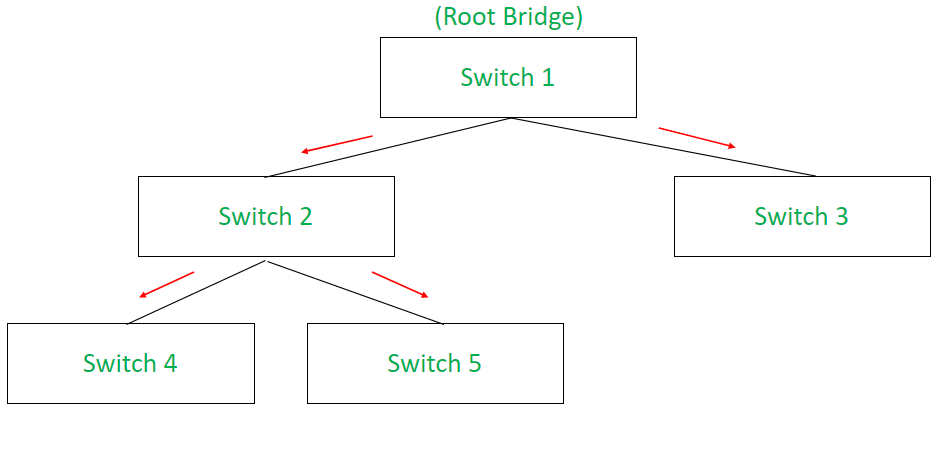
Bridge Protocol Data Unit is fundamentally a tree traversed convention which portrays each message of the organization with the various sorts of characteristics on the organization like the MAC address or the IP address utilizing distinctive switch ports present on the organization.
The Spanning Tree Protocol (STP) can empower and impair every one of the switches in a specific region network like LAN (neighborhood) or PAN (individual) region network so the course of trade of data stays flawless and the crossing tree calculation might turn out appropriately for the system’s administration.
Types of BPDU
There are basically two types of BPDUs:
- Configuration BPDUs: Configuration BPDUs are mainly used in the presence of the network root bridge where they are responsible for controlling and authenticating the outward flow of data and act as a firewall of protection from outside.
- Topology Change Notification (TCN) BPDUs: Topology Change Notification (TCN) BPDUs maintain upward data streaming where it continuously regulates which network topologies are being used currently and it notifies with a reminder when the topology changes.
Working

Working of BPDU
BPDU works in its own way to send a specific information message across the neighborhood for its work for distinguishing the anomalies in the different organization geographies around the framework. It incorporates a switch artist with its need port in it, data of the multitude of different ports and the MAC, IP addresses.
BPDU can arrange and change different settings in the crossing geographies of the tree in the organization signal. This data of BDPU assists it with empowering unmistakable pass-through data by the different switches utilized in the organization sign to ascertain the transfer speed of each wave to go BPDUs through them.
The primary component behind the Bridge Protocol information unit is that when they are associated with different switches and ports in their environmental factors, they will quite often disregard the transmission of information bundles by then. In another way, they utilize one more strategy for setting up the information prepared for handling until the Bridge Protocol information unit (BPDU) prepares with choosing the right crossing tree geography which can be utilized for information transmission.
After the information handling is finished, then, at that point, the information is projected towards other organization ports and switches which is then moved to the primary base of the organization. When the root signal in the BPDU receives the message from the sender, it forwards this message to the original receiver by identifying him with the help of his MAC address.
After this, the Bridge Protocol information unit (BPDU) transmits the signal to the Switch Port to enable the message recipient to receive this message by decrypting it with the help of his decryption key.
Significance of BPDU
The Bridge Protocol information unit (BPDU) stores all the important information about the PC like its Switch Port ID and its MAC address for all the computers connected to that network. Also, the address of the original Switch Port and of the adjacent ports are used to identify the credentials of each user of the organization on that network.
Bridge Data Unit Protocol (BPDU) is mostly used for authenticating the messages sent and received across any organization by using their MAC address. Switch Ports in the BPDU helps to apply Spanning Tree Protocol (STP) in order to manage the layers of communication across an organization. It makes an effective plan for the most efficient way of transfer of messages as it uses the Spanning Tree for finding the nearest Switch Port to divert it from the traffic. It is extremely useful in conditions like Broadcast Storm takes place when the entire server is attacked.
Last Updated :
03 Dec, 2021
Like Article
Save Article
I think that I shall never see
A graph more lovely than a tree.
A tree whose crucial propertyеу
Is loop-free connectivity.
A tree that must be sure to span
So packets can reach every LAN.
First, the root must be selected.
By ID, it is elected.
Least-cost paths from root are traced.
In the tree, these paths are placed.
A mesh is made by folks like me,
Then bridges find a spanning tree.
— Radia Joy Perlman
Все выпуски
6. Сети для самых маленьких. Часть шестая. Динамическая маршрутизация
5. Сети для самых маленьких: Часть пятая. NAT и ACL
4. Сети для самых маленьких: Часть четвёртая. STP
3. Сети для самых маленьких: Часть третья. Статическая маршрутизация
2. Сети для самых маленьких. Часть вторая. Коммутация
1. Сети для самых маленьких. Часть первая. Подключение к оборудованию cisco
0. Сети для самых маленьких. Часть нулевая. Планирование
В прошлом выпуске мы остановились на статической маршрутизации. Теперь надо сделать шаг в сторону и обсудить вопрос стабильности нашей сети.
Однажды, когда вы — единственный сетевой админ фирмы “Лифт ми Ап” — отпросились на полдня раньше, вдруг упала связь с серверами, и директора не получили несколько важных писем. После короткой, но ощутимой взбучки вы идёте разбираться, в чём дело, а оказалось, по чьей-то неосторожности выпал из разъёма единственный кабель, ведущий к коммутатору в серверной. Небольшая проблема, которую вы могли исправить за две минуты, и даже вообще избежать, существенно сказалась на вашем доходе в этом месяце и возможностях роста.
Итак, сегодня обсуждаем:
- проблему широковещательного шторма
- работу и настройку протокола STP и его модификаций (RSTP, MSTP, PVST, PVST+)
- технологию агрегации интерфейсов и перераспределения нагрузки между ними
- некоторые вопросы стабильности и безопасности
- как изменить схему существующей сети, чтобы всем было хорошо
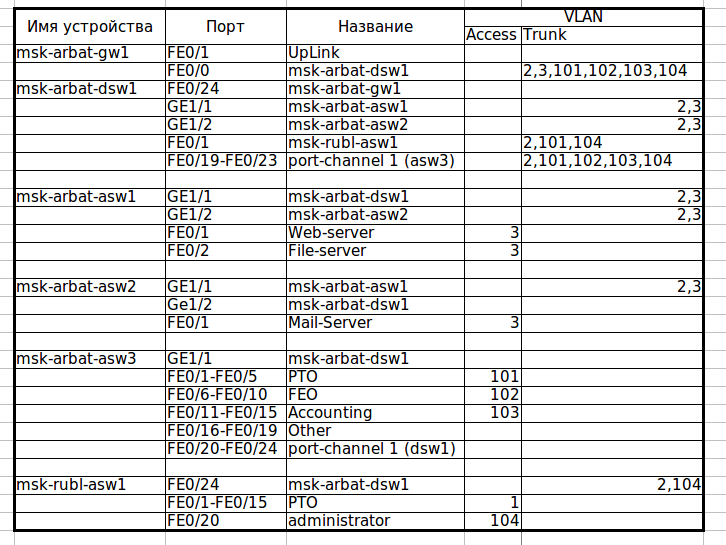
Оборудование, работающее на втором уровне модели OSI (коммутатор), должно выполнять 3 функции: запоминание адресов, перенаправление (коммутация) пакетов, защита от петель в сети. Разберем по пунктам каждую функцию.
Запоминание адресов и перенаправление пакетов: Как мы уже говорили ранее, у каждого свича есть таблица сопоставления MAC-адресов и портов (aka CAM-table — Content Addressable Memory Table). Когда устройство, подключенное к свичу, посылает кадр в сеть, свич смотрит MAC-адрес отправителя и порт, откуда получен кадр, и добавляет эту информацию в свою таблицу. Далее он должен передать кадр получателю, адрес которого указан в кадре. По идее, информацию о порте, куда нужно отправить кадр, он берёт из этой же CAM-таблицы. Но, предположим, что свич только что включили (таблица пуста), и он понятия не имеет, в какой из его портов подключен получатель. В этом случае он отправляет полученный кадр во все свои порты, кроме того, откуда он был принят. Все конечные устройства, получив этот кадр, смотрят MAC-адрес получателя, и, если он адресован не им, отбрасывают его. Устройство-получатель отвечает отправителю, а в поле отправителя ставит свой адрес, и вот свич уже знает, что такой-то адрес находится на таком-то порту (вносит запись в таблицу), и в следующий раз уже будет переправлять кадры, адресованные этому устройству, только в этот порт. Чтобы посмотреть содержимое CAM-таблицы, используется команда show mac address-table. Однажды попав в таблицу, информация не остаётся там пожизненно, содержимое постоянно обновляется и если к определенному mac-адресу не обращались 300 секунд (по умолчанию), запись о нем удаляется.
Тут всё должно быть понятно. Но зачем защита от петель? И что это вообще такое?
Широковещательный шторм
Часто, для обеспечения стабильности работы сети в случае проблем со связью между свичами (выход порта из строя, обрыв провода), используют избыточные линки (redundant links) — дополнительные соединения. Идея простая — если между свичами по какой-то причине не работает один линк, используем запасной. Вроде все правильно, но представим себе такую ситуацию: два свича соединены двумя проводами (пусть будет, что у них соединены fa0/1 и fa0/24).
Одной из их подопечных — рабочих станций (например, ПК1) вдруг приспичило послать широковещательный кадр (например, ARP-запрос). Раз широковещательный, шлем во все порты, кроме того, с которого получили.

Второй свич получает кадр в два порта, видит, что он широковещательный, и тоже шлет во все порты, но уже, получается, и обратно в те, с которых получил (кадр из fa0/24 шлет в fa0/1, и наоборот).

Первый свич поступает точно также, и в итоге мы получаем широковещательный шторм (broadcast storm), который намертво блокирует работу сети, ведь свичи теперь только и занимаются тем, что шлют друг другу один и тот же кадр.

Как можно избежать этого? Ведь мы, с одной стороны, не хотим штормов в сети, а с другой, хотим повысить ее отказоустойчивость с помощью избыточных соединений? Тут на помощь нам приходит STP (Spanning Tree Protocol)
STP
Основная задача STP — предотвратить появление петель на втором уровне. Как это сделать? Да просто отрубить все избыточные линки, пока они нам не понадобятся. Тут уже сразу возникает много вопросов: какой линк из двух (или трех-четырех) отрубить? Как определить, что основной линк упал, и пора включать запасной? Как понять, что в сети образовалась петля? Чтобы ответить на эти вопросы, нужно разобраться, как работает STP.
STP использует алгоритм STA (Spanning Tree Algorithm), результатом работы которого является граф в виде дерева (связный и без простых циклов)
Для обмена информацией между собой свичи используют специальные пакеты, так называемые BPDU (Bridge Protocol Data Units). BPDU бывают двух видов: конфигурационные (Configuration BPDU) и панические “ААА, топология поменялась!” TCN (Topology Change Notification BPDU). Первые регулярно рассылаются корневым свичом (и ретранслируются остальными) и используются для построения топологии, вторые, как понятно из названия, отсылаются в случае изменения топологии сети (проще говоря, подключении\отключении свича). Конфигурационные BPDU содержат несколько полей, остановимся на самых важных:
- идентификатор отправителя (Bridge ID)
- идентификатор корневого свича (Root Bridge ID)
- идентификатор порта, из которого отправлен данный пакет (Port ID)
- стоимость маршрута до корневого свича (Root Path Cost)
Что все это такое и зачем оно нужно, объясню чуть ниже. Так как устройства не знают и не хотят знать своих соседей, никаких отношений (смежности/соседства) они друг с другом не устанавливают. Они шлют BPDU из всех работающих портов на мультикастовый ethernet-адрес 01-80-c2-00-00-00 (по умолчанию каждые 2 секунды), который прослушивают все свичи с включенным STP.
Итак, как же формируется топология без петель?
Сначала выбирается так называемый корневой мост/свич (root bridge). Это устройство, которое STP считает точкой отсчета, центром сети; все дерево STP сходится к нему. Выбор базируется на таком понятии, как идентификатор свича (Bridge ID). Bridge ID это число длиной 8 байт, которое состоит из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768+номер vlan или инстанс MSTP, в зависимости от реализации протокола), и MAC-адреса устройства. В начале выборов каждый коммутатор считает себя корневым, о чем и заявляет всем остальным с помощью BPDU, в котором представляет свой идентификатор как ID корневого свича. При этом, если он получает BPDU с меньшим Bridge ID, он перестает хвастаться своим и покорно начинает анонсировать полученный Bridge ID в качестве корневого. В итоге, корневым оказывается тот свич, чей Bridge ID меньше всех.
Такой подход таит в себе довольно серьезную проблему. Дело в том, что, при равных значениях Priority (а они равные, если не менять ничего) корневым выбирается самый старый свич, так как мак адреса прописываются на производстве последовательно, соответственно, чем мак меньше, тем устройство старше (естественно, если у нас все оборудование одного вендора). Понятное дело, это ведет к падению производительности сети, так как старое устройство, как правило, имеет худшие характеристики. Подобное поведение протокола следует пресекать, выставляя значение приоритета на желаемом корневом свиче вручную, об этом в практической части.
Роли портов
После того, как коммутаторы померились айдями и выбрали root bridge, каждый из остальных свичей должен найти один, и только один порт, который будет вести к корневому свичу. Такой порт называется корневым портом (Root port). Чтобы понять, какой порт лучше использовать, каждый некорневой свич определяет стоимость маршрута от каждого своего порта до корневого свича. Эта стоимость определяется суммой стоимостей всех линков, которые нужно пройти кадру, чтобы дойти до корневого свича. В свою очередь, стоимость линка определяется просто- по его скорости (чем выше скорость, тем меньше стоимость). Процесс определения стоимости маршрута связан с полем BPDU “Root Path Cost” и происходит так:
- Корневой свич посылает BPDU с полем Root Path Cost, равным нулю
- Ближайший свич смотрит на скорость своего порта, куда BPDU пришел, и добавляет стоимость согласно таблице
Скорость порта Стоимость STP (802.1d) 10 Mbps 100 100 Mbps 19 1 Gbps 4 10 Gbps 2 - Далее этот второй свич посылает этот BPDU нижестоящим коммутаторам, но уже с новым значением Root Path Cost, и далее по цепочке вниз
Если имеют место одинаковые стоимости (как в нашем примере с двумя свичами и двумя проводами между ними — у каждого пути будет стоимость 19) — корневым выбирается меньший порт.
Далее выбираются назначенные (Designated) порты. Из каждого конкретного сегмента сети должен существовать только один путь по направлению к корневому свичу, иначе это петля. В данном случае имеем в виду физический сегмент, в современных сетях без хабов это, грубо говоря, просто провод. Назначенным портом выбирается тот, который имеет лучшую стоимость в данном сегменте. У корневого свича все порты — назначенные.
И вот уже после того, как выбраны корневые и назначенные порты, оставшиеся блокируются, таким образом разрывая петлю.

