Опубликовано: 10 мар 2019
Данная статья возникла, как результат желания протестировать функционал ClickHouse на простом привычном окружении. Поскольку я в основном использую Windows 10, в которой имеется возможность подключить компонент Windows Subsystem for Linux, эта операционная система и была выбрана для развертывания ClickHouse. Фактически все описанное здесь было выполнено на самом простом домашнем ноутбуке.
Поскольку я не являюсь экспертом Linux, я искал такой вариант развертывания, который можно было бы осуществить просто следуя небольшому набору команд. Пришлось протестировать несколько вариантов, и так как в некоторых случаях возникали ошибки, с которыми не очень хотелось разбираться, я выбрал тот дистрибутив, в котором все прошло наиболее гладко. Таким дистрибутивом оказалась Ubuntu 16.04, пакет которой для WSL можно скачать на странице Manually download Windows Subsystem for Linux.
Установка Ubuntu
Прежде чем устанавливать Ubuntu нужно активировать компонент Windows Subsystem for Linux в Windows 10. Для этого, нажав клавиши Win + R нужно запустить команду appwiz.cpl, затем в открывшемся окне перейти на вкладку «Включение и отключение компонентов Windows» и поставить галочку на против нужного компонента:
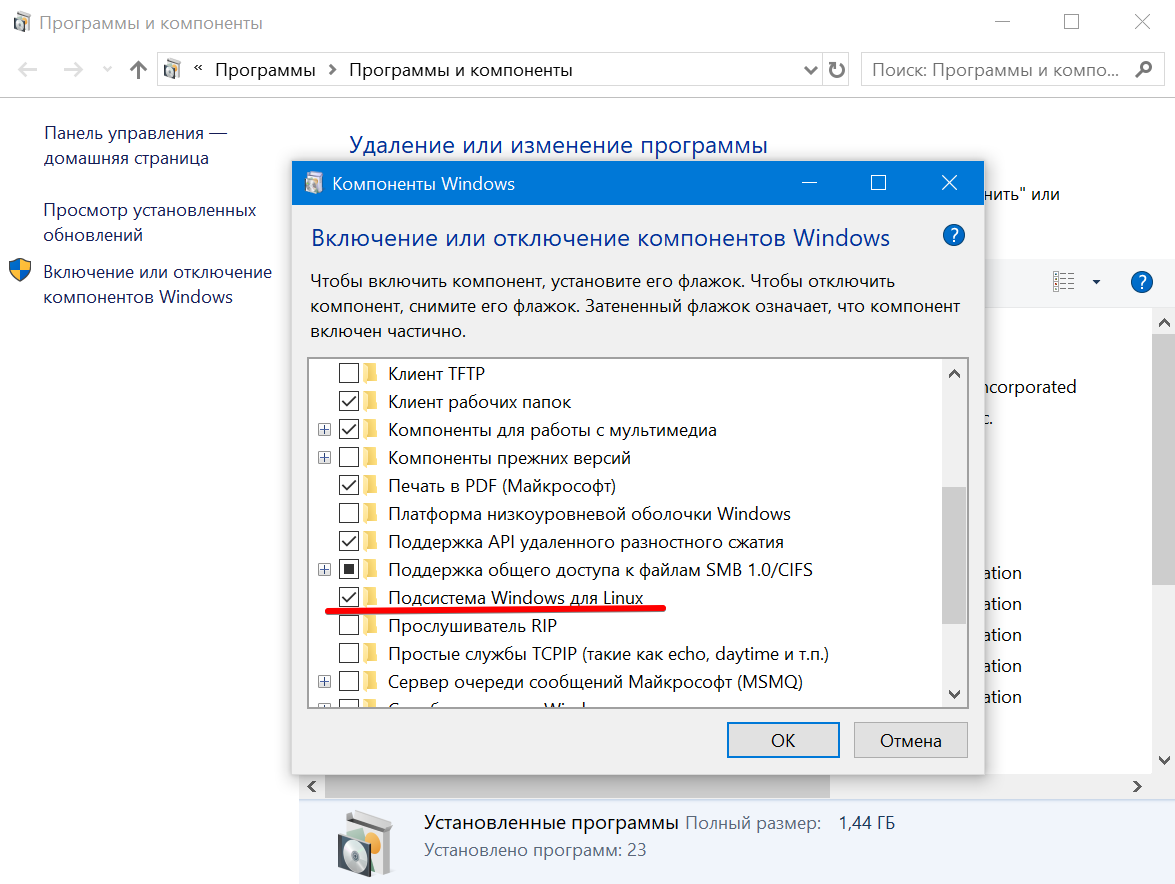
Развертывание ClickHouse
После установки Ubuntu на наш ноутбук с Windows 10 можно приступить к установке ClickHause. Cледуя шагам, предложенным в инструкции от Яндекса, выполним ряд соответствующих команд в терминале Ubuntu:
1. Добавляем репозиторий яндекса в список репозиториев
sudo sh -c "echo deb http://repo.yandex.ru/clickhouse/deb/stable/ main/ >> /etc/apt/sources.list"
2. Добавляем ключ авторизации пакета
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv E0C56BD4
3. Устанавливаем пакет ClickHouse, состоящий из сервера и клиента
sudo apt-get update sudo apt-get install clickhouse-client clickhouse-server
4. Поскольку мы разворачиваем ClickHouse на локальной машине, мы можем дать ему расширенные права доступа к соответсвующим директориям, что упростит процесс установки.
sudo chmod 777 /var/lib/clickhouse/ sudo chmod 777 /var/log/clickhouse-server/ sudo chown -R clickhouse:clickhouse /var/log/clickhouse-server/ sudo chown -R clickhouse:clickhouse /var/lib/clickhouse
5. По ходу установки выяснилось, что дополнительно нужно сконфигурировать в развернутой Ubuntu региональную временную зону
sudo dpkg-reconfigure tzdata
6. Теперь мы можем проверить готов ли к работе развернутый clickhouse-server, запустив его в режиме логирования в окно терминала:
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
На экране появится много информационных сообщений, из которых нам по сути важно только поддтверждение запуска сервера и слушания приложением портов localhost:
Application: Listening http://127.0.0.1:8123
Ubuntu напрямую коммуницирует с localhost в Windows, что естественно очень удобно, и что позволяет работать с ClickHouse непосредственно из браузера в Windows, в том числе в Jupyter Notebook.
7. Если все установилось, запускаем сервер и клиент ClickHouse:
sudo service clickhouse-server start --config-file=/etc/clickhouse-server/config.xml clickhouse-client
Увидев приглашение от clickhouse-client, вы можете отправить тестовый запрос:
ClickHouse client version 0.0.18749. Connecting to localhost:9000. Connected to ClickHouse server version 0.0.18749. :) SELECT 1 ┌─1─┐ │ 1 │ └───┘ 1 rows in set. Elapsed: 0.003 sec.
Параметр config-file в большинстве случаев можно опустить. Эти две команды и будут в дальнейшем использоваться для запуска ClickHouse:
sudo service clickhouse-server start clickhouse-client
Доступ по API к отчетам Яндекс Метрики и к Logs API
Чтобы иметь возможность обращаться по API к данным отчетов метрики и к данным хитов в Logs API нужно выполнить несколько несложных действий, следуя инструкциям от Яндекса:
- API отчетов v1 — Введение
- Logs API — Введение
По сути все сводится к регистрации условного приложения и получения для него токена для авторизации в вышеперечисленных API. Наиболее простой способ для начала работы — это получить отладочный токен, который действует достаточно долго, затем его можно будет обновить.
Работа с ClickHouse и Logs API в Jupyter Notebook
Благодаря сообществу пользователей ClickHouse появились ряд визуальных интерфейсов и библиотек, упрощающих взаимодействие с инструментом. Данная же статья будет следовать примерам, которые демонстрировали сами специалисты Яндекса на проводимых ими лекциях и вебинарах.
