Data Deduplication (дедупликация данных) — это возможность уменьшать пространства за счет удаления одной части дублирующих данных. Впервые Microsoft выпустила такую возможность в Windows Server 2012 и технически она менялась вплоть до самой последней версии сервера 2019. Технология дедупликации реализована у множества брендов в том числе: HP, CISCO, IBM и VmWare.
Для чего нужна и как работает дедупликация
Если взять обычный файловый или бэкап сервер, то мы увидим большой объем полностью или частично дублирующих файлов. На файловых серверах это полные копии данных, которые хранят разные пользователи, а на бэкап серверах — это минимум файлы с ОС. С определенным интервалом происходит процесс сканирования блоков с данными в 32-128 Кб и проверка уникальности. Такие блоки так же называются чанками (chunk/куски) и это важно запомнить, так как это название вы будете видеть в Powershell. При нахождении одинаковых чанков они оба будут удалены и заменен ссылкой на уникальный чанк помещенный в специальное место. Такие ссылки будут помещены в папку System Volume Information, а блоки, с уникальными данными, в контейнеры. Все такие данные, в Windows Server, имеют возможность восстановления в случае критических повреждений.
Дедупликация работает по томам и в целом мы можем увидеть такую схему:
- Оптимизированные файлы, состоящие из ссылок на уникальные чанки;
- Чанки, организованные в контейнеры, которые сжимаются и помещаются в хранилище;
- Не оптимизированные файлы.
Бренды реализуют дедуликацию по-разному. Она может работать с целым файлом, блоком или битом. В Windows Server реализована только блочная дедупликация. Файловая дедупликация была реализована в Microsoft DPM, но в этом случае, файл измененный на бит, уже будет являться новым и это было бы оправдано в случаях бэкапа. В сетях можно увидеть битовую.
Картинки, которые так же немного демонстрирует описанный процесс:


Кроме реализации дедупликации на уровне томов, у некоторых брендов, она работает и на уровне сети. Вместо отправки файлов будут отправлены хэш суммы (SHA-1, SHA-2, SHA-256) чанков и если хэш будет совпадать с тем, что уже имеется на стороне принимающего сервера, он не будет перенесен. Похожая возможность, в Windos Server, реализована с помощью работы BranchCache и роли Data Deduplication.
Изменения в версиях
Дедупликация не работает на томах меньше чем 2 Гб.
Windows Server 2012 + r2
- файловая система только NTFS;
- поддержка томов до 10 Тб;
- не рекомендуется использовать с файлами объем которых достигает 1 Тб;
- 2012 не поддерживает VSS (не может работать с открытыми файлами) с 2012 r2 эта поддержка появилась;
- один режим работы.
Windows Server 2016
- файловая система только NTFS;
- поддержка томов до 64 Тб;
- дедупликация работает с первым 1 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- возможность доступна в Nano Server.
Windows Server 2019
- файловая система NTFS или ReFS;
- поддержка томов до 64 Тб;
- работа с первыми 4 Тб данных у файла (ранее могли быть ошибки после 1 Тб данных, но исправилась после выпуска обновлений kb3216755, kb4025334, kb4013429);
- три режима работы;
- интеграция с BranchCache;
- возможность доступна в Nano Server.
Процесс дедупликации происходит по расписанию, а не «на лету», и из-за этого есть общие рекомендации по размеру разделов. Если разделы будут больше описанных выше, то скорость работы сканирования может быть меньше чем обновление этих файлов. В версии 2016 в процесс дедупликации была добавлена парализация, что позволило увеличить скорость и общий объем работы для работы этой роли:

Если вы используете кластер, то роль должна быть установлена на каждую ноду.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
- Файловые сервера
- VDI
- Архивы с бэкапом
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
- файлы зашифрованные (EFS);
- файлы с расширенными атрибутами;
- размер файлов меньше чем 32 Кб;
- том является системным или загрузочным;
- тома не являющиеся дисками (сетевые папки, USB носители).
В теории вы можете работать с любыми остальными типами файлов и серверов, но дедупликация очень ресурсозатратный процесс и лучше следовать объемам, указанным выше. Допустим у вас на сервере много файлов формата mp4 и вы предполагаете, что существенная их часть разная — вы можете попробовать исключить их из анализа. Если сервер будет успевать обрабатывать остальные типы файлов, то вы включите файлы mp4 в анализ позже.
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
Дедупликация работает по расписанию и может использовать минимум и максимум мощностей. В зависимости от общего объема и мощности сервера разный процесс дедупликации (их 4) может занять как час, так и дни. Microsoft рекомендует использовать 10 Gb оперативной памяти на 10 Тb тома. Часть операций нужно делать после работы, какие-то в выходные — все индивидуально.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
При копировании файлов между двумя серверами, с установленной ролью, они будут перенесены в дедуплицированном виде. При переносе на том, где этой роли нет — они будут сохранены в исходном состоянии.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.
Установка
В панели Server Manager открываем мастер по установке ролей и компонентов:

Пропускаем первые три шага (область 1) или выбираем другой сервер если планируем устанавливать роль не на этот сервер (область 2):

На этапе выбора ролей сервера, во вкладе «Файловые службы и службы хранилища» и «Файловые службы и службы iSCSI» выбираем «Дедупликация данных»:

Раздел выбора компонентов не понадобится и его можно пропустить. На шаге подтверждения можно еще раз проверить выбранные операции и нажать кнопку установки:

Установка занимает несколько минут и без необходимости в последующей перезагрузке. Окно подтверждающее успешную установку можно закрыть:

Оценка потенциального освобождающегося места с DDPEval.exe
Вместе с установкой роли у появляется программа DDPEval.exe, позволяющая предварительно оценить пространство, которое будет освобождено в последующем.
Статистика, которую предоставляет Microsoft в зависимости от разных типов данных, примерно следующая:
- Документы пользователей — экономия 30-50%
- Установочные файлы — экономия 70-80%
- Файлы виртуализации — экономия 80-95%
- Файловые хранилища — экономия 50-60%

Для оценки места я поместил 3 одинаковых установочных архива с Exchange 2013 общим объемом 6 Гб на диск Е.
Открываем Powershell/CMD и пишем команду, которая имеет следующий синтаксис:
DDPEval.exe <раздел>
DDPEval.exe <раздел><папка>
# Пример
DDPEval.exe E:\Folder1
По каким-то причинам у меня определилась Windows 10, хотя я использую Windows Server 2019
Как можно увидеть — экономия на полностью идентичных файлах в 69 % или 4.27 Gb.
Я удалил файлы с Exchange и поместил 3 разных образа Linux (Ubuntu, Debian, Centos):


Экономия в 2%.
И последний результат с 11 разными csv/xlsx/docx файлами. Экономия 51%:

Настройка роли
Возможность управлять ролью находится на вкладе «Файловые службы»:

Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим «Настройка дедупликации данных»:

По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
- Файловый сервер общего назначения;
- Сервер инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированный резервный сервер.
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:

Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации. Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе. Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.

