Сеть “Лифт ми Ап” вместе со своим штатом разрастается вдоль и поперёк. Обслуживание ИТ-инфраструктуры вынесли в отдельную специально созданную организацию “Линк ми Ап”.
Буквально на днях были куплены ещё четыре филиала в различных городах и инвесторы открыли для себя новые измерения движения лифтов. А сеть выросла с четырёх маршрутизаторов сразу до десяти. При этом количество подсетей теперь увеличилось с 9 до 20, не считая линков точка-точка между маршрутизаторами. И тут во весь рост встаёт управления всем этим хозяйством. Согласитесь, добавлять на каждом из узлов маршруты во все сети вручную — мало удовольствия.
Ситуация усложняется тем, что сеть в Калининграде уже имеет свою адресацию и на ней запущен протокол динамической маршрутизации EIGRP.
Итак, сегодня:
— Разбираемся с теорией протоколов динамической маршрутизации.
— Внедряем в сеть “Лифт ми Ап” протокол OSPF
— Настраиваем передачу (редистрибуцию) маршрутов между OSPF и EIGRP
— В этом выпуске мы добавляем раздел “Задачи”. Идентифицировать по ходу статьи их будут такие пиктограммы:
Уровень сложности будет разный. Ко всем задачам будут ответы, которые можно посмотреть на сайте цикла. В некоторых из них вам понадобится подумать, в других почитать документацию, в третьих разобраться в топологии и, может, даже смотреть отладочную информацию. Если задача нереализуема в РТ, мы сделаем специальную пометку об этом.
Теория протоколов динамической маршрутизации
Для начала разберемся с понятием “динамическая маршрутизация”. До сего момента мы использовали так называемую статическую маршрутизацию, то есть прописывали руками таблицу маршрутизации на каждом роутере. Использование протоколов маршрутизации позволяет нам избежать этого нудного однообразного процесса и ошибок, связанных с человеческим фактором. Как понятно из названия, эти протоколы призваны строить таблицы маршрутизации сами, автоматически, исходя из текущей конфигурации сети. В общем, вещь нужная, особенно когда ваша сеть это не 3 роутера, а 30, например.
Помимо удобства есть и другие аспекты. Например, отказоустойчивость. Имея сеть со статической маршрутизацией, вам крайне сложно будет организовать резервные каналы — некому отслеживать доступность того или иного сегмента.
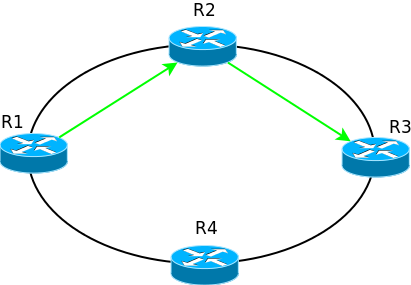
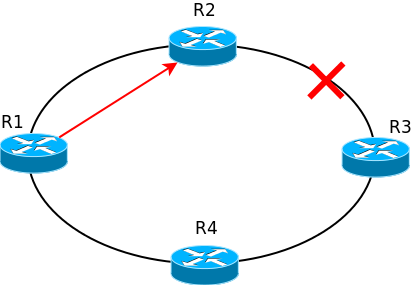
Например, если в такой сети разорвать линк между R2 и R3, то пакеты с R1 будут уходить по прежнему на R2, где будут уничтожены, потому что их некуда отправить.
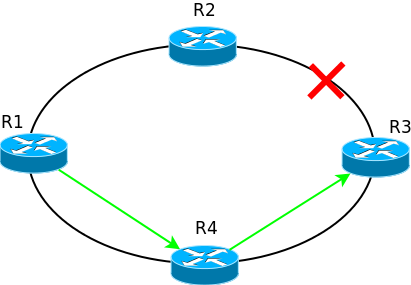
Протоколы динамической маршрутизации в течение нескольких секунд (а то и миллисекунд) узнают о проблемах на сети и перестраивают свои таблицы маршрутизации и в вышеописанном случае пакеты будут отправляться уже по актуальному маршруту
Ещё один важный момент — балансировка трафика. Протоколы динамической маршрутизации практически из коробки поддерживают эту фичу и вам не нужно добавлять избыточные маршруты вручную, высчитывая их.
Ну и внедрение динамической маршрутизации сильно облегчает масштабирование сети. Когда вы добавляете новый элемент в сеть или подсеть на существующем маршрутизаторе, вам нужно выполнить всего несколько действий, чтобы всё заработало и вероятность ошибки минимальна, при этом информация об изменениях мгновенно расходится по всем устройствам. Ровно то же самое можно сказать и о глобальных изменениях топологии.
Все протоколы маршрутизации можно разделить на две большие группы: внешние (EGP — Exterior Gateway Protocol) и внутренние (IGP — Interior Gateway Protocol). Чтобы объяснить различия между ними, нам потребуется термин “автономная система”. В общем смысле, автономной системой (доменом маршрутизации) называется группа роутеров, находящихся под общим управлением.
В случае нашей обновлённой сети AS будет такой:
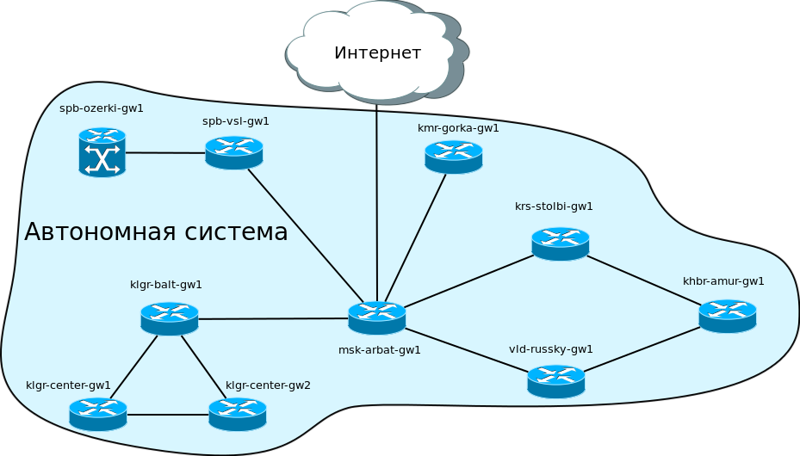
Так вот, протоколы внутренней маршрутизации используются внутри автономной системы, а внешние — для соединения автономных систем между собой. В свою очередь, внутренние протоколы маршрутизации подразделяются на Distance-Vector (RIP, EIGRP) и Link State (OSPF, IS-IS). В этой статье мы не будем
пинать трупы
затрагивать протоколы RIP и IGRP в силу их почтенного возраста, а так же IS-IS в силу его отсутствия в ПТ.
Коренные различия между этими двумя видами состоят в следующем:
1) типе информации, которой обмениваются роутеры: таблицы маршрутизации у Distance-Vector и таблицы топологии у Link State,
2) процессе выбора лучшего маршрута,
3) количестве информации о сети, которое “держит в голове” каждый роутер: Distance-Vector знает только своих соседей, Link State имеет представление обо всей сети.
Как мы видим, количество протоколов маршрутизации невелико, но все же не один-два. А что будет, если на роутере запустить несколько протоколов одновременно? Может оказаться, что у каждого протокола будет свое мнение о том, как лучше добраться до определенной сети. А если у нас еще и статические маршруты настроены? Кому роутер отдаст предпочтение и чей маршрут добавит в таблицу маршрутизации? Ответ на этот вопрос связан с новым термином: административная дистанция (на нащ вкус, довольно посредственная калька с английского Аdministrative distance, но лучше выдумать не смогли). Аdministrative distance это целое число от 0 до 255, выражающее “меру доверия” роутера к данному маршруту. Чем меньше AD, тем больше доверия. Вот табличка такого доверия с точки зрения Cisco:
| Протокол | Административная дистанция |
|---|---|
| Connected interface | 0 |
| Static route | 1 |
| Enhanced Interior Gateway Routing Protocol (EIGRP) summary route | 5 |
| External Border Gateway Protocol (BGP) | 20 |
| Internal EIGRP | 90 |
| IGRP | 100 |
| OSPF | 110 |
| Intermediate System-to-Intermediate System (IS-IS) | 115 |
| Routing Information Protocol (RIP) | 120 |
| Exterior Gateway Protocol (EGP) | 140 |
| On Demand Routing (ODR) | 160 |
| External EIGRP | 170 |
| Internal BGP | 200 |
| Unknown | 255 |
В сегодняшней статье мы разберём OSPF и EIGRP. Первый вам будет встречаться везде и постоянно, а второй очень хорош в сетях, где присутствует только оборудование Cisco.
У каждого из них есть свои достоинства и недостатки. Можно сказать, что EIGRP выигрывает перед OSPF, но все плюсы нивелируются его проприетарностью. EIGRP — фирменный протокол Cisco и больше никто его не поддерживает.
На самом деле у EIGRP много недостатков, но об этом не особо распространяются в популярных статьях. Вот только одна из проблем: SIA
Итак, приступим.
OSPF
Статей и видео о том, как настроить OSPF горы. Гораздо меньше описаний принципов работы. Вообще, тут такое дело, что OSPF можно просто настроить согласно мануалам, даже не зная про алгоритмы SPF и непонятные LSA. И всё будет работать и даже, скорее всего, прекрасно работать — на то он и рассчитан. То есть тут не как с вланами, где приходилось знать теорию вплоть до формата заголовка.
Но инженера от эникейщика отличает то, что он понимает, почему его сеть функционирует так, а не иначе, и не хуже самогo OSPF знает, какой маршрут будет выбран протоколом.
В рамках статьи, которая уже на этот момент составляет 8 000 символов, мы не сможем погрузиться в глубины теории, но рассмотрим принципиальные моменты.
Очень просто и понятно, кстати, написано про OSPF на xgu.ru или в английской википедии.
Итак, OSPFv2 работает поверх IP, а конкретно, он заточен только под IPv4 (OSPFv3 не зависит от протоколов 3-го уровня и потому может работать с IPv6).
Рассмотрим его работу на примере вот такой упрощённой сети:
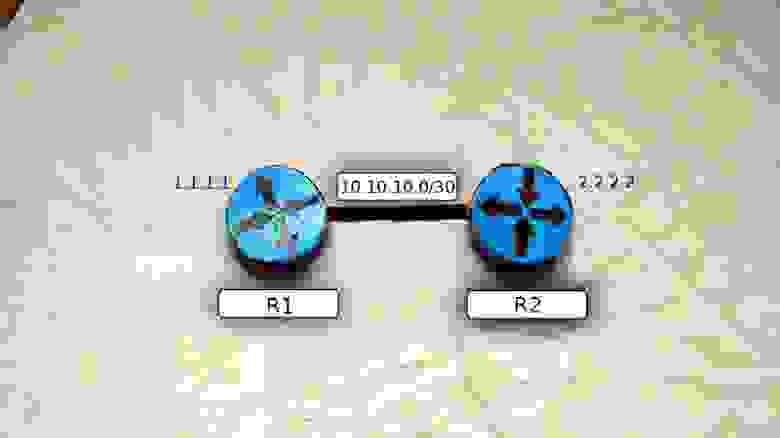
Для начала надо сказать, что для того, чтобы между маршрутизаторами завязалась дружба (отношения смежности) должны выполниться следующие условия:
1) в OSPF должны быть настроены одинаковые Hello Interval на тех маршрутизаторах, что подключены друг к другу. По умолчанию это 10 секунд в Broadcast сетях, типа Ethernet. Это своего рода KeepAlive сообщения. То есть каждые 10 секунд каждый маршрутизатор отправляет Hello пакет своему соседу, чтобы сказать: “Хей, я жив”,
2) Одинаковыми должны быть и Dead Interval на них. Обычно это 4 интервала Hello — 40 секунд. Если в течение этого времени от соседа не получено Hello, то он считается недоступным и начинается
ПАНИКА
процесс перестроения локальной базы данных и рассылка обновлений всем соседям,
3) Интерфейсы, подключенные друг к другу, должны быть в одной подсети,
4) OSPF позволяет снизить нагрузку на CPU маршрутизаторов, разделив Автономную Систему на зоны. Так вот номера зон тоже должны совпадать,
5) У каждого маршрутизатора, участвующего в процессе OSPF есть свой уникальный индентификатор — Router ID. Если вы о нём не позаботитесь, то маршрутизатор выберет его автоматически на основе информации о подключенных интерфейсах (выбирается высший адрес из интерфейсов, активных на момент запуска процесса OSPF). Но опять же у хорошего инженера всё под контролем, поэтому обычно создаётся Loopback интерфейс, которому присваивается адрес с маской /32 и именно он назначается Router ID. Это бывает удобно при обслуживании и траблшутинге.
6) Должен совпадать размер MTU
Далее пьеса в восьми частях.
1) Штиль. Состояние OSPF — DOWN
В это короткое мгновение в сети ничего не происходит — все молчат.
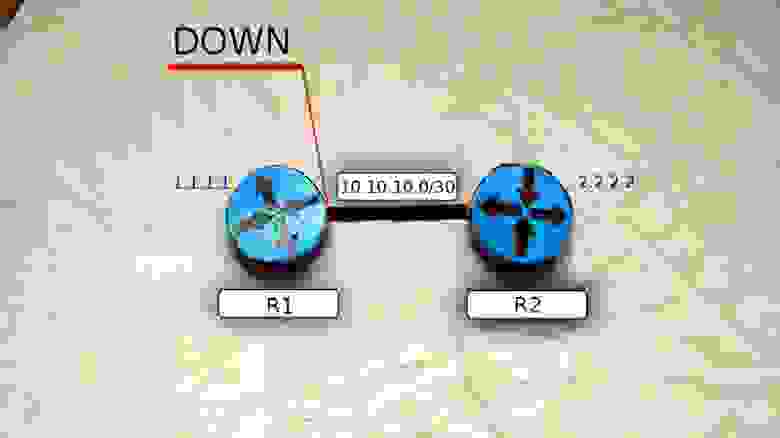
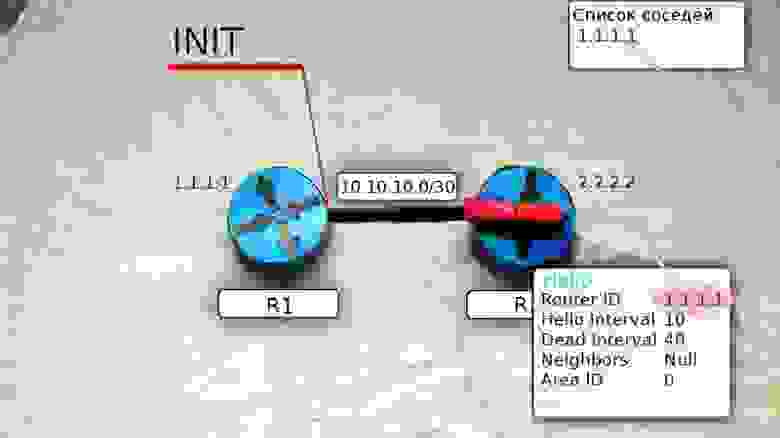
2) Поднимается ветер: маршрутизатор рассылает Hello-пакеты на мультикастный адрес 224.0.0.5 со всех интерфейсов, где запущен OSPF. TTL таких сообщений равен одному, поэтому их получат только маршрутизаторы, находящиеся в том же сегменте сети. R1 переходит в состояние INIT.
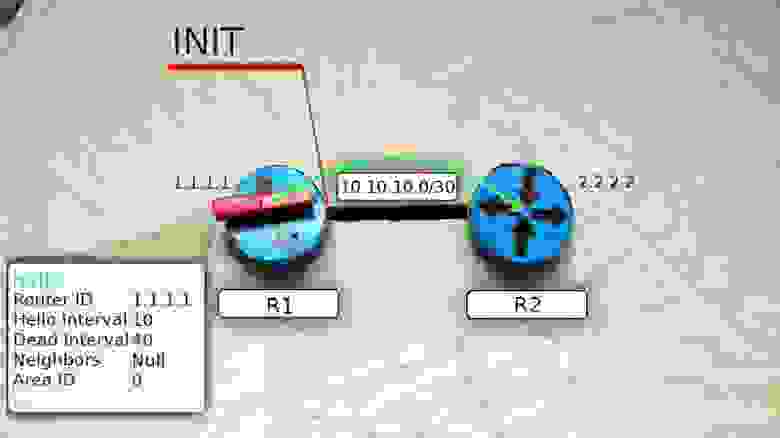
В пакеты вкладывается следующая информация:
- Router ID
- Hello Interval
- Dead Interval
- Neighbors
- Subnet mask
- Area ID
- Router Priority
- Адреса DR и BDR маршрутизаторов
- Пароль аутентификации
Нас интересуют пока первые четыре или точнее вообще только Router ID и Neighbors.
Сообщение Hello от маршрутизатора R1 несёт в себе его Router ID и не содержит Neighbors, потому что у него их пока нет.
После получения этого мультикастного сообщения маршрутизатор R2 добавляет R1 в свою таблицу соседей (если совпали все необходимые параметры).
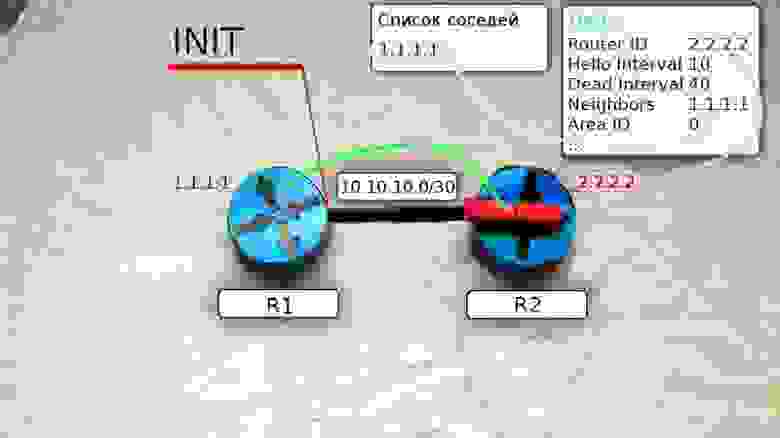
И отправляет на R1 уже юникастом новое сообщение Hello, где содержится Router ID этого маршрутизатора, а в списке Neigbors перечислены все его соседи. В числе прочих соседей в этом списке есть Router ID R1, то есть R2 уже считает его соседом.
3) Дружба. Когда R1 получает это сообщение Hello от R2, он пролистывает список соседей и находит в нём свой собственный Router ID, он добавляет R2 в свой список соседей.
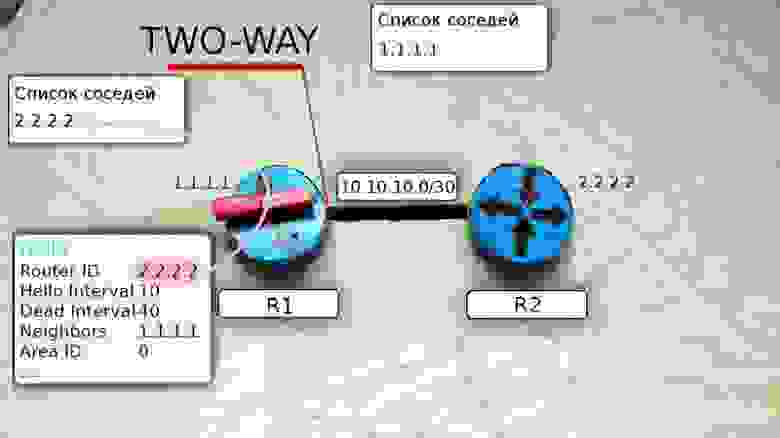
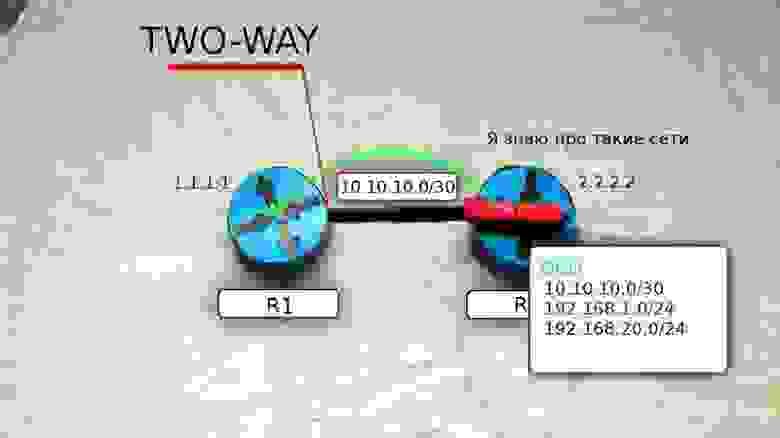
Теперь R1 и R2 друг у друга во взаимных соседях — это означает, что между ними установлены отношения смежности и маршрутизатор R1 переходит в состояние TWO WAY.
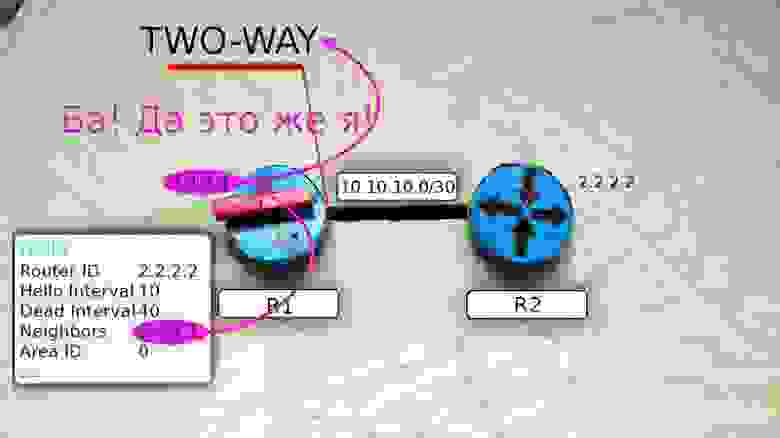
Далее происходит выбор DR и BDR, но мы не будем на этом останавливаться, хоть это и довольно важные вещи.
4) Затишье перед бурей. Далее все переходят в состояние EXSTART. Здесь все соседи решают между собой, кто босс. Им становится маршрутизатор с наибольшим Router ID — R2.
5) Когда выбран Батька, соседи переходят в состояние Exchange и обмениваются DBD-сообщениями (или DD) — Data Base Description, которые содержат описание LSDB (Link State Data Base), мол, я знаю про вот такие подсети.
Тут надо пояснить, что такое LSDB. Если перевести на русский дословно: база данных о состоянии линков. В изначальном состоянии маршрутизатор знает только о тех линках (интерфейсах), на которых запущен процесс OSPF. По ходу пьесы, каждый маршрутизатор собирает всю информацию о сети и составляет топологию. Именно она и будет являться LSDB, которая должна быть одинакова на всех членах зоны.
Первым отсылает свою DBD маршрутизатор, выбранный главным на данном интерфейсе — 2.2.2.2. Следом за ним то же делает и 1.1.1.1.
