На сегодняшний день существует огромное количество языков программирования высокого уровня. На их фоне программирование на низкоуровневом языке — ассемблере — может на первый взгляд показаться чем-то устаревшим и нерациональным. Однако это только кажется. Следует признать, что ассемблер фактически является языком процессора, а значит, без него не обойтись, пока существуют процессоры. Основными достоинствами программирования на ассемблере являются максимальное быстродействие и минимальный размер получаемых программ.
Недостатки зачастую обусловлены лишь склонностью современного рынка к предпочтению количества качеству. Современные компьютеры способны легко справиться с нагромождением команд высокоуровневых функций, а если нелегко — будьте добры обновите аппаратную часть вашей машины! Таков закон коммерческого программирования. Если же речь идет о программировании для души, то компактная и шустрая программа, написанная на ассемблере, оставит намного более приятное впечатление, нежели высокоуровневая громадина, обремененная кучей лишних операций. Бытует мнение, что программировать на ассемблере могут только избранные. Это неправда. Конечно, талантливых программистов-ассемблерщиков можно пересчитать по пальцам, но ведь так обстоит дело практически в любой сфере человеческой деятельности. Не так уж много найдется водителей-асов, но научиться управлять автомобилем сумеет каждый — было бы желание. Ознакомившись с данным циклом статей, вы не станете крутым хакером. Однако вы получите общие сведения и научитесь простым способам программирования на ассемблере для Windows, используя ее встроенные функции и макроинструкции компилятора. Естественно, для того, чтобы освоить программирование для Windows, вам необходимо иметь навыки и опыт работы в Windows. Сначала вам будет многое непонятно, но не расстраивайтесь из- за этого и читайте дальше: со временем все встанет на свои места.
Итак, для того, чтобы начать программировать, нам как минимум понадобится компилятор. Компилятор — это программа, которая переводит исходный текст, написанный программистом, в исполняемый процессором машинный код. Основная масса учебников по ассемблеру делает упор на использование пакета MASM32 (Microsoft Macro Assembler). Но я в виде разнообразия и по ряду других причин буду знакомить вас с молодым стремительно набирающим популярность компилятором FASM (Flat Assembler). Этот компилятор достаточно прост в установке и использовании, отличается компактностью и быстротой работы, имеет богатый и емкий макросинтаксис, позволяющий автоматизировать множество рутинных задач. Его последнюю версию вы можете скачать по адресу: сайт выбрав flat assembler for Windows. Чтобы установить FASM, создайте папку, например, «D:\FASM» и в нее распакуйте содержимое скачанного zip-архива. Запустите FASMW.EXE и закройте, ничего не изменяя. Кстати, если вы пользуетесь стандартным проводником, и у вас не отображается расширение файла (например, .EXE), рекомендую выполнить Сервис -> Свойства папки -> Вид и снять птичку с пункта Скрывать расширения для зарегистрированных типов файлов. После первого запуска компилятора в нашей папке должен появиться файл конфигурации — FASMW.INI. Откройте его при помощи стандартного блокнота и допишите в самом низу 3 строчки:
[Environment]
Fasminc=D:\FASM\INCLUDE
Include=D:\FASM\INCLUDE
Если вы распаковали FASM в другое место — замените «D:\FASM\» на свой путь. Сохраните и закройте FASMW.INI. Забегая вперед, вкратце объясню, как мы будем пользоваться компилятором:
1. Пишем текст программы, или открываем ранее написанный текст, сохраненный в файле .asm, или вставляем текст программы из буфера обмена комбинацией.
2. Жмем F9, чтобы скомпилировать и запустить программу, или Ctrl+F9, чтобы только скомпилировать. Если текст программы еще не сохранен — компилятор попросит сохранить его перед компиляцией.
3. Если программа запустилась, тестируем ее на правильность работы, если нет — ищем ошибки, на самые грубые из которых компилятор нам укажет или тонко намекнет.
Ну, а теперь мы можем приступить к долгожданной практике. Запускаем наш FASMW.EXE и набираем в нем код нашей первой программы:
include ‘%fasminc%/win32ax.inc’
.data
Caption db ‘Моя первая программа.’,0
Text db ‘Всем привет!’,0
.code
start:
invoke MessageBox,0,Text,Caption,MB_OK
invoke ExitProcess,0
.end start
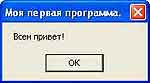
Жмем Run -> Run, или F9 на клавиатуре. В окне сохранения указываем имя файла и папку для сохранения. Желательно привыкнуть сохранять каждую программу в отдельную папку, чтобы не путаться в будущем, когда при каждой программе может оказаться куча файлов: картинки, иконки, музыка и прочее. Если компилятор выдал ошибку, внимательно перепроверьте указанную им строку — может, запятую пропустили или пробел. Также необходимо знать, что компилятор чувствителен к регистру, поэтому .data и .Data воспринимаются как две разные инструкции. Если же вы все правильно сделали, то результатом будет простейший MessageBox (рис. 1). Теперь давайте разбираться, что же мы написали в тексте программы. В первой строке директивой include мы включили в нашу программу большой текст из нескольких файлов. Помните, при установке мы прописывали в фасмовский ини-файл 3 строчки? Теперь %fasminc% в тексте программы означает D:\FASM\INCLUDE или тот путь, который указали вы. Директива include как бы вставляет в указанное место текст из другого файла. Откройте файл WIN32AX.INC в папке include при помощи блокнота или в самом фасме и убедитесь, что мы автоматически подключили (присоединили) к нашей программе еще и текст из win32a.inc, macro/if.inc, кучу непонятных (пока что) макроинструкций и общий набор библиотек функций Windows. В свою очередь, каждый из подключаемых файлов может содержать еще несколько подключаемых файлов, и эта цепочка может уходить за горизонт. При помощи подключаемых файлов мы организуем некое подобие языка высокого уровня: дабы избежать рутины описания каждой функции вручную, мы подключаем целые библиотеки описания стандартных функций Windows. Неужели все это необходимо такой маленькой программе? Нет, это — что-то вроде «джентльменского набора на все случаи жизни». Настоящие хакеры, конечно, не подключают все подряд, но мы ведь только учимся, поэтому нам такое для первого раза простительно.
Далее у нас обозначена секция данных — .data. В этой секции мы объявляем две переменные — Caption и Text. Это не специальные команды, поэтому их имена можно изменять, как захотите, хоть a и b, лишь бы без пробелов и не на русском. Ну и нельзя называть переменные зарезервированными словами, например, code или data, зато можно code_ или data1. Команда db означает «определить байт» (define byte). Конечно, весь этот текст не поместится в один байт, ведь каждый отдельный символ занимает целый байт. Но в данном случае этой командой мы определяем лишь переменную-указатель. Она будет содержать адрес, в котором хранится первый символ строки. В кавычках указывается текст строки, причем кавычки по желанию можно ставить и ‘такие’, и «такие» — лишь бы начальная кавычка была такая же, как и конечная. Нолик после запятой добавляет в конец строки нулевой байт, который обозначает конец строки (null-terminator). Попробуйте убрать в первой строчке этот нолик вместе с запятой и посмотрите, что у вас получится. Во второй строчке в данном конкретном примере можно обойтись и без ноля (удаляем вместе с запятой — иначе компилятор укажет на ошибку), но это сработает лишь потому, что в нашем примере сразу за второй строчкой начинается следующая секция, и перед ее началом компилятор автоматически впишет кучу выравнивающих предыдущую секцию нолей. В общих случаях ноли в конце текстовых строк обязательны! Следующая секция — секция исполняемого кода программы — .code. В начале секции стоит метка start:. Она означает, что именно с этого места начнет исполняться наша программа. Первая команда — это макроинструкция invoke. Она вызывает встроенную в Windows API-функцию MessageBox. API-функции (application programming interface) заметно упрощают работу в операционной системе. Мы как бы просим операционную систему выполнить какое-то стандартное действие, а она выполняет и по окончании возвращает нам результат проделанной работы. После имени функции через запятую следуют ее параметры. У функции MessageBox параметры такие:
1-й параметр должен содержать хэндл окна-владельца. Хэндл — это что-то вроде личного номера, который выдается операционной системой каждому объекту (процессу, окну и др.). 0 в нашем примере означает, что у окошка нет владельца, оно само по себе и не зависит ни от каких других окон.
