CREATE DATABASE — create a new database
Synopsis
CREATE DATABASEname[ WITH ] [ OWNER [=]user_name] [ TEMPLATE [=]template] [ ENCODING [=]encoding] [ STRATEGY [=]strategy] ] [ LOCALE [=]locale] [ LC_COLLATE [=]lc_collate] [ LC_CTYPE [=]lc_ctype] [ ICU_LOCALE [=]icu_locale] [ ICU_RULES [=]icu_rules] [ LOCALE_PROVIDER [=]locale_provider] [ COLLATION_VERSION =collation_version] [ TABLESPACE [=]tablespace_name] [ ALLOW_CONNECTIONS [=]allowconn] [ CONNECTION LIMIT [=]connlimit] [ IS_TEMPLATE [=]istemplate] [ OID [=]oid]
Description
CREATE DATABASE creates a new PostgreSQL database.
To create a database, you must be a superuser or have the special CREATEDB privilege. See CREATE ROLE.
By default, the new database will be created by cloning the standard system database template1. A different template can be specified by writing TEMPLATE . In particular, by writing nameTEMPLATE template0, you can create a pristine database (one where no user-defined objects exist and where the system objects have not been altered) containing only the standard objects predefined by your version of PostgreSQL. This is useful if you wish to avoid copying any installation-local objects that might have been added to template1.
Parameters
name#-
The name of a database to create.
user_name#-
The role name of the user who will own the new database, or
DEFAULTto use the default (namely, the user executing the command). To create a database owned by another role, you must be able toSET ROLEto that role. template#-
The name of the template from which to create the new database, or
DEFAULTto use the default template (template1). encoding#-
Character set encoding to use in the new database. Specify a string constant (e.g.,
'SQL_ASCII'), or an integer encoding number, orDEFAULTto use the default encoding (namely, the encoding of the template database). The character sets supported by the PostgreSQL server are described in Section 24.3.1. See below for additional restrictions. strategy#-
Strategy to be used in creating the new database. If the
WAL_LOGstrategy is used, the database will be copied block by block and each block will be separately written to the write-ahead log. This is the most efficient strategy in cases where the template database is small, and therefore it is the default. The olderFILE_COPYstrategy is also available. This strategy writes a small record to the write-ahead log for each tablespace used by the target database. Each such record represents copying an entire directory to a new location at the filesystem level. While this does reduce the write-ahead log volume substantially, especially if the template database is large, it also forces the system to perform a checkpoint both before and after the creation of the new database. In some situations, this may have a noticeable negative impact on overall system performance. locale#-
Sets the default collation order and character classification in the new database. Collation affects the sort order applied to strings, e.g., in queries with
ORDER BY, as well as the order used in indexes on text columns. Character classification affects the categorization of characters, e.g., lower, upper, and digit. Also sets the associated aspects of the operating system environment,LC_COLLATEandLC_CTYPE. The default is the same setting as the template database. See Section 24.2.2.3.1 and Section 24.2.2.3.2 for details.Can be overridden by setting
lc_collate,lc_ctype, oricu_localeindividually.Tip
The other locale settings lc_messages, lc_monetary, lc_numeric, and lc_time are not fixed per database and are not set by this command. If you want to make them the default for a specific database, you can use
ALTER DATABASE ... SET. lc_collate#-
Sets
LC_COLLATEin the database server’s operating system environment. The default is the setting oflocaleif specified, otherwise the same setting as the template database. See below for additional restrictions.If
locale_providerislibc, also sets the default collation order to use in the new database, overriding the settinglocale. lc_ctype#-
Sets
LC_CTYPEin the database server’s operating system environment. The default is the setting oflocaleif specified, otherwise the same setting as the template database. See below for additional restrictions.If
locale_providerislibc, also sets the default character classification to use in the new database, overriding the settinglocale. icu_locale#-
Specifies the ICU locale (see Section 24.2.2.3.2) for the database default collation order and character classification, overriding the setting
locale. The locale provider must be ICU. The default is the setting oflocaleif specified; otherwise the same setting as the template database. icu_rules#-
Specifies additional collation rules to customize the behavior of the default collation of this database. This is supported for ICU only. See Section 24.2.3.4 for details.
locale_provider#-
Specifies the provider to use for the default collation in this database. Possible values are
icu(if the server was built with ICU support) orlibc. By default, the provider is the same as that of thetemplate. See Section 24.1.4 for details. collation_version#-
Specifies the collation version string to store with the database. Normally, this should be omitted, which will cause the version to be computed from the actual version of the database collation as provided by the operating system. This option is intended to be used by
pg_upgradefor copying the version from an existing installation.See also ALTER DATABASE for how to handle database collation version mismatches.
tablespace_name#-
The name of the tablespace that will be associated with the new database, or
DEFAULTto use the template database’s tablespace. This tablespace will be the default tablespace used for objects created in this database. See CREATE TABLESPACE for more information. allowconn#-
If false then no one can connect to this database. The default is true, allowing connections (except as restricted by other mechanisms, such as
GRANT/REVOKE CONNECT). connlimit#-
How many concurrent connections can be made to this database. -1 (the default) means no limit.
istemplate#-
If true, then this database can be cloned by any user with
CREATEDBprivileges; if false (the default), then only superusers or the owner of the database can clone it. oid#-
The object identifier to be used for the new database. If this parameter is not specified, PostgreSQL will choose a suitable OID automatically. This parameter is primarily intended for internal use by pg_upgrade, and only pg_upgrade can specify a value less than 16384.
Optional parameters can be written in any order, not only the order illustrated above.
Notes
CREATE DATABASE cannot be executed inside a transaction block.