6) Получив сообщение, маршрутизаторы R1 и R2 отправляют подтверждение о приёме DBD (LSAck), а затем сравнивают новую информацию с той, что содержится у них в LSDB и, если есть отличия, посылают LSR (Link State Request) друг другу, тем самым переходя в новое состояние LOADING. В LSR они говорят — “Я про вот эту сеть ничего не знаю. Расскажи мне подробнее”.
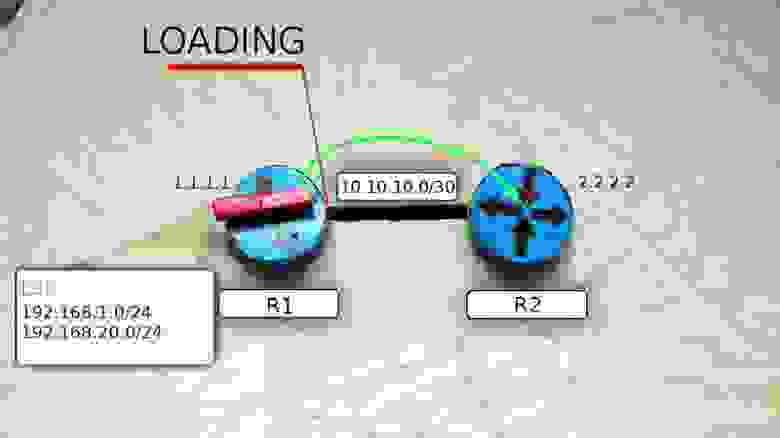
7) R2, получив LSR от R1, высылает LSU (Link State Update), которые содержат в себе LSA (Link State Advertisement) c детальной информацией о нужных подсетях.
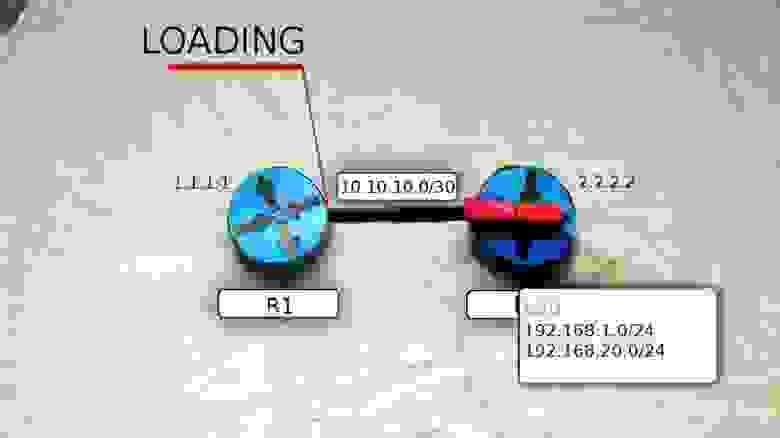
И вот, как только R1 получит последнюю порцию данных о всех подсетях и сформирует свою LSDB, он переходит в своё конечное состояние FULL STATE.
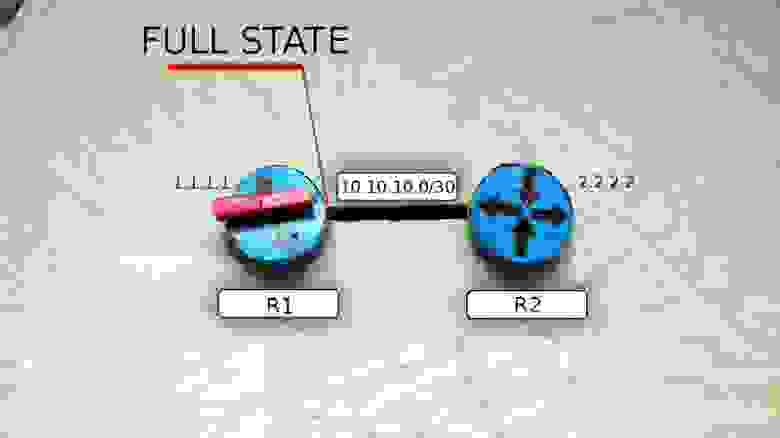
К тому моменту, как все маршрутизаторы зоны придут к состоянию Full State на всех на них должна быть полностью одинаковая LSDB — они же одну и ту же сеть изучали. То есть фактически это означает, что маршрутизатор знает всю вашу сеть, что, как и куда подключено.
Авторы осознают, что понять и запомнить все эти аббревиатуры и правила довольно сложно, но прочитав это 5 -7 раз в разных местах с некоторой периодичностью, можно будет составить представление о том, как OSPF работает.
 Итак, сейчас у нас все маршрутизаторы знают всё о сети, но это знание не помогает в маршрутизации.
Итак, сейчас у нас все маршрутизаторы знают всё о сети, но это знание не помогает в маршрутизации.
Следующим шагом OSPF, используя алгоритм Дейкстры (или его ещё называют SPF — Shortest Path First), вычисляет кратчайший маршрут до каждого маршрутизатора в зоне — он ведь знает всю топологию. В этом ему помогают метрики. Чем она ниже, тем маршрут лучше. Метрика — это стоимость движения по маршруту.
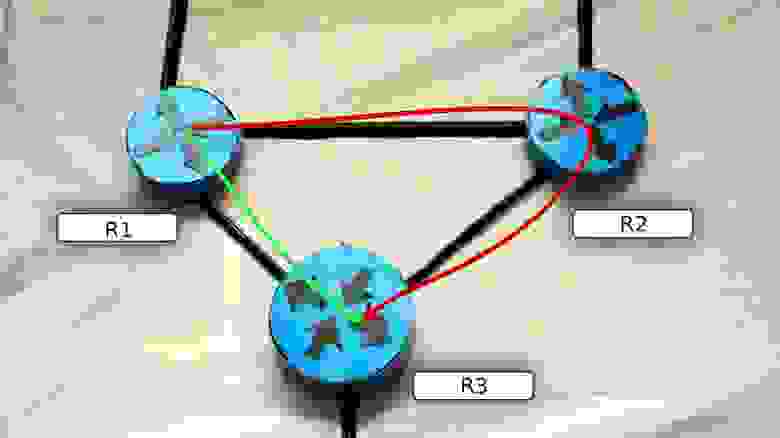
Например, в такой сети из R1 в R3 можно добраться напрямую или через R2.
Естественно первый вариант будет стоить меньше. Но это при условии, что у вас везде одинаковый тип интерфейсов. А если, например, между R1 и R3 у вас модемное соединение в 56к или крайне нестабильный GPRS линк? Тогда у них будет очень высокая стоимость и OSPF предпочтёт более длинный, но быстрый путь.
Найденный путь потом добавляется в таблицу маршрутизации.
Теперь каждые 10 секунд каждый маршрутизатор будет отправлять Hello-пакеты, а каждые 30 минут рассылаются LSA — это типа данные уже считаются устаревшими, надо бы обновить, даже если изменений не было.
В идеальном мире на этом бы и установилось равновесие. Но мы живём в мире жестоком и равнодушном, где инженер — это итшник, а то и компьютерщик вообще, а лифты научились ездить вниз всего три выпуска назад И в этом будничном мире кипят страсти: рвут оптику, вырубают питание, мыши перегрызают ножки процессоров (или это не в этом мире?) — иными словами, топология непрестанно меняется. И чем больше сеть, тем чаще и глобальнее изменения.
Разумеется, было бы несколько странно ждать 40 секунд (Dead Interval) и только потом начинать перестраивать таблицу. Это было бы простительно ещё RIP’у, но не протоколу, который используется в огромном количестве современных сетей. Итак, как только падает какой-либо из линков (или несколько), маршрутизатор изменяет свою LSDB и генерирурет LSU, присваивая ей номер больше, чем он был прежде (у каждой LSDB есть номер, который берётся из последнего полученного LSA).
Это LSU сообщение рассылается на мультикастовый адрес 224.0.0.5. Маршрутизаторы получившие его, проверяют номер LSA, содержащихся в LSU.
1) Если номер больше, чем номер текущей LSA маршрутизатора — LSDB меняется. (Версия LSDB старая, информация новая),
2) Если номер такой же, ничего не происходит. Этот маршрутизатор уже получил данный LSA по какому-то другому пути,
3) Если номер полученного LSA меньше локальной LSDB, это означает, что у маршрутизатора уже более актуальная информация, и он посылает новый LSA (на основе своей LSDB) отправителю прежнего.
После произведённых (или непроизведённых) действий соседу, от которого пришёл LSU пересылаются LSAck (мол, «посылку получили — всё в порядке»), а другим соседям отправляется изначальный LSU без изменений. На данном маршрутизаторе снова запускается алгоритм SPF и, при необходимости, обновляется таблица маршрутизации.
В общем, всё это происходит в целях поддержания актуальности информации на всех устройствах — LSDB должна быть одинаковой у всех.
Тут надо оговориться, что маршрутизатор замечает изменения только при прямом подключении к своему соседу. Если между ними будет, например, коммутатор, то устройство не обнаружит падения физического интерфейса и ничего не будет делать. Для таких ситуаций есть два решения.
1) Настроить таймеры. Для OSPF их можно уменьшить до уровня мс.
2) Использовать очень крутой протокол BFD (Bidirectional Forwarding Detection). Он позволяет отслеживать состояние линков также на миллисекундном уровне. В конфигурации BFD связывается с другими протоколами и позволяет очень быстро сообщить кому надо, что есть проблемы на сети. Конкретно с BFD мы будем разбираться в другой части.
Как вы заметили, на все сообщения есть подтверждения: либо это LSAck, либо ответ Hello на Hello. Это плата за отказ от TCP — как-то ведь надо убеждаться в успешной доставке.
Всего существует 7 типов LSA, которые очень завязаны на зоны, коих тоже 5 штук. Маршрутизаторы тоже бывают четырёх типов. А так же есть понятия Designated Router (DR) и Backup DR (BDR), ABR и ASBR. Есть формулы расчёт метрик и прочее, прочее. Оставляем это на самостоятельное изучение.
Практика OSPF
Помните, как мы мучились, настраивая маршрутизацию в прошлый раз: на каждом устройстве до каждой сети и не дай бог что-нибудь забыть. Теперь это в прошлом — да здравствуют IGP!
Не будем терять время, объясняя отдельно команды, а сразу окунёмся в удивительный мир конфигурации.
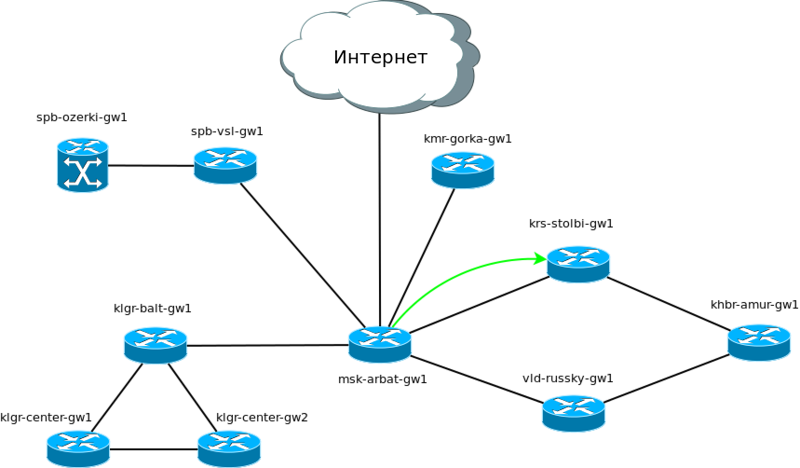
Такс, имеет место сейчас следующая логическая схема:
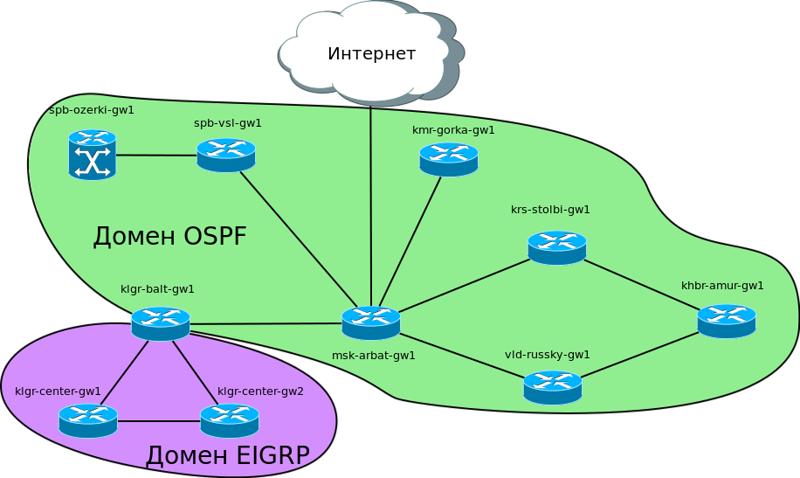
Пока нас интересует вот это большое Сибирское кольцо через Красноярск, Хабаровск и Владивосток. Здесь и на нашей уже построенной сети мы запустим OSPF. Там, где прежде была статика, нам придётся от неё отказаться и плавно перейти на динамические протоколы.
Предположим, что Красноярск у нас так же подключен через «Балаган телеком», как и предыдущие точки, а далее через разных провайдеров нам организованы линки к другим городам. Кольцо замыкается в Москве через провайдера “Филькин сертификат”. Предположим, что везде между городами у нас куплен L2-VPN и IP-трафик ходит прозрачно.
Что внедрение IGP даст конкретно нашей сети?
1) Простоту конфигурации, разумеется. На каждом узле нужно знать только локальные сети, вопросом их распространения озадачится OSPF.
2) Избыточные линки, которые обеспечат нам резервирование каналов связи. Если, например, бомжи срежут оптику между Москвой и Красноярском, ни один филиал не останется без связи: весь трафик пойдёт через Владивосток
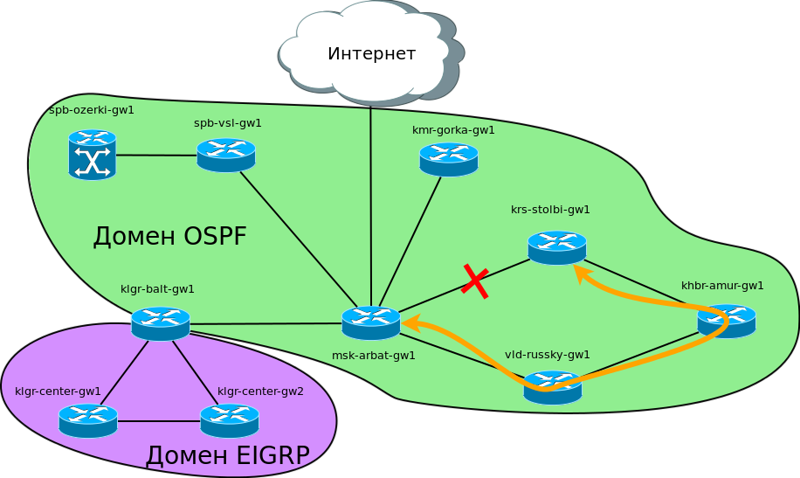
3) Автоматическое обнаружение проблем, перестроение топологии и изменение таблицы маршрутизации. Именно это обеспечивает возможность выполнения пункта 2.
4) Нет опасности создать петлю маршрутизации, когда пакет у нас будет метаться между двумя узлами, пока TTL не истечёт. При статической настройке такая ситуация более, чем возможна.
5) Удобство расширения. Представьте, что вам нужно добавить новый филиал, например в Томске и подключать его будете через Кемерово. Тогда статические маршруты вам придётся прописывать в Москве, Кемерово и в самом Томске. При использовании динамики вы настраиваете только новый маршрутизатор… и всё.
IP-план подсетей филиалов и линков Point-to-Point мы уже подготовили Предположим, что и все начальные настройки тоже выполнили на всех узлах:
— hostname
— параметры безопасности (пароли на телнет, ssh)
— IP-адреса линковых интерфейсов
— IP адреса подсетей LAN
— IP-адреса Loopback-интерфейсов.
Мы тут вводим новое понятие Loopback-интерфейса. Он будет сконфигурирован на каждом маршрутизаторе. Для этого выделена специальная подсеть 172.16.255.0/24. Нужно оно нам сейчас для OSPF, а в будущем может понадобиться для BGP, MPLS.
Положа руку на сердце, сам долгое время не понимал значения этих интерфейсов. Вообще говоря, это виртуальный интерфейс, состояние которого всегда UP, независимо от состояния физических интерфейсов (если только на нём самом shutdown не выполнили). Попытаемся объяснить одну из его ролей:
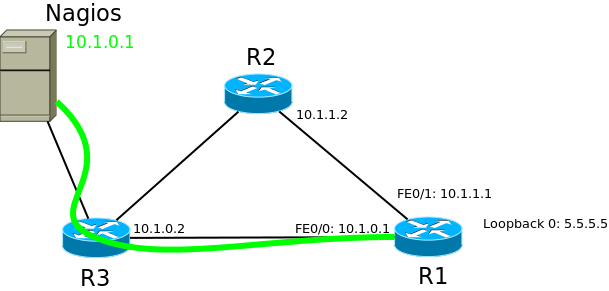
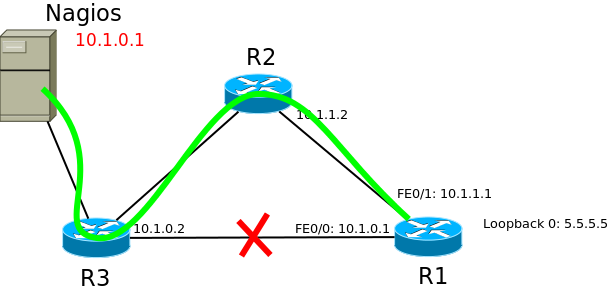
Вот, к примеру, есть у вас сервер мониторинга Nagios. В нём вы завели для наблюдения маршрутизатор R1 и для связи с ним использовали адрес интерфейса FE0/0 — 10.1.0.1.
На первый взгляд все прекрасно — всё работает. Но предположим теперь, что этот кабель порвали.
Благодаря динамической маршрутизации, связь до роутера А не нарушится, и он будет доступен через FE0/1. А в Nagios’е у вас будет авария, всё будет красное, повалятся смс и почта. При падении линка, IP-адрес этого интерфейса становится недоступен.
А вот если вы настроите в Nagios’е адрес Loopback-интерфейса, то тем или иным путём он всегда будет доступен, опять же благодаря динамической маршрутизации.В качестве маски IP-адреса Loopback-интерфейса практически всегда выбирается /32, то есть 11111111.11111111.11111111.1111111 — один единственный адрес — а больше и не надо.
Поскольку все приготовления уже закончились, перед нами стоит очень простая задача: пройтись по всем маршрутизаторам и активировать процесс OSPF.
1) Первое, что нам нужно сделать — запустить процесс OSPF маршрутизаторе:
msk-arbat-gw1(config)# router OSPF 1
Первым словом указываем, что запускаем протокол динамической маршрутизации, далее указываем какой именно и в последнюю очередь номер процесса (теоретически их может быть несколько на одном роутере).
Сразу после этого автоматически назначается router ID. По умолчанию это наибольший адрес Loopbaсk-интерфейсов.
2) Не оставляем это дело на самотёк. Главное правило: Router ID обязан быть уникальным. Нет, вы, конечно, можете их сделать и одинаковыми, но в этом случае у вас начнутся странности.
Одна из моих заявок была такой: на оборудовании заканчиваются метки LDP. Из 8 с гаком тысяч осталась только одна свободная. Никакие новые VPN не создавались и не работали. Разбирались, разбирались и в итоге увидели что процесс OSPF создаёт и удаляет тысячи записей в минуту в таблице маршрутизации. Топология постоянно перестраивается и на каждое такое перестроение выделяются новые метки LDP, после чего не освобождаются. А всё дело в случайно настроенных одинаковых Router ID.
Настраивать его можно, в принципе, как угодно, можно даже не настраивать, маршрутизатор назначит его сам, но для порядку мы это сделаем — в будущем обслуживать будет проще. Назначаем его в соответствии с адресом Loopback-интерфейса.
msk-arbat-gw1(config-router)#router-id 172.16.255.1
3) Теперь мы объявляем, какие сети мы будем анонсировать (передавать соседям OSPF). Обратите внимание, что в этой команде используется wildcard- маска, как в ACL
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
Тут остановимся подробно. Командой network мы задаём не ту сеть, что будет вещать наш маршрутизатор, мы определяем интерфейсы, участвующие в процессе.
Все интерфейсы маршрутизатора, IP адреса которых попадают в настроенный диапазон 172.16.0.0 0.0.255.255 (172.16.0.0-172.16.255.255), включатся в процесс.
Это означает следующее:
а) с данных интерфейсов будут рассылаться Hello-сообщения, через них будут устанавливаться отношения соседства и отправляться обновления о топологии сети.
б) OSPF изучает подсети данных интерфейсов и именно их будет аносировать и следить за их состоянием. То есть не 172.16.0.0 0.0.255.255, как мы настроили, а те, что удовлетворяют этому диапазону

В нашем случае не имеет значения как мы настроим:
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
или
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.15.255 area 0
или
msk-arbat-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.1.0 0.0.255.255 area 0
msk-arbat-gw1(config-router)#network 172.16.2.0 0.0.255.255 area 0
……
msk-arbat-gw1(config-router)#network 172.16.15.0 0.0.255.255 area 0
Все эти команды сработают одинаково в нашем случае.
Поскольку у нас все локальные сети имеют адреса из сети 172.16.0.0/16, то мы будем использовать наиболее общую запись. При этом туда, разумеется, не попадёт внешний интерфейс в интернет FastEthernet0/1.6, потому что его адрес — 198.51.100.2 — не из этого диапазона.
При такой настройке любой новый интерфейс, на котором вы укажете адрес из диапазона 172.16.0.0 — 172.16.255.255, автоматически становится участником процесса OSPF. Плохо это или хорошо, зависит от ваших желаний.
area 0 означает принадлежность данных подсетей зоне с номером ноль (в наших примерах только такая и будет).
Area 0 это не простая зона- это так называемая Backbone-area. Это означает, что она объединяет все остальные зоны, т.е. пакет, идущий от любой ненулевой зоны в любую ненулевую, обязан проходить через area 0
Как только вы задали команду network с правильных интерфейсов слетают слова приветствия, но отвечать на них пока некому — соседей нет:
msk-arbat-gw1#sh ip OSPF neighbor
msk-arbat-gw1#
Теперь пропишем настройки OSPF в Кемерово (router ID=IP адрес Loopback интерфейса, взятоый из IP-плана):
kmr-gorka-gw1(config)#router OSPF 1
kmr-gorka-gw1(config-router)#router-id 172.16.255.48
kmr-gorka-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
И сразу после этого вы видите в консоли сообщение
02:27:33: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.1 on FastEthernet0/0.5 from LOADING to FULL, Loading Done
Такое же показывает и маршрутизатор в Москве:
02:27:33: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.48 on FastEthernet0/1.5 from LOADING to FULL, Loading Done.
Здесь вы можете видеть, что были успешно установлены отношения смежности и произошёл обмен LSA. Каждый маршрутизатор построил свою LSDB.
