Давным-давно скопипастил/написал и использую для перекодировки такую функцию:
public static void convert(
String infile, //input file name, if null reads from console/stdin
String outfile, //output file name, if null writes to console/stdout
String from, //encoding of input file (e.g. UTF-8/windows-1251, etc)
String to) //encoding of output file (e.g. UTF-8/windows-1251, etc)
throws IOException, UnsupportedEncodingException
{
// set up byte streams
InputStream in;
if(infile != null)
in=new FileInputStream(infile);
else
in=System.in;
OutputStream out;
if(outfile != null)
out=new FileOutputStream(outfile);
else
out=System.out;
// Use default encoding if no encoding is specified.
if(from == null) from=System.getProperty("file.encoding");
if(to == null) to=System.getProperty("file.encoding");
// Set up character stream
Reader r=new BufferedReader(new InputStreamReader(in, from));
Writer w=new BufferedWriter(new OutputStreamWriter(out, to));
// Copy characters from input to output. The InputStreamReader
// converts from the input encoding to Unicode,, and the OutputStreamWriter
// converts from Unicode to the output encoding. Characters that cannot be
// represented in the output encoding are output as '?'
char[] buffer=new char[4096];
int len;
while((len=r.read(buffer)) != -1)
w.write(buffer, 0, len);
r.close();
w.flush();
w.close();
}
Работает как часы — с успехом кодировал даже с китайского-писишного на UTF-8. Думаю ее несложно будет приспособить под декодирование строк
Строки в java хранятся в Unicode. Для того что бы собрать строку в кодировке windows-1251 для неё нужно подготовить «правильные» байты.
public class Test {
public static void main(String[] args) throws IOException {
BufferedReader is = new BufferedReader(new InputStreamReader(new FileInputStream("/home/maks/myFile")));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("/home/maks/myFileout")));
while(is.ready()){
byte[] byte1251 = is.readLine().getBytes("windows-1251");
String outString = new String(byte1251,"windows-1251");
System.out.println(outString);
bw.write(outString);
bw.newLine();
}
is.close();
bw.flush();
bw.close();
}
}
Кодировка windows 1251 является одной из самых часто используемых кодировок в среде Windows. Она позволяет правильно отображать текст на русском языке и других языках, использующих символы Юникода. В Java также возможна работа с кодировкой windows 1251, и в данной статье мы рассмотрим основные принципы работы с этой кодировкой.
Для начала необходимо убедиться, что ваша среда разработки правильно настроена для работы с кодировкой windows 1251. Это можно сделать, указав соответствующий параметр в настройках проекта или среды разработки. Если вы используете IDE, такую как IntelliJ IDEA или Eclipse, вы можете изменить настройки кодировки в меню «Настройки» или «Preferences». Если вы работаете из командной строки или используете консольный инструмент для компиляции и выполнения Java-программ, вы можете установить нужную кодировку, используя команду «chcp 1251» для Windows или «export LC_ALL=ru_RU.CP1251» для Linux.
Важно отметить, что при работе с кодировкой windows 1251 необходимо быть внимательным к тому, что именно вы хотите сделать с данными в этой кодировке. Если вам нужно корректно отобразить текст, то вам понадобится использовать соответствующие методы для преобразования кодировки, например, String.getBytes(«Cp1251») для преобразования строки в массив байтов с кодировкой windows 1251.
Кроме того, в Java есть набор классов, предоставляющих дополнительные возможности для работы с кодировкой windows 1251. Например, классы InputStreamReader и OutputStreamWriter позволяют читать и записывать данные в определенной кодировке, включая кодировку windows 1251. Чтение и запись символов в кодировке windows 1251 можно осуществить следующим образом:
try (InputStreamReader reader = new InputStreamReader(new FileInputStream(«file.txt»), «Cp1251»)) {
// Чтение символов из файла в кодировке windows 1251
}
try (OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(«file.txt»), «Cp1251»)) {
// Запись символов в файл в кодировке windows 1251
}
В данной статье мы рассмотрели основные принципы работы с кодировкой windows 1251 в Java. Мы познакомились с методами преобразования кодировки, а также с использованием классов InputStreamReader и OutputStreamWriter для чтения и записи данных в кодировке windows 1251. Надеемся, что эта информация будет полезна для вас при работе с кодировкой windows 1251 в Java.
