Apache NiFi is a software project from the Apache Software Foundation designed to automate the flow of data between software systems.
Apache NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic.
Prerequisites
- JDK 8
Add JAVA_HOME in Environment Variables
Once you have installed the JDK 8, we need to setup the System Variable in Environment variables. Open Environment variables from the Start Menu.

In System Variables, click on New. If JAVA_HOME is already present pointing to JRE 1.8 path, then you do not have to perform these steps.

Give a new System variable name JAVA_HOME and choose the directory of jre 1.8.

When you have added the system variable, click on OK.

Download Apache NiFi
Go to the official website and click on the zip file under binaries. At the time of writing this blog, the latest version is 1.14.0.

Download from the first link. The download size is approx. over 1.3 GB.

Unzip the file and this is how the folder structure will be.

Check the Configuration
Open the conf folder and open the nifi.properties file. Scroll to the web properties. Make a note of host and the port where the NiFi will be running.

Run NiFi
Go to the bin folder and open command line from there.

To start the NiFi, you can directly double click on run-nifi.bat file. Or you can just type the file name in command prompt.

If the command line produces a process ID, that means your NiFi is running. You can also check the status of NiFi if it is running or not by executing the status-nifi.bat file.

Go to the following URL – https://127.0.0.1:8443/nifi/ to check if the NiFi has started. Your port might be different. Don’t worry if this URL is not loading instantly. NiFi takes time after starting. It creates the repository folders at the root location.

Once the folders are created, you can check the URL. If you see the below warning, click on Advanced and Proceed.

Following is the login screen you will see.

To get the Username and Password, refer to my blog here. To shutdown the NiFi, just type Cntrl+C on the command line where NiFi is running.
Thank you All!!! Hope you find this useful.
Apache NiFi can be used to create dataflow pipelines.
We can follow below steps to install Apache NiFi in ubuntu or in any Linux machine.
- Download the apache NiFi zip binary package.
At time of writing this post the available version was 1.12.1 . This is 1.5 GB file.
https://archive.apache.org/dist/nifi/1.12.1/nifi-1.12.1-bin.zip.
Please vision Nifi download page to get updated version https://nifi.apache.org/download.html
2. Unzip the NiFi zip package
3. Go to the extract directory nifi-1.12.1. Go to bin directory. Now double click “run-nifi” windows batch file

It will be better to start the process with admin previliages.
We can see new directories got created in install location

4. Now got to internet browser and type
http://localhost:8080/nifi/You can see the nifi canvas ready for development

Please note Java JDK is required for running Apache nifi in windows. Please make sure Java is installed and JAVA_HOME variable is set in windows environment.
Contents
- 1 Введение в Apache NiFi
- 1.1 Apache NiFi Introduction
- 1.2 Что такое Apache NiFi?
- 1.2.1 Apache Nifi Crash Course
- 1.2.2 Почему мы используем Apache NiFi?
- 1.2.3 Особенности Apache NiFi
- 1.2.4 Архитектура Apache NiFi
- 1.2.5 Ключевые концепции Apache NiFi
- 1.2.6 Пользовательский интерфейс Apache NiFi
- 1.2.7 Компоненты Apache NiFi
- 1.2.8 Классификация процессоров в Apache NiFi
- 1.2.9 Как установить Apache NiFi?
- 1.2.10 Как построить поток?
- 1.2.10.1 Добавить и настроить процессоры
- 1.2.11 Преимущества Apache NiFi
- 1.2.12 Недостатки Apache NiFi
В этом руководстве вы познакомитесь с Apache NiFi и подробно ознакомитесь с его концепциями и архитектурой. Вы обнаружите, насколько просто и адаптируемо создавать конвейеры данных в режиме реального времени и управлять ими.
Apache NiFi — это система потоков данных, основанная на концепциях программирования на основе потоков. Он разработан Агентством национальной безопасности (АНБ), а затем в 2015 году стал официальной частью Apache Project Suite.
Каждые 6-8 недель Apache NiFi выпускает новое обновление для удовлетворения требований пользователей.
Это руководство по Apache NiFi предназначено для начинающих и профессионалов, которые хотят изучить основы Apache NiFi. Он включает в себя несколько разделов, которые предоставляют основные знания о том, как работать с NiFi.
Что такое Apache NiFi?
Apache NiFi — это надежная, масштабируемая и надежная система, которая используется для обработки и распространения данных. Он создан для автоматизации передачи данных между системами.
- NiFi предлагает пользовательский веб-интерфейс для создания, мониторинга и управления потоками данных. NiFi расшифровывается как Niagara Files, который был разработан Агентством национальной безопасности (АНБ), но теперь поддерживается фондом Apache.
- Apache NiFi — это веб-платформа пользовательского интерфейса, в которой нам необходимо определить источник, место назначения и процессор для сбора, хранения и передачи данных соответственно.
- У каждого процессора в NiFi есть отношения, которые используются при соединении одного процессора с другим.
NiFi построен на ряде основных концепций, включая процессоры, соединения и flowfiles. Процессоры — это модули, которые выполняют конкретные действия с данными, такие как фильтрация, трансформация или маршрутизация. Соединения используются для связи процессоров между собой, позволяя данным перемещаться от одного процессора к другому. Flowfiles — это пакеты данных, которые передаются между процессорами через соединения.