Подробная информация по соседу:
msk-arbat-gw1#sh ip OSPF neighbor detail
Neighbor 172.16.255.48, interface address 172.16.2.18
In the area 0 via interface FastEthernet0/1.5
Neighbor priority is 1, State is FULL, 4 state changes
DR is 172.16.2.17 BDR is 172.16.2.18
Options is 0x00
Dead timer due in 00:00:38
Neighbor is up for 00:02:51
Index 1/1, retransmission queue length 0, number of retransmission 0
First 0x0(0)/0x0(0) Next 0x0(0)/0x0(0)
Last retransmission scan length is 0, maximum is 0
Last retransmission scan time is 0 msec, maximum is 0 msec
Тут вся ключевая информация о состоянии соседа:
Его router-id (172.16.255.48), который суть loopback, адрес интерфейса удалённой стороны, через который установлено соседство (172.16.2.18), тип и номер физического интерфейса (FastEthernet0/1.5), текущий статус (FULL) и Dead timer. Последний не доходит до нуля, если вы за ним понаблюдаете. Его значение уменьшается, уменьшается, а потом Оп! и снова 40. Это потому что каждые 10 секунд маршрутизаторы получают сообщения Hello и
обсороколяют
обнуляют Dead-интервал.
Командой show ip route мы можем посмотреть, как изменилась таблица маршрутизации:
msk-arbat-gw1#show ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static routeGateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 17 subnets, 5 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:13:03, FastEthernet0/1.5
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
Кроме известных ранее сетей (C — directly connected и S — Static) у нас появились два новых маршрута с пометкой O (OSPF). Тут всё должно быть понятно, но наблюдательный читатель спросит: “почему в таблице маршрутизации присутствуют два маршрута в сеть 172.16.24.0. Почему не останется более предпочтительный статический?” и будет прав. Вообще говоря, в таблицу маршрутизации попадает только лучший маршрут до сети — по умолчанию один. Но обратите внимание, что статический маршрут идёт до подсети 172.16.24.0/22, а полученный от OSPF до 172.16.24.0/24. Это разные подсети, поэтому обеим им нашлось место до солнцем. Дело в том, что OSPF понятия не имеет чего вы там напланировали и какой диапазон выделили — он оперирует реальными данными, то есть IP-адресом и маской:
interface FastEthernet0/0.2
ip address 172.16.24.1 255.255.255.0
Что у нас творится в Кемерово:
kmr-gorka-gw1#sh ip route
Gateway of last resort is 172.16.2.17 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 14 subnets, 3 masks
O 172.16.0.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.1.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.0/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.2.16/30 is directly connected, FastEthernet0/0.5
O 172.16.2.32/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.128/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.2.196/30 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.3.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.4.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.5.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
O 172.16.6.0/24 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.24.0/24 is directly connected, FastEthernet0/0.2
O 172.16.255.1/32 [110/2] via 172.16.2.17, 00:32:42, FastEthernet0/0.5
C 172.16.255.48/32 is directly connected, Loopback0
S* 0.0.0.0/0 [1/0] via 172.16.2.17
Как видим, помимо настроенного прежде маршрута по умолчанию, тут появились все подсети из Москвы.
Обратите внимание на цифры в квадратных скобках:
S* 0.0.0.0/0 [1/0]
O 172.16.6.0/24 [110/2]
Первая цифра — это административная дистанция, которая у OSPF значительно больше, чем у статики и, соответственно, приоритет ниже.
На самом деле до подсети 172.16.24.0/24 трафик уже пошёл по маршруту предоставленному OSPF, потому что у него более узкая маска (24 против 22).
Но попробуем удалить статические маршруты и посмотрим, что получится.
Совершенно предсказуемо всё работает:
msk-arbat-gw1#ping 172.16.24.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.24.1, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 8/10/15 ms
И это прекрасно.
Настроим OSPF в Питере:
spb-vsl-gw1(config)#router OSPF 1
spb-vsl-gw1(config-router)#router-id 172.16.255.32
spb-vsl-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0
Настройки, как видите, везде предельно простые. При этом замечу, что номер процесса OSFP на разных маршрутизаторах не обязательно должен быть одинаковым, но лучше, если это будет так.
На msk-arbat-gw1 у нас теперь два соседа
msk-arbat-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:39 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DROTHER 00:00:31 172.16.2.18 FastEthernet0/1.5
А вот в Питере (и в Кемерово) один:
spb-vsl-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.1 1 FULL/DR 00:00:34 172.16.2.1 FastEthernet1/0.4
Дело в том, что отношения смежности устанавливаются только между непосредственно подключенными устройствами, а spb-vsl-gw1 коммуницирует с kmr-gorka-gw1 через msk-arbat-gw1, поэтому их нет в соседях друг у друга.
Последний оплот консерватизма — spb-ozerki-gw1 сдастся вам без особых проблем, как и три маршрутизатора Сибирского кольца. Делается всё по аналогии — по сути меняется только Router ID. И не забудьте удалить статические маршруты.
Задача №1
Между маршрутизаторами в Питере надо уменьшить время обнаружения пропажи соседа. Маршрутизаторы должны отправлять сообщения Hello каждые 3 секунды, и считать друг друга недоступными, если 12 секунд не было сообщение Hello от соседа.
Ответ
Общий совет по всем задачам:
Даже если Вы сразу не знаете ответа и решения, постарайтесь подумать к чему относится условие задачи:
— К каким особенностям, настройкам протокола?
— Глобальные эти настройки или привязаны к конкретному интерфейсу?
Если Вы не знаете или забыли команду, такие размышления, скорее всего, приведут Вас к правильному контексту, где Вы просто, с помощью подсказки в командной строке, можете догадаться или вспомнить как настроить то, что требуется в задании.
Постарайтесь поразмышлять в таком ключе прежде чем пойдете в гугл или на какой-то сайт в поиске команд.
На реальной сети при выборе диапазона анонсируемых подсетей нужно руководствоваться регламентом и насущными потребностями.
Прежде чем мы перейдём к тестированию резервных линков и скорости, сделаем ещё одну полезную вещь.
Если бы у нас была возможность отловить трафик на интерфейсе FE0/0.2 msk-arbat-gw1, который смотрит в сторону серверов, то мы бы увидели, что каждые 10 секунд в неизвестность улетают сообщения Hello. Ответить на Hello некому, отношения смежности устанавливать не с кем, поэтому и пытаться рассылать отсюда сообщения смысла нет.
Выключается это очень просто:
msk-arbat-gw1(config)#router OSPF 1
msk-arbat-gw1(config-router)#passive-interface fastEthernet 0/0.2
Такую команду нужно дать для всех интерфейсов, на которых точно нет соседей OSPF (в том числе в сторону интернета).
В итоге картина у вас будет такая:
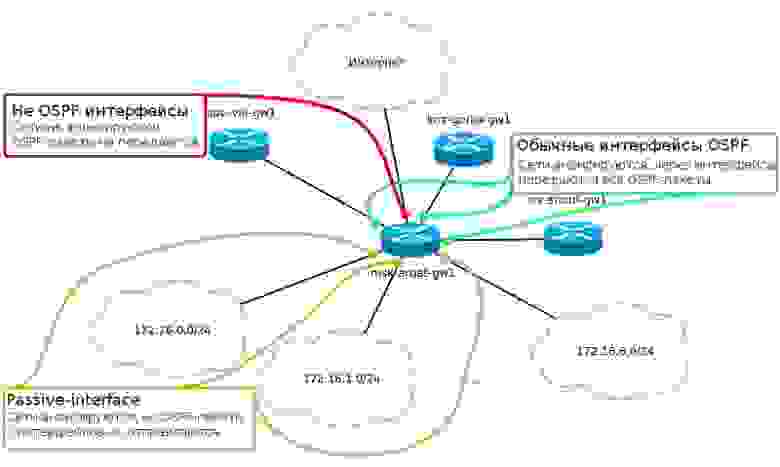
*Не представляю, как вы до сих пор не запутались*
Кроме того, эта команда повышает безопасность — никто из этой сети не прикинется маршрутизатором и не будет пытаться поломать нас полностью.
Теперь займёмся самым интересным — тестированием.
Ничего сложного нет в настройке OSPF на всех маршрутизаторах в Сибирском кольце — сделаете сами.
И после этого картина должна быть следующей:
msk-arbat-gw1#sh ip OSPF neighbor
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DR 00:00:31 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:31 172.16.2.18 FastEthernet0/1.5
172.16.255.80 1 FULL/BDR 00:00:36 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/BDR 00:00:37 172.16.2.197 FastEthernet1/0.911
Питер, Кемерово, Красноярск и Владивосток — непосредственно подключенные.
msk-arbat-gw1#sh ip route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 25 subnets, 6 masks
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
S 172.16.2.4/30 [1/0] via 172.16.2.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 00:05:53, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:04:18, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
S 172.16.16.0/21 [1/0] via 172.16.2.2
S 172.16.24.0/22 [1/0] via 172.16.2.18
O 172.16.24.0/24 [110/2] via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.32/32 [110/2] via 172.16.2.2, 00:24:03, FastEthernet0/1.4
O 172.16.255.48/32 [110/2] via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.255.80/32 [110/2] via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:04:18, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:04:18, FastEthernet1/0.911
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:04:28, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
Все обо всех всё знают.
Каким маршрутом трафик доставляется из Москвы в Красноярск? Из таблицы видно, что krs-stolbi-gw1 подключен напрямую и это же видно из трассировки:
msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abort.
Tracing the route to 172.16.128.11 172.16.2.130 35 msec 8 msec 5 msec
Теперь рвём интерфейс между Москвой и Красноярском и смотрим, через сколько линк восстановится.
Не проходит и 5 секунд, как все маршрутизаторы узнали о происшествии и пересчитали свои таблицы маршрутизации:
msk-arbat-gw1(config-subif)#do sh ip ro 172.16.128.0
Routing entry for 172.16.128.0/24
Known via «OSPF 1», distance 110, metric 4, type intra area
Last update from 172.16.2.197 on FastEthernet1/0.911, 00:00:53 ago
Routing Descriptor Blocks:
* 172.16.2.197, from 172.16.255.80, 00:00:53 ago, via FastEthernet1/0.911
Route metric is 4, traffic share count is 1vld-gw1#sh ip route 172.16.128.0
Routing entry for 172.16.128.0/24
Known via «OSPF 1», distance 110, metric 3, type intra area
Last update from 172.16.2.193 on FastEthernet1/0, 00:01:57 ago
Routing Descriptor Blocks:
* 172.16.2.193, from 172.16.255.80, 00:01:57 ago, via FastEthernet1/0
Route metric is 3, traffic share count is 1msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abort.
Tracing the route to 172.16.128.11 172.16.2.197 4 msec 10 msec 10 msec
2 172.16.2.193 8 msec 11 msec 15 msec
3 172.16.2.161 15 msec 13 msec 6 msec
То есть теперь Красноярска трафик достигает таким путём:
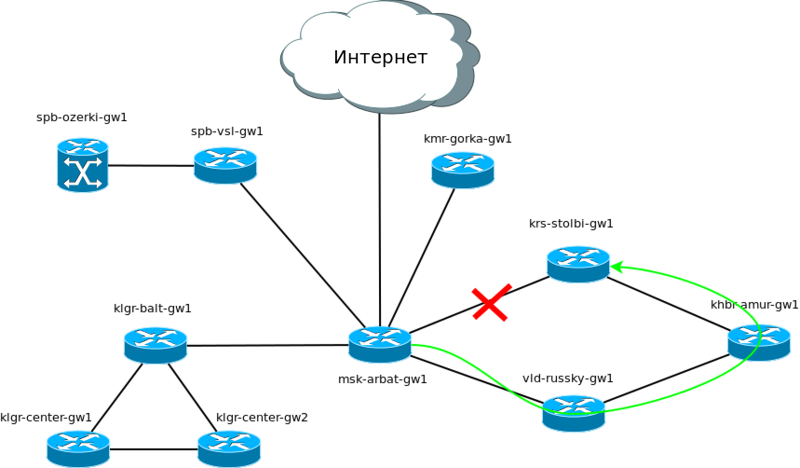
Как только вы поднимете линк, маршрутизаторы снова вступают в связь, обмениваются своими базами, пересчитываются кратчайшие пути и заносятся в таблицу маршрутизации.
На видео всё это более наглядно. Рекомендую ознакомиться.
Задача №2
После настройки OSPF на маршрутизаторах в сибирском кольце, все сети, которые находятся за маршрутизатором в центральном офисе в Москве (msk-arbat-gw1), для Хабаровска доступны по двум маршрутам (через Красноярск и через Владивосток). Но, так как канал через Красноярск лучше, то надо изменить настройки по умолчанию таким образом, чтобы Хабаровск использовал канал через Красноярск, когда он доступен. И переключался на Владивосток только если что-то случилось с каналом на Красноярск.
Ответ
Как любой хороший протокол, OSPF поддерживает аутентификацию — два соседа перед установлением соотношений соседства могут проверять подлинность полученных OSPF-сообщений. Оставляем на самостоятельное изучение — довольно просто.
Задача №3
С провайдером «Филькин сертификат» случилась неприятная история. Из-за их ошибки в настройках VPN на маршрутизатор во Владивостоке начали приходить какие-то непонятные маршруты, вероятно, от другого клиента или внутренние самого сети провайдера. Некоторые сети пересекались с локальными сетями и была потеряна связь с некоторыми участками сети. После этого случая было решено защититься на будущее от подобных ситуаций.
Ситуация, вообще говоря, надуманная и маловероятная, но в качестве задачки подойдёт.
На участке между Москвой и Владивостоком необходимо настроить маршрутизаторы таким образом, чтобы они, при установке отношений соседства, проверяли ещё и установленный пароль. Пароль должен быть: MskVladPass и передаваться он должен в виде хеша md5 (номер ключа 1).
Ответ
EIGRP
Теперь займёмся другим очень важным протоколом
Итак, чем хорош EIGRP?
— прост в конфигурации
— быстрое переключение на заранее просчитанный запасной маршрут
— требует меньше ресурсов роутера (по сравнению с OSPF)
— суммирование маршрутов на любом роутере (в OSPF только на ABR\ASBR)
— балансировка трафика на неравноценных маршрутах (OSPF только на равноценных)
Мы решили перевести одну из записей блога Ивана Пепельняка, в которой разбирается ряд популярных мифов про EIGRP:
— “EIGRP это гибридный протокол маршрутизации”. Если я правильно помню, это началось с первой презентации EIGRP много лет назад и обычно понимается как «EIGRP взял лучшее от link-state и distance-vector протоколов». Это совершенно не так. У EIGRP нет никаких отличительных особенностей link-state. Правильно будет говорить «EIGRP это продвинутый distance-vector- протокол маршрутизации».— “EIGRP это distance-vector протокол”. Неплохо, но не до конца верно тоже. EIGRP отличается от других DV способом, которым обрабатывает потерянные маршруты (или маршруты с возрастающей метрикой). Все остальные протоколы пассивно ждут обновления информации от соседа (некоторые, например, RIP, даже блокируют маршрут для предотвращения петель маршрутизации), в то время как EIGRP ведет себя активнее и запрашивает информацию сам.
— “EIGRP сложен во внедрении и обслуживании”. Неправда. В свое время, EIGRP в больших сетях с низкоскоростными линками было сложновато правильно внедрить, но ровно до того момента, как были введены stub routers. С ними (а также несколькими исправлениями работы DUAL-алгоритма), он не чуть не хуже, чем OSPF.
— “Как и LS протоколы, EIGRP хранит таблицу топологии маршрутов, которыми обменивается”. Просто удивительно, насколько это неверно. EIGRP не имеет вообще никакого понятия о том, что находится дальше ближайших соседей, в то время как LS протоколы точно знают топологию всей области, к которой они подключены.
— “EIGRP это DV протокол, который действует, как LS”. Неплохая попытка, но по-прежнему, абсолютно неверно. LS протоколы строят таблицу маршрутизации, проходя через следующие шаги:
— каждый маршрутизатор описывает сеть, исходя из информации, доступной ему локально (его линки, подсети, в которых он находится, соседи, которых он видит) посредством пакета (или нескольких), называемого LSA (в OSPF) или LSP (IS-IS)
— LSA распространяются по сети. Каждый маршрутизатор должен получить каждую LSA, созданную в его сети. Информация, полученная из LSA, заносится в таблицу топологии.
— каждый маршрутизатор независимо анализирует свою таблицу топологии и запускает SPF алгоритм для подсчета лучших маршрутов к каждому из других маршрутизаторов
Поведение EIGRP даже близко не напоминает эти шаги, поэтому непонятно, с какой стати он «действует, как LS»Единственное, что делает EIGRP — это хранит информацию, полученную от соседа (RIP сразу же забывает то, что не может быть использовано в данный момент). В этом смысле, он похож на BGP, который тоже хранит все в таблице BGP и выбирает лучший маршрут оттуда. Таблица топологии (содержащая всю информацию, полученную от соседей), дает EIGRP преимущество перед RIP – она может содержать информацию о запасном (не используемом в данный момент) маршруте.
Теперь чуть ближе к теории работы:
Каждый процесс EIGRP обслуживает 3 таблицы:
— Таблицу соседей (neighbor table), в которой содержится информация о “соседях”, т.е. других маршрутизаторах, непосредственно подключенных к текущему и участвующих в обмене маршрутами. Можно посмотреть с помощью команды show ip eigrp neighbors
— Таблицу топологии сети (topology table), в которой содержится информация о маршрутах, полученная от соседей. Смотрим командой show ip eigrp topology
— Таблицу маршрутизации (routing table), на основе которой роутер принимает решения о перенаправлении пакетов. Просмотр через show ip route
Метрика.
Для оценки качества определенного маршрута, в протоколах маршрутизации используется некое число, отражающее различные его характеристики или совокупность характеристик- метрика. Характеристики, принимаемые в расчет, могут быть разными- начиная от количества роутеров на данном маршруте и заканчивая средним арифметическим загрузки всех интерфейсов по ходу маршрута. Что касается метрики EIGRP, процитируем Jeremy Cioara: “у меня создалось впечатление, что создатели EIGRP, окинув критическим взглядом свое творение, решили, что все слишком просто и хорошо работает. И тогда они придумали формулу метрики, что бы все сказали “ВАУ, это действительно сложно и профессионально выглядит”. Узрите же полную формулу подсчета метрики EIGRP: (K1 * bw + (K2 * bw) / (256 — load) + K3 * delay) * (K5 / (reliability + K4)), в которой:
— bw это не просто пропускная способность, а (10000000/самая маленькая пропускная способность по дороге маршрута в килобитах) * 256
— delay это не просто задержка, а сумма всех задержек по дороге в десятках микросекунд * 256 (delay в командах show interface, show ip eigrp topology и прочих показывается в микросекундах!)
— K1-K5 это коэффициенты, которые служат для того, чтобы в формулу “включился” тот или иной параметр.
Страшно? было бы, если бы все это работало, как написано. На деле же из всех 4 возможных слагаемых формулы, по умолчанию используются только два: bw и delay (коэффициенты K1 и K3=1, остальные нулю), что сильно ее упрощает — мы просто складываем эти два числа (не забывая при этом, что они все равно считаются по своим формулам). Важно помнить следующее: метрика считается по худшему показателю пропускной способности по всей длине маршрута.
Интересная штука получилась с MTU: довольно часто можно встретить сведения о том, что MTU имеет отношение к метрике EIGRP. И действительно, значения MTU передаются при обмене маршрутами. Но, как мы можем видеть из полной формулы, никакого упоминания об MTU там нет. Дело в том, что этот показатель принимается в расчет в довольно специфических случаях: например, если роутер должен отбросить один из равнозначных по остальным характеристикам маршрутов, он выберет тот, у которого меньший MTU. Хотя, не все так просто (см. комментарии).
Определимся с терминами, применяемыми внутри EIGRP. Каждый маршрут в EIGRP характеризуется двумя числами: Feasible Distance и Advertised Distance (вместо Advertised Distance иногда можно встретить Reported Distance, это одно и то же). Каждое из этих чисел представляет собой метрику, или стоимость (чем больше-тем хуже) данного маршрута с разных точек измерения: FD это “от меня до места назначения”, а AD- “от соседа, который мне рассказал об этом маршруте, до места назначения”. Ответ на закономерный вопрос “Зачем нам надо знать стоимость от соседа, если она и так включена в FD?”- чуть ниже (пока можете остановиться и поломать голову сами, если хотите).
У каждой подсети, о которой знает EIGRP, на каждом роутере существует Successor- роутер из числа соседей, через который идет лучший (с меньшей метрикой), по мнению протокола, маршрут к этой подсети. Кроме того, у подсети может также существовать один или несколько запасных маршрутов (роутер-сосед, через которого идет такой маршрут, называется Feasible Successor). EIGRP- единственный протокол маршрутизации, запоминающий запасные маршруты (в OSPF они есть, но содержатся, так сказать, в “сыром виде” в таблице топологии- их еще надо обработать алгоритмом SPF), что дает ему плюс в быстродействии: как только протокол определяет, что основной маршрут (через successor) недоступен, он сразу переключается на запасной. Для того, чтобы роутер мог стать feasible successor для маршрута, его AD должно быть меньше FD successor’а этого маршрута (вот зачем нам нужно знать AD). Это правило применяется для того, чтобы избежать колец маршрутизации.
Предыдущий абзац взорвал мозг? Материал трудный, поэтому еще раз на примере. У нас есть вот такая сеть:
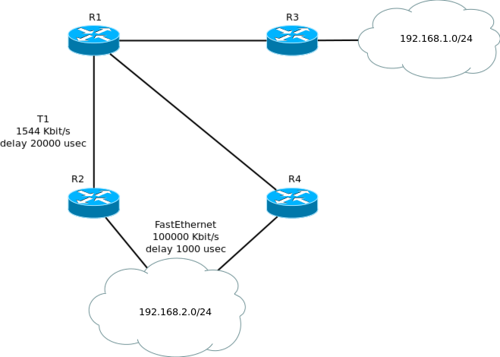
С точки зрения R1, R2 является Successor’ом для подсети 192.168.2.0/24. Чтобы стать FS для этой подсети, R4 требуется, чтобы его AD была меньше FD для этого маршрута. FD у нас ((10000000/1544)*256)+(2100*256) =2195456, AD у R4 (с его точки зрения это FD, т.е. сколько ему стоит добраться до этой сети) = ((10000000/100000)*256)+(100*256)=51200. Все сходится, AD у R4 меньше, чем FD маршрута, он становится FS. *тут мозг такой и говорит: “БДЫЩЬ”*. Теперь смотрим на R3- он анонсирует свою сеть 192.168.1.0/24 соседу R1, который, в свою очередь, рассказывает о ней своим соседям R2 и R4. R4 не в курсе, что R2 знает об этой подсети, и решает ему рассказать. R2 передает информацию о том, что он имеет доступ через R4 к подсети 192.168.1.0/24 дальше, на R1. R1 строго смотрит на FD маршрута и AD, которой хвастается R2 (которая, как легко понять по схеме, будет явно больше FD, так как включает и его тоже) и прогоняет его, чтобы не лез со всякими глупостями. Такая ситуация довольно маловероятна, но может иметь место при определенном стечении обстоятельств, например, при отключении механизма “расщепления горизонта” (split-horizon). А теперь к более вероятной ситуации: представим, что R4 подключен к сети 192.168.2.0/24 не через FastEthernet, а через модем на 56k (задержка для dialup составляет 20000 usec), соответственно, добраться ему стоит ((10000000/56)*256)+(2000*256)= 46226176. Это больше, чем FD для этого маршрута, поэтому R4 не станет Feasible Successor’ом. Но это не значит, что EIGRP вообще не будет использовать данный маршрут. Просто переключение на него займет больше времени (подробнее об этом дальше).
