Информатика, 10 класс. Урок № 14.
Тема — Кодирование текстовой информации
Цели и задачи урока:
— познакомиться со способами кодирования и декодирования текстовой информации с помощью кодовых таблиц и компьютера;
— познакомиться со способом определения информационного объема текстового сообщения;
— познакомиться с алгоритмом Хаффмана.

Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Формула Хартли определяет количество информации в зависимости от количества возможных вариантов:
N=2i, где
N — это количество вариантов,
i — это количество бит, не обходимых для кодирования.
Если же мы преобразуем эту формулу и примем за N — количество символов в используемом алфавите (назовем это мощностью алфавита), то мы поймем, сколько памяти потребуется для кодирования одного символа.

N=2i, где N — кол-во возможных вариантов
i — кол-во бит, потребуемых для кодирования
Итак, если в нашем алфавите будет присутствовать только 32 символа, то каждый из них займет только 5 бит.

И тогда каждому символу мы дадим уникальный двоичный код. Такую таблицу мы будем назвать кодировочной.


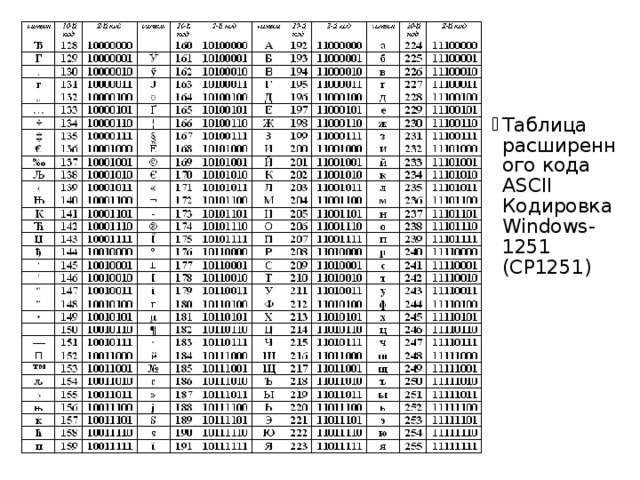
Первая широко используемая кодировочная таблица была создана в США и называлась ASCII, что в переводе означало American standard code for information interchange. Как вы видите, в таблице присутствуют не только латинские буквы, но и цифры, и даже действия. Каждому символу отводится 7 бит, а значит, всего было закодировано 128 символов.

Но так как этого количества было недостаточно, стали создаваться другие таблицы, в которых можно было закодировать и другие символы. Например, таблица Windows-1251, которая, по сути, являлась изменением таблицы ASCII, в которую добавили буквы кириллицы. Таких таблиц было создано множество: MS-DOS, КОИ-8, ISO, Mac и другие:

Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:

Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков. На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст. Поэтому существуют различные алгоритмы неравномерной кодировки текста, например, алгоритм Хаффмана.

АЛГОРИТМ ХАФФМАНА
Идея алгоритма Хаффмана основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
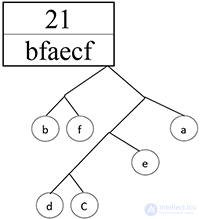
Пусть нам дано сообщение aaabcbeeffaabfffedbac.
Чтобы узнать наиболее выгодный префиксный код для такого сообщения, надо узнать частоту появления каждого символа в сообщении.
Шаг 1.
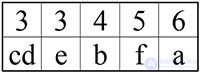
Подсчитайте и внесите в таблицу частоту появления каждого символа в сообщении:

У вас должно получиться:

Шаг 2.
Расположите буквы в порядке возрастания их частоты.

Шаг 3.
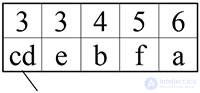
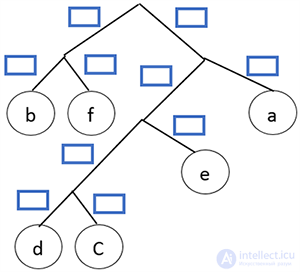
Теперь возьмем два символа с наименьшей чистотой и представим их листьями в дереве, частота которого будет равна сумме частот этих листьев.
Символы d и c превращаются в ветку дерева:

Шаг 4.
Проделываем эти шаги до тех пор, пока не получится дерево, содержащее все символы.
Итак, сортируем таблицу:

Шаг 5.
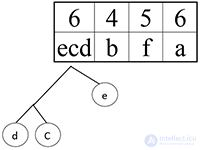
Объединяем символ e и символ cd в ветку дерева:
d
C

Шаг 6.
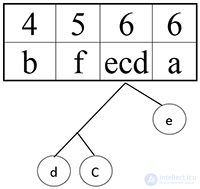
Сортируем:

Шаг 7.

Шаг 8.
Сортируем:

Шаг 9.

Шаг 10.
Сортируем:

Шаг 11.

Шаг 12.
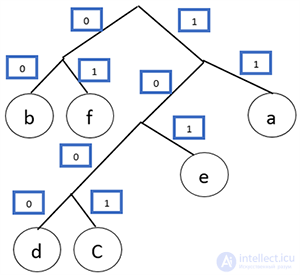
Получился префиксный код. Теперь осталось расставить 1 и 0. Пусть каждая правая ветвь обозначает 1, а левая — 0.

Шаг 13.
Составляем код буквы, идя по ветке дерева от буквы к основанию дерева.
Тогда код для каждой буквы будет:


Задание №1
Закодируйте ASCII кодом слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
|
M |
O |
S |
C |
O |
W |
|
1001101 |
1001111 |
1010011 |
1000011 |
1001111 |
1110111 |
ОТВЕТ: 100110110011111010011100001110011111110111
Задание №2
Используя табличный код Windows1251, закодируйте слово КОМПЬЮТЕР.
Решение:
|
К |
О |
М |
П |
Ь |
Ю |
Т |
Е |
Р |
|
234 |
206 |
204 |
239 |
252 |
254 |
242 |
197 |
208 |
Ответ: 234206204239252254242197208
Задание №3
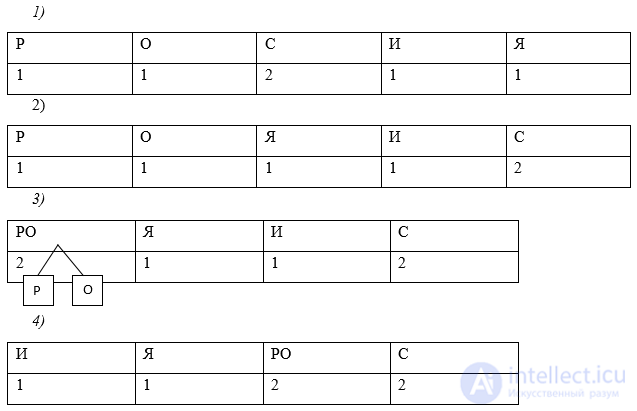
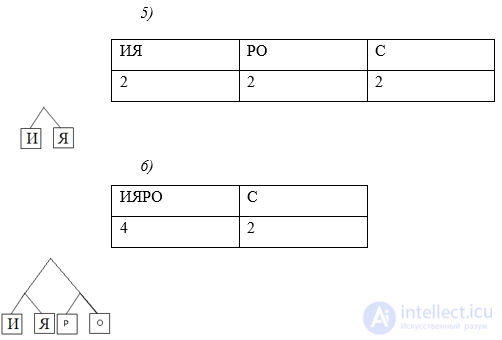
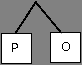
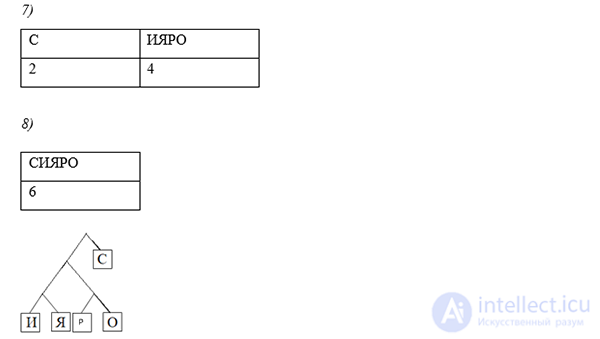
Используя алгоритма Хаффмана, закодируйте сообщение: Россия
Решение:





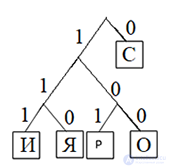
Давайте все левые ветви обозначим «1», а правые – «0»

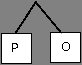
Таким образом: С — 0, Р — 101, О — 100, И — 111, Я — 110
ОТВЕТ: 10110000111110
Сразу хочу сказать, что здесь никакой воды про кодирование текстовой информации, и только нужная информация. Для того чтобы лучше понимать что такое
кодирование текстовой информации, алгоритм хаффмана , настоятельно рекомендую прочитать все из категории Информатика.
Текстовую информацию кодируют двоичным кодом через обозначение каждого символа алфавита определенным целым числом. С помощью восьми двоичных разрядов возможно закодировать 256 различных символов. Данного количества символов достаточно для выражения всех символов английского и русского алфавитов.
В первые годы развития компьютерной техники трудности кодирования текстовой информации были вызваны отсутствием необходимых стандартов кодирования. В настоящее время, напротив, существующие трудности связаны с множеством одновременно действующих и зачастую противоречивых стандартов.
Для английского языка, который является неофициальным международным средством общения, эти трудности были решены. Институт стандартизации США выработал и ввел в обращение систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США).
Для кодировки русского алфавита были разработаны несколько вариантов кодировок:
1) Windows-1251 – введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение;
2) КОИ-8 (Код Обмена Информацией, восьмизначный) – другая популярная кодировка российского алфавита, распространенная в компьютерных сетях на территории Российской Федерации и в российском секторе Интернет;
3) ISO (International Standard Organization – Международный институт стандартизации) – международный стандарт кодирования символов русского языка. На практике эта кодировка используется редко.
Ограниченный набор кодов (256) создает трудности для разработчиков единой системы кодирования текстовой информации. Вследствие этого было предложено кодировать символы не 8-разрядными двоичными числами, а числами с большим разрядом, что вызвало расширение диапазона возможных значений кодов. Система 16-разрядного кодирования символов называетсяуниверсальной – UNICODE. Шестнадцать разрядов позволяет обеспечить уникальные коды для 65 536 символов, что вполне достаточно для размещения в одной таблице символов большинства языков.
Несмотря на простоту предложенного подхода, практический переход на данную систему кодировки очень долго не мог осуществиться из-за недостатков ресурсов средств вычислительной техники, так как в системе кодирования UNICODE все текстовые документы становятся автоматически вдвое больше. В конце 1990-х гг. технические средства достигли необходимого уровня, начался постепенный перевод документов и программных средств на систему кодирования UNICODE.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вспомним некоторые известные нам факты:
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
1 байт = 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
 |
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду. |
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е . Об этом говорит сайт https://intellect.icu . символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер |
Код |
Символ |
0 — 31 |
00000000 — 00011111 |
Символы с номерами от 0 до 31 принято называть управляющими. |
32 — 127 |
00100000 — 01111111 |
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. |
128 — 255 |
10000000 — 11111111 |
Альтернативная часть таблицы (русская). |
Первая половина таблицы кодов ASCII
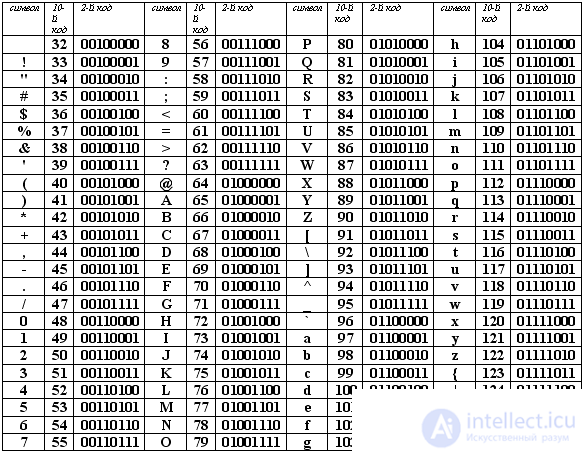 |
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII
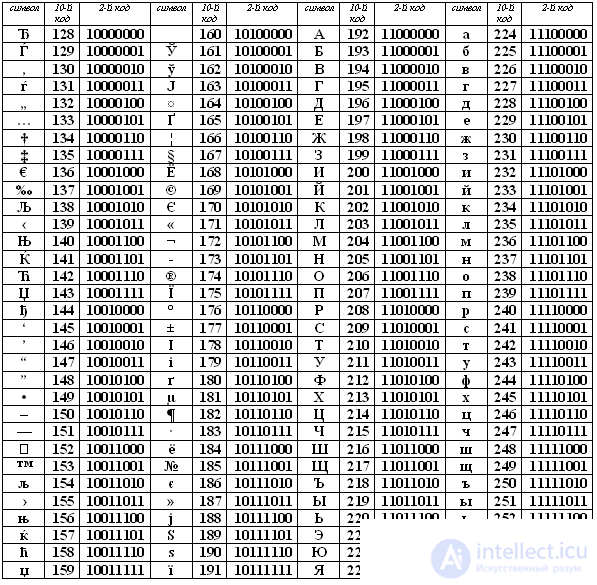
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.
Внутреннее представление слов в памяти компьютера
Слова |
Память |
file |
01100110011010010110110001100101 |
disk |
01100100011010010111001101101011 |
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать — на экране монитора видна какая-то «абракадабра». Это происходит оттого, что на компьютерах применяется разная кодировка кирилистических символов .
Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:
Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков. На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст. Поэтому существуют различные алгоритмы неравномерной кодировки текста, например,
алгоритм хаффмана .
АЛГОРИТМ ХАФФМАНА
Идея алгоритма Хаффмана основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
Пусть нам дано сообщение aaabcbeeffaabfffedbac.
Чтобы узнать наиболее выгодный префиксный код для такого сообщения, надо узнать частоту появления каждого символа в сообщении.
Шаг 1.
Подсчитайте и внесите в таблицу частоту появления каждого символа в сообщении:
У вас должно получиться:
Шаг 2.
Расположите буквы в порядке возрастания их частоты.
Шаг 3.
Теперь возьмем два символа с наименьшей чистотой и представим их листьями в дереве, частота которого будет равна сумме частот этих листьев.
Символы d и c превращаются в ветку дерева:
Шаг 4.
Проделываем эти шаги до тех пор, пока не получится дерево, содержащее все символы.
Итак, сортируем таблицу:
Шаг 5.
Объединяем символ e и символ cd в ветку дерева:
d
C
Шаг 6.
Сортируем:
Шаг 7.
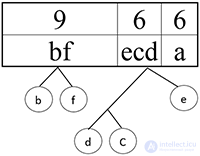
Шаг 8.
Сортируем:
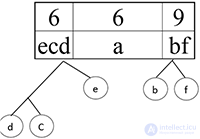
Шаг 9.
Шаг 10.
Сортируем:
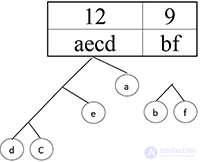
Шаг 11.
Шаг 12.
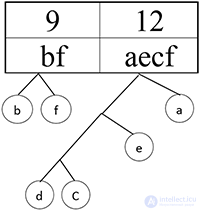
Получился префиксный код. Теперь осталось расставить 1 и 0. Пусть каждая правая ветвь обозначает 1, а левая — 0.
Шаг 13.
Составляем код буквы, идя по ветке дерева от буквы к основанию дерева.
Тогда код для каждой буквы будет:
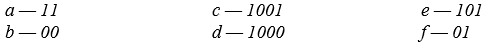
Задание №1
Закодируйте ASCII кодом слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
|
M |
O |
S |
C |
O |
W |
|
1001101 |
1001111 |
1010011 |
1000011 |
1001111 |
1110111 |
ОТВЕТ: 100110110011111010011100001110011111110111
Задание №2
Используя табличный код Windows1251, закодируйте слово КОМПЬЮТЕР.
Решение:
|
К |
О |
М |
П |
Ь |
Ю |
Т |
Е |
Р |
|
234 |
206 |
204 |
239 |
252 |
254 |
242 |
197 |
208 |
Ответ: 234206204239252254242197208
Задание №3
Используя алгоритма Хаффмана, закодируйте сообщение: Россия
Решение:
Давайте все левые ветви обозначим «1», а правые – «0»
Таким образом: С — 0, Р — 101, О — 100, И — 111, Я — 110
ОТВЕТ: 10110000111110
Статью про кодирование текстовой информации я написал специально для тебя. Если ты хотел бы внести свой вклад в развии теории и практики,
ты можешь написать коммент или статью отправив на мою почту в разделе контакты.
Этим ты поможешь другим читателям, ведь ты хочешь это сделать? Надеюсь, что теперь ты понял что такое кодирование текстовой информации, алгоритм хаффмана
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Информатика
Информатика, 10 класс. Урок № 14.
- Тема — Кодирование текстовой информации
- Цели и задачи урока:
- — познакомиться со способами кодирования и декодирования текстовой информации с помощью кодовых таблиц и компьютера;
- — познакомиться со способом определения информационного объема текстового сообщения;
- — познакомиться с алгоритмом Хаффмана.
Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
- Формула Хартли определяет количество информации в зависимости от количества возможных вариантов:
- N=2i, где
- N — это количество вариантов,
- i — это количество бит, не обходимых для кодирования.
- Если же мы преобразуем эту формулу и примем за N — количество символов в используемом алфавите (назовем это мощностью алфавита), то мы поймем, сколько памяти потребуется для кодирования одного символа.
- N=2i, где N — кол-во возможных вариантов
- i — кол-во бит, потребуемых для кодирования
- Итак, если в нашем алфавите будет присутствовать только 32 символа, то каждый из них займет только 5 бит.
![]()
И тогда каждому символу мы дадим уникальный двоичный код. Такую таблицу мы будем назвать кодировочной.
![]()
Первая широко используемая кодировочная таблица была создана в США и называлась ASCII, что в переводе означало American standard code for information interchange. Как вы видите, в таблице присутствуют не только латинские буквы, но и цифры, и даже действия. Каждому символу отводится 7 бит, а значит, всего было закодировано 128 символов.

Но так как этого количества было недостаточно, стали создаваться другие таблицы, в которых можно было закодировать и другие символы. Например, таблица Windows-1251, которая, по сути, являлась изменением таблицы ASCII, в которую добавили буквы кириллицы. Таких таблиц было создано множество: MS-DOS, КОИ-8, ISO, Mac и другие:
Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:

Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков.
На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст.
Поэтому существуют различные алгоритмы неравномерной кодировки текста, например, алгоритм Хаффмана.

АЛГОРИТМ ХАФФМАНА
Идея алгоритма Хаффмана основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
- Пусть нам дано сообщение aaabcbeeffaabfffedbac.
- Чтобы узнать наиболее выгодный префиксный код для такого сообщения, надо узнать частоту появления каждого символа в сообщении.
- Шаг 1.
- Подсчитайте и внесите в таблицу частоту появления каждого символа в сообщении:
- У вас должно получиться:
- Шаг 2.
- Расположите буквы в порядке возрастания их частоты.
- Шаг 3.
- Теперь возьмем два символа с наименьшей чистотой и представим их листьями в дереве, частота которого будет равна сумме частот этих листьев.
- Символы d и c превращаются в ветку дерева:
- Шаг 4.
- Проделываем эти шаги до тех пор, пока не получится дерево, содержащее все символы.
- Итак, сортируем таблицу:
- Шаг 5.
- Объединяем символ e и символ cd в ветку дерева:
- d
- C
- Шаг 6.
- Сортируем:
- Шаг 7.
- Шаг 8.
- Сортируем:
- Шаг 9.
- Шаг 10.
- Сортируем:
- Шаг 11.
- Шаг 12.
Получился префиксный код. Теперь осталось расставить 1 и 0. Пусть каждая правая ветвь обозначает 1, а левая — 0.
- Шаг 13.
- Составляем код буквы, идя по ветке дерева от буквы к основанию дерева.
- Тогда код для каждой буквы будет:
- Задание №1
- Закодируйте ASCII кодом слово MOSCOW.
- Решение:
- Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
| M | O | S | C | O | W |
| 1001101 | 1001111 | 1010011 | 1000011 | 1001111 | 1110111 |
- ОТВЕТ: 100110110011111010011100001110011111110111
- Задание №2
- Используя табличный код Windows1251, закодируйте слово КОМПЬЮТЕР.
- Решение:
| К | О | М | П | Ь | Ю | Т | Е | Р |
| 234 | 206 | 204 | 239 | 252 | 254 | 242 | 197 | 208 |
- Ответ: 234206204239252254242197208
- Задание №3
- Используя алгоритма Хаффмана, закодируйте сообщение: Россия
- Решение:
- Давайте все левые ветви обозначим «1», а правые – «0»
- Таким образом: С — 0, Р — 101, О — 100, И — 111, Я — 110
- ОТВЕТ: 10110000111110
Источник: https://resh.edu.ru/subject/lesson/5225/conspect/
Урок 17§14. Кодирование текстовой информации
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 10 классы | Планирование уроков на учебный год (ФГОС) | Кодирование текстовой информации
![]()
| 14.1. Кодировка ASCII и её расширения | ||
| Кодирование текстовой информации | 14.2. Стандарт Unicode |
![]()
14.1. Кодировка ASCII и её расширения
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.).
Этот код 7-битовый: общее количество символов составляет 27 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы.
Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII

Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов.
При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п.
Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер.
Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10).
В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251

Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах.
Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов.
Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Cкачать материалы урока
Источник: https://xn—-7sbbfb7a7aej.xn--p1ai/informatika_10_fgos/informatika_materialy_zanytii_10_17_fgos_02.html
Кодирование текстовой информации

Кодирование текстовой информации
Если у вас имеются какие-либо непонимания с такой темой, как «Кодирование текстовой информации», то записывайтесь ко мне на индивидуальный урок по информатике. На репетиторском уроке мы с вами детально разберем абсолютно все возникшие у вас вопросы и прорешаем колоссальное количество тематических упражнений.
Общие сведения о текстовой информации
На текущий момент времени большая часть всей информации, находящейся в сети Интернет, представлена в виде текста на различных национальных языках. Персональные компьютеры еще со времен 60-х годов научились правильно распознавать, обрабатывать, хранить и передавать текстовую информацию.
Сложно себе представить современный и актуальный вебсайт, который не содержит ни одного символа. Ежедневно глобальная паутина пополняется десятками миллионов текстовых публикаций различного объема.
Все поисковые системы в основном «заточены» на релевантный поиск веб-страниц в соответствии с текстовым запросом пользователей.
Не стоит забывать о том, что процессор любого компьютера, любой марки, любого бренда способен обрабатывать информацию, выраженную комбинацией только из 0 и 1. Следовательно, текстовая информация также должна быть преобразована в двоичный набор кодов. Значит, существует некий алгоритм, позволяющий кодировать текстовую информацию в вид, понятный процессору компьютера.
Свойства текстовой информации
Давайте выделим ключевые свойства, которыми должны обладать текстовые материалы:
- Ценность
- Новизна
- Полезность
- Адекватность
- Истинность
Что можно понимать под ценностью текстовой информации? Ценность информации – пожалуй, одно из основных свойств любой информации. Если информация для пользователя не является ценной, аксиологически значимой, то она для него не является информативной. Разные читали по-разному воспринимают ценность информации.
Для одного – новая, самая свежая информация, для другого – полная, детально разобранная информация о каком-либо объекте или событии. Лично для меня ценна та текстовая информация, которая написана понятным мне языком и глубоко освещает проблематику, на которую она ориентирована. Думаю, что всем знаком такой ресурс, как Википедия.
На мой взгляд, авторы данного популярнейшего ресурса очень структурированно и полно описывают события в текстовых публикациях.
Что можно понимать под новизной информации? Думаю, здесь всем понятно, что означает данное свойство из самого названия.
Любой текстовый материал должен содержать в своем контексте какую-то новизну, описание проблемы, которую раньше никто еще пристально не рассматривал.
Как правило, новая текстовая информация является актуальной, но далеко не факт, что она является полной или достоверной, истинной.
Что можно понимать под полезностью информации? Свойство полезности и ценности очень сильно коррелируют между собой. Как правило ценная текстовая информация одновременно является и полезной. Для меня полезной является та информация, которая помогает решить спонтанно возникшую у меня проблему.
Данная информация может быть неновой, неполной, недостоверной и даже неактуальной. Например, если вам требуется написать реферат на тему «Что такое текстовая информация?», и вы, прочитав данный материал, какие-то мысли позаимствовали отсюда, это означает, что данная статья для вас является полезной.
Хотя с другой стороны, это информация не новая и давно хорошо изученная различными экспертами.
Что можно понимать под адекватностью информацию? Под адекватностью следует понимать то, насколько текстовое описание объекта или события соответствует в реальности описываемому объекту или событию.
Если, например, в какой-либо статье говорится про задачи по программированию, а в решении приводятся стереометрические математические построения, то данная информация не является адекватной, так как упражнения по программированию в первую очередь связаны с написание программного кода. Информация в такой статье не будет являться адекватной.
Что можно понимать под истинностью информации? Под истинностью текстовой информации следует понимать то, насколько описываемые характеристики какого-либо объекта соответствуют его реальным характеристикам.
Например, если мы будем утверждать следующее: для того, чтобы получить на экзамене ГИА или ЕГЭ по информатике 100 баллов, нам не нужно уметь программировать. Данная информация не является истинной. И не умея программировать, не удастся решить все упражнения на экзамене.
С другой стороны, нельзя эту информацию считать неадекватной, но, не зная ни одного языка программирования, какое-то количество баллов все-таки можно получить. Или еще пример, если мы скажем, что текущий президент Российской Федерации Борис Николаевич Ельцин, это тоже ложная информация.
Да, он был когда-то президентом, но в данный момент таковым не является. Это уже неактуальная информация, она устарела.
В данном примере наш тезис про президента является:
- Не ценным, так как информация устаревшая и недостоверная.
- Новым для нас, так как раньше нам об этом никто не писал.
- Не полезным, так как никакого профита мы не получили, прочитав данное утверждение.
- Адекватным, так как Ельцин Б.Н. когда-то был президентом.
- Ложным, так как в настоящий момент времени президентом РФ является другой человек.
Что такое кодировочная таблица
Для кодирования текстовой информации в двоичные коды, понятные процессору персонального компьютера, необходимо прибегать к специальным кодировочным таблицам.
Давайте представим, что мы напечатали какое-то предложение в текстовом редакторе, например, «Подготовка к ГИА и ЕГЭ» и решили сохранить документ на жесткий диск нашего ПК. Информация любого формата перед тем, как записаться на жесткий диск проходит этап кодирования.
В результате наше предложение «Подготовка к ГИА и ЕГЭ» после кодирования преобразуется в двоичный набор, состоящий из цепочек 0 и 1. Но каков алгоритм этого кодирования? Все очень просто!
Существует специальная таблица, в которой представлены абсолютно все символы компьютерного алфавита, и каждому такому символу соответствует некий, строго заданный двоичный код. Для разных типов электронно-вычислительных машин применяются различные кодировки.
Самой распространенной кодировочной таблицей в начале 2000-го года являлась таблица кодировки ASCII. ASCII – American Standard Code for Information Interchange, или американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов.
Первая половина этой таблицы (это 128 двоичных кодов) является стандартной, так как в нее входит буквы латинского алфавита, цифры, знаки препинания, скобки, а также так называемые непечатаемые символы.
Вторая половина (это 128 двоичных кодов), как правило, содержит символы национального алфавита.
Кстати, в настоящее время существует пять различных кодировочных таблиц для русских букв:
С одной стороны, кажется, что удобно иметь столько вариантов кодирования текстовой информации, записанной на русском языке, а с другой – имеется большая проблема с совместимостью и соответствию двоичных кодов в разных кодировочных таблицах.
Ассоциация символа и кода символа
Давайте более детально поговорим об анатомии кодировочных таблиц и непосредственно о самом алгоритме кодирования текстовой информации. В качестве примера возьмем на рассмотрение кодировочную таблицу ASCII.
Как мы раньше поняли, первая половина этой таблицы является строго стандартной и не содержит кодов ни одного русского символа. Рассмотрим вторую половину таблицы ASCII.
Сразу хочу заметить, что двоичных кодов для букв ‘ё’ и ‘Ё’ в таблице нет.
Вернемся к исследованию предложения «Подготовка к ГИА и ЕГЭ».
Как видно, данное предложение содержит достаточно много различных букв из русского алфавита, а также имеются повторяющиеся буквы, например, буквы ‘о’, ‘а’, ‘к’, ‘Г’ и др.
Сразу небольшая оговорка: одна и та же малая и большая буквы имеют различный двоичный код в таблице ASCII, то есть буквы ‘а’ и ‘А’ будут кодироваться различным набором из 0 и 1.
Для простоты можете представить себе таблицу ASCII как таблицу, состоящую из двух колонок: в первой колонке указывается физический символ, а во второй колонке указывается двоичный код, соответствующий символу из первой колонки. Я лишь приведу небольшой фрагмент второй половины таблицы ASCII:
| Символ русского алфавита | Двоичный код символа |
| ‘А’ | 11000000 |
| ‘Б’ | 11000001 |
| ‘В’ | 11000010 |
| ‘Г’ | 11000011 |
| … | … |
| ‘Я’ | 11011111 |
| ‘а’ | 11100000 |
| … | … |
| ‘я’ | 11111111 |
Когда процессор ПК встречает в тексте символ ‘В’, он его заменяет на двоичный восьмиразрядный код 11000010, а если букву ‘а’, то на 111000.
Сходу возникает вопрос: а почему отводится восемь позиций на двоичный код символа при кодировании текстовой информации? Потому что для хранения одного символа будет задействован 1 байт информации или 8 бит. Таким образом устроена кодировочная таблица ASCII.
Отсюда вытекает умозаключение, что максимальное количество закодированных символов в таблице ASCII не может превышать 256, так как 28 = 256. Существует кодировочная таблица, называемая Unicode, вот она при кодировании текстовой информации преобразует символы в шестнадцатипозиционный двоичный код.
Это связано с тем, что для хранения одного символа задействуется 2 байта памяти или 16 бит информации. Следовательно, таблица Unicode может кодировать до 216 = 65536 различных символов.
Еще одной важной характеристикой кодировочных таблиц является то, что символы в ней упорядочены в соответствии с национальным алфавитом.
В русском алфавите за буквой ‘а’, следует буква ‘б’, затем буква ‘в’ и так далее.
Также можно заметить, что в строках кодировочных таблиц сначала следуют заглавные буквы национального алфавита, а затем строчные, а, следовательно, и соответствующие двоичные коды заглавных букв будут меньше соответствующих кодов строчных букв.
Давайте произведем кодирование текстовой информации, а конкретно предложения «Подготовка к ГИА и ЕГЭ». Для этого построим таблицу, в которой каждому символу русского алфавита сопоставим двоичный код из кодировочной таблицы ASCII. Разделители между словами, то есть знаки пробела, также закодируем.
| П | о | д | г | о | т | о | в | к | а |
| 11001111 | 11101110 | 11100100 | 11100011 | 11101110 | 11110010 | 11101110 | 11100010 | 11101010 | 11100000 |
| к | Г | И | А | и | Е | Г | Э | ||||
| 00100000 | 11101010 | 00100000 | 11000011 | 11001000 | 11000000 | 00100000 | 11101000 | 00100000 | 11000101 | 11000011 | 11011101 |
- То есть перед тем, как записать текстовое предложение «Подготовка к ГИА и ЕГЭ» на жесткий диск, компьютер произведет кодирование текстовой информации и получит следующий бинарный код:
- 11001111111011101110010011100011111011101111001011101110111000101110101011100000001000001110101000100000110000111100100011000000001000001110100000100000110001011100001111011101
- А вот подобные цепочки, наборы из 0 и 1 прекрасно распознаются процессором и он максимально оперативно произведет всю необходимую обработку над ними.
Если у вас остались какие-либо вопросы, связанные с кодирование текстовой информации, то записывайтесь ко мне на индивидуальный урок. На моих уроках мы с вами еще более детально погрузимся в область кодирования текстовой информации и рассмотрим внушительное количество ценных, полезных и актуальных примеров.
Источник: http://www.videoege.ru/informatika/kodirovanie-tekstovoy-informacii
Кодирование информации 3 (стр. 1 из 2)
Сожержание
I. История кодирования информации………………………………..3
II. Кодирование информации…………………………………………4
III. Кодирование текстовой информации…………………………….4
IV. Виды таблиц кодировок……………………………………………6
V. Расчет количества текстовой информации………………………14
Список используемой литературы…………………………………..16
- I. История кодирования информации
- Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были изобретены на различных этапах развития человеческой мысли:
- — криптография – это тайнопись, система изменения письма с целью сделать текст непонятным для непосвященных лиц;
— азбука Морзе или неравномерный телеграфный код, в котором каждая буква или знак представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);
—
сурдожесты – язык жестов, используемый людьми с нарушениями слуха.
Один из самых первых известных методов шифрования носит имя римского императора Юлия Цезаря (I век до н.э.) .
Этот метод основан на замене каждой буквы шифруемого текста, на другую, путем смещения в алфавите от исходной буквы на фиксированное количество символов, причем алфавит читается по кругу, то есть после буквы я рассматривается а.
Так слово «байт» при смещении на два символа вправо кодируется словом «гвлф». Обратный процесс расшифровки данного слова – необходимо заменять каждую зашифрованную букву, на вторую слева от неё.
II. Кодирование информации
Код – это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
- Обычно каждый образ при кодировании (иногда говорят – шифровке) представлении отдельным знаком.
- Знак — это элемент конечного множества отличных друг от друга элементов.
- В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
На компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей).
Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми.
Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
III. Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом.
Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества — письменность и арифметика — есть не что иное, как система кодирования речи и числовой информации.
Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации.
Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1).
Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц — машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы — это возможные события): К = 2I = 28 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
- IV. Виды таблиц кодировок
- Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
- Для разных типов ЭВМ используются различные таблицы кодировки.
- В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange — Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
- Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Первая половина таблицы кодов ASCII
Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Источник: https://mirznanii.com/a/310544/kodirovanie-informatsii-3
Кодирование текстовой информации
Аппаратное (оптическое) разрешение
Аппаратное (оптическое) разрешение (Hardware/optical Resolution) непосредственно связано с плотностью размещения светочувствительных элементов в матрице сканера. Это — основной параметр сканера (точнее, его оптико-электронной системы). Обычно указывается разрешение по горизонтали и вертикали, например, 300×600 ppi.
Следует ориентироваться на меньшую величину, т. е. на горизонтальное разрешение.
Вертикальное разрешение, которое обычно вдвое больше горизонтального, получается в конечном счете интерполяцией (обработкой результатов непосредственного сканирования) и напрямую не связано с плотностью чувствительных элементов (это так называемое разрешение двойного шага).
Чтобы увеличить разрешение сканера, нужно уменьшить размер светочувствительного элемента. Но с уменьшением размера теряется чувствительность элемента к свету и, как следствие, ухудшается соотношение сигнал/шум. Таким образом, повышение разрешения — нетривиальная техническая задача.
Интерполяционное разрешение
Интерполяционное разрешение (Interpolated Resolution) — разрешение изображения, полученного в результате обработки (интерполяции) отсканированного оригинала. Этот искусственный прием повышения разрешения обычно не приводит к увеличению качества изображения.
Представьте себе, что реально отсканированные пикселы изображения раздвинуты, а в образовавшиеся промежутки вставлены «вычисленные» пикселы, похожие в каком-то смысле на своих соседей. Результат такой интерполяции зависит от ее алгоритма, но не от сканера.
Однако эту операцию можно выполнить средствами графического редактора, например, Photoshop, причем даже лучше, чем собственным программным обеспечением сканера.
Интерполяционное разрешение, как правило, в несколько раз больше аппаратного, но практически это ничего не означает, хотя может ввести в заблуждение покупателя. Значимым параметром является именно аппаратное (оптическое) разрешение.
В техническом паспорте сканера иногда указывается просто разрешение. В этом случае имеется в виду аппаратное (оптическое) разрешение. Нередко указываются и аппаратное, и интерполяционное разрешение, например, 600х 1200 (9600) ppi. Здесь 600 — аппаратное разрешение, а 9600 — интерполяционное.
Кодирование текстовой информации
Текстовую информацию кодируют двоичным кодом через обозначение каждого символа алфавита определенным целым числом. С помощью восьми двоичных разрядов возможно закодировать 256 различных символов. Данного количества символов достаточно для выражения всех символов английского и русского алфавитов.
- Традиционно для кодирования одного символа используется количество информации = 1 байту (1 байт = 8 битов).
- Для кодирования одного символа требуется один байт информации.
- Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (28 = 256)
- Кодирование заключается в том, что каждому символу ставится в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255).
Для английского языка, который является неофициальным международным средством общения, эти трудности были решены. Институт стандартизации США выработал и ввел в обращение систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США).
- Для кодировки русского алфавита были разработаны несколько вариантов кодировок:
- 1) Windows-1251 – введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение;
- 2) КОИ-8 (Код Обмена Информацией, восьмизначный) – другая популярная кодировка российского алфавита, распространенная в компьютерных сетях на территории Российской Федерации и в российском секторе Интернет;
3) ISO (International Standard Organization – Международный институт стандартизации) – международный стандарт кодирования символов русского языка. На практике эта кодировка используется редко.
В настоящее время существует 5 разных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO).
Ограниченный набор кодов (256) создает трудности для разработчиков единой системы кодирования текстовой информации.
Вследствие этого было предложено кодировать символы не 8-разрядными двоичными числами, а числами с большим разрядом, что вызвало расширение диапазона возможных значений кодов. Система 16-разрядного кодирования символов называется универсальной – UNICODE.
Шестнадцать разрядов позволяет обеспечить уникальные коды для 65 536 символов, что вполне достаточно для размещения в одной таблице символов большинства языков.
Несмотря на простоту предложенного подхода, практический переход на данную систему кодировки очень долго не мог осуществиться из-за недостатков ресурсов средств вычислительной техники, так как в системе кодирования UNICODE все текстовые документы становятся автоматически вдвое больше. В конце 1990-х гг. технические средства достигли необходимого уровня, начался постепенный перевод документов и программных средств на систему кодирования UNICODE.
Вся информация, которую обрабатывает компьютер должна быть представлена двоичным кодом с помощью двух цифр 0 и 1. Эти два символа принято называть двоичными цифрами или битами. С помощью двух цифр 0 и 1 можно закодировать любое сообщение. Это явилось причиной того, что в компьютере обязательно должно быть организованно два важных процесса: кодирование и декодирование.
Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код.
- Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.
- С точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось намного более простым, чем применение других способов. Действительно, удобно кодировать информацию в виде последовательности нулей и единиц, если представить эти значения как два возможных устойчивых состояния электронного элемента:
- 0 – отсутствие электрического сигнала;
- 1 – наличие электрического сигнала.
Эти состояния легко различать. Недостаток двоичного кодирования – длинные коды. Но в технике легче иметь дело с большим количеством простых элементов, чем с небольшим числом сложных.
Вам приходится постоянно сталкиваться с устройством, которое может находится только в двух устойчивых состояниях: включено/выключено. Конечно же, это хорошо знакомый всем выключатель.
А вот придумать выключатель, который мог бы устойчиво и быстро переключаться в любое из 10 состояний, оказалось невозможным. В результате после ряда неудачных попыток разработчики пришли к выводу о невозможности построения компьютера на основе десятичной системы счисления.
И в основу представления чисел в компьютере была положена именно двоичная система счисления.
- Способы кодирования и декодирования информации в компьютере, в первую очередь, зависит от вида информации, а именно, что должно кодироваться: числа, текст, графические изображения или звук.
- 34. Аппаратные средства получения информационной модели изображения объекта
- Эволюция аппаратных средств получения информационной модели изображения объекта
- Пантелеграф Казелли
Системы для сканирования изображения являются неотъемлемой частью таких устройств, как фототелеграф, телефакс, телекамера. Они существуют уже более ста лет.
В 1856 году итальянский физик Казелли (Giovanni Caselli, 1815 — 1891) создал прибор для передачи изображений, названный пантелеграфом. В этом приборе игла сканировала изображение, нарисованное токопроводящими чернилами. Приемник действовал по аналогичному принципу.
Игла перемещалась по листу, покрытому крахмальным клеем с примесью йодистого калия. Когда через иголку проходил ток, крахмал окрашивался в синий цвет.
Похожий принцип действия прибора описан Александром Байном (Alexander Bain, 1811(10) — 1877) в 1840-х годах, но про пантелеграф точно известно, что он был воплощен в металле, например, в России работал на линии Москва — Петербург уже 1862 году.
С современной точки зрения это изобретение следует отнести к процессу фиксации электронного изображения на бумаге. Можно сказать, что 1856 год — это дата появления графического принтера с электрохимическим способом фиксации изображения.
Следует отметить, что здесь мы видим одновременно и фиксацию, и визуализацию изображения. В дальнейшем, в электронной фотографии, эти два процесса очень часто будут разделены. В частности, в телевидении способы визуализации будут изобретены существенно раньше, чем способы сохранения изображения.
- К современным аппаратным средствам получения первичной модели изображения объекта можно отнести оборудование, позволяющее перекодировать информацию об объекте в цифровую форму с помощью технологических процессов:
- Сканирование, цифровое фотографирование, создание изображения
- Сканирование
- Сканирование — процесс поэлементного считывания аналоговой информации с оригинала и/или запись оцифрованного изображения в электронном виде по заданной траектории.
- Сканирование — аналого-цифровое преобразование плоского изображения в цифровую растровую форму с помощью сканера.
Сканер (англ. scanner) — устройство, которое, анализируя какой-либо объект (обычно изображение, текст), создаёт цифровую копию изображения объекта. Процесс получения этой копии называется сканированием.
- Цифровое фотографирование
- Цифровая фотография — фотография, результатом которой является изображение в виде массива цифровых данных — файла, а в качестве светочувствительного материала применяется электронное устройство — матрица.
- Создание изображения
Графический планшет (дигитайзер, диджитайзер от англ. digitizer) — это устройство для ввода рисунков от руки непосредственно в компьютер. Состоит из пера и плоского планшета, чувствительного к нажатию или близости пера. Также может прилагаться специальная мышь.
- Основными областями применения являются:
- создание и редактирование изображений;
- мультипликация;
- оцифровывание географических карт для работы с географическими информационными системами;
- инженерное проектирование;
- научная визуализация.
- Графические планшеты применяются как для создания изображений на компьютере способом, максимально приближенным к тому, как создаются изображения на бумаге, так и для обычной работы с интерфейсами.
Статьи к прочтению:
Источник: http://csaa.ru/kodirovanie-tekstovoj-informacii/
Конспект урока по информатике на тему «Кодирование текстовой информации»
бюджетное профессиональное образовательное учреждение
Вологодской области «Череповецкий металлургический колледж
имени академика И.П. Бардина»
- Для всех специальностей
- КОНСПЕКТ
- урока
- по дисциплине «Информатика и ИКТ»
- Тема «Кодирование текстовой информации»
- Для студентов 1 курса
Составитель: Лебедева Т.В.,
- преподаватель колледжа
- Череповец, 2016
- Дисциплина: Информатика и ИКТ
- Курс: I
- Тема урока: «Кодирование текстовой информации»
- Познакомить обучающихся со способами кодирования текстовой информации в компьютере.
- Научить определять числовые коды символов, вводить символы с помощью числовых кодов.
- Рассмотреть примеры решения задач.
- Способствовать развитию познавательных интересов обучающихся.
- Воспитывать выдержку и терпение в работе, чувства товарищества и взаимопонимания.
Урок изучения нового материала.
- Общекультурная компетенция
- умение проводить анализ и структурирование информации;
- владеть навыками работы с текстовой информацией.
- Информационная компетенция
- анализ информации с целью выделения общих черт, закономерностей; знакомство с программным обеспечением;
- анализ предметной области, умение определять числовые коды символов, вводить символы с помощью числовых кодов.
-
Коммуникативная компетенция
- участие в общем обсуждении, умение аргументировать свою точку зрения, выслушивать собеседника.
-
Организационный момент в начале урока.
-
Основная часть.
-
Актуализация ранее изученного материала.
-
Изучение нового материала.
-
Закрепление изученного материала. Решение задач.
-
Практическая работа.
-
Домашнее задание.
-
Итог урока. Организационный момент в конце урока.
- Интерактивная доска, ПК, мультимедийная презентация, рабочие места (персональный компьютер), карточки с заданием.
- фронтальная, индивидуальная, парная формы обучения.
- проблемный метод, инструктаж, упражнения, практические задания, наглядный метод обучения.
- устный фронтальный опрос, письменный контроль, индивидуальный практический контроль, взаимоконтроль, самоконтроль.
- ХОД УРОКА
-
Организационный момент в начале урока.
- Сегодня на уроке мы начинаем изучать новую тему, в которой вы узнаете, каким образом представляются различные тексты в памяти компьютера, какие возможности предоставляют различные текстовые редакторы при редактировании и форматировании текстового документа. А тема урока следующая:
- «202 238 228 232 240 238 226 224 237 232 229 032 242 229 234 241 242 238
- 226 238 233 032 232 237 244 238 240 236 224 246 232 232».
Кто-нибудь догадался, что это за тема урока, на что это похоже? На самом деле тема нашего урока «Кодирование текстовой информации».
А почему именно так необычно выглядит тема нашего урока, может быть и слово «бит» представляется следующим образом – 225 232 242, а слово «текст» – 242 229 234 241 242.
Почему это именно так? Наша задача это сегодня выяснить, т.е. каким образом происходит кодирование текстовой информации в компьютере. Вы согласны выяснить, в чем тут проблема.
Если да, то в тетрадях запишем число и тему урока «Кодирование текстовой информации».
Цели урока (формулируют студенты).
План урока:
-
Вопросы для повторения
-
Изучение нового материала.
-
Двоичное кодирование текстовой информации.
-
Доклад студента «Кодовые таблицы в России»
-
Расчет количества текстовой информации.
-
-
Решение задач.
-
Практическая работа.
-
Домашнее задание.
-
Итог урока.
Ребята, сегодня вы сами будете себя оценивать. Я вам выдаю оценочные листы, где вы будете проставлять баллы. А в конце урока мы подведем итоги и вы поставите себе оценку.
Оценочный лист
Фамилия, имя: _____________________________________
- 2
- Решение задач
- задание 1.
- задание 2.
- задание 3.
- 3
- Работа в парах
- 4
- Практическая работа
- Рекомендации
- Результат: ____________
Источник: https://infourok.ru/konspekt-uroka-po-informatike-na-temu-kodirovanie-tekstovoy-informacii-1240620.html

