Tesseract is an open source text recognition (OCR) Engine, available under the Apache 2.0 license. It can be used directly, or (for programmers) using an API to extract printed text from images. It supports a wide variety of languages.
Tesseract doesn’t have a built-in GUI, but there are several available from the 3rdParty page.
Installation
There are two parts to install, the engine itself, and the traineddata for the languages.
Tesseract is available directly from many Linux distributions. The package is generally called ‘tesseract’ or ‘tesseract-ocr’ — search your distribution’s repositories to find it.
Packages for over 130 languages and over 35 scripts are also available directly from the Linux distributions. The language traineddata packages are called ‘tesseract-ocr-langcode’ and ‘tesseract-ocr-script-scriptcode’, where langcode is three letter language code and scriptcode is four letter script code.
Examples: tesseract-ocr-eng (English), tesseract-ocr-ara (Arabic), tesseract-ocr-chi-sim (Simplified Chinese), tesseract-ocr-script-latn (Latin Script), tesseract-ocr-script-deva (Devanagari script), etc.
** FOR EXPERTS ONLY. **
If you are experimenting with OCR Engine modes, you will need to manually install language training data beyond what is available in your Linux distribution.
Various types of training data can be found on GitHub. Unpack and copy the .traineddata file into a ‘tessdata’ directory. The exact directory will depend both on the type of training data, and your Linux distribution. Possibilities are /usr/share/tesseract-ocr/tessdata or /usr/share/tessdata or /usr/share/tesseract-ocr/4.00/tessdata.
Training data for obsolete Tesseract versions =< 3.02 reside in another location.
If Tesseract is not available for your distribution, or you want to use a newer version than they offer, you can compile your own.
Ubuntu
You can install Tesseract and its developer tools on Ubuntu by simply running:
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
Note for Ubuntu users: In case apt is unable to find the package try adding universe entry to the sources.list file as shown below.
sudo vi /etc/apt/sources.list
Copy the first line "deb http://archive.ubuntu.com/ubuntu bionic main" and paste it as shown below on the next line.
If you are using a different release of ubuntu, then replace bionic with the respective release name.
deb http://archive.ubuntu.com/ubuntu bionic universe
Debian packages
- Tesseract 4
- Tesseract 5
- Tesseract 5 (devel)
Raspbian packages
- Tesseract 4
- Tesseract 5
- Tesseract 5 (devel)
Ubuntu packages
- Tesseract 4
- Tesseract 5
- Tesseract 5 (devel)
Ubuntu ppa
- Tesseract 4
- Tesseract 5
- Tesseract 5 (devel-daily)
RHEL/CentOS/Scientific Linux, Fedora, openSUSE packages
- Tesseract 4
- Tesseract 5
See Installation on OpenSuse page for detailed instructions.
AppImage
Instruction
- Download AppImage from releases page
- Open your terminal application, if not already open
- Browse to the location of the AppImage
- Make the AppImage executable:
$ chmod a+x tesseract*.AppImage - Run it:
./tesseract*.AppImage -l eng page.tif page.txt
AppImage compatibility
- Debian: ≥ 10
- Fedora: ≥ 29
- Ubuntu: ≥ 18.04
- CentOS ≥ 8
- openSUSE Tumbleweed
Included traineddata files
- deu — German
- eng — English
- fin — Finnish
- fra — French
- osd — Script and orientation
- por — Portuguese
- rus — Russian
- spa — Spanish
snap
For distributions that are supported by snapd you may also run the following command to install the tesseract built binaries(Don’t have snapd installed?):
sudo snap install --channel=edge tesseract
The traineddata is currently not shipped with the snap package and must be placed manually to ~/snap/tesseract/current.
macOS
You can install Tesseract using either MacPorts or Homebrew.
A macOS wrapper for the Tesseract API is also available at Tesseract macOS.
MacPorts
To install Tesseract run this command:
sudo port install tesseract
To install any language data, run:
sudo port install tesseract-<langcode>
List of available langcodes can be found on MacPorts tesseract page.
Homebrew
To install Tesseract run this command:
The tesseract directory can then be found using brew info tesseract,
e.g. /usr/local/Cellar/tesseract/3.05.02/share/tessdata/.
Windows
Installer for Windows for Tesseract 3.05, Tesseract 4 and Tesseract 5 are available from Tesseract at UB Mannheim. These include the training tools. Both 32-bit and 64-bit installers are available.
An installer for the OLD version 3.02 is available for Windows from our download page.
This includes the English training data.
If you want to use another language, download the appropriate training data,
unpack it using 7-zip, and copy the .traineddata file into the ‘tessdata’ directory, probably C:\Program Files\Tesseract-OCR\tessdata.