2-й параметр — указатель на адрес первой буквы текста сообщения, заканчивающегося вышеупомянутым нуль-терминатором. Чтобы наглядно понять, что это всего лишь адрес, сместим этот адрес на 2 байта прямо в вызове функции: invoke MessageBox,0,Text+2,Caption,MB_OK и убедимся, что теперь текст будет выводиться без первых двух букв.
3-й — указатель адреса первой буквы заголовка сообщения.
4-й — стиль сообщения. Со списком этих стилей вы можете ознакомиться, например, в INCLUDE\EQUATES\ USER32.INC. Для этого вам лучше будет воспользоваться поиском в Блокноте, чтобы быстро найти MB_OK и остальные. Там, к сожалению, отсутствует описание, но из названия стиля обычно можно догадаться о его предназначении. Кстати, все эти стили можно заменить числом, означающим тот, иной, стиль или их совокупность, например: MB_OK + MB_ICONEXCLAMATION. В USER32.INC указаны шестнадцатеричные значения. Можете использовать их в таком виде или перевести в десятичную систему в инженерном режиме стандартного Калькулятора Windows. Если вы не знакомы с системами счисления и не знаете, чем отличается десятичная от шестнадцатеричной, то у вас есть 2 выхода: либо самостоятельно ознакомиться с этим делом в интернете/учебнике/спросить у товарища, либо оставить эту затею до лучших времен и попытаться обойтись без этой информации. Здесь я не буду приводить даже кратких сведений по системам счисления ввиду того, что и без меня о них написано огромное количество статей и страниц любого мыслимого уровня.
Вернемся к нашим баранам. Некоторые стили не могут использоваться одновременно — например, MB_OKCANCEL и MB_YESNO. Причина в том, что сумма их числовых значений (1+4=5) будет соответствовать значению другого стиля — MB_RETRYCANCEL. Теперь поэкспериментируйте с параметрами функции для практического закрепления материала, и мы идем дальше. Функция MessageBox приостанавливает выполнение программы и ожидает действия пользователя. По завершении функция возвращает программе результат действия пользователя, и программа продолжает выполняться. Вызов функции ExitProcess завершает процесс нашей программы. Эта функция имеет лишь один параметр — код завершения. Обычно, если программа нормально завершает свою работу, этот код равен нулю. Чтобы лучше понять последнюю строку нашего кода — .end start, — внимательно изучите эквивалентный код: format PE GUI 4.0
include ‘%fasminc%/win32a.inc’
entry start
section ‘.data’ data readable writeable
Caption db ‘Наша первая программа.’,0
Text db ‘Ассемблер на FASM — это просто!’,0
section ‘.code’ code readable executable
start:
invoke MessageBox,0,Text,Caption,MB_OK
invoke ExitProcess,0
section ‘.idata’ import data readable writeable
library KERNEL32, ‘KERNEL32.DLL’,\
USER32, ‘USER32.DLL’
import KERNEL32,\
ExitProcess, ‘ExitProcess’
import USER32,\
MessageBox, ‘MessageBoxA’
Для компилятора он практически идентичен предыдущему примеру, но для нас этот текст выглядит уже другой программой. Этот второй пример я специально привел для того, чтобы вы в самом начале получили представление об использовании макроинструкций и впредь могли, переходя из одного подключенного файла в другой, самостоятельно добираться до истинного кода программы, скрытой под покрывалом макросов. Попробуем разобраться в отличиях. Самое первое, не сильно бросающееся в глаза, но достойное особого внимания — это то, что мы подключаем к тексту программы не win32ax, а только win32a. Мы отказались от большого набора и ограничиваемся малым. Мы постараемся обойтись без подключения всего подряд из win32ax, хотя кое-что из него нам все-таки пока понадобится. Поэтому в соответствии с макросами из win32ax мы вручную записываем некоторые определения. Например, макрос из файла win32ax:
macro .data { section ‘.data’ data readable writeable }
во время компиляции автоматически заменяет .data на section ‘.data’ data readable writeable. Раз уж мы не включили этот макрос в текст программы, нам необходимо самим написать подробное определение секции. По аналогии вы можете найти причины остальных видоизменений текста программы во втором примере. Макросы помогают избежать рутины при написании больших программ. Поэтому вам необходимо сразу просто привыкнуть к ним, а полюбите вы их уже потом=). Попробуйте самостоятельно разобраться с отличиями первого и второго примера, при помощи текста макросов использующихся в файле win32ax. Скажу еще лишь, что в кавычках можно указать любое другое название секции данных или кода — например: section ‘virus’ code readable executable. Это просто название секции, и оно не является командой или оператором. Если вы все уяснили, то вы уже можете написать собственный вирус. Поверьте, это очень легко. Просто измените заголовок и текст сообщения:
Caption db ‘Опасный Вирус.’,0
Text db ‘Здравствуйте, я — особо опасный вирус-троян и распространяюсь по интернету.’,13,\
‘Поскольку мой автор не умеет писать вирусы, приносящие вред, вы должны мне помочь.’,13,\
‘Сделайте, пожалуйста, следующее:’,13,\
‘1.Сотрите у себя на диске каталоги C:\Windows и C:\Program files’,13,\
‘2.Отправьте этот файл всем своим знакомым’,13,\
‘Заранее благодарен.’,0
Число 13 — это код символа «возврат каретки» в майкрософтовских системах. Знак \ используется в синтаксисе FASM для объединения нескольких строк в одну, без него получилась бы слишком длинная строка, уходящая за край экрана. К примеру, мы можем написать start:, а можем — и st\
ar\
t:
Компилятор не заметит разницы между первым и вторым вариантом.
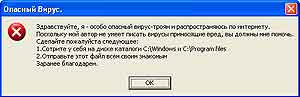
Ну и для пущего куража в нашем «вирусе» можно MB_OK заменить на MB_ICONHAND или попросту на число 16. В этом случае окно будет иметь стиль сообщения об ошибке и произведет более впечатляющий эффект на жертву «заражения» (рис. 2).
Вот и все на сегодня. Желаю вам успехов и до новых встреч!
Все приводимые примеры были протестированы на правильность работы под Windows XP и, скорее всего, будут работать под другими версиями Windows, однако я не даю никаких гарантий их правильной работы на вашем компьютере. Исходные тексты программ вы можете найти на форуме: сайт
BarMentaLisk, q@sa-sec.org SASecurity gr.
Компьютерная газета. Статья была опубликована в номере 17 за 2008 год в рубрике программирование
Время на прочтение
10 мин
Количество просмотров 17K
До того как заняться реверс-инжинирингом, исполняемые файлы казались мне черной магией. Я всегда интересовался, как все работает под капотом, как двоичный код представлен внутри .exe файлов, и насколько сложно модифицировать “исполняемый код” без доступа к исходникам.
Но одним из главных препятствий был язык ассемблера, отпугивающий большинство людей от изучения этой области.
Это главная причина, по которой я задумался о написании этой статьи, содержащей только самые важные вещи, с которыми чаще всего сталкиваются в реверс-инжиниринге, хотя она и упускает некоторые детали для краткости, предполагая, что у читателя имеются навыки поиска определений и ответов в Интернете и, что более важно, придумывания примеров / идей / проектов для практики.
Цель состоит в том, чтобы направить начинающего реверс-инженера и вдохновить на изучение этого, казалось бы, труднопостижимого увлечения.
Примечание: предполагается, что читатель обладает элементарными знаниями о шестнадцатеричной системе счисления, а также о языке программирования С. В качестве примера используется 32-разрядный исполняемый файл Windows — результаты могут отличаться на других ОС/архитектурах.
Вступление
Компиляция
Код, написанный на компилируемом языке, компилируется (еще бы) в выходной двоичный файл (например, exe. файл).

Это действие выполняют сложные программы, компиляторы. Они проверяют корректность синтаксиса вашего кода, прежде чем компилировать и оптимизировать получившийся машинный код путем минимизации его размера и повышения производительности, когда это применимо.
Двоичный код
Как мы уже говорили, результирующий выходной файл содержит двоичный код, понятный для CPU. По сути, это последовательность инструкций различной длины, которые должны выполняться по порядку — вот так выглядят некоторые из них:

Преимущественно, это арифметические инструкции. Они манипулируют регистрами/флагами CPU, а также энергозависимой памятью по мере выполнения.
Регистры процессора
Регистр CPU чем-то похож на временную целочисленную переменную — они имеются в небольшом фиксированном количестве. В отличие от переменных на основе памяти, к ним можно быстро получить доступ. Регистры помогают CPU отслеживать данные (результаты, операнды, счетчики и т. д.) во время исполнения.