Открываем Jupyter Notebook и первым делом загружаем ряд необходимых пакетов:
In [1]:
import requests import sys from datetime import date from datetime import timedelta import urllib
Мы можем сохранить выданный нашему приложению авторизационный токен в файл и прочитать его с помощью команды:
In [2]:
with open('token.txt') as f: TOKEN = f.read().strip()
В качетсве димонстрации вот пример обращения к API отчетов метрики, где мы берем некоторые данные за вчерашний день:
In [3]:
header = {'Authorization': 'OAuth '+TOKEN} ids = 11113333 payload = { 'metrics': 'ym:s:pageviews, ym:s:users', 'date1': (date.today() - timedelta(days=1)).isoformat(), 'date2': (date.today() - timedelta(days=1)).isoformat(), 'ids': ids, 'accuracy': 'full', 'pretty': True, } r = requests.get('https://api-metrika.yandex.ru/stat/v1/data', params=payload, headers=header).content
In [4]:
import json print (json.dumps(json.loads(r)['data'], indent = 2))
[
{
"metrics": [
112770.0,
15020.0
],
"dimensions": []
}
]
При обращение же к Logs API вначале нам нужно проверить возможность формирования данных. Зададим параметры: мы обращаемся к хитам, а не к визитам и берем данные за вчерашний день. Отправим соответствующий запрос:
In [5]:
API_HOST = 'https://api-metrika.yandex.ru' COUNTER_ID = 11113333 START_DATE = (date.today() - timedelta(days=1)).isoformat() END_DATE = (date.today() - timedelta(days=1)).isoformat() SOURCE = 'hits' API_FIELDS = ('ym:pv:date', 'ym:pv:dateTime', 'ym:pv:URL', 'ym:pv:deviceCategory', 'ym:pv:operatingSystemRoot', 'ym:pv:clientID', 'ym:pv:browser', 'ym:pv:lastTrafficSource')
In [6]:
url_params = urllib.urlencode( [ ('date1', START_DATE), ('date2', END_DATE), ('source', SOURCE), ('fields', ','.join(API_FIELDS)) ] )
In [7]:
url = 'https://api-metrika.yandex.ru/management/v1/counter/11113333/logrequests/evaluate?'\ .format(host=API_HOST, counter_id=COUNTER_ID) + url_params r = requests.get(url, headers={'Authorization': 'OAuth '+TOKEN}) r.status_code
Код 200 означает, что запрос отправлен успешно. А вот ответ о возможности получить данные:
In [8]:
json.loads(r.text)['log_request_evaluation']
Out[8]:
{u'max_possible_day_quantity': 340, u'possible': True}
Как видно, в случае данного сайта есть возможность получить одним запросом данные за 341 день. Теперь отправим запрос непосредственно на получение данных:
In [9]:
url_params = urllib.urlencode( [ ('date1', START_DATE), ('date2', END_DATE), ('source', SOURCE), ('fields', ','.join(sorted(API_FIELDS, key=lambda s: s.lower()))) ] ) url = '{host}/management/v1/counter/{counter_id}/logrequests?'\ .format(host=API_HOST, counter_id=COUNTER_ID) \ + url_params r = requests.post(url, headers={'Authorization': 'OAuth '+TOKEN})
In [11]:
print (json.dumps(json.loads(r.text)['log_request'], indent = 2))
{
"date1": "2019-03-09",
"status": "created",
"date2": "2019-03-09",
"counter_id": 11113333,
"fields": [
"ym:pv:browser",
"ym:pv:clientID",
"ym:pv:date",
"ym:pv:dateTime",
"ym:pv:deviceCategory",
"ym:pv:lastTrafficSource",
"ym:pv:operatingSystemRoot",
"ym:pv:URL"
],
"source": "hits",
"request_id": 2782240
}
Поскольку данные могут формироваться некоторое время из этих данных нам потребуется request_id для проверки готовности ответа.
In [12]:
request_id = json.loads(r.text)['log_request']['request_id']
Задаем параметры и проверяем готовность ответа:
In [13]:
url = '{host}/management/v1/counter/{counter_id}/logrequest/{request_id}' \ .format(request_id=request_id, counter_id=COUNTER_ID, host=API_HOST) r = requests.get(url, params="", headers=header)
In [15]:
print (json.dumps(json.loads(r.text)['log_request'], indent = 4))
{
"date1": "2019-03-09",
"status": "processed",
"date2": "2019-03-09",
"counter_id": 11113333,
"fields": [
"ym:pv:browser",
"ym:pv:clientID",
"ym:pv:date",
"ym:pv:dateTime",
"ym:pv:deviceCategory",
"ym:pv:lastTrafficSource",
"ym:pv:operatingSystemRoot",
"ym:pv:URL"
],
"source": "hits",
"parts": [
{
"part_number": 0,
"size": 25338635
}
],
"request_id": 2782240,
"size": 25338635
}
Если видим статус "created" — ждем, если статус "processed", это означает, что данные готовы, и что ответ будет состоять из какого-то количества частей.
In [16]:
parts = json.loads(r.text)['log_request']['parts'] print(parts)
[{u'part_number': 0, u'size': 25338635}]
Получаем ответ и помещаем его в Pandas DataFrame
In [17]:
import io import StringIO import pandas as pd
In [18]:
tmp_dfs = [] for part_num in map(lambda x: x['part_number'], parts): url = '{host}/management/v1/counter/{counter_id}/logrequest/{request_id}/part/{part}/download' \ .format( host=API_HOST, counter_id=COUNTER_ID, request_id=request_id, part=part_num ) r = requests.get(url, headers=header) if r.status_code == 200: tmp_df = pd.read_csv(io.StringIO(r.text), sep = '\t') tmp_dfs.append(tmp_df) else: raise ValueError(r.text) df = pd.concat(tmp_dfs)
Мы можем сохранить полученные данные в csv файл, если в дальнейшем они нам могут понадобится
In [20]:
df.to_csv('site_data.csv', sep = '\t', index = False, encoding='utf-8', line_terminator='\n')
Один из параметров, которые нужны для взаимодействия с ClickHouse через браузер это хост:
In [21]:
HOST = 'http://localhost:8123'
Так, к примеру, если вы зайдете на http://localhost:9000 то можно прочесть:
Port 9000 is for clickhouse-client program.
You must use port 8123 for HTTP.
Определим функции для работы с ClickHouse из нашего Jupyter Notebook. Функции повторяют примеры, размещенные на вебинарах Яндекса1:
In [22]:
def get_clickhouse_data(query, host = HOST, connection_timeout = 1500): r = requests.post(host, params = {'query': query}, timeout = connection_timeout) if r.status_code == 200: return r.text else: raise ValueError(r.text) def get_clickhouse_df(query, host = HOST, connection_timeout = 1500): data = get_clickhouse_data(query, host, connection_timeout) df = pd.read_csv(StringIO.StringIO(data), sep = '\t') return df def upload(table, content, host=HOST): # content = content.encode('utf-8') query_dict = { 'query': 'INSERT INTO ' + table + ' FORMAT TabSeparatedWithNames ' } r = requests.post(host, data=content, params=query_dict) result = r.text if r.status_code == 200: return result else: raise ValueError(r.text)
С чегобы начать? Давайте, например, посмотрим что за базы данных в ClickHouse есть в текущеий момент:
In [23]:
q = ''' SHOW DATABASES ''' get_clickhouse_df(q)
Out[23]:
| datasets | |
|---|---|
| 0 | default |
| 1 | funnels |
| 2 | system |
Поскольку я уже немного поработал с данными, мы видим три базы данных, одна из которых системная. Создадим таблицу в базе funnels, в которую поместим данные из Logs API:
In [24]:
q = 'drop table if exists funnels.visits' get_clickhouse_data(q) q = ''' create table funnels.visits ( browser String, clientID UInt64, date Date, dateTime DateTime, deviceCategory String, trafficSource String, system String, URL String ) ENGINE = MergeTree(date, intHash32(clientID), (date, intHash32(clientID)), 8192) ''' get_clickhouse_data(q)
Для демонстрации возможности прочтем полученные данные из созданного нами на предыдущих шагах csv файла
In [25]:
df = pd.read_csv('site_data.csv', sep='\t',encoding='utf-8')
Загружаем данные в нашу таблицу:
In [27]:
# %%time upload( 'funnels.visits', df.to_csv(index = False, sep = '\t', encoding='utf-8',line_terminator='\n'))
Квест пройден, а вот и приз — посмотрим, к примеру, сколько пользователей было вчера на основном разделе нашего сайта:
In [28]:
q = ''' SELECT uniq(clientID) as users FROM funnels.visits WHERE date = yesterday() AND match(URL,'^https://yoursite.ru/main') FORMAT TabSeparatedWithNames ''' get_clickhouse_df(q)
На чтение 3 мин Опубликовано Обновлено
ClickHouse — мощная и быстрая колоночная СУБД (система управления базами данных), разработанная компанией Яндекс. Она обрабатывает огромные объемы данных с невероятной скоростью и эффективностью. ClickHouse используется для анализа больших данных, хранения журналов и регистрации событий.
Хотите использовать ClickHouse на своем персональном компьютере под управлением Windows 10? Не волнуйтесь, в этой статье я расскажу вам пошаговую инструкцию по установке ClickHouse на вашем компьютере.