*На картинке маршрутизаторы выступают в качестве коммутаторов. В реальной жизни это можно сделать с помощью дополнительной свитчёвой платы.
Состояния портов
Чуть раньше мы упомянули состояние блокировки порта, теперь поговорим о том, что это значит, и о других возможных состояниях порта в STP. Итак, в обычном (802.1D) STP существует 5 различных состояний:
- блокировка (blocking): блокированный порт не шлет ничего. Это состояние предназначено, как говорилось выше, для предотвращения петель в сети. Блокированный порт, тем не менее, слушает BPDU (чтобы быть в курсе событий, это позволяет ему, когда надо, разблокироваться и начать работать)
- прослушивание (listening): порт слушает и начинает сам отправлять BPDU, кадры с данными не отправляет.
- обучение (learning): порт слушает и отправляет BPDU, а также вносит изменения в CAM- таблицу, но данные не перенаправляет.
- перенаправление\пересылка (forwarding): этот может все: и посылает\принимает BPDU, и с данными оперирует, и участвует в поддержании таблицы mac-адресов. То есть это обычное состояние рабочего порта.
- отключен (disabled): состояние administratively down, отключен командой shutdown. Понятное дело, ничего делать не может вообще, пока вручную не включат.
Порядок перечисления состояний не случаен: при включении (а также при втыкании нового провода), все порты на устройстве с STP проходят вышеприведенные состояния именно в таком порядке (за исключением disabled-портов). Возникает закономерный вопрос: а зачем такие сложности? А просто STP осторожничает. Ведь на другом конце провода, который только что воткнули в порт, может быть свич, а это потенциальная петля. Вот поэтому порт сначала 15 секунд (по умолчанию) пребывает в состоянии прослушивания — он смотрит BPDU, попадающие в него, выясняет свое положение в сети — как бы чего ни вышло, потом переходит к обучению еще на 15 секунд — пытается выяснить, какие mac-адреса “в ходу” на линке, и потом, убедившись, что ничего он не поломает, начинает уже свою работу. Итого, мы имеем целых 30 секунд простоя, прежде чем подключенное устройство сможет обмениваться информацией со своими соседями. Современные компы грузятся быстрее, чем за 30 секунд. Вот комп загрузился, уже рвется в сеть, истерит на тему “DHCP-сервер, сволочь, ты будешь айпишник выдавать, или нет?”, и, не получив искомого, обижается и уходит в себя, извлекая из своих недр айпишник автонастройки. Естественно, после таких экзерсисов, в сети его слушать никто не будет, ибо “не местный” со своим 169.254.x.x. Понятно, что все это не дело, но как этого избежать?
Portfast
Для таких случаев используется особый режим порта — portfast. При подключении устройства к такому порту, он, минуя промежуточные стадии, сразу переходит к forwarding-состоянию. Само собой, portfast следует включать только на интерфейсах, ведущих к конечным устройствам (рабочим станциям, серверам, телефонам и т.д.), но не к другим свичам.
Есть очень удобная команда режима конфигурации интерфейса для включения нужных фич на порту, в который будут включаться конечные устройства: switchport host. Эта команда разом включает PortFast, переводит порт в режим access (аналогично switchport mode access), и отключает протокол PAgP (об этом протоколе подробнее в разделе агрегация каналов).
Виды STP
STP довольно старый протокол, он создавался для работы в одном LAN-сегменте. А что делать, если мы хотим внедрить его в нашей сети, которая имеет несколько VLANов?
Стандарт 802.1Q, о котором мы упоминали в статье о коммутации, определяет, каким образом вланы передаются внутри транка. Кроме того, он определяет один процесс STP для всех вланов. BPDU по транкам передаются нетегированными (в native VLAN). Этот вариант STP известен как CST (Common Spanning Tree). Наличие только одного процесса для всех вланов очень облегчает работу по настройке и разгружает процессор свича, но, с другой стороны, CST имеет недостатки: избыточные линки между свичами блокируются во всех вланах, что не всегда приемлемо и не дает возможности использовать их для балансировки нагрузки.
Cisco имеет свой взгляд на STP, и свою проприетарную реализацию протокола — PVST (Per-VLAN Spanning Tree) — которая предназначена для работы в сети с несколькими VLAN. В PVST для каждого влана существует свой процесс STP, что позволяет независимую и гибкую настройку под потребности каждого влана, но самое главное, позволяет использовать балансировку нагрузки за счет того, что конкретный физический линк может быть заблокирован в одном влане, но работать в другом. Минусом этой реализации является, конечно, проприетарность: для функционирования PVST требуется проприетарный же ISL транк между свичами.
Также существует вторая версия этой реализации — PVST+, которая позволяет наладить связь между свичами с CST и PVST, и работает как с ISL- транком, так и с 802.1q. PVST+ это протокол по умолчанию на коммутаторах Cisco.
RSTP
Все, о чем мы говорили ранее в этой статье, относится к первой реализация протокола STP, которая была разработана в 1985 году Радией Перлман (ее стихотворение использовано в качестве эпиграфа). В 1990 году эта реализации была включена в стандарт IEEE 802.1D. Тогда время текло медленнее, и перестройка топологии STP, занимающая 30-50 секунд (!!!), всех устраивала. Но времена меняются, и через десять лет, в 2001 году, IEEE представляет новый стандарт RSTP (он же 802.1w, он же Rapid Spanning Tree Protocol, он же Быстрый STP). Чтобы структурировать предыдущий материал и посмотреть различия между обычным STP (802.1d) и RSTP (802.1w), соберем таблицу с основными фактами:
| STP (802.1d) | RSTP (802.1w) |
| В уже сложившейся топологии только корневой свич шлет BPDU, остальные ретранслируют | Все свичи шлют BPDU в соответствии с hello-таймером (2 секунды по умолчанию) |
| Состояния портов | |
| — блокировка (blocking) — прослушивание (listening) — обучение (learning) — перенаправление\пересылка (forwarding) — отключен (disabled) |
— отбрасывание (discarding), заменяет disabled, blocking и listening — learning — forwarding |
| Роли портов | |
| — корневой (root), участвует в пересылке данных, ведет к корневому свичу — назначенный (designated), тоже работает, ведет от корневого свича — неназначенный (non-designated), не участвует в пересылке данных |
— корневой (root), участвует в пересылке данных — назначенный (designated), тоже работает — дополнительный (alternate), не участвует в пересылке данных — резервный (backup), тоже не участвует |
| Механизмы работы | |
| Использует таймеры: Hello (2 секунды) Max Age (20 секунд) Forward delay timer (15 секунд) |
Использует процесс proposal and agreement (предложение и соглашение) |
| Свич, обнаруживший изменение топологии, извещает корневой свич, который, в свою очередь, требует от всех остальных очистить их записи о текущей топологии в течение forward delay timer | Обнаружение изменений в топологии влечет немедленную очистку записей |
| Если не-корневой свич не получает hello- пакеты от корневого в течение Max Age, он начинает новые выборы | Начинает действовать, если не получает BPDU в течение 3 hello-интервалов |
| Последовательное прохождение порта через состояния Blocking (20 сек) — Listening (15 сек) — Learning (15 сек) — Forwarding | Быстрый переход к Forwarding для p2p и Edge-портов |
Как мы видим, в RSTP остались такие роли портов, как корневой и назначенный, а роль заблокированного разделили на две новых роли: Alternate и Backup. Alternate — это резервный корневой порт, а backup — резервный назначенный порт. Как раз в этой концепции резервных портов и кроется одна из причин быстрого переключения в случае отказа. Это меняет поведение системы в целом: вместо реактивной (которая начинает искать решение проблемы только после того, как она случилась) система становится проактивной, заранее просчитывающей “пути отхода” еще до появления проблемы. Смысл простой: для того, чтобы в случае отказа основного переключится на резервный линк, RSTP не нужно заново просчитывать топологию, он просто переключится на запасной, заранее просчитанный.
Ранее, для того, чтобы убедиться, что порт может участвовать в передаче данных, требовались таймеры, т.е. свич пассивно ждал в течение означенного времени, слушая BPDU. Ключевой фичей RSTP стало введение концепции типов портов, основанных на режиме работы линка- full duplex или half duplex (типы портов p2p или shared, соответственно), а также понятия пограничный порт (тип edge p2p), для конечных устройств. Пограничные порты назначаются, как и раньше, командой spanning-tree portfast, и с ними все понятно- при включении провода сразу переходим к forwarding-состоянию и работаем. Shared-порты работают по старой схеме с прохождением через состояния BLK — LIS — LRN — FWD. А вот на p2p-портах RSTP использует процесс предложения и соглашения (proposal and agreement). Не вдаваясь в подробности, его можно описать так: свич справедливо считает, что если линк работает в режиме полного дуплекса, и он не обозначен, как пограничный, значит, на нем только два устройства- он и другой свич. Вместо того, чтобы ждать входящих BPDU, он сам пытается связаться со свичом на том конце провода с помощью специальных proposal BPDU, в которых, конечно, есть информация о стоимости маршрута к корневому свичу. Второй свич сравнивает полученную информацию со своей текущей, и принимает решение, о чем извещает первый свич посредством agreement BPDU. Так как весь этот процесс теперь не привязан к таймерам, происходит он очень быстро- только подключили новый свич- и он практически сразу вписался в общую топологию и приступил к работе (можете сами оценить скорость переключения в сравнении с обычным STP на видео). В Cisco-мире RSTP называется PVRST (Per-Vlan Rapid Spanning Tree).
MSTP
Чуть выше, мы упоминали о PVST, в котором для каждого влана существует свой процесс STP. Вланы это довольно удобный инструмент для многих целей, и поэтому, их может быть достаточно много даже в некрупной организации. И в случае PVST, для каждого будет рассчитываться своя топология, тратиться процессорное время и память свичей. А нужно ли нам рассчитывать STP для всех 500 вланов, когда единственное место, где он нам нужен- это резервный линк между двумя свичами? Тут нас выручает MSTP. В нем каждый влан не обязан иметь собственный процесс STP, их можно объединять. Вот у нас есть, например, 500 вланов, и мы хотим балансировать нагрузку так, чтобы половина из них работала по одному линку (второй при этом блокируется и стоит в резерве), а вторая- по другому. Это можно сделать с помощью обычного STP, назначив один корневой свич в диапазоне вланов 1-250, а другой- в диапазоне 250-500. Но процессы будут работать для каждого из пятисот вланов по отдельности (хотя действовать будут совершенно одинаково для каждой половины). Логично, что тут хватит и двух процессов. MSTP позволяет создавать столько процесов STP, сколько у нас логических топологий (в данном примере- 2), и распределять по ним вланы. Думаем, нет особого смысла углубляться в теорию и практику MSTP в рамках этой статьи (ибо теории там ого-го), интересующиеся могут пройти по ссылке.
Агрегация каналов
Но какой бы вариант STP мы не использовали, у нас все равно существует так или иначе неработающий линк. А возможно ли задействовать параллельные линки по полной и при этом избежать петель? Да, отвечаем мы вместе с циской, начиная рассказ о EtherChannel.
Иначе это называется link aggregation, link bundling, NIC teaming, port trunkinkg
Технологии агрегации (объединения) каналов выполняют 2 функции: с одной стороны, это объединение пропускной способности нескольких физических линков, а с другой — обеспечение отказоустойчивости соединения (в случае падения одного линка нагрузка переносится на оставшиеся). Объединение линков можно выполнить как вручную (статическое агрегирование), так и с помощью специальных протоколов: LACP (Link Aggregation Control Protocol) и PAgP (Port Aggregation Protocol). LACP, опеределяемый стандартом IEEE 802.3ad, является открытым стандартом, то есть от вендора оборудования не зависит. Соответственно, PAgP — проприетарная цисковская разработка.
В один такой канал можно объединить до восьми портов. Алгоритм балансировки нагрузки основан на таких параметрах, как IP/MAC-адреса получателей и отправителей и порты. Поэтому в случае возникновения вопроса: “Хей, а чего так плохо балансируется?” в первую очередь смотрите на алгоритм балансировки.
Тема агрегации каналов заслуживает отдельной статьи, а то и книги, поэтому углубляться не будем, интересующимся- ссылка.
Port security
Теперь расскажем вкратце, как обеспечить безопасность сети на втором уровне OSI. В этой части статьи теория и практическая конфигурация совмещены. Увы, Packet Tracer не умеет ничего из упомянутых в этом разделе команд, поэтому все без иллюстраций и проверок.
Для начала, следует упомянуть команду конфигурации интерфейса switchport port-security, включающую защиту на определенном порту свича. Затем, с помощью switchport port-security maximum 1 мы можем ограничить количество mac-адресов, связанных с данным портом (т.е., в нашем примере, на данном порту может работать только один mac-адрес). Теперь указываем, какой именно адрес разрешен: его можно задать вручную switchport port-security mac-address адрес, или использовать волшебную команду switchport port-security mac-address sticky, закрепляющую за портом тот адрес, который в данный момент работает на порту. Далее, задаем поведение в случае нарушения правила switchport port-security violation {shutdown | restrict | protect}: порт либо отключается, и потом его нужно поднимать вручную (shutdown), либо отбрасывает пакеты с незарегистрированного мака и пишет об этом в консоль (restrict), либо просто отбрасывает пакеты (protect).
Помимо очевидной цели — ограничение числа устройств за портом — у этой команды есть другая, возможно, более важная: предотвращать атаки. Одна из возможных — истощение CAM-таблицы. С компьютера злодея рассылается огромное число кадров, возможно, широковещательных, с различными значениями в поле MAC-адрес отправителя. Первый же коммутатор на пути начинает их запоминать. Одну тысячу он запомнит, две, но память-то оперативная не резиновая, и среднее ограничение в 16000 записей будет довольно быстро достигнуто. При этом дальнейшее поведение коммутатора может быть различным. И самое опасное из них с точки зрения безопасности: коммутатор может начать все кадры, приходящие на него, рассылать, как широковещательные, потому что MAC-адрес получателя не известен (или уже забыт), а запомнить его уже просто некуда. В этом случае сетевая карта злодея будет получать все кадры, летающие в вашей сети.
DHCP Snooping
Другая возможная атака нацелена на DHCP сервер. Как мы знаем, DHCP обеспечивает клиентские устройства всей нужной информацией для работы в сети: ip-адресом, маской подсети, адресом шюза по умолчанию, DNS-сервера и прочим. Атакующий может поднять собственный DHCP, который в ответ на запрос клиентского устройства будет отдавать в качестве шлюза по умолчанию (а также, например, DNS-сервера) адрес подконтрольной атакующему машины. Соответственно, весь трафик, направленный за пределы подсети обманутыми устройствами, будет доступен для изучения атакующему — типичная man-in-the-middle атака. Либо такой вариант: подлый мошенник генерируют кучу DHCP-запросов с поддельными MAC-адресами и DHCP-сервер на каждый такой запрос выдаёт IP-адрес до тех пор, пока не истощится пул.
Для того, чтобы защититься от подобного вида атак, используется фича под названием DHCP snooping. Идея совсем простая: указать свичу, на каком порту подключен настоящий DHCP-сервер, и разрешить DHCP-ответы только с этого порта, запретив для остальных. Включаем глобально командой ip dhcp snooping, потом говорим, в каких вланах должно работать ip dhcp snooping vlan номер(а). Затем на конкретном порту говорим, что он может пренаправлять DHCP-ответы (такой порт называется доверенным): ip dhcp snooping trust.
IP Source Guard
После включения DHCP Snooping’а, он начинает вести у себя базу соответствия MAC и IP-адресов устройств, которую обновляет и пополняет за счет прослушивания DHCP запросов и ответов. Эта база позволяет нам противостоять еще одному виду атак — подмене IP-адреса (IP Spoofing). При включенном IP Source Guard, каждый приходящий пакет может проверяться на:
- соответствие IP-адреса источника адресу, полученному из базы DHCP Snooping (иными словами, айпишник закрепляется за портом свича)
- соответствие MAC-адреса источника адресу, полученному из базы DHCP Snooping
Включается IP Source Guard командой ip verify source на нужном интерфейсе. В таком виде проверяется только привязка IP-адреса, чтобы добавить проверку MAC, используем ip verify source port-security. Само собой, для работы IP Source Guard требуется включенный DHCP snooping, а для контроля MAC-адресов должен быть включен port security.
Dynamic ARP Inspection
Как мы уже знаем, для того, чтобы узнать MAC-адрес устройства по его IP-адресу, используется проткол ARP: посылается широковещательный запрос вида “у кого ip-адрес 172.16.1.15, ответьте 172.16.1.1”, устройство с айпишником 172.16.1.15 отвечает. Подобная схема уязвима для атаки, называемой ARP-poisoning aka ARP-spoofing: вместо настоящего хоста с адресом 172.16.1.15 отвечает хост злоумышленника, заставляя таким образом трафик, предназначенный для 172.16.1.15 следовать через него. Для предотвращения такого типа атак используется фича под названием Dynamic ARP Inspection. Схема работы похожа на схему DHCP-Snooping’а: порты делятся на доверенные и недоверенные, на недоверенных каждый ARP-ответ подвергаются анализу: сверяется информация, содержащаяся в этом пакете, с той, которой свич доверяет (либо статически заданные соответствия MAC-IP, либо информация из базы DHCP Snooping). Если не сходится- пакет отбрасывается и генерируется сообщение в syslog. Включаем в нужном влане (вланах): ip arp inspection vlan номер(а). По умолчанию все порты недоверенные, для доверенных портов используем ip arp inspection trust.
Практика
Наверное, большинство ошибок в Packet Tracer допущено в части кода, отвечающего за симуляцию STP, будте готовы. В случае сомнения сохранитесь, закройте PT и откройте заново
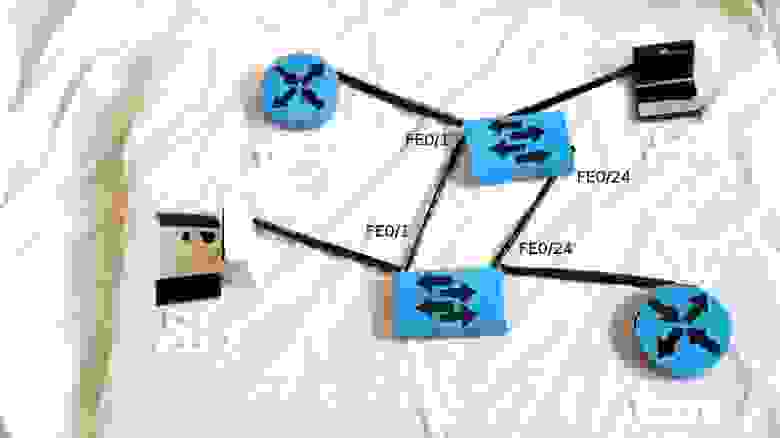
Итак, переходим к практике. Для начала внесем некоторые изменения в топологию — добавим избыточные линки. Учитывая сказанное в самом начале, вполне логично было бы сделать это в московском офисе в районе серверов — там у нас свич msk-arbat-asw2 доступен только через asw1, что не есть гуд. Мы отбираем (пока, позже возместим эту потерю) гигабитный линк, который идет от msk-arbat-dsw1 к msk-arbat-asw3, и подключаем через него asw2. Asw3 пока подключаем в порт Fa0/2 dsw1. Перенастраиваем транки:
msk-arbat-dsw1(config)#interface gi1/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw2
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-dsw1(config-if)#int fa0/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw3
msk-arbat-dsw1(config-if)#switchport mode trunk
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,101-104msk-arbat-asw2(config)#int gi1/2
msk-arbat-asw2(config-if)#description msk-arbat-dsw1
msk-arbat-asw2(config-if)#switchport mode trunk
msk-arbat-asw2(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-asw2(config-if)#no shutdown
Не забываем вносить все изменения в документацию!
Скачать актуальную версию документа.
Теперь посмотрим, как в данный момент у нас самонастроился STP. Нас интересует только VLAN0003, где у нас, судя по схеме, петля.
msk-arbat-dsw1>en
msk-arbat-dsw1#show spanning-tree vlan 3
Разбираем по полочкам вывод команды

Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем- таблица состояния портов, которая состоит из следующих колонок (слева направо):
- собственно, порт
- его роль (Root- корневой порт, Desg- назначенный порт, Altn- дополнительный, Back- резервный)
- его статус (FWD- работает, BLK- заблокирован, LIS- прослушивание, LRN- обучение)
- стоимость маршрута до корневого свича
- Port ID в формате: приоритет порта.номер порта
- тип соединения
Итак, мы видим, что Gi1/1 корневой порт, это дает некоторую вероятность того, что на другом конце линка корневой свич. Смотрим по схеме, куда ведет линк: ага, некий msk-arbat-asw1.
msk-arbat-asw1#show spanning-tree vlan 3
И что же мы видим?
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 32771
Address 0007.ECC4.09E2
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Вот он, наш корневой свич для VLAN0003.
А теперь посмотрим на схему. Ранее, мы увидели в состоянии портов, что dsw1 блокирует порт Gi1/2, разрывая таким образом петлю. Но является ли это оптимальным решением? Нет, конечно. Сейчас наша новая сеть работает точь-в-точь как старая- трафик от asw2 идет только через asw1. Выбор корневого маршрутизатора никогда не нужно оставлять на совесть глупого STP. Исходя из схемы, наиболее оптимальным будет выбор в качестве корневого свича dsw1- таким образом, STP заблокирует линк между asw1 и asw2. Теперь это все надо объяснить недалекому протоколу. А для него главное что? Bridge ID. И он неслучайно складывается из двух чисел. Приоритет- это как раз то слагаемое, которое отдано на откуп сетевому инженеру, чтобы он мог повлиять на результат выбора корневого свича. Итак, наша задача сводится к тому, чтобы уменьшить (меньше-лучше, думает STP) приоритет нужного свича, чтобы он стал Root Bridge. Есть два пути:
1) вручную установить приоритет, заведомо меньший, чем текущий:
msk-arbat-dsw1>enable
msk-arbat-dsw1#configure terminal
msk-arbat-dsw1(config)#spanning-tree vlan 3 priority?
<0-61440> bridge priority in increments of 4096
msk-arbat-dsw1(config)#spanning-tree vlan 3 priority 4096
Теперь он стал корневым для влана 3, так как имеет меньший Bridge ID:
msk-arbat-dsw1#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 4099
Address 000B.BE2E.392C
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
2) дать умной железке решить все за тебя:
msk-arbat-dsw1(config)#spanning-tree vlan 3 root primary
Проверяем:
msk-arbat-dsw1#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 24579
Address 000B.BE2E.392C
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Мы видим, что железка поставила какой-то странный приоритет. Откуда взялась эта круглая цифра, спросите вы? А все просто- STP смотрит минимальный приоритет (т.е. тот, который у корневого свича), и уменьшает его на два шага инкремента (который составляет 4096, т.е. в итоге 8192). Почему на два? А чтобы была возможность на другом свиче дать команду spanning-tree vlan n root secondary (назначает приоритет=приоритет корневого-4096), что позволит нам быть уверенными, что, если с текущим корневым свичом что-то произойдет, его функции перейдут к этому, “запасному”. Вероятно, вы уже видите на схеме, как лампочка на линке между asw2 и asw1 пожелтела? Это STP разорвал петлю. Причем именно в том месте, в котором мы хотели. Sweet! Зайдем проверим: лампочка — это лампочка, а конфиг — это факт.
msk-arbat-asw2#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 24579
Address 000B.BE2E.392C
Cost 4
Port 26(GigabitEthernet1/2)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 32771 (priority 32768 sys-id-ext 3)
Address 000A.F385.D799
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 20
Interface Role Sts Cost Prio.Nbr Type
---------------- ---- --- --------- -------- --------------------------------
Fa0/1 Desg FWD 19 128.1 P2p
Gi1/1 Altn BLK 4 128.25 P2p
Gi1/2 Root FWD 4 128.26 P2p
Теперь полюбуемся, как работает STP: заходим в командную строку на ноутбуке PTO1 и начинаем бесконечно пинговать наш почтовый сервер (172.16.0.4). Пинг сейчас идет по маршруту ноутбук-asw3-dsw1-gw1-dsw1(ну тут понятно, зачем он крюк делает — они из разных вланов)-asw2-сервер. А теперь поработаем Годзиллой из SimСity: нарушим связь между dsw1 и asw2, вырвав провод из порта (замечаем время, нужное для пересчета дерева).
Пинги пропадают, STP берется за дело, и за каких-то 30 секунд коннект восстанавливается. Годзиллу прогнали, пожары потушили, связь починили, втыкаем провод обратно. Пинги опять пропадают на 30 секунд! Мда-а-а, как-то не очень быстро, особенно если представить, что это происходит, например, в процессинговом центре какого-нибудь банка.
Но у нас есть ответ медленному PVST+! И ответ этот — Быстрый PVST+ (так и называется, это не шутка: Rapid-PVST). Посмотрим, что он нам дает. Меняем тип STP на всех свичах в москве командой конфигурационного режима: spanning-tree mode rapid-pvst
Снова запускаем пинг, вызываем Годзиллу… Эй, где пропавшие пинги? Их нет, это же Rapid-PVST. Как вы, наверное, помните из теоретической части, эта реализация STP, так сказать, “подстилает соломку” на случай падения основного линка, и переключается на дополнительный (alternate) порт очень быстро, что мы и наблюдали. Ладно, втыкаем провод обратно. Один потерянный пинг. Неплохо по сравнению с 6-8, да?
EtherChannel
Помните, мы отобрали у офисных работников их гигабитный линк и отдали его в пользу серверов? Сейчас они, бедняжки, сидят, на каких-то ста мегабитах, прошлый век! Попробуем расширить канал, и на помощь призовем EtherChannel. В данный момент у нас соединение идет от fa0/2 dsw1 на Gi1/1 asw3, отключаем провод. Смотрим, какие порты можем использовать на asw3: ага, fa0/20-24 свободны, кажется. Вот их и возьмем. Со стороны dsw1 пусть будут fa0/19-23. Соединяем порты для EtherChannel между собой. На asw3 у нас на интерфейсах что-то настроено, обычно в таких случаях используется команда конфигурационного режима default interface range fa0/20-24, сбрасывающая настройки порта (или портов, как в нашем случае) в дефолтные. Packet tracer, увы, не знает такой хорошей команды, поэтому в ручном режиме убираем каждую настройку, и тушим порты (лучше это сделать, во избежание проблем)
msk-arbat-asw3(config)#interface range fa0/20-24
msk-arbat-asw3(config-if-range)#no description
msk-arbat-asw3(config-if-range)#no switchport access vlan
msk-arbat-asw3(config-if-range)#no switchport mode
msk-arbat-asw3(config-if-range)#shutdown
ну а теперь волшебная команда
msk-arbat-asw3(config-if-range)#channel-group 1 mode on
то же самое на dsw1:
msk-arbat-dsw1(config)#interface range fa0/19-23
msk-arbat-dsw1(config-if-range)#channel-group 1 mode on
поднимаем интерфейсы asw3, и вуаля: вот он, наш EtherChannel, раскинулся аж на 5 физических линков. В конфиге он будет отражен как interface Port-channel 1. Настраиваем транк (повторить для dsw1):
msk-arbat-asw3(config)#int port-channel 1
msk-arbat-asw3(config-if)#switchport mode trunk
msk-arbat-asw3(config-if)#switchport trunk allowed vlan 2,101-104
Как и с STP, есть некая трудность при работе с etherchannel в Packet Tracer’e. Настроить-то мы, в принципе, можем по вышеописанному сценарию, но вот проверка работоспособности под большим вопросом: после отключения одного из портов в группе, трафик перетекает на следующий, но как только вы вырубаете второй порт — связь теряется и не восстанавливается даже после включения портов.
Отчасти в силу только что озвученной причины, отчасти из-за ограниченности ресурсов мы не сможем раскрыть в полной мере эти вопросы и посему оставляем бОльшую часть на самоизучение.
Материалы выпуска
Новый план коммутации
Файл PT с лабораторной.
Конфигурация устройств
STP или STP
Безопасность канального уровня
Агрегация каналов
По сложившейся традиции все неотвеченные вопросы безымянными читателями хабра задаются в блоге цикла в ЖЖ.
За видео и помощь в подготовке статьи спасибо eucariot
Bridge Protocol Data Units (BPDUs) are the messages that are transmitted across LAN networks to enable switches to participate in Spanning Tree Protocol (STP) by gathering information about each other. It contains information regarding switch ports such as port ID, port priority, port cost, and MAC addresses. A switch sends BPDUs from their origin port to a multicast address with a destination MAC address.
There are mainly two types of Bridge Protocol Data Units:
- Configuration BPDU
- Topology Change Notification (TCN) BPDU
Configuration Bridge Protocol Data Units:
Configuration BPDUs are generated by the root switch of the network. These are responsible for controlling and authenticating the flow of data away from the root bridge and they also act as a firewall to protect the network from external threats. Configuration BPDUs also helps in selecting the root switch for the network as when configuration BPDUs are transmitted switch compares the switch ID with the current root switch ID and switch with the lowest ID is selected as the root switch and BPDUs are relayed from the selected root switch.
Working:
When the network is initiated, every switch considers itself as a root switch and generates configuration BPDUs and transmits them at regular intervals. Every switch port receiving the configuration BPDU compares its own switch ID with the switch ID of the root of the received BPDU and if the switch ID of the root is superior to its own switch ID then it work as a non-root switch and doesn’t generate configuration BPDUs but just update certain fields of received BPDU such as message age, root path cost, sender bridge ID, etc. and transmits this BPDU to the designated port. On the contrary, if the ID of the root of the received BPDU is lower than the ID of receiving port then the port responds with its own configuration BPDU. In case of path failure root port does not receive new configuration BPDUs then, in this case, it transmits configuration BPDUs and TCN BPDUs with itself as root and trigger the STP calculation process to establish a new path and restore network connectivity.
Applications:
- Control and authenticate flow of data within the network
- Protect the network from external actions
- Select root switch of the network
- Detect loop in network topology
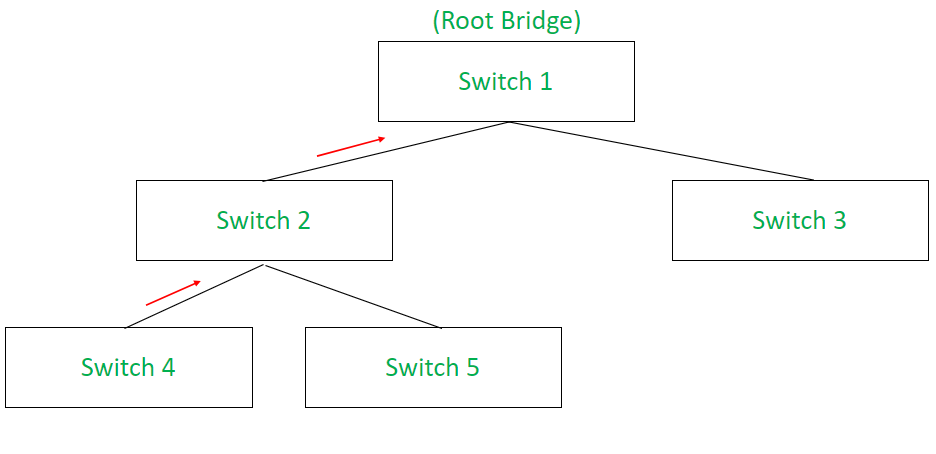
Topology Change Notification Bridge Protocol Data Units:
Topology Change Notification (TCN) BPDUs are generated by non-root switches of the network and they flow towards the root switch. These are responsible to notify topology changes in the network to root switch along with regulating the currently used topology by the network. Network topology can be changed due to various reasons like link failure, switch failure, etc. This topology change must be notified to every switch of the network which is done with help of TCN BPDUs which notifies the root switch about this change and the root switch further broadcasts topology change information to the whole network.
Working:
When a switch encounters a topology change in the network it generates a Topology Change Notification BPDU with all the information about the topology that is currently being used and sends it to the root port. Root port on receiving the TCN BPDU responds back sender with Topology Change Acknowledgment (TCA) BPDU. Now, the upstream switch that received the TCN BPDU generates its own TCN BPDU and transmits it to its root port. This process is continued till the root bridge receives TCN BPDU. Once, root bridge is notified about topology change, it generates a configuration BPDU with topology change bit set and broadcast this BPDU to the entire network so that all the switches are notified about topology change within the network.
Applications:
- Notifies root bridge about topology change within the network
- Carries information about the topology change
Last Updated :
18 Jan, 2022
Like Article
Save Article
Сертификации R&S больше нет, но данная информация по-прежнему полезна.
Материалы курса Cisco CCNA-3 часть 1 ( третья часть курса CISCO CCNA R&S ), уроки 1 — 5.
Кратко — нужно чётко знать, чем отличаются 802.1D, 802.1Q, 802.1s, 802.1w, 802.1X и что такое AAA, порты RADIUS. Много вопросов на экзамене про STP, выбор корневого моста и альтернативных портов. Нужно знать диапазон MAC адресов для HSRP.
Урок 1
Иерархическая модель архитектуры сети
Основные понятия, которые потом очень часто используются:
- Уровень доступа;
- Уровень распределения;
- Уровень ядра.
Уровень доступа обеспечивает возможность подключения пользователей — VLAN, безопасность портов, STP.
Уровень распределения используется для пересылки трафика из одной локальной сети в другую — EtherChannel, ACL, QoS.
И наконец, центральный уровень, уровень ядра, представляет собой высокоскоростную магистраль между распределенными сетями — OSPF, EIGRP, для ускорения пересылки сервисы нагружающие процессор, такие как ACL, QoS — не используются.
В целях экономии уровень ядра может быть слит воедино с уровнем распределения — свёрнутое (вырожденное) ядро.
Если вся сеть предприятия находится в 1 здании, занимает здание целиком или часть здания, то скорее всего это будет 2 уровневая модель сети со свёрнутым ядром. Когда предприятие занимает несколько соседних зданий, в этом случае можно ожидать, что модель сети будет 3 уровневая.
В любом случае необходимость выделения отдельного уровня ядра возникает, когда уровень распределения сильно разрастается. Если в уровне распределения 3 и более слоёв коммутаторов, то уже есть необходимость в уровне ядра.
Корпоративная архитектура Cisco
Основные понятия:
- Комплекс зданий предприятия (Enterprise Campus);
- Границы предприятия (Enterprise Edge);
- Границы поставщика услуг (Service Provider Edge);
- Удаленный (филиал, сотрудник, ЦОД).
Enterprise Campus охватывает всю инфраструктуру комплекса (уровни доступа, распределения и ядра). Модуль уровня доступа содержит коммутаторы 2 и 3 уровней, обеспечивающие необходимую плотность портов. Здесь осуществляется реализация сетей VLAN и транковых каналов к уровню распределения. Важно предусмотреть избыточные каналы к коммутаторам уровня распределения здания (STP). Модуль уровня распределения объединяет уровни доступа здания с помощью устройств 3 уровня. На этом уровне осуществляются маршрутизация, контроль доступа и работы службы QoS. Модуль уровня ядра обеспечивает высокоскоростное соединение между модулями уровня распределения, серверными фермами в ЦОД и границей корпорации. При проектировании данного модуля особое внимание уделяется резервным каналам, быстрой сходимости и отказоустойчивости.
Комплекс зданий предприятия может включать дополнительные модули:
- Серверная ферма и ЦОД — данная область обеспечивает возможность высокоскоростного подключения и защиту для серверов. Критически важно обеспечить безопасность, избыточность и отказоустойчивость (STP, EtherChannel). Системы управления сетями отслеживают производительность с помощью специального устройства и доступности сети;
- Сервисный модуль — данная область обеспечивает доступ ко всем сервисам (службы IP-телефонии, беспроводной контроллер и объединенные сервисы).
Enterprise Edge включает в себя модули для подключения к Интернету и сетям VPN и WAN.
Service Provider Edge предоставляет службы для доступа к Интернету, коммутируемой телефонной сети (PSTN) и сети WAN.
Все входящие и исходящие данные в модели составной корпоративной сети (ECNM) проходят через пограничное устройство. На этом этапе система может проверить все пакеты и принять решение об их допуске в корпоративную сеть. Кроме того, на границе предприятия можно настроить системы обнаружения вторжений (IDS) и системы предотвращения вторжений (IPS) для защиты от вредоносных действий.
Качественно спроектированная сеть не только контролирует трафик, но и ограничивает размер доменов возникновения ошибки. Домен сбоя — представляет собой область сети, на которую влияют сбои в работе критически важного устройства или сетевой службы.
Иерархическая модель архитектуры обеспечивает самый простой и дешевый метод контроля размера домена сбоя на уровне распределения.
Маршрутизаторы или многоуровневые коммутаторы обычно развертываются парами, при этом коммутаторы уровня доступа распределяются между ними равномерно. Данная конфигурация называется блоком коммутации здания или отдела. Каждый блок коммутации функционирует независимо от других. Поэтому в случае отказа отдельного устройства сеть будет продолжать работать
Принципы масштабируемости
Базовая стратегия проектирования сети включает в себя следующие рекомендации:
- Следует использовать расширяемое модульное оборудование или кластерные устройства, которые можно легко модернизировать для увеличения их возможностей. Некоторые устройства можно интегрировать в кластер, чтобы они работали как одно устройство. Это упрощает управление и настройку;
- Иерархическую сеть следует проектировать с учетом возможностей добавления, обновления и изменения модулей в случае необходимости, не затрагивая при этом схему других функциональных областей сети. Например, создание отдельного уровня доступа, который можно расширить, не затрагивает уровни распределения и ядра сети комплекса зданий;
- Создайте иерархическую стратегию адресов IPv4 или IPv6. При тщательном планировании IPv4-адресов исключается необходимость повторной адресации сети для поддержки дополнительных пользователей и сервисов;
- Выберите маршрутизаторы или многоуровневые коммутаторы, чтобы ограничить широковещательные рассылки и отфильтровать нежелательный трафик из сети. Используйте устройства 3 уровня для фильтрации и сокращения объема трафика к ядру сети.
К дополнительным требованиям в отношении проектирования сети относятся следующие:
- Реализация избыточных каналов в сети между критически важными устройствами, а также между устройствами уровня доступа и уровня ядра;
- Реализация нескольких каналов между различными устройствами с использованием функций агрегирования каналов (EtherChannel) или распределением нагрузки в соответствии с равной стоимостью в целях увеличения пропускной способности, технологию EtherChannel можно использовать в том случае, если в связи с ограничениями бюджета невозможно приобрести высокоскоростные интерфейсы и оптоволоконные кабели;
- Реализация беспроводного подключения для поддержки мобильности и расширения;
- Использование масштабируемого протокола маршрутизации и реализация в этом протоколе маршрутизации функций, позволяющих изолировать обновления маршрутизации и минимизировать размер таблицы маршрутизации.
Принципы избыточности
- Одним из способов реализации избыточности является установка запасного оборудования и обеспечение отказоустойчивых сервисов для критически важных устройств;
- Другим способом реализации избыточности является использование избыточных путей;
Протокол STP обеспечивает избыточность, необходимую для надёжности, и при этом устраняет логические петли. Это обеспечивается за счёт механизма отключения резервных путей в коммутируемой сети до тех пор, пока этот путь не потребуется (например, в случае сбоя).
Принципы увеличения пропускной способности
В иерархической модели сети в некоторых каналах между коммутаторами доступа и коммутаторами распределения может потребоваться обработка большего объема трафика, чем в других каналах.
EtherChannel использует существующие порты коммутатора. Таким образом, исключены дополнительные затраты на модернизацию канала с помощью более скоростного и дорогостоящего подключения.
Принципы расширения уровня доступа
Сеть должна быть спроектирована таким образом, чтобы при необходимости доступ к сети мог расширяться для пользователей и устройств. Все более важное значение приобретает расширение возможностей подключения на уровне доступа посредством беспроводного подключения. Беспроводное подключение обладает множеством преимуществ, среди которых повышенная гибкость, снижение затрат и возможность роста и адаптации в соответствии с изменением требований сети.
Платформы коммутации
На уровне доступа можно использовать менее дорогостоящие коммутаторы с более низкой производительностью, используя коммутаторы с более высокой производительностью на уровнях распределения и ядра, где скорость передачи данных в большей степени влияет на производительность сети.
Многоуровневые коммутаторы, как правило, развертываются на уровнях ядра и распределения коммутируемой сети предприятия. Многоуровневые коммутаторы характеризуются своей способностью создавать таблицу маршрутизации, поддерживать несколько протоколов маршрутизации и передавать IP-пакеты со скоростью, приближенной к скорости передачи данных на 2 уровне (аппаратная обработка пакетов в отличие от маршрутизатора).
Под плотностью портов коммутатора подразумевается количество портов, доступных на одном коммутаторе.
Примечание. Уровень доступа можно оборудовать коммутаторами серии 2960 или для удешевления 2950, уровень распределения коммутаторами 3560 или для удешевления 3550.
Требования к маршрутизатору
Маршрутизаторы используют сетевую часть IP-адреса назначения для маршрутизации пакетов к нужному получателю. Если канал недоступен или перегружен трафиком, то они выбирают альтернативный путь. Интерфейс маршрутизатора — это шлюз по умолчанию в локальной сети, которая подключена к данному интерфейсу.
Функции:
- Ограничивают широковещательные рассылки;
- Соединяют удаленные площадки;
- Логически группируют пользователей по отделам и используемым приложениям;
- Обеспечивают повышенную безопасность.