соседство
Роутеры не разговаривают о маршрутах с кем попало — прежде чем начать обмениваться информацией, они должны установить отношения соседства. После включения процесса командой router eigrp с указанием номера автономной системы, мы, командой network говорим, какие интерфейсы будут участвовать и одновременно, информацию о каких сетях мы желаем распространять. Незамедлительно, через эти интерфейсы начинают рассылаться hello-пакеты на мультикаст- адрес 224.0.0.10 (по умолчанию каждые 5 секунд для ethernet). Все маршрутизаторы с включенным EIGRP получают эти пакеты, далее каждый маршрутизатор-получатель делает следующее:
— сверяет адрес отправителя hello-пакета, с адресом интерфейса, из которого получен пакет, и удостоверяется, что они из одной подсети
— сверяет значения полученных из пакета K-коэффициентов (проще говоря, какие переменные используются в подсчете метрики) со своими. Понятно, что если они различаются, то метрики для маршрутов будут считаться по разным правилам, что недопустимо
— проверяет номер автономной системы
— опционально: если настроена аутентификация, проверяет соответствие ее типа и ключей.
Если получателя все устраивает, он добавляет отправителя в список своих соседей, и посылает ему (уже юникастом) update-пакет, в котором содержится список всех известных ему маршрутов (aka full-update). Отправитель, получив такой пакет, в свою очередь, делает то же самое. Для обмена маршрутами EIGRP использует Reliable Transport Protocol (RTP, не путать с Real-time Transport Protocol, который используется в ip-телефонии), который подразумевает подтверждение о доставке, поэтому каждый из роутеров, получив update- пакет, отвечает ack -пакетом (сокращение от acknowledgement- подтверждение). Итак, отношение соседства установлены, роутеры узнали друг у друга исчерпывающую информацию о маршрутах, что дальше? Дальше они будут продолжать посылать мультикаст hello-пакеты в подтверждение того, что они на связи, а в случае изменения топологии- update-пакеты, содержащие сведения только об изменениях (partial update).
Теперь вернемся к предыдущей схеме с модемом.
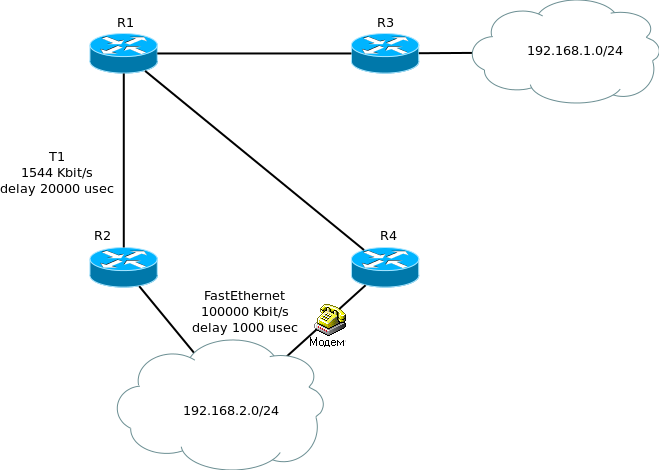
R2 по каким-то причинам потерял связь с 192.168.2.0/24. До этой подсети у него нет запасных маршрутов (т.е. отсутствует FS). Как всякий ответственный роутер с EIGRP, он хочет восстановить связь. Для этого он начинает рассылать специальные сообщения (query- пакеты) всем своим соседям, которые, в свою очередь, не находя нужного маршрута у себя, расспрашивают всех своих соседей, и так далее. Когда волна запросов докатывается до R4, он говорит “погодите-ка, у меня есть маршрут к этой подсети! Плохонький, но хоть что-то. Все про него забыли, а я-то помню”. Все это он упаковывает в reply-пакет и отправляет соседу, от которого получил запрос (query), и дальше по цепочке. Понятное дело, это все занимает больше времени, чем просто переключение на Feasible Successor, но, в итоге, мы получаем связь с подсетью.
А сейчас опасный момент: может, вы уже обратили внимание и насторожились, прочитав момент про эту веерную рассылку. Падение одного интерфейса вызывает нечто похожее на широковещательный шторм в сети (не в таких масштабах, конечно, но все-таки), причем чем больше в ней роутеров, тем больше ресурсов потратится на все эти запросы-ответы. Но это еще пол-беды. Возможна ситуация и похуже: представим, что роутеры, изображенные на картинке- это только часть большой и распределенной сети, т.е. некоторые могут находится за много тысяч километров от нашего R2, на плохих каналах и прочее. Так вот, беда в том, что, послав query соседу, роутер обязан дождаться от него reply. Неважно, что в ответе- но он должен прийти. Даже если роутер уже получил положительный ответ, как в нашем случае, он не может поставить этот маршрут в работу, пока не дождется ответа на все свои запросы. А запросы-то, может, еще где-нибудь на Аляске бродят. Такое состояние маршрута называется stuck-in-active. Тут нам нужно познакомится с терминами, отражающими состояние маршрута в EIGRP: active\passive route. Обычно они вводят в заблуждение. Здравый смысл подсказывает, что active значит маршрут “активен”, включен, работает. Однако тут все наоборот: passive это “все хорошо”, а состояние active означает, что данная подсеть недоступна, и маршрутизатор находится в активном поиске другого маршрута, рассылая query и ожидая reply. Так вот, состояние stuck-in-active (застрял в активном состоянии) может продолжатся до 3 минут! По истечение этого срока, роутер обрывает отношения соседства с тем соседом, от которого он не может дождаться ответа, и может использовать новый маршрут через R4. Подробно о проблеме
История, леденящая кровь сетевого инженера. 3 минуты даунтайма это не шутки. Как мы можем избежать
инфаркта
этой ситуации? Выхода два: суммирование маршрутов и так называемая stub-конфигурация.
Вообще говоря, есть еще один выход, и он называется фильтрация маршрутов (route filtering). Но это настолько объемная тема, что впроу отдельную статью под нее писать, а у нас и так уже пол-книги получилось в этот раз. Поэтому на ваше усмотрение.
Как мы уже упоминали, в EIGRP суммирование маршрутов можно проводить на любом роутере. Для иллюстрации, представим, что к нашему многострадальному R2 подключены подсети от 192.168.0.0/24 до 192.168.7.0/24, что очень удобненько суммируется в 192.168.0.0/21 (вспоминаем binary math). Роутер анонсирует этот суммарный маршрут, и все остальные знают: если адрес назначения начинается на 192.168.0-7, то это к нему. Что будет происходить, если одна из подсетей пропадет? Роутер будет рассылать query-пакеты с адресом этой сети (конкретным, например, 192.168.5.0/24), но соседи, вместо того, чтобы уже от своего имени продолжить порочную рассылку, будут сразу в ответ слать отрезвляющие реплаи, мол, это твоя подсеть, ты и разбирайся.
Второй вариант- stub- конфигурация. Образно говоря, stub означает “конец пути”, “тупик” в EIGRP, т.е., чтобы попасть в какую-то подсеть, не подключенную напрямую к такому роутеру, придется идти назад. Роутер, сконфигурированный, как stub, не будет пересылать трафик между подсетями, которые ему стали известны от EIGRP (проще говоря, которые в show ip route помечены буквой D). Кроме того, его соседи не будут отправлять ему query-пакеты. Самый распространенный случай применения- hub-and-spoke топологии, особенно с избыточными линками. Возьмем такую сеть: слева- филиалы, справа- основной сайт, главный офис и т.п. Для отказоустойчивости избыточные линки. Запущен EIGRP с дефолтными настройками.
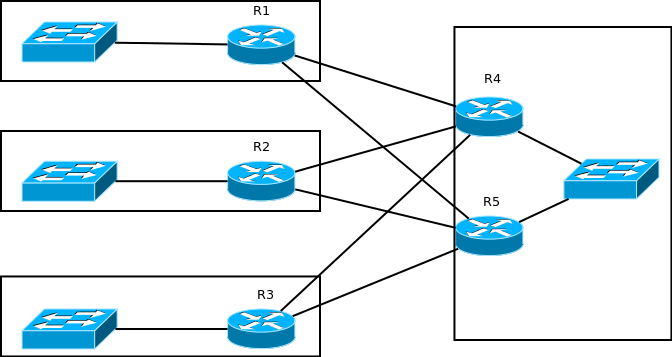
А теперь “внимание, вопрос”: что будет, если R1 потеряет связь с R4, а R5 потеряет LAN? Трафик из подсети R1 в подсеть главного офиса будет идти по маршруту R1->R5->R2(или R3)->R4. Будет это эффективно? Нет. Будет страдать не только подсеть за R1, но и подсеть за R2 (или R3), из-за увеличения объемов трафика и его последствий. Вот для таких-то ситуаций и придуман stub. За роутерами в филиалах нет других роутеров, которые вели бы в другие подсети, это “конец дороги”, дальше только назад. Поэтому мы с легким сердцем можем сконфигурировать их как stub’ы, что, во-первых, избавит нас от проблемы с “кривым маршрутом”, изложенной чуть выше, а во-вторых, от флуда query-пакетов в случае потери маршрута.
Существуют различные режимы работы stub-роутера, задаются они командой eigrp stub:
R1(config)#router eigrp 1
R1(config-router)#eigrp stub?
connected Do advertise connected routes
leak-map Allow dynamic prefixes based on the leak-map
receive-only Set IP-EIGRP as receive only neighbor
redistributed Do advertise redistributed routes
static Do advertise static routes
summary Do advertise summary routes
По умолчанию, если просто дать команду eigrp stub, включаются режимы сonnected и summary. Интерес представляет режим receive-only, в котором роутер не анонсирует никаких сетей, только слушает, что ему говорят соседи (в RIP есть команда passive interface, которая делает то же самое, но в EIGRP она полностью отключает протокол на выбранном интерфейсе, что не позволяет установить соседство).
Важные моменты в теории EIGRP, не попавшие в статью:
- В EIGRP можно настроить аутентификацию соседей
- Концепция graceful shutdown
- Балансировка нагрузки
Практика EIGRP
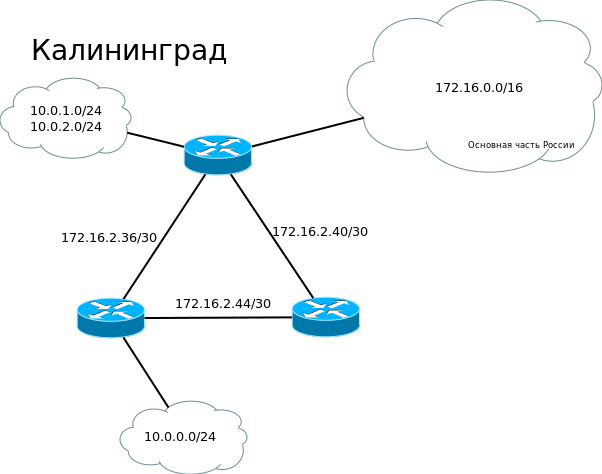
“Лифт ми Ап” купили фабрику в Калининграде. Там производят мозги лифтов: микросхемы, ПО. Фабрика очень крупная — три точки по городу — три маршрутизатора соединены в кольцо.
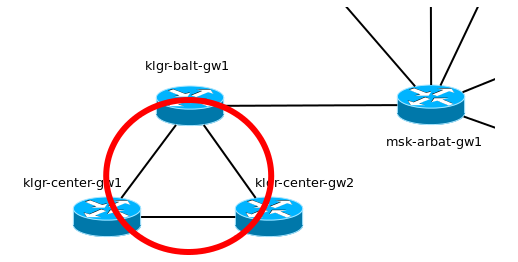
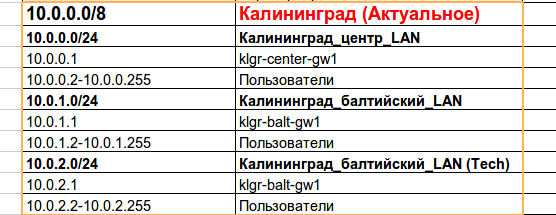
Но вот незадача — на них уже запущен EIGRP в качестве протокола динамической маршрутизации. Причём адресация конечных узлов совсем из другой подсети — 10.0.0.0/8. Все другие параметры (линковые адреса, адреса лупбэк интерфейсов) мы поменяли, но несколько тысяч адресов локальной сети с серверами, принтерами, точками доступа — работа не на пару часов — отложили на потом, а в IP-плане зарезервировали на будущее для Калининграда подсеть 172.16.32.0/20.
Сейчас у нас используются такие сети:
Как настраивается это чудо? Незамысловато, на первый взгляд:
router eigrp 1
network 172.16.0.0 0.0.255.255
network 10.0.0.0
В EIGRP обратную маску можно задавать, указывая тем самым более узкие рамки, либо не задавать, тогда будет выбрана стандартная маска для этого класса (16 для класса B — 172.16.0.0 и 8 для класса 8 — 10.0.0.0)
Такие команды даются на всех маршрутизаторах Автономной Системы. АС определяется цифрой в команде router eigrp, то есть в нашем случае имеем АС №1. Эта цифра должна быть одинаковой на всех маршрутизаторах (в отличии от OSPF).
Но есть в EIGRP серьёзный подвох: по умолчанию включено автоматическое суммирование маршрутов в классовом виде (в версиях IOS до 15).
Сравним таблицы маршрутизации на трёх калининградских маршрутизаторах:
Сеть 10.0.0.1/24 подключена у нас к klgr-center-gw1 и он о ней знает:
klgr-center-gw1:
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:35:23, Null0
C 10.0.0.0/24 is directly connected, FastEthernet1/0
Но не знает о 10.0.1.0/24 и 10.0.2.0/24/
klgr-balt-gw1 знает о своих двух сетях 10.0.1.0/24 и 10.0.2.0/24, но вот сеть 10.0.0.0/24 он куда-то спрятал.
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:42:05, Null0
C 10.0.1.0/24 is directly connected, FastEthernet1/1.2
C 10.0.2.0/24 is directly connected, FastEthernet1/1.3
Они оба создали маршрут 10.0.0.0/8 с адресом next hop Null0.
А вот klgr-center-gw2 знает, что подсети 10.0.0.0/8 находятся за обоими его WAN интерфейсами.
D 10.0.0.0/8 [90/30720] via 172.16.2.41, 00:42:49, FastEthernet0/1
[90/30720] via 172.16.2.45, 00:38:05, FastEthernet0/0
Что-то очень странное творится.
Но, если вы проверите конфигурацию этого маршрутизатора, то, вероятно, заметите:
router eigrp 1
network 172.16.0.0
network 10.0.0.0
auto-summary
Во всём виновато автоматическое суммирование. Это самое большое зло EIGRP. Рассмотрим более подробно, что происходит. klgr-center-gw1 и klgr-balt-gw1 имеют подсети из 10.0.0.0/8, они их суммируют по умолчанию, когда передают соседям.
То есть, например, msk-balt-gw1 передаёт не две сети 10.0.1.0/24 и 10.0.2.0/24, а одну обобщённую: 10.0.0.0/8. То есть его сосед будет думать, что за msk-balt-gw1 находится вся эта сеть.
Но, что произойдёт, если вдруг на balt-gw1 попадёт пакет с адресатом 10.0.50.243, о котором тот ничего не знает? На этот случай и создаётся так называетмый Blackhole-маршрут:
10.0.0.0/8 is a summary, 00:42:05, Null0
Полученный пакет будет выброшен в эту чёрную дыру. Это делается во избежание петель маршрутизации.
Так вот оба эти маршрутизатора создали свои blackhole-маршруты и игнорируют чужие анонсы. Реально на такой сети эти три девайса друг друга так и не смогут пинговать, пока… пока вы не отключите auto-summary.
Первое, что вы должны сделать при настройке EIGRP:
router eigrp 1
no auto-summary
На всех устройствах. И всем будет хорошо:
klgr-center-gw1:
10.0.0.0/24 is subnetted, 3 subnets
C 10.0.0.0 is directly connected, FastEthernet1/0
D 10.0.1.0 [90/30720] via 172.16.2.37, 00:03:11, FastEthernet0/0
D 10.0.2.0 [90/30720] via 172.16.2.37, 00:03:11, FastEthernet0/0
klgr-balt-gw1
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 [90/30720] via 172.16.2.38, 00:08:16, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet1/1.2
C 10.0.2.0 is directly connected, FastEthernet1/1.3
klgr-center-gw2:
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 [90/30720] via 172.16.2.45, 00:11:50, FastEthernet0/0
D 10.0.1.0 [90/30720] via 172.16.2.41, 00:11:48, FastEthernet0/1
D 10.0.2.0 [90/30720] via 172.16.2.41, 00:11:48, FastEthernet0/1
Задача №4
Из-за настроек различных механизмов QoS на маршрутизаторах Калининграда, было изменено значение пропускной способности на интерфейсах, эти значения теперь не соответствуют действительности. Поэтому было решено, что необходимо изменить подсчет метрики EIGRP на маршрутизаторах Калининграда таким образом, чтобы учитывала только задержка (delay) и не учитывала пропускная способность интерфейса (bandwidth).
Ответ
Настройка передачи маршрутов между различными протоколами
Наша задача организовать передачу маршрутов между этими протоколами: из OSPF в EIGRP и наоборот, чтобы все знали маршрут до любой подсети.
Это называется редистрибуцией (перераспределением) маршрутов.
Для её осуществления нам нужна хотя бы одна точка стыка, где будут запущены одновременно два протокола. Это может быть msk-arbat-gw1 или klgr-balt-gw1. Выберем второй.
Из EIGRP в OSPF:
klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1 subnets
Смотрим маршруты на msk-arbat-gw1:
msk-arbat-gw1#sh ip route
Codes: C — connected, S — static, I — IGRP, R — RIP, M — mobile, B — BGP
D — EIGRP, EX — EIGRP external, O — OSPF, IA — OSPF inter area
N1 — OSPF NSSA external type 1, N2 — OSPF NSSA external type 2
E1 — OSPF external type 1, E2 — OSPF external type 2, E — EGP
i — IS-IS, L1 — IS-IS level-1, L2 — IS-IS level-2, ia — IS-IS inter area
* — candidate default, U — per-user static route, o — ODR
P — periodic downloaded static routeGateway of last resort is 198.51.100.1 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
O E2 10.0.0.0/8 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.1.0/24 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.2.0/24 [110/20] via 172.16.2.34, 00:24:50, FastEthernet0/1.7
172.16.0.0/16 is variably subnetted, 30 subnets, 5 masks
O E2 172.16.0.0/16 [110/20] via 172.16.2.34, 00:25:11, FastEthernet0/1.7
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
O E2 172.16.2.36/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.40/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.44/30 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.2.192/30 [110/2] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.24.0/24 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O 172.16.128.0/24 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.129.0/26 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.144.0/24 [110/3] via 172.16.2.130, 00:13:21, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.160.0/24 [110/2] via 172.16.2.197, 00:13:31, FastEthernet1/0.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 [110/2] via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O E2 172.16.255.64/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.65/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.66/32 [110/20] via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O 172.16.255.80/32 [110/2] via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.255.96/32 [110/3] via 172.16.2.130, 00:13:21, FastEthernet0/1.8
[110/3] via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.255.112/32 [110/2] via 172.16.2.197, 00:13:31, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1
Вот те, что с меткой Е2 — новые импортированные маршруты. Е2 — означает, что это внешние маршруты 2-го типа (External), то есть они были введены в процесс OSPF извне
Теперь из OSPF в EIGRP. Это чуточку сложнее:
klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500
Без указания метрики (вот этого длинного набора цифр) команда выполнится, но редистрибуции не произойдёт.
Импортированные маршруты получают метку EX в таблице маршрутизации и административную дистанцию 170, вместо 90 для внутренних:
klgr-gw2#sh ip route
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 30 subnets, 4 masks
D EX 172.16.0.0/24 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.1.0/24 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.0/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.4/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.16/30 [170/33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D 172.16.2.32/30 [90/30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
C 172.16.2.36/30 is directly connected, FastEthernet0/0
D 172.16.2.40/30 [90/30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
[90/30720] via 172.16.2.46, 00:38:59, FastEthernet0/1
….
Вот так, казалось бы незамысловато это делается, но простота поверхностная — редистрибуция таит в себе много тонких и неприятных моментов, когда добавляется хотя бы один избыточный линк между двумя разными доменами.
Универсальный совет — старайтесь избегать редистрибуции, если это возможно. Тут работает главное жизненное правило — чем проще, тем лучше.
Задача №5 (нереализуема в РТ)
Маршрутизатор в Москве анонсирует всем остальным маршрутизаторам в сети маршрут по умолчанию. Но на все остальные маршрутизаторы он приходит с одинаковой метрикой равной 1 и метрика не увеличивается по пути передачи маршрута.
Для удобства решено было изменить настройки по умолчанию таким образом, чтобы начальная метрика маршрута по умолчанию была 30 и по пути, с передачей маршрута по умолчанию по сети, к начальной метрике добавлялась стоимость пути. Кроме того, в дальнейшем возможно добавление резервного маршрутизатора в Москве, с которого на провайдера будет указывать ещё один маршрут по умолчанию. Резервный маршрутизатор будет использоваться только если пропадет основной, поэтому маршруты по умолчанию, которые они анонсируют должны быть с разными метриками.
Ответ
Маршрут по умолчанию
Теперь самое время проверить доступ в интернет. Из Москвы он прекрасно себе работает, а вот если проверить, например из Петербурга (помним, что мы удалили все статические маршруты):
PC>ping linkmeup.ru
Pinging 192.0.2.2 with 32 bytes of data:
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.Ping statistics for 192.0.2.2:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
Это связано с тем, что ни spb-ozerki-gw1, ни spb-vsl-gw1, ни кто-либо другой в нашей сети не знает о маршруте по умолчанию, кроме msk-arbat-gw1, на котором он настроен статически.
Чтобы исправить эту ситуацию, нам достаточно дать одну команду в Москве:
msk-arbat-gw1(config)#router ospf 1
msk-arbat-gw1(config-router)#default-information originate
После этого по сети лавинно распространяется информация о том, где находится шлюз последней надежды.
Интернет теперь доступен:
PC>tracert linkmeup.ru
Tracing route to 192.0.2.2 over a maximum of 30 hops:
1 3 ms 3 ms 3 ms 172.16.17.1
2 4 ms 5 ms 12 ms 172.16.2.5
3 14 ms 20 ms 9 ms 172.16.2.1
4 17 ms 17 ms 19 ms 198.51.100.1
5 22 ms 23 ms 19 ms 192.0.2.2Trace complete.
Задача №6 (нереализуема в РТ)
На маршрутизаторе klgr-balt-gw1 настроено перераспределение маршрутов EIGRP в OSPF. Далее по сети маршруты передаются как внешние с метрикой 20, которая не увеличивается по пути передачи маршрута. Необходимо изменить настройки так, чтобы по пути, с передачей внешних маршрутов по сети, к метрике внешних маршрутов добавлялась стоимость пути.