Прежде чем начать, убедитесь, что у вас уже установлено и настроено следующее программное обеспечение: Docker Desktop и git.
Шаг 1: Загрузите ClickHouse с помощью git.
Откройте командную строку и перейдите в папку, где вы хотите сохранить ClickHouse. Затем введите следующую команду:
git clone https://github.com/yandex/ClickHouse.git
Этот шаг загружает исходный код ClickHouse на ваш компьютер.
Шаг 2: Установите Docker Desktop.
Перейдите на официальный сайт Docker и загрузите установочный файл Docker Desktop для Windows. Запустите установку и следуйте инструкциям по установке.
Шаг 3: Запустите ClickHouse в Docker.
Откройте командную строку и перейдите в папку, где находится ClickHouse. Затем введите следующую команду:
cd ClickHouse/docker
После этого запустите ClickHouse, выполнив следующую команду:
docker-compose up -d
Примечание: этот процесс может занять некоторое время, так как Docker должен загрузить и настроить все необходимые компоненты внутри контейнера.
Шаг 4: Проверьте, что ClickHouse правильно установлен.
Откройте веб-браузер и перейдите по адресу http://localhost:8123. Если вы видите страницу «ClickHouse HTTP CLI», значит ClickHouse успешно установлен и работает на вашем компьютере.
Теперь у вас есть полностью функциональный ClickHouse на вашем компьютере под управлением Windows 10. Вы можете начать использовать его для анализа данных и хранения информации.
В следующих статьях мы погрузимся в более детальные аспекты работы с ClickHouse и научимся создавать и управлять базами данных.
Установка ClickHouse на Windows 10
Если вам нужно установить ClickHouse на операционную систему Windows 10, следуйте этой пошаговой инструкции:
- Перейдите на официальный сайт ClickHouse по адресу https://clickhouse.tech/docs/ru/getting-started/install/.
- Выберите раздел «Установка ClickHouse на Windows» и нажмите на ссылку «Скачать MSI-файл» для загрузки установочного пакета.
- После загрузки MSI-файла запустите его и следуйте инструкциям мастера установки.
- На первом шаге мастера установки выберите язык установки и нажмите «Далее».
- Прочтите и принимайте лицензионное соглашение, затем нажмите «Далее».
- Выберите папку для установки ClickHouse и нажмите «Далее».
- Выберите компоненты, которые вы хотите установить (сервер, клиентские утилиты и т. д.) и нажмите «Далее».
- Выберите порт для сервера ClickHouse и нажмите «Далее».
- Выберите папку для журналов ClickHouse и нажмите «Далее».
- Выберите параметры запуска ClickHouse (автоматический запуск при загрузке Windows и т. д.) и нажмите «Далее».
- Нажмите «Установить», чтобы начать установку ClickHouse.
- После завершения установки нажмите «Готово», чтобы закрыть мастер установки.
Теперь ClickHouse успешно установлен на вашем компьютере с операционной системой Windows 10. Вы можете начать использовать его для обработки и анализа больших объемов данных.
Пошаговая инструкция
- Скачайте установщик ClickHouse для Windows с официального сайта.
- Запустите установщик ClickHouse и следуйте инструкциям мастера установки.
- Выберите путь установки ClickHouse на вашем компьютере.
- Нажмите на кнопку «Установить», чтобы начать процесс установки.
- После завершения установки, откройте командную строку.
- Введите команду «clickhouse-server.exe» для запуска сервера ClickHouse.
- Ожидайте, пока сервер полностью запустится.
- Откройте браузер и введите адрес «http://localhost:8123» для доступа к веб-интерфейсу ClickHouse.
- На главной странице веб-интерфейса, вы сможете создавать базы данных, таблицы и выполнять запросы к данным.
Теперь у вас установлена ClickHouse на Windows 10, и вы можете начать использовать ее для анализа и обработки больших объемов данных.
Search code, repositories, users, issues, pull requests…
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
Article catalog
- Foreword
- I. Introduction to Clickhouse Database
- Second, preparation
-
- 1. Install Linux
-
- 1. Open Windows Developer Mode
- 2. Install the Windows subsystem suitable for Linux
- 3. Install Ubuntu
- 4. Set up administrator privileges
-
- Question 1: SU: AUTHENTICATION FAILURE solution
- Third, install CLICKHOUSE
-
- Get installation files
- 2. Execute the installation
- 3. Start the Clickhouse service
-
- The first, can run the following command in the background:
- Second, you can also start the service directly in the console:
-
- Question 1: Time zone error
- Question 2: Starting an error
- Question 3: Connection Server Error Connection Refused: Connet
- Question 4: Can’t include Node Clickhouse_remote_servers
- 4. Start / stop / restart service
- 5. Connect the Clickhouse server
- 6. Connect Clickhouse with Database Tools
- to sum up
-
- Reference blog
Foreword
Recently, listening to the roommate said that their company uses Clickhouse’s database, just caught up with overtime mission, and studied it. The first is the installation of the database. I found a lot of tutorial on the Internet. Although I’ve been very detailed, it is very smooth, I feel very strange, there is no step on the pit during the installation process. This blog records the whole process of this person, with some stepping pits and solutions.
Tip: The following is the textual content of this article, the case is available for reference
I. Introduction to Clickhouse Database
Clickhouse is an online analysis (OLAP)Columns databaseManagement System (DBMS).
Common columnar database has: Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA, Google Dremel, Google PowerDrill, Druid, kdb +.
Clickhouse is the most commonly used in the column database, which is the true DBMS. There are a lot of very detailed blog articles on the Internet to learn. Specific learning is not the main content of this blog.
Attach Clickhouse official documentation:Clickhouse official documentation
Second, preparation
1. Install Linux
First, Clickhouse is currently supporting operating in Linux, Mac OS X, and does not support direct installation in the Windows platform. So you need to know about Linux related knowledge and experience.
Installing Linux You can install the virtual machine, then install the LINUX release system such as CENT OS or Ubuntu. But the installation is more troublesome, but also to install the virtual machine, but also download the system image. Here is a method herein to use the built-in Linux subsystem of Windows 10. This method is also shared on the Internet, it is really easy to use. The specific installation is as follows:
1. Open Windows Developer Mode
Open «Settings» -> «Update and Security» -> «Developer Options» to select «Developer Mode».
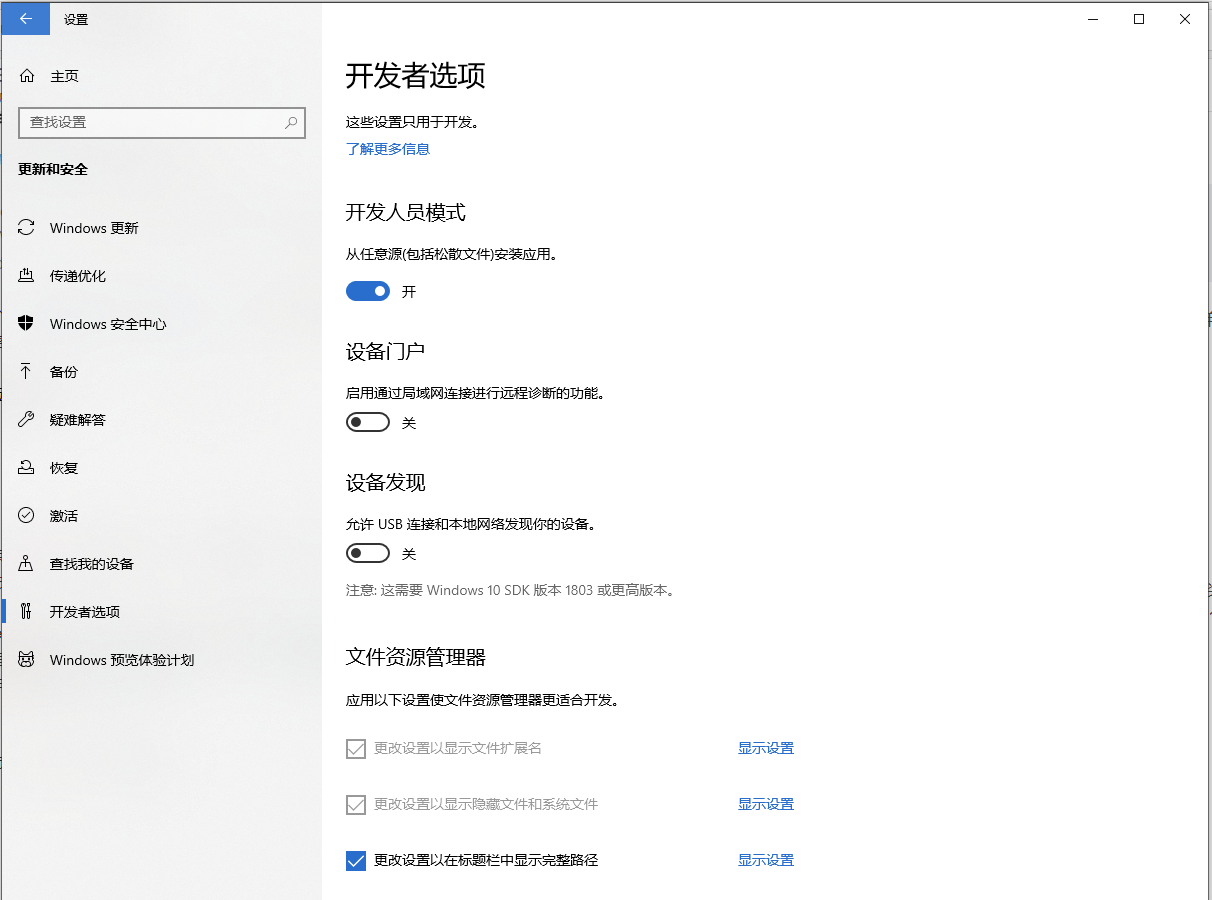
There will be a toolkit to install the developer option, you can wait a few minutes.