Содержание
- Основы кодировки windows 1251 в Java
- Преобразование текста в кодировку windows 1251
- Чтение и запись файлов с кодировкой windows 1251
- Примеры кода работы с кодировкой windows 1251 в Java
Основы кодировки windows 1251 в Java
Для работы с кодировкой windows-1251 необходимо правильно настроить окружение Java. Для этого можно использовать методы класса Charset, предоставляемые в стандартной библиотеке Java. Например, чтобы получить объект Charset для кодировки windows-1251, можно воспользоваться следующим кодом:
Charset charset = Charset.forName("windows-1251");Затем, чтобы преобразовать строку из кодировки windows-1251 в Unicode, можно использовать класс String и его конструктор, принимающий массив байтов и объект Charset. Например:
String str = new String(bytes, charset);Для преобразования строки из Unicode в кодировку windows-1251 можно использовать метод getBytes() класса String, указывая объект Charset. Например:
byte[] bytes = str.getBytes(charset);Также, часто необходимо записать строку в файл или вывести ее на консоль с помощью кодировки windows-1251. Для этого можно воспользоваться классом OutputStreamWriter для записи в файл или классом PrintStream для вывода на консоль, задав соответствующую кодировку через объект Charset. Например:
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("file.txt"), charset);
writer.write(str);
writer.close();В данном примере мы записываем строку str в файл «file.txt» с использованием кодировки windows-1251.
В заключение стоит отметить, что кодировка windows-1251 имеет свои ограничения, например, она не поддерживает все символы из юникода. Если вам требуется работать с широким спектром символов, возможно, вам потребуется использовать другую кодировку, например, UTF-8 или UTF-16.
Преобразование текста в кодировку windows 1251
В Java есть возможность преобразовывать текст из одной кодировки в другую. Рассмотрим пример, как можно преобразовать текст в кодировку windows 1251.
Сначала необходимо создать объект типа Charset, представляющий кодировку windows 1251:
Charset windows1251Charset = Charset.forName("windows-1251");
Затем создадим объект типа CharsetEncoder, который будет использоваться для преобразования текста в кодировку windows 1251:
CharsetEncoder encoder = windows1251Charset.newEncoder();
Кодировщик (encoder) будет использовать дополнительные правила, чтобы преобразовывать текст из исходной кодировки в кодировку windows 1251. Если символ невозможно преобразовать, кодировщик может сгенерировать исключение или использовать специальный символ замены.
Теперь создадим объект типа ByteBuffer для представления текста в исходной кодировке (например, UTF-8):
String inputText = "Текст в исходной кодировке UTF-8";
ByteBuffer inputBuffer = ByteBuffer.wrap(inputText.getBytes(StandardCharsets.UTF_8));
Затем создадим объект типа CharBuffer, в котором будет сохранен преобразованный текст в кодировку windows 1251:
CharBuffer outputBuffer = CharBuffer.allocate(inputText.length());
Далее воспользуемся методом encode нашеего кодировщика, чтобы преобразовать исходный текст в кодировку windows 1251:
encoder.encode(inputBuffer, outputBuffer, true);
Наконец, получим преобразованный текст в кодировке windows 1251 и выведем его:
String outputText = new String(outputBuffer.array());
System.out.println(outputText);
Теперь наш текст будет выведен в кодировке windows 1251.
Чтение и запись файлов с кодировкой windows 1251
При работе с файлами в кодировке windows 1251 в Java необходимо учитывать особенности этой кодировки и правильно выполнить чтение и запись данных.
Для чтения файла в кодировке windows 1251 можно воспользоваться классом BufferedReader и специально созданным для этого InputStreamReader. Пример кода:
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("file.txt"), "windows-1251"))) {
String line;
while ((line = reader.readLine()) != null) {
// обработка строки
}
} catch (IOException e) {
e.printStackTrace();
}
В данном примере создается объект BufferedReader, который оборачивает объект InputStreamReader. В конструкторе InputStreamReader указывается кодировка «windows-1251», а также создается объект FileInputStream для чтения файла «file.txt». Затем используется метод readLine() для последовательного чтения строк из файла.
