASCII 8-bit SBCS encodings, and were designed by Microsoft for use as ANSI codepages on Windows. They are commonly known by their IANA-registered[6] names as windows-<number>, but are also sometimes called cp<number>, «cp» for «code page». They are all used as ANSI code pages; Windows-1258 is also used as an OEM code page.
The Windows-125x series includes nine of the ANSI code pages, and mostly covers scripts from Europe and West Asia with the addition of Vietnam. System encodings for Thai and for East Asian languages were numbered to match similar IBM code pages and are used as both ANSI and OEM code pages; these are covered in following sections.
| ID | Description | Relationship to ISO 8859 or other established encodings |
|---|---|---|
| 1250[7][8] | Latin 2 / Central European | Similar to ISO-8859-2 but moves several characters, including multiple letters. |
| 1251[9][10] | Cyrillic | Incompatible with both ISO-8859-5 and KOI-8. |
| 1252[11][12] | Latin 1 / Western European | Superset of ISO-8859-1 (without C1 controls). Letter repertoire accordingly similar to CP850. |
| 1253[13][14] | Greek | Similar to ISO 8859-7 but moves several characters, including a letter. |
| 1254[15][16] | Turkish | Superset of ISO 8859-9 (without C1 controls). |
| 1255[17][18] | Hebrew | Almost a superset of ISO 8859-8, but with two incompatible punctuation changes. |
| 1256[19][20] | Arabic | Not compatible with ISO 8859-6; rather, OEM Code page 708 is an ISO 8859-6 (ASMO 708) superset. |
| 1257[21][22] | Baltic | Not ISO 8859-4; the later ISO 8859-13 is closely related, but with some differences in available punctuation. |
| 1258[23][24] | Vietnamese (also OEM) | Not related to VSCII or VISCII, uses fewer base characters with combining diacritics. |
DOS code pages[edit]
These are also ASCII-based. Most of these are included for use as OEM code pages; code page 874 is also used as an ANSI code page.
- 437 – IBM PC US, 8-bit SBCS extended ASCII.[25] Known as OEM-US, the encoding of the primary built-in font of VGA graphics cards.
- 708 – Arabic, extended ISO 8859-6 (ASMO 708)
- 720 – Arabic, retaining box drawing characters in their usual locations
- 737 – «MS-DOS Greek». Retains all box drawing characters. More popular than 869.
- 775 – «MS-DOS Baltic Rim»
- 850 – «MS-DOS Latin 1». Full (re-arranged) repertoire of ISO 8859-1.
- 852 – «MS-DOS Latin 2»
- 855 – «MS-DOS Cyrillic». Mainly used for South Slavic languages. Includes (re-arranged) repertoire of ISO-8859-5. Not to be confused with cp866.
- 857 – «MS-DOS Turkish»
- 858 – Western European with euro sign
- 860 – «MS-DOS Portuguese»
- 861 – «MS-DOS Icelandic»
- 862 – «MS-DOS Hebrew»
- 863 – «MS-DOS French Canada»
- 864 – Arabic
- 865 – «MS-DOS Nordic»
- 866 – «MS-DOS Cyrillic Russian», cp866. Sole purely OEM code page (rather than ANSI or both) included as a legacy encoding in WHATWG Encoding Standard for HTML5.
- 869 – «MS-DOS Greek 2», IBM869. Full (re-arranged) repertoire of ISO 8859-7.
- 874 – Thai, also used as the ANSI code page, extends ISO 8859-11 (and therefore TIS-620) with a few additional characters from Windows-1252. Corresponds to IBM code page 1162 (IBM-874 is similar but has different extensions).
East Asian multi-byte code pages[edit]
These often differ from the IBM code pages of the same number: code pages 932, 949 and 950 only partly match the IBM code pages of the same number, while the number 936 was used by IBM for another Simplified Chinese encoding which is now deprecated and Windows-951, as part of a kludge, is unrelated to IBM-951. IBM equivalent code pages are given in the second column. Code pages 932, 936, 949 and 950/951 are used as both ANSI and OEM code pages on the locales in question.