2. Install the Windows subsystem suitable for Linux
Turn on the control panel, select «Programs», click «Enable or turn Windows function», check «Windows Subsystem for Linux». The package will be installed here, you can wait a few minutes.Restart the system after installation。
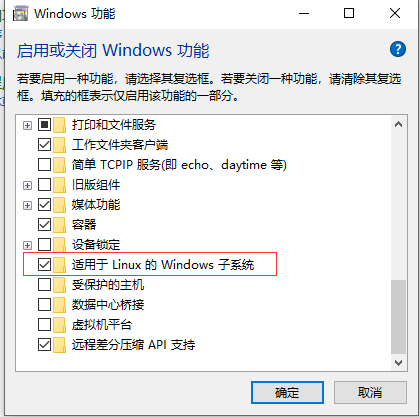
3. Install Ubuntu
Open Microsoft Store, search Ubuntu, select a nearest department, click Get to be automatically installed.
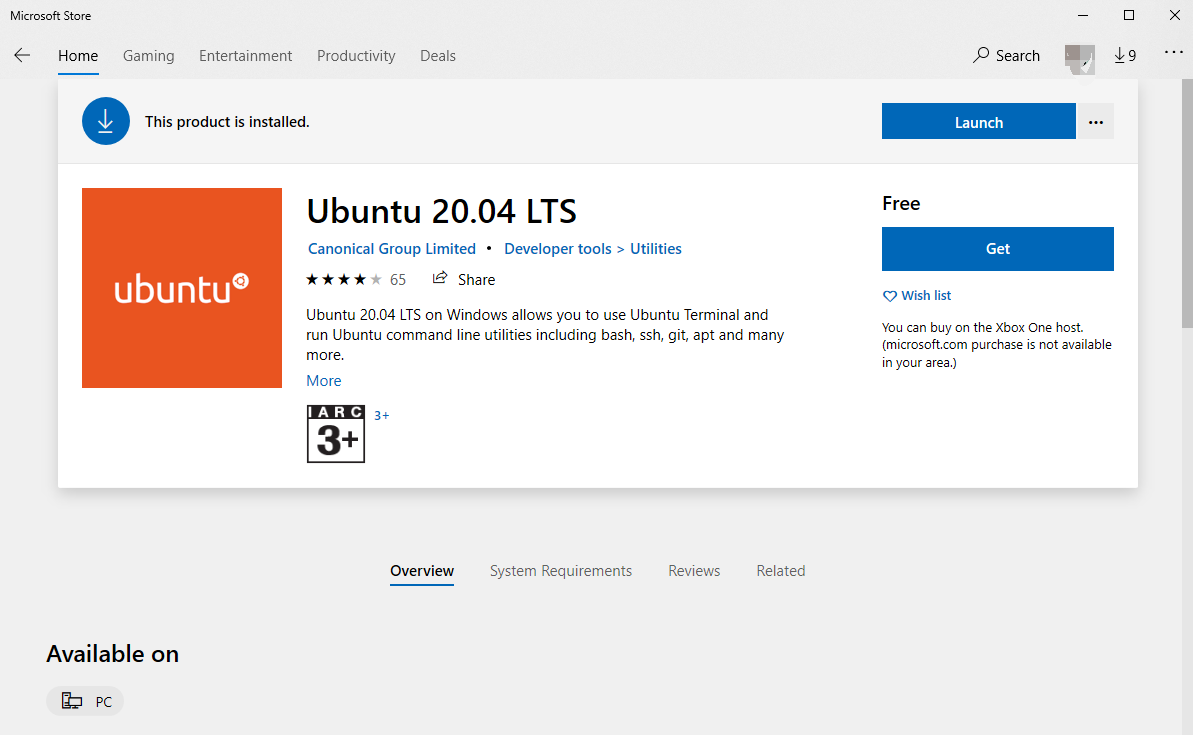
Start Ubuntu after installation, there will be a short initial process, then go to the username and password, as shown below, it is successful.
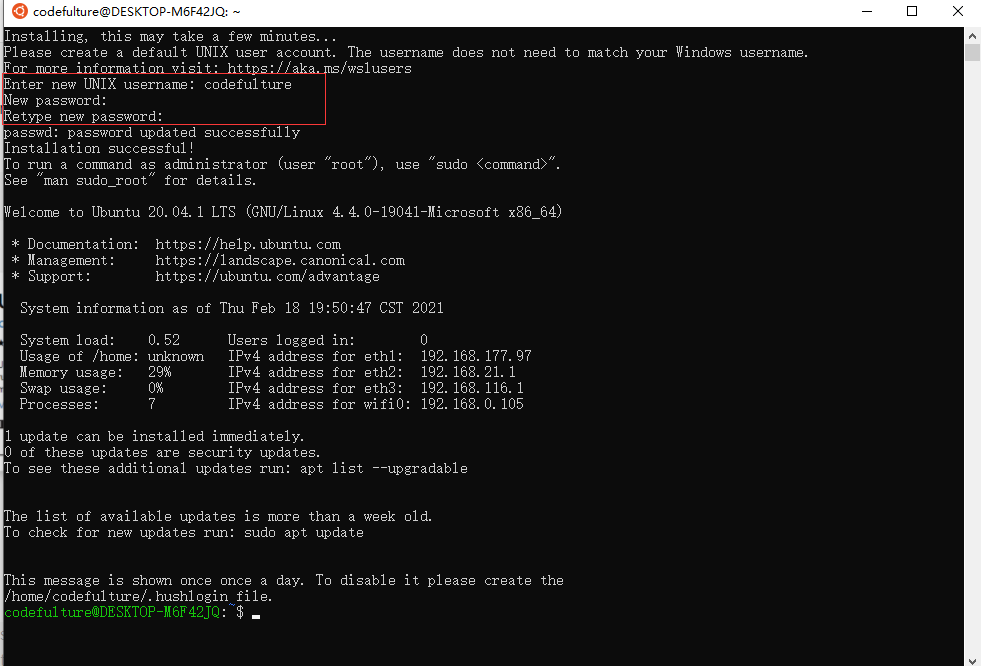
4. Set up administrator privileges
Using Linux systems often require administrator privileges. So here is set first, so as not to trouble later. Since Ubuntu is not known, I have stepped on a pit.
Question 1: SU: AUTHENTICATION FAILURE solution
The reason is: Ubuntu is not allowed to log in by default, so the initial root account cannot be used, and the root password is required to use sudo permissions under normal accounts.
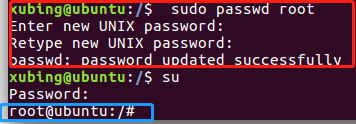
The solution is very simple: set a root password. Note that SUDO is not SU. This is solved!
Reference Blog Original:SU: AUTHENTICATION FAILURE solution
The previous work is ready, you can enter the installation of Clickhouse.
Third, install CLICKHOUSE
At first installed Clickhouse is to refer to this blog post:Ubuntu under Clickhouse installation and accessHowever, the installation process is not as smooth as the blog post, and the installation process is not very detailed. Here, the following will be combined with the blog post and its own actual operation, and make a detailed installation deployment.