Ответ
Полезные команды для траблшутинга
1) Список соседей и состояние связи с ними вызывается командой show ip ospf neighbor
msk-arbat-gw1:
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:33 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:34 172.16.2.18 FastEthernet0/1.5
172.16.255.64 1 FULL/DR 00:00:33 172.16.2.34 FastEthernet0/1.7
172.16.255.80 1 FULL/DR 00:00:33 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/DR 00:00:33 172.16.2.197 FastEthernet1/0.911
2) Или для EIGRP: show ip eigrp neighbors
IP-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 172.16.2.38 Fa0/1 12 00:04:51 40 1000 0 54
1 172.16.2.42 Fa0/0 13 00:04:51 40 1000 0 58
3) С помощью команды show ip protocols можно посмотреть информацию о запущенных протоколах динамической маршрутизации и их взаимосвязи.
klgr-balt-gw1:
Routing Protocol is «EIGRP 1 »
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: EIGRP 1, OSPF 1
Automatic network summarization is in effect
Automatic address summarization:
Maximum path: 4
Routing for Networks:
172.16.0.0
Routing Information Sources:
Gateway Distance Last Update
172.16.2.42 90 4
172.16.2.38 90 4
Distance: internal 90 external 170Routing Protocol is «OSPF 1»
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.255.64
It is an autonomous system boundary router
Redistributing External Routes from,
EIGRP 1
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.2.32 0.0.0.3 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.255.64 110 00:00:23
Distance: (default is 110)
4) Для отладки и понимания работы протоколов будет полезно воспользоваться следующими командами:
debug ip OSPF events
debug ip OSPF adj
debug EIGRP packets
Попробуйте подёргать разные интерфейсы и посмотреть, что происходит в дебаге, какие сообщения летят.
Задача №7
На последок комплесная задачка.
На последнем совещании Лифт ми Ап было решено, что сеть Калининграда необходимо также переводить на OSPF.
Переход должен быть совершен без разрывов связи. Было решено, что лучшим вариантом будет параллельно с EIGRP поднять OSPF на трёх маршрутизаторах Калининграда и после того, как будет проверено, что вся информация о маршрутах Калининграда распространилась по остальной сети и наоборот, отключить EIGRP.
Но, так как сеть Калининграда достаточно большая, с большим количеством сетей, было решено, что необходимо отделить её от остальной сети так, чтобы изменения в сети Калининграда не приводили к запуску алгоритма SPF на других маршрутизаторах сети.
Ответ.
Материалы выпуска
Новый IP-план, планы коммутации по каждой точке и регламент
Файл РТ с лабораторной
Конфигурация устройств
Полезные ссылки
Наш большой помощник XGU.ru
OSPF в cisco
OSPF
Коллеги по хабру
Inter-domain Routing Loops
Особенности работы External Type 1 и External Type 2 маршрутов в OSPF. Часть 1
Особенности работы External Type 1 и External Type 2 маршрутов в OSPF. Часть 2
Другие
Cisco
В википедии
То же самое на русском
Минутка саморекламы
У Сетей для самых маленьких появился свой сайт — linkmeup.ru. Теперь читать и оставлять комментарии вы можете не только в ЖЖ, но и в личном блоге этого цикла.
Слова благодарности хочу выразить своему соавтору — Максиму theGluck за помощь в написании статьи. Дмитрию JDima за правки и бесценные комментарии, неотразимой Наташе Самойленко за предоставленные задачки. Антону Antuan за программирование сайта для блога. И девушке со славным именем Нина за логотип сайта.
P.S.
Нашему будущему подкасту ЛинкМиАп требуется джингл и музыка на фон. Будем рады помощи, а имя композитора будет прославлено в веках.
P.P.S
Возможностей Packet Tracer нам уже не хватает. Следующий шаг — переход на что-то более серьёзное. Есть пожелания? Предлагаю устроить холивар в комментариях на тему IOU vs GNS.
Любое сетевое оборудование в квартире или офисе работает по принципу передачи пакетов данных из точки А в точку B. Такой принцип называется маршрутизацией. В этой статье мы поговорим о статической и динамической маршрутизации: рассмотрим принципы работы и отличия, а также поговорим о том, какие устройства какую маршрутизацию поддерживают.
Чем же различаются статика и динамика? В первую очередь тем, что статический маршрут всегда известен наперед:
- номер порта;
- IP-адрес;
- DNS-сервер.
Вплоть до имени пользователя и его расположения в офисе. Такой подход полностью оправдан при определенных условиях (о которых ниже), но имеет и недостатки, когда избыток пакетов создает чрезмерную нагрузку на какой-то участок пути, в то время как соседние участки могут простаивать. Динамическая маршрутизация гибка в плане выбора пути следования траффика, поскольку у нее есть только цель, но нет строго оговоренных маршрутов.
Исходя из вышесказанного, можно предположить, что динамическая маршрутизация является более продвинутой технологией, а без статической и вовсе можно было бы обойтись. Однако это далеко не так, а в чем нюансы, расскажем далее.
Как работает статическая маршрутизация
Статический маршрут — путь движения трафика, заданный администратором на этапе конфигурации роутера. Для этого используют ряд вводных:
- Адрес и маска сети (IP);
- Адрес шлюза для дальнейшего передвижения, или адрес, закрепленный за маршрутизируемой сетью;
- Метрика маршрута. Если таковых много, то устройство выбирает самый удобный по критериям длины и загруженности путь.
Поскольку все статические маршруты прописывают вручную, любое изменение топологии должно быть согласовано с администратором для корректировки таблицы. Причина, по которой администраторам приходится настраивать связи руками (а не, приспособив под эту задачу какой-нибудь хитроумный софт) в том, что каждому подключенному устройству присваивается постоянный адрес, который закрепляется за устройством и позволяет найти его в сети для регулярного обмена данными на долговременной основе. При любых внештатных изменениях в схеме подключения устройств (отсоединили принтер, перенесли в кабинет на другом этаже, подключили к свободному порту коммутации, и всё — компьютеры в сети уже не узнают старый принтер, считая его новым устройством), данные продолжают отсылаться на прежний адрес, раз за разом выдавая ошибку.
Чтобы таких вещей не происходило, любые изменения конфигурации сети при настроенной статической маршрутизации должны находиться под контролем человека.
Возможно, момент, когда при статической маршрутизации система научится самостоятельно распознавать устройства, сопоставлять их физическое подключение с хранящимися в таблицах коммутации адресами и автоматически вносить правки в топологию сети, станет прорывом в технологии. Но в настоящий момент, машины еще не настолько умны. И следить за тем, что и куда подключено, приходится людям.
В случае с малой сетью особых проблем такой подход не приносит, поскольку любое устройство легко отследить и перекалибровать. Но если дело касается крупной корпоративной инфраструктуры, подобная перенастройка превращается в тотальную головную боль.
Из этого следует, что статический принцип хорош в том случае, если конечная точка передачи сигнала всегда находится на своем месте. Как пример — тот самый сетевой принтер для офиса. Все компьютеры в сети знают, по какому IP-адресу отправлять документы на печать.
Как работает динамическая маршрутизация
Это сугубо практичный вариант, где все таблицы маршрутизации заполняются не вручную, а программно. А это дарит определенные преимущества:
- минимальный риск ошибки;
- система четко понимает, что кому отправлять;
- масштабирование сети происходит быстрее;
- удаление человеческого фактора из цепочки.
Пользователю сети всего лишь нужен интернет, доступ к облаку и корпоративным приложениям? Не проблема. Устройству выдается временный адрес и ограниченный доступ, пользуясь которым он может установить одноразовое подключение.
Пользователи этих тонкостей не замечают, им неважно, какое у них подключение: временное или постоянное. Интернет в наличии, программы работают, доступ к корпоративной базе по логину-паролю есть — значит, все в порядке. Таким образом, протоколы динамической маршрутизации могут обслуживать тысячи подключений, без выдачи задействованным в обмене устройствам статических адресов прописки. В большинстве случаев, они и не нужны.
Помимо автоматизации и легкого масштабирования, принцип динамической маршрутизации позволяет роутерам и прочему оборудованию строить дорогу самостоятельно. Один маршрут сломан? Не беда, пойдем другим. И это здравый подход, когда инфраструктура включает 10 и более роутеров, не говоря о точках доступа, коммутаторах и километрах витой пары по зданию.
Также возрастает отказоустойчивость сети, поскольку не требуется думать над резервными каналами. Балансировка трафика не вызовет проблем, поскольку все современные роутеры из коробки поддерживают подобную функцию.
И напоследок о масштабировании. Если вы подключаете новый элемент в сеть или подсеть, он автоматически передает всем «привет». Головное устройство при этом делает все необходимые изменения в таблице маршрутизации и оповещает остальных участников сети о том, что у них появился новый временный сосед.
Сравнение динамической и статической маршрутизации
Сравнивая преимущества и недостатки подходов, в действительности говорить о том, что лучше, а что хуже было бы не совсем корректно, поскольку, по сути, эти виды маршрутизации используются для разных целей.
Например, настроить постоянный удаленный доступ к ПК или серверу возможно только через статическую маршрутизацию. Аналогично и с другими системами:
- камеры видеонаблюдения;
- файловый сервер;
- почтовый сервер;
- бекап-сервер;
- архив 1С и т.д.
Почему именно так? Потому что главный плюс динамической маршрутизации — и ее же существенный недостаток —в однократном использовании присваиваемых устройствам при каждом новом подключении IP-адресов. Представьте, что вы полдня потратили на подключение и настройку нескольких десятков IP-камер для видеонаблюдения, затем перезагрузили сервер и, вот незадача, — ни одного «глаза» система уже не видит, поскольку адреса сменились.
При статической маршрутизации подобные казусы невозможны, так как адреса всегда будут сохраняться в неизменном виде. Такой принцип важен для закрытых локальных сетей, где обращение к серверам и системам хранения данных всегда происходит по одному адресу. Он важен во всемирной паутине, где каждому онлайн-ресурсу присвоен свой IP-адрес, который также должен оставаться неизменным.
Если подключения временные, с ограниченными привилегиями, и происходят в больших количествах, то идеальным решением для такой сети станет динамическая маршрутизация с ее очевидными преимуществами в автоматизации и простом масштабировании.
Если устройства обязаны всегда находиться по определенному адресу, а передача данных требует усложненных протоколов безопасности или, к примеру, подразумевает пересылку больших объёмов данных, то в этом случае стоит настраивать статическую маршрутизацию и никак иначе.
Какие устройства какой тип маршрутизации поддерживают
Коммутаторы и роутеры, представленные на рынке, работают с уровнем маршрутизации L2, L2+ и L3. Что это означает для администраторов и желающих построить сеть?
Устройства уровня L2 — умеют обрабатывать только MAC-адреса, перенаправляют трафик, поддерживают QoS и VLAN. На полноценную статическую маршрутизацию такие устройства не способны из-за слабости железа и встроенного ПО. Для настройки динамической маршрутизации и объединения нескольких устройств подходят идеально (недорогие, портов много, просты в настройке).
- Устройства уровня L2+ — промежуточные L2 с некоторыми возможностями L3. Среди этих возможностей — добавление ограниченной статической маршрутизации и физического объединения нескольких устройств для управления и перенаправления трафика. Также здесь улучшены протоколы безопасности. Идеальны для нужд VoIP, IPTV, видеоконференций и камер наблюдения.
- Коммутаторы и роутеры L3 — полностью берут на себя функцию маршрутизации, проверку логической адресаций и путь доставки информации (статический режим с заранее прописанными IP-адресами). Работают как с MAC-адресом, так и с полным перечнем TCP/IP.
Иными словами, для обустройства полновесной статической маршрутизации без коммутации уровня L3 не обойтись. Только эти роутеры/коммутаторы предлагают полноценные таблицы маршрутизации с возможностью грамотно направлять трафик на любое устройство в сети.
Для базовых «статических» потребностей хватит и L2+, поскольку они позволяют назначить адрес подключаемому устройству для регистрации. Актуальное поколение роутеров L2+ научилось самостоятельно выделять имена подключаемым устройствам, таким образом администратору останется только задать направление движения трафика (берем пакет из точки «А» и несем в точку «B») на корневом маршрутизаторе, а дальше с пересылкой тот справится сам. При этом, если вам требуется строгое построение движения трафика, то для таких целей нужно устройство классом повыше. С последним справится только L3.
Что касается динамики, то в настоящее время протоколы маршрутизации для динамических сетей поддерживаются всеми сетевыми устройствами от L2 и выше. Таким образом, потенциальному владельцу остается только выбрать технику по количеству портов и пропускной способности.
Заключение
В этой статье мы постарались пояснить различия между статической и динамической маршрутизацией и осветить вопрос применения этих технологий к конкретным устройствам в сети. Если у вас еще остались вопросы относительно возможностей того или иного вида маршрутизации или выбора устройств для построения сети, задайте их нашем специалистам. Закажите консультацию, и специалисты Маркет.Марвел ответят на все ваши вопросы.
 Ваши темы для Вебинаров
Ваши темы для Вебинаров
![]()
В Москве:
РФ (звонок бесплатный):
+7 (495) 103-99-88
+7 (800) 600-20-56

Статическая и динамическая маршрутизация

Благодарим за помощь Андрея Донецкого

889
Статическая маршрутизация — та маршрутизация, которую мы можем прописать в наше устройство, то есть мы можем зайти в роутер и просто прописать статический маршрут. Такой же маршрут мы можем прописать и на любом устройстве, которое имеет у себя протокол IP. Вся работа сводится к ручному конфигурированию нашей маршрутизации.
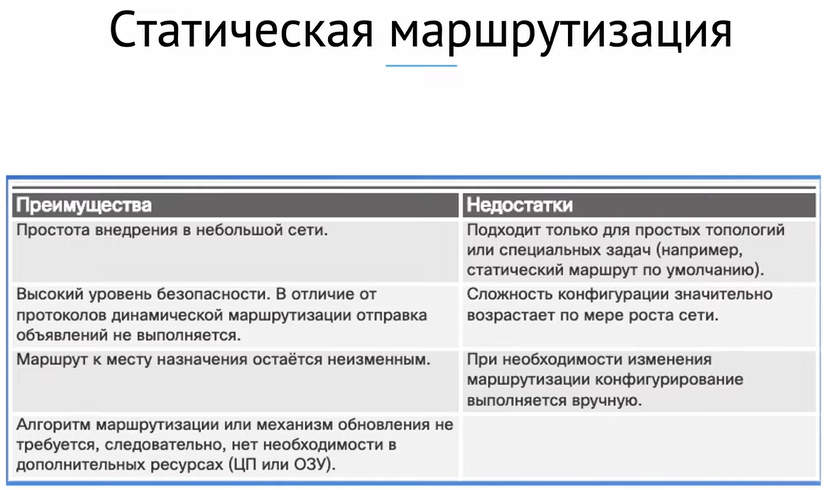
Какие имеются преимущества:
- Простота внедрения в небольшой сети. Если у нас сеть небольшая, мы полностью все контролируем. Мы контролируем то, какие маршруты мы пишем. Мы понимаем, что если у нас отваливается линк, как нам изменить нашу маршрутизацию, чтобы продолжить работу;
- Высокий уровень безопасности. Пока наш роутер не будет скомпрометирован и пока никто не зайдет внутрь него, все будет прекрасно работать.
- Маршрут к месту назначения остается неизменным. Это как преимущество, так и недостаток статической маршрутизации. То есть у нас не может произойти ситуации, когда наш трафик пойдет, например, по не оптимальному пути или мы сразу сделаем так, что он будет идти по не оптимальному пути. То есть в некоторых ситуациях системный администраторы, например, в случае с интернет-каналами пускают трафик, например, по более быстрому каналу или же по более дешевому, где не взимается плата за каждый мегабайт информации.
- Также преимущество статической маршрутизации можно отметить, что алгоритм маршрутизации не расходует дополнительные ресурсы центрального процессора оперативной памяти. То есть не требуется никаких дополнительных ресурсов на поддержание статической маршрутизации все то, что есть в таблицах маршрутизации то и работает.
Недостатки:
- Подходит только для очень простых топологий например:
- Следующий недостаток статической маршрутизация – это, при необходимости изменения маршрутизации, конфигурацию приходится выполнять вручную.
перед вами сейчас небольшая картинка, которая описывает в целом не очень большую сеть (здесь 28 роутеров), но исходя из данной схемы, уже немножко страшно становится и выглядит это все не сильно дружелюбно. Прописывать сюда маршруты и решать вопросы с альтернативными подключениями будет достаточно сложно. Приблизительно работы на полдня. Сложность конфигурации значительно возрастает по мере роста сети, например, была у нас достаточно простая сеть:
У нас есть центральный офис и есть четыре филиала, простая топология хорошо укладывается в рамках статической маршрутизации и все прекрасно работает.
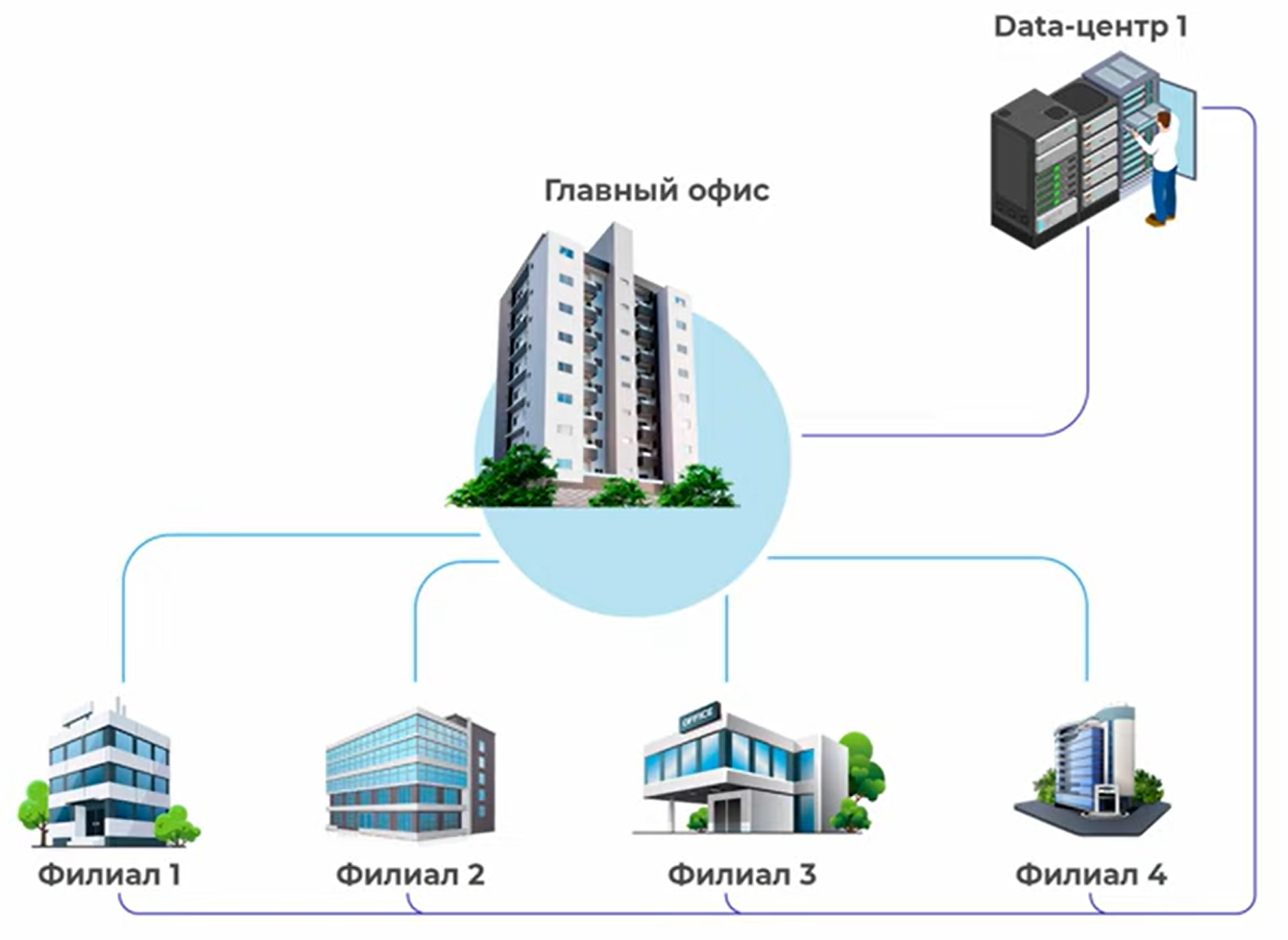
В какой-то момент компания начала расти и, например, решила, что было бы неплохо арендовать место в стойке, организовать свой импровизированный дата-центр. Было бы неплохо от каждого филиала подключить дата-центр, также сделать общую связь между центральным офисом и дата-центром, а также сделать так, чтобы трафик ходил сначала в дата-центр и по-своему же линку, он ходил в центральный офис. В рамках статической маршрутизации работать адекватно. В какой-то момент компания поняла, что, если произойдет отказ дата-центра, где находится все ресурсы нашей сети, то будет очень печально и плохо. Мы все работать не сможем, поэтому взяли и арендовали еще один дата-центр у другого поставщика услуг
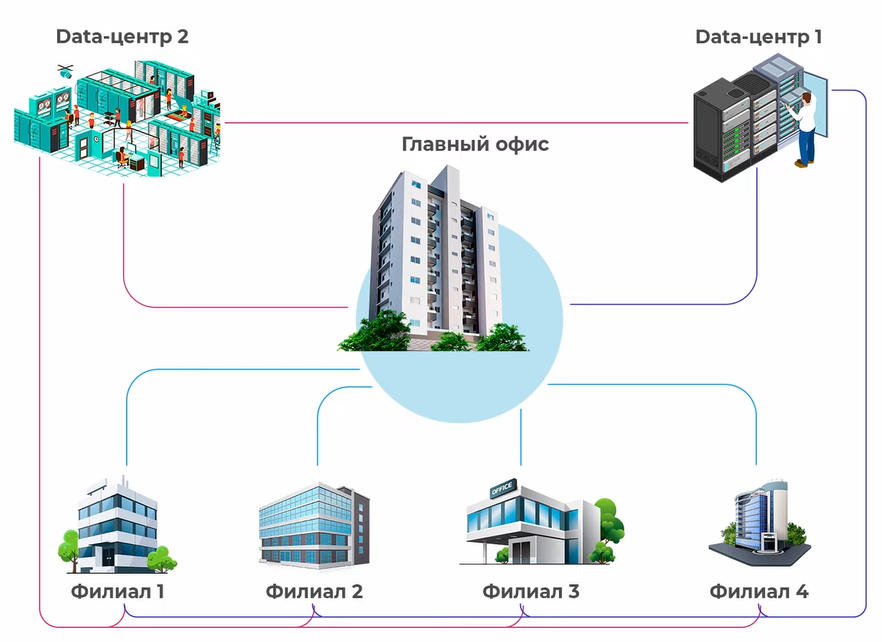
И тут решили все наши филиалы подключить к альтернативному дата-центру, а потом подключить дата-центры между собой и подключить еще туда же центральный офис. И в итоге у нас здесь есть всего лишь 7 устройств сетевых, а количество подключений очень сильно и кратно растет и в данной ситуации обслуживать такую сеть на статической маршрутизации становится уже очень некомфортно.
