The only prerequisite for installing NumPy is Python itself. If you don’t have
Python yet and want the simplest way to get started, we recommend you use the
Anaconda Distribution — it includes
Python, NumPy, and many other commonly used packages for scientific computing
and data science.
NumPy can be installed with conda, with pip, with a package manager on
macOS and Linux, or from source.
For more detailed instructions, consult our Python and NumPy
installation guide below.
CONDA
If you use conda, you can install NumPy from the defaults or conda-forge
channels:
# Best practice, use an environment rather than install in the base env
conda create -n my-env
conda activate my-env
# If you want to install from conda-forge
conda config --env --add channels conda-forge
# The actual install command
conda install numpy
PIP
If you use pip, you can install NumPy with:
Also when using pip, it’s good practice to use a virtual environment —
see Reproducible Installs below for why, and
this guide
for details on using virtual environments.
Python and NumPy installation guide
Installing and managing packages in Python is complicated, there are a
number of alternative solutions for most tasks. This guide tries to give the
reader a sense of the best (or most popular) solutions, and give clear
recommendations. It focuses on users of Python, NumPy, and the PyData (or
numerical computing) stack on common operating systems and hardware.
Recommendations
We’ll start with recommendations based on the user’s experience level and
operating system of interest. If you’re in between “beginning” and “advanced”,
please go with “beginning” if you want to keep things simple, and with
“advanced” if you want to work according to best practices that go a longer way
in the future.
Beginning users
On all of Windows, macOS, and Linux:
- Install Anaconda (it installs all
packages you need and all other tools mentioned below). - For writing and executing code, use notebooks in
JupyterLab for
exploratory and interactive computing, and
Spyder or Visual Studio Code
for writing scripts and packages. - Use Anaconda Navigator to
manage your packages and start JupyterLab, Spyder, or Visual Studio Code.
Advanced users
Conda
- Install Miniforge.
- Keep the
baseconda environment minimal, and use one or more
conda environments
to install the package you need for the task or project you’re working on.
Alternative if you prefer pip/PyPI
For users who know, from personal preference or reading about the main
differences between conda and pip below, they prefer a pip/PyPI-based solution,
we recommend:
- Install Python from python.org,
Homebrew, or your Linux package manager. - Use Poetry as the most well-maintained tool
that provides a dependency resolver and environment management capabilities
in a similar fashion as conda does.
Python package management
Managing packages is a challenging problem, and, as a result, there are lots of
tools. For web and general purpose Python development there’s a whole
host of tools
complementary with pip. For high-performance computing (HPC),
Spack is worth considering. For most NumPy
users though, conda and
pip are the two most popular tools.
Pip & conda
The two main tools that install Python packages are pip and conda. Their
functionality partially overlaps (e.g. both can install numpy), however, they
can also work together. We’ll discuss the major differences between pip and
conda here — this is important to understand if you want to manage packages
effectively.
The first difference is that conda is cross-language and it can install Python,
while pip is installed for a particular Python on your system and installs other
packages to that same Python install only. This also means conda can install
non-Python libraries and tools you may need (e.g. compilers, CUDA, HDF5), while
pip can’t.
The second difference is that pip installs from the Python Packaging Index
(PyPI), while conda installs from its own channels (typically “defaults” or
“conda-forge”). PyPI is the largest collection of packages by far, however, all
popular packages are available for conda as well.
The third difference is that conda is an integrated solution for managing
packages, dependencies and environments, while with pip you may need another
tool (there are many!) for dealing with environments or complex dependencies.
Reproducible installs
As libraries get updated, results from running your code can change, or your
code can break completely. It’s important to be able to reconstruct the set
of packages and versions you’re using. Best practice is to:
- use a different environment per project you’re working on,
- record package names and versions using your package installer;
each has its own metadata format for this:- Conda: conda environments and environment.yml
- Pip: virtual environments and
requirements.txt - Poetry: virtual environments and pyproject.toml
NumPy packages & accelerated linear algebra libraries
NumPy doesn’t depend on any other Python packages, however, it does depend on an
accelerated linear algebra library — typically
Intel MKL or
OpenBLAS. Users don’t have to worry about
installing those (they’re automatically included in all NumPy install methods).
Power users may still want to know the details, because the used BLAS can
affect performance, behavior and size on disk:
-
The NumPy wheels on PyPI, which is what pip installs, are built with OpenBLAS.
The OpenBLAS libraries are included in the wheel. This makes the wheel
larger, and if a user installs (for example) SciPy as well, they will now
have two copies of OpenBLAS on disk. -
In the conda defaults channel, NumPy is built against Intel MKL. MKL is a
separate package that will be installed in the users’ environment when they
install NumPy. -
In the conda-forge channel, NumPy is built against a dummy “BLAS” package. When
a user installs NumPy from conda-forge, that BLAS package then gets installed
together with the actual library — this defaults to OpenBLAS, but it can also
be MKL (from the defaults channel), or even
BLIS or reference BLAS. -
The MKL package is a lot larger than OpenBLAS, it’s about 700 MB on disk
while OpenBLAS is about 30 MB. -
MKL is typically a little faster and more robust than OpenBLAS.
Besides install sizes, performance and robustness, there are two more things to
consider:
- Intel MKL is not open source. For normal use this is not a problem, but if
a user needs to redistribute an application built with NumPy, this could be
an issue. - Both MKL and OpenBLAS will use multi-threading for function calls like
np.dot, with the number of threads being determined by both a build-time
option and an environment variable. Often all CPU cores will be used. This is
sometimes unexpected for users; NumPy itself doesn’t auto-parallelize any
function calls. It typically yields better performance, but can also be
harmful — for example when using another level of parallelization with Dask,
scikit-learn or multiprocessing.
Troubleshooting
If your installation fails with the message below, see Troubleshooting
ImportError.
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy c-extensions failed. This error can happen for
different reasons, often due to issues with your setup.
NumPy (Numerical Python) — это библиотека с открытым исходным кодом для языка программирования Python. Она используется для научных вычислений и работы с массивами. Помимо объекта многомерного массива, он также предоставляет функциональные инструменты высокого уровня для работы с массивами. В этой статье я покажу вам, как установить NumPy с помощью PIP в Windows 10.
РЕКОМЕНДУЕМ:
Что Python 3.9 нам готовит?
В отличие от большинства дистрибутивов Linux, Windows по умолчанию не поставляется с языком программирования Python.
Содержание
- Установка Python в Windows
- Установка PIP в Windows
- Установите NumPy с помощью PIP в Windows 10
Установка Python в Windows
Чтобы установить NumPy с помощью PIP в Windows 10, вам сначала необходимо загрузить (на момент написания этой статьи последняя версия Python 3 — 3.8.5) и установить Python на свой компьютер с Windows 10.
Убедитесь, что вы выбрали установку запуска для всех пользователей и отметили флажками Добавить Python 3.8 в PATH. Последний помещает интерпретатор в путь выполнения.
После того, как у вас будет установлена последняя версия Python, вы можете приступить к установке NumPy с помощью PIP в Windows 10.
Теперь, если вы используете старую версию Python в Windows, вам может потребоваться установить PIP вручную. ПИП автоматически устанавливается вместе с Python 2.7.9+ и Python 3.4+.
Вы можете легко установить PIP в Windows, загрузив установочный пакет, открыв командную строку и запустив установщик. Вы можете установить ПИП в Windows 10 через командную строку CMD, выполнив команду:
Возможно, вам потребуется запустить командную строку от имени администратора. Если вы получите сообщение об ошибке, в котором говорится, что у вас нет необходимых разрешений для выполнения задачи, вам нужно будет открыть приложение от имени администратора.
Установка пипа должна начаться. Если файл не найден, еще раз проверьте путь к папке, в которой сохранили файл.
Можете просмотреть содержимое вашего текущего каталога, используя следующую команду:
Команда dir возвращает полный список содержимого каталога.
После того, как вы установили PIP, вы можете проверить, прошла ли установка успешно, набрав следующее:
Если ПИП был установлен, программа запустится, и вы должны увидеть следующее:
|
pip 20.1.1 from c:\users\<username>\appdata\local\programs\python\python38—32\lib\site—packages\pip (python 3.8) |

Теперь, когда вы подтвердили, что у вас установлен Pip, вы можете приступить к установке NumPy.
Установите NumPy с помощью PIP в Windows 10

После настройки PIP вы можете использовать его командную строку для установки NumPy.
Чтобы установить NumPy с менеджером пакетов для Python 3, выполните следующую команду:
Пип загружает пакет NumPy и уведомляет вас, что он был успешно установлен.
Чтобы обновить PIP в Windows, введите в командной строке следующее:
|
python —m pip install —upgrade pip |
Эта команда сначала удаляет старую версию PIP, а затем устанавливает самую последнюю версию PIP.
После установки вы можете использовать команду show, чтобы проверить, является ли NumPy частью ваших пакетов Python. Выполните следующую команду:

Вывод должен подтвердить, что у вас есть NumPy, какую версию вы используете, а также где хранится пакет.
РЕКОМЕНДУЕМ:
Как написать базу данных на Python
На этом все. Теперь вы знаете, как установить NumPy с помощью PIP в Windows 10.