Get installation files
Here is the installation of the installation package through the official website, and you can attempt yourself through the way, this is not repeated, and the installed version is in the same blog post.
Official address:download link
Download three installation packages:
clickhouse-common-static_20.9.2.20_amd64
clickhouse-server_20.9.2.20_all
clickhouse-client_20.9.2.20_all
Search directly in the download list can be found.
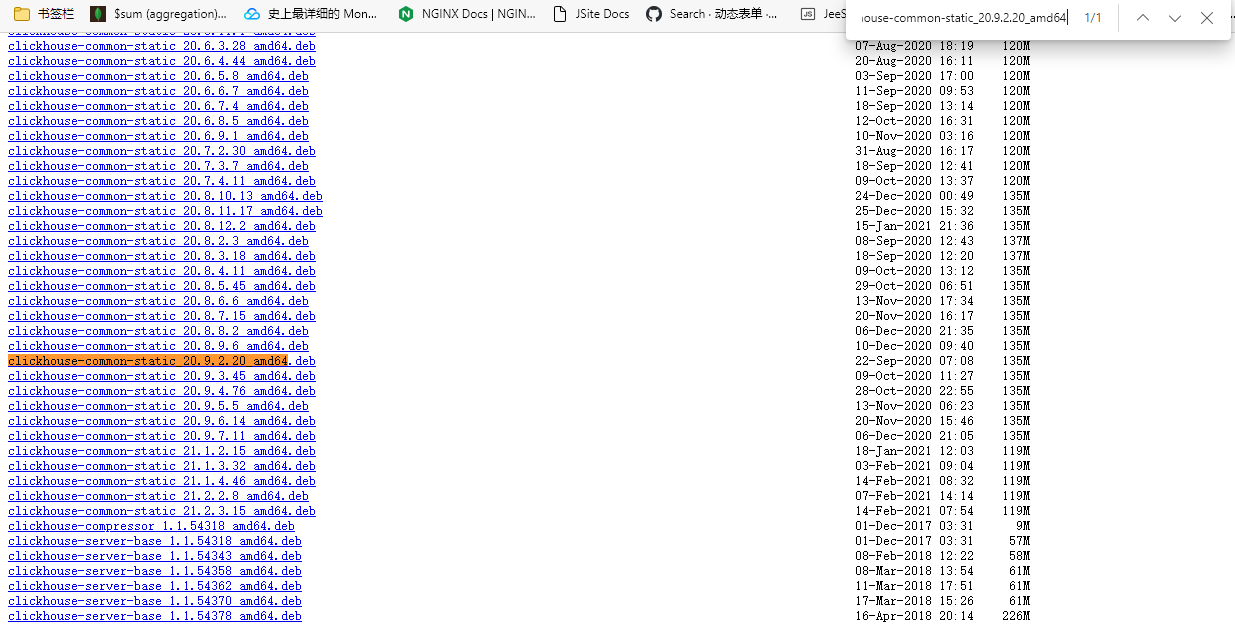
2. Execute the installation
After downloading, the three files download can be copied to the TMP file, and then move it to this folder via the CD command, the ls command views the file in the Ubuntu system. Because this is in this pit, it is always prompted that the file does not exist when the command is executed, so I have to move to other places.

Then install it, execute the command:
sudo dpkg -i clickhouse-common-static_20.9.2.20_amd64.deb
sudo dpkg -i clickhouse-server_20.9.2.20_all.deb
sudo dpkg -i clickhouse-client_20.9.2.20_all.deb
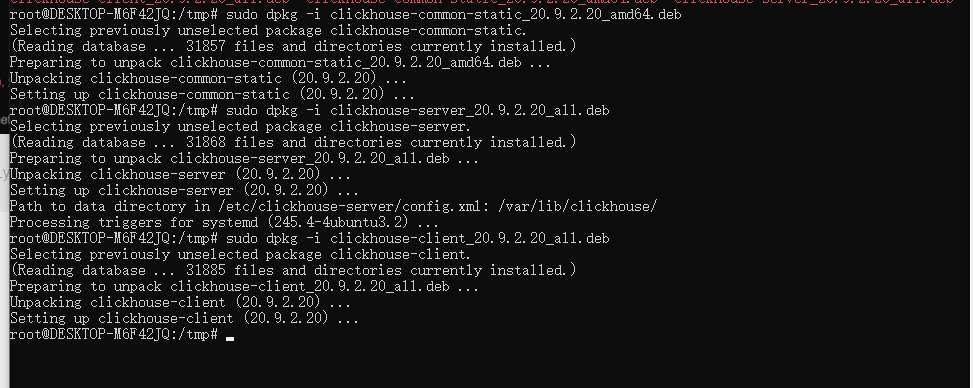
The installed is already installed as shown. It should be noted that when installing Clickhouse-Server, prompt the input password. I have entered 123456 this (Very important), If you do not enter a password, you can use it directly to you.
And I saw the installed Clickhouse under the ETC folder.
3. Start the Clickhouse service
It can be said that it has been successful here, you can start Clickhouse service. However, when starting the service, you will report an error, and the solution is to modify the content file content. Here we first start the service directly, what will be reported. (Focus)
There are two ways to start the service:
The first, can run the following command in the background:
sudo service clickhouse-server start
You can view the log in the / var / log / clickhouse-server / directory.
If the service is not started, check the configuration file /etc/clickhouse-server/config.xml.
Second, you can also start the service directly in the console:
clickhouse-server --config-file=/etc/clickhouse-server/config.xml
In this case, the log will be printed into the console, which is very convenient during development.
If the configuration file is in the current directory, you may not specify the ‘-config-file’ parameter. It uses ‘./config.xml’ by default.
Let’s execute it first.sudo service clickhouse-server startWatch what will be prompted (it is possible to succeed, talk about the pit encountered).
Question 1: Time zone error
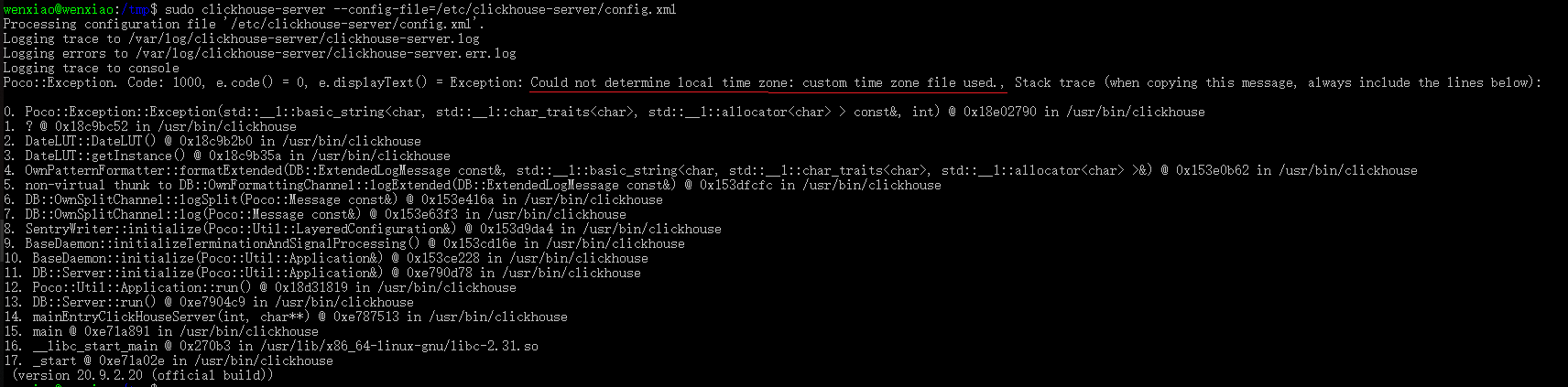
Note that the red line is wrong, meaning that this is not to determine the time zone of this machine operating system, you need to manually set yourself.