Contents
- 1 используя табличный код Windows 1251 закодируй
- 2 %d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9 %d0%b4%d1%80%d1%83%d0%b3 1
- 2.1 Conclusion
- 2.1.1 Related image with используя табличный код windows 1251 закодируй
- 2.1.2 Related image with используя табличный код windows 1251 закодируй
- 2.1 Conclusion
Step into a world where your используя табличный код Windows 1251 закодируй passion takes center stage. We’re thrilled to have you here with us, ready to embark on a remarkable adventure of discovery and delight.

The One Edp 1882400 Dolce Gabbana
The One Edp 1882400 Dolce Gabbana

1 Fitness Men
1 Fitness Men

Main 2 D0 Bc D0 Be D1 80 D0 Be D0 B7 D0 B0
Main 2 D0 Bc D0 Be D1 80 D0 Be D0 B7 D0 B0
%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9 %d0%b4%d1%80%d1%83%d0%b3 1
%d0%bb%d1%83%d1%87%d1%88%d0%b8%d0%b9 %d0%b4%d1%80%d1%83%d0%b3 1
video uploaded from my mobile phone. Мда .с моим братом было и не такое. created with aximedia slide show creator. download this app: play.google store apps details?id=com.amem. massimo dutti Новая осенне зимняя коллекция 2023. Актуальные вещи сезона! ПОДПИСЫВАЙТЕСЬ на канал и не 00%3a15%20http%3a%2f%2fmagicsand.biz%2fdiet%2fmedvestink%2f%20%0d%0a%20%d0%92%20%d0%bf%d0%be Роза пытается разорвать отношения с парнем, потому что боится свадьбы и серьёзных отношений. Сериал Бруклин 9 9, Музыка: Максим Фадеев Слова: Ольга Серябкина directed by irma po dop: savva fadeev, alexey good, julian taran Эндокринолог с научным подходом Подписывайтесь, чтобы не пропустить другие полезные видео Записаться на
Conclusion
All things considered, there is no doubt that article delivers valuable insights concerning используя табличный код Windows 1251 закодируй. From start to finish, the writer presents a wealth of knowledge on the topic. Especially, the discussion of Z stands out as a highlight. Thank you for reading this post. If you need further information, please do not hesitate to reach out through social media. I am excited about your feedback. Moreover, below are some similar articles that you may find helpful:
Практическая работа «Кодирование текстовой информации»
Задание 1. Закодировать с помощью таблицы ASCII слова:
a. Excel;
b. Access;
c. Windows;
d. Информация.
Задание 2. Декодируйте следующие тексты, заданные десятичным кодом:
a. 192 235 227 238 240 232 242 236;
b. 193 235 238 234 45 241 245 229 236 224;
c. 115 111 102 116 119 97 114 101.
Задание 3. В текстовом редакторе Блокнот ввести с помощью числовых кодов последовательность символов в кодировках Windows и MS-DOS.
Ввод символов с помощью числовых кодов в текстовом редакторе Блокнот
а) Запустить стандартное приложение Блокнот командой [Программы-Стандартные-Блокнот].
б) С помощью дополнительной цифровой клавиатуры при нажатой клавише {Alt} ввести число 0224, отпустить клавишу {Alt}, в документе появится символ «а». Повторить процедуру для числовых кодов от 0225 до 0233, в документе появится последовательность из 12 символов «абвгдежзий» в кодировке Windows.
в) С помощью дополнительной цифровой клавиатуры при нажатой клавише {Alt} ввести число 224, в документе появится символ «р». Повторить процедуру для числовых кодов от 225 до 233, в документе появится последовательность из 12 символов «рстуфхцчшщ» в кодировке MS-DOS.
Упражнение.
- 143 174 162 239 167 160 171 160 32 174 225 165 173 236 32 175 165 225 226 224 235 169 32 228 160 224 226 227 170
- 136 32 162 165 164 165 224 170 168 32 225 32 170 224 160 225 170 160 172 168 32 162 167 239 171 160 46
- 144 160 173 168 172 32 227 226 224 174 172 44 32 175 224 174 229 174 164 239 32 175 174 32 175 160 224 170 227 44
- 138 168 225 226 236 239 32 175 174 167 174 171 174 226 174 169 32 174 161 162 165 171 160 46
- Задание 4. Кодирование и декодирование текстовой информации
а) Заполните таблицу в программе Microsoft Word:
Практическая работа №4 Представление и сжатие текстов
Работа 1.4. Представление текстов. Сжатие текстов
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодировочной таблицы ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
|
Буква в ANSI |
Буква в ASCII |
Буква в ANSI |
Буква в ASCII |
Буква в ANSI |
Буква в ASCII |
|
А |
К |
Х |
|||
|
Б |
Л |
Ц |
|||
|
В |
М |
Ч |
|||
|
Г |
Н |
Ш |
|||
|
Д |
О |
Щ |
|||
|
Е |
П |
Ъ |
|||
|
Ё |
Р |
Ы |
|||
|
Ж |
С |
Ь |
|||
|
З |
Т |
Э |
|||
|
И |
У |
Ю |
|||
|
Й |
Ф |
Я |
1. Используем готовый текстовый файл ANSI.txt..
2. Далее открывает Unreal Commander (Free Commander) и ищем в нём наш файл.
4. Затем нажимаем на режим просмотра F3. Там отобразится содержимое файла в изначальной кодировке (ANSI) и там же есть возможность, просмотреть это же содержимое в разных кодировках.
В нашем случае нужно найти значение кодировки ASCII (DOS).
5. Получаем результат:
Ответ: Таких символов нет. Вместо них на экране в режиме просмотра появляются символы псевдографики.
Задание 2
Закодировать текст с помощью кодировочной таблицы ASCII.
Happy Birthday to you!
Записать двоичное и шестиадцатеричное представления кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
в 16-ричной СС (используем кодовую таблицу в текстовом файле ASCII. docx)
docx)
48 61 70 70 79 20 42 69
72 74 68 64 61 79 20 74
6F 20 79 6F 75 21 21
в двоичной СС (4816=100 10002 где1000 — код цифру 8, а 100 — код цифры 4)
1001000 1100001 1110000 1110000 1111001 0100000 1000010 1101001
1110010 1110100 1101000 1100100 1100001 1111001 0100000 1110100
1101111 0100000 1111001 1101111 1110101 0100001 0100001
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Для раскодирования используем таблицу в файле «Коды символов ASCII.mht»
где Dec — десятизначный код
Ответ: Hello, my friend!
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101110 00100000 01010101 01101110 01101001 01110110 01100101 01110010 01110011 01101001 01110100 01111001
Переведем в 16-ричный код отделяя группу двоичных разрядов, справа налево, по 4 бита:
01010000=0101 0000=5016
Используя кодовую таблицу из файла Коды символов ASCII.mht по найденному Hex коду (50) определим первый символ латинского текста «P»
50 65 72 6E 20 55 6D 69 76
65 72 73 69 74 79
Ответ: Perm University
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Используем кодовую таблицу в файле «Таблица Windows-1251.mht»
Согласно этой таблицы русская заглавная буква «И» (в колонке Hex)
имеет 16-ричный код — C8
Ответ: C8 CD D4 CE D0 CC C0 D2 C8 C7 C0 D6 C8 DF
Задание 6
Во сколько раз увеличится объем памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode?
Для кодирования одного символа в кодировке KOI-8 используется 1 байт, а в кодировке UNICODE — 2 байта, следовательно, информационный объем страницы текста увеличится в 2 раза
Ответ: в 2 раза
Задание 7
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы будут автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).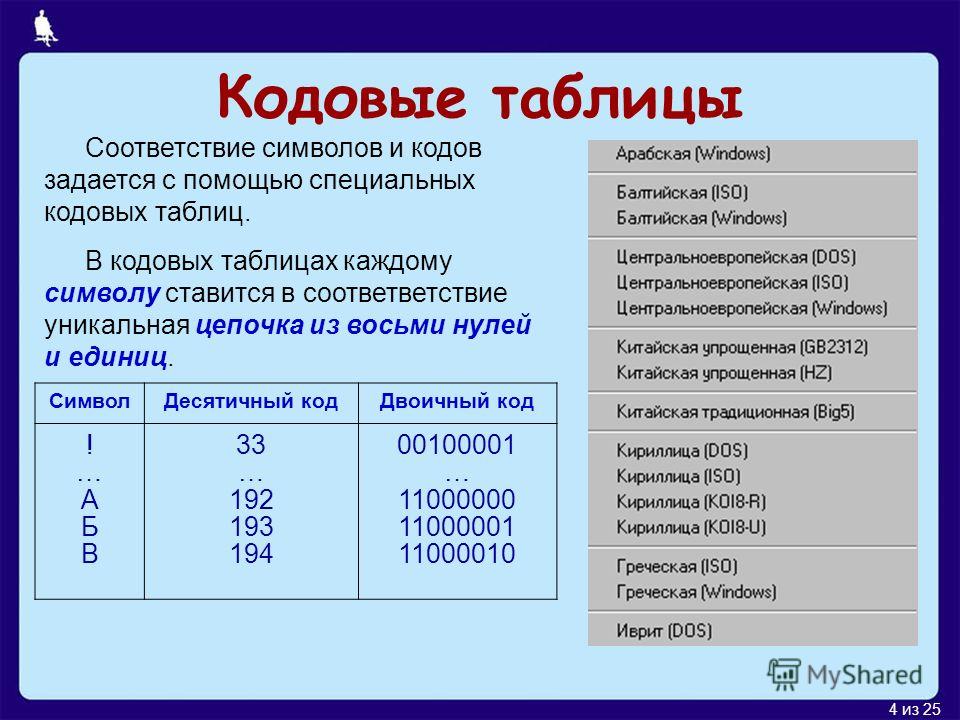
Введите ускоренным методом числа от 33 до 254 (по 25 в каждой строке через столбец:
А, С, E, … , Q)
В ячейку B1 введите формулу =СИМВОЛ(A1) и далее используя ускоренный метод, скопируйте ее в остальные ячейки столбцов: B, D, F,…, R.
Справка:
Алгоритм Хаффмана. Сжатием информации в памяти компьютера называют такое ее преобразование, которое ведет к сокращению объема занимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации — алгоритм Хаффмана. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьных кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведен пример такого дерева, построенного для алфавита английского языка с учетом частоты встречаемости его букв.
Закодируем с помощью данного дерева слово «hello»: 0101 100 01111 01111 1110
При размещении этого кода в памяти побитно он примет вид: 01011000 11110111 11110
Таким образом, текст, занимающий в кодировке ASCII 5 байтов, в кодировке Хаффмана займет только 3 байта.
Задание 8
Используя метод сжатия Хаффмана, закодируйте следующие слова:
а) administrator 1111 11011 00011 1010 1100 1010 0110 001 1011 1111 001 1110 1011
(11111101 10001110 10110010 10011000 11011111 10011110 1011)
б) revolution 1011 100 1101001 1110 01111 00010 001 1010 1110 1100
(10111001 10100111 10011110 00100011 01011101 100)
в) economy 100 01000 1110 1100 1110 00011 00000 (10001000 11101100 11100001 100000)
г) department 11011 100 110101 1111 1011 001 00011 100 1100 001
(11011100 11010111 11101100 10001110 01100001)
Задание 9
Используя дерево Хаффмана, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
(011100 1111 001 001 100 1011 01001 01111 00000) BATTERFLY
б) 00010110 01010110 10011001 01101101 01000100 000
(00010 1100 1010 1101001 100 1011 0110 1010 001 00000) UNIVERSITY
Представление текста, изображения и звука в компьютере (§ 6)
Планирование уроков на учебный год
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 10 классы | Планирование уроков на учебный год | Представление текста, изображения и звука в компьютере (§ 6)
В этом параграфе обсудим способы компьютерного кодирования текстовой, графической и звуковой информации. С текстовой и графической информацией конструкторы «научили» работать ЭВМ, начиная с третьего поколения (1970-е годы). А работу со звуком «освоили» лишь машины четвертого поколения, современные персональные компьютеры. С этого момента началось распространение технологии мультимедиа.
С текстовой и графической информацией конструкторы «научили» работать ЭВМ, начиная с третьего поколения (1970-е годы). А работу со звуком «освоили» лишь машины четвертого поколения, современные персональные компьютеры. С этого момента началось распространение технологии мультимедиа.
Что принципиально нового появлялось в устройстве компьютеров с освоением ими новых видов информации? Главным образом, это периферийные устройства для ввода и вывода текстов, графики, видео, звука. Процессор же и оперативная память по своим функциям изменились мало. Существенно возросло их быстродействие, объем памяти. Но как это было на первых поколениях ЭВМ, так и осталось на современных ПК — основным навыком процессора в обработке данных является умение выполнять вычисления с двоичными числами. Обработка текста, графики и звука представляет собой тоже обработку числовых данных. Если сказать еще точнее, то это
обработка целых чисел. По этой причине компьютерные технологии называют цифровыми технологиями.
О том, как текст, графика и звук сводятся к целым числам, будет рассказано дальше. Предварительно отметим, что здесь мы снова встретимся с главной формулой информатики:
2i = N.
Смысл входящих в нее величин здесь следующий: i — разрядность ячейки памяти (в битах), N — количество различных целых положительных чисел, которые можно записать в эту ячейку.
Текстовая информация
Принципиально важно, что текстовая информация уже дискретна — состоит из отдельных знаков. Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Напомним о байтовом принципе организации памяти компьютеров, обсуждавшемся в курсе информатики основной школы. Вернемся к рис. 1.5. Каждая клеточка на нем обозначает бит памяти. Восемь подряд расположенных битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера.
Именно по адресам процессор обращается к данным, читая или записывая их в память (рис. 1.10).
Модель представления текста в памяти весьма проста. За каждой буквой алфавита, цифрой, знаком препинания и иным общепринятым при записи текста символом закрепляется определенный двоичный код, длина которого фиксирована. В популярных системах кодировки (Windows-1251, KOI8 и др.) каждый символ заменяется на 8-разрядное целое положительное двоичное число; оно хранится в одном байте памяти. Это число является порядковым номером символа в кодовой таблице. Согласно главной формуле информатики, определяем, что размер алфавита, который можно закодировать, равен: 2
8 = 256. Этого количества вполне достаточно для размещения двух алфавитов естественных языков (английского и русского) и всех необходимых дополнительных символов.
Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды.
Например, если код символа занимает 2 байта, то с его помощью можно закодировать 216 = 65 536 различных символов.
При работе с электронной почтой почтовая программа иногда нас спрашивает, не хотим ли мы прибегнуть к кодировке Unicode для пересылаемых сообщений. Таким способом можно избежать проблемы несоответствия кодировок, из-за которой иногда не удается прочитать русский текст.
Текстовый документ, хранящийся в памяти компьютера, состоит не только из кодов символьного алфавита. В нем также содержатся коды, управляющие форматами текста при его отображении на мониторе или на печати: тип и размер шрифта, положение строк, поля и отступы и пр. Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Графическая информация
Из курса информатики 7 — 9 классов вы знакомы с общими принципами компьютерной графики, с графическими технологиями. Здесь мы немного подробнее, чем это делалось раньше, рассмотрим способы представления графических изображений в памяти компьютера.
Здесь мы немного подробнее, чем это делалось раньше, рассмотрим способы представления графических изображений в памяти компьютера.
Принцип дискретности компьютерных данных справедлив и для графики. Здесь можно говорить о дискретном представлении изображения (рисунка, фотографии, видеокадров) и дискретности цвета.
Дискретное представление изображения
Изображение на экране монитора дискретно. Оно составляется из отдельных точек, которые называются пикселями (picture elements — элементы рисунка). Это связано с техническими особенностями устройства экрана, независимо от его физической реализации, будь то монитор на электронно-лучевой трубке, жидкокристаллический или плазменный. Эти «точки» столь близки друг другу, что глаз не различает промежутков между ними, поэтому изображение воспринимается как непрерывное, сплошное. Если выводимое из компьютера изображение формируется на бумаге (принтером или плоттером), то линии на нем также выглядят непрерывными. Однако в основе все равно лежит печать близких друг к другу точек.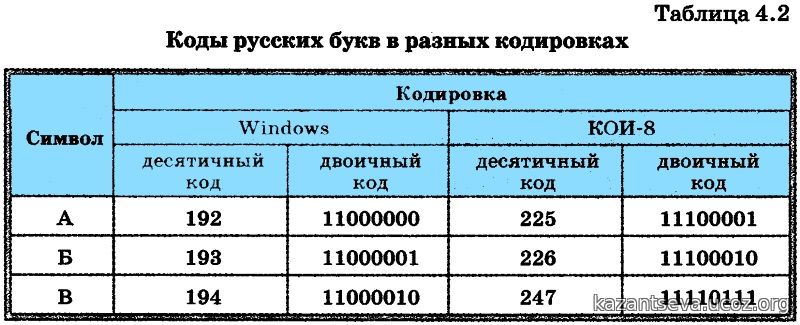
В зависимости от того, на какое графическое разрешение экрана настроена операционная система компьютера, на экране могут размещаться изображения, имеющие размер 800 х 600, 1024 х 768 и более пикселей. Такая прямоугольная матрица пикселей на экране компьютера называется растром.
Качество изображения зависит не только от размера растра, но и от размера экрана монитора, который обычно характеризуется длиной диагонали. Существует параметр разрешения экрана. Этот параметр измеряется в точках на дюйм (по-английски dots per inch — dpi). У монитора с диагональю 15 дюймов размер изображения на экране составляет примерно 28 х 21 см. Зная, что в одном дюйме 25,4 мм, можно рассчитать, что при работе монитора в режиме 800 х 600 пикселей разрешение экранного изображения равно 72 dpi.
При печати на бумаге разрешение должно быть намного выше. Полиграфическая печать полноцветного изображения требует разрешения 200-300 dpi. Стандартный фотоснимок размером 10 х 15 см должен содержать примерно 1000 х 1500 пикселей.
Дискретное представление цвета
Восстановим ваши знания о кодировании цвета, полученные из курса информатики основной школы. Основное правило звучит так: любой цвет точки на экране компьютера получается путем смешивания трех базовых цветов: красного, зеленого, синего. Этот принцип называется цветовой моделью RGB (Red, Green, Blue).
Двоичный код цвета определяет, в каком соотношении находятся интенсивности трех базовых цветов. Если все они смешиваются в одинаковых долях, то в итоге получается белый цвет. Если все три компоненты «выключены», то цвет пикселя — черный. Все остальные цвета лежат между белым и черным.
Дискретность цвета состоит в том, что интенсивности базовых цветов могут принимать конечное число дискретных значений.
Пусть, например, размер кода цвета пикселя равен 8 битам — 1 байту. Между базовыми цветами они могут быть распределены так:
2 бита — под красный цвет, 3 бита — под зеленый и 3 бита — под синий.
Интенсивность красного цвета может принимать 22 = 4 значения, интенсивности зеленого и синего цветов — по 23 = 8 значений. Полное число цветов, которые кодируются 8-разрядными кодами, равно: 4 — 8 — 8 = 256 = 28. Снова работает главная формула информатики.
Из описанного правила, в частности, следует:
Обобщение этих частных примеров приводит к следующему правилу. Если размер кода цвета равен b битов, то количество цветов (размер палитры) вычисляется по формуле:
К = 2b.
Величину b в компьютерной графике называют битовой глубиной цвета.
Еще один пример. Битовая глубина цвета равна 24. Размер палитры будет равен:
К = 224 = 16 777 216.
В компьютерной графике используются разные цветовые модели для изображения на экране, получаемого путем излучения света, и изображения на бумаге, формируемого с помощью отражения света.
Первую модель мы уже рассмотрели — это модель RGB. Вторая модель носит название CMYK.
Цвет, который мы видим на листе бумаги, — это отражение белого (солнечного) света. Нанесенная на бумагу краска поглощает часть палитры, составляющей белый цвет, а другую часть отражает. Таким образом, нужный цвет на бумаге получают путем «вычитания» из белого света «ненужных красок». Поэтому в цветной полиграфии действует не правило сложения цветов (как на экране компьютера), а правило вычитания. Мы не будем углубляться в механизм такого способа цветообразования.
Расшифруем лишь аббревиатуру CMYK: Cyan — голубой, Magenta — пурпурный, Yellow — желтый, blасk — черный.
Растровая и векторная графика
О двух технологиях компьютерной графики — растровой и векторной — вы знаете из курса информатики основной школы.
В растровой графике графическая информация — это совокупность данных о цвете каждого пикселя на экране. Это то, о чем говорилось выше. В векторной графике графическая информация — это данные, математически описывающие графические примитивы, составляющие рисунок: прямые, дуги, прямоугольники, овалы и пр. Положение и форма графических примитивов представляются в системе экранных координат.
В векторной графике графическая информация — это данные, математически описывающие графические примитивы, составляющие рисунок: прямые, дуги, прямоугольники, овалы и пр. Положение и форма графических примитивов представляются в системе экранных координат.
Растровую графику (редакторы растрового типа) применяют при разработке электронных (мультимедийных) и полиграфических изданий. Растровые иллюстрации редко создают вручную с помощью компьютерных программ. Чаще для этой цели используют сканированные иллюстрации, подготовленные художником на бумаге, или фотографии. Для ввода растровых изображений в компьютер применяются цифровые фото- и видеокамеры. Большинство графических редакторов растрового типа в большей мере ориентированы не на создание изображений, а на их обработку.
Достоинство растровой графики — эффективное представление изображений фотографического качества. Основной недостаток растрового способа представления изображения — большой объем занимаемой памяти. Для его сокращения приходится применять различные способы сжатия данных. Другой недостаток растровых изображений связан с искажением изображения при его масштабировании. Поскольку изображение состоит из фиксированного числа точек, увеличение изображения приводит к тому, что эти точки становятся крупнее. Увеличение размера точек растра визуально искажает иллюстрацию и делает ее грубой.
Для его сокращения приходится применять различные способы сжатия данных. Другой недостаток растровых изображений связан с искажением изображения при его масштабировании. Поскольку изображение состоит из фиксированного числа точек, увеличение изображения приводит к тому, что эти точки становятся крупнее. Увеличение размера точек растра визуально искажает иллюстрацию и делает ее грубой.
Векторные графические редакторы предназначены в первую очередь для создания иллюстраций и в меньшей степени для их обработки.
Достоинства векторной графики — сравнительно небольшой объем памяти, занимаемой векторными файлами, масштабирование изображения без потери качества. Однако средствами векторной графики проблематично получить высококачественное художественное изображение. Обычно средства векторной графики используют не для создания художественных композиций, а для оформительских, чертежных и проектно-конструкторских работ.
Графическая информация сохраняется в файлах на диске. Существуют разнообразные форматы графических файлов. Они делятся на растровые и векторные. Растровые графические файлы (форматы JPEG, BMP, TIFF и другие) хранят информацию о цвете каждого пикселя изображения на экране. В графических файлах векторного формата (например, WMF, CGM) содержатся описания графических примитивов, составляющих рисунок.
Существуют разнообразные форматы графических файлов. Они делятся на растровые и векторные. Растровые графические файлы (форматы JPEG, BMP, TIFF и другие) хранят информацию о цвете каждого пикселя изображения на экране. В графических файлах векторного формата (например, WMF, CGM) содержатся описания графических примитивов, составляющих рисунок.
Следует понимать, что графические данные, помещаемые в видеопамять и выводимые на экран, имеют растровый формат вне зависимости от того, с помощью каких программных средств (растровых или векторных) они получены.
Звуковая информация
Принципы дискретизации звука («оцифровки» звука) отражены на рис. 1.11.
Ввод звука в компьютер производится с помощью звукового устройства (микрофона, радио и др.), выход которого подключается к порту звуковой карты. Задача звуковой карты — с определенной частотой производить измерения уровня звукового сигнала (преобразованного в электрические колебания) и результаты измерения записывать в память компьютера. Этот процесс называют оцифровкой звука.
Этот процесс называют оцифровкой звука.
Промежуток времени между двумя измерениями называется периодом измерений — τ с. Обратная величина называется частотой дискретизации — 1/τ (герц). Чем выше частота измерений, тем выше качество цифрового звука.
Результаты таких измерений представляются целыми положительными числами с конечным количеством разрядов. Вы уже знаете, что в таком случае получается дискретное конечное множество значений в ограниченном диапазоне. Размер этого диапазона зависит от разрядности ячейки — регистра памяти звуковой карты. Снова работает формула 2i, где i — разрядность регистра. Число i называют также разрядностью дискретизации. Записанные данные сохраняются в файлах специальных звуковых форматов.
Существуют программы обработки звука — редакторы звука, позволяющие создавать различные музыкальные эффекты, очищать звук от шумов, согласовывать с изображениями для создания мультимедийных продуктов и т. д. С помощью специальных устройств, генерирующих звук, звуковые файлы могут преобразовываться в звуковые волны, воспринимаемые слухом человека.
д. С помощью специальных устройств, генерирующих звук, звуковые файлы могут преобразовываться в звуковые волны, воспринимаемые слухом человека.
При хранении оцифрованного звука приходится решать проблему уменьшения объема звуковых файлов. Для этого кроме кодирования данных без потерь, позволяющего осуществлять стопроцентное восстановление данных из сжатого потока, используется кодирование данных с потерями. Цель такого кодирования — добиться схожести звучания восстановленного сигнала с оригиналом при максимальном сжатии данных. Это достигается путем использования различных алгоритмов, сжимающих оригинальный сигнал путем выкидывания из него слабослышимых элементов. Методов сжатия, а также программ, реализующих эти методы, существует много.
Для сохранения звука без потерь используется универсальный звуковой формат файлов WAV. Наиболее известный формат «сжатого» звука (с потерями) — MP3. Он обеспечивает сжатие данных в 10 раз и более.
Вопросы и задания
1.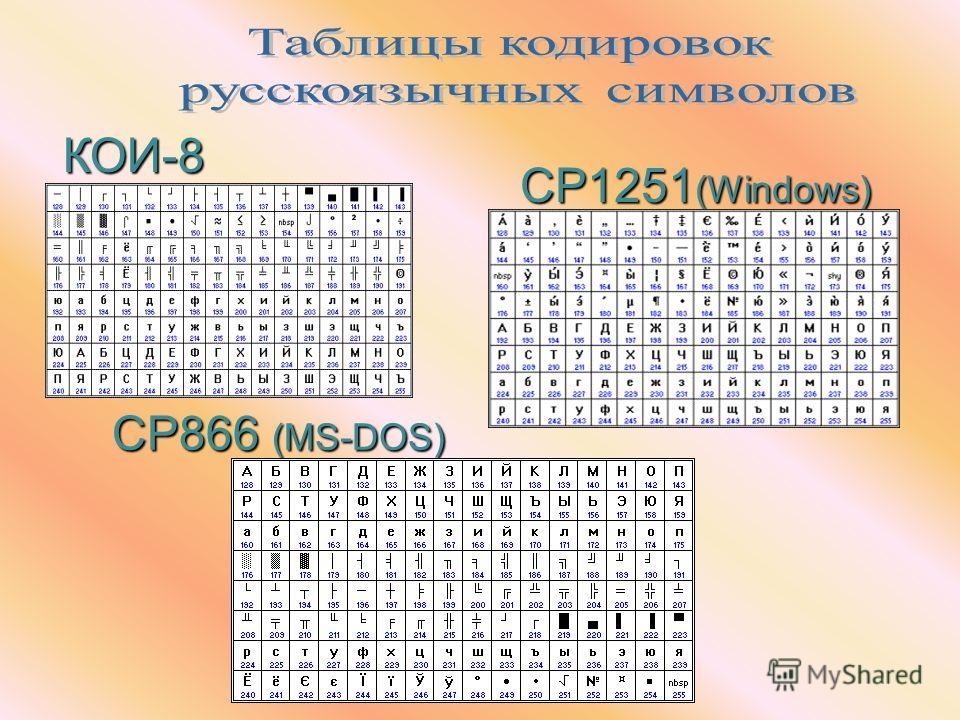 Когда компьютеры начали работать с текстом, с графикой, со звуком?
Когда компьютеры начали работать с текстом, с графикой, со звуком?
2. Что такое таблица кодировки? Какие существуют таблицы кодировки?
3. На чем основывается дискретное представление изображения?
4. Что такое модель цвета RGB?
5. Напишите 8-разрядный код ярко-синего цвета, ярко-желтого (смесь красного с зеленым), бледно-желтого.
6. Почему в полиграфии не используется модель RGB?
7. Что такое CMYK?
8. Какое устройство в компьютере производит оцифровку вводимого звукового сигнала?
9. Как (качественно) качество цифрового звука зависит от частоты дискретизации и разрядности дискретизации?
10. Чем удобен формат MP3?
Практическая работа № 1.4 «Представление текстов. Сжатие текстов»
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодируются таблицей ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
Задание 2
Закодировать текст Happy Birthday to you!! с помощью кодировочной таблицы ASCII
Записать двоичное и шестнадцатеричное представление кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 00100000 01010101
01101110 01101001 01110110 01100101 01110010 01110011
01101001 01110100 01111001
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Задание 6
Во сколько раз увеличится объём памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode?
Задание 7
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы буду автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Справочная информация
Алгоритм Хаффмена. Сжатием информации в памяти компьютера называют такое её преобразование, которое ведёт к сокращению объёма ханимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации — алгоритм Хаффмена. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьный кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведён пример такого дерева, построенный для алфавита английского языка с учётом частоты встречаемости его букв.
Рассмотрим один из способов сжатия текстовой информации — алгоритм Хаффмена. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьный кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведён пример такого дерева, построенный для алфавита английского языка с учётом частоты встречаемости его букв.
Закодируем с помощью данного дерева слово «hello»:
0101 100 01111 01111 1110
При размещении этого кода в памяти побитово он примет вид:
010110001111011111110
Таким образом, текст, занимающий в кодировки ASCII 5 байтов, в кодировке Хаффмена займет 3 байта.
Задание 8
Используя метод сжатия Хаффмена, закодируйте следующие слова:
а) administrator
б) revolution
в) economy
г) department
Задание 9
Используя дерево Хаффмена, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
б) 00010110 01010110 10011001 01101101 01000100 000
Практическая работа № 1.
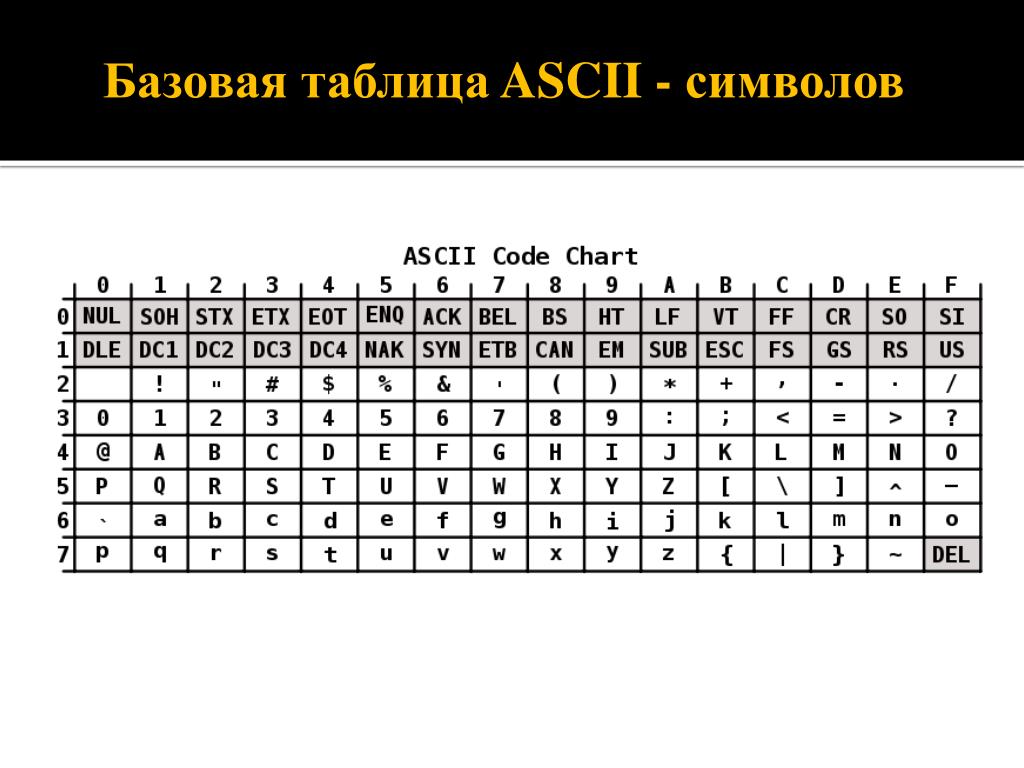 5 «Представление изображения и звука»
5 «Представление изображения и звука»
Цель работы: практическое закрепление знаний о представлении в компьютере графических данных и звука.
Справочная информация
В некоторых заданиях используется модельный (учебный) вариант монитора с размером растра 10×10 пикселей.