To access tesseract-OCR from any location you may have to add the directory where the tesseract-OCR binaries are located to the Path variables, probably C:\Program Files\Tesseract-OCR.
Experts can also get binaries build with Visual Studio from the build artifacts of the Appveyor Continuous Integration.
Cygwin
Released version >= 3.02 of tesseract-ocr are part of Cygwin
The latest version available is 4.1.0. Please see announcement.
MSYS2
Install tesseract-OCR:
pacman -S mingw-w64-{i686,x86_64}-tesseract-ocr
and the data files:
pacman -S mingw-w64-{i686,x86_64}-tesseract-data-eng
In the above command, “eng” may be replaced with the ISO 639 3-letter language code for supported languages. For a list of available language packages use:
pacman -Ss tesseract-data
Other Platforms
Tesseract may work on more exotic platforms too. You can either try compiling it yourself, or take a look at the list of other projects using Tesseract.
Running Tesseract
Tesseract is a command-line program, so first open a terminal or command prompt. The command is used like this:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
So basic usage to do OCR on an image called ‘myscan.png’ and save the result to ‘out.txt’ would be:
Or to do the same with German:
tesseract myscan.png out -l deu
It can even be used with multiple languages traineddata at a time eg. English and German:
tesseract myscan.png out -l eng+deu
Tesseract also includes a hOCR mode, which produces a special HTML file with the coordinates of each word. This can be used to create a searchable pdf, using a tool such as Hocr2PDF. To use it, use the ‘hocr’ config option, like this:
tesseract myscan.png out hocr
You can also create a searchable pdf directly from tesseract ( versions >=3.03):
tesseract myscan.png out pdf
More information about the various options is available in the Tesseract manpage.
Other Languages
Tesseract has been trained for many languages, check for your language in the Tessdata repository.
It can also be trained to support other languages and scripts; for more details see TrainingTesseract.
Development
Tesseract can also be used in your own project, under the terms of the Apache License 2.0. It has a fully featured API, and can be compiled for a variety of targets including Android and the iPhone. See the 3rdParty page for a sample of what has been done with it. Note that as yet there are very few 3rdParty Tesseract OCR projects being developed for Mac (with the only one being Tesseract macOS.md), although there are several online OCR services that can be used on Mac that may use Tesseract as their OCR engine.
Also, it is free software, so if you want to pitch in and help, please do!
If you find a bug and fix it yourself, the best thing to do is to attach the patch to your bug report in the Issues List
Support
First read the documentation, particularly the FAQ to see if your problem is addressed there.
If not, search the Tesseract user forum or the
Tesseract developer forum, and if you still can’t find what you need, please ask us there.
1. Установка Tesseract-OCR
Сначала загрузите установочный файл Тессеракт-OCR.
Адрес загрузки:(1) https://github.com/tesseract-ocr/tesseract/wiki/Downloads
(2) https://digi.bib.uni-mannheim.de/tesseract
Я использовал второй адрес и загрузил установочный файл Tesseract-OCR-Setup-3.05.01.exe.
Вы можете начать устанавливать этот файл.
Есть два очка, чтобы обратить внимание:
(1)При загрузке данных языка, по умолчанию для установки на английском языке, если вы хотите использовать Тессеракт текст ручки текст, вам необходимо проверить дополнительный язык данных. Но рекомендуется не проверять все, потому что мы не используем большинство языков, а установка за проверкой будет потреблять долгое время.
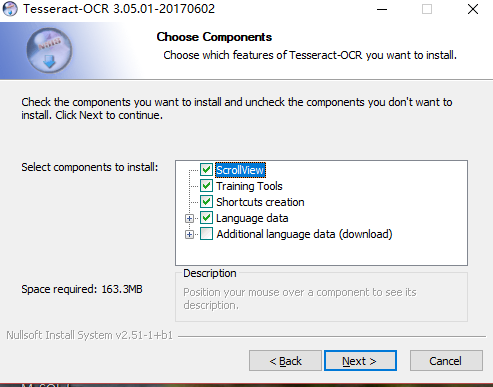
(2)Будьте осторожны, чтобы запомнить ваш путь установки, потому что он должен использоваться, когда переменная среды установлена.
Например, я устанавливаю здесь в папке D: / Tesseract.
2. Изменить переменные среды
2.1 После установки Тессеракта-OCR закончена, необходимо добавить его путь для установки переменной PATH среды системы.