Python NumPy is a general-purpose array processing package that provides tools for handling n-dimensional arrays. It provides various computing tools such as comprehensive mathematical functions, linear algebra routines. NumPy provides both the flexibility of Python and the speed of well-optimized compiled C code. Its easy-to-use syntax makes it highly accessible and productive for programmers from any background.
Pre-requisites:
The only thing that you need for installing Numpy on Windows are:
- Python
- PIP or Conda (depending upon user preference)
Installing Numpy on Windows:
For Conda Users:
If you want the installation to be done through conda, you can use the below command:
conda install -c anaconda numpy
You will get a similar message once the installation is complete

Make sure you follow the best practices for installation using conda as:
- Use an environment for installation rather than in the base environment using the below command:
conda create -n my-env conda activate my-env
Note: If your preferred method of installation is conda-forge, use the below command:
conda config --env --add channels conda-forge
For PIP Users:
Users who prefer to use pip can use the below command to install NumPy:
pip install numpy
You will get a similar message once the installation is complete:
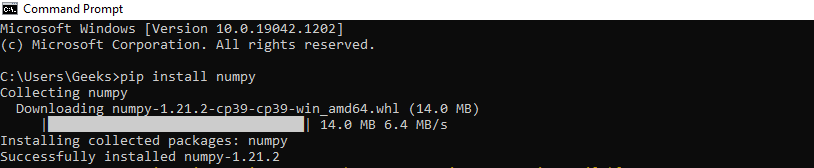
Now that we have installed Numpy successfully in our system, let’s take a look at few simple examples.
Example of Numpy
Python3
import numpy as np
arr = np.array( [[ 1, 2, 3],
[ 4, 2, 5]] )
print("Array is of type: ", type(arr))
print("No. of dimensions: ", arr.ndim)
print("Shape of array: ", arr.shape)
print("Size of array: ", arr.size)
print("Array stores elements of type: ", arr.dtype)
Output:
Array is of type: No. of dimensions: 2 Shape of array: (2, 3) Size of array: 6 Array stores elements of type: int64
Install Numpy FAQ
Q: How do I install NumPy?
A: You can install NumPy by using the pip package installer. Open your command prompt or terminal and run the following command: pip install numpy. This will download and install the latest version of NumPy from PyPI.
Q: Do I need to install any dependencies for NumPy?
A: NumPy has a few dependencies, such as the Python development headers and a C compiler. However, when you install NumPy using pip, it automatically handles the dependencies for you.
Q: Can I install a specific version of NumPy?
A: Yes, you can install a specific version of NumPy by specifying the version number in the pip install command. For example, to install version 1.19.5, you would run: pip install numpy==1.19.5.
Q: I encountered an error related to building or compiling NumPy. What should I do?
A: Building NumPy from source requires certain development tools. On Windows, you might need to install Microsoft Visual C++ Build Tools. On macOS, you may need to install the Xcode Command Line Tools. On Linux, you may need to install the build-essential package. Refer to the NumPy documentation for detailed instructions based on your operating system.
Last Updated :
25 Jun, 2023
Like Article
Save Article
Search code, repositories, users, issues, pull requests…
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
#статьи
-

0
Подробный гайд по самому популярному Python-инструменту для анализа данных и обучения нейронных сетей.
Иллюстрация: A Wolker / Pexels / Colowgee для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
NumPy — это открытая бесплатная Python-библиотека для работы с многомерными массивами, этакий питонячий аналог Matlab. NumPy чаще всего используют в анализе данных и обучении нейронных сетей — в каждой из этих областей нужно проводить много вычислений с такими матрицами.
В этой статье мы собрали всё необходимое для старта работы с этой библиотекой — вам хватит получаса, чтобы разобраться в основных возможностях.
- Базовые функции
- Доступ к элементам
- Создание специальных массивов
- Математические операции
- Копирование и организации
- Дополнительные возможности
Что запомнить
NumPy не просто работает с многомерными массивами, но и делает это быстро. Вообще, интерпретируемые языки производят вычисления медленнее компилируемых, а Python как раз язык интерпретируемый. NumPy же сделана так, чтобы эффективно работать с наборами чисел любого размера в Python.
Библиотека частично написана на Python, а частично на C и C++ — в тех местах, которые требуют скорости. Кроме того, код NumPy оптимизирован под большинство современных процессоров. Кстати, как и у Matlab, для NumPy существуют пакеты, расширяющие её функциональность, — например, библиотека SciPy или Matplotlib.
Инфографика: Оля Ежак для Skillbox Media
Массивы в NumPy отличаются от обычных списков и кортежей в Python тем, что они должны состоять только из элементов одного типа. Такое ограничение позволяет увеличить скорость вычислений в 50 раз, а также избежать ненужных ошибок с приведением и обработкой типов.
Мы установим NumPy через платформу Anaconda, которая содержит много разных библиотек для Python. А ещё покажем, как это сделать через PIP.
NumPy можно также использовать через Jupyter Notebook, Google Colab или другими средствами — как вам удобнее. Поэтому выбирайте любой способ и пойдёмте изучать его.
Сначала надо зайти на официальный сайт Anaconda, чтобы скачать последнюю версию Python и NumPy: есть готовые пакеты под macOS, Windows и Linux.
Скриншот: Skillbox Media
Затем открываем установщик, соглашаемся со всеми пунктами и выбираем место для установки.
Скриншот: Skillbox Media
Чтобы убедиться, что Python точно установился, открываем консоль и вводим туда команду python3 — должен запуститься интерпретатор Python, в котором можно писать код. Выглядит всё это примерно так:
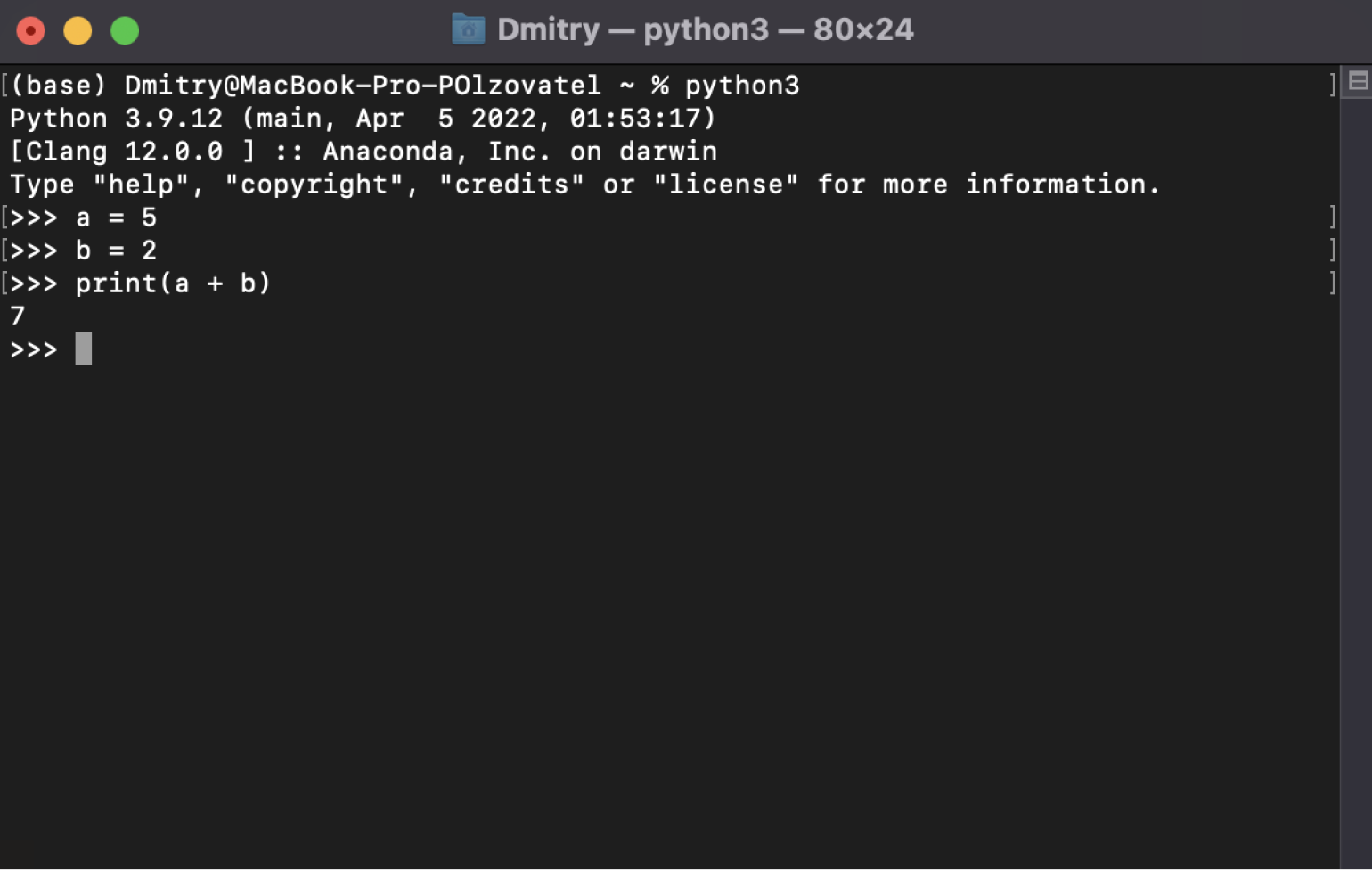
Скриншот: Skillbox Media
Anaconda уже содержит в себе много полезностей — например, NumPy, SciPy, Pandas. Поэтому больше ничего устанавливать не нужно. Достаточно проверить, что библиотека NumPy действительно работает. Введите в интерпретаторе Python в консоли такие команды — пока не важно, что это и как работает, об этом поговорим ниже.