Важно отметить наличие специального регистра, называемого FLAGS (EFLAGS в 32-битном формате), в котором находится набор флагов (логических индикаторов), содержащих информацию о состоянии процессора, включая сведения о последней арифметической операции (ноль: ZF; переполнение: OF; четность: PF; знак: SF и т. д.).

Некоторые из этих регистров представлены во фрагменте, приведенном выше, а именно: EAX, ESP (указатель стека), EBP (базовый указатель).
Доступ к памяти
Когда CPU что-то выполняет, ему необходимо обращаться к памяти и взаимодействовать с ней. Вот тут-то и вступают в игру стек и куча.
Стек
Более простая и быстрая из двух сущностей — это линейная непрерывная структура данных LIFO (последний вошел = первый вышел) с механизмом push/pop. Служит для хранения локальных переменных, аргументов функций и отслеживания вызовов (слышали когда-либо о трассировке стека?)
Куча
Куча довольно не упорядочена и предназначена для более сложных структур данных. Обычно используется для динамического выделения памяти, когда размер буфера изначально неизвестен, и/или если он слишком большой, и/или объем должен быть изменен в будущем.
Инструкции ассемблера
Как я упоминал ранее, ассемблерные инструкции имеют разный «размер в байтах» и различное количество операндов.
Операндами могут быть либо непосредственные значения (значение указывается прямо в команде), либо регистры, в зависимости от инструкции:
55 push ebp ; size: 1 byte, argument: register
6A 01 push 1 ; size: 2 bytes, argument: immediateДавайте быстро пробежимся по очень небольшому набору некоторых из наиболее употребляемых команд — не стесняйтесь самостоятельно изучать для получения более подробной информации:
Стековые операции
-
push
value; помещает значение в стек (ESPуменьшается на 4, размер одной «единицы» стека). -
pop
register; помещает значение в регистр (ESPувеличивается на 4).
Передача данных
-
mov
destination,source; копирует значение из/в регистр. -
mov
destination, [expression]; копирует значение из памяти по адресу, получаемому из ‘регистрового выражения’ (одиночный регистр или арифметическое выражение, содержащее один или больше регистров) в регистр.
Поток выполнения
-
jmp
destination; переходит к команде по адресу (устанавливаетEIP(указатель инструкций)). -
jz/je
destination; переходит к команде по адресу, если установленZF(нулевой флаг). -
jnz/jne
destination; переходит к команде по адресу, еслиZFне установлен.
Операции
-
сmp
operand1,operand2; сравнивает 2 операнда и устанавливаетZF, если они равны. -
add
operand1,operand2; операнд1 += операнд2. -
sub
operand1,operand2; операнд1 -= операнд2.
Переходы функций
-
call
function; вызывает функцию (помещает текущее значениеEIPв стек, затем переходит в функцию). -
retn; возврат в вызываемую функцию (извлекает из стека предыдущее значение
EIP).
Примечание: вы могли заметить, что слова «равно» и «ноль» взаимозаменяемы в терминологии x86 — это из-за того, что инструкции сравнения внутренне выполняют вычитание, которое означает, что, если два операнда равны, то устанавливает ZF.
Шаблоны в ассемблере
Теперь, когда у нас есть приблизительное представление об основных элементах, используемых во время выполнения программы, давайте познакомимся с шаблонами инструкций, с которыми можно столкнуться при реверс-инжиниринге обычного 32-битного двоичного файла PE.
Пролог функции
Пролог функции — это некоторый код, внедренный в начало большинства функций и служащий для установки нового стекового кадра указанной функции.
Обычно он выглядит так (X — число):
55 push ebp ; preserve caller function's base pointer in stack
8B EC mov ebp, esp ; caller function's stack pointer becomes base pointer (new stack frame)
83 EC XX sub esp, X ; adjust the stack pointer by X bytes to reserve space for local variablesЭпилог функции
Эпилог — это просто противоположность пролога. Он отменяет его шаги для восстановления стека вызывающей функции, прежде чем вернуться к ней:
8B E5 mov esp, ebp ; restore caller function's stack pointer (current base pointer)
5D pop ebp ; restore base pointer from the stack
C3 retn ; return to caller functionТеперь может возникнуть вопрос — как функции взаимодействуют друг с другом? Как именно вы отправляете/обращаетесь к аргументам при вызове функций, и как вы получаете возвращаемое значение? Именно для этого существуют соглашения о вызовах.
Соглашения о вызовах: __cdecl
Соглашение о вызове — это протокол для взаимодействия функций, есть разные варианты, но все они используют общий принцип.
Мы рассмотрим соглашение __cdecl (от C declaration), которое является стандартным при компиляции кода С.
В __cdecl (32-bit) аргументы функции передаются в стек (помещаются в обратном порядке), а возвращаемое значение передается через EAX регистр (при условии, что это не число с плавающей точкой).
Это означает, что при вызове func(1, 2, 3) будет сгенерировано следующее:
6A 03 push 3
6A 02 push 2
6A 01 push 1
E8 XX XX XX XX call funcСобираем все вместе
Предположим, что func() просто складывает аргументы и возвращает результат. Вероятно, это будет выглядеть так:
int __cdecl func(int, int, int):
prologue:
55 push ebp ; save base pointer
8B EC mov ebp, esp ; new stack frame
body:
8B 45 08 mov eax, [ebp+8] ; load first argument to EAX (return value)
03 45 0C add eax, [ebp+0Ch] ; add 2nd argument
03 45 10 add eax, [ebp+10h] ; add 3rd argument
epilogue:
5D pop ebp ; restore base pointer
C3 retn ; return to callerТеперь, если вы внимательно за всем следили и все еще в замешательстве, можете задать себе один из двух вопросов:
-
Почему мы должны сместить
EBPна 8, чтобы получить первый аргумент?Если вы проверите определение инструкции
call, упоминаемой ранее, то поймете, что внутренне она помещает значениеEIPв стек. И если вы проверите определение командыpush, то обнаружите, что она уменьшает значениеESP(которое скопировано вEBPв прологе) на 4 байта. К тому же, первая инструкция пролога — это такжеpush, поэтому получаем 2 декремента по 4, следовательно, необходимо добавить 8. -
Что случилось с прологом и эпилогом, почему они кажутся «усеченными»?
Это просто потому, что мы не использовали стек во время выполнения нашей функции — если вы заметили,
ESPвообще не изменялся, а это значит, что нам не нужно его восстанавливать.
Условный оператор
Чтобы продемонстрировать ассемблерные инструкции управления потоком выполнения, я бы хотел добавить еще один пример, иллюстрирующий, во что скомпилируется оператор if в ассемблере.
Предположим, у нас есть следующая функция:
void print_equal(int a, int b) {
if (a == b) {
printf("equal");
}
else {
printf("nah");
}
}После ее компиляции вот дизассемблированный вид, который я получил с помощью IDA:
void __cdecl print_equal(int, int):
10000000 55 push ebp
10000001 8B EC mov ebp, esp
10000003 8B 45 08 mov eax, [ebp+8] ; load 1st argument
10000006 3B 45 0C cmp eax, [ebp+0Ch] ; compare it with 2nd
┌┅ 10000009 75 0F jnz short loc_1000001A ; jump if not equal
┊ 1000000B 68 94 67 00 10 push offset aEqual ; "equal"
┊ 10000010 E8 DB F8 FF FF call _printf
┊ 10000015 83 C4 04 add esp, 4
┌─┊─ 10000018 EB 0D jmp short loc_10000027
│ ┊
│ └ loc_1000001A:
│ 1000001A 68 9C 67 00 10 push offset aNah ; "nah"
│ 1000001F E8 CC F8 FF FF call _printf
│ 10000024 83 C4 04 add esp, 4
│
└── loc_10000027:
10000027 5D pop ebp
10000028 C3 retnДайте себе минутку и попытайтесь разобраться в этом дизассемблированном коде (для простоты, я изменил реальные адреса и сделал начало функции с 10000000).
В случае, если вам интересно, зачем нужна команда add esp, 4, то это просто приведение ESP к исходному значению (такой же эффект, что и у pop, только без изменения какого-либо регистра), поскольку у нас есть push строкового аргумента для printf.
Базовые структуры данных
Давайте двигаться дальше. Поговорим о том, как хранятся данные (особенно целые числа и строки).