Для записи данных в кодировке windows 1251 можно воспользоваться классом BufferedWriter и специально созданным для этого OutputStreamWriter. Пример кода:
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("file.txt"), "windows-1251"))) {
// запись данных
writer.write("Пример записи строки в файл");
writer.newLine();
} catch (IOException e) {
e.printStackTrace();
}
В данном примере создается объект BufferedWriter, который оборачивает объект OutputStreamWriter. В конструкторе OutputStreamWriter указывается кодировка «windows-1251», а также создается объект FileOutputStream для записи в файл «file.txt». Затем используется метод write() для записи строки в файл, а метод newLine() для добавления новой строки.
При работе с кодировкой windows 1251 также необходимо обрабатывать исключения, связанные с возможными ошибками чтения и записи файлов.
Пользуйтесь примерами кода выше, чтобы освоить чтение и запись файлов в кодировке windows 1251 на платформе Java.
Примеры кода работы с кодировкой windows 1251 в Java
Кодировка windows 1251 широко используется в русскоязычных приложениях Java для работы с текстом на русском языке. В этом разделе представлены примеры кода, которые помогут вам правильно использовать кодировку windows 1251 в ваших Java-проектах.
Пример 1: Конвертация строки из кодировки UTF-8 в кодировку windows 1251
String utf8String = "Привет, мир!"; byte[] utf8Bytes = utf8String.getBytes(StandardCharsets.UTF_8); String windows1251String = new String(utf8Bytes, "Windows-1251"); System.out.println(windows1251String);
Пример 2: Чтение и запись файла в кодировке windows 1251
// Чтение файла в кодировке windows 1251
File file = new File("file.txt");
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file), "Windows-1251"))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
// Запись файла в кодировке windows 1251
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file), "Windows-1251"))) {
String text = "Пример текста на русском языке";
writer.write(text);
} catch (IOException e) {
e.printStackTrace();
}
Пример 3: Работа со строками в кодировке windows 1251
String windows1251String = "Пример текста на русском языке";
byte[] windows1251Bytes = windows1251String.getBytes("Windows-1251");
String utf8String = new String(windows1251Bytes, StandardCharsets.UTF_8);
System.out.println(utf8String);
Надеюсь, что эти примеры кода помогут вам успешно работать с кодировкой windows 1251 в ваших Java-проектах. Удачи!
1. Введение
|
Некоторые проблемы настолько сложны, |
|
Лоренс Дж. Питер |
Кодировки
Когда я только начинал программировать на языке C, первой моей программой (не считая HelloWorld) была программа перекодировки текстовых файлов из основной кодировки ГОСТ-а (помните такую?  в альтернативную.
в альтернативную.
Было это в далёком 1991-ом году.
С тех пор многое изменилось, но за прошедшие 10 лет подобные программки свою актуальность, к сожалению, не потеряли.
Слишком много уже накоплено данных в разнообразных кодировках и слишком много используется программ, которые умеют работать только с одной.
Для русского языка существует не менее десятка различных кодировок, что делает проблему ещё более запутанной.
Откуда же взялись все эти кодировки и для чего они нужны?
Компьютеры по своей природе могут работать только с числами.
Для того чтобы хранить буквы в памяти компьютера надо поставить в соответствие каждой букве некое число (примерно такой же принцип использовался и до появления компьютеров — вспомните про ту же азбуку Морзе).
Причём число желательно поменьше — чем меньше двоичных разрядов будет задействовано, тем эффективнее можно будет использовать память.
Вот это соответствие набора символов и чисел собственно и есть кодировка.
Желание любой ценой сэкономить память, а так же разобщённость разных групп компьютерщиков и привела к нынешнему положению дел.
Самым распространённым способом кодирования сейчас является использование для одного символа одного байта (8 бит), что определяет общее кол-во символов в 256.