import numpy as np
Следом вот это:
a = np.array ([1,2,3])
А потом выводим значение переменной a — чтобы убедиться, что всё работает:
print (a)
Должно получиться что-то вроде вывода на скриншоте:
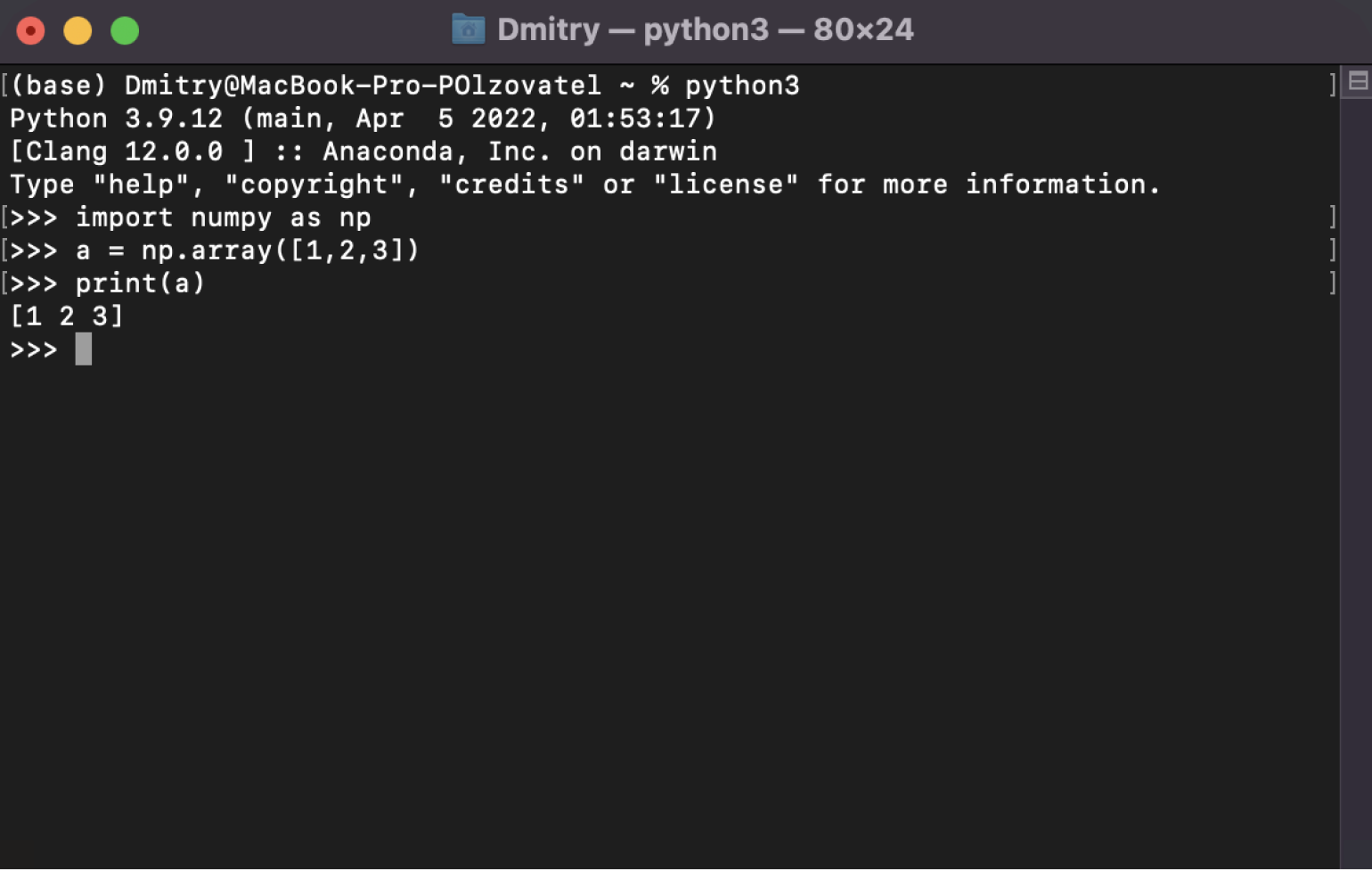
Скриншот: Skillbox Media
Если вам не хочется скачивать огромный пакет Anaconda, вы можете установить только NumPy с помощью встроенного питоновского менеджера пакетов PIP.
Для этого сначала нужно установить Python с официального сайта. Заходим на него, переходим во вкладку Downloads и видим справа последнюю актуальную версию Python:
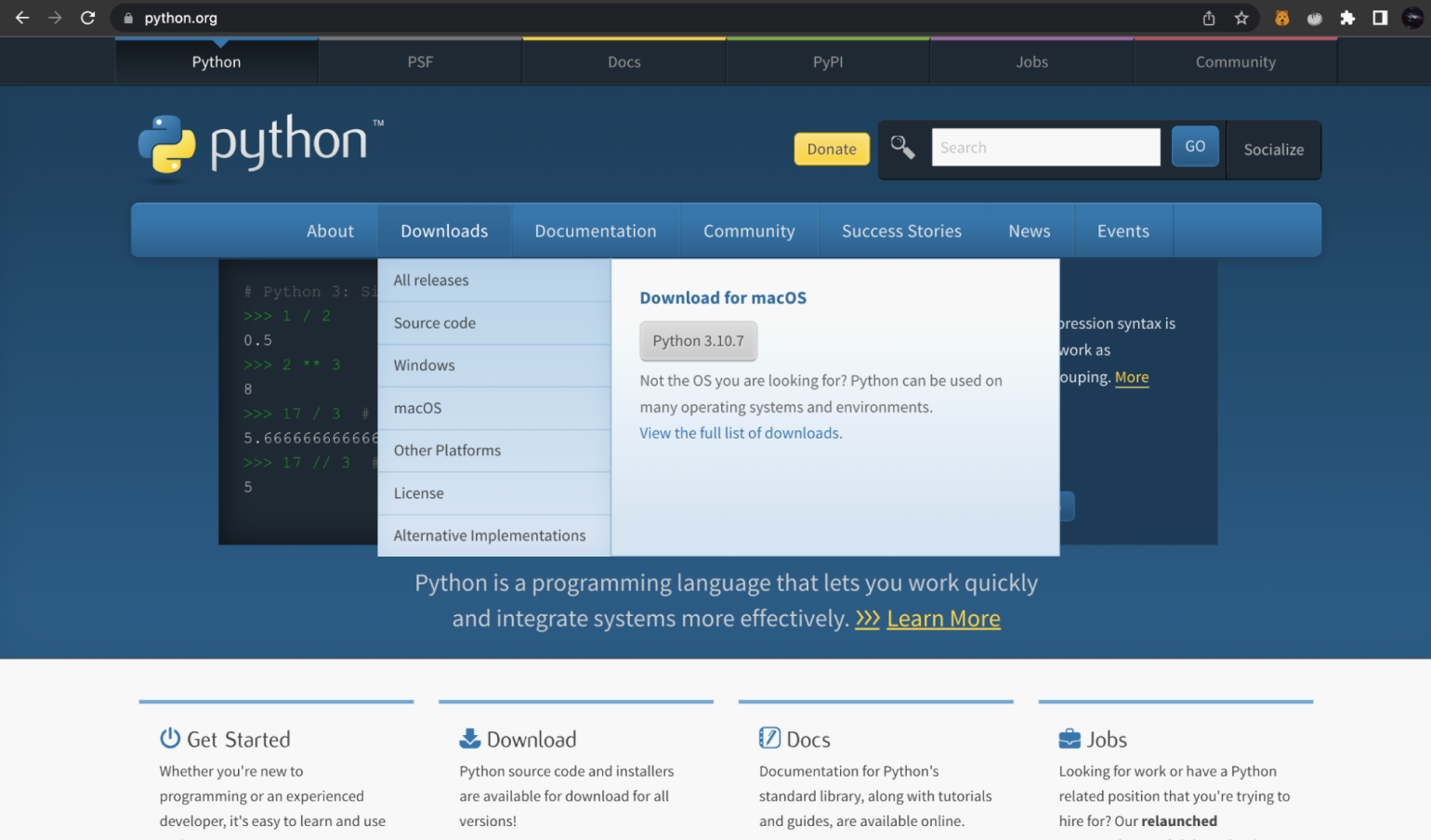
Скриншот: Skillbox Media
После этого начинается стандартная процедура: выбираем место установки и соглашаемся со всеми пунктами.
