5 способов создать словарь для Bruteforcing
overbafer1
Доброго времени суток! Сегодня мы рассмотрим 5 доступных способов как создать свой личный словарь для bruteforcing.
Для начала разберём, что такое атака по словарю и поймем с чем её едят.
Атака по словарю — это попытка входа в цифровую систему, которая использует предварительно составленный список возможных паролей, и на основе этого перебирает эти пароли. Вот например один из инструментов, который делает это:
Crunch
Лучшее в Crunch то, что вы можете использовать его как в автономном режиме, так и в сеnb. Он генерирует список слов в соответствии с вашими требованиями. Вы можете указать максимальную и минимальную длину пароля, а также предоставить ему набор символов, который вы хотите использовать при создании словаря. А затем crunch создаст ваш словарь, сохраняя ваши требования в приоритете. Следовательно, будет создан словарь со всеми возможными комбинациями.
Теперь давайте посмотрим, как его использовать. Сначала обратите внимание на его синтаксис:
crunch <min> <max> <character-set> -t <pattern> -o <path>
crunch — crunch — это ключевое слово, которое уведомляет систему об использовании этого инструмента.
<min> — здесь вы указываете минимальную длину символов
<max> – здесь вы указываете максимальную длину символов.
<character-set> — здесь вы указываете символы, которые хотите использовать при создании словаря.
-t <pattern>- — это необязательно, но в этом пункте вы можете указать шаблон, с которым вы хотите, чтобы ваш набор символов создался.
-o <path> — здесь вы указываете путь, для сохранения словаря.
На практике это выглядит так:
- crunch 3 4 ignite –o /root/Desktop/dict.txt
Теперь приведенная выше команда создаст словарь с возможными комбинациями слова ignite длиной от 3 до 4 символов. Файл будет сохранен в текстовом виде на рабочем столе.
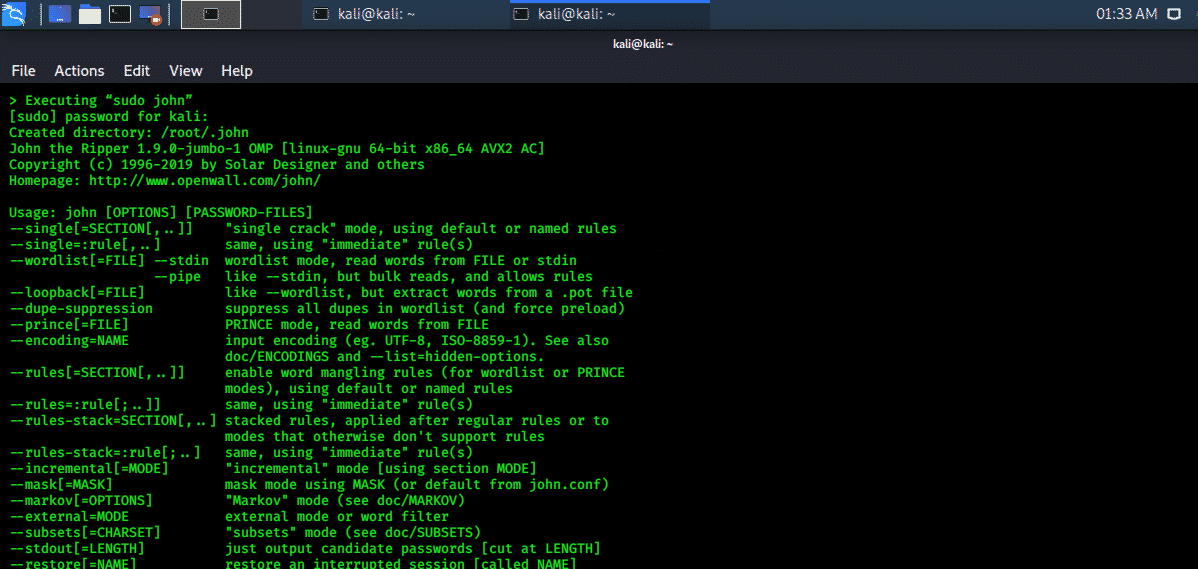
Давайте теперь прочитаем файл dict.txt.
- cat dict.txt
Все слова будут отображаться следующим образом:

Cewl
Следующий способ — использовать Cewl. Как вы все знаете, человеческая психика использует слова, значимые для них и встречающиеся в их повседневной жизни. Cewl работает с URL-адресом, который вы ему предоставляете. Он возьмет этот URL-адрес и просканирует его до глубины 2 ссылок (по умолчанию вы также можете увеличить или уменьшить глубину) и будет искать каждое слово, которое может быть паролем. Со всеми этими словами он сгенерирует список слов, который вы сможете использовать в качестве словаря при атаке по словарю.
- cewl <url> -d<depth> -w<path>
- Cewl — сам инструмент
- <url> — здесь укажите URL-адрес, который вы хотите использовать в качестве основы для своего словаря.
- -d<depth> — здесь укажите количество ссылок, которые вы хотите использовать при создании словаря.
- -w<path> — здесь укажите путь, по которому вы хотите хранить все возможные пароли.
Давайте посмотрим на деле:
cewl www.ignitetechnologies.in -d 2 -w /root/Desktop/dict.txt
Приведенная выше команда создаст файл словаря, используя слово из URL-адреса.

Теперь откроем словарь:
cat dict.txt
Все слова будут отображаться следующим образом:

Cupp
Следующий способ — использование стороннего инструмента Cupp
Предыдущие инструменты были предустановлены, но этот вам придется установить самостоятельно. Чтобы установить его, введите:
- git clone https://github.com/Mebus/cupp.git
CUPP разработан на Python и представляет собой очень персонализированный инструмент для проверки на уязвимость. Исследования показывают, что при настройке пароля люди демонстрируют аналогичную модель, например, они склонны персонализировать пароль, добавляя дату своего рождения, дату годовщины, имя домашнего животного и т. д., и CUPP фокусируется на этой слабости и помогает эффективно узнать пароль. Перед созданием списка слов он запросит у вас необходимую информацию о вашей цели. И создаст список слов в соответствии с информацией. Теперь давайте пошагово изучим, как это работает. Сначала запустите cupp, набрав:
- ./cupp.py -i
После запуска он запросит у вас информацию о вашей цели, как показано на скриншоте:
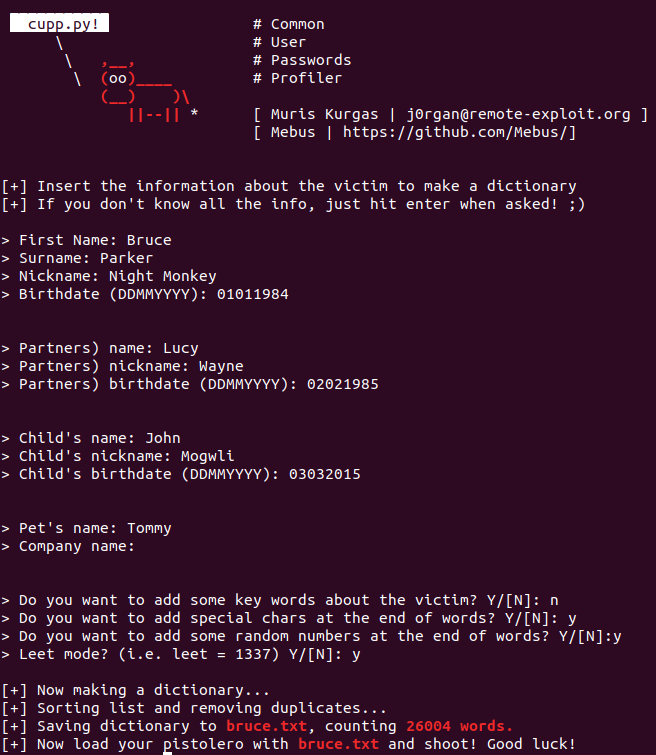
Вводим необходимую информацию, и ваш список слов будет сгенерирован следующим образом:

Pydictor
Следующий инструмент — Pydictor . Это крутой инструмент, так как он единственный, кто создает список слов как в обычных словах, так и в шифровании base64. Так что, если кто-то достаточно умен, чтобы сохранить безопасный пароль, этот инструмент поможет вам в этом. Pydictor написан на питоне. Существует два метода перебора пароля с помощью этого инструмента: один создает обычный список слов, а другой создает список слов в формате base64. Мы попробуем оба метода. Но обо всем по порядку, это сторонний инструмент, поэтому нам придется его установить, и для этого введите:
- git clone https://github.com/LandGrey/pydictor.git
Как только инструмент будет установлен и готов к использованию, дайте ему инструкции о том, что вы хотите от словаря.
- ./pydictor.py –len <min> <max> -base d –o <path> — запускает инструмент
- –len – указывает длину символов
- <min> – здесь укажите минимальную длину символов
- <max> – здесь укажите максимальную длину символов
- -o — указывает путь
- <path>— здесь укажите путь, по которому вы хотите сохранить свой список слов.
Теперь давайте дадим команду сгенерировать список слов:
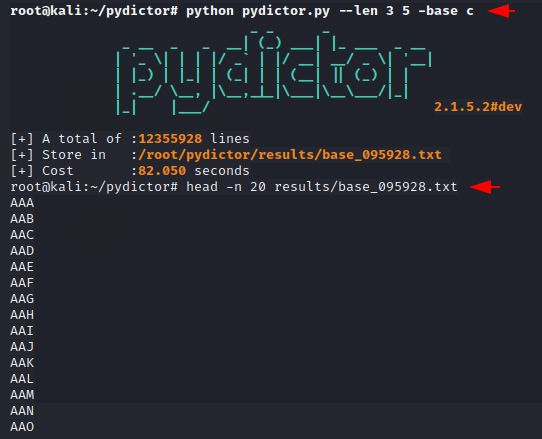
- ./pydictor.py —len 5 5 —base d –o /root/Desktop/dict.txt
Давайте прочитаем созданный файл, чтобы посмотреть на сгенерированные им слова.
- cat dict.txt/BASE_5_5_d_095928.txt
Другой метод, использующий аналогичный инструмент, дает нам пароль в кодировке base64. Сначала изучим синтаксис:
- ./pydictor.py –len <min> <max> -base d —encode <тип кодировки> –o <путь>./pydictor.py — запускает инструмент
- –len – указывает длину символов
- <min> – здесь укажите минимальную длину символов
- <max> – здесь укажите максимальную длину символов
- —encode – указывает тип шифрования/кодирования
- <encoding type> — здесь укажите тип кодировки, который вы хотите
- -o — указывает путь
- <path> — здесь укажите путь, по которому вы хотите сохранить свой список слов.
Дадим команду сгенерировать список слов:
- ./pydictor.py —len 5 5 -base d —encode b64 –o /root/Desktop/dict.txt
Приведенная выше команда сгенерирует список слов в base64, давайте посмотрим на него:
- cat dict.txt/BASE_5_5_d_095928.txt
Dymerge
Ну и последним на сегодня инструментом будет Dymerge. Dymerge — интересный и мощный инструмент, написанный на питоне. По сути, dymerge берет несколько ранее созданных словарей и объединяет их в один, т.е даёт возможность объединить все словари и использовать готовый за один раз. Вы можете объединить любое количество словарей, как стандартных, так и созданных на заказ. Это опять сторонний инструмент, поэтому давайте сначала установим его:
- git clone https://github.com/k4m4/dymerge.git
- python dymerge.py <path> <path> -s –o <path>
- Python dymerge.py à — запускает инструмент
- <path> — здесь укажите путь к первому словарю, который вы хотите объединить
- <path> — здесь укажите путь ко второму словарю, который вы хотите объединить
- -o — указывает путь, по которому будет сохранен полученный список слов
- <path> — здесь укажите путь, по которому будет сохранен окончательный список слов
Давайте попробуем на практике:
- python dymerge.py /root/Desktop/digit.txt /root/Desktop/words.txt –s –o /root/Desktop/awlg.txt
Здесь мы взяли два списка слов (вы также можете взять больше), где один содержит числа, а другой содержит алфавиты, и объединил их в один, чтобы использовать несколько словарей одновременно.
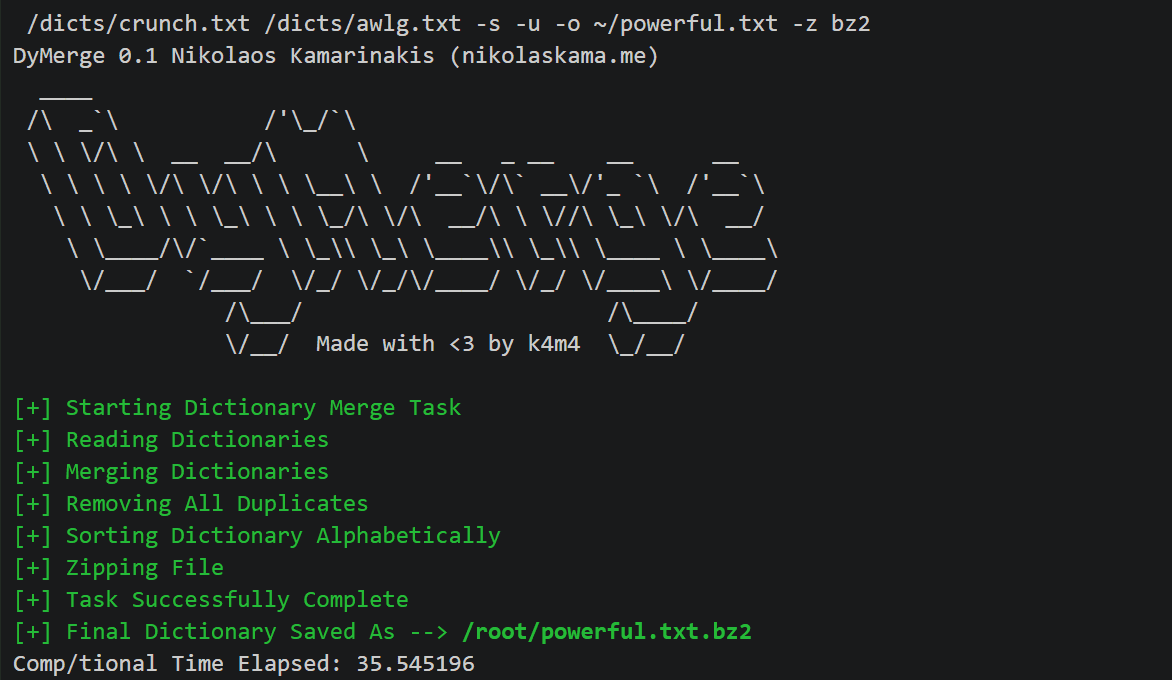
Давайте посмотрим на словарь, который он создал:
- cat awlg.txt

Это 5 мощных и эффективных способов создать себе словарь. Которые в дальнейшем вам помогут в изучении IT
• Канал про криптовалюту: CryptOVER
• Наш чат: OVER-CHAT
• Наш мерч: Магазин
•Телеграм канал: TESTLAND
•Личный телеграм канал: overbafer1
•Группа ВК: overpublic1
•Youtube: overbafer1
•Второй Youtube: IGOR OVER
•🤖 https://overbafer1.ru/ — эксклюзивный бот для разведки и поиска информации в сети
Создание и нормализация словарей. Выбираем лучшее, убираем лишнее
Время на прочтение
5 мин
Количество просмотров 33K

Использование подходящих словарей во время проведения тестирования на проникновение во многом определяет успех подбора учетных данных. В данной публикации я расскажу, какие современные инструменты можно использовать для создания словарей, их оптимизации для конкретного случая и как не тратить время на перебор тысяч заведомо ложных комбинации.
Инструменты
crunch
Пожалуй, один из самых известных инструментов для быстрого создания словарей. Он по умолчанию входит в популярный дистрибутив для проведения пентеста Kali Linux.
Инструмент работает в нескольких режимах:
Создание словаря, состоящего из перечисленных символов, например чисел
crunch 4 5 1234567890 -o all_numbers_from_4_to_5.txt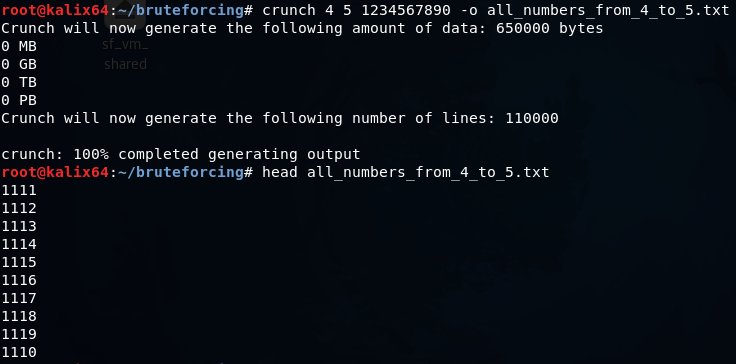
Создается словарь длиной от четырех до пяти цифр.
Создание словаря по шаблону
crunch 10 10 qwe RTY 123 \#\@ -t P^@@,ord%% -o Password_template.txt