Базовая стратегия проектирования сети (обобщение)
- Следует использовать расширяемое модульное оборудование или кластерные устройства;
- Иерархическую сеть следует проектировать с учетом возможностей добавления, обновления и изменения модулей в случае необходимости, не затрагивая при этом схему других функциональных областей сети;
- Создайте иерархическую стратегию адресов IPv4 или IPv6;
- Выберите устройства 3 уровня, чтобы ограничить широковещательные рассылки и отфильтровать нежелательный трафик из сети;
- Реализация избыточных каналов в сети между критически важными устройствами (STP), а также между устройствами уровня доступа и уровня ядра;
- Реализация нескольких каналов между различными устройствами с использованием функций агрегирования каналов (EtherChannel);
- Реализация беспроводного подключения для поддержки мобильности и расширения;
- Использование масштабируемого протокола маршрутизации (OSPF, EIGRP) и реализация в этом протоколе маршрутизации функций, позволяющих изолировать обновления маршрутизации и минимизировать размер таблицы маршрутизации.
Выбор маршрутизатора

Поскольку серия 1900 рассчитана на небольшие офисы в 15-20 рабочих мест, а серия 3900 уже довольно дорогая, то оптимальным выбором можно считать серию 2900. Не следует забывать, что второе поколение маршрутизаторов с интегрированными службами Cisco (ISR G2) серий 1900, 2900 и 3900 поставляется с универсальным образом прошивки universalk9, который по умолчанию содержит функционал IP Base. Для расширения функционала требуется установка лицензии, а не установка нового образа прошивки. При этом каждый ключ лицензирования уникален для конкретного устройства и привязан к серийному номеру устройства. Подробнее в последнем уроке части 2.
Управление
Внеполосное управление (out-band) используется для начальной настройки или в том случае, если сетевое подключение недоступно. Для настройки с использованием внеполосного управления необходимо следующее:
- Прямое подключение к консольному порту или порту AUX;
- Клиент с поддержкой эмуляции терминала.
Внутриполосное (in-band — через общий канал) используется для отслеживания и внесения изменений конфигурации в сетевом устройстве через сетевое подключение. Для настройки необходимо следующее:
- Хотя бы один подключенный и исправный сетевой интерфейс;
- Протоколы Telnet, SSH или HTTP для доступа к устройству Cisco.
Базовая настройка коммутатора

Проверьте и сохраните конфигурацию коммутатора, используя команду copy running-config startup-config. Чтобы очистить конфигурацию коммутатора, введите команду erase startup-config, а затем команду reload. Кроме того, может потребоваться удаление всех данных сети VLAN с помощью команды delete flash:vlan.dat. При наличии необходимых конфигураций коммутатора их можно просмотреть с помощью команды show running-config.
Базовые команды show коммутатора
- show port-security – отображает все порты с включенной системой безопасности. Чтобы изучить данные конкретного интерфейса, добавьте в команду идентификатор интерфейса. В выходных данных указывается информация о максимально разрешенном количестве адресов, текущем количестве, количестве нарушений безопасности и действиях, которые необходимо выполнить;
- show port-security address – отображает все защищенные MAC-адреса, настроенные на всех интерфейсах коммутатора;
- show interfaces – отображает все интерфейсы с данными о состоянии канала (протокола), пропускной способности, надёжности, инкапсуляции, параметрах дуплексного режима и статистике ввода-вывода;
- show mac-address-table – отображает все MAC-адреса, полученные коммутатором, в том виде, в котором они получены (динамические/статические), номер порта и сеть VLAN, назначенную порту.
Как и маршрутизатор, коммутатор также поддерживает использование команды show cdp neighbor.
Базовые команды show маршрутизатора
Связанные с маршрутизацией:
- show ip protocols – отображает сведения о настроенных протоколах маршрутизации. Если настроен протокол OSPF, к таким данным относятся идентификатор процесса OSPF, идентификатор маршрутизатора, сети, объявляемые маршрутизатором, соседние устройства, от которых маршрутизатор принимает обновления, и значение административной дистанции по умолчанию, равное 110 для OSPF;
- show ip route – отображает сведения в таблице маршрутизации, в том числе: коды маршрутизации, известные сети, значение административной дистанции и метрики, способы получения маршрутов, следующий переход, статические маршруты и маршруты по умолчанию;
- show ip ospf neighbor – отображает сведения о соседях OSPF, данные о которых были получены, включая идентификатор маршрутизатора соседнего устройства, приоритет, состояние (Full = отношения смежности установлены), IP-адрес и локальный интерфейс, получивший сведения о соседнем устройстве;
Связанные с интерфейсом:
- show interfaces – отображает все интерфейсы с данными о состоянии канала (протокола), пропускной способности, надёжности, инкапсуляции, дуплексном режиме и статистике ввода-вывода. Если команда задана без указания конкретного интерфейса, отображаются все интерфейсы. Если конкретный интерфейс указывается после команды, отображаются сведения только для этого интерфейса;
- show ip interfaces – отображает сведения об интерфейсах, включая: состояние протокола, IP-адрес, если настроен вспомогательный адрес, а также информацию о том, настроен ли список контроля доступа (ACL) на интерфейсе. Если команда задана без указания конкретного интерфейса, отображаются все интерфейсы. Если конкретный интерфейс указывается после команды, отображаются сведения только для этого интерфейса;
- show ip interface brief – отображает все интерфейсы с данными об IP-адресации и состоянием канального протокола;
- show protocols – отображает сведения о включенном маршрутизируемом протоколе и состоянии протокола для интерфейсов.
show cdp neighbors – еще одна команда, связанная с подключением. Данная команда отображает сведения об устройствах с прямым подключением, включая идентификатор устройства, локальный интерфейс, к которому подключено устройство, функции поддержки (R = маршрутизатор, S = коммутатор), платформу и идентификатор порта удалённого устройства. Параметр details включает в себя сведения об IP-адресации и версию IOS.
Урок 2
Проблемы избыточности 1 уровня
Трехуровневая иерархическая модель сети, которая использует уровни ядра, распределения и доступа с избыточностью, призвана устранить единую точку отказа в сети. Использование нескольких физически подключенных каналов между коммутаторами обеспечивает физическую избыточность в коммутируемой сети.
Это повышает надёжность и доступность сети. Наличие альтернативных физических каналов для передачи данных по сети позволяет пользователям получить доступ к сетевым ресурсам даже в случае сбоя одного из каналов.
Нестабильность базы данных MAC-адресов
В отличие от IP-пакетов, кадры Ethernet не содержат атрибут время жизни (TTL). Как результат, если не используется механизм блокирования постоянного распространения этих кадров в коммутируемой сети, кадры продолжают распространяться между коммутаторами бесконечно или до тех пор, пока не произойдет сбой канала, в результате чего петля будет прервана. Такое постоянное распространение между коммутаторами может привести к нестабильности базы данных MAC-адресов. Это может произойти вследствие пересылки широковещательных кадров.
Широковещательные кадры пересылаются из всех портов коммутатора, за исключением исходного входного порта. Это гарантирует, что все устройства в домене широковещательной рассылки могут получить кадр. При наличии нескольких путей для пересылки кадров может возникнуть бесконечная петля. В случае возникновении петли таблица MAC-адресов на коммутаторе может постоянно изменяться за счёт обновлений от широковещательных кадров, что приводит к нестабильности базы данных MAC-адресов.
Широковещательный шторм
Широковещательный шторм возникает в случае, когда в петлю на 2 уровне попадает столько кадров широковещательной рассылки, что при этом потребляется вся доступная полоса пропускания. Соответственно, для пользовательского трафика нет доступной полосы пропускания, и сеть становится недоступной для обмена данными. Описанная ситуация — отказ в обслуживании (DoS), CPU коммутатора загружен на 100% (основной признак петли на 2 уровне), CLI коммутатора отвечает с большой задержкой либо либо вообще недоступен.
Множественная передача кадров
Кадры широковещательной рассылки являются не единственным типом кадров, на которые влияет возникновение петель. Кадры одноадресной рассылки, отправленные в сеть, где возникла петля, могут стать причиной дублирования кадров, поступающих на устройство назначения.
Spanning Tree Protocol (STP)
Протокол связующего дерева — при реализации в проектировании физической избыточности возникают петли. Петли являются причиной серьезных неполадок в коммутируемой сети.
Протокол STP разработан для решения подобных проблем.
Протокол STP обеспечивает наличие только одного логического пути между всеми узлами назначения в сети путем намеренного блокирования резервных путей, которые могли бы вызвать петлю.
Порт считается заблокированным, когда заблокирована отправка и прием данных на этот порт. К таким данным не относятся кадры BPDU, которые используются протоколом STP для предотвращения петель.
Типы протоколов STP

Протоколов много, легко в них запутаться, поэтому разобьём их на 2 класса.
Протоколы IEEE
Это свободно распространяемые протоколы:
- STP, Spanning Tree Protocol: первая версия IEEE 802.1D предполагает использование только одного экземпляра протокола spanning-tree для всей сети независимо от количества VLANs;
- RSTP, Rapid Spanning Tree Protocol (IEEE 802.1w): доработанный протокол STP, который обеспечивает более быстрое схождение, чем протокол STP. По-прежнему один экземпляр на все VLANs;
- MSTP, Multipul Spanning Tree Protocol (IEEE 802.1s): или просто MST — стандарт, созданный на основе предыдущей собственной реализации протокола MISTP компании Cisco. Является расширением протокола RSTP. Несколько экземпляров RSTP, но не по одному экземпляру на все VLANs, а по одному экземпляру на группу VLANs.
Протоколы CISCO
Проприетарные протоколы, собственность компании CISCO:
- PVST+ (Per VLAN STP): является усовершенствованным протоколом STP компании Cisco, в котором для каждой отдельной VLAN используется отдельный экземпляр STP;
- Rapid PVST+: усовершенствованный корпорацией Cisco протокол RSTP. Rapid PVST+ предоставляет отдельный экземпляр RSTP для каждой VLAN.
Также CISCO использует в своих коммутаторах MSTP(MST). Изначально реализация CISCO протокола MSTP обеспечивала до 16 экземпляров протокола RSTP (посмотреть можно здесь):
В соответствии со спецификацией IEEE 802.1s мост MST должен поддерживать, по крайней мере, два экземпляра: Один внутренний экземпляр связующего дерева (IST); Один или более экземпляров множественного связующего дерева (MSTI). ... Реализация Cisco поддерживает 16 экземпляров: один IST (экземпляр 0) и 15 экземпляров MSTI.
В новых прошивках количество инстансов приведено к стандарту — 64.
Примечание. Устаревшие проприетарные функции Cisco UplinkFast и BackboneFast в рамках данного курса не рассматриваются. Эти функции заменены реализацией протокола Rapid PVST+, в которую данные функции включены как часть реализации стандарта RSTP.
Примечание. Коммутатор Catalyst 2960 поддерживает протоколы PVST+, Rapid PVST+ и MST, однако только одна из версий может быть настроена для всех VLANs.
Основные версии стандарта STP:
- 802.1D-1998: первая версия стандарта STP;
- 802.1D-2004: обновленная версия стандарта STP, в которую входит RSTP
Протоколы STP IEEE находятся в постоянной доработке по настоящее время (802.1Q-2014, 802.1Q-2018..).
Характеристики протоколов STP

В коммутаторах Cisco Catalyst по умолчанию используется режим протокола spanning-tree PVST+, включенный на всех портах. Для использования быстрого протокола Rapid PVST+ на таком коммутаторе его необходимо явно настроить. Коммутаторы Catalyst 2960 с IOS 15.0, по умолчанию используют PVST+, однако содержат многие характеристики стандарта IEEE 802.1D-2004 (например, альтернативные порты вместо неназначенных портов).
Кадр BPDU
Bridge protocol data unit (BPDU) представляет собой кадр обмена сообщениями, которым обмениваются коммутаторы с STP.
Рассмотрим структуру BPDU:

- В первых четырех полях указаны протокол, версия, тип сообщения и флаги состояния;
- Следующие четыре поля используются для определения корневого моста и стоимости пути к нему (в поле BID — Bridge ID указывается приоритет и идентификатор MAC адреса моста, отправляющего сообщение);
- Последние четыре поля являются полями таймера, которые определяют интервал отправки сообщений BPDU и продолжительность хранения данных, полученных посредством процесса BPDU (по умолчанию max age — 20 секунд, hello time -2 секунды, forward delay — 15 секунд);
- Кадр содержит MAC-адрес назначения 01:80:C2:00:00:00, который является адресом групповой рассылки для группы протокола spanning-tree. При адресации кадра с использованием этого MAC-адреса все коммутаторы, настроенные для протокола spanning-tree, принимают и считывают данные из кадра. Все остальные устройства в сети игнорируют кадр.

Корневой мост
Корневой мост (Root Bridge) — одно из основных понятий STP. Алгоритм протокола spanning-tree (STA) назначает один из коммутаторов в качестве корневого моста и использует его как точку привязки для расчёта всех путей.
Выбор корневого моста
Коммутатор с наименьшим значением BID автоматически становится корневым мостом для расчётов STA (алгоритм протокола spanning-tree).
BID
- Каждый кадр BPDU содержит идентификатор BID, который определяет коммутатор, отправивший BPDU;
- Идентификатор BID состоит из 3 полей: значение приоритета, дополнительный расширенный идентификатор системы, MAC-адрес отправляющего кадр BPDU коммутатора
- Самое низкое значение BID определяется комбинацией значений в этих трех полях.

Подробнее: сначала сравниваются приоритеты коммутаторов, если они равны, то MAC адреса — выбирается коммутатор с меньшим значением.
Свойства корневого моста
- Корневой мост выбирается для каждого экземпляра протокола STP;
- Экземпляр протокола STP определяется номером VLAN (если все порты на всех коммутаторе являются принадлежат одной VLAN (например, VLAN1), значит, существует только один экземпляр протокола STP);
- Расширенный идентификатор системы используется для определения экземпляра протокола STP.
Приоритет моста
- По умолчанию для всех коммутаторов Cisco используется значение приоритета 32768;
- Значения варьируются в диапазоне от 0 до 61440 с шагом в 4096;
- Допустимые значения приоритета: 0, 4096, 8192, 12288, 16384, 20480, 24576, 28672, 32768, 36864, 40960, 45056, 49152, 53248, 57344, 61440 (коммутаторы Catalyst серий 2960 и 3560 не поддерживают настройку приоритета моста равному значению 65536 = 16 x 4096, поскольку это предполагает использование пятого бита) ;
- Все остальные значения отклоняются;
- Приоритет моста 0 имеет преимущество по сравнению со всеми остальными значениями приоритета моста.
Расширенный идентификатор системы
- IEEE 802.1D — VLAN не использовались, на всех коммутаторах использовалось один общий экземпляр STP, приоритет моста был 16 бит;
- IEEE 802.1D-2004 — от приоритета моста «откусили» 12 бит для VLAN, то есть в этом поле указывается номер VLAN;
- Это объясняет, почему значение приоритета моста можно настроить только кратным 4096 или 2^12.

Приоритет моста получается из суммирования поля Приоритет моста и поля Расширенный идентификатор системы. По умолчанию для VLAN 1 это 32768+1 = 32769, а если VLAN 10, то соответственно 32768+10=32778.
Механизм STP
Расчёт STP производится следующим образом:
- Сначала происходят выборы корневого моста;
- Затем каждый некорневой свич выбирает среди своих портов корневой порт;
- Затем выбираются назначенные порты для каждого сегмента;
- Корневые и назначенные порты переводятся в состояние передачи, остальные в состояние блокировки.
Основные сложности возникают для пункта 3: какой порт будет назначенным в режиме передачи, а какой альтернативным в режиме блокировки.
Рекомендации по корневому мосту
- По умолчанию коммутаторы настроены с одинаковым приоритетом и содержат один и тот же расширенный идентификатор системы, поэтому коммутатор, MAC-адрес которого имеет наименьшее шестнадцатеричное значение, будет иметь наименьший идентификатор BID и станет корневым;
- Чтобы гарантировать, что решение относительно корневого моста оптимально соответствует требованиям сети, администратору рекомендуется настроить выбранный коммутатор корневого моста с наименьшим приоритетом;
- При этом также гарантируется, что добавление в сеть новых коммутаторов не спровоцирует выбор нового корневого моста;
- Корневой коммутатор выбирается по причине более централизованного расположения, или по причине более высокой мощности, или по причине удобства/безопасности доступа;
- Чтобы предотвратить случайную смену корневого моста настраивается Root Guard, который предотвращает изучение через эти порты информации о новом корневом мосте:
SW1(config)# interface fa 0/24 SW1(config-if)# spanning-tree guard root %SPANTREE-2-ROOTGUARD_CONFIG_CHANGE: Root guard enabled on port FastEthernet0/24.
Порты
Определение оптимального пути
- Пока STA определяет оптимальные пути до корневого моста для всех портов коммутатора в домене широковещательной рассылки, пересылка трафика по сети заблокирована;
- Стоимость порта, зависит от скорости порта коммутатора на данном маршруте;
- Стоимость пути равна сумме всех значений стоимости порта по пути к корневому мосту;
- Если для выбора доступно несколько путей, STA выбирает путь с наименьшей стоимостью.
Стоимость порта

Команды IOS установки стоимости порта
spanning-tree cost number - назначение стоимости no spanning-tree cost - сброс стоимости

Роли портов описывают их связь с корневым мостом в сети, а также указывают, разрешена ли для них пересылка трафика:
- Назначенные порты (Designated Port) — все некорневые порты, которым разрешено пересылать трафик по сети;
- Альтернативные и резервные порты (Alternate и Backup) — альтернативные и резервные порты настраиваются в состояние блокировки во избежание возникновения петель;
- Корневые порты (Root Port) — порты коммутатора, находящиеся максимально близко к корневому мосту;
- Отключенные порты (Disabled Port) – отключенным называется порт коммутатора, питание которого отключено.

Выбор корневого порта на коммутаторе
- Сначала сравниваются значения стоимости пути к корневому мосту, порт с меньшей стоимостью пути выбирается корневым;
- Если имеются 2 порта с одинаковой минимальной стоимостью пути к корневому мосту и порты подключены к разным соседним коммутаторам, то каждый порт смотрит в пришедший кадр BPDU и находит там значение BID (то есть BridgeID соседнего коммутатора, к которому подключен этот порт). Порт, для которого BID меньше, становится корневым;
- Если BridgeID равны или порты подключены к одному и тому же соседнему коммутатору, то каждый порт смотрит в пришедший кадр BPDU и находит там значение PortID (это PortID порта соседнего коммутатора, куда подключён данный порт). Порт, для которого данное значение меньше, становится корневым.
Выбор назначенных и альтернативных портов
Для простоты предположим что только один VLAN и соответственно один экземпляр STP (независимо от вида протокола, будет далее). Задача разбивается на две части:
- Нахождение заблокированных линков между коммутаторами.
Корневой мост найден, все его порты назначенные, корневые порты на некорневых коммутаторах тоже найдены. Все альтернативные пути от каждого коммутатора к корневому мосту должны быть заблокированы.
Проще всего нарисовать схему, подписать корневой мост, его назначенные порты, проставить корневые порты, тогда заблокированные линки обычно без труда находятся.
- Линк блокируется только с одной стороны (так сделано для быстрого его включения в работу в случае необходимости). На одной стороне заблокированного линка будет назначенный порт, на другой стороне заблокированный альтернативный порт.
С какой стороны линка порт будет альтернативный? Если STA нужно заблокировать передачу по линку между 2 коммутаторами, назначенным становится порт у коммутатора с меньшей стоимостью пути до корневого моста. В случае когда стоимости равны, то сравниваются последовательно:
- BID — порт коммутатора с меньшим BID становится назначенным;
- PortID — порт коммутатора с меньшим PortID становится назначенным;
- MAC адреса портов — порт с меньшим MAC становится назначенным
Такая длинная процедура сравнения гарантирует выбор назначенного и альтернативного порта.
Приоритет порта и PortID
По умолчанию приоритет порта равен 128 и меняется командой из режима интерфейса:
S1(config-if)#spanning-tree port-priority number
Диапазон от 0 до 240 с шагом 16:
Some older switches may allow setting the priority in different increments.
Поскольку дефолтное значение приоритета одинаково, оно не играет значения в выборе роли порта. Менять приоритет нужно для тонкой настройки в случае необходимости.
PortID формируется добавлением к приоритету порта значения идентификатора интерфейса. Идентификатор интерфейса в общем случае это номер порта, поэтому, допустим, у F0/18 он будет больше (десятичное значение 18), чем у F0/1 (1).
PortID выводится либо в шестнадцатеричном виде, например, 0x8016, либо в десятичном, тогда приоритет отделён точкой, например, 128.22 для F0/22:
PortID = PortPriority.IntID
Пример по выбору корневого порта
Возьмем 2 коммутатора 2950, соединим порты, придётся сделать кросс кабели, Auto-MDIX на 2950 нет.
Часть 1, приоритеты портов не меняем
На Switch1 будут порты 10 и 17, на Switch2 18 и 24, соответственно 24 -> 10, а 18 -> 17. Коммутатор Switch1 принудительно сделаем корневым, его порты назначенные:
Switch1(config)# spanning-tree vlan 1 root primary
Коммутатор Switch2 должен решить какой порт 18 или 24 будет альтернативным, а какой корневой.
Достаточно хитрый механизм. Как уже говорил, важно помнить, что порт всегда смотрит информацию в пришедшем кадре BPDU.
- Стоимость пути до корневого моста, понятное дело, для обоих портов одинаковая. Переходим к следующему шагу;
- Каждый порт (18 и 24) смотрит в пришедшем кадре BPDU BID соседнего коммутатора. Поскольку подключены они оба к Switch1, то значения будут равны. Переходим к следующему шагу;
- Каждый порт (18 и 24) смотрит в пришедшем кадре BPDU PortID смежного порта на другом коммутаторе. Для Fa0/18 это 128.17, для Fa0/24 это 128.10. Поскольку 128.10 меньше чем 128.17, то корневым будет Fa0/24.
И хотя F0/24 имеет собственный PorID больше, чем у F0/18:

Именно он становится корневым портом, потому что подключён к порту с меньшим PortID (на F0/1 не надо обращать внимание, это линк к моему компьютеру):

Теперь переключим порт F0/18 коммутатора Switch2 из порта F0/17 в порт F0/9.

Теперь уже F0/18 корневой порт, так как теперь он подключён к порту с меньшим PortID 128.9 против 128.10 для F0/24.

Наглядно видно, что порты выбираются указанным выше способом.
Часть 2, с изменением приоритетов портов
Побалуемся приоритетами портов. Для этого у порта F0/24 на коммутаторе Switch2 явно изменим приоритет на 64 и для верности перезагрузим коммутатор, чтобы STA пересчитал всё заново:

Смотрим:

Порт F0/24 как он был в конце прошлого примера альтернативным в состоянии блокировки, так и остался. Ничего не изменилось и пока ничего интересного. Теперь поменяем на 64 приоритет порта F0/10 на Switch1, куда включён F0/24:

Ждём перерасчёт и смотрим на Switch2.