Apache Nifi Crash Course
This workshop will provide a hands on introduction to simple event data processing and data flow processing using a Sandbox on students’ personal machines.
Почему мы используем Apache NiFi?
Apache NiFi имеет открытый исходный код; поэтому он находится в свободном доступе на рынке. Он поддерживает несколько форматов данных, таких как социальные сети, географическое положение, журналы и т.д.
Apache NiFi поддерживает широкий спектр протоколов, таких как SFTP, KAFKA, HDFS и т.д., что делает эту платформу более популярной в ИТ-индустрии. Есть так много причин, чтобы выбрать Apache NiFi. Они следующие.
- Apache NiFi помогает организациям интегрировать NiFi в существующую инфраструктуру.
- Это позволяет пользователям использовать функции экосистемы Java и существующие библиотеки.
- Он обеспечивает управление в режиме реального времени, что позволяет пользователю управлять потоком данных между любым источником, процессором и пунктом назначения.
- Это помогает визуализировать DataFlow на уровне предприятия.
- Это помогает агрегировать, преобразовывать, маршрутизировать, извлекать, прослушивать, разделять и перетаскивать поток данных.
- Это позволяет пользователям запускать и останавливать компоненты на индивидуальном и групповом уровнях.
- NiFi позволяет пользователям извлекать данные из различных источников в NiFi и позволяет им создавать потоковые файлы.
- Он предназначен для масштабирования в кластерах, которые обеспечивают гарантированную доставку данных.
- Визуализируйте и отслеживайте производительность и поведение в бюллетене потока, который предлагает встроенную и информативную документацию.
Особенности Apache NiFi
Особенности Apache NiFi заключаются в следующем:
- Apache NiFi — это пользовательский веб-интерфейс, который предлагает беспрепятственный опыт проектирования, мониторинга, управления и обратной связи.
- Он даже предоставляет модуль происхождения данных, который помогает отслеживать и контролировать данные от источника до места назначения потока данных.
- Разработчики могут создавать свои настраиваемые процессоры и задачи отчетности в соответствии с требованиями.
- Он поддерживает устранение неполадок и оптимизацию потока.
- Он обеспечивает быструю разработку и эффективное тестирование.
- Он обеспечивает шифрование контента и связь по защищенному протоколу.
- Он поддерживает буферизацию всех данных в очереди и обеспечивает возможность обратного давления, поскольку очереди могут достигать заданных пределов.
- Apache NiFi предоставляет систему пользователю, пользователя системе и функции безопасности мультитенантной аутентификации.
Архитектура Apache NiFi
Архитектура Apache NiFi включает веб-сервер, контроллер потока и процессор, работающий на виртуальной машине Java (JVM).
Он имеет три репозитория, такие как репозиторий FlowFile, репозиторий контента и репозиторий происхождения.
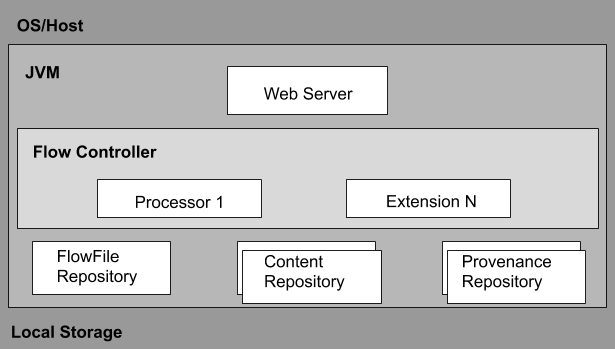
- Веб сервер
Веб-сервер используется для размещения API управления и контроля на основе HTTP.
- Контроллер потока
Контроллер потока — это мозг операции. Он предлагает потоки для запуска расширений и управляет расписанием, когда расширения получают ресурсы для запуска.
- Расширения
Несколько типов расширений NiFi определены в других документах. Расширения используются для работы и выполнения в JVM.
- Репозиторий FlowFile
Репозиторий FlowFile включает текущее состояние и атрибут каждого FlowFile, который проходит через поток данных NiFi.
Он отслеживает состояние, которое активно в потоке в данный момент. Стандартным подходом является непрерывный журнал упреждающей записи, который находится в описанном разделе диска.
- Репозиторий контента
Репозиторий контента используется для хранения всех данных, присутствующих в файлах потока. Подход по умолчанию — довольно простой механизм, который хранит блоки данных в файловой системе.
Чтобы уменьшить конкуренцию за любой отдельный том, укажите более одного места хранения файловой системы, чтобы получить разные разделы.
- Репозиторий происхождения
В репозитории происхождения хранятся все данные о событиях происхождения. Конструкцию репозитория можно подключить к реализации по умолчанию, использующей один или несколько томов физических дисков.
Данные о событиях индексируются и доступны для поиска в каждом месте.
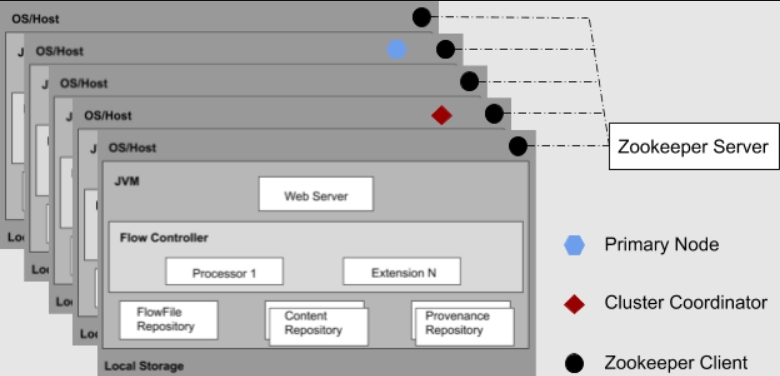
Начиная с версии NiFi 1.0, включен шаблон кластеризации с нулевым лидером. Каждый узел в кластере выполняет аналогичные задачи с данными, но работает с другим набором данных.
Apache Zookeeper выбирает один узел в качестве координатора кластера. Координатор кластера используется для подключения и отключения узлов. Кроме того, в каждом кластере есть один основной узел.
Ключевые концепции Apache NiFi
Ключевые концепции Apache NiFi заключаются в следующем:
- Поток : Поток создается для подключения различных процессоров для совместного использования и изменения данных, которые требуются от одного источника данных к другому месту назначения.
- Соединение : Соединение используется для соединения процессоров, которые действуют как очередь для хранения данных в очереди, когда это необходимо. Он также известен как ограниченный буфер в терминах программирования на основе потоков (FBP). Это позволяет нескольким процессам взаимодействовать с разной скоростью.
- Процессоры . Процессор — это модуль Java, который используется либо для извлечения данных из исходной системы, либо для их сохранения в целевой системе. Для добавления атрибута или изменения содержимого в FlowFile можно использовать несколько процессоров. Он отвечает за отправку, слияние, маршрутизацию, преобразование, обработку, создание, разделение и получение потоковых файлов.
- FlowFile : FlowFile — это базовая концепция NiFi, которая представляет собой единый объект данных, выбранных из исходной системы в NiFi. Это позволяет пользователям вносить изменения в Flowfile, когда он перемещается из исходного процессора в место назначения. Различные события, такие как создание, получение, клонирование и т. д., которые выполняются в Flowfile с использованием разных процессоров в потоке.
- Событие : событие представляет собой изменение в Flowfile при обходе потоком NiFi. Такие события отслеживаются в источнике данных.
- Происхождение данных : Происхождение данных — это репозиторий, который позволяет пользователям проверять данные, касающиеся файла Flow, и помогает в устранении неполадок, если возникают какие-либо проблемы при обработке файла Flow.
- Группа процессов : группа процессов представляет собой набор процессов и их соответствующих соединений, которые могут получать данные от входного порта и отправлять их через выходные порты.
Пользовательский интерфейс Apache NiFi
Apache NiFi — это веб-платформа, к которой пользователь может получить доступ через веб-интерфейс. Пользовательский интерфейс NiFi позволяет создавать, визуализировать, отслеживать и редактировать автоматизированные потоки данных.
Пользовательский интерфейс разделен на несколько сегментов, и каждый сегмент отвечает за разные функции приложения. Эти сегменты включают в себя различные типы команд, которые обсуждаются следующим образом:
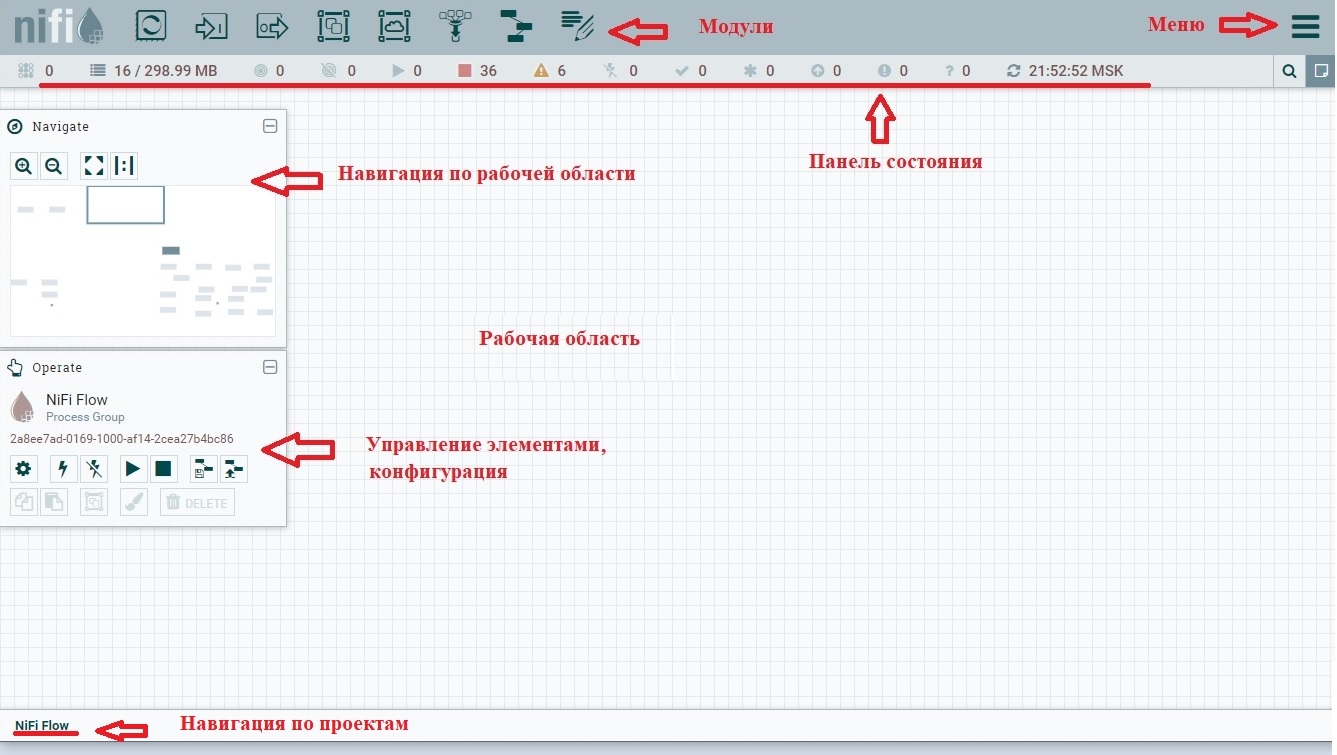
Когда диспетчер потока данных (DFM) переходит к пользовательскому интерфейсу (UI), на экране появляется пустой холст, на котором можно построить поток данных.
На рисунке панель инструментов компонентов располагается в верхней левой части экрана. Он включает компоненты, которые позволяют перетаскивать элементы на холст для создания потока данных.
Строка состояния предоставляет информацию о количестве активных потоков, объеме существующих данных, количестве существующих групп удаленных процессов, количестве существующих процессоров, количестве существующих групп процессов с управлением версиями и отметке времени последнего обновления всей информации.
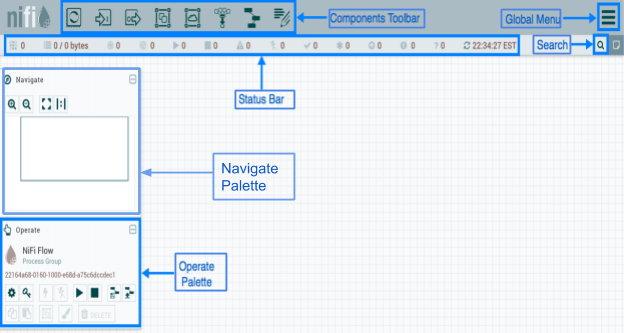
Глобальное меню находится в правой части пользовательского интерфейса и содержит параметры, используемые для управления существующими компонентами на холсте.
Строка поиска используется для поиска информации о компонентах в DataFlow. Палитра навигации используется для панорамирования холста, а также для увеличения и уменьшения масштаба.
Вид с высоты птичьего полета в палитре навигации предлагает высокоуровневое представление потока данных и позволяет охватить большие части потока данных.
Палитра Operate в левой части экрана содержит различные кнопки, которые используются DFM для управления потоком, а также для доступа и настройки свойств системы.
Компоненты Apache NiFi
Ниже перечислены компоненты Apache NiFi:
Процессор
![]()
Пользователи могут перетащить значок процессора на холст и добавить необходимый процессор для потока данных в NiFi.
Входной порт
![]()
Входной порт используется для получения данных от процессора, который недоступен в группе процессов. Когда значок ввода перетаскивается на холст, это позволяет добавить порт ввода в поток данных.
Выходной порт
Выходной порт используется для передачи данных процессору, которого нет в группе процессов. Когда значок выходного порта перетаскивается на холст, он позволяет добавить выходной порт.
Группа процессов
Группа процессов помогает добавлять группы процессов в холст NiFi. Когда значок группы процессов перетаскивается на холст, он позволяет ввести имя группы процессов, а затем он добавляется на холст.
Группа удаленных процессов
Воронка
Воронка используется для отправки вывода процессора на различные процессоры. Пользователи могут перетащить значок воронки на холст, чтобы добавить воронку в поток данных.
Это позволяет добавить группу удаленных процессов на холст NiFi.
Шаблон
Значок шаблона используется для добавления шаблона потока данных на холст NiFi. Это помогает повторно использовать поток данных в одном или разных экземплярах.
После перетаскивания он позволяет пользователям выбирать существующий шаблон для потока данных.
Этикетка
Они используются для добавления текста на холст NiFi относительно любого компонента, доступного в NiFi. Он предоставляет цвета, используемые пользователем для добавления эстетического ощущения.
Классификация процессоров в Apache NiFi
Ниже приводится классификация процессов Apache NiFi.
- Процессоры AWS
Процессоры AWS отвечают за связь с системой веб-сервисов Amazon. Такими обработчиками категорий являются PutSNS, FetchS3Object, GetSQS, PutS3Object и т. д.
- Процессоры извлечения атрибутов
Процессоры извлечения атрибутов отвечают за извлечение, изменение и анализ обработки атрибутов FlowFile в потоке данных NiFi.
Примерами являются ExtractText, EvaluateJSONPath, AttributeToJSON, UpdateAttribute и т. д.
- Процессоры доступа к базе данных
Процессоры доступа к базе данных используются для выбора или вставки данных, а также для выполнения и подготовки других операторов SQL из базы данных.
Такие процессоры используют настройки контроллера подключения к данным Apache NiFi. Примерами являются PutSQL, ListDatabaseTables, ExecuteSQL, PutDatabaseRecord и т. д.
- Процессоры приема данных
Процессоры приема данных используются для приема данных в поток данных, таких как начальная точка любого потока данных в Apache NiFi. Примеры: GetFile, GetFTP, GetKAFKA, GetHTTP и т. д.
- Процессоры преобразования данных
Процессоры преобразования данных используются для изменения содержимого FlowFiles.
Их можно использовать для замены данных FlowFile, когда пользователю необходимо отправить FlowFile в формате HTTP для вызова процессора HTTP. Примеры: JoltTransformJSON ReplaceText и т. д.
- HTTP-процессоры
Процессоры HTTP работают с вызовами HTTP и HTTPS. Примеры: InvokeHTTP, ListenHTTP, PostHTTP и т. д.
- Процессоры маршрутизации и посредничества
Процессоры маршрутизации и посредничества используются для маршрутизации FlowFiles к разным процессорам в зависимости от информации в атрибутах FlowFiles.
Он отвечает за управление потоками данных NiFi. Примерами являются RouteOnContent, RouteText, RouteOnAttribute и т. д.
- Отправка процессоров данных
Отправляющие процессоры данных — это конечные процессоры в потоке данных. Он отвечает за хранение или отправку данных в пункт назначения.
После отправки данных процессор DROP FlowFile с успешным отношением. Примеры: PutKAFKA, PutFTP, PutSFTP, PutEmail и т. д.
- Процессоры разделения и агрегации
Процессоры разделения и агрегации используются для разделения и объединения контента, доступного в потоке данных. Примеры: SplitXML, SplitJSON, SplitContent, MergeContent и т. д.
- Процессоры системного взаимодействия
Процессоры системного взаимодействия используются для запуска процесса в любой операционной системе. Он также запускает сценарии на разных языках с разными системами.
Примерами являются ExecuteScript, ExecuteStreamCommand, ExecuteGroovyScript, ExecuteProcess и т. д.
Как установить Apache NiFi?
Чтобы установить Apache NiFi, выполните следующие действия.
1. Нажмите на ссылку и загрузите последнюю версию Apache NiFi.
2. В разделе «Двоичные файлы» щелкните zip-файл установки приложения NiFi для ОС Windows.
3. Приведенная выше ссылка перенаправляет вас на новую страницу. Здесь вы получите ссылку для загрузки Apache NiFi.
4. После загрузки файла распакуйте его.
5. Откройте папку bin (т.е. nifi-1.12.1 > bin) и нажмите run-nifi и запустите для запуска.
6. Панель инструментов NiFi запустится в браузере после успешной установки. Панель инструментов Apache известна как холст, где мы создаем потоки данных.
Как построить поток?
Чтобы построить поток, нам нужно добавить два процессора на холст и настроить их. Давайте посмотрим, как добавить и настроить процессоры.
Добавить и настроить процессоры
Чтобы добавить и настроить процессоры, выполните следующие действия.
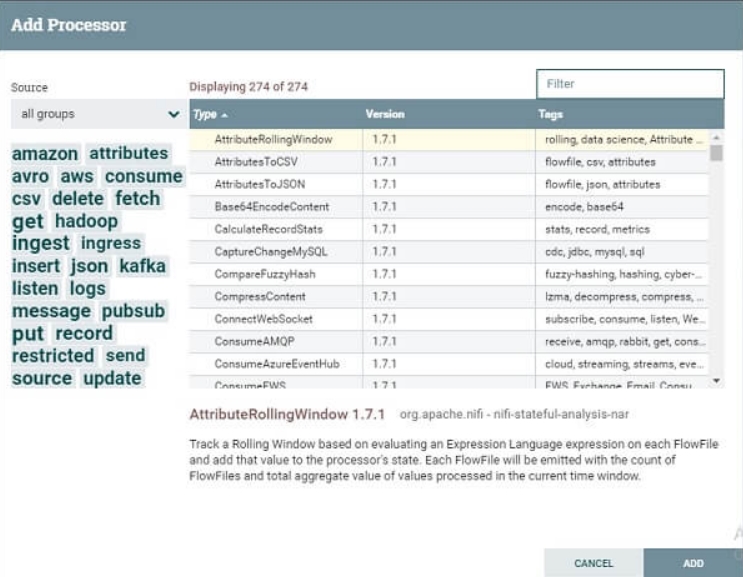
- Перейдите в раздел компонентов на панели инструментов и перетащите процессор. Откроется окно Добавить процессор со списком процессоров.
- Найдите нужный процессор или сократите список процессоров в зависимости от категории и функциональности.
- Нажмите на процессор, который вы хотите выбрать, и добавьте его на холст, дважды щелкнув процессор или нажав «Добавить».
- Если вы знаете имя процессора, вы можете ввести его в строке фильтра. Добавьте еще один процессор на холст.
- Вы увидите, что оба процессора недействительны, потому что они имеют предупреждающее сообщение, указывающее, что требования должны быть настроены, чтобы сделать процессоры действительными и выполняться.
- Чтобы удовлетворить требования предупреждения, нам нужно настроить и запустить процессоры.
Преимущества Apache NiFi
Преимущества Apache NiFi заключаются в следующем:
- Apache NiFi предлагает пользовательский веб-интерфейс (UI). Чтобы он мог работать в веб-браузере, используя порт и локальный хост.
- В веб-браузере Apache NiFi использует протокол HTTPS для обеспечения безопасного взаимодействия с пользователем.
- Он поддерживает протокол SFTP, который позволяет получать данные с удаленных компьютеров.
- Он также предоставляет политики безопасности на уровне группы процессов, уровне пользователя и других модулях.
- NiFi поддерживает все устройства, на которых работает Java.
- Он обеспечивает управление в режиме реального времени, что упрощает перемещение данных между источником и получателем.
- Apache NiFi поддерживает кластеризацию, поэтому он может работать на нескольких узлах с одним и тем же потоком, обрабатывая разные данные, что повышает производительность обработки данных.
- NiFi поддерживает более 188 процессоров, и пользователь может создавать собственные плагины для поддержки различных типов систем данных.
Недостатки Apache NiFi
Ниже приведены недостатки Apache NiFi.
- У Apache NiFi есть проблема с сохранением состояния в случае переключения основного узла, из-за которого процессоры не могут получать данные из исходных систем.
- При внесении пользователем каких-либо изменений узел отключается от кластера, а затем файл flow.xml становится недействительным. Узел не может подключиться к кластеру, пока администратор не скопирует XML-файл вручную с узла.
- Чтобы работать с Apache NiFi, вы должны хорошо разбираться в базовой системе.
- Он предлагает уровень темы, и авторизации SSL может быть недостаточно.
- Требуется поддерживать цепочку хранения данных.
Вывод
И наконец, Apache NiFi используется для автоматизации и управления потоками данных между системами. Как только данные извлекаются из внешнего источника, они представляются как FlowFile в архитектуре Apache NiFi.
Я надеюсь, что это руководство поможет вам разработать и настроить потоки данных в Apache NiFi. Теперь ваша очередь исследовать NiFi. Если возникнут какие-либо запросы, не стесняйтесь оставлять свой запрос в сеансе комментариев.