Errors along the line of “could not initialize database directory” are most likely related to insufficient permissions on the data directory, a full disk, or other file system problems.
Use DROP DATABASE to remove a database.
The program createdb is a wrapper program around this command, provided for convenience.
Database-level configuration parameters (set via ALTER DATABASE) and database-level permissions (set via GRANT) are not copied from the template database.
Although it is possible to copy a database other than template1 by specifying its name as the template, this is not (yet) intended as a general-purpose “COPY DATABASE” facility. The principal limitation is that no other sessions can be connected to the template database while it is being copied. CREATE DATABASE will fail if any other connection exists when it starts; otherwise, new connections to the template database are locked out until CREATE DATABASE completes. See Section 23.3 for more information.
The character set encoding specified for the new database must be compatible with the chosen locale settings (LC_COLLATE and LC_CTYPE). If the locale is C (or equivalently POSIX), then all encodings are allowed, but for other locale settings there is only one encoding that will work properly. (On Windows, however, UTF-8 encoding can be used with any locale.) CREATE DATABASE will allow superusers to specify SQL_ASCII encoding regardless of the locale settings, but this choice is deprecated and may result in misbehavior of character-string functions if data that is not encoding-compatible with the locale is stored in the database.
The encoding and locale settings must match those of the template database, except when template0 is used as template. This is because other databases might contain data that does not match the specified encoding, or might contain indexes whose sort ordering is affected by LC_COLLATE and LC_CTYPE. Copying such data would result in a database that is corrupt according to the new settings. template0, however, is known to not contain any data or indexes that would be affected.
There is currently no option to use a database locale with nondeterministic comparisons (see CREATE COLLATION for an explanation). If this is needed, then per-column collations would need to be used.
The CONNECTION LIMIT option is only enforced approximately; if two new sessions start at about the same time when just one connection “slot” remains for the database, it is possible that both will fail. Also, the limit is not enforced against superusers or background worker processes.
Examples
To create a new database:
CREATE DATABASE lusiadas;
To create a database sales owned by user salesapp with a default tablespace of salesspace:
CREATE DATABASE sales OWNER salesapp TABLESPACE salesspace;
To create a database music with a different locale:
CREATE DATABASE music
LOCALE 'sv_SE.utf8'
TEMPLATE template0;
In this example, the TEMPLATE template0 clause is required if the specified locale is different from the one in template1. (If it is not, then specifying the locale explicitly is redundant.)
To create a database music2 with a different locale and a different character set encoding:
CREATE DATABASE music2
LOCALE 'sv_SE.iso885915'
ENCODING LATIN9
TEMPLATE template0;
The specified locale and encoding settings must match, or an error will be reported.
Note that locale names are specific to the operating system, so that the above commands might not work in the same way everywhere.
Compatibility
There is no CREATE DATABASE statement in the SQL standard. Databases are equivalent to catalogs, whose creation is implementation-defined.
PostgreSQL — это бесплатная объектно-реляционная СУБД с мощным функционалом, который позволяет конкурировать с платными базами данных, такими как Microsoft SQL, Oracle. PostgreSQL поддерживает пользовательские данные, функции, операции, домены и индексы. В данной статье мы рассмотрим установку и краткий обзор по управлению базой данных PostgreSQL. Мы установим СУБД PostgreSQL в Windows 10, создадим новую базу, добавим в неё таблицы и настроим доступа для пользователей. Также мы рассмотрим основы управления PostgreSQL с помощью SQL shell и визуальной системы управления PgAdmin. Надеюсь эта статья станет хорошей отправной точкой для обучения работы с PostgreSQL и использованию ее в разработке и тестовых проектах.
Содержание:
- Установка PostgreSQL 11 в Windows 10
- Доступ к PostgreSQL по сети, правила файерволла
- Утилиты управления PostgreSQL через командную строку
- PgAdmin: Визуальный редактор для PostgresSQL
- Query Tool: использование SQL запросов в PostgreSQL
Установка PostgreSQL 11 в Windows 10
Для установки PostgreSQL перейдите на сайт https://www.postgresql.org и скачайте последнюю версию дистрибутива для Windows, на сегодняшний день это версия PostgreSQL 11 (в 11 версии PostgreSQL поддерживаются только 64-х битные редакции Windows). После загрузки запустите инсталлятор.
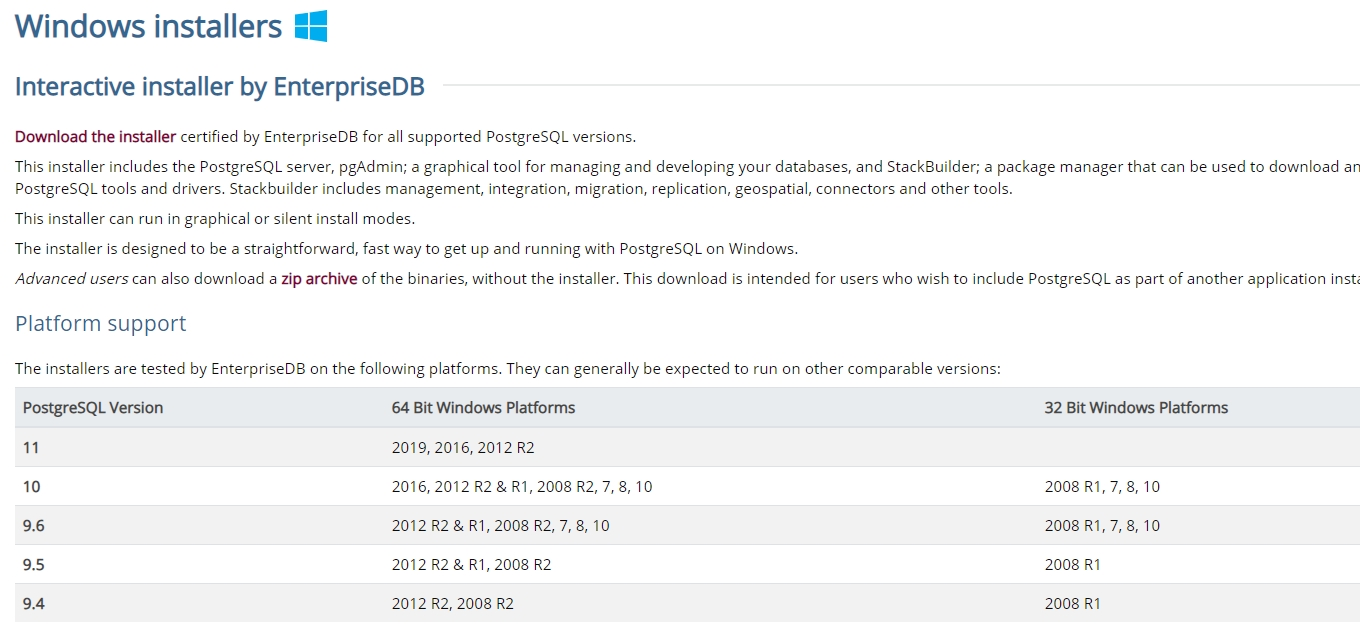
В процессе установки установите галочки на пунктах:
- PostgreSQL Server – сам сервер СУБД
- PgAdmin 4 – визуальный редактор SQL
- Stack Builder – дополнительные инструменты для разработки (возможно вам они понадобятся в будущем)
- Command Line Tools – инструменты командной строки
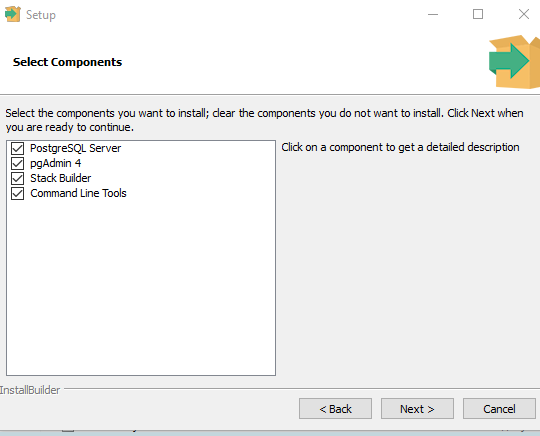
Установите пароль для пользователя postgres (он создается по умолчанию и имеет права суперпользователя).
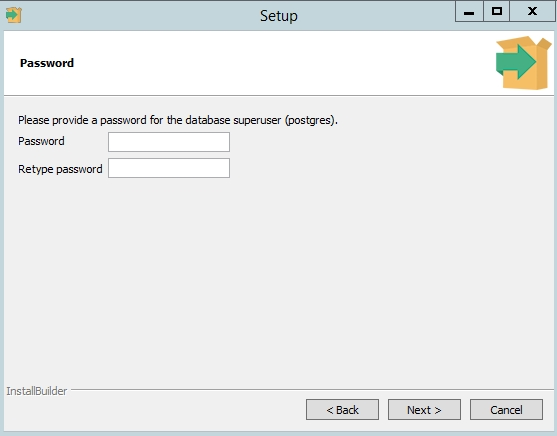
По умолчание СУБД слушает на порту 5432, который нужно будет добавить в исключения в правилах фаерволла.
Нажимаете Далее, Далее, на этом установка PostgreSQL завершена.
Доступ к PostgreSQL по сети, правила файерволла
Чтобы разрешить сетевой доступ к вашему экземпляру PostgreSQL с других компьютеров, вам нужно создать правила в файерволе. Вы можете создать правило через командную строку или PowerShell.
Запустите командную строку от имени администратора. Введите команду:
netsh advfirewall firewall add rule name="Postgre Port" dir=in action=allow protocol=TCP localport=5432
- Где rule name – имя правила
- Localport – разрешенный порт
Либо вы можете создать правило, разрешающее TCP/IP доступ к экземпляру PostgreSQL на порту 5432 с помощью PowerShell:
New-NetFirewallRule -Name 'POSTGRESQL-In-TCP' -DisplayName 'PostgreSQL (TCP-In)' -Direction Inbound -Enabled True -Protocol TCP -LocalPort 5432
После применения команды в брандмауэре Windows появится новое разрешающее правило для порта Postgres.
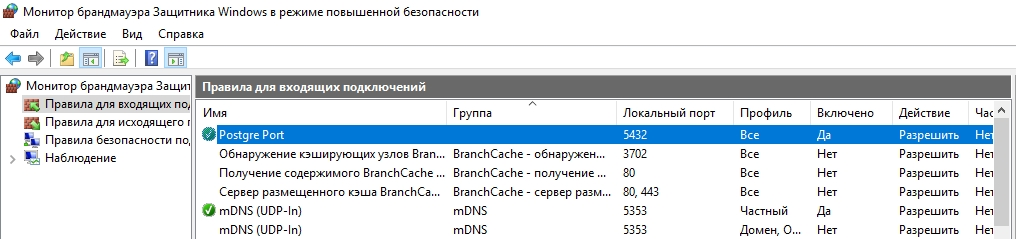
Совет. Для изменения порта в установленной PostgreSQL отредактируйте файл postgresql.conf по пути C:\Program Files\PostgreSQL\11\data.
Измените значение в пункте
port = 5432
. Перезапустите службу сервера postgresql-x64-11 после изменений. Можно перезапустить службу с помощью PowerShell:
Restart-Service -Name postgresql-x64-11