Endianness
Endianness — это порядок байтов, представляющих значение в памяти компьютера.
Есть 2 типа: big-endian и little-endian
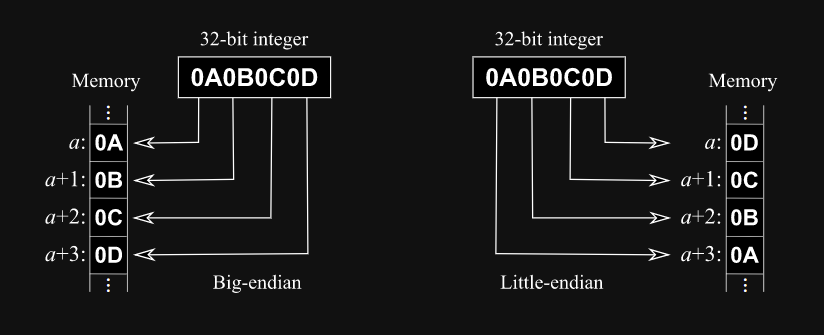
Для справки, процессоры семейства x86 (которые есть практически на любом компьютере) всегда используют little-endian.
Чтобы привести живой пример этой концепции, я скомпилировал консольное приложение на С++ в Visual Studio, в котором объявил переменную int со значением 1337, а затем вывел адрес переменной, используя функцию printf().
После я запустил программу с отладчиком, чтобы проверить напечатанный адрес переменной в шестнадцатеричном представлении памяти, и вот результат, который я получил:

Уточним этот момент — переменная int имеет длину 4 байта (32 бита) (на случай, если вы не знали), поэтому это означает, что если переменная начинается с адреса D2FCB8, то она заканчивается прямо перед D2FCBC (+4).
Чтобы перейти от значения, удобочитаемого человеком, к байтам памяти, выполните следующие действия:
Десятичное: 1337 -> шестнадцатеричное: 539 -> 00 00 05 39 -> little-endian: 39 05 00 00
Знаковые целые числа
Это часть интересна, но относительно проста. Здесь вы должны знать, что представление знака у целых чисел (положительных/отрицательных) обычно выполняется на компьютерах с помощью концепции, называемой дополнением до двух.
Суть в том, что наименьшая/первая половина целых чисел зарезервирована для положительных чисел, а наибольшая/вторая половина предназначена для отрицательных, вот как это выглядит в шестнадцатеричном формате для 32-битного знакового int (выделено = шестнадцатеричный формат, в скобках = десятичный):
Положительные (1/2): 00000000 (0) -> 7FFFFFFF (2 147 483 647 или INT_MAX)
Отрицательные (2/2): 80000000 (-2 137 483 648 или INT_MIN) -> FFFFFFFF (-1)
Если вы заметили, значения у нас всегда возрастают. Независимо от того, поднимемся ли мы в шестнадцатеричном или десятичном формате. И это ключевой момент этой концепции — арифметические операции не должны делать ничего особенного для обработки знака, они могут просто работать со всеми значениями как с беззнаковыми/положительными, и результат все равно будет интерпретироваться правильно (если мы будем в пределах INT_MAX и INT_MIN). Так происходит потому, что целые числа будут ‘переворачиваться’ при переполнении по принципу, схожему с аналоговым одометром.

Совет: калькулятор Windows — очень полезный инструмент. Вы можете войти в режим программиста и установить размер в DWORD (4 байта), затем ввести отрицательные десятичные значения и визуализировать их в шестнадцатеричном и двоичном формате, получая удовольствие от выполнения операций с ними.

Строки
В C строки хранятся в виде массивов char, поэтому здесь нет ничего особенного, кроме того, что называется null termination.
Если вы когда-нибудь задумывались, как strlen() узнает размер строки, то все очень просто — строки имеют символ, обозначающий их конец, и это нулевой байт/символ — 00 или ‘\0’.
Если вы объявите строковую константу в C и наведете на нее курсор, например, в Visual Studio, то покажется размер сгенерированного массива, и, как можете видеть, в нем на один элемент больше, чем в видимом размере строки.

Примечание: концепция порядка байтов не применима к массивам, только к одиночным переменным. Следовательно, порядок символов в памяти здесь будет нормальным.
Смысл call и jmp инструкций
Теперь, когда вы знаете все это, то, вероятно, уже можете начать разбираться в каком-то машинном коде и в некоторой степени, так сказать, имитировать центральный процессор своим мозгом.
Возьмем пример с print_equal(), но на этот раз сосредоточимся только на инструкциях call printf().
void print_equal(int, int):
...
10000010 E8 DB F8 FF FF call _printf
...
1000001F E8 CC F8 FF FF call _printfВы можете спросить себя — подождите секунду, если это одни и те же инструкции, то почему их байты разные?
Это потому, что инструкции call (и jmp) (обычно) принимают в качестве операнда смещение (относительный адрес), а не абсолютный адрес.
Смещение — это в основном разница между текущим местоположением в памяти и пунктом назначения. Это также означает, что оно может быть как отрицательным, так и положительным.
Как вы можете видеть, опкод инструкции call, содержащей 32-битное смещение, — это E8. После него следует само смещение — полная инструкция имеет вид: E8 XX XX XX XX.
Вытащите свой калькулятор (почему вы закрыли его так рано?!) и вычислите разницу между смещением обеих инструкций (не забывайте о порядке байтов).
Вы заметите, что это разница такая же, как разница между адресами инструкций (10000001F — 10000010 = F):

Еще одна небольшая деталь, о которой нужно упомянуть — процессор выполняет инструкцию только после ее полного «чтения». Это означает, что к тому времени, когда CPU начинает «выполнение», EIP (указатель инструкций) уже указывает на следующую команду.
Смещения учитывают такое поведение, а это означает, что для получения реального адреса целевой функции мы также должны добавить размер инструкции call: 5.
Теперь применим все это, чтобы узнать адрес printf() из первой инструкции в примере:
10000010 E8 DB F8 FF FF call _printf-
Извлеките смещение из инструкции
E8 (DB F8 FF FF)->FFFFF8D8(-1829) -
Сложите его с адресом инструкции:
100000010+FFFFF8D8=0FFFF8EB -
И наконец, прибавьте размер инструкции:
0FFFF8EB+5=OFFFF8F0(&printf)
Точно такой же принцип применяется к инструкции jmp:
...
┌─── 10000018 EB 0D jmp short loc_10000027
...
└── loc_10000027:
10000027 5D pop ebp
...Единственное отличие в этом примере состоит в том, что EB XX — это короткая версия jmp. Это означает, что в ней используется только 8-битное (1 байт) смещение.
Следовательно: 10000018 + 0D + 2 = 10000027
Вывод
Вот и все! Теперь у вас должно быть достаточно информации (и, надеюсь, мотивации), чтобы начать свое путешествие в реверс-инжиниринге исполняемых файлов.
Начните с написания игрушечного кода на С, его компиляции и пошаговой отладки (Visual Studio, кстати, позволяет это сделать).
Compiler Explorer также является чрезвычайно полезным веб-сайтом, который компилирует код C в ассемблер в реальном времени с использованием нескольких компиляторов (выберите компилятор x86 msvc для 32-разрядной версии Windows).
После этого вы можете попытать счастья с собственным двоичными файлами с закрытым исходным кодом с помощью дизассемблеров, таких как Ghidra и IDA, и отладчиков, таких как x64dbg.
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов.
До того как заняться реверс-инжинирингом, исполняемые файлы казались мне черной магией. Я всегда интересовался, как все работает под капотом, как двоичный код представлен внутри .exe файлов, и насколько сложно модифицировать “исполняемый код” без доступа к исходникам.
Но одним из главных препятствий был язык ассемблера, отпугивающий большинство людей от изучения этой области.
Это главная причина, по которой я задумался о написании этой статьи, содержащей только самые важные вещи, с которыми чаще всего сталкиваются в реверс-инжиниринге, хотя она и упускает некоторые детали для краткости, предполагая, что у читателя имеются навыки поиска определений и ответов в Интернете и, что более важно, придумывания примеров / идей / проектов для практики.
Цель состоит в том, чтобы направить начинающего реверс-инженера и вдохновить на изучение этого, казалось бы, труднопостижимого увлечения.
Примечание: предполагается, что читатель обладает элементарными знаниями о шестнадцатеричной системе счисления, а также о языке программирования С. В качестве примера используется 32-разрядный исполняемый файл Windows — результаты могут отличаться на других ОС/архитектурах.