Набор первых 128 символов стандартизован (набор ASCII) и является одинаковыми во всех распространённых кодировках (те кодировки, где это не так уже практически вышли из употребления).
Англицкие буковки и символы пунктуации находятся в этом диапазоне, что и определяет их поразительную живучесть в компьютерных системах :-).
Другие языки находятся не в столь счастливом положении — им всем приходится ютиться в оставшихся 128 числах.
Unicode
В конце 80-х многие осознали необходимость создания единого стандарта на кодирование символов, что и привело к появлению Unicode.
Unicode — это попытка раз и навсегда зафиксировать конкретное число за конкретным символом.
Понятно, что в 256 символов тут не уложишься при всём желании.
Довольно долгое время казалось, что уж 2-х то байт (65536 символов) должно хватить.
Ан нет — последняя версия стандарта Unicode — 3.1 определяет уже 94140 символов.
Для такого количества символов, наверное, уже придётся использовать 4 байта (4294967296 символов).
Может быть и хватит на некоторое время…
В набор символов Unicode входят всевозможные буквы со всякими чёрточками и припендюльками, греческие, математические, иероглифы, символы псевдографики и пр. и пр.
В том числе и так любимые нами символы кириллицы (диапазон значений 0x0400-0x04ff).
Так что с этой стороны никакой дискриминации нет.
Если Вам интересны конкретные кода символов, для их просмотра удобно использовать программу «Таблица символов» из WinNT.
Вот, например, диапазон кириллицы:
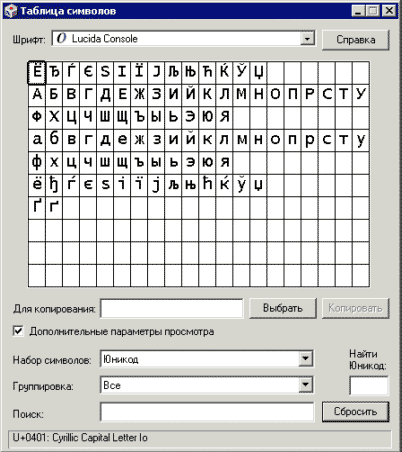
Если у Вас другая OS или Вас интересует официальное толкование, то полную раскладку символов (charts) можно найти на официальном сайте Unicode.
Типы char и byte
В Java для символов выделен отдельный тип данных char размером в 2 байта.
Это часто порождает путаницу в умах начинающих (особенно если они раньше программировали на других языках, например на C/C++).
Дело в том, что в большинстве других языков для обработки символов используются типы данных размером в 1 байт.
Например, в C/C++ тип char в большинстве случаев используется как для обработки символов, так и для обработки байтов — там нет разделения.
В Java для байтов имеется свой тип — тип byte.
Таким образом C-ишному char соответствует Java-вский byte, а Java-вскому char из мира C ближе всего тип wchar_t.
Надо чётко разделять понятия символов и байтов — иначе непонимание и проблемы гарантированны.
Java практически с самого своего рождения использует для кодирования символов стандарт Unicode.
Библиотечные функции Java ожидают увидеть в переменных типа char символы, представленные кодами Unicode.
В принципе, Вы, конечно, можете запихнуть туда что угодно — цифры есть цифры, процессор всё стерпит, но при любой обработке библиотечные функции будут действовать исходя из предположения что им передали кодировку Unicode.
Так что можно спокойно полагать, что у типа char кодировка зафиксирована.
Но это внутри JVM.
Когда данные читаются извне или передаются наружу, то они могут быть представлены только одним типом — типом byte.
Все прочие типы конструируются из байтов в зависимости от используемого формата данных.
Вот тут то на сцену и выходят кодировки — в Java это просто формат данных для передачи символов, который используется для формирования данных типа char.
Для каждой кодовой страницы в библиотеке имеется по 2 класса перекодировки (ByteToChar и CharToByte).
Классы эти лежат в пакете sun.io.
Если, при перекодировке из char в byte не было найдено соответствующего символа, он заменяется на символ «?«.
Кстати, эти файлы кодовых страниц в некоторых ранних версиях JDK 1.1 содержат ошибки, вызывающие ошибки перекодировок, а то и вообще исключения при выполнении.