Введите следующий интерфейс с помощью панели управления Панель системной системы Расширенные настройки:

Нажмите на переменную среды:
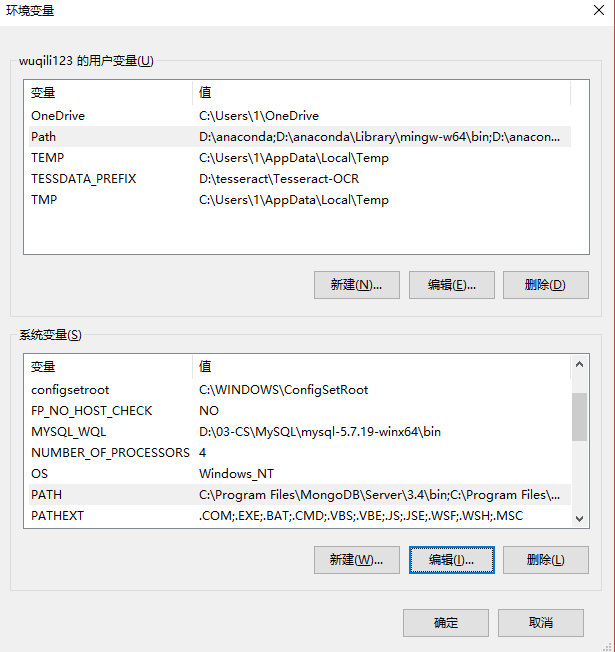
Выберите путь в системной переменной, нажмите кнопку Изменить, а затем добавить в папку D: \ Тессеракта \ Тессеракта-OCR на пути Путь к пути PATH по newting.
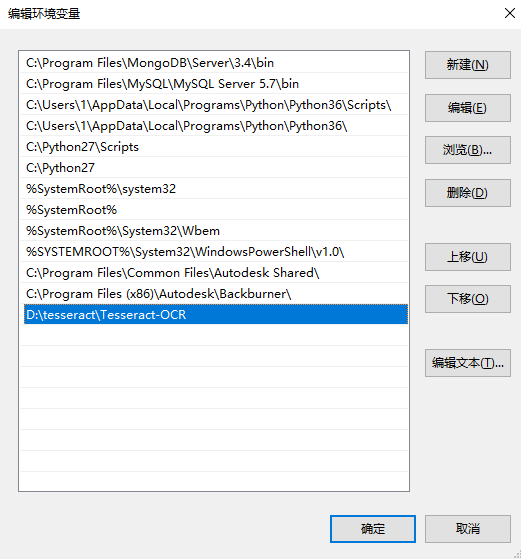
2.2 Добавить переменную Tessdata_prefix
После установки пути мы также будем создавать переменную TESSDATA_PREFIX в системной переменной, а значение переменной является дорожной мощностью D: \ Tesseract \ Tesseract-OCR. Если это не установлено, введите tesseract -list-langs, отобразит любые языковые пакеты, которые не могут быть загружены.
Нажмите кнопку Создать, задайте имя переменной и значение переменной следующим образом:
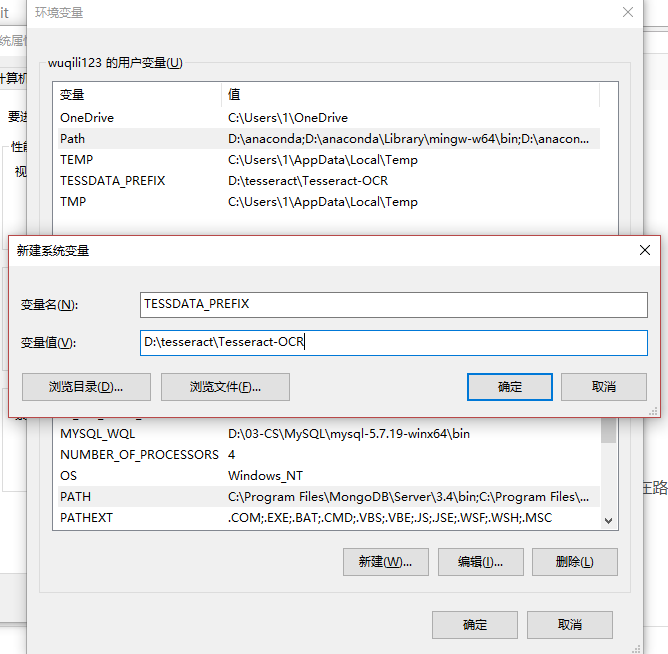
На данный момент Tesseract-OCR завершен.
3. Проверьте, если Tesseract-OCR успешно установлен
Откройте командную строку, введите tesseract -v, вернется версию Tesseract, которая в настоящее время устанавливается.

Введите Tesseract —list-langs Проверьте языковой пакет
Если все идет хорошо, Tesseract-OCR был успешно установлен и может быть использован.