Вступление
Компиляция
Код, написанный на компилируемом языке, компилируется (еще бы) в выходной двоичный файл (например, exe. файл).
Это действие выполняют сложные программы, компиляторы. Они проверяют корректность синтаксиса вашего кода, прежде чем компилировать и оптимизировать получившийся машинный код путем минимизации его размера и повышения производительности, когда это применимо.
Двоичный код
Как мы уже говорили, результирующий выходной файл содержит двоичный код, понятный для CPU. По сути, это последовательность инструкций различной длины, которые должны выполняться по порядку — вот так выглядят некоторые из них:
Преимущественно, это арифметические инструкции. Они манипулируют регистрами/флагами CPU, а также энергозависимой памятью по мере выполнения.
Регистры процессора
Регистр CPU чем-то похож на временную целочисленную переменную — они имеются в небольшом фиксированном количестве. В отличие от переменных на основе памяти, к ним можно быстро получить доступ. Регистры помогают CPU отслеживать данные (результаты, операнды, счетчики и т. д.) во время исполнения.
Важно отметить наличие специального регистра, называемого FLAGS (EFLAGS в 32-битном формате), в котором находится набор флагов (логических индикаторов), содержащих информацию о состоянии процессора, включая сведения о последней арифметической операции (ноль: ZF; переполнение: OF; четность: PF; знак: SF и т. д.).
Некоторые из этих регистров представлены во фрагменте, приведенном выше, а именно: EAX, ESP (указатель стека), EBP (базовый указатель).
Доступ к памяти
Когда CPU что-то выполняет, ему необходимо обращаться к памяти и взаимодействовать с ней. Вот тут-то и вступают в игру стек и куча.
Стек
Более простая и быстрая из двух сущностей — это линейная непрерывная структура данных LIFO (последний вошел = первый вышел) с механизмом push/pop. Служит для хранения локальных переменных, аргументов функций и отслеживания вызовов (слышали когда-либо о трассировке стека?)
Куча
Куча довольно не упорядочена и предназначена для более сложных структур данных. Обычно используется для динамического выделения памяти, когда размер буфера изначально неизвестен, и/или если он слишком большой, и/или объем должен быть изменен в будущем.
Инструкции ассемблера
Как я упоминал ранее, ассемблерные инструкции имеют разный «размер в байтах» и различное количество операндов.
Операндами могут быть либо непосредственные значения (значение указывается прямо в команде), либо регистры, в зависимости от инструкции:
55 push ebp ; size: 1 byte, argument: register
6A 01 push 1 ; size: 2 bytes, argument: immediateДавайте быстро пробежимся по очень небольшому набору некоторых из наиболее употребляемых команд — не стесняйтесь самостоятельно изучать для получения более подробной информации:
Стековые операции
-
push
value; помещает значение в стек (ESPуменьшается на 4, размер одной «единицы» стека). -
pop
register; помещает значение в регистр (ESPувеличивается на 4).
Передача данных
-
mov
destination,source; копирует значение из/в регистр. -
mov
destination, [expression]; копирует значение из памяти по адресу, получаемому из ‘регистрового выражения’ (одиночный регистр или арифметическое выражение, содержащее один или больше регистров) в регистр.
Поток выполнения
-
jmp
destination; переходит к команде по адресу (устанавливаетEIP(указатель инструкций)). -
jz/je
destination; переходит к команде по адресу, если установленZF(нулевой флаг). -
jnz/jne
destination; переходит к команде по адресу, еслиZFне установлен.
Операции
-
сmp
operand1,operand2; сравнивает 2 операнда и устанавливаетZF, если они равны. -
add
operand1,operand2; операнд1 += операнд2. -
sub
operand1,operand2; операнд1 -= операнд2.
Переходы функций
-
call
function; вызывает функцию (помещает текущее значениеEIPв стек, затем переходит в функцию). -
retn; возврат в вызываемую функцию (извлекает из стека предыдущее значение
EIP).
Примечание: вы могли заметить, что слова «равно» и «ноль» взаимозаменяемы в терминологии x86 — это из-за того, что инструкции сравнения внутренне выполняют вычитание, которое означает, что, если два операнда равны, то устанавливает ZF.
Шаблоны в ассемблере
Теперь, когда у нас есть приблизительное представление об основных элементах, используемых во время выполнения программы, давайте познакомимся с шаблонами инструкций, с которыми можно столкнуться при реверс-инжиниринге обычного 32-битного двоичного файла PE.
Пролог функции
Пролог функции — это некоторый код, внедренный в начало большинства функций и служащий для установки нового стекового кадра указанной функции.
Обычно он выглядит так (X — число):
55 push ebp ; preserve caller function's base pointer in stack
8B EC mov ebp, esp ; caller function's stack pointer becomes base pointer (new stack frame)
83 EC XX sub esp, X ; adjust the stack pointer by X bytes to reserve space for local variablesЭпилог функции
Эпилог — это просто противоположность пролога. Он отменяет его шаги для восстановления стека вызывающей функции, прежде чем вернуться к ней:
8B E5 mov esp, ebp ; restore caller function's stack pointer (current base pointer)
5D pop ebp ; restore base pointer from the stack
C3 retn ; return to caller functionТеперь может возникнуть вопрос — как функции взаимодействуют друг с другом? Как именно вы отправляете/обращаетесь к аргументам при вызове функций, и как вы получаете возвращаемое значение? Именно для этого существуют соглашения о вызовах.
Соглашения о вызовах: __cdecl
Соглашение о вызове — это протокол для взаимодействия функций, есть разные варианты, но все они используют общий принцип.
Мы рассмотрим соглашение __cdecl (от C declaration), которое является стандартным при компиляции кода С.
В __cdecl (32-bit) аргументы функции передаются в стек (помещаются в обратном порядке), а возвращаемое значение передается через EAX регистр (при условии, что это не число с плавающей точкой).
Это означает, что при вызове func(1, 2, 3) будет сгенерировано следующее:
6A 03 push 3
6A 02 push 2
6A 01 push 1
E8 XX XX XX XX call funcСобираем все вместе
Предположим, что func() просто складывает аргументы и возвращает результат. Вероятно, это будет выглядеть так:
int __cdecl func(int, int, int):
prologue:
55 push ebp ; save base pointer
8B EC mov ebp, esp ; new stack frame
body:
8B 45 08 mov eax, [ebp+8] ; load first argument to EAX (return value)
03 45 0C add eax, [ebp+0Ch] ; add 2nd argument
03 45 10 add eax, [ebp+10h] ; add 3rd argument
epilogue:
5D pop ebp ; restore base pointer
C3 retn ; return to callerТеперь, если вы внимательно за всем следили и все еще в замешательстве, можете задать себе один из двух вопросов:
-
Почему мы должны сместить
EBPна 8, чтобы получить первый аргумент?Если вы проверите определение инструкции
call, упоминаемой ранее, то поймете, что внутренне она помещает значениеEIPв стек. И если вы проверите определение командыpush, то обнаружите, что она уменьшает значениеESP(которое скопировано вEBPв прологе) на 4 байта. К тому же, первая инструкция пролога — это такжеpush, поэтому получаем 2 декремента по 4, следовательно, необходимо добавить 8. -
Что случилось с прологом и эпилогом, почему они кажутся «усеченными»?
Это просто потому, что мы не использовали стек во время выполнения нашей функции — если вы заметили,
ESPвообще не изменялся, а это значит, что нам не нужно его восстанавливать.
Условный оператор
Чтобы продемонстрировать ассемблерные инструкции управления потоком выполнения, я бы хотел добавить еще один пример, иллюстрирующий, во что скомпилируется оператор if в ассемблере.
Предположим, у нас есть следующая функция:
void print_equal(int a, int b) {
if (a == b) {
printf("equal");
}
else {
printf("nah");
}
}После ее компиляции вот дизассемблированный вид, который я получил с помощью IDA:
void __cdecl print_equal(int, int):
10000000 55 push ebp
10000001 8B EC mov ebp, esp
10000003 8B 45 08 mov eax, [ebp+8] ; load 1st argument
10000006 3B 45 0C cmp eax, [ebp+0Ch] ; compare it with 2nd
┌┅ 10000009 75 0F jnz short loc_1000001A ; jump if not equal
┊ 1000000B 68 94 67 00 10 push offset aEqual ; "equal"
┊ 10000010 E8 DB F8 FF FF call _printf
┊ 10000015 83 C4 04 add esp, 4
┌─┊─ 10000018 EB 0D jmp short loc_10000027
│ ┊
│ └ loc_1000001A:
│ 1000001A 68 9C 67 00 10 push offset aNah ; "nah"
│ 1000001F E8 CC F8 FF FF call _printf
│ 10000024 83 C4 04 add esp, 4
│
└── loc_10000027:
10000027 5D pop ebp
10000028 C3 retnДайте себе минутку и попытайтесь разобраться в этом дизассемблированном коде (для простоты, я изменил реальные адреса и сделал начало функции с 10000000).