В конце нас должны поздравить.
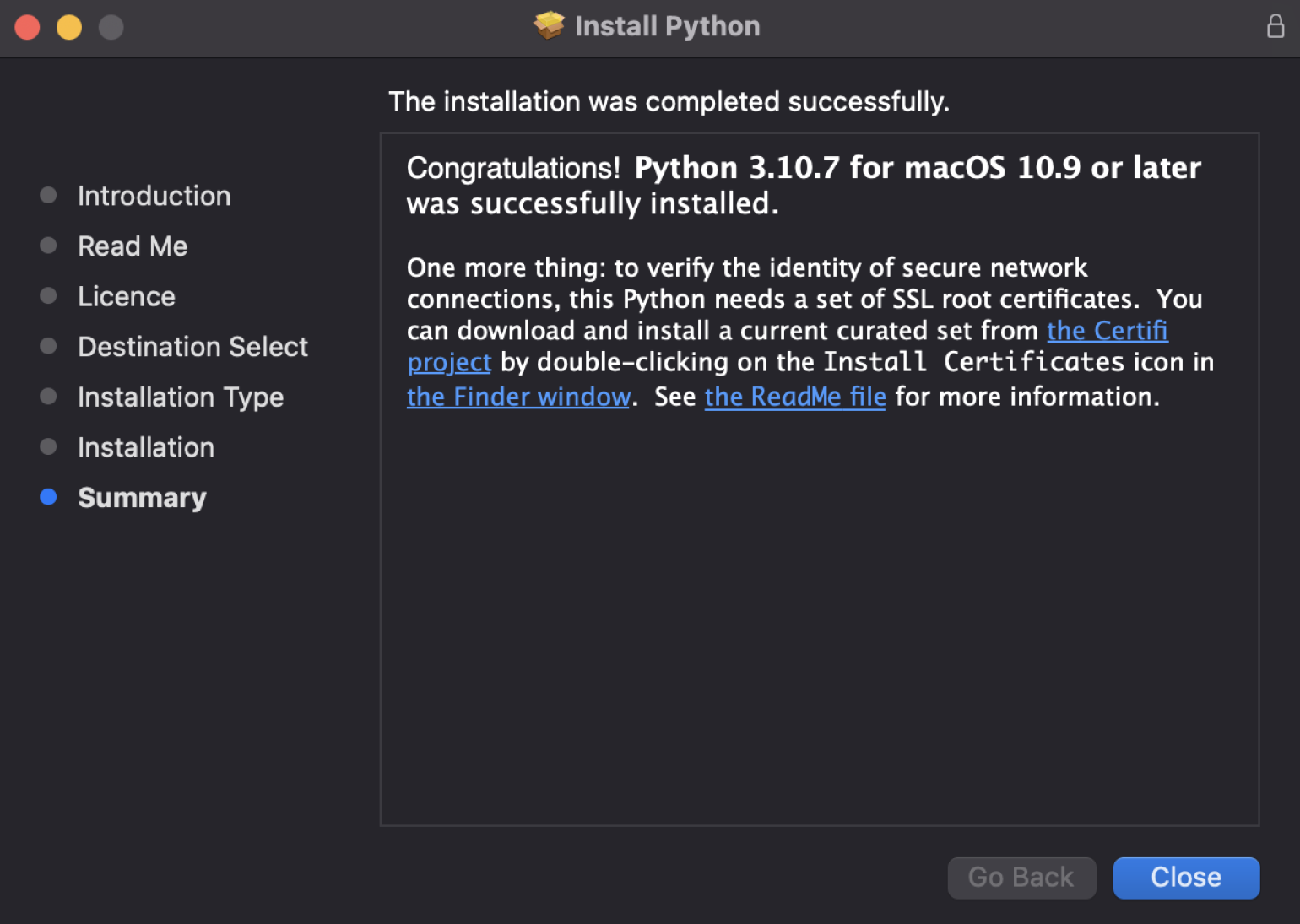
Скриншот: Skillbox Media
Теперь нужно скачать библиотеку NumPy. Открываем консоль и вводим туда команду pip install numpy.
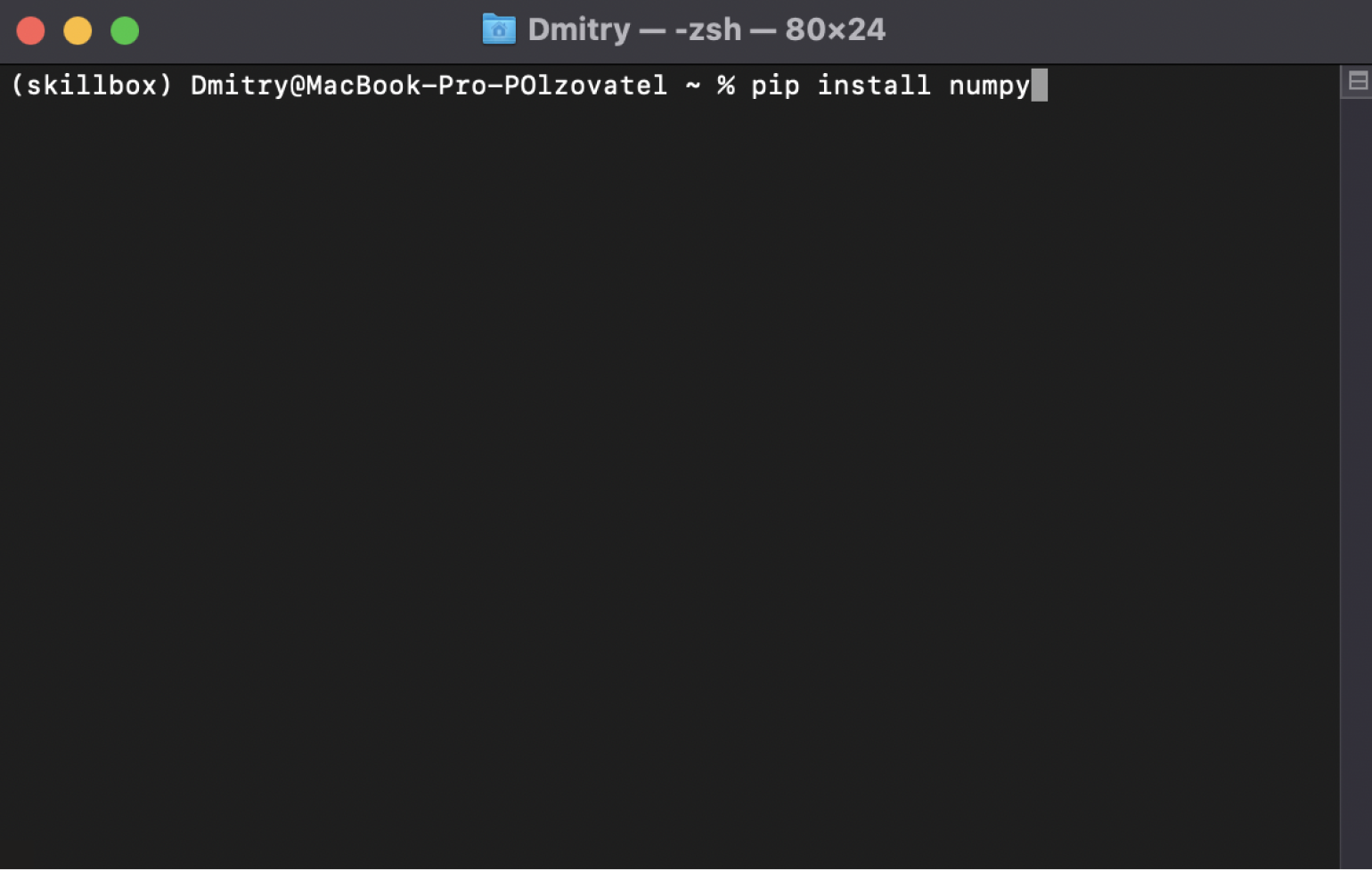
Скриншот: Skillbox Media
Если вдруг у вас выпала ошибка, значит, нужно написать другую похожую команду — pip3 install numpy.