При векторном подходе изображение рассматривается как совокупность простых элементов: прямых линий, дуг, окружностей, эллипсов,
прямоугольников, закрасок и пр., которые называются графическими примитивами. Графическая информация — это данные, однозначно
определяющие все графические примитивы, составляющие рисунок.
Положение и форма графических примитивов задаются в системе графических координату связанных с экраном. Обычно начало координат
расположено в верхнем левом углу экрана. Сетка пикселей совпадает с координатной сеткой. Горизонтальная ось X направлена слева направо; вертикальная ось У — сверху вниз.
Отрезок прямой линии однозначно определяется указанием координат его концов; окружность — координатами центра и радиусом; многоугольник — координатами его углов, закрашенная область — граничной линией и цветом закраски и пр.
Учебная система векторных команд представлена в таблице.
Например, требуется написать последовательность получения изображения буквы К:
Изображение буквы «К» на рисунке описывается тремя векторными командами:
Линия(4, 2, 4, 
Линия(5, 5, 8, 2)
Линия(5, 5, 8,
Задание 1
Построить двоичный код приведенного черно-белого растрового изображения, полученного на мониторе с размером растра 10×10.
Задание 2
Определить, какой объем памяти требуется для хранения 1 бита изображения на вашем компьютере (для этого нужно через Свойства экрана определить битовую глубину цвета).
Задание 3
Битовая глубина цвета равна 24. Сколько различных оттенков серого цвета может быть отображено на экране (серый цвет получается, если уровни яркости всех трех базовых цветов одинаковы)?
Задание 4
Дан двоичный код 8-цветного изображения. Размер монитора — 10×10 пикселей. Что изображено на рисунке (зарисовать)?
Размер монитора — 10×10 пикселей. Что изображено на рисунке (зарисовать)?
001 111 111 111 010 010 111 111 111 001
111 111 111 011 011 011 011 111 111 111
111 111 011 111 111 111 111 011 111 111
111 011 111 111 111 111 111 111 011 111
110 011 111 111 110 110 111 111 011 110
110 011 111 111 110 110 111 111 011 110
111 011 111 111 111 111 111 111 011 111
111 111 011 111 111 111 111 011 111 111
111 111 111 011 011 011 011 111 111 111
001 111 111 111 010 010 111 111 111 001
Задание 5
Описать с помощью векторных команд следующие рисунки (цвет заливки произвольный).
Задание 6
Получить растровое и векторное представления всех цифр от 0 до 9.
Задание 7
По приведенному ниже набору векторных команд определить, что изображено на рисунке (зарисовать).
Цвет рисования Голубой
Прямоугольник 12, 2, 18, 8
Прямоугольник 10, 1, 20, 21
Прямоугольник 20, 6, 50, 21
Цвет рисования Желтый
Цвет закраски Зеленый
Окружность 20, 24, 3
Окружность 40, 24, 3
Закрасить 20, 24, Желтый
Закрасить 40, 24, Желтый
Цвет закраски Голубой
Закрасить 30, 10, Голубой
Закрасить 15, 15, Голубой
Цвет закраски Розовый
Закрасить 16, 6, Голубой
Задание 8
Определить, какой объем имеет 1 страница видеопамяти на вашем компьютере (узнать для этого, какое у компьютера разрешение и битовая глубина цвета).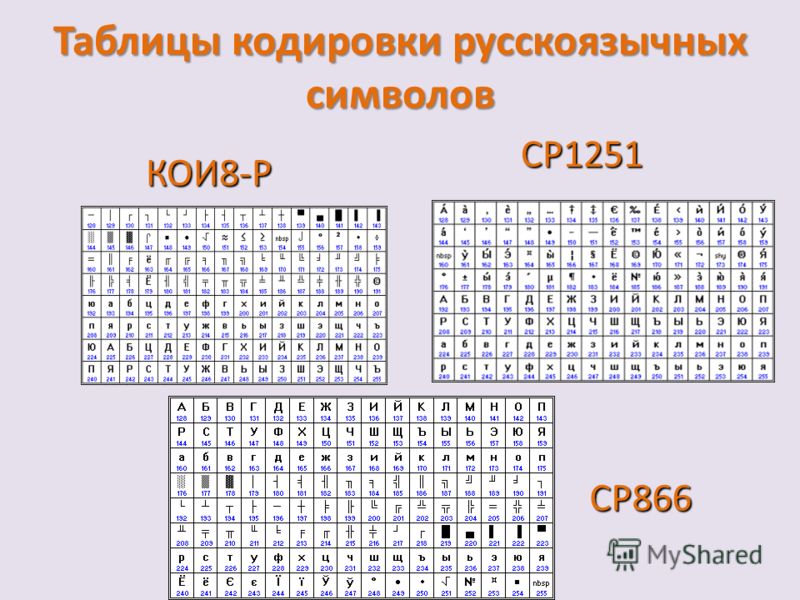 Ответ записать в мегабайтах.
Ответ записать в мегабайтах.
Задание 9
Нарисовать в редакторе Paint изображение солнца, сохранить его в формате BMP, а затем с помощью Photoshop преобразовать его в форматы JPEG (с наивысшим качеством), JPEG (с наименьшим качеством), GIF, TIFF.
Сравнить эффективность сжатия каждого формата, заполнив таблицу.
Задание 10
Битовая глубина цвета равна 32. Видеопамять делится на две страницы. Разрешающая способность дисплея 800×600. Вычислить объем видеопамяти.
Задание 11
На компьютере установлена видеокарта объемом 2 Мбайт. Какое максимально возможное количество цветов теоретически допустимо в палитре при работе с монитором, имеющим разрешение 1280×1024?
Задание 12
Какой объем видеопамяти в килобайтах нужен для хранения изображения размером 600×350 пикселей, использующего 8-цветную палитру?
Задание 13
Зеленый цвет на компьютере с объемом страницы видеопамяти 125 Кбайт кодируется кодом 0010. Какова может быть разрешающая способность монитора?
Какова может быть разрешающая способность монитора?
Задание 14
Монитор работает с 16-цветной палитрой в режиме 640×400 пикселей. Для кодирования изображения требуется 1250 Кбайт. Сколько страниц видеопамяти оно занимает?
Задание 15
Сколько цветов можно максимально использовать для хранения изображения размером 350×200 пикселей, если объем страницы видеопамяти — 65 Кбайт?
Задание 16
Определить объем памяти для хранения цифрового аудиофайла, время звучания которого 5 минут при частоте дискретизации 44,1 КГц и глубине кодирования 16 битов.
Задание 17
Записать с помощью стандартного приложения «Звукозапись» звук длительностью 1 минута с частотой дискретизации 22,050 КГц и глубиной кодирования 8 битов (моно), а затем тот же самый звук с частотой дискретизации 44,1 КГц и глубиной кодирования 16 битов (моно). Сравнить объемы полученных файлов.
Задание 18
Одна минута записи цифрового аудиофайла занимает на диске 1,3 Мбайт, разрядность звуковой платы — 8. С какой частотой дискретизации записан звук?
С какой частотой дискретизации записан звук?
Задание 19
Две минуты записи цифрового аудиофайла занимают на диске 5,1 Мбайт. Частота дискретизации — 22 050 Гц. Какова разрядность аудиоадаптера?
Задание 20
Объем свободной памяти на диске — 0,01 Гбайт, разрядность звуковой платы — 16. Какова будет длительность звучания цифрового аудиофайла, если его записать с частотой дискретизации 44 100 Гц?
Лабораторная работа №3 Измерение информации
|
Заглавная страница КАТЕГОРИИ: Археология ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрации Техника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ? Влияние общества на человека Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. |
⇐ ПредыдущаяСтр 2 из 12Следующая ⇒ Цель работы: закрепление знаний о различных подходах к измерению информации. Задание 1 Лабораторная работа №4 Представление чисел Цель работы. Закрепление знаний о системах счисления и о представлении чисел в памяти компьютера, полученных при изучении курса информатики. Задание 1 Ответьте письменно на вопросы: 1.Какое множество понятий однозначно определяет позиционную систему счисления: 1) {базис, алфавит, основание}; 2) {базис, алфавит}; 3) {базис}? 2. 3. Какие символы могут быть использованы в качестве цифр системы счисления? Задание 2 Решите задачи:
1.Запишите десятичные представления чисел: а) 1011001112; 4. 11001,0112; б) 1AC9F16; 5.ED4A,C116; в) 17458; 6.147,258. 2.Переведите числа в десятичную систему, а затем проверьте результаты, выполнив обратные переводы:
3.Сложите числа:
4.
5.Перемножьте числа:
Задание 3 6. Представьте числа в двоичном виде в восьмибитовой ячейке в формате целого со знаком: а) 56 б) -56 в) 127 г) -127. 7. Представьте вещественные числа в четырехбайтовой ячейке памяти в формате с плавающей точкой: а) 0,5 б) 25,12 в) – 25,12 Лабораторная работа №5. Представление текста. Сжатие текста. Цель работы. Практическое закрепление знаний о представлении в компьютере текстовых данных. Задание 1 Определить, какие символы кодировочной таблицы ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows).
Задание 2 Закодировать текст с помощью кодировочной таблицы ASCII «Happy Birthday to you!» Записать двоичное и шестнадцатеричное представления кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера). Задание 3 Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление). 71 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33 Задание 4 Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов. 01010000 01100101 01110010 01101101 001О0000 01010101 01101110 01101001 01110110 01100101 01110010 01110011 01101001 01110100 01111001 Задание 5 Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ. Задание 6 Во сколько раз увеличится объем памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode? ⇐ Предыдущая12345678910Следующая ⇒ Читайте также: Техника прыжка в длину с разбега Организация работы процедурного кабинета Области применения синхронных машин Оптимизация по Винеру и Калману |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Последнее изменение этой страницы: 2016-12-30; просмотров: 706; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia. |
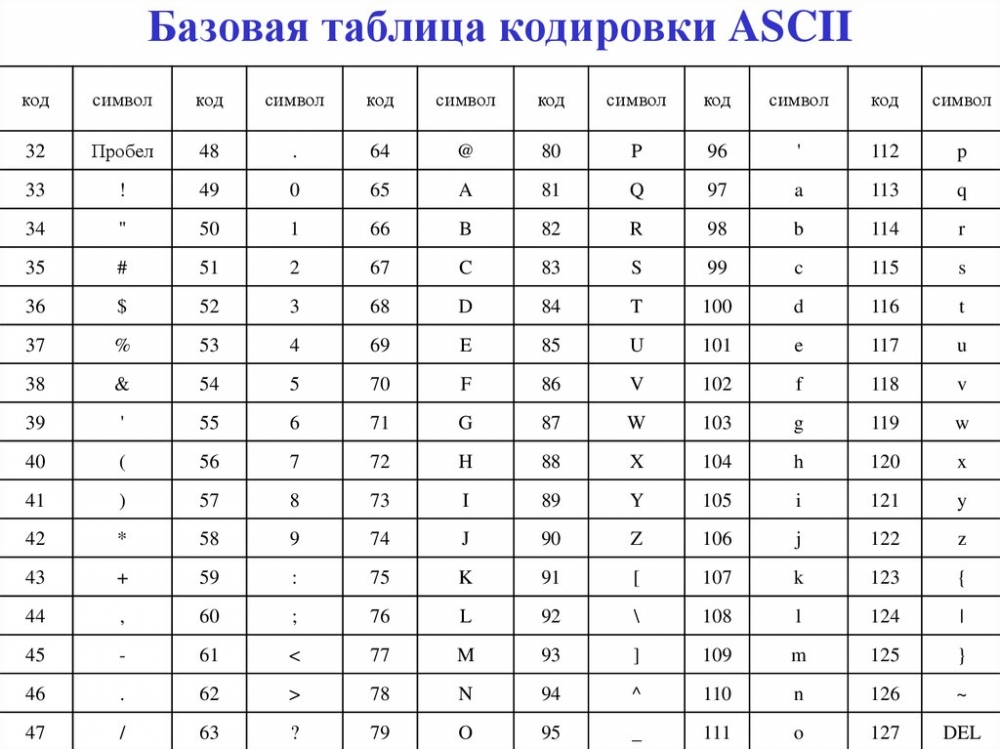
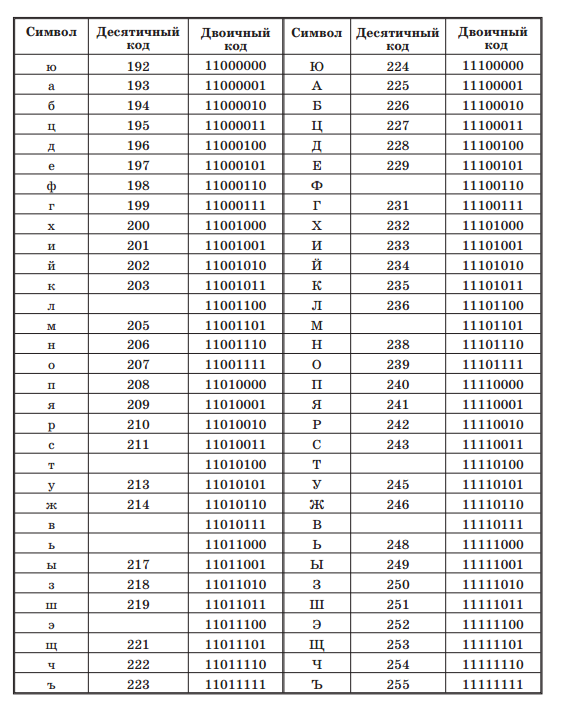 Определение реакций опор и моментов защемления
Определение реакций опор и моментов защемления
 Сколько бит несет слово «ИНФОРМАЦИЯ»?
Сколько бит несет слово «ИНФОРМАЦИЯ»? Сообщение «Первым из зала выйдет юноша» содержит 4 бита информации. Сколько юношей в зале.
Сообщение «Первым из зала выйдет юноша» содержит 4 бита информации. Сколько юношей в зале. Какая последовательность чисел может быть использована в качестве базиса позиционной системы счисления?
Какая последовательность чисел может быть использована в качестве базиса позиционной системы счисления? Вычтите числа:
Вычтите числа: Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.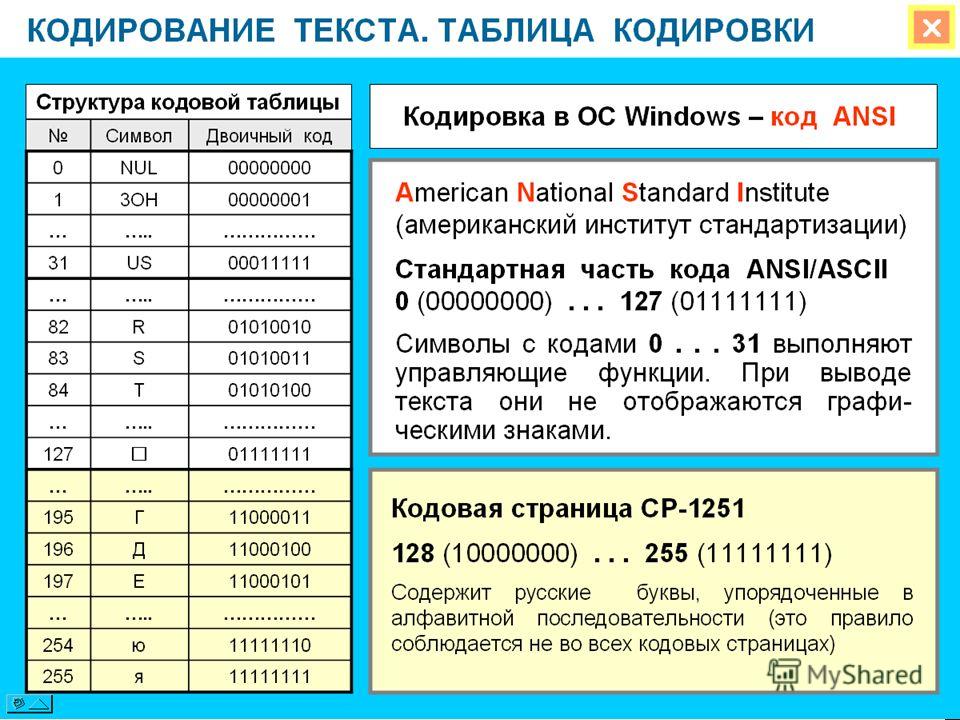
 su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь — 161.97.168.212 (0.008 с.)
su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь — 161.97.168.212 (0.008 с.)Лабораторная работа №3 Измерение информации — Мегаобучалка
Цель работы: закрепление знаний о различных подходах к измерению информации.
Задание 1
Решите следующие задачи:
1. В корзине лежат 16 шаров. Все шары разного цвета и среди них есть красный. Сколько информации несет сообщение о том, что из корзины достали красный шар?
2. В корзине лежат 8 черных и 8 белых шаров. Сколько информации несет сообщение о том, что из корзины достали белый шар?
3. В корзине лежат 16 шаров. Среди них 4 белых, 4 черных, 4 красных и 4 зеленых. Сколько информации несет сообщение о том, что из корзины достали красный шар?
4. При угадывании целого числа в диапазоне от 1 до N было получено 7 бит информации.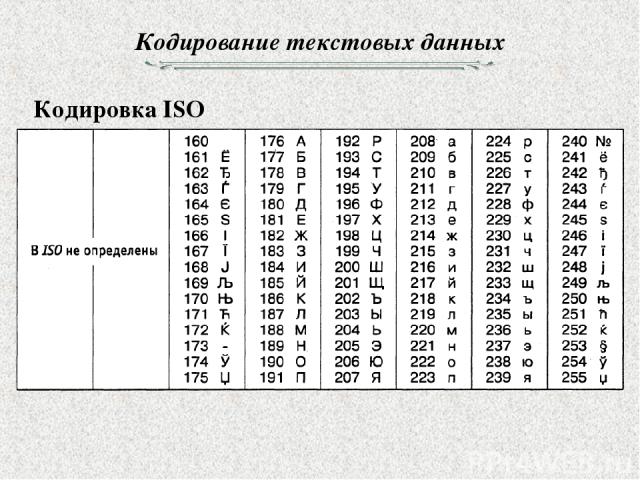 Чему равно N?
Чему равно N?
5. Какое количество информации содержит один символ алфавита, состоящего из 1024 символов?
6. Сколько бит несет слово «ИНФОРМАЦИЯ»?
7. В алфавите некоторого языка две буквы «А» и «Б». Все слова на этом языке состоят из 11 букв. Каков словарный запас этого языка, т.е. сколько слов он содержит?
8. Информационное сообщение объемом 1,5 килобайта содержит 3072 символа. Сколько символов содержит алфавит, при помощи которого было записано это сообщение?
9. Алфавит первого племени содержит N символов, алфавит второго – в два раза больше. Племена обменялись приветствиями, каждое по 100 символов. Приветствие какого племени содержит больше информации (в битах) и на сколько?
10. В процессе преобразования растрового графического файла количество всех возможных цветов было уменьшено с 1024 до 32. Как и во сколько раз изменился размер файла?
Задание 2
Решите следующие задачи:
1. В ящике лежат 36 красных и несколько зеленых яблок. Сообщение «Из ящика достали зеленое яблоко» несет 2 бита информации.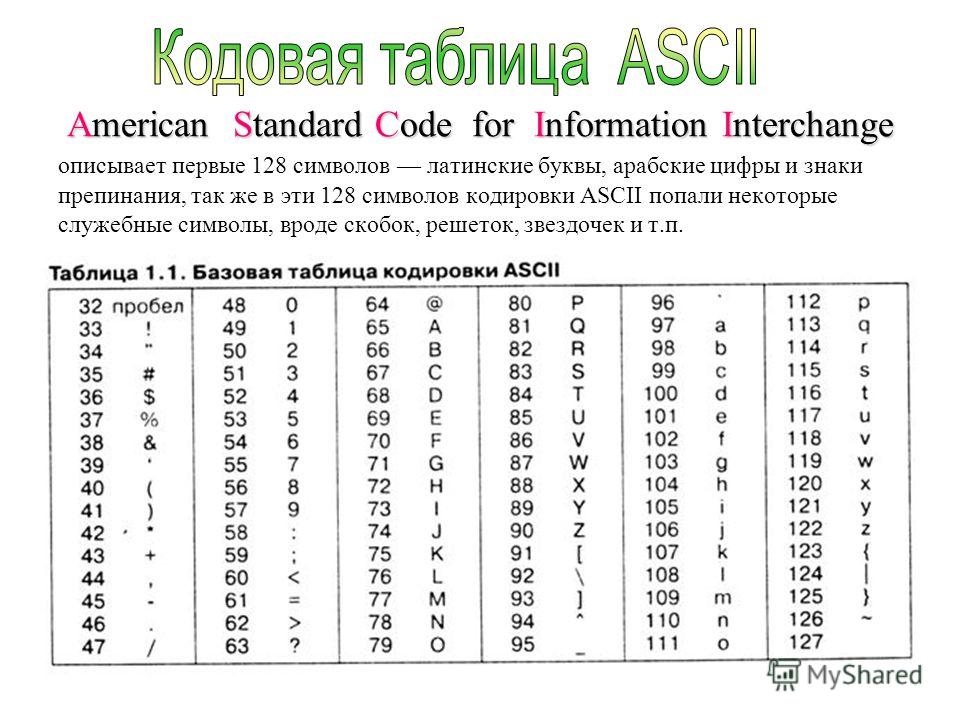 Сколько яблок в ящике?
Сколько яблок в ящике?
2. В концертном зале 270 девушек и несколько юношей. Сообщение «Первым из зала выйдет юноша» содержит 4 бита информации. Сколько юношей в зале.
3. На остановке останавливаются автобусы с разными номерами. Сообщение о том, что к остановке подошел Автобус с номером N1 несет 4 бита информации. Вероятность появления на остановке автобуса с номером N2 в два раза меньше, чем вероятность появления автобуса с номером N1. Сколько информации несет сообщение о появлении на остановке автобуса с номером N2?
4.Известно, что в ящике лежат 20 шаров. Из них 10 — черных, 4 — белых, 4 — желтых и 2 — красных. Какое количество информации несѐт сообщения о цвете вынутого шара?
Лабораторная работа №4 Представление чисел
Цель работы. Закрепление знаний о системах счисления и о представлении чисел в памяти компьютера, полученных при изучении курса информатики.
Задание 1
Ответьте письменно на вопросы:
1.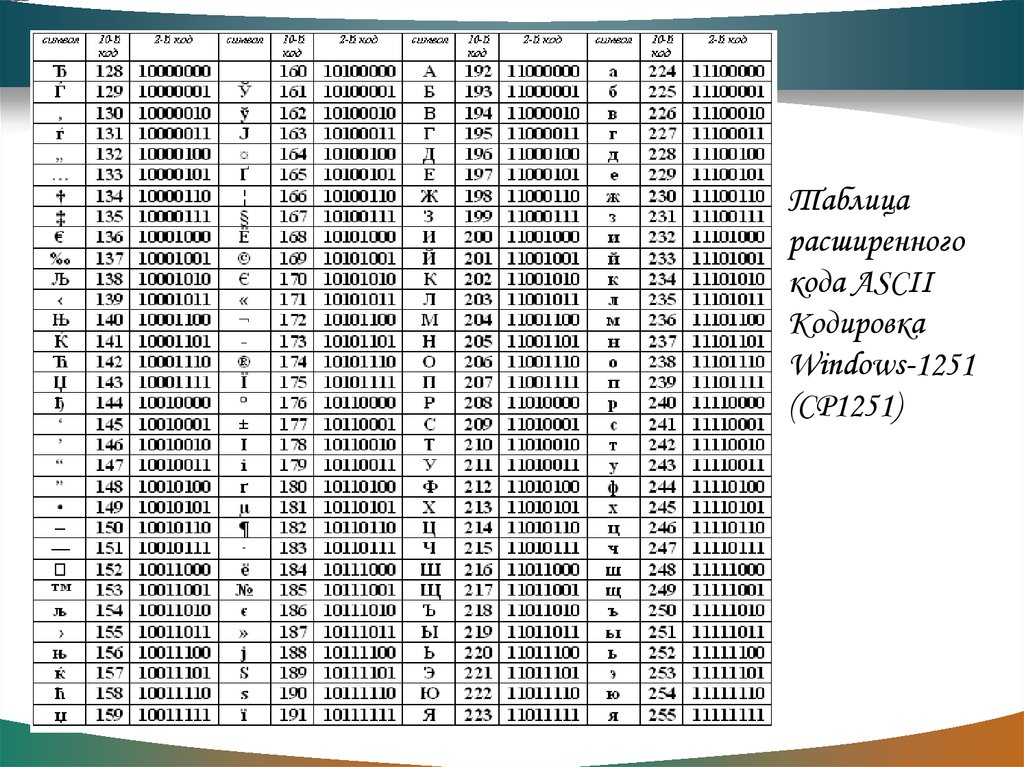 Какое множество понятий однозначно определяет позиционную систему счисления:
Какое множество понятий однозначно определяет позиционную систему счисления:
1) {базис, алфавит, основание};
2) {базис, алфавит};
3) {базис}?
2. Какая последовательность чисел может быть использована в качестве базиса позиционной системы счисления?
3. Какие символы могут быть использованы в качестве цифр системы счисления?
Задание 2
1.Запишите десятичные представления чисел:
а) 1011001112; 4. 11001,0112;
б) 1AC9F16; 5.ED4A,C116;
в) 17458; 6.147,258.
2.Переведите числа в десятичную систему, а затем проверьте результаты, выполнив обратные переводы:
| а) 10110112; | г) 5178; | ж) 1F16; | |
| б) 0,10001102; | д) 0,348; | з) 0,А416; | |
| в) 110100,112; | е) 123,418; | и) 1DE,C816 |
3. Сложите числа:
Сложите числа:
| а) 10111012 и 11101112; | д) 378 и 758; | и) A16 и F16; |
4.Вычтите числа:
| а) 1112 из 101002; | д) 158 из 208; | и) 1А16 из 3116 |
5.Перемножьте числа:
| а) 1011012 и 1012; | д) 378 и 48; |
Задание 3
6. Представьте числа в двоичном виде в восьмибитовой ячейке в формате целого со знаком:
а) 56 б) -56 в) 127 г) -127.
7. Представьте вещественные числа в четырехбайтовой ячейке памяти в формате с плавающей точкой:
а) 0,5 б) 25,12 в) – 25,12
Лабораторная работа №5. Представление текста. Сжатие текста.
Цель работы. Практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодировочной таблицы ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
| Буква в ANSI | Буква в ASCII | Буквав ANSI | Буква вASCII | Буква в ANSI | Буква в ASCII |
| А | К | X | |||
| Б | Л | Ц | |||
| В | М | Ч | |||
| Г | Н | III | |||
| Д | О | Щ | |||
| Е | П | Ъ | |||
| Ё | Р | Ы | |||
| ЭК | С | Ь | |||
| Т | Э | ||||
| И | У | Ю | |||
| Й | Ф | Я |
Задание 2
Закодировать текст с помощью кодировочной таблицы ASCII «Happy Birthday to you!»
Записать двоичное и шестнадцатеричное представления кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
71 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 001О0000 01010101 01101110 01101001 01110110 01100101 01110010 01110011 01101001 01110100 01111001
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Задание 6
Во сколько раз увеличится объем памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode?
Лабораторная работа №6 Представление изображения и звука
Цель работы.Практическое закрепление знаний о представлении в компьютере графических данных и звука.
Справочная информация
В некоторых заданиях используется модельный (учебный) вариант монитора с размером растра 10×10 пикселей. При векторном подходе изображение рассматривается как совокупность простых элементов: прямых линий, дуг, окружностей, эллипсов, прямоугольников, закрасок и пр., которые называются графическими примитивами. Графическая информация — это данные, однозначно определяющие все графические примитивы, составляющие рисунок. Положение и форма графических примитивов задаются в системе графических координат, связанных с экраном. Обычно начало координат расположено в верхнем левом углу экрана. Сетка пикселей совпадает с координатной сеткой. Горизонтальная ось X направлена слева направо; вертикальная ось Y — сверху вниз.
Отрезок прямой линии однозначно определяется указанием координат его концов; окружность — координатами центра и радиусом; многоугольник — координатами его углов, закрашенная область — граничной линией и цветом закраски и пр.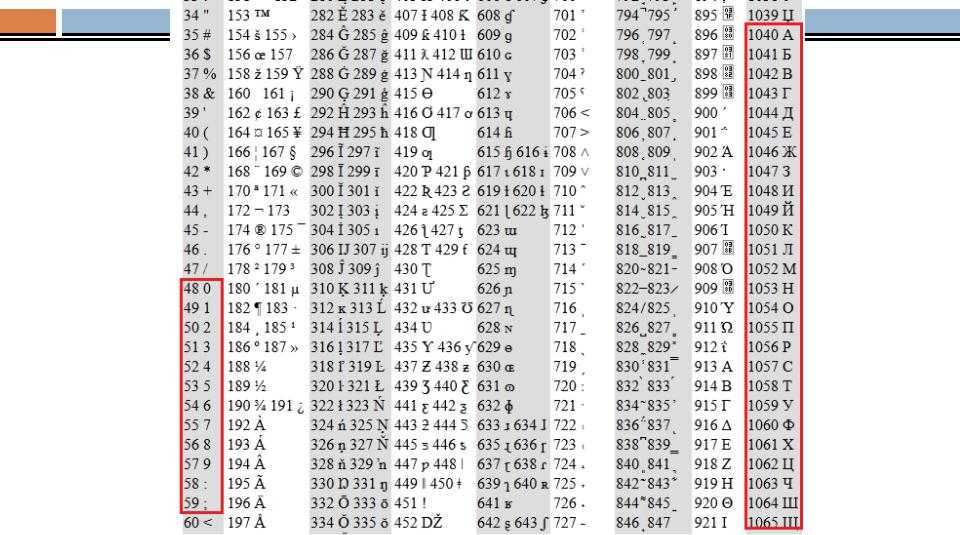
Учебная система векторных команд представлена в таблице.
| Установить X, У | Установить текущую позицию (X, У) |
| Линия к XI, У1 | Нарисовать линию от текущей позиции в позицию (XI, У1), позиция (XI, У1) становится текущей |
| ЛинияXI, У1,Х2, У2 | Нарисовать линию с координатами начала XI, У1 и координатами конца Х2, У2. Текущая позиция не устанавливается |
| Окружность X, У, R | Нарисовать окружность; X, У — координаты центра, ft — длина радиуса в пикселях |
| ЭллипсХ1,У1,Х2,У2 | Нарисовать эллипс, ограниченный прямоугольником; (XI, У1) — координаты левого верхнего, а (Х2, У2) — правого нижнего угла этого прямоугольника |
| Прямоугольник XI,У1,Х2,У2 | Нарисовать прямоугольник; (XI, У1) — координаты левого верхнего угла, а (Х2, У2) — правого нижнего угла этого прямоугольника |
| Цвет_рисования ЦВЕТ | Установить текущий цвет рисования |
| Цвет_закраски ЦВЕТ | Установить текущий цвет закраски |
| Закрасить X, У, ЦВЕТ ГРАНИЦЫ | Закрасить произвольную замкнутую фигуру; X, У — координаты любой точки внутри замкнутой фигуры, ЦВЕТ ГРАНИЦЫ — цвет граничной линии |
Например, требуется написатьпоследовательность получения изображения буквы К:
Изображение буквы «К» на рисунке описывается тремя векторными командами:
Линия(4, 2, 4,
Линия(5, 5, 8, 2)
Линия(5, 5, 8,
Задание 1
Построить двоичный код приведенного черно-белого растрового изображения, полученного на мониторе размером растра 10×10.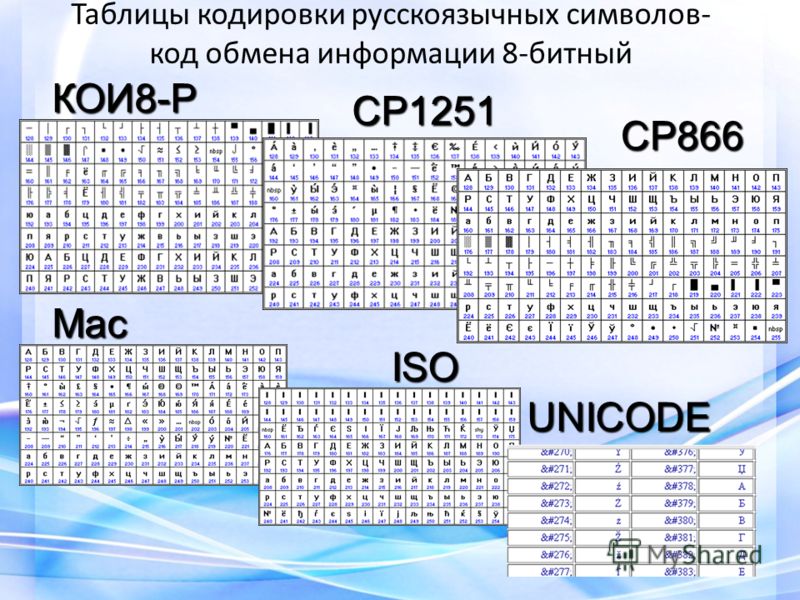
Задание 2
Определить, какой объем памяти потребуется для хранения 1 бита изображения на вашем компьютере (для этого нужно через Свойства экрана определить битовую глубину цвета).
Задание 3
Битовая глубина цвета равна 24. Сколько различных оттенков цвета может быть отображено на экране (серый цвет получается,’ уровни яркости всех трех базовых цветов одинаковы)?
Задание 4
Дан двоичный код 8-цветного изображения. Размер монитора — 1 пикселей. Что изображено на рисунке (зарисовать)?
001 111 111 111 111 111 111011 110011 110011 111011
111111 111111
001 111
111 111
111011 011111
111111 111111
111111 111 111
011 111 111011
010 010 111 011011011
111 111 111 111 111 111
110 110 111 110110 111
111111111 111111111
011011011 010 010 111
111 111001
011 111 111 111011 111 111011 110 111011 110 111011 111 011 111 111
111 111001
Задание 5
Описать с помощью векторных команд следующие рисунки (цвет заливки произвольный).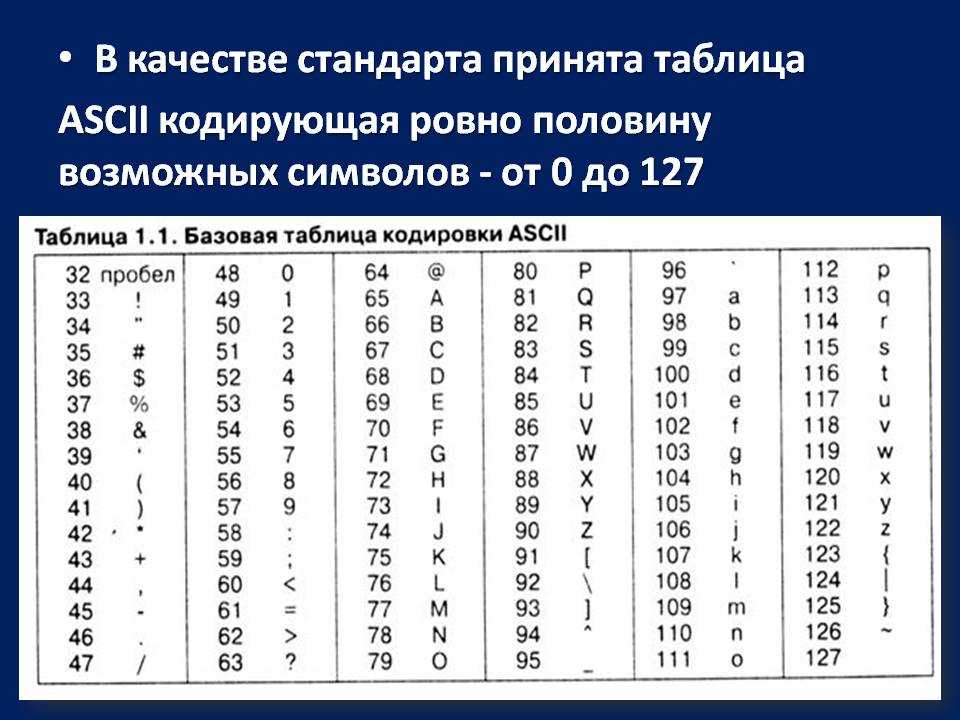
Задание 6
Получить растровое и векторное представления всех цифр от 0 до 9.
Задание 7
По приведенному ниже набору векторных команд определить, что изображено на рисунке (зарисовать).
Цвет рисования Голубой
Прямоугольник 12, 2, 18, 8
Прямоугольник 10, 1, 20, 21
Прямоугольник 20, 6, SO, 21
Цвет рисования Желтый
Цвет закраски Зеленый Окружность 20, 24, 3
Окружность 40, 24, 3
Закрасить 20, 24, Желтый
Закрасить 40, 24, Желтый
Цвет закраски Голубой
Закрасить 30, 10, Голубой
Закрасить 15, 15, Голубой
Цвет закраски Розовый
Закрасить 16, 6, Голубой
Задание 8
Определить, какой объем имеет 1 страница видеопамяти на вашем компьютере (узнать для этого, какое у компьютера разрешение и битовая глубина цвета). Ответ записать в мегабайтах.
Задание 9
Нарисовать в редакторе Paintизображение солнца, сохранить его в формате BMP, а затем преобразовать его в форматы JPEG (с наивысшим качеством), JPBG(с наименьшим качеством), GIF, TIFF.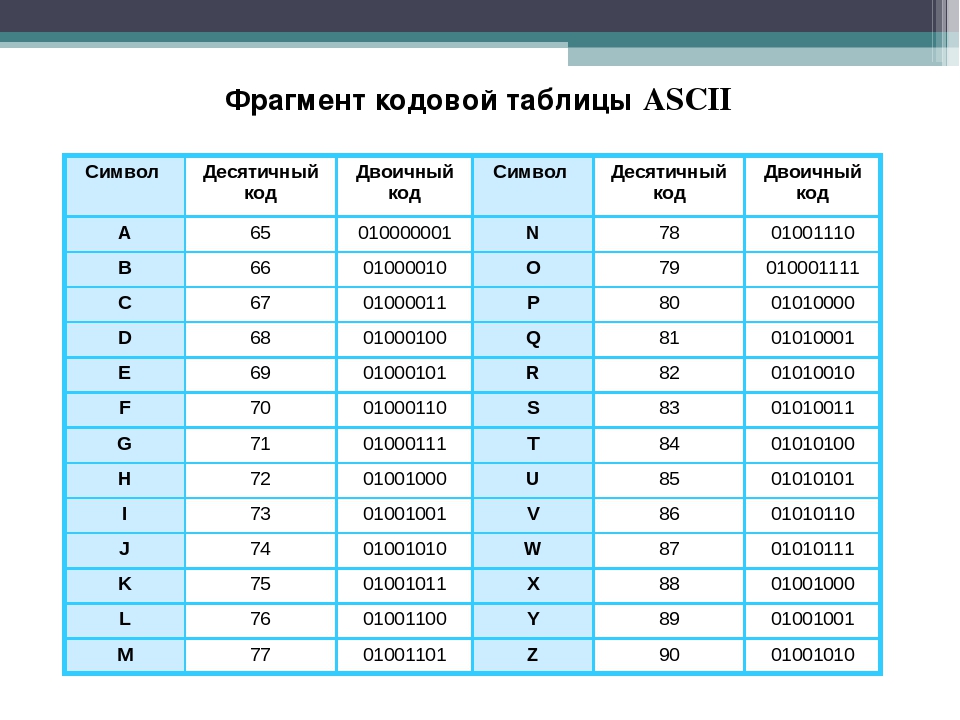 Сравнить эффективность сжатия каждого формата, заполнив таблицу.
Сравнить эффективность сжатия каждого формата, заполнив таблицу.
| Формат | Размер файла | Коэффициент сжатия (по сравнению с BMP) |
| JPEG (высшее качество) | ||
| JPEG (низкое качество) | ||
| GIF | ||
| TIFF |
Задание 10
Битовая глубина цвета равна 32. Видеопамять делится на две страницы. Разрешающая способность дисплея 800×600. Вычислить объем видеопамяти.
Задание 11
На компьютере установлена видеокарта объемом 2 Мбайт. Какое максимально возможное количество цветов теоретически допустимо в палитре при работе с монитором, имеющим разрешение 1280×1024?
Задание 12
Какой объем видеопамяти в килобайтах нужен для хранения изображения размером 600×350 пикселей, использующего 8-цветную палитру?
Задание 13
Зеленый цвет на компьютере с объемом страницы видеопамяти 125 Кбайт кодируется кодом 0010. Какова может быть разрешающая способность монитора?
Какова может быть разрешающая способность монитора?
Задание 14
Монитор работает с 16-цветной палитрой в режиме 640×400 пикселей. Для кодирования изображения требуется 1250 Кбайт. Сколько страниц видеопамяти оно занимает?
Задание 15
Сколько цветов можно максимально использовать для хранения изображения размером 350×200 пикселей, если объем страницы видеопамяти — 65 Кбайт?
Задание 16
Определить объем памяти для хранения цифрового аудиофайла, время звучания которого 5 минут при частоте дискретизации 44,1 КГц и глубине кодирования 16 битов.
Задание 17
Записать с помощью стандартного приложения «Звукозапись» звук длительностью 1 минута с частотой дискретизации 22,050 КГци глубиной кодирования 8 битов (моно), а затем тот же самый звук с частотой дискретизации 44,1 КГц и глубиной кодирования 16 битов (моно). Сравнить объемы полученных файлов.
Задание 18
Одна минута записи цифрового аудиофайла занимает на диске 1,3 Мбайт, разрядность звуковой платы — 8. С какой частотой дискретизации записан звук?
С какой частотой дискретизации записан звук?
Задание 19
Две минуты записи цифрового аудиофайла занимают на диске 5,1 Мбайт. Частота дискретизации — 22 050 Гц. Какова разрядность аудиоадаптера?
Что такое ansi. Character encoding
В основном «ANSI» относится к устаревшей кодовой странице в Windows. См. Также по этой теме. Первые 127 символов идентичны ASCII на большинстве кодовых страниц, однако верхние символы различаются.
Однако ANSI автоматически не означает CP1252 или Latin 1.
Несмотря на всю путаницу, вы должны просто избегать таких проблем в настоящее время и использовать Unicode.
Что такое формат кодировки ANSI? Это системный формат по умолчанию? Чем он отличается от ASCII?
Когда-то Microsoft, как и все остальные, использовала 7-битные наборы символов, и они придумали свои собственные, когда они им подошли, хотя они сохранили ASCII в качестве основного подмножества. Затем они поняли, что мир перешел к 8-битным кодировкам и что существуют международные стандарты, такие как семейство ISO-8859.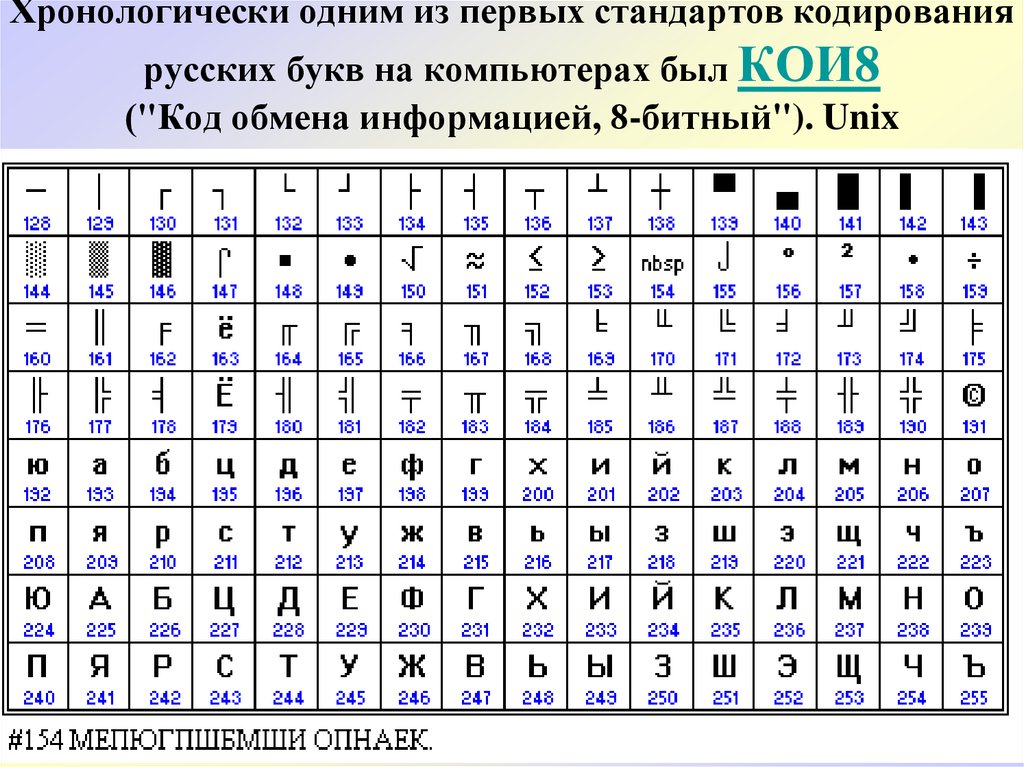 В те дни, если вы хотели получить международный стандарт, и вы жили в США, вы купили его у Американского национального института стандартов ANSI, который переиздал международные стандарты со своим собственным брендингом и цифрами (это потому, что правительство США хочет соответствие американским стандартам, а не международным стандартам). Итак, копия Microsoft ISO-8859 сказала «ANSI» на обложке. И поскольку Microsoft в те дни не очень привыкла к стандартам, они не понимали, что ANSI опубликовала множество других стандартов. Поэтому они ссылались на стандарты семейства ISO-8859 (и варианты, которые они изобрели, потому что в те дни они не понимали стандартов) по названию на обложке «ANSI», и он нашел свой путь в Microsoft пользовательскую документацию и, следовательно, в сообщество пользователей. Это было около 30 лет назад, но вы все еще иногда слышите это имя сегодня.
В те дни, если вы хотели получить международный стандарт, и вы жили в США, вы купили его у Американского национального института стандартов ANSI, который переиздал международные стандарты со своим собственным брендингом и цифрами (это потому, что правительство США хочет соответствие американским стандартам, а не международным стандартам). Итак, копия Microsoft ISO-8859 сказала «ANSI» на обложке. И поскольку Microsoft в те дни не очень привыкла к стандартам, они не понимали, что ANSI опубликовала множество других стандартов. Поэтому они ссылались на стандарты семейства ISO-8859 (и варианты, которые они изобрели, потому что в те дни они не понимали стандартов) по названию на обложке «ANSI», и он нашел свой путь в Microsoft пользовательскую документацию и, следовательно, в сообщество пользователей. Это было около 30 лет назад, но вы все еще иногда слышите это имя сегодня.
Или вы можете запросить свой реестр:
C:\>reg query HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage /f ACP
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage
ACP REG_SZ 1252
End of search: 1 match(es) found.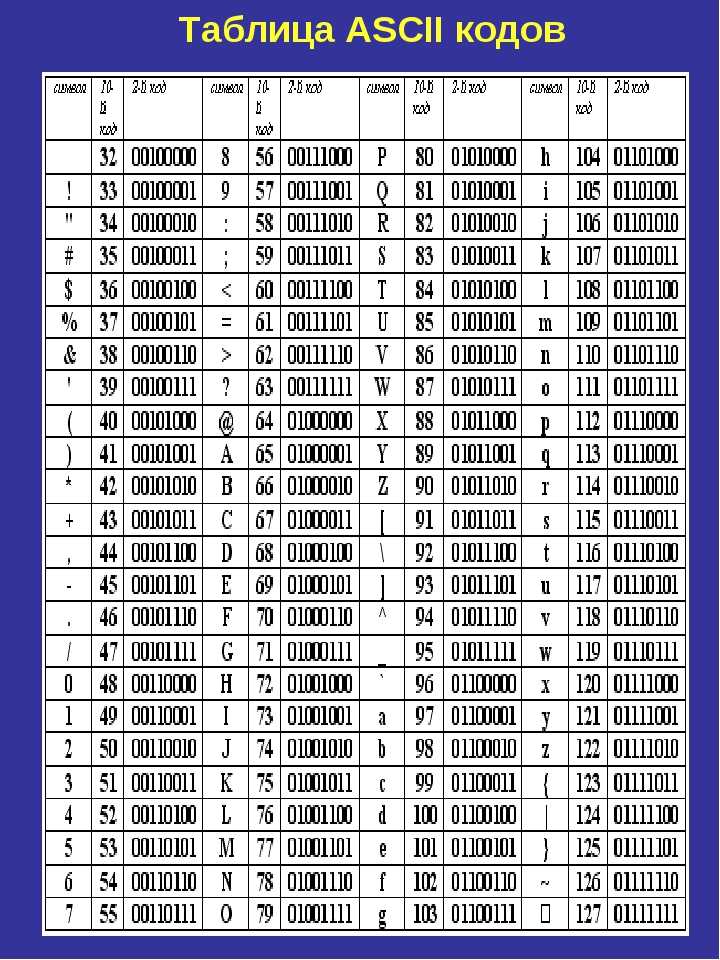 C:\>
C:\>
При использовании однобайтовых символов формат ASCII определяет первые 127 символов. Расширенные символы из 128-255 определяются различными кодами ANSI, чтобы обеспечить ограниченную поддержку других языков. Чтобы понять кодировку ANSI, вам нужно знать, какую кодовую страницу она использует.
Технически ANSI должен быть таким же, как US-ASCII. Он относится к стандарту ANSI X3.4, который является просто утвержденной версией ASCII организации ANSI . Использование символов с верхним битом не определено в ASCII / ANSI, так как это 7-разрядный набор символов.
Однако годы неправильного использования термина DOS и впоследствии сообщества Windows оставили свое практическое значение как «системную кодовую страницу какой бы то ни было машины». Системная кодовая страница также иногда известна как «mbcs», так как в системах Восточной Азии, которая может быть кодировкой с несколькими байтами на символ. Некоторые кодовые страницы могут даже использовать байты с верхним битом в качестве байтов байтов в многобайтовой последовательности, поэтому он даже не является строго совместимым с простым ASCII . .. но даже тогда он по-прежнему называется ANSI.
.. но даже тогда он по-прежнему называется ANSI.
В настройках по умолчанию в США и Западной Европе «ANSI» сопоставляется с кодовой страницей Windows 1252. Это не то же самое, что и ISO-8859-1 (хотя это довольно похоже). На других машинах это могло быть что угодно. Это делает ANSI совершенно бесполезным в качестве внешнего идентификатора кодирования.
Я помню, когда текст ANSI ссылался на escape-коды псевдо-VT-100, используемые в DOS через драйвер ANSI.SYS, чтобы изменить поток потокового текста…. Вероятно, это не то, о чем вы говорите, но если он видит
ANSI – это учреждение для стандартизации промышленных методов и технологий. Оно является членом Международной организации по нормированию (ИСО). В Германии существует свой аналог такой организации – немецкий институт нормирования (DIN), в Австрии – Австрийский институт стандарта (ASI), в Швейцарии — Швейцарское объединение норм (SNV).
Хотя нормы ANSI и находят свое распространение во многих промышленных областях, отдельное сокращение «ANSI» в компьютерной технике обозначает определенную группу символов, базирующуюся на ASCII.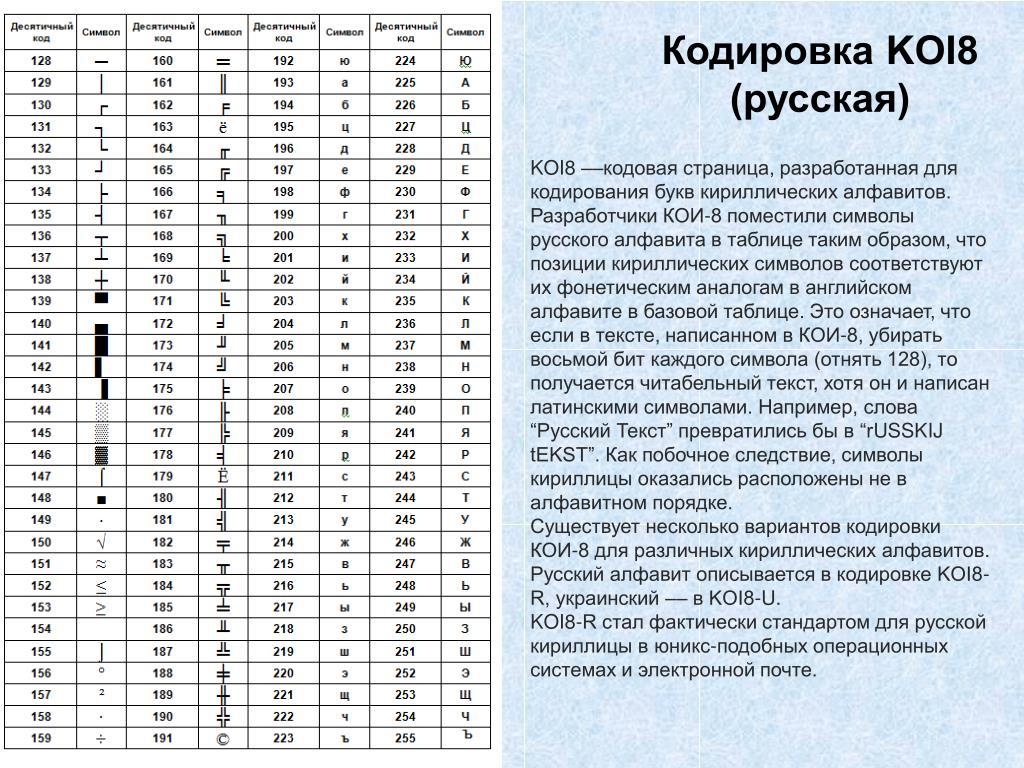 Подлинной ANSI — нормы не существует, однако, проекты ANSI плавно переняли норму ИСО 8859.
Подлинной ANSI — нормы не существует, однако, проекты ANSI плавно переняли норму ИСО 8859.
Задачи ANSI
Главным заданием Американского национального института стандартов (ANSI) является распространение и внедрение национальных стандартов США по всему миру, на предприятиях всех стран.
Кроме этого, работа данного института решает задачи мирового масштаба:
- защита окружающей среды,
- производственная безопасность,
- бытовая безопасность.
Известно, что в США, как и в России, стандарты регулирует, прежде всего, государство (хотя ANSI и позиционирует себя как некоммерческую негосударственную организацию), поэтому стремление заполнить эту нишу и привести все нормы к американскому знаменателю – вполне логичная и последовательная мысль. Ведь через стандарты можно распространять не только чисто технические инновации, но также проводить государственную внешнюю политику глобализации и всемирной интеграции.