Более подробно о настройке параметров в конфигурационном файле postgresql.conf с помощью тюнеров смотрите в статье.
Утилиты управления PostgreSQL через командную строку
Рассмотрим управление и основные операции, которые можно выполнять с PostgreSQL через командную строку с помощью нескольких утилит. Основные инструменты управления PostgreSQL находятся в папке bin, потому все команды будем выполнять из данного каталога.
- Запустите командную строку.
Совет. Перед запуском СУБД, смените кодировку для нормального отображения в русской Windows 10. В командной строке выполните:
chcp 1251 - Перейдите в каталог bin выполнив команду:
CD C:\Program Files\PostgreSQL\11\bin

Основные команды PostgreSQL:

PgAdmin: Визуальный редактор для PostgresSQL
Редактор PgAdmin служит для упрощения управления базой данных PostgresSQL в понятном визуальном режиме.
По умолчанию все созданные базы хранятся в каталоге base по пути C:\Program Files\PostgreSQL\11\data\base.
Для каждой БД существует подкаталог внутри PGDATA/base, названный по OID базы данных в pg_database. Этот подкаталог по умолчанию является местом хранения файлов базы данных; в частности, там хранятся её системные каталоги. Каждая таблица и индекс хранятся в отдельном файле.
Для резервного копирования и восстановления лучше использовать инструмент Backup в панели инструментов Tools. Для автоматизации бэкапа PostgreSQL из командной строки используйте утилиту pg_dump.exe.
Query Tool: использование SQL запросов в PostgreSQL
Для написания SQL запросов в удобном графическом редакторе используется встроенный в pgAdmin инструмент Query Tool. Например, вы хотите создать новую таблицу в базе данных через инструмент Query Tool.
- Выберите базу данных, в панели Tools откройте Query Tool
- Создадим таблицу сотрудников:
CREATE TABLE employee
(
Id SERIAL PRIMARY KEY,
FirstName CHARACTER VARYING(30),
LastName CHARACTER VARYING(30),
Email CHARACTER VARYING(30),
Age INTEGER
);
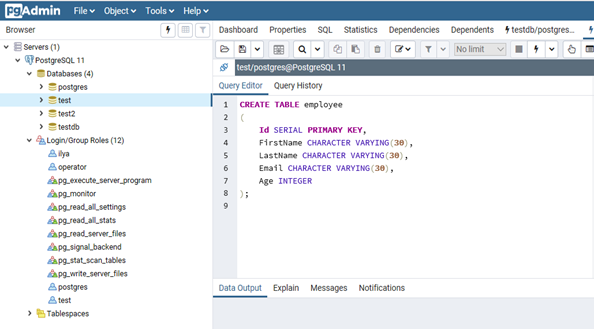
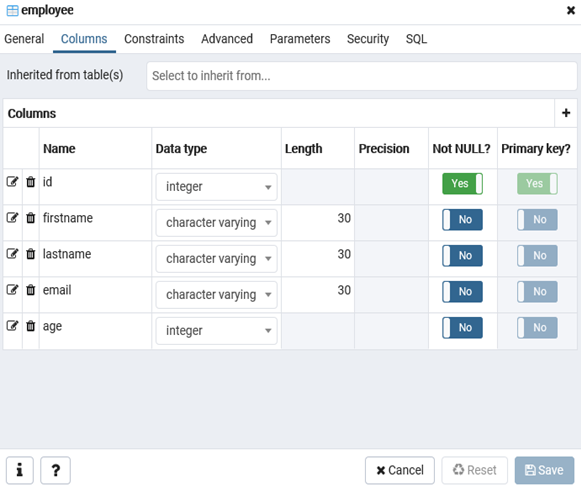
Id — номер сотрудника, которому присвоен ключ SERIAL. Данная строка будет хранить числовое значение 1, 2, 3 и т.д., которое для каждой новой строки будет автоматически увеличиваться на единицу. В следующих строках записаны имя, фамилия сотрудника и его электронный адрес, которые имеют тип CHARACTER VARYING(30), то есть представляют строку длиной не более 30 символов. В строке — Age записан возраст, имеет тип INTEGER, т.к. хранит числа.
После того, как написали код SQL запроса в Query Tool, нажмите клавишу F5 и в базе будет создана новая таблица employee.
Для заполнения полей в свойствах таблицы выберите таблицу employee в разделе Schemas -> Tables. Откройте меню Object инструмент View/Edit Data.
Здесь вы можете заполнить данные в таблице.
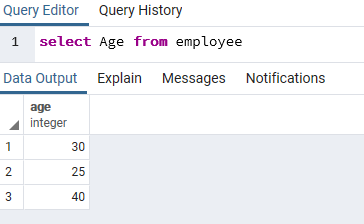
После заполнения данных выполним инструментом Query простой запрос на выборку:
select Age from employee;
Introduction
PostgreSQL is an open-source, advanced database management system supporting relational (SQL) and non-relational (JSON) querying.
In PostgreSQL, the emphasis is mainly on extensibility and SQL compliance while maintaining ACID properties (Atomicity, Consistency, Isolation, Durability) in transactions.
In this tutorial, you will learn how to create a database in PostgreSQL using three different methods.