F0/24 теперь рутовый. Наглядно видно, что играет роль не собственный приоритет порта, а порта соседнего коммутатора, куда данный порт подключён.
Процесс BPDU
- Изначально каждый коммутатор в домене широковещательной рассылки считает себя корневым мостом для экземпляра протокола spanning-tree, поэтому отправленные кадры BPDU содержат идентификатор BID локального коммутатора в качестве идентификатора корневого моста;
- Когда смежные коммутаторы принимают кадр BPDU, они сопоставляют содержащийся в нем идентификатор корневого моста с локальным идентификатором корневого моста. Если идентификатор корневого моста в кадре BPDU имеет меньшее значение, чем локальный идентификатор корневого моста, коммутатор обновляет локальный идентификатор и тот идентификатор, который содержится в сообщениях BPDU;
- Если локальный идентификатор корневого моста имеет меньшее значение, чем идентификатор корневого моста, полученный в кадре BPDU, кадр BPDU отбрасывается;
- Сначала сравнивается значение приоритета, если значения приоритета равны, тогда сравниваются значения MAC-адресов;
- После обновления идентификатора корневого моста в целях определения нового корневого моста, все последующие кадры BPDU, отправленные с этого коммутатора, будут содержать новый идентификатор корневого моста и обновленное значение стоимости пути.
Рекомендации по STP
Выбор протокола STP
Предположим, планируется к внедрению новая сеть на некоторых коммутаторах, коммутаторы естественно поддерживают разные протоколы STP. Возникает вопрос: какой из протоколов STP выбрать?
Малое количество VLANs (пара десятков или чуть больше):
- Все коммутаторы CISCO, выбираем Rapid PVST+;
- Смешанная среда разных вендоров, выбираем MSTP(MST).
Большое количество VLANs (сотни):
- Выбираем MSTP(MST) вне зависимости от вендора.
Такой подход обеспечит распределение нагрузки по линкам с учётом VLANs на втором уровне. Что это значит? Например, когда протокол RSTP блокирует линк, он это делает для всех VLANs. Через линк никакая информация (кроме BPDU) не ходит. Когда протокол MSTP блокирует линк, то он это делает для группы VLANs, при этом информация для других VLANs передаётся через линк. Таким образом суммарное количество передаваемой информации увеличивается.
Расходуемые ресурсы CPU, памяти на обсчёт инстансов и отправку BPDU возрастают при возрастании количества VLANs. Если разговор про большое количество VLANs, то тут надо сказать, что количество поддерживаемых экземпляров STP тоже конечно и зависит от модели коммутатора. Только MSTP здесь сможет помочь.
Выбор протокола также сильно зависит от топологии. Например, если топология звезда (она же Hub and Spoke), тогда каждый периферийный коммутатор соединён с центральным или одиночным линком, или агрегацией линков. В этом случае никакого преимущества от использования MSTP не будет, все линки между коммутаторами задействованы для всех VLANs. В этом случае выберу RSTP, так как его настройка проще и компактнее в конфигурации (зависит от вендора).
Самое важное тут: есть подход один инстанс на все VLANs, есть подход инстанс на каждую VLAN и есть компромиссный MST. Какой подход выбрать зависит от многих факторов.
Да, ещё один момент: MSTP требует ручной настройки, так как по умолчанию все VLANs помещаются в нулевой инстанс. То есть заработать-то заработает, но только одно дерево, выигрыша никакого не будет по сравнению с RSTP, не будет распределения нагрузки по линкам. Как найду время выложу статью. Тот же Rapid PVST+ автоматически создаст отдельный инстанс на каждую VLAN и всё замечательно. А здесь нет, извольте инстанс для каждой группы VLANs прописать ручками.
На каких портах включать STP?
Понятное дело STP нужно включать на транках между коммутаторами. Нужно ли включать STP для пользовательских портов? Встречал в сети комментарии, что STP «есть чистое зло и его нужно выключать везде, где только можно», ну а уж на пользовательских портах особенно. Это заблуждение. На пользовательских портах STP нужно включать обязательно.
Пример. На IP-телефоне (допустим AVAYA) есть 2 гнезда: для сети и для компьютера (сам он по сути и есть коммутатор). Если оба гнезда подключить к сети, к одной VLAN, то сеть без STP (и без LoopBack Detection (LBD)) за несколько секунд ляжет. Причём не только коммутатор, куда подключен этот телефон, а вообще вся часть сети, на которую этот VLAN распространяется. Это может сделать по незнанию или по ошибке любой сотрудник. Вы долго будете бегать по этажам «кудахтая» и пытаясь понять что же случилось. Так что можете не включать STP, но.. это до первой петли 🙂
Что ещё можно улучшить?
При использовании классического STP порт при подключении устройства поднимается довольно долго. Чтобы ускорить включение порта используйте быстрые протоколы STP: RSTP, MSTP и Rapid PVST+.
На пользовательских портах (где это совместимо с оконечным оборудованием) включайте опцию PortFast. Рекомендация CISCO: совместно с BPDU Guard. Порты будут подниматься мгновенно. При получении на порту BPDU, порт блокируется. Требуется ручная разблокировка или настройка очистки состояний errdisable по таймеру. На транках к серверам, на транке к маршрутизатору, используйте опцию PortFast Trunk.
STP (802.1D)
- Один заблокированный порт должен блокировать все сети VLAN;
- Требуется вычисление только одного экземпляра протокола spanning-tree.
Роли портов
- Root Port — корневой порт коммутатора;
- Designated Port — назначенный порт сегмента;
- Nondesignated Port — неназначенный порт сегмента;
- Disabled Port — порт который находится в выключенном состоянии.
Состояния портов
- Blocking — блокирование;
- Listening — прослушивание;
- Learning — обучение;
- Forwarding — пересылка;
- Disabled — отключённый.
CISCO в своих коммутаторах расширяет стандарт 802.1D проприетарными решениями и называется он PVST+ Этот стандарт используется в коммутаторах CISCO по умолчанию.
RSTP (802.1w)
- Протокол RSTP (802.1w) заменяет собой исходный стандарт 802.1D, поддерживая при этом функции обратной совместимости. Сохраняется большая часть терминологии, относящейся к исходному стандарту 802.1D, и большинство параметров остаются неизменными. Кроме того, 802.1w поддерживает возврат к более ранней версии 802.1D, обеспечивающей взаимодействие с предыдущими моделями коммутаторов на отдельных портах. Например, алгоритм протокола spanning-tree RSTP выбирает корневой мост точно так же, как и исходная версия 802.1D;
- RSTP сохраняет те же форматы BPDU, что и исходный IEEE 802.1D, за исключением того, что в поле версии установлено значение 2, что указывает на протокол RSTP, а поле флагов задействует все 8 бит;
- Протокол RSTP может активно подтвердить возможность безопасного перехода порта в состояние пересылки, не полагаясь на конфигурацию таймера.

Протокол RSTP использует байт флага BPDU версии 2:
- Биты 0 и 7 используются для изменения топологии и подтверждения их поступления в исходный 802.1D;
- Биты 1 и 6 используются для процесса согласования предложения (для быстрого схождения);
- Биты со 2 по 5 выполняют кодирование роли и состояния порта;
- Биты 4 и 5 используются для кодирования роли порта с использованием 2-битного кода.
Особенности RSTP
- Данные протокола на порте могут устареть сразу же, если пакеты приветствия не приняты три раза подряд (по умолчанию — в течение шести секунд) или по истечении максимального времени существования;
- Поскольку BPDU используется в качестве механизма keepalive, три подряд пропущенных BPDU указывают на потерю соединения между мостом и его соседним корневым мостом или выделенным мостом. Быстрое устаревание данных позволяет быстро обнаруживать сбои;
- Протокол RSTP использует BPDU типа 2 версии 2 (исходный стандарт 802.1D используется BPDU типа 0 версии 0).
Пограничный порт
- Никогда не будет подключен к коммутатору;
- Немедленно переходит в режим пересылки.
spanning-tree portfast
Примечание. Не рекомендуется настраивать граничные порты, которые будут соединены с другим коммутатором. Это может иметь негативные последствия для RSTP, поскольку появляется вероятность возникновения временной петли, приводящей к задержке схождения RSTP.
Поскольку PortFast предназначен для минимизации времени ожидания портами доступа схождения протокола spanning-tree, эту функцию рекомендуется использовать только на портах доступа.
Тип канала
- Точка-точка: порт, работающий в полнодуплексном режиме; как правило, соединяет два коммутатора и является кандидатом на быстрый переход в состояние пересылки;
- Общий: порт, работающий в полудуплексном режиме; соединяет коммутатор с концентратором, объединяющим несколько устройств;
- Тип канала позволяет определить, может ли порт сразу перейти в состояние пересылки при условии выполнения определённых условий;
- Для граничных и неграничных портов требуются разные условия;
- Тип канала определяется автоматически, но его можно переопределить с помощью явной команды.
spanning-tree link-type parameter
Характеристики ролей портов с учетом типа канала
- корневые порты не используют параметр типа канала; корневые порты могут осуществлять быстрый переход в состояние пересылки после синхронизации порта;
- альтернативные и резервные порты в большинстве случаев не используют параметр типа канала;
- назначенные порты максимально эффективно используют параметр типа канала. Быстрый переход в состояние пересылки для назначенного порта выполняется только в том случае, если для параметра типа канала установлено значение point-to-point.
Чтобы проверить, включен ли PortFast и BPDU для порта коммутатора, используйте команду show running-config,
Роли портов
- Root;
- Designated;
- Alternate — альтернативный путь к корневому коммутатору. Путь отличается от того, который использует корневой порт;
- Backup — запасной путь в сегмент.
Состояния портов
- Learning;
- Forwarding;
- Discarding.
По сравнению с исходной версией STP новые роли портов: Alternate и Backup.

Из рисунка видно: Blocking+Listening -> Discarding. STP ждёт 30 секунд (по умолчанию) перед переводом в состояние передачи:
- 15 секунд на состояние Listening, где смотрится приходят ли на порт кадры BPDUs. В течении этого времени MAC адреса не заносятся в динамическую таблицу;
- 15 секунд на состояние Learning, также просматривается приходят ли BPDUs, но также заполняется таблица MAC адресов.
Если порт находится в состоянии блокировки, то требуются ещё дополнительные 20 секунд. Чтобы истек таймер и коммутатор понял, что, связанный с данным блокированным портом, форвардящий порт отвалился.
PVST+
Per-VLAN Spanning Tree Plus (разработан CISCO на основе 802.1D)
отличие PVST+ от 802.1D
- Сеть может использовать независимый экземпляр реализации стандарта CST для каждой сети VLAN в пределах сети;
- Позволяет одному транковому порту на коммутаторе блокировать отдельную сеть VLAN, не блокируя при этом остальные сети VLAN;
- PVST+ можно использовать для распределения нагрузки на 2 уровне;
- Привносит некоторые фичи из Rapid PVST+, такие как: PortFast, UplinkFast, BackboneFast.
PVST+ имеют следующие характеристики
- Поддерживается оптимальное распределение нагрузки;
- Может привести к значительному необоснованному потреблению ресурсов ЦП, если настроено большое количество сетей VLAN.
Состояние портов
Аналогично исходному STP. Ещё раз подробнее.
Каждый порт коммутатора проходит через пять возможных состояний порта и три таймера BPDU. Если порт коммутатора переходит непосредственно из состояния блокировки в состояние пересылки, не используя во время перехода данные о полной топологии, порт может временно создавать петлю данных:
- Blocking: порт не участвует в пересылке кадров. Порт принимает кадры BPDU, чтобы определить местоположение и идентификатор корневого моста;
- Listening: прослушивание пути к корневому мосту. На этом этапе порт коммутатора не только принимает кадры BPDU, но также передает свои собственные кадры BPDU и сообщает смежным коммутаторам о том, что порт коммутатора готовится к участию в активной топологии;
- Learning: изучение MAC-адресов. На этапе подготовки к пересылке кадров порт начинает заполнять таблицу MAC-адресов;
- Forwarding: порт считается частью активной топологии. Он пересылает кадры данных, отправляет и принимает кадры BPDU;
- Disabled: ( отключен администратором) порт 2 уровня не участвует в протоколе spanning-tree и не пересылает кадры.
show spanning-tree summary

Алгоритм PVST+
- Выбор одного корневого моста: только один коммутатор может выступать в роли корневого моста (для данной сети VLAN);
- Выбор корневого порта на каждом некорневом мосту: протокол STP устанавливает один корневой порт на каждом некорневом мосту. Корневой порт является путем с наименьшей стоимостью от некорневого моста к корневому мосту, указывая оптимальный путь к корневому мосту;
- Выбор назначенного порта в каждом сегменте: назначенный порт предоставляет маршрут с наименьшей стоимостью к корневому мосту;
- Остальные порты в коммутируемой сети являются альтернативными: как правило, остаются в состоянии блокировки, что позволяет логически разорвать петлевую топологию. Когда порт находится в состоянии блокировки, он не пересылает трафик, но по-прежнему может обрабатывать полученные сообщения BPDU.
Параметры по умолчанию для Catalyst 2960

Настройка корневого моста метод 1
spanning-tree vlan vlan-id root primary spanning-tree vlan vlan-id root secondary
Настройка корневого моста метод 2
spanning-tree vlan vlan-id priority number
PortFast и BPDU Guard
- PortFast можно использовать на портах доступа для обеспечения немедленного подключения этих устройств к сети;
- В конфигурации PortFast прием кадров BPDU никогда не допускается;
- Когда функция BPDU guard включена, она переводит порт в состояние отключения из-за ошибки при получении BPDU;
At the reception of BPDUs, the BPDU guard operation disables the port that has PortFast configured. The BPDU guard transitions the port into errdisable state, and a message appears on the console. This message is an example: 2000 May 12 15:13:32 %SPANTREE-2-RX_PORTFAST:Received BPDU on PortFast enable port. Disabling 2/1
- Технологию Cisco PortFast рекомендуется использовать для DHCP. Без PortFast компьютер может отправить запрос DHCP до перехода порта в состояние пересылки;
- Если функция PortFast включена на порте, подключенном к другому коммутатору, возникнет риск возникновения петли протокола spanning-tree.
В глобальном режиме:
spanning-tree portfast default - используется для включения PortFast на всех нетранковых интерфейсах spanning-tree portfast bpduguard default - включает BPDU guard на всех портах с поддержкой PortFast
в режиме конфигурации порта:
spanning-tree portfast spanning-tree bpduguard enable
show spanning-tree active - отобразить сведения только для активных интерфейсов
Rapid PVST+
Разработан CISCO на основе 802.1D.
отличие Rapid PVST+ от RSTP
- Сеть может использовать независимый экземпляр реализации стандарта RSTP для каждой сети VLAN в пределах сети;
- Позволяет одному транковому порту на коммутаторе блокировать отдельную сеть VLAN, не блокируя при этом остальные сети VLAN;
- Rapid PVST+ можно использовать для распределения нагрузки на 2 уровне.
Роли портов
Аналогично RSTP.
- Root;
- Designated;
- Alternate — альтернативный путь к корневому коммутатору. Путь отличается от того, который использует корневой порт;
- Backup — запасной путь в сегмент.
RSTP поддерживает новый тип порта: альтернативный порт в состоянии отбрасывания. Отсутствуют порты, работающие в режиме блокирования;
Если порт настроен в качестве альтернативного или резервного, он может немедленно перейти в состояние пересылки, не дожидаясь схождения сети.
Состояние портов
Аналогично RSTP.
- Learning;
- Forwarding;
- Discarding.
Для настройки конфигурации Rapid PVST+ требуется только команда режима глобальной конфигурации:
spanning-tree mode rapid-pvst
и может быть команда очистки:
cleaning spanning-tree detected-protocols
При определении настраиваемого интерфейса к допустимым интерфейсам относятся физические порты, сети VLAN и агрегированные каналы. Диапазон идентификаторов сети VLAN — от 1 до 4094, если установлен расширенный образ ПО или от 1 до 1005, если установлен стандартный образ ПО.
Примечание. Как правило, нет необходимости в настройке параметра типа канала точка-точка для протокола Rapid PVST+, поскольку совместно используемый тип канала является нетипичным.
Команды для проверки:
show spanning-tree vlan number show running-config
Ещё раз основные отличия протоколов CISCO от старых первоначальных протоколов IEEE: поддерживают 1 экземпляр протокола связующего дерева на VLAN, а не 1 экземпляр на все VLAN, поэтому могут служить для распределения нагрузки на уровне 2.
FHRP
Одним из способов для устранения единой точки отказа на шлюзе по умолчанию является реализация виртуального маршрутизатора.
Несколько роутеров сгруппированы в один виртуальный роутер, имеющий свой виртуальный IP и виртуальный MAC, которые используются на клиентах для работы со шлюзом. Помимо этого каждый роутер имеет свой отдельный IP и MAC.
Протоколы
- HSRP является проприетарным протоколом Cisco, который предназначен для обеспечения сквозного переключения IPv4-устройства первого перехода;
- HSRP для IPv6 проприетарный протокол FHRP Cisco, который предоставляет те же функции HSRP, но для среды IPv6. Группа IPv6 HSRP содержит виртуальный MAC-адрес, производный от номера группы HSRP и виртуального локального IPv6-адреса канала, производного от виртуального MAC-адреса HSRP. Для виртуального локального IPv6-адреса канала HSRP отправляются периодические объявления маршрутизатора (RA), если группа HSRP активна. Когда группа становится неактивной, RA прекращаются после отправки последнего из них;
- VRRPv2 открытый протокол выбора, динамически назначающий VRRP-маршрутизаторам ответственность за один или несколько виртуальных маршрутизаторов в IPv4-сети LAN;
- VRRPv3 предоставляет функции поддержки IPv4- и IPv6-адресов. VRRPv3 работает в неоднородных средах и предоставляет более широкие возможности масштабирования, чем VRRPv2;
- GLBP проприетарный протокол FHRP Cisco, который обеспечивает балансировку нагрузки;
- GLBP для IPv6: проприетарный протокол FHRP Cisco, который предоставляет те же функции GLBP, но для среды IPv6;
- IRDP заявлен в RFC 1256, является предыдущей версией решения FHRP.
HSRP
Версии протокола
Существует две версии протокола HSRP 1 и 2:
- Multicast адрес:
- в версии 1 используется адрес 224.0.0.2 (как и в CGMP);
- в версии 2 используется адрес 224.0.0.102.
- Количество групп:
- в версии 1 до 255 групп;
- в версии 2 до 4096.
- Виртуальный MAC адрес (xx и xxx — номер группы HSRP):
- в версии 1 0000:0C07:ACxx;
- в версии 2 0000:0C9F:Fxxx.

HSRP standby группа — эмулирует виртуальный маршрутизатор. В одном VLAN может быть 255 групп. Группа состоит из:
- 1 Active маршрутизатор;
- 1 Standby маршрутизатор;
- один виртуальный маршрутизатор;
- другие маршрутизаторы.
Тут уточнение, разговор идёт обычно про 2 маршрутизатора — Active и Standby и как-то забывается, что физических маршрутизаторов может быть больше 2.
IP-адрес группы — должен быть из сети, в которой находятся маршрутизаторы, однако не может быть адресом, который уже присвоен маршрутизатору или хосту.
Настройка HSRP на интерфейсе активного роутера:
standby 1 ip virtual_ip standby 1 priority number - где number больше 100 (у активного маршрутизатора приоритет больше) standby 1 preempt - позволяет перехватывать роль active роутеру с большим приоритетом, например, после перезагрузки (по умолчанию эта функция выключена)
Настройка HSRP на интерфейсе резервного роутера:
standby 1 ip virtual_ip
Примечание. Virtual_ip указывается без маски.
Для проверки HSRP:
show standby {brief}
Для проверки на стороне компьютера после настройки шлюза по умолчанию на Virtual_ip, можно проверить таблицу ARP:
arp -a
Тогда можно увидеть среди MAC адресов автоматически сгенерированный MAC из требуемого диапазона и относится он к Virtual_ip:

Подробнее о HSRP можно посмотреть в курсе CCNA R&S 6.0 Bridging Course.
Пример схемы внедрения HSRP
Несколько запутанно, но разобрать полезно.