sudo vim /etc/clickhouse-server/config.xml
Find Timezone, modify as follows:
<timezone>Asia/Shanghai</timezone>
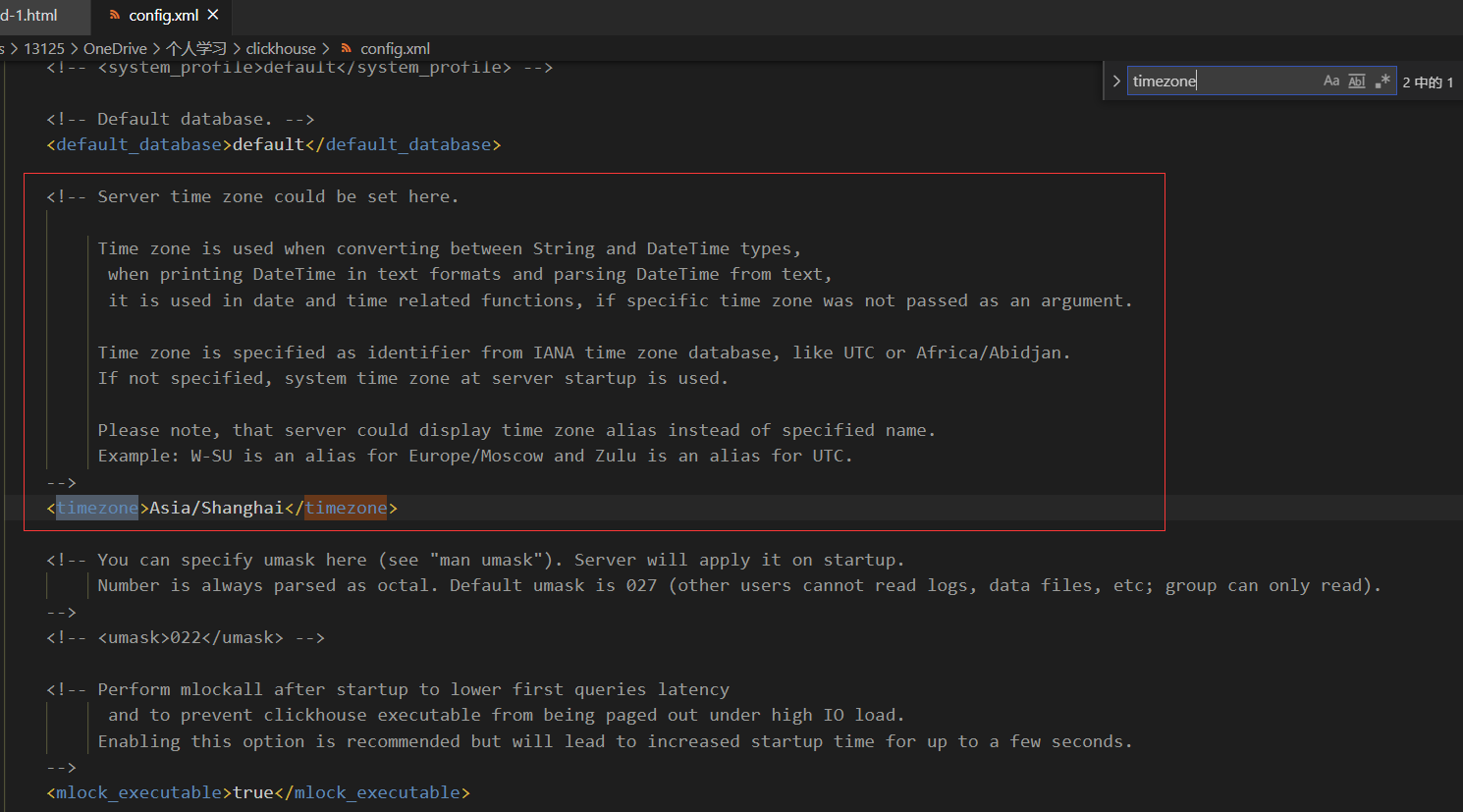
This time zone is default that this code is not available by default, so try to add it in advance.
Question 2: Starting an error
Startup parameters: sudo clickhouse-server —config-file = / etc / clickhouse-server / config.xml
2020.08.20 18:49:28.189321 [ 29338 ] {} <Error> Application: DB::Exception: Effective user of the process (root) does not match the owner of the data (clickhouse). Run under 'sudo -u clickhouse'
Tip is already very clear, Run Under ‘Sudo -u Clickhouse’.
Start the parameters after modification: sudo -u clickhouse clickhouse-server —config-file = / etc / clickhouse-server / config.xml
Question 3: Connection Server Error Connection Refused: Connet
Configure external network access (remote access).
In Config.xml, the red box part is opened.
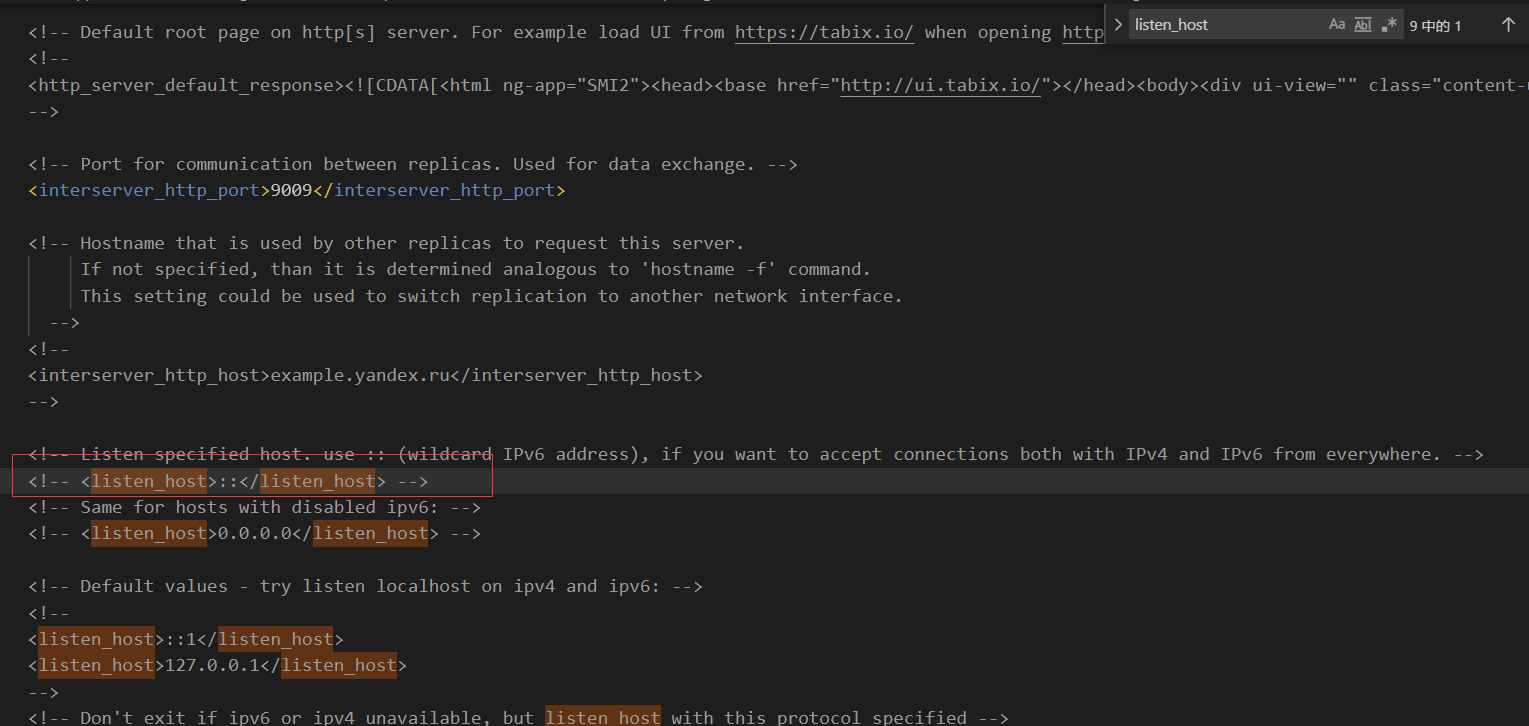
Question 4: Can’t include Node Clickhouse_remote_servers
When startup, you may prompt the error that cannot be introduced into the clickhouse_remote_servers node, this node is mainly configuring the cluster. It may be because there is no Metrika.xml file, resulting in the introduction node error. Since it is a single-machine version installation, here you can temporarily delete the nodes of the following image (recommended backup original files before modifying the configuration file).Note: You cannot directly Ctrl + / annotation here, because there is a comment in the node, it will report an error.