Оглавление:
1. Что такое Apache NiFi .
2. Установка и настройка Apache NiFi.
3. Начало работы с Apache NiFi (NiFi Flow, Process Group, Processors).
Что такое Apache NiFi
Apache NiFi — это визуальная среда разработки, предназначенная для передачи и обработки данных.
Название NiFi происходит от «Niagara Files». Проект в течение восьми лет разрабатывался агентством национальной безопасности США, а в ноябре 2014 года его исходный код был открыт и передан Apache Software Foundation в рамках программы по передаче технологий (NSA Technology Transfer Program).
NiFi — мощный инструмент, который умеет работать с большим количеством источников данных. Вы можете получать данные из Интернета по HTTP (есть даже отдельный модуль для работы с Твиттером) или FTP, можно читать данные из локальных и даже распределенных (HDFS) каталогов или баз данных. Полученные данные можно обрабатывать, модифицировать, есть даже свой встроенный язык (Expression Language). Затем данные можно сохранить либо в файл, либо распределенное хранилище, либо базу данных. Особенно радует поддержка большого числа различных технологий и протоколов передачи и хранения данных: HDFS, Hive, HBase, Solr, Cassandra, MongoDB, ElastcSearch, Kafka, RabbitMQ, HTTPS, SFTP и другие.
Так же важной особенностью NiFi является кросплатформенность, он одинаково удобно устанавливается и работает в Windows и Linux системах.
Установка и настройка Apache NiFi.
Установка NiFi предельно проста. Сначала качаем нужную версию с официального сайта, на данный момент это файл nifi-1.11.4-bin.tar.gz. У меня уже установлена версия 1.9.0, поэтому далее в статье я буду оперировать командами под эту версию. Архив большой (1.2 ГБ), поэтому придется подождать.
После успешной загрузки файла его необходимо распаковать в необходимую директорию, у меня это /usr/local. На этом установка завершена, следует отметить, что для Windows абсолютно такая же последовательность действий, только качать удобнее архив zip.
Для работы в NiFi применяется web-интерфейс, доступный по адресу: http://Адрес_сервера:8080/nifi
Адрес_сервера — это на локальном компьютере localhost, на удаленном — IP или DNS-адрес удаленной машины.
8080 — порт, настроен по умолчанию.
У меня уже этот порт занят, поэтому изменим его. Для этого нужно войти в каталог conf в установочной директории NiFi:
cd /usr/local/nifi-1.9.0/conf
И отредактировать файл nifi.properties
sudo gedit nifi.properties
Далее в редакторе найти строку nifi.web.http.port и присвоить необходимое значение, у меня 1111.
Теперь все готово к запуску. В Linux это делается командой:
sudo /usr/local/nifi-1.9.0/bin/nifi.sh start
Для Windows в каталоге bin запустить двойным щелчком run-nifi.bat/
Запускается NiFi долго, несколько минут. Для работы необходимо запустить браузер, и набрать в адресной строке строку, указанную выше. Для моего примера так: http://Адрес_сервера:1111/nifi
Если все успешно прошло, вы увидите рабочую область, все готово к работе, но об этом поговорим далее.
Стоит отметить, браузер должен поддерживать HTML5.
Начало работы с Apache NiFi (NiFi Flow, Process Group, Processors).
После запуска NiFi в браузере будет отображено рабочее поле и элементы управления, смотрим скриншот.
Не буду расписывать назначение модулей, сразу приступим к практике. Каждый проект объединяется с помощью модуля Process Group. Основные функциональные модули — Processors.
NiFi поддерживает Drug and Drop, поэтому возьмем модуль Process Group и перетащим его в рабочую область, смотрим скриншоты.
Введем имя для группы процессоров, у меня MyTest. Вот что имеем:

По правому клику мышью открывается окно управления и свойств. Двойной клик мыши позволяет войти в рабочую область низшего уровня, что отображается в Навигации по проектам, смотрим скриншот.
Уровней вложенности может быть достаточно много, но обычно хватает одного или двух.
Теперь давайте приступим к задаче копирования фалов из каталога в каталог, задача простая, но позволит понять основные принципы NiFi.
Сначала создадим на машине, где установлен NiFi (пример для ОС Linux), два каталога /usr/local/temp и /usr/local/temp1.
Теперь в модулях NiFi выберем Processor и перетащим его в рабочую область.
В результате появится окно выбора процессора, найдем нужный (GetFile), двойным кликом или кнопкой Add добавим его:
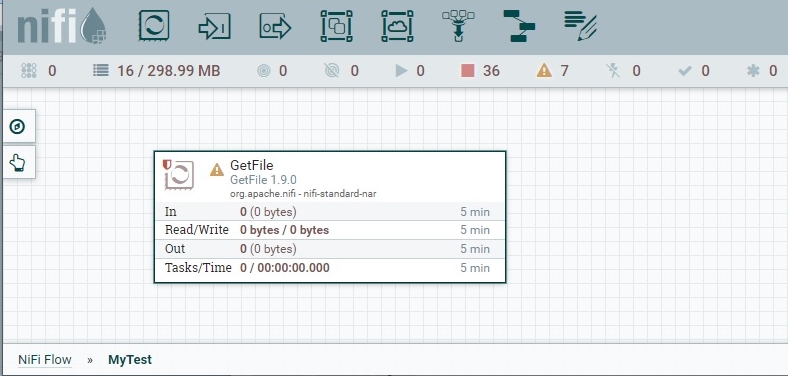
Процессор GetFile выполняет простую задачу: читает файл из указанной директории, преобразует его в формат FlowFile и отправляет следующему процессору.
Для настройки процессора необходимо открыть окно конфигурации (двойной клик по процессору, или клик правой кнопкой и выбрать Configure, см скриншот.).
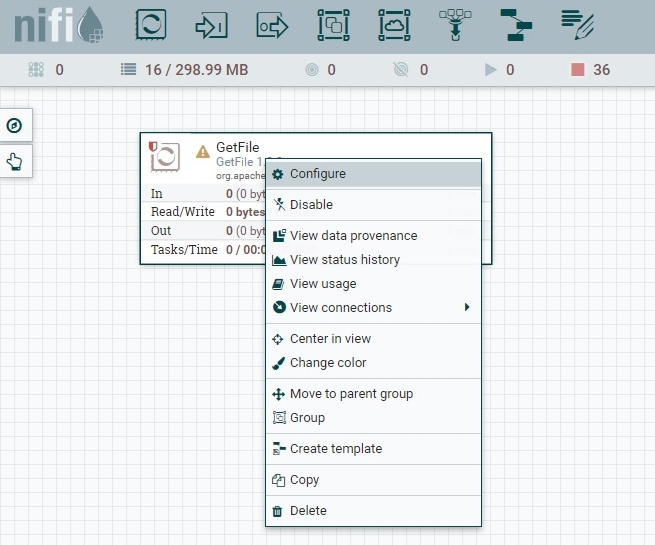
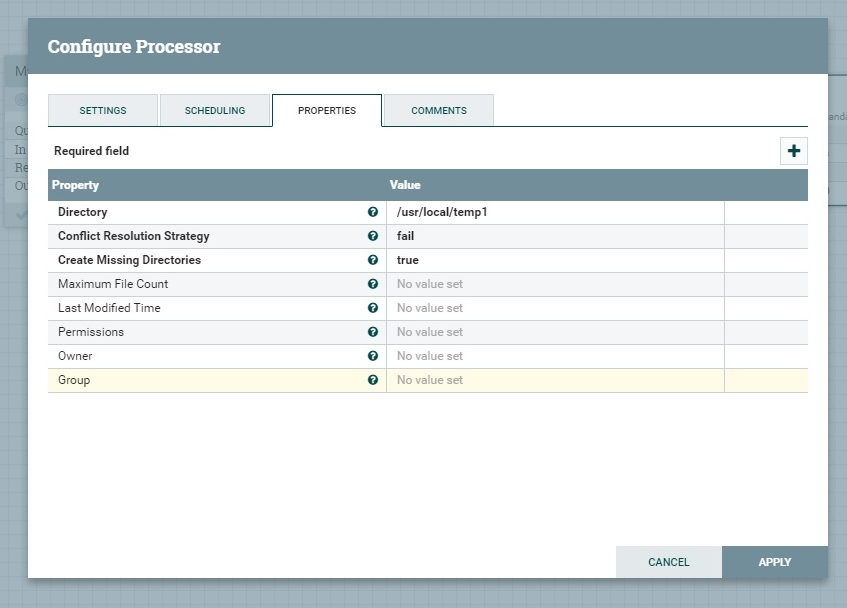
В открывшемся окне выбрать вкладку PROPERTIES и указать (двойной клик по значению свойства) нужное нам свойство — входной каталог (Input Directory, у нас /usr/local/temp), как на скриншоте.
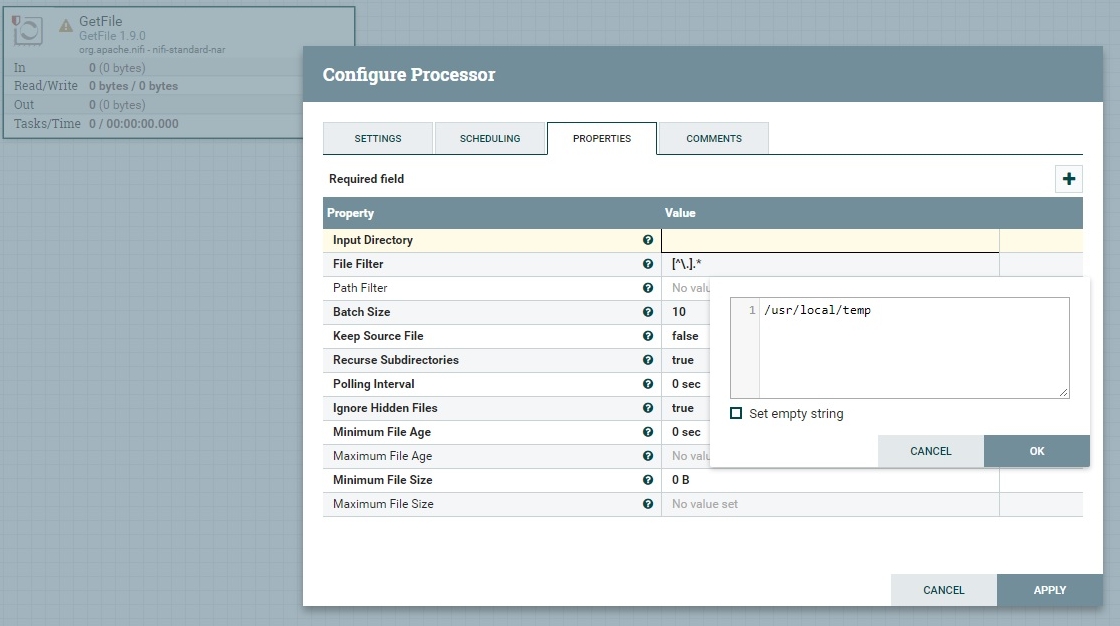
Настроенный процессор будет читать все файлы (свойство FileFilter) из указанного каталога, удалять их (свойство Keep Source File) и в формате FlowFile (если файл успешно считался) отправлять на выход процессора Succes (вкладка настроек SETTINGS).
Для примера возьмем модуль Output Port и направим на него поток Succes от процессора GetFile. Смотрим серию скриншотов ниже:
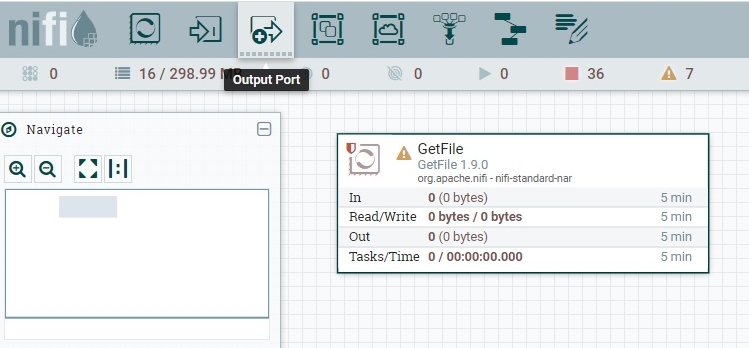
Для соединения выхода процессора с портом или с другим процессором необходимо навести указатель мыши на центр процессора, появится стрелка, которую нужно перетащить к модулю назначения. Имя порта в примере OUT.
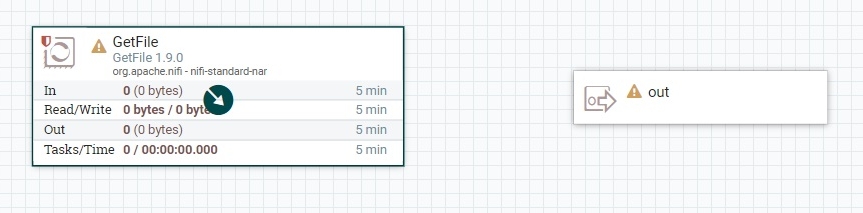

После соединения модулей появится окно настроек потока.

Таким образом мы создали выходной поток для группу процессоров MyTest. Через навигацию по проектам поднимемся выше, где находится модуль MyTest и разместим там процессор PutFile.
Процессор PutFile производит запись файла из потока в директорию, указанную в настройках процессора (директория должна существовать в системе).
Осталось соединить выходной порт процессора MyTest (OUT) с процессором PutFile.
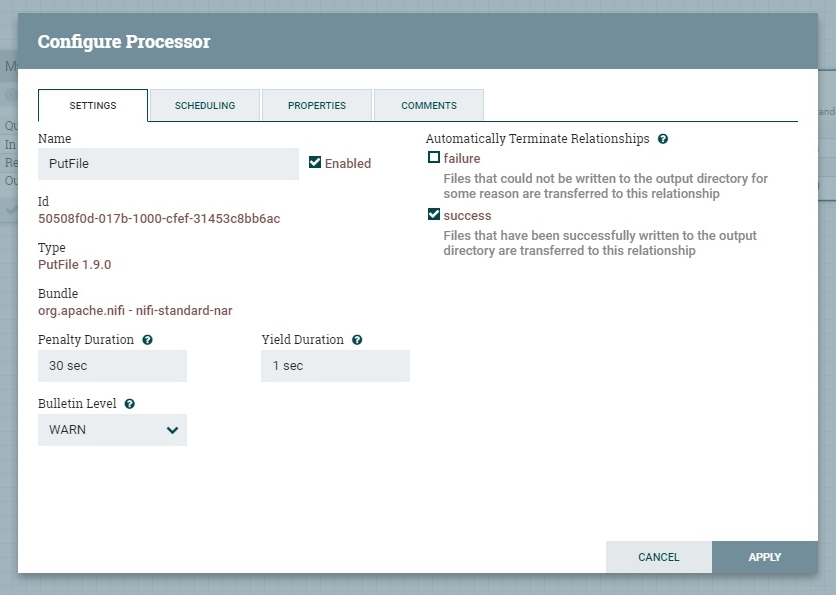
Вроде все готово, но в процессоре PutFile мы видим предупреждение, при наведении указателя мыши на него, открывается описание, которое гласит, что делать с потоком в случае успешной и неуспешной операции записи файла.