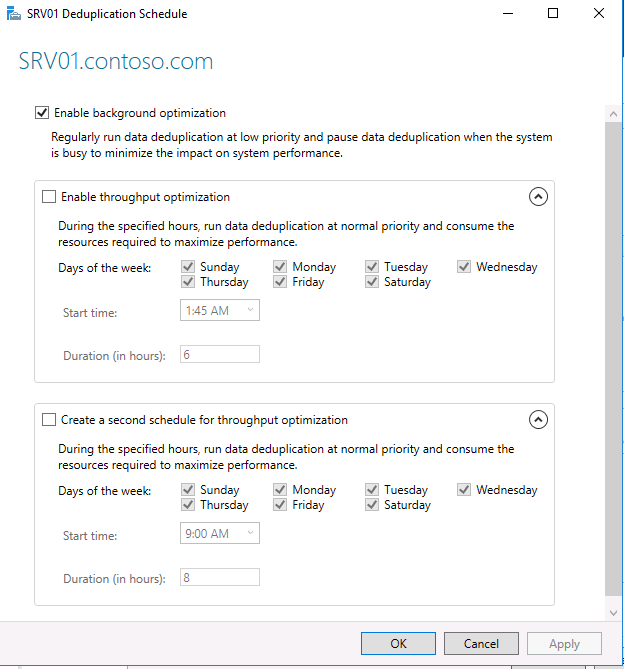
В окне расписания мы можем настроить следующее:
- Фоновая оптимизация (Enable background optimization) — включена по умолчанию. Работает с низким приоритетом не мешая основным процессам. При высокой нагрузке останавливается автоматически. Срабатывает один раз в час;
- Включить оптимизацию пропускной способности (Enable throughput optimization) — расписание, когда дедупликация может выполнятся без ограничения в ресурсах. Можно настроить на выходные дни например;
- Создать второе расписание оптимизации пропускной способности (Create a second schedule for throughput optimization) — расписание аналогично предыдущему. Можно настроить на вечернее время.

На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Расширенные настройки с Powershell
С помощью Powershell мы можем установить роль и настроить ее сразу на множестве компьютеров. Для установки роли локально или удаленно можно использовать следующую команду:
Install-WindowsFeature -Name "FS-Data-Deduplication" -ComputerName "Имя компьютера" -IncludeAllSubFeature -IncludeManagementToolsСледующим способом мы увидим все команды модуля дедупликации:
Get-Command -Module Deduplication
Включение и настройка дедупликации для томов
Как уже говорилось выше, при настройке в GUI у нас есть три рекомендованных режима работы с уже установленным расписанием:
- HyperV;
- Backup;
- Default (файловый сервер, устанавливается по умолчанию).
Каждый из этих режимов устанавливается для одного или множества томов следующим путем:
Enable-DedupVolume -Volume 'E:\','D:\' -UsageType 'Default'
В некоторых командах может появится ошибка, которая связана с написанием буквы раздела со слэшем. Если у вас она тоже появится попробуйте исправить ‘E:\’ на ‘E:’:
No MSFT_DedupVolume objects found with property ‘Volume’ equal to ‘E:\’
Так мы узнаем на каких томах настроена дедупликация:
Get-DedupVolume
Так же как и в GUI мы можем ограничить обработку папок и файлов по их расширению. Для этого есть следующие аргументы:
- ExcludeFolder — ограничения на папки, например ‘E:\Folder1’,’E:\Folder2»
- ExcludeFileType — ограничения по расширениям, например ‘txt’,’jpg’;
- MinimumFileAgeDays — минимальный возраст файла в днях, который будет оптимизироваться.
Следующий пример установит эти настройки и вернет их:
Set-DedupVolume `
-Volume 'E:' `
-ExcludeFolder 'E:\folder_exclude' `
-ExcludeFileType 'txt','rar' `
-MinimumFileAgeDays 15
Get-DedupVolume | Select *
По умолчанию дедуплкиция работает только с файлами больше чем 32Kb. В отличие от GUI это меняется в Powershell, но не в меньшую сторону. На примере ниже я установлю этот минимум для файлов в 1GB:
Set-DedupVolume `
-Volume 'E:' `
-MinimumFileSize 1GB
Get-DedupVolume | Select *
Есть еще несколько параметров, которые устанавливаются:
- ChunkRedundancyThreshold — устанавливает порог ссылок после которого будет создан еще один идентичный чанк. По умолчанию равен 100. С помощью этого параметра увеличивается избыточность. Проявляется она в более быстром и гарантированном (в случае повреждения) доступе файла. Не рекомендуется менять;
- InputOutputScale — установка значения I/O для распараллеливания процесса от 0 до 36. По умолчанию значение рассчитывается само;
- NoCompress — значению в $True или $False устанавливающая будет ли происходить сжатие;
- NoCompressionFileType — расширение файлов к которым не будет применяться сжатие;
- OptimizeInUseFiles — будут ли оптимизированы открытые файлы, например подключенные файлы VHDx;
- OptimizePartialFiles — если $True — будет работать блочная дедупликация. В ином случае будет работать файловая дедупликация;
- Verify — добавляет еще одну проверку идентичности чанков. Они будут сравниваться побайтно. Не могу сказать о ситуациях, где это могло бы пригодиться.
Для отключения используется следующая команда:
Disable-DedupVolume -Volume 'E:\'
Отключенная дедупликация не конвертирует файлы в их исходное состояние. В примере выше у нас просто не будут оптимизироваться новые файлы и выполнятся задачи. Если к команде добавить параметр -DataAccess, то мы отключим доступ к файлам прошедшим через процесс дедупликации. О том как отменить дедупликацию полностью — будет рассказано далее.
Изменение расписаний
Дедупликация делится на 4 типа задач отдельно которые можно запустить в Powershell:
- Оптимизация (Optimization) — разбиение данных на блоки, их сравнение, сжатие и помещение в хранилище System Volume Information. По умолчанию происходит раз в час;
- Сбор мусора (GarbageCollection) — удаление устаревших фрагментов (например восстановление тех данных у которых нет дубликатов). По умолчанию происходит каждую субботу;
- Проверка целостности (Scrubbing) — обнаружение повреждений в хранилище блоков и их восстановление. По умолчанию происходит каждую субботу;
- Отмена оптимизации (Unoptimization)— отмена или отключение оптимизации на томе. Выполняется по требованию.
Каждое такое задание, а так же созданные вами лично, можно увидеть в планировщике задач. Там же можно увидеть время запуска и результат выполнения:

Например можно увидеть, что задача фоновой оптимизации запускается каждый час.
Более конкретно узнать время задач мы можем через получение расписания:
Get-DedupSchedule
Задания никогда не выполняются одновременно — только в процессе очереди.
Мы можем изменить каждое из этих заданий. Например процесс GarbageCollection является очень ресурсозатратным процессом и я хочу что бы его работа начиналась в пятницу в 22:00 (по умолчанию работает в субботу в 2:45 ночи), что бы точно завершилась к понедельнику. Я так же установлю параметр StopWhenSystemBusy, который остановит процесс очистки мусора если система будет сильно нагружена другой задачей. Я сделаю это так:
Set-DedupSchedule `
-Name 'WeeklyGarbageCollection' `
-Type 'GarbageCollection' `
-Enabled $True `
-StopWhenSystemBusy $True `
-Days 'Friday' `
-Start 22:00 `

Где:
- Name — имя процесса, который мы хотим изменить;
- Type — тип процесса. В нашем случае это сборка мусора (GarbageCollection);
- Enabled — будет ли включен этот процесс;
- StopWhenSystemBusy — остановится ли процесс, если сервер будет сильно нагружен другой задачей (затем попробует запустится снова);
- Days — дни, в которые этот процесс должен запускаться;
- Start — время запуска.
Есть еще параметры, которые есть не только у этого командлета, но и у других команд дедупликации:
- DurationHours — продолжительность работы задачи в часах, после которого он будет корректно завершен. По умолчанию равен 0, что означает работу до полного завершения без ограничения во времени.
- Full — параметр со значениями $True и $False. Зависит от того что указано в Type. Если мы выполняем сборку мусора, то этот параметр будет удалять все устаревшие данные сразу, а не до достижения определенного порога. При выполнении очистки (Scrubbing), если указан параметр Full, происходит проверка всех данных, а не только критически важных. В обоих случаях этот параметр стоит использовать раз в месяц.
- ReadOnly — при работе очистки не исправляет ошибки, а только уведомляет
Кроме этого, почти во всех командах при работе с дедупликацией есть настройка ресурсов, которые мы планируем выделять:
- Cores — число с количеством ядер (в процентном соотношении), которые будут участвовать в процессе;
- Memory — количество памяти от общего значения (в процентном соотношении);
- StopWhenSystemBusy — останавливает задачу, если сервер, в данный момент, сильно нагружен (возобновляет ее позже);
- Priority — указывает тип нагрузки на процессор (ввод, вывод) со значениями: Low, Normal, High;
- InputOutputThrottle — ограничения работы ввода вывода при троттлинге в значениях от 0 до 100,;
- InputOutputThrottleLevel — ограничения работы ввода вывода при троттлинге со следующими значениями: None, Low, Medium, High. InputOutputThrottle имеет более высокий приоритет и при установке двух аргументов — InputOutputThrottleLevel может не работать.
- ThrottleLimit — указывает предел троттлинга. Если указан 0, то расчет будет выполнен автоматически.
На примере параметров выше я создам новую задачу по оптимизации. Она будет проходить в будни, после 21:00, с нагрузкой в 70% от максимальной на протяжении 8 часов:
New-DedupSchedule `
-Name 'Оптимизация по будням' `
-Cores 80 `
-Days Monday,Tuesday,Wednesday,Thursday,Friday `
-DurationHours 8 `
-InputOutputThrottleLevel Medium `
-Priority Normal `
-Memory 80 `
-Start 21:00 `
-Type 'Optimization' `
-StopWhenSystemBusy `