Prerequisites
- PostgreSQL installed and set up
- Administrator privileges
Create a Database in PostgreSQL via pgAdmin
To create a database using pgAdmin, follow these steps:
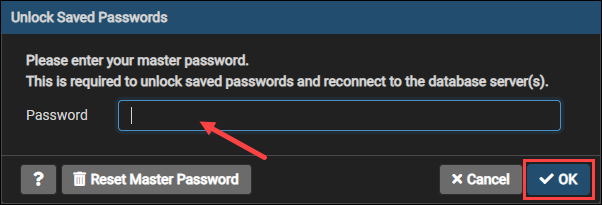
Step 1: Open pgAdmin and enter your password to connect to the database server.
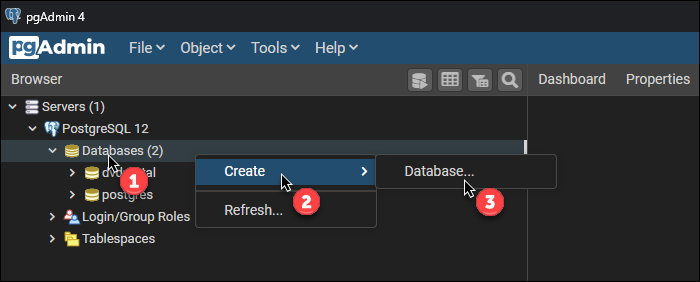
Step 2: In the browser section, expand the Servers and then PostgreSQL items. Right-click the Databases item. Click Create and Database…
Step 3: A new window pops up where you need to specify the database name, add a comment if necessary and click Save.
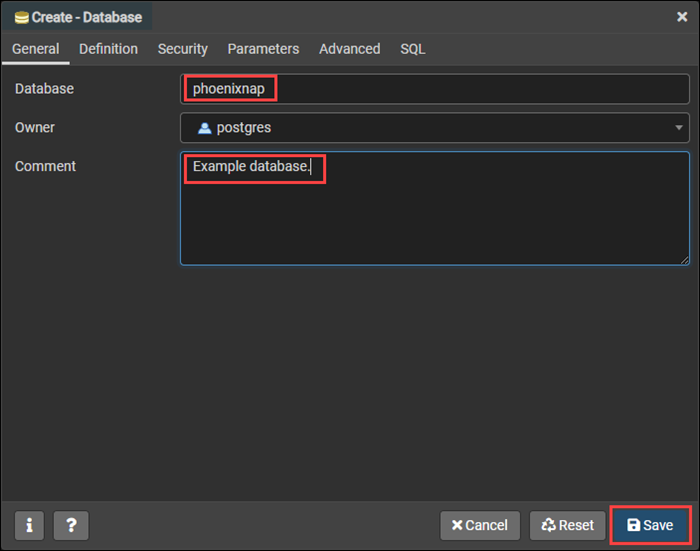
The database appears in the Databases object tree.
The right section of the pgAdmin window contains tabs that display database statistics, SQL commands used to create the database, any dependencies, etc.
Create a Database in PostgreSQL via CREATE DATABASE
Another method to create a PostrgreSQL database is to use the CREATE DATABASE command.
Follow these steps to create a database:
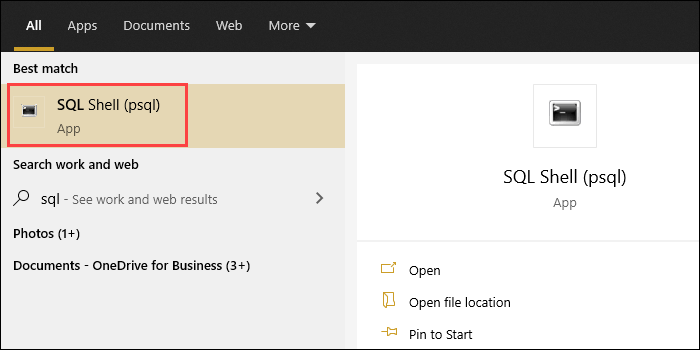
Step 1: Open the SQL Shell (psql) app.
Step 2: Connect to the DB server by pressing ENTER four times. Type in your master password if asked. If you didn’t set up a password, press ENTER again to connect.
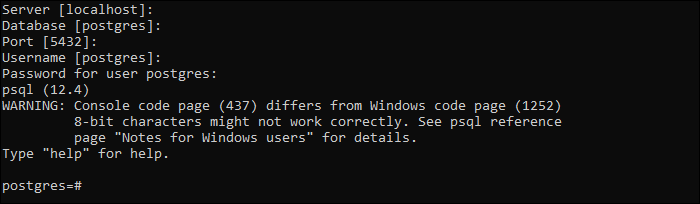
Step 3: Use the following syntax to create a new database:
CREATE DATABASE [database_name]In place of [database_name], enter a name for your database. Make sure to enter a unique name because using an existing database name results in an error.
For example:

Creating a database without specifying any parameters takes the parameters from the default template database. See the available parameters in the next section.
Step 4: Use the following command to list all the databases in PostgreSQL:
\l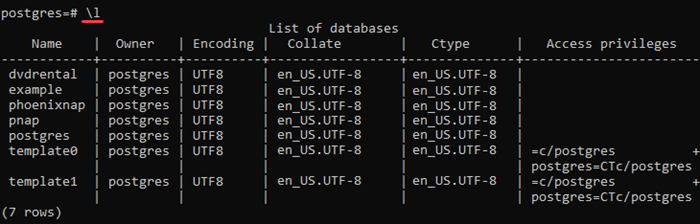
The output shows a list of available databases and their characteristics.
CREATE DATABASE Parameters
The available parameters for creating a database are:
[OWNER = role_name]
The OWNER parameter assigns the database owner role. Omitting the OWNER parameter means that the database owner is the role used to execute the CREATE DATABASE statement.
[TEMPLATE = template]
The TEMPLATE parameter allows you to specify the template database from which to create the new database. Omitting the TEMPLATE parameter sets template1 as the default template database.
[ENCODING = encoding]
The ENCODING parameter determines the character set encoding in the new database.
[LC_COLLATE = collate]
The LC_COLLATE parameter specifies the collation order of the new database. This parameter controls the string sort order in the ORDER BY clause. The effect is visible when using a locale that contains special characters.
Omitting the LC_COLLATE parameter takes the settings from the template database.
[LC_CTYPE = ctype]
The LC_CTYPE parameter specifies the character classification used in the new database. Character classification includes lower, upper case, and digits. Omitting the LC_CTYPE parameter takes the default settings from the template database.
[TABLESPACE = tablespace_name]
Use the TABLESPACE parameter to specify the tablespace name for the new database. Omitting the TABLESPACE parameter takes the tablespace name of the template database.
[ALLOW_CONNECTIONS = true | false]
The ALLOW_CONNECTIONS parameter can be TRUE or FALSE. Specifying the value as FALSE prevents you from connecting to the database.
[CONNECTION LIMIT = max_concurrent_connections]
The CONNECTION LIMIT parameter lets you to set the maximum simultaneous connections to a PostgreSQL database. The default value is -1, which means unlimited connections.
[IS_TEMPLATE = true | false ]
Set the IS_TEMPLATE parameter to TRUE or FALSE. Setting IS_TEMPLATE to TRUE allows any user with the CREATEDB privilege to clone the database. Otherwise, only superusers or the database owner can clone the database.
To create a database with parameters, add the keyword WITH after the CREATE DATABASE statement and then list the parameters you want.
For example:

This example shows how to set a new database to use the UTF-8 character encoding and to support a maximum of 200 concurrent connections.
Create a Database in PostgreSQL via createdb Command
The createdb command is the third method for creating a database in PostgreSQL. The only difference between the createdb and CREATE DATABASE command is that users run createdb directly from the command line and add a comment into the database, all at once.
To create a database using the createdb command, use the following syntax:
createdb [argument] [database_name [comment]]The parameters are discussed in the following section.
Note: createdb internally runs CREATE DATABASE from psql while connected to the template1 database. The user creating the database is the only DBA and the only one who can drop the database, other than the postgres superuser.
createdb Parameters
The createdb syntax parameters are:
| Parameter | Description |
|---|---|
[argument] |
Command-line arguments that createdb accepts. Discussed in the next section. |
[database_name] |
Set the database name in place of the database_name parameter. |
[comment] |
Optional comment to be associated with the new database. |
createdb Command Line Arguments
The available createdb arguments are:
| Argument | Description |
|---|---|
-D |
Specifies the tablespace name for the new database. |
-e |
Shows the commands that createdb sends to the server. |
-E |
Specifies which character encoding to use in the database. |
-l |
Specifies which locale to use in the database. |
-T |
Specifies which database to use as a template for the new database. |
--help |
Show help page about the createdb command line arguments. |
-h |
Displays the hostname of the machine running the server. |
-p |
Sets the TCP port or the local Unix domain socket file extension which the server uses to listen for connections. |
-U |
Specifies which username to use to connect. |
-w |
Instructs createdb never to issue a password prompt. |
-W |
Instructs createdb to issue a password prompt before connecting to a database. |
For example:

Here, we created a database called mydatabase using the default admin user postgres. We used the phoenixnap database as a template and instructed the program not to ask for a password.
createdb Command Common Errors
There are some common errors users may encounter when using the createdb command.
See the createdb error list below:
| Error | Description |
|---|---|
createdb command not found. |
Occurs when PostgreSQL was not installed properly. Run createdb from the PostgreSQL installation path or add the psql.exe path to the system variables section in PC advanced settings. |
| No such file or directory Is the server running locally and accepting connections on Unix domain socket …? |
Happens when the PostgreSQL server wasn’t properly started or is not currently running. |
| Fatal: role «username» does not exist. | Occurs when users run initdb with a role without superuser privileges.To fix the error, create a new Postgres user with the --superuser option or login to the default admin role, postgres. |
| Database creation failed: ERROR: permission denied to create database. | Appears when trying to create a database with an account that doesn’t have the necessary permissions. To fix the error, grant superuser permissions to the role in question. |
Conclusion
Now you know how to create a database in PostgreSQL using three different methods. If you prefer a GUI environment, use pgAdmin, or use the CLI or SQL Shell if you prefer running SQL commands.
To find out how can you delete an existing PostgreSQL database, read our article PostgreSQL drop database.
If you are interested to learn more about PostgreSQL, make sure to check how to install PostgreSQL Workbench, how to Export PostgreSQL Table to CSV, how to Check PostgreSQL Version, how to Download and Install PostgreSQL on Windows, or how to use the PostgreSQL SELECT Statement.
And for information about different built-in data types available in PostgreSQL, you might find helpful our article PostgreSQL data types.