Сперва указывается длина пароля — 10 символов. Затем перечисляются наборы символов: буквы в нижнем регистре, буквы в верхнем регистре, цифры и спецсимволы. Ключ -t задает шаблон, где
- ^ — спецсимволы
- @ — буквы в нижнем регистре
- , — буквы в верхнем регистре
- % — цифры
И третий режим работы crunch — перестановки.
crunch 1 1 -p Alex Company Position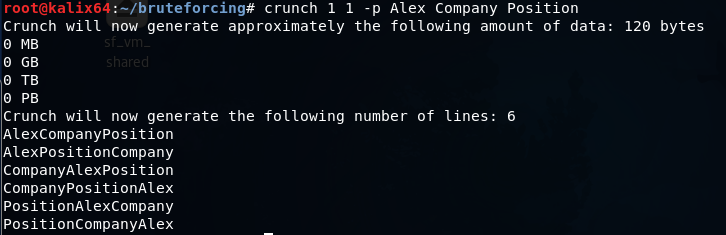
Словарь состоит из всех возможных комбинаций слов Alex, Company и Position.
Подробнее изучить инструмент можно через стандартные man страницы, они достаточно подробные.
maskprocessor
Иногда требуется указать не только наборы под конкретный тип символов, а вообще свой набор, включающий и буквы, и цифры, и спецсимволы. В этом случае можно воспользоваться утилитой maskprocessor от брутфорсера hashcat. Скачать ее можно с официального гитхаба hashcat.
Вы можете задать до четырех собственных наборов символов и использовать готовые наборы
?l = abcdefghijklmnopqrstuvwxyz
?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ
?d = 0123456789
?s = !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
?a = ?l?u?d?s
?b = 0x00 - 0xffПример использования
mp64.bin -1 Pp -2 \@\#\$ ?1assw?2r?d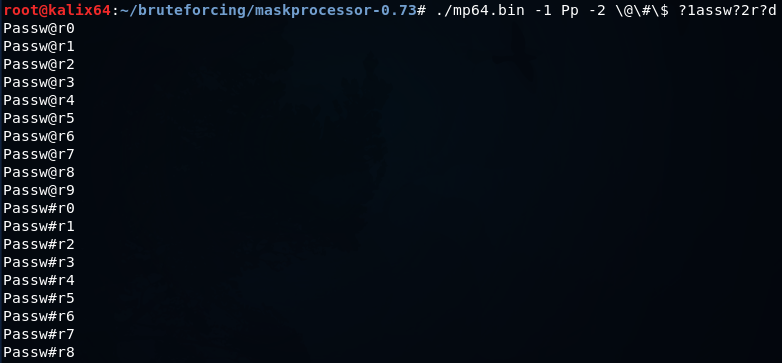
Или можно задать набор из цифр, но добавить к нему еще несколько спецсимволов так
mp64.bin -1 Qq -2 ?d\@\#\$ ?1werty_12?2Получаем такой результат
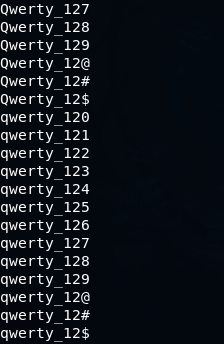
John the Ripper
Популярный брутфорсер John the Ripper (JTR) тоже позволяет генерировать словари на основе правил. Делается это при помощи ключа —rules, а сами правила описываются в файле john.conf
Вот так выглядит стандартное правило, используемое для взлома NTLM хэша
[List.Rules:NT]
:
-c T0Q
-c T1QT[z0]
-c T2QT[z0]T[z1]
-c T3QT[z0]T[z1]T[z2]
-c T4QT[z0]T[z1]T[z2]T[z3]
-c T5QT[z0]T[z1]T[z2]T[z3]T[z4]
-c T6QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]
-c T7QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]
-c T8QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]
-c T9QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]
-c TAQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]
-c TBQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]
-c TCQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]
-c TDQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]T[zC]В первой строчке сказано, что нужно изменить регистр символа на нулевой позиции (T0), символ Q позволяет не допустить дубликатов в результирующем словаре. Во второй строке символ на первой позиции меняет свой регистр, затем скобки задают препроцессор, чтобы были сгенерированы пароли и с измененным нулевым символом и так далее.
Предположим, вы успешно провели брутфорс LM хэша и получили значение QWERTY123, так как для LM регистр не важен.
Но для авторизации вам нужно провести брутфорс NTLM хэша, где регистр имеет значение. Воспользовавшись правилом, описанным выше, можно получить следующий словарь
john -w:QWERTY123.dict --stdout --rules:NT
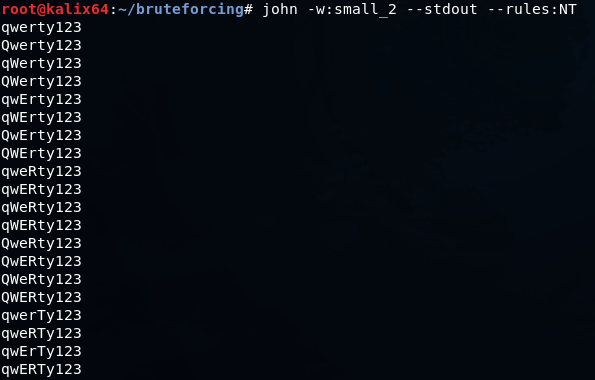
JTR по умолчанию содержит множество готовых правил, но можно написать и свои, либо взять за основу уже написанное и скорректировать под текущую ситуацию.
Подробно про синтаксис правил можно почитать здесь.
hashcat-tools
Еще одним полезным инструментом является набор утилит от популярного брутфорсера hashcat.
Скачать их можно с официального сайта.
Рассмотрим некоторые их них. Описания всех утилит на английском языке можно найти тут.
combinanor.bin — позволяет генерировать словарь из слов, входящих в два других словаря.
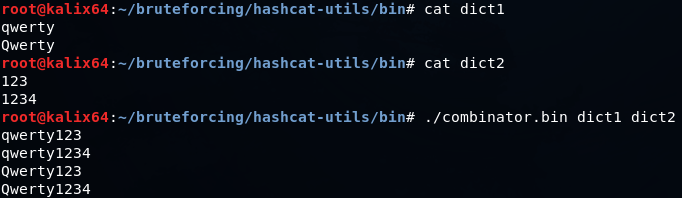
combinanor3.bin делает то же самое, но на вход принимает три файла, вместо двух.
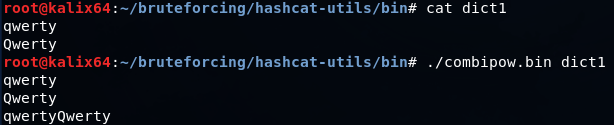
combipow.bin — создает все возможные комбинации из слов, перечисленных в файле (похоже на ключ -p в crunch)
cutb.bin — обрезает слова в словаре до указанной длины. Можно указывать смещение (offset)