На поддержку программы АНСИ государством тратится не малый бюджет, который расходуется, главным образом, на оптимизацию, актуализацию и реорганизацию методик производства. В сталелитейной промышленности стандарты ANSI уже давно зарекомендовали себя как одни из самых лучших в мире.
В сталелитейной промышленности стандарты ANSI уже давно зарекомендовали себя как одни из самых лучших в мире.
Наша фирма также охотно в своей работе при производстве фланцевой продукции, которая расходится огромными партиями по промышленным предприятиям России и стран СНГ.
Иногда даже достаточно опытный специалист не сразу скажет вам, чему соответствует то или иное значение давления или длины в одной системе значениям в другой системе величин.
Чтобы облегчить вам эту задачу, мы предлагаем таблицы соотношения величин давления и длины в европейской и американской системах с небольшими пояснениями . Но сначала несколько слов о самих стандартах.
DIN — это немецкий стандарт (расшифровывается как Deutsches Institut für Normung , то есть разработанный Германским институтом стандартизации), который разрабатывается строго в рамках положений Международной организации по стандартизации — ISO (International Organization for Standardization).
ANSI – стандарт, принятый в Соединённых Штатах Америки.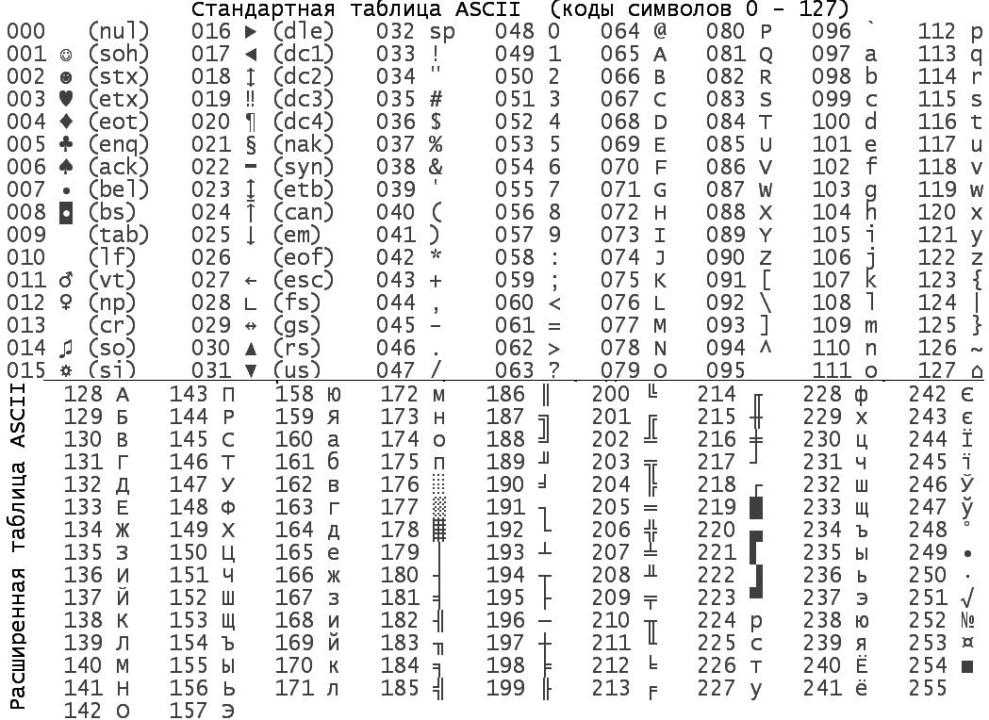 Расшифровывается как American National Standards Institute , то есть стандарт Американского национального института по стандартизации.
Расшифровывается как American National Standards Institute , то есть стандарт Американского национального института по стандартизации.
Соответственно, нормы ANSI определяются именно этим институтом, и далеко не всегда между стандартами DIN и ANSI можно проследить точные соответствия в различных сферах.
Перевод единиц давления из ANSI в DIN
Здесь всё просто: если по стандарту ANSI напротив давления стоит цифра 150 — это означает, что номинальное (на которое рассчитана арматура) давление составляет 20 бар, 300 — 50 бар и т.д. Максимальное значение по ANSI Class – 2500 будет равно 420 бар по европейскому стандарту DIN .
Пользуясь этой таблицей, несложно переводить значения давления и обратно: из DIN в ANSI , хотя осуществлять такой перевод нашим инженерам требуется гораздо реже .
Перевод единиц длины из американской системы в европейскую (российскую)
Как известно, американцы всё измеряют дюймами и футами, а мы и европейцы — миллиметрами, сантиметрами и метрами, то есть, как и подавляющее большинство государств мира, мы живём в метрической системе единиц.
Как же переводить дюймы в миллиметры? На самом деле, в этом также нет ничего сложного, достаточно лишь запомнить, что 1 дюйм равняется 25,4 мм. Однако нередко цифрой после запятой пренебрегают и для ровного счёта указывают, что 1 дюйм = 25 мм .
Таким образом, если, например, сечение входного отверстия равно 2 дюймам по американской системе мер, то, переведя по вышеуказанному правилу это значение в нашу систему мер, получаем 50 мм или, что более точно — 51 мм (округлив 50,8 по правилам).
Осталось добавить, что диаметр в технических характеристиках маркируется латинскими буквами DN и нередко указывается именно в дюймах , а давление обозначается при помощи букв PN и указывается чаще всего в барах — во всяком случае, мы используем именно такую маркировку как наиболее удобную .
А следующая таблица поможет вам высчитать не только точное количество миллиметров в одном дюйме (с точностью до тысячной миллиметра), но и поможет узнать, сколько миллиметров содержится, например, в 2,5 дюймах.
Для этого находим колонку 2″» (2 дюйма), а слева ищем значение 1/2. Итого 2,5 дюйма = 63,501 мм, что вполне можно округлить до 64 мм, а, например, 6,25 дюйма (то есть 6 и 1/4) = 158,753 мм или 159 мм.
|
Дюймы «» в миллиметрах |
||||||||
ANSI-люмен (лм, lm), единица измерения — это.
 ..
..
ANSI-люмен – единица измерения освещенности в мультимедийных проекторах, создаваемой лампой при просвечивании через линзу. «Lumen» по-латыни означает «свет», ANSI расшифровывается как «American National Standards Institute». Это стандарт для измерения светового потока, используемый для сравнения проекторов.
Этот параметр был введен в 1992 году Американским институтом Национальных Стандартов в качестве единицы, характеризующей среднюю величину светового потока на контрольном экране с диагональю 40″ при минимальном фокусном расстоянии вариообъектива проектора.
Измерение проводится на полностью белой картинке (full white), освещенность экрана измеряется с помощью люксметра в люксах (Lux) в 9 контрольных точках экрана. Значение светового потока рассчитывается как среднее значение этих 9 измерений — умножаются на его площадь и усредняются.
Результирующая световая энергия на экране на каждый квадратный метр указывается в люксах и находится по формуле: люкс = люмен /м². Но измерение люменов/люксов варьируется в зависимости от окружения, настройки прибора и проецируемого изображения, поэтому сегодня в качестве стандарта всеобщее признание получила процедура определения полезного светового потока в ANSI-люменах.
Но измерение люменов/люксов варьируется в зависимости от окружения, настройки прибора и проецируемого изображения, поэтому сегодня в качестве стандарта всеобщее признание получила процедура определения полезного светового потока в ANSI-люменах.
Такое измерение позволяет оценить равномерности распределения светового потока по поверхности экрана. Снижение яркости изображения по его краям называют «Hot Spot» или световым пятном. Равномерность распределения светового потока рассчитывается как соотношение наименьшего и наибольшего из полученных измерений освещенности. В хороших проекторах это значение не падает ниже 70%.
Данная методика точно описывает порядок проведения измерений. При строго определенных условиях окружающей среды и настройках прибора проецируемое на экран изображение делится на девять равных частей, и в каждой из них определяется световая энергия. Среднее значение, полученное из всех девяти замеров и умноженное на площадь экрана в м², дает значение ANSI-люмена.
Интересно, что световой поток, в отличие от освещенности (измеряемой в ANSI-люменах), не зависит от проецируемой площади. К тому же, указанные производителем значения в ANSI-люменах часто опираются на эталонные максимальные настройки, которые редко используются на практике.
Также часто значение в ANSI-люменах является лишь средним значением, поэтому на основе него трудно сделать вывод, насколько хорошо или плохо проектор распределяет свет по поверхности экрана.
Значения ANSI-люменов у цифровых проекторов могут достигать от 900 ANSI-люменов у более старых моделей до 4700 ANSI-люменов у современных мощных приборов. Хороший цифровой проектор для домашнего кинотеатра должен иметь порядка 2000 ANSI-люменов.
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
*Наведите курсор мыши для приостановки прокрутки.
Назад
Вперед
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров , т.е. нечитаемых символов.
Итак, поехали…
Что такое кодировка?
Упрощенно говоря, кодировка — это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов , которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII .
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка , в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков , помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R — это тоже расширенная кодировка ASCII , предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок .
По сути это были те же расширенные версии ASCII , однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251 . Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
ANSI-кодировка — это собирательное название . В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами — нечитаемым бессмысленным набором символов.
Причина их появления проста — это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу .
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере .
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст — вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда .
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32 .
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита , т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов , что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка — UTF-16 .
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального , и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 — это многобайтовая кодировка с переменной длинной символа . Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII . Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++ , phpDesigner , rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
ANSI
— UTF-8
— UTF-8 без BOM
Сразу скажу, что выбирать всегда стоит именно последний вариант — UTF-8 без BOM .
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark . Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM . Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом , в результате чего возникают ошибки в работе скриптов.
Длина кодовой комбинации, включающая информационные символы и проверочные (контрольные) символы, называется _ кода
Другие предметы,
17.04.2019 04:50,
danarinka
Действия, при которых абонент А заявляет, что не посылал сообщения абоненту В, хотя на самом деле посылал, называются
(*ответ*) ренегатством
подменой
переделкой
маскарадом
Действия, при которых абонент В изменяет документ и утверждает, что данный документ (измененный) получил от абонента A, называются
(*ответ*) переделкой
ренегатством
маскарадом
подменой
Действия, при которых абонент В формирует документ (новый) и заявляет, что получил его от абонента A, называется
(*ответ*) подменой
активным перехватом
маскарадом
переделкой
Действия, при которых абонент С посылает документ от имени абонента А, называется
(*ответ*) маскарадом
пассивным перехватом
активным перехватом
ренегатством
Действия, при которых абонент С посылает ранее переданный документ, который абонент A послал абоненту В, называются
(*ответ*) повтором
маскарадом
ренегатством
подменой
Действия, при которых нарушитель, подключившийся к сети, получает документы (файлы) и изменяет их, называются
(*ответ*) активным перехватом
фальсификацией
копированием
пассивным перехватом
Дефекты, проявляющиеся в невозможности правильного чтения и/или записи данных на отдельных участках магнитного диска из-за механических повреждений, неудовлетворительного качества или старения магнитного покрытия диска, называются
(*ответ*) физическими
нерезидентными вирусами
безвредными вирусами
логическими
Деятельность субъекта, в ходе которой он получает сведения об интересующем его объекте, называется _ информации
(*ответ*) сбором
обработкой
накоплением
обменом
Длина ключа в шифроалгоритме DES в битах составляет
(*ответ*) 56
16
64
65
Длина кодовой комбинации, включающая информационные символы и проверочные (контрольные) символы, называется _ кода
(*ответ*) значностью
корректирующей способностью
размерностью
избыточностью
Для «взламывания» системы защиты используется
(*ответ*) криптоанализ
шифроанализ
шифрография
криптография
Всего ответов: 2
Посмотреть ответы
Похожие вопросы
Другие предметы, 16. 04.2019 22:42, кракозябрлохиябра2
04.2019 22:42, кракозябрлохиябра2
Устройство, переводящее цифры, буквы и другие языковые символы в комбинации проколов, доступных для обработки на ЭВМ
Ответов: 2
Посмотреть
Другие предметы, 17.04.2019 00:20, Oleksandra2005
Информационные технологии, которые реализуют технологию решения задач в конкретной предметной области путем использования комбинации
Ответов: 2
Посмотреть
Другие предметы, 17.04.2019 05:30, Аккаунт удален
Кодовая комбинация состоит из 10 импульсов трех форм: А, В и С, причем в каждой кодовой комбинации три импульса имеют форму
Ответов: 2
Посмотреть
Другие предметы, 16.04.2019 23:00, перемена1
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Ответов: 2
Посмотреть
Знаешь правильный ответ?
Длина кодовой комбинации, включающая информационные символы и проверочные (контрольные) символы, наз…
Вопросы по предметам
Математика
Назови попарно номера машин, которые двигаются: в одном направлении; в противоположных направлениях в разных направлениях. ..
..
3 ответ(ов)
Биология
Каково значение фотосинтеза отдельно для растений и…
2 ответ(ов)
Русский язык
Подберите антонимы к словам: 1)темный(ночь, лицо, рубашка) 2)верный(друг, решение, вывод) 3)легкий(танец, решение, запах)…
2 ответ(ов)
Математика
Назовите 10 писателей 10 поэтов 10 художников…
3 ответ(ов)
Русский язык
Подобрать 6 слов на каждый чередующейся корень…
2 ответ(ов)
Химия
Какой объем водорода надо затратить, (при н. у) , чтобы восстановить 125 г оксида магния до металла?…
2 ответ(ов)
Математика
Кобщему знаменателю знаменатели 693 672…
2 ответ(ов)
Русский язык
Словообразовательный разбор слов: спор (*_*)…
3 ответ(ов)
Литература
Скакой главы по какую в романе «война и мир» идет речь о партизанской войне? том 4,часть 3,глава 1-начало. а конец? последняя глава 3 части или дальше еще есть?…
1 ответ(ов)
Алгебра
X*(x-2)(x-4)(x-6)=33 произведение корней найти. ..
..
1 ответ(ов)
Больше вопросов по предмету: Другие предметы
Случайные вопросы
Задать вопрос
Популярные вопросы
Из ряда чисел выбери то, в записи которого отсутст…
1 ответ(ов)
.(Сторона квадрата равна 20 см. на сколько процент…
1 ответ(ов)
Сочинение на тему мы в ответе за того, кого прируч…
1 ответ(ов)
Напишите всё что знаите про имя существительное…
2 ответ(ов)
С: для образования средней соли к раствору серной…
1 ответ(ов)
Составте предложение со словом «пренебрегать»…
2 ответ(ов)
Врастворённом виде минеральные соли поступают в ра…
2 ответ(ов)
Решите уравнение пож 1) х/3 — х/4 =1/6 2)х/4=х-1/6…
1 ответ(ов)
Знайти векторний добуток векторів a(-5; 5; -5) b(4…
2 ответ(ов)
Вектор а=-3i + 4j, чему тогда равна длинна вектора…
2 ответ(ов)
Кодовая страница Windows 1251
Кодовая страница Windows 1251
Эта страница содержит таблицу кодовой страницы Microsoft Windows 1251 для русского и
некоторые другие языки, написанные кириллицей. CP1251
CP1251
символы заключены буквально в скобки слева от каждой строки.
Если вы сохраните эту страницу, у вас будет таблица CP1251, которую вы сможете использовать для проверки своих
конфигурация набора символов эмулятора терминала.
Кодовая страница Microsoft Windows 1251 char dec col/row oct шестнадцатеричное описание [] 128 08/00 200 80 ЗАГЛАВНАЯ БУКВА DJE [] 12901.08.201 81 ЗАГЛАВНАЯ БУКВА ГЖЕ [] 130 02/08 202 82 LOW 9 ОДИНОЧНАЯ ЦИТАТА [] 131 03/08 203 83 СТРОЧНАЯ БУКВА ГЖЕ [] 132 08/04 204 84 LOW 9 ДВОЙНАЯ ЦИТАТА [] 133 05.08.205 85 ЭЛЛИПСИС [] 134 08/06 206 86 КИНЖАЛ [] 135 07.08 207 87 ДВОЙНОЙ КИНЖАЛ [] 136 08/08 210 88 ЗНАК ЕВРО [] 137 08/09 211 89 ПРОМИЛЬ ЗНАК [] 138 08/10 212 8A ЗАГЛАВНАЯ БУКВА LJE [] 139 08/11 213 8B ЛЕВАЯ ОДИНАРНАЯ СКОБКА [] 140 08/12 214 8C ЗАГЛАВНАЯ БУКВА NJE [] 141 08/13 215 8D ЗАГЛАВНАЯ БУКВА KJE [] 142 08/14 216 8E ЗАГЛАВНАЯ БУКВА ТШЕ [] 143 08/15 217 8F ЗАГЛАВНАЯ БУКВА ДЖЕ [] 144 09/00 220 90 СТРОЧНАЯ БУКВА DJE [] 145 09/01 221 91 HIGH 6 ОДИНОЧНАЯ ЦИТАТА [] 146 09/02 222 92 ВЫСОКИЙ 9 ОДИНОЧНАЯ ЦИТАТА [] 147 03/09 223 93 HIGH 6 ДВОЙНАЯ ЦИТАТА [] 148 04/04 224 94 HIGH 9 ДВОЙНАЯ ЦИТАТА [] 149 05/09 225 95 БОЛЬШАЯ ТОЧКА ПО ЦЕНТРУ [] 150 09/06 226 96 РУССКИЙ ТИРЕ [] 151 07.09.227 97 EM ТИРЕ [] 152 08/09 230 98 (НЕОПРЕДЕЛЕНО) [] 153 09/09 231 99 ЗНАК ТОРГОВОГО ЗНАКА [] 154 09/10 232 9A СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА LJE [] 155 09/11 233 9B ПРАВАЯ ОДИНАРНАЯ КАТЫЧКА [] 156 09/12 234 9C СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА NJE [] 157 09/13 235 9D СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА KJE [] 158 09/14 236 9E ЗАГЛАВНАЯ БУКВА ЦШЕ [] 159 09/15 237 9F ЗАГЛАВНАЯ БУКВА ДЖЕ [] 160 10/00 240 A0 НЕРАЗРЫВНЫЙ ПРОБЕЛ [] 161 10/01 241 A1 КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ U [] 162 10/02 242 A2 СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ U [] 163 10/03 243 A3 ЗАГЛАВНАЯ БУКВА JE [] 164 10/04 244 A4 ЗНАК ВАЛЮТЫ [] 165 10/05 245 A5 ЗАГЛАВНАЯ БУКВА GHE С ПЕРЕВЕРТОМ ВВЕРХ [] 166 10/06 246 A6 Сломанная полоса [] 167 10/07 247 A7 ЗНАК АБЗАЦА [] 168 10/08 250 A8 ЗАГЛАВНАЯ БУКВА IO [] 16910/09 251 A9 ЗНАК АВТОРСКОГО ПРАВА [] 170 10/10 252 АА КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ ИЕ [] 171 10/11 253 AB ЛЕВАЯ УГЛОВАЯ КАвычка [] 172 12/10 254 AC НЕ ЗНАК [] 173 13/10 255 ОБЪЯВЛЕНИЕ МЯГКИЙ ДЕФЕС [] 174 10/14 256 AE ЗНАК ЗАРЕГИСТРИРОВАННОЙ ТОРГОВОЙ МАРКИ [] 175 10/15 257 AF ЗАГЛАВНАЯ БУКВА ЙИ [] 176 11/00 260 B0 ЗНАК ГРАДУСА, КОЛЬЦО ВВЕРХУ [] 177 11/01 261 B1 ЗНАК ПЛЮС-МИНУС [] 178 11/02 262 B2 ЗАГЛАВНАЯ БУКВА БЕЛОРУСЬ-УКРАИНСКАЯ I [] 179 11/03 263 B3 СТРОЧНАЯ КИРИЛЛИЧНАЯ БЕЛОРУССКАЯ-УКРАИНСКАЯ I [] 180 11/04 264 B4 КИРИЛЛИЧНАЯ СТРОЧНАЯ БУКВА GHE С ПЕРЕВЕРТОМ [] 181 11/05 265 B5 МИКРОЗНАК [] 182 11/06 266 B6 ЗНАК ПОДУШКА [] 183 11/07 267 B7 СРЕДНЯЯ ТОЧКА [] 184 11/08 270 B8 СТРОЧНАЯ БУКВА IO [] 185 11/09271 B9 ЦИФРОВОЙ ЗНАК [] 186 11/10 272 БА СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА УКРАИНСКИЙ ИЕ [] 187 11/11 273 BB ПРЯМОЙ УГОЛ КАвычки [] 188 12/11 274 г.
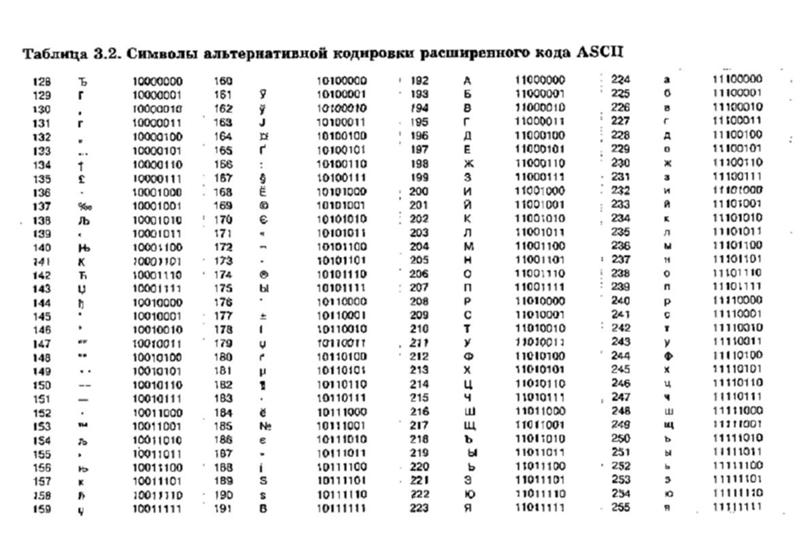 09.227 97 EM ТИРЕ
[] 152 08/09 230 98 (НЕОПРЕДЕЛЕНО)
[] 153 09/09 231 99 ЗНАК ТОРГОВОГО ЗНАКА
[] 154 09/10 232 9A СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА LJE
[] 155 09/11 233 9B ПРАВАЯ ОДИНАРНАЯ КАТЫЧКА
[] 156 09/12 234 9C СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА NJE
[] 157 09/13 235 9D СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА KJE
[] 158 09/14 236 9E ЗАГЛАВНАЯ БУКВА ЦШЕ
[] 159 09/15 237 9F ЗАГЛАВНАЯ БУКВА ДЖЕ
[] 160 10/00 240 A0 НЕРАЗРЫВНЫЙ ПРОБЕЛ
[] 161 10/01 241 A1 КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ U
[] 162 10/02 242 A2 СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ U
[] 163 10/03 243 A3 ЗАГЛАВНАЯ БУКВА JE
[] 164 10/04 244 A4 ЗНАК ВАЛЮТЫ
[] 165 10/05 245 A5 ЗАГЛАВНАЯ БУКВА GHE С ПЕРЕВЕРТОМ ВВЕРХ
[] 166 10/06 246 A6 Сломанная полоса
[] 167 10/07 247 A7 ЗНАК АБЗАЦА
[] 168 10/08 250 A8 ЗАГЛАВНАЯ БУКВА IO
[] 16910/09 251 A9 ЗНАК АВТОРСКОГО ПРАВА
[] 170 10/10 252 АА КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ ИЕ
[] 171 10/11 253 AB ЛЕВАЯ УГЛОВАЯ КАвычка
[] 172 12/10 254 AC НЕ ЗНАК
[] 173 13/10 255 ОБЪЯВЛЕНИЕ МЯГКИЙ ДЕФЕС
[] 174 10/14 256 AE ЗНАК ЗАРЕГИСТРИРОВАННОЙ ТОРГОВОЙ МАРКИ
[] 175 10/15 257 AF ЗАГЛАВНАЯ БУКВА ЙИ
[] 176 11/00 260 B0 ЗНАК ГРАДУСА, КОЛЬЦО ВВЕРХУ
[] 177 11/01 261 B1 ЗНАК ПЛЮС-МИНУС
[] 178 11/02 262 B2 ЗАГЛАВНАЯ БУКВА БЕЛОРУСЬ-УКРАИНСКАЯ I
[] 179 11/03 263 B3 СТРОЧНАЯ КИРИЛЛИЧНАЯ БЕЛОРУССКАЯ-УКРАИНСКАЯ I
[] 180 11/04 264 B4 КИРИЛЛИЧНАЯ СТРОЧНАЯ БУКВА GHE С ПЕРЕВЕРТОМ
[] 181 11/05 265 B5 МИКРОЗНАК
[] 182 11/06 266 B6 ЗНАК ПОДУШКА
[] 183 11/07 267 B7 СРЕДНЯЯ ТОЧКА
[] 184 11/08 270 B8 СТРОЧНАЯ БУКВА IO
[] 185 11/09271 B9 ЦИФРОВОЙ ЗНАК
[] 186 11/10 272 БА СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА УКРАИНСКИЙ ИЕ
[] 187 11/11 273 BB ПРЯМОЙ УГОЛ КАвычки
[] 188 12/11 274 г.
09.227 97 EM ТИРЕ
[] 152 08/09 230 98 (НЕОПРЕДЕЛЕНО)
[] 153 09/09 231 99 ЗНАК ТОРГОВОГО ЗНАКА
[] 154 09/10 232 9A СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА LJE
[] 155 09/11 233 9B ПРАВАЯ ОДИНАРНАЯ КАТЫЧКА
[] 156 09/12 234 9C СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА NJE
[] 157 09/13 235 9D СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА KJE
[] 158 09/14 236 9E ЗАГЛАВНАЯ БУКВА ЦШЕ
[] 159 09/15 237 9F ЗАГЛАВНАЯ БУКВА ДЖЕ
[] 160 10/00 240 A0 НЕРАЗРЫВНЫЙ ПРОБЕЛ
[] 161 10/01 241 A1 КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ U
[] 162 10/02 242 A2 СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ U
[] 163 10/03 243 A3 ЗАГЛАВНАЯ БУКВА JE
[] 164 10/04 244 A4 ЗНАК ВАЛЮТЫ
[] 165 10/05 245 A5 ЗАГЛАВНАЯ БУКВА GHE С ПЕРЕВЕРТОМ ВВЕРХ
[] 166 10/06 246 A6 Сломанная полоса
[] 167 10/07 247 A7 ЗНАК АБЗАЦА
[] 168 10/08 250 A8 ЗАГЛАВНАЯ БУКВА IO
[] 16910/09 251 A9 ЗНАК АВТОРСКОГО ПРАВА
[] 170 10/10 252 АА КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ ИЕ
[] 171 10/11 253 AB ЛЕВАЯ УГЛОВАЯ КАвычка
[] 172 12/10 254 AC НЕ ЗНАК
[] 173 13/10 255 ОБЪЯВЛЕНИЕ МЯГКИЙ ДЕФЕС
[] 174 10/14 256 AE ЗНАК ЗАРЕГИСТРИРОВАННОЙ ТОРГОВОЙ МАРКИ
[] 175 10/15 257 AF ЗАГЛАВНАЯ БУКВА ЙИ
[] 176 11/00 260 B0 ЗНАК ГРАДУСА, КОЛЬЦО ВВЕРХУ
[] 177 11/01 261 B1 ЗНАК ПЛЮС-МИНУС
[] 178 11/02 262 B2 ЗАГЛАВНАЯ БУКВА БЕЛОРУСЬ-УКРАИНСКАЯ I
[] 179 11/03 263 B3 СТРОЧНАЯ КИРИЛЛИЧНАЯ БЕЛОРУССКАЯ-УКРАИНСКАЯ I
[] 180 11/04 264 B4 КИРИЛЛИЧНАЯ СТРОЧНАЯ БУКВА GHE С ПЕРЕВЕРТОМ
[] 181 11/05 265 B5 МИКРОЗНАК
[] 182 11/06 266 B6 ЗНАК ПОДУШКА
[] 183 11/07 267 B7 СРЕДНЯЯ ТОЧКА
[] 184 11/08 270 B8 СТРОЧНАЯ БУКВА IO
[] 185 11/09271 B9 ЦИФРОВОЙ ЗНАК
[] 186 11/10 272 БА СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА УКРАИНСКИЙ ИЕ
[] 187 11/11 273 BB ПРЯМОЙ УГОЛ КАвычки
[] 188 12/11 274 г. до н.э. СТРОЧНАЯ БУКВА ДЖЕ
[] 189 13/11 275 БД ЗАГЛАВНАЯ БУКВА ДЗЕ
[] 190 14/11 276 BE СТРОЧНАЯ БУКВА ДЗЕ
[] 191 15/11 277 BF СТРОЧНАЯ БУКВА ЙИ
[] 192 12/00 300 C0 ЗАГЛАВНАЯ БУКВА A
[] 193 12/01 301 C1 ЗАГЛАВНАЯ БУКВА BE
[] 194 12/02 302 C2 ЗАГЛАВНАЯ БУКВА VE
[] 195 12/03 303 C3 ЗАГЛАВНАЯ БУКВА GHE
[] 196 12/04 304 C4 ЗАГЛАВНАЯ БУКВА DE
[] 197 12/05 305 C5 ЗАГЛАВНАЯ БУКВА IE
[] 198 12/06 306 C6 ЗАГЛАВНАЯ БУКВА ЖЕ
[] 199 12/07 307 C7 ЗАГЛАВНАЯ БУКВА ZE
[] 200 12/08 310 C8 ЗАГЛАВНАЯ БУКВА I
[] 201 12/09 311 C9 ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
[] 202 12/10 312 CA ЗАГЛАВНАЯ БУКВА КА
[] 203 12/11 313 CB ЗАГЛАВНАЯ БУКВА EL
[] 204 12/12 314 CC ЗАГЛАВНАЯ БУКВА EM
[] 205 12/13 315 CD ЗАГЛАВНАЯ БУКВА RU
[] 206 12/14 316 CE ЗАГЛАВНАЯ БУКВА O
[] 207 12/15 317 CF ЗАГЛАВНАЯ БУКВА PE
[] 208 13/00 320 D0 ЗАГЛАВНАЯ БУКВА ER
[] 20913/01 321 D1 ЗАГЛАВНАЯ БУКВА ES
[] 210 13/02 322 D2 ЗАГЛАВНАЯ БУКВА TE
[] 211 13/03 323 D3 ЗАГЛАВНАЯ БУКВА U
[] 212 13/04 324 D4 ЗАГЛАВНАЯ БУКВА EF
[] 213 13/05 325 D5 ЗАГЛАВНАЯ БУКВА HA
[] 214 13/06 326 D6 ЗАГЛАВНАЯ БУКВА ТСЕ
[] 215 13/07 327 D7 ЗАГЛАВНАЯ БУКВА ЧЕ
[] 216 13/08 330 D8 ЗАГЛАВНАЯ БУКВА ША
[] 217 13/09 331 D9 ЗАГЛАВНАЯ БУКВА ЩА
[] 218 13/10 332 DA КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА ПРОБНЫЙ ЗНАК
[] 21913/11 333 ДБ ЗАГЛАВНАЯ БУКВА ЕРУ
[] 220 13/12 334 DC КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
[] 221 13/13 335 DD ЗАГЛАВНАЯ БУКВА E
[] 222 13/14 336 DE ЗАГЛАВНАЯ БУКВА Ю
[] 223 13/15 337 DF ЗАГЛАВНАЯ БУКВА Я
[] 224 14/00 340 E0 СТРОЧНАЯ БУКВА А
[] 225 14/01 341 E1 СТРОЧНАЯ БУКВА BE
[] 226 14/02 342 E2 СТРОЧНАЯ БУКВА VE
[] 227 14/03 343 E3 СТРОЧНАЯ БУКВА GHE
[] 228 14/04 344 E4 СТРОЧНАЯ БУКВА DE
[] 22914/05 345 E5 СТРОЧНАЯ БУКВА IE
[] 230 14/06 346 E6 СТРОЧНАЯ БУКВА ЖЕ
[] 231 14/07 347 E7 СТРОЧНАЯ БУКВА ZE
[] 232 14/08 350 E8 СТРОЧНАЯ БУКВА I
[] 233 14/09 351 E9 СТРОЧНАЯ БУКВА КИРИЛЛИЦЫ КОРОТКАЯ I
[] 234 14/10 352 EA СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КА
[] 235 14/11 353 EB СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EL
[] 236 14/12 354 EC СТРОЧНАЯ БУКВА EM
[] 237 14/13 355 ЭД СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EN
[] 238 14/14 356 EE СТРОЧНАЯ БУКВА О
[] 23914/15 357 EF СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА PE
[] 240 15/00 360 F0 СТРОЧНАЯ БУКВА ER
[] 241 15/01 361 F1 СТРОЧНАЯ БУКВА ES
[] 242 15/02 362 F2 СТРОЧНАЯ БУКВА TE
[] 243 15/03 363 F3 СТРОЧНАЯ БУКВА U
[] 244 15/04 364 F4 СТРОЧНАЯ БУКВА EF
[] 245 15/05 365 F5 СТРОЧНАЯ БУКВА HA
[] 246 15/06 366 F6 СТРОЧНАЯ БУКВА ТСЭ
[] 247 15/07 367 F7 СТРОЧНАЯ БУКВА ЧЕ
[] 248 15/08 370 F8 СТРОЧНАЯ БУКВА ЧА
[] 24915/09 371 F9 СТРОЧНАЯ БУКВА ЩА
[] 250 15/10 372 FA СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЖЕСТКИЙ ЗНАК
[] 251 15/11 373 FB СТРОЧНАЯ БУКВА ЕРУ
[] 252 15/12 374 FC СТРОЧНАЯ БУКВА КИРИЛИЦЫ МЯГКИЙ ЗНАК
[] 253 15/13 375 FD СТРОЧНАЯ БУКВА Е
[] 254 15/14 376 ФЕ СТРОЧНАЯ БУКВА Ю
[] 255 15/15 377 FF СТРОЧНАЯ БУКВА Я
до н.э. СТРОЧНАЯ БУКВА ДЖЕ
[] 189 13/11 275 БД ЗАГЛАВНАЯ БУКВА ДЗЕ
[] 190 14/11 276 BE СТРОЧНАЯ БУКВА ДЗЕ
[] 191 15/11 277 BF СТРОЧНАЯ БУКВА ЙИ
[] 192 12/00 300 C0 ЗАГЛАВНАЯ БУКВА A
[] 193 12/01 301 C1 ЗАГЛАВНАЯ БУКВА BE
[] 194 12/02 302 C2 ЗАГЛАВНАЯ БУКВА VE
[] 195 12/03 303 C3 ЗАГЛАВНАЯ БУКВА GHE
[] 196 12/04 304 C4 ЗАГЛАВНАЯ БУКВА DE
[] 197 12/05 305 C5 ЗАГЛАВНАЯ БУКВА IE
[] 198 12/06 306 C6 ЗАГЛАВНАЯ БУКВА ЖЕ
[] 199 12/07 307 C7 ЗАГЛАВНАЯ БУКВА ZE
[] 200 12/08 310 C8 ЗАГЛАВНАЯ БУКВА I
[] 201 12/09 311 C9 ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
[] 202 12/10 312 CA ЗАГЛАВНАЯ БУКВА КА
[] 203 12/11 313 CB ЗАГЛАВНАЯ БУКВА EL
[] 204 12/12 314 CC ЗАГЛАВНАЯ БУКВА EM
[] 205 12/13 315 CD ЗАГЛАВНАЯ БУКВА RU
[] 206 12/14 316 CE ЗАГЛАВНАЯ БУКВА O
[] 207 12/15 317 CF ЗАГЛАВНАЯ БУКВА PE
[] 208 13/00 320 D0 ЗАГЛАВНАЯ БУКВА ER
[] 20913/01 321 D1 ЗАГЛАВНАЯ БУКВА ES
[] 210 13/02 322 D2 ЗАГЛАВНАЯ БУКВА TE
[] 211 13/03 323 D3 ЗАГЛАВНАЯ БУКВА U
[] 212 13/04 324 D4 ЗАГЛАВНАЯ БУКВА EF
[] 213 13/05 325 D5 ЗАГЛАВНАЯ БУКВА HA
[] 214 13/06 326 D6 ЗАГЛАВНАЯ БУКВА ТСЕ
[] 215 13/07 327 D7 ЗАГЛАВНАЯ БУКВА ЧЕ
[] 216 13/08 330 D8 ЗАГЛАВНАЯ БУКВА ША
[] 217 13/09 331 D9 ЗАГЛАВНАЯ БУКВА ЩА
[] 218 13/10 332 DA КИРИЛЛИЧНАЯ ЗАГЛАВНАЯ БУКВА ПРОБНЫЙ ЗНАК
[] 21913/11 333 ДБ ЗАГЛАВНАЯ БУКВА ЕРУ
[] 220 13/12 334 DC КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
[] 221 13/13 335 DD ЗАГЛАВНАЯ БУКВА E
[] 222 13/14 336 DE ЗАГЛАВНАЯ БУКВА Ю
[] 223 13/15 337 DF ЗАГЛАВНАЯ БУКВА Я
[] 224 14/00 340 E0 СТРОЧНАЯ БУКВА А
[] 225 14/01 341 E1 СТРОЧНАЯ БУКВА BE
[] 226 14/02 342 E2 СТРОЧНАЯ БУКВА VE
[] 227 14/03 343 E3 СТРОЧНАЯ БУКВА GHE
[] 228 14/04 344 E4 СТРОЧНАЯ БУКВА DE
[] 22914/05 345 E5 СТРОЧНАЯ БУКВА IE
[] 230 14/06 346 E6 СТРОЧНАЯ БУКВА ЖЕ
[] 231 14/07 347 E7 СТРОЧНАЯ БУКВА ZE
[] 232 14/08 350 E8 СТРОЧНАЯ БУКВА I
[] 233 14/09 351 E9 СТРОЧНАЯ БУКВА КИРИЛЛИЦЫ КОРОТКАЯ I
[] 234 14/10 352 EA СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КА
[] 235 14/11 353 EB СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EL
[] 236 14/12 354 EC СТРОЧНАЯ БУКВА EM
[] 237 14/13 355 ЭД СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА EN
[] 238 14/14 356 EE СТРОЧНАЯ БУКВА О
[] 23914/15 357 EF СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА PE
[] 240 15/00 360 F0 СТРОЧНАЯ БУКВА ER
[] 241 15/01 361 F1 СТРОЧНАЯ БУКВА ES
[] 242 15/02 362 F2 СТРОЧНАЯ БУКВА TE
[] 243 15/03 363 F3 СТРОЧНАЯ БУКВА U
[] 244 15/04 364 F4 СТРОЧНАЯ БУКВА EF
[] 245 15/05 365 F5 СТРОЧНАЯ БУКВА HA
[] 246 15/06 366 F6 СТРОЧНАЯ БУКВА ТСЭ
[] 247 15/07 367 F7 СТРОЧНАЯ БУКВА ЧЕ
[] 248 15/08 370 F8 СТРОЧНАЯ БУКВА ЧА
[] 24915/09 371 F9 СТРОЧНАЯ БУКВА ЩА
[] 250 15/10 372 FA СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ЖЕСТКИЙ ЗНАК
[] 251 15/11 373 FB СТРОЧНАЯ БУКВА ЕРУ
[] 252 15/12 374 FC СТРОЧНАЯ БУКВА КИРИЛИЦЫ МЯГКИЙ ЗНАК
[] 253 15/13 375 FD СТРОЧНАЯ БУКВА Е
[] 254 15/14 376 ФЕ СТРОЧНАЯ БУКВА Ю
[] 255 15/15 377 FF СТРОЧНАЯ БУКВА Я
Франк да Круз,
Проект Кермит,
Колумбийский университет,
март 2003 г.