В этом примере используется конфигурация на DSW1:
track 10 ip route 10.1.21.128 255.255.255.224 metric threshold threshold metric up 63 down 64 interface Vlan10 ip address 10.2.1.1 255.255.255.0 ip helper-address 10.1.21.129 standby 10 ip 10.2.1.254 standby 10 priority 200 standby 10 preempt standby 10 track 10 decrement 60
И конфигурация на DSW2:
interface Vlan10
ip address 10.2.1.2 255.255.255.0
ip helper-address 10.1.21.129
standby 10 ip 10.2.1.254
standby 10 priority 150
standby 10 preempt
Приоритет для DSW1 200, а для DSW2 150, поэтому DSW1 в состоянии active. Но также происходит IP SLA отслеживание маршрута по метрике. Если метрика выходит за переделы, то срабатывает decrement 60 и приоритет DSW1 становится 200 — 60 = 140, меньше чем у DSW2.
За счёт команды standby 10 preempt при измении приоритета сразу происходят перевыборы активного маршрутизатора. Тогда DSW2 становится active, DSW1 standby.
Что это за маршрут?
DSW1# show ip route
...
D 10.1.21.128/27 [90/156160] via 10.1.4.5, 00:22:55, Ethernet1/0
Это некий «важный» маршрут от DSW1 к R4 и происходит отслеживание его доступности. Почему важный? Потому что 10.1.21.129, как видно (ip helper-address 10.1.21.129), сервер DHCP, обслуживающий внутреннюю подсеть.
Что значит threshold metric up 63 down 64? Пороги срабатывания:
| up | Specifies the up threshold. The state is up if the scaled metric for that route is less than or equal to the up threshold. The default up threshold is 254. |
| down | Specifies the down threshold. The state is down if the scaled metric for that route is greater than or equal to the down threshold. The default down threshold is 255. |
Метрика 63 и меньше считается состоянием Up, 64 и больше — Down. Почему так? Ведь метрика для маршрута на самом деле 156160. Потому что для исходных метрик используется делитель:
| Routing protocol | Metric Resolution |
|---|---|
| Static | 10 |
| EIGRP | 2560 |
| OSPF | 1 |
| RIP | is scaled directly to the range from 0 to 255 because its maximum metric is less than 255 |
К метрике применяется делитель 2560: 156160 / 2560 = 61. Подробнее тут. Получается 61 < 63 и состояние Up. Смотрим ещё:
DSW1# show track 10Track 10
IP route 10.1.21.128 255.255.255.224 metric threshold
Metric threshold is Up (EIGRP/156160/61)
2 changes, last change 00:44:41
Metric threshold down 64 up 63
First-hop interface is Ethernet1/0
Tracked by:
HSRP Vlan10 10
Возможно отлеживание не маршрута, а интерфейса:
track 10 interface FastEthernet1/0/1 line-protocol
Для конфигурации HSRP при этом остаётся:
standby 10 track 10 decrement 60
Задействование обоих маршрутизаторов
В примере выше трафик маршрутизирует только DSW1, DSW2 простаивает. А если схема будет не внутри сети? Если 2 маршрутизатора (R1 и R2), каждый из маршрутизаторов подключен к своему провайдеру и хочется использовать распределение нагрузки?
Тогда создаётся 2 группы HSRP. В одной группе активным роутером будет будет R1, во второй R2. В каждой группе свой виртуальный роутер по умолчанию. Разделяем устройства внутри сети: часть устройств использует первый виртуальный роутер по умолчанию, другая часть второй. При отвале маршрута, линка или самого физического роутера, обе группы HSRP используют оставшийся физический роутер как активный.
GLBP
GLBP обеспечивает распределение нагрузки на несколько маршрутизаторов (шлюзов) используя 1 виртуальный IP-адрес и несколько виртуальных MAC-адресов.
Члены GLBP группы выбирают один шлюз который будет активным виртуальным шлюзом Active Virtual Gateway (AVG) для этой группы.
GLBP Gateway Priority — определяет выбор нового AVG, если старый AVG станет недоступным. Приоритет можно определить на каждом маршрутизаторе значением от 1 до 255 командой:
glbp priority value
Маршрутизатор с большим приоритетом становится AVG.
Каждый член группы участвует в передаче пакетов, используя виртуальный MAC адрес, выданный AVG. Этих членов группы называют Active Virtual Forwarders (AVF). AVG ответственен за выдачу ответов по протоколу Address Resolution Protocol (ARP) на запросы к виртуальному IP-адресу. Распределение нагрузки достигается тем что AVG отвечает на ARP запросы используя разные виртуальные MAC адреса. GLBP поддерживает до 1024 групп на интерфейс и максимум 4 AVF на группу. MAC адреса AVF выдаются по механизму round-robin (round-robin используется по умолчанию, есть и другие механизмы), другими словами попеременно.
Пример. Если пользовательский хост запросит у AVG MAC адрес для формирования пакета, то AVG вернёт 1 из 4 MAC адресов AVF.
Парольная аутентификация между членами группы производится используя MD5 или в виде plain text.
Подробнее:
- http://xgu.ru/wiki/GLBP
- www.cisco.com
Настройка GLBP на интерфейсе пересылающего роутера:
glbp 1 ip virtual_ip glbp 1 load-balancing round-robin
Настройка GLBP на интерфейсе резервного роутера:
glbp 1 ip virtual_ip glbp 1 preemt standby 1 priority number - где number >100 glbp 1 load-balancing round-robin
Для проверки GLBP:
show glbp {brief}
Отличить HSRP от GLBP можно по тому, что в выводе для GLBP указано Forwarder, а в выводе для HSRP Active router, Standby router.
Урок 3
EtherChannel
Предпосылки
- Можно использовать каналы с более высокой скоростью (например 10 Гбит/с) в агрегированном канале между коммутаторами уровня доступа и распределения. Однако добавление каналов с более высокой скоростью — довольно дорогостоящее решение;
- Можно увеличить число физических каналов между коммутаторами, что позволит увеличить общую скорость обмена данными между коммутаторами. Однако по умолчанию на устройствах коммутации включён протокол связующего дерева (STP). Протокол STP блокирует избыточные каналы во избежание петель коммутации.
По этим причинам оптимальным решением для ускорения обмена является реализация технологии EtherChannel. При настройке EtherChannel создаётся виртуальный интерфейс, который называется агрегированный канал (port channel). Физические интерфейсы объединяются в интерфейс агрегированного канала.
Технология EtherChannel имеет много достоинств:
- Большинство задач конфигурации выполняется на интерфейсе EtherChannel, а не на отдельных портах. Это обеспечивает согласованную конфигурацию на всех каналах;
- EtherChannel использует существующие порты коммутатора. Для обеспечения более высокой пропускной способности не требуется дорогостоящая замена канала на более быстрый;
- Между каналами, которые являются частью одного и того же EtherChannel, происходит распределение нагрузки. В зависимости от используемого оборудования может быть реализован один или несколько методов распределения нагрузки.
- EtherChannel создает объединение, которое рассматривается, как один логический канал. Если между двумя коммутаторами существует несколько объединений EtherChannel, протокол STP может блокировать одно из объединений во избежание петель коммутации. Если протокол STP блокирует один из избыточных каналов, он блокирует весь EtherChannel. При этом блокируются все порты, относящиеся к этому каналу EtherChannel. Если существует только один канал EtherChannel, все физические каналы в EtherChannel активны, поскольку STP видит только один (логический) канал;
- EtherChannel предоставляет функции избыточности, поскольку общий канал считается одним логическим соединением. Кроме того, потеря одного физического соединения в пределах канала не приводит к изменению в топологии. Следовательно, пересчёт дерева кратчайших путей не требуется. При условии, что имеется хотя бы одно физическое соединение, EtherChannel продолжает работать даже в том случае, если общая пропускная способность снижается из-за потери соединения в пределах EtherChannel.
Виды распределения нагрузки
- Распределение нагрузки по физическим каналам на основе МАС-адреса источника и МАС-адреса назначения;
- Распределение нагрузки по физическим каналам на основе IP-адреса источника и IP-адреса назначения.
Ограничения:
- Типы интерфейсов нельзя смешивать. Например, нельзя смешивать Fast Ethernet и Gigabit Ethernet в пределах одного канала EtherChannel;
- В настоящее время все каналы EtherChannel могут содержать до восьми совместимо настроенных Ethernet-портов;
- Коммутаторы Cisco IOS в настоящее время поддерживают шесть каналов EtherChannel;
- EtherChannel создает связь типа «один в один», то есть один канал EtherChannel соединяет только два устройства. Канал EtherChannel можно создать между двумя коммутаторами или между сервером с включённым EtherChannel и коммутатором;
- Конфигурация порта отдельного участника группы EtherChannel должна выполняться согласованно на обоих устройствах. Если физические порты на одной стороне настроены в качестве транковых, то физические порты на другой стороне также должны быть настроены в качестве транковых с тем же самым native VLAN. Кроме того, все порты в каждом канале EtherChannel должны быть настроены как порты 2 уровня;
- В EtherChannel все порты обязательно должны иметь одинаковую скорость, одинаковые настройки дуплекса и одинаковые настройки VLAN. При любом изменении порта после создания канала также изменяются все остальные порты канала.
Примечание. На многоуровневых коммутаторах Cisco Catalyst можно настроить каналы EtherChannel 3 уровня. Канал EtherChannel 3 уровня имеет один IP-адрес. Настройка интерфейса агрегированного канала применяется на все физические интерфейсы, связанные с этим каналом.
Ручное включение и согласование
Etherchannel можно образовать путем согласования с использованием одного из двух протоколов, PAgP или LACP.
Также возможна настройка статического или безусловного канала EtherChannel без использования PAgP или LACP.
PAgP
PAgP — это проприетарный протокол Cisco, который предназначен для автоматизации создания каналов EtherChannel. Когда канал EtherChannel настраивается с помощью PAgP, пакеты PAgP пересылаются между портами с поддержкой EtherChannel в целях согласования создания канала. Когда PAgP определяет совпадающие соединения Ethernet, он группирует их в канал EtherChannel. Далее EtherChannel добавляется в дерево кратчайших путей как один порт.
Если включён протокол PAgP, он также участвует в управлении EtherChannel. Отправка пакетов PAgP выполняется с интервалом в 30 секунд.
Режимы протокола PAgP:
- On — этот режим принудительно назначает интерфейс в канал без использования PAgP. Интерфейсы, настроенные в режиме On (Вкл), не обмениваются пакетами PAgP;
- PAgP desirable (рекомендуемый) — этот режим PAgP помещает интерфейс в активное состояние согласования, в котором интерфейс инициирует согласование с другими интерфейсами путем отправки пакетов PAgP;
- PAgP auto (автоматический) — этот режим PAgP помещает интерфейс в пассивное состояние согласования, в котором интерфейс отвечает на полученные пакеты PAgP, но не инициирует согласование PAgP.
Режимы должны быть совместимыми на каждой из сторон. Если одна из сторон настроена в автоматическом режиме, она помещается в пассивное состояние, ожидая инициации согласования EtherChannel другой стороной. Если для другой стороны также задан автоматический режим, то согласование не начнётся и EtherChannel не образуется. Если все режимы отключены с помощью команды no или ни один из режимов не настроен, EtherChannel отключается.
Режим Вкл помещает интерфейс в канал EtherChannel без выполнения согласования. Этот режим работает только в том случае, если для другой стороны также задан режим Вкл. Если для другой стороны параметры согласования заданы с помощью PAgP, образование EtherChannel не выполняется, поскольку та сторона, для которой задан режим Вкл, не выполняет согласование.

LACP
LACP изначально определён как стандарт IEEE 802.3ad. Тем не менее, теперь протокол LACP определяется более новой версией, стандартом IEEE 802.1AX для локальных и городских сетей.
Поскольку протокол LACP относится к стандарту IEEE, его можно использовать для упрощения работы с каналами EtherChannel в неоднородных средах. На устройствах Cisco поддерживаются оба протокола.
Режимы протокола LACP:
- On (Вкл) — этот режим принудительно помещает интерфейс в канал без использования LACP. Интерфейсы, настроенные в режиме On, не обмениваются пакетами LACP;
- LACP active (активный) — в этом режиме LACP порт помещается в активное состояние согласования. В этом состоянии порт инициирует согласование с другими портами путем отправки пакетов LACP;
- LACP passive (пассивный) — в этом режиме LACP порт помещается в пассивное состояние согласования. В этом состоянии порт отвечает на полученные пакеты LACP, но не инициирует согласование пакетов LACP.
Как и в случае с PAgP, для формирования канала EtherChannel режимы должны быть совместимы на обеих сторонах. Режим Вкл повторяется, поскольку он создает конфигурацию EtherChannel безусловно, без динамического согласования PAgP или LACP.

Рекомендации
При настройке EtherChannel рекомендуется соблюдать следующие инструкции и ограничения:
- Поддержка EtherChannel. Все интерфейсы Ethernet на всех модулях должны поддерживать EtherChannel; при этом не требуется, чтобы эти интерфейсы были физически смежными или находились на одном модуле;
- Скорость и дуплексный режим.Настройте все интерфейсы в EtherChannel для работы на одной скорости и в одном дуплексном режиме;
- Сопоставление сетей VLAN. Все интерфейсы в объединении EtherChannel должны быть назначены в один VLAN или настроены в качестве транкового канала;
- Диапазон сетей VLAN. EtherChannel поддерживает одинаковые разрешённые диапазоны сетей VLAN на всех интерфейсах в транковом канале EtherChannel. Если разрешённый диапазон сетей VLAN не совпадает, интерфейсы не смогут создать EtherChannel даже при выборе auto илиdesirable режимов.
Если данные параметры необходимо изменить, настройку следует выполнять в режиме конфигурации интерфейса агрегированного канала. После настройки интерфейса агрегированного канала все введённые команды также применяются на отдельные интерфейсы. Однако конфигурации, примененные к отдельным интерфейсам, не влияют на интерфейс агрегированного канала. Следовательно, изменение конфигурации интерфейса, относящегося к каналу EtherChannel, может вызвать проблемы с совместимостью.
Ещё раз: 8 портов в 1 EhterChannel максимум, 6 EtherChannel на коммутатор максимум.
Настройка
Настройка EtherChannel с использованием LACP проходит в два этапа:
Шаг 1. Укажите интерфейсы, составляющие группу EtherChannel, используя команду режима глобальной конфигурации interface range interface. Ключевое слово range позволяет выбрать несколько интерфейсов и настроить их одновременно. Рекомендуется сперва отключить эти интерфейсы, чтобы избежать активности в канале из-за неполной конфигурации.
Шаг 2. Создайте интерфейс агрегированного канала с помощью команды channel-group identifier mode mode режима конфигурации диапазона интерфейса.

Проверка
Сначала с помощью команды show interface port-channel отображается общий статус интерфейса агрегированного канала.
Когда на одном устройстве настроено несколько интерфейсов агрегированного канала, необходимо использовать команду show etherchannel summary.
Используйте команду show etherchannel port-channel, чтобы отобразить сведения о конкретном интерфейсе агрегированного канала.
Чтобы просмотреть данные о роли физического интерфейса в работе EtherChannel, следует выполнить команду show interfaces etherchannel.
Устранение неполадок
Все интерфейсы в EtherChannel должны иметь одинаковые настройки скорости и дуплексного режима, на транковых каналах одинаковые настройки native VLAN и разрешенных VLAN, на портах доступа — одинаковый VLAN:
- назначьте все порты в EtherChannel одной VLAN или настройте их в качестве транковых каналов. Порты с различными native VLAN не могут образовать EtherChannel;
- При настройке EtherChannel на транковых каналах необходимо убедиться, что во всех транковых каналах режим транка настроен одинаково. Несогласованность режимов транка на портах EtherChannel может привести к тому, что EtherChannel не будет работать, а порты будут отключены (состояние errdisable );
- Все входящие в EtherChannel порты поддерживают одинаковый диапазон разрешённых VLAN. Если диапазоны разрешённых VLAN не совпадают, порты не смогут сформировать EtherChannel;
- Параметры динамического согласования для PAgP и LACP должны быть настроены с учётом совместимости на обоих концах EtherChannel.
Примечание. Легко спутать протокол PAgP или LACP с DTP, поскольку оба протокола используются для автоматизации поведения на транковых каналах. Протоколы PAgP и LACP используются для агрегирования каналов (EtherChannel). DTP используется для автоматизации создания транковых каналов. Как правило, если настроен транковый канал EtherChannel, то EtherChannel (PAgP или LACP) настраивается в первую очередь, и только после этого настраивается DTP.
Примечание. EtherChannel и STP должны взаимодействовать. По этой причине важен порядок выполнения связанных с EtherChannel команд, и именно поэтому лучше Port-Channel удалить и снова добавить с новыми параметрами, а не изменять напрямую. При попытке изменить конфигурацию интерфейса напрямую ошибки STP приводят к тому, что связанные порты переходят в состояние блокировки или в состояние errdisable (не дружит с STP).
Урок 4
Беспроводные сети
Беспроводные сети в целом можно разделить на следующие категории:
- Беспроводная персональная сеть (WPAN).Радиус действия данной сети составляет несколько метров. В сетях WPAN используются устройства с поддержкой Bluetooth или Wi-Fi Direct;
- Беспроводные сети LAN (WLAN). Сети данного типа работают в диапазоне нескольких сотен метров (например, в комнате, в доме, в офисе и даже в сетях комплекса зданий);
- Глобальные сети (WWAN). Эти сети действуют в радиусе нескольких километров (например, в муниципальной сети, сети сотовой связи или даже в каналах междугородней связи посредством СВЧ-реле).
Стандарты
- Bluetooth. Изначально является стандартом WPAN IEEE 802.15, который использует процесс сопряжения устройств для обмена данными на расстояниях до 100 метров (0,1 км);
- Wi-Fi (wireless fidelity, беспроводная достоверность). Стандарт сетей WLAN IEEE 802.11, обычно развертываемых в целях предоставления доступа к сети для пользователей домашней и корпоративной сети (включая передачу данных, голоса и видео) на расстояниях до 300 м (0,18 мили);
- WiMAX (протокол широкополосной радиосвязи). Стандарт сетей WWAN IEEE 802.16, который обеспечивает беспроводной широкополосный доступ на расстояниях до 50 км (30 миль);
- Сотовый широкополосный доступ. Впервые использован для сотовых телефонов 2-го поколения в 1991 году (2G). В 2001 и 2006 гг. в рамках технологий мобильной связи третьего (3G) и четвертого (4G) поколений стали доступный более высокие скорости;
- Спутниковый широкополосный доступ.Предоставляет сетевой доступ к удалённым объектам за счёт использования направленной спутниковой антенны, отрегулированной по геостационарному спутнику (GEO). Как правило, эта технология отличается более высокой стоимостью и к тому же требует обеспечения прямой видимости.
Для беспроводных LAN стандарта 802.11 выделяются следующие частотные полосы:
- 2,4 ГГц (УВЧ): 802.11b/g/n/ad
- 5 ГГц (СВЧ): 802.11a/n/ac/ad
- 60 ГГц (КВЧ): 802.11ad