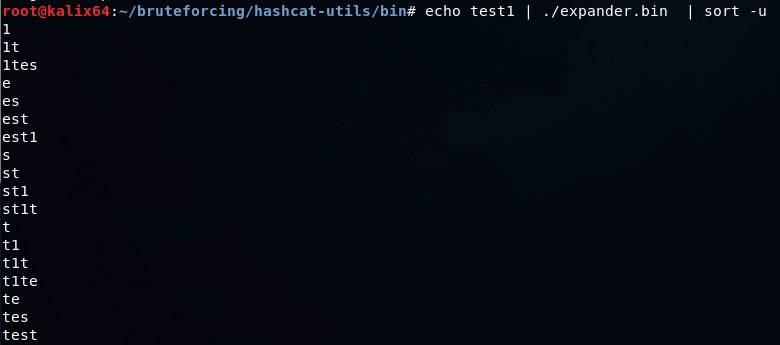
expander.bin — получает на ввод слова, разбирает их на символы, комбинирует и отправляет в STDOUT
permute.bin — создает словарь, который используется hashcat при атаке типа Permutation attack. Перед использованием словарь нужно пропустить через утилиту prepare.
gate.bin — разбивает словарь на несколько частей для параллельной обработки несколькими ядрами или несколькими машинами. В примере ниже мы разбиваем стандартный словарь JTR на две части. В первую часть попадают слова под номером 0, 2, 4, 6,…. Во вторую 1, 3, 5, 7,…
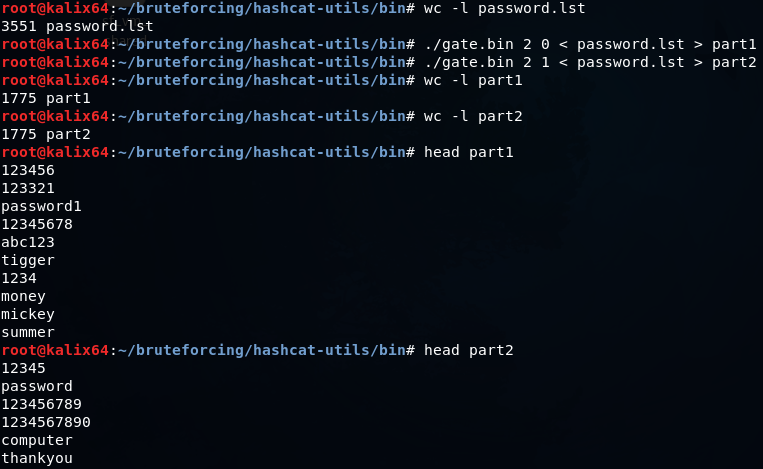
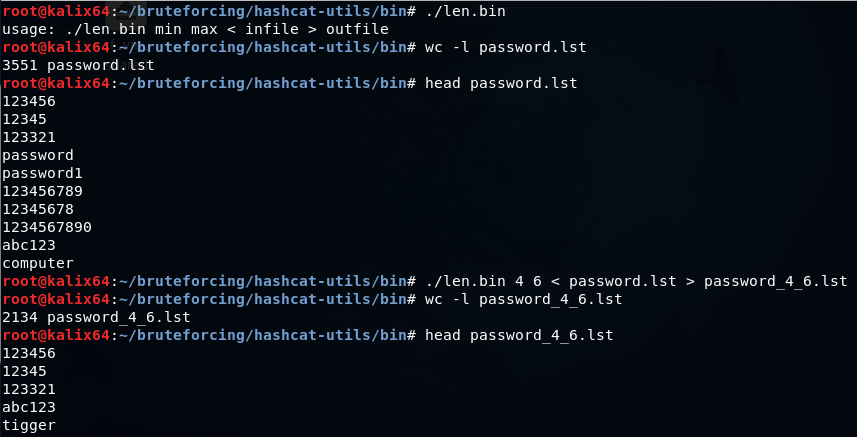
len.bin — оставляет в словаре только слова определенной длины от min до max
mli2.bin — объединяет два словаря.
req-include.bin — крайне полезный инструмент, который убирает из словаря все, что не подходит под заданные правила. Например, вы знаете, что по парольной политике в пароле обязательно присутствует буква в верхнем регистре, цифра и спецсимвол.

Число выбрано исходя из таблицы

Если таким образом нормализовать известный словарь rockyou, то можно сократить его размер в 270 раз! и не тратить ресурсы на заведомо ложные комбинации.