Языковые драйверы > Образцы языковых драйверов BDE
Многие или, по крайней мере, некоторые современные базы данных используют символы Unicode для представления текста, что позволяет избежать проблем с неправильным представлением символов, используемых в региональных языках.
Поскольку BDE не обновлялся с 2001 года и никогда не будет обновляться, таблицы, зависящие от поддержки BDE, никогда не будут совместимы с Unicode (UTF-8 или Unicode) и, таким образом, будут по-прежнему зависеть от интерпретации символов на основе различных кодовых страниц для 224-символьного расширенного ASCII. набор символов (коды символов 32-255).
Единственными символьными данными, способными поддерживать правильное представление символов независимо от языкового драйвера, являются данные, хранящиеся в формате RTF либо в FormattedMemo, либо в формате RTF в обычных полях Memo.
Таким образом, чтобы удовлетворить потребности различных надписей, адаптирующихся к различным языкам, даже при использовании только обычного диапазона из 224 символов, каждая таблица данных связана с драйверами языка и набора символов, что позволяет интерпретировать региональные символы одних и тех же числовых кодов символов в пределах расширенный набор символов ASCII.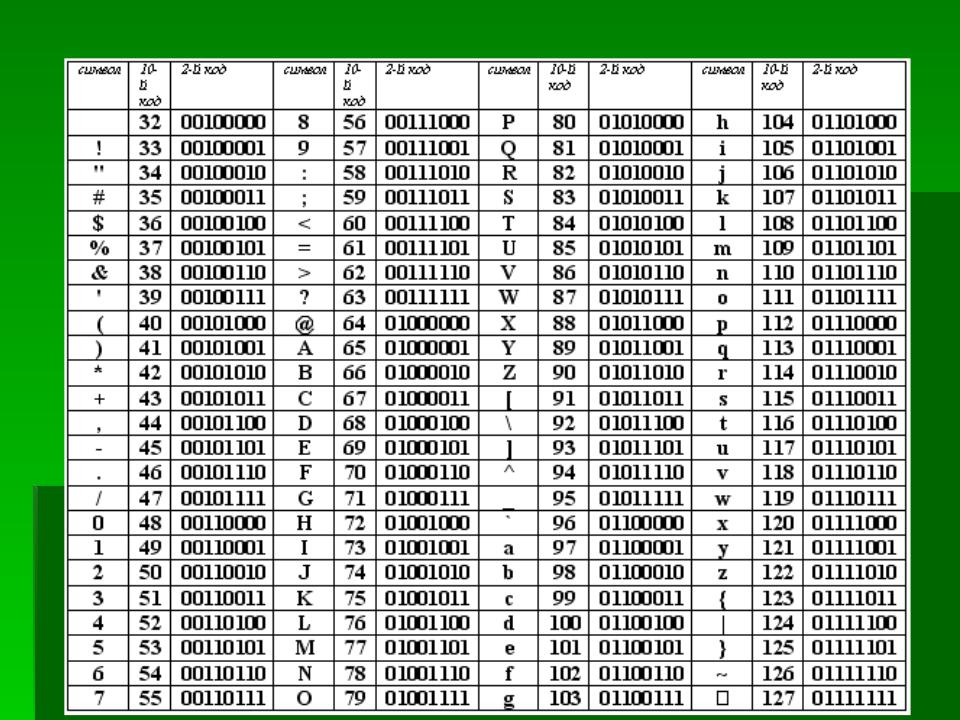
Это означает, что таблицу Paradox или dBase можно переносить от одного пользователя к другому без потери надлежащих настроек символов для заголовков столбцов и содержимого строк таблицы, поскольку настройка языкового драйвера встроена в каждую таблицу данных .db и .dbf.
Поскольку наборы символов, используемые с переносимыми таблицами, могут быть неправильными во время экспорта или импорта между различными системами баз данных, вам может потребоваться настроить выбор символов, используемых с определенными таблицами, например. получение таблицы Paradox, экспортированной из базы данных MS Access.
Изменение языкового драйвера таблицы вообще не меняет данные, меняется только символ, считываемый из каждого сохраненного числового кода символа.
Смена языкового драйвера для текущей отображаемой таблицы осуществляется через меню таблицы.
В меню «Справка» вы можете увидеть большое количество доступных кодов драйверов.
См. также внешнюю ссылку Коды символов.
Расширенный набор символов ASCII в таблицах BDE и системные настройки, отличные от Unicode
Поскольку BDE не поддерживает Unicode, отображение символов, отличных от тех, которые поддерживаются символами, не поддерживающими Unicode по умолчанию в вашей текущей системе, зависит от адаптации системных настроек Windows для приложений, не поддерживающих Unicode, как показано в справке PdxEditor | Диалоговое окно «О программе» (IBM/OEM CodePage).
Обычно набор символов Windows по умолчанию сопровождается определенным набором символов DOS по умолчанию, например. cp1252 с cp850, cp1251 с cp866 и т. д.
Однако это можно изменить в системных настройках по мере необходимости (но обычно это не рекомендуется!).
Отображение символов таблицы BDE зависит от этих настроек, однако псевдографические символы не будут отображаться даже при применении, например, cp437 для приложений Windows, не поддерживающих Юникод.
При отображении таблицы BDE с помощью драйвера ASCII все псевдографические символы недоступны, отображаются с символом замены #, как и исторические Pesetas Pts (₧ — #158), малоиспользуемый знак «Не перевернуто» (⌐ — #169), а также большинство греческих и математических символов.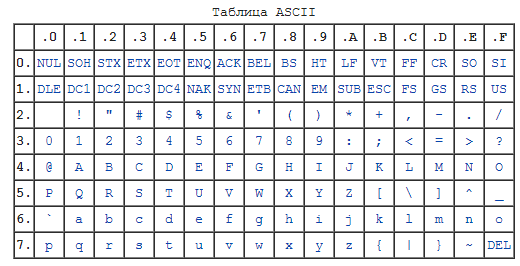
На современном компьютере (например, с Windows 7, 8 или 10 и западными системными настройками) при отображении таблицы BDE все символы набора CodePage 1252 отображаются с использованием, например, любой из языковых драйверов Windows DBWINUS0, DBWINES0 или DBWINWE0.
С драйвером INTL850 отображаются все символы CodePage 850, за исключением псевдографических рисунков и символов штриховки, используемых в старых системах DOS.
В некоторых настройках некоторые символы могут отображаться соответствующими замещающими символами, например. в CodePage 850 символ i без точки #213 (используется в турецком и армянском языках) заменен в BDE стандартным i (системная настройка cp1252/cp850).
Что касается DBWINWE0, то на самом деле он не указывает набор символов Windows Western 1252, а только текущий набор символов Windows, поэтому при отображении таблицы BDE с драйвером DBWINWE0 на компьютере, использующем набор символов кириллицы cp1251/cp866, расширенный набор символов не будет отображаться.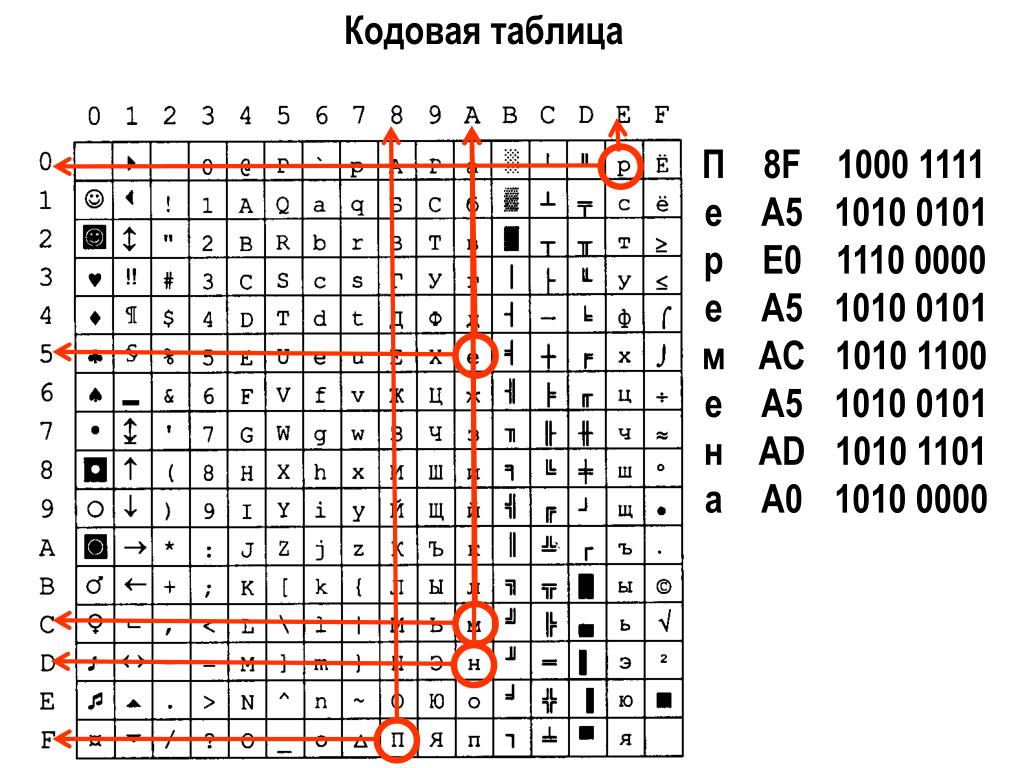 символы из CodePage 1252, а скорее символы кириллицы из CodePage 1251.
символы из CodePage 1252, а скорее символы кириллицы из CodePage 1251.
Кроме того, в той же таблице в системе, использующей cp1252/cp866 (необычная настройка!) неожиданно будет отображаться полный набор кириллических символов, такой как CP1251 (см. ниже).
Отображение других символов, напр. Таким образом, кириллица в диапазоне 128–255 с применением драйвера ancyrr будет зависеть от системных настроек для приложений, не поддерживающих юникод, например. Кодовая страница 866 для кириллицы.
Таблица BDE (Paradox) при просмотре с примененным драйвером языка ASCII и системными настройками CodePage 1252 с CP437 для приложений, не поддерживающих Unicode:
Таблица BDE (Paradox) при просмотре с примененным языковым драйвером INTL850 и системными настройками CodePage 12502 с CP8552 с CP8502 для приложений, не поддерживающих Юникод:
Таблица BDE (Paradox) просматривается с примененным драйвером языка DBWINWE0 и системными настройками CodePage 1252 с CP850 для приложений, не поддерживающих Unicode:
Таблица BDE с применением системного драйвера DBWINWE (Paradox) CodePage 1252 с CP866 для приложений, не поддерживающих Unicode:
Таблица BDE (Paradox), просмотренная с применением драйвера языка cyrr и системных настроек CodePage 1252 с CP866 для приложений, не поддерживающих Unicode:
Таблица BDE (Paradox), просмотренная с применением драйвера языка ancyrr и системных настроек CodePage 1252 с CP866 для приложений, не поддерживающих Unicode:
Различия кодовых страниц
Для сравнения в следующих примерах показан один и тот же код символов из незакодированного текстового файла, открытого в текстовом редакторе с четырьмя разными кодовыми страницами: 437 (США), 850 (международная западная), 1252 (западная Windows) и 1251 (кириллица Windows).
При просмотре с кодовой страницей 437:
При просмотре с кодовой страницей 850:
При просмотре с кодовой страницей 1252:
При просмотре с кодовой страницей 1251 (кириллица):
1
__________________________
Справка по приложению PdxEditor, 18 июля 2022 г.; © 2010-2022 Нильс Кнабе
Кодовая страница и компания
Кодовая страница и компания
В начале 1980-х годов еще не существовало согласованных международных стандартов.
например, ISO-8859 или Unicode о том, как расширить US-ASCII для международных пользователей, и многие
производители придумали собственные кодировки, используя трудно запоминаемые
номера:
Кодовые страницы MS-DOS
CP437 (DOSLatinUS)
Промышленный стандарт IBM
Персональный компьютер начинался со знаменитой кодовой страницы CP437 с
множество символов, рисующих прямоугольники, и несколько избранных иностранных букв:
кодировка=cp437
[ТЕКСТ]
[БДФ]
CP850 (DOSLatin1)
Некоторые более поздние версии MS-DOS позволяли изменять кодовые страницы на
Видеокарты VGA до чего-то вроде CP850, которые представляли репертуар Latin1 на позициях
совместим с CP437, так что рисование линий по-прежнему
работал:
кодировка=cp850
[ТЕКСТ]
[БДФ]
CP852 (DOSLatin2)
CP852 сделал то же самое для Latin2 (Восточная Европа):
кодировка=cp852
[ТЕКСТ]
[БДФ]
CP855 (DOSCyrillic)
CP855 был введен как соответствующая кодовая страница кириллицы:
кодировка=cp855
[ТЕКСТ]
[БДФ]
CP866 (DOSCyrillicRussian)
За
CP855 вскоре последовал CP866, который
следовал более логичному порядку русского алфавита
альтернативный вариант, который предпочли многие российские пользователи:
кодировка=cp866
[ТЕКСТ]
[БДФ]
Еще более широко используемая кириллическая кодировка (KOI8-R) позже получила номер CP878.
CP874 (DOSThai)
Тайский процессор Microsoft CP874 также соответствует установленным стандартам.
а именно ТИС-620, но добавляет
нестандартные символы в неиспользуемых позициях:
кодировка=cp874
[ТЕКСТ]
[БДФ]
CP737..CP862
Теперь я избавил вас от кровавых подробностей
из
- CP737
- DOSГреческий
- CP775
- ДОСБалтРим
- CP857
- DOSТурецкий
- CP860
- DOSПортугальский
- CP861
- DOSисландский
- CP862
- DOSИврит
- CP863
- DOSCanadaF
- CP864
- DOSAрабский
- CP865
- DOSNordic
- CP869
- DOSGreek2
Кодовые страницы MS-Windows
CP1252 (WinLatin1)
С появлением Windows Microsoft осмелилась попрощаться с
символы рисования линий и совместимость с CP437, а также принят модифицированный расширенный набор ISO-8859.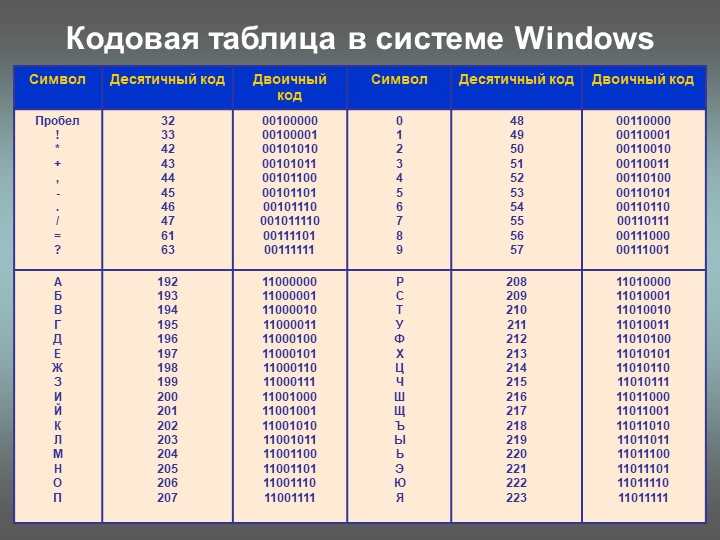 -1 как CP1252:
-1 как CP1252:
кодировка = Windows-1252
[ТЕКСТ]
[БДФ]
CP1250 (WinLatin2)
Как ни странно, WinLatin2 получил номер CP1250 и отличается от ISO-8859-2 в некоторых позициях, но
принесли Microsoft большой доход на развивающихся рынках
Восточная Европа в 1990-е годы:
кодировка = Windows-1250
[ТЕКСТ]
[БДФ]
CP1251 (WinCyrillic)
Другим таким примером является кириллица.
кодовая страница CP1251, для которой Microsoft зарегистрировала метку «Windows-1251». По состоянию на декабрь
1997, даже новый веб-сервер ГОСТа (Lotus Notes) приветствует вас
с кодировкой=WINDOWS-1251. ГОСТ (российская стандартизация
органа и организации-члена ISO) не
даже после своего
стандартов больше нет!
CP1251 имеет богатый репертуар в порядке, несовместимом с обоими
ISO-IR-111 (KOI8) и ISO-8859-5:
кодировка = Windows-1251
[ТЕКСТ]
[БДФ]
CP1257 (WinBaltic)
Это WinBaltic, который мог послужить моделью для ISOLatin7:
кодировка = Windows-1257
[ТЕКСТ]
[БДФ]
CP1253.
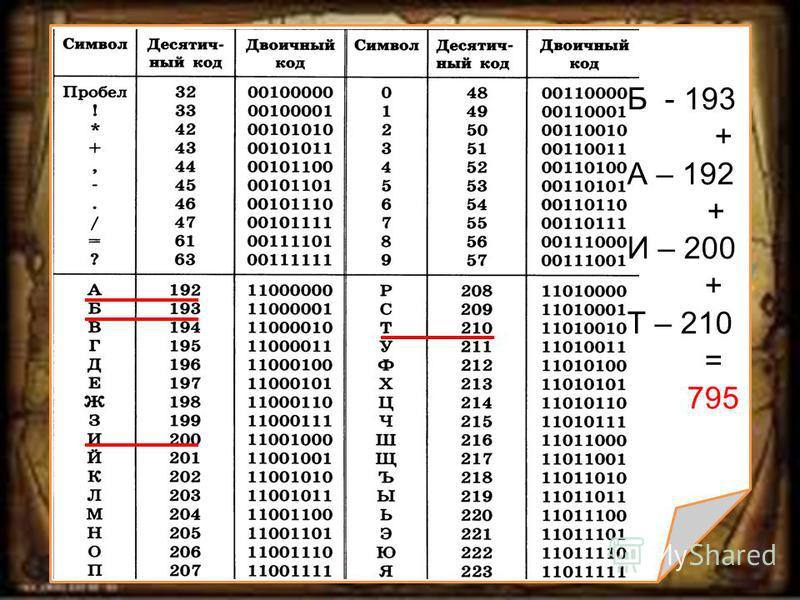 ..CP1258 Вы понимаете, другие кодовые страницы Windows:
..CP1258 Вы понимаете, другие кодовые страницы Windows:
- 1253
- WinGreek отличается от ISO-8859-7 расположением заглавной буквы с тонами и
только несколько символов. - 1254
- WinTurkish делает с WinLatin1 что
ISO-8859-9 соответствует ISO-8859-1. - 1255
- WinHebrew совместим по буквам с ISO-8859-8.
- 1256
- WinArabic сохраняет символы и маленькие французские буквы
из WinLatin1 и вставляет арабские буквы
в свободные слоты так, чтобы только позиции =C1..=D6 (первая половина
арабский алфавит) совместимы с ISO-8859-6. - 1257
- WinBaltic совместим с ISOLatin7 по буквам.
- 1258
- WinVietnamese похож на WinLatin1 и сильно отличается от VISCII.
Кодовые страницы CJK
Очень сильно отличается от кодировок расширенного кодирования Unix EUC, все
следующие кодовые страницы Восточной Азии незаконно повторно используют C1
управляющие коды {=80. .=9F} для их ведущих байтов и значений ASCII
.=9F} для их ведущих байтов и значений ASCII
{=40..=7E} для их вторых байтов, чтобы закодировать более десяти
тысяча символов с двумя байтами. Это означает, что значения ASCII
за пределами =3F в своих потоках байтов не всегда означают символы ASCII.
- CP932
- Shift-JIS сочетает в себе Японские кодировки JIS X 0201 (один байт на символ) и JIS X
0208 (два байта на символ), чтобы JIS X 0201 Hiragana оставался
однобайтовые символы половинной ширины и 60 свободных 8-битных кодовых позиций
которые не содержат хираганы, используются в качестве ведущих байтов для 7076 кандзи и
648 других символов полной ширины. В отличие от EUC-JP, Shift-JIS не имеет
осталось место для дополнительных 5802 кандзи из JIS X 0212. - CP936
- GBK расширяет EUC-CN (8-битный
кодировка GB 2312-80 с 6763 hanzi) для упрощенного zh_CN Материк китайский , чтобы охватить все 20902 иероглифов хань, найденных в
Юникод (GB 13000.1-93). - CP949
- UnifiedHangul (UHC) — это расширенный набор Корейский EUC-KR (8-битная кодировка KS C 5601-1992 с
его 2350 слогов хангыль и 4888 ханджа) с 8822 дополнительными
предварительно составленные слоги хангыль в диапазоне C1. - CP950
- Big5 (13072 традиционный zh_TW
китайский ханзи) для тайваньский вместо EUC-TW (ЦНС
11643-1992).