Точки доступа могут быть автономными и управляемыми контроллером.
Примечание. Некоторые точки доступа могут работать как в автономном режиме, так и в режиме точки доступа, управляемой контроллером.
Для небольших беспроводных сетей Cisco предлагает следующие решения в виде беспроводных автономных точек доступа.
- Точка доступа Cisco WAP4410N. Эта точка доступа идеально подходит для небольших компаний, которым требуются две точки доступа и поддержка небольшой группы пользователей;
- Точки доступа Cisco WAP121 и WAP321. Эти точки доступа идеально подходят для небольших компаний, которым требуется упростить беспроводную сеть за счёт использования нескольких точек доступа;
- Точка доступа Cisco AP541N. Эта точка доступа идеально подходит для небольших и средних компаний, которым требуется надежный и простой в управлении кластер точек доступа.
Примечание. Большинство точек доступа корпоративного уровня поддерживает PoE.
Кластеры
Точки доступа WAP121, WAP321 и AP541N поддерживают кластеризацию точек доступа без использования контроллера. Кластер предоставляет единую точку администрирования и позволяет администратору просматривать развертывание точек доступа как одну беспроводную сеть, а не как набор отдельных беспроводных устройств. В частности, точки доступа WAP121 и WAP321 поддерживают единую точку настройки (Single Point Setup, SPS).
SPS позволяет включить для сети LAN возможность масштабирования до четырех точек доступа WAP121 и до восьми точек доступа WAP321, точка доступа Cisco AP541N способна объединить в кластер до 10 точек доступа и поддерживает несколько кластеров.
Существует возможность создания кластера с использованием двух точек доступа. Для этого необходимо соблюдать следующие условия:
- На точках доступа включен режим кластеризации;
- Точки доступа, входящие в кластер, имеют одно имя кластера;
- Точки доступа подключены к одному сегменту сети;
- Точки доступа используют один режим радиосвязи (т. е. оба модуля радиосвязи относятся к стандарту 802.11n).
Meraki
Для управляемой облачной архитектуры Cisco Meraki требуются следующие компоненты:
- Точки беспроводного доступа под облачным управлением Cisco. Для различных беспроводных сетей существуют различные модели;
- Облачный контроллер Meraki (MCC). Контроллер MCC предоставляет для системы беспроводной локальной сети Meraki функции централизованного управления, оптимизации и мониторинга. MCC — это не устройство, которое нужно приобрести и установить для управления точками беспроводного доступа. MCC, скорее, представляет собой облачный сервис, который постоянно выполняет мониторинг, оптимизацию и создание отчетов о поведении сети;
- Веб-панель управления. Веб-панель управления Meraki Dashboard выполняет удалённую настройку и диагностику.
Cisco Unified
Архитектура беспроводной сети Cisco Unified требует наличия следующих устройств:
- «Легкие» точки доступа. Точки беспроводного доступа моделей Cisco Aironet 1600, 2600 и 3600 обеспечивают надежный сетевой доступ для узлов;
- Контроллеры для предприятий малого и среднего бизнеса. Беспроводные контроллеры Cisco серии 2500, виртуальный контроллер беспроводной сети Cisco или модуль контроллера беспроводной сети Cisco для Cisco ISR G2 предоставляют возможность развертывания корпоративных сетей WLAN базового уровня для предприятий малого или среднего бизнеса с целью беспроводной передачи данных.
Антенны
Точки доступа Cisco Aironet могут использовать:
- Всенаправленные антенны Wi-Fi. Заводской модуль Wi-Fi зачастую использует базовые дипольные антенны, которые также называются гибкими штыревыми выдвижными антеннами, аналогичные тем, которые используются в портативных рациях. Всенаправленные антенны обеспечивают покрытие на 360 градусов и идеально подходят для офисов открытой планировки, вестибюлей, конференц-залов и наружных площадок;
- Направленные антенны Wi-Fi. Направленные антенны фокусируют радиосигнал в заданном направлении. Таким образом, улучшается сигнал к точке доступа и от нее в том направлении, куда направлена антенна, что обеспечивает большую мощность сигнала в одном направлении и меньшую — во всех остальных направлениях;
- Антенны типа «волновой канал» (Yagi) — это радиоантенны направленного действия, которые можно использовать для создания сетей Wi-Fi дальнего действия. Эти антенны, как правило, используются для расширения диапазона «горячих точек» вне здания в определённом направлении или для обеспечения доступа к пристройке.
Стандарты IEEE 802.11n/ac/ad используют технологию MIMO для повышения пропускной способности и поддержки до четырех антенн одновременно.
Примечание. Маршрутизаторы 802.11n начального уровня поддерживают пропускную способность 150 Мбит/с, используя один радиомодуль Wi-Fi и одну антенну, присоединённую к устройству, два радиомодуля и две антенны на маршрутизаторе 802.11n поддерживают скорость передачи данных до 300 Мбит/с, а для обеспечения скорости 450 и 600 Мбит/с требуются три и четыре радиомодуля и антенны соответственно.
Топология
Стандарт 802.11 определяет два основных режима топологии беспроводной сети:
- Режим прямого подключения (ad hoc). В этом режиме два устройства соединены по беспроводной сети без использования таких устройств инфраструктуры, как беспроводной маршрутизатор или точка доступа. К примерам этого режима можно отнести Bluetooth и Wi-Fi Direct;
- Инфраструктурный режим. В этом режиме беспроводные клиенты соединены друг с другом посредством беспроводного маршрутизатора или точки доступа (например, как в сетях WLAN). Точки доступа подключены к сетевой инфраструктуре посредством кабельной распределительной системы, например, Ethernet.
Архитектура IEEE 802.11 определяет два структурных элемента топологии инфраструктурного режима: базовый набор сервисов (BSS) и расширенный набор сервисов (ESS).
Базовый набор сервисов
BSS состоит из одной точки доступа, которая взаимодействует со всеми связанными беспроводными клиентами. Зона покрытия, в пределах которой беспроводные клиенты BSS могут поддерживать связь друг с другом называется зоной основного обслуживания (BSA). Если беспроводной клиент выходит из зоны основного обслуживания, он больше не может напрямую связываться с другими беспроводными устройствами в пределах зоны BSA. BSS является структурным элементом топологии, а BSA — фактической зоной покрытия (термины BSA и BSS зачастую используются как взаимозаменяемые).
MAC-адрес 2 уровня используется для уникальной идентификации каждого набора BSS, который называется идентификатором базового набора сервисов (BSSID). Таким образом, идентификатор BSSID является формальным именем BSS и всегда связан только с одной точкой доступа.
Расширенный набор сервисов
Когда один набор BSS обеспечивает недостаточное радиочастотное покрытие, то с помощью общей распределительной системы можно связать два или более наборов BSS, что образует расширенный набор сервисов (ESS). Набор сервисов ESS представляет собой объединение двух или более наборов BSS, взаимосвязанных посредством кабельной распределительной системы. Теперь беспроводные клиенты в одной зоне BSA могут обмениваться данными с беспроводными клиентами в другой зоне BSA в пределах одного набора ESS. Перемещающиеся мобильные беспроводные клиенты в роуминге могут переходить из одной зоны BSA в другую (с тем же набором ESS) и без проблем выполнять подключение. Зоны BSA в составе ESS должны перекрываться на 10-15%.
Примечание. В рамках стандарта 802.11 режим прямого соединения называется IBSS.
Кадр

802.11 содержат следующие поля:
- Управление кадром (Frame Control). Определяет тип кадра беспроводной сети и содержит подполя для версии протокола, типа кадра, типа адреса, настроек управления питанием и безопасности;
- Продолжительность (Duration). Как правило, используется для обозначения оставшегося времени, требуемого для приема следующего передаваемого кадра;
- Адрес 1 (Address1). Как правило, содержит MAC-адрес принимающего беспроводного устройства или точки доступа;
- Адрес 2 (Address2). Как правило, содержит MAC-адрес передающего беспроводного устройства или точки доступа;
- Адрес 3 (Address3). В отдельных случаях содержит MAC-адрес назначения, например, интерфейс маршрутизатора (шлюз по умолчанию), к которому подключена точка доступа;
- Контроль последовательности (Sequence Control).Содержит подполя для номера последовательности и номера фрагмента. Номер последовательности обозначает номер последовательности каждого кадра. Номер фрагмента обозначает номер каждого кадра, отправленного из фрагментированного кадра;
- Адрес 4 (Address4). Обычно отсутствует, поскольку используется только в режиме прямого соединения;
- Полезная нагрузка (Payload). Содержит данные для передачи;
- FCS. Контрольная последовательность кадра, которая используется для контроля ошибок 2 уровня.
Типы кадра
Кадр беспроводной сети может относиться к одному из трех типов:
- Кадр управления — используется в процессе обслуживания процесса обмена данными, например, при поиске, аутентификации и ассоциации с точкой доступа;
- Контрольный кадр — используется для упрощения обмена кадрами данных между беспроводными клиентами;
- Кадр данных — используется для переноса полезной нагрузки.
Технологии насыщения канала
- Распределение сигнала в прямой последовательности (Direct-sequence spread spectrum, DSSS) — DSSS представляет собой технологию модуляции распределения сигнала. Технология распределения спектра разработана в целях распространения сигнала по большей частотной полосе, что повышает его устойчивость к помехам. С помощью технологии DSSS сигнал умножается на значение «искусственно созданного шума», которое также называется кодом расширения спектра. Поскольку получателю известен код расширения спектра, то после его добавления он может математически удалить и повторно выстроить исходный сигнал. По факту это обеспечивает избыточность передаваемого сигнала, предотвращая, таким образом, снижение качества среды беспроводной сети. Технология DSSS используется стандартом 802.11b, а также в радиотелефонах, работающих на частоте 900 МГц, 2,4 ГГц, 5,8 ГГц, сотовых сетях CDMA и сетях GPS;
- Скачкообразная смена рабочей частоты с расширением спектра (Frequency-hopping spread spectrum, FHSS) — для обмена данными тоже использует методы распределения спектра. Эта технология аналогична DSSS, но передает радиосигналы посредством быстрой коммутации сигнала несущей частоты по множеству частотных каналов. При использовании FHSS отправитель и получатель должны синхронизироваться, чтобы «узнать», на какие каналы следует перейти. Этот процесс перехода сигнала между каналами обеспечивает более эффективное использование каналов, что снижает их перегрузку. Портативные рации и радиотелефоны, работающие на частоте 900 МГц, тоже используют FHSS, в то время как Bluetooth полагается на одну из вариаций этой технологии. Технология FHSS, кроме того, используется исходным стандартом 802.11;
- Мультиплексирование с ортогональным делением частот (Orthogonal frequency-division multiplexing, OFDM) — представляет собой разновидность мультиплексирования с делением частот, в рамках которой один канал использует несколько подканалов на смежных частотах. Подканалы в системе OFDM точно ортогональны относительно друг друга, что позволяет подканалам перекрываться без взаимных помех. В результате система OFDM позволяет максимально увеличить эффективность спектра без помех на смежных каналах. В сущности эта технология позволяет принимающей станции «услышать» сигнал. Поскольку OFDM использует подканалы, это делает использование канала максимально эффективным. OFDM используется несколькими системами связи, включая стандарт 802.11a/g/n/ac.
Ассоциация клиента с точкой доступа
Кадры управления используются беспроводными устройствами для выполнения следующего процесса, состоящего из трех этапов.
- Обнаружение новой точки беспроводного доступа;
- Аутентификация на точке доступа;
- Ассоциация с точкой доступа.
Общие настраиваемые параметры беспроводной сети
- Идентификатор SSID — идентификатор SSID представляет собой уникальный идентификатор, который беспроводной клиент использует, чтобы различать беспроводные сети в одной зоне. Имя SSID отображается в списке доступных беспроводных сетей на клиенте. В зависимости от конфигурации сети идентификатор SSID может совместно использоваться несколькими точками доступа в сети. Обычно длина имени составляет от 2 до 32 символов;
- Пароль — обязательно предоставляется беспроводным клиентом для аутентификации на точке доступа. Иногда пароль называют ключом безопасности;
- Сетевой режим (Network mode) — относится к стандартам сети WLAN 802.11a/b/g/n/ac/ad. Точки доступа и беспроводные маршрутизаторы могут работать в смешанном режиме, т. е. они могут одновременно использовать несколько стандартов;
- Режим безопасности (Security mode) — этот термин относится к настройкам параметров безопасности (WEP, WPA или WPA2). Следует всегда активировать самый высокий из доступных уровней безопасности;
- Настройки канала (Channel settings) — относится к частотным полосам, которые используются для передачи беспроводных данных. Беспроводные маршрутизаторы и точка доступа могут выбирать настройки канала. Также, в случае помех со стороны другой точки доступа или беспроводного устройства, эти настройки также можно задать вручную.
Обнаружение точек доступа
Этот процесс может выполняться в следующих режимах:
- Пассивный режим (Passive mode) — точка доступа открыто объявляет свою службу путем регулярной отправки кадров сигнала широковещательной рассылки, содержащих имя SSID, сведения о поддерживаемых стандартах и настройки безопасности. Основная задача сигнала — разрешить беспроводным клиентам получать данные о доступных сетях и точках доступа в данной зоне для выбора нужной сети и точки доступа;
- Активный режим (Active mode) — беспроводные клиенты должны знать имя SSID. Беспроводной клиент инициирует процесс путем отправки по широковещательной рассылке кадра запроса поиска на несколько каналов. Запрос поиска содержит имя SSID и сведения о поддерживаемых стандартах. Активный режим может понадобиться в том случае, если для беспроводного маршрутизатора или точки доступа настроен запрет широковещательной рассылки кадров сигнала.
Аутентификация
Стандарт 802.11 изначально разработан с учетом двух механизмов аутентификации:
- Открытая аутентификация — по сути аутентификация NULL, в рамках которой беспроводной клиент отправляет запрос аутентификации, и точка доступа отправляет в ответ подтверждение. Открытая аутентификация обеспечивает подключение к беспроводной сети для любого беспроводного устройства. Такой метод аутентификации следует использовать только в тех случаях, когда безопасность не имеет большого значения;
- Аутентификация согласованного ключа — эта технология подразумевает использование ключа, предварительно согласованного клиентом и точкой доступа.
Каналы

Полоса 2,4 ГГц поделена на несколько каналов. В целом общая пропускная способность канала составляет 22 МГц, и каждый канал отделяется полосой 5 ГГц. Стандарт 802.11b определяет 11 каналов для Северной Америки. Пропускная способность 22 МГц вкупе с разделением частот полосами 5 МГц, подразумевает перекрывание последовательных каналов.

Примечание. В Европе работают 13 каналов 802.11b.
Стандарт 802.11n может использовать соединение каналов, при котором два канала 20 МГц объединяются в один канал 40 МГц. Соединение каналов увеличивает пропускную способность за счёт использования для доставки данных одновременно двух каналов.
Большинство современных точек доступа могут автоматически регулировать каналы, чтобы обойти помехи.
Примечание. Стандарт IEEE 802.11ac использует OFDM с шириной каналов в 80,160 и 80+80.
Угрозы
Беспроводные сети особенно подвержены следующим угрозам:
- Беспроводные злоумышленники;
- Вредоносные приложения;
- Перехват данных;
- Атаки DoS.
Две функции обеспечения безопасности:
- Сокрытие идентификатора SSID. Точки доступа и некоторые беспроводные маршрутизаторы позволяют отключить кадр сигнала идентификатора SSID. Беспроводные клиенты должны вручную определить имя SSID, чтобы подключиться к сети;
- Фильтрация MAC-адресов. Администратор может вручную разрешить или запретить клиентам беспроводной доступ в зависимости от MAC-адреса их физического оборудования.

Примечание. В целях оптимизации производительности, сети Wireless-N должны использовать режим безопасности WPA2-Personal.
Стандарты IEEE 802.11i, Wi-Fi Alliance WPA и WPA2 используют следующие протоколы шифрования:
- Шифрование с использованием временных ключей (TKIP). TKIP является методом шифрования, который используется стандартом WPA. Он обеспечивает поддержку предыдущих версий оборудования сетей WLAN за счёт устранения исходных уязвимостей, характерных для метода шифрования 802.11 WEP. Он использует WEP, однако выполняет шифрование полезной нагрузки 2 уровня с использованием TKIP и выполняет проверку целостности сообщений в зашифрованном пакете, чтобы убедиться в том, что сообщение не используется несанкционированно;
- Усовершенствованный стандарт шифрования (AES). AES является методом шифрования, который используется стандартом WPA2. Этот метод является предпочтительным, поскольку соответствует отраслевому стандарту IEEE 802.11i. AES выполняет те же функции, что и TKIP, но обеспечивает значительно более надежный метод шифрования. Он использует протокол CCMP, который позволяет узлам назначения распознавать зашифрованные и незашифрованные биты, используемые несанкционированно.
Примечание. По возможности всегда следует выбирать 802.11i/WPA2 с AES.
WPA и WPA2 поддерживают два типа аутентификации.
- Персональная — предназначена для домашних сетей и небольших корпоративных сетей. Пользователи выполняют аутентификацию, используя предварительно согласованный ключ (PSK). Беспроводные клиенты выполняют аутентификацию на точке доступа, используя предварительно согласованный пароль. Специализированный сервер аутентификации не требуется;
- Корпоративная — предназначена для корпоративных сетей, но требует наличия сервера аутентификации службы дистанционной аутентификации пользователей (RADIUS). Хотя этот тип аутентификации более сложен для настройки, он обеспечивает повышенную безопасность. Устройство должно выполнить аутентификацию посредством сервера RADIUS, после чего пользователи должны пройти аутентификацию, используя стандарт 802.1X, который задействует для аутентификации усовершенствованный протокол аутентификации (EAP).
Для корпоративного режима безопасности требуется сервер аутентификации, авторизации и учета (AAA) RADIUS.
Эти поля являются обязательными для передачи точке доступа требуемых данных для связи с сервером AAA, которые представлены ниже:
- IP-адрес сервера RADIUS — доступный адрес сервера RADIUS;
- Номера портов UDP — официально назначенные порты UDP 1812 для аутентификации RADIUS и 1813 для учета RADIUS. Также возможно использование портов UDP 1645 и 1646;
- Согласованный ключ — используется для аутентификации на точке доступа посредством сервера RADIUS.
Примечание. Поле пароля не отображается, так как аутентификация и авторизация текущего пользователя обрабатываются стандартом 802.1X, который предоставляет централизованную аутентификацию конечных пользователей на базе сервера.
При входе в систему по стандарту 802.1X для обмена данными с точкой доступа и сервером RADIUS используется протокол EAP. EAP представляет собой платформу для аутентификации доступа к сети. Этот протокол предоставляет механизм безопасной аутентификации и согласование безопасного закрытого ключа, который впоследствии можно использовать для сеанса шифрования беспроводной связи с использованием механизмов шифрования TKIP или AES.
Урок 5
Устранение неполадок в OSPF для одной области
Маршрутизаторы и коммутаторы 3 уровня узнают об удалённых сетях одним из двух следующих способов:
- Вручную — удалённые сети задаются вручную в таблице маршрутизации с помощью статических маршрутов;
- Динамически — удалённые маршруты вносятся автоматически с помощью протокола динамической маршрутизации.
Примечание. Все протоколы динамической маршрутизации способны объявлять и распространять статические маршруты в своих обновлениях маршрутизации.
Свойства OSPF
- Бесклассовость — протокол разработан как бесклассовый, следовательно, он поддерживает использование VLSM и маршрутизации CIDR;
- Эффективность — изменения маршрутизации запускают обновления маршрутизации (без периодических обновлений). Протокол использует алгоритм поиска кратчайшего пути SPF для выбора оптимального пути;
- Быстрая сходимость — быстрота распространения изменений сети;
- Масштабируемость — подходит для использования как в небольших, так и в больших сетях. Для поддержки иерархической структуры маршрутизаторы группируются в области;
- Безопасность — поддерживает аутентификацию Message Digest 5 (MD5). Если эта функция включена, маршрутизаторы OSPF принимают только зашифрованные сообщения маршрутизации от равноправных узлов с одинаковым предварительно заданным паролем.
Типичная настройка OSPFv2 для одной области

Проверка OSPFv2
- show ip ospf neighbor — команда используется для того, чтобы убедиться, что маршрутизатор сформировал отношения смежности с соседними маршрутизаторами. Если идентификатор соседнего маршрутизатора не отображается или не показывает состояние FULL, это значит, что оба маршрутизатора не создали отношения смежности OSPF;
- show ip protocols — эта команда обеспечивает быструю проверку критически важных данных конфигурации OSPF. К таким данным относятся идентификатор процесса OSPF, идентификатор маршрутизатора, сети, объявляемые маршрутизатором, соседние устройства, от которых маршрутизатор принимает обновления, и значение административной дистанции по умолчанию, равное 110 для OSPF;
- show ip ospf — эта команда используется для отображения идентификатора процесса OSPF и идентификатора маршрутизатора, а также сведений об OSPF SPF и об области OSPF;
- show ip ospf interface — эта команда предоставляет подробный список интерфейсов, где работает протокол OSPF, с ее помощью можно определить, правильно ли были составлены выражения network;
- show ip ospf interface brief — эту команду рекомендуется использовать для отображения краткой информации и состояния интерфейсов по протоколу OSPF.
Типичная настройка OSPFv3 для одной области

Проверка OSPFv3
- show ipv6 ospf neighbor — команда используется для того, чтобы убедиться, что маршрутизатор сформировал отношения смежности с соседними маршрутизаторами. Если идентификатор соседнего маршрутизатора не отображается или не показывает состояние FULL, это значит, что оба маршрутизатора не создали отношения смежности OSPF;
- show ipv6 protocols — позволяет быстро проверить критически важные данные конфигурации OSPFv3, включая идентификатор процесса OSPF, идентификатор маршрутизатора и интерфейсы, включенные для OSPFv3;
- show ipv6 route ospf — предоставляет сведения о маршрутах OSPFv3, содержащихся в таблице маршрутизации;
- show ipv6 ospf interface brief — эту команду рекомендуется использовать для отображения краткой информации и состояния интерфейсов, участвующих в OSPFv3.
Типы сетей OSPF
- Точка-точка — это сеть, которая содержит два маршрутизатора, подключенных друг к другу по одному общему каналу. Как правило, эта конфигурация используется в сетях WAN;
- Широковещательная сеть множественного доступа — содержит несколько маршрутизаторов, подключенных друг к другу по сети Ethernet;
- Нешироковещательная сеть множественного доступа (NBMA) — содержит несколько маршрутизаторов, подключенных друг к другу в сети, которая запрещает широковещательную адресацию, например, Frame Relay;
- Многоточечная сеть — содержит несколько маршрутизаторов, подключенных в звездообразной топологии через сеть NBMA. Часто используется для подключения филиалов (концы звезд) к центральному узлу (концентратор);
- Виртуальные каналы — особая сеть OSPF, используемая для соединения отдалённых областей OSPF с областью магистрали.