Если привести в пример предыдущую нашу схему, то на каждом роутере нам придется изменить статические маршруты, то есть тем самым мы должны зайти на каждое устройство, изменить его конфигурацию и проверить, что все работоспособно, что однозначно ведет к каким-то ошибкам ну и уменьшает нашу общую производительность.
Поэтому для решения подобных задач, когда у нас есть, допустим, схема такой сложной сети, придумали динамическую маршрутизацию.
По сути, динамическая маршрутизация ничего серьезного не меняет, принцип остается тот же самый. У нас есть адреса назначений и у нас есть гетвей или шлюзы, через которые доступны те или иные адреса назначений. Но все эти маршруты в таблицу маршрутизации добавляет некая служба, которая работает в автоматическом режиме. То есть у нас есть какой-то протокол (служба), который(ая) с помощью своих служебных сообщений и по каким-то собственным принципам, добавляет в таблицу маршрутизации наши маршруты, которые нам требуются. По сути, вся работа, связанная с маршрутизацией, сводится к конфигурированию этих протоколов динамической маршрутизации, чтобы каждый роутер был правильно сконфигурирован и понимал сообщение от другого роутера.
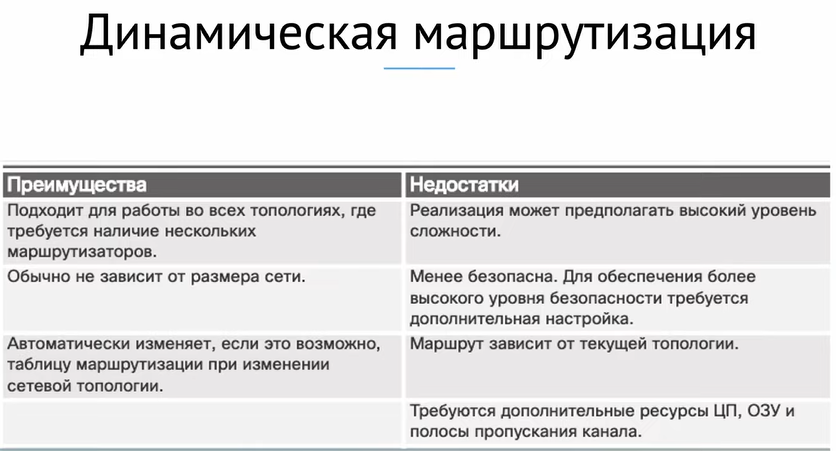
Преимущества динамической маршрутизации:
- Во-первых, подходит для работы в любых топологиях. У вас есть два роутера, вам уже подходит динамическая маршрутизация. Вы можете ее настраивать. Обычно не зависит от размера сети. Например, у вас есть весь интернет, где работает протокол динамической маршрутизации BGP. Для всего интернета существует протокол динамической маршрутизации. Если какой-то зависимости от размера сети нет, есть зависимость от протокола. Есть, например, протоколы динамической маршрутизации, которые подходят, когда вы работаете в небольших организациях. Они очень простые, тем самым их удобно использовать.
- Автоматически изменяют таблицу маршрутизации. Если произошло какое-то изменение в сети, то есть, если где-то у нас что-то отвалилось. Например, VPN туннель до дата-центра у нас отвалился. В этот момент мы перестроим таблицу маршрутизации, чтобы ходить к этой сети через, например, центральный офис и так далее. И это все происходит автоматически, но, как всегда, есть преимущества и недостатки.
Недостатки динамической маршрутизации:
- Реализация может предполагать очень высокий уровень сложности. Каждый протокол динамической маршрутизации может быть, за исключением RIPа, имеет достаточно большое количество настроек и в этих настройках нужно достаточно глубоко разбираться. Чтобы понимать, что эти настройки делают и для каких сценариев они подходят. Например, OSPF мы разбираем примерно полтора дня на курсе, и мы его разбираем по верхам. То есть нельзя сказать, что мы рассматриваем прям абсолютно все сценарии, которые предусмотрены в протоколе OSPF, но за полтора дня вы получаете какое-то плюс-минус адекватное понимание протокола OSPF. BGP можно разбирать особенно с учетом комьюнити и фильтров достаточно продолжительное время. И так в целом происходит с каждым протоколом динамической маршрутизации. В них очень много глубины. Это не просто руками прописать маршруты с нужной метрикой, так как у нас есть разговоры между роутерами, присутствует два роутера, которые между собой разговаривают. В эти разговоры может кто-то вклиниться и естественно протоколы динамической маршрутизации несмотря на то, что там есть аутентификация шифрования сообщений, не на сто процентов безопасны и их можно скомпрометировать.
- Недостаток и преимущества одновременно: маршрут зависит от текущей топологии. Нормальная ситуация, когда вдруг вы до сайта, находящегося в России, начинаете ходить через Ванкувер и это как раз протокол динамической маршрутизации внутри вашего провайдера. Что-то случилось и ему показалось, что ближе будет дойти до российского сайта через Ванкувер. Почему бы и нет. Очень быстро только скорость света немножко мешает, но в целом почему бы и нет.
- Требуется дополнительные ресурсы для центрального процессора, для оперативной памяти и полосы пропускания канала. Во-первых, вам нужно потратить какие-то ресурсы на поддержание этого протокола. А во-вторых, надо сразу заранее рассчитать, какие ресурсы вам нужны в самых плохих сценариях. Потому что эти сценарии периодически происходят у провайдеров интернета.
Давайте познакомимся в целом с протоколами динамической маршрутизации и немножко о них поговорим. У нас есть два класса протоколов динамической маршрутизации:
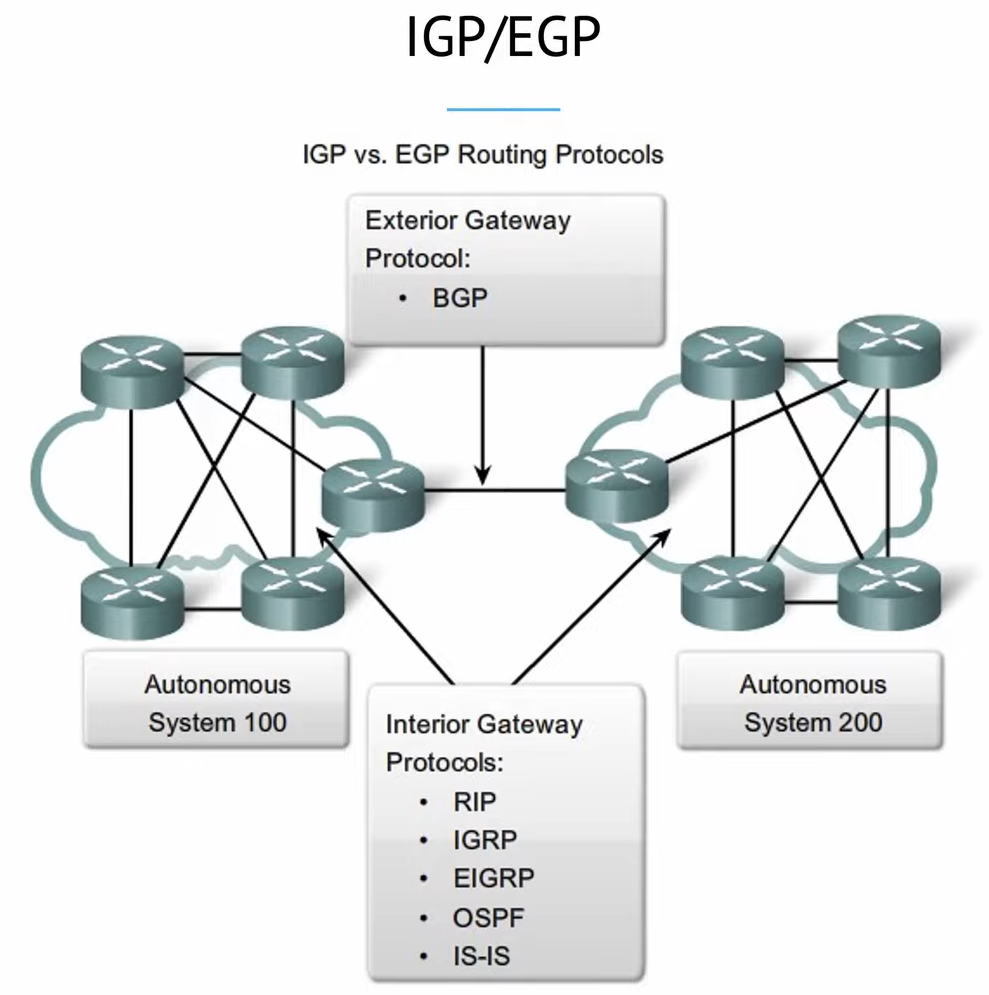
Это протоколы динамической маршрутизации IGP и EGP. IGP это Interior Gateway Protocol, а EGP это Exterior Gateway Protocol, протоколы для применения внутри автономных систем и снаружи автономных систем.
Автономная система — это совокупность роутеров, которые находятся под единым административным управлением. Эти роутеры могут быть дома, на работе, у провайдера и так далее, то есть любые роутеры, которыми управляет какая-то группа специалистов.
Когда вы управляете каким-то количеством маршрутизаторов, вы для этих маршрутизаторов являетесь администратором и вправе выбирать любой протокол динамической маршрутизации, который вы смогли внедрить, которые вы можете обслуживать и которые вы понимаете и внутри автономных систем производства — дом, компания и так далее могут работать любые протоколы. Вы можете использовать там RIP, вы можете использовать и EGRP, EIGRP, OSPF, IS-IS и так далее. Вообще в целом протоколов динамической маршрутизации много. Вы вправе выбирать, но если мы говорим про работу между автономными системами, например, когда две компании хотят подружиться между собой и одна компания хочет поделиться с другой компанией своими маршрутами, что у него происходит, то вероятнее всего и правильнее всего для этой задачи выбрать протокол BGP, если мы говорим про публичные автономные системы.
Когда вы зарегистрировались в каком-нибудь регистраторе, например, у нас в Европе это Ripe NCC, получили публичный номер автономной системы, заплатили за это деньги и вы стали провайдером, который может приземлять у себя белые IP-адреса, вам дают номер автономной системы, чтобы подружиться с другими автономными системами и сообщить свои белые IP-адреса глобальному интернету. Ну например, белый IPv6 адрес. Вам необходимо подружиться с другими автономными системами, с другими провайдерами по протоколу BGP. Глобально в Интернете у нас работает протокол BGP, поэтому у нас есть куча всяких IGP протоколов Interior Gateway Protocol, которые вы вправе использовать, как угодно, как хотите, и так далее. И у нас есть один глобальный протокол для дружбы между это BGP (Border Getway Protocol), который, по сути, один и который является стандартом.
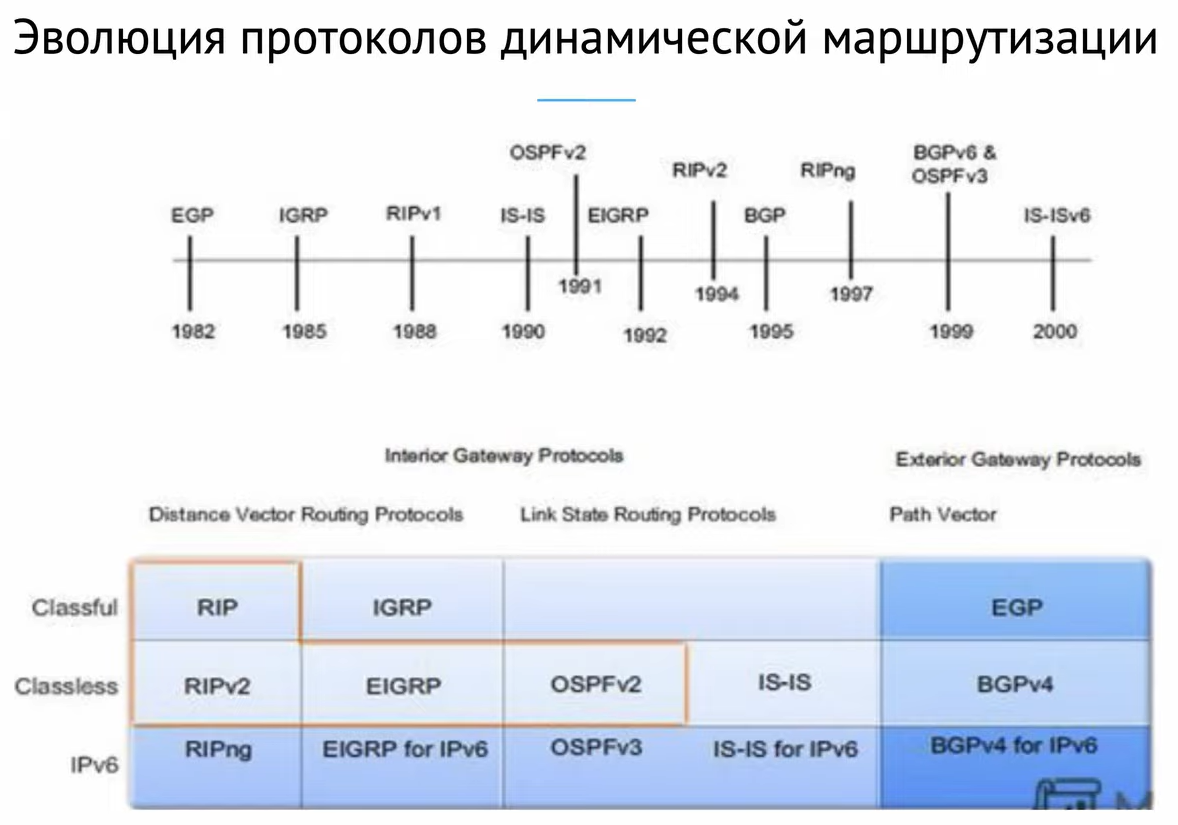
На этом слайде у нас показана эволюция протоколов маршрутизации.
Серьезный переход был, когда протоколы классовые перешли в без классовый протоколы.
Но это произошло достаточно давно и с тех пор в целом у нас все протоколы динамической маршрутизации без классовые, а также сейчас уже набирают свою мощность и силу протоколы для IPv6 сетей обзорная лекция по статической динамической маршрутизации закончена увидимся в следующих роликах.
Категории
Курсы Mikrotik-Training.
Знания, которые дают результат.
From Wikipedia, the free encyclopedia
Dynamic routing, also called adaptive routing,[1][2]
is a process where a router can forward data via a different route for a given destination based on the current conditions of the communication circuits within a system.[3] The term is most commonly associated with data networking to describe the capability of a network to ‘route around’ damage, such as loss of a node or a connection between nodes, as long as other path choices are available.[4] Dynamic routing allows as many routes as possible to remain valid in response to the change.
Systems that do not implement dynamic routing are described as using static routing, where routes through a network are described by fixed paths. A change, such as the loss of a node, or loss of a connection between nodes, is not compensated for. This means that anything that wishes to take an affected path will either have to wait for the failure to be repaired before restarting its journey, or will have to fail to reach its destination and give up the journey.[5]
All Protocols[edit]
There are several protocols that can be used for dynamic routing. Routing Information Protocol (RIP) is a distance-vector routing protocol that prevents routing loops by implementing a limit on the number of hops allowed in a path from source to destination.[6] Open Shortest Path First (OSPF) uses a link state routing (LSR) algorithm and falls into the group of interior gateway protocols (IGPs).[7] Intermediate System to Intermediate System (IS-IS) determines the best route for data through a packet-switched network.[7] Interior Gateway Routing Protocol (IGRP) and its advanced form Enhanced Interior Gateway Routing Protocol (EIGRP) are used by routers to exchange routing data within an autonomous system.[7]
Alternate paths[edit]
Many systems use some next-hop forwarding protocol—when a packet arrives at some node, that node decides on-the-fly which link to use to push the packet one hop closer to its final destination.
Routers that use some adaptive protocols, such as the Spanning Tree Protocol, in order to «avoid bridge loops and routing loops», calculate a tree that indicates the one «best» link for a packet to get to its destination.
Alternate «redundant» links not on the tree are temporarily disabled—until one of the links on the main tree fails, and the routers calculate a new tree using those links to route around the broken link.
Routers that use other adaptive protocols, such as grouped adaptive routing, find a group of all the links that could be used to get the packet one hop closer to its final destination.
The router sends the packet out any link of that group which is idle.
The link aggregation of that group of links effectively becomes a single high-bandwidth connection.[8]
Outside of computer networks[edit]
Contact centres employ dynamic routing based on the customer’s enquiry and agent’s skills to increase the operational efficiency of the call handling by agents, which boosts both agent and customer satisfaction. This adaptive strategy is known as omnichannel.[9]
Dynamic routing in found the brain in relation between sensory and mnemonic signals and decision making, and is a subject of studies in neuroscience.[10]
People using public transport also exhibit dynamic routing behaviour. For example, if a local railway station is closed, people can alight from the train at a different station and use a bus to reach their destination. Yet another example of dynamic routing can be seen within financial markets.
See also[edit]
- Static routing
- Convergence (routing)
- Routing in delay-tolerant networking
References[edit]
- ^
Terrence Mak; Peter Y. K. Cheung; Kai-Pui Lam; and Wayne Luk.
«Adaptive Routing in Network-on-Chips Using a Dynamic-Programming Network».
2011.
doi:10.1109/TIE.2010.2081953
p. 1. - ^
Lugones, Diego; Franco, Daniel; Luque, Emilio (2008). «Dynamic Routing Balancing On InfiniBand Networks» (PDF). Journal of Computer Science and Technology. 8 (2). Archived from the original (PDF) on 6 May 2015. - ^ Haiyong Xie; Lili Qiu; Yang Richard Yang; and Yin Zhang.
«On Self Adaptive Routing in Dynamic Environments — An Evaluation and Design Using a Simple, Probabilistic Scheme» Archived 2011-09-02 at the Wayback Machine.
2004. - ^ «Definition of». PC.
- ^ «Static and Dynamic Routers». TechNet.
- ^ «Dynamic routing with RIP». Tech Republic.
- ^ a b c «Comparing Dynamic Routing Protocols». Network Computing.
- ^
Stefan Haas.
«The IEEE 1355 Standard: Developments, Performance and Application in High Energy Physics».
1998.
p. 91. - ^ «Best Practices for Contact Center Routing». Genesys.
- ^ «Dynamic routing of task-relevant signals for decision making in dorsolateral prefrontal cortex». Nature.
External links[edit]
- Session-based routing holds the key to the Internet’s future
OSPF расшифровывается как Open Shortest Path First. Если переводить дословно, получится что-то вроде «открытый короткий путь первым». Под названием скрывается протокол внутренней маршрутизации, который передает информацию по лучшему пути. Но, несмотря на название, он не всегда короткий. Чтобы найти лучший путь, протокол отслеживает состояние каналов, а путь рассчитывается по алгоритму Дейкстры.
OSPF довольно просто настраивается по инструкциям, но вот объяснить порядок его работы довольно сложно. Попробуем это сделать.
Основы протокола OSPF
Чтобы объяснить работу OSPF-протокола, сначала вспомним, что такое статическая маршрутизация. Представим небольшую компанию с внутренней базой знаний, которая хранится на сервере в соседнем помещении. Когда сотрудник хочет открыть документ из базы, пакет с запросом передается на маршрутизатор. Последний обращается к таблице маршрутизации и понимает, в какую сеть отправить пакет.
Для этого администратор вручную прописывает все маршруты к сетям в таблице маршрутизации. Но когда в компании десяток департаментов и сотни маршрутизаторов, такой сценарий нереализуем (особенно при добавлении новых маршрутизаторов). Здесь на помощь приходит динамическая маршрутизация с помощью протокола OSPF.
Протокол OSPF заполняет таблицы маршрутизации автоматически, при этом маршрутизаторы постоянно обмениваются данными о состоянии сети и актуализируют таблицу. Администратору не нужно бегать и самостоятельно переписывать таблицы.
Аналогично в случае сбоев: со статической маршрутизацией тяжело отслеживать доступность сетей. Если канал между маршрутизаторами прерван, то пакеты, которые M2 получил от M1 (см. схему ниже), никуда не отправятся.
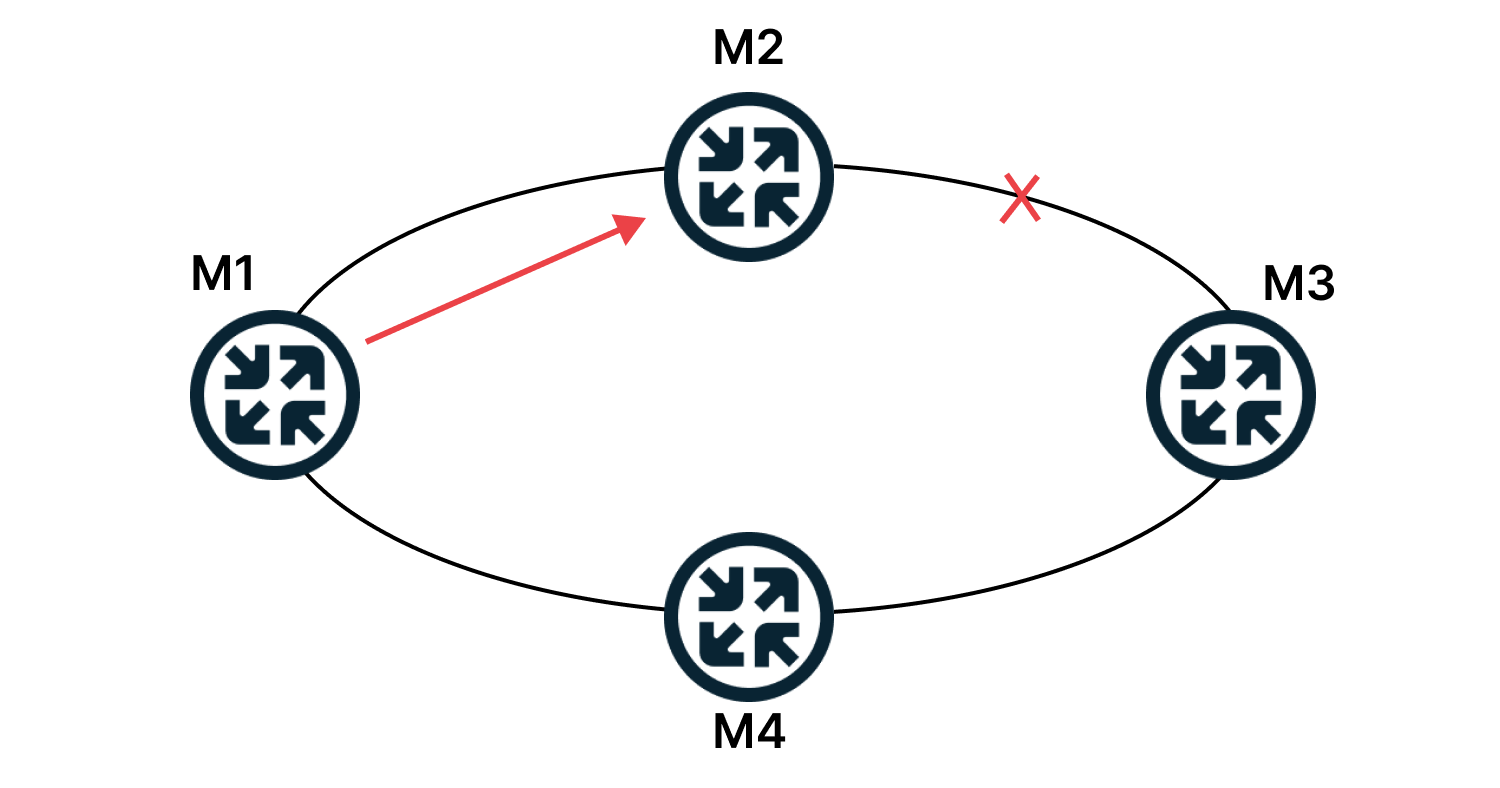
Если сети работают на протоколе OSPF, маршруты перестроятся автоматически.