Дополнительные сведения см. в CJK.INF Кена Лунде или в таблицах сопоставления Unicode. Вы найдете эти кодировки проиллюстрированными
у Кена Лунде
и бестселлеры Надин Кано, хотя последний написан с
чистая перспектива Microsoft с небольшим упоминанием стандартов ISO.
Стандарты других поставщиков
Microsoft — не единственная компания, изобретающая собственные более или менее
несовместимые стандарты, как вы можете видеть на ftp://ftp.unicode.org/Public/MAPPINGS/VENDORS/:
AdobeStandardEncoding
Страница Adobe PostScript
язык описания называет свою собственную кодировку StandardEncoding и
требует, чтобы вы сначала переключились на ISOLatin1Encoding, если хотите
печатать тексты ISO-8859-1.
charset=Adobe-Standard-Encoding
[ТЕКСТ]
[БДФ]
МакРоман
Macintosh от Apple давно
традиция многоязычной поддержки Apple
собственные кодировки, из которых MacRoman был первым:
кодировка=макинтош
[ТЕКСТ]
[БДФ]
СЛЕДУЮЩИЙ ШАГ
NeXTSTEP имеет нечто подобное:
набор символов = следующий
[ТЕКСТ]
[БДФ]
HP-Roman8
Hewlett-Packard HPUX и hpterm
есть их HP-Roman8:
кодировка=HP-Roman8
[ТЕКСТ]
[БДФ]
Отправьте письмо на roman@czyborra.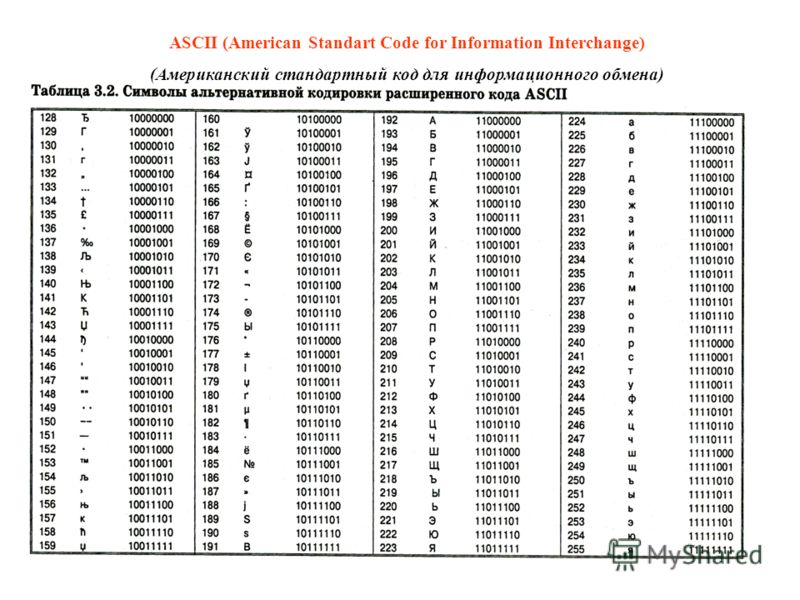 com, если вам нужны дополнительные шрифты или вы нашли ошибки
com, если вам нужны дополнительные шрифты или вы нашли ошибки
как Андреас Прилоп, Кент Карлссон, Юнгшик Шин и Ян Томасек.
Роман Чиборра
$Дата: 27.06.1998 08:25:38 $
PostgreSQL: Документация: 14: 24.3. Поддержка набора символов
- 24.3.1. Поддерживаемые наборы символов
- 24.3.2. Установка набора символов
- 24.3.3. Автоматическое преобразование набора символов между сервером и клиентом
- 24.3.4. Доступные преобразования набора символов
- 24.3.5. Дальнейшее чтение
Поддержка набора символов в PostgreSQL позволяет хранить текст в различных наборах символов (также называемых кодировками), включая однобайтовые наборы символов, такие как серия ISO 8859, и многобайтовые наборы символов, такие как EUC (расширенный код Unix). ), UTF-8 и внутренний код Mule. Все поддерживаемые наборы символов могут использоваться клиентами прозрачно, но некоторые из них не поддерживаются для использования на сервере (то есть в качестве кодировки на стороне сервера). Набор символов по умолчанию выбирается при инициализации кластера базы данных PostgreSQL с использованием
Набор символов по умолчанию выбирается при инициализации кластера базы данных PostgreSQL с использованием initdb . Его можно переопределить при создании базы данных, поэтому у вас может быть несколько баз данных, каждая из которых имеет свой набор символов.
Однако важным ограничением является то, что набор символов каждой базы данных должен быть совместим с настройками локали базы данных LC_CTYPE (классификация символов) и LC_COLLATE (порядок сортировки строк). Для локали C или POSIX разрешен любой набор символов, но для других локалей, предоставляемых libc, корректно работает только один набор символов. (Однако в Windows кодировку UTF-8 можно использовать с любой локалью.) Если у вас настроена поддержка ICU, локали, предоставленные ICU, можно использовать с большинством, но не со всеми кодировками на стороне сервера.
24.3.1. Поддерживаемые наборы символов
В таблице 24.1 показаны наборы символов, доступные для использования в PostgreSQL.
Таблица 24.1. Наборы символов PostgreSQL
| Имя | Описание | Язык | Сервер? | ОИТ? | байт/ | Псевдонимы |
|---|---|---|---|---|---|---|
БОЛЬШОЙ5 |
Большая пятерка | Традиционный китайский | № | № | 1–2 | ВИН950 , Виндовс950 |
EUC_CN |
Расширенный код UNIX-CN | Упрощенный китайский | Да | Да | 1–3 | |
EUC_JP |
Расширенный код UNIX-JP | японский | Да | Да | 1–3 | |
EUC_JIS_2004 |
Расширенный код UNIX-JP, JIS X 0213 904:00 | японский | Да | № | 1–3 | |
EUC_KR |
Расширенный код UNIX-KR | Корейский | Да | Да | 1–3 | |
EUC_TW |
Расширенный код UNIX-TW | Традиционный китайский, тайваньский | Да | Да | 1–3 | |
ГБ18030 |
Национальный стандарт | китайский | № | № | 1–4 | |
ГБК |
Расширенный национальный стандарт | Упрощенный китайский | № | № | 1–2 | ВИН936 , Виндовс936 |
ИСО_8859_5 |
ИСО 8859-5, ЕСМА 113 | Латиница/кириллица | Да | Да | 1 | |
ИСО_8859_6 |
ИСО 8859-6, ЕСМА 114 | Латинский/арабский | Да | Да | 1 | |
ИСО_8859_7 |
ИСО 8859-7, ЕСМА 118 | Латинский/греческий 904:00 | Да | Да | 1 | |
ИСО_8859_8 |
ИСО 8859-8, ЕСМА 121 | Латинский/иврит | Да | Да | 1 | |
ДЖОХАБ |
ЙОХАБ | Корейский (хангыль) | № | № | 1–3 | |
КОИ8Р |
КОИ8-Р | Кириллица (русская) | Да | Да | 1 | КОИ8 |
КОИ8У |
КОИ8-У | Кириллица (украинский) | Да | Да | 1 | |
ЛАТИНА1 |
ИСО 8859-1, ЕСМА 94 | Западноевропейская | Да | Да | 1 | ИСО88591 |
ЛАТИНСКИЙ2 |
ИСО 8859-2, ЕСМА 94 | Центральноевропейский | Да | Да | 1 | ИСО88592 |
ЛАТИН3 |
ИСО 8859-3, ЕСМА 94 | Южно-Европейский | Да | Да | 1 | ИСО88593 |
ЛАТИН4 |
ИСО 8859-4, ЕСМА 94 | Североевропейский | Да | Да | 1 | ИСО88594 |
ЛАТИНСКИЙ5 |
ИСО 8859-9, ЕСМА 128 | Турецкий 904:00 | Да | Да | 1 | ИСО88599 |
ЛАТИНСКИЙ6 |
ИСО 8859-10, ЕСМА 144 | Северный | Да | Да | 1 | ИСО885910 |
ЛАТИНСКИЙ 7 |
ИСО 8859-13 | Балтика | Да | Да | 1 | ИСО885913 |
ЛАТИНСКИЙ 8 |
ИСО 8859-14 | Селтик | Да | Да | 1 | ИСО885914 |
ЛАТИНСКИЙ 9 |
ИСО 8859-15 | LATIN1 с евро и акцентами | Да | Да | 1 | ИСО885915 |
ЛАТИНСКИЙ10 |
ИСО 8859-16, АСРО СР 14111 | Румынский | Да | № 904:00 | 1 | ИСО885916 |
MULE_INTERNAL |
Мул внутренний код | Многоязычный Emacs | Да | № | 1–4 | |
СЖИС |
Сдвиг JIS | японский 904:00 | № | № | 1–2 | Мсканджи , ШифтДжИС , ВИН932 , Виндовс932 |
SHIFT_JIS_2004 |
Сдвиг JIS, JIS X 0213 | японский | № | № | 1–2 | |
SQL_ASCII |
не указано (см. текст) текст) |
любой | Да | № | 1 | |
УВК |
Единый код хангыль | Корейский | № | № | 1–2 | ВИН949 , Виндовс949 |
UTF8 |
Юникод, 8-битный | все | Да | Да | 1–4 | Юникод |
WIN866 |
Windows CP866 | Кириллица | Да | Да | 1 | АЛЬТЕРНАТИВНЫЙ |
WIN874 |
Windows CP874 | тайский | Да | № | 1 | |
WIN1250 |
Windows CP1250 | Центральноевропейский | Да | Да | 1 | |
WIN1251 |
Windows CP1251 | Кириллица | Да | Да | 1 | ВЫИГРЫШ |
WIN1252 |
Windows CP1252 | Западноевропейская | Да | Да | 1 | |
WIN1253 |
Windows CP1253 | Греческий | Да | Да | 1 | |
WIN1254 |
Windows CP1254 | Турецкий | Да | Да | 1 | |
WIN1255 |
Windows CP1255 | Иврит | Да | Да | 1 | |
WIN1256 |
Windows CP1256 | Арабский | Да | Да | 1 | |
WIN1257 |
Windows CP1257 | Балтика | Да | Да | 1 | 904:00 |
WIN1258 |
Windows CP1258 | вьетнамский | Да | Да | 1 | АБК , ТКВН , ТКВН5712 , ВСКИИ |
символов
Не все клиентские API поддерживают все перечисленные наборы символов. Например, драйвер JDBC PostgreSQL не поддерживает
Например, драйвер JDBC PostgreSQL не поддерживает MULE_INTERNAL , LATIN6 , LATIN8 и LATIN10 .
Параметр SQL_ASCII ведет себя значительно иначе, чем другие параметры. Когда набор символов сервера равен SQL_ASCII , сервер интерпретирует байтовые значения 0–127 в соответствии со стандартом ASCII, а байтовые значения 128–255 воспринимаются как неинтерпретируемые символы. Преобразование кодировки не будет выполнено, если задано значение SQL_ASCII . Таким образом, эта установка является не столько декларацией того, что используется конкретная кодировка, сколько декларацией незнания кодировки. В большинстве случаев, если вы работаете с любыми данными, отличными от ASCII, неразумно использовать SQL_ASCII , потому что PostgreSQL не сможет помочь вам путем преобразования или проверки символов, отличных от ASCII.
24.3.2. Установка набора символов
initdb определяет набор символов по умолчанию (кодировку) для кластера PostgreSQL.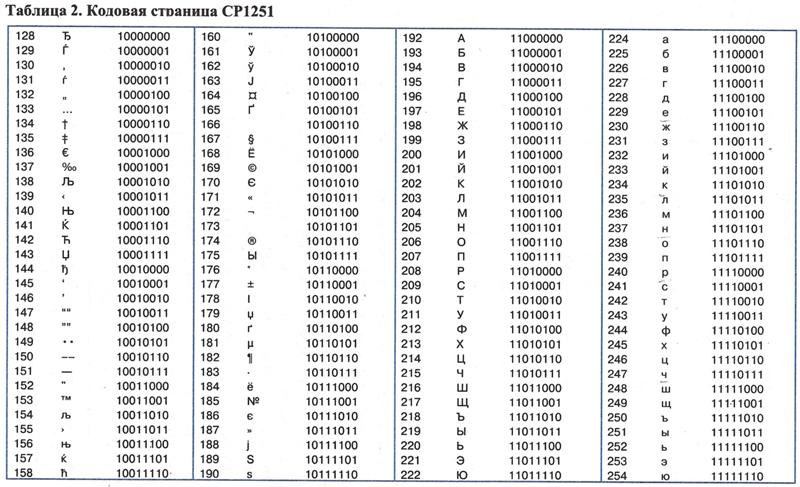 Например,
Например,
initdb -E EUC_JP
задает набор символов по умолчанию EUC_JP (расширенный код Unix для японского языка). Вы можете использовать --encoding вместо -E , если вы предпочитаете более длинные строки параметров. Если нет -E или --encoding указана опция, initdb пытается определить подходящую кодировку для использования на основе указанной локали или локали по умолчанию.
Во время создания базы данных можно указать кодировку, отличную от используемой по умолчанию, при условии, что кодировка совместима с выбранной локалью:
createdb -E EUC_KR -T template0 --lc-collate=ko_KR.euckr --lc-ctype=ko_KR.euckr корейский
Это создаст базу данных с именем korean , которая использует набор символов EUC_KR и языковой стандарт ko_KR . Другой способ сделать это — использовать следующую команду SQL:
. СОЗДАТЬ БАЗУ ДАННЫХ на корейском языке С КОДИРОВАНИЕМ 'EUC_KR' LC_COLLATE='ko_KR.
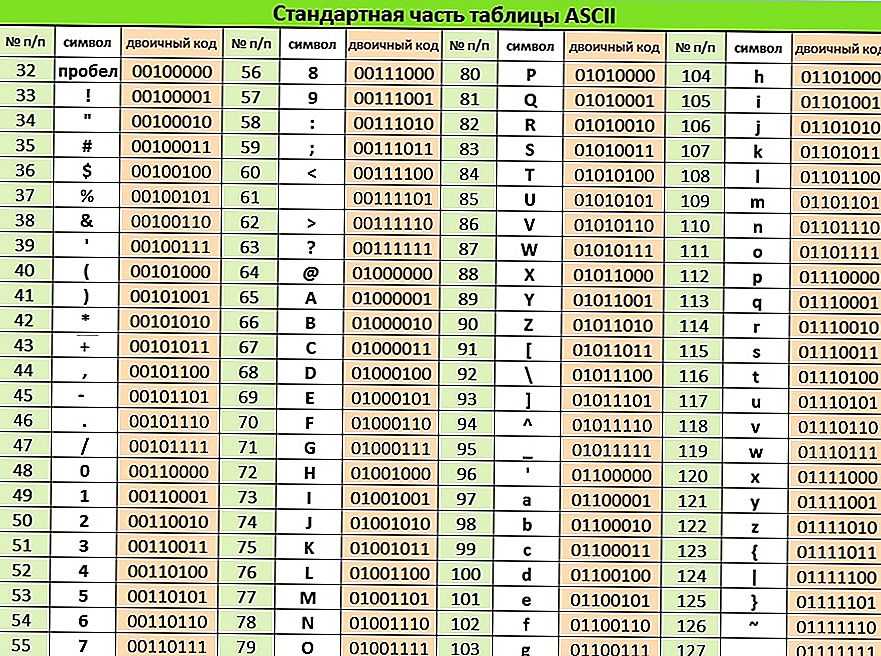 euckr' LC_CTYPE='ko_KR.euckr' TEMPLATE=template0;
euckr' LC_CTYPE='ko_KR.euckr' TEMPLATE=template0;
Обратите внимание, что приведенные выше команды задают копирование базы данных template0 . При копировании любой другой базы данных параметры кодировки и локали нельзя изменить по сравнению с исходной базой данных, поскольку это может привести к повреждению данных. Для получения дополнительной информации см. раздел 23.3.
Кодировка базы данных хранится в системном каталоге pg_database . Вы можете увидеть это, используя опцию psql -l или команду \l .
$psql -lСписок баз данных Имя | Владелец | Кодирование | сортировка | Тип | Права доступа -----------+----------+------------+-------------+- ---------------------------+------------------------------------- клокаледб | глиннака | SQL_ASCII | С | С | английский БД | глиннака | UTF8 | en_GB.UTF8 | en_GB.UTF8 | японский | глиннака | UTF8 | ja_JP.
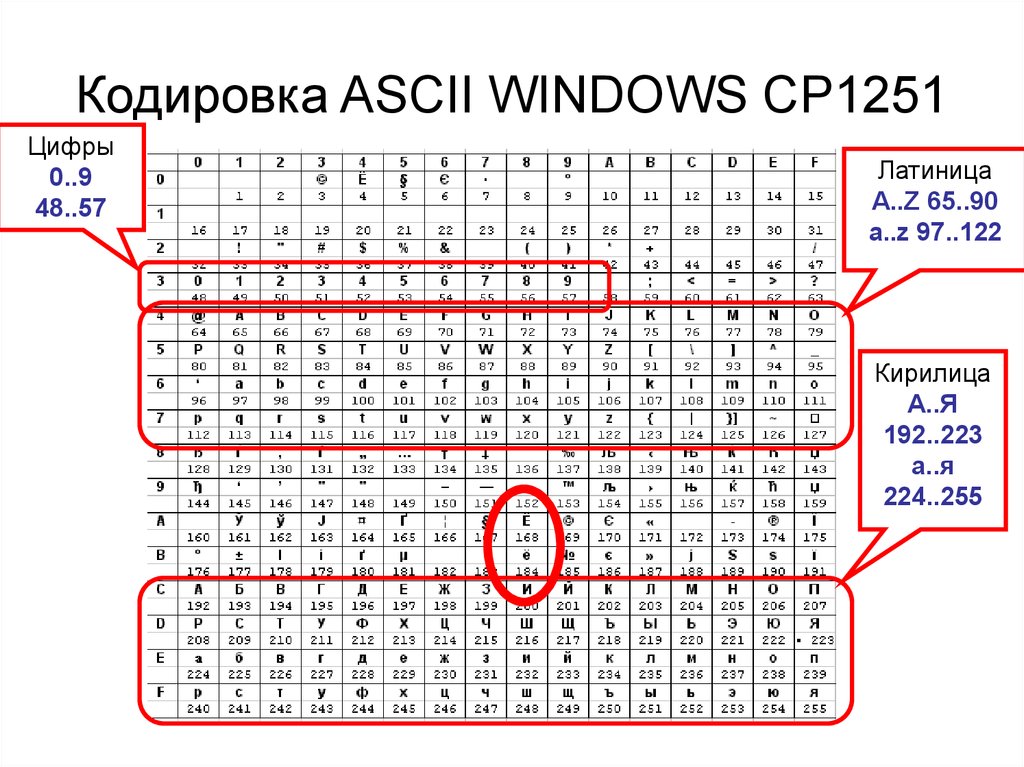 UTF8 | ja_JP.UTF8 |
корейский | глиннака | ЕСК_КР | ko_KR.euckr | ko_KR.euckr |
постгрес | глиннака | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 |
шаблон0 | глиннака | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka}
шаблон1 | глиннака | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka}
(7 рядов)
UTF8 | ja_JP.UTF8 |
корейский | глиннака | ЕСК_КР | ko_KR.euckr | ko_KR.euckr |
постгрес | глиннака | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 |
шаблон0 | глиннака | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka}
шаблон1 | глиннака | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka}
(7 рядов)
Important
В большинстве современных операционных систем PostgreSQL может определить, какой набор символов подразумевается параметром LC_CTYPE , и обеспечит использование только соответствующей кодировки базы данных. В более старых системах вы несете ответственность за использование кодировки, ожидаемой выбранной вами локалью. Ошибка в этой области может привести к странному поведению операций, зависящих от языкового стандарта, таких как сортировка.
PostgreSQL позволит суперпользователям создавать базы данных с Кодировка SQL_ASCII , даже если LC_CTYPE не является C или POSIX . Как отмечалось выше,
Как отмечалось выше, SQL_ASCII не требует, чтобы данные, хранящиеся в базе данных, имели какую-либо конкретную кодировку, и поэтому этот выбор создает риск неправильного поведения, зависящего от локали. Использование этой комбинации настроек устарело и может быть когда-нибудь вообще запрещено.
24.3.3. Автоматическое преобразование наборов символов между сервером и клиентом
PostgreSQL поддерживает автоматическое преобразование наборов символов между сервером и клиентом для многих комбинаций наборов символов (раздел 24.3.4 показывает, какие именно).
Чтобы включить автоматическое преобразование набора символов, вы должны указать PostgreSQL набор символов (кодировку), который вы хотите использовать в клиенте. Это можно сделать несколькими способами:
-
С помощью команды
\encodingв psql.\encodingпозволяет менять кодировку клиента на лету. Например, чтобы изменить кодировку наSJIS, введите:\кодирование SJIS
-
libpq (раздел 34.
11) имеет функции для управления кодировкой клиента. -
Использование
SET client_encoding TO. Задать кодировку клиента можно с помощью этой команды SQL:УСТАНОВИТЕ CLIENT_ENCODING TO '
значение';Также для этой цели можно использовать стандартный синтаксис SQL
SET NAMES:УСТАНОВИТЬ ИМЕНА '
значение';Чтобы запросить текущую кодировку клиента:
ПОКАЗАТЬ client_encoding;
Чтобы вернуться к кодировке по умолчанию:
СБРОС client_encoding;
-
Использование
PGCLIENTENCODING. Если переменная средыPGCLIENTENCODINGопределена в среде клиента, эта клиентская кодировка выбирается автоматически при подключении к серверу. (Впоследствии это можно переопределить, используя любой из других методов, упомянутых выше. ) -
Использование переменной конфигурации client_encoding. Если установлена переменная
client_encoding, эта клиентская кодировка выбирается автоматически при подключении к серверу. (Впоследствии это можно переопределить любым из других методов, упомянутых выше.)
 11) имеет функции для управления кодировкой клиента.
11) имеет функции для управления кодировкой клиента. )
) Если преобразование определенного символа невозможно — допустим, вы выбрали EUC_JP для сервера и LATIN1 для клиента, и возвращаются некоторые японские символы, не имеющие представления в LATIN1 — сообщается об ошибке.
Если набор символов клиента определен как SQL_ASCII , преобразование кодировки отключено, независимо от набора символов сервера. (Однако, если набор символов сервера отличается от SQL_ASCII , сервер все равно будет проверять, допустимы ли входящие данные для этой кодировки; таким образом, чистый эффект будет таким, как если бы набор символов клиента был таким же, как у сервера.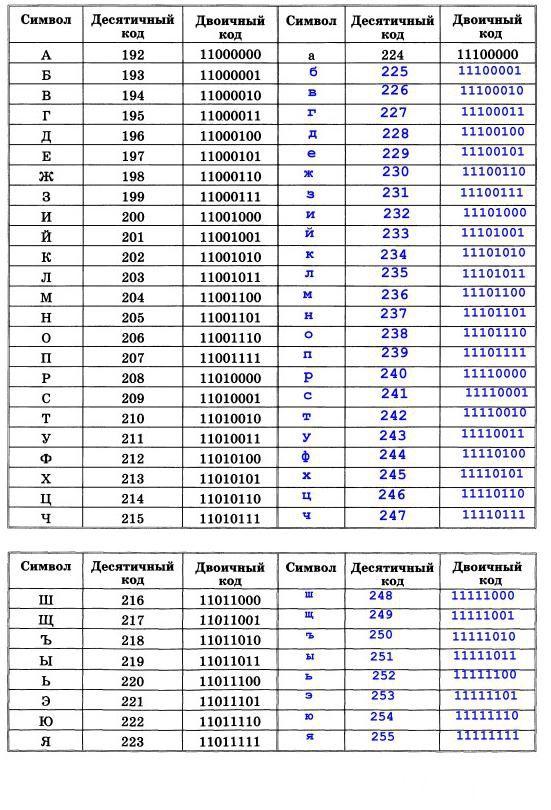 ) Так же, как и для сервер, использование
) Так же, как и для сервер, использование SQL_ASCII неразумно, если только вы не работаете с данными, полностью состоящими из ASCII.
24.3.4. Доступные преобразования наборов символов
PostgreSQL допускает преобразование между любыми двумя наборами символов, для которых функция преобразования указана в системном каталоге pg_conversion . PostgreSQL поставляется с некоторыми предопределенными преобразованиями, которые обобщены в таблице 24.2 и более подробно показаны в таблице 24.3. Вы можете создать новое преобразование с помощью команды SQL CREATE CONVERSION. (Чтобы использоваться для автоматического преобразования клиент/сервер, преобразование должно быть помечено как «по умолчанию» для его пары наборов символов.)
Таблица 24.2. Преобразование встроенного набора символов клиент/сервер
| Набор символов сервера | Доступные клиентские наборы символов |
|---|---|
БОЛЬШОЙ5 |
не поддерживается в качестве серверной кодировки |
EUC_CN |
EUC_CN , MULE_INTERNAL , УТФ8 |
EUC_JP |
EUC_JP , MULE_INTERNAL , SJIS , UTF8 |
EUC_JIS_2004 |
EUC_JIS_2004 , SHIFT_JIS_2004 , UTF8 |
EUC_KR |
EUC_KR , MULE_INTERNAL , УТФ8 |
EUC_TW |
EUC_TW , BIG5 , MULE_INTERNAL , UTF8 |
ГБ18030 |
не поддерживается в качестве серверной кодировки |
ГБК |
не поддерживается в качестве серверной кодировки |
ИСО_8859_5 |
ISO_8859_5 , KOI8R , MULE_INTERNAL , UTF8 , WIN866 , WIN1201 |
ИСО_8859_6 |
ИСО_8859_6 , УТФ8 |
ИСО_8859_7 |
ИСО_8859_7 , УТФ8 |
ИСО_8859_8 |
ИСО_8859_8 , УТФ8 |
ДЖОХАБ |
не поддерживается в качестве серверной кодировки |
КОИ8Р |
КОИ8Р , ИСО_8859_5 , МУЛЕ_ИНТЕРНАЛ , УТФ8 , ВИН866 , ВИН1201 |
КОИ8У |
КОИ8У , УТФ8 |
ЛАТИНА1 |
LATIN1 , MULE_INTERNAL , UTF8 |
ЛАТИНА2 |
LATIN2 , MULE_INTERNAL , UTF8 , WIN1250 |
ЛАТИН3 |
LATIN3 , MULE_INTERNAL , UTF8 |
ЛАТИН4 |
LATIN4 , MULE_INTERNAL , UTF8 |
ЛАТИНСКИЙ5 |
ЛАТИН5 , УТФ8 |
ЛАТИНСКИЙ6 |
ЛАТИН6 , UTF8 |
ЛАТИНСКИЙ 7 |
ЛАТИН7 , УТФ8 |
ЛАТИНСКИЙ 8 |
ЛАТИН8 , УТФ8 |
ЛАТИНСКИЙ 9 |
ЛАТИН9 , УТФ8 |
ЛАТИНСКИЙ10 |
LATIN10 , UTF8 |
MULE_INTERNAL |
MULE_INTERNAL , BIG5 , EUC_CN , EUC_JP , EUC_KR , EUC_TW , ISO_8859_5 , KOI8R , LATIN1 to LATIN4 , SJIS , WIN866 , ВИН1250 , ВИН1251 |
СЖИС |
не поддерживается в качестве серверной кодировки |
SHIFT_JIS_2004 |
не поддерживается в качестве серверной кодировки |
SQL_ASCII |
любой (преобразование производиться не будет) |
УВК |
не поддерживается в качестве серверной кодировки |
UTF8 |
все поддерживаемые кодировки |
WIN866 |
ВИН866 , ИСО_8859_5 , КОИ8Р , МУЛЕ_ИНТЕРНАЛ , УТФ8 , ВИН1201 |
WIN874 |
ВИН874 , УТФ8 |
WIN1250 |
WIN1250 , LATIN2 , MULE_INTERNAL , UTF8 |
WIN1251 |
ВИН1251 , ИСО_8859_5 , КОИ8Р , МУЛЕ_ИНТЕРНАЛ , УТФ8 , ВИН866
|
WIN1252 |
ВИН1252 , UTF8 |
WIN1253 |
ВИН1253 , УТФ8 |
WIN1254 |
ВИН1254 , УТФ8 |
WIN1255 |
ВИН1255 , УТФ8 |
WIN1256 |
ВИН1256 , УТФ8 |
WIN1257 |
ВИН1257 , УТФ8 |
WIN1258 |
ВИН1258 , УТФ8 |
5555555
Таблица 24.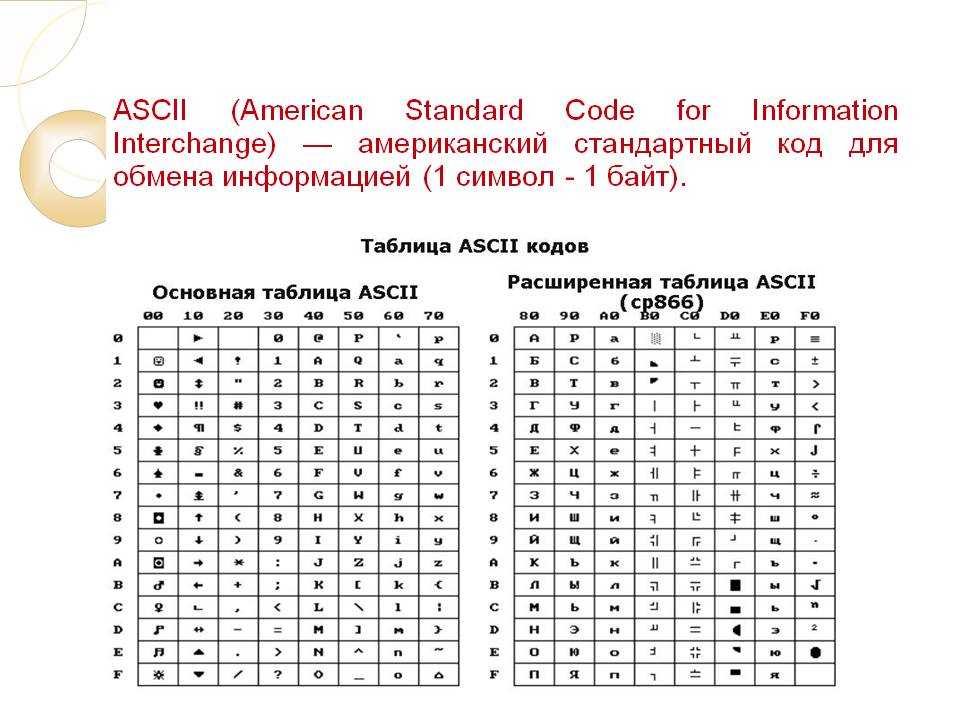 3. Преобразования всех встроенных наборов символов
3. Преобразования всех встроенных наборов символов
| Имя преобразования [а] | Исходное кодирование | Кодировка назначения |
|---|---|---|
big5_to_euc_tw |
БОЛЬШОЙ5 |
EUC_TW |
big5_to_mic |
БОЛЬШОЙ5 |
МУЛЕ_ВНУТРЕННИЙ |
big5_to_utf8 |
БОЛЬШОЙ5 |
UTF8 |
euc_cn_to_mic |
EUC_CN |
МУЛЕ_ВНУТРЕННИЙ |
euc_cn_to_utf8 |
EUC_CN |
UTF8 |
euc_jp_to_mic 904:00 |
EUC_JP |
МУЛЕ_ВНУТРЕННИЙ |
euc_jp_to_sjis |
EUC_JP |
СЖИС |
euc_jp_to_utf8 |
EUC_JP |
UTF8 |
euc_kr_to_mic 904:00 |
EUC_KR |
МУЛЕ_ВНУТРЕННИЙ |
euc_kr_to_utf8 |
EUC_KR |
UTF8 |
euc_tw_to_big5 |
EUC_TW |
БОЛЬШОЙ5 |
euc_tw_to_mic 904:00 |
EUC_TW |
МУЛЕ_ВНУТРЕННИЙ |
euc_tw_to_utf8 |
EUC_TW |
UTF8 |
gb18030_to_utf8 |
ГБ18030 |
UTF8 |
gbk_to_utf8 904:00 |
ГБК |
UTF8 |
iso_8859_10_to_utf8 |
ЛАТИНСКИЙ6 |
UTF8 |
iso_8859_13_to_utf8 |
ЛАТИНСКИЙ 7 |
UTF8 |
iso_8859_14_to_utf8 904:00 |
ЛАТИНСКИЙ 8 |
UTF8 |
iso_8859_15_to_utf8 |
ЛАТИНСКИЙ9 |
UTF8 |
iso_8859_16_to_utf8 |
ЛАТИНСКИЙ10 |
UTF8 |
iso_8859_1_to_mic |
ЛАТИНСКИЙ1 |
МУЛЕ_ВНУТРЕННИЙ |
iso_8859_1_to_utf8 |
ЛАТИНСКИЙ1 |
UTF8 |
iso_8859_2_to_mic |
ЛАТИНСКИЙ2 |
МУЛЕ_ВНУТРЕННИЙ |
изо_8859_2_to_utf8 |
ЛАТИНСКИЙ2 |
UTF8 |
iso_8859_2_to_windows_1250 |
ЛАТИНСКИЙ2 |
WIN1250 |
iso_8859_3_to_mic |
ЛАТИНСКИЙ3 |
МУЛЕ_ВНУТРЕННИЙ |
iso_8859_3_to_utf8 |
ЛАТИНСКИЙ3 |
UTF8 |
iso_8859_4_to_mic |
ЛАТИНСКИЙ4 |
МУЛЕ_ВНУТРЕННИЙ |
iso_8859_4_to_utf8 |
ЛАТИНСКИЙ4 |
UTF8 |
iso_8859_5_to_koi8_r |
ИСО_8859_5 |
КОИ8Р |
iso_8859_5_to_mic |
ИСО_8859_5 |
МУЛЕ_ВНУТРЕННИЙ |
iso_8859_5_to_utf8 |
ИСО_8859_5 |
UTF8 |
iso_8859_5_to_windows_1251 |
ИСО_8859_5 |
WIN1251 |
iso_8859_5_to_windows_866 |
ИСО_8859_5 |
WIN866 |
iso_8859_6_to_utf8 |
ИСО_8859_6 |
UTF8 |
iso_8859_7_to_utf8 |
ИСО_8859_7 |
UTF8 |
iso_8859_8_to_utf8 |
ИСО_8859_8 |
UTF8 |
iso_8859_9_to_utf8 |
ЛАТИНСКИЙ5 |
UTF8 |
johab_to_utf8 |
ЙОХАБ |
UTF8 |
koi8_r_to_iso_8859_5 |
КОИ8Р |
ИСО_8859_5 |
кои8_р_то_мик |
КОИ8Р |
МУЛЕ_ВНУТРЕННИЙ |
koi8_r_to_utf8 |
КОИ8Р |
UTF8 |
koi8_r_to_windows_1251 |
КОИ8Р |
WIN1251 |
koi8_r_to_windows_866 |
КОИ8Р |
WIN866 |
koi8_u_to_utf8 |
КОИ8У |
UTF8 |
mic_to_big5 |
МУЛЕ_ВНУТРЕННИЙ |
БОЛЬШОЙ5 |
mic_to_euc_cn |
МУЛЕ_ВНУТРЕННИЙ |
EUC_CN |
mic_to_euc_jp |
МУЛЕ_ВНУТРЕННИЙ |
EUC_JP |
mic_to_euc_kr |
МУЛЕ_ВНУТРЕННИЙ |
EUC_KR |
mic_to_euc_tw |
МУЛЕ_ВНУТРЕННИЙ |
EUC_TW |
mic_to_iso_8859_1 |
МУЛЕ_ВНУТРЕННИЙ |
ЛАТИНСКИЙ1 |
mic_to_iso_8859_2 |
МУЛЕ_ВНУТРЕННИЙ |
ЛАТИНСКИЙ2 |
mic_to_iso_8859_3 |
МУЛЕ_ВНУТРЕННИЙ |
ЛАТИНСКИЙ3 |
mic_to_iso_8859_4 |
МУЛЕ_ВНУТРЕННИЙ |
ЛАТИНСКИЙ4 |
mic_to_iso_8859_5 |