Откроем конфигурацию процессора, вкладка Settings и включим опцию уничтожать поток в случае успешной операции.
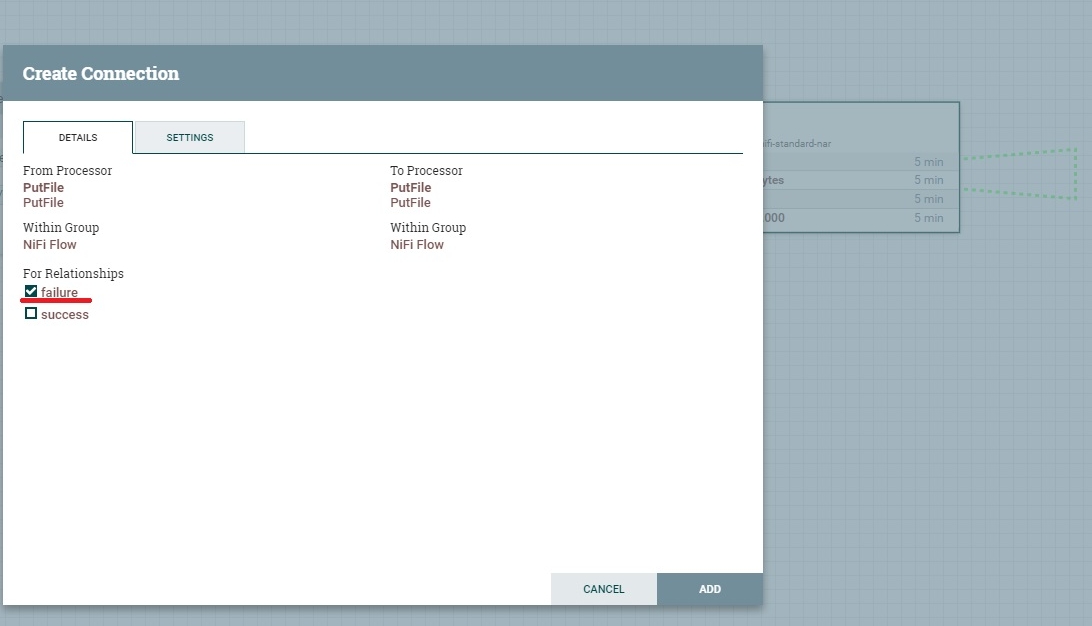
В случае ошибки обычно поток возвращают обратно в процессор.
Теперь нам можно приступать к запуску нашего проекта. Для запуска всех процессоров в группе процессоров необходимо кликнуть правой кнопкой мыши по группе и выбрать Start, либо выбрать нужный процессор левой кнопкой мыши и запустить его через панель управления проектами слева. Смотрим скриншот и разбираемся.
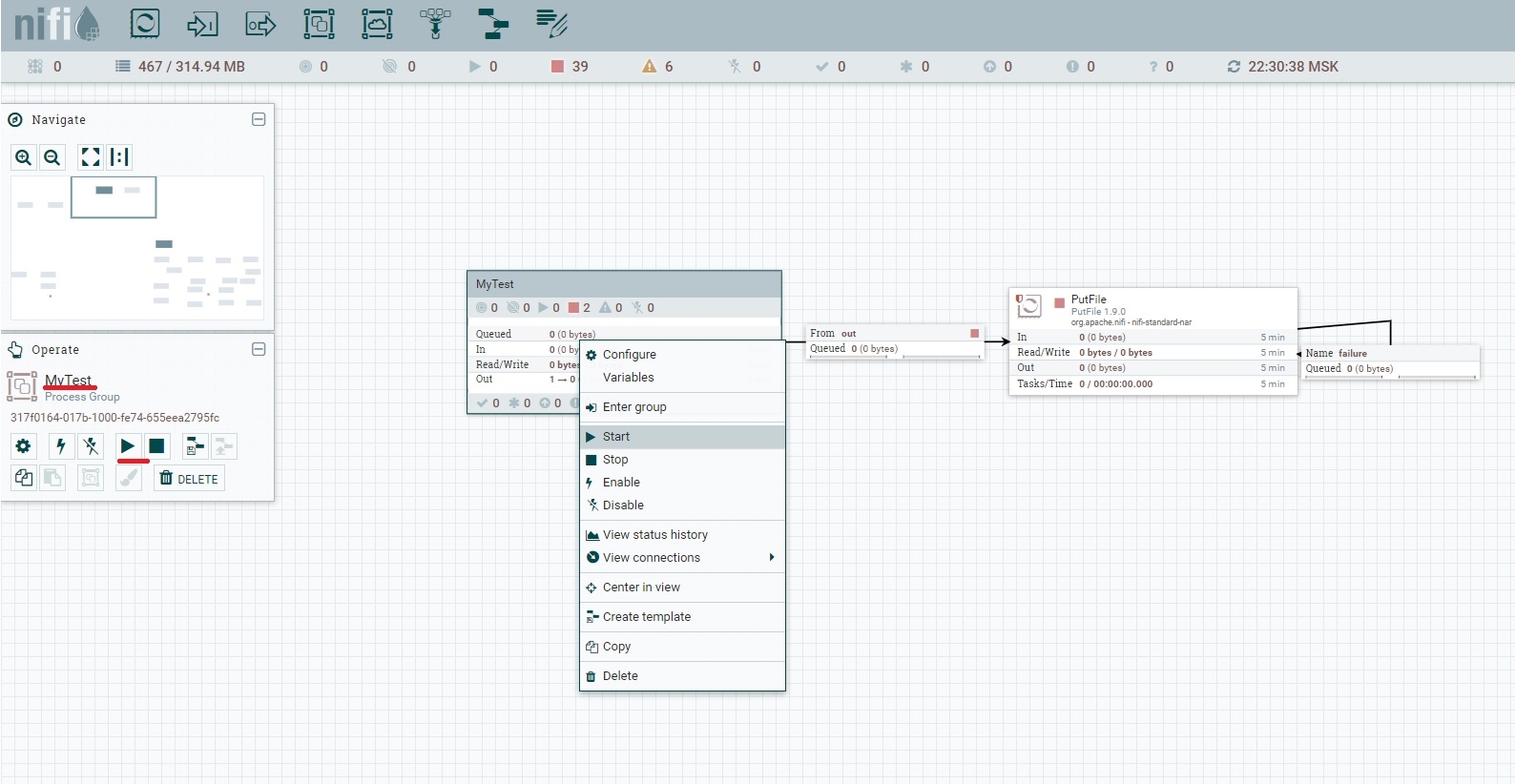
В результате все содержимое внутри группы процессоров будет запущено, в панели состояния процессоров появится зеленый треугольник. Отдельно запустите процессор PutFile.
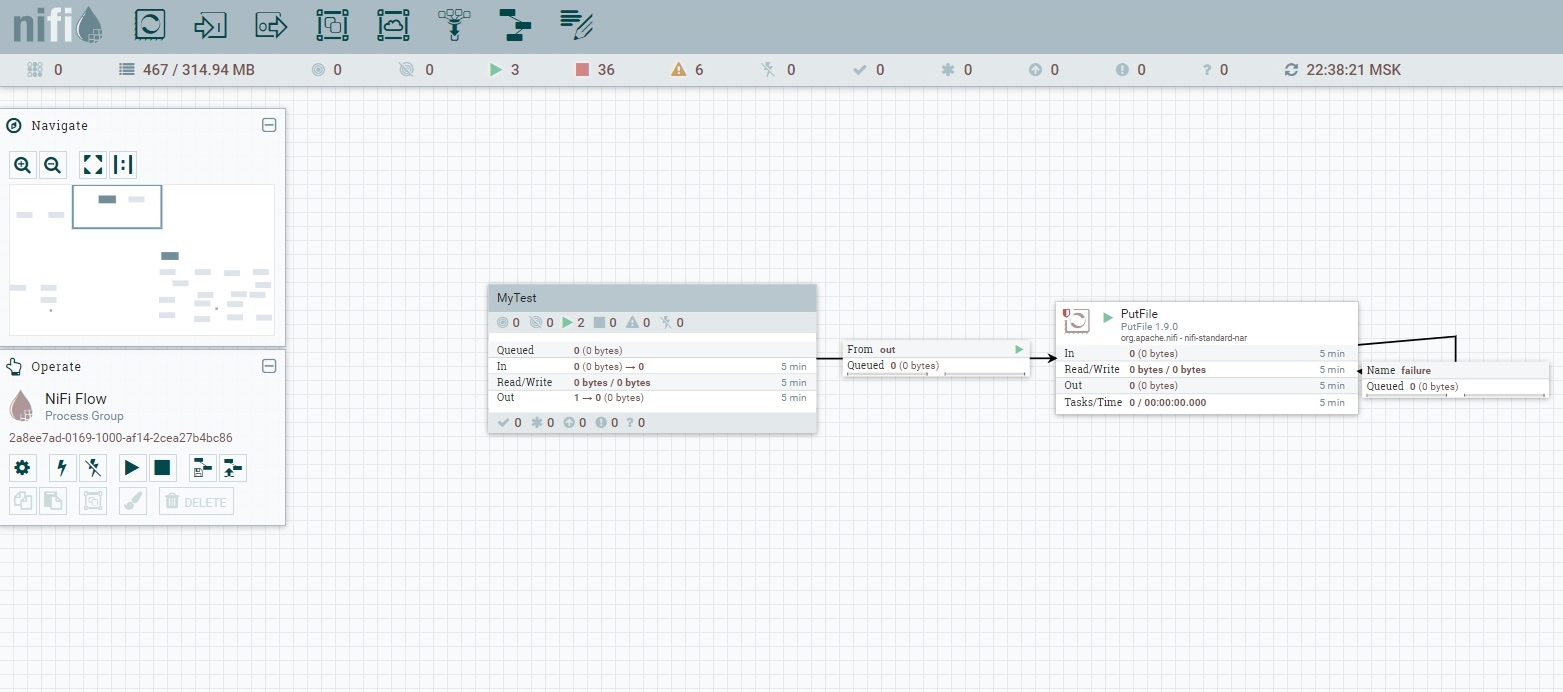
Проект запущен, теперь создайте или скопируйте файл в каталог /usr/local/temp. Данный файл будет автоматически скопирован в каталог /usr/local/temp1 и удален.
Вот мы и создали первый проект в NiFi, но возможности данного средства очень широки, и позволяют копировать файлы в HDFS, топики Kafka, удаленные серверы TCP, HTTP, FTP.
Для кого это руководство?
Это руководство подходит для пользователей, которые никогда не использовали его раньше, имеют ограниченный доступ к NiFi или выполняют только определенные задачи. Это руководство не является исчерпывающим руководством по эксплуатации или справочным руководством. «Гид пользователя»Предоставляет много информации, нацелено на предоставление более подробных ресурсов и очень полезно в качестве справочного руководства. Напротив, это руководство направлено на предоставление пользователям информации, необходимой им для понимания того, как использовать NiFi для быстрого и простого создания мощных и гибких потоков данных.
Некоторые из-за того, что часть информации в этом руководстве предназначена только для начинающих пользователей, в то время как другая информация может быть подходящей для тех, кто использовал NiFi, это руководство разделено на несколько разных разделов, некоторые из которых могут быть бесполезны для некоторых читателей. . Не стесняйтесь переходить к той части, которая вам больше всего подходит.
Это руководство действительно надеется, что пользователи имеют базовое представление о том, что такое NiFi, и не вникает в эти детали. допустимыйOverviewНайдите этот уровень информации в документе.
Термины, используемые в этом руководстве
Чтобы говорить о NiFi, читатели должны знать некоторые ключевые термины. Мы подробно объясним эти термины, относящиеся к NiFi, здесь.
FlowFile: Каждая часть «пользовательских данных» (то есть данных, которые пользователь передает в NiFi для обработки и распространения) называется FlowFile. FlowFile состоит из двух частей: атрибутов и содержимого. Контент — это сами данные пользователя. Атрибуты связаны с пользовательскими даннымиkey-value Верный. Чтобы
Processor: Процессор — это компонент NiFi, отвечающий за создание, отправку, получение, преобразование, маршрутизацию, разделение, объединение и обработку FlowFiles. Это самый важный компонент, который пользователи NiFi могут использовать для построения своего потока данных.
Скачайте и установите NiFi
NiFi можно скачать сСтраница загрузки NiFi скачать. Доступны два варианта упаковки: «tarball», настроенный для Linux, и zip-файл, более подходящий для пользователей Windows. Пользователи Mac OS X также могут использовать tarball или устанавливать через Homebrew.
Для установки через Homebrew достаточно выполнить командуbrew install nifi。
Для пользователей, которые не используют OS X или не установили Homebrew, после загрузки версии NiFi, которую вы хотите использовать, просто распакуйте архив в то место, где вы хотите запустить приложение.
Для получения информации о том, как настроить экземпляр NiFi (например, настроить безопасность, конфигурацию хранилища данных или порт, на котором работает NiFi), см. «Руководство администратора «。
Запустить NiFi
После загрузки и установки NiFi, как описано выше, вы можете запустить его, используя механизм, соответствующий вашей операционной системе.
Для пользователей Windows
Для пользователей Windows перейдите в папку, в которой установлен NiFi. В этой папке есть файл с именемbinПодпапки. Перейдите в эту подпапку и дважды щелкните значокrun-nifi.batфайл.
Это запустит NiFi и позволит ему работать на переднем плане. Чтобы закрыть NiFi, выберите открывшееся окно и, удерживая клавишу Ctrl, нажмите C.
Для пользователей Linux / Mac OS X
Для пользователей Linux и OS X используйте окно терминала, чтобы перейти в каталог, в котором установлен NiFi. Чтобы запустить NiFi на переднем плане, запуститеbin/nifi.sh run. Это будет поддерживать работу приложения до тех пор, пока пользователь не нажмет Ctrl-C. В это время он инициирует завершение работы приложения.
Чтобы запустить NiFi в фоновом режиме, запуститеbin/nifi.sh start. Это запустит приложение для запуска. Чтобы проверить статус и увидеть, работает ли NiFi в настоящее время, выполните эту командуbin/nifi.sh status. Вы можете закрыть NiFi, выполнив командуbin/nifi.sh stop。
Установить как услугу
В настоящее время только пользователи Linux и Mac OS X могут устанавливать NiFi как услугу. Чтобы установить приложение как службу, перейдите в каталог установки в окне Терминала и выполните командуbin/nifi.sh installУстановите службу с именем по умолчаниюnifi. Чтобы указать настраиваемое имя для службы, выполните команду с необязательным вторым параметром (именем службы). Например, чтобы установить NiFi как сервис с именемdataflow, Пожалуйста, используйте эту командуbin/nifi.sh install dataflow。
После установки вы можете запускать и останавливать службу с помощью соответствующих команд, напримерsudo service nifi start сsudo service nifi stop. Кроме того, вы можете проверить текущий статусsudo service nifi status。
Я начал использовать NiFi. Как сделать?
Теперь, когда NiFi запущен, мы можем вызвать пользовательский интерфейс (UI) для создания и отслеживания нашего потока данных. Для начала откройте веб-браузер и перейдите кhttp://localhost:8080/nifi. Может редактироватьсяnifi.propertiesNiFi confФайл в каталоге для изменения порта, но порт по умолчанию — 8080.
Это откроет пользовательский интерфейс, который теперь представляет собой пустой холст для оркестровки потока данных:
В пользовательском интерфейсе есть несколько инструментов для создания и управления первым потоком данных:
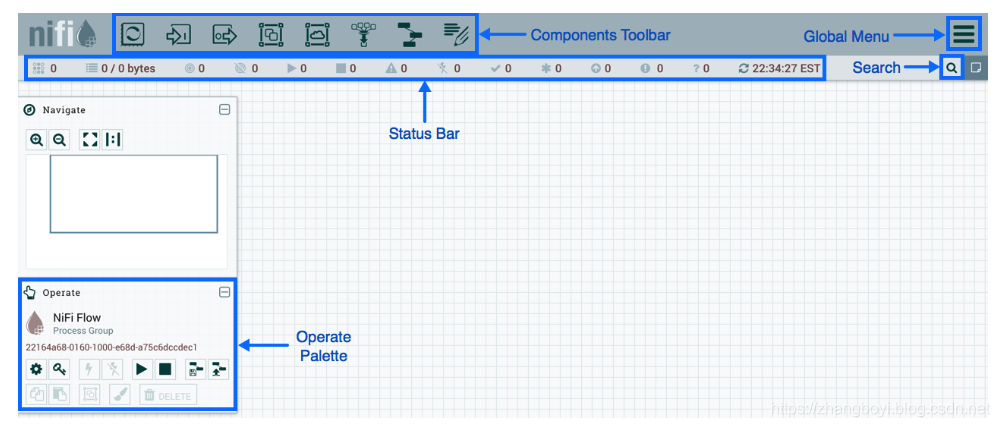
Глобальное меню содержит следующие параметры:

Добавить процессор
Теперь мы можем начать создавать поток данных, добавив процессор на холст. Для этого измените значок процессора ( ) Перетащите от верхнего левого угла экрана к середине холста (фон рисунка) и поместите его туда. Это предоставит нам диалог, который позволяет нам выбрать процессор для добавления:
) Перетащите от верхнего левого угла экрана к середине холста (фон рисунка) и поместите его туда. Это предоставит нам диалог, который позволяет нам выбрать процессор для добавления:
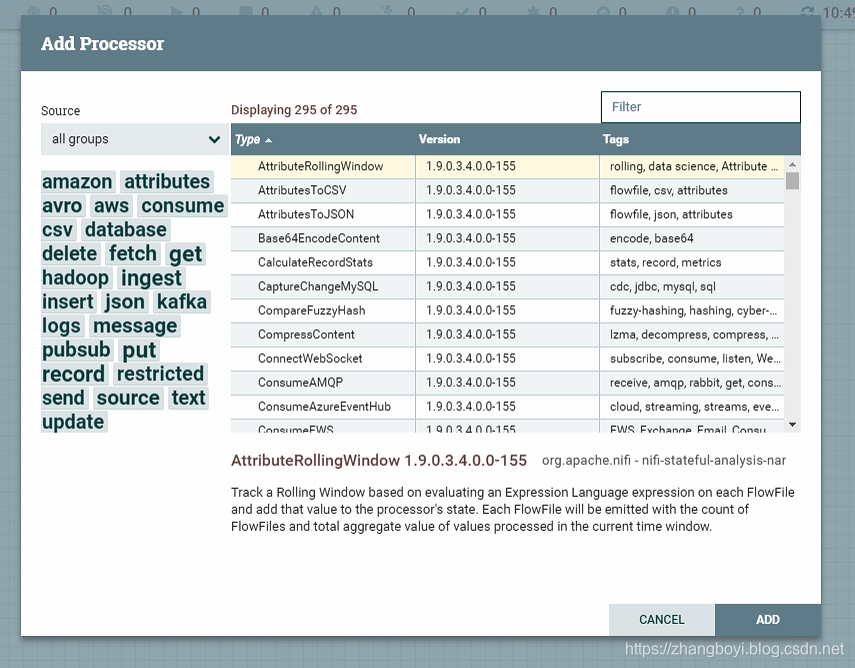
У нас есть много вариантов на выбор. Предположим, что мы хотим импортировать файлы только с локального диска в NiFi, чтобы руководить системой. Когда разработчик создает процессор, он может присвоить процессору «метку». Их можно считать ключевыми словами. Мы можем фильтровать по этим тегам или именам процессоров, набрав в поле «Фильтр» в верхнем правом углу диалогового окна. Если вы хотите извлечь файлы с локального диска, введите ключевые слова, которые вам придутся по душе. Например, ввод ключевого слова «файл» предоставит нам несколько разных процессоров для обработки файлов. Фильтрация по слову «локальный» также быстро сузит список. Если мы выберем процессор из списка, мы увидим краткое описание процессора в нижней части диалогового окна. Это должно сказать нам точную функцию процессора.GetFile Описание процессора говорит нам, что он извлекает данные с нашего локального диска в NiFi, а затем удаляет локальные файлы. Затем мы можем дважды щелкнуть тип процессора или выбрать его и выбратьAddКнопка. Процессор будет добавлен на холст, где он будет удален.
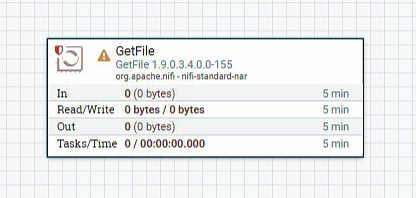
Настроить процессор
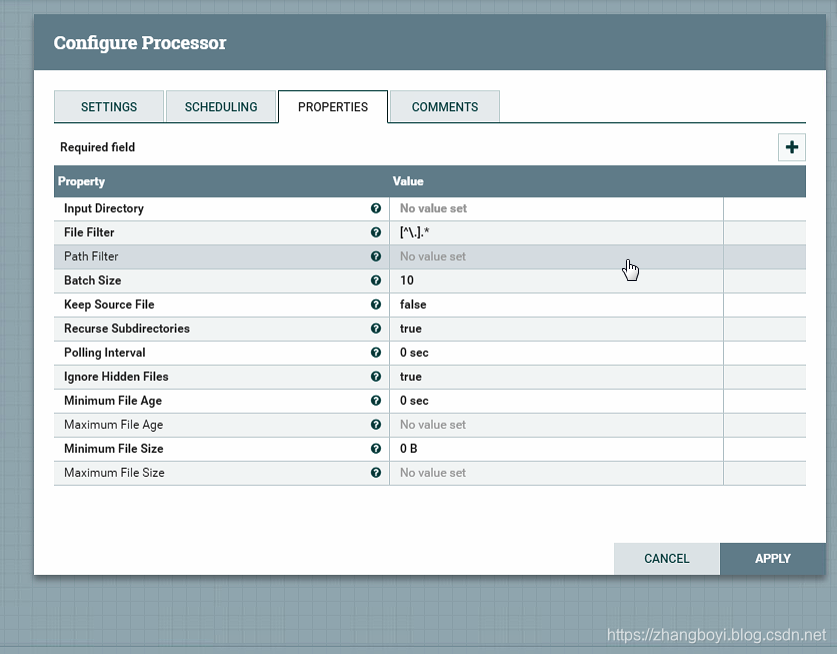
Теперь, когда мы добавили процессор GetFile, мы можем щелкнуть правой кнопкой мыши процессор и выбратьConfigureПункт меню для его настройки. Предоставленный диалог позволяет нам настроить многиеРуководство пользователяВозможны разные варианты чтения, но в этом руководстве мы остановимся на вкладке «Свойства». После выбора вкладки «Свойства» мы получим список из нескольких различных свойств, которые можно настроить для процессора. Доступные атрибуты зависят от типа процессора, и каждый тип обычно отличается. Полужирный шрифт — обязательные атрибуты. Процессор нельзя запустить, пока не будут настроены все необходимые атрибуты. Наиболее важным свойством, настраиваемым для GetFile, является каталог, из которого получен файл. Если мы установим имя каталога на./data-in, Что приведет к тому, что процессор начнет собирать любые данныеdata-in Подкаталог основного каталога NiFi. Мы можем настроить несколько различных атрибутов для этого процессора. Если вы не знаете, что делает конкретный атрибут, мы можем навести указатель мыши на На значке справки () рядом с именем атрибута можно прочитать описание атрибута. Кроме того, всплывающая подсказка, отображаемая при наведении курсора мыши на значок «Справка», предоставит значение атрибута по умолчанию (если он существует) и информацию о том, поддерживает ли атрибут язык выражения (см. «Значение атрибута «»Язык выражения / атрибуты использования «)) и значение, ранее настроенное для этого атрибута.
На значке справки () рядом с именем атрибута можно прочитать описание атрибута. Кроме того, всплывающая подсказка, отображаемая при наведении курсора мыши на значок «Справка», предоставит значение атрибута по умолчанию (если он существует) и информацию о том, поддерживает ли атрибут язык выражения (см. «Значение атрибута «»Язык выражения / атрибуты использования «)) и значение, ранее настроенное для этого атрибута.
data-inЧтобы сделать это свойство эффективным, создайте каталог с именем в домашнем каталоге NiFi и нажмитеOkКнопка закрытия диалога.
Подключите процессор
Каждый процессор имеет набор определенных «Relationships«, он может отправлять данные. После того, как процессор завершит обработку FlowFile, он передаст их одной из взаимосвязей. Это позволяет пользователю настроить, как обрабатывать FlowFile на основе результатов Processing. Например, многие процессоры определяют две взаимосвязи:successсfailure. Затем, если процессор может успешно обработать данные и если процессор не может обработать данные по какой-либо причине и маршрутизирует данные через поток совершенно другим способом, пользователь может настроить данные для однонаправленной маршрутизации через поток. Или, в зависимости от варианта использования, он может просто направить две связи по одному и тому же маршруту в потоке.
Теперь, когда мы добавили и настроили наш процессор GetFile и применили конфигурацию, мы можем увидеть значок предупреждения в верхнем левом углу процессора ( ), указывая на то, что процессор не находится в допустимом состоянии. Наведя курсор на этот значок, мы можем увидеть
), указывая на то, что процессор не находится в допустимом состоянии. Наведя курсор на этот значок, мы можем увидетьsuccessОтношения еще не определены. Это просто означает, что мы не сказали NiFi, как обрабатывать передачу процессора наsuccessДанные о родстве.
Чтобы решить эту проблему, давайте добавим еще один процессор, который может подключаться к процессору GetFile, выполнив те же действия, что и выше. Однако на этот раз нам нужно только записать существующие атрибуты FlowFile. Для этого мы добавим процессор LogAttributes.
Теперь мы можем отправить результат процессора GetFile в процессор LogAttribute. Наведите указатель мыши на процессор GetFile и подключите значок ( ) Появится в середине процессора. Мы можем перетащить этот значок из процессора GetFile в процессор LogAttribute. Это предоставляет нам диалоговое окно для выбора, какие отношения мы хотим включить в это соединение. Поскольку GetFile имеет только одно отношение
) Появится в середине процессора. Мы можем перетащить этот значок из процессора GetFile в процессор LogAttribute. Это предоставляет нам диалоговое окно для выбора, какие отношения мы хотим включить в это соединение. Поскольку GetFile имеет только одно отношениеsuccess, Так что он будет выбран для нас автоматически.
Щелкнув вкладку «Настройки», вы получите несколько параметров для настройки поведения этого подключения:
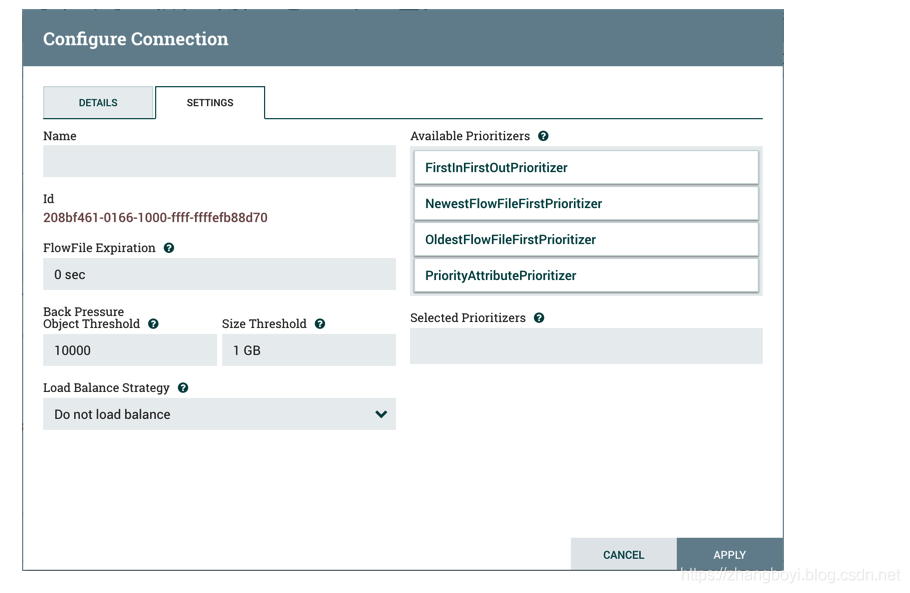
Если мы хотим, мы можем дать Connection имя. В противном случае имя соединения будет основано на выбранной связи. Мы также можем установить срок действия данных. По умолчанию установлено значение «0 секунд», что указывает на то, что срок хранения данных не истекает. Однако мы можем изменить значение так, чтобы, когда данные в этом соединении достигли определенного возраста, они будут автоматически удалены (и будет создано соответствующее событие EXPIRE Provenance).
Порог противодавления позволяет нам указать, насколько полная очередь разрешена до того, как исходный процессор больше не будет запланирован для запуска. Это позволяет нам справляться с ситуациями, когда один процессор может генерировать данные быстрее, чем следующий процессор может их потреблять. Если противодавление настроено для каждого соединения на протяжении всего процесса, процессор, который вводит данные в систему, в конечном итоге столкнется с противодавлением и перестанет вводить новые данные, чтобы наша система могла восстановиться.
Наконец, у нас есть порядок приоритета справа. Это позволяет нам контролировать сортировку данных в этой очереди. Мы можем перетащить приоритет из списка «Доступный сортировщик приоритетов» в список «Выбранный сортировщик приоритетов», чтобы активировать сортировщик приоритетов. Если активировано несколько сортировщиков по приоритету, они будут оцениваться так, чтобы сортировщик приоритета, указанный первым, оценивался первым, а если два FlowFile определены как равные в соответствии с сортировщиком приоритета, будет использоваться второй приоритет Секвенсор.
Чтобы облегчить обсуждение, мы просто нажимаемAddВы можете добавить подключение к диаграмме. Теперь мы должны увидеть, что значок предупреждения был изменен на значок остановки ( ). Однако обработчик LogAttribute теперь недействителен, поскольку его
). Однако обработчик LogAttribute теперь недействителен, поскольку егоsuccessОтношения пока ни с чем не связаны. Подать сигналsuccessДанные, маршрутизируемые LogAttribute, должны «автоматически завершаться» для решения этой проблемы, а это означает, что NiFi должен рассмотреть завершение обработки FlowFile и «отбросить» данные. Для этого мы настраиваем процессор LogAttribute. В правой части вкладки «Настройки» мы можем выбрать «successПоле рядом с «Автоматически прекращать данные о взаимоотношениях». ЩелкнитеOKДиалоговое окно закроется и покажет, что оба процессора остановлены.
Запускать и останавливать процессор
На данный момент на нашей диаграмме два процессора, но ничего не происходит. Чтобы запустить процессоры, мы можем щелкнуть каждый процессор по отдельности, затем щелкнуть правой кнопкой мыши и выбратьStartПункт меню. В качестве альтернативы мы можем выбрать первый процессор, а затем, удерживая клавишу Shift, выбрать другие процессоры, чтобы выбрать оба. Затем мы можем щелкнуть правой кнопкой мыши и выбратьStartПункт меню. В качестве альтернативы использованию контекстного меню мы можем выбрать процессор и щелкнуть значок «Пуск» в палитре «Действия».
После запуска значок в верхнем левом углу процессора изменится с остановленного на значок работающего. Затем мы можем использовать палитру «действие» илиStopЗначок «Стоп» в пункте меню останавливает процессор.
После запуска процессора мы больше не можем его настраивать. И наоборот, когда мы щелкаем правой кнопкой мыши по процессору, мы можем просмотреть его текущую конфигурацию. Чтобы настроить процессор, мы должны сначала остановить процессор и дождаться завершения любых задач, которые могут выполняться. Количество задач, которые в настоящее время выполняются, отображается в правом верхнем углу процессора, но если в настоящее время задач нет, ничего не отображается.
Получите дополнительную информацию о процессоре
Поскольку каждый процессор может предоставлять множество различных атрибутов и взаимосвязей, может быть трудно вспомнить, как работают все различные части каждого процессора. Чтобы решить эту проблему, вы можете щелкнуть правой кнопкой мыши процессор и выбратьUsageПункт меню. Это предоставит вам информацию об использовании процессора, такую как описание процессора, различные доступные отношения, когда использовать различные отношения, атрибуты, раскрываемые процессором и его документами, и какие атрибуты FlowFile (есть во входящих FlowFiles Что ожидается, и какие атрибуты (если есть) добавляются к исходящим FlowFiles.
Прочие компоненты
Панель инструментов, на которой пользователь может перетащить процессор на диаграмму, включает несколько других компонентов, которые можно использовать для построения потока данных. Эти компоненты включают порты ввода и вывода, воронки, группы процессов и группы удаленных процессов. Из-за ожидаемого объема этого документа мы не будем здесь обсуждать эти элементы, но вы можете»Гид пользователя»Создание потока данных »разделНайдите соответствующую информацию в.
Какой процессор есть в наличии
Чтобы создать эффективный поток данных, пользователи должны понимать типы доступных процессоров. NiFi содержит много разных процессоров. Эти процессоры предоставляют функции для извлечения данных из множества различных систем, маршрутизации, преобразования, обработки, разделения и агрегирования данных, а также распределения данных по множеству систем.
Количество процессоров, доступных почти в каждой версии NiFi, увеличивается. Поэтому мы не будем пытаться назвать все доступные процессоры, а сосредоточимся на некоторых из наиболее часто используемых процессоров, классифицируя их по функциям.
Конверсия данных
-
CompressContent: Сжатие или распаковка содержимого
-
ConvertCharacterSet: Преобразование набора символов, используемого для кодирования содержимого, из одного набора символов в другой.
-
EncryptContent: Зашифровать или расшифровать контент
-
ReplaceText: Используйте регулярные выражения для изменения текстового содержимого.
-
TransformXml: Применить преобразование XSLT к содержимому XML
-
JoltTransformJSON: Применить спецификацию JOLT для преобразования содержимого JSON
Маршрутизация и посредничество
-
ControlRate: Ограничить скорость, с которой данные проходят через часть трафика.
-
DetectDuplicate: Отслеживайте повторяющиеся FlowFiles в соответствии с определенными пользователем критериями. Обычно используется с HashContent
-
DistributeLoad: Балансировка нагрузки или выборка данных путем распределения только части данных по каждой определяемой пользователем взаимосвязи.
-
MonitorActivity: Отправить уведомление, когда определенный пользователем период времени прошел без прохождения каких-либо данных через определенную точку в потоке. (Необязательно) Отправьте уведомление, когда поток данных возобновится.
-
RouteOnAttribute: Маршрутизация FlowFile в соответствии с атрибутами, содержащимися в FlowFile.
-
ScanAttribute: сканированиеFlowFileВ наборе определяемых пользователем атрибутов проверьте, соответствуют ли какие-либо атрибуты терминам, найденным в пользовательском словаре.
-
RouteOnContent:искатьFlowFileКонтент, чтобы проверить, соответствует ли он каким-либо пользовательским регулярным выражениям. Если это так, FlowFile направит на настроенную связь.
-
ScanContent:искатьFlowFileКонтент для поиска терминов, которые существуют в пользовательских словарях, и маршрутизации в зависимости от наличия или отсутствия этих терминов. Словарь может содержать текстовые или двоичные записи.
-
ValidateXml: Проверка содержимого XML на соответствие схеме XML; в соответствии с определяемой пользователем схемой XML, является ли содержимое FlowFile допустимым, маршрутизируйте FlowFile.
Доступ к базе данных
-
ConvertJSONToSQL: Преобразование документов JSON в команды SQL INSERT или UPDATE, которые затем могут быть переданы процессору PutSQL.
-
ExecuteSQL: Выполнить пользовательскую команду SQL SELECT и записать результат в FlowFile в формате Avro.
-
PutSQL: Обновить базу данных, выполнив SQL-оператор DDM, определенный содержимым FlowFile.
-
SelectHiveQL: Выполнение пользовательской команды HiveQL SELECT в базе данных Apache Hive и запись результата в FlowFile в формате Avro или CSV.
-
PutHiveQL: Обновить базу данных Hive, выполнив оператор HiveQL DDM, определенный содержимым FlowFile.
Извлечение атрибутов
-
EvaluateJsonPath: Пользователь предоставляет выражения JSONPath (аналогичные XPath, используемые для синтаксического анализа / извлечения XML), а затем оценивает эти выражения на основе содержимого JSON для замены содержимого FlowFile или извлечения значения в указанный пользователем атрибут.
-
EvaluateXPath: Пользователь предоставляет выражения XPath, а затем оценивает эти выражения на основе содержимого XML для замены содержимого FlowFile или извлечения значения в атрибут, названный пользователем.
-
EvaluateXQuery: Пользователь предоставляет запрос XQuery, а затем оценивает запрос на основе содержимого XML для замены содержимого FlowFile или извлечения значения в атрибут, названный пользователем.
-
ExtractText: Пользователь предоставляет одно или несколько регулярных выражений, затем оценивает их на основе текстового содержимого FlowFile, а затем добавляет извлеченные значения как атрибуты, названные пользователем.
-
HashAttribute: Выполнить хэш-функцию для объединения существующих пользовательских списков атрибутов.
-
HashContent: Выполнить хэш-функцию для содержимого FlowFile и добавить хеш-значение в качестве атрибута.
-
IdentifyMimeType: Оценить содержимое FlowFile, чтобы определить тип файла, инкапсулированного FlowFile. Этот процессор может обнаруживать множество различных типов MIME, таких как изображения, документы текстового процессора, текст и сжатые форматы, и многие другие.
-
UpdateAttribute: кFlowFileДобавить или обновить любое количество определенных пользователем атрибутов. Это полезно для добавления статически настроенных значений и динамического получения значений атрибутов с использованием языка выражений. Процессор также предоставляет «расширенный пользовательский интерфейс», который позволяет пользователям условно обновлять атрибуты на основе правил, предоставленных пользователем.
Системное взаимодействие
-
ExecuteProcess: Запускать пользовательские команды операционной системы. StdOut процесса перенаправляется, так что содержимое, записанное в StdOut, становится содержимым исходящего FlowFile. Этот процессор является исходным процессором — ожидается, что на его выходе будет создан новый FlowFile, а системный вызов не получит никаких входных данных. Чтобы обеспечить ввод в процесс, используйте ExecuteStreamCommand Processor.
-
ExecuteStreamCommand: Запускать пользовательские команды операционной системы. Содержимое FlowFile необязательно передается в StdIn процесса. Контент, записанный в StdOut, станет контентом исходящего FlowFile hte. Этот процессор нельзя использовать в качестве исходного процессора — входящие FlowFiles должны быть введены для выполнения его работы. Чтобы использовать исходный процессор для выполнения того же типа функции, см. Процессор ExecuteProcess.
Получение данных
-
GetFile: Потоковая передача содержимого файла с локального диска (или диска, подключенного к сети) в NiFi, а затем удаление исходного файла. Этот процессор должен перемещать файлы из одного места в другое, а не для копирования данных.
-
GetFTP: Загрузите содержимое удаленного файла в NiFi через FTP, а затем удалите исходный файл. Ожидается, что этот процессор будет перемещать данные из одного места в другое, а не для копирования данных.
-
GetSFTP: Загрузите содержимое удаленного файла в NiFi через SFTP, а затем удалите исходный файл. Ожидается, что этот процессор будет перемещать данные из одного места в другое, а не для копирования данных.
-
GetJMSQueue: Загрузите сообщение из очереди JMS и создайте FlowFile на основе содержимого сообщения JMS. При желании атрибуты JMS также могут быть скопированы как атрибуты.
-
GetJMSTopic: Загрузите сообщение из раздела JMS и создайте FlowFile на основе содержимого сообщения JMS. При желании атрибуты JMS также могут быть скопированы как атрибуты. Этот процессор поддерживает постоянные и краткосрочные подписки.
-
GetHTTP: Загрузить содержимое удаленного URL-адреса на основе HTTP или HTTPS в NiFi. Процессор запомнит ETag и дату последнего изменения, чтобы гарантировать, что данные не будут загружаться постоянно.
-
ListenHTTP: Запустите сервер HTTP (или HTTPS) и прослушивайте входящие соединения. Для любого входящего запроса POST запрошенный контент будет записан как FlowFile, и будет возвращен ответ 200.
-
ListenUDP: Слушайте входящие пакеты UDP и создайте FlowFile для каждого пакета или каждого пакета (в зависимости от конфигурации) и отправьте FlowFile для отношения «успех».
-
GetHDFS: Отслеживать указанные пользователем каталоги в HDFS. Каждый раз, когда новый файл попадает в HDFS, он копируется в NiFi и удаляется из HDFS. Этот процессор должен перемещать файлы из одного места в другое, а не для копирования данных. При работе в кластере ожидается, что этот процессор также будет работать только на основном узле. Чтобы скопировать данные из HDFS и сохранить их как есть, или для потоковой передачи данных с нескольких узлов в кластере, см. Процессор ListHDFS.
-
ListHDFS / FetchHDFS: ListHDFS отслеживает указанный пользователем каталог в HDFS и отправляет FlowFile, содержащий имя файла, с которым он сталкивается. Затем он поддерживает это состояние во всем кластере NiFi через распределенный кеш. Затем эти FlowFiles могут быть распределены в кластере и отправлены процессору FetchHDFS, который отвечает за получение фактического содержимого этих файлов и выдачу FlowFiles, содержащих контент, полученный из HDFS.
-
FetchS3Object: Получить содержимое объекта из Amazon Web Services (AWS) Simple Storage Service (S3). Исходящий FlowFile содержит контент, полученный от S3.
-
GetKafka: Получайте новости от Apache Kafka, особенно версии 0.8.x. Сообщения могут быть отправлены как FlowFile каждого сообщения, или они могут обрабатываться вместе с использованием разделителя, указанного пользователем.
-
GetMongo: Выполнить указанный пользователем запрос в MongoDB и записать содержимое в новый FlowFile.
-
GetTwitter: Разрешить пользователям регистрировать фильтры для прослушивания «садового шланга» Twitter или корпоративной конечной точки, создавая FlowFile для каждого полученного твита.
Экспорт / отправка данных
-
PutEmail: Отправить электронное письмо настроенному получателю. Содержимое FlowFile можно отправить как вложение.
-
PutFile:будемFlowFileКонтент записывается в каталог в локальной (или подключенной к сети) файловой системе.
-
PutFTP:будемFlowFileСкопируйте содержимое на удаленный FTP-сервер.
-
PutSFTP:будемFlowFileСкопируйте содержимое на удаленный SFTP-сервер.
-
PutJMS:будемFlowFileКонтент отправляется агенту JMS в виде сообщения JMS, и вы можете добавить атрибуты JMS на основе атрибутов.
-
PutSQL:будемFlowFileСодержимое выполняется как операторы SQL DDL (INSERT, UPDATE или DELETE). Содержимое FlowFile должно быть допустимым оператором SQL. Атрибуты могут использоваться в качестве параметров, чтобы содержимое FlowFile можно было параметризовать операторами SQL, чтобы избежать атак с использованием SQL-инъекций.
-
PutKafka:будемFlowFileСодержимое отправляется в Apache Kafka в виде сообщения, особенно версии 0.8.x. FlowFile можно отправлять как одно сообщение или как разделитель, например, можно указать символ новой строки для отправки множества сообщений для одного FlowFile.
-
PutMongo:будемFlowFileКонтент отправляется в Mongo как INSERT или UPDATE.
Разделить и объединить
-
SplitText: SplitText получает один FlowFile, содержимое которого является текстом, и разбивает его на 1 или несколько FlowFile в соответствии с настроенным количеством строк. Например, процессор можно настроить для разделения FlowFile на несколько FlowFile, каждый из которых имеет только одну строку.
-
SplitJson: Разрешить пользователям разбивать объект JSON, содержащий массив или несколько подобъектов, в FlowFile для каждого элемента JSON.
-
SplitXml: Разрешить пользователям разбивать XML-сообщение на несколько FlowFiles, каждый FlowFiles содержит исходный сегмент. Обычно это используется, когда несколько элементов XML связаны с элементом «оболочка». Затем этот процессор позволяет разделить эти элементы на отдельные элементы XML.