req-exclude.bin делает то же самое, что req-include, но с точностью до наоборот.
rli.bin — эта утилита удаляет значения из первого словаря, если они встречаются во втором. Полезно использовать, если вы создаете один словарь из нескольких.
Когда под рукой нет утилит
Может оказаться так, что воспользоваться набором hashcat-utils или crunch нет возможности, а нужно срочно создать словарь или нормализовать его. Некоторые алгоритмы довольно сложны в реализации, но базовые операции можно выполнить просто в командной строке.
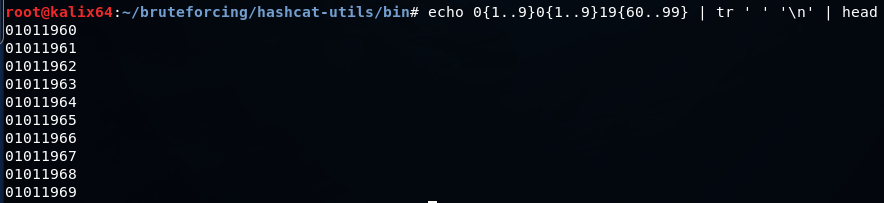
Простой словарь с датами можно создать серией подобных команд
echo 0{1..9}0{1..9}19{60..99} | tr ' ' '\n' >> dates
Если нужно разбить словарь на части для параллельной обработки, можно воспользоваться командой split
split -d -l 1000 password.lst splitted_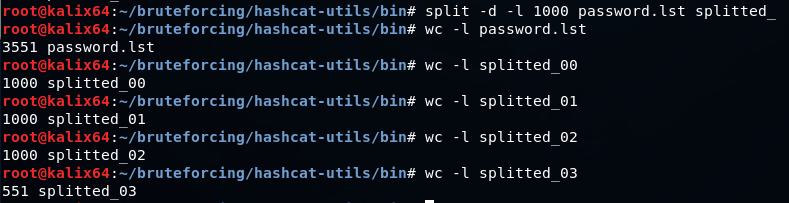
Быстро объединить два словаря можно так
cat dict1 dict2 > combined_dict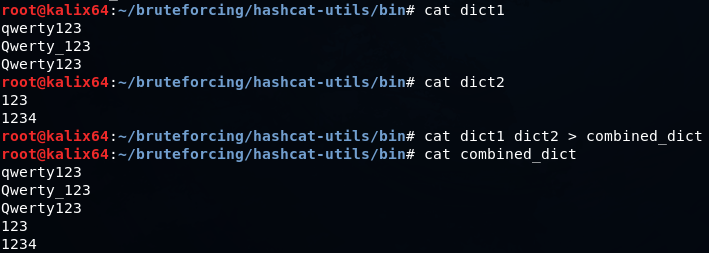
Чтобы сделать заглавной первую или последнюю буквы в каждом слове, нужно выполнить, соответственно, команды
sed 's/^./\u&/' dict_file
sed 's/.$/\u&/' dict_fileДля перевода регистра в нижний нужно заметить «u» на «l»
Дописать что-то в начало каждого слова из словаря можно так
sed 's/^./word/' dict_fileА так можно дописать слово в конец
sed 's/.$/word/' dict_file
Следующей командой можно добавить в начало число от 0 до 99 к каждому слову в словаре
for i in $(cat dict_file) ; do seq -f %02.0f$i 0 99 ; done > numbers_dict_file
Можно очистить словарь от значений, в которых не присутствует хотя бы 2 числа так
nawk 'gsub("[0-9]","&",$0)==2' password.lstПолучаем
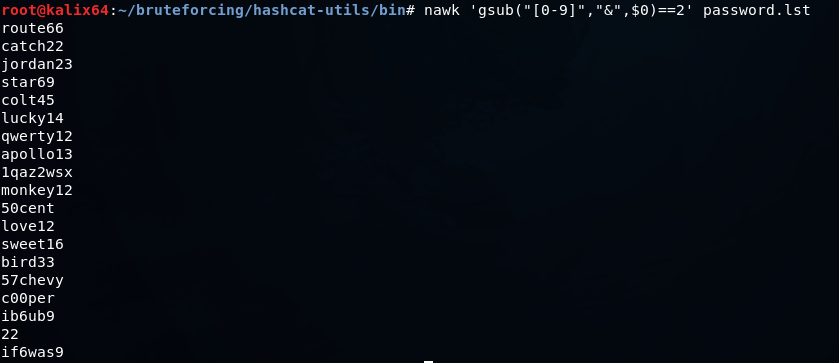
Это лишь некоторые примеры. Можно писать более сложные обработки на Python и других скриптовых языках. Но всегда нужно помнить, что создание качественного словаря и его нормализация под целевой протокол — важный этап при проведении тестирования на проникновение.
CRUNCH — программа предназначенная для создания собственных словарей.
Размеры списков не определены, однако crunch может использовать так называемые “шаблоны” для уменьшения размеров словаря;
crunch может сжимать выходные файлы в различных форматах и (начиная с версии 2.6) выводит сообщения о том, какого размера будет словарь.
Набор опций
Перед тем, как начинать использовать crunch, давайте пробежимся по опциям:
-b — задание размера файла; эта опция используется, если вы хотите задать размер файла в KB/MB/GB (должна использоваться с опцией “-o START“)
-c — задание количества строк (должна использоваться с опцией “-o START“)
-d — ограничение числа последовательно одинаковых символов
-e — задается тогда, когда нужно остановить crunch (crunch v3.1)
-f — задает путь к файлу charset.lst
-i — инвертирует вывод; вместо слева-направо будет справа-налево (т.е. вместо ААС, ААВ, ААF будет САА, ВАА, FAA)
-o — позволяет указать выходной файл
-p — перестановка слов или символов (командная строка)
-q — перестановка слов или символов (указать в файле)
-r — возобновить синтаксис предыдущей сессии для использования след. -r
-s — позволяет указать начальную строку в wordlist
-t — позволяет указать конкретный шаблон для использования
-u — запрещает вывод размера словаря и кол-во строк до начала генерации
-z — добавляет поддержку сжатия вывода (поддерживается gzip, bzip & lzma)
Установка crunch
Установить crunch можно несколькими способами, например из исходных кодов. Для этого скачиваем crunch http://sourceforge.net/projects/crunch-wordlist/. После чего выполняем следующие команды:
# tar -xvf crunch-3.6.tgz
# cd crunch3.6
# make && make install
Основное использование
По умолчанию crunch устанавливается в следующий каталог (на примере BackTrack): /pentest/passwords/crunch/. Основной синтаксис команды:# crunch [min_length] [max_length] [character_set] [options]
min_length — минимальная длина слова
max_length — максимальная длина слова
character_set — набор символов
options — опции
Синтаксис:
crunch [min length] [max length] [character set] [options]
Если вы не определили набор символов, тогда cranch будет использовать по умолчанию нижний регистр букв (alpha):
# crunch 4 4
Задать символы вручную:
# crunch 6 6 0123456789ABCDEF
Некоторые символы необходимо “изолировать” косой чертой \ :
# crunch 6 6 ABC\!\@\#\$
Создание списков слов по блокам определенного размера
Чтобы указать crunch создавать списки слов определенного размера, используется опция -b. Должно быть использовано в сочетании с опцией -o START. Размер файлов может задаваться в след. форматах: kb, mb, gb или kib, mib, gib. kb, mb и gb — основывается на 10 (т.е. 1KB = 1000 bytes). kib, mib и gib основывается на 2 (т.е. 1KB = 1024 bytes).
Создать словарь, файлы которого не будут превышать 1mb:
# crunch 6 6 0123456789 -b 1mb -o START
Создать словарь, файлы которого не будут превышать 100mb:
# crunch 8 8 abcDEF123 -b 100mb -o START
Создать словарь, файлы которого не будут превышать 10kb:
# crunch 4 4 0123456789 -b 10kb -o START
Создать словарь, файлы которого не будут превышать 2GB:
# crunch 8 8 0123456789ABCDEF -b 2gb -o START
Создание словаря с определенным количеством строк
Используя опцию -с, можно “сказать” crunch, чтобы он создавал файлы с определенным количеством строк. Для этого, также нужно использовать -o START.
Создать словарь, файлы которого будут содержать не более 200000 строк:
# crunch 6 6 0123456789 -c 200000 -o START
Создать список слов, файлы которых будут содержать не более 150000 строк:
# crunch 6 6 abcDEF123 -c 150000 -o START
Остановка crunch в заданное время (на определенном слове)
В версии Crunch v3.1 появилась новая опция -e, которая “говорит” crunch остановиться, когда он дойдет до определенного слова. Например следующая команда указывает crunch остановиться тогда, когда он дойдет до 333333:
# crunch 6 6 -t %%%%%% -e 333333
Использование фиксированных наборов символов
Crunch позволяет работать с фиксированными наборами символов, названия которых находятся в файле charset.lst. Это позволяет сэкономить время при вводе:
# charset configuration file for winrtgen v1.2 by Massimiliano Montoro (mao@oxid.it)
# compatible with rainbowcrack 1.1 and later by Zhu Shuanglei <shuanglei@hotmail.com>
hex-lower = [0123456789abcdef]
hex-upper = [0123456789ABCDEF]
numeric = [0123456789]
numeric-space = [0123456789 ]
symbols14 = [!@#$%^&*()-_+=]
symbols14-space = [!@#$%^&*()-_+= ]
symbols-all = [!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/]
symbols-all-space = [!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/ ]
ualpha = [ABCDEFGHIJKLMNOPQRSTUVWXYZ]
ualpha-space = [ABCDEFGHIJKLMNOPQRSTUVWXYZ ]
ualpha-numeric = [ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789]
ualpha-numeric-space = [ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 ]
ualpha-numeric-symbol14 = [ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+=]
ualpha-numeric-symbol14-space = [ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+= ]
ualpha-numeric-all = [ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/]
ualpha-numeric-all-space = [ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/ ]
lalpha = [abcdefghijklmnopqrstuvwxyz]
lalpha-space = [abcdefghijklmnopqrstuvwxyz ]
lalpha-numeric = [abcdefghijklmnopqrstuvwxyz0123456789]
lalpha-numeric-space = [abcdefghijklmnopqrstuvwxyz0123456789 ]
lalpha-numeric-symbol14 = [abcdefghijklmnopqrstuvwxyz0123456789!@#$%^&*()-_+=]
lalpha-numeric-symbol14-space = [abcdefghijklmnopqrstuvwxyz0123456789!@#$%^&*()-_+= ]
lalpha-numeric-all = [abcdefghijklmnopqrstuvwxyz0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/]
lalpha-numeric-all-space = [abcdefghijklmnopqrstuvwxyz0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/ ]
mixalpha = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ]
mixalpha-space = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ ]
mixalpha-numeric = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789]
mixalpha-numeric-space = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 ]
mixalpha-numeric-symbol14 = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+=]
mixalpha-numeric-symbol14-space = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+= ]
mixalpha-numeric-all = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/]
mixalpha-numeric-all-space = [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/ ]
#########################################################################################
# SWEDISH CHAR-SUPPORT #
#########################################################################################
#########################
# Uppercase #
#########################
ualpha-sv = [ABCDEFGHIJKLMNOPQRSTUVWXYZ???]
ualpha-space-sv = [ABCDEFGHIJKLMNOPQRSTUVWXYZ??? ]
ualpha-numeric-sv = [ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789]
ualpha-numeric-space-sv = [ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789 ]
ualpha-numeric-symbol14-sv =[ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+=]
ualpha-numeric-symbol14-space-sv =[ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+= ]
ualpha-numeric-all-sv = [ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/]
ualpha-numeric-all-space-sv = [ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/ ]
#########################
# Lowercase #
#########################
lalpha-sv = [abcdefghijklmnopqrstuvwxyz???]
lalpha-space-sv = [abcdefghijklmnopqrstuvwxyz??? ]
lalpha-numeric-sv = [abcdefghijklmnopqrstuvwxyz???0123456789]
lalpha-numeric-space-sv = [abcdefghijklmnopqrstuvwxyz???0123456789 ]
lalpha-numeric-symbol14-sv = [abcdefghijklmnopqrstuvwxyz???0123456789!@#$%^&*()-_+=]
lalpha-numeric-symbol14-space-sv = [abcdefghijklmnopqrstuvwxyz???0123456789!@#$%^&*()-_+= ]
lalpha-numeric-all-sv = [abcdefghijklmnopqrstuvwxyz???0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/]
lalpha-numeric-all-space-sv = [abcdefghijklmnopqrstuvwxyz???0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/ ]
#########################
# Mixcase #
#########################
mixalpha-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ???]
mixalpha-space-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ??? ]
mixalpha-numeric-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789]
mixalpha-numeric-space-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789 ]
mixalpha-numeric-symbol14-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+=]
mixalpha-numeric-symbol14-space-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+= ]
mixalpha-numeric-all-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/]
mixalpha-numeric-all-space-sv = [abcdefghijklmnopqrstuvwxyz???ABCDEFGHIJKLMNOPQRSTUVWXYZ???0123456789!@#$%^&*()-_+=~`[]{}|\:;»‘<>,.?/ ]
Для того, чтобы воспользоваться фиксированными наборами символов, используйте опцию -f. Например, чтобы создать список слов ualpha (заглавные буквы), воcпользуйтесь следующей командой:
# crunch 6 6 -f charset.lst ualpha
Создать числовой (numeric) список слов:
# crunch 6 6 -f charset.lst numeric
Создать шестнадцатеричный список слов, где символы ABCDEF будут заглавными (hex-upper):
# crunch 8 8 -f charset.lst hex-upper
Использование инверсии в crunch
Используя опцию -i можно заставить crunch создавать список слов справа налево. В принципе в этой опции нету особо смысла, так как в любом случае будет тоже самое, но только наоборот. Например:
# crunch 4 4 -i
Опция -i может использоваться, как при ручном наборе символов (см. пример выше), так и при фиксированном наборе:
# crunch 4 4 -f charset.lst ualpha -i
Создание подстановок
Crunch может быть использован для создания подстановок, которые включают:
символы/слова введенные в команду – опция -p
строки в списке слов – опция -q
С помощью опции -p можно создавать перестановки символов или слов, введенные в командной строке. Создание перестановки букв (анаграмма):
# crunch 1 1 -p abcd
Создание перестановки со списком слов:
# crunch 1 1 -p bird cat dog
Опция -p должна находиться последней в команде. Для примера возьмем опцию -u, которая не выводит “подавляет” информацию о размере будущего файла. Т.е. команда будет следующего вида:
# crunch 1 1 -p abcd -u
В результате crunch посчитает ее как (abcd + -u). Так что будьте внимательны. А теперь запишем команду, так как надо. Т.е. поставим опцию -p последней:
# crunch 1 1 -u -p abcd
В результате мы получили то, что хотели, а также “подавили” вывод размера будущего файла с помощью опции -u. Используя опцию -q можно создать список слов со всевозможными комбинациями из файла. Т.е. опция -q берет каждую строку из файла и комбинирует ее с другими строками.
Например создадим файл test.txt с тремя строками bird, cat и dog:
# touch test.txt && echo «bird» > test.txt && echo «cat» >> test.txt && echo «dog» >> test.txt
# cat test.txt
bird
cat
dog
# crunch 1 1 -q test.txt
Crunch will now generate approximately the following amount of data:
66 bytes
0 MB
0 GB
0 TB
0 PB
Crunch will now generate the following number of lines: 6
birdcatdog
birddogcat
catbirddog
catdogbird
dogbirdcat
dogcatbird
Как видно, crunch скомбинировала каждую строку из файла в новое слово. Думаю смысл понятен. Возобновление создания списка слов, после отмены Crunch позволяет создавать список слов (словарь), после его отмены (остановки). Для этого нужно воспользоваться опцией -r (resume – возобновление):
# crunch 8 8 0123456789 -o test.txt
Останавливаем выполнение команды нажатием Crtl + C, после чего добавляем в предыдущую команду опцию -r:
# crunch 8 8 0123456789 -o test.txt -r
Если словарь начинается с определенной позиции (см. главу ниже), то при возобновлении, опция -s не должна выводиться. Рассмотрим этот случай на примере. Для этого создаем список слов (словарь) с фиксированным начальным пределом, опция -s:
# crunch 8 8 0123456789 -s 59999999 -o test.txt
root@bt:/pentest/passwords/crunch# head -n 2 test.txt
59999999
60000000
root@bt:/pentest/passwords/crunch# tail -n 2 test.txt
99999998
99999999
После чего останавливаем выполнение (Crtl + C) и запускаем команду с опцией -r, но уже без опции -s:
# crunch 8 8 0123456789 -o test.txt -r
Запуск с определенной позиции
Если нужно создать список слов (словарь) с определенной позиции, используйте опцию -s. Допустим, что при создании словаря у вас закончилось место на HDD или еще что то случилось, после чего вы остановили работу crunch. В этом случае вам поможет временный файл “START”, который находится в директории /pentest/passwords/crunch/.
1. создаем список слов (словарь):
# crunch 7 7 0123456789 -o test.txt
2. останавливаем выполнение программы — Ctrl + C
3. проверяем последние две записи:
# tail -n 2 START
4. копируем/переименовываем словарь:
# cp START file1.txt
5. возобновляем работу crunch с последней записи:
# crunch 7 7 0123456789 -s 9670549 -o test.txt
Важно!
crunch перезапишет временный файл START, когда начнется новый процесс создания списка слов (словаря), поэтому не забудьте скопировать/переименовать файл START, если вы хотите сохранить предыдущую работу.
Создание шаблонов
Настоящая сила crunch в шаблонах. Для задания шаблона используйте опцию -t. Crunch поддерживает четыре вида шаблонов:
@ – строчные буквы
, – заглавные буквы
% – цифры
^ – спец. символы
Создать список слов (словарь) состоящий из строчных букв, длинной 6 символов, начинающиеся с dog:
# crunch 6 6 -t dog@@@
Чтобы dog был в конце:
# crunch 6 6 -t @@@dog
Чтобы dog был по середине:
# crunch 7 7 -t @@dog@@
Или, чтобы dog следовал за заглавной буквы, потом цифра, а потом спец. символ:
# crunch 6 6 -t dog,%^
Также можно комбинировать шаблоны, так как вам взбредет в голову:
# crunch 8 8 -t ,,^^@@%%
Создание словаря только из строчных букв:
# crunch 4 4 -t @@@@
Создание словаря только из цифр:
# crunch 4 4 -t %%%%
Создание словаря только из заглавных букв:
# crunch 4 4 -t ,,,,
Создание словаря только из спец. символов:
# crunch 4 4 -t ^^^^
Можно указать crunch использовать шаблоны, но только с определенным набором символов. Например, давайте создадим список слов (словарь), который будет в себя включать:
abcdef — буквы нижнего регистра
ABCDEF — буквы верхнего регистра
12345 — символы
@#$% — спец. символы
# crunch 8 8 abcdef ABCDEF 12345 @#$%- -t @@,,%%^^
Некоторые спец. символы нужно экранировать \ :
# crunch 10 10 123abcDEF\!\@\# -t TESTING@@@
Если вы решили добавить пробел к своим символам, тогда это можно сделать так:
# crunch «123abcDEF » -t TEST@@@@

Ранее мы уже рассказывали про Hashcat в статье «Использовании Hashcat на Kali Linux». Сегодня покажу, как установить и использовать Hashcat на Windows. Будем взламывать хеш пароля в MD5, MD4, SHA1, SHA3 и коснемся других способов взлома хешей.
Еще по теме: Создание флешки Kali Linux (быстрый способ)
Hashcat — самый быстрый инструментом для взлома паролей. Он кроссплатформенный и доступен для Windows, macOS и Linux. Взломщик паролей поддерживает большое количество алгоритмов хеширования, включая LM Hash, NT hash, MD4, MD5, SHA-1 и 2 и многие другие. На сегодняшний день поддерживает 237 различных типов хешей.
Как пользоваться Hashcat на Windows
Рассмотрим команду использования Hashcat в Windows:
|
.\hashcat —m 0 —a 0 .\crackme.txt .\rockyou.txt |
.\hashcat -m 0 -a 0 .\файл_хешей.txt .\словарь.txt
- -m (тип хеша) — Например, MD5, SHA1 и т. д. В этом примере мы будем использовать
—m 0 для MD5. - -a (тип атаки) — Указывает Hashcat, каким методом взламывать пароль. Например, с использованием словаря слов, или перебора, или знаменитой комбинированной атаки. В этом примере мы будем использовать
—a 0 для атаки по словарю. - [файл_хешей.txt] — Задает расположение файла, содержащего хеш-коды, которые вы собираетесь взломать. В примере я использовал
crackme.txt. - [словарь.txt | маска | каталог] — Задает используемый словарь (список слов), маску или каталог. В этом примере мы будем использовать словарь для брута
rockyou.txt.
Установка и настройка Hashcat в Windows
Зайдите на сайт Хешкэт и скачайте бинарник (версию для Windows).
Запустите командную строку и с помощью команды
cd перейдите в папку с извлеченным из архива Hashcat.

Убедитесь, что находитесь в папке Hashcat введя hashcat.exe.