- IronOCR
- IronOCR Blog
- OCR Tools
- How to Use Tesseract OCR in Windows
Published April 8, 2022
What is Tesseract OCR?
Tesseract is an optical character recognition engine that can be used on a variety of operating systems. It is a free software, released under the Apache License. In this guide, I will take you through the steps that I followed in order to install Tesseract on my Windows 10 machine. The major version 5 is the current stable version and began with release 5.0. 0 on November 30, 2021.
Step 1: Install Tesseract OCR in Windows 10 using .exe File:
To install language data: sudo port install tesseract —<langcode> A list of langcodes is found on the MacPorts Tesseract page Homebrew. The first step to install Tesseract OCR for Windows is to download the .exe installer that corresponds to your machine’s operating system
Step 2: Configure Installation
Next, we’ll need to configure the Tesseract installation. If you’re feeling confident and only want to run Tesseract OCR for Windows with the default language set to English, running through the installation screens with all of the default options selected should work.
Installer Language
This is just the language for the dialog boxes and help information. If we want to then we can run Tesseract OCR for Windows in multiple languages:

Installer language for Tesseract OCR for Windows
Tesseract OCR Setup
The setup screen recommends that all other applications are closed before continuing with the installation.

The Tesseract OCR for Windows installation screen.
Choose Install Location
Next, we’ll choose the installation location. Before proceeding to the next step, make sure to copy the install location to a .txt file. We will need to add the installation location to our machine’s environment variables once the installation is complete.

Choose the installation location.
Choose Components
By default, the ScrollView, Training Tools, Shortcuts creation, and Language data are all selected. Unless you have a specific reason not to install these, we will want to keep all of these selected.

Default Tesseract OCR for Windows installation components.
If we scroll down and expand the ‘Additional script data’, we will see that we have the option to download and install additional script data. This can be helpful in improving the accuracy of text extraction from certain scripted languages. It’s up to you if you want to install these.

Optional script installation components.
In the last step of the installation, we’ll be asked to choose the start menu folder for Tesseract OCR for Windows shortcuts. I’ve left mine set to the default name: ‘Tesseract-OCR’.

Choose the start menu folder for the Tesseract OCR for Windows shortcuts.
After we click install, Tesseract OCR for Windows will begin installing. Our next step is to add the installation path to our machine’s environment variables.
Step 3: Add Installation Path to Environment Variables
Control Panel
To add the installation location to our environment variables, go to the Start menu and search for ‘environment variables’. You should see a result to edit the system environment variables. If you don’t, you can always use the following steps: Start menu > Control Panel > Edit the system environment variables.

Searching for ‘environment variables’
System Properties
When presented with the ‘System Properties’ dialog box , we’ll want to make sure the Advanced tab is clicked, then click the Environment Variables button towards the bottom right of the screen.

Environment Variables
Under system variables, we will click the Edit button.

When presented with the «Edit environment variable» screen, click the New button, and paste in your Tesseract OCR installation path that we copied earlier in Step 2. Once you’ve done this, click the ‘OK‘ button.
Add Tesseract OCR for Windows Installation Directory to Environment Variables

That’s it! Now that we’ve run the .exe installer and added the Tesseract OCR for Windows install location to our environment variables, we can test that our installation is working by running Tesseract on a test image.
Step 4: Run Tesseract OCR for Windows on a Test Image
To test that Tesseract OCR for Windows was installed successfully, open command prompt on your machine, then run the Tesseract command. You should see an output with a quick explanation of Tesseract’s usage options.

Checking successful installation of Tesseract OCR for Windows
Congratulations! You’ve successfully installed Tesseract OCR for Windows on your machine.
Advantages of using IronOCR to do OCR Work:
IronOCR provides Tesseract OCR on Mac, Windows, Linux, Azure and Docker for:
- .NET Framework 4.0 +
- .NET Standard 2.0 +
- .NET Core 2.0 +
- .NET 5
- Mono for macOS and Linux
- Xamarin for macOS
IronOCR reads text, barcodes, and QR codes from all major image and PDF formats using the latest Tesseract 5 engine. This library adds OCR functionality to Desktop, Console and Web applications in minutes. It supports 127+ international languages. Licenses start from $749.
Step 1: Install the latest version of IronOCR
Install DLL
Download the IronOcr DLL directly to your machine.
Install NuGet
Alternatively, you can install it through NuGet.
PM > Install-Package IronOcrStep 2: Apply Your License Key
Set your IronOCR license key using code
Add this code to the startup of your application before IronOCR is used.