Now is a great time to learn relational databases and SQL. From web development to data science, they are used everywhere.
In the Stack Overflow 2021 Survey, 4 out of the top 5 database technologies used by professional developers were relational database management systems.
PostgreSQL is an excellent choice as a first relational database management system to learn.
- It’s widely used in industry, including at Uber, Netflix, Instagram, Spotify, and Twitch.
- It’s open source, so you won’t be locked into a particular vendor.
- It’s more than 25 years old, and in that time it has earned a reputation for stability and reliability.
Whether you’re learning from the freeCodeCamp Relational Database Certification or trying out PostgreSQL on your own computer, you need a way to create and manage databases, insert data into them, and query data from them.
While there are several graphical applications for interacting with PostgreSQL, using psql and the command line is probably the most direct way to communicate with your database.
What is psql?
psql is a tool that lets you interact with PostgreSQL databases through a terminal interface. When you install PostgreSQL on a machine, psql is automatically included.
psql lets you write SQL queries, send them to PostgreSQL, and view the results. It also lets you use meta-commands (which start with a backslash) for administering the databases. You can even write scripts and automate tasks relating to your databases.
Now, running a database on your local computer and using the command line can seem intimidating at first. I’m here to tell you it’s really not so bad. This guide will teach you the basics of managing PostgreSQL databases from the command line, including how to create, manage, back up, and restore databases.
Prerequisite – Install PostgreSQL
If you haven’t already installed PostgreSQL on your computer, follow the instructions for your operating system on the official PostgreSQL documentation.
When you install PostgreSQL, you will be asked for a password. Keep this in a safe place as you’ll need it to connect to any databases you create.
How to Connect to a Database
You have two options when using psql to connect to a database: you can connect via the command line or by using the psql application. Both provide pretty much the same experience.
Option 1 – Connect to a database with the command line
Open a terminal. You can make sure psql is installed by typing psql --version. You should see psql (PostgreSQL) version_number, where version_number is the version of PostgreSQL that’s installed on your machine. In my case, it’s 14.1.
The pattern for connecting to a database is:
psql -d database_name -U usernameThe -d flag is shorter alternative for --dbname while -U is an alternative for --username.
When you installed PostgreSQL, a default database and user were created, both called postgres. So enter psql -d postgres -U postgres to connect to the postgres database as the postgres superuser.
psql -d postgres -U postgresYou will be prompted for a password. Enter the password you chose when you installed PostgreSQL on your computer. Your terminal prompt will change to show that you’re now connected to the postgres database.
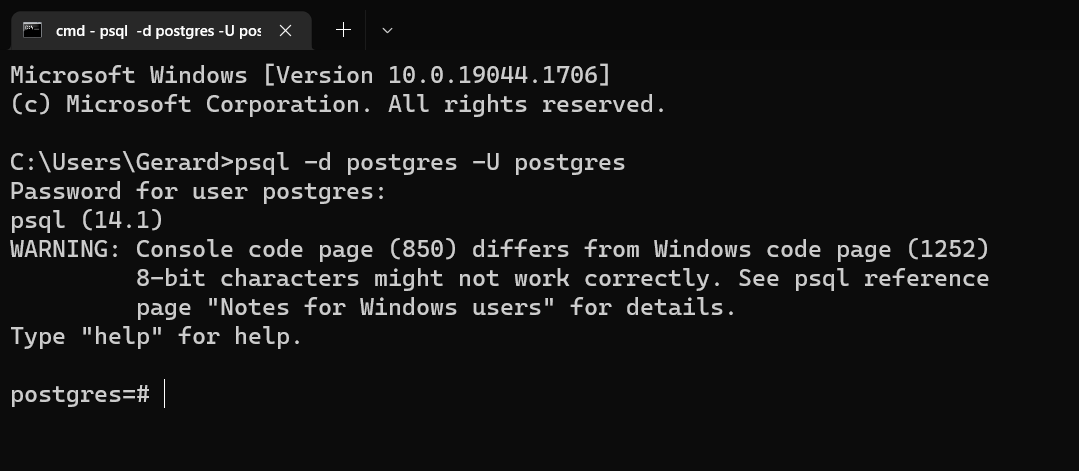
If you want to directly connect to a database as yourself (rather than as the postgres superuser), enter your system username as the username value.
Option 2 – Connect to a database with the psql application
Launch the psql application – it’ll be called «SQL Shell (psql)». You will be prompted for a server, a database, a port and a username. You can just press enter to select the default values, which are localhost, postgres, 5432, and postgres.
Next, you’ll be prompted for the password you chose when you installed PostgreSQL. Once you enter this, your terminal prompt will change to show that you’re connected to the postgres database.

Note: If you’re on Windows you might see a warning like “Console code page (850) differs from Windows code page (1252) 8-bit characters might not work correctly. See psql reference page ‘Notes for Windows users’ for details.” You don’t need to worry about this at this stage. If you want to read more about it, see the psql documentation.
How to Get Help in psql
To see a list of all psql meta-commands, and a brief summary of what they do, use the \? command.
\?
If you want help with a PostgreSQL command, use \h or \help and the command.
\h COMMANDThis will give you a description of the command, its syntax (with optional parts in square brackets), and a URL for the relevant part of the PostgreSQL documentation.

How to Quit a Command in psql
If you’ve run a command that’s taking a long time or printing too much information to the console, you can quit it by typing q.
qHow to Create a Database
Before you can manage any databases, you’ll need to create one.
Note: SQL commands should end with a semicolon, while meta-commands (which start with a backslash) don’t need to.
The SQL command to create a database is:
CREATE DATABASE database_name;For this guide, we’re going to be working with book data, so let’s create a database called books_db.
CREATE DATABASE books_db;You can view a list of all available databases with the list command.
\l
You should see books_db, as well as postgres, template0, and template1. (The CREATE DATABASE command actually works by copying the standard database, called template1. You can read more about this in the PostgreSQL documentation.)
Using \l+ will display additional information, such as the size of the databases and their tablespaces (the location in the filesystem where the files representing the database will be stored).
\l+
How to Switch Databases
You’re currently still connected to the default postgres database. To connect to a database or to switch between databases, use the \c command.
\c database_nameSo \c books_db will connect you to the books_db database. Note that your terminal prompt changes to reflect the database you’re currently connected to.

How to Delete a Database
If you want to delete a database, use the DROP DATABASE command.
DROP DATABASE database_name;You will only be allowed to delete a database if you are a superuser, such as postgres, or if you are the database’s owner.
If you try to delete a database that doesn’t exist, you will get an error. Use IF EXISTS to get a notice instead.
DROP DATABASE IF EXISTS database_name;
You can’t delete a database that has active connections. So if you want to delete the database you are currently connected to, you’ll need to switch to another database.
How to Create Tables
Before we can manage tables, we need to create a few and populate them with some sample data.
The command to create a table is:
CREATE TABLE table_name();This will create an empty table. You can also pass column values into the parentheses to create a table with columns. At the very least, a basic table should have a Primary Key (a unique identifier to tell each row apart) and a column with some data in it.
For our books_db, we’ll create a table for authors and another for books. For authors, we’ll record their first name and last name. For books, we’ll record the title and the year they were published.
We’ll make sure that the authors’ first_name and last_name and the books’ title aren’t null, since this is pretty vital information to know about them. To do this we include the NOT NULL constraint.
CREATE TABLE authors(
author_id SERIAL PRIMARY KEY,
first_name VARCHAR(100) NOT NULL,
last_name VARCHAR(100) NOT NULL
);
CREATE TABLE books(
book_id SERIAL PRIMARY KEY,
title VARCHAR(100) NOT NULL,
published_year INT
);You will see CREATE TABLE printed to the terminal if the table was created successfully.
Now let’s connect the two tables by adding a Foreign Key to books. Foreign Keys are unique identifiers that reference the Primary Key of another table. Books can, of course, have multiple authors but we’re not going to get into the complexities of many to many relationships right now.
Add a Foreign Key to books with the following command:
ALTER TABLE books ADD COLUMN author_id INT REFERENCES authors(author_id);Next, let’s insert some sample data into the tables. We’ll start with authors.
INSERT INTO authors (first_name, last_name)
VALUES (‘Tamsyn’, ‘Muir’), (‘Ann’, ‘Leckie’), (‘Zen’, ‘Cho’);Select everything from authors to make sure the insert command worked.
SELECT * FROM authors;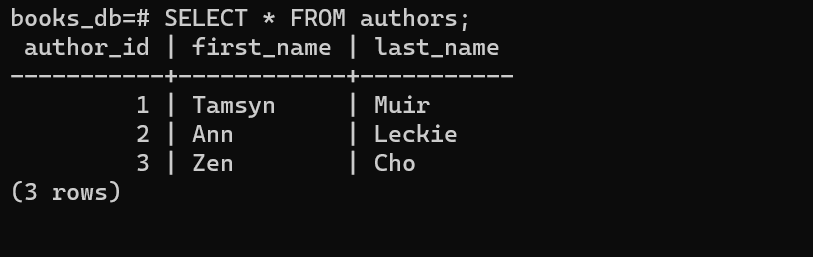
Next, we’ll insert some books data into books.
INSERT INTO books(title, published_year, author_id)
VALUES (‘Gideon the Ninth’, 2019, 1), (‘Ancillary Justice’, 2013, 2), (‘Black Water Sister’, 2021, 3);If you run SELECT * FROM books; you’ll see the book data.