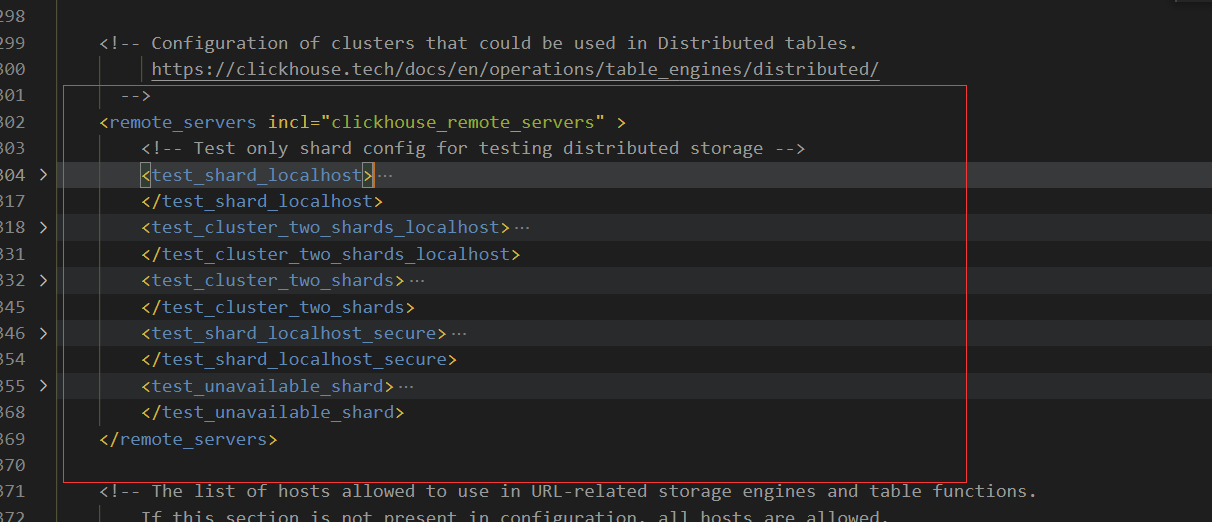
4. Start / stop / restart service
sudo service clickhouse-server start #start up
sudo service clickhouse-server stop #Stop
sudo service clickhouse-server restart # Restart the service, actually a first Stop, then start
5. Connect the Clickhouse server
Excuting an order:
clickhouse-client
Note: If the password is set, there will be such a prompt.

So use the following command (now the default account):
clickhouse-client --port 9000 --host 127.0.0.1 --password 123456 --multiline
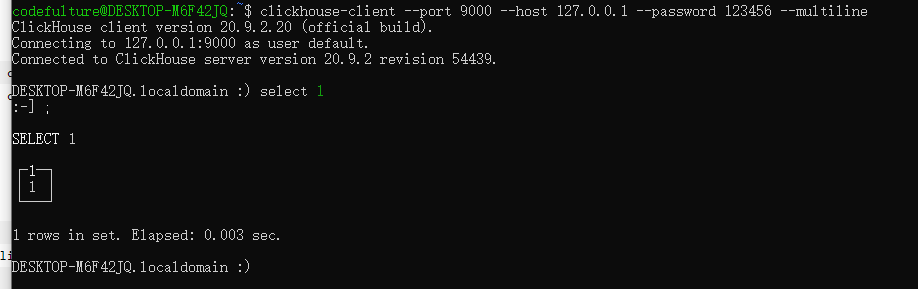
This is successful.
6. Connect Clickhouse with Database Tools
If Java is developed, the Clickhouse tool built into IDEA can be connected, and the operation is also very simple.
Here the port is 8123 default, and the HTTP port connected to Clickhouse is 8123.
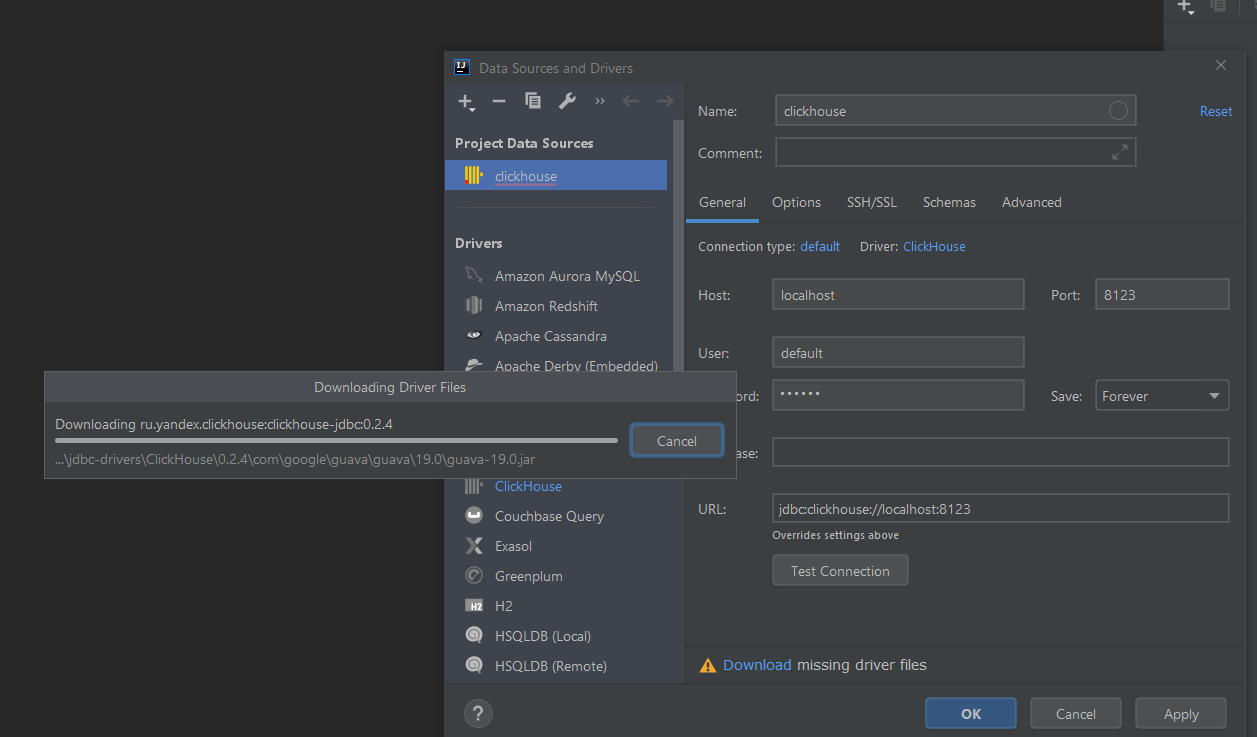
After installing the plugin, you can use it in Idea.
to sum up
It is basically over, and the first installation has stepped on many pits, and a lot of strange blame has also appeared. The second installation is very smooth. This is just a single-machine deployment, but in actual work, production, important or cluster, will continue to study the deployment of the cluster in the future.
Reference blog
Here are some of the books, and there is a cluster deployment method, you can reference:
1.clickhouse cluster installation
2. One of the Clickhouse Series: Clickhouse Introduction and Installation
3. Clickhouse Series 2: Clickhouse encountered error issues and solutions
4. Under the installation and access of Clickhouse under theUbuntu
5.Clickhouse Basic Operation One User Rights Management
The premise
With the development of current services, the amount of data in several business systems began to expand dramatically. Before, I used relational database MySQL to conduct a data warehouse modeling, and found that after the amount of data came up, a large number of JOIN operations were still a little unbearable after improving the configuration of cloud MySQL. In addition, I developed a label service based on relational database design. Daily full label data (unavoidable Cartesian product) single table exceeds 5000W. At present, the user ID-based segmentation with multi-process processing method has temporarily delayed the deterioration of performance, but considering the near future, we still need to build a small data platform. The system of Hadoop is too large, with too many components and high learning costs of hardware and software, which cannot be mastered overnight by all members of a small team. With all these factors in mind, ClickHouse is a dark technology that needs to be invoked to see if it can get out of the way.

Software version
ClickHouse is not covered here, but is fully documented at https://clickhouse.tech. In Windows10, you can install Docker directly and run ClickHouse images directly using hyper-V features. The software required for setting up the development environment is listed below:
| software | version | note |
|---|---|---|
Windows |
10 |
Make sure you use itWindows10And turn it onHyper-VIn order to useDocker |
Docker Desktop |
any | DockertheWindowsThe desktop version |
ClickHouse Server |
X 20.3. |
Direct pulllatestThe mirror image of |
ClickHouse Client |
X 20.3. |
Direct pulllatestThe mirror image of |
Cmder |
The latest version | Optional, used to replace the unusable console that comes with it |
In Windows10, you can enable the Hyper-V feature by running the following command: Control Panel — Programs — Enable or Disable Windows Features — Hyper-V

Then the Docker official site https://www.docker.com/get-started child pages can find Docker Desktop download entry:

After installation, Docker Desktop will automatically start with the system, and the software interface is as follows:

Install and use ClickHouse
Note that you need to have a preliminary understanding of ClickHouse’s core directory before starting the container installation.