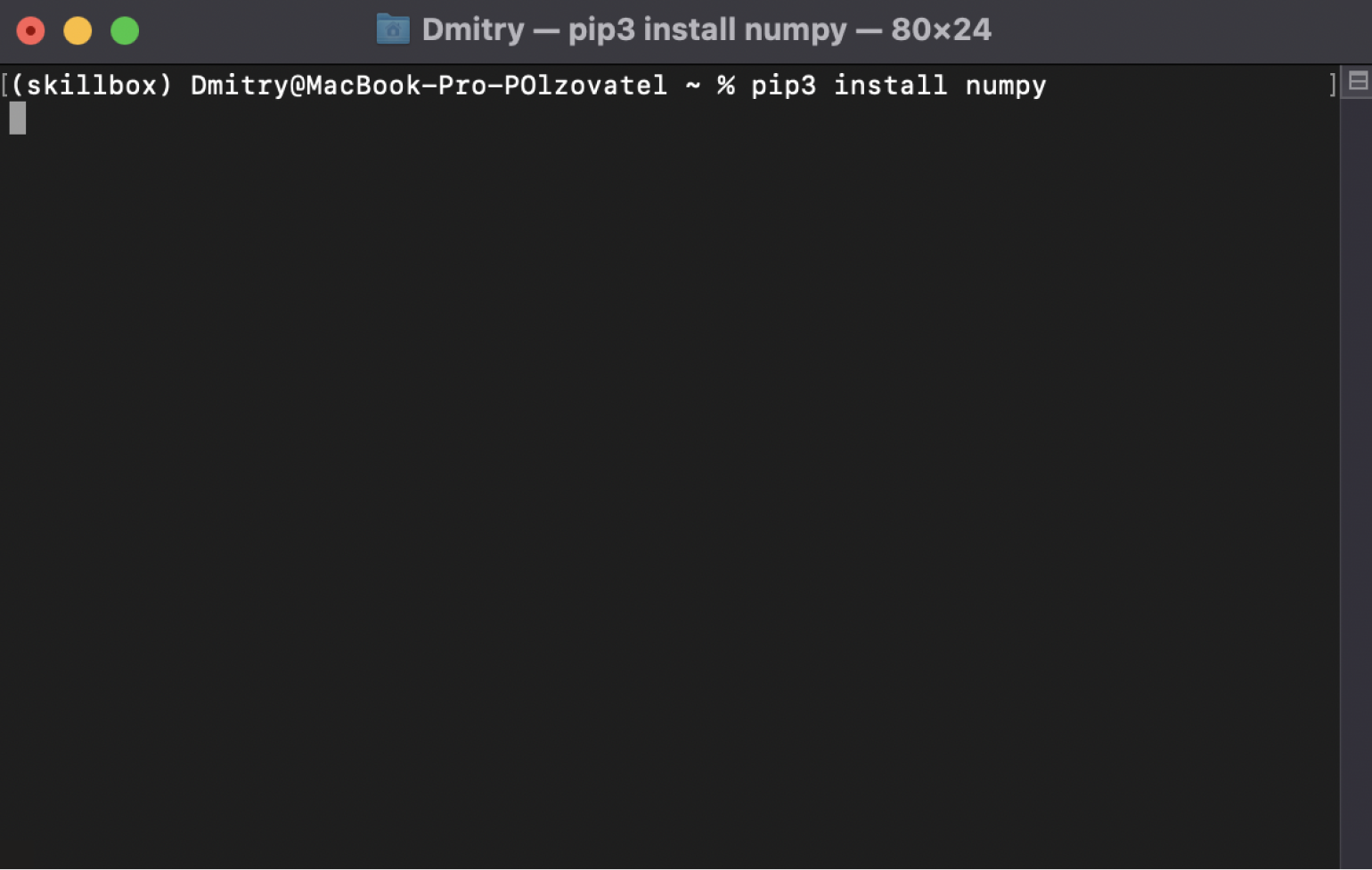
Скриншот: Skillbox Media
Теперь у нас точно должна установиться NumPy. Правда, тут нас уже никто не поздравляет — лишь сухо отмечают, что установка завершилась успешно.
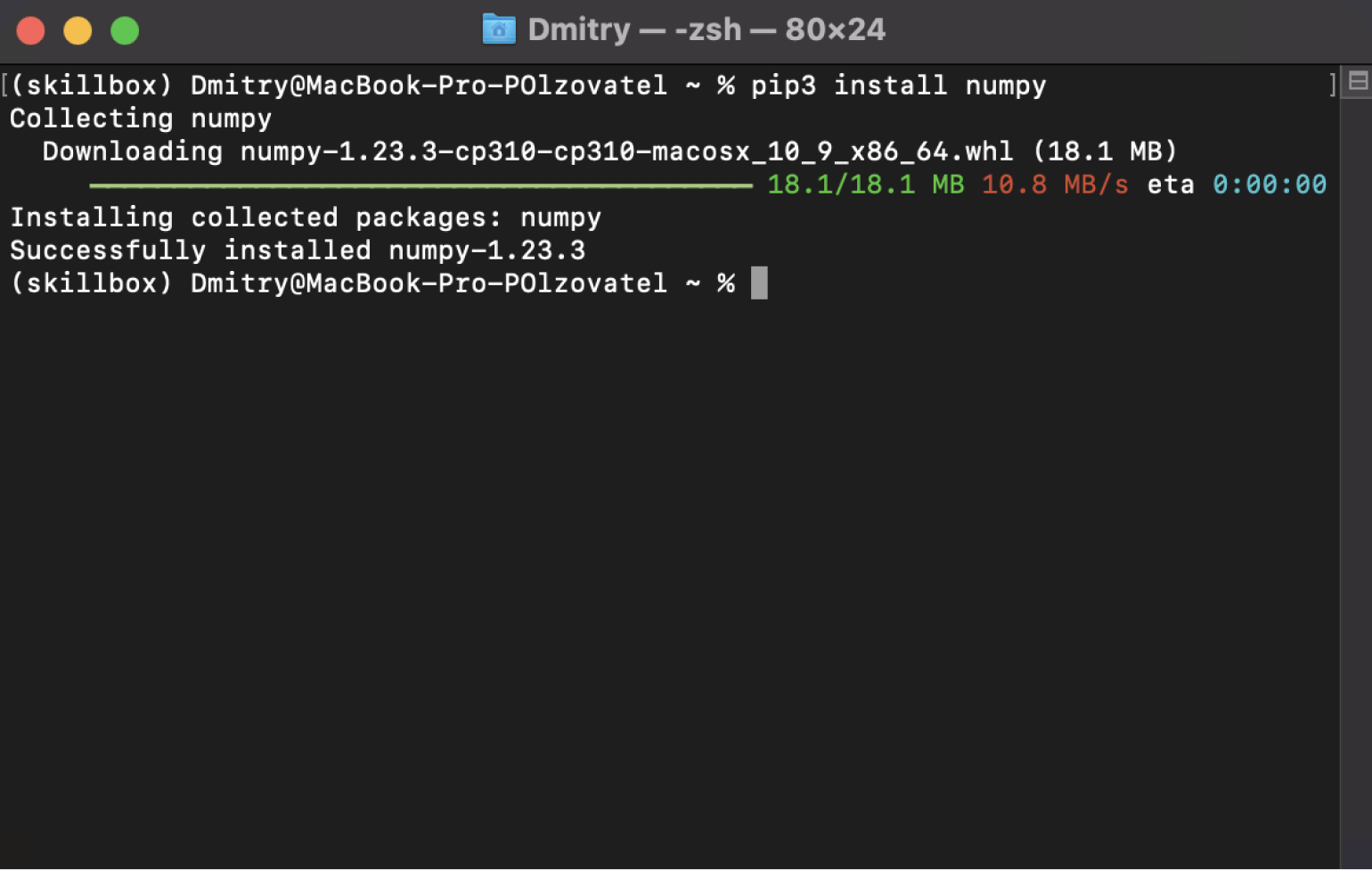
Скриншот: Skillbox Media
Перед тем как использовать NumPy, нужно подключить библиотеку в Python-коде — а вы думали, достаточно установить его? Нет, Python ещё должен узнать, что конкретно в этом проекте NumPy нам нужен.
import numpy as np
np — это уже привычное сокращение для NumPy в Python-сообществе. Оно позволяет быстро обращаться к методам библиотеки (две буквы проще, чем пять). Мы тоже будем придерживаться этого сокращения — мы же профессионалы! Хотя можно использовать NumPy и без присваивания отдельного сокращения или назвать её любыми приятными для вас буквами и символами. Но всё же рекомендуем следовать традициям сообщества, чтобы избежать недопонимания со стороны других программистов.
Теперь приступим к изучению базовых понятий и функций NumPy. А чтобы лучше усвоить изученный материал, рекомендуем внимательно изучать код, самостоятельно переписывать его и поиграться с параметрами и числами.