How to List All Tables
You can use the \dt command to list all the tables in a database.
\dtFor books_db you will see books and authors. You’ll also see books_book_id_seq and authors_author_id_seq. These keep track of the sequence of integers used as ids by the tables because we used SERIAL to generate their Primary Keys.

How to Describe a Table
To see more information about a particular table, you can use the describe table command: \d table_name. This will list the columns, indexes, and any references to other tables.
\d table_name
Using \dt+ table_name will provide more information, such as about storage and compression.
How to Rename a Table
If you ever need to change the name of a table, you can rename it with the ALTER TABLE command.
ALTER TABLE table_name RENAME TO new_table_name;How to Delete a Table
If you want to delete a table, you can use the DROP TABLE command.
DROP TABLE table_name;If you try to delete a table that doesn’t exist, you will get an error. You can avoid this by including the IF EXISTS option in the statement. This way you’ll get a notice instead.
DROP TABLE IF EXISTS table_name;How to Manage Longer Commands and Queries
If you’re writing longer SQL queries, the command line isn’t the most ergonomic way to do it. It’s probably better to write your SQL in a file and then have psql execute it.
If you are working with psql and think your next query will be long, you can open a text editor from psql and write it there. If you have an existing query, or maybe want to run several queries to load sample data, you can execute commands from a file that is already written.
Option 1 – Open a text editor from psql
If you enter the \e command, psql will open a text editor. When you save and close the editor, psql will run the command you just wrote.
\e
On Windows, the default text editor for psql is Notepad, while on MacOs and Linux it’s vi. You can change this to another editor by setting the EDITOR value in your computer’s environment variables.
Option 2 – Execute commands and queries from a file
If you have particularly long commands or multiple commands that you want to run, it would be better to write the SQL in a file ahead of time and have psql execute that file once you’re ready.
The \i command lets you read input from a file as if you had typed it into the terminal.
\i path_to_file/file_name.sqlNote: If you’re executing this command on Windows, you still need to use forward slashes in the file path.
If you don’t specify a path, psql will look for the file in the last directory that you were in before you connected to PostgreSQL.

How to Time Queries
If you want to see how long your queries are taking, you can turn on query execution timing.
\timingThis will display in milliseconds the time that the query took to complete.
If you run the \timing command again, it will turn off query execution timing.

How to Import Data from a CSV File
If you have a CSV file with data and you want to load this into a PostgreSQL database, you can do this from the command line with psql.
First, create a CSV file called films.csv with the following structure (It doesn’t matter if you use Excel, Google Sheets, Numbers, or any other program).

Open psql and create a films_db database, connect to it, and create a films table.
CREATE DATABASE films_db;
\c films_db
CREATE TABLE films(
id SERIAL PRIMARY KEY,
title VARCHAR(100),
year INT,
running_time INT
);You can then use the \copy command to import the CSV file into films. You need to provide an absolute path to where the CSV file is on your computer.
\copy films(title, year, running_time) FROM 'path_to_file' DELIMITER ‘,’ CSV HEADER;The DELIMITER option specifies the character that separates the columns in each row of the file being imported, CSV specifies that it is a CSV file, and HEADER specifies that the file contains a header line with the names of the columns.
Note: The column names of the films table don’t need to match the column names of films.csv but they do need to be in the same order.
Use SELECT * FROM films; to see if the process was successful.

How to Back Up a Database with pg_dump
If you need to backup a database, pg_dump is a utility that lets you extract a database into a SQL script file or other type of archive file.
First, on the command line (not in psql), navigate to the PostgreSQL bin folder.
cd "C:\Program Files\PostgreSQL\14\bin"Then run the following command, using postgres as the username, and filling in the database and output file that you want to use.
pg_dump -U username database_name > path_to_file/filename.sqlUse postgres for the username and you will be prompted for the postgres superuser’s password. pg_dump will then create a .sql file containing the SQL commands needed to recreate the database.

If you don’t specify a path for the output file, pg_dump will save the file in the last directory that you were in before you connected to PostgreSQL.

You can pass the -v or --verbose flag to pg_dump to see what pg_dump is doing at each step.

You can also backup a database to other file formats, such as .tar (an archive format).
pg_dump -U username -F t database_name > path_to_file/filename.tarHere the -F flag tells pg_dump that you’re going to specify an output format, while t tells it it’s going to be in the .tar format.
How to Restore a Database
You can restore a database from a backup file using either psql or the pg_restore utility. Which one you choose depends on the type of file you are restoring the database from.
- If you backed up the database to a plaintext format, such as
.sql, use psql. - If you backed up the database to an archive format, such as
.tar, usepg_restore.
Option 1 – Restore a database using psql
To restore a database from a .sql file, on the command line (so not in psql), use psql -U username -d database_name -f filename.sql.
You can use the films_db database and films.sql file you used earlier, or create a new backup file.
Create an empty database for the file to restore the data into. If you’re using films.sql to restore films_db, the easiest thing might be to delete films_db and recreate it.
DROP DATABASE films_db;
CREATE DATABASE films_db;In a separate terminal (not in psql), run the following command, passing in postgres as the username, and the names of the database and backup file you are using.
psql -U username -d database_name -f path_to_file/filename.sqlThe -d flag points psql to a specific database, while the -f flag tells psql to read from the specified file.
If you don’t specify a path for the backup file, psql will look for the file in the last directory that you were in before you connected to PostgreSQL.
You will be prompted for the postgres superuser’s password and then will see a series of commands get printed to the command line while psql recreates the database.
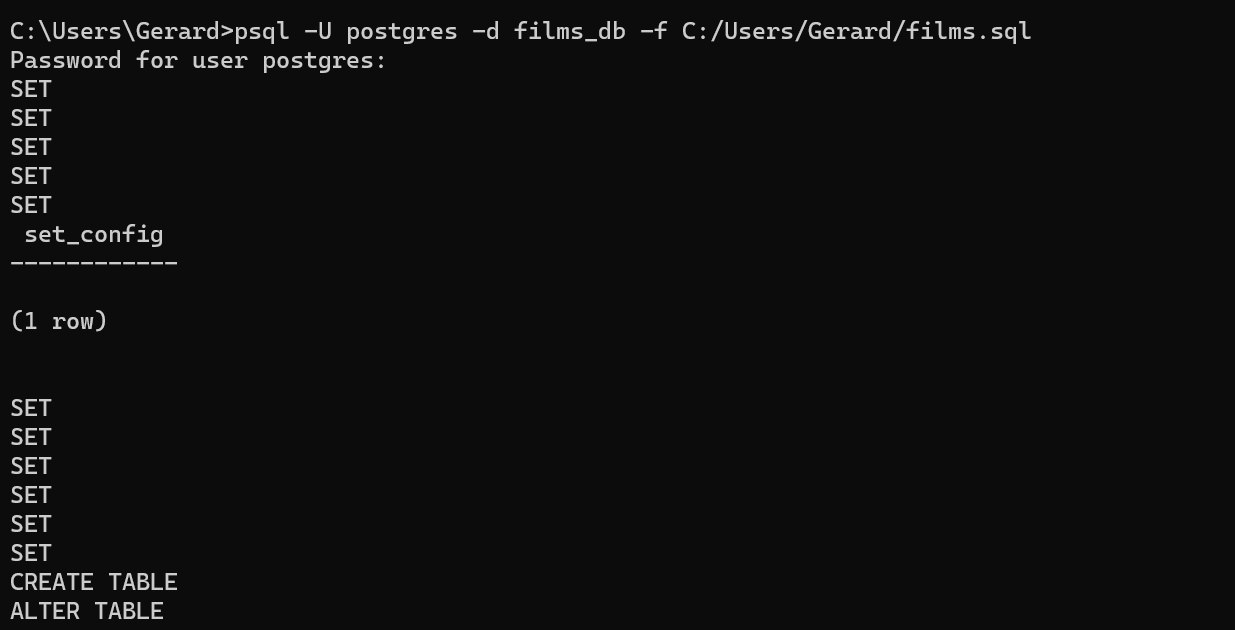
This command ignores any errors that occur during the restore. If you want to stop restoring the database if an error occurs, pass in --set ON_ERROR_STOP=on.
psql -U username -d database_name --set ON_ERROR_STOP=on -f filename.sqlOption 2 – Restore a database using pg_restore
To restore a database using pg_restore, use pg_restore -U username -d database_name path_to_file/filename.tar.
Create an empty database for the file to restore the data into. If you’re restoring films_db from a films.tar file, the easiest thing might be to delete films_db and recreate it.
DROP DATABASE films_db;
CREATE DATABASE films_db;On the command line (not in psql), run the following command, passing in postgres as the username, and the names of the database and backup file you are using.
pg_restore -U username -d database_name path_to_file/filename.tar
You can also pass in the -v or --verbose flag to see what pg_restore is doing at each step.