Mirror pull and core directory
Download the images of ClickHouse Server and ClickHouse Client:
docker pull yandex/clickhouse-server
docker pull yandex/clickhouse-client
Copy the codeAfter downloading, the following prompt will be displayed:

Check this out with Docker Images:
λ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
yandex/clickhouse-server latest c85f84ea6550 10 days ago 515MB
yandex/clickhouse-client latest f94470cc9cd9 10 days ago 488MB
Copy the codeBoth images are actually wrapped in a tiny Ubuntu system, so the container can be used as if it were a Linux system. The core directory portion of ClickHouse Server in the container is as follows:
/etc/clickhouse-serverThis is:ClickHouse ServerDefault configuration file directory, including global configurationconfig.xmlAnd user configurationusers.xmlAnd so on./var/lib/clickhouseThis is:ClickHouse ServerDefault data storage directory./var/log/clickhouse-serverThis is:ClickHouse ServerDefault log output directory.
In order to facilitate configuration management, data viewing and log searching, the above three directories can be directly mapped to the specific directory of the host computer. The author has done the following mapping in this development machine:
| Docker container directory | Host directory |
|---|---|
/etc/clickhouse-server |
E:/Docker/images/clickhouse-server/single/conf |
/var/lib/clickhouse |
E:/Docker/images/clickhouse-server/single/data |
/var/log/clickhouse-server |
E:/Docker/images/clickhouse-server/single/log |
A few points to note before starting ClickHouse Server:
ClickHouse ServerThe service itself depends on three ports, whose default value is9000(TCPProtocol),8123(HTTPAgreement) and9009(Cluster data replication), the mapping to the host should be one-to-one, so you need to ensure that the three ports on the host are not occupied and can be usedDockerThe parameters of the-pSpecifies the port mapping between the container and the host.ClickHouse ServerThe number of file handles in the container system needs to be modifiedulimit nofile, you can useDockerparameter--ulimit nofile=262144:262144Specifies the number of file handles.- There’s a technique that you can use. Use
Dockerthe--rmParameter to create a temporary container, obtained first/etc/clickhouse-serverDirectory configuration file, passDocker cp container directory Host directoryCommand to copy the container configuration file to the host directory. After the container is stopped, it will be deleted directly, so that the host configuration file template can be retained.
Temporary container copy configuration
Docker run —rm -d —name=temp-clickhouse-server Yandex /clickhouse-server After success, copy the container’s config. XML and users. XML files to the host using the following command:
docker cp temp-clickhouse-server:/etc/clickhouse-server/config.xml E:/Docker/images/clickhouse-server/single/conf/config.xmldocker cp temp-clickhouse-server:/etc/clickhouse-server/users.xml E:/Docker/images/clickhouse-server/single/conf/users.xml
After these two commands are executed, you can see that config.xml and users.xml have been generated in the host’s disk directory. Then you need to do a few configurations:
- create
defaultPassword of the account. - Create a new one
rootAccount. - Open client listening
Host, avoid later useJDBCClient orClickHouse ClientCannot connect whenClickHouse Server.
Docker exec-it temp-clickhouse-server /bin/bash:
PASSWORD=$(base64 /dev/urandom | head -c8); echo "default"; echo -n "default" | sha256sum | tr -d '-'PASSWORD=$(base64 /dev/urandom | head -c8); echo "root"; echo -n "root" | sha256sum | tr -d '-'
root@607c5abcc132:/# PASSWORD=$(base64 /dev/urandom | head -c8); echo "default"; echo -n "default" | sha256sum | tr -d '-'
default
37a8eec1ce19687d132fe29051dca629d164e2c4958ba141d5f4133a33f0688f
root@607c5abcc132:/# PASSWORD=$(base64 /dev/urandom | head -c8); echo "root"; echo -n "root" | sha256sum | tr -d '-'
root
4813494d137e1631bba301d5acab6e7bb7aa74ce1185d456565ef51d737677b2
Copy the codeThis gives you the SHA256 digest of the passwords for the default:default and root:root accounts. Modify the users.xml file on the host:

Then modify the config.xml file on the host:

Finally, the temporary container is stopped and destroyed with the Docker Stop temp-clickhouse-server.
Run the ClickHouse service
Then create and run an instance of the ClickHouse Server container using the following command (make sure config.xml and users.xml already exist) :
Name and container name: docker run -d --name=single-clickhouse-server Port mapping: -p 8123:8123 -p 9000:9000 -p 9009:9009 Number of file handles: - the ulimit nofiles = 262144-262144 data directory mapping: - v E: / Docker/images/clickhouse - server/use/data: / var/lib/clickhouse: rw configuration directory mapping: - v E: / Docker/images/clickhouse - server/use/conf: / etc/clickhouse - server: rw log directory mapping: - v E: / Docker/images/clickhouse - server/use/log: / var/log/clickhouse - server: rw mirror: another dual/clickhouse - serverCopy the codeDocker run -d —name=single-clickhouse-server -p 8123:8123 -p 9000:9000 -p 9009:9009 —ulimit nofile=262144:262144 -v E:/Docker/images/clickhouse-server/single/data:/var/lib/clickhouse:rw -v E:/Docker/images/clickhouse-server/single/conf:/etc/clickhouse-server:rw -v E: / Docker/images/clickhouse — server/use/log: / var/log/clickhouse — server: rw another dual/clickhouse — server.
After executing the command above, the Docker Desktop will have several pop-ups confirming whether to share the host directory. Simply press the Share it button.

Finally, the native command line Client, ClickHouse Client, is used to connect. Use the docker run-it —rm —link single-clickhouse-server:clickhouse-server yandex/ clickhouse-client-uroot —password command Root — host clickhouse — server:
λ docker run-it --rm --link single-clickhouse-server:clickhouse-server yandex/ clickhouse-client-uroot --password root -- Host Clickhouse-server Clickhouse Client Version 20.10.3.30 (Official build). Connecting to Clickhouse-server :9000 AS Connected to ClickHouse server version 20.10.3 revision 54441.f5abc88ff7e4 :) select 1; SELECT 1 ┌ ─ ─ 1 ┐ │ │ 1 └ ─ ─ ─ ┘ 1 rows in the set. The Elapsed: 0.004 SEC.Copy the codeThe next time your computer restarts the ClickHouse Server container and the container does not start, simply use the command docker (re)start single-clickhouse-server to pull up the container instance.
Connect to the ClickHouse service using JDBC
ClickHouse currently has three JDBC drivers:
clickhouse-jdbc(Official) : The address ishttps://github.com/ClickHouse/clickhouse-jdbc, the current version is based onApache Http ClientThe implementation.ClickHouse-Native-JDBC(Third party) : The address ishttps://github.com/housepower/ClickHouse-Native-JDBCBased on theSocketThe implementation.clickhouse4j(Third party) : The address ishttps://github.com/blynkkk/clickhouse4jLighter than the official driver.
To be honest, it is a little embarrassing that the official driver package does not connect with TCP private protocol stack, but uses HTTP protocol for interaction. I do not know how much performance will be reduced, but based on the thinking of «official is better», I still choose the official driver package for Demo demonstration. Introducing clickHouse-JDBC dependencies:
dependency
groupIdru.yandex.clickhouse/groupId
artifactIdclickhouse-jdbc/artifactId
version0.2.4/version
/dependency
Copy the codeWrite a test class:
public class ClickHouseTest {
@Test
public void testCh(a) throws Exception {
ClickHouseProperties props = new ClickHouseProperties();
props.setUser("root");
props.setPassword("root");
The result is as follows:
Table default.t_test already exists # Default Table in the database :[t_test] Query result,id:1,name:throwable query result, ID :2,name:dogeCopy the codesummary
After the ClickHouse development environment is set up, you will learn the basic syntax of ClickHouse, the features and usage scenarios of the various engines, and clustering (sharding and multiple copies).
References:
https://clickhouse.tech
remind
After a direct power outage, I found that the ClickHouse service in Docker was successfully restarted, but the error log output File not found, causing all clients to fail to connect to the service. The initial judgment is that metadata and actual stored data caused by the «power failure» caused by inconsistency. So proposal in a development environment to turn it off before you enter the container calls the service clickhouse — stop server, and then in the host machine call docker stop container name | containers ID stop to shut down, Otherwise, you need to recursively delete all the files in the Store directory in the data directory to restart ClickHouse Server and use it properly (this is a very rude method and has a high chance of directly causing data loss, so be careful).
(C-2-D E-A-20201108)
Personal blog
- Throwable’s Blog