МУЛЕ_ВНУТРЕННИЙ |
ИСО_8859_5 |
mic_to_koi8_r |
МУЛЕ_ВНУТРЕННИЙ |
КОИ8Р |
mic_to_sjis |
МУЛЕ_ВНУТРЕННИЙ |
СЖИС |
mic_to_windows_1250 |
МУЛЕ_ВНУТРЕННИЙ |
WIN1250 |
mic_to_windows_1251 904:00 |
МУЛЕ_ВНУТРЕННИЙ |
WIN1251 |
mic_to_windows_866 |
МУЛЕ_ВНУТРЕННИЙ |
WIN866 |
sjis_to_euc_jp |
СЖИС |
EUC_JP |
sjis_to_mic |
СЖИС |
МУЛЕ_ВНУТРЕННИЙ |
sjis_to_utf8 |
СЖИС |
UTF8 |
windows_1258_to_utf8 |
WIN1258 |
UTF8 |
uhc_to_utf8 |
УВК |
UTF8 |
utf8_to_big5 |
UTF8 |
БОЛЬШОЙ5 |
utf8_to_euc_cn |
UTF8 |
EUC_CN |
utf8_to_euc_jp |
UTF8 |
EUC_JP |
utf8_to_euc_kr |
UTF8 |
EUC_KR |
utf8_to_euc_tw |
UTF8 |
EUC_TW |
utf8_to_gb18030 |
UTF8 |
ГБ18030 |
utf8_to_gbk |
UTF8 |
ГБК |
utf8_to_iso_8859_1 |
UTF8 |
ЛАТИНСКИЙ1 |
utf8_to_iso_8859_10 |
UTF8 |
ЛАТИНСКИЙ6 |
utf8_to_iso_8859_13 |
UTF8 |
ЛАТИНСКИЙ 7 |
utf8_to_iso_8859_14 |
UTF8 |
ЛАТИНСКИЙ 8 |
utf8_to_iso_8859_15 |
UTF8 |
ЛАТИНСКИЙ9 |
utf8_to_iso_8859_16 |
UTF8 |
ЛАТИНСКИЙ10 |
utf8_to_iso_8859_2 |
UTF8 |
ЛАТИНСКИЙ2 |
utf8_to_iso_8859_3 |
UTF8 |
ЛАТИНСКИЙ3 |
utf8_to_iso_8859_4 |
UTF8 |
ЛАТИНСКИЙ4 |
utf8_to_iso_8859_5 |
UTF8 |
ИСО_8859_5 |
utf8_to_iso_8859_6 |
UTF8 |
ИСО_8859_6 |
utf8_to_iso_8859_7 |
UTF8 |
ИСО_8859_7 |
utf8_to_iso_8859_8 |
UTF8 |
ИСО_8859_8 |
utf8_to_iso_8859_9 |
UTF8 |
ЛАТИНСКИЙ5 |
utf8_to_johab |
UTF8 |
ЙОХАБ |
утф8_то_кои8_р |
UTF8 |
КОИ8Р |
утф8_то_кои8_у |
UTF8 |
КОИ8У |
utf8_to_sjis |
UTF8 |
СЖИС |
utf8_to_windows_1258 |
UTF8 |
WIN1258 |
utf8_to_uhc |
UTF8 904:00 |
УВК |
utf8_to_windows_1250 |
UTF8 |
WIN1250 |
utf8_to_windows_1251 |
UTF8 |
WIN1251 |
utf8_to_windows_1252 |
UTF8 |
WIN1252 |
utf8_to_windows_1253 |
UTF8 |
WIN1253 |
utf8_to_windows_1254 |
UTF8 |
WIN1254 |
utf8_to_windows_1255 |
UTF8 |
WIN1255 |
utf8_to_windows_1256 |
UTF8 |
WIN1256 |
utf8_to_windows_1257 |
UTF8 |
WIN1257 |
utf8_to_windows_866 |
UTF8 |
WIN866 |
utf8_to_windows_874 |
UTF8 |
WIN874 |
windows_1250_to_iso_8859_2 |
WIN1250 |
ЛАТИНСКИЙ2 |
windows_1250_to_mic |
WIN1250 |
МУЛЕ_ВНУТРЕННИЙ |
windows_1250_to_utf8 |
WIN1250 |
UTF8 |
windows_1251_to_iso_8859_5 |
WIN1251 |
ИСО_8859_5 |
windows_1251_to_koi8_r |
WIN1251 |
КОИ8Р |
windows_1251_to_mic |
WIN1251 |
МУЛЕ_ВНУТРЕННИЙ |
windows_1251_to_utf8 |
WIN1251 |
UTF8 |
windows_1251_to_windows_866 |
WIN1251 |
WIN866 |
windows_1252_to_utf8 |
WIN1252 |
UTF8 |
windows_1256_to_utf8 |
WIN1256 |
UTF8 |
windows_866_to_iso_8859_5 |
WIN866 |
ИСО_8859_5 |
windows_866_to_koi8_r |
WIN866 |
КОИ8Р |
windows_866_to_mic |
WIN866 |
МУЛЕ_ВНУТРЕННИЙ |
windows_866_to_utf8 |
WIN866 |
UTF8 |
windows_866_to_windows_1251 |
WIN866 |
ВЫИГРЫШ |
windows_874_to_utf8 |
WIN874 |
UTF8 |
euc_jis_2004_to_utf8 |
EUC_JIS_2004 |
UTF8 |
utf8_to_euc_jis_2004 |
UTF8 |
EUC_JIS_2004 |
shift_jis_2004_to_utf8 |
SHIFT_JIS_2004 |
UTF8 |
utf8_to_shift_jis_2004 |
UTF8 |
SHIFT_JIS_2004 |
euc_jis_2004_to_shift_jis_2004 |
EUC_JIS_2004 |
SHIFT_JIS_2004 |
shift_jis_2004_to_euc_jis_2004 |
SHIFT_JIS_2004 |
EUC_JIS_2004 |
|
[a] Имена преобразования следуют стандартной схеме именования: официальное имя исходной кодировки, в котором все небуквенно-цифровые символы заменены символами подчеркивания, за которыми следует |
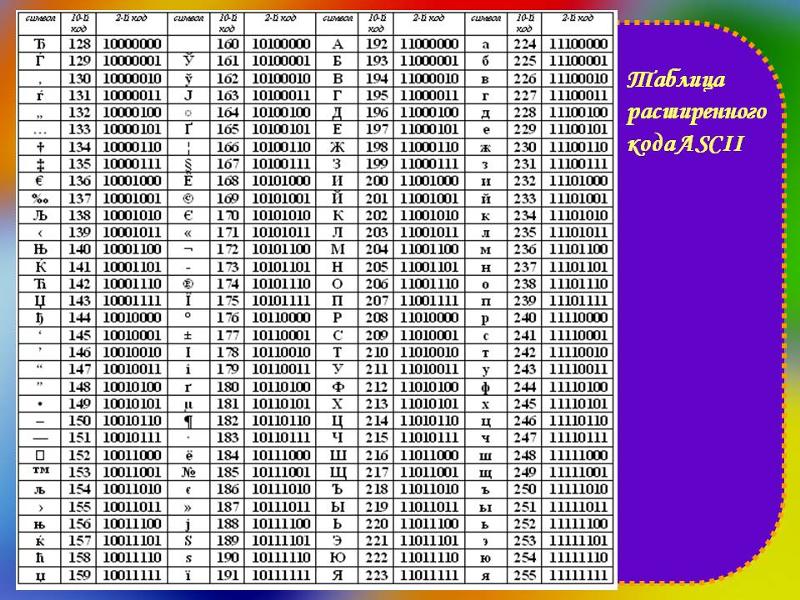 Поэтому эти имена иногда отличаются от обычных имен кодировок, показанных в таблице 24.1.
Поэтому эти имена иногда отличаются от обычных имен кодировок, показанных в таблице 24.1.24.3.5. Дополнительная литература
Это хорошие источники для начала изучения различных систем кодирования.
- CJKV Обработка информации: китайские, японские, корейские и вьетнамские вычисления
-
Содержит подробные объяснения
EUC_JP,EUC_CN,EUC_KR,EUC_TW. - https://www.unicode.org/
-
Веб-сайт Консорциума Unicode.
- RFC 3629
- Здесь определяется
UTF-8 (8-битный формат преобразования UCS/Unicode).
Коды символов Windows 1251. Кодировка ASCII (американский стандартный код для обмена информацией)
Главная / Яндекс.Диск
/ Коды символов Windows 1251. Кодировка ASCII (американский стандартный код для обмена информацией) — базовая кодировка текста для латинского алфавита
Кодировка ASCII (американский стандартный код для обмена информацией) — базовая кодировка текста для латинского алфавита
28.06.2021
Яндекс.Диск
Как известно, компьютер хранит информацию в двоичном виде, представляя ее в виде последовательности нулей и единиц. Для перевода информации в форму, удобную для восприятия человеком, каждая уникальная последовательность цифр при отображении заменяется соответствующим символом.
Одной из систем соотнесения двоичных кодов с печатными и управляющими символами является
При современном уровне развития компьютерных технологий от пользователя не требуется знать код каждого конкретного символа. Однако общее представление о том, как осуществляется кодирование, крайне полезно, а для некоторых категорий специалистов даже необходимо.
Создание ASCII
В своем первоначальном виде кодировка была разработана в 1963 году и затем дважды обновлялась в течение 25 лет.
В исходной версии таблица символов ASCII включала 128 символов, позже появилась расширенная версия, где были сохранены первые 128 символов, а отсутствующие ранее символы были присвоены кодам с задействованием восьмого бита.
На протяжении многих лет эта кодировка была самой популярной в мире. В 2006 году лидирующее место заняла латиница 1252, а с конца 2007 года и по настоящее время Unicode прочно удерживает лидирующие позиции.
Компьютерное представление ASCII
Каждый символ ASCII имеет собственный код из 8 символов, представляющих ноль или единицу. Минимальное число в этом представлении — ноль (восемь нулей в двоичной системе), что является кодом первого элемента в таблице.
Два кода в таблице зарезервированы для переключения между стандартным US-ASCII и его национальной версией.
После того, как ASCII стал включать не 128, а 256 символов, распространение получил вариант кодировки, при котором исходный вариант таблицы сохранялся в первых 128 кодах с нулевым 8-м битом.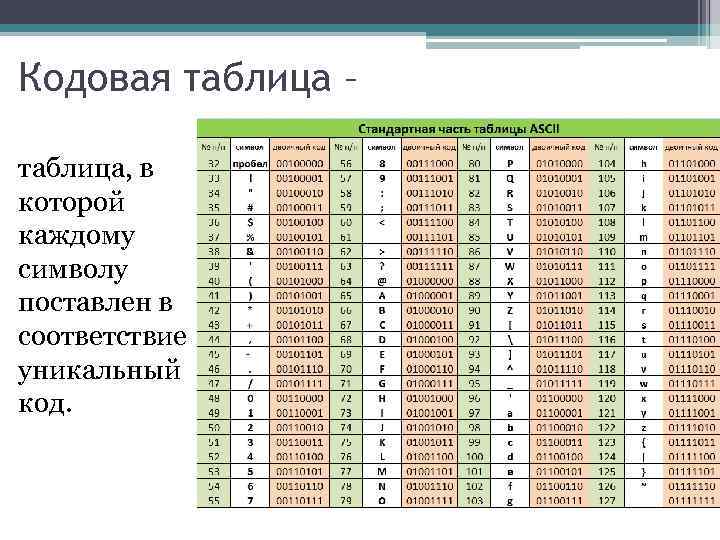 Знаки национальной письменности сохранились в верхней половине таблицы (позиции 128-255).
Знаки национальной письменности сохранились в верхней половине таблицы (позиции 128-255).
Пользователю не обязательно знать коды символов ASCII напрямую. Для девелоперского ПО обычно достаточно знать номер элемента в таблице, чтобы при необходимости вычислить его код в двоичной системе.
Русский язык
После разработки кодировок для скандинавских языков, китайского, корейского, греческого и т.д. в начале 70-х, в СССР тоже начал создавать свою версию. Вскоре была разработана версия 8-битной кодировки под названием KOI8, которая сохраняет первые 128 кодов символов ASCII и выделяет такое же количество позиций для букв национального алфавита и дополнительных символов.
До введения Unicode KOI8 доминировал в русскоязычном сегменте Интернета. Были варианты кодировки как для русского, так и для украинского алфавита.
Проблемы с ASCII
Так как количество элементов даже в расширенной таблице не превышало 256, не было возможности разместить несколько разных шрифтов в одной кодировке. В 90-е годы в Рунете появилась проблема «крокозябров», когда тексты, набранные русскими символами ASCII, отображались некорректно.
В 90-е годы в Рунете появилась проблема «крокозябров», когда тексты, набранные русскими символами ASCII, отображались некорректно.
Проблема заключалась в том, что коды различных вариантов ASCII не совпадали друг с другом. Напомним, что позиции 128-255 могли содержать разные символы, и при смене одной кириллической кодировки на другую все буквы текста заменялись на другие, имеющие идентичный номер в другой версии кодировки.
Текущее состояние
С появлением Unicode популярность ASCII резко упала.
Причина этого кроется в том, что новая кодировка позволила вместить знаки почти всех письменных языков. В этом случае первые 128 символов ASCII соответствуют тем же символам в Unicode.
В 2000 году ASCII была самой популярной кодировкой в Интернете и использовалась на 60% веб-страниц, проиндексированных Google. К 2012 году доля таких страниц упала до 17%, а место самой популярной кодировки занял Юникод (UTF-8). 9→
Примечание : в старых шрифтах апостроф «рисовался с наклоном влево, а тильда ~ смещалась вверх, чтобы они как раз подходили на роль акут и тильда сверху.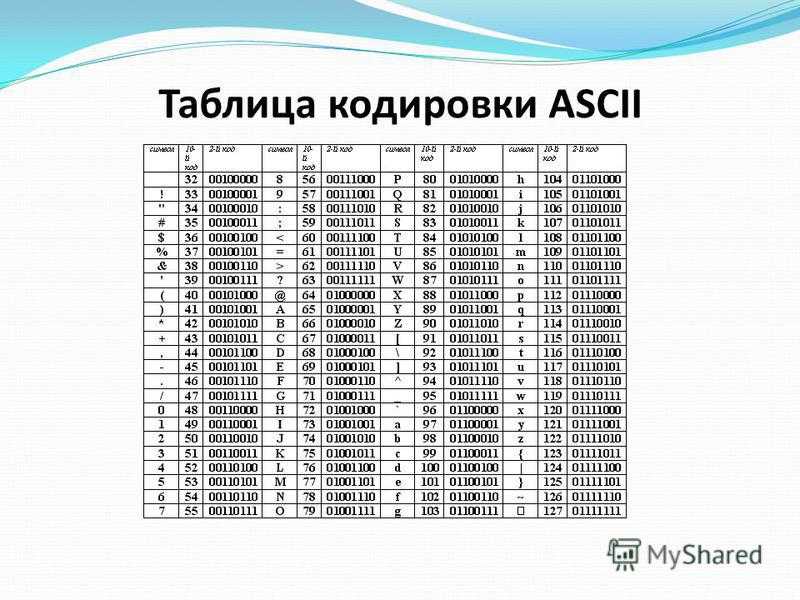
Если тот же символ накладывается на символ, то получается эффект жирного шрифта, а если на символ накладывается подчеркивание, то получается подчеркнутый текст.` { | } ~ … Кроме этого вместо # можно разместить £ , а вместо $ — ¤ … Эта система хорошо подходит для европейских языков, где требуется всего несколько дополнительных символов. Версия ASCII без национальных символов называется US-ASCII или «Международная справочная версия».
Впоследствии оказалось удобнее использовать 8-битные кодировки (кодовые страницы), где нижняя половина кодовой таблицы (0-127) занята символами US-ASCII, а верхняя половина (128- 255) занимают дополнительные символы, в том числе набор национальных символов. Таким образом, верхняя половина таблицы ASCII до широкого внедрения Unicode активно использовалась для представления локализованных символов, букв местного языка. Отсутствие единого стандарта размещения символов кириллицы в таблице ASCII вызывало множество проблем с кодировками (КОИ-8, Windows-1251 и др. ). Другие языки с нелатинской письменностью также страдали от наличия нескольких разных кодировок.
). Другие языки с нелатинской письменностью также страдали от наличия нескольких разных кодировок.
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .А | .Б | .С | .Д | .Е | .Ф | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0. | НУЛ | ЭОА | ЕОМ | ЭКВТ | ВРУ | РУ | ЗВОНОК | БКСП 904:00 | НТ | ЛФ | ВТ | ФФ | КР | СО | СИ | |
| 1. | DC 0 | DC 1 | DC 2 | DC 3 | DC 4 | ОШИБКА | СИНХРОНИЗАЦИЯ | ЛЕМ | С 0 | С 1 | С 2 | С 3 | С 4 | С 5 | С 6 | С 7 |
2. |
||||||||||||||||
| 3. | 904:00 | |||||||||||||||
| 4. | ПУСТОЙ | ! | « | # | $ | % | & | « | ( | ) | * | + | , | — | . | / |
| 5. | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | = | > | ? | |
6.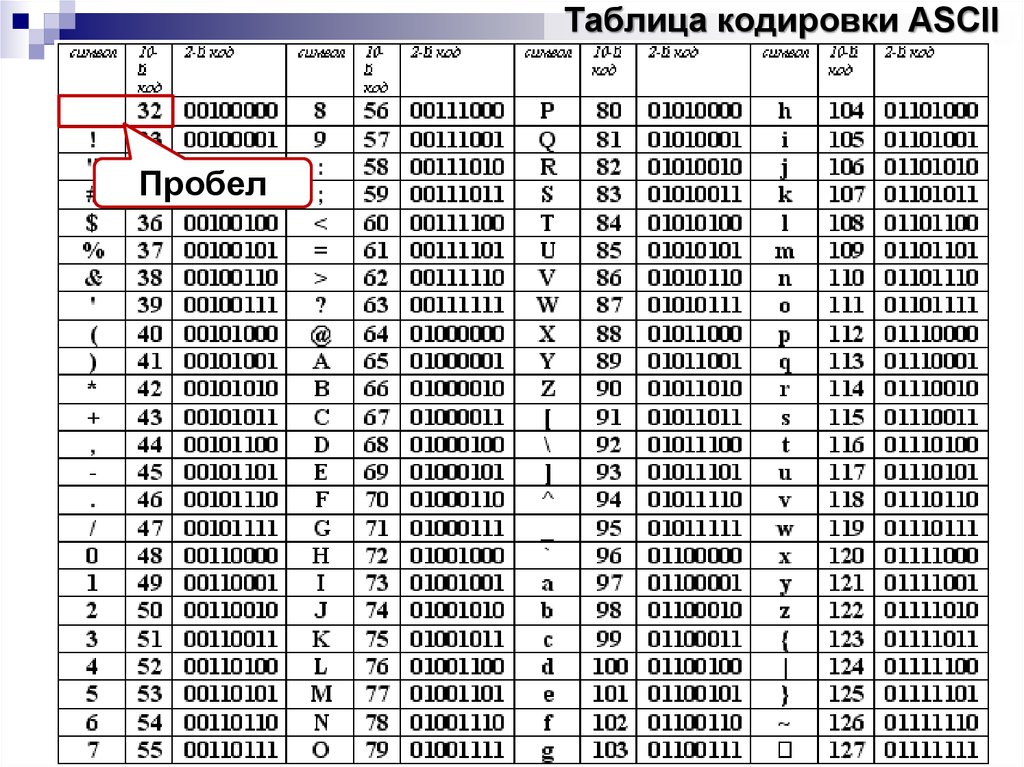 |
||||||||||||||||
| 7. | ||||||||||||||||
| 8. | ||||||||||||||||
| 9. | ||||||||||||||||
| А. | @ | А | Б | С | Д | Е | Ф | Г | Х | я | Дж | К | л | М | Н | О |
Б.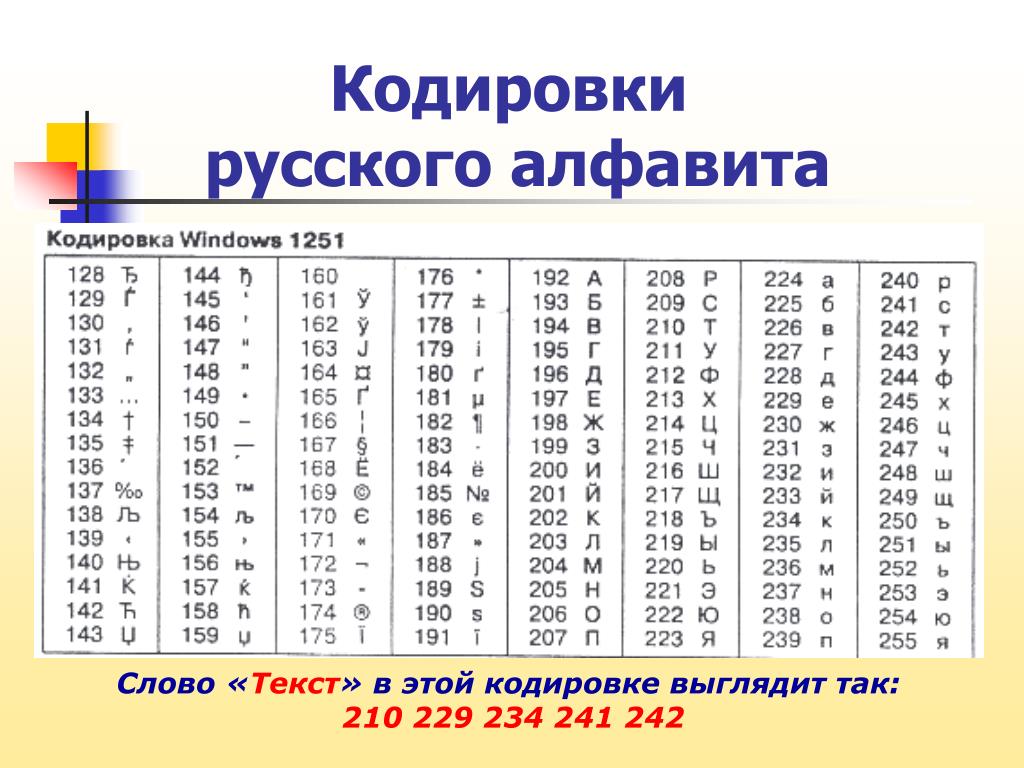 |
Р | В | Р | С | Т | У | В | Вт | х | Д | З | [ | \ | ] | ← | |
| С. | ||||||||||||||||
| Д. | ||||||||||||||||
| Э. | и | б | с | д | и | ф | г | ч | и | и | к | л | м | н | или | |
| Ф. | р | к | р | с | т | и | против | ш | х | г | из | ЭСК | ДЕЛ |
сомов
На тех компьютерах, где минимальной адресуемой единицей памяти было 36-битное слово, изначально использовались 6-битные символы (1 слово = 6 символов).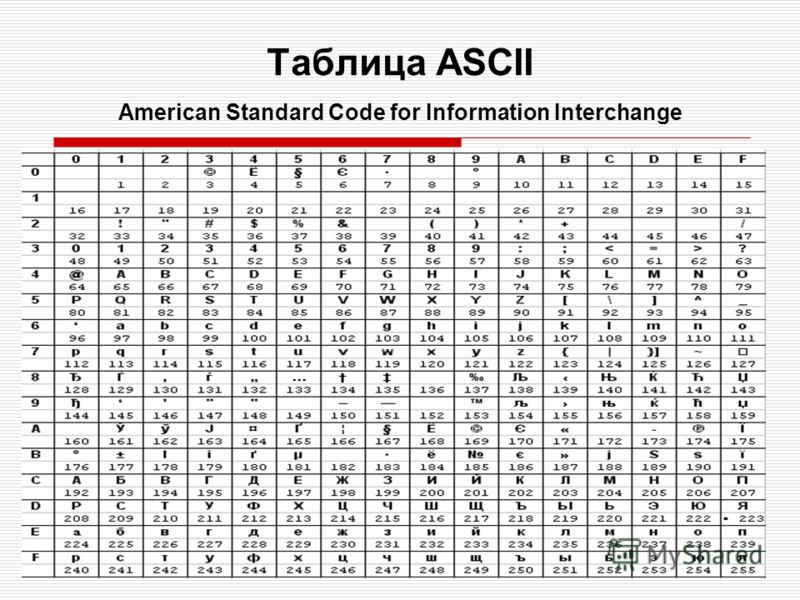 После перехода на ASCII на таких компьютерах стали размещать в одном слове либо 5 семибитных символов (1 бит оставался лишним), либо 4 девятибитных символа.
После перехода на ASCII на таких компьютерах стали размещать в одном слове либо 5 семибитных символов (1 бит оставался лишним), либо 4 девятибитных символа.
Коды ASCII также используются для идентификации нажатой клавиши во время программирования. Для стандартной QWERTY-клавиатуры кодовая таблица выглядит так:
| 904:00 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Набор символов, которыми записывается текст, называется алфавитом . Количество символов в алфавите его сила . Формула определения количества информации: N = 2 b , где N — мощность алфавита (количество символов), b — количество бит (информационный вес символа). 256-символьный алфавит может вместить почти все необходимые вам символы. Этот алфавит называется достаточным. Поскольку 256 = 2 8, вес 1 символа равен 8 битам. 8-битный блок был назван 1 байт: 1 байт = 8 бит. Двоичный код каждого символа компьютерного текста занимает 1 байт памяти. Как текстовая информация представлена в памяти компьютера? Удобство байтового кодирования символов очевидно, так как байт является наименьшей адресуемой частью памяти и, следовательно, процессор может обращаться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов вполне достаточно для представления большого разнообразия символьной информации. Теперь возникает вопрос, какой восьмибитный двоичный код присвоить каждому символу.Понятно, что это дело условное, способов кодирования можно придумать много. Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждое число соответствует восьмизначному двоичному коду от 00000000 до 11111111. Этот код представляет собой просто порядковый номер символа в двоичной системе. Таблица, в которой всем символам компьютерного алфавита присвоены порядковые номера, называется таблицей кодирования.Для разных типов компьютеров используются разные таблицы кодирования. Международным стандартом для ПК стала таблица ASCII (читается asci) (американский стандартный код для обмена информацией). Таблица ASCII разделена на две части. Международный стандарт — это только первая половина таблицы, т.е. символы с цифрами от 0 (00000000), до 127 (01111111). Структура таблицы кодирования ASCII
Первая половина таблицы ASCIIОбращаю внимание, что в таблице кодировки буквы (прописные и строчные) расположены в алфавитном порядке, а цифры в порядке возрастания значений. Это соблюдение лексикографического порядка в расположении знаков называется принципом последовательного кодирования алфавита. Для букв русского алфавита также соблюдается принцип последовательного кодирования. Вторая половина таблицы ASCII К сожалению, в настоящее время существует пять различных кодировок кириллицы (KOI8-R, Windows, MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, с одной программной системы на другую. Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка использовалась еще в 70-х годах на ЭВМ серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях. операционная система UNIX. С начала 90-х, времени господства операционной системы MS DOS, сохраняется кодировка CP866 («CP» расшифровывается как «Code Page»). Компьютеры Apple под управлением Mac OS используют собственную кодировку Mac. Кроме того, Международная организация по стандартизации (ISO) утвердила в качестве стандарта для русского языка другую кодировку под названием ISO 8859-5. В настоящее время наиболее распространенной является кодировка Microsoft Windows, сокращенно обозначаемая как CP1251. С конца 90s проблема стандартизации кодировки символов была решена введением нового международного стандарта под названием Unicode . Это 16-битная кодировка т. Давайте попробуем использовать таблицу ASCII, чтобы представить, как слова будут выглядеть в памяти компьютера.Внутреннее представление слов в памяти компьютераИногда бывает, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, не читается — на экране монитора видна какая-то «тарабарщина». Это связано с тем, что в компьютерах используется разная кодировка символов русского языка. Unicode (англ. Unicode) — стандарт кодировки символов. Проще говоря, это таблица соответствия текстовых символов (, букв, элементов пунктуации) двоичным кодам. Компьютер понимает только последовательность нулей и единиц. Символы Символы в таблицах Unicode нумеруются шестнадцатеричными числами. Например, кириллическая заглавная буква М обозначается U+041C. Это значит, что он стоит на пересечении строки 041 и столбца С. Его можно просто скопировать и потом куда-нибудь вставить. Стандарт Unicode является международным. Он включает в себя знаки практически всех письменностей мира. В том числе и те, которые больше не используются. Египетские иероглифы, германские руны, письменность майя, клинопись и алфавиты древних государств. Представлены и обозначения мер и весов, нотная запись, математические понятия. Сам Консорциум Unicode не изобретает новые символы. В таблицы добавляются те значки, которые находят свое применение в обществе. Например, знак рубля активно использовался в течение шести лет, прежде чем был добавлен в Юникод. Excel для Office 365 Word для Office 365 Outlook для Office 365 PowerPoint для Office 365 Publisher для Office 365 Excel 2019 Word 2019 Outlook 2019 PowerPoint 2019 OneNote 2016 Publisher 2019 Visio Professional 2019 В этой статьеВставка символа ASCII или Юникода в документ Если вам нужно ввести только несколько специальных символов или символов, вы можете использовать любые сочетания клавиш. Примечания:
Вставка символов ASCIIЧтобы вставить символ ASCII, нажмите и удерживайте клавишу ALT при вводе кода символа. Например, чтобы вставить символ градуса (º), нажмите и удерживайте клавишу Alt, затем введите 0176 на цифровой клавиатуре. Используйте цифровую клавиатуру для ввода цифр вместо цифр на основной клавиатуре. Если вам нужно ввести цифры на цифровой клавиатуре, убедитесь, что горит индикатор NUM LOCK. Вставка символов UnicodeЧтобы вставить символ Unicode, введите код символа, затем последовательно нажмите клавиши ALT и X. Например, чтобы вставить знак доллара ($), введите 0024 и последовательно нажмите клавиши ALT и X. Все коды символов Unicode см. Важно: Некоторые программы Microsoft Office, такие как PowerPoint и InfoPath, не поддерживают преобразование кодов Unicode в символы. Примечания: Если вы видите неверный символ Unicode после нажатия ALT + X, выберите правильный код, а затем снова нажмите ALT + X. Кроме того, перед кодом необходимо ввести «U+». Например, если ввести «1U + B5» и нажать Alt + X, отобразится текст «1µ», а если ввести «1B5» и нажать Alt + X, отобразится символ «Ƶ». Использование таблицы символовКарта символов — это программа, встроенная в Microsoft Windows, которая позволяет просматривать символы, доступные для выбранного шрифта. Используя таблицу символов, вы можете копировать отдельные символы или группу символов в буфер обмена и вставлять их в любую программу, которая может отображать эти символы. Открытие таблицы символов В Windows 10 Введите слово «символ» в поле поиска на панели задач и выберите таблицу символов из результатов поиска. В Windows 8 Введите слово «персонаж» на главном экране и выберите таблицу символов из результатов поиска. В Windows 7 нажать кнопку Пуск , последовательно выбрать Все программы , Стандарт , Сервис и нажать Таблица символов . Символы сгруппированы по шрифту. Нажмите на список шрифтов, чтобы выбрать соответствующий набор символов. Чтобы выбрать символ, нажмите его, затем нажмите Выберите … Чтобы вставить символ, щелкните правой кнопкой мыши нужное место в документе и выберите Вставить . Часто используемые коды символовПолный список символов см. на компьютере, в таблице кодов символов ASCII или в таблицах наборов символов Unicode.
2016-05-11 Назад Почему Вконтакте не играет музыка на Android? Следующая ошибка E_FAIL (0x80004005) при запуске виртуальной машины VirtualBox Почему виртуальная коробка выдает ошибку |