В случае, если вам интересно, зачем нужна команда add esp, 4, то это просто приведение ESP к исходному значению (такой же эффект, что и у pop, только без изменения какого-либо регистра), поскольку у нас есть push строкового аргумента для printf.
Базовые структуры данных
Давайте двигаться дальше. Поговорим о том, как хранятся данные (особенно целые числа и строки).
Endianness
Endianness — это порядок байтов, представляющих значение в памяти компьютера.
Есть 2 типа: big-endian и little-endian
Для справки, процессоры семейства x86 (которые есть практически на любом компьютере) всегда используют little-endian.
Чтобы привести живой пример этой концепции, я скомпилировал консольное приложение на С++ в Visual Studio, в котором объявил переменную int со значением 1337, а затем вывел адрес переменной, используя функцию printf().
После я запустил программу с отладчиком, чтобы проверить напечатанный адрес переменной в шестнадцатеричном представлении памяти, и вот результат, который я получил:
Уточним этот момент — переменная int имеет длину 4 байта (32 бита) (на случай, если вы не знали), поэтому это означает, что если переменная начинается с адреса D2FCB8, то она заканчивается прямо перед D2FCBC (+4).
Чтобы перейти от значения, удобочитаемого человеком, к байтам памяти, выполните следующие действия:
Десятичное: 1337 -> шестнадцатеричное: 539 -> 00 00 05 39 -> little-endian: 39 05 00 00
Знаковые целые числа
Это часть интересна, но относительно проста. Здесь вы должны знать, что представление знака у целых чисел (положительных/отрицательных) обычно выполняется на компьютерах с помощью концепции, называемой дополнением до двух.
Суть в том, что наименьшая/первая половина целых чисел зарезервирована для положительных чисел, а наибольшая/вторая половина предназначена для отрицательных, вот как это выглядит в шестнадцатеричном формате для 32-битного знакового int (выделено = шестнадцатеричный формат, в скобках = десятичный):
Положительные (1/2): 00000000 (0) -> 7FFFFFFF (2 147 483 647 или INT_MAX)
Отрицательные (2/2): 80000000 (-2 137 483 648 или INT_MIN) -> FFFFFFFF (-1)
Если вы заметили, значения у нас всегда возрастают. Независимо от того, поднимемся ли мы в шестнадцатеричном или десятичном формате. И это ключевой момент этой концепции — арифметические операции не должны делать ничего особенного для обработки знака, они могут просто работать со всеми значениями как с беззнаковыми/положительными, и результат все равно будет интерпретироваться правильно (если мы будем в пределах INT_MAX и INT_MIN). Так происходит потому, что целые числа будут ‘переворачиваться’ при переполнении по принципу, схожему с аналоговым одометром.
Совет: калькулятор Windows — очень полезный инструмент. Вы можете войти в режим программиста и установить размер в DWORD (4 байта), затем ввести отрицательные десятичные значения и визуализировать их в шестнадцатеричном и двоичном формате, получая удовольствие от выполнения операций с ними.
Строки
В C строки хранятся в виде массивов char, поэтому здесь нет ничего особенного, кроме того, что называется null termination.
Если вы когда-нибудь задумывались, как strlen() узнает размер строки, то все очень просто — строки имеют символ, обозначающий их конец, и это нулевой байт/символ — 00 или ‘’.
Если вы объявите строковую константу в C и наведете на нее курсор, например, в Visual Studio, то покажется размер сгенерированного массива, и, как можете видеть, в нем на один элемент больше, чем в видимом размере строки.
Примечание: концепция порядка байтов не применима к массивам, только к одиночным переменным. Следовательно, порядок символов в памяти здесь будет нормальным.
Смысл call и jmp инструкций
Теперь, когда вы знаете все это, то, вероятно, уже можете начать разбираться в каком-то машинном коде и в некоторой степени, так сказать, имитировать центральный процессор своим мозгом.
Возьмем пример с print_equal(), но на этот раз сосредоточимся только на инструкциях call printf().
void print_equal(int, int):
...
10000010 E8 DB F8 FF FF call _printf
...
1000001F E8 CC F8 FF FF call _printfВы можете спросить себя — подождите секунду, если это одни и те же инструкции, то почему их байты разные?
Это потому, что инструкции call (и jmp) (обычно) принимают в качестве операнда смещение (относительный адрес), а не абсолютный адрес.
Смещение — это в основном разница между текущим местоположением в памяти и пунктом назначения. Это также означает, что оно может быть как отрицательным, так и положительным.
Как вы можете видеть, опкод инструкции call, содержащей 32-битное смещение, — это E8. После него следует само смещение — полная инструкция имеет вид: E8 XX XX XX XX.
Вытащите свой калькулятор (почему вы закрыли его так рано?!) и вычислите разницу между смещением обеих инструкций (не забывайте о порядке байтов).
Вы заметите, что это разница такая же, как разница между адресами инструкций (10000001F — 10000010 = F):
Еще одна небольшая деталь, о которой нужно упомянуть — процессор выполняет инструкцию только после ее полного «чтения». Это означает, что к тому времени, когда CPU начинает «выполнение», EIP (указатель инструкций) уже указывает на следующую команду.
Смещения учитывают такое поведение, а это означает, что для получения реального адреса целевой функции мы также должны добавить размер инструкции call: 5.
Теперь применим все это, чтобы узнать адрес printf() из первой инструкции в примере:
10000010 E8 DB F8 FF FF call _printf-
Извлеките смещение из инструкции
E8 (DB F8 FF FF)->FFFFF8D8(-1829) -
Сложите его с адресом инструкции:
100000010+FFFFF8D8=0FFFF8EB -
И наконец, прибавьте размер инструкции:
0FFFF8EB+5=OFFFF8F0(&printf)
Точно такой же принцип применяется к инструкции jmp:
...
┌─── 10000018 EB 0D jmp short loc_10000027
...
└── loc_10000027:
10000027 5D pop ebp
...Единственное отличие в этом примере состоит в том, что EB XX — это короткая версия jmp. Это означает, что в ней используется только 8-битное (1 байт) смещение.
Следовательно: 10000018 + 0D + 2 = 10000027
Вывод
Вот и все! Теперь у вас должно быть достаточно информации (и, надеюсь, мотивации), чтобы начать свое путешествие в реверс-инжиниринге исполняемых файлов.
Начните с написания игрушечного кода на С, его компиляции и пошаговой отладки (Visual Studio, кстати, позволяет это сделать).
Compiler Explorer также является чрезвычайно полезным веб-сайтом, который компилирует код C в ассемблер в реальном времени с использованием нескольких компиляторов (выберите компилятор x86 msvc для 32-разрядной версии Windows).
После этого вы можете попытать счастья с собственным двоичными файлами с закрытым исходным кодом с помощью дизассемблеров, таких как Ghidra и IDA, и отладчиков, таких как x64dbg.
Дата-центр ITSOFT — размещение и аренда серверов и стоек в двух дата-центрах в Москве. UPTIME 100%. Размещение GPU-ферм и ASIC-майнеров, аренда GPU-серверов, лицензии связи, SSL-сертификаты, администрирование серверов и поддержка сайтов.
Ассемблер под windows для чайников часть 1
В данной главе я намерен дать некоторую вводную информацию по средствам программирования на языке ассемблера. Данная глава предназначена для начинающих программирование на ассемблере, поэтому программистам более опытным ее можно пропустить без особого ущерба для себя.
Прежде всего замечу, что в названии главы есть некоторая натяжка, т.к. технологии трансляции и в MS DOS, и в Windows весьма схожи. Однако программирование в MS DOS уходит в прошлое.

Рис.1.1.1. Схема трансляции ассемблерного модуля.
Двум стадиям трансляции (Рис.1.1.1) соответствуют две основные программы: ассемблер ML.EXE и редактор связей LINK.EXE 7 (или TASM32.EXE и TLINK32.EXE в Турбо Ассемблере).