| ID | Language | Encoding | IBM Equivalent | Difference from IBM CCSID of same number | Use |
|---|---|---|---|---|---|
| 932 | Japanese | Shift JIS (Microsoft variant) | 943[26] | IBM-932 is also Shift JIS, has fewer extensions (but those extensions it has are in common), and swaps some variant Chinese characters (itaiji) for interoperability with earlier editions of JIS C 6226. | ANSI/OEM (Japan) |
| 936 | Chinese (simplified) | GBK | 1386 | IBM-936 is a different Simplified Chinese encoding with a different encoding method, which has been deprecated since 1993. | ANSI/OEM (PRC, Singapore) |
| 949 | Korean | Unified Hangul Code | 1363 | IBM-949 is also an EUC-KR superset, but with different (colliding) extensions. | ANSI/OEM (Republic of Korea) |
| 950 | Chinese (traditional) | Big5 (Microsoft variant) | 1373[27] | IBM-950 is also Big5, but includes a different subset of the ETEN extensions, adds further extensions with an expanded trail byte range, and lacks the Euro. | ANSI/OEM (Taiwan, Hong Kong) |
| 951 | Chinese (traditional) including Cantonese | Big5-HKSCS (2001 ed.) | 5471[28] | IBM-951 is the double-byte plane from IBM-949 (see above), and unrelated to Microsoft’s internal use of the number 951. | ANSI/OEM (Hong Kong, 98/NT4/2000/XP with HKSCS patch) |
A few further multiple-byte code pages are supported for decoding or encoding using operating system libraries, but not used as either sort of system encoding in any locale.
| ID | IBM Equivalent | Language | Encoding | Use |
|---|---|---|---|---|
| 1361 | — | Korean | Johab (KS C 5601-1992 annex 3) | Conversion |
| 20000 | — | Chinese (traditional) | An encoding of CNS 11643 | Conversion |
| 20001 | — | Chinese (traditional) | TCA | Conversion |
| 20002 | — | Chinese (traditional) | Big5 (ETEN variant) | Conversion |
| 20003 | 938 | Chinese (traditional) | IBM 5550 | Conversion |
| 20004 | — | Chinese (traditional) | Teletext | Conversion |
| 20005 | — | Chinese (traditional) | Wang | Conversion |
| 20932 | 954 (roughly) | Japanese | EUC-JP | Conversion |
| 20936 | 5479 | Chinese (simplified) | GB 2312 | Conversion |
| 20949, 51949 | 970 | Korean | Wansung (8-bit with ASCII, i.e. EUC-KR)[29] | Conversion |
EBCDIC code pages[edit]
- 37 – IBM EBCDIC US-Canada, 8-bit SBCS[30]
- 500 – Latin 1
- 870 – IBM870
- 875 – cp875
- 1026 – EBCDIC Turkish
- 1047 – IBM01047 – Latin 1
- 1140 – IBM01141
- 1141 – IBM01141
- 1142 – IBM01142
- 1143 – IBM01143
- 1144 – IBM01144
- 1145 – IBM01145
- 1146 – IBM01146
- 1147 – IBM01147
- 1148 – IBM01148
- 1149 – IBM01149
- 20273 – EBCDIC Germany
- 20277 – EBCDIC Denmark/Norway
- 20278 – EBCDIC Finland/Sweden
- 20280 – EBCDIC Italy
- 20284 – EBCDIC Latin America/Spain
- 20285 – EBCDIC United Kingdom
- 20290 – EBCDIC Japanese
- 20297 – EBCDIC France
- 20420 – EBCDIC Arabic
- 20423 – EBCDIC Greek
- 20424 – x-EBCDIC-KoreanExtended
- 20833 – Korean
- 20838 – EBCDIC Thai
- 20924 – IBM00924 – IBM EBCDIC Latin 1/Open System (1047 + Euro symbol)
- 20871 – EBCDIC Icelandic
- 20880 – EBCDIC Cyrillic
- 20905 – EBCDIC Turkish
- 21025 – EBCDIC Cyrillic
- 21027 – Japanese EBCDIC (incomplete,[31] deprecated)[32]
[edit]
- 1200 – Unicode (BMP of ISO 10646, UTF-16LE). Available only to managed applications.[32]
- 1201 – Unicode (UTF-16BE). Available only to managed applications.[32]
- 12000 – UTF-32. Available only to managed applications.[32]
- 12001 – UTF-32. Big-endian. Available only to managed applications.[32]
- 65000 – Unicode (UTF-7)
- 65001 – Unicode (UTF-8)
Macintosh compatibility code pages[edit]
- 10000 – Apple Macintosh Roman
- 10001 – Apple Macintosh Japanese
- 10002 – Apple Macintosh Chinese (traditional) (BIG-5)
- 10003 – Apple Macintosh Korean
- 10004 – Apple Macintosh Arabic
- 10005 – Apple Macintosh Hebrew