IronOcr.Installation.LicenseKey = "IRONOCR-MYLICENSE-KEY-1EF01";IronOcr.Installation.LicenseKey = "IRONOCR-MYLICENSE-KEY-1EF01";IronOcr.Installation.LicenseKey = "IRONOCR-MYLICENSE-KEY-1EF01"VB C#
Step 3: Test your Key
Test if your key has been installed correctly.
BoolresultIronOcr.License.IsValidLicense("IRONOCR-MYLICENSE-KEY-1EF0");BoolresultIronOcr.License.IsValidLicense("IRONOCR-MYLICENSE-KEY-1EF0");BoolresultIronOcr.License.IsValidLicense("IRONOCR-MYLICENSE-KEY-1EF0")VB C#
Get started with the project
// PM > Install-Package IronOcr
// using IronOcr;
var Ocr = new IronTesseract();
// Hundreds of languages available
Ocr.Language = OcrLanguage.English;
using (var Input = new OcrInput())
{
OcrInput.Add(@"img\example.tiff")
// Input.DeNoise(); optional
// Input.Deskew(); optional
IronOcr.OcrResult Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
// Explore the OcrResult using IntelliSense
}// PM > Install-Package IronOcr
// using IronOcr;
var Ocr = new IronTesseract();
// Hundreds of languages available
Ocr.Language = OcrLanguage.English;
using (var Input = new OcrInput())
{
OcrInput.Add(@"img\example.tiff")
// Input.DeNoise(); optional
// Input.Deskew(); optional
IronOcr.OcrResult Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
// Explore the OcrResult using IntelliSense
}' PM > Install-Package IronOcr
' using IronOcr;
Dim Ocr = New IronTesseract()
' Hundreds of languages available
Ocr.Language = OcrLanguage.English
Using Input = New OcrInput()
OcrInput.Add("img\example.tiff") IronOcr.OcrResult Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
' ' Explore the OcrResult using IntelliSense
End UsingVB C#
How to Use Tesseract OCR in C# for .NET?
- Install Google Tesseract and IronOCR for .NET into Visual Studio
- Check the latest builds in C#
- Review accuracy and image compatibility
- Test performance and API function
- Consider Multi-Language Support
Use NuGet Package Manager to install the IronOCR NuGet Package into your Visual Studio solution.
// PM > Install-Package IronOcr
// using IronOcr;
var Ocr = new IronTesseract();
// Hundreds of languages available
Ocr.Language = OcrLanguage.English;
using (var Input = new OcrInput())
{
OcrInput.Add(@"img\example.tiff")
// Input.DeNoise(); optional
// Input.Deskew(); optional
IronOcr.OcrResult Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
// Explore the OcrResult using IntelliSense
}// PM > Install-Package IronOcr
// using IronOcr;
var Ocr = new IronTesseract();
// Hundreds of languages available
Ocr.Language = OcrLanguage.English;
using (var Input = new OcrInput())
{
OcrInput.Add(@"img\example.tiff")
// Input.DeNoise(); optional
// Input.Deskew(); optional
IronOcr.OcrResult Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
// Explore the OcrResult using IntelliSense
}' PM > Install-Package IronOcr
' using IronOcr;
Dim Ocr = New IronTesseract()
' Hundreds of languages available
Ocr.Language = OcrLanguage.English
Using Input = New OcrInput()
OcrInput.Add("img\example.tiff") IronOcr.OcrResult Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
' ' Explore the OcrResult using IntelliSense
End UsingVB C#
IronOCR Tesseract for C#
With IronOCR, all Tesseract installation happens entirely using the NuGet Package Manager.
PM > Install-Package IronOcrTesseract 5 API in IronOCR Tesseract
To date, IronTesseract is the only known implementation of Tesseract 5 for .NET Framework or Core.
// using IronOcr;
var Ocr = new IronTesseract(); // nothing to configure
using (var Input = new OcrInput(@"images\image.png"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}// using IronOcr;
var Ocr = new IronTesseract(); // nothing to configure
using (var Input = new OcrInput(@"images\image.png"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}' using IronOcr;
Dim Ocr = New IronTesseract() ' nothing to configure
Using Input = New OcrInput("images\image.png")
Dim Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
End UsingVB C#
Tesseract 4 API in IronOCR Tesseract
// using IronOcr;
var Ocr = new IronTesseract();
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract4;
using (var Input = new OcrInput(@"images\image.png"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}// using IronOcr;
var Ocr = new IronTesseract();
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract4;
using (var Input = new OcrInput(@"images\image.png"))
{
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}' using IronOcr;
Dim Ocr = New IronTesseract()
Ocr.Configuration.TesseractVersion = TesseractVersion.Tesseract4
Using Input = New OcrInput("images\image.png")
Dim Result = Ocr.Read(Input)
Console.WriteLine(Result.Text)
End UsingVB C#
Why IronOCR Is Better Than Tesseract:
ACCURACY
TESSERACT:
If Tesseract encounters an image that is rotated, skewed, is of a low DPI, scanned, or has background noise, it becomes almost impossible for Tesseract to get data from that image. In addition, Tesseract will also take a very long time to process that document before providing you with nonsensical information.