Главный объект библиотеки NumPy — массив. Создаётся он очень просто:
a = np.array([1, 2, 3])
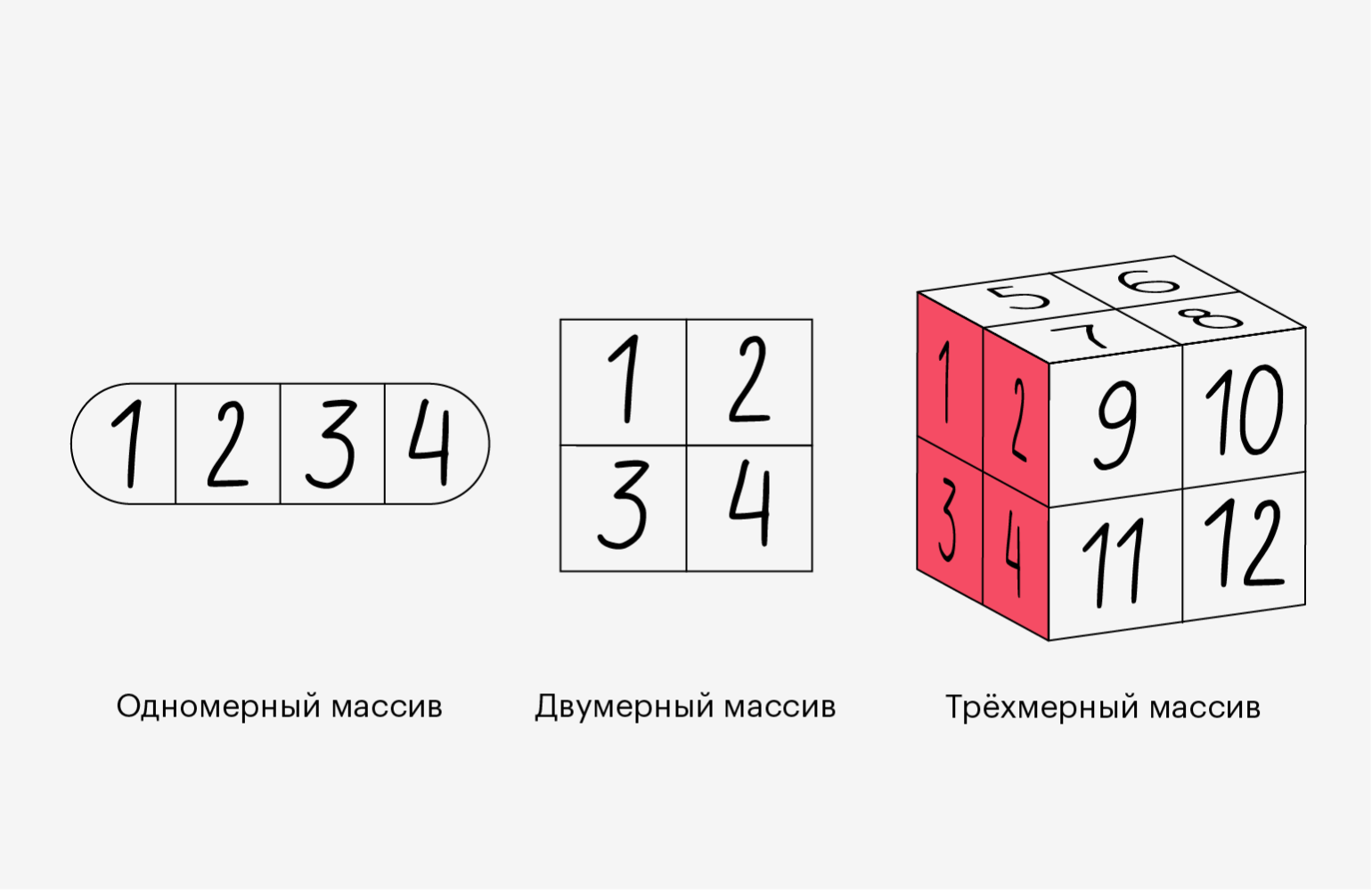
Мы объявили переменную a и использовали встроенную функцию array. В неё нужно положить сам Python-список, который мы хотим создать. Он может быть любой формы: одномерный, двумерный, трёхмерный и так далее. Выше мы создали одномерный массив. Давайте создадим и другие:
a2 = np.array([[1, 2, 3], [4, 5, 6]]) a3 = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
Получилось огромное количество скобок. Чтобы понять, как всё это выглядит, воспользуемся функцией print:
print(a) [1 2 3] print(a2) [[1 2 3] [4 5 6]] print(a3) [[[1 2 3] [4 5 6]] [[7 8 9] [10 11 12]]]
Как мы видим, в первом случае получился двумерный массив, который состоит из двух одномерных. А во втором — трёхмерный, состоящий из двумерных. Если двигаться вверх по измерениям, то они будут следовать похожей логике:
- четырёхмерный массив состоит из трёхмерных;
- пятимерный массив — это несколько четырёхмерных;
- n-мерный массив — это несколько (n-1)-мерных.
Проще показать это на иллюстрации (главное, не потеряйтесь в измерениях):
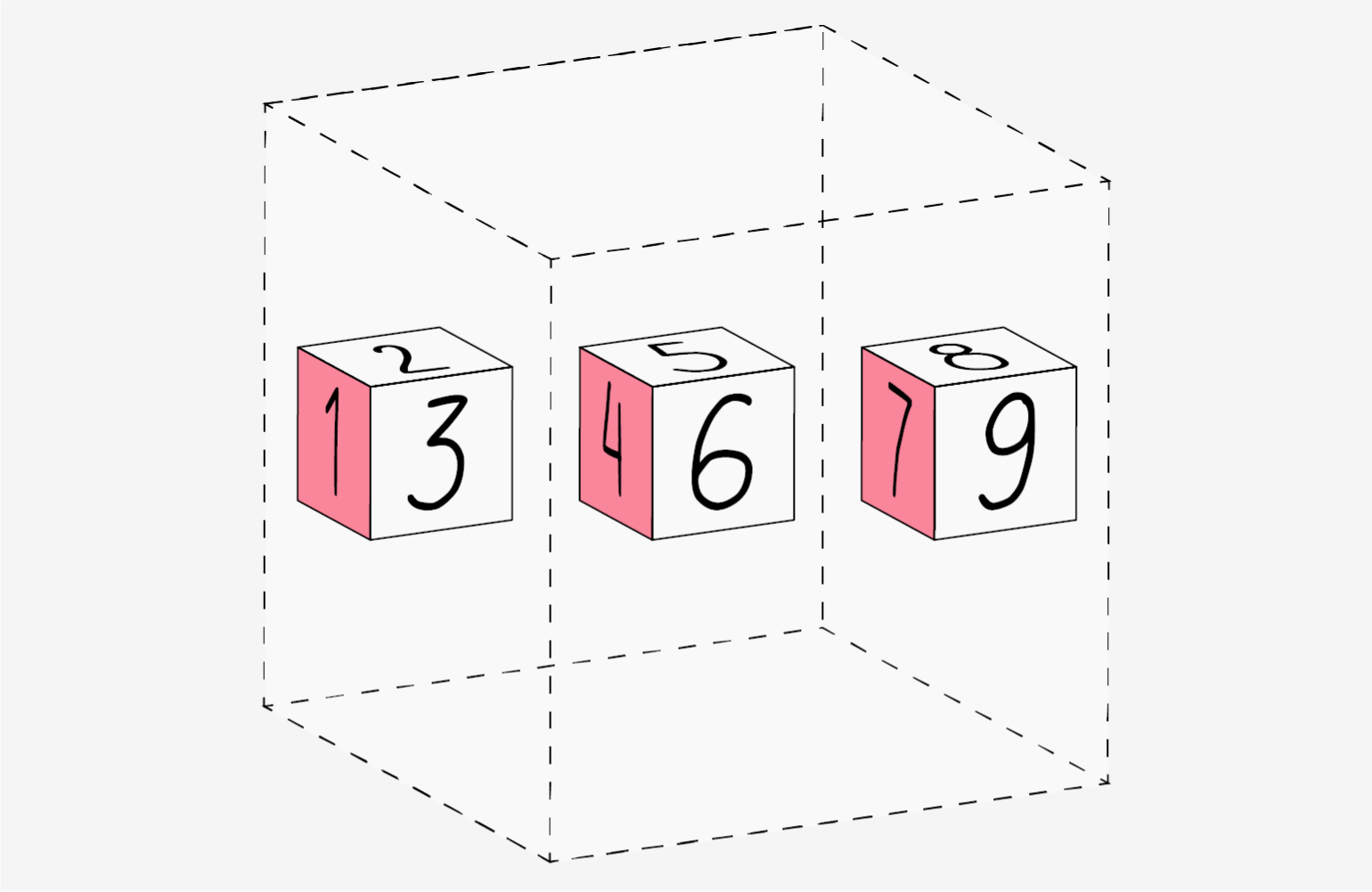
Инфографика: Оля Ежак для Skillbox Media
В NumPy-массивы можно передавать не только целые числа, но и дробные:
b = np.array([1.4, 2.5, 3.7]) print(b) [1.4 2.5 3.7]
А если вы хотите указать конкретный тип, то это можно сделать с помощью дополнительного параметра dtype:
c = np.array([1, 2, 3], dtype='float32') print(c) [1. 2. 3.]
Целые числа сразу были приведены к числам с плавающей точкой. Таких преобразований существует много — они нужны, чтобы не занимать лишнюю память. Например, числа int32 занимают 32 бита, или 4 байта, а int16 — 16 бит, или 2 байта. Программисты используют параметр dtype, когда точно знают, что их переменные будут находиться в диапазоне от −32 768 до 32 767.
Если реальные значения элементов массива выйдут за рамки явно указанного типа, то их значения в какой-то момент просто обнулятся и начнут отсчёт заново:
# Допустим, a — это переменная типа int16, у которой максимальное значение — 32 767
a = 32 000
b = 768
print(a + b)
-32768
Как мы видим, результат обнулился до своего минимального значения — –32 768.
Теперь, когда мы умеем создавать массивы и задавать им разные значения, давайте узнаем, какие у них есть встроенные функции.