- 10006 – Apple Macintosh Greek
- 10007 – Apple Macintosh Cyrillic
- 10008 – Apple Macintosh Chinese (simplified) (GB 2312)
- 10010 – Apple Macintosh Romanian
- 10017 – Apple Macintosh Ukrainian
- 10021 – Apple Macintosh Thai
- 10029 – Apple Macintosh Roman II / Central Europe
- 10079 – Apple Macintosh Icelandic
- 10081 – Apple Macintosh Turkish
- 10082 – Apple Macintosh Croatian
ISO 8859 code pages[edit]
- 28591 – ISO-8859-1 – Latin-1 (IBM equivalent: 819)
- 28592 – ISO-8859-2 – Latin-2
- 28593 – ISO-8859-3 – Latin-3 or South European
- 28594 – ISO-8859-4 – Latin-4 or North European
- 28595 – ISO-8859-5 – Latin/Cyrillic
- 28596 – ISO-8859-6 – Latin/Arabic
- 28597 – ISO-8859-7 – Latin/Greek
- 28598 – ISO-8859-8 – Latin/Hebrew
- 28599 – ISO-8859-9 – Latin-5 or Turkish
- 28600 – ISO-8859-10 – Latin-6
- 28601 – ISO-8859-11 – Latin/Thai
- 28602 – ISO-8859-12 – reserved for Latin/Devanagari but abandoned (not supported)
- 28603 – ISO-8859-13 – Latin-7 or Baltic Rim
- 28604 – ISO-8859-14 – Latin-8 or Celtic
- 28605 – ISO-8859-15 – Latin-9
- 28606 – ISO-8859-16 – Latin-10 or South-Eastern European
- 38596 – ISO-8859-6-I – Latin/Arabic (logical bidirectional order)
- 38598 – ISO-8859-8-I – Latin/Hebrew (logical bidirectional order)
ITU-T code pages[edit]
- 20105 – 7-bit IA5 IRV (Western European)[33][34][35]
- 20106 – 7-bit IA5 German (DIN 66003)[33][34][36]
- 20107 – 7-bit IA5 Swedish (SEN 850200 C)[33][34][37]
- 20108 – 7-bit IA5 Norwegian (NS 4551-2)[33][34][38]
- 20127 – 7-bit US-ASCII[33][34][39]
- 20261 – T.61 (T.61-8bit)
- 20269 – ISO-6937
KOI8 code pages[edit]
- 20866 – Russian – KOI8-R
- 21866 – Ukrainian – KOI8-U (or KOI8-RU in some versions)[40]
Problems arising from the use of code pages[edit]
Microsoft strongly recommends using Unicode in modern applications, but many applications or data files still depend on the legacy code pages.
- Programs need to know what code page to use in order to display the contents of (pre-Unicode) files correctly. If a program uses the wrong code page it may show text as mojibake.
- The code page in use may differ between machines, so (pre-Unicode) files created on one machine may be unreadable on another.
- Data is often improperly tagged with the code page, or not tagged at all, making determination of the correct code page to read the data difficult.
- These Microsoft code pages differ to various degrees from some of the standards and other vendors’ implementations. This isn’t a Microsoft issue per se, as it happens to all vendors, but the lack of consistency makes interoperability with other systems unreliable in some cases.
- The use of code pages limits the set of characters that may be used.
- Characters expressed in an unsupported code page may be converted to question marks (?) or other replacement characters, or to a simpler version (such as removing accents from a letter). In either case, the original character may be lost.
See also[edit]
- AppLocale – a utility to run non-Unicode (code page-based) applications in a locale of the user’s choice.
References[edit]
- ^ «Code Pages». 2016-03-07. Archived from the original on 2016-03-07. Retrieved 2021-05-26.
- ^ a b c «Glossary of Terms Used on this Site». December 8, 2018. Archived from the original on 2018-12-08.
The term «ANSI» as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community. The source of this comes from the fact that the Windows code page 1252 was originally based on an ANSI draft—which became International Organization for Standardization (ISO) Standard 8859-1. «ANSI applications» are usually a reference to non-Unicode or code page–based applications.
- ^ «Character Sets». www.iana.org. Archived from the original on 2021-05-25. Retrieved 2021-05-26.