Например, это касается кодировки KOI8_R.
Лучшее, что можно при этом сделать — сменить версию на более позднюю.
Судя по Sun-овскому описанию, большинство этих проблем было решено в версии JDK 1.1.6.
До появления версии JDK 1.4 набор доступных кодировок определялся только производителем JDK.
Начиная с 1.4 появилось новое API (пакет java.nio.charset), при помощи которого Вы уже можете создать свою собственную кодировку (например поддержать редко используемую, но жутко необходимую именно Вам).
Класс String
В большинстве случаев для представления строк в Java используется объект типа java.lang.String.
Это обычный класс, который внутри себя хранит массив символов (char[]), и который содержит много полезных методов для манипуляции символами.
Самые интересные — это конструкторы, имеющие первым параметром массив байтов (byte[]) и методы getBytes().
При помощи этих методов Вы можете выполнять преобразования из массива байтов в строки и обратно.
Для того, чтобы указать какую кодировку при этом использовать у этих методов есть строковый параметр, который задаёт её имя.
Вот, например, как можно выполнить перекодировку байтов из КОИ-8 в Windows-1251:
//Данные в кодировке КОИ-8
byte[] koi8Data=...;
//Преобразуем из КОИ-8 в Unicode
String string=new String(koi8Data,"KOI8_R");
//Преобразуем из Unicode в Windows-1251
byte[] winData=string.getBytes("Cp1251");
Список 8-ми битовых кодировок, доступных в современных JDK и поддерживающих русские буквы Вы можете найти ниже, в разделе «8-ми битовые кодировки русских букв».
Так как кодировка — это формат данных для символов, кроме знакомых 8-ми битовых кодировок в Java также на равных присутствуют и многобайтовые кодировки.
К таким относятся UTF-8, UTF-16, Unicode и пр.
Например вот так можно получить байты в формате UnicodeLittleUnmarked (16-ти битовое кодирование Unicode, младший байт первый, без признака порядка байтов):
//Строка Unicode
String string="...";
//Преобразуем из Unicode в UnicodeLittleUnmarked
byte[] data=string.getBytes("UnicodeLittleUnmarked");
При подобных преобразованиях легко ошибиться — если кодировка байтовых данных не соответствуют указанному параметру при преобразовании из byte в char, то перекодирование будет выполнено неправильно.
Иногда после этого можно вытащить правильные символы, но чаще всего часть данных будет безвозвратно потеряна.
В реальной программе явно указывать кодовую страницу не всегда удобно (хотя более надёжно).
Для этого была введена кодировка по умолчанию.
По умолчанию она зависит от системы и её настроек (для русских виндов принята кодировка Cp1251), и в старых JDK её можно изменить установкой системного свойства file.encoding.
В JDK 1.3 изменение этой настройки иногда срабатывает, иногда — нет.
Вызвано это следующим: первоначально file.encoding ставится по региональным настройкам компьютера.
Ссылка на кодировку по умолчанию запоминается в нутрях при первом преобразовании.
При этом используется file.encoding, но это преобразование происходит ещё до использования аргументов запуска JVM (собсно, при их разборе).
Вообще-то, как утверждают в Sun, это свойство отражает системную кодировку, и она не должна изменяться в командной строке (см., например, комментарии к BugID 4163515).
Тем не менее в JDK 1.4 Beta 2 смена этой настройки опять начала оказывать эффект.
Что это, сознательное изменение или побочный эффект, который может опять исчезнуть — Sun-овцы ясного ответа пока не дали.
Эта кодировка используется тогда, когда явно не указанно название страницы.
Об этом надо всегда помнить — Java не будет пытаться предсказать кодировку байтов, которые Вы передаёте для создания строки String (так же она не сможет прочитать Ваши мысли по этому поводу :-).
Она просто использует текущую кодировку по умолчанию.
Т.к. эта настройка одна на все преобразования, иногда можно наткнуться на неприятности.
Для преобразования из байтов в символы и обратно следует пользоваться только этими методами.
Простое приведение типа использовать в большинстве случаев нельзя — кодировка символов при этом не будет учитываться.