IRONOCR:
IronOCR takes this headache away. Users often achieve 99.8-100% accuracy with minimal configuration.
IMAGE COMPATIBILITY
TESSERACT:
Only accepts Leptonica PIX image format which is an IntPtr C++ object in C#. PIX objects are not managed memory — and failure to handle them with care in C# results in memory leaks.
IRONOCR:
Images are memory managed. PDF & Tiff supported. System. Drawing, Stream, and Byte Array are included for every file format.
Broad image support:
- PDF Documents
- PDF Pages
- MultiFrame TIFF files
- JPEG & JPEG2000
- GIF
- PNG
- System.Drawing.Image
- Binary image Data (byte[])
- And many more…
PERFORMANCE
TESSERACT:
Google Tesseract can perform fast and accurate results if properly tuned and input images have been preprocessed using Photoshop or ImageMagick.
IRONOCR:
The IronOcr .NET Tesseract DLL works accurately and at speed for most images out of the box. We have implemented multithreading to make use of the multi-core processors that most machines now use. Even low-resolution images generally work with a high degree of accuracy in your program. No PhotoShop required.
API
TESSERACT:
We have two free choices:
- Work with Interop layers — many that are found on GitHub are out of date, have unresolved tickets, memory leaks, and Console warnings. May not support .NET Core or Standard.
- Work with the command line EXE — difficult to deploy and constantly interrupted by virus scanners and security policies.
IRONOCR:
A managed and tested .NET Library for Tesseract called IronTesseract.
Fully documented with IntelliSense support.
LANGUAGE
TESSERACT:
Supports only 100 languages.
IRONOCR:
Supports 127+ languages.
Conclusion
Tesseract is an excellent resource for C++ developers, but it is not a complete OCR library for .NET. Scanned or photographed images need to be processed so as to be orthogonal, standardized, high-resolution, and free of digital noise before Tesseract can accurately work with them.
In contrast, IronOCR can do this and more, with just a single line of code. It is true that IronOCR uses Tesseract for its internal OCR engine, a very finely-tuned Tesseract, built for C#, with a lot of performance improvements and features added as standard.
3 Answers
Simple steps for tesseract installation in windows.
-
Download tesseract exe from https://github.com/UB-Mannheim/tesseract/wiki.
-
Install this exe in
C:\Program Files (x86)\Tesseract-OCR -
Open virtual machine command prompt in windows or anaconda prompt.
-
Run
pip install pytesseract -
To test if tesseract is installed type in python prompt:
import pytesseract
print(pytesseract)
![]()
zeit
3472 silver badges13 bronze badges
answered Oct 25, 2020 at 8:42
![]()
2
-
I had to install pytesseract instead
Sep 17, 2021 at 19:38
-
@Aashish Raina Please change
pip install tesseracttopip install pytesseract.tesseractis some other unrelated package.Dec 5, 2021 at 23:35
To accomplish OCR with Python on Windows, you will need Python and OpenCV which you already have, as well as Tesseract and the Pytesseract Python package.
To install Tesseract OCR for Windows:
- Run the installer(find 2021) from UB Mannheim
- Configure your installation (choose installation path and language data to include)
- Add Tesseract OCR to your environment variables
To install and use Pytesseract on Windows:
- Simply run
pip install pytesseract - You will also need to install Pillow with
pip install Pillowto use Pytesseract. Import it in your Python document like sofrom PIL import Image. - You will need to add the following line in your code in order to be able to call pytesseract on your machine:
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
I’ve given a detailed walkthrough of how to install Tesseract OCR for Windows here if you would like further guidance.
![]()
Smart Manoj
5,2504 gold badges34 silver badges59 bronze badges
answered May 23, 2021 at 9:06
![]()
bradbrad
1971 silver badge16 bronze badges
2
-
Can’t you just add this path to PATH variable?
May 28 at 18:04
-
I thought this as well, but when I tried to execute the pytesseract script without the additional line of code to include the path, it didn’t work despite having added the path to the PATH variable as you mentioned.
May 28 at 19:16
UB Mannheim provide pre-built binaries for the latest versions of tesseract.
From tesseract Github wiki.