- ^ «Extensible Markup Language (XML) 1.1 (Second Edition): Character encodings». W3C. 29 September 2006. Archived from the original on 19 April 2021. Retrieved 5 October 2020.
- ^ hylom (2017-11-14). «Windows 10のInsider PreviewでシステムロケールをUTF-8にするオプションが追加される» [The option to make UTF-8 the system locale added in Windows 10 Insider Preview]. スラド (in Japanese). Archived from the original on 2018-05-11. Retrieved 2018-05-10.
- ^ «Character Sets». IANA. Archived from the original on 2016-12-03. Retrieved 2019-04-07.
- ^ Microsoft. «Windows 1250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01250». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01251». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1252». Archived from the original on 2013-05-04. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01252». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01253». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01254». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01255». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01256». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1257». Archived from the original on 2013-03-16. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01257». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ Microsoft. «Windows 1258». Archived from the original on 2013-10-25. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document CPGID 01258». Archived from the original on 2014-07-14. Retrieved 2014-07-06.
- ^ IBM. «SBCS code page information document — CPGID 00437». Archived from the original on 2016-06-09. Retrieved 2014-07-04.
- ^ «IBM-943 and IBM-932». IBM Knowledge Center. IBM. Archived from the original on 2018-08-18. Retrieved 2020-07-08.
- ^ «Converter Explorer: ibm-1373_P100-2002». ICU Demonstration. International Components for Unicode. Archived from the original on 2021-05-26. Retrieved 2020-06-27.
- ^ «Coded character set identifiers – CCSID 5471». IBM Globalization. IBM. Archived from the original on 2014-11-29.
- ^ Julliard, Alexandre. «dump_krwansung_codepage: build Korean Wansung table from the KSX1001 file». make_unicode: Generate code page .c files from ftp.unicode.org descriptions. Wine Project. Archived from the original on 2021-05-26. Retrieved 2021-03-14.
- ^ IBM. «SBCS code page information document — CPGID 00037». Archived from the original on 2014-07-14. Retrieved 2014-07-04.
- ^ Steele, Shawn (2005-09-12). «Code Page 21027 «Extended/Ext Alpha Lowercase»«. MSDN. Archived from the original on 2019-04-06. Retrieved 2019-04-06.
- ^ a b c d e «Code Page Identifiers». docs.microsoft.com. Archived from the original on 2019-04-07. Retrieved 2019-04-07.
- ^ a b c d e «Code Page Identifiers». Microsoft Developer Network. Microsoft. 2014. Archived from the original on 2016-06-19. Retrieved 2016-06-19.
- ^ a b c d e «Web Encodings — Internet Explorer — Encodings». WHATWG Wiki. 2012-10-23. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Western European (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «German (IA5) encoding – Windows charsets». WUtils.com – Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Swedish (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «Norwegian (IA5) encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Foller, Antonin (2014) [2011]. «US-ASCII encoding — Windows charsets». WUtils.com — Online web utility and help. Motobit Software. Archived from the original on 2016-06-20. Retrieved 2016-06-20.
- ^ Nechayev, Valentin (2013) [2001]. «Review of 8-bit Cyrillic encodings universe». Archived from the original on 2016-12-05. Retrieved 2016-12-05.
External links[edit]
- National Language Support (NLS) API Reference. Table showing ANSI and OEM codepages per language (from web-archive since Microsoft removed the original page)
- IANA Charset Name Registrations
- Unicode mapping table for Windows code pages
- Unicode mappings of windows code pages with «best fit»
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
Когда и если вы прочитали теорию о разнице кодировок utf-8 и windows 1251 — это уже победа! 
смайлы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн! 
смайлы, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим…
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
Опять var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Марат’);
Результат:
string(10) «Марат»
И что мы здесь видим!?
Что количество элементов в строке 10… Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается…!
Поэтому, и возникают проблемы с текстом в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример…как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций…
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’);:
string(5) «Marat»
Результат var_dump(‘Марат’);:
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
И третий вариант перекодировать строку из utf-8 в windows 1251
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
(
[0] => �
[1] => �
[2] => �
[3] => �
[4] => �
[5] => �
[6] => �
[7] => �
[8] => �
[9] => �
)
print_r (mb_str_split(‘Марат’)); выдаст :

Как видим… полный отстой…
Мы далее разбирались с этим здесь.