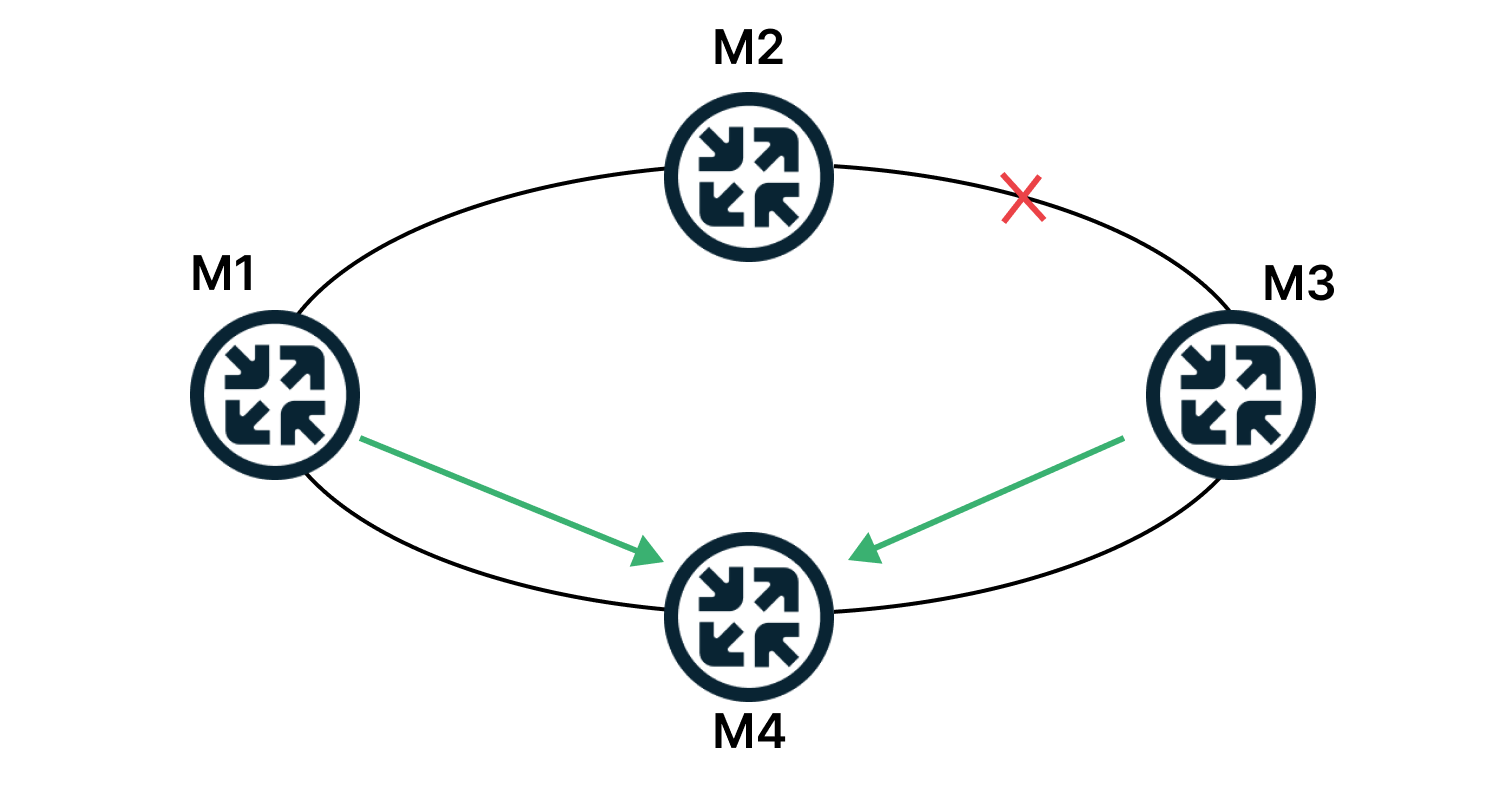
OSPF — протокол внутренней маршрутизации. «Внутренней» означает, что маршрутизаторы связаны в замкнутой системе или в одном домене. Понимание принципов работы протокола и алгоритмов облегчат настройку OSPF, поэтому о них подробнее.
Терминология
- Автономная система — это сети под общим управлением, с едиными политиками маршрутизации для всех устройств.
- Интерфейс — соединение маршрутизатора и сети. В контексте OSPF термины «интерфейс» и «канал» (link) синонимичны.
- Area, или зона, — это условная «площадка» в виде комплекса маршрутизаторов, которые обмениваются LSA друг с другом. У маршрутизаторов в этой зоне единый идентификатор.
- LSA, или Link State Advertisement, — это сообщение (объявление, пакеты) о состоянии канала между маршрутизаторами. В нем содержатся данные о каналах маршрутизатора и их состоянии — например, прерывании, маршруте, интерфейсах.
- Состояние канала, или Link State, — состояние канала между двумя маршрутизаторами, которое обновляется посредством пакетов LSA.
- LSU, или Link State Update, — это пакет, в котором передается LSA (один или несколько).
- Link-State DataBase — это база сообщений LSA, в ней содержатся все записи о состоянии каналов. Встречается также термин «топологическая база данных» (topological database), это синоним.
- Router ID — индивидуальный и уникальный номер маршрутизатора для идентификации. Чаще всего это сетевой адрес интерфейса — 32-х битный номер.
- Маршрутизаторы, у которых интерфейс в одной зоне, называются соседями. Список всех соседей содержится в базе данных соседей.
- Для определения соседа маршрутизаторы обмениваются hello-сообщениями, или hello-пакетами. В hello-сообщениях содержатся LSA.
- Состояние смежности, или Adjacency, — взаимосвязь между определенными соседними маршрутизаторами для обмена информацией о маршрутах.
- Shortest Path First — алгоритм, который рассчитывает лучший маршрут между сетями.
- Стоимость — это условный показатель «цены» пересылки данных по каналу. В OSPF стоимость зависит от разных факторов — например, пропускной способности канала.
- Designated Router (DR) — выделенный маршрутизатор. Каждый маршрутизатор устанавливает с ним отношения, потому что DR управляет рассылкой LSA в сети и отправляет информацию остальным об изменениях в сети.
- Backup Designated Router (BDR) — резервный выделенный маршрутизатор. Маршрутизатор на случай выхода DR из строя. Каждый маршрутизатор в сети также устанавливает с ним отношения.
Алгоритм работы протокола OSPF
Примечание. Здесь мы изначально считаем, что на маршрутизаторе и интерфейсе установлен и включен OSPF.
Как работает динамическая маршрутизация OSPF? Краткое описание:
- Когда маршрутизатор включают, он выбирает Router ID, либо администратор устанавливает его значение вручную.
- Протокол ищет другие маршрутизаторы — подключенных соседей, отправляя им через определенные промежутки времени hello-пакеты с информацией о соседях и состоянии каналов.
- Если маршрутизатор получает в ответ пакет по интерфейсу, на которых активирован OSPF, то устанавливает с ним «соседские» отношения. Если не получает, маршрутизатор считает устройство «мертвым» — не отправляет ему трафик и перестраивает маршруты.
- После того как маршрутизаторы подружились, они обмениваются LSA-сообщениями о подключенных и доступных сетях, о соседском роутере и стоимости. Эти данные нужны, чтобы построить карту сети (топологию) — она пригодится для расчетов кратчайшего пути трафика. Карта одинакова на всех маршрутизаторах.
- Маршрутизаторы синхронизируют общую базу LSDB, где хранят LSA.
- В сети могут быть сотни или тысячи маршрутизаторов. Отправка сообщений LSA от каждого устройства к каждому обязательно забьет каналы. Чтобы этого не произошло, отправкой сообщений заведует DR: через него отправляется информация об изменениях в сети ко всем маршрутизаторам — например, когда какой-то маршрутизатор упал. Если DR не прописан изначально, то им становится маршрутизатор с самым большим IP-адресом.
- Дальше запускается алгоритм SPF, который рассчитывает оптимальный маршрут к каждой сети. Процесс похож на построение дерева, где корень — маршрутизатор, а ветви — пути к доступным сетям. В общей таблице маршрутизации будут храниться лучшие пути к каждой сети.
Теперь подробнее о каждом этапе.
Запуск протокола
Для запуска OSPF-протокола нам нужно запустить процесс OSPF на маршрутизаторе подобной командой:
selectel-gw1(config)# router OSPF 1Мы сообщаем, что запускаем протокол, указываем, какой именно, уточняем номер процесса (в конце).
Автоматически назначается Router ID. По умолчанию это наибольший IP-адрес устройства. Но можно настроить идентификатор вручную:
selectel-gw1(config-router)#router-id 172.16.255.1Следующим шагом объявляем, какие сети будем передавать соседям OSPF. С помощью этой команды сообщаем, с каких интерфейсов будут отправляться hello-пакеты и какие сети хотим анонсировать другим маршрутизаторам:
selectel-gw1(config-router)#network 172.16.0.0 0.0.255.255 area 0Первый параметр — номер сети, второй — wildcard-маска, последний — номер зоны.
Готово! Если другие роутеры в сети настроены, то они установят соседские отношения.
Примечания. На соседских маршрутизаторах должны совпадать интервалы hello-пакетов, Dead Interval, интерфейсы и номера зон.
Установка отношений соседства
Если есть Router ID, совпадают интерфейсы, запущен OSPF-протокол и указаны сети, которые необходимо анонсировать по OSPF, то маршрутизаторы установят отношения соседства и произойдет обмен маршрутов.
Установка отношений происходит в несколько этапов. Рассмотрим на примере, когда у нас есть четыре маршрутизатора M1, M2, M3 и M4, который считаем новым. При этом M2 выбран как DR, а M3 как BDR.
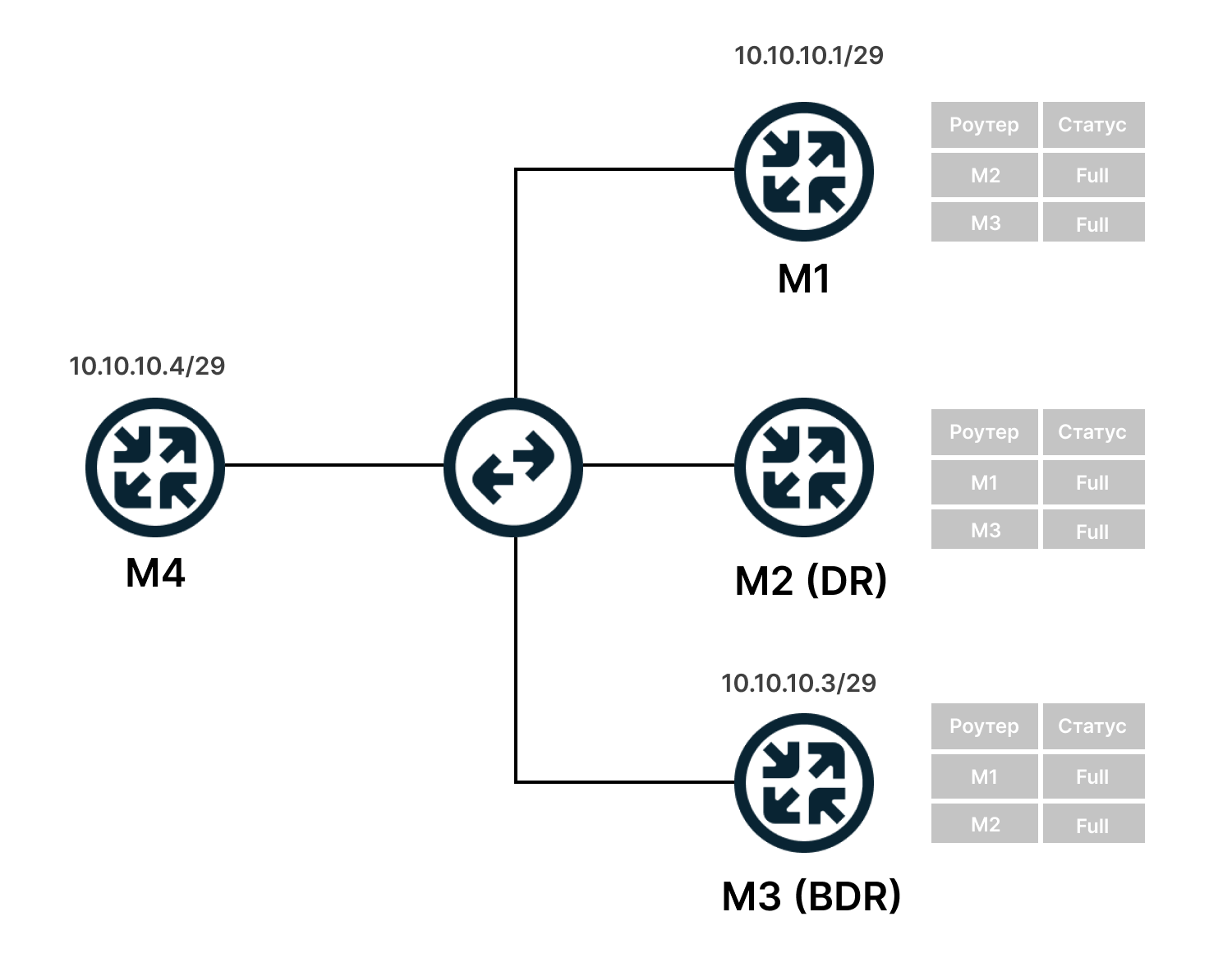
- Маршрутизатор M4 рассылает hello-сообщения на групповой адрес 224.0.0.5.
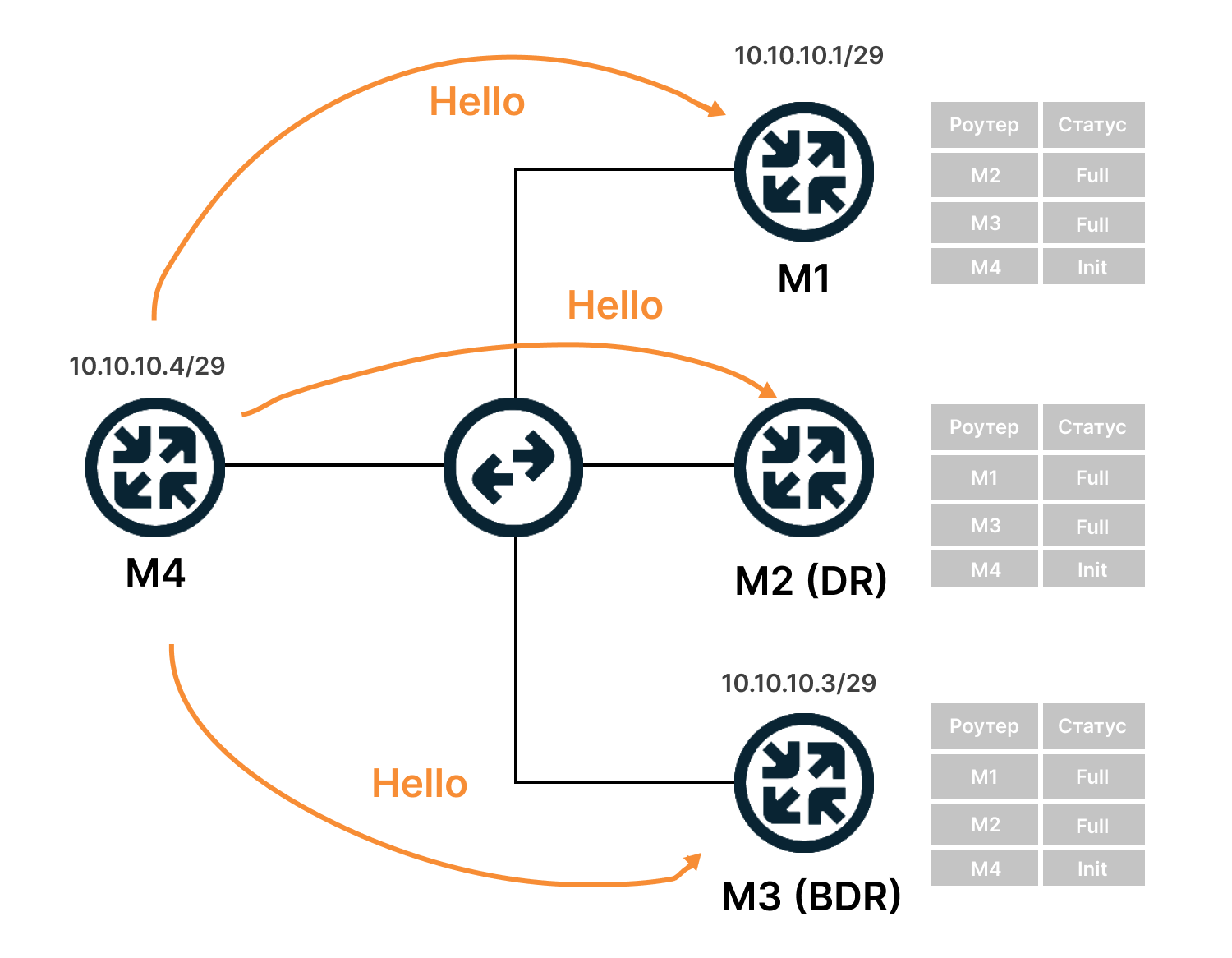
- Маршрутизаторы M1, M2 и M3 получили сообщения и добавили M4 в список соседей. Его статус они определяют как Init (состояние попытки поиска).
- Маршрутизаторы M1, M2, M3 отправляют сообщения маршрутизатору M4 с его Router ID и списком соседей. M4 добавляет их в список соседей.
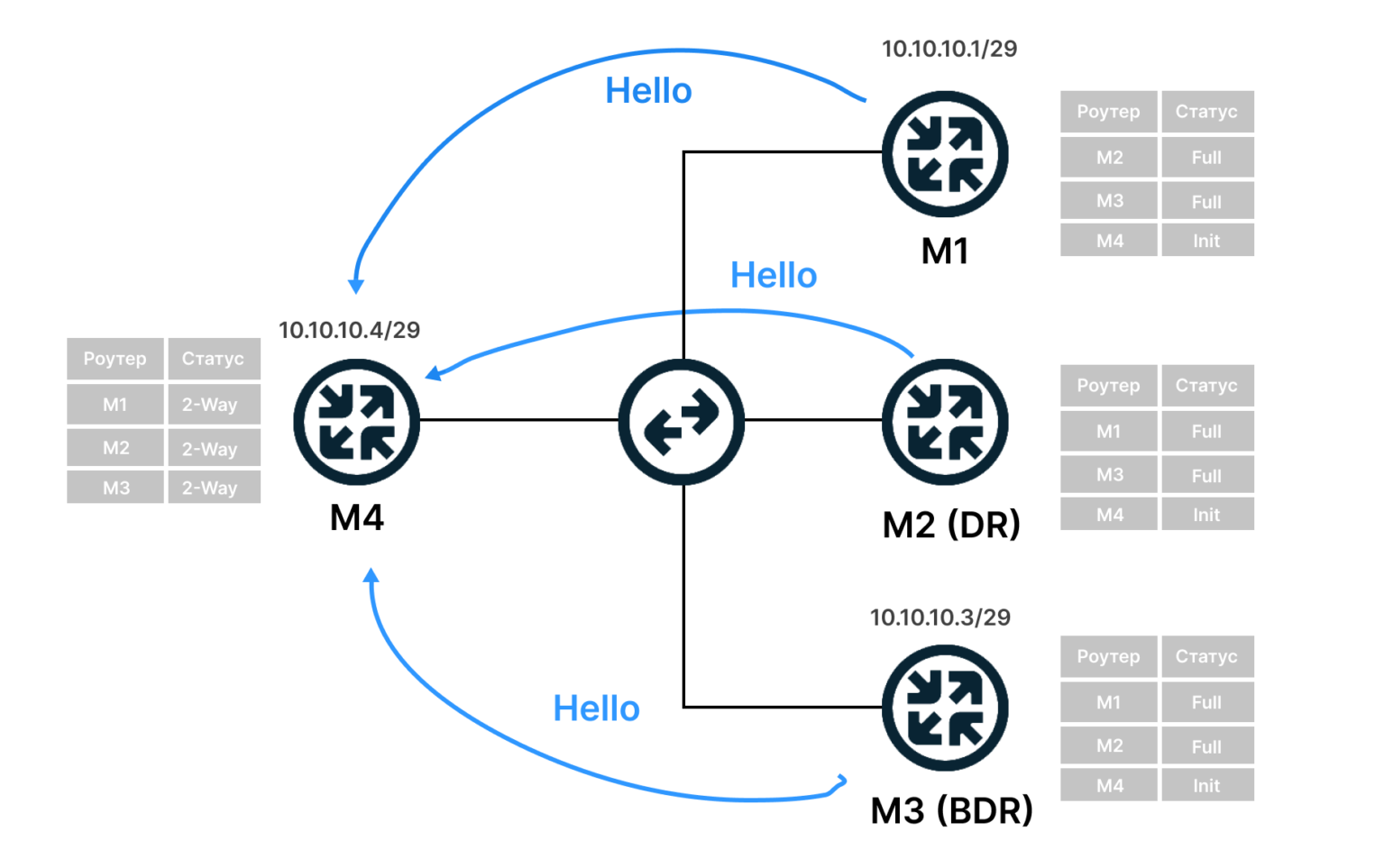
- Устанавливаются симметричные соседские отношения 2-Way (состояние, когда есть обмен сообщениями, но без передачи маршрутов).