Обращу внимание, что мы можем не писать все эти настройки, а просто копировать их используя обычные методы Powershell. Так я создам копию задачи очистки (Scrubbing), которая будет дополнена ключом Full и отключена по умолчанию:
Get-DedupSchedule -Name '*Scrub*' | New-DedupSchedule `
-Name 'Полная проверка целостности раз в месяц' `
-Full `
-Disable `
Так же можно и удалять задачи:
Get-DedupSchedule -Name '*Полная*' | Remove-DedupSchedule
# или
Remove-DedupSchedule -Name '*Полная*'
Если вы убрали дедупликацию на томе и планируете обратить файлы в исходное состояние вы можете выполнить следующую команду установив свои настройки:
New-DedupSchedule -Type UnoptimizationУчитывайте, что вам потребуется больше свободного пространства для файлов (иначе дедупликация остановится с ошибкой) и процесс займет много ресурсов и времени. Копирование данных на другой том так же возможен и в этом случае файл тоже вернется в исходное состояние.
Запуск отдельных задач
Предыдущий пример, где мы устанавливали параметр Full, для проверки целостности всей базы, был не очень удачный. Дело в том, что мы можем устанавливать расписание только на неделю, а такая проверка рекомендуется раз в месяц. Для исправления этой ситуации мы можем использовать разовые задачи. Так я создам и запущу похожую задачу:
Start-DedupJob `
-Full `
-Volume 'E:\' `
-Type 'Scrubbing'
Вернуть состояние задачи можно так:
Get-DedupJob
Если у вас есть настроенное расписание, то вы тоже его можете скопировать и запустить т.е. использовать как шаблон. Такая возможность явно не планировалась разработчиками и поэтому могут быть ошибки на этапе запуска. Например у меня была такие ошибки:
- Exception calling «EndProcessing» with «0» argument(s)
- Start-DedupJob : MSFT_DedupVolume.Volume=’
Одна из них была связана с отсутствием буквы раздела, так как я его не указал. Я дополнил параметры и все сработало корректно. Так же как и на примерах выше мы можем исправлять шаблон из планировщика как хотим. Ошибки могут быть разными, но они достаточно ясные и легко исправляются:
Get-DedupSchedule -Name '*полная проверка*' | Start-DedupJob -InputOutputThrottleLevel Low -Volume 'E:'
Так же как и при создании запланированной задачи мы можем установить следующие параметры (более детально они описаны выше):
- Cores
- Full
- InputOutputThrottle
- InputOutputThrottleLevel
- Memory
- Priority
- ReadOnly
- StopWhenSystemBusy
- ThrottleLimit
- Type
А эти параметры есть только у Start-DedupSchedule:
- Preempt — форсированный запуск задачи, отменяющий иные;
- Timestamp — работает только с задачами типа ‘Unoptimization’ и принимает значения типа данных DateTime. Отменяет оптимизацию файлов оптимизированных с указанной даты;
- Volume — можно указать один или несколько томов. Можно указывать буквы формата ‘E:’, ID и GUID;
- Wait — в фоне будет отображаться процесс задачи и ее результат. Пример ниже.

Пример отмены задач:
Get-DedupJob -Type Scrubbing | Stop-DedupJob
# или
Stop-DedupJob -Volume 'E:','C:'Отмену дедупликации вы так же можете запустить задачей:
Start-DedupJob -Type UnoptimizationСтатус дедупликации
Следующая команда вернет текущий статус дедупликации:
# Сокращенный вариант
Get-DedupStatus
# Полный отчет
Get-DedupStatus | select *
Предыдущая команда возвращает закэшированные данные, но если вы хотите получить наиболее актуальную информацию вы можете выполнить следующую команду:
# Для всех томов
Update-DedupStatus
# Для одного тома
Update-DedupStatus -Volume 'E:'
# Возвращение полной актуальной информации по тому
Update-DedupStatus -Volume 'E:' | SELECT *
Следующая команда вернет время последнего выполнения каждого из процессов дедупликации:
Get-DedupStatus -Volume 'E:' | select -Property "*time*" | fl
Эта команда вернет информацию по работе с файлами:
Get-DedupStatus -Volume 'E:' | select -Property "*file*",'s*rate*' | fl
Где:
- InPolicyFilesCount — количество файлов, которые подходят для оптимизации;
- InPolicyFilesSize — общий размер файлов, которые подходят для оптимизации;
- OptimizedFilesCount — количество файлов, которые были оптимизированы;
- OptimizedFilesSavingRate — процент оптимизированных файлов относительно всех файлов которые подходят под установленные параметры;
- OptimizedFilesSize — общий размер оптимизированных файлов.
Более точно эти данные отображаются после процесса сборки мусора и оптимизации.
Следующая команда вернет данные из базы дедупликации по определенному тому:
Get-DedupMetadata -Volume 'E:'
Если такой запрос завершится ошибкой, то скорее всего, в данный момент, происходит один из процессов дедупликации, который меняет эти метаданные.
По выводу мы можем увидеть:
- DataChunkCount — количество чанков, размером 32-128 Кб на одном томе;
- DataContainerCount — количество контейнеров;
- DataChunkAverageSize — средний размер одного чанка (размер контейнера поделенный на количество чанков);
- TotalChunkStoreSize — размер хранилища;
- CorruptionLogEntryCount — количество ошибок на томе.
Свойства типа «Stream*» скорее всего показывают данные по открытым файлам или проходящие через Volume Shadow Copy.
Если будет необходимость в освобождения места (переносом или удалением) подсчет потенциально освобождающегося пространства будет сложной задачей. Связано это с тем, что не ясно количество дедуплицированных файлов (они могут быть в трех, четырех копиях, в разных местах и т.д.). В этом случае можно использовать команду Measure-DedupFileMetadata:
Measure-DedupFileMetadata -Path 'E:\New folder\'
Где:
- FilesCount — количество файлов на всем томе;
- OptimizedFilesCount — количество оптимизированных файлов на всем томе;
- Size — суммарный размер всех файлов;
- DedupSize — итоговый размер дедуплицированных файлов в этой папке;
Восстановление дедуплицированных файлов
Команда Expand-DedupFile восстанавливает файл, который был оптимизирован в его исходное место. Такая операция может понадобится, когда стороннее приложение (например программы бэкапа) не могут корректно работать с файлом. Важным моментом восстановления таких файлов является достаточное количество места на диске. Следующим образом я восстановлю два файла в их исходное местоположение:
Expand-DedupFile -Path 'E:\New folder\Otchet2020.doc','E:\New folder\3285.wav'Никакого вывода команда не выдает, но если файл не был дедуплицирован, то вы получите ошибку:
Expand-DedupFile : MSFT_DedupVolume.Path=’E:\file1′ — HRESULT 0x80070057, The parameter is incorrect.
…
Теги:
#powershell
#дедупликация
#windows server
Время на прочтение
8 мин
Количество просмотров 50K
Всем доброго времени суток!
Сегодня хотелось бы провести обзор такой интересной новой фичи в Windows Server 2012 как дедупликация данных (data deduplication). Фича крайне интересная, но все же сначала нужно разобраться насколько она нужна…

А нужна ли вообще деупликация?
С каждым годом (если не днем) объемы жестких дисков растут, а при этом носители сами еще и дешевеют.
Исходя из этой тенденции возникает вопрос: «А нужна ли вообще дедупликация данных?».
Однако, если мы с вами живем в нашей вселенной и на нашей планете, то практически все в этом мире имеет свойство подчиняться 3-му закону Ньютона. Может аналогия и не совсем прозрачная, но я подвожу к тому, что как бы не дешевели дисковые системы и сами диски, как бы не увеличивался объем самих носителей — требования с точки зрения бизнеса к доступному для хранения данных пространства постоянно растут и тем самым нивелируют увеличение объем и падение цен.
По прогнозам IDC примерно через год в суммарном объеме будет требоваться порядка 90 миллионов терабайт. Объем, скажем прямо, не маленький.

И вот тут как раз вопрос о дедупликации данных очень сильно становится актуальным. Ведь данные, которые мы используем бывают и разных типов, и назначение у них могут быть разные — где-то это production-данные, где-то это архивы и резервные копии, а где-то это потоковые данные — я специально привел такие примеры, поскольку в первом случае эффект от использования дедупликации будет средним, в архивных данных — максимальным, а в случае с потоковыми данным — минимальным. Но все же экономить пространство мы с вами сможем, тем более что теперь дедупликация — это удел не только специализированных систем хранения данных, но и компонент, фича серверной ОС Windows Server 2012.
Типы дедупликации и их применение
Прежде чем перейти к обзору самого механизма дедупликации в Windows Server 2012, давайте разберемся какие типы дедупликации бывают. Предлагаю начать сверху-вниз, на мой взгляд так оно будет нагляднее.
1) Файловая дедупликация — как и любой механизм дедупликации, работа алгоритма сводится к поиску уникальных наборов данных и повторяющихся, где вторые типы наборов заменяются ссылками на первые наборы. Иными словами алгоритм пытается хранить только уникальные данные, заменяя повторяющиеся данные ссылками на уникальные. Как нетрудно догадаться из названия данного типа дедупликации — все подобные операции происходят на уровне файлов. Если вспомнить историю продуктов Microsoft — то данный подход уже неоднократно применялся ранее — в Microsoft Exchange Server и Microsoft System Center Data Protection Manager — и назывался этот механизм S.I.S. (Single Instance Storage). В продуктах линейки Exchange от него в свое время отказались из соображений производительности, а вот в Data Protection Manager этот механизм до сих пор успешно применяется и кажется будет продолжать это делать. Как нетрудно догадаться — файловый уровень самый высокий (если вспомнить устройство систем хранения данных в общем) — а потому и эффект будет самый минимальный по сравнению с другими типами дедупликации. Область применения — в основном применяется данный тип дедупликации к архивным данным.
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он суб-файловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы все те же, что и раньше — но на уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично — особенно для VDI-сценариев. Если учесть что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно по этому файловая дедупликация тут бессильна) — то блочная дедупликация — наш выбор!
3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных — обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю что есть системы дедупликации трафика, которые работают на битовом уровне, допустим тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого трафика — это очень критично для сценариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде еще и раскроют свои таланты.
Очень интересным в этом плане выглядит доклад Microsoft на USENIX 2012, который состоялся в Бостоне в июне месяце. Был проведен достаточно масштабный анализ первичных данных с точки зрения применения к ним механизмов блочной дедупликации в WIndows Server 2012 — рекомендую ознакомиться с данным материалом.
Вопросы эффективности
Для того чтобы понять насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые шары, документы пользователей из папки «Мои документы», Хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
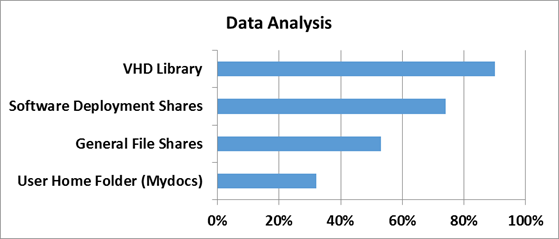
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок проверили в Microsoft в отделе разработки ПО.
3 наиболее популярных сценария стали объектами исследования:
1) Сервера сборки билдов ПО — в MS каждый день собирается приличное количество билдов самых разных продуктов. Даже не значительно изменение в коде приводит к процессу сборки билда — и следовательно дублирующихся данных создается очень много
2) Шары с дистрибутивами продуктов на релиз — Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать — внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
3) Групповые шары — это сочетание шар с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.

А теперь самое интересное — ниже приведен скриншот с томами в Windows Server 2012, на которых размещаются все эти данные.
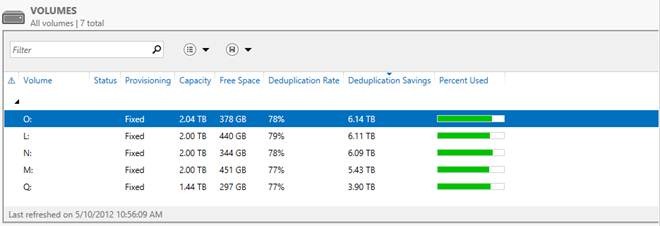
Я думаю слова здесь будут лишними — и все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Характеристики дедупликации в Windows Server 2012
А теперь давайте рассмотрим основные характеристики дедупликации в Windows Server 2012.
1) Прозрачность и легкость в использовании — настроить дедупликацию крайне просто. Сначала в мастере ролей в Windows Server вы раскрывайте роль File and Storage Services, далее File and iSCSI Services — а у же там включаете опцию Data Deduplication.
После этого в Server Manager вы выбираете Fike and Storage Services, клик правой кнопкой мыши — и там вы выбираете пункт «Enable Volume Deduplication». Спешл линк для любителей PowerShell. Все крайне просто. С точки зрения конечного пользователя и приложений доступ и работа с данными осуществляются прозрачно и незаметно. Если говорить про дедупликацию с точки зрения фаловой системы — то поддерживается только NTFS. ReFS не поддается дедупликации, ровно как и тома защищенные с помощью EFS (Encrypted Fike System). Также под дедупликацию не попадают фалы объемом менее 32 KB и файлы с расширенными атрибутами (extended attributes). Дедупликация, однако, распространяется на динамические тома, тома зашифрованные с помощью BitLocker, но не распространяется на тома CSV, а также системные тома (что логично).
2) Оптимизация под основные данные — стоит сразу отметить, что дедупликация — это не онлайн-процесс. Дедупликации подвергаются файлы, которые достигают определенного уровня старости с точки зрения задаваемой политики. После достижения определенного срока хранения данные начинают проходить через процесс дедупликации — по умолчанию этот промежуток времени равен 5 дням, но никто не мешает вам изменить этот параметр — но будьте разумны в своих экспериментах!
3) Планирование процессов оптимизации — механизм который каждый час проверяет файлы на соответствия параметрам дедупликации и добавляет их в расписание.
4) Механизмы исключения объектов из области дедупликации — данный механизм позволяет исключит файлы из области дедупликации по их типу (JPG, MOV, AVI — как пример, это потоковые данны — то, что меньше всего поддается дедупликации — если вообще поддается). Можно также исключить сразу целые папки с файлами из области дедупликации (это для любителей немецких фильмов, у которых их тьма-тьмущая).
5) Мобильность — дедуплицированный том — это целостный объект — его можно переносить с одного сервера на другой (речь идет исключительно о Windows Server 2012). При этом вы без проблем получите доступ к вашим данным и сможете продолжить работу с ними. Все что для этого необходимо — это включенная опция Data Deduplication на целевом сервере.
6) Оптимизация ресурсоемкости — данные механизмы подразумевают оптимизацию алгоритмов для снижения нагрузки по операциям чтения/записи, таким образом если мы говорим про размер хеш-индекса блоков данных, то размер индекса на 1 блок данных составляет 6 байт. Таким образом применять дедупликацию можно даже к очень массивным наборам данных.
Также алгоритм всегда проверяет достаточно ли ресурсов памяти для проведения процесса дедупликации — если ответ отрицательный, то алгоритм отложит процесс до высвобождения необходимого объема ресурсов.
7) Интеграция с BranchCache — механизмы индексация для дедупликация являются общими также и для BranchCache — поэтому эффективность использования данных технологий в связке не вызывает сомнений!
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от корого зависят по-крайней мере 1000 файлов безнадежно поврежден… Думаю, валидол-эз-э-сервис тогда точно пригодится, но не в нашем случае.
1) Резервное копирование — Windows Server 2012, как и System Center Data Protection Manager 2012 SP1 полностью поддерживают дедуплицированные тома, с точки зрения процессов резервного копирования. Также доступно специальное API, которое позволяет сторонним разработчикам использовать и поддерживать механизмы дедупликации, а также восстанавливать данные из дедуплицированных архивов.
2) Дополнительные копии для критичных данных — те данные, которые имеет самый частый параметр обращения продвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождение сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
3) По умолчанию, 1 раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
С чего начать и как померить
Перед тем как включать дедупликацию, всегда нормальному человеку в голову придет мысль о том насколько эффективен будет данный механизм конкретно в его случае. Для этого вы можете использовать Deduplication Data Evaluation Tool.
После установки дедупликации вы можете найти инструмент под названием DDPEval.exe, который находится в \Windows\System32\ — данная утиль может быть портирована на сменный носитель или другой том. Поддерживаются ОС Windows 7 и выше. Так что вы можете проанализировать ваши данный и понять стоимость овечье шкурки. (смайл).
На этом мой обзор завершен. Надеюсь вам было интересно. Если у вас возникнут вопросы — можете смело найти меня в соц.сетях — ВКонтакте, Facebook — по имени и фамилии — и я постараюсь вам помочь.
Для тех, кто хочет узнать про новые возможности в Windows Server 2012, а также System Center 2012 SP1 — я всех приглашаю посетить IT Camp — 26 ноября, накануне TechEd Russia 2012 состоится данное мероприятие — проводить его будем я, Георгий Гаджиев и Саймон Перриман, который специально прилетает к нам из США.
До встречи на IT Camp и на TechEd!
С уважением,
человек-огонь
Георгий А. Гаджиев
Microsoft Corporation
Возможность дедупликации данных впервые появилась еще в Windows Server 2012. В Windows Server 2016 представлена уже третья версия компонента дедупликации, значительно переработанная и улучшенная. В этой статье мы поговорим о новых функциях дедупликации, ее настройках и отличиях от предыдущих реализаций.
- Новые возможности дедупликации данных в Windows Server 2016
- Установка компонента дедупликации в Windows Server 2016
- Включение и настройка дедупликации
- Ручной запуск дедупликации
- Просмотр состояния дедупликации
- Как отключить дедупликацию
Содержание:
Новые возможности дедупликации данных в Windows Server 2016
-
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
Обновленный движок дудупликации в Windows Server 2016 выполнять задания дедупликации в многопоточном режиме, причем каждый том использует несколько вычислительных потоков и очередей ввода-вывода. Введение многопоточности и других изменений в компоненте сказалось на ограничениях на размер файлов и томов. Поскольку многопоточная дедупликация повышает производительность и устраняет необходимость разбиения диска на несколько томов в Windows Server 2016, вы можете использовать дедупликацию для тома до 64 ТБ. Также увеличен максимальный размер файла, теперь поддерживается дедупликация файлов до 1 Тб. - Поддержка виртуализированных приложений резервного копирования. В Windows Server 2012 был только один тип дедупликации, предназначенный в основном для обычных файловых серверов. Дедупликация непрерывно работающей ВМ не поддерживается, поскольку дедупликации не знает, как работать с открытыми файлами.
Дедупликация в Windows Server 2012 R2 начала использовать VSS, соответственно, стала поддерживаться дедупликация виртуальных машин. Для таких задач использовался отдельный тип дедупликации.В Windows Server 2016 добавлен еще третий тип дедупликации, предназначенный специально для виртуализированных серверов резервного копирования (например, DPM). - Поддержка Nano Server. Nano Server – эта технология позволяет развертывать операционную систему Windows Server 2016 с минимальным количеством установленных компонентов. Nano Server полностью поддерживает дедупликацию.
- Поддержка последовательного обновления кластера (Cluster OS Rolling Upgrade). Cluster OS Rolling Upgrade – это новая функция Windows Server 2016, которая может использоваться для обновления операционной системы на каждом узле кластера с Windows Server 2012 R2 до Windows Server 2016 без остановки кластера. Это возможно благодаря специальной смешанной работе кластера, когда узлы кластера одновременно могут работать под управлением Windows Server 2012 R2 и Windows Server 2016.Смешанный режим означает, что одни и те же данные могут быть расположены на узлах с разными версиями компонента дедупликации. Дедупликация в Windows Server 2016 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в процессе обновления кластера.
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
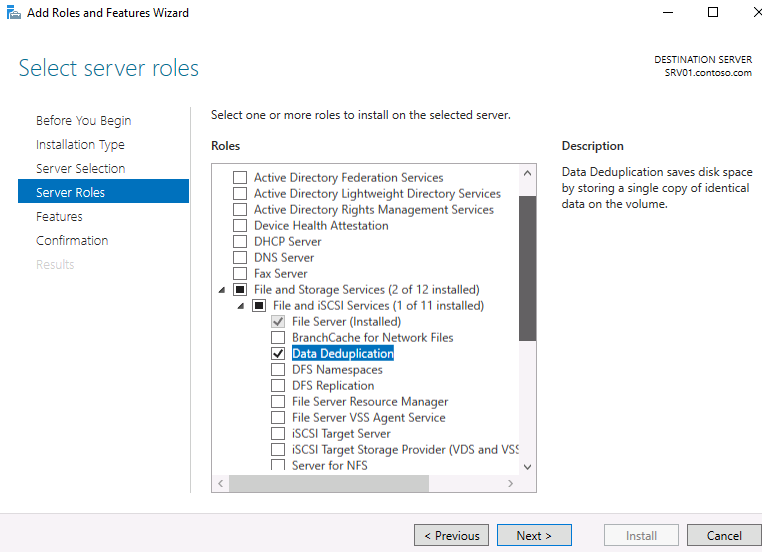
Установка компонента дедупликации в Windows Server 2016
Первое, что нужно сделать, чтобы включить дедупликацию — это установить соответствующую роль сервера. Запустите Server Role wizard и добавьте роль файлового сервера с компонентом «Data Deduplication».
Или выполните следующую команду PowerShell:
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Включение и настройка дедупликации
После установки компонентов вам необходимо включить дедупликацию для определенного тома (или нескольких томов). Это можно сделать двумя способами: с помощью графического интерфейса или с помощью PowerShell.
Чтобы настроить компонент из GUI, откройте Server Manager, перейдите в File and storage services -> Volumes, выберите нужный том, щелкните правой кнопкой мыши и в меню выберите «Configure Data Deduplication».
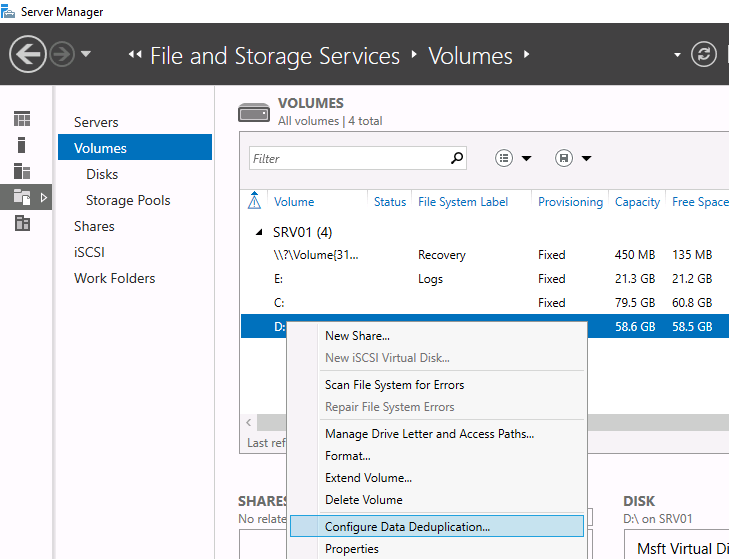
Затем выберите нужный тип дедупликации (например, General puprose file server) и нажмите «Применить». Кроме того, вы можете указать типы файлов, которые не должны подвергаться дедупликации, а также создать исключения для определенных каталогов (каталоги с мультимедиа файйлами, базами и т.д.).
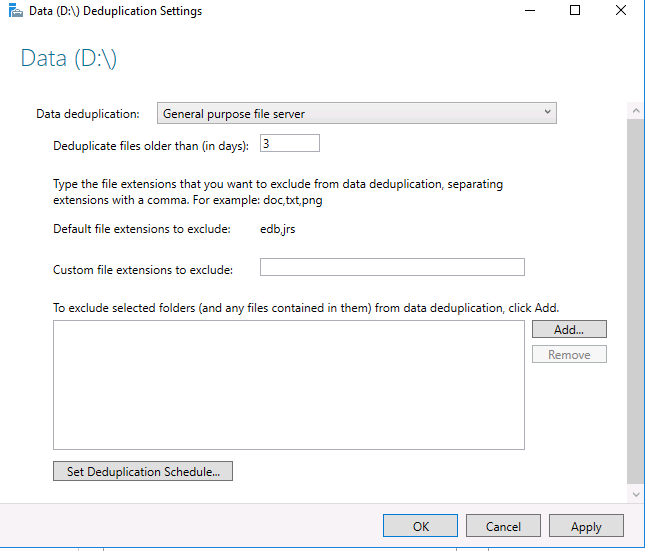
Затем вам необходимо настроить расписание, по которому будет работать задание дедупликации. Нажмите кнопку Set Deduplication Schedule.
По умолчанию включена фоновая оптимизация (background optimization), и вы можете настроить две дополнительные задачи принудительной оптимизации (throughput optimization). Здесь есть несколько настроек — вы можете выбрать дни недели, время начала и продолжительность работы.
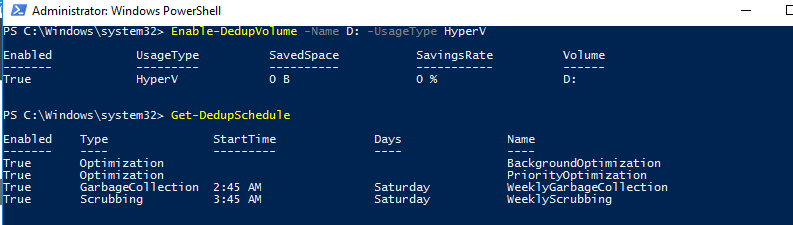
Еще больше возможностей для настройки дедупликации предоставляет PowerShell. Чтобы включить дедупликацию, используйте следующую команду:
Enable-DedupVolume -Name D: -UsageType HyperV
Список текущих заданий дедупликации:
Get-DedupSchedule
Как вы видите, в дополнении к фоновой задачи оптимизации есть задача приоритетной оптимизации (PriorityOptimization), а также задания по сбору мусора (GarbageCollection) и очистке (Scrubbing). Все эти задачи нельзя увидеть в графическом интерфейсе.
PowerShell позволяет вам точно настроить параметры заданий дедупликации. Например, создадим такую задачу оптимизации: задача должна запускаться в 9 утра с понедельника по пятницу и работать 11 часов, с нормальным приоритетом, используя не более 20% ОЗУ и 20% CPU:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 11 -Start (Get-Date ″20/05/2017 9:00 PM″) -Memory 20 -Cores 20 -Priority Normal
Отключим приоритетную оптимизацию:
Set-DedupSchedule -Name PriorityOptimization -Enabled $false
Ручной запуск дедупликации
При необходимости вы можете запустить задание дедупликации вручную. Например, запустим полную оптимизацию тома D: с наивысшим приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -Full

Отслеживать выполнение заданий дедупликации можно с помощью команды Get-DedupJob. Заметим, что одновременно может выполняться только одна такая задача, остальные при этом находятся в очереди и ждут ее завершения.
Просмотр состояния дедупликации
Состояние дедупликации данных для тома можно просмотреть, используя команду:
Get-DedupVolume -Volume D: | fl
Таким образом, вы можете видеть основные параметры тома — общий размер тома, использованный и сохраненный объем, уровень сжатия и т.д.
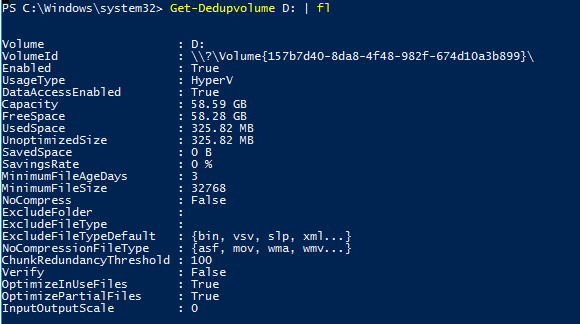
Чтобы проверить статус задания дедупликации, используйте команду:
Get-DedupStatus -Volume D: | fl
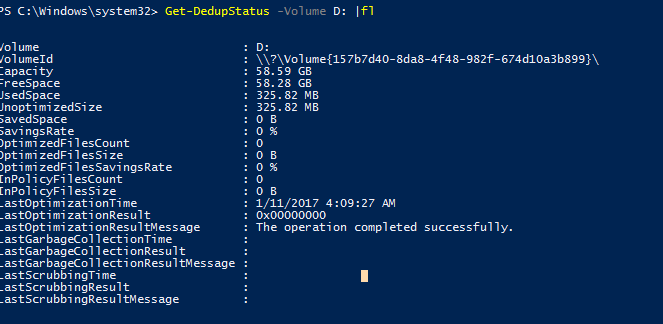
Как отключить дедупликацию
Вы можете отключить дедупликацию на диске из графического интерфейса или с помощью PowerShell. Например:
Disable-DedupVolume -Name D:

Отключение дедупликации для тома отменяет все запланированные задачи, а также предотвращает выполнение любых задач дедупликации, кроме операций на чтение (таких команд, как Get и unoptimization). Данные при этом остаются в неизменном состоянии, останавливается лишь дедупликация новых файлов.
Чтобы вернуть данные в исходное состояние, используйте процедуру обратной дедупликации. Например, выполните следующую команду для выполнения дедупликации данных на диске D с максимально возможной скоростью:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full

Обратите внимание, что для выполнения раздедупликации потребуется дополнительное пространство. Если свободного места на томе недостаточно, процедура не будет выполнена.
В Windows Server 2012 появилась новая функция Data Deduplication (Дедупликация данных). Что же такое дедубликация? Дедупликация данных в общем случае – это процедура поиска и удаления дублирующих данных на носителе информации без ущерба для целостности информации. Цель дудупликации – хранить информацию в небольших блоках (32-128 Кб), выявлять одинаковые (дублирующие блоки) и сохранять только одну копию для каждого блока, а блоки-дубликаты заменять ссылками на единственную копию.
Ранее для организации дедупликации приходилось использовать сторонние продукты (существуют как аппаратные решение по дедупликации на уровне дисковых массивов, так и программные на уровне файлов). Стоимость подобных решений была достаточно высока, ведь они в первую очередь ориентированы на богатых корпоративных заказчиков. Теперь эта функция абсолютно бесплатно доступна всем пользователям a Windows Server 2012.
Есть небольшой хак, позволяющий включить дедупликацию и в клиентских ОС (Windows 8 и Windows 8.1).
В Windows Server 2012 функция дедупликация реализована в виде двух компонентов:
- Драйвера–фильтра, который контролирует функции ввода/вывода
- Службы дедупликации – контролирует три операции («Сборка мусора», «Оптимизация» и «Очистка»).
Указанные компоненты отвечают за поиск совпадающих данных, организации их хранения в единственном числе и корректное предоставление к ним доступа.
Ранее дедупликация в продуктах Microsoft встречалась в почтовом сервер Exchange 200/2003/2007 – в компоненте Single Instance Storage (на сервере в ящике одного из адресатов хранится только один экземпляр сообщения, а остальные адресаты получают просто ссылку на него).
Дедупликация данных в Windows Server 2012 выполняется в фоновом режиме и по-умолчанию запускается каждый час. Процесс запускается при низкой нагрузке на сервер и не снижает общую производительность сервера. Также по-умолчанию дедупликации подвергаются файлы, к которым не было доступа более 30 дней. Кроме того, процедура не осуществляется для следующих типов файлов:: aac, aif, aiff, asf, asx, au, avi, flac, jpeg, m3u, mid, midi, mov, mp1, mp2, mp3, mp4, mpa, mpe, mpeg, mpeg2, mpeg3, mpg, ogg, qt, qtw, ram, rm, rmi, rmvb, snd, swf, vob, wav, wax, wma, wmv, wvx, accdb, accde, accdr, accdt, docm, docx, dotm, dotx, pptm, potm, potx, ppam, ppsx, pptx, sldx, sldm, thmx, xlsx, xlsm, xltx, xltm, xlsb, xlam, xll, ace, arc, arj, bhx, b2, cab, gz, gzip, hpk, hqx, jar, lha, lzh, lzx, pak, pit, rar, sea, sit, sqz, tgz, uu, uue, z, zip, zoo.
Функционал управления дедупликацей доступен из графического интерфейса и через PowerShell. Рассмотрим оба варианта.
Windows Server 2012 Data Deduplication GUI
Чтобы включить дедупликацию данных нужно установить компонент Data Deduplicaion роли File and Storage Services. Сделать это можно из консоли Server Manahger.

После окончания установки компонента откройте консоль Server manager -> File and Storage Servcies -> Volumes –> и щелкните правой кнопкой по разделу, для которого хотите включить дедупликацию и выберите Configure Data Deduplication.

В следующем окне поставьте галочку на пункт “Enable data deduplication”. Здесь же можно указать каталоги, которые не нужно дедуплицировать и настройки планировщика дедупликации.
Текущий уровень дедупликации будет отображаться в столбце Deduplication Rate (обновится через несколько часов).
Для анализа использования дискового пространства и возможной экономии от включения дедупликаций для данного тома, разработана утилита DDPEVAL.exe. Оценить, сколько же дискового пространства получится сэкономить после включении Data deduplication, можно с помощью следующей команды (учтите, для больших томов она может создать существенную нагрузку на CPU)
c:\windows\system32\ddpeval.exe e:\
В моем случае экономия составила бы порядка 57%.
Дедупликация с Powershell
Процессом дедупликации можно управлять и из Powershell. Для этого нужно установить функцию Data-Deduplicationс помощью команд:
Import-Module ServerManager
Add-WindowsFeature -name FS-Data-Deduplication
Import-Module Deduplication
После того, как функция дедупликации включена, ее нужно сконфигурировать. Чтобы включить дедуплликацию для диска D:, выполним команду:
Enable-DedupVolume D:

По-умолчаию дедупликации подвергаются файлы, к которым не было доступа (Last Access)более 30 дней. Это значение можно изменить, например, на 2 дня, для этого выполните команду:
Set-DedupVolume D: -MinimumFileAgeDays 2
Обычно процесс дедупликации запускается планировщиком Windows, но его можно запустить и вручную:
Start-DedupJob D: –Type Optimization
Текущую статистику можно посмотреть с помощью команды:
Get-DedupStatus

Со списком текущих заданий можно познакомится с помощью команды:
Get-DedupJob
Все результаты работы для тома можно отобразить командой PoSH:
Get-DedupMetadata -Volume D:
И, наконец, полностью отменить дедупликацию для тома можно командой:
Start-DedupJob -Volume D: -Type Unoptimization
На скриншоте ниже видно, что после включения дедупликации на диске E: (для теста я сложил на него 4 одинаковых ISO с Windows 8), размер занятого места на диске уменьшился с 12 Гб до 3Гб. 
Служба дедупликации хранит свою базу и дедуплицированные чанки в каталоге System Volume Information. Поэтому ни в коем случае не стоит вручную вмешиваться в его структуру.
Рекомендации по использованию технологии Data Deduplication в Windows Server 2012
Microsoft опубликовала следующие результаты исследования эффективности при дудупликации различных типов данных.
| Типы данных | Возможная экономия места |
| Общие данные | 50-60% |
| Документы | 30-50% |
| Библиотека приложений | 70-80% |
| Библиотека VHD(X) | 80-95% |
Основные особенности Data Deduplication в Windows Server 2012:
- Работает только на NTFS томах и не подерживает файловую систему ReFS
- Не поддерживается для загрузочных и системных томов
- Не работает со сжатыми и шифрованными файлами NTFS
- Поддерживает кеширование и BITS
- Не поддерживает файлы меньше 32KB
- Не настраивается через групповые политики
- Не поддерживает Cluster Shared Volumes
- Дедупликация – процесс не мгновенный и требует определённого времени
Возможность дедупликации данных впервые появилась в Windows Server 2012. С тех пор прошло много времени и в Windows Server 2016 включена уже третья версия дедупликации, переработанная и улучшенная. О том, что именно умеет новая дедупликация и чем она отличается от предыдущих реализаций, а также об особенностях ее настройки и работы и пойдет речь в этой и последующих статьях.
Начнем с изменений. Итак
Что нового
Первое и наиболее важное изменение в работе дедупликации Windows Server 2016 — это введение многопоточности.
Многопоточность
В Windows Server 2012 R2 дедупликация работает в однопоточном режиме и может задействовать не более 1 процессорного ядра на один том. Это серьезно ограничивает производительность, а для обхода этого ограничения необходимо разбивать диски на несколько томов меньшего размера. При этом максимальный размер тома не должен быть больше 10Тб.
В Windows Server 2016 движок дедупликации переработан и задание дедупликации может работать в многопоточном режиме, используя для каждого тома сразу несколько вычислительных потоков и очередей ввода\вывода. Изменения эти наглядно проиллюстрированы на картинке ниже, честно позаимствованной 🙂 на технете.

На картинке все выглядит красиво и убедительно, а как обстоит дело на практике? Чтобы убедиться в том, что многопоточность действительно работает, я провел небольшой эксперимент. Для эксперимента я взял сервер с двумя 6-ядерными процессорами, что при включенном HyperThreading дает нам 24 логических процессора. На сервере была установлена Windows Server 2012 R2 и включена дедупликация для одного тома.
Я запустил на сервере процедуру оптимизации, замерил производительность и выяснил, что процесс дедупликации (fsdmhost.exe) использует максимум 4% мощности процессора, что примерно соответствует 1 логическому ядру.
![]()
Затем операционная система на сервере была проапгрейжена на Windows Server 2016, после чего я повторно замерил производительность. И как видите, после апгрейда дедупликация уже не ограничена одним ядром и может использовать больше 4% процессорной мощности сервера.
![]()
Внедрение многопоточности и другие изменения в движке повлияли на ограничения по размеру томов и файлов. Поскольку многопоточность увеличивает производительность дедупликации и снимает необходимость в разбиении диска на несколько томов, в Windows Server 2016 для дедупликации можно использовать тома до 64Тб. Также увеличен максимальный размер файла, теперь поддерживается дедупликация файлов размером до 1Тб.
Ну и изменения помельче.
Поддержка виртуализованных приложений резервного копирования
В Windows Server 2012 был всего один тип дедупликации, предназначенный в основном для обычных файловых серверов. Дедупликация таких нагрузок, как постоянно работающие виртуальные сервера, не поддерживалась, поскольку дедупликация не умела работать с открытыми файлами.
В Windows Server 2012 R2 дедупликация научилась использовать VSS, соответственно стала поддерживаться дедупликация виртуальных серверов. Для таких нагрузок появился отдельный тип дедупликации.
В Windows Server 2016 добавился еще один, третий тип дедупликации, предназначенный специально для виртуализованных серверов резервного копирования (напр. DPM). Надо сказать, что такой вариант был и раньше, однако в связи со специфическими нагрузками настройки дедупликации требовалось подбирать вручную. В Windows Server 2016 для таких нагрузок добавлен отдельный тип дедупликации, уже включающий в себя необходимые настройки.
Поддержка Nano Server
Nano Server — это вариант развертывания операционной системы Windows Server 2016 с минимальным количеством устанавливаемых компонентов. Nano Server полностью поддерживает дедупликацию.
Поддержка последовательного обновления кластера
Последовательное обновление кластера (Cluster OS Rolling Upgrade) — это новая функция Windows Server 2016, с помощью которой можно последовательно проапгрейдить операционную систему на каждом узле кластера с Server 2012 R2 до Server 2016, при этом не останавливая работу кластера. Это возможно благодаря специальному смешанному режиму работы кластера, когда в кластере одновременно могут работать узлы Windows Server 2012 R2 и Windows Server 2016.
Смешанный режим означает, что одни и те-же данные могут находиться на узлах с разными версиями дедупликации. Дедупликация Windows Server 2016 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в течение всего процесса обновления кластера.
Установка и включение дедупликации
Первое, что нужно сделать для включения дедупликации — это установить соответствующую роль сервера. Можно из оснастки «Server Manager» запустить мастер и добавить роль файлового сервера с компонентом «Data Deduplication».

Либо из PowerShell выполнить команду:
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Включение и настройка дедупликации
После добавления компонента надо включить дедупликацию для конкретного тома (или нескольких томов). Сделать это можно двумя разными способами — из графической оснастки либо с помощью PowerShell.
Для настройки из GUI открываем «Server Manager», переходим в раздел «File and storage services» — «Volumes», встаем на нужный том, кликаем по нему правой клавишей мыши и в открывшемся меню выбираем пункт «Configure Data Deduplication».

Затем выбираем необходимый тип дедупликации и жмем «Apply». Дополнительно можно указать типы файлов, которые не должны подвергаться дедупликации, а также исключить из дедупликации определенные директории.

Следующее, что необходимо сделать после включения — это настроить расписание, по которому будут отрабатывать задания дедупликации, поэтому дальше жмем на кнопку «Set Deduplication Schedule».
По умолчанию включена фоновая оптимизация (background optimization), а также можно настроить два дополнительных задания принудительной оптимизации (throughput optimization). Настроек здесь немного — можно только выбрать дни недели, задать время запуска и продолжительность работы.

Гораздо больше возможностей для настройки предоставляет PowerShell. Для включения дедупликации используем такую команду:
Enable-DedupVolume -Name D: -UsageType HyperV
После включения просмотрим имеющиеся задания дедупликации:
Get-DedupSchedule
Как видите, здесь картина несколько иная. Так кроме фоновой оптимизации имеется задание приоритетной оптимизации (PriorityOptimization), а также задания сборки мусора (GarbageCollection) и очистки (Scrubbing). Все эти задания не видны из графической оснастки.

Кроме этого, PowerShell позволяет более тонко настроить параметры выполнения задания. Для примера создадим новое задание оптимизации. Задание должно запускаться в 8 утра с понедельника по пятницу и работать 12 часов, с нормальным приоритетом, использовать не более 50% оперативной памяти и 100% процессорной мощности:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 12 -Start (Get-Date ″12/8/2016 8:00 PM″) -Memory 50 -Cores 100 -Priority Normal
Примечание. В принципе заданию можно дать любое имя. Но если создать задание с именем ThroughputOptimization, то оно будет отображаться и в графической оснастке.
Затем произведем еще несколько изменений. Во первых сменим время и параметры запуска задания сбора мусора:
Set-DedupSchedule -Name WeeklyGarbageCollection -DurationHours 12 -Start (Get-Date ″12/8/2016 8:00 PM″) -Memory 50 -Cores 100 -Priority Normal -Full $true
Перенесем на воскресенье задание очистки:
Set-DedupSchedule -Name WeeklyScrubbing -Days Sunday -DurationHours 12 -Start (Get-Date ″12/8/2016 8:00 PM″) -Memory 50 -Cores 100 -Priority Normal
И отключим приоритетную оптимизацию:
Set-DedupSchedule -Name PriorityOptimization -Enabled $false

Ручной запуск дедупликации
При необходимости задание дедупликации можно запустить вручную. Для примера запустим полную оптимизацию тома D с максимальным приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -Full

Отследить запущенные задания дедупликации можно с помощью команды Get-DedupJob. Обратите внимание, что одновременно отрабатывает только одна задача, а остальные стоят в очереди и ждут ее завершения. Если текущая задача не завершится в ближайшее время, то задания в очереди отменятся и очередь будет очищена. Об этом необходимо помнить при составлении расписания, так как если различные задачи пересекаются между собой, то некоторые из них не смогут вовремя отработать.

Просмотр состояния дедупликации
Данные о состоянии дедупликации для тома можно посмотреть командой:
Get-DedupVolume -Volume D: | fl
Так мы можем посмотреть основные параметры тома — полный объем, свободное место, уровень сжатия и т.д.

А проверить состояние заданий дедупликации можно такой командой:
Get-DedupStatus -Volume D: | fl
Эта команда кроме всего прочего покажет, когда и с каким результатом были завершены задания дедупликации. В случае проблем с дедупликацией эту информацию можно использовать для диагностики.

Выключение дедупликации
Отключить дедупликацию для тома можно либо из графической оснастки, убрав соответствующую галочку, либо с помощью PowerShell. Например:
Disable-DedupVolume -Name D:

Выключение дедупликации для тома отменяет все запланированные задания, а также запрещает запуск любых задач дедупликации, кроме read-only операций (команды типа Get) и раздедупликации (unoptimization). При этом сами данные остаются в том же состоянии, в котором они были до выключения дедупликации, просто новые данные перестают дедуплицироваться.
После выключения дедупликации доступ к данным остается и с ними можно работать так же, как и раньше. Это поведение можно изменить, воспользовавшись ключом DataAccess, например:
Disable-DedupVolume -Name D: -DataAccess
Эта команда удаляет драйвер-фильтр файловой системы для указанного тома, тем самым останавливая все операции ввода-вывода для дедуплицированных файлов. Соответственно при попытке обращения к файлам вы получите отказ в доступе. Вернуть доступ можно командой Enable-DedupVolume с ключом DataAccess.

Ну и если необходимо полностью убрать дедупликацию и вернуть данные к исходному состоянию, то можно воспользоваться процедурой раздедупликации. Например следующей командой запустим раздедупликацию для тома D с максимально-возможной скоростью:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full

Обратите внимание, что для раздедупликации потребуется дополнительное дисковое пространство. Если свободного места на томе недостаточно, то процедура завершится ошибкой. В этом случае можно воспользоваться альтернативным способом — просто скопировать данные на другой том. При копировании данные автоматически разжимаются, опять же можно раздедуплицировать не сразу весь том, а скопировать данные по частям.
На этом пока закончим. А в следующей части более подробно разберем настройки дедупликации и рассмотрим некоторые особенности ее работы.