Как перекодировать строку из utf-8 в windows 1251
Итак… есть третий вариант, борьбы с квадратиками(непонимание кодировки) — перекодировать строку из utf-8 в windows 1251:
iconv(«UTF-8», «windows-1251», $text)
После того, как вы выполнили все намеченные действия с текстом, возвращаем его в исходную кодировку :
iconv(«windows-1251», «UTF-8», $text)
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
Мы использовали var_dump, и он посчитал не правильно, поскольку просто так, на страницу вывести данные с помощью var_dump нельзя, мы использовали вот такой костыль :
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
string(5) «�����»
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
string(5) «Марат»
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить… 
смайлы
Что лучше для кириллицы utf-8 или…
Интересный поисковый запрос — «Что лучше для кириллицы utf-8 или…«…
Дело в том, что я выбрал кодировку «utf-8» уже… 14 лет(число динамическое) назад… и… уже сейчас трудно вспомнить, почему именно её… но точно вам могу заявить, что когда-то пользовался «windows-1251″… и у неё были какие-то заморочки, в виде неадекватного вывода информации, что, я волей неволей перешел на «utf-8»
Какие минусы у utf-8?
Одна из самых главных проблем «utf-8» — это многобайтовость…
Да! Это несколько неудобно в самом начале, но для всякой функции, которая не хочет работать с кириллицей, существуют замены.
В процессе создания сайта у вас может возникнуть несколько проблем, которые вы решите и «тупо» забудете об этом…
Задумывался ли я о переходе с кодировки utf-8 на другую?
Смысл задумываться о переходе с кодировки utf-8 на другую, если всё работает так, как нужно!
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 3 сентября 2014;
проверки требуют 9 правок.

Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»).
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Windows-1251 имеет два недостатка:
- строчная буква «я» имеет код 0XFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 — ÿ, оба варианта практически не используются; число же
-1, в дополнительном коде длиной 8 бит представляющееся числом255, часто используется в программировании как специальное значение). - отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Содержание
- 1 Таблицы
- 1.1 Кодировка Windows-1251 (синоним CP1251)
- 1.2 Другие варианты
- 1.2.1 Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)
- 1.2.2 Кодировка CP1251-k (KazWin, казахская кодировка)
- 1.2.3 Кодировка Windows-1251 (чувашский вариант)
- 1.2.4 Татарский вариант
- 2 Ссылки
Таблицы[править | править вики-текст]
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251 (синоним CP1251)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Ќ 40C |
Ћ 40B |
Џ 40F |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
ќ 45C |
ћ 45B |
џ 45F |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Ј 408 |
¤ A4 |
Ґ 490 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ґ 491 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
ј 458 |
Ѕ 405 |
ѕ 455 |
ї 457 |
| C. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
| D. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
| E. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
| F. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
-

Таблица основного кода ASCII
-

Таблица расширенного кода ASCII


Другие варианты[править | править вики-текст]
(Показаны только отличающиеся строки, поскольку всё остальное совпадает)
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A. |
A0 |
¡ A1 |
¢ A2 |
£ A3 |
€ 20AC |
¥ A5 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
№ 2116 |
« AB |
¬ AC |
AD |
® AE |
¯ AF |
| B. |
° B0 |
± B1 |
² B2 |
³ B3 |
´ B4 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
¹ B9 |
º BA |
» BB |
¼ BC |
½ BD |
¾ BE |
¿ BF |
Кодировка CP1251-k (KazWin, казахская кодировка)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ұ 4B0 |
Ғ 492 |
‚ 201A |
ғ 493 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ң 4A2 |
Қ 49A |
Һ 4BA |
Ү 4AE |
| 9. |
ұ 4B1 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ң 4A3 |
қ 49B |
һ 4BB |
ү 4AF |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Җ 496 |
¤ A4 |
Ҳ 4B2 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ҳ 4B3 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
җ 497 |
Ә 4D8 |
ә 4D9 |
ї 457 |
Кодировка Windows-1251 (чувашский вариант)[править | править вики-текст]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Ӑ 4D0 |
Ӗ 4D6 |
Ҫ 4AA |
Ӳ 4F2 |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
ӑ 4D1 |
ӗ 4D7 |
ҫ 4AB |
ӳ 4F3 |
Татарский вариант[править | править вики-текст]
Эта кодировка была официально принята в Татарстане в 1996 г.