Создайте новый текстовый документ внутри папки hashcat, где будут хранятся хеши ваших паролей, в моем случае — это файл crackme.txt. Ниже приведен список тестовых хэшей, которые вы можете использовать.
|
6c569aabbf7775ef8fc570e228c16b98 e10adc3949ba59abbe56e057f20f883e 25f9e794323b453885f5181f1b624d0 5f4dcc3b5aa765d61d8327deb882cf9 d8578edf8458ce06fbc5bb76a58c5ca4 fcea920f7412b5da7be0cf42b8c93759 96e79218965eb72c92a549dd5a330112 25d55ad283aa400af464c76d713c07ad e99a18c428cb38d5f260853678922e03 7c6a180b36896a0a8c02787eeafb0e4c 3f230640b78d7e71ac5514e57935eb69 f6a0cb102c62879d397b12b62c092c06 |
Добавьте не менее 5 хешей.
Можете сгенерировать свои собственные хэши каким-нибудь онлайн-сервисом.
Теперь создайте словарь для брута. Hashcat имеет свой словарь example (файл DICT), но лучше использовать словарь Kali Linux rockyou.txt или свой словарь.
Использование Hashcat в Windows
Откройте командную строку и убедитесь, что находитесь в папке Hashcat.
Для справки введите команду:

Большой выбор алгоритмов хеширования:

Для взлома наших хешей используем атаку по словарю
—a 0 на хеш MD5
—m 0.

Как можно видеть на скрине ниже, Хешкэт взломал несколько хешей.