Проблемы сетей множественного доступа
Сеть множественного доступа — это сеть с несколькими устройствами в одной и той же среде передачи, которые обмениваются данными между собой. Локальные сети Ethernet — это наиболее распространённый пример широковещательных сетей множественного доступа
- Установление большого количества отношений смежности;
- Избыточная лавинная рассылка пакетов LSA.
Проблема управления большим количеством отношений смежности и лавинной рассылки пакетов LSA в сети с множественным доступом решается за счёт выделенного маршрутизатора (DR).
На случай сбоя выделенного маршрутизатора (DR) также выбирается резервный назначенный маршрутизатор (BDR).
Остальные маршрутизаторы, не являющиеся DR или BDR, станут маршрутизаторами DROTHER.
Вместо лавинной рассылки объявлений LSA всем маршрутизаторам в сети, маршрутизаторы DROTHER отправляют свои LSA только маршрутизаторам DR и BDR с помощью адреса групповой рассылки 224.0.0.6 (все маршрутизаторы DR).
DR использует групповую рассылку 224.0.0.5 (все маршрутизаторы OSPF). В конечном счёте, только один маршрутизатор производит рассылку объявлений LSA по сети с множественным доступом.
Примечание. Выбор DR/BDR происходит только в сетях с множественным доступом и не может произойти в сетях «точка-точка».
Проверка ролей OSPF
Для проверки отношений смежности OSPF используйте команду show ip ospf neighbor.
В отличие от последовательных каналов, которые отображают только состояние FULL/-, состояние соседних устройств в сетях с множественным доступом может быть:
- FULL/DROTHER — это маршрутизатор DR или BDR, полностью смежный с маршрутизатором, который не является DR или BDR. Эти два соседних устройства могут обмениваться пакетами приветствия (hello), обновлениями, запросами, ответами и подтверждениями;
- FULL/DR — маршрутизатор полностью смежен с указанным соседним маршрутизатором DR. Эти два соседних устройства могут обмениваться пакетами приветствия (hello), обновлениями, запросами, ответами и подтверждениями;
- FULL/BDR — маршрутизатор полностью смежен с указанным соседним маршрутизатором BDR. Эти два соседних устройства могут обмениваться пакетами приветствия (hello), обновлениями, запросами, ответами и подтверждениями;
- 2-WAY/DROTHER — маршрутизатор, не являющийся DR или BDR, имеет соседские отношения с другим маршрутизатором, который тоже не является DR или BDR. Эти два соседних устройства обмениваются пакетами приветствия (hello).
Нормальное состояние для маршрутизатора OSPF — FULL. Если маршрутизатор длительное время находится в другом состоянии, это означает, что у него возникли проблемы с формированием отношений смежности. Единственным исключением из этого правила является состояние 2-WAY, что нормально для широковещательной сети с множественным доступом.
Выбор ролей DR и BDR по протоколу OSPF
- Маршрутизаторы в сети выбирают маршрутизатор с самым высоким приоритетом интерфейса в качестве DR. Маршрутизатор со вторым по величине приоритетом интерфейса становится BDR. Приоритет может быть представлен любым числом от 0 до 255. Чем выше приоритет, тем больше вероятность, что маршрутизатор будет выбран в качестве DR. Если приоритет настроен на значение 0, то маршрутизатор не получит роль DR. Приоритет по умолчанию интерфейсов, подключенных к широковещательной сети множественного доступа, равен 1. Соответственно, при отсутствии иных настроек, все маршрутизаторы обладают равным приоритетом, и для выборов DR/BDR будет использоваться другой метод;
- Если приоритеты интерфейсов равны, то в качестве DR будет выбран маршрутизатор с наивысшим идентификатором. Маршрутизатор со вторым по величине идентификатором становится BDR.
Идентификатор маршрутизатора определяется одним из трех способов:
- Идентификатор маршрутизатора может быть настроен вручную;
- Если идентификатор маршрутизатора не настроен, тогда в качестве идентификатора маршрутизатора принимается наивысший IPv4 адрес интерфейса Loopback;
- Если интерфейсы loopback не настроены, то идентификатор маршрутизатора определяется по наивысшему IPv4 адресу активного физического интерфейса.
Процедура выбора DR и BDR начинается сразу после появления в сети с множественным доступом первого активного маршрутизатора с интерфейсом, где включен OSPF.
Примечание. Если в сети IPv6 на маршрутизаторе не настроены IPv4-адреса, то идентификатор маршрутизатора необходимо настроить вручную с помощью команды router-id, в противном случае OSPFv3 не запускается.
Примечание. На последовательных интерфейсах приоритет по умолчанию настроен на значение 0, поэтому они не выбирают DR и BDR.
Процедура выбора занимает всего несколько секунд. Если в сети с множественным доступом загрузились не все маршрутизаторы, то роль DR может получить маршрутизатор не с самым высоким идентификатором. Это может быть более простой маршрутизатор, загрузка которого занимает меньше времени.
Примечание. Процесс выбора DR и BDR по протоколу OSPF не является приоритетным. Если после завершения выбора DR/BDR в сети появляется новый маршрутизатор с более высоким приоритетом или идентификатором, то этот новый маршрутизатор не перенимает роль DR или BDR, поскольку эти роли уже назначены. Добавление нового маршрутизатора не приводит к новому процессу выбора.
Смена ролей
Когда какой-либо маршрутизатор выбран в качестве DR, то он сохраняет эту роль, пока не произойдет одно из следующих событий:
- Сбой DR;
- Сбой или остановка OSPF-процесса на DR;
- Сбой или отключение интерфейса с множественным доступом на DR.
Если происходит сбой DR, то его роль автоматически перенимает BDR. Это происходит даже в том случае, если после первоначального выбора DR/BDR к сети добавляется другой маршрутизатор DROTHER с более высоким идентификатором или приоритетом. Однако когда BDR перенимает роль DR, происходит новый выбор BDR и его роль получает маршрутизатор DROTHER с высоким идентификатором или приоритетом.
Рекомендации
Вместо того чтобы полагаться на идентификатор маршрутизатора, рекомендуется управлять выбором посредством настройки приоритетов интерфейсов. Приоритеты — это значение для интерфейса, исходя из которого интерфейс обеспечивает улучшенное управление сетью с множественным доступом. Также это позволяет маршрутизатору выполнять роль DR в одной сети, и DROTHER — в другой.
Чтобы настроить приоритет интерфейса, используйте следующие команды:
ip ospf priority value — команда интерфейса OSPFv2 ipv6 ospf priority value — команда интерфейса OSPFv3
value может быть:
- 0 — маршрутизатор не становится DR или BDR;
- От 1 до 255 — чем выше значение приоритета, тем больше вероятность, что маршрутизатор станет DR или BDR на данном интерфейсе.
Примечание. Если приоритет интерфейса настраивается после включения OSPF, то администратор должен отключить процесс OSPF на всех маршрутизаторах, а затем повторно включить его, чтобы инициировать новый процесс выбора DR/BDR.
Очистка процесса OSPF производится из привилегированного режима:
clear ip ospf process — на всех маршрутизаторах
Распространение маршрута по умолчанию
Для распространения маршрута по умолчанию на граничном маршрутизаторе должны быть настроены:
ip route 0.0.0.0 0.0.0.0 {ip-address | exit-intf} - статический маршрут по умолчанию
default-information originate
ipv6 route ::/0 {ipv6-address | exit-intf} default-information originate
Примечание. Обозначение E2 в таблице маршрутизации указывает на то, что это внешний маршрут.
Интервалы OSPF
Интервалы приветствия (hello) и простоя (dead) OSPF настраиваются для каждого интерфейса. По умолчанию 10 секунд и 40 секунд. Интервалы OSPF должны совпадать, иначе соседские отношения смежности не установятся.
Рекомендуется изменять таймеры OSPF, чтобы маршрутизаторы быстрее могли обнаружить сбои в сети. Это увеличивает трафик, но иногда важнее обеспечить быструю сходимость, чем экономить на трафике.
ip ospf hello-interval seconds ip ospf dead-interval seconds
Чтобы восстановить значения интервалов по умолчанию:
no ip ospf hello-interval no ip ospf dead-interval
Сразу после изменения интервала приветствия hello CISCO IOS автоматически приравнивает интервал простоя dead к четырем интервалам приветствия. Однако чтобы изменения были задокументированы в конфигурации, всегда полезно явно изменить таймер, а не полагаться на автоматические функции IOS.
ipv6 ospf hello-interval seconds ipv6 ospf dead-interval seconds
Атаки на маршрутизаторы
К видам фальсификации данных о маршрутах относятся:
- перенаправление трафика для создания петель маршрутизации;
- перенаправление трафика в целях его прочтения на незащищённом канале;
- перенаправление трафика в целях его удаления.
Для защиты обновлений от фальсификации применяется аутентификация.
Аутентификация OSPF
OSPF поддерживает три типа аутентификации:
- Нулевая (Null) — это способ по умолчанию, который означает, что аутентификация для OSPF не используется;
- Простая аутентификация по паролю — также ее называют аутентификацией на базе открытого ключа, поскольку пароль в обновлении отправляется по сети в виде обычного текста. Этот способ аутентификации OSPF считается устаревшим;
- Аутентификация MD5 — наиболее безопасный и рекомендуемый способ аутентификации. Аутентификация MD5 гарантирует более высокий уровень безопасности, равноправные узлы не обмениваются паролями. Вместо этого он вычисляется по алгоритму MD5. Отправителя аутентифицируют совпадающие результаты.
Примечание. Различные формы аутентификации MD5 поддерживаются протоколами RIPv2, EIGRP, OSPF, IS-IS и BGP.
Примечание. OSPFv3 не обладает собственными возможностями аутентификации. Вместо этого для защиты передачи данных между соседними устройствами он полностью полагается на IPsec с помощью команды режима конфигурации интерфейса:
ipv6 ospf authentication ipsec spi
Механизм MD5
Message Digest 5 (MD5) не шифрует сообщение, поэтому его содержимое легко прочитать. Отправляющий маршрутизатор R2 объединяет сообщение маршрутизации с предварительно согласованным секретным ключом и рассчитывает подпись с помощью алгоритма MD5. Принимающий маршрутизатор делает тоже самое:
- Если подписи совпадают, то R2 принимает обновление маршрутизации;
- Если подписи не совпадают, то R2 отбрасывает обновление.
Настройка MD5
Чтобы включить аутентификацию MD5 OSPF глобально, выполните следующие настройки:
ip ospf message-digest-key number md5 пароль - команда режима конфигурации интерфейса area area-id authentication message-digest - команда режима конфигурации маршрутизатора
Пример. Настраиваем аутентификацию на маршрутизаторе R5 и смотрим соседей OSPF:

Таймер истёк и сосед R3 отвалился. Настраиваем аутентификацию на R3:

и проверяем ещё раз:

Работоспособность восстановлена, теперь уже с аутентификацией MD5.
Чтобы включить аутентификацию MD5 на отдельных интерфейсах, настройте следующее:
ip ospf message-digest-key number md5 пароль - команда режима конфигурации интерфейса ip ospf authentication message-digest - команда режима конфигурации интерфейса
На одном и том же маршрутизаторе аутентификация OSPF MD5 может использоваться как глобально, так и по отдельности. Однако настройки на интерфейсе заменяют настройки, выполненные в глобальном режиме. Используемые пароли аутентификации MD5 в одной области могут быть разными. Однако они должны совпадать между соседними устройствами.
Проверка аутентификации
show ip ospf interface | include Message show ip route ospf
Условия формирования отношений смежности
Протокол маршрутизации OSPF является одним из самых распространённых протоколов маршрутизации, используемых в больших корпоративных сетях. Поиск и устранение неполадок, связанных с обменом информацией о маршрутах, является одним из важнейших навыков для сетевого специалиста, который занимается реализацией и поддержкой крупных маршрутизируемых корпоративных сетей, в которых протокол OSPF используется в качестве протокола внутреннего шлюза.
Значение process-id имеет локальное значение, то есть оно не обязательно должно быть идентичным значениям на других маршрутизаторах OSPF для установления отношений смежности между этими соседними устройствами.
Типичные причины проблем со смежностью:
- Интерфейсы находятся в разных подсетях;
- Типы сетей OSPF не совпадают;
- Таймеры приветствия или простоя OSPF не совпадают;
- Интерфейс по направлению к соседнему устройству неправильно настроен в качестве пассивного;
- Отсутствует или неправильна настроена одна из команд network OSPF;
- Аутентификация настроена неверно.
Состояния OSPF

Примечание. При поиске и устранении неполадок в работе соседних устройств OSPF помните, что нормальные состояния — это FULL или 2WAY. Все остальные состояния являются временными, маршрутизатор не должен находиться в этих состояниях слишком долго.
Настройка пути OSPF
Команда passive-interface запрещает отправку обновлений маршрутов через указанный интерфейс маршрутизатора. В большинстве случаев команда используется для уменьшения трафика в локальных сетях, поскольку им не нужно получать сообщения протокола динамической маршрутизации.
Команда изменяет только метрику пропускной способности, используемую алгоритмом OSPF для расчёта стоимости маршрутизации, но не меняет фактическую пропускную способность (скорость) канала:
bandwidth kilobits
Изменение метрик стоимости канала с помощью команды
ip ospf cost number
это наиболее простой и предпочтительный способ изменения стоимости маршрутов OSPF. Помимо изменения
стоимости, используя пропускную способность, у сетевого администратора могут быть другие причины
для изменения стоимости маршрута. Например, предпочтение конкретного поставщика услуг или фактическая стоимость канала или маршрута в денежном выражении.
Чтобы протокол OSPF правильно определил путь, необходимо изменить эталонную пропускную способность, задав более высокое значение с учетом сетей, содержащих каналы, скорость которых выше 100Mbit. Для настройки эталонной пропускной способности используйте команду режима конфигурации маршрутизатора:
auto-cost reference-bandwidth Mbps
10. Протокол Spanning Tree Protocol (STP)
10.2. Bridge Protocol Data Unit (BPDU)
Вычисление структуры связующего дерева происходит при включении коммутатора и при изменении топологии. Эти вычисления требуют периодического обмена информацией между коммутаторами связующего дерева, что достигается при помощи специальных кадров, называемых блоками данных протокола моста – BPDU (Bridge Protocol Data Unit).
Коммутатор отправляет BPDU, используя уникальный МАС-адрес порта в качестве адреса-отправителя и групповой МАС-адрес протокола STP 01-80-C2-00-00-00 в качестве адреса-получателя. Кадры BPDU помещаются в поле данных кадров канального уровня, например кадров Ethernet.
Внимание: иногда, в целях повышения безопасности, администраторам необходимо отключать возможность передачи кадров BPDU на граничные коммутаторы сети, чтобы избежать получения случайных кадров BPDU клиентскими портами, которые могут распространить вычисления STP по клиентским сетям. Управляемые коммутаторы D-Link поддерживают возможность включения и отключения передачи кадров BPDU для каждого порта.
Существует три типа кадров BPDU:
- Configuration BPDU (CBPDU) – конфигурационный кадр BPDU, который используется для вычисления связующего дерева (тип сообщения: 0x00).
- Topology Change Notification (TCN) BPDU – уведомление об изменении топологии сети (тип сообщения: 0x80).
- Topology Change Notification Acknowledgement (TCA) – подтверждение о получении уведомления об изменении топологии сети.
Коммутаторы обмениваются BPDU через равные интервалы времени (по умолчанию 2 с), что позволяет им отслеживать состояние топологии сети.

Рис. 6.16 Формат кадра BPDU
Кадр BPDU состоит из следующих полей:
- Идентификатор протокола (Protocol Identifier) – занимает 2 байта, значение всегда равно 0.
- Версия протокола STP (Protocol VersionIdentifier) – 1 байт, значение всегда равно 0.
- Тип BPDU (BPDU Type) – 1 байт, значение «00» – конфигурационный BPDU, «01» – изменение топологии.
- Флаги (Flags) – 1 байт. Бит 1 – флаг изменения топологии, бит 8 – флаг подтверждения изменения топологии.
- Идентификатор корневого моста (Root Identifier) – 8 байт. Идентификатор текущего моста.
- Расстояние до корневого моста (Root Path Cost) – 2 байта. Суммарная стоимость пути до корневого моста.
- Идентификатор моста (Bridge Identifier) – 8 байт. Идентификатор текущего моста.
- Идентификатор порта (Port Identifier) – 2 байта. Уникальный идентификатор порта, который отправил этот BPDU.
- Время жизни сообщения (Message Age) – 2 байта. Нефиксированный временной интервал в секундах, прошедший с момента отправки BPDU корневым мостом. Служит для выявления устаревших сообщений BPDU. Первоначальное значение равно 0. По мере передачи кадра BPDU по сети, каждый коммутатор, добавляет ко времени жизни сообщения время его задержки данным коммутатором. По умолчанию оно равно 1 с. Значение параметра Message Age должно быть меньше значения таймера Max Age.
- Максимальное время жизни сообщения (Max Age) – 2 байта. Временной интервал в секундах, определяющий максимальное время хранения конфигурации STP, прежде чем коммутатор ее отбросит.
- Время приветствия (Hello Time) – 2 байта. Временной интервал в секундах, через который посылаются кадры BPDU.
- Задержка смены состояний (Forward Delay) – 2 байта. Временной интервал в секундах, в течение которого порт коммутатора находится в состояниях «Прослушивание» и «Обучение».