Допустим, у нас есть такой объект:
a = np.array([1,2,3], dtype='int32') print(a) [1 2 3]
Чтобы узнать, сколько у него измерений, воспользуемся функцией ndim:
print(a.ndim)
1
Всё верно, ведь у нас одномерный массив, или вектор. Если бы он был двумерным, то и результат оказался бы другим:
b = np.array([[1, 2, 3], [4, 5, 6]]) print(b.ndim) 2
Хорошо, с размерностью понятно. А как посчитать количество строк и столбцов? Для этого есть функция shape:
print(a.shape)
(3, )
Получилось слегка странно, но всему есть объяснение. Дело в том, что вектор — это всего лишь одномерный массив. У векторов в библиотеке NumPy есть только строки — или элементы. Поэтому функция shape выдала число 3.
С двумерными массивами ситуация понятнее:
print(b.shape) (2, 3)
В b — 2 строки и 3 столбца.
Для трёхмерных и n-мерных массивов функция shape будет добавлять дополнительные цифры в кортеже через запятую:
с = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]) print(c.shape) (2, 2, 3)
Читается это так: в объекте c два трёхмерных массива с двумя строками и тремя столбцами.
Кроме размерностей, можно также узнать тип элементов — в этом поможет функция dtype (не путайте её с одноимённым параметром):
a = np.array([1,2,3], dtype='int32') print(a.dtype) dtype('int32')
Если не присваивать тип элементам вручную, по умолчанию будет задан int32.
Ещё можно узнать количество элементов с помощью функции size:
print(a.size)
3
А через функции itemsize и nbytes можно узнать, какое количество байт в памяти занимает один элемент и какое количество байт занимает весь массив:
b = np.array([[1, 2, 3], [4, 5, 6]], dtype='int16') print(b.itemsize) 2 print(b.nbytes) 12
Один элемент занимает 2 байта, а весь объект b из 6 элементов — 2 × 6 = 12 байтов.
В NumPy можно обращаться к отдельным элементам, строкам или столбцам, а также точечно выбирать последовательность нужных элементов. Рассмотрим всё подробнее.
Допустим, у нас есть двумерный массив:
a = np.array([[1, 2, 3, 4, 5, 6, 7], [8, 9, 10, 11, 12, 13, 14]]) print(a) [[ 1 2 3 4 5 6 7] [ 8 9 10 11 12 13 14]]
И мы хотим достать их него элемент, который находится в первой строке на пятом месте. Сделать это можно с помощью специального оператора []:
print(a[0, 4]) 5
Почему 0 и 4? Потому что нумерация элементов в Python начинается с нуля, а значит, первая строка будет нулевой, а пятый столбец — четвёртым.
Если бы у нас был трёхмерный массив, обращение к его элементам было бы похожим:
c = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]) print(c) [[[ 1 2 3] [ 4 5 6]] [[ 7 8 9] [10 11 12]]] print(c[1, 1, 1]) 11
Здесь мы сначала обратились ко второму двумерному массиву, а затем выбрали в нём вторую строку и второй столбец. Там и находилось число 11.
Кроме отдельных элементов, в библиотеке NumPy можно обратиться к целой строке или столбцу с помощью оператора :. Он позволяет выбрать все элементы указанной строки или столбца:
print(a[0, :]) [1 2 3 4 5 6 7] print(a[:, 0]) [1 8]
В первом случае мы выбрали всю первую строку, а во втором — первый столбец.
Ещё можно использовать продвинутые способы выделения нужных нам элементов.
Кстати, оператор : на самом деле представляет собой сокращённую форму конструкции начальный_индекс: конечный_индекс: шаг.
Давайте остановимся на ней подробнее:
b = np.array([[1, 2, 3, 4], [5, 6, 7, 8]]) print(b[0, 1:4:2]) [2 4]
Мы указали, что хотим выбрать первую строку, а затем уточнили, какие именно столбцы нам нужны: 1:4:2.
- Первое число означает, что мы начинаем брать элементы с первого индекса — второго столбца.
- Второе число — что мы заканчиваем итерацию на четвёртом индексе, то есть проходим всю строку.
- Третье число указывает, с каким шагом мы идём по строке. В нашем примере — с шагом в два элемента. То есть мы пройдём по элементам 1, 3 и 5.
Давайте посмотрим на другой пример:
a = np.array([[1, 2, 3, 4, 5, 6, 7], [8, 9, 10, 11, 12, 13, 14]]) print(a) [[ 1 2 3 4 5 6 7] [ 8 9 10 11 12 13 14]] print(a[1, 0:-1:3]) [8, 11]
Здесь мы использовали отрицательные индексы — они позволяют считать индексы элементов справа налево. –1 означает, что последний индекс — это последний столбец второй строки. Заметьте, что 6-й столбец не вывелся. Это значит, что NumPy не доходит до этого индекса, а заканчивает обход на один индекс раньше.

Инфографика: Оля Ежак для Skillbox Media
Ещё мы можем менять значения в NumPy-массиве с помощью той же операции доступа к элементам. Например:
c = np.array([[0, 2], [4, 6]]) c[0, 0] = 1 print(c) [[1 2] [4 6]]
Мы заменили элемент из первой строки и первого столбца (элемент 0) на единицу. И наш массив успешно изменился.
Кроме отдельных элементов, можно заменять любые последовательности элементов с помощью конструкции начальный_индекс: конечный_индекс: шаг и её упрощённой версии — :.
c = np.array([[0, 2], [4, 6]]) с[0, :] = [3, 3] print(c) [[3 3] [4 6]]
Теперь в с вся первая строка заменилась на тройки. Главное при такой замене — учитывать размер строки, чтобы не возникло ошибок. Например, если присвоить первой строке вектор из трёх элементов, интерпретатор будет ругаться:
c = np.array([[0, 2], [4, 6]]) c[0, :] = [3, 3, 3] Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: could not broadcast input array from shape (3,) into shape (2,)
Текст ошибки сообщает, что нельзя присвоить одномерному массиву с размером 2 массив размером 3.
Мы научились создавать массивы любой размерности. Но иногда хочется создать их с уже заполненными значениями — например, забить все ячейки нулями или единицами. NumPy может и это.
Массив из нулей. Чтобы создать его, используем функцию zeros.
a = np.zeros((2, 2)) print(a) [[0. 0.] [0. 0.]]
Первое, что нужно помнить, — как задавать размер. Он задаётся кортежем (2, 2). Если указать размер без скобок, то снова получим ошибку:
a = np.zeros(2, 2) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: Cannot interpret '2' as a data type
А всё потому, что без скобок NumPy расценивает второй элемент (число 2) как тип данных, который должен быть указан для параметра dtype.
Если указать только одно число, создастся вектор размером два элемента. В этом случае уже не нужно ставить дополнительные скобки:
a = np.zeros(2) print(a) [0. 0.]
Ещё стоит отметить, что элементам по умолчанию присваивается тип float64. Это дробные числа, которые занимают в памяти 64 бита, или 8 байт. Если нужны именно целые числа, то мы по старой схеме указываем это в параметре dtype — через запятую:
a = np.zeros(2, dtype='int32') print(a) [0 0]
Массив из единиц. Он создаётся точно так же, как и из нулей, но используется функция ones:
b = np.ones((4, 2, 2), dtype='int32') print(b) [[[1 1] [1 1]] [[1 1] [1 1]] [[1 1] [1 1]] [[1 1] [1 1]]]
Здесь мы создали трёхмерный массив из четырёх двумерных, каждый из которых имеет две строки и два столбца. А также указали, что элементы должны иметь тип int32.
Массив из произвольных чисел. Иногда бывает нужно заполнить массив какими-то отличными от нуля и единицы числами. В этом поможет функция full:
c = np.full((2, 2), 5) print(c) [[5 5] [5 5]]
Здесь мы сначала указали, какой размер должен быть у массива через кортеж, — (2,2), а затем число, которым мы хотим заполнить все его элементы, — 5.
Равно как и у функций zeros и ones, элементы по умолчанию будут иметь тип float64. А размер должен передаваться в виде кортежа — (2, 2).
Массив случайных чисел. Он создаётся с помощью функции random.rand:
d = np.random.rand(3, 2) print(d) [[0.76088962 0.14281283] [0.32124888 0.34894434] [0.66903093 0.72899792]]
Получилось что-то странное. Но так и должно быть — ведь NumPy генерирует случайные числа в диапазоне от 0 до 1 с восемью знаками после запятой.
Ещё одна странность — то, как задаётся размер. Здесь это нужно делать не через кортеж (3, 2), а просто указывая размерности через запятую. Всё потому, что в функции random.rand нет параметра dtype.
Чтобы создать массив случайных чисел, нужно воспользоваться функцией random.randint:
e = np.random.randint(-5, 10, size=(4, 4)) print(e) [[ 3 1 -4 3] [ 0 -2 5 3] [ 5 -1 9 2] [ 0 -4 9 -2]]
У нас получился массив размером четыре на четыре — size=(4, 4) — с целыми числами из диапазона от –5 до 10. Как и в предыдущем случае, создаётся такой массив слегка странно — но такова жизнь NumPy-программистов.