Например, одной из самых распространённых ошибок является чтение данных побайтно при помощи метода read() из InputStream, а затем приведение полученного значения к типу char:
InputStream is=...;
int b;
StringBuffer sb=new StringBuffer();
while((b=is.read())!=-1){
sb.append((char)b); // так делать нельзя
}
String s=sb.toString();
Обратите внимание на приведение типа — «(char)b».
Значения байтов вместо перекодирования просто скопируются в char (диапазон значений 0-0xFF, а не тот, где находится кириллица).
Такому копированию соответствует кодировка ISO-8859-1 (которая один в один соответствует первым 256 значениям Unicode), а значит, можно считать, что этот код просто использует её (вместо той, в которой реально закодированы символы в оригинальных данных).
Если Вы попытаетесь отобразить полученное значение — на экране будут или вопросики или кракозяблы.
Например, при чтении строки «АБВ» в виндовой кодировке может запросто отобразиться что-то вроде такого: «»ÀÁ».
Подобного рода код часто пишут программисты на западе — с английскими буквами работает, и ладно.
Исправить такой код легко — надо просто заменить StringBuffer на ByteArrayOutputStream:
InputStream is=...;
int b;
ByteArrayOutputStream baos=new ByteArrayOutputStream();
while((b=is.read())!=-1){
baos.write(b);
}
//Перекодирование байтов в строку с использованием
//кодировки по умолчанию
String s=baos.toString();
//Если нужна конкретная кодировка - просто укажите
//её при вызове toString():
//
//s=baos.toString("Cp1251");
Более подробно о распространённых ошибках смотрите раздел «Типичные ошибки».
При разработке программ на Java необходимо учитывать различия в кодировках символов. Одной из наиболее распространенных кодировок является windows 1251, которая используется в операционных системах Windows. В этой статье мы рассмотрим основные принципы работы с кодировкой windows 1251 в Java для начинающих разработчиков.
Первым шагом при работе с кодировкой windows 1251 в Java является установка правильной кодировки по умолчанию. Для этого можно воспользоваться методом System.setProperty() и указать значение «Cp1251». Таким образом, все строки, которые будут созданы в программе, будут использовать данную кодировку.
Если вам необходимо преобразовать строку из кодировки windows 1251 в Unicode, вы можете воспользоваться классом String. Для преобразования используйте конструктор String(byte[] bytes, Charset charset), где bytes — это массив байтов строки, полученной из кодировки windows 1251, а charset — объект класса Charset с установленной кодировкой windows 1251.
Example:
byte[] bytes = "Привет, мир!".getBytes(Charset.forName("Cp1251"));
String unicodeString = new String(bytes, Charset.forName("UTF-8"));
System.out.println(unicodeString);
Если же вам необходимо преобразовать строку из Unicode в кодировку windows 1251, воспользуйтесь методом getBytes() класса String. Данный метод принимает один параметр — объект класса Charset с установленной кодировкой windows 1251.
Example:
String unicodeString = "Привет, мир!";
byte[] bytes = unicodeString.getBytes(Charset.forName("Cp1251"));
System.out.println(new String(bytes, Charset.forName("Cp1251")));
Теперь, когда вы знакомы с основными принципами работы с кодировкой windows 1251 в Java, вы можете без проблем обрабатывать строки этой кодировки и работать с ними в своих программах.
Содержание
- Перевод кодировки в Java
- Работа с кодировкой windows 1251 в строках
- Чтение и запись файлов в кодировке windows 1251
Перевод кодировки в Java
Для начала, нужно создать объект InputStreamReader и передать в него InputStream, содержащий строку, которую необходимо перевести:
InputStream inputStream = new ByteArrayInputStream(string.getBytes(StandardCharsets.UTF_8));
Reader reader = new InputStreamReader(inputStream, "Windows-1251");Здесь string — это исходная строка, а StandardCharsets.UTF_8 указывает, что исходная строка закодирована в UTF-8.