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ә 4D8 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ү 4AE |
Җ 496 |
Ң 4A2 |
Һ 4BA |
| 9. |
ә 4D9 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ү 4AF |
җ 497 |
ң 4A3 |
һ 4BB |
Ссылки[править | править вики-текст]
- Информация о кодировке на Microsoft GlobalDev
- История создании кодировки в сообщении Игоря Семенюка в эхоконференции SU.LAN от 14 января 1996
- Юникод-коды символов на unicode.org
- 2cyr.com — универсальный декодер, конвертер кириллицы online
| Кодировки символов | ||
|---|---|---|
| Основы | алфавит • текст ( файл • данные ) • набор символов • конверсия | |
| Исторические кодировки | Докомп.: | семафорная (Макарова) • Морзе • Бодо • МТК-2 |
| Комп.: | 6-битная • УПП • RADIX-50 • EBCDIC ( ДКОИ-8 ) • КОИ-7 • ISO 646 | |
| современное 8-битное представление |
символы | ASCII ( управляющие • печатные ) • не-ASCII ( псевдографика ) |
| 8-битные код.стр. | Кириллица: КОИ-8 • ГОСТ 19768-87 • MacCyrillic | |
| ISO 8859 | 1 (лат.) • 2 • 3 • 4 • 5 (кир.) • 6 • 7 • 8 • 9 • 10 • 11 • 12 • 13 • 14 • 15 (€) • 16 | |
| Windows | 1250 • 1251 (кир.) • 1252 • 1253 • 1254 • 1255 • 1256 • 1257 • 1258 • WGL4 | |
| IBM & DOS | 437 • 850 • 852 • 855 • 866 «альт.» • МИК • НИИ ЭВМ | |
| Многобайтные | Традиционные | DBCS ( GB2312 ) • HTML |
| Unicode | UTF-32 • UTF-16 • UTF-8 • список символов ( кириллица ) | |
| Связанные темы | интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • шрифт • кракозябры • транслит • нестандартные шрифты • текст как изображение | |
| Утилиты | iconv • recode |
![]()
Не каждый человек обладает большими познаниями в компьютерной технике.
Что такое windows-1251 кодировка и какую роль играет в работе компьютера предстоит узнать.

Содержание:
Что это такое?
Кодировка 1251 представляет собой совокупность символов, которая составляет восьми-битную систему Windows для русифицированных устройств.
Стоит отметить, что довольное широкое применение она нашла на территории Европы.
Считается одной из самых выгодных кодировок, поскольку в ней присутствует все необходимые символы, которые используются в российской типографии. Все кириллические символы имею алфавитную последовательность.
к содержанию ↑
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.
Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
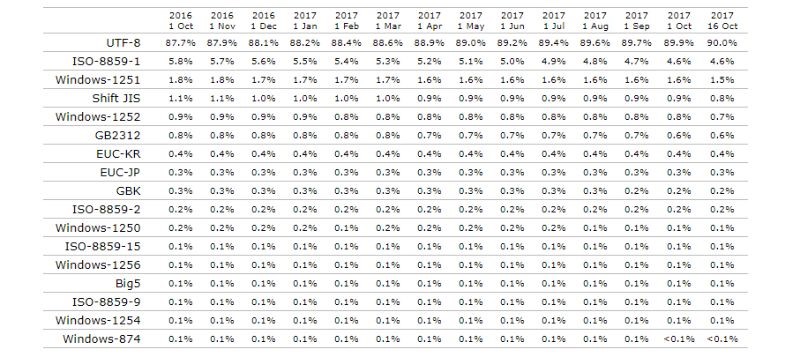
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
к содержанию ↑
UTF-8 против 1251
Вся информация, которая хранится на компьютере, имеет кодированный вид.
Можно предположить, что символ имеет вес порядком 1 байт. 1251 – это разновидность кодировки однобайтовой, а UTF-8 – восьмибайтная.
Отсюда можно сделать вывод, что первый вариант способен к программированию 256 знаков.
Что касается второго варианта, то он представляет большее количество. Кроме того, для этого выделяют большой размер.