Пусть файл с текстом программы на языке ассемблера называется PROG.ASM, тогда, не вдаваясь в подробный анализ, две стадии трансляции будут выглядеть следующим образом: c:\masm32\bin\ml /c /coff PROG.ASM — в результате появляется модуль PROG.OBJ, а также c:\masm32\bin\link /SUBSYSTEM:WINDOWS PROG.OBJ — в результате появляется исполняемый модуль PROG.EXE. Как Вы, я надеюсь, догадались /с и /coff являются параметрами программы ML.EXE, a /SUBSYSTEM:WINDOWS является параметром для программы LINK.EXE. О других ключах этих программ более подробно см. Гл. 1.5.
Чем больше я размышляю об этой схеме трансляции, тем более совершенной она мне кажется. Действительно, формат конечного модуля зависит от операционной системы. Установив стандарт на структуру объектного модуля, мы получаем возможность: а) использовать уже готовые объектные модули, б) стыковать между собой программы, написанные на разных языках. Но самое прекрасное здесь то, что если стандарт объектного модуля распространить на разные операционные системы, то можно использовать модули, написанные в разных операционных системах 8 .
Чтобы процесс трансляции сделать для Вас привычным, рассмотрим несколько простых, «ничего не делающих» программ.
На Рис. 1.1.2 представлена «ничего не делающая» программа. Назовем ее PROG1. Сразу отмечу на будущее: команды микропроцессора и директивы макроассемблера будем писать заглавными буквами.
Итак, чтобы получить загружаемый модуль, выполним следующие команды:
или для Турбо Ассемблера
Примем пока параметры трансляции программ как некую данность и продолжим наши изыскания.
Часто удобно разбить текст программы на несколько частей и объединять эти части еще на 1-й стадии трансляции. Это достигается посредством директивы INCLUDE. Например, один файл будет содержать код программы, а константы, данные (определение переменных) и прототипы внешних процедур помещаются в отдельные файлы. Часто такие файлы записывают с расширением .INC.
Именно такая разбивка демонстрируется в следующей программе (Рис.1.1.3).
Программа на Рис. 1.1.3 также достаточно бессмысленна (как и все программы данной главы), но зато демонстрирует удобства использования директивы INCLUDE. Напомню, что мы не останавливаемся в книге на очевидных командах микропроцессора. Замечу только по поводу команды IDIV. В данном случае команда IDIV осуществляет операцию деления над операндом, находящемся в паре регистров EDX:EAX. Обнуляя EDX, мы указываем, что операнд целиком находится в регистре EAX.
Трансляция программы осуществляется так, как это было указано ранее для ассемблеров MASM и TASM.
Замечание о типах данных. В данной книге Вы встретитесь в основном с тремя типами данных (простых): байт, слово, двойное слово. При этом используются следующие стандартные обозначения. Байт — BYTE или DB, слово — WORD или DW, двойное слово — DWORD или DD. Выбор, скажем, в одном случае DB, а в другом BYTE, продиктован лишь желанием автора несколько разнообразить изложение.
7 Программу LINK.EXE называют также компоновщиком или просто линковщиком.
8 Правда, весьма ограниченно, т.к. согласование системных вызовов в разных операционных системах может весьма сильно различаться.
Перейдем теперь к вопросу о подсоединении других объектных модулей и библиотек во второй стадии трансляции. Прежде всего замечу, что, сколько бы ни подсоединялось объектных модулей, один объектный модуль является главным. Смысл этого весьма прост: именно с этого модуля начинается исполнение программы. На этом различие между модулями заканчивается. Условимся далее, что главный модуль всегда в начале сегмента кода будет содержать метку START, ее мы указываем после директивы END — транслятор должен знать точку входа программы, чтобы указать ее в заголовке загружаемого модуля (см. Гл.5.1).
Обычно во второстепенные модули помещаются процедуры, которые будут вызываться из основного и других модулей. Рассмотрим такой модуль. Этот модуль Вы можете видеть на Рис. 1.4.
Прежде всего, обращаю Ваше внимание на то, что после директивы END не указана никакая метка. Ясно, что это не главный модуль, процедуры его будут вызываться из других модулей.
Второе, на что я хотел бы обратить Ваше внимание, это то, что процедура, которая будет вызываться, должна быть объявлена как PUBLIC. В этом случае это имя будет сохранено в объектном модуле и далее может быть связано с вызовами из других модулей.
Итак, выполняем команду ML /coff /c PROG1.ASM. В результате на диске появляется объектный модуль PROG2.OBJ.
А теперь проведем маленькое исследование. Просмотрим объектный модуль с помощью какого-нибудь простого Viewer’a, например того, что есть у программы Far. И что же мы обнаружим: вместо имени PROC1 мы увидим имя _PROC1@0. Это особый разговор — будьте сейчас внимательны! Во-первых, подчеркивание спереди отражает стандарт ANSI, предписывающий всем внешним именам (доступным нескольким модулям) автоматически добавлять символ подчеркивания. Здесь ассемблер будет действовать автоматически, и у нас по этому поводу не будет никаких забот.
Сложнее с припиской @0. Что она значит? На самом деле все просто: цифра после знака @ означает количество байт, которые необходимо передать в стек в виде параметров при вызове процедуры. В данном случае ассемблер понял так, что наша процедура параметров не требует. Сделано это для удобства использования директивы INVOKE. Но о ней речь пойдет ниже, а пока попытаемся сконструировать основной модуль PROG1.ASM.
Как Вы понимаете, процедура, вызываемая из другого модуля, объявляется как EXTERN. Далее, вместо имени PROC1 нам приходится использовать имя PROC1@0. Здесь пока ничего нельзя сделать. Может возникнуть вопрос о типе NEAR. Дело в том, что в операционной системе MS DOS тип NEAR означал, что вызов процедуры (или безусловный переход) будет происходить в пределах одного сегмента. Тип FAR означал, что процедура (или переход) будет вызываться из другого сегмента. В операционной системе Windows реализована так называемая плоская модель, когда всю память можно рассматривать как один большой сегмент. И здесь логично использовать тип NEAR.
Выполним команду ML /coff /c PROG1.ASM, в результате получим объектный модуль PROG1.OBJ. Теперь можно объединить модули и получить загружаемую программу PROG1.EXE:
При объединении нескольких модулей первым должен идти главный, а остальные — в произвольном порядке.
Обратимся теперь к директиве INVOKE. Это довольно удобная команда, правда, по некоторым причинам (которые станут понятными позже) я почти не буду употреблять ее в своих программах.
Удобство ее заключается, во-первых, в том, что мы сможем забыть о добавке @N. Во-вторых, эта команда сама заботится о помещении передаваемых параметров в стек. Последовательность команд
Причем параметрами могут являться регистр, непосредственно значение или адрес. Кроме того, для адреса может использоваться как оператор OFFSET, так и оператор ADDR. Видоизменим теперь модуль PROG1.ASM (модуль PROG2.ASM изменять не придется).
Как видите, внешняя процедура объявляется теперь при помощи директивы PROTO. Данная директива позволяет при необходимости указывать и наличие параметров. Например, строка
будет означать, что процедура требует два параметра длиной в четыре и два байта (всего 6, т.е. @6).
Как уже говорилось, я буду редко использовать оператор INVOKE. Теперь я назову первую причину такого пренебрежения к данной возможности. Дело в том, что я сторонник чистоты языка ассемблера и любое использование макросредств вызывает у меня чувство несовершенства. На мой взгляд, и начинающим программистам не стоит увлекаться макросредствами, иначе не чувствуется вся красота этого языка. О второй причине Вы узнаете ниже.
На нашей схеме, на Рис. 1.1, говорится не только о возможности подсоединения объектных модулей, но и библиотек. Собственно, если объектных модулей несколько, то это по понятным причинам вызовет неудобства. Поэтому объектные модули объединяются в библиотеки. Для подсоединения библиотеки в MASM удобнее всего использовать директиву INCLUDELIB, которая сохраняется в объектном коде и используется программой LINK.EXE.
Но как создать библиотеку из объектных модулей? Для этого имеется специальная программа, называемая библиотекарем. Предположим, мы хотим создать библиотеку LIB1.LIB, состоящую из одного модуля — PROG2.OBJ. Выполним для этого следующую команду: LIB /OUT:LIB1.LIB PROG2.OBJ.