-
UnpackContent: Распакуйте архивы различных типов, такие как ZIP и TAR. Затем каждый файл в архиве передается как один FlowFile.
-
MergeContent: Этот процессор отвечает за объединение многих FlowFiles в один FlowFile. Вы можете объединить FlowFiles, объединив их содержимое с дополнительными заголовками, нижними колонтитулами и разделителями или указав формат архива (например, ZIP или TAR). FlowFiles могут быть объединены на основе общих атрибутов, или, если они разделены другими процессами разделения, они могут быть «дефрагментированы». В зависимости от количества элементов или общего размера содержимого FlowFiles, минимальный и максимальный размер каждой корзины указывается пользователем, а также может быть назначен дополнительный тайм-аут, чтобы FlowFiles ждал только того, как долго его корзина станет полной.
-
SegmentContent: Разделите FlowFile на множество возможных меньших FlowFile в соответствии с некоторым сконфигурированным размером данных. Разделение не выполняется ни по одному типу разделителя, а только по смещению байта. Это используется перед передачей FlowFiles, чтобы уменьшить задержку за счет параллельной отправки множества различных частей. С другой стороны, процессор MergeContent может повторно собрать эти FlowFiles, используя режим дефрагментации.
-
SplitContent: Разделить один FlowFile на множество возможных FlowFile, аналогично SegmentContent. Однако для SplitContent разделение не выполняется на произвольных границах байтов, а указывается последовательность байтов содержимого, которое нужно разделить.
HTTP
-
GetHTTP: Загрузить содержимое удаленного URL-адреса на основе HTTP или HTTPS в NiFi. Процессор запомнит ETag и дату последнего изменения, чтобы гарантировать, что данные не будут загружаться постоянно.
-
ListenHTTP: Запустите сервер HTTP (или HTTPS) и прослушивайте входящие соединения. Для любого входящего запроса POST запрошенный контент будет записан как FlowFile, и будет возвращен ответ 200.
-
InvokeHTTP: Выполнить HTTP-запрос, настроенный пользователем. Этот процессор более универсален, чем GetHTTP и PostHTTP, но требует дополнительной настройки. Этот процессор нельзя использовать в качестве исходного процессора, и для выполнения своих задач он должен иметь входящие FlowFiles.
-
PostHTTP: Выполнить HTTP-запрос POST и отправить содержимое FlowFile в качестве тела сообщения. Обычно это используется вместе с ListenHTTP для передачи данных между двумя разными экземплярами NiFi, когда связь между сайтами невозможна (например, когда узел не доступен напрямую и может обмениваться данными через HTTP-прокси). Чтобынота: В дополнение к существующей передаче через сокет RAW HTTP также может использоваться какС сайта на сайтПротокол передачи. Он также поддерживает HTTP-прокси. Рекомендуется использовать HTTP-соединение между сайтами, поскольку он более масштабируемый и может обеспечивать двустороннюю передачу данных с использованием портов ввода / вывода с улучшенной аутентификацией и авторизацией пользователя.
-
HandleHttpRequest / HandleHttpResponse: HandleHttpRequest Processor — это исходный процессор, похожий на ListenHTTP, который запускает встроенный HTTP (S) сервер. Однако он не отправит ответ клиенту. Вместо этого FlowFile отправляется как его содержимое и атрибуты вместе с телом HTTP-запроса, как и все типичные параметры сервлета, заголовки и т. Д. Атрибутов. Затем HandleHttpResponse может отправить ответ обратно клиенту после того, как FlowFile завершит обработку. Эти процессоры всегда хотят использовать вместе друг с другом и позволяют пользователям визуально создавать веб-сервисы в NiFi. Это особенно полезно для добавления внешних интерфейсов к не-веб-протоколам или добавления простых веб-сервисов для определенных функций, которые уже выполняются NiFi (например, преобразование формата данных).
Веб-сервисы Amazon
-
FetchS3Object: Получить содержимое объекта, хранящегося в Amazon Simple Storage Service (S3). Затем содержимое, полученное из S3, будет записано в содержимое FlowFile.
-
PutS3Object: Используя настроенные учетные данные, ключ и имя сегмента будутFlowFileСодержимое записывается в объект Amazon S3.
-
PutSNS:будемFlowFileКонтент отправляется в Amazon Simple Notification Service (SNS) в качестве уведомления.
-
GetSQS: Извлеките сообщение из Amazon Simple Queuing Service (SQS) и запишите содержимое сообщения в содержимое FlowFile.
-
PutSQS:будемFlowFileКонтент отправляется в Amazon Simple Queuing Service (SQS) в виде сообщения.
-
DeleteSQS: Удаление сообщений из Amazon Simple Queuing Service (SQS). Это можно использовать с GetSQS для получения сообщения от SQS, выполнения над ним некоторой обработки и последующего удаления объекта из очереди только после успешного завершения обработки.
Использовать атрибут
Каждый FlowFile создается с несколькими атрибутами, и эти атрибуты будут меняться в течение жизненного цикла FlowFile. Концепция FlowFile очень эффективна и предлагает три основных преимущества. Во-первых, он позволяет пользователям принимать решения о маршрутизации в потоке, чтобы FlowFiles, удовлетворяющие определенным условиям, могли обрабатываться иначе, чем другие FlowFiles. Это делается с помощью RouteOnAttribute и подобных процессоров.
Во-вторых, используйте атрибуты для настройки процессора таким образом, чтобы конфигурация процессора зависела от самих данных. Например, PutFile Processor может использовать атрибуты, чтобы узнать место хранения каждого FlowFile, а атрибуты имени каталога и файла для каждого FlowFile могут быть разными.
Наконец, атрибуты предоставляют чрезвычайно ценный контекст данных. Это очень полезно при просмотре данных о происхождении FlowFile. Это позволяет пользователям искать данные о происхождении, которые соответствуют определенным критериям, а также позволяет пользователям просматривать этот контекст при проверке деталей событий о происхождении. Таким образом, пользователь может получить ценную информацию о том, почему данные так или иначе обрабатываются, просто просматривая контекст, который передается с контентом.
Общие атрибуты
Каждый FlowFile имеет минимальный набор атрибутов:
-
filename: Имя файла, которое можно использовать для хранения данных в локальной или удаленной файловой системе.
-
path: Имя каталога, который можно использовать для хранения данных в локальной или удаленной файловой системе.
-
uuid: Универсальный уникальный идентификатор, используемый для отличия FlowFile от других FlowFiles в системе.
-
entryDate: Дата и время, когда FlowFile вошел в систему (то есть был создан). Значением этого атрибута является число, представляющее количество миллисекунд с полуночи (UTC) 1 января 1970 года.
-
lineageStartDate: Каждый раз, когда FlowFile клонируется, объединяется или разделяется, это приводит к созданию «дочерних» FlowFile. Когда эти дети были клонированы, объединены или разделены, была установлена серия предков. Это значение представляет дату и время, когда самый ранний предок вошел в систему. Другой способ подумать об этом — это то, что этот атрибут представляет задержку FlowFile в системе. Значение представляет собой число, представляющее количество миллисекунд с полуночи (UTC) 1 января 1970 года.
-
fileSize: Этот атрибут представляет количество байтов, занятых содержимым FlowFile.
нужно знатьuuid,entryDate,lineageStartDate,сfileSizeАтрибуты генерируются системой и не могут быть изменены.
Извлечь атрибуты
NiFi предоставляет несколько различных процессоров для извлечения атрибутов из FlowFiles. Может быть в «Извлечение атрибутов «Найдите в разделе список часто используемых процессоров для этой цели. Это очень распространенный вариант использования для создания собственных процессоров. Многие процессоры написаны для понимания определенного формата данных, извлечения соответствующей информации из содержимого FlowFile и создания атрибутов для хранения этой информации, чтобы вы могли решить, как маршрутизировать или обрабатывать данные.
Добавить определенные пользователем атрибуты
В дополнение к процессору, который может извлекать определенные фрагменты информации из содержимого FlowFile в атрибуты, пользователи также хотят добавлять свои собственные определенные пользователем атрибуты в каждый FlowFile в определенном месте в потоке. Процессор UpdateAttribute специально разработан для этой цели. Пользователь может добавить новые свойства процессора в диалоговом окне «Конфигурация», нажав кнопку «+» в правом верхнем углу вкладки «Свойства». Затем пользователю предлагается ввести имя атрибута, а затем ввести значение. Для каждого FlowFile, обрабатываемого этим процессором UpdateAttribute, будет добавлен атрибут для каждого определенного пользователем атрибута. Имя атрибута будет таким же, как имя добавленного атрибута.
Значение атрибута также может включать язык выражения. Это позволяет изменять или добавлять атрибуты на основе других атрибутов. Например, если мы хотим добавить имя хоста и дату обработки файла перед именем файла, мы можем добавить имяfilenameИ значения атрибутов для достижения${hostname()}-${now():format('yyyy-dd-MM')}-${filename}. Хотя поначалу это может сбивать с толку, нижеЯзык выражений / Используйте часть атрибута в значении атрибутаПоможем навести порядок в том, что здесь произошло.
Помимо постоянного добавления набора определенных атрибутов, UpdateAttribute Processor также имеет расширенный пользовательский интерфейс, который позволяет пользователям настраивать набор правил для добавления атрибутов, когда. Чтобы получить доступ к этой функции, на вкладке «Свойства» диалогового окна «Конфигурация» щелкнитеAdvancedКнопка внизу диалогового окна. Это предоставит пользовательский интерфейс, специально предназначенный для этого процессора, а не простую таблицу атрибутов для всех процессоров. В этом пользовательском интерфейсе пользователь может настроить механизм правил, по сути, указав правила, которые должны быть сопоставлены, чтобы добавить настроенные атрибуты в FlowFile.
Маршрутизация атрибутов
Одна из самых мощных функций NiFi — это возможность маршрутизировать FlowFiles на основе атрибутов. Основным механизмом для выполнения этой операции является процессор RouteOnAttribute. Этот процессор, как и UpdateAttribute, настраивается путем добавления определенных пользователем атрибутов. Любое количество атрибутов можно добавить, нажав кнопку «+» в верхнем правом углу вкладки «Свойства» в диалоговом окне «Конфигурация» процессора.
Атрибуты каждого FlowFile будут сравниваться с настроенными атрибутами, чтобы определить, соответствует ли FlowFile указанным условиям. Значение каждого атрибута должно быть выражением языка выражений и возвращать логическое значение. Дополнительную информацию о языке выражений см. В разделе «Значение атрибутаизЯзык выражения / атрибуты использования «раздел.
После оценки выражения языка выражений, предоставленного для атрибутов FlowFile, процессор определяет, как маршрутизировать FlowFile в соответствии с выбранной стратегией маршрутизации. Наиболее распространенной стратегией является стратегия «путь к имени свойства». После выбора этой стратегии процессор отобразит взаимосвязь для каждого настроенного атрибута. Если свойства FlowFile удовлетворяют данному выражению, копия FlowFile будет направлена в соответствующее отношение. Например, если у нас есть новый атрибут с именем «begin-with-r» и значение «$ {filename: startWith (\ ‘r’)}», то любой FlowFile, имя файла которого начинается с буквы ‘r’, будет маршрутом К этим отношениям. Все остальные FlowFiles будут перенаправлены на «несогласованные».
Язык выражений / Использование атрибутов в значениях атрибутов
Когда мы извлекаем атрибуты из содержимого FlowFiles и добавляем определенные пользователем атрибуты, если у нас нет какого-либо механизма для их использования, они не будут хорошо работать в качестве операторов. Язык выражений NiFi позволяет нам получать доступ и управлять значениями атрибутов FlowFile при настройке потока. Не все свойства процессора позволяют использовать язык выражений, но многие это делают. Чтобы определить, поддерживает ли атрибут язык выражения, пользователь может навести указатель мыши наНа значке «Справка» на вкладке «Свойства» диалогового окна «Конфигурация процессора». Это предоставит всплывающую подсказку, показывающую описание свойства, значение по умолчанию (если есть) и то, поддерживает ли свойство язык выражений.
Для атрибутов, поддерживающих язык выражений, вы можете использовать${Отметить и закончить}Добавьте выражение к тегу, чтобы использовать его. Выражения могут быть такими же простыми, как имена атрибутов. Например, чтобы процитироватьuuidАтрибут, мы можем просто использовать значение${uuid}. Если имя атрибута начинается с любого символа, кроме букв, или содержит символы, отличные от цифр, букв, точек (.) Или подчеркиваний (_), необходимо заключить имя атрибута в кавычки. Например,${My Attribute Name}Будет недействительным, но${'My Attribute Name'}Ссылочный атрибутMy Attribute Name。
Помимо ссылок на значения атрибутов, мы также можем выполнять множество функций и сравнивать эти атрибуты. Например, если мы хотим проверитьfilenameНезависимо от того, содержит ли атрибут букву ‘r’ независимо от регистра (верхнего или нижнего), мы можем использовать выражения для завершения${filename:toLower():contains('r')}. Обратите внимание, что функции разделяются двоеточиями. Мы можем связать любое количество функций вместе, чтобы построить более сложные выражения. Также важно понимать, что даже если мы звонимfilename:toLower(), Это не изменитсяfilenameЗначение атрибута, но дает нам только новое значение.
Мы также можем встроить выражение в другое. Например, если мы хотимattr1Сравните значение атрибута со значением атрибутаattr2, Для этого мы можем использовать следующее выражение:${attr1:equals( ${attr2} )}。
Язык выражений содержит множество различных функций, которые можно использовать для выполнения задач, необходимых для маршрутизации и управления атрибутами. Существуют функции для синтаксического анализа и управления строками, сравнения строк и значений, управления и замены значений и сравнения значений. Полное объяснение различных доступных функций выходит за рамки этого документа, но «Руководство по языку выражений «Для каждой функции предоставляется более подробная информация.
Кроме того, это руководство по языку выражений встроено в приложение, чтобы пользователи могли легко видеть, какие функции доступны, и просматривать свою документацию по мере ввода. При установке значения атрибута, поддерживающего язык выражений, если курсор находится в пределах начального и конечного тегов языка выражения, нажатие Ctrl + Пробел на ключевом слове вызовет все доступные функции и предоставит функции автоматического завершения. Если щелкнуть или использовать клавиатуру для перехода к функции, указанной во всплывающем окне, отобразится всплывающая подсказка, в которой объясняется функция функции, ожидаемые параметры и тип возвращаемого значения функции.
Настраиваемые атрибуты на языке выражений
Помимо атрибутов FlowFile, вы также можете определить пользовательские атрибуты, используемые языком выражений. Определение настраиваемых атрибутов обеспечивает дополнительную гибкость при обработке и настройке потоков данных. Например, вы можете ссылаться на настраиваемые свойства для свойств соединения, сервера и службы. После создания настраиваемого атрибута вы можетеnifi.variable.registry.propertiesОпределите их расположение в полях файла «nifi.properties». После обновления файла ‘nifi.properties’ и перезапуска NiFi вы можете использовать настраиваемые свойства по мере необходимости.
Использовать шаблоны
Когда мы используем процессоры для построения все более сложных потоков данных в NiFi, мы часто обнаруживаем, что объединяем одну и ту же последовательность процессоров для выполнения определенных задач. Это может стать утомительным и неэффективным. Для решения этой проблемы NiFi предлагает концепцию шаблонов. Шаблоны можно рассматривать как повторно используемые подпотоки. Чтобы создать шаблон, выполните следующие действия:
-
Выберите компоненты, которые будут включены в шаблон. Мы можем выбрать несколько компонентов, щелкнув первый компонент, а затем, удерживая клавишу Shift, выбирая другие компоненты (чтобы включить связи между этими компонентами), или удерживая Shift, перетаскивая рамку вокруг нужного компонента на холсте. ключ.
-
 Выберите «Создать значок шаблона» () на палитре «Операция».
Выберите «Создать значок шаблона» () на палитре «Операция». -
Укажите имя и необязательное описание шаблона.
-
Нажмите на
CreateКнопка.
 Выберите «Создать значок шаблона» () на палитре «Операция».
Выберите «Создать значок шаблона» () на палитре «Операция».Создав шаблон, мы можем использовать его как строительный блок в процессе, как и процессор. Для этого щелкнем и разместим значок «Шаблон» ( ) Перетащите из панели инструментов «Компоненты» на наш холст. Затем мы можем выбрать шаблон для добавления на холст и нажать
) Перетащите из панели инструментов «Компоненты» на наш холст. Затем мы можем выбрать шаблон для добавления на холст и нажатьAddКнопка.
Наконец, мы можем использовать диалог «Управление шаблонами» для управления шаблонами. Чтобы открыть это диалоговое окно, выберите шаблон в глобальном меню. Отсюда мы можем увидеть, какие шаблоны существуют, и отфильтровать их, чтобы найти интересующие шаблоны. В правой части таблицы находится значок для экспорта или загрузки шаблона в виде файла XML. Затем вы можете предоставить его другим, чтобы они могли использовать ваш шаблон.
Чтобы импортировать шаблон в экземпляр NiFi, пожалуйста, Выберите значок «Загрузить шаблон» () на палитре «Операция», щелкните значок «Поиск» и перейдите к файлу на своем компьютере. Затем нажмите
Выберите значок «Загрузить шаблон» () на палитре «Операция», щелкните значок «Поиск» и перейдите к файлу на своем компьютере. Затем нажмитеUploadКнопка. Теперь шаблон появится в вашей таблице, и вы сможете перетащить его на холст, как и любой другой созданный вами шаблон.
При использовании шаблонов следует помнить о некоторых важных моментах:
-
Любые атрибуты, определенные как конфиденциальные (например, пароли, настроенные в процессоре), не будут добавлены в шаблон. Эти конфиденциальные атрибуты необходимо заполнять каждый раз, когда на холст добавляется шаблон.
-
Если компоненты, содержащиеся в шаблоне, ссылаются на службу контроллера, служба контроллера также будет добавлена в шаблон. Это означает, что каждый раз, когда на диаграмму добавляется шаблон, он создает копию службы контроллера.
Монитор NiFi
Когда данные проходят через ваш поток данных в NiFi, важно понимать производительность вашей системы, чтобы оценить, нужно ли вам больше ресурсов, и оценить текущее состояние ресурсов. NiFi предоставляет некоторые механизмы для мониторинга системы.
Статус бар
В верхней части экрана NiFi под панелью инструментов «Компоненты» есть панель, называемая строкой состояния. Он содержит важную статистику о текущем состоянии NiFi. Количество активных потоков может указывать на текущий рабочий статус NiFi, а статистика очередей указывает количество FlowFiles, находящихся в настоящее время в очереди во всем процессе, и общий размер этих FlowFiles.
Если экземпляр NiFi находится в кластере, мы также увидим здесь индикатор, который сообщает нам, сколько узлов находится в кластере и сколько узлов в данный момент подключено. В этом случае количество активных потоков и размер очереди указывают сумму всех узлов, подключенных в данный момент.
Статистика компонентов
Каждый процессор, группа процессов и группа удаленных процессов на холсте предоставляет несколько статистических данных о том, сколько данных обработал компонент. Эти статистические данные предоставляют информацию о том, сколько данных было обработано за последние пять минут. Это окно с прокруткой, которое позволяет нам просматривать количество FlowFiles, потребляемых процессором, и количество FlowFiles, выпущенных процессором.
Связь между процессорами также показывает количество элементов в очереди.
Также может быть полезно увидеть исторические значения этих показателей и (если они сгруппированы) сравнить разные узлы друг с другом. Чтобы просмотреть эту информацию, мы можем щелкнуть компонент правой кнопкой мыши и выбратьStatsПункт меню. Это покажет нам график, который охватывает время с момента запуска NiFi или до 24 часов, в зависимости от того, что меньше. Вы можете увеличить или уменьшить отображаемое здесь время, изменив конфигурацию в файле свойств.
В верхнем правом углу этого диалогового окна есть раскрывающийся список, который позволяет пользователям выбрать индикатор, который они просматривают. Диаграмма внизу позволяет пользователю выбрать меньшую часть диаграммы для увеличения.
объявление
Помимо статистической информации, предоставляемой каждым компонентом, пользователи также хотят знать, есть ли какие-либо проблемы. Хотя мы можем отслеживать любой интересный контент в журнале, удобнее выводить уведомление на экран. Если процессор записывает что-либо как ПРЕДУПРЕЖДЕНИЕ или ОШИБКУ, мы увидим «Индикатор бюллетеня» в правом верхнем углу процессора. Этот индикатор выглядит как стикер и отображается через пять минут после события. При наведении курсора мыши на бюллетень отображается информация о том, что произошло, чтобы пользователи могли ее найти, не фильтруя сообщения журнала. Если в кластере, объявление также будет указывать, какой узел в кластере публикует объявление. Мы также можем изменить уровень журнала объявления во вкладке «Настройки» диалогового окна «Конфигурация» процессора.
Если платформа делает объявление, мы также выделим индикатор объявления в правом верхнем углу экрана. В глобальном меню есть опция доски объявлений. При выборе этой опции мы попадаем на доску объявлений, где можем видеть все объявления, которые появляются в экземпляре NiFi, и можем фильтровать их по компонентам, сообщениям и т. Д.
Источники данных
NiFi сохраняет очень подробную информацию для всех данных, которые он принимает. Когда данные обрабатываются в системе и преобразуются, маршрутизируются, разделяются, агрегируются и распределяются по другим конечным точкам, эта информация сохраняется в репозитории NiFi Provenance. Чтобы найти и просмотреть эту информацию, мы можем выбрать источник данных из глобального меню. Это предоставит нам таблицу со списком событий Provenance, которые мы искали:

Первоначально эта таблица заполняется 1000 самых последних событий Provenance (хотя обработка информации после события может занять несколько секунд). В этом диалоговом окне естьSearchКнопка позволяет пользователю искать события, которые происходят в конкретном процессоре, и искать конкретный FlowFile по имени файла, UUID или нескольким другим полям. Вnifi.propertiesФайл предоставляет возможность настроить, какие из этих атрибутов индексируются или доступны для поиска. Кроме того, файл свойств позволяет выбрать определенные свойства FlowFile, которые будут проиндексированы. Таким образом, вы можете выбрать, какие атрибуты важны для вашего конкретного потока данных, и сделать эти атрибуты доступными для поиска.
подробности деятельности
После того, как мы выполнили поиск, наша таблица будет заполнена только событиями, соответствующими критериям поиска. Отсюда мы можем выбрать Значок информации () в левой части таблицы для просмотра подробной информации о событии:
Значок информации () в левой части таблицы для просмотра подробной информации о событии:

Отсюда мы можем точно видеть, когда произошло событие, FlowFile, на который повлияло событие, компоненты (процессоры и т. Д.), Которые выполняло событие, время, затраченное на событие, и общее время, в течение которого данные NiFi произошли, когда событие произошло (общая задержка).
На следующей вкладке представлен список всех атрибутов, которые существовали в FlowFile, когда произошло событие:

Отсюда мы можем увидеть все атрибуты, которые существовали в FlowFile, когда произошло событие, и предыдущие значения этих атрибутов. Это позволяет нам узнать, какие свойства изменились в результате события и как они изменились. Кроме того, в правом углу находится флажок, который позволяет пользователям просматривать только те атрибуты, которые были изменены. Это может быть не особенно полезно, если FlowFile имеет только несколько атрибутов, но может быть очень полезно, когда FlowFile имеет сотни атрибутов.
Это очень важно, потому что позволяет пользователям понять точный контекст обработки FlowFile. Полезно понять «почему» FlowFile, особенно при настройке процессора с использованием языка выражений.
Наконец, у нас есть вкладка Content:

Эта вкладка предоставляет нам информацию о местонахождении репозитория контента, в котором хранится контент FlowFile. Если событие изменяет содержимое FlowFile, мы увидим объявления содержимого «до» (ввод) и «после» (вывод). Если формат данных является форматом данных, который NiFi понимает, как представлять, мы можем выбрать загрузку контента или просмотр контента внутри NiFi.
Кроме того, в разделе воспроизведения на вкладке есть кнопка «воспроизведения», которая позволяет пользователю повторно вставить FlowFile в поток и повторно обработать его с момента, когда произошло событие. Это обеспечивает очень мощный механизм, потому что мы можем изменять процесс в реальном времени, повторно обрабатывать FlowFile, а затем просматривать результаты. Если они не оправдывают ожиданий, мы можем снова изменить процесс и повторно обработать FlowFile. Мы можем выполнять итеративную разработку процесса до тех пор, пока он не обработает данные точно так, как ожидалось.
Схема родословной
Помимо просмотра деталей событий Provenance, мы также можем нажать Значок «Происхождение» () в представлении таблицы, чтобы просмотреть происхождение задействованного FlowFile.
Значок «Происхождение» () в представлении таблицы, чтобы просмотреть происхождение задействованного FlowFile.
Это дает нам графическое представление о том, что произошло с данными, когда мы проходим через систему:

Отсюда мы можем щелкнуть правой кнопкой мыши любое представленное событие и нажатьView DetailsПункт меню для просмотраДетали мероприятия. Это графическое представление показывает нам, что именно произошло с данными. Есть некоторые «особые» типы событий, о которых следует знать. Если мы видим событие JOIN, FORK или CLONE, мы можем щелкнуть правой кнопкой мыши и выбрать Find Parents или Expand. Это позволяет нам просматривать родословную родительских FlowFiles и созданных дочерних FlowFiles.
Ползунок в нижнем левом углу позволяет нам увидеть, когда произошли эти события. Проводя пальцем влево и вправо, мы можем видеть, какие события вызывают задержки в системе, так что мы можем иметь хорошее представление о том, где в системе может потребоваться больше ресурсов, например, количество одновременных задач процессора. Или это может показать, например, что большая часть задержки вызвана событием JOIN, и мы ждем, когда будут соединены другие FlowFiles. В любом случае возможность легко увидеть, где это произошло, — очень мощная функция, которая может помочь пользователям понять, как работает компания.
Где я могу получить дополнительную информацию
Сообщество NiFi разработало большое количество документов о том, как использовать программное обеспечение. В дополнение к этому руководству по началу работы также предоставляются следующие руководства:
-
Обзор Apache NiFi-Обзор того, что такое Apache NiFi, для чего он нужен и для чего был создан.
-
Руководство пользователя Apache NiFi-Достаточно обширное руководство, часто используемое в качестве справочного руководства, поскольку в нем довольно долго обсуждаются все различные компоненты, составляющие приложение. Это руководство написано для операторов NiFi как их аудитории. Он предоставляет информацию о каждом из различных компонентов, доступных в NiFi, и объясняет, как использовать различные функции, предоставляемые приложением.
-
Руководство по управлению-Руководство по настройке и управлению Apache NiFi в производственной среде. В этом руководстве представлена информация о различных настройках системного уровня, таких как настройка кластера NiFi и защита доступа к веб-интерфейсу и данным.
-
Руководство по языку выражения-Более подробное руководство по пониманию языка выражения, чем указано выше. Это руководство является авторитетным документом языка выражения NiFi. Он предоставляет введение в EL и объяснение каждой функции, ее параметров и возвращаемых типов, а также предоставляет примеры.
-
Руководство разработчика-Несмотря на то, что это не исчерпывающее руководство по разработке All Things NiFi, это руководство дает исчерпывающий обзор доступности различных API и способов их использования. Кроме того, он предоставляет лучшие практики для разработки компонентов NiFi и общих идиом процессоров, чтобы помочь понять логику многих существующих компонентов NiFi.
-
Руководство для авторов-Руководство, объясняющее, как внести свой вклад в сообщество Apache NiFi, чтобы другие могли его использовать.
На сайт блога Apache NiFi было добавлено несколько сообщений блога:https://blogs.apache.org/nifi/
Помимо представленных здесь блогов и руководств, вы также можете просматривать различныеСписок рассылки NiFi,Или отправьте электронное письмо по адресу[email protected]или[email protected]Один из списков рассылки.
Многие члены сообщества NiFi также доступны через Twitter и активно отслеживают твиты, в которых упоминается @apachenifi.
Исходный текст:
http://nifi.apache.org/docs.html