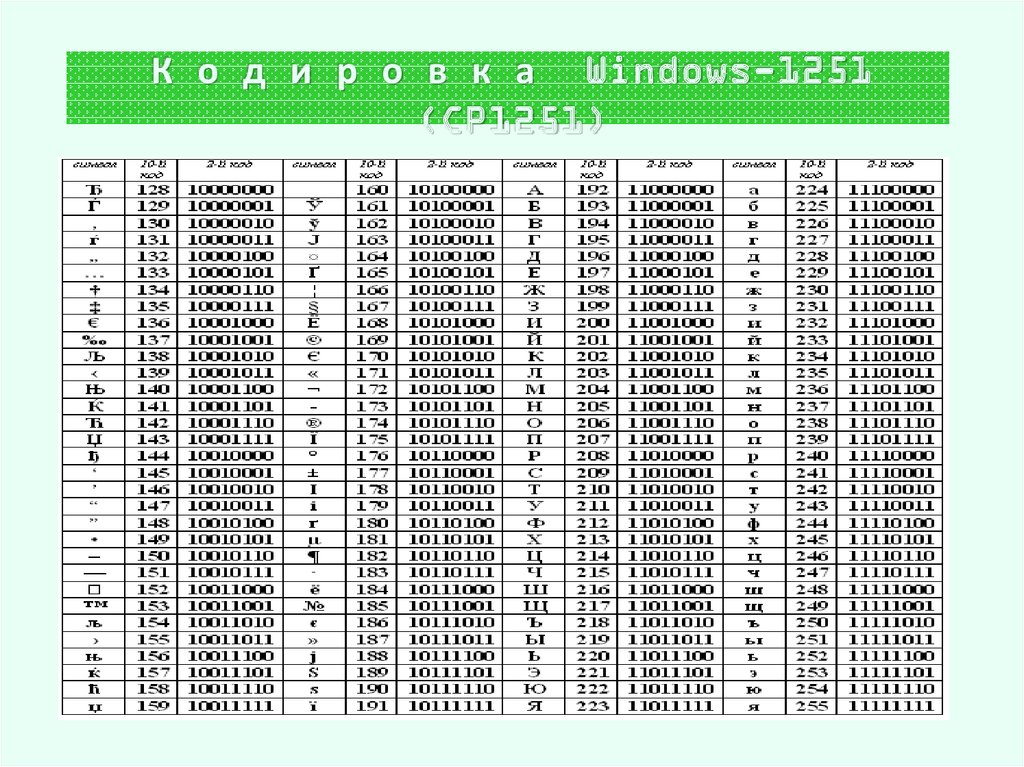


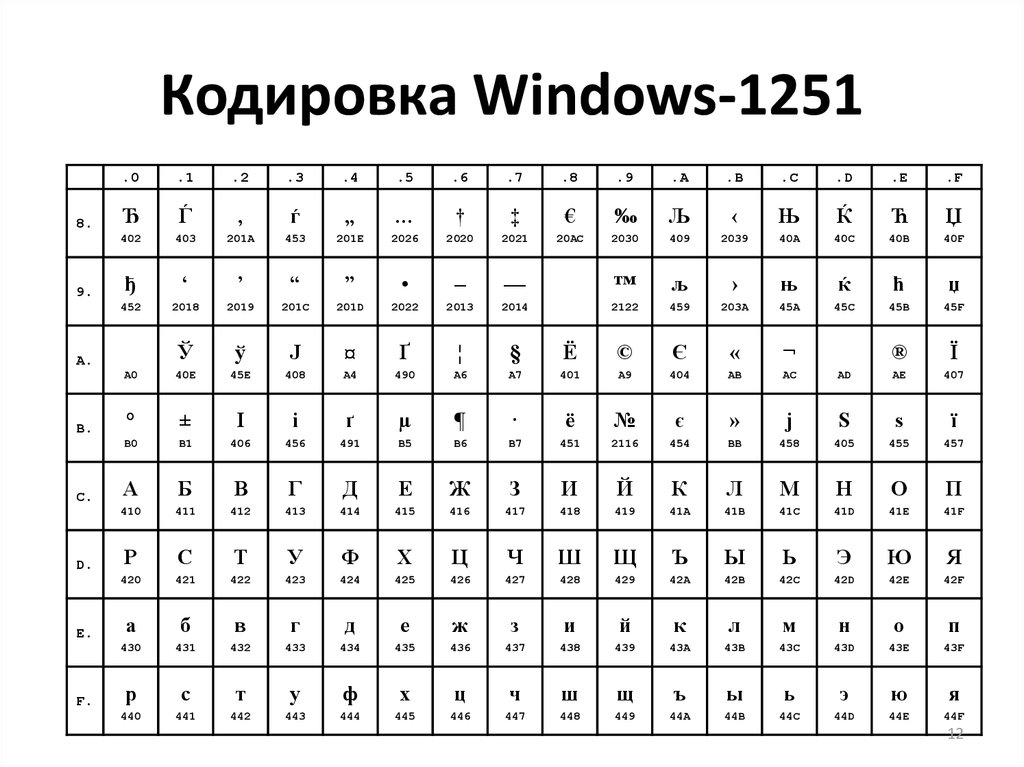
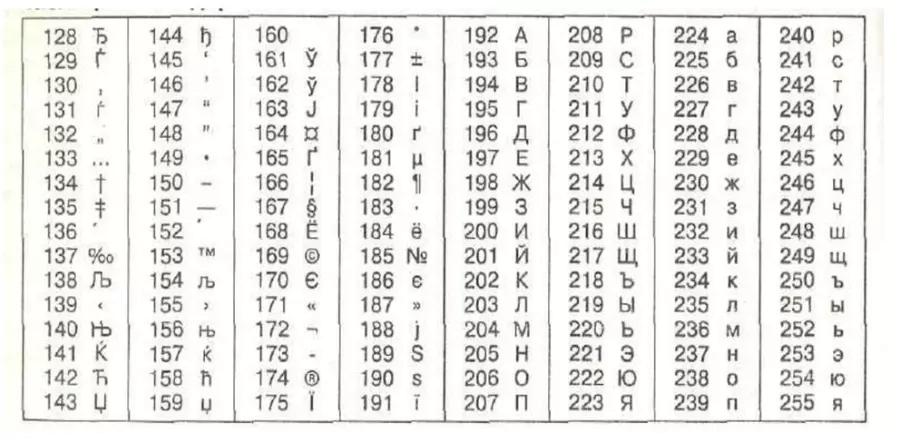 е. она выделяет 2 байта памяти для каждого символа. Конечно, это удваивает объем используемой памяти. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и других символов.
е. она выделяет 2 байта памяти для каждого символа. Конечно, это удваивает объем используемой памяти. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и других символов. Для того чтобы он знал, что именно он должен отображать на экране, необходимо присвоить каждому символу уникальный номер. В восьмидесятых годах символы кодировались одним байтом, то есть восемью битами (каждый бит равен 0 или 1). Таким образом, оказалось, что одна таблица (она же кодировка или набор) может содержать только 256 символов. Этого может быть недостаточно даже для одного языка. Поэтому появилось множество различных кодировок, путаница с которыми часто приводила к тому, что вместо читаемого текста на экране появлялись какие-то странные кракозябры. Требовался единый стандарт, которым стал Unicode. Наиболее часто используемой кодировкой является UTF-8 (формат преобразования Unicode), в которой для отображения символа используется от 1 до 4 байтов.
Для того чтобы он знал, что именно он должен отображать на экране, необходимо присвоить каждому символу уникальный номер. В восьмидесятых годах символы кодировались одним байтом, то есть восемью битами (каждый бит равен 0 или 1). Таким образом, оказалось, что одна таблица (она же кодировка или набор) может содержать только 256 символов. Этого может быть недостаточно даже для одного языка. Поэтому появилось множество различных кодировок, путаница с которыми часто приводила к тому, что вместо читаемого текста на экране появлялись какие-то странные кракозябры. Требовался единый стандарт, которым стал Unicode. Наиболее часто используемой кодировкой является UTF-8 (формат преобразования Unicode), в которой для отображения символа используется от 1 до 4 байтов. Чтобы не рыться в многокилометровом списке, стоит воспользоваться поиском. Зайдя на страницу символа, вы увидите его номер в Юникоде и то, как он прорисован разными шрифтами. Можно и сам знак вбить в строку поиска, пусть вместо него нарисован квадрат, хотя бы для того, чтобы узнать, что это было. Также на этом сайте есть специальные (причем — случайные) наборы однотипных иконок, собранные из разных разделов, для удобства использования.
Чтобы не рыться в многокилометровом списке, стоит воспользоваться поиском. Зайдя на страницу символа, вы увидите его номер в Юникоде и то, как он прорисован разными шрифтами. Можно и сам знак вбить в строку поиска, пусть вместо него нарисован квадрат, хотя бы для того, чтобы узнать, что это было. Также на этом сайте есть специальные (причем — случайные) наборы однотипных иконок, собранные из разных разделов, для удобства использования. Пиктограммы эмодзи (смайлики) также впервые широко использовались в Японии и до того, как их включили в кодировку. Но товарные знаки и логотипы компаний не добавляются в принципе. Даже такое обычное, как яблоко Apple или флаг Windows. На сегодняшний день в версии 8.0 закодировано около 120 тысяч символов.
Пиктограммы эмодзи (смайлики) также впервые широко использовались в Японии и до того, как их включили в кодировку. Но товарные знаки и логотипы компаний не добавляются в принципе. Даже такое обычное, как яблоко Apple или флаг Windows. На сегодняшний день в версии 8.0 закодировано около 120 тысяч символов. Список символов ASCII см. в следующих таблицах или в статье Вставка национальных алфавитов с помощью сочетаний клавиш.
Список символов ASCII см. в следующих таблицах или в статье Вставка национальных алфавитов с помощью сочетаний клавиш. Если вам нужно вставить символ Unicode в одну из этих программ, используйте.
Если вам нужно вставить символ Unicode в одну из этих программ, используйте.
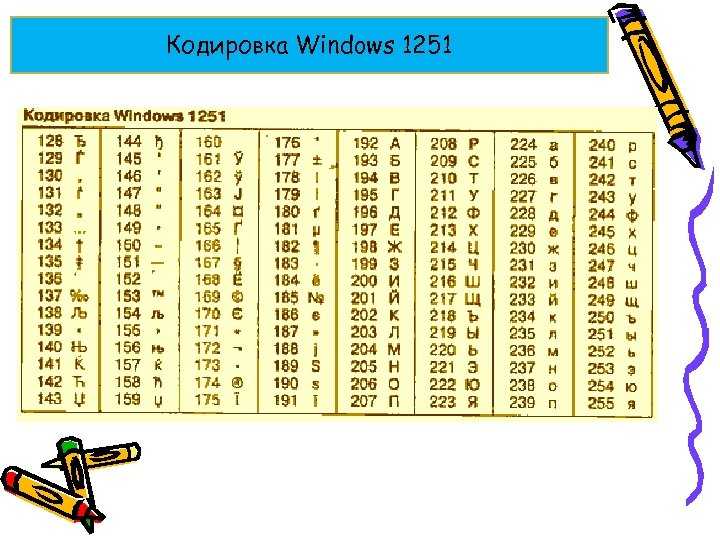
 Например, символ подачи/новой страницы имеет номер 12. Этот символ указывает принтеру перейти к началу следующей страницы.
Например, символ подачи/новой страницы имеет номер 12. Этот символ указывает принтеру перейти к началу следующей страницы.HTML Справочник по Windows-1252
❮ Предыдущий
Далее ❯
Windows-1252
Windows-1252 был первым набором символов по умолчанию в Microsoft Windows.
Это был самый популярный набор символов в Windows с 1985 по 1990 год.
ANSI
Исторически термин «кодовые страницы ANSI» использовался в Windows для обозначения наборов символов, отличных от DOS.
Намерение состояло в том, чтобы эти наборы символов соответствовали стандартам ANSI, таким как ISO-8859.-1.
Несмотря на то, что Windows-1252 почти идентична ISO-8859-1, она никогда не была стандартом ANSI.
или стандарт ISO.
Windows-1252 и ASCII
Первая часть Windows-1252 (номера объектов от 0 до 127) является исходным ASCII
набор символов. Он содержит цифры, прописные и строчные английские буквы и
некоторые специальные символы.
Для более подробного ознакомления, пожалуйста, изучите наш Полный
Ссылка ASCII.
Набор символов Windows-1252
7 # 30394 1
| Символ | Номер | Имя объекта | Описание | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 — 31 | Control characters (see below) | ||||||||
| 32 | space | ||||||||
| ! | 33 | восклицательный знак | |||||||
| « | 34 | « | кавычки | 35 | number sign | ||||
| $ | 36 | dollar sign | |||||||
| % | 37 | percent sign | |||||||
| & | 38 | & ; | Ampersand | ||||||
| ‘ | 39 | Apostrophe | |||||||
| ( | 40 0 |
||||||||
| ( | 8 | . 0400 0400 |
|||||||
| ) | 41 | right parenthesis | |||||||
| * | 42 | asterisk | |||||||
| + | 43 | plus sign | |||||||
| , | 44 | запятая | |||||||
| — | 45 | дефис-минус | |||||||
| . | 46 | точка | |||||||
| / | 47 | solidus | |||||||
| 0 | 48 | digit zero | |||||||
| 1 | 49 | digit one | |||||||
| 2 | 50 | digit two | |||||||
| 3 | 51 | digit three | |||||||
| 4 | 52 | digit four | |||||||
| 5 | 53 | digit five | |||||||
| 6 | 54 | digit six | |||||||
| 7 | 55 | digit seven | |||||||
| 8 | 56 | digit eight | |||||||
| 9 | 57 | digit nine | |||||||
| : | 58 | colon | |||||||
| ; | 59 | точка с запятой | |||||||
| < | 60 | < | знак «меньше» | ||||||
| = | 61 | знак равенства | |||||||
| > | 0 0; | знак больше | |||||||
| ? | 63 | знак вопроса | |||||||
| @ | 64 | commercial at | |||||||
| A | 65 | Latin capital letter A | |||||||
| B | 66 | Latin capital letter B | |||||||
| C | 67 | Latin capital буква C | |||||||
| D | 68 | заглавная латинская буква D | |||||||
| E | 69 | заглавная 9 E
|
|||||||
| F | 70 | Latin capital letter F | |||||||
| G | 71 | Latin capital letter G | |||||||
| H | 72 | Latin capital letter H | |||||||
| I | 73 | Латинская заглавная буква I | |||||||
| J | 74 | 90 9030 Латинская заглавная буква0397 K | 75 | Latin capital letter K | |||||
| L | 76 | Latin capital letter L | |||||||
| M | 77 | Latin capital letter M | |||||||
| N | 78 | Latin capital letter N | |||||||
| O | 79 | Latin capital letter O | |||||||
| P | 80 | Latin capital letter P | |||||||
| Q | 81 | Latin capital letter Q | |||||||
| R | 82 | Latin capital letter R | |||||||
| S | 83 | Заглавная латинская буква S | |||||||
| T | 84 | Заглавная латинская буква T | |||||||
| U | 9 9 0397 0 850397 Latin capital letter U | ||||||||
| V | 86 | Latin capital letter V | |||||||
| W | 87 | Latin capital letter W | |||||||
| X | 88 | Latin заглавная X | |||||||
| Y | 89 | латинская заглавная буква Y | |||||||
| Z | 90 |
|
94 | circumflex accent | |||||
| _ | 95 | low line | |||||||
| ` | 96 | grave accent | |||||||
| a | 97 | Latin строчная a | |||||||
| b | 98 | строчная латинская b | |||||||
| c | 99 |
|
|||||||
| d | 100 | Latin small letter d | |||||||
| e | 101 | Latin small letter e | |||||||
| f | 102 | Latin small letter f | |||||||
| g | 103 | Latin small letter g | |||||||
| h | 104 | Latin small letter h | |||||||
| i | 105 | Latin small letter i | |||||||
| j | 106 | Latin small letter j | |||||||
| k | 107 | Latin small letter k | |||||||
| l | 108 | Latin small letter l | |||||||
| m | 109 | Latin small letter m | |||||||
| n | 110 | Latin small letter n | |||||||
| o | 111 | Latin small letter o | |||||||
| p | 112 | Latin small letter p | |||||||
| q | 113 | Латинская маленькая буква Q | |||||||
| R | 114 | Латинская маленькая буква R | |||||||
| S | 115 | S | 115 | S | 115 | SMAL0400 | |||
| t | 116 | Latin small letter t | |||||||
| u | 117 | Latin small letter u | |||||||
| v | 118 | Latin small letter v | |||||||
| w | 119 | Latin small letter w | |||||||
| x | 120 | Latin small letter x | |||||||
| y | 121 | Latin small letter y | |||||||
| z | 122 | Latin small letter z | |||||||
| { | 123 | left curly bracket | |||||||
| | | 124 | vertical line | |||||||
| } | 125 | right curly bracket | |||||||
| ~ | 126 | тильда | |||||||
| 127 | Управляющий символ (см. ниже) ниже) |
||||||||
| € | 128 904; | Знак евро | |||||||
| 129 | НЕ ИСПОЛЬЗУЕТСЯ | ||||||||
| ‚ | одинарная нижняя девятка | ||||||||
| ƒ | 131 | ƒ | Строчная латинская буква f с крючком | ||||||
| „ | 132 | „ | двойная нижняя девятка | ||||||
| … | 133 | … | горизонтальный многоточие | ||||||
| † | 134 | † | Кинжал | ||||||
| ‡ | 135 | &Кинжал; | двойной кинжал | ||||||
| ˆ | 136 | ˆ | буква-модификатор с циркумфлексным акцентом | ||||||
| ‰ | 137 | ‰ | Знак промилле | ||||||
| Š | 138 | Š | Заглавная латинская буква S с кароном | ||||||
| ‹ | 139 | ‹ | одинарная левая кавычка | ||||||
| Œ | 140 | Œ | Латинская заглавная лигатура OE | ||||||
| 141 | НЕ ИСПОЛЬЗУЕТСЯ | ||||||||
| Ž | 142 | Ž | Latin capital letter Z with caron | ||||||
| 143 | NOT USED | ||||||||
| 144 | NOT USED | ||||||||
| ‘ | 145 | ‘ | левая одинарная кавычка | ||||||
| ’ | 146 | ’ | правая одинарная кавычка | ||||||
| « | 147 | “ | левая двойная кавычка | ||||||
| ” | 148 | ” | правая двойная кавычка | ||||||
| • | 149 | • | пуля | ||||||
| – | 150 | – | в тире | ||||||
| — | 151 | – | длинное тире | ||||||
| ˜ | 152 | ˜ | маленькая тильда | ||||||
| ™ | 153 | ™ | товарный знак | ||||||
| š | 154 | š | Строчная латинская буква s с двоеточием | ||||||
| › | 155 | › | одинарная правая кавычка | ||||||
| – | 156 | œ | Малая латинская лигатура oe | ||||||
| 157 | НЕ ИСПОЛЬЗУЕТСЯ | ||||||||
| ž | 158 | ž | Строчная латинская буква z с кароном | ||||||
| Ÿ | 159 | Ÿ | Латинская заглавная буква Y с диэрезисом | ||||||
| 160 | неразрывный пробел | ||||||||
| ¡ | 161 | ¡ | перевернутый восклицательный знак | ||||||
| ¢ | 162 | ¢ | знак цента | ||||||
| £ | 163 | фунт; | Знак фунта | ||||||
| ¤ | 164 | ¤ | знак валюты | ||||||
| ¥ | 165 | ¥ | знак иены | ||||||
| ¦ | 166 | ¦ | сломанный стержень | ||||||
| § | 167 | § | знак сечения | ||||||
| ¨ | 168 | ¨ | диэрезис | ||||||
| © | 169 | © | знак авторского права | ||||||
| ª | 170 | ª | женский порядковый номер | ||||||
| « | 171 | « | двойная кавычка, указывающая влево | ||||||
| ¬ | 172 | ¬ | без знака | ||||||
| 173 | | мягкий дефис | |||||||
| ® | 174 | ® | зарегистрированный знак | ||||||
| ¯ | 175 | ¯ | макрон | ||||||
| ° | 176 | &град; | знак градуса | ||||||
| ± | 177 | +плюсмн; | знак плюс-минус | ||||||
| ² | 178 | ² | верхний индекс два | ||||||
| ³ | 179 | ³ | верхний индекс три | ||||||
| ´ | 180 | ´ | острый акцент | ||||||
| µ | 181 | &микро; | микро знак | ||||||
| ¶ | 182 | ¶ | знак подушки | ||||||
| · | 183 | · | средняя точка | ||||||
| ¸ | 184 | ¸ | седилья | ||||||
| ¹ | 185 | ¹ | верхний индекс один | ||||||
| º | 186 | º | мужской порядковый номер | ||||||
| » | 187 | » | двойная кавычка, указывающая вправо | ||||||
| = | 188 | ¼ | вульгарная дробь одна четверть | ||||||
| ½ | 189 | ½ | вульгарная дробь одна половина | ||||||
| ¾ | 190 | ¾ | вульгарная дробь три четверти | ||||||
| ¿ | 191 | ¿ | перевернутый вопросительный знак | ||||||
| À | 192 | À | Заглавная латинская буква А с гравировкой | ||||||
| Á | 193 | Á | Латинская заглавная буква А с острым знаком | ||||||
| Â | 194 | Â | Заглавная латинская буква A с циркумфлексом | ||||||
| Ã | 195 | &Атильда; | Заглавная латинская буква A с тильдой | ||||||
| Ä | 196 | Ä | Заглавная латинская буква А с диэрезисом | ||||||
| Å | 197 | Å | Заглавная латинская буква A с кольцом вверху | ||||||
| Æ | 198 | Æ | Заглавная латинская буква AE | ||||||
| Ç | 199 | Ç | Заглавная латинская буква C с седильей | ||||||
| È | 200 | È | Заглавная латинская буква E с гравировкой | ||||||
| É | 201 | É | Латинская заглавная буква E с острым знаком | ||||||
| Ê | 202 | Ê | Заглавная латинская буква E с циркумфлексом | ||||||
| Ë | 203 | Ë | Заглавная латинская буква Е с диэрезисом | ||||||
| М | 204 | Ì | Латинская заглавная буква I с гравировкой | ||||||
| Í | 205 | Í | Латинская заглавная буква I с острым знаком | ||||||
| Î | 206 | Î | Заглавная латинская буква I с циркумфлексом | ||||||
| Ï | 207 | Ï | Латинская заглавная буква I с диэрезисом | ||||||
| Р | 208 | Ð | Заглавная латинская буква Eth | ||||||
| Ñ | 209 | Ñ | Заглавная латинская буква N с тильдой | ||||||
| Ò | 210 | Ò | Заглавная латинская буква O с гравировкой | ||||||
| Ó | 211 | Ó | Латинская заглавная буква O с острым знаком | ||||||
| Ô | 212 | Ô | Заглавная латинская буква O с циркумфлексом | ||||||
| Õ | 213 | Õ | Заглавная латинская буква O с тильдой | ||||||
| Ö | 214 | Ö | Латинская заглавная буква O с диэрезисом | ||||||
| × | 215 | × | знак умножения | ||||||
| Ø | 216 | Ø | Заглавная латинская буква О со штрихом | ||||||
| Ù | 217 | Ù | Латинская заглавная буква U с гравировкой | ||||||
| Ú | 218 | Ú | Латинская заглавная буква U с острым знаком | ||||||
| Û | 219 | Û | Латинская заглавная буква U с циркумфлексом | ||||||
| Ü | 220 | Ü | Латинская заглавная буква U с диэрезисом | ||||||
| Ý | 221 | Ý | Латинская заглавная буква Y с остротой | ||||||
| Þ | 222 | Þ | Заглавная латинская буква Thorn | ||||||
| ß | 223 | ß | Латинская строчная буква диез s | ||||||
| à | 224 | à | Строчная латинская буква а с запятой | ||||||
| á | 225 | á | Строчная латинская буква а с острым знаком | ||||||
| â | 226 | &acir; | Строчная латинская буква a с циркумфлексом | ||||||
| ã | 227 | ã | Строчная латинская буква a с тильдой | ||||||
| ä | 228 | ä | Строчная латинская буква a с диэрезисом | ||||||
| å | 229 | å | Строчная латинская буква а с кольцом над цифрой | ||||||
| æ | 230 | æ | Строчная латинская буква ae | ||||||
| ç | 231 | ç | Строчная латинская буква c с седилью | ||||||
| и | 232 | è | Строчная латинская буква e с запятой | ||||||
| é | 233 | é | Строчная латинская буква e с акутом | ||||||
| ê | 234 | ê | Строчная латинская буква e с циркумфлексом | ||||||
| ë | 235 | ë | Строчная латинская буква e с диэрезисом | ||||||
| ì | 236 | ` | Строчная латинская буква i с запятой | ||||||
| í | 237 | í | Строчная латинская буква i с акутом | ||||||
| î | 238 | î | Строчная латинская буква i с циркумфлексом | ||||||
| ï | 239 | ï | Строчная латинская буква i с диэрезисом | ||||||
| ð | 240 | ð | Латинская строчная буква eth | ||||||
| – | 241 | ñ | Строчная латинская буква n с тильдой | ||||||
| ò | 242 | ò | Строчная латинская буква о с запятой | ||||||
| — | 243 | ó | Строчная латинская буква o с акутом | ||||||
| ô | 244 | ô | Строчная латинская буква o с циркумфлексом | ||||||
| х | 245 | õ | Строчная латинская буква o с тильдой | ||||||
| ö | 246 | ö | Строчная латинская буква o с диэрезисом | ||||||
| ÷ | 247 | &разделить; | Знак деления | ||||||
| ø | 248 | ø | Строчная латинская буква o со штрихом | ||||||
| ù | 249 | ù | Строчная латинская буква u с запятой | ||||||
| ú | 250 | ú | Строчная латинская буква u с акутом | ||||||
| û | 251 | û | Строчная латинская буква u с циркумфлексом | ||||||
| ü | 252 | ü | Строчная латинская буква u с диэрезисом | ||||||
| ý | 253 | ý | Строчная латинская буква y с акутом | ||||||
| þ | 254 | þ | Латинская строчная буква thorn | ||||||
| ÿ | 255 | ÿ | Строчная латинская буква y с диэрезисом |
Управляющие символы
Управляющие символы (диапазон 00-31, плюс 127) предназначены для управления
аппаратные устройства.