How to Quit psql
If you’ve finished with psql and want to exit from it, enter quit or \q.
\qThis will close the psql application if you were using it, or return you to your regular command prompt if you were using psql from the command line.
Where to Take it from Here
There are lots more things you can do with psql, such as managing schemas, roles, and tablespaces. But this guide should be enough to get you started with managing PostgreSQL databases from the command line.
If you want to learn more about PostgreSQL and psql, you could try out freeCodeCamp’s Relational Database Certificate . The official PostgreSQL documentation is comprehensive, and PostgreSQL Tutorial offers several in-depth tutorials.
I hope you find this guide helpful as you continue to learn about PostgreSQL and relational databases.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
In this tutorial, you’ll learn how to install PostgreSQL 14.7 on Windows 10.
The process is straightforward and consists of the following steps:
- Install PostgreSQL
- Configure Environment Variables
- Verify the Installation
- Download the Northwind PostgreSQL SQL file
- Create a New PostgreSQL Database
- Import the Northwind SQL file
- Verify the Northwind database installation
- Connect to the Database Using Jupyter Notebook
Prerequisites
- A computer running Windows 10
- Internet connection
- Download the official PostgreSQL 14.7 at https://get.enterprisedb.com/postgresql/postgresql-14.7-2-windows-x64.exe
- Save the installer executable to your computer and run the installer.
Note: We recommend version 14.7 because it is commonly used. There are newer versions available, but their features vary substantially!
Step 1: Install PostgreSQL
We’re about to initiate a vital part of this project — installing and configuring PostgreSQL.
Throughout this process, you’ll define critical settings like the installation directory, components, data directory, and the initial ‘postgres’ user password. This password grants administrative access to your PostgreSQL system. Additionally, you’ll choose the default port for connections and the database cluster locale.
Each choice affects your system’s operation, file storage, available tools, and security. We’re here to guide you through each decision to ensure optimal system functioning.
-
In the PostgreSQL Setup Wizard, click Next to begin the installation process.

-
Accept the default installation directory or choose a different directory by clicking Browse. Click Next to continue.
-
Choose the components you want to install (e.g., PostgreSQL Server, pgAdmin 4 (optional), Stack Builder (optional), Command Line Tools),no characters will appear on the screen as you type your password and click Next.
-
Select the data directory for storing your databases and click Next.
-
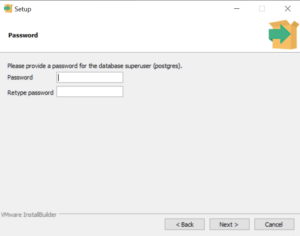
Set a password for the PostgreSQL “postgres” user and click Next.
-
There will be some points where you’re asked to enter a password in the command prompt. It’s important to note that for security reasons, as you type your password, no characters will appear on the screen. This standard security feature is designed to prevent anyone from looking over your shoulder and seeing your password. So, when you’re prompted for your password, don’t be alarmed if you don’t see any response on the screen as you type. Enter your password and press ‘Enter’. Most systems will allow you to re-enter the password if you make a mistake.
-
Remember, it’s crucial to remember the password you set during the installation, as you’ll need it to connect to your PostgreSQL databases in the future.
-
-
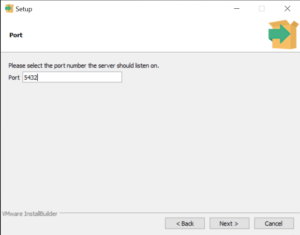
Choose the default port number (5432) or specify a different port, then click Next.
-
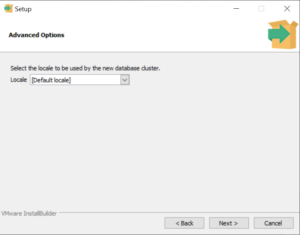
Select the locale to be used by the new database cluster and click Next.
-
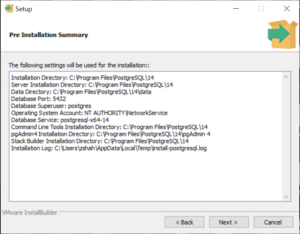
Review the installation settings and click Next to start the installation process. The installation may take a few minutes.
-
Once the installation is complete, click Finish to close the Setup Wizard.