Windows
An unofficial installer for windows for Tesseract 3.05-dev and
Tesseract 4.00-dev is available from Tesseract at UB
Mannheim. This
includes the training tools.…
To access tesseract-OCR from any location you may have to add the
directory where the tesseract-OCR binaries are located to the Path
variables, probablyC:\Program Files\Tesseract-OCR.
answered Sep 10, 2017 at 12:41
![]()
wklwkl
77.4k16 gold badges165 silver badges176 bronze badges
Please do not change the title of any wiki page without permission from Tesseract developers.
Introduction
Tesseract is an open source text recognition (OCR) Engine, available under the Apache 2.0 license. It can be used directly, or (for programmers) using an API to extract printed text from images. It supports a wide variety of languages.
Tesseract doesn’t have a built-in GUI, but there are several available from the 3rdParty page.
Installation
There are two parts to install, the engine itself, and the training data for a language.
Linux
Tesseract is available directly from many Linux distributions. The package is generally called ‘tesseract’ or ‘tesseract-ocr’ — search your distribution’s repositories to find it.
Thus you can install Tesseract 4.x and its developer tools on Ubuntu 18.x bionic by simply running:
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
Note for Ubuntu users: In case apt is unable to find the package try adding universe entry to the sources.list file as shown below.
sudo vi /etc/apt/sources.list
Copy the first line "deb http://archive.ubuntu.com/ubuntu bionic main" and paste it as shown below on the next line.
If you are using a different release of ubuntu, then replace bionic with the respective release name.
deb http://archive.ubuntu.com/ubuntu bionic universe
Packages for over 130 languages and over 35 scripts are also available directly from the Linux distributions. The language packages are called ‘tesseract-ocr-langcode’ and ‘tesseract-ocr-script-scriptcode’, where langcode is three letter language code and scriptcode is four letter script code.
Examples: tesseract-ocr-eng (English), tesseract-ocr-ara (Arabic), tesseract-ocr-chi-sim (Simplified Chinese), tesseract-ocr-script-latn (Latin Script), tesseract-ocr-script-deva (Devanagari script), etc.
For distributions that are supported by snapd you may also run the following command to install the tesseract built binaries(Don’t have snapd installed?):
sudo snap install --channel=edge tesseract
The traineddata is currently not shipped with the snap package and must be placed manually to ~/snap/tesseract/current.
Tesseract 4 packages with LSTM engine and related traineddata.
Debian
- Debian 10 Buster (stable)
- Debian 9 Stretch backports (oldstable)
- Debian 8 Jessie (oldoldstable) — notesalexp.org
- Debian testing
- Debian Sid (unstable)
Ubuntu
- Ubuntu Bionic 18.04
Ubuntu PPA
- Ubuntu Bionic 18.04
- Ubuntu Xenial 16.04
- Ubuntu Trusty 14.04
Raspbian
- Raspbian Stretch(notesalexp.org)
- Raspbian Buster
RHEL/CentOS/Scientific Linux, Fedora, openSUSE packages
- rpm package with tesseract-ocr
For example to install Tesseract with German language traineddata:
For CentOS 8 run the following as root:
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_8/
rpm --import https://build.opensuse.org/projects/home:Alexander_Pozdnyakov/public_key
dnf install tesseract
dnf install tesseract-langpack-deu
For RHEL 7 run the following as root:
yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/RHEL_7/
yum update
yum install tesseract
yum install tesseract-langpack-deu
For CentOS 7 run the following as root:
yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/CentOS_7/
sudo rpm --import https://build.opensuse.org/projects/home:Alexander_Pozdnyakov/public_key
yum update
yum install tesseract
yum install tesseract-langpack-deu
For Scientific Linux 7 run the following as root:
yum-config-manager --add-repo https://download.opensuse.org/repositories/home:/Alexander_Pozdnyakov/ScientificLinux_7/
yum update
yum install tesseract
yum install tesseract-langpack-deu
For Fedora 29 run the following as root:
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:Alexander_Pozdnyakov/Fedora_29/home:Alexander_Pozdnyakov.repo
dnf install tesseract
dnf install tesseract-langpack-deu
For openSUSE Tumbleweed run the following as root:
zypper addrepo https://download.opensuse.org/repositories/home:Alexander_Pozdnyakov/openSUSE_Tumbleweed/home:Alexander_Pozdnyakov.repo
zypper refresh
zypper install tesseract-ocr
zypper install tesseract-ocr-traineddata-german
For openSUSE Leap 15.0 run the following as root:
zypper addrepo https://download.opensuse.org/repositories/home:Alexander_Pozdnyakov/openSUSE_Leap_15.0/home:Alexander_Pozdnyakov.repo
zypper refresh
zypper install tesseract-ocr
zypper install tesseract-ocr-traineddata-german
FOR EXPERTS ONLY.