Можно сделать вывод, что оба варианта имеют следующие отличия:
- В верхней части необходимо указывать кодировку, которая необходима для использования. В противном случае, вместо обыкновенных символов появляются нечитаемые иероглифы. Используя UTF-8 (которая считается более универсальной кодировкой), все переводы и расшифровки осуществляются в автоматическом режиме
- Вне зависимости от того, на территории какой страны будет загружаться страница, символика останется без изменения. Важно отметить, что местоположение в данном случае не играет абсолютно никакой роли. Главное обращать внимание на языковые серверы, используемые пользователем. Каждый человек обращается к программному обеспечению на родном языке. Для жителей Европы, 1251 будет недоступна в силу использования латиницы. Соответственно можно сделать вывод о том, что русскоязычные сайты не будут открывать в корректном формате. Что касается юникода, то он присутствует в любой ОС
- Второй вид имеет возможность кодировки большего количества символов. На сегодняшний день стоит отметить 6 и 8 байт. Что касается кириллицы, то для ее кодировки достаточно двух байт.
В связи с выше перечисленными отличиями можно сделать вывод о том, что универсальная кодировка более актуальна для использования, чем 1251, поскольку она подойдет только для славянской группы языков.
Для профессиональных программистов и технических специалистов, знание кодировки 1251 является обязательным условием для осуществления полноценной работы.
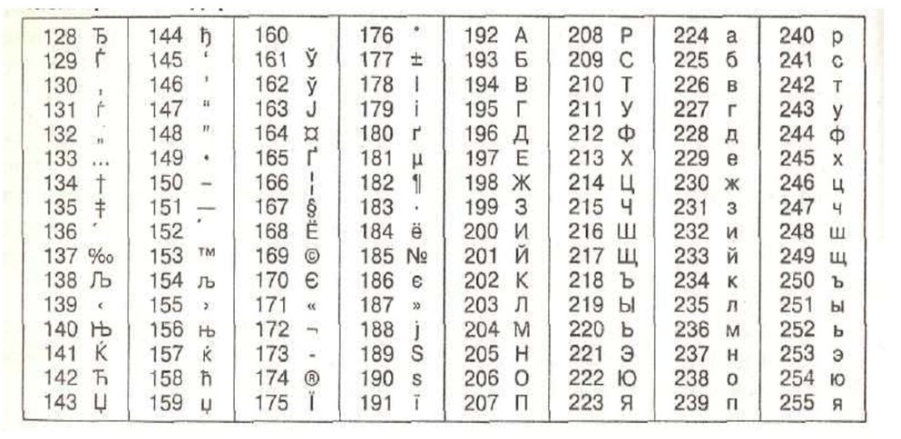
Чтобы символы можно было запомнить быстро и просто, чаще всего используют следующую таблицу:
к содержанию ↑
Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:
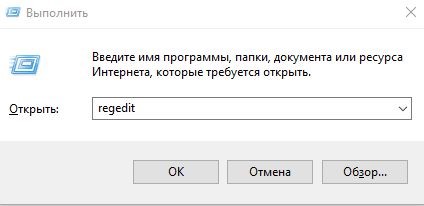
- Чтобы вызвать командную строку, нажимаем сочетание клавиш Win и R. Пишем regedit, при помощи которого открывается специальный реестр
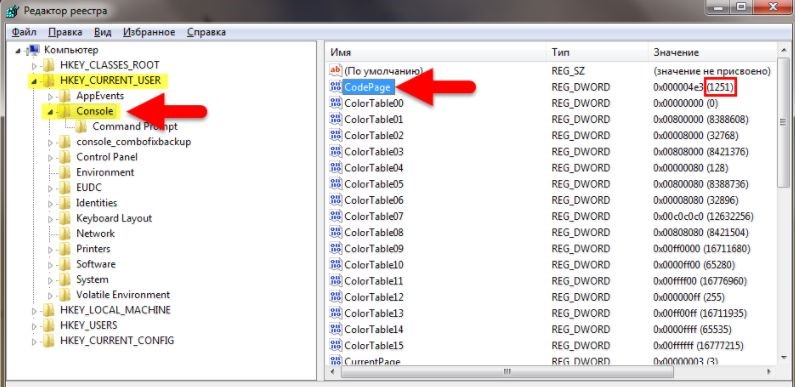
- Как показано на рисунке, находим соответствующую папку HKEY_CURRENT_USER далее выбираем Console. Далее смотрим какой код задан для страниц (Code Page). В том случае, если там стоит число не 866, что скорее всего так и будет, значит проблема была определена верно
- Исправляем в строке на десятичное значение
- Чтобы править, произошли ли изменения, достаточно открыть и снова вызвать командную строчку.
к содержанию ↑
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
Существуют и другие аргументы, активно выступающие «ЗА» использование данной системы:
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251.
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием.