Step 2: Configure Environment Variables
Next, we’re going to configure environment variables on your Windows system. Why are we doing this? Well, environment variables are a powerful feature of operating systems that allow us to specify values — like directory locations — that can be used by multiple applications. In our case, we need to ensure that our system can locate the PostgreSQL executable files stored in the «bin» folder of the PostgreSQL directory.
By adding the PostgreSQL «bin» folder path to the system’s PATH environment variable, we’re telling our operating system where to find these executables. This means you’ll be able to run PostgreSQL commands directly from the command line, no matter what directory you’re in, because the system will know where to find the necessary files. This makes working with PostgreSQL more convenient and opens up the possibility of running scripts that interact with PostgreSQL.
Now, let’s get started with the steps to configure your environment variables on Windows!
-
On the Windows taskbar, right-click the Windows icon and select System.
-
Click on Advanced system settings in the left pane.
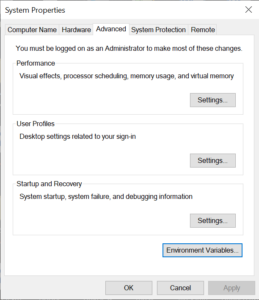
-
In the System Properties dialog, click on the Environment Variables button.
-
Under the System Variables section, scroll down and find the Path variable. Click on it to select it, then click the Edit button.
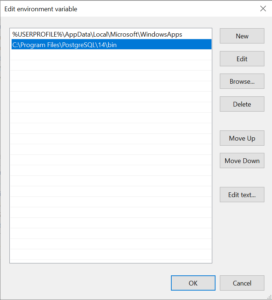
-
In the Edit environment variable dialog, click the New button and add the path to the PostgreSQL bin folder, typically
C:\\Program Files\\PostgreSQL\\14\\bin. -
Click OK to close the «Edit environment variable» dialog, then click OK again to close the «Environment Variables» dialog, and finally click OK to close the «System Properties» dialog.
Step 3: Verify the Installation
After going through the installation and configuration process, it’s essential to verify that PostgreSQL is correctly installed and accessible. This gives us the assurance that the software is properly set up and ready to use, which can save us from troubleshooting issues later when we start interacting with databases.
If something went wrong during installation, this verification process will help you spot the problem early before creating or managing databases.
Now, let’s go through the steps to verify your PostgreSQL installation.
- Open the Command Prompt by pressing Win + R, typing cmd, and pressing Enter.
- Type
psql --versionand press Enter. You should see the PostgreSQL version number you installed if the installation was successful. - To connect to the PostgreSQL server, type
psql -U postgresand press Enter. - When prompted, enter the password you set for the postgres user during installation. You should now see the postgres=# prompt, indicating you are connected to the PostgreSQL server.
Step 4: Download the Northwind PostgreSQL SQL File
Now, we’re going to introduce you to the Northwind database and help you download it. The Northwind database is a sample database originally provided by Microsoft for its Access Database Management System. It’s based on a fictitious company named «Northwind Traders,» and it contains data on their customers, orders, products, suppliers, and other aspects of the business. In our case, we’ll be working with a version of Northwind that has been adapted for PostgreSQL.
The following steps will guide you on how to download this PostgreSQL-compatible version of the Northwind database from GitHub to your local machine. Let’s get started:
First, you need to download a version of the Northwind database that’s compatible with PostgreSQL. You can find an adapted version on GitHub. To download the SQL file, follow these steps:
-
Open your Terminal application.
-
Create a new directory for the Northwind database and navigate to it:
mkdir northwind && cd northwind -
Download the Northwind PostgreSQL SQL file using curl:
curl -O <https://raw.githubusercontent.com/pthom/northwind_psql/master/northwind.sql>This will download the
northwind.sqlfile to thenorthwinddirectory you created.
Step 5: Create a New PostgreSQL Database
Now that we’ve downloaded the Northwind SQL file, it’s time to prepare our PostgreSQL server to host this data. The next steps will guide you in creating a new database on your PostgreSQL server, a crucial prerequisite before importing the Northwind SQL file.
Creating a dedicated database for the Northwind data is good practice as it isolates these data from other databases in your PostgreSQL server, facilitating better organization and management of your data. These steps involve connecting to the PostgreSQL server as the postgres user, creating the northwind database, and then exiting the PostgreSQL command-line interface.
Let’s proceed with creating your new database:
-
Connect to the PostgreSQL server as the
postgresuser:psql -U postgres -
Create a new database called
northwind:postgres-# CREATE DATABASE northwind; -
Exit the
psqlcommand-line interface:postgres-# \\q
Step 6: Import the Northwind SQL File
We’re now ready to import the Northwind SQL file into our newly created northwind database. This step is crucial as it populates our database with the data from the Northwind SQL file, which we will use for our PostgreSQL learning journey.
These instructions guide you through the process of ensuring you’re in the correct directory in your Terminal and executing the command to import the SQL file. This command will connect to the PostgreSQL server, target the northwind database, and run the SQL commands contained in the northwind.sql file.
Let’s move ahead and breathe life into our northwind database with the data it needs!
With the northwind database created, you can import the Northwind SQL file using psql. Follow these steps:
- In your Terminal, ensure you’re in the
northwinddirectory where you downloaded thenorthwind.sqlfile. -
Run the following command to import the Northwind SQL file into the
northwinddatabase:psql -U postgres -d northwind -f northwind.sqlThis command connects to the PostgreSQL server as the
postgresuser, selects thenorthwinddatabase, and executes the SQL commands in thenorthwind.sqlfile.
Step 7: Verify the Northwind Database Installation
You’ve successfully created your northwind database and imported the Northwind SQL file. Next, we must ensure everything was installed correctly, and our database is ready for use.
These upcoming steps will guide you on connecting to your northwind database, listing its tables, running a sample query, and finally, exiting the command-line interface. Checking the tables and running a sample query will give you a sneak peek into the data you now have and verify that the data was imported correctly. This means we can ensure everything is in order before diving into more complex operations and analyses.
To verify that the Northwind database has been installed correctly, follow these steps:
-
Connect to the
northwinddatabase usingpsql:psql -U postgres -d northwind -
List the tables in the Northwind database:
postgres-# \\dtYou should see a list of Northwind tables: categories, customers, employees, orders, and more.
-
Run a sample query to ensure the data has been imported correctly. For example, you can query the
customerstable:postgres-# SELECT * FROM customers LIMIT 5;This should return the first five rows from the
customerstable. -
Exit the
psqlcommand-line interface:postgres-# \\q
Congratulations! You’ve successfully installed the Northwind database in PostgreSQL using an SQL file and psql.
Step 8: Connect to the Database Using Jupyter Notebook
As we wrap up our installation, we will now introduce Jupyter Notebook as one of the tools available for executing SQL queries and analyzing the Northwind database. Jupyter Notebook offers a convenient and interactive platform that simplifies the visualization and sharing of query results, but it’s important to note that it is an optional step. You can also access Postgres through other means. However, we highly recommend using Jupyter Notebook for its numerous benefits and enhanced user experience.
To set up the necessary tools and establish a connection to the Northwind database, here is an overview of what each step will do:
-
!pip install ipython-sql: This command installs theipython-sqlpackage. This package enables you to write SQL queries directly in your Jupyter Notebook, making it easier to execute and visualize the results of your queries within the notebook environment. -
%load_ext sql: This magic command loads thesqlextension for IPython. By loading this extension, you can use the SQL magic commands, such as%sqland%%sql, to run SQL queries directly in the Jupyter Notebook cells. -
%sql postgresql://postgres@localhost:5432/northwind: This command establishes a connection to the Northwind database using the PostgreSQL database system. The connection string has the following format:postgresql://username@hostname:port/database_nameIn this case,
usernameispostgres,hostnameislocalhost,portis5432, anddatabase_nameisnorthwind. The%sqlmagic command allows you to run a single-line SQL query in the Jupyter Notebook. -
Copy the following text into a code cell in the Jupyter Notebook:
!pip install ipython-sql
%load_ext sql
%sql postgresql://postgres@localhost:5432/northwindOn Windows you may need to try the following command because you need to provide the password you set for the “postgres” user during installation:
%sql postgresql://postgres:{password}@localhost:5432/northwindBear in mind that it’s considered best practice not to include sensitive information like passwords directly in files that could be shared or accidentally exposed. Instead, you can store your password securely using environment variables or a password management system (we’ll link to some resources at the end of this guide if you are interested in doing this).
-
Run the cell by either:
- Clicking the «Run» button on the menu bar.
- Using the keyboard shortcut:
Shift + EnterorCtrl + Enter.
-
Upon successful connection, you should see an output similar to the following:
'Connected: postgres@northwind'This output confirms that you are now connected to the Northwind database, and you can proceed with the guided project in your Jupyter Notebook environment.
Once you execute these commands, you’ll be connected to the Northwind database, and you can start writing SQL queries in your Jupyter Notebook using the %sql or %%sql magic commands.
Next Steps
Based on what you’ve accomplished, here are some potential next steps to continue your learning journey:
- Deepen Your SQL Knowledge:
- Try formulating more complex queries on the Northwind database to improve your SQL skills. These could include joins, subqueries, and aggregations.
- Understand the design of the Northwind database: inspect the tables, their relationships, and how data is structured.
- Experiment with Database Management:
- Learn how to backup and restore databases in PostgreSQL. Try creating a backup of your Northwind database.
- Explore different ways to optimize your PostgreSQL database performance like indexing and query optimization.
- Integration with Python:
- Learn how to use
psycopg2, a popular PostgreSQL adapter for Python, to interact with your database programmatically. - Experiment with ORM (Object-Relational Mapping) libraries like
SQLAlchemyto manage your database using Python.
- Learn how to use
- Security and Best Practices:
- Learn about database security principles and apply them to your PostgreSQL setup.
- Understand best practices for storing sensitive information, like using
.envfiles for environment variables. - For more guidance on securely storing passwords, you might find the following resources helpful:
- Using Environment Variables in Python
- Python Secret Module