Затем, можно создать объект OutputStreamWriter и передать в него OutputStream, в который будет записываться результат перевода:
OutputStream outputStream = new ByteArrayOutputStream();
Writer writer = new OutputStreamWriter(outputStream, "UTF-8");Теперь можно перевести строку из кодировки Windows 1251 в кодировку Unicode:
char[] buffer = new char[1024];
int bytesRead;
while ((bytesRead = reader.read(buffer)) != -1) {
writer.write(buffer, 0, bytesRead);
}Наконец, не забудьте закрыть потоки, чтобы избежать утечек памяти:
reader.close();
writer.close();После выполнения этих шагов, исходная строка будет переведена в кодировку Unicode и записана в outputStream.
Работа с кодировкой windows 1251 в строках
При работе с кодировкой windows 1251 в Java необходимо учитывать особенности работы с этой кодировкой в строках.
Windows 1251 — это широко используемая кодировка в русскоязычных странах. Чтобы работать с этой кодировкой в Java, необходимо преобразовать строки из Unicode в windows 1251 и обратно.
Для преобразования строки из Unicode в кодировку windows 1251, можно использовать классы String и Charset. Пример использования:
String text = "Привет, мир!";
Charset utfCharset = Charset.forName("UTF-8");
Charset winCharset = Charset.forName("windows-1251");
byte[] utfBytes = text.getBytes(utfCharset);
byte[] winBytes = new String(utfBytes, utfCharset).getBytes(winCharset);
String winText = new String(winBytes, winCharset);
System.out.println(winText); // Выводит "Привет, мир!"Обратное преобразование строки из кодировки windows 1251 в Unicode осуществляется аналогичным образом:
String winText = "Привет, мир!";
byte[] winBytes = winText.getBytes(winCharset);
byte[] utfBytes = new String(winBytes, winCharset).getBytes(utfCharset);
String text = new String(utfBytes, utfCharset);
System.out.println(text); // Выводит "Привет, мир!"Обратите внимание, что для корректного преобразования строки из кодировки windows 1251 в Unicode и обратно, необходимо использовать правильные кодировки Charset.forName("windows-1251") и Charset.forName("UTF-8").
Таким образом, работа с кодировкой windows 1251 в строках в Java может быть достигнута с помощью преобразования строк из Unicode в windows 1251 и обратно с использованием классов String и Charset.
Чтение и запись файлов в кодировке windows 1251
Способ 1: Использование класса BufferedReader и BufferedWriter
Для чтения и записи файлов в кодировке windows 1251 можно использовать классы BufferedReader и BufferedWriter из пакета java.io. Вот пример кода:
FileInputReader fileReader = new InputStreamReader(new FileInputStream("file.txt"), "windows-1251");
BufferedReader bufferedReader = new BufferedReader(fileReader);
FileWriter fileWriter = new OutputStreamWriter(new FileOutputStream("output.txt"), "windows-1251");
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
String line;
while ((line = bufferedReader.readLine()) != null) {
bufferedWriter.write(line);
bufferedWriter.newLine();
}
bufferedReader.close();
bufferedWriter.close();
Способ 2: Использование классов FileInputStream и FileOutputStream
Если вам необходимо работать с байтами, вы можете использовать классы FileInputStream и FileOutputStream. Вот пример кода:
FileInputStream fileInputStream = new FileInputStream("file.txt");
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "windows-1251");
FileOutputStream fileOutputStream = new FileOutputStream("output.txt");
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream, "windows-1251");
int character;
while ((character = inputStreamReader.read()) != -1) {
outputStreamWriter.write(character);
}
inputStreamReader.close();
outputStreamWriter.close();
Способ 3: Использование класса Files
В Java 7 и выше можно использовать класс Files из пакета java.nio.file для чтения и записи файлов в определенной кодировке. Вот пример кода:
Path path = Paths.get("file.txt");
Charset charset = Charset.forName("windows-1251");
List lines = Files.readAllLines(path, charset);
Path outputPath = Paths.get("output.txt");
Files.write(outputPath, lines, charset);
Важно помнить, что при работе с кодировкой windows 1251 в Java необходимо указывать эту кодировку явно при чтении и записи файлов. В противном случае, Java будет использовать кодировку по умолчанию, которая может отличаться от windows 1251.