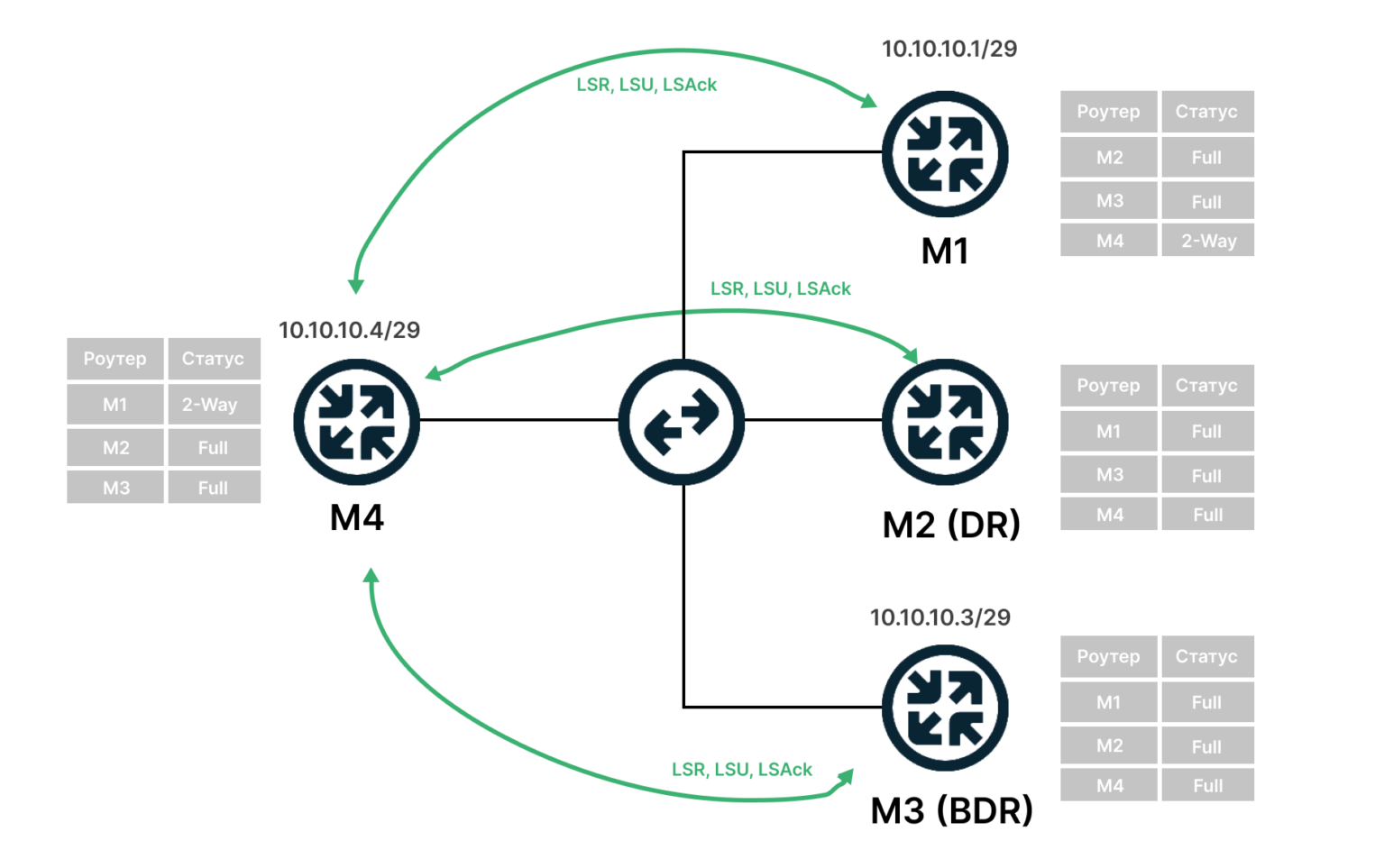
- Устройства обмениваются служебными сообщениями с кратким описанием базы данных маршрутов и LSR-сообщениями (Link State Request), запросами о неизвестных сетях.
- Устройства обмениваются сообщениями с более подробным описанием маршрутов и синхронизируют LSDB. Статус отношений устанавливается в Full, передаются маршруты.
Отношения соседства устанавливаются со всеми маршрутизаторами, включая DR и BDR.
Распределение ролей
Выше мы писали, что в сети назначаются две важные роли:
- Designated Router (DR) — выделенный маршрутизатор,
- Backup Designated Router (BDR) — резервный выделенный маршрутизатор.
DB и BDR назначаются администратором вручную или автоматически во время установления отношений соседства. Вручную обычно DR/BDR ставят корневые, а автоматически выбирается маршрутизатор с самым высоким приоритетом интерфейса OSPF или с наибольшим Router ID. BDR выбирается второй маршрутизатор по приоритету. Когда DR выходит из строя, то его заменяет BDR. Далее проводится выбор нового BDR.
Обе роли нужны, чтобы уменьшить количество LSA-сообщений. Работает это так.
Маршрутизаторы обмениваются маршрутной информацией и отправляют сообщения об изменениях в сети в DR. Он, в свою очередь, отправляет информацию остальным. Каждый маршрутизатор в сети также устанавливает с ним отношения, потому что фактически все маршрутизаторы устанавливают отношения друг с другом через DR.
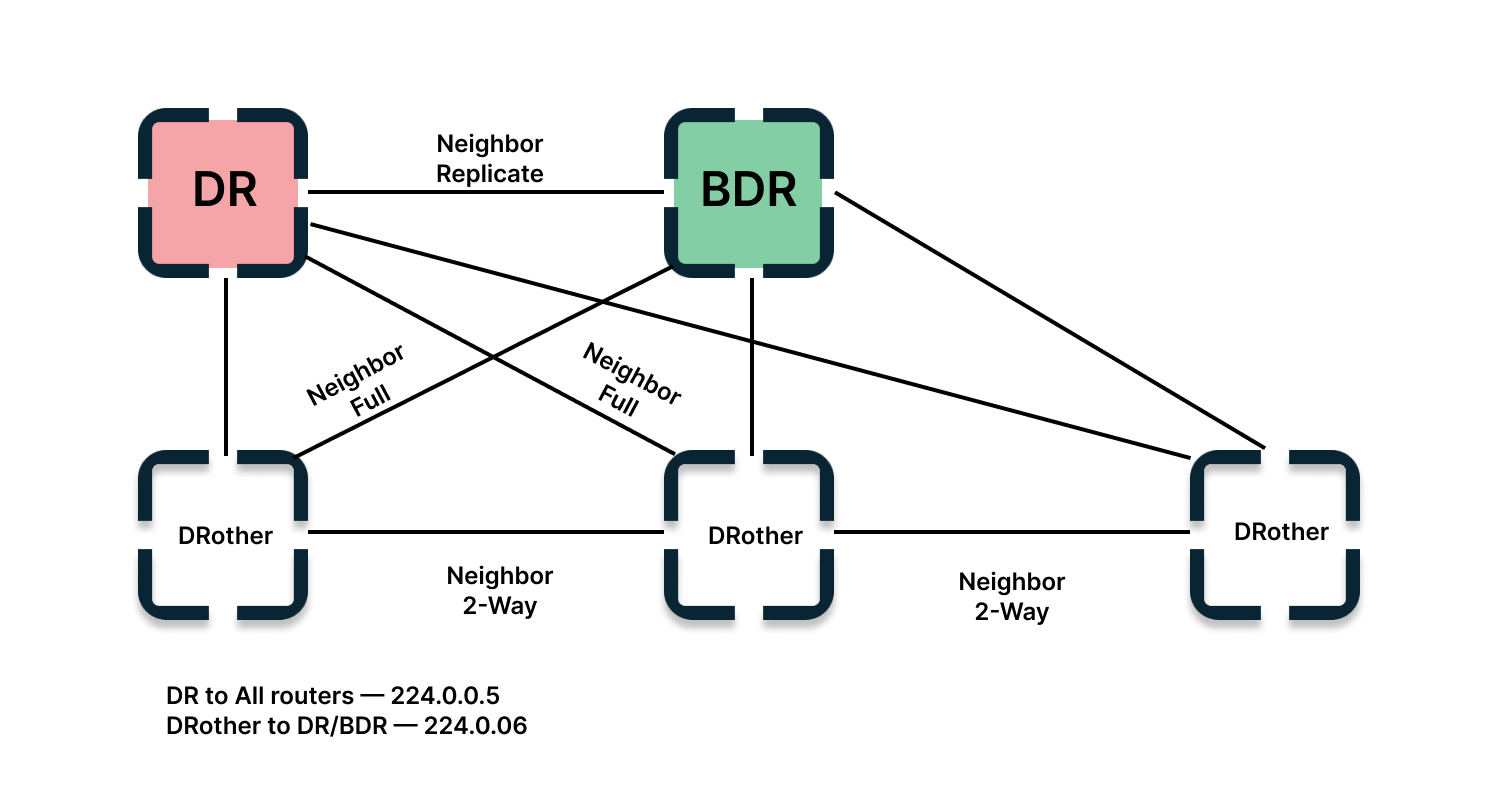
После выбора DR соседи обмениваются DBD-сообщениями — они содержат описание LSDB (Link-State DataBase), чтобы синхронизироваться. Для этого за устройствами DR и BDR закрепляется групповой адрес — например, 224.0.0.5, как на схеме выше.
Зоны OSPF: магистральная, стандартная, NSSA, stub area
OSPF позволяет делить сеть на зоны — логические объединения узлов и сетей. Зона — это набор маршрутизаторов со своей базой, LSA, топологией. Маршрутизаторы другой зоны не знают о топологии других зон. У каждой зоны есть свой идентификатор — area ID. Идентификатор может быть указан в формате IP-адреса, но это не IP-адреса. Идентификация маршрутизаторов зоны проходит с помощью Router ID.
В OSPF есть несколько зон.
Магистральная (Area 0, Backbone-area, зона 0.0.0.0). Она особенная — формирует ядро сети OSPF. Все остальные зоны подключаются к ней. Все пакеты от любой ненулевой зоны в другую ненулевую проходят через магистральную. Магистральный маршрутизатор — Backbone Router, у которого хотя бы один интерфейс принадлежит магистральной зоне.
Стандартная (обычная, Normal). Это область без определенной цели: создается по умолчанию, принимает обновления каналов, суммарные и внешние маршруты.
Транзитная. Зона, которая используется для передачи сетевого трафика из одной смежной области в другую. Магистральная зона, например, тоже транзитная, но особого типа.
NSSA (Not-so-stubby area). Это специфичная область, которая может инжектировать внешние маршруты сообщений в систему с помощью специального типа LSA и отправлять их в другие области. Но зона не может получать внешние маршруты из других областей.
Для передачи данных в этой зоне используется маршрутизатор ASBR, Autonomous System Boundary Router. Он применяется не только здесь, а, в целом, для получения маршрутов из внешних систем. Для передачи данных на границах зон используются пограничные маршрутизаторы ABR, или Area Border Router.
Тупикова зона (stub area). Эта зоне не принимает информацию о внешних маршрутах для автономной системы, но принимает маршруты из других зон. В тупиковой зоне не может находиться ASBR. Для передачи сообщений за границу системы из тупиковой зоны маршрутизаторы используют маршрут по умолчанию.
Также есть totally stub area — это «усиление» тупиковой зоны (термин внедрен компанией Cisco). В отличие от stub area в ней заменены на маршрут по умолчанию и внешние, и межзональные маршруты.
Все маршрутизаторы, которые находятся внутри зон (магистральной тоже), называются Internal Router — внутренними. Их интерфейсы принадлежат одной зоне. У таких маршрутизаторов только одна база данных состояния каналов.
Примечание. Маршрутизаторы могут выполнять несколько функций/ролей одновременно.
Зона не обязательно должны быть физической — соединение может быть установлено и с помощью виртуальных каналов.
Мультизона и ее преимущества
Мультизона, или мультизональность, удобна при большом количестве маршрутизаторов. Разделение позволяет:
- Сегментировать сеть, например, по отделам или департаментам.
- Снизить нагрузку на ЦПУ маршрутизаторов, потому что уменьшается количества перерасчетов по алгоритму SPF. Например, делим 100 роутеров на три зоны. При падении одного из них маршрут перестраивается не для всех, а лишь для трети роутеров.
- Снизить размер таблиц маршрутизации, потому что маршруты на границах зон суммируются.
- Снизить число пакетов LSA.
Объявления о состоянии канала — LSA
LSA, или Link State Advertisement, — это сообщение с описанием локального состояния маршрутизатора или сети. Вместе они создают базу данных состояния каналов LSDB. Есть 11 типов LSA сообщений (пакетов), у каждого своя функция.
Рассмотрим каждый LSA type.
LSA 1 (Router LSA). Каждый маршрутизатор создает этот тип. Он отправляется между маршрутизаторами одной зоны и дальше не идет. Содержит описание интерфейсов, как соединены маршрутизаторы и сети внутри зоны.

LSA 2 (Network). Этот тип рассылается между соседями в одной зоне, а создает его DR для описания маршрутизаторов, которые подключены к нему.

LSA 3 (Summary, Network Summary). Эти сообщения (пакеты) создает ABR, чтобы передать информацию о маршрутах соседей (из первого и второго типов) в другую область, в сокращенном виде. В сообщениях описываются подсети, стоимость маршрута, но не топология зоны.

LSA 4 (ASBR Summary). Как третий тип, но передает маршрут до локального ASBR соседям из других зон.

LSA 5 (External) содержат информацию из внешних систем — например, из другого протокола. Сообщения создает ASBR.
LSA 6 (Group Membership LSA) разработаны для протокола Multicast OSPF (MOSPF) , который поддерживает многоадресную маршрутизацию через OSPF. Не поддерживается Cisco.
LSA 7 (NSSA External) как пятый тип, но создает ASBR, если он находится в зоне NSSA.
Тип LSA 8 используется для передачи атрибутов BGP через сеть OSPF, а специальные типы LSA с 9 до 11 — специальные, используются для расширения возможностей, например, потоковой передачи данных.
Типы пакетов OSPF
LSA сами по себе не передаются. Маршрутизаторы передают LSA внутри других пакетов. Например, LSU или DD (Database Description), где передается описание всех LSA, которые хранятся в LSDB маршрутизатора. Кроме них, в OSPF используется еще три типа пакетов: Hello, Link-State Request (LSR) и Link-State Acknowledgment (LSAck).
В заголовке любого OSPF-пакета передается такая информация:
- Version — номер версии протокола OSPF.
- Type — тип OSPF-пакета, например, Hello.
- Packet length — длина пакета с заголовком в байтах.
- Router ID — идентификатор маршрутизатора.
- Area ID — 32-битный идентификатор зоны, определяет, в какой зоне создан пакет.
- Checksum — контрольная сумма, для проверки целостности пакета.
- Authentication type — тип используемой схемы аутентификации. Есть три типа: 0 (нет), 1 (есть аутентификация), 2 (MD5-аутентификация).
- Authentication — поле данных аутентификации.
Каждый тип пакета передает еще дополнительную информацию, кроме общей.
Hello. Пакеты передаются маршрутизаторами для обнаружения соседей, подтверждения их работы и построения отношения.
Пакет выглядит примерно так.
В сообщении передаются параметры, о которых маршрутизаторы должны договориться перед тем, как станут соседями.
- Network mask — сетевая маска интерфейса.
- HelloInterval — информация о частоте отправки.
- Options — дополнительные опции, которые поддерживает маршрутизатор, например, MC-bit.
- Router Priority — приоритет маршрутизатора. Эта информация используется при выборе DR и BDR.
- RouterDeadInterval — интервал времени, после которого сосед считается «мертвым».
- Designated Router — IP-адрес DR для сети, в которую отправлен hello-пакет.
- Backup Designated Router — IP-адрес BDR.
- Neighbor — идентификаторы соседей-маршрутизаторов.
Database Description (DBD). Проверяет синхронизацию базы данных между маршрутизаторами. В пакете содержатся данные:
- Interface MTU — максимальный размер в байтах IP-дейтаграммы, которая может быть отправлена через интерфейс без фрагментации.
- I-бит — устанавливается для первого пакета в последовательности.
- M-бит — указывает наличие последующих дополнительных пакетов.
- MS-бит — устанавливается для ведущего.
- DD sequence number — уникальное значение, устанавливается в начальном пакете; в каждом следующем увеличивается на единицу, пока не будет передана вся база данных.
- LSA headers — массив заголовков базы данных состояния каналов.
Link-State Request (LSR). Предназначен для запроса части базы данных соседнего маршрутизатора. В пакете содержатся.
- LS Type — тип сообщения.
- Link State ID — идентификатор домена маршрутизации.
- Advertising Router — идентификатор маршрутизатора, который создал объявление о состоянии канала.
Link-State Update (LSU). Предназначен для рассылки записей о состоянии каналов. В нем содержится Number of LSA — количество объявлений в пакете.
Link-State Acknowledgment (LSAck). Сообщение, которое подтверждает получение других типов пакетов.
Синхронизация LSDB
Все LSA всех типов образуют LSDB. У каждого маршрутизатора есть своя копия LSDB и они синхронизируют свою LSDB с DR.
- Каждый маршрутизатор отвечает за записи в LSDB о связях, которые исходят от него.
- Когда появляется новая связь или происходит обрыв, маршрутизатор меняет свою копию базы и извещает DR.
- Остальные будут забирать данную информацию с DR.
За извещение отвечает Flooding protocol — все маршрутизаторы пересылают сообщения об обновлении состояния связей (LSA). Получение подтверждается сообщениями LSA с типом OSPF, о котором говорили выше. У каждой записи в LSDB есть номер версии. У следующей записи номер больше, чем у предыдущей, чтобы в базу не попадали устаревшие версии.
Выбор лучшего маршрута
За выбор лучшего маршрута отвечает алгоритм SPF. Например, у нас есть сеть в виде графа, в узлах которой маршрутизаторы, а за ними сети. Как выбрать маршрут передачи данных?
У каждого ребра — пути между соседними маршрутизаторами — есть стоимость. Чтобы рассчитать маршрут, нужно знать всю топологию сети: каждый маршрутизатор передает друг другу знания о соседях, соединении и его стоимости.
Когда топология известна, проводится расчет по алгоритму Дейкстры (SPF) — нидерландского ученого, который разработал его еще в 1959 году. Маршрутизатор выбирает маршрут на основании наименьшего значения стоимости пути.
Стоимость рассчитывается по нескольким метрикам. Метрикой может быть загрузка канала, задержка, надежность связи или полоса пропускания канала. Например, последнюю метрику производители устройств считают каждый по своему: для маршрутизаторов Cisco это время передачи 100 Мбит данных по каналу в секундах.
Также у маршрута есть приоритет (в порядке убывания):
- Внутренние маршруты зоны.
- Маршруты между зонами.
- Внешние маршруты.
Выбирая путь, маршрутизатор будет выбирать сначала приоритетные маршруты. В первую очередь учитываются связи между маршрутизаторами и транзитными сетями, потом включаются тупиковые ветви, дальше — межзональные маршруты и маршруты к внешним сетям.
После расчета маршрутов создается дерево SPF.
Маршруты добавляются в таблицу маршрутизации.
Для получения маршрута маршрутизатор обращается к таблице LSDB. При этом таблица постоянно обновляется. Но обновление означает обнуление — маршруты строятся снова, с нуля, даже если изменились параметры всего одного маршрутизатора. Этот процесс сильно нагружает CPU.
От серверов до сетевых услуг и оборудования.
Реализации OSPF в Cisco и Juniper
Запуск и настройка OSPF протокола на оборудовании Cisco практически ничем не отличается от стандартного, описанного выше. Мы также включаем протокол на маршрутизаторах:
ter ospf 1Задаем Router ID, сеть и зоны:
router ospf 1
router-id 1.1.1.1
log-adjacency-changes
redistribute static
network 1.1.1.1 0.0.0.0 area 0
network 172.16.1.0 0.0.0.255 area 0
!Проверяем, заработала ли маршрутизация:
show ip ospf neighborsПроверяем таблицу маршрутизации:
show ip routeРеализация OSPF-протокола на устройствах Juniper аналогична, но команды другие. Включаем OSPF, определяем интерфейсы и зоны:
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0
set protocols ospf area 0.0.0.0 interface ge-0/0/1.0Здесь мы настроили область OSPF 0 (0.0.0.0) на интерфейсах ge-0/0/0.0 и ge-0/0/1.0 для маршрутизатора.
Для примера возьмем второй роутер:
set protocols ospf area 0.0.0.0 interface ge-0/0/0.0
set protocols ospf area 0.0.0.0 interface ge-0/0/2.0Проверяем соседа:
root@R1> show ospf neighborУвидим подобный ответ — значит, сосед активен:
| Address | Interface | State | ID | Pri | Dead |
| 1.1.1.2 | ge-0/0/0.0 | Full | 1.1.1.2 | 128 | 39 |
Проверяем интерфейсы:
root@R1> show ospf interfaceПроверим маршруты, таблицу:
root@R1> show routeГотово.
OSPF для IPv6
IPv6 поддерживается протоколом OSPF, но только третьей версии. Версия OSPFv2 поддерживает только IPv4. При переходе на протокол OSPFv3 почти ничего не меняется — вся теория работает и на этой версии.
В целом, настройка выглядит примерно так же:
- Включаем OSPF.
- Задаем идентификатор маршрутизатора. В OSPFv3 Router ID. Для IPv6 он настраивается только вручную, если не настроен адрес IPv4.
Как это выглядит в виде команд:
ipv6 router ospf 1
router-id 1.0.0.0
exit
interface Serial0/0/0
ipv6 ospf 1 area 0
exit
interface Serial0/0/1
ipv6 ospf 1 area 0
exitКоманда для проверки базы LSDB:
show ipv6 ospf database
Команда проверки соседей:
show ipv6 ospf neighbor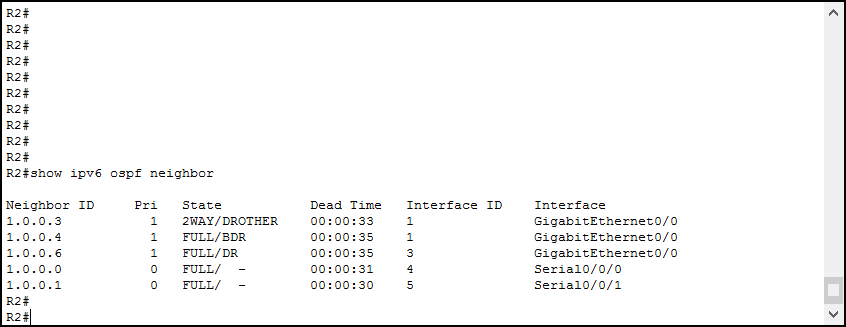
В контексте настроек OSPF для IPv6 остаются те же идентификаторы, те же области и зоны, так же настраиваются IP-адреса. При этом все маршрутизаторы Cisco поставляются с предварительно настроенными адресами IPv6.
Итог
OSPF — это открытый протокол для динамической маршрутизации внутренних сетей.
- Основа OSPF — протокол SPF, вычисляющий лучший (не кратчайший) маршрут.
- Для вычислений в протоколе реализована общая база маршрутов LSDB.
- База синхронизируется благодаря постоянным LSA сообщениям о состоянии каналов от маршрутизаторов.
- OSPF инкапсулируется в IP, без TCP/UDP, их замена — hello-сообщения.
- Hello-сообщения помогают реализовать отношения соседства и смежности с другими маршрутизаторами. Это позволяет протоколу проверять состояния канала и автоматически перестраивать маршруты, используя SPF-алгоритм.
- Перестройка маршрутов происходит локально, поэтому быстро, но затратно для процессора и оперативной памяти.
- Протокол поддерживает иерархические структуры зон, а значит — масштабирование.
- Есть несколько версий протокола, чаще используется вторая, а третья поддерживает IPv6.