If you are experimenting with OCR Engine modes, you will need to manually install language training data beyond what is available in your Linux distribution.
Various types of training data can be found on GitHub. Unpack and copy the .traineddata file into a ‘tessdata’ directory. The exact directory will depend both on the type of training data, and your Linux distribution. Possibilities are /usr/share/tesseract-ocr/tessdata or /usr/share/tessdata or /usr/share/tesseract-ocr/4.00/tessdata.
Training data for obsolete Tesseract versions =< 3.02 reside in another location.
If Tesseract is not available for your distribution, or you want to use a newer version than they offer, you can compile your own.
macOS
You can install Tesseract using either MacPorts or Homebrew.
A macOS wrapper for the Tesseract API is also available at Tesseract macOS.
MacPorts
To install Tesseract run this command:
sudo port install tesseract
To install any language data, run:
sudo port install tesseract-<langcode>
List of available langcodes can be found on MacPorts tesseract page.
Homebrew
To install Tesseract run this command:
Training directories can be found using brew list tesseract
Possible location can be /usr/local/Cellar/tesseract/3.05.02/share/tessdata/
Windows
Installer for Windows for Tesseract 3.05 and Tesseract 4 are available from Tesseract at UB Mannheim. These include the training tools. Both 32-bit and 64-bit installers are available.
An installer for the OLD version 3.02 is available for Windows from our download page. This includes the English training data. If you want to use another language, download the appropriate training data, unpack it using 7-zip, and copy the .traineddata file into the ‘tessdata’ directory, probably C:\Program Files\Tesseract-OCR\tessdata.
To access tesseract-OCR from any location you may have to add the directory where the tesseract-OCR binaries are located to the Path variables, probably C:\Program Files\Tesseract-OCR.
Experts can also get binaries build with Visual Studio from the build artifacts of the Appveyor Continuous Integration.
Cygwin
Released version >= 3.02 of tesseract-ocr are part of Cygwin
The latest version available is 4.1.0. Please see announcement.
MSYS2
Install tesseract-OCR:
pacman -S mingw-w64-{i686,x86_64}-tesseract-ocr
and the data files:
pacman -S mingw-w64-{i686,x86_64}-tesseract-data-eng
In the above command, «eng» may be replaced with the ISO 639 3-letter language code for supported languages. For a list of available language packages use:
pacman -Ss tesseract-data
Other Platforms
Tesseract may work on more exotic platforms too. You can either try compiling it yourself, or take a look at the list of other projects using Tesseract.
Running Tesseract
Tesseract is a command-line program, so first open a terminal or command prompt. The command is used like this:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
So basic usage to do OCR on an image called ‘myscan.png’ and save the result to ‘out.txt’ would be:
Or to do the same with German:
tesseract myscan.png out -l deu
It can even be used with multiple languages traineddata at a time eg. English and German:
tesseract myscan.png out -l eng+deu
Tesseract also includes a hOCR mode, which produces a special HTML file with the coordinates of each word. This can be used to create a searchable pdf, using a tool such as Hocr2PDF. To use it, use the ‘hocr’ config option, like this:
tesseract myscan.png out hocr
You can also create a searchable pdf directly from tesseract ( versions >=3.03):
tesseract myscan.png out pdf
More information about the various options is available in the Tesseract manpage.
Other Languages
Tesseract has been trained for many languages, check for your language in the Tessdata repository.
It can also be trained to support other languages and scripts; for more details see TrainingTesseract.
Development
Tesseract can also be used in your own project, under the terms of the Apache License 2.0. It has a fully featured API, and can be compiled for a variety of targets including Android and the iPhone. See the 3rdParty page for a sample of what has been done with it. Note that as yet there are very few 3rdParty Tesseract OCR projects being developed for Mac (with the only one being Tesseract macOS), although there are several online OCR services that can be used on Mac that may use Tesseract as their OCR engine.
Also, it is free software, so if you want to pitch in and help, please do!
If you find a bug and fix it yourself, the best thing to do is to attach the patch to your bug report in the Issues List
Support
First read the Wiki, particularly the FAQ to see if your problem is addressed there. If not, search the Tesseract user forum or the Tesseract developer forum, and if you still can’t find what you need, please ask us there.
3rd-Party tools & sample usage:
-
PDF2SearchablePDF: this is a lightweight bash-script wrapper around tesseract.
- Sample usage:
pdf2searchablepdf mypdf.pdf—produces mypdf_searchable.pdf as an output.
- Sample usage: