Список из 256 символов и их коды в ASCII.
1
Управляющие символы
| DEC | OCT | HEX | BIN | Символ | Escape послед. | HTML код | Описание |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL | \0 | � | Нулевой байт |
| 1 | 001 | 0x01 | 00000001 | SOH |  | Начало заголовка | |
| 2 | 002 | 0x02 | 00000010 | STX |  | Начало текста | |
| 3 | 003 | 0x03 | 00000011 | ETX |  | Конец «текста» | |
| 4 | 004 | 0x04 | 00000100 | EOT |  | конец передачи | |
| 5 | 005 | 0x05 | 00000101 | ENQ |  | «Прошу подтверждения!» | |
| 6 | 006 | 0x06 | 00000110 | ACK |  | «Подтверждаю!» | |
| 7 | 007 | 0x07 | 00000111 | BEL | \a |  | Звуковой сигнал – звонок |
| 8 | 010 | 0x08 | 00001000 | BS | \b |  | Возврат на один символ (BACKSPACE) |
| 9 | 011 | 0x09 | 00001001 | TAB | \t | 	 | Табуляция |
| 10 | 012 | 0x0A | 00001010 | LF | \n | 
 | Перевод строки |
| 11 | 013 | 0x0B | 00001011 | VT | \v |  | Вертикальная табуляция |
| 12 | 014 | 0x0C | 00001100 | FF | \f |  | Прогон страницы, новая страница |
| 13 | 015 | 0x0D | 00001101 | CR | \r | 
 | Возврат каретки |
| 14 | 016 | 0x0E | 00001110 | SO |  | Переключиться на другую ленту (кодировку) | |
| 15 | 017 | 0x0F | 00001111 | SI |  | Переключиться на исходную ленту (кодировку) | |
| 16 | 020 | 0x10 | 00010000 | DLE |  | Экранирование канала данных | |
| 17 | 021 | 0x11 | 00010001 | DC1 |  | 1-й символ управления устройством | |
| 18 | 022 | 0x12 | 00010010 | DC2 |  | 2-й символ управления устройством | |
| 19 | 023 | 0x13 | 00010011 | DC3 |  | 3-й символ управления устройством | |
| 20 | 024 | 0x14 | 00010100 | DC4 |  | 4-й символ управления устройством | |
| 21 | 025 | 0x15 | 00010101 | NAK |  | «Не подтверждаю!» | |
| 22 | 026 | 0x16 | 00010110 | SYN |  | Символ для синхронизации | |
| 23 | 027 | 0x17 | 00010111 | ETB |  | Конец текстового блока | |
| 24 | 030 | 0x18 | 00011000 | CAN |  | Отмена | |
| 25 | 031 | 0x19 | 00011001 | EM |  | Конец носителя | |
| 26 | 032 | 0x1A | 00011010 | SUB |  | Подставить | |
| 27 | 033 | 0x1B | 00011011 | ESC | \e |  | Escape (Расширение) |
| 28 | 034 | 0x1C | 00011100 | FS |  | Разделитель файлов | |
| 29 | 035 | 0x1D | 00011101 | GS |  | Разделитель групп | |
| 30 | 036 | 0x1E | 00011110 | RS |  | Разделитель записей | |
| 31 | 037 | 0x1F | 00011111 | US |  | Разделитель юнитов | |
| 127 | 177 | 0x7F | 01111111 | Delete |  | Символ для удаления (на перфолентах) |
2
Печатные символы
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | Пробел |   | |
| 33 | 041 | 0x21 | 00100001 | ! | ! | |
| 34 | 042 | 0x22 | 00100010 | « | " | " |
| 35 | 043 | 0x23 | 00100011 | # | # | |
| 36 | 044 | 0x24 | 00100100 | $ | $ | |
| 37 | 045 | 0x25 | 00100101 | % | % | |
| 38 | 046 | 0x26 | 00100110 | & | & | & |
| 39 | 047 | 0x27 | 00100111 | ‘ | ' | ' |
| 40 | 050 | 0x28 | 00101000 | ( | ( | |
| 41 | 051 | 0x29 | 00101001 | ) | ) | |
| 42 | 052 | 0x2A | 00101010 | * | * | |
| 43 | 053 | 0x2B | 00101011 | + | + | |
| 44 | 054 | 0x2C | 00101100 | , | , | |
| 45 | 055 | 0x2D | 00101101 | — | - | |
| 46 | 056 | 0x2E | 00101110 | . | . | |
| 47 | 057 | 0x2F | 00101111 | / | / | |
| 48 | 060 | 0x30 | 00110000 | 0 | 0 | |
| 49 | 061 | 0x31 | 00110001 | 1 | 1 | |
| 50 | 062 | 0x32 | 00110010 | 2 | 2 | |
| 51 | 063 | 0x33 | 00110011 | 3 | 3 | |
| 52 | 064 | 0x34 | 00110100 | 4 | 4 | |
| 53 | 065 | 0x35 | 00110101 | 5 | 5 | |
| 54 | 066 | 0x36 | 00110110 | 6 | 6 | |
| 55 | 067 | 0x37 | 00110111 | 7 | 7 | |
| 56 | 070 | 0x38 | 00111000 | 8 | 8 | |
| 57 | 071 | 0x39 | 00111001 | 9 | 9 | |
| 58 | 072 | 0x3A | 00111010 | : | : | |
| 59 | 073 | 0x3B | 00111011 | ; | ; | |
| 60 | 074 | 0x3C | 00111100 | < | < | < |
| 61 | 075 | 0x3D | 00111101 | = | = | |
| 62 | 076 | 0x3E | 00111110 | > | > | > |
| 63 | 077 | 0x3F | 00111111 | ? | ? | |
| 64 | 100 | 0x40 | 01000000 | @ | @ | |
| 65 | 101 | 0x41 | 01000001 | A | A | |
| 66 | 102 | 0x42 | 01000010 | B | B | |
| 67 | 103 | 0x43 | 01000011 | C | C | |
| 68 | 104 | 0x44 | 01000100 | D | D | |
| 69 | 105 | 0x45 | 01000101 | E | E | |
| 70 | 106 | 0x46 | 01000110 | F | F | |
| 71 | 107 | 0x47 | 01000111 | G | G | |
| 72 | 110 | 0x48 | 01001000 | H | H | |
| 73 | 111 | 0x49 | 01001001 | I | I | |
| 74 | 112 | 0x4A | 01001010 | J | J | |
| 75 | 113 | 0x4B | 01001011 | K | K | |
| 76 | 114 | 0x4C | 01001100 | L | L | |
| 77 | 115 | 0x4D | 01001101 | M | M | |
| 78 | 116 | 0x4E | 01001110 | N | N | |
| 79 | 117 | 0x4F | 01001111 | O | O | |
| 80 | 120 | 0x50 | 01010000 | P | P | |
| 81 | 121 | 0x51 | 01010001 | Q | Q | |
| 82 | 122 | 0x52 | 01010010 | R | R | |
| 83 | 123 | 0x53 | 01010011 | S | S | |
| 84 | 124 | 0x54 | 01010100 | T | T | |
| 85 | 125 | 0x55 | 01010101 | U | U | |
| 86 | 126 | 0x56 | 01010110 | V | V | |
| 87 | 127 | 0x57 | 01010111 | W | W | |
| 88 | 130 | 0x58 | 01011000 | X | X | |
| 89 | 131 | 0x59 | 01011001 | Y | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | [ | |
| 92 | 134 | 0x5C | 01011100 | \ | \ | |
| 93 | 135 | 0x5D | 01011101 | ] | ] | |
| 94 | 136 | 0x5E | 01011110 | ^ | ^ | |
| 95 | 137 | 0x5F | 01011111 | _ | _ | |
| 96 | 140 | 0x60 | 01100000 | ` | ` | |
| 97 | 141 | 0x61 | 01100001 | a | a | |
| 98 | 142 | 0x62 | 01100010 | b | b | |
| 99 | 143 | 0x63 | 01100011 | c | c | |
| 100 | 144 | 0x64 | 01100100 | d | d | |
| 101 | 145 | 0x65 | 01100101 | e | e | |
| 102 | 146 | 0x66 | 01100110 | f | f | |
| 103 | 147 | 0x67 | 01100111 | g | g | |
| 104 | 150 | 0x68 | 01101000 | h | h | |
| 105 | 151 | 0x69 | 01101001 | i | i | |
| 106 | 152 | 0x6A | 01101010 | j | j | |
| 107 | 153 | 0x6B | 01101011 | k | k | |
| 108 | 154 | 0x6C | 01101100 | l | l | |
| 109 | 155 | 0x6D | 01101101 | m | m | |
| 110 | 156 | 0x6E | 01101110 | n | n | |
| 111 | 157 | 0x6F | 01101111 | o | o | |
| 112 | 160 | 0x70 | 01110000 | p | p | |
| 113 | 161 | 0x71 | 01110001 | q | q | |
| 114 | 162 | 0x72 | 01110010 | r | r | |
| 115 | 163 | 0x73 | 01110011 | s | s | |
| 116 | 164 | 0x74 | 01110100 | t | t | |
| 117 | 165 | 0x75 | 01110101 | u | u | |
| 118 | 166 | 0x76 | 01110110 | v | v | |
| 119 | 167 | 0x77 | 01110111 | w | w | |
| 120 | 170 | 0x78 | 01111000 | x | x | |
| 121 | 171 | 0x79 | 01111001 | y | y | |
| 122 | 172 | 0x7A | 01111010 | z | z | |
| 123 | 173 | 0x7B | 01111011 | { | { | |
| 124 | 174 | 0x7C | 01111100 | | | | | |
| 125 | 175 | 0x7D | 01111101 | } | } | |
| 126 | 176 | 0x7E | 01111110 | ~ | ~ |
3
Расширенные символы ASCII Win-1251 кириллица
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ | € | |
| 129 | 201 | 0x81 | 10000001 | Ѓ |  | |
| 130 | 202 | 0x82 | 10000010 | ‚ | ‚ | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ | ƒ | |
| 132 | 204 | 0x84 | 10000100 | „ | „ | „ |
| 133 | 205 | 0x85 | 10000101 | … | … | … |
| 134 | 206 | 0x86 | 10000110 | † | † | † |
| 135 | 207 | 0x87 | 10000111 | ‡ | ‡ | ‡ |
| 136 | 210 | 0x88 | 10001000 | € | ˆ | € |
| 137 | 211 | 0x89 | 10001001 | ‰ | ‰ | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ | Š | |
| 139 | 213 | 0x8B | 10001011 | ‹ | ‹ | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ | Œ | |
| 141 | 215 | 0x8D | 10001101 | Ќ |  | |
| 142 | 216 | 0x8E | 10001110 | Ћ | Ž | |
| 143 | 217 | 0x8F | 10001111 | Џ |  | |
| 144 | 220 | 0x90 | 10010000 | Ђ |  | |
| 145 | 221 | 0x91 | 10010001 | ‘ | ‘ | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ | ’ | ’ |
| 147 | 223 | 0x93 | 10010011 | “ | “ | “ |
| 148 | 224 | 0x94 | 10010100 | ” | ” | ” |
| 149 | 225 | 0x95 | 10010101 | • | • | • |
| 150 | 226 | 0x96 | 10010110 | – | – | – |
| 151 | 227 | 0x97 | 10010111 | — | — | — |
| 152 | 230 | 0x98 | 10011000 | Начало строки | ˜ | |
| 153 | 231 | 0x99 | 10011001 | ™ | ™ | ™ |
| 154 | 232 | 0x9A | 10011010 | љ | š | |
| 155 | 233 | 0x9B | 10011011 | › | › | › |
| 156 | 234 | 0x9C | 10011100 | њ | œ | |
| 157 | 235 | 0x9D | 10011101 | ќ |  | |
| 158 | 236 | 0x9E | 10011110 | ћ | ž | |
| 159 | 237 | 0x9F | 10011111 | џ | Ÿ | |
| 160 | 240 | 0xA0 | 10100000 | Неразрывный пробел |   | |
| 161 | 241 | 0xA1 | 10100001 | Ў | ¡ | |
| 162 | 242 | 0xA2 | 10100010 | ў | ¢ | |
| 163 | 243 | 0xA3 | 10100011 | Ј | £ | |
| 164 | 244 | 0xA4 | 10100100 | ¤ | ¤ | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ | ¥ | |
| 166 | 246 | 0xA6 | 10100110 | ¦ | ¦ | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § | § | § |
| 168 | 250 | 0xA8 | 10101000 | Ё | ¨ | |
| 169 | 251 | 0xA9 | 10101001 | © | © | © |
| 170 | 252 | 0xAA | 10101010 | Є | ª | |
| 171 | 253 | 0xAB | 10101011 | « | « | « |
| 172 | 254 | 0xAC | 10101100 | ¬ | ¬ | ¬ |
| 173 | 255 | 0xAD | 10101101 | Мягкий перенос | ­ | ­ |
| 174 | 256 | 0xAE | 10101110 | ® | ® | ® |
| 175 | 257 | 0xAF | 10101111 | Ї | ¯ | |
| 176 | 260 | 0xB0 | 10110000 | ° | ° | ° |
| 177 | 261 | 0xB1 | 10110001 | ± | ± | ± |
| 178 | 262 | 0xB2 | 10110010 | І | ² | |
| 179 | 263 | 0xB3 | 10110011 | і | ³ | |
| 180 | 264 | 0xB4 | 10110100 | ґ | ´ | |
| 181 | 265 | 0xB5 | 10110101 | µ | µ | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ | ¶ | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · | · | · |
| 184 | 270 | 0xB8 | 10111000 | ё | ¸ | |
| 185 | 271 | 0xB9 | 10111001 | № | ¹ | |
| 186 | 272 | 0xBA | 10111010 | є | º | |
| 187 | 273 | 0xBB | 10111011 | » | » | » |
| 188 | 274 | 0xBC | 10111100 | ј | ¼ | |
| 189 | 275 | 0xBD | 10111101 | Ѕ | ½ | |
| 190 | 276 | 0xBE | 10111110 | ѕ | ¾ | |
| 191 | 277 | 0xBF | 10111111 | ї | ¿ | |
| 192 | 300 | 0xC0 | 11000000 | А | À | |
| 193 | 301 | 0xC1 | 11000001 | Б | Á | |
| 194 | 302 | 0xC2 | 11000010 | В | Â | |
| 195 | 303 | 0xC3 | 11000011 | Г | Ã | |
| 196 | 304 | 0xC4 | 11000100 | Д | Ä | |
| 197 | 305 | 0xC5 | 11000101 | Е | Å | |
| 198 | 306 | 0xC6 | 11000110 | Ж | Æ | |
| 199 | 307 | 0xC7 | 11000111 | З | Ç | |
| 200 | 310 | 0xC8 | 11001000 | И | È | |
| 201 | 311 | 0xC9 | 11001001 | Й | É | |
| 202 | 312 | 0xCA | 11001010 | К | Ê | |
| 203 | 313 | 0xCB | 11001011 | Л | Ë | |
| 204 | 314 | 0xCC | 11001100 | М | Ì | |
| 205 | 315 | 0xCD | 11001101 | Н | Í | |
| 206 | 316 | 0xCE | 11001110 | О | Î | |
| 207 | 317 | 0xCF | 11001111 | П | Ï | |
| 208 | 320 | 0xD0 | 11010000 | Р | Ð | |
| 209 | 321 | 0xD1 | 11010001 | С | Ñ | |
| 210 | 322 | 0xD2 | 11010010 | Т | Ò | |
| 211 | 323 | 0xD3 | 11010011 | У | Ó | |
| 212 | 324 | 0xD4 | 11010100 | Ф | Ô | |
| 213 | 325 | 0xD5 | 11010101 | Х | Õ | |
| 214 | 326 | 0xD6 | 11010110 | Ц | Ö | |
| 215 | 327 | 0xD7 | 11010111 | Ч | × | |
| 216 | 330 | 0xD8 | 11011000 | Ш | Ø | |
| 217 | 331 | 0xD9 | 11011001 | Щ | Ù | |
| 218 | 332 | 0xDA | 11011010 | Ъ | Ú | |
| 219 | 333 | 0xDB | 11011011 | Ы | Û | |
| 220 | 334 | 0xDC | 11011100 | Ь | Ü | |
| 221 | 335 | 0xDD | 11011101 | Э | Ý | |
| 222 | 336 | 0xDE | 11011110 | Ю | Þ | |
| 223 | 337 | 0xDF | 11011111 | Я | ß | |
| 224 | 340 | 0xE0 | 11100000 | а | à | |
| 225 | 341 | 0xE1 | 11100001 | б | á | |
| 226 | 342 | 0xE2 | 11100010 | в | â | |
| 227 | 343 | 0xE3 | 11100011 | г | ã | |
| 228 | 344 | 0xE4 | 11100100 | д | ä | |
| 229 | 345 | 0xE5 | 11100101 | е | å | |
| 230 | 346 | 0xE6 | 11100110 | ж | æ | |
| 231 | 347 | 0xE7 | 11100111 | з | ç | |
| 232 | 350 | 0xE8 | 11101000 | и | è | |
| 233 | 351 | 0xE9 | 11101001 | й | é | |
| 234 | 352 | 0xEA | 11101010 | к | ê | |
| 235 | 353 | 0xEB | 11101011 | л | ë | |
| 236 | 354 | 0xEC | 11101100 | м | ì | |
| 237 | 355 | 0xED | 11101101 | н | í | |
| 238 | 356 | 0xEE | 11101110 | о | î | |
| 239 | 357 | 0xEF | 11101111 | п | ï | |
| 240 | 360 | 0xF0 | 11110000 | р | ð | |
| 241 | 361 | 0xF1 | 11110001 | с | ñ | |
| 242 | 362 | 0xF2 | 11110010 | т | ò | |
| 243 | 363 | 0xF3 | 11110011 | у | ó | |
| 244 | 364 | 0xF4 | 11110100 | ф | ô | |
| 245 | 365 | 0xF5 | 11110101 | х | õ | |
| 246 | 366 | 0xF6 | 11110110 | ц | ö | |
| 247 | 367 | 0xF7 | 11110111 | ч | ÷ | |
| 248 | 370 | 0xF8 | 11111000 | ш | ø | |
| 249 | 371 | 0xF9 | 11111001 | щ | ù | |
| 250 | 372 | 0xFA | 11111010 | ъ | ú | |
| 251 | 373 | 0xFB | 11111011 | ы | û | |
| 252 | 374 | 0xFC | 11111100 | ь | ü | |
| 253 | 375 | 0xFD | 11111101 | э | ý | |
| 254 | 376 | 0xFE | 11111110 | ю | þ | |
| 255 | 377 | 0xFF | 11111111 | я | ÿ |
Windows-1251 (cp1251) — это стандартная 8-битная кодировка, разработанная компанией Microsoft. Она содержит практически все символы, которые Вы можете встретить на стандартной русской клавиатуре. Также 1251 имеет символы для таких языков, как белорусский, украинский, болгарский и сербский.
|
DEC |
HEX |
СИМВ |
DEC |
HEX |
СИМВ |
DEC |
HEX |
СИМВ |
|
000 |
00 |
NOP |
086 |
56 |
V |
171 |
AB |
« |
|
001 |
01 |
SOH |
087 |
57 |
W |
172 |
AC |
¬ |
|
002 |
02 |
STX |
088 |
58 |
X |
173 |
AD |
|
|
003 |
03 |
ETX |
089 |
59 |
Y |
174 |
AE |
® |
|
004 |
04 |
EOT |
090 |
5A |
Z |
175 |
AF |
Ї |
|
005 |
05 |
ENQ |
091 |
5B |
[ |
176 |
B0 |
° |
|
006 |
06 |
ACK |
092 |
5C |
\ |
177 |
B1 |
± |
|
007 |
07 |
BEL |
093 |
5D |
] |
178 |
B2 |
І |
|
008 |
08 |
BS |
094 |
5E |
^ |
179 |
B3 |
і |
|
009 |
09 |
Табуляция |
095 |
5F |
_ |
180 |
B4 |
ґ |
|
010 |
0A |
LF |
096 |
60 |
` |
181 |
B5 |
µ |
|
011 |
0B |
VT |
097 |
61 |
a |
182 |
B6 |
¶ |
|
012 |
0C |
FF |
098 |
62 |
b |
183 |
B7 |
· |
|
013 |
0D |
CR |
099 |
63 |
c |
184 |
B8 |
Ё |
|
014 |
0E |
SO |
100 |
64 |
d |
185 |
B9 |
№ |
|
015 |
0F |
SI |
101 |
65 |
e |
186 |
BA |
Є |
|
016 |
10 |
DLE |
102 |
66 |
f |
187 |
BB |
» |
|
017 |
11 |
DC1 |
103 |
67 |
g |
188 |
BC |
ј |
|
018 |
12 |
DC2 |
104 |
68 |
h |
189 |
BD |
Ѕ |
|
019 |
13 |
DC3 |
105 |
69 |
i |
190 |
BE |
Ѕ |
|
020 |
14 |
DC4 |
106 |
6A |
j |
191 |
BF |
Ї |
|
021 |
15 |
NAK |
107 |
6B |
k |
192 |
C0 |
А |
|
022 |
16 |
SYN |
108 |
6C |
l |
193 |
C1 |
Б |
|
023 |
17 |
ETB |
109 |
6D |
m |
194 |
C2 |
В |
|
024 |
18 |
CAN |
110 |
6E |
n |
195 |
C3 |
Г |
|
025 |
19 |
EM |
111 |
6F |
o |
196 |
C4 |
Д |
|
026 |
1A |
SUB |
112 |
70 |
p |
197 |
C5 |
Е |
|
027 |
1B |
ESC |
113 |
71 |
q |
198 |
C6 |
Ж |
|
028 |
1C |
FS |
114 |
72 |
r |
199 |
C7 |
З |
|
029 |
1D |
GS |
115 |
73 |
s |
200 |
C8 |
И |
|
030 |
1E |
RS |
116 |
74 |
t |
201 |
C9 |
Й |
|
031 |
1F |
US |
117 |
75 |
u |
202 |
CA |
К |
|
032 |
20 |
Пробел |
118 |
76 |
v |
203 |
CB |
Л |
|
033 |
21 |
! |
119 |
77 |
w |
204 |
CC |
М |
|
034 |
22 |
« |
120 |
78 |
x |
205 |
CD |
Н |
|
035 |
23 |
# |
121 |
79 |
y |
206 |
CE |
О |
|
036 |
24 |
$ |
122 |
7A |
z |
207 |
CF |
П |
|
037 |
25 |
% |
123 |
7B |
{ |
208 |
D0 |
Р |
|
038 |
26 |
& |
124 |
7C |
| |
209 |
D1 |
С |
|
039 |
27 |
‘ |
125 |
7D |
} |
210 |
D2 |
Т |
|
040 |
28 |
( |
126 |
7E |
~ |
211 |
D3 |
У |
|
041 |
29 |
) |
127 |
7F |
|
212 |
D4 |
Ф |
|
042 |
2A |
* |
128 |
80 |
Ђ |
213 |
D5 |
Х |
|
043 |
2B |
+ |
129 |
81 |
Ѓ |
214 |
D6 |
Ц |
|
044 |
2C |
, |
130 |
82 |
‚ |
215 |
D7 |
Ч |
|
045 |
2D |
— |
131 |
83 |
ѓ |
216 |
D8 |
Ш |
|
046 |
2E |
. |
132 |
84 |
„ |
217 |
D9 |
Щ |
|
047 |
2F |
/ |
133 |
85 |
… |
218 |
DA |
Ъ |
|
048 |
30 |
0 |
134 |
86 |
† |
219 |
DB |
Ы |
|
049 |
31 |
1 |
135 |
87 |
‡ |
220 |
DC |
Ь |
|
050 |
32 |
2 |
136 |
88 |
€ |
221 |
DD |
Э |
|
051 |
33 |
3 |
137 |
89 |
‰ |
222 |
DE |
Ю |
|
052 |
34 |
4 |
138 |
8A |
Љ |
223 |
DF |
Я |
|
053 |
35 |
5 |
139 |
8B |
‹ |
224 |
E0 |
а |
|
054 |
36 |
6 |
140 |
8C |
Њ |
225 |
E1 |
б |
|
055 |
37 |
7 |
141 |
8D |
Ќ |
226 |
E2 |
в |
|
056 |
38 |
8 |
142 |
8E |
Ћ |
227 |
E3 |
г |
|
057 |
39 |
9 |
143 |
8F |
Џ |
228 |
E4 |
д |
|
058 |
3A |
: |
144 |
90 |
Ђ |
229 |
E5 |
е |
|
059 |
3B |
; |
145 |
91 |
‘ |
230 |
E6 |
ж |
|
060 |
3C |
< |
146 |
92 |
’ |
231 |
E7 |
з |
|
061 |
3D |
= |
147 |
93 |
“ |
232 |
E8 |
и |
|
062 |
3E |
> |
148 |
94 |
” |
233 |
E9 |
й |
|
063 |
3F |
? |
149 |
95 |
• |
234 |
EA |
к |
|
064 |
40 |
@ |
150 |
96 |
– |
235 |
EB |
л |
|
065 |
41 |
A |
151 |
97 |
— |
236 |
EC |
м |
|
066 |
42 |
B |
152 |
98 |
237 |
ED |
н |
|
|
067 |
43 |
C |
153 |
99 |
™ |
238 |
EE |
о |
|
068 |
44 |
D |
154 |
9A |
љ |
239 |
EF |
п |
|
069 |
45 |
E |
155 |
9B |
› |
240 |
F0 |
р |
|
070 |
46 |
F |
156 |
9C |
њ |
241 |
F1 |
с |
|
071 |
47 |
G |
157 |
9D |
ќ |
242 |
F2 |
т |
|
072 |
48 |
H |
158 |
9E |
ћ |
243 |
F3 |
у |
|
073 |
49 |
I |
159 |
9F |
џ |
244 |
F4 |
ф |
|
074 |
4A |
J |
160 |
A0 |
245 |
F5 |
х |
|
|
075 |
4B |
K |
161 |
A1 |
Ў |
246 |
F6 |
ц |
|
076 |
4C |
L |
162 |
A2 |
ў |
247 |
F7 |
ч |
|
077 |
4D |
M |
163 |
A3 |
Ј |
248 |
F8 |
ш |
|
078 |
4E |
N |
164 |
A4 |
¤ |
249 |
F9 |
щ |
|
079 |
4F |
O |
165 |
A5 |
Ґ |
250 |
FA |
ъ |
|
080 |
50 |
P |
166 |
A6 |
¦ |
251 |
FB |
ы |
|
081 |
51 |
Q |
167 |
A7 |
§ |
252 |
FC |
ь |
|
082 |
52 |
R |
168 |
A8 |
Ё |
253 |
FD |
э |
|
083 |
53 |
S |
169 |
A9 |
© |
254 |
FE |
ю |
|
084 |
54 |
T |
170 |
AA |
Є |
255 |
FF |
я |
|
085 |
55 |
U |
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
Таблица CP1251 (windows-1251)
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.

Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.

Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Reference of Extended ASCII Table for Windows-1251
The ASCII table, when defined according to the Windows-1251 character encoding (also known as Code page 1251), includes ASCII control characters and ASCII printable characters. Moreover, it also includes the extended ASCII character set unique to Windows-1251. This character set is particularly designed to support Cyrillic languages.
ASCII control characters (character code 0-31)
The first 32 characters in the ASCII-table are unprintable control codes and are used to control peripherals such as printers.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 0 | 000 | 00 | 00000000 | ␀ | � | Null character | ||
| 1 | 001 | 01 | 00000001 | ␁ |  | Start of Heading | ||
| 2 | 002 | 02 | 00000010 | ␂ |  | Start of Text | ||
| 3 | 003 | 03 | 00000011 | ␃ |  | End of Text | ||
| 4 | 004 | 04 | 00000100 | ␄ |  | End of Transmission | ||
| 5 | 005 | 05 | 00000101 | ␅ |  | Enquiry | ||
| 6 | 006 | 06 | 00000110 | ␆ |  | Acknowledge | ||
| 7 | 007 | 07 | 00000111 | ␇ |  | Bell, Alert | ||
| 8 | 010 | 08 | 00001000 | ␈ |  | Backspace | ||
| 9 | 011 | 09 | 00001001 | ␉ | 	 | Horizontal Tab | ||
| 10 | 012 | 0A | 00001010 | ␊ | | Line Feed | ||
| 11 | 013 | 0B | 00001011 | ␋ |  | Vertical Tabulation | ||
| 12 | 014 | 0C | 00001100 | ␌ |  | Form Feed | ||
| 13 | 015 | 0D | 00001101 | ␍ | | Carriage Return | ||
| 14 | 016 | 0E | 00001110 | ␎ |  | Shift Out | ||
| 15 | 017 | 0F | 00001111 | ␏ |  | Shift In | ||
| 16 | 020 | 10 | 00010000 | ␐ |  | Data Link Escape | ||
| 17 | 021 | 11 | 00010001 | ␑ |  | Device Control One (XON) | ||
| 18 | 022 | 12 | 00010010 | ␒ |  | Device Control Two | ||
| 19 | 023 | 13 | 00010011 | ␓ |  | Device Control Three (XOFF) | ||
| 20 | 024 | 14 | 00010100 | ␔ |  | Device Control Four | ||
| 21 | 025 | 15 | 00010101 | ␕ |  | Negative Acknowledge | ||
| 22 | 026 | 16 | 00010110 | ␖ |  | Synchronous Idle | ||
| 23 | 027 | 17 | 00010111 | ␗ |  | End of Transmission Block | ||
| 24 | 030 | 18 | 00011000 | ␘ |  | Cancel | ||
| 25 | 031 | 19 | 00011001 | ␙ |  | End of medium | ||
| 26 | 032 | 1A | 00011010 | ␚ |  | Substitute | ||
| 27 | 033 | 1B | 00011011 | ␛ |  | Escape | ||
| 28 | 034 | 1C | 00011100 | ␜ |  | File Separator | ||
| 29 | 035 | 1D | 00011101 | ␝ |  | Group Separator | ||
| 30 | 036 | 1E | 00011110 | ␞ |  | Record Separator | ||
| 31 | 037 | 1F | 00011111 | ␟ |  | Unit Separator |
ASCII printable characters (character code 32-127)
Codes 32-127 are common for all the different variations of the ASCII table, they are called printable characters, represent letters, digits, punctuation marks, and a few miscellaneous symbols. You will find almost every character on your keyboard. Character 127 represents the command DEL.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 32 | 040 | 20 | 00100000 | ␠ |   | Space | ||
| 33 | 041 | 21 | 00100001 | ! | ! | ! | Exclamation mark | |
| 34 | 042 | 22 | 00100010 | « | " | " | Double quotes (or speech marks) | |
| 35 | 043 | 23 | 00100011 | # | # | # | Number sign | |
| 36 | 044 | 24 | 00100100 | $ | $ | $ | Dollar | |
| 37 | 045 | 25 | 00100101 | % | % | % | Per cent sign | |
| 38 | 046 | 26 | 00100110 | & | & | & | Ampersand | |
| 39 | 047 | 27 | 00100111 | ‘ | ' | ' | Single quote | |
| 40 | 050 | 28 | 00101000 | ( | ( | &lparen; | Open parenthesis (or open bracket) | |
| 41 | 051 | 29 | 00101001 | ) | ) | &rparen; | Close parenthesis (or close bracket) | |
| 42 | 052 | 2A | 00101010 | * | * | * | Asterisk | |
| 43 | 053 | 2B | 00101011 | + | + | + | Plus | |
| 44 | 054 | 2C | 00101100 | , | , | , | Comma | |
| 45 | 055 | 2D | 00101101 | — | - | Hyphen-minus | ||
| 46 | 056 | 2E | 00101110 | . | . | . | Period, dot or full stop | |
| 47 | 057 | 2F | 00101111 | / | / | / | Slash or divide | |
| 48 | 060 | 30 | 00110000 | 0 | 0 | Zero | ||
| 49 | 061 | 31 | 00110001 | 1 | 1 | One | ||
| 50 | 062 | 32 | 00110010 | 2 | 2 | Two | ||
| 51 | 063 | 33 | 00110011 | 3 | 3 | Three | ||
| 52 | 064 | 34 | 00110100 | 4 | 4 | Four | ||
| 53 | 065 | 35 | 00110101 | 5 | 5 | Five | ||
| 54 | 066 | 36 | 00110110 | 6 | 6 | Six | ||
| 55 | 067 | 37 | 00110111 | 7 | 7 | Seven | ||
| 56 | 070 | 38 | 00111000 | 8 | 8 | Eight | ||
| 57 | 071 | 39 | 00111001 | 9 | 9 | Nine | ||
| 58 | 072 | 3A | 00111010 | : | : | : | Colon | |
| 59 | 073 | 3B | 00111011 | ; | ; | ; | Semicolon | |
| 60 | 074 | 3C | 00111100 | < | < | < | Less than (or open angled bracket) | |
| 61 | 075 | 3D | 00111101 | = | = | = | Equals | |
| 62 | 076 | 3E | 00111110 | > | > | > | Greater than (or close angled bracket) | |
| 63 | 077 | 3F | 00111111 | ? | ? | ? | Question mark | |
| 64 | 100 | 40 | 01000000 | @ | @ | @ | At sign | |
| 65 | 101 | 41 | 01000001 | A | A | Uppercase A | ||
| 66 | 102 | 42 | 01000010 | B | B | Uppercase B | ||
| 67 | 103 | 43 | 01000011 | C | C | Uppercase C | ||
| 68 | 104 | 44 | 01000100 | D | D | Uppercase D | ||
| 69 | 105 | 45 | 01000101 | E | E | Uppercase E | ||
| 70 | 106 | 46 | 01000110 | F | F | Uppercase F | ||
| 71 | 107 | 47 | 01000111 | G | G | Uppercase G | ||
| 72 | 110 | 48 | 01001000 | H | H | Uppercase H | ||
| 73 | 111 | 49 | 01001001 | I | I | Uppercase I | ||
| 74 | 112 | 4A | 01001010 | J | J | Uppercase J | ||
| 75 | 113 | 4B | 01001011 | K | K | Uppercase K | ||
| 76 | 114 | 4C | 01001100 | L | L | Uppercase L | ||
| 77 | 115 | 4D | 01001101 | M | M | Uppercase M | ||
| 78 | 116 | 4E | 01001110 | N | N | Uppercase N | ||
| 79 | 117 | 4F | 01001111 | O | O | Uppercase O | ||
| 80 | 120 | 50 | 01010000 | P | P | Uppercase P | ||
| 81 | 121 | 51 | 01010001 | Q | Q | Uppercase Q | ||
| 82 | 122 | 52 | 01010010 | R | R | Uppercase R | ||
| 83 | 123 | 53 | 01010011 | S | S | Uppercase S | ||
| 84 | 124 | 54 | 01010100 | T | T | Uppercase T | ||
| 85 | 125 | 55 | 01010101 | U | U | Uppercase U | ||
| 86 | 126 | 56 | 01010110 | V | V | Uppercase V | ||
| 87 | 127 | 57 | 01010111 | W | W | Uppercase W | ||
| 88 | 130 | 58 | 01011000 | X | X | Uppercase X | ||
| 89 | 131 | 59 | 01011001 | Y | Y | Uppercase Y | ||
| 90 | 132 | 5A | 01011010 | Z | Z | Uppercase Z | ||
| 91 | 133 | 5B | 01011011 | [ | [ | [ | Opening bracket | |
| 92 | 134 | 5C | 01011100 | \ | \ | \ | Backslash | |
| 93 | 135 | 5D | 01011101 | ] | ] | ] | Closing bracket | |
| 94 | 136 | 5E | 01011110 | ^ | ^ | ^ | Caret — circumflex | |
| 95 | 137 | 5F | 01011111 | _ | _ | _ | Underscore | |
| 96 | 140 | 60 | 01100000 | ` | ` | ` | Grave accent | |
| 97 | 141 | 61 | 01100001 | a | a | Lowercase a | ||
| 98 | 142 | 62 | 01100010 | b | b | Lowercase b | ||
| 99 | 143 | 63 | 01100011 | c | c | Lowercase c | ||
| 100 | 144 | 64 | 01100100 | d | d | Lowercase d | ||
| 101 | 145 | 65 | 01100101 | e | e | Lowercase e | ||
| 102 | 146 | 66 | 01100110 | f | f | Lowercase f | ||
| 103 | 147 | 67 | 01100111 | g | g | Lowercase g | ||
| 104 | 150 | 68 | 01101000 | h | h | Lowercase h | ||
| 105 | 151 | 69 | 01101001 | i | i | Lowercase i | ||
| 106 | 152 | 6A | 01101010 | j | j | Lowercase j | ||
| 107 | 153 | 6B | 01101011 | k | k | Lowercase k | ||
| 108 | 154 | 6C | 01101100 | l | l | Lowercase l | ||
| 109 | 155 | 6D | 01101101 | m | m | Lowercase m | ||
| 110 | 156 | 6E | 01101110 | n | n | Lowercase n | ||
| 111 | 157 | 6F | 01101111 | o | o | Lowercase o | ||
| 112 | 160 | 70 | 01110000 | p | p | Lowercase p | ||
| 113 | 161 | 71 | 01110001 | q | q | Lowercase q | ||
| 114 | 162 | 72 | 01110010 | r | r | Lowercase r | ||
| 115 | 163 | 73 | 01110011 | s | s | Lowercase s | ||
| 116 | 164 | 74 | 01110100 | t | t | Lowercase t | ||
| 117 | 165 | 75 | 01110101 | u | u | Lowercase u | ||
| 118 | 166 | 76 | 01110110 | v | v | Lowercase v | ||
| 119 | 167 | 77 | 01110111 | w | w | Lowercase w | ||
| 120 | 170 | 78 | 01111000 | x | x | Lowercase x | ||
| 121 | 171 | 79 | 01111001 | y | y | Lowercase y | ||
| 122 | 172 | 7A | 01111010 | z | z | Lowercase z | ||
| 123 | 173 | 7B | 01111011 | { | { | { | Opening brace | |
| 124 | 174 | 7C | 01111100 | | | | | | | Vertical bar | |
| 125 | 175 | 7D | 01111101 | } | } | } | Closing brace | |
| 126 | 176 | 7E | 01111110 | ~ | ~ | ˜ | Equivalency sign — tilde | |
| 127 | 177 | 7F | 01111111 | ␡ |  | Delete |
The extended ASCII codes (character code 128-255)
Windows-1251 is a character encoding standard used to represent text in the Cyrillic script. It was introduced by Microsoft in the Windows operating system and is based on ISO 8859-5. Windows-1251 supports a range of characters and symbols used in the Cyrillic script, including Russian, Bulgarian, Serbian, and others.
Windows-1251 is widely used in the former Soviet Union countries and other countries that use the Cyrillic script. It is commonly used in word processing software, spreadsheets, and databases. However, it is important to note that Windows-1251 may not provide full support for all of the characters used in these languages and may cause issues when dealing with text in certain scripts.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 128 | 200 | 80 | 10000000 | Ђ | Ђ | Ђ | Cyrillic capital letter Dje | |
| 129 | 201 | 81 | 10000001 | Ѓ | Ѓ | Ѓ | Cyrillic capital letter Gje | |
| 130 | 202 | 82 | 10000010 | ‚ | ‚ | ‚ | Single low-9 quotation mark | |
| 131 | 203 | 83 | 10000011 | ѓ | ѓ | ѓ | Cyrillic small letter gje | |
| 132 | 204 | 84 | 10000100 | „ | „ | „ | Double low-9 quotation mark | |
| 133 | 205 | 85 | 10000101 | … | … | … | Horizontal ellipsis | |
| 134 | 206 | 86 | 10000110 | † | † | † | Dagger | |
| 135 | 207 | 87 | 10000111 | ‡ | ‡ | ‡ | Double dagger | |
| 136 | 210 | 88 | 10001000 | € | € | € | Euro sign | |
| 137 | 211 | 89 | 10001001 | ‰ | ‰ | ‰ | Per mille sign | |
| 138 | 212 | 8A | 10001010 | Љ | Љ | Љ | Cyrillic capital letter Lje | |
| 139 | 213 | 8B | 10001011 | ‹ | ‹ | ‹ | Single left-pointing angle quotation | |
| 140 | 214 | 8C | 10001100 | Њ | Њ | Њ | Cyrillic capital letter Nje | |
| 141 | 215 | 8D | 10001101 | Ќ | Ќ | Ќ | Cyrillic capital letter Kje | |
| 142 | 216 | 8E | 10001110 | Ћ | Ћ | Ћ | Cyrillic capital letter Tshe | |
| 143 | 217 | 8F | 10001111 | Џ | Џ | Џ | Cyrillic capital letter Dzhe | |
| 144 | 220 | 90 | 10010000 | ђ | ђ | ђ | Cyrillic small letter dje | |
| 145 | 221 | 91 | 10010001 | ‘ | ‘ | ‘ | Left single quotation mark | |
| 146 | 222 | 92 | 10010010 | ’ | ’ | ’ | Right single quotation mark | |
| 147 | 223 | 93 | 10010011 | “ | “ | “ | Left double quotation mark | |
| 148 | 224 | 94 | 10010100 | ” | ” | ” | Right double quotation mark | |
| 149 | 225 | 95 | 10010101 | • | • | • | Bullet | |
| 150 | 226 | 96 | 10010110 | – | – | – | En dash | |
| 151 | 227 | 97 | 10010111 | — | — | — | Em dash | |
| 152 | 230 | 98 | 10011000 | Unused | ||||
| 153 | 231 | 99 | 10011001 | ™ | ™ | ™ | Trade mark sign | |
| 154 | 232 | 9A | 10011010 | љ | љ | љ | Cyrillic small letter lje | |
| 155 | 233 | 9B | 10011011 | › | › | › | Single right-pointing angle quotation mark | |
| 156 | 234 | 9C | 10011100 | њ | њ | њ | Cyrillic small letter nje | |
| 157 | 235 | 9D | 10011101 | ќ | ќ | ќ | Cyrillic small letter Kje | |
| 158 | 236 | 9E | 10011110 | ћ | ћ | ћ | Cyrillic small letter Tshe | |
| 159 | 237 | 9F | 10011111 | џ | џ | џ | Cyrillic small letter Dzhe | |
| 160 | 240 | A0 | 10100000 |   | | Non-breaking space | ||
| 161 | 241 | A1 | 10100001 | Ў | Ў | Ў | Cyrillic capital letter short U | |
| 162 | 242 | A2 | 10100010 | ў | ў | ў | Cyrillic small letter short u | |
| 163 | 243 | A3 | 10100011 | Ј | Ј | Ј | Cyrillic capital letter Je | |
| 164 | 244 | A4 | 10100100 | ¤ | ¤ | ¤ | Currency sign | |
| 165 | 245 | A5 | 10100101 | Ґ | Ґ | Cyrillic capital letter Ghe with upturn | ||
| 166 | 246 | A6 | 10100110 | ¦ | ¦ | ¦ | Pipe, broken vertical bar | |
| 167 | 247 | A7 | 10100111 | § | § | § | Section sign | |
| 168 | 250 | A8 | 10101000 | Ё | Ё | Ё | Cyrillic capital letter Io | |
| 169 | 251 | A9 | 10101001 | © | © | © | Copyright sign | |
| 170 | 252 | AA | 10101010 | Є | Є | Є | Cyrillic capital letter Ukrainian Ie | |
| 171 | 253 | AB | 10101011 | « | « | « | Left double angle quotes | |
| 172 | 254 | AC | 10101100 | ¬ | ¬ | ¬ | Negation | |
| 173 | 255 | AD | 10101101 | | ­ | ­ | Soft hyphen | |
| 174 | 256 | AE | 10101110 | ® | ® | ® | Registered trade mark sign | |
| 175 | 257 | AF | 10101111 | Ї | Ї | Ї | Cyrillic capital letter Yi | |
| 176 | 260 | B0 | 10110000 | ° | ° | ° | Degree sign | |
| 177 | 261 | B1 | 10110001 | ± | ± | ± | Plus-or-minus sign | |
| 178 | 262 | B2 | 10110010 | І | І | І | Cyrillic capital letter Byelorussian-Ukrainian I | |
| 179 | 263 | B3 | 10110011 | і | і | і | Cyrillic small letter Byelorussian-Ukrainian i | |
| 180 | 264 | B4 | 10110100 | ґ | ґ | Cyrillic small letter ghe with upturn | ||
| 181 | 265 | B5 | 10110101 | µ | µ | µ | Micro sign | |
| 182 | 266 | B6 | 10110110 | ¶ | ¶ | ¶ | Pilcrow sign — paragraph sign | |
| 183 | 267 | B7 | 10110111 | · | · | · | Middle dot — Georgian comma | |
| 184 | 270 | B8 | 10111000 | ё | ё | ё | Cyrillic small letter io | |
| 185 | 271 | B9 | 10111001 | № | № | № | Numero Sign | |
| 186 | 272 | BA | 10111010 | є | є | є | Cyrillic small letter Ukrainian ie | |
| 187 | 273 | BB | 10111011 | » | » | » | Right double angle quotes | |
| 188 | 274 | BC | 10111100 | ј | ј | ј | Cyrillic small letter je | |
| 189 | 275 | BD | 10111101 | Ѕ | Ѕ | Ѕ | Cyrillic capital letter Dze | |
| 190 | 276 | BE | 10111110 | ѕ | ѕ | ѕ | Cyrillic small letter dze | |
| 191 | 277 | BF | 10111111 | ї | ї | ї | Cyrillic small letter yi | |
| 192 | 300 | C0 | 11000000 | А | А | А | Cyrillic capital letter A | |
| 193 | 301 | C1 | 11000001 | Б | Б | Б | Cyrillic capital letter Be | |
| 194 | 302 | C2 | 11000010 | В | В | В | Cyrillic capital letter Ve | |
| 195 | 303 | C3 | 11000011 | Г | Г | Г | Cyrillic capital letter Ghe | |
| 196 | 304 | C4 | 11000100 | Д | Д | Д | Cyrillic capital letter De | |
| 197 | 305 | C5 | 11000101 | Е | Е | Е | Cyrillic capital letter Ie | |
| 198 | 306 | C6 | 11000110 | Ж | Ж | Ж | Cyrillic capital letter Zhe | |
| 199 | 307 | C7 | 11000111 | З | З | З | Cyrillic capital letter Ze | |
| 200 | 310 | C8 | 11001000 | И | И | И | Cyrillic capital letter I | |
| 201 | 311 | C9 | 11001001 | Й | Й | Й | Cyrillic capital letter Short I | |
| 202 | 312 | CA | 11001010 | К | К | К | Cyrillic capital letter Ka | |
| 203 | 313 | CB | 11001011 | Л | Л | Л | Cyrillic capital letter El | |
| 204 | 314 | CC | 11001100 | М | М | М | Cyrillic capital letter Em | |
| 205 | 315 | CD | 11001101 | Н | Н | Н | Cyrillic capital letter En | |
| 206 | 316 | CE | 11001110 | О | О | О | Cyrillic capital letter O | |
| 207 | 317 | CF | 11001111 | П | П | П | Cyrillic capital letter Pe | |
| 208 | 320 | D0 | 11010000 | Р | Р | Р | Cyrillic capital letter Er | |
| 209 | 321 | D1 | 11010001 | С | С | С | Cyrillic capital letter Es | |
| 210 | 322 | D2 | 11010010 | Т | Т | Т | Cyrillic capital letter Te | |
| 211 | 323 | D3 | 11010011 | У | У | У | Cyrillic capital letter U | |
| 212 | 324 | D4 | 11010100 | Ф | Ф | Ф | Cyrillic capital letter Ef | |
| 213 | 325 | D5 | 11010101 | Х | Х | Х | Cyrillic capital letter Ha | |
| 214 | 326 | D6 | 11010110 | Ц | Ц | Ц | Cyrillic capital letter Tse | |
| 215 | 327 | D7 | 11010111 | Ч | Ч | Ч | Cyrillic capital letter Che | |
| 216 | 330 | D8 | 11011000 | Ш | Ш | Ш | Cyrillic capital letter Sha | |
| 217 | 331 | D9 | 11011001 | Щ | Щ | Щ | Cyrillic capital letter Shcha | |
| 218 | 332 | DA | 11011010 | Ъ | Ъ | Ъ | Cyrillic capital letter Hard Sign | |
| 219 | 333 | DB | 11011011 | Ы | Ы | Ы | Cyrillic capital letter Yeru | |
| 220 | 334 | DC | 11011100 | Ь | Ь | Ь | Cyrillic capital letter Soft Sign | |
| 221 | 335 | DD | 11011101 | Э | Э | Э | Cyrillic capital letter E | |
| 222 | 336 | DE | 11011110 | Ю | Ю | Ю | Cyrillic capital letter Yu | |
| 223 | 337 | DF | 11011111 | Я | Я | Я | Cyrillic capital letter Ya | |
| 224 | 340 | E0 | 11100000 | а | а | а | Cyrillic Small Letter A | |
| 225 | 341 | E1 | 11100001 | б | б | б | Cyrillic small letter be | |
| 226 | 342 | E2 | 11100010 | в | в | в | Cyrillic small letter ve | |
| 227 | 343 | E3 | 11100011 | г | г | г | Cyrillic small letter ghe | |
| 228 | 344 | E4 | 11100100 | д | д | д | Cyrillic small letter de | |
| 229 | 345 | E5 | 11100101 | е | е | е | Cyrillic small letter ie | |
| 230 | 346 | E6 | 11100110 | ж | ж | ж | Cyrillic small letter zhe | |
| 231 | 347 | E7 | 11100111 | з | з | з | Cyrillic small letter ze | |
| 232 | 350 | E8 | 11101000 | и | и | и | Cyrillic small letter i | |
| 233 | 351 | E9 | 11101001 | й | й | й | Cyrillic small letter short i | |
| 234 | 352 | EA | 11101010 | к | к | к | Cyrillic small letter ka | |
| 235 | 353 | EB | 11101011 | л | л | л | Cyrillic small letter el | |
| 236 | 354 | EC | 11101100 | м | м | м | Cyrillic small letter em | |
| 237 | 355 | ED | 11101101 | н | н | н | Cyrillic small letter en | |
| 238 | 356 | EE | 11101110 | о | о | о | Cyrillic small letter o | |
| 239 | 357 | EF | 11101111 | п | п | п | Cyrillic small letter pe | |
| 240 | 360 | F0 | 11110000 | р | р | р | Cyrillic small letter er | |
| 241 | 361 | F1 | 11110001 | с | с | с | Cyrillic small letter es | |
| 242 | 362 | F2 | 11110010 | т | т | т | Cyrillic small letter te | |
| 243 | 363 | F3 | 11110011 | у | у | у | Cyrillic small letter u | |
| 244 | 364 | F4 | 11110100 | ф | ф | ф | Cyrillic small letter ef | |
| 245 | 365 | F5 | 11110101 | х | х | х | Cyrillic small letter ha | |
| 246 | 366 | F6 | 11110110 | ц | ц | ц | Cyrillic small letter tse | |
| 247 | 367 | F7 | 11110111 | ч | ч | ч | Cyrillic small letter che | |
| 248 | 370 | F8 | 11111000 | ш | ш | ш | Cyrillic small letter sha | |
| 249 | 371 | F9 | 11111001 | щ | щ | щ | Cyrillic small letter shcha | |
| 250 | 372 | FA | 11111010 | ъ | ъ | ъ | Cyrillic small letter hard sign | |
| 251 | 373 | FB | 11111011 | ы | ы | ы | Cyrillic small letter yeru | |
| 252 | 374 | FC | 11111100 | ь | ь | ь | Cyrillic small letter soft sign | |
| 253 | 375 | FD | 11111101 | э | э | э | Cyrillic small letter e | |
| 254 | 376 | FE | 11111110 | ю | ю | ю | Cyrillic small letter yu | |
| 255 | 377 | FF | 11111111 | я | я | я | Cyrillic small letter ya |
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Время на прочтение
10 мин
Количество просмотров 104K
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Содержание
- 1 Представление символов в вычислительных машинах
- 2 Таблицы кодировок
- 3 Кодировки стандарта ASCII
- 3.1 Структурные свойства таблицы
- 4 Кодировки стандарта UNICODE
- 4.1 Кодовое пространство
- 4.2 Модифицирующие символы
- 4.3 Способы представления
- 4.4 UTF-8
- 4.4.1 Принцип кодирования
- 4.4.1.1 Правила записи кода одного символа в UTF-8
- 4.4.1.2 Определение длины кода в UTF-8
- 4.4.1 Принцип кодирования
- 4.5 UTF-16
- 4.5.1 UTF-16LE и UTF-16BE
- 4.6 UTF-32
- 4.7 Порядок байт
- 4.7.1 Варианты записи
- 4.7.1.1 Порядок от старшего к младшему
- 4.7.1.2 Порядок от младшего к старшему
- 4.7.1.3 Переключаемый порядок
- 4.7.1.4 Смешанный порядок
- 4.7.1.5 Различия
- 4.7.2 Маркер последовательности байт
- 4.7.1 Варианты записи
- 4.8 Проблемы Юникода
- 5 Примеры
- 5.1 Код на python
- 5.2 hex-дамп файла exampleBOM
- 6 См. также
- 7 Источники информации
Представление символов в вычислительных машинах
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины , задается простой формулой . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов.
Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания.
Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение символов: основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ] | ^ | _ | |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до кодовых позиций, было принято решение использовать лишь для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее кодовых позиций ( графических и прочих символов).
Кодовое пространство разбито на плоскостей (англ. planes) по символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости и выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов ) или «U+xxxxx» (для кодов ) или «U+xxxxxx» (для кодов ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
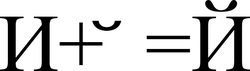
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими -битные символы. Текст, состоящий только из символов с номером меньше , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид , а остальные — .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
111111xx |
служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = байт
- Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 байт (то есть от до ):
- 2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления;
2 — 11 3 — 111 4 — 1111 5 — 1111 1 6 — 1111 11
- 2.2 «0» — бит терминатор, означающий завершение кода размера
- 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
(1 байт) 0aaa aaaa (2 байта) 110x xxxx 10xx xxxx (3 байта) 1110 xxxx 10xx xxxx 10xx xxxx (4 байта) 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx (5 байт) 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx (6 байт) 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
В общем случае количество значащих бит , кодируемых байтами UTF-8, определяется по формуле:
при
при
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством ), причем -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от до ). При этом можно кодировать символы Unicode в диапазонах и . Исключенный отсюда диапазон используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя -битными словами. Символы Unicode до включительно (исключая диапазон для суррогатов) записываются как есть -битным словом. Символы же в диапазоне (больше бит) уже кодируются парой -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число ). В результате получится значение от нуля до , которое занимает до бит. Старшие бит этого значения идут в лидирующее (первое) слово, а младшие бит — в последующее (второе). При этом в обоих словах старшие бит используются для обозначения суррогата. Биты с по имеют значения , а -й бит содержит у лидирующего слова и — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа , большего (здесь — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число записывается в позиционной системе счисления по основанию :
Набор целых чисел , каждое из которых лежит в интервале от до , является последовательностью байт, составляющих . При этом называется младшим байтом, а — старшим байтом числа .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление -байтных целых чисел на -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия

Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число , то прочитав его как int16 (два байта) мы получим число , прочитав один байт — число . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
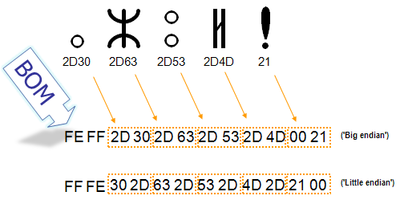
Представление BOM в кодировках
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF
|
| UTF-16 (BE) | FE FF
|
| UTF-16 (LE) | FF FE
|
| UTF-32 (BE) | 00 00 FE FF
|
| UTF-32 (LE) | FF FE 00 00
|
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его или байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на python
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOM
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
См. также
- Представление целых чисел: прямой код, код со сдвигом, дополнительный код
- Представление вещественных чисел
Источники информации
- Wikipedia — таблица ASCII
- Wikipedia — стандарт UNICODE
- Wikipedia — Byte order mark
- Wikipedia — Порядок байтов
- Wikipedia — Юникод
- Wikipedia — Windows-1251
- Wikipedia — UTF-8
- Wikipedia — UTF-16
- Wikipedia — UTF-32