Hashcat добавляет все взломанные пароли в файл potfile и сохраняет в своей папке.
На этом все. Теперь вы знаете как пользоваться мощным инструментом Хешкэт, для взлома паролей.
ПОЛЕЗНЫЕ ССЫЛКИ:
- Лучшие словари для Hashcat
- Актуальные методы взлома паролей
- Брут секретного ключа JWT с помощью Hashcat
На текущий момент пароли остаются самыми популярным методом аутентификации. Атака перебора паролей по словарю также стара как мир и существует множество механизмов защиты от подобного вида атак. Однако возможны ситуации, когда брутфорс (bruteforce) весьма эффективен. Словарей паролей для брута можно найти огромное количество на просторах Интернета. Однако в них в большинстве случаев в них будут англоязычные слова, редко применяемые в России, например названия городов США, баскетбольных команд, американских имен и т.д.
Для успешной атаки нам необходимо учитывать территориально-лингвистические особенности использования паролей. Предположим, что мы провели разведку по открытым источникам и нашли резюме системного администратора компании ООО “Ромашка” Владимира Ягодичкина из города Томск, в дальнейшем изучив его страницу в соц. сети соберем небольшой словарь исходя из полученной информации. Очень часто пользователями задают пароли по названиям хобби, любимых животных, футбольных команд, городов, имен т.д. Анализируя фотографии, аудиозаписи, публикации, а также членство в сообществах мы выяснили информацию о объекте исследования и теперь формализуем ее в заготовки для будущей базы паролей:
- Имя – Владимир -> Vladimir, Volodya, Vovka. Vova.Vovchik, Vov4ik
- Живет в городе Томск -> Tomsk, компания ООО “Ромашка” -> Romashka, LLCRomashka
- Его жену зовут зовут Лариса – Larisa, детей – Игорь и Глеб -> Igor,igorek, Gleb ,Glebushka собаку зовут Шерри -> Sherry, Sher, Sherra
- Объект подписан на фан клуб любителей автомобилей Lada -> Lada, Vaz, Sedan, Vesta, Largus, Granta
- Судя по публикациям, болеет за ФК Локомотив -> FCLokomotiv, Lokomotiv, Paravoz, Loko, Syomin, Smolov, Barinov, Miranchuk, Gilerme
- Политические взгяды объекта исследования указаны как коммунистические -> Lenin, Stalin, Marks, USSR, Сommunism, KPRF,KPSS, KGB, Zyuganov
В результате из полученных данных составляем список:
Vladimir Volodya Vovka Vova Vovchik Vov4ik Tomsk Romashka LLCRomashka Larisa Igor igorek Gleb Glebushka Sherry Shery Sherka Shera Lada Vaz Sedan Vesta Largus Granta FCLokomotiv Lokomotiv Paravoz Loko Syomin Smolov Barinov Miranchuk Gilerme Lenin Stalin Marks USSR Сommunism KPRF KPSS KGB Zyuganov
Учитывая тот факт, что пароли могут задаваться “русскими буквами в английской расскладке” дублируем уже составленный список на основе указанного критерия:
Dkflbvbh Djkjlz Djdrf Djdf Djdxbr Djd4br Njvcr Hjvfirf JJJHjvfirf Kfhbcf Bujh bujhtr Ukt, Ukt,eirf Ithhb Iths Ithrf Ithf Kflf Dfp Ctlfy Dtcnf Kfhuec Uhfynf ARKjrjvjnbd Kjrjvjnbd Gfhfdjp Kjrj C`vby Cvjkjd <fhbyjd Vbhfyxer Ubkthvt Ktyby Cnfkby Vfhrc ECCH Rjvveybpv RGHA RGCC RU< P.ufyjd
Далее объединяем оба списка в один и сохраняем wordlist.txt. Стоит отметить, что наш словарь составил лишь 84 слова и создан для примера. Понятно, что для эффетивного словаря необходимо куда большее колличество слов, например если словарь создается под определенную организацию необходимо указать все города присутсвия, выпускаемую продукцию, наименование используемых сервисов, структурных подразделений, список имен в соответствии с территориальным расположением (например в республике Башкортостан, помимо русских имен популярны такие как: Эмир, Амир, Шариф, Тагир, Самир, Рамазан), также крылатые фразы, профессиональный слэнг, текущие тренды, (например COVID19) и т.д.
Для дальнейшей модификации созданного wordlist.txt в более эффективный словарь в соответствии с парольной политикой и возможной замены некоторых символов букв на спец символы (например a=@) воспользуемся программным обеспечением Mentalist. https://github.com/sc0tfree/mentalist. Mentalist является графическим инструментом для создания словарей для брута. Он использует общие человеческие парадигмы для создания паролей и формирует из них список слов, а также правила, совместимые с Hashcat и John the Ripper. Возможна как установка на Linux, так и запуск на Python Windows.
Для примера снова вновь созданного wordlist.txt , в котором после слова идёт от 2 до 4 цифр и в котором буквы замены на специальные символы.
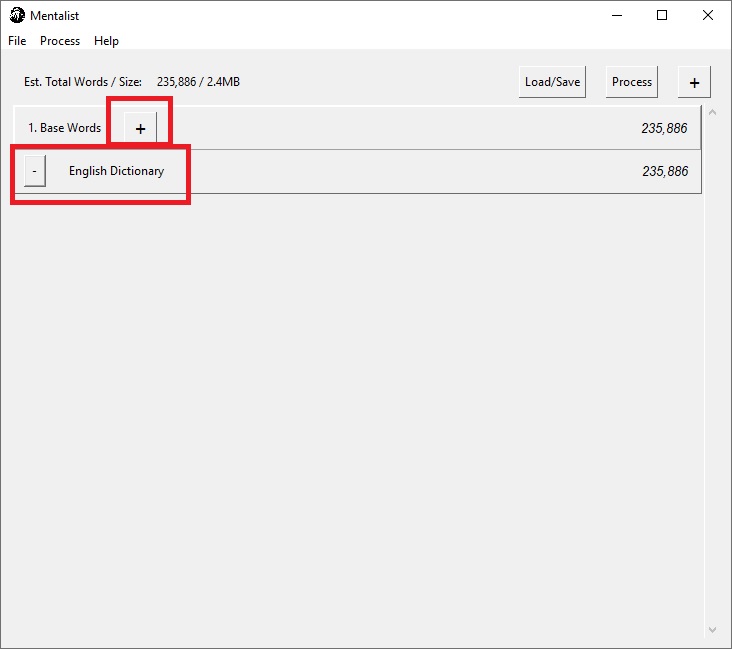
После запуска, в первую очередь необходимо заменить дефолтный список английских слов нашим подготовленным набором слов. Удаляем English Dictionary, нажимает “+” справа от Base Words, выбираем Custom fileи выбираем файл worklist.txt
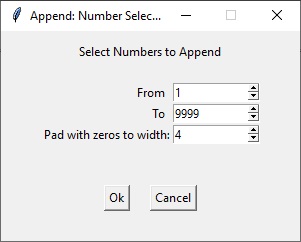
Затем жмём на “+” справ от кнопки Process и выбираем Append. Затем на появившемся блоке нажимаем на “+” , выберем Number -> User Defined…
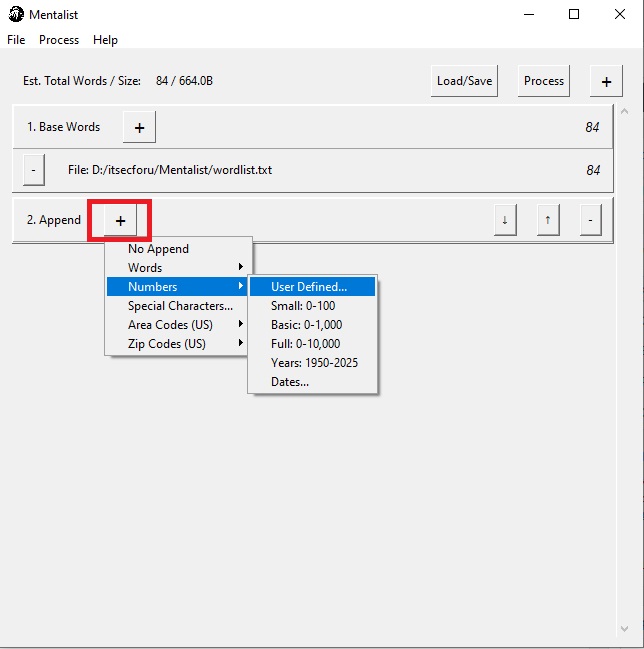
В появившемся окне зададим значения от 1 до 9999 с нулями в каждой ячейке, чтобы в конце слова добилось 4 цифры
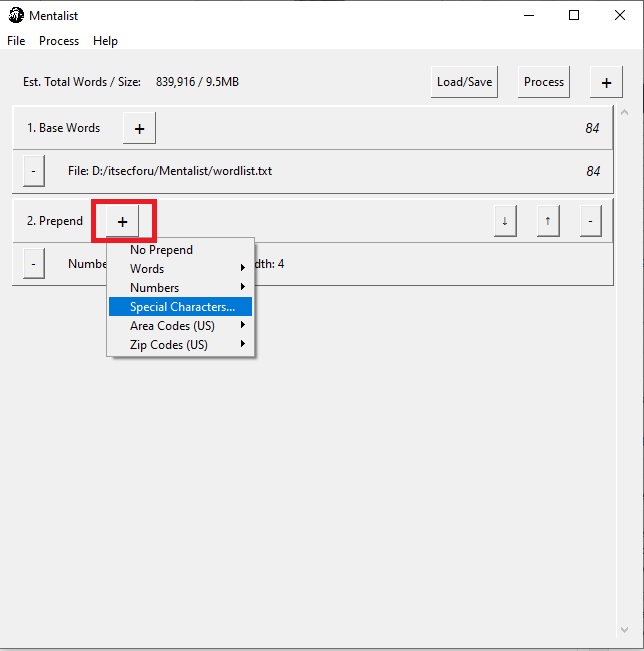
Добавим начало слов специальные символы “!“,“#“,“*“. Для этого справа от Prepend выберем Special Characters…
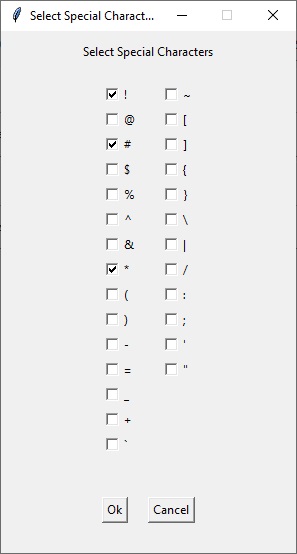
И в появившемся окне выберем необходимые символы:
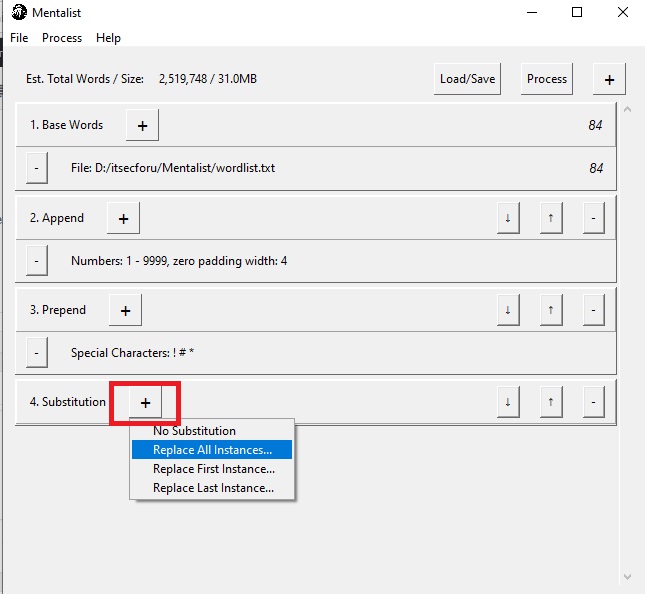
Теперь заменим буквы на специальные символы, а именно a=”@”, s=“$“, o=“0“, i=“1“, для этого справа от кнопки Process нажмем “+” и выбираем Substitution, затем жмем на “+” на новом блоке и выбираем Replace All Instances…
Далее указываем интересующие нас символы:
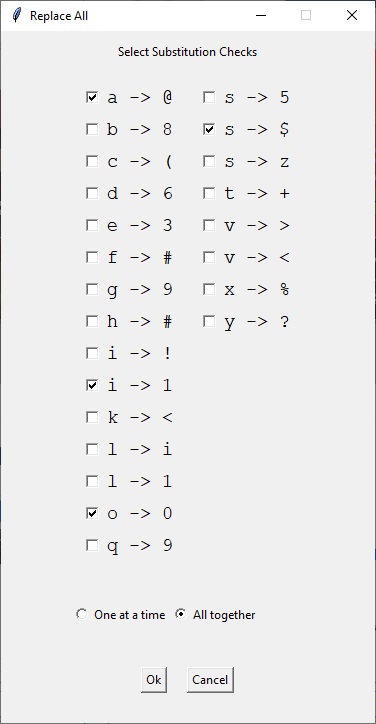
Если указать параметр One at a time, меняться будет первый символ из слова и потом это слово будет отправляться далее по конвейеру, затем будет делаться замена во следующем символе и слово вновь будет отправлено далее по конвейеру. Если указать All together то все буквы из слова преобразуются в специальные символы, его мы и укажем. Стоит сразу отметить, что замена букв в специальные символы относительно второго блока слов (“русскими буквами в английской раскладке”) не эффективна, однако мы преследуем сугубо академические цели, поэтому применим наши правила ко всему списку.
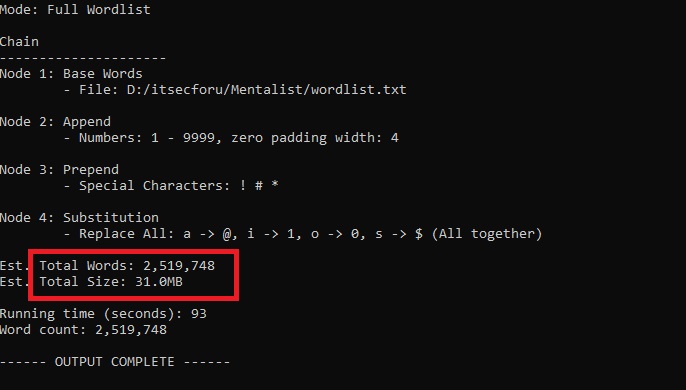
После конфигурирования всех нужных правил нажимаем на кнопку Process, выбираем Full Wordlist и куда сохранить результаты формирования словаря. В результате получаем словарь из 2 519 748 слов, размером 31 MB.

Сформированный словарь можно использовать для получения доступа к информационным системам, которые, например, администрирует и сопровождает наш объект исследования Владимир Ягодичкин (в целях аудита информационной безопасности конечно же). Сразу отметим, что рассмотрены не все возможности указанного инструмента. Для более подробного ознакомления: https://github.com/sc0tfree/mentalist/wiki
Люби ИБ, уважай ИТ!
¯\_(ツ)_/¯
Примечание: Информация для исследования, обучения или проведения аудита. Применение в корыстных целях карается законодательством РФ.