Время на прочтение
6 мин
Количество просмотров 58K
 Давным-давно, в далекой-далекой галактике…, стояла передо мной задача организовать подключение нового филиала к центральному офису. В филиале доступно было два сервера, и я думал, как было бы неплохо организовать из двух серверов отказоустойчивый кластер hyper-v. Однако времена были давние, еще до выхода 2012 сервера. Для организации кластера требуется внешнее хранилище и сделать отказоустойчивость из двух серверов было в принципе невозможно.
Давным-давно, в далекой-далекой галактике…, стояла передо мной задача организовать подключение нового филиала к центральному офису. В филиале доступно было два сервера, и я думал, как было бы неплохо организовать из двух серверов отказоустойчивый кластер hyper-v. Однако времена были давние, еще до выхода 2012 сервера. Для организации кластера требуется внешнее хранилище и сделать отказоустойчивость из двух серверов было в принципе невозможно.
Однако недавно я наткнулся на статью Romain Serre в которой эта проблема как раз решалась с помощью Windows Server 2016 и новой функции которая присутствует в нем — Storage Spaces Direct (S2D). Картинку я как раз позаимствовал из этой статьи, поскольку она показалась очень уместной.
Технология Storage Spaces Direct уже неоднократно рассматривалась на Хабре. Но как-то прошла мимо меня, и я не думал, что можно её применять в «народном хозяйстве». Однако это именно та технология, которая позволяет собрать кластер из двух нод, создав при этом единое общее хранилище между серверами. Некий единый рейд из дисков, которые находятся на разных серверах. Причем выход одного из дисков или целого сервера не должны привести к потере данных.

Звучит заманчиво и мне было интересно узнать, как это работает. Однако двух серверов для тестов у меня нет, поэтому я решил сделать кластер в виртуальной среде. Благо и вложенная виртуализация в hyper-v недавно появилась.
Для своих экспериментов я создал 3 виртуальные машины. На первой виртуальной машине я установил Server 2016 с GUI, на котором я поднял контроллер AD и установил средства удаленного администрирования сервера RSAT. На виртуальные машины для нод кластера я установил Server 2016 в режиме ядра. В этом месяце загадочный Project Honolulu, превратился в релиз Windows Admin Center и мне также было интересно посмотреть насколько удобно будет администрировать сервера в режиме ядра. Четвертная виртуальная машина должна будет работать внутри кластера hyper-v на втором уровне виртуализации.
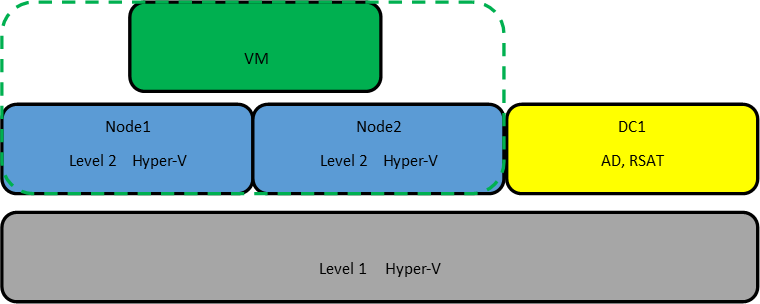
Для работы кластера и службы Storage Spaces Direct необходим Windows Server Datacenter 2016. Отдельно стоит обратить внимание на аппаратные требования для Storage Spaces Direct. Сетевые адаптеры между узлами кластера должны быть >10ГБ с поддержкой удаленного прямого доступа к памяти (RDMA). Количество дисков для объединения в пул – минимум 4 (без учета дисков под операционную систему). Поддерживаются NVMe, SATA, SAS. Работа с дисками через RAID контроллеры не поддерживается. Более подробно о требованиях docs.microsoft.com
Если вы, как и я, никогда не работали со вложенной виртуализацией hyper-v, то в ней есть несколько нюансов. Во-первых, по умолчанию на новых виртуальных машинах она отключена. Если вы захотите в виртуальной машине включить роль hyper-v, то получите ошибку, о том, что оборудование не поддерживает данную роль. Во-вторых, у вложенной виртуальной машины (на втором уровне виртуализации) не будет доступа к сети. Для организации доступа необходимо либо настраивать nat, либо включать спуфинг для сетевого адаптера. Третий нюанс, для создания нод кластера, нельзя использовать динамическую память. Подробнее по ссылке.
Поэтому я создал две виртуальные машины – node1, node2 и сразу отключил динамическую память. Затем необходимо включить поддержку вложенной виртуализации:
Set-VMProcessor -VMName node1,node2 -ExposeVirtualizationExtensions $trueВключаем поддержку спуфинга на сетевых адаптерах ВМ:
Get-VMNetworkAdapter -VMName node1,node2 | Set-VMNetworkAdapter -MacAddressSpoofing On
HDD10 и HDD 20 я использовал как системные разделы на нодах. Остальные диски я добавил для общего хранилища и не размечал их.
Сетевой интерфейс Net1 у меня настроен на работу с внешней сетью и подключению к контроллеру домена. Интерфейс Net2 настроен на работу внутренней сети, только между нодами кластера.
Для сокращения изложения, я опущу действия необходимые для того, чтобы добавить ноды к домену и настройку сетевых интерфейсов. С помощью консольной утилиты sconfig это не составит большого труда. Уточню только, что установил Windows Admin Center с помощью скрипта:
msiexec /i "C:\WindowsAdminCenter1804.msi" /qn /L*v log.txt SME_PORT=6515 SSL_CERTIFICATE_OPTION=generateПо сети из расшаренной папки установка Admin Center не прошла. Поэтому пришлось включать службу File Server Role и копировать инсталлятор на каждый сервер, как в мс собственно и рекомендуют.
Когда подготовительная часть готова и перед тем, как приступать к созданию кластера, рекомендую обновить ноды, поскольку без апрельских обновлений Windows Admin Center не сможет управлять кластером.
Приступим к созданию кластера. Напомню, что все необходимые консоли у меня установлены на контролере домена. Поэтому я подключаюсь к домену и запускаю Powershell ISE под администратором. Затем устанавливаю на ноды необходимые роли для построения кластера с помощью скрипта:
$Servers = "node1","node2"
$ServerRoles = "Data-Center-Bridging","Failover-Clustering","Hyper-V","RSAT-Clustering-PowerShell","Hyper-V-PowerShell","FS-FileServer"
foreach ($server in $servers){
Install-WindowsFeature –Computername $server –Name $ServerRoles} И перегружаю сервера после установки.
Запускаем тест для проверки готовности нод:
Test-Cluster –Node "node1","node2" –Include "Storage Spaces Direct", "Inventory", "Network", "System ConfigurationОтчёт в фомате html сформировался в папке C:\Users\Administrator\AppData\Local\Temp. Путь к отчету утилита пишет, только если есть ошибки.
Ну и наконец создаем кластер с именем hpvcl и общим IP адресом 192.168.1.100
New-Cluster –Name hpvcl –Node "node1","node2" –NoStorage -StaticAddress 192.168.1.100 После чего получаем ошибку, что в нашем кластере нет общего хранилища для отказоустойчивости. Запустим Failover cluster manager и проверим что у нас получилось.

Включаем (S2D)
Enable-ClusterStorageSpacesDirect –CimSession hpvcl И получаем оповещение, что не найдены диски для кэша. Поскольку тестовая среда у меня на SSD, а не на HDD, не будем переживать по этому поводу.
Затем подключаемся к одной из нод с помощью консоли powershell и создаем новый том. Нужно обратить внимание, что из 4 дисков по 40GB, для создания зеркального тома доступно порядка 74GB.
New-Volume -FriendlyName "Volume1" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 74GB -ResiliencySettingName Mirror 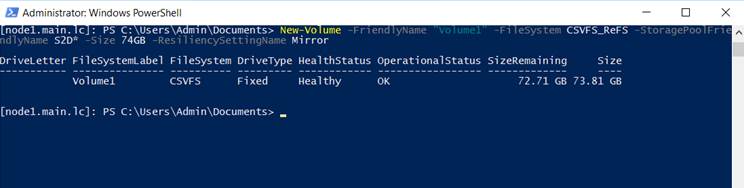
На каждой из нод, у нас появился общий том C:\ClusterStorage\Volume1.
Кластер с общим диском готов. Теперь создадим виртуальную машину VM на одной из нод и разместим её на общее хранилище.
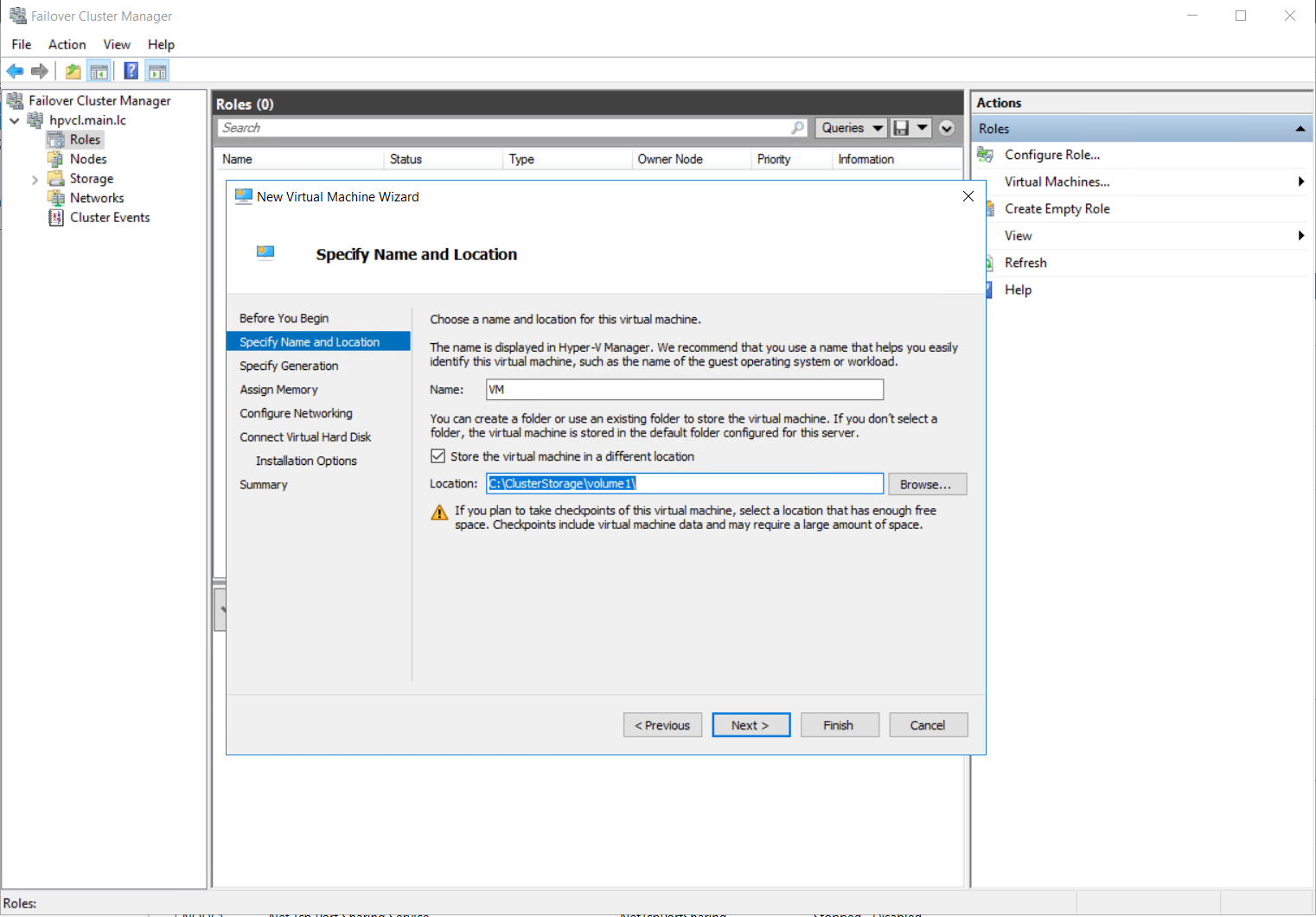
Для настроек сети виртуальной машины, необходимо будет подключиться консолью hyper-v manager и создать виртуальную сеть с внешним доступом на каждой из нод с одинаковым именем. Затем мне пришлось перезапустить службу кластера на одной из нод, чтобы избавиться от ошибки с сетевым интерфейсом в консоли failover cluster manager.
Пока на виртуальную машину устанавливается система, попробуем подключиться к Windows Admin Center. Добавляем в ней наш гиперконвергентный кластер и получаем грустный смайлик
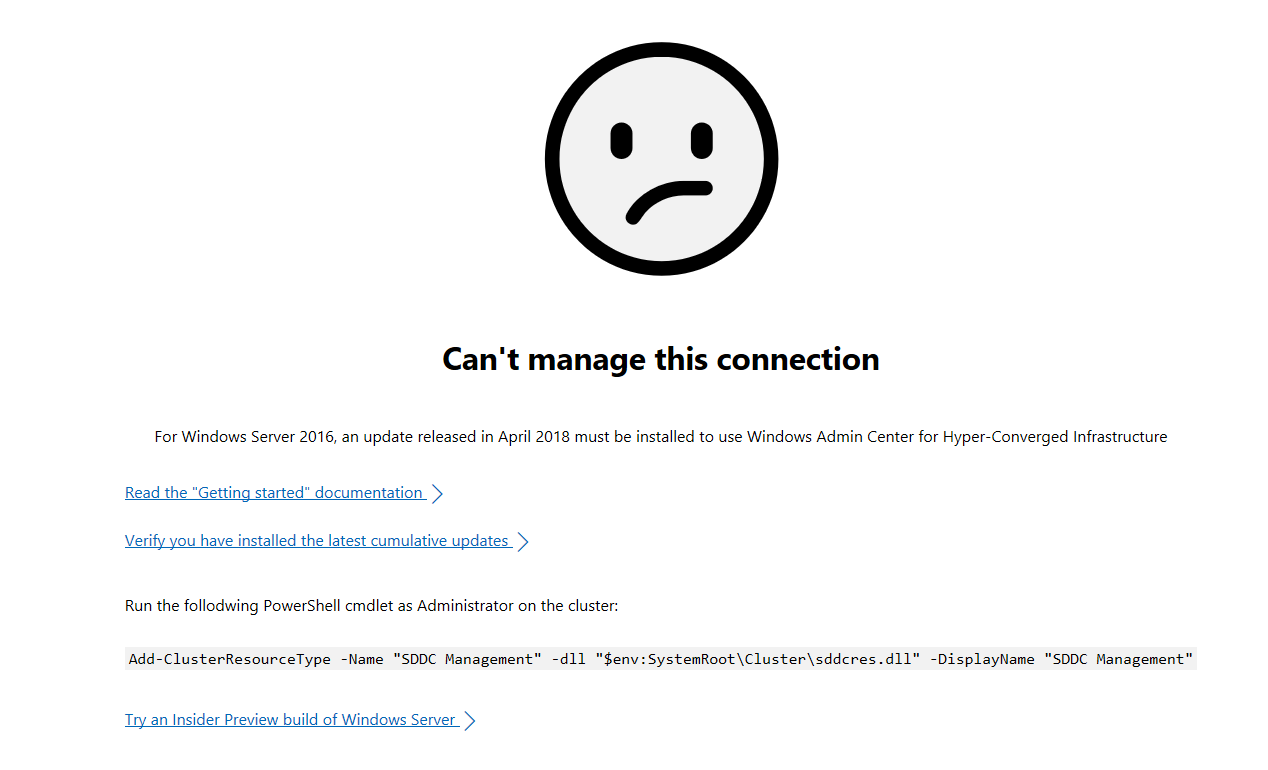
Подключимся к одной из нод и выполним скрипт:
Add-ClusterResourceType -Name "SDDC Management" -dll "$env:SystemRoot\Cluster\sddcres.dll" -DisplayName "SDDC Management"Проверяем Admin Center и на этот раз получаем красивые графики
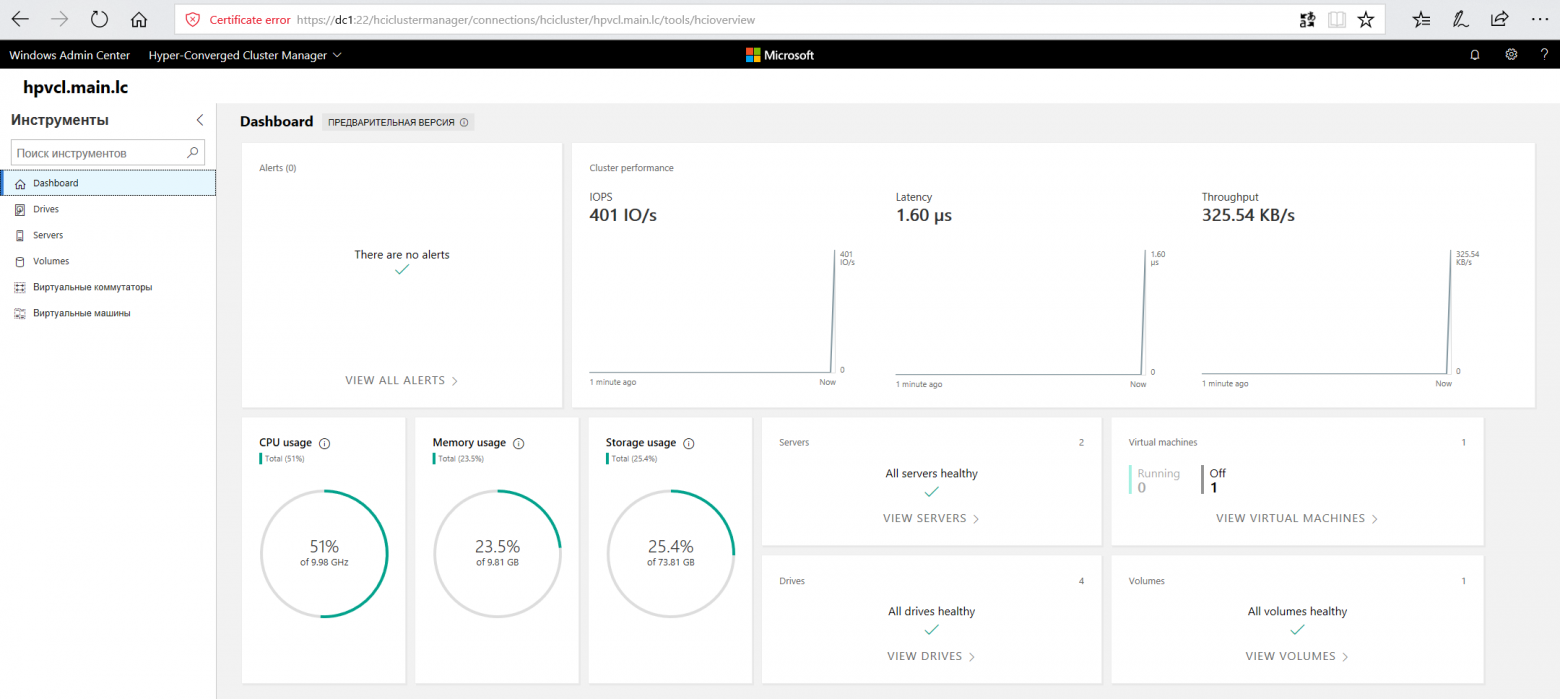
После того, как установил ОС на виртуальную машину VM внутри кластера, первым делом я проверил Live migration, переместив её на вторую ноду. Во время миграции я пинговал машину, чтобы проверить насколько быстро происходит миграция. Связь у меня пропала только на 2 запроса, что можно считать весьма неплохим результатом.
И тут стоит добавить несколько ложек дёгтя в эту гиперконвергентную бочку мёда. В тестовой и виртуальной среде все работает неплохо, но как это будет работать на реальном железе вопрос интересный. Тут стоит вернуться к аппаратным требованиям. Сетевые адаптеры 10GB с RDMA стоят порядка 500$, что в сумме с лицензией на Windows Server Datacenter делает решение не таким уж и дешёвым. Безусловно это дешевле чем выделенное хранилище, но ограничение существенное.
Вторая и основная ложка дёгтя, это новость о том, что функцию (S2D) уберут из следующей сборки server 2016 . Надеюсь, сотрудники Microsoft, читающие Хабр, это прокомментируют.
В заключении хотел бы сказать несколько слов о своих впечатлениях. Знакомство с новыми технологиями это был для меня весьма интересный опыт. Назвать его полезным, пока не могу. Я не уверен, что смогу применить эти навыки на практике. Поэтому у меня вопросы к сообществу: готовы ли вы рассматривать переход на гиперконвергентные решения в будущем? как относитесь к размещению виртуальных контроллеров домена на самих нодах?
Что быстрее одного ПК? Два (или больше) ПК? И да, и нет. Как это часто бывает, всё зависит от ваших рабочих нагрузок. И даже если ваши рабочие нагрузки подходят для работы на нескольких ПК, как вы можете объединить их вычислительную мощность?
В этой статье мы рассмотрим различные рабочие нагрузки – от рендеринга до игр – и посмотрим, когда вам выгодно объединять несколько ПК – и как это сделать.
Преимущества объединения вычислительной мощности нескольких ПК
Давайте посмотрим, что вы можете получить от использования ресурсов нескольких ПК, и стоит ли это того для ваших вариантов использования.
Соединение компьютеров и объединение их ресурсов вместе осуществляется по трём основным причинам:
- Вы можете продолжать использовать свой основной компьютер без замедлений. То есть, вы можете продолжать работать над своим следующим проектом или даже играть, в то время как, например, рендеринг или другие задачи обработки выполняются на вспомогательном компьютере.
- Чтобы ускорить чрезвычайно трудоемкие задачи. Некоторые задачи могут выполняться ужасно долго. На ум сразу приходят «Визуализация» и «Моделирование». Такие задачи обычно можно разделить на подзадачи и назначить их на одновременный запуск на разных компьютерах, что часто приводит к почти линейному уменьшению времени обработки. Однако, узким местом здесь является задержка сетевого подключения, но для хорошо распараллеленных рабочих нагрузок ею можно пренебречь.
- Из соображений безопасности и надёжности. Может быть вы ведёте процесс, который вы не хотите прерывать, так почему бы не иметь дополнительный компьютер, который может взять на себя управление, если первый выйдет из строя? Это может уберечь вас от любой потенциальной потери данных или временных задержек, которые могут замедлить проект или текущий процесс (например, сеанс прямой трансляции).
Как объединяется вычислительная мощность (на высоком уровне)
Слово «объединяется» здесь немного вводит в заблуждение. Если бы я действительно объединил 2 ПК, я бы ожидал, что в результате один ПК будет в два раза мощнее. Но, объединение вычислительной мощности не работает таким образом. Вы не собираете и не комбинируете оборудование физически.
Это больше похоже на соединение двух или более ПК, чтобы вы могли «использовать производительность обоих отдельных ПК максимально эффективно, с некоторой простотой использования».
Для простоты мы будем измерять вычислительную мощность ПК тем, сколько времени требуется для выполнения одной задачи. Этой задачей может быть, например, рендеринг видео (последовательности изображений).
Если одному ПК требуется 1 час для рендеринга нашего видео, то двум ПК оптимально потребуется всего 30 минут для завершения рендеринга. Если у вас 10 ПК, то рендеринг видео будет выполнен всего за 6 минут.
Это оптимальный случай.
Теперь, если вы запустите рендеринг видео на своём первом ПК, все остальные ПК не узнают, что они должны помочь с этой задачей. Вам нужно будет соединить их и сказать им, чтобы они говорили друг с другом.
Существует множество способов объединения ПК, но наиболее часто используемым и самым простым является сетевое подключение. Вы идёте, покупаете коммутатор и несколько LAN-кабелей и подключаете их друг к другу.
Так же работают сервера. Сервер – это просто красивое слово для компьютера с другим форм-фактором и предполагаемым вариантом использования, но все они подключены друг к другу через сетевое соединение.
Задержка сетевого соединения
Конечно, сетевое (или любое другое) соединение приводит к задержке.
Чем дальше данные должны перемещаться, тем больше становится задержка (с точки зрения непрофессионала).
Расстояния внутри ПК очень малы, поэтому передача данных чрезвычайно быстрая (например, между ЦП и ОЗУ одного ПК). Но, от одного ПК к другому ПК по неоптимальным проводам (кабелям локальной сети) намного медленнее.
Что нам нужно сделать, чтобы максимально обойти узкое место задержки, это убедиться, что ПК могут выполнять как можно больше работы самостоятельно, прежде чем снова разговаривать по кабелю LAN с другими ПК.
Это также означает, что не все задачи можно легко распараллелить. Только задачи, которые можно легко разделить на независимые подзадачи. Подробнее об этом позже.
Какие виды производительности можно совмещать
Начнём с того, что выясним, какие именно компоненты вашего дополнительного ПК вы можете использовать и извлечь из них наибольшую пользу.

Процессор объединенного ПК
Если вы собираетесь делегировать задачу рендеринга дополнительному компьютеру, скорее всего, вам понадобится мощность его процессора.
Лучший процессор для рендеринга – это процессор с большим количеством ядер и высокой тактовой частотой.
Если у вас есть второй компьютер, который стоит без дела, вы можете использовать то, что у вас уже есть, даже если у него нет процессора, специально созданного с учетом ваших рабочих нагрузок.
Но, если вы хотите спланировать новую сборку на основе оптимизации вычислительной мощности процессора дополнительного ПК, вам нужно убедиться, что он имеет наилучшие характеристики для этой задачи.
Вот тут и пригодится статья о лучших процессорах для рендеринга.
Резюмируем: вы сможете использовать CPU второго ПК, но, в зависимости от его производительности, польза может быть не такой уж большой.
Видеокарта объединенного ПК
Если ваши рабочие нагрузки зависят от производительности графического процессора (например, рендеринг на GPU), то второй, неиспользуемый графический процессор может очень помочь вам в сокращении ресурсов или добавлении ресурсов к вашему основному ПК.
ПК могут управлять более чем одним графическим процессором. С помощью сборок рабочей станции HEDT, которые могут функционировать как узлы рендеринга, вы можете добавить до 4 видеокарт на (настольный) ПК.
Если рабочие нагрузки рендеринга входят в ваш список ежедневных задач, вы будете рады узнать, что некоторые механизмы рендеринга даже поддерживают гибридный рендеринг. Это означает, что в дополнение к производительности графических процессоров второго ПК вы также можете использовать вычислительную мощность центрального процессора.

Другие элементы объединенного ПК
Хотя вторичный ПК, скорее всего, будет использоваться либо из-за его ЦП, либо из-за видеокарты, в некоторых случаях могут использоваться аппаратные компоненты без прямой обработки.
Хранилище объединенного ПК
Например, вы можете использовать дополнительные устройства хранения для создания системы сетевого хранилища (NAS), конфигурации RAID или того и другого через соединение Ethernet.
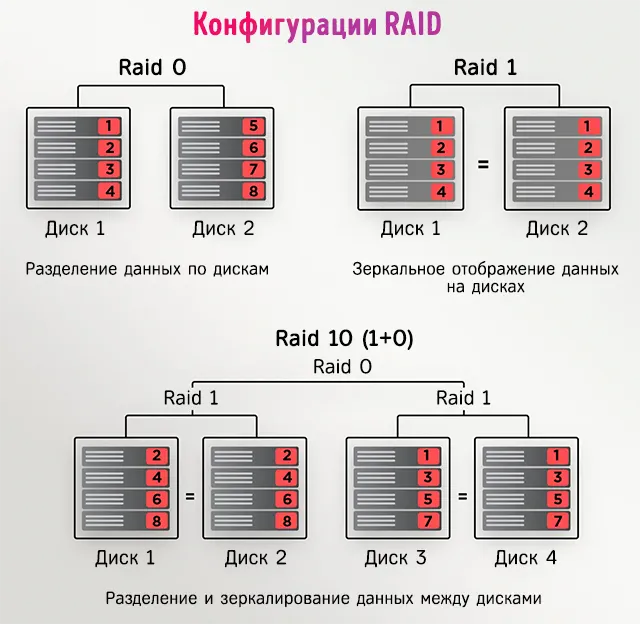
Кроме того, использование ПК в качестве файлового сервера позволит вам получить доступ к своим данным через несколько устройств и создать избыточность, которая обеспечит безопасность ваших файлов.
Однако, это может означать не столько объединение «вычислительной мощности», сколько «наилучшее использование независимых ресурсов».
ОЗУ / видеопамять объединенного ПК
В некоторых случаях вы также можете использовать ОЗУ (память) дополнительного устройства.
Оперативная память подключена к ЦП через высокоскоростную шину, поэтому к ней можно получить доступ в одно мгновение.
Если бы ЦП одного компьютера обращался к ОЗУ другого, это заняло бы значительное количество времени, что сделало бы весь процесс бессмысленным.
Однако, если вы назначаете подзадачу второму ПК и ЦП использует ОЗУ этого ПК для выполнения задачи, вы можете освободить память ОЗУ на своём основном компьютере.
Это делается автоматически и идёт рука об руку с использованием вычислительной мощности ЦП или GPU (и его видеопамяти) дополнительного ПК.
Таким образом, косвенно вы также можете использовать системную память или графическую память дополнительного ПК.
Какие рабочие нагрузки можно запускать на нескольких ПК
Давайте рассмотрим некоторые из наиболее распространенных задач, которые можно выполнять, используя несколько компьютеров:
- 3D визуализация
- Рендеринг видео
- Симуляторы
- Пакетная обработка
- Майнинг криптовалюты
- Последовательная обработка изображений
- Машинное обучение
- Потоковая трансляция
Вы можете добавить в этот список любые другие рабочие нагрузки, которые можно разделить на независимые подзадачи.
Почему подзадачи?
Помните, что мы говорили о задержке выше? Чем меньше «разговоров в сети», тем быстрее могут выполняться процессы.
Если простой задаче требуется 1 секунда для передачи данных по сети, то задача, состоящая из 1 миллиона таких простых задач, займёт целую вечность.
Вот если бы эта простая задача получала данные не через сеть, а из своей локальной памяти, этот запрос занял бы всего 10 наносекунд! В 100000000 раз быстрее.
Таким образом, наша главная цель должна состоять в том, чтобы уменьшить количество разговоров по сети.
Мы можем сделать это, взяв большую задачу и разделив её на независимые подзадачи.
Независимые, так что отдельный ПК может работать над этой подзадачей без необходимости какого-либо доступа к сети (до тех пор, пока задание не будет завершено и результат не будет отправлен обратно на хост).
Давайте сделаем пример. Рабочая нагрузка/задача, которую можно легко распараллелить:
Обработка изображений (например, пакетное масштабирование изображений до другого разрешения)
Если вы хотите изменить размер 1000 изображений на 4 компьютерах, нет ничего проще, чем изменить размер 250 изображений на каждом компьютере.
Задачу изменения размера 1000 изображений можно легко разделить на 1000 подзадач. Каждое изменение размера изображения является одной подзадачей.
Рендеринг 3D-анимации
Это работает так же. Рендеринг анимации, состоящей из 100 кадров, можно легко разделить на 100 отдельных подзадач. Рендеринг 1 кадра является подзадачей.
Если бы у вас было 100 ПК, эта анимация из 100 кадров отображалась бы в 100 раз быстрее, чем на одном ПК (оптимально).
Что, если бы у нас был 101 ПК? Или 1000 ПК? Поможет ли это?
Нет!
Поскольку подзадачи не могут быть легко разделены дальше, наличие большего количества компьютеров, чем количество подзадач, не поможет ускорить процесс.
Это подводит нас к следующему разделу:
Можно ли объединить вычислительную мощность двух ПК для игр
Это пример задачи, которую нельзя разделить на подзадачи:
Вы не можете разделить запуск игры на подзадачи, которые выиграют от запуска на нескольких ПК. Из-за задержки.
Допустим, вы хотите использовать видеокарту на дополнительном ПК для графических вычислений, а не на основном ПК, на котором запущена ваша игра.
Поскольку графическому процессору требуется доступ к данным 3D-модели, данным сцены, текстурам, анимации заданного уровня в режиме реального времени, 60 раз (или более) в секунду, ваше сетевое соединение слишком медленное и имеет неподходящую задержку для отправки требуемых данных. Вы столкнётесь с ужасным отставанием.
Любая задача, требующая взаимодействия в реальном времени, обычно не подходит для выполнения на нескольких ПК.
Конечно, вы можете просто запустить игру на своём втором ПК, а также удаленно / совместно использовать экран и управлять этим вторым ПК с вашего первого ПК, но это не объединяет вычислительную мощность. Это просто игра на втором ПК и управление им с первого.
Задержка намного меньше, но некоторая задержка всё же есть, так как готовые отрендеренные кадры все равно должны быть отправлены вам по сети для отображения на мониторе вашего первого ПК. Кстати, именно так работают онлайн-игры.
Что насчёт стриминга?
Есть случай, когда подключение двух ПК может быть полезно для геймеров. Если вы любите транслировать свои игровые достижения аудитории, делегирование задачи потоковой передачи на второй компьютер может быть невероятно полезным.
Если использовать термины, которые мы ввели выше: запуск игры – это одна (под) задача, запуск потока – другая (под) задача. Хотя это не идеально масштабируется, у вас есть две задачи, и потоковая трансляция может быть передана на второй компьютер без каких-либо проблем.
Это не только высвобождает ресурсы главного компьютера, позволяя процессору и видеокарте сосредоточиться на обработке игрового приложения, но и обеспечивает безопасность.

Если ваш компьютер выходит из строя, второй компьютер всё ещё может запускать поток в режиме реального времени без перерыва. Зрители по-прежнему будут видеть вас кристально чистыми, даже если игра полностью остановится.
Для потоковой передачи с двух ПК вам понадобится специальное периферийное устройство, называемое картой захвата. Она подключается как к игровому, так и к потоковому компьютеру. Она захватывает аудио и видео с игрового ПК и выводит его на потоковый ПК, чтобы его можно было обработать с помощью потокового приложения, такого как OBS или XSplit.
Как объединить вычислительную мощность нескольких ПК
Допустим, вам нужно объединить компьютеры, как вы можете это сделать? Что ж, есть разные методы, которые вы можете использовать, некоторые из них более прямолинейны и просты, чем другие.
Объединение компьютеров через сеть
Мы уже немного говорили о сетевых соединениях.
Это, пожалуй, самый простой способ соединить несколько компьютеров друг с другом. Вы можете использовать устройства в сети домашней группы (Windows), чтобы обмениваться файлами и периферийными устройствами.
Это также шаг, который позволяет определенному специализированному программному обеспечению (например, Render Manager Thinkbox Deadline) использовать вычислительную мощность обоих ваших ПК за счёт возможностей конкретного приложения.
Программные возможности для объединения ПК
Специализированные приложения позволят использовать компьютеры, подключенные к сети, для обработки определенной рабочей нагрузки.
Например, некоторые механизмы 3D-рендеринга, такие как OctaneRender, будут иметь опцию «сетевой рендеринг». Использование этой опции в настройках позволит вам отправлять задачи рендеринга на второй компьютер одним нажатием кнопки (после некоторой настройки).
Менеджеры рендеринга
Поскольку у вас может быть более одной конкретной рабочей нагрузки, которую вы хотели бы распределить по сетевым компьютерам, имеет смысл использовать сторонний диспетчер рендеринга.
Менеджеры рендеринга – это инструменты, которые могут управлять заданиями по обработке для самых разных программ. Они ставят в очередь, распределяют и назначают задания на основе вычислительных возможностей различных ПК и собирают результат для дальнейшего использования.
Если вы хотите сделать инвестиции и создать собственную рендер-ферму, ваши компьютеры могут стать узлами рендеринга. Эти узлы рендеринга впоследствии контролируются менеджером рендеринга.
Как следует из названия, это приложение управляет любыми процессами рендеринга и позволяет назначать задачу через любое устройство в рендер-ферме.
Одним из таких приложений Render Manager является Deadline от Thinkbox.
Параллельная виртуальная машина
Две широко используемые формы распределенных вычислений: параллельная виртуальная машина (PVM) и интерфейс передачи сообщений (MPI). Они немного сложнее и сложны в настройке.
PVM позволяет вам подключать разнородные компьютеры (в основном, ПК с разной аппаратной архитектурой, например, AMD или Intel) для параллельных операций.
Интерфейс передачи сообщений
Когда дело доходит до MPI, VirtualBox находится там, где он есть. Вы можете использовать это приложение для подключения нескольких гостевых машин к единой виртуальной машине.
VirtualBox также позволяет создавать гостевые операционные системы на устройстве, что даёт вам возможность тестировать приложения в разных операционных системах (если есть проблема совместимости).
Например, если вы используете Mac, но приложение, которое вы хотите запустить, работает только в Windows, вы можете установить виртуальную ОС и подключить свои отдельные компьютеры к этой ОС и заставить их выполнять приложение.
Я знаю, это звучит сложно, но на самом деле это проще, чем кажется.
В конце концов, вы всегда ограничены узким местом, которое создает сетевое подключение.
Имеет ли смысл объединение нескольких компьютеров
Как уже говорилось, это зависит от выполняемых вами рабочих нагрузок.
Спросите себя:
- Можно ли разделить вашу рабочую нагрузку на независимые подзадачи? (это хорошо для распределения между несколькими ПК). Примеры – пассивные задачи, такие как рендеринг, пакетная обработка.
- Или ваши рабочие нагрузки сильно зависят от задержки? (это плохо для распределения между несколькими ПК). Примеры – активные задачи, такие как игры, активная работа в программном приложении.
Можно ли объединить ноутбук и ПК
Конечно! Ноутбуки – это просто ПК в другом форм-факторе, поэтому всё вышесказанное относится и к ним.
Однако, их более низкая производительность по сравнению с настольными ПК или серверами не делает их моим первым выбором.
Если у вас уже есть ноутбук, смело используйте его, но не покупайте дополнительный ноутбук для повышения производительности.
Производительность на рубль всегда будет хуже в ноутбуках. Они сделаны, в первую очередь, из соображений мобильности.
Выводы
Объединение вычислительной мощности двух или более ПК может значительно повысить вашу эффективность, ускорить рабочие нагрузки и снизить риск потери данных или потери времени.
Конечно, для новичков это может быть несколько сложно настроить, но – для правильных задач – это может стоить каждой потраченной минуты и каждой копейки.
Просто помните: это метод, используемый в основном для разделения процесса на подзадачи и распределения их по разным машинам, чтобы они могли выполняться одновременно.
Это не сделает ваш основной компьютер более мощным.
В данной статье будет показано, как построить отказоустойчивый кластер Server 2012 с двумя узлами. Сначала я перечислю обязательные условия и представлю обзор настроек аппаратной среды, сети и хранилища данных. Затем будет подробно описано, как дополнить Server 2012 функциями отказоустойчивой кластеризации и использовать диспетчер отказоустойчивого кластера для настройки кластера с двумя узлами
В Windows Server 2012 появилось так много новшеств, что за всеми уследить трудно. Часть наиболее важных строительных блоков новой ИТ-инфраструктуры связана с улучшениями в отказоустойчивой кластеризации. Отказоустойчивая кластеризация зародилась как технология для защиты важнейших приложений, необходимых для производственной деятельности, таких как Microsoft SQL Server и Microsoft Exchange. Но впоследствии отказоустойчивая кластеризация превратилась в платформу высокой доступности для ряда служб и приложений Windows. Отказоустойчивая кластеризация — часть фундамента Dynamic Datacenter и таких технологий, как динамическая миграция. Благодаря Server 2012 и усовершенствованиям нового протокола Server Message Block (SMB) 3.0 область действия отказоустойчивой кластеризации стала увеличиваться, обеспечивая непрерывно доступные файловые ресурсы с общим доступом. Обзор функциональности отказоустойчивой кластеризации в Server 2012 приведен в опубликованной в этом же номере журнала статье «Новые возможности отказоустойчивой кластеризации Windows Server 2012».
.
Обязательные условия отказоустойчивой кластеризации
Для построения двухузлового отказоустойчивого кластера Server 2012 необходимы два компьютера, работающие с версиями Server 2012 Datacenter или Standard. Это могут быть физические компьютеры или виртуальные машины. Кластеры с виртуальными узлами можно построить с помощью Microsoft Hyper-V или VMware vSphere. В данной статье используются два физических сервера, но этапы настройки кластера для физических и виртуальных узлов одни и те же. Ключевая особенность заключается в том, что узлы должны быть настроены одинаково, чтобы резервный узел мог выполнять рабочие нагрузки в случае аварийного переключения или динамической миграции. Компоненты, использованные в тестовом отказоустойчивом кластере Server 2012 представлены на рисунке.
 |
| Рисунок. Просмотр компонентов кластера |
Для отказоустойчивого кластера Server 2012 необходимо общее хранилище данных типа iSCSI, Serially Attached SCSI или Fibre Channel SAN. В нашем примере используется iSCSI SAN. Следует помнить о следующих особенностях хранилищ этого типа.
- Каждый сервер должен располагать по крайней мере тремя сетевыми адаптерами: одним для подключения хранилища iSCSI, одним для связи с узлом кластера и одним для связи с внешней сетью. Если предполагается задействовать кластер для динамической миграции, то полезно иметь четвертый сетевой адаптер. Однако динамическую миграцию можно выполнить и через внешнее сетевое соединение — она просто будет выполняться медленнее. Если серверы используются для виртуализации на основе Hyper-V и консолидации серверов, то нужны дополнительные сетевые адаптеры для передачи сетевого трафика виртуальных машин.
- В быстрых сетях работать всегда лучше, поэтому быстродействие канала связи iSCSI должно быть не менее 1 ГГц.
- Цель iSCSI должна соответствовать спецификации iSCSI-3, в частности обеспечивать постоянное резервирование. Это обязательное требование динамической миграции. Оборудование почти всех поставщиков систем хранения данных соответствует стандарту iSCSI 3. Если нужно организовать кластер в лабораторной среде с небольшими затратами, обязательно убедитесь, что программное обеспечение цели iSCSI соответствует iSCSI 3 и требованиям постоянного резервирования. Старые версии Openfiler не поддерживают этот стандарт, в отличие от новой версии Openfiler с модулем Advanced iSCSI Target Plugin (http://www.openfiler.com/products/advanced-iscsi-plugin). Кроме того, бесплатная версия StarWind iSCSI SAN Free Edition компании StarWind Software (http://www.starwindsoftware.com/starwind-free) полностью совместима с Hyper-V и динамической миграцией. Некоторые версии Microsoft Windows Server также могут функционировать в качестве цели iSCSI, совместимой со стандартами iSCSI 3. В состав Server 2012 входит цель iSCSI. Windows Storage Server 2008 R2 поддерживает программное обеспечение цели iSCSI. Кроме того, можно загрузить программу Microsoft iSCSI Software Target 3.3 (http://www.microsoft.com/en-us/download/details.aspx?id=19867), которая работает с Windows Server 2008 R2.
Дополнительные сведения о настройке хранилища iSCSI для отказоустойчивого кластера приведены во врезке «Пример настройки хранилища iSCSI». Более подробно о требованиях к отказоустойчивой кластеризации рассказано в статье «Failover Clustering Hardware Requirements and Storage Options» (http://technet.microsoft.com/en-us/library/jj612869.aspx).
Добавление функций отказоустойчивой кластеризации
Первый шаг к созданию двухузлового отказоустойчивого кластера Server 2012 — добавление компонента отказоустойчивого кластера с использованием диспетчера сервера. Диспетчер сервера автоматически открывается при регистрации в Server 2012. Чтобы добавить компонент отказоустойчивого кластера, выберите Local Server («Локальный сервер») и прокрутите список вниз до раздела ROLES AND FEATURES. Из раскрывающегося списка TASKS выберите Add Roles and Features, как показано на экране 1. В результате будет запущен мастер добавления ролей и компонентов.
|
|
| Экран 1. Запуск мастера добавления ролей и компонентов |
Первой после запуска мастера откроется страница приветствия Before you begin. Нажмите кнопку Next для перехода к странице выбора типа установки, на которой задается вопрос, нужно ли установить компонент на локальном компьютере или в службе Remote Desktop. Для данного примера выберите вариант Role-based or feature-based installation и нажмите кнопку Next.
На странице Select destination server выберите сервер, на котором следует установить функции отказоустойчивого кластера. В моем случае это локальный сервер с именем WS2012-N1. Выбрав локальный сервер, нажмите кнопку Next, чтобы перейти к странице Select server roles. В данном примере роль сервера не устанавливается, поэтому нажмите кнопку Next. Или можно щелкнуть ссылку Features в левом меню.
На странице Select features прокрутите список компонентов до пункта Failover Clustering. Щелкните в поле перед Failover Clustering и увидите диалоговое окно со списком различных компонентов, которые будут установлены как части этого компонента. Как показано на экране 2, по умолчанию мастер установит средства управления отказоустойчивыми кластерами и модуль отказоустойчивого кластера для Windows PowerShell. Нажмите кнопку Add Features, чтобы вернуться на страницу выбора компонентов. Щелкните Next.
|
|
| Экран 2. Добавление средства отказоустойчивого кластера и инструментов |
На странице Confirm installation selections будет показана функция отказоустойчивого кластера наряду с инструментами управления и модулем PowerShell. С этой страницы можно вернуться и внести любые изменения. При нажатии кнопки Install начнется собственно установка компонентов. После завершения установки работа мастера будет завершена и функция отказоустойчивого кластера появится в разделе ROLES AND FEATURES диспетчера сервера. Этот процесс необходимо выполнить на обоих узлах.
Проверка отказоустойчивого кластера
Следующий шаг после добавления функции отказоустойчивого кластера — проверка настроек среды, в которой создан кластер. Здесь можно воспользоваться мастером проверки настроек в диспетчере отказоустойчивого кластера. Этот мастер проверяет параметры аппаратных средств и программного обеспечения всех узлов кластера и сообщает обо всех проблемах, которые могут помешать организации кластера.
Чтобы открыть диспетчер отказоустойчивого кластера, выберите параметр Failover Cluster Manager в меню Tools в диспетчере сервера. В области Management щелкните ссылку Validate Configuration, как показано на экране 3, чтобы запустить мастер проверки настроек.
|
|
| Экран 3. Запуск мастера проверки конфигурации |
Сначала выводится страница приветствия мастера. Нажмите кнопку Next, чтобы перейти к выбору серверов или странице Cluster. На этой странице введите имена узлов кластера, который необходимо проверить. Я указал WS2012-N1 и WS2012-N2. Нажмите кнопку Next, чтобы показать страницу Testing Options, на которой можно выбрать конкретные наборы тестов или запустить все тесты. По крайней мере в первый раз я рекомендую запустить все тесты. Нажмите кнопку Next, чтобы перейти на страницу подтверждения, на которой показаны выполняемые тесты. Нажмите кнопку Next, чтобы начать процесс тестирования кластера. В ходе тестирования проверяется версия операционной системы, настройки сети и хранилища всех узлов кластера. Сводка результатов отображается после завершения теста.
Если тесты проверки выполнены успешно, можно создать кластер. На экране 4 показан экран сводки для успешно проверенного кластера. Если при проверке обнаружены ошибки, то отчет будет отмечен желтым треугольником (предупреждения) или красным значком «X» в случае серьезных ошибок. С предупреждениями следует ознакомиться, но их можно игнорировать. Серьезные ошибки необходимо исправить перед созданием кластера.
|
|
| Экран 4. Просмотр отчета о проверке |
Создание отказоустойчивого кластера
На данном этапе можно создать кластер, начиная с любого узла кластера. Я организовал кластер, начав на первом узле (WS2012-N1).
Чтобы создать новый кластер, выберите ссылку Create Cluster на панели Management или панели Actions, как показано на экране 5.
|
|
| Экран 5. Запуск мастера создания кластера |
В результате будет запущен мастер создания кластера, работа которого начинается со страницы приветствия. Нажмите кнопку Next, чтобы перейти на страницу выбора серверов, показанную на экране 6. На этой странице введите имена всех узлов кластера, затем нажмите кнопку Next.
|
|
| Экран 6. Выбор серверов для кластера |
На странице Access Point for Administering the Cluster следует указать имя и IP-адрес кластера, которые должны быть уникальными в сети. На экране 7 видно, что имя моего кластера WS2012-CL01, а IP-адрес — 192.168.100.200. При использовании Server 2012 IP-адрес кластера может быть назначен через DHCP, но я предпочитаю для своих серверов статически назначаемый IP-адрес.
|
|
| Экран 7. Настройка точки доступа кластера |
После ввода имени и IP-адреса нажмите кнопку Next, чтобы увидеть страницу подтверждения (экран 8). На этой странице можно проверить настройки, сделанные при создании кластера. При необходимости можно вернуться и внести изменения.
|
|
| Экран 8. Подтверждение параметров, выбранных при создании кластера |
После нажатия кнопки Next на странице подтверждения формируется кластер на всех выбранных узлах. На странице хода выполнения показаны шаги мастера в процессе создания нового кластера. По завершении мастер покажет страницу сводки с настройками нового кластера.
Мастер создания кластера автоматически выбирает хранилище для кворума, но часто он выбирает не тот диск кворума, который хотелось бы администратору. Чтобы проверить, какой диск используется для кворума, откройте диспетчер отказоустойчивого кластера и разверните кластер. Затем откройте узел Storage и щелкните узел Disks. Диски, доступные в кластере, будут показаны на панели Disks. Диск, выбранный мастером для кворума кластера, будет указан в разделе Disk Witness in Quorum.
В данном примере для кворума был использован Cluster Disk 4. Его размер 520 Мбайт, чуть больше минимального значения для кворума 512 Мбайт. Если нужно использовать другой диск для кворума кластера, можно изменить настройки кластера, щелкнув правой кнопкой мыши имя кластера в диспетчере отказоустойчивого кластера, выбрав пункт More Actions и Configure Cluster Quorum Settings. В результате появится мастер выбора конфигурации кворума, с помощью которого можно изменить параметры кворума кластера.
Настройка общих томов кластера и роли виртуальных машин
Оба узла в моем кластере имеют роль Hyper-V, так как кластер предназначен для виртуальных машин с высокой доступностью, обеспечивающих динамическую миграцию. Чтобы упростить динамическую миграцию, далее требуется настроить общие тома кластера Cluster Shared Volumes (CSV). В отличие от Server 2008 R2, в Server 2012 общие тома кластера включены по умолчанию. Однако все же требуется указать, какое хранилище следует использовать для общих томов кластера. Чтобы включить CSV на доступном диске, разверните узел Storage и выберите узел Disks. Затем выберите диск кластера, который нужно использовать как CSV, и щелкните ссылку Add to Cluster Shared Volumes на панели Actions диспетчера отказоустойчивого кластера (экран 9). Поле Assigned To этого диска кластера изменится с Available Storage на Cluster Shared Volume (общий том кластера), как показано на экране 9.
|
|
| Экран 9. Добавление CSV |
В это время диспетчер отказоустойчивого кластера настраивает хранилище диска кластера для CSV, в частности добавляет точку подключения в системном диске. В данном примере общие тома кластера включаются как на Cluster Disk 1, так и на Cluster Disk 3 с добавлением следующих точек подключения:
* C:ClusterStorageVolume1 * C:ClusterStorageVolume2
На данном этапе построен двухузловой кластер Server 2012 и включены общие тома кластера. Затем можно установить кластеризованные приложения или добавить в кластер роли. В данном случае кластер создан для виртуализации, поэтому добавляем роль виртуальной машины в кластер.
Чтобы добавить новую роль, выберите имя кластера на панели навигации диспетчера отказоустойчивого кластера и щелкните ссылку Configure Roles на панели Actions, чтобы запустить мастер высокой готовности. Нажмите кнопку Next на странице приветствия, чтобы перейти на страницу выбора роли. Прокрутите список ролей, пока не увидите роль виртуальной машины, как показано на экране 10. Выберите роль и нажмите кнопку Next.
|
|
| Экран 10. Добавление роли виртуальной машины |
На странице выбора виртуальной машины будут перечислены все VM на всех узлах кластера, как показано на экране 11. Прокрутите список и выберите виртуальные машины, которым необходимо обеспечить высокую готовность. Нажмите кнопку Next. Подтвердив свой выбор, нажмите Next, чтобы добавить роли виртуальной машины в диспетчер отказоустойчивого кластера.
|
|
| Экран 11. Выбор виртуальных машин, которым необходимо обеспечить высокую надежность |
Пример настройки хранилища iSCSI
Для отказоустойчивого кластера Windows Server 2012 требуется общее хранилище, которое может быть типа iSCSI, Serially Attached SCSI или Fibre Channel SAN. В данном отказоустойчивом кластере используется Channel SAN.
Сначала в сети iSCSI SAN были созданы три логических устройства LUN. Один LUN был создан для диска кворума кластера (520 Мбайт). Другой LUN предназначен для 10 виртуальных машин и имеет размер 375 Гбайт. Третий LUN выделен для небольшой тестовой виртуальной машины. Все три LUN представлены в формате NTFS.
После того, как были созданы LUN, была выполнена настройка iSCSI Initiator на обоих узлах Server 2012. Чтобы добавить цели iSCSI, был выбран iSCSI Initiator в меню Tools в диспетчере сервера. На вкладке Discovery я нажал кнопку Discover Portal. В результате появилось диалоговое окно Discover Portal, куда были введены IP-адрес (192.168.0.1) и порт iSCSI (3260) сети SAN.
Затем я перешел на вкладку Targets и нажал кнопку Connect. В диалоговом окне Connect To Target («Подключение к целевому серверу») я ввел целевое имя iSCSI SAN. Оно было получено из свойств SAN. Имя зависит от поставщика SAN, имени домена и имен созданных LUN. Помимо целевого имени я установил режим Add this connection to the list of Favorite Targets.
По завершении настройки iSCSI эти LUN появились на вкладке Targets iSCSI Initiator. Чтобы автоматически подключать LUN при запуске Server 2012, я убедился, что они перечислены на вкладке Favorite Targets, как показано на экране A.
|
|
| Экран A. Настройка iSCSI Initiator |
Наконец, были назначены буквенные обозначения устройствам LUN с помощью оснастки Disk Management консоли управления Microsoft (MMC). Я выбрал Q для диска кворума и W для диска, используемого для виртуальных машин и общих томов кластера (CSV). При назначении буквенных обозначений необходимо сначала назначить их на одном узле. Затем нужно перевести диски в автономный режим и сделать аналогичные назначения на втором узле. Результаты назначения букв дискам для одного узла приведены на экране B. При создании кластера диски будут показаны как доступное хранилище.
|
|
| Экран B. Буквенные обозначения, назначенные дискам iSCSI узла |
This article gives a short overview of how to create a Microsoft Windows Failover Cluster (WFC) with Windows Server 2019 or 2016. The result will be a two-node cluster with one shared disk and a cluster compute resource (computer object in Active Directory).
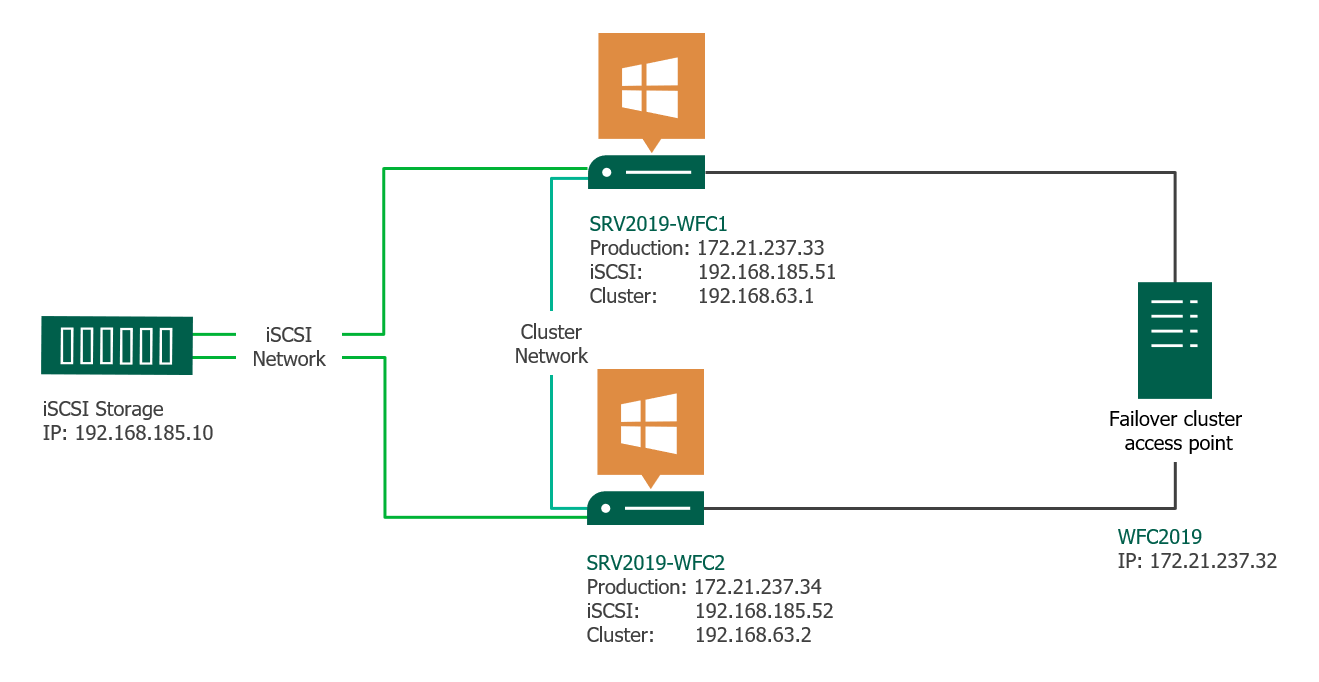
Preparation
It does not matter whether you use physical or virtual machines, just make sure your technology is suitable for Windows clusters. Before you start, make sure you meet the following prerequisites:
Two Windows 2019 machines with the latest updates installed. The machines have at least two network interfaces: one for production traffic, one for cluster traffic. In my example, there are three network interfaces (one additional for iSCSI traffic). I prefer static IP addresses, but you can also use DHCP.
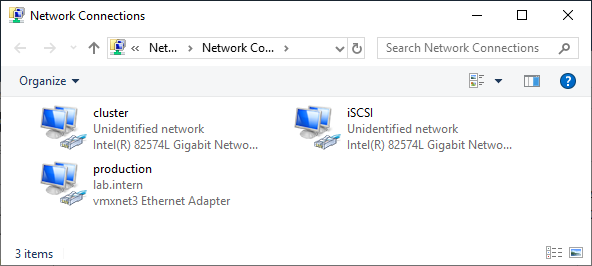
Join both servers to your Microsoft Active Directory domain and make sure that both servers see the shared storage device available in disk management. Don’t bring the disk online yet.
The next step before we can really start is to add the Failover clustering feature (Server Manager > add roles and features).
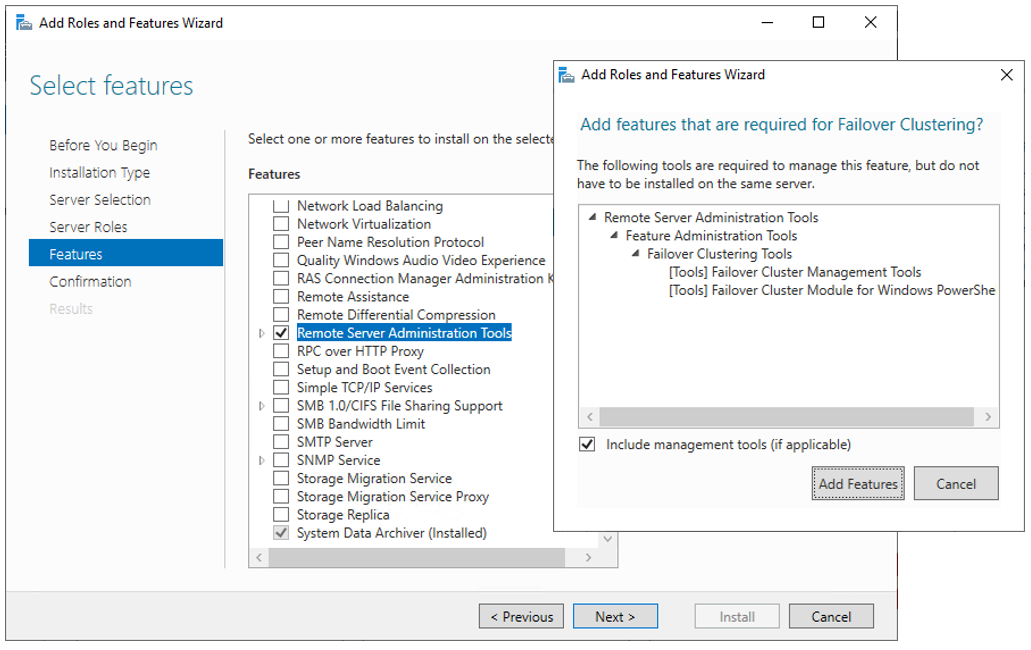
Reboot your server if required. As an alternative, you can also use the following PowerShell command:
Install-WindowsFeature -Name Failover-Clustering –IncludeManagementTools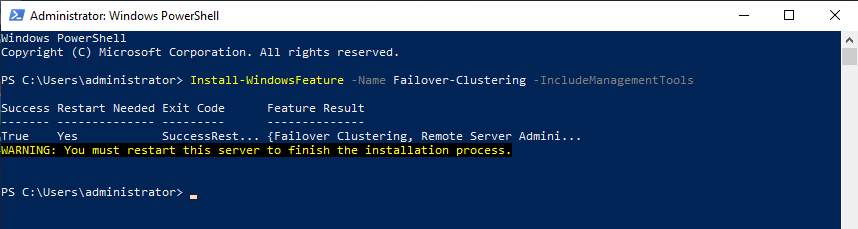
After a successful installation, the Failover Cluster Manager appears in the start menu in the Windows Administrative Tools.
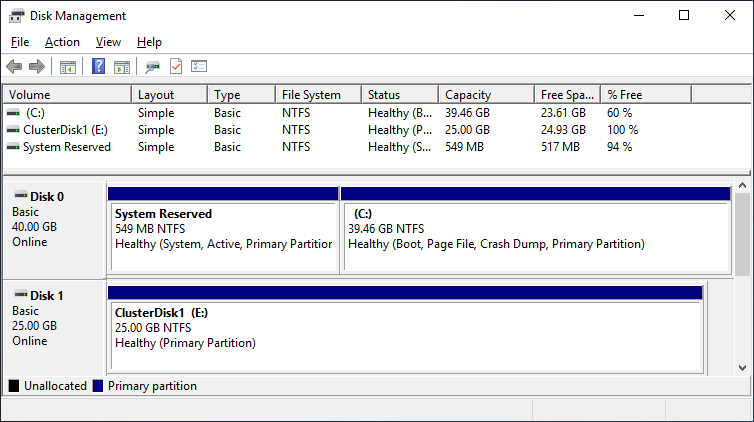
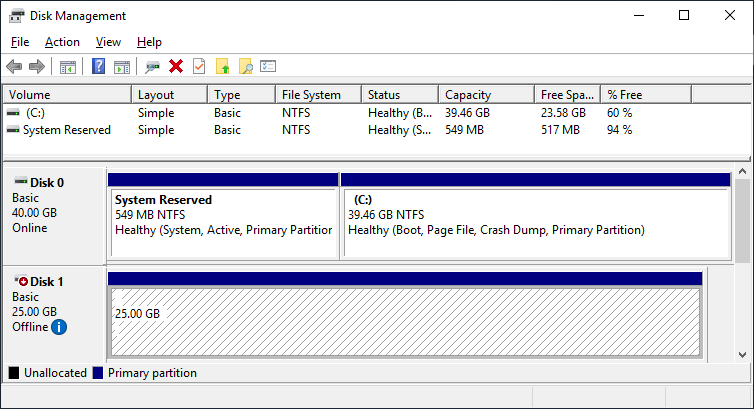
After you installed the Failover-Clustering feature, you can bring the shared disk online and format it on one of the servers. Don’t change anything on the second server. On the second server, the disk stays offline.
After a refresh of the disk management, you can see something similar to this:
Server 1 Disk Management (disk status online)
Server 2 Disk Management (disk status offline)
Failover Cluster readiness check
Before we create the cluster, we need to make sure that everything is set up properly. Start the Failover Cluster Manager from the start menu and scroll down to the management section and click Validate Configuration.
Select the two servers for validation.
Run all tests. There is also a description of which solutions Microsoft supports.
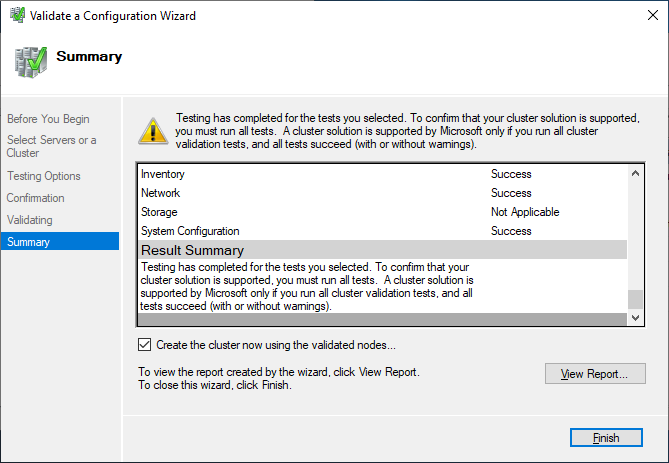
After you made sure that every applicable test passed with the status “successful,” you can create the cluster by using the checkbox Create the cluster now using the validated nodes, or you can do that later. If you have errors or warnings, you can use the detailed report by clicking on View Report.
If you choose to create the cluster by clicking on Create Cluster in the Failover Cluster Manager, you will be prompted again to select the cluster nodes. If you use the Create the cluster now using the validated nodes checkbox from the cluster validation wizard, then you will skip that step. The next relevant step is to create the Access Point for Administering the Cluster. This will be the virtual object that clients will communicate with later. It is a computer object in Active Directory.
The wizard asks for the Cluster Name and IP address configuration.
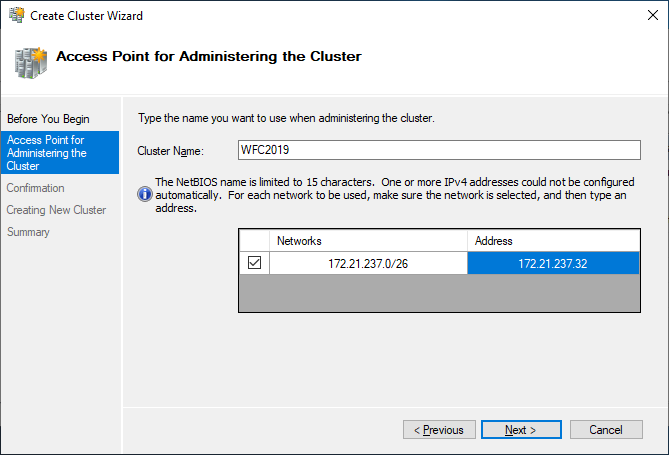
As a last step, confirm everything and wait for the cluster to be created.
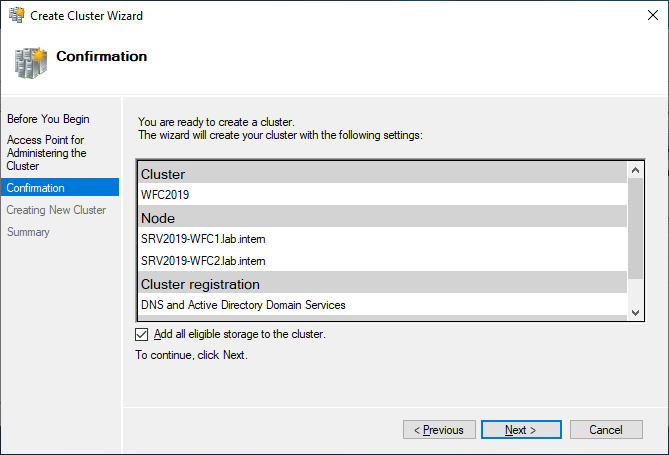
The wizard will add the shared disk automatically to the cluster per default. If you did not configure it yet, then it is also possible afterwards.
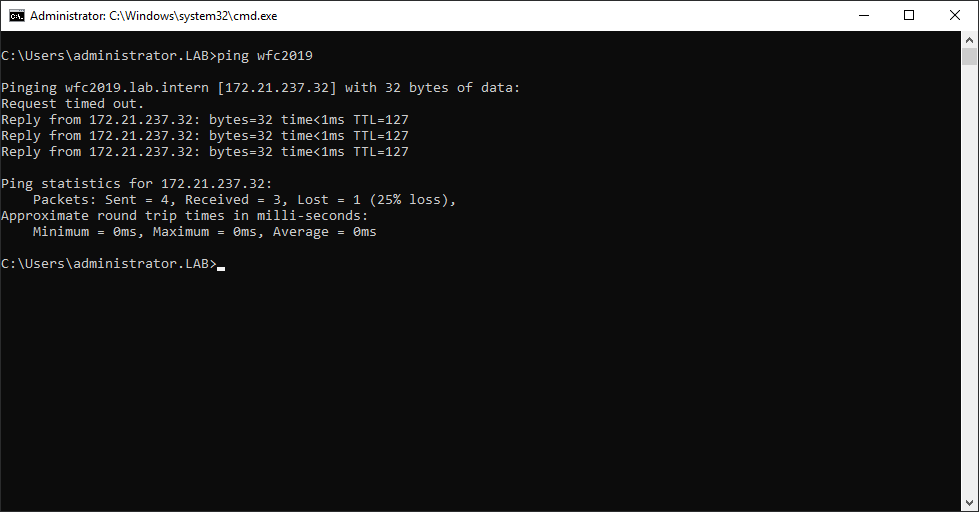
As a result, you can see a new Active Directory computer object named WFC2019.

You can ping the new computer to check whether it is online (if you allow ping on the Windows firewall).
As an alternative, you can create the cluster also with PowerShell. The following command will also add all eligible storage automatically:
New-Cluster -Name WFC2019 -Node SRV2019-WFC1, SRV2019-WFC2 -StaticAddress 172.21.237.32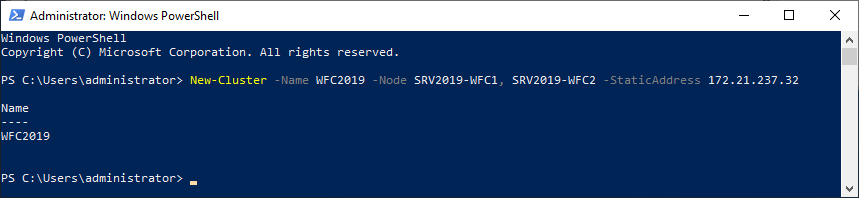
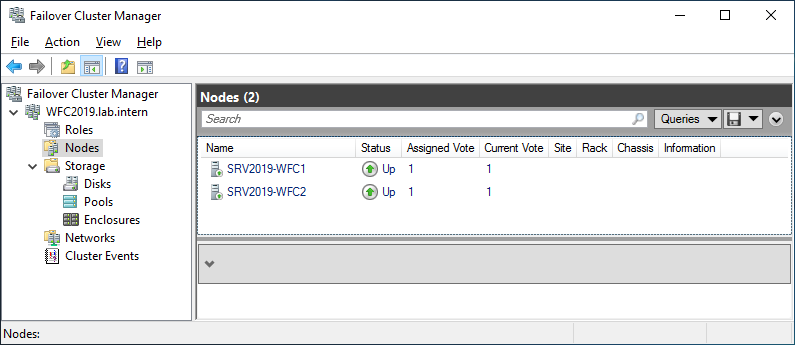
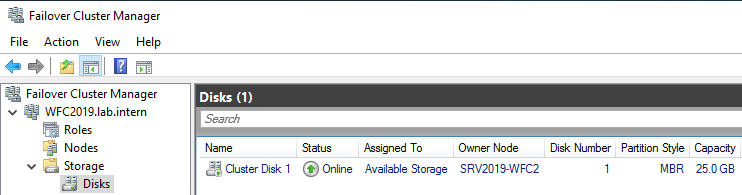
You can see the result in the Failover Cluster Manager in the Nodes and Storage > Disks sections.
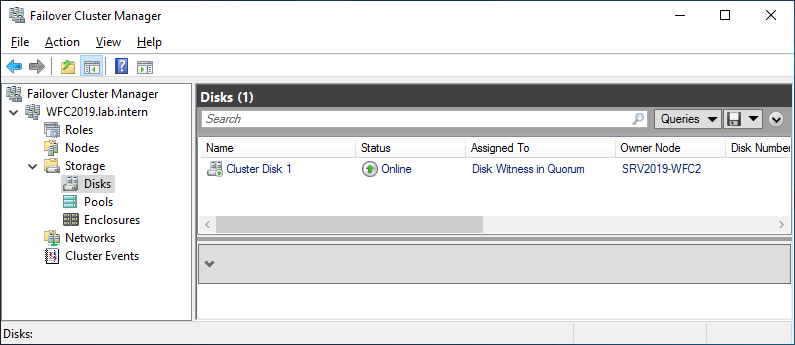
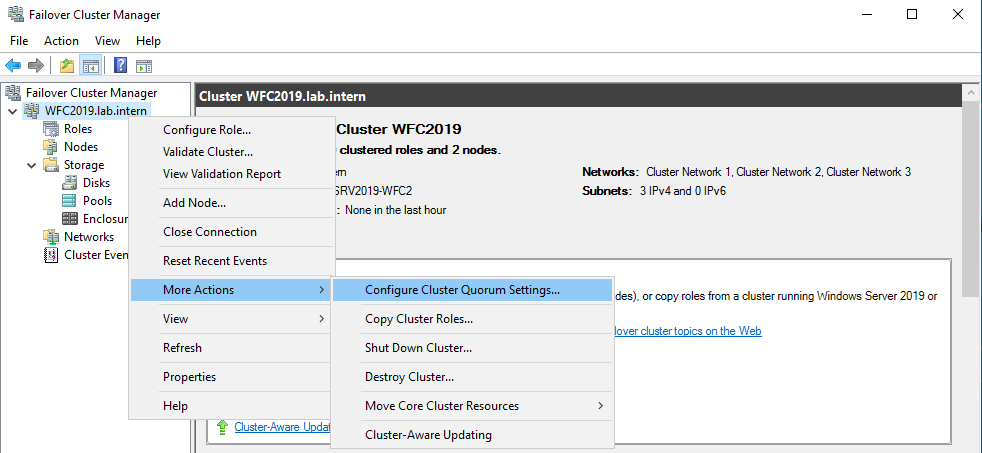
The picture shows that the disk is currently used as a quorum. As we want to use that disk for data, we need to configure the quorum manually. From the cluster context menu, choose More Actions > Configure Cluster Quorum Settings.
Here, we want to select the quorum witness manually.
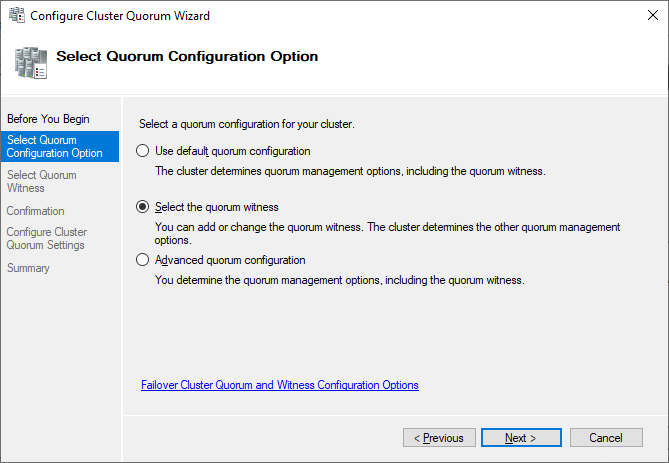
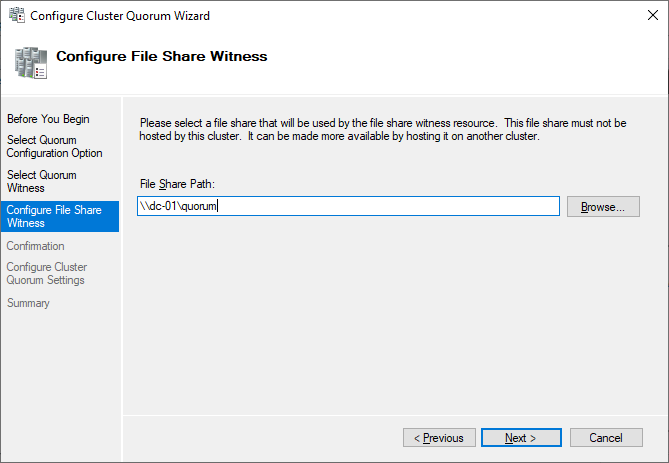
Currently, the cluster is using the disk configured earlier as a disk witness. Alternative options are the file share witness or an Azure storage account as witness. We will use the file share witness in this example. There is a step-by-step how-to on the Microsoft website for the cloud witness. I always recommend configuring a quorum witness for proper operations. So, the last option is not really an option for production.
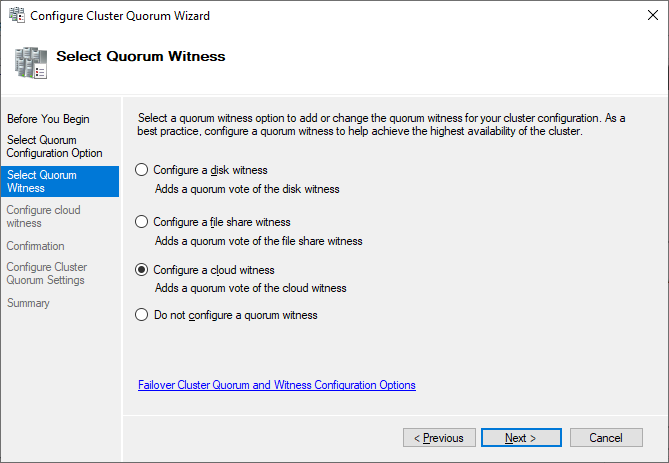
Just point to the path and finish the wizard.
After that, the shared disk is available for use for data.
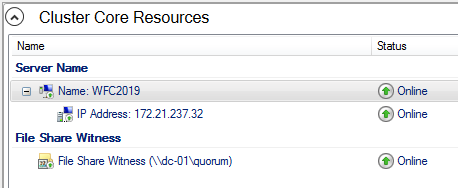
Congratulations, you have set up a Microsoft failover cluster with one shared disk.
Next steps and backup
One of the next steps would be to add a role to the cluster, which is out of scope of this article. As soon as the cluster contains data, it is also time to think about backing up the cluster. Veeam Agent for Microsoft Windows can back up Windows failover clusters with shared disks. We also recommend doing backups of the “entire system” of the cluster. This also backs up the operating systems of the cluster members. This helps to speed up restore of a failed cluster node, as you don’t need to search for drivers, etc. in case of a restore.
See More:
- On-Demand Sessions from VeeamON Virtual
В этой небольшой инструкции мы покажем пошагово как создать простой отказоустойчивый кластер Hyper-V Cluster из двух серверов с Windows Server 2016. Такой кластер позволяет без особых проблем организовать отказоустойчивость для виртуальных машин Hyper-V при аппаратных проблемах с одним из серверов.
- Предварительные требования к отказоустойчивому кластеру Hyper-V
- Настройки сети Hyper V
- Установка кластера Hyper-V
- Настройка кластера Hyper-V
Содержание:
Предварительные требования к отказоустойчивому кластеру Hyper-V
- Два сервера с установленной ОС Windows Server 2016 (желательно чтобы количество памяти и CPU на обоих серверах было одинаково)
- Установленная роль Hyper-V с компонентами Failover Cluster и MPIO ( iSCSI по необходимости)
- Как минимум по 2 сетевых карты на каждом сервере (одна сетевая карта будет использоваться для управления и через нее будет идти трафик ВМ, вторая – для взаимодействия хостов между собой – трафик CSV и Heartbeat)
- Общее дисковое хранилище, подключенное к обоим серверам (в этом примере дисковый массив подключается к каждому серверу через 2 порта Fiber Channel, при этом компонент MPIO нужен для того, чтобы каждый сервер видел только одно подключение к диску, а не два)
- Как минимум один диск (LUN) с общего хранилища презентован обоим сервера, инициализирован и отформатирован.
Настройки сети Hyper V
В нашем примере мы настроим следующую IP адресацию для компонентов кластера:
Общее имя кластера: HVCLUSTER2016 (IP адрес 10.0.0.10)
Первый сервер: имя HOST01, с двумя интерфейсами
10.0.0.11 – интерфейс управления, и трафика виртуальных машин
10.0.1.11 – интерфейс для трафика Cluster Shared Volume и Heartbeat
Второй сервер: имя HOST02, с двумя интерфейсами
10.0.0.12 — интерфейс управления, и трафика виртуальных машин
10.0.1.12 – интерфейс для трафика Cluster Shared Volume и Heartbeat
Установка кластера Hyper-V
Итак, на любом из серверов запускаем оснастку Failover Cluster Manager и запускаем мастер создания кластера (Create Cluster).
На странице выбора серверов кластера добавляем обе наших ноды.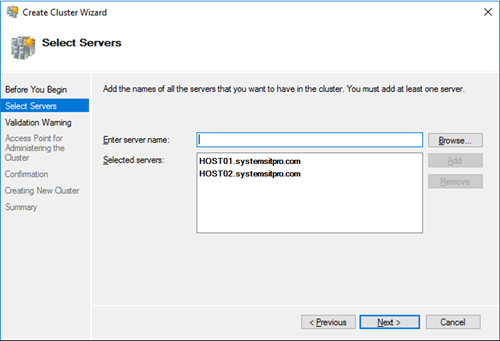
На странице Validation Warning соглашаемся с запуском встроенных тестов валидации кластерной конфигурации.
Выберите, что нужно прогнать все тесты.
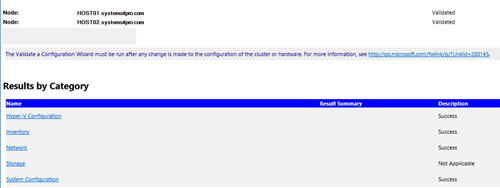
Нужно дождаться окончания валидации. Если будут найдены ошибки – их нужно исправить. После этого нажать на Finish.
Далее на странице настройки Access Point for Administering the Cluster нужно указать имя кластера и его IP адрес и подсеть.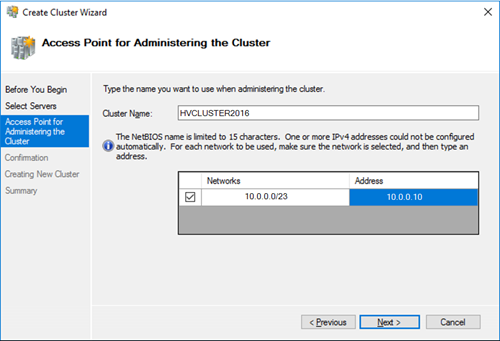
Осталось нажать 2 раза кнопку Next и мастер создаст новый кластер.
Настройка кластера Hyper-V
Теперь в кластер нужно добавить диски. Для этого откройте консоль Failover Cluster Management и в разделе Storage -> Disks добавьте общие в кластер общие диски (они должны быть инициализированы и отформатированы)
Задайте содержательные имена дискам. В нашем примере один кластерный диск будет использоваться как том Cluster Shared Volumes (CSV) для хранения файлов ВМ, а второй использоваться для кворума (диск небольшого размера).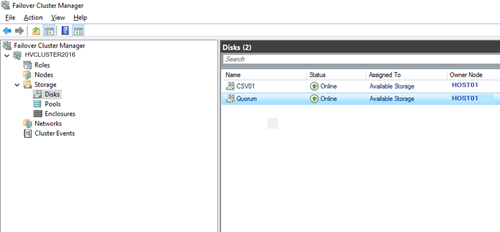
Далее нужно настроить кластерный кворум. Для этого щелкните ПКМ по имени кластера и выберите пункт меню More Actions-> Configure Cluster Quorum Settings.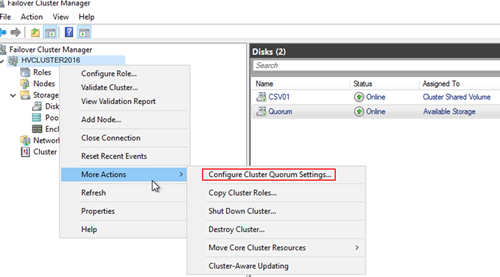
Выберите вариант настройки кворума для кластера Select the quorum witness.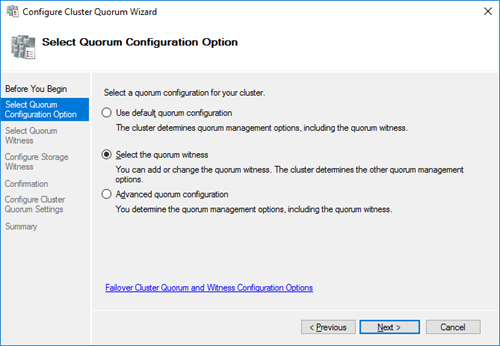
В качестве типа кворума выберите Quorum Witness Select Disk Witness (кворум с использованием диска свидетеля).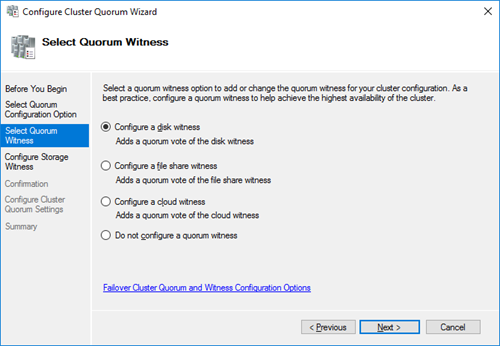
Выберите кластерный диск, который вы хотите использовать в качестве диска-свидетеля.
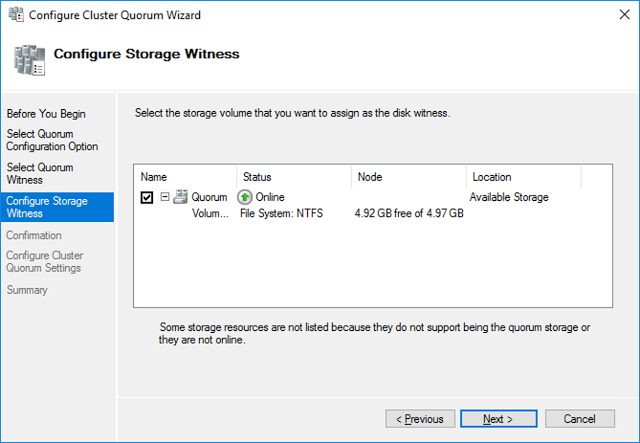
Теперь в настройках Hyper-V на каждой из нод нужно указать кластерный том CSV в качестве диска по-умолчанию для хранения виртуальных машин.
Теперь можно в консоли управления кластером создать новую виртуальную машину: Roles -> Virtual Machines -> New Virtual Machine.
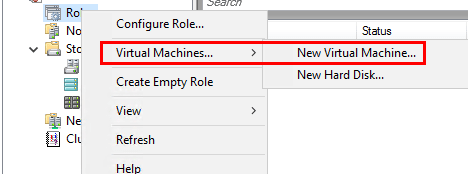
Затем с помощью обычного мастера Hyper-V нужно создать новую виртуальную машину. С помощью Live Migration в дальнейшем можно убедится, что ВМ на легко перемещается между узлами кластера Hyper-V.