Кодировка — это способ представления символов и текста в компьютерных системах. В операционной системе Windows используется широко известная и распространенная кодировка — UTF-8.
UTF-8 (Unicode Transformation Format — 8 bit) является стандартной кодировкой в Windows. Она позволяет представлять символы разных языков и записывать текст на разных алфавитах, включая латинский, кириллический и даже иероглифы.
UTF-8 обеспечивает большую гибкость и универсальность, поскольку поддерживает все возможные символы Unicode. Это позволяет пользователям Windows создавать и читать текст на разных языках без каких-либо ограничений.
Однако UTF-8 не является единственной кодировкой, используемой в Windows. В прошлом были также популярны кодировки, которые ограничивались только определенным алфавитом или символами, такие как ASCII или ANSI.
Знание о том, какая кодировка используется в Windows, важно при работе с текстовыми файлами или при разработке программного обеспечения, поскольку неправильное представление текста может привести к проблемам с отображением или восприятием информации.
Содержание
- Кодировка в Windows: определение и значение
- Кодировка символов: понятие и роль
- Какие кодировки применяются в Windows?
Кодировка в Windows: определение и значение
Одной из наиболее распространенных кодировок в Windows является Windows-1251, также известная как CP1251 или просто ANSI. Эта кодировка предоставляет таблицу символов, включающую основные символы кириллицы, а также специальные символы и знаки пунктуации.
Другой распространенной кодировкой в Windows является UTF-8. Эта многоязыковая кодировка может представлять символы из всех возможных языков, включая кириллицу, латиницу и другие. UTF-8 также поддерживает подробную работу с различными символами юникода.
Выбор кодировки в Windows зависит от конкретного приложения или среды разработки. Некоторые приложения могут автоматически выбирать кодировку на основе локализации или языковых настроек операционной системы, в то время как другие могут предоставлять возможность вручную выбирать нужную кодировку.
Правильный выбор кодировки в Windows критичен для правильного отображения и обработки текста в различных языках. Неправильная кодировка может привести к некорректному отображению и неверной интерпретации символов, что может привести к проблемам с читаемостью и функциональностью программ и файлов.
Кодировка символов: понятие и роль
Благодаря кодировкам символов, компьютеры могут понимать и обрабатывать текст на различных языках, включая весьма разнообразные наборы символов. Кодировка определяет способ представления символов в памяти компьютера и правила, по которым символы преобразуются в их бинарные представления и наоборот.
Роль кодировки символов особенно актуальна в контексте операционной системы Windows, где она определяет взаимодействие между пользователем и операционной системой, а также между различными приложениями. Windows использует несколько основных кодировок символов, таких как UTF-8, UTF-16, Windows-1251 и другие.
Корректная работа с кодировкой символов особенно важна для разработчиков программного обеспечения, чтобы убедиться, что текст отображается и передается правильно между разными системами и устройствами. Правильная выборка кодировки может предотвратить множество проблем, связанных с отображением и обработкой символов.
Важно помнить, что при создании и обработке текста в Windows следует учитывать выбранную кодировку символов, чтобы гарантировать правильное отображение и обработку текстовой информации.
Какие кодировки применяются в Windows?
Windows поддерживает различные кодировки символов, которые определяют способ представления и хранения текста. Каждая кодировка имеет свои особенности и подходит для конкретных задач.
В операционной системе Windows наиболее распространенными кодировками являются:
Windows-1251: также известная как «кодировка Win-совместимая», это кодировка, используемая по умолчанию для текстовых файлов и веб-страниц на русском языке в Windows. Она содержит все необходимые символы русского алфавита, а также латиницу, знаки препинания и специальные символы.
UTF-8: это универсальная кодировка символов, которая поддерживается практически всеми программами и операционными системами, включая Windows. UTF-8 позволяет использовать символы из разных языков, включая русский, китайский, японский и другие.
ISO-8859-1: также известная как «латинская кодировка», используется для представления символов основных европейских языков. Она содержит символы латиницы, знаки препинания и специальные символы, но не поддерживает кириллицу.
CP1252: это расширение кодировки ISO-8859-1, которое также содержит некоторые дополнительные символы и знаки препинания.
Каждая из этих кодировок имеет свои сильные и слабые стороны, и правильный выбор зависит от требований вашего проекта. Чтобы обеспечить правильное отображение текста, важно выбрать подходящую кодировку при работе с текстовыми файлами и веб-страницами в Windows.