Единичная матрица. Она нужна тем, кто занимается линейной алгеброй. По диагонали такой матрицы элементы равны единице, а все остальные элементы — нулю. Создаётся она с помощью функции identity или eye:
i = np.identity(4) print(i) [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]]
Здесь задаётся только количество строк матрицы, потому что единичная матрица должна быть симметричной — иметь одинаковое количество строк и столбцов.
И всё также можно указать тип элементов с помощью параметра dtype:
i = np.identity(4, dtype='int32') print(i) [[1 0 0 0] [0 1 0 0] [0 0 1 0] [0 0 0 1]]
Массивы из NumPy поддерживают все стандартные арифметические операции — например, сложение, деление, вычитание. Работает это поэлементно:
a = np.array([1, 2, 3, 4]) print(a) [1 2 3 4] print(a + 3) [4 5 6 7]
К каждому элементу a прибавилось число 3, а размерность не изменилась. Все остальные операции работают точно так же:
print(a - 2) [-1 0 1 2] print(a * 2) [2 4 6 8] print(a / 2) [0.5 1. 1.5 2.] #Здесь тип элементов приведён к 'float64' print(a ** 2) [1 4 9 16]
Ещё можно проводить любые математические операции с массивами одинакового размера:
a = np.array([[1, 2], [3, 4]]) b = np.array([[2, 2], [2, 2]]) print(a + b) [[3 4] [5 6]] print(a * b) [[2 4] [6 8]] print(a ** b) [[ 1 4] [ 9 16]]
Здесь каждый элемент a складывается, умножается и возводится в степень на элемент из такой же позиции массива b.
Кроме примитивных операций, в NumPy можно проводить и более сложные — например, вычислить косинус:
a = np.array([[1, 2], [3, 4]]) print(np.cos(a)) [[ 0.54030231 -0.41614684] [-0.9899925 -0.65364362]]
Все математические функции вызываются по похожему шаблону: сначала пишем np.название_математической_функции, а потом передаём внутрь массив — как мы и сделали выше.
Ещё к массивам можно применять различные операции из линейной алгебры, математической статистики и так далее. Давайте для примера перемножим матрицы по правилам линейной алгебры:
a = np.ones((2, 3)) print(a) [[1. 1. 1.] [1. 1. 1.]] b = np.full((3, 2), 2) print(b) [[2 2] [2 2] [2 2]] print(np.matmul(a, b)) [[6. 6.] [6. 6.]]
Не будем разбирать математическую составляющую — предполагается, что вы уже знакомы с математикой и используете NumPy для выражения операций языком программирования. Полный список всех поддерживаемых в библиотеке операций можно найти в официальной документации.
Если в NumPy вы присвоите массив другой переменной, то просто создадите ссылку на него. Разберём на примере:
a = np.array([1, 2, 3]) b = a b[0] = 5 print(b) [5 2 3] print(a) [5 2 3]
Как мы видим, при изменении b меняется также и a. Дело в том, что массивы в NumPy — это только ссылки на области в памяти. Поэтому, когда мы присвоили a переменной b, на самом деле мы просто присвоили ей ссылку на первый элемент a в памяти.
Чтобы создать независимую копию a, используйте функцию copy:
a = np.array([1, 2, 3]) b = a.copy() b[0] = 5 print(b) [5 2 3] print(a) [1 2 3]
Ещё мы можем менять размер массива с помощью функции reshape:
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8]]) print(a) [[1 2 3 4] [5 6 7 8]] b = a.reshape((4, 2)) print(b) [[1 2] [3 4] [5 6] [7 8]]
Изначально размер a был 2 на 4. Мы переделали его под 4 на 2. Заметьте: новые размеры должны соответствовать количеству элементов. В противном случае Python вернет ошибку:
a = np.array([[1, 2, 3, 4], [5, 6, 7, 8]]) b = a.reshape((4, 3)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: cannot reshape array of size 8 into shape (4,3)
Ещё NumPy позволяет нам «наслаивать» массивы друг на друга и соединять их с помощью функций vstack и hstack:
v1 = np.array([1, 2, 3]) v2 = np.array([9, 8, 7]) v3 = np.vstack([v1, v2]) print(v3) [[1 2 3] [9 8 7]]
Здесь мы создали двумерный массив из двух векторов одинакового размера, которые «поставили» друг на друга. То же самое можно сделать и горизонтально:
h1 = np.ones((2, 4)) h2 = np.zeros((2, 2)) h3 = np.hstack((h1, h2)) print(h3) [[1. 1. 1. 1. 0. 0.] [1. 1. 1. 1. 0. 0.]]
К массиву из единиц справа присоединился массив из нулей. Главное — чтобы количество строк в обоих было одинаковым, иначе вылезет ошибка:
h1 = np.ones((2, 4)) h2 = np.zeros((3, 2)) h3 = np.hstack((h1, h2)) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<__array_function__ internals>", line 5, in hstack File "/Users/Dmitry/opt/anaconda3/lib/python3.9/site-packages/numpy/core/shape_base.py", line 345, in hstack return _nx.concatenate(arrs, 1) File "<__array_function__ internals>", line 5, in concatenate ValueError: all the input array dimensions for the concatenation axis must match exactly, but along dimension 0, the array at index 0 has size 2 and the array at index 1 has size 3
Эта ошибка говорит, что количество строк не совпадает.
NumPy поддерживает другие полезные функции, которые используются реже, но знать о которых полезно. Например, одна из таких функций — чтение файлов с жёсткого диска.
Чтение данных из файла. Допустим, у нас есть файл data.txt с таким содержимым:
1,2,3,5,6,7 8,1,4,2,6,4 9,0,1,7,3,4
Мы можем записать числа в NumPy-массив с помощью функции genfromtxt:
filedata = np.genfromtxt('data.txt', delimiter=',') filedata = filedata.astype('int32') print(filedata) [[1 2 3 5 6 7] [8 1 4 2 6 4] [9 0 1 7 3 4]]
Сначала мы достали данные из файла data.txt через функцию genfromtxt. В ней нужно указать считываемый файл, а затем разделитель — чтобы NumPy понимал, где начинаются и заканчиваются числа. У нас разделителем будет ,.
Затем нам нужно привести числа к формату int32 с помощью функции astype, передав в неё нужный нам тип.
Булевы выражения. Ещё одна из возможностей NumPy — булевы выражения для элементов массива. Они позволяют узнать, какие элементы отвечают определённым условиям — например, больше ли каждое число массива 50.
Допустим, у нас есть массив a и мы хотим проверить, действительно ли все его элементы больше 5:
a = np.array([[1, 5, 8], [3, 4, 2]]) print(a > 5) [[False False True] [False False False]]
На выходе — массив с «ответом» для каждого элемента: больше ли он числа 5. Если меньше или равно, то стоит False, иначе — True.
С помощью булевых выражений можно составлять и более сложные конструкции — например, создавать новые массивы из элементов, которые отвечают определённым условиям:
a = np.array([[1, 5, 8], [3, 4, 2], [2, 6, 7]]) print(a[a > 3]) [5 8 4 6 7]
Мы получили вектор, состоящий из элементов массива a, которые больше трёх.
- NumPy — это библиотека для эффективной работы с массивами любого размера. Она достигает высокой производительности, потому что написана частично на C и C++ и в ней соблюдается принцип локальности — она хранит все элементы последовательно в одном месте.
- Перед тем как использовать NumPy в коде, его нужно подключить с помощью команды import numpy as np.
- Основа NumPy — массив. Чтобы его создать, нужно использовать функцию array и передать туда список в качестве первого аргумента. Вторым аргументом через dtype можно указать тип для всех элементов — например, int16 или float32. По умолчанию для целых чисел указывается int32, а для десятичных — float64.
- Функция ndim позволяет узнать, сколько измерений у массива; shape — его структуру (сколько столбцов и строк); dtype — какой тип у элементов; size — количество элементов; itemsize — сколько байтов занимает один элемент; nbytes — сколько всего памяти занимает массив.
- К элементам массива можно обращаться с помощью оператора [], где указываются индексы нужного элемента. Важно помнить, что индексация начинается с нуля. А ещё в NumPy можно выбирать сразу целые строки или столбцы с помощью оператора : и его продвинутой версии — начальный_индекс: конечный_индекс: шаг.
- Функции zeros, ones, full, random.rand, random.randint, identity и eye помогают быстро создать массивы любого размера с заполненными элементами.
- Все арифметические операции, которые доступны в Python, применимы и к массивам NumPy. Главное — помнить, что операции проводятся поэлементно. А для сложных операций, таких как вычисление производной, также есть свои функции.
- NumPy-массивы нельзя просто присвоить другой переменной, чтобы скопировать. Для этого существует функция copy. А чтобы поменять структуру данных, можно применить функции reshape, vstack и hstack.
- Ещё в NumPy есть дополнительные функции — например, чтение из файла с помощью genfromtxt и булевы выражения, которые позволяют выбирать элементы из набора данных по заданным условиям.

Жизнь можно сделать лучше!
Освойте востребованную профессию, зарабатывайте больше и получайте от работы удовольствие. А мы поможем с трудоустройством и важными для работодателей навыками.
Посмотреть курсы