Если необходимо добавить в библиотеку еще один модуль (MODUL.OBJ), то достаточно выполнить команду: LIB LIB1.LIB MODUL.OBJ.
Вот еще два полезных примера использования библиотекаря:
LIB /LIST LIB1.LIB — выдает список модулей библиотеки.
LIB /REMOVE:MODUL.OBJ LIB1.LIB — удаляет из библиотеки модуль MODUL.OBJ.
Вернемся теперь к нашему примеру. Вместо объектного модуля мы используем теперь библиотеку LIB1.LIB. Видоизмененный текст программы PROG1.ASM представлен на Рис. 1.7.
Рассмотрим теперь менее важный (для нас) вопрос об использовании данных (переменных), определенных в другом объектном модуле. Здесь читателю, просмотревшему предыдущий материал, должно быть все понятно, а модули PROG2.ASM и PROG1.ASM, демонстрирующие технику использования внешних 9 переменных, приводятся на Рис.1.8-1.9.
Заметим, что в отличие от внешних процедур, внешняя переменная не требует добавки @N, поскольку размер переменной известен.
А теперь проверим все представленные в данной главе программы на предмет их трансляции средствами пакета TASM.
С программами на Рис. 1.2-1.3 дело обстоит просто. Для их трансляции достаточно выполнить команды:
Обратимся теперь к модулям PROG2.ASM и PROG1.ASM, приведенным на Рис. 1.4 и 1.5 соответственно.
Получение объектных модулей происходит без каких-либо трудностей. Просматривая модуль PROG2.OBJ, мы увидим, что внешняя процедура представлена просто именем PROC1.
Следовательно, единственное, что нам следует сделать, это заменить в модуле PROC1.ASM имя PROC1@0 на PROC1.
Объединение модулей далее производится элементарно:
Для работы с библиотекой в пакете TASM имеется программа — библиотекарь TLIB.ЕХЕ. Создание библиотеки, состоящей из модуля PROG2.OBJ, производится по команде
В результате на диске появится библиотека LIB1.LIB. Далее компонуем модуль PROG1.OBJ с этой библиотекой:
В результате получается загружаемый модуль PROG1.EXE.
Вообще, стоит разобраться с командной строкой TLINK32 более подробно. В расширенном виде 11 эта строка выглядит следующим образом:
OBJFILES — один или несколько объектных файлов (через пробел). Первый главный модуль.
EXEFILE — исполняемый модуль.
MAPFILE — МАР-файл, содержащий информацию о структуре модуля.
LIBFILES — одна или несколько библиотек (через пробел).
В TASM отсутствует директива INVOKE, поэтому в дальнейшем я буду избегать ее использования 12 .
В начале книги я объявил о своем намерении примирить два ассемблера. Поскольку различие между ними заключается в директивах и макрокомандах (см. Гл.1.5), то напрашивается вывод, что совместимости можно добиться, избегая таких директив и макрокоманд. Основой программы для Windows является вызов API-функций (см. Гл. 1.2), а мы знаем, что различие в вызове внешней процедуры заключается в том, что в именах для MASM в конце есть добавка @N. И здесь не обойтись без макроопределений, и начинается самое интересное. Но об этом, дорогой читатель, Вы узнаете в свое время.
И MASM и TASM поддерживают так называемую упрощенную сегментацию. Я являюсь приверженцем классической структуры ассемблерной программы и должен признаться, что упрощенная сегментация довольно удобная штука, особенно при программировании под Windows. Суть такой сегментации в следующем: начало сегмента определяется директивой .CODE, а сегмента данных — .DATA 13 . Причем обе директивы могут появляться в тексте программы несколько раз. Транслятор затем собирает код и данные вместе, как положено. Основной целью такого подхода, по-видимому, является возможность приблизить в тексте программы данные к тем строкам, где они используются. Такая возможность, как известно, в свое время была реализована в C++. На мой взгляд, она приводит к определенному неудобству при чтении текста программы. Кроме того, не сочтите меня за эстета, но когда я вижу данные, перемешанные в тексте программы с кодом, у меня возникает чувство дискомфорта.
Ниже представлена программа, демонстрирующая упрощенный режим сегментации.
В заключительной части главы я хотел дать краткий обзор ряда других программ, которые часто используются при программировании на ассемблере. С некоторыми из перечисленных программ мы познакомимся в дальнейшем более подробно, а некоторые более упоминаться не будут.
Редакторы. Хотя сам я никогда не использую специализированные редакторы для написания программ на ассемблере, полноты ради кратко расскажу о двух известных мне редакторах. Начну с редактора QEDITOR.EXE, который поставляется вместе с пакетом MASM32. Сам редактор и все сопутствующие ему утилиты написаны на ассемблере. Анализ их размера и возможностей действительно впечатляет. Например, сам редактор имеет длину всего 27 Кб, а утилита, используемая для просмотра отчетов о трансляции — всего 6 Кб. Редактор вполне годится для работы с небольшими одномодульными приложениями. Для работы с несколькими модулями он не очень удобен. Работа редактора основана на взаимодействии с различными утилитами посредством пакетных файлов. Например, трансляцию программ осуществляет пакетный файл ASSMBL.BAT, который использует ассемблер ML.EXE, а результат ассемблирования направляется в текстовый файл ASMBL.TXT. Далее для просмотра этого файла используется простая утилита THEGUN.EXE. Аналогично осуществляется редактирование связей. Для дизассемблирования исполняемого модуля используется утилита DUMPPE.EXE, результат работы этой утилиты помещается в текстовый файл DISASM.TXT. Аналогично осуществляются и другие операции. Вы легко сможете настроить эти операции, отредактировав соответствующий пакетный файл с модификацией (при необходимости) используемых утилит (заменив, например, ML.EXE на TASM32.EXE и т.п.).
Вторая программа, с которой я хочу познакомить читателя, это EAS.EXE (Easy Assembler Shell). Редактор, а точнее оболочка, позволяет создавать и транслировать довольно сложные проекты, состоящие из ASM-,OВJ-,RC-,RES-,DEF-файлов. Программа позволяет работать как с TASM, так и MASM, а также с другими утилитами (отладчиками, редакторами ресурсов и т.д.). Непосредственно в программе можно настроить компиляторы и редакторы связей на определенный режим работы путем задания ключей этих утилит.
Отладчики позволяют исполнять программу в пошаговом режиме. В IV части книги мы более подробно будем рассматривать отладчики и дизассемблеры. Приведу несколько наиболее известных отладчиков 14 : CodeView (Микрософт), Turbo Debugger (Borland), Ice.
Дизассемблеры переводят исполняемый модуль в ассемблерный код. Примером простейшего дизассемблера является программа DUMPPE.EXE, работающая в строковом режиме. Пример работы программы DUMPPE.EXE представлен на Рис. 1.1.11. Здесь дизассемблируется программа, приведенная на Рис.1.1.5. Ну как, узнали нашу программу? Смысл обозначений будет ясен из дальнейшего изложения.
Рис. 1.1.11. Пример дизассемблированш программы с помощью DUMPPE.EXE.
Отмечу также дизассемблер W32Dasm, который подробно будет описан в последней части книги, и знаменитый дизассемблер IDA Pro. В части IV мы будем подробно рассматривать и сами дизассемблеры, и методику их использования.
Нех-редакторы позволяют просматривать и редактировать загружаемые модули в шестнадцатеричном виде. Их великое множество, к тому же отладчики и дизассемблеры, как правило, имеют встроенные НЕХ-редакторы. Отмечу только, весьма популярную в хакерских кругах программу HIEW.EXE. Эта программа позволяет просматривать загружаемые модули как в шестнадцатеричном виде, так и в виде ассемблерного кода. И не только просматривать, но и редактировать.
В пакетах MASM32 и TASM32 есть компиляторы ресурсов, которые будут описаны ниже. Это программы RC.EXE и BRC32.EXE соответственно.
Обычно я пользуюсь редактором ресурсов из пакета ВС5 (Borland C++ 5.0) Простые ресурсы можно создавать в обычном текстовом редакторе. Язык описания ресурсов будет подробно рассмотрен далее.
Источник
![]()
|
Поляков А.В. Ассемблер для чайников. |
1 |
|
|
Информация об авторе: |
||
|
Автор: |
Поляков Андрей Валерьевич |
|
|
Web: |
http://info-master.su |
|
|
e-mail: |
mail@info-master.su |
|
|
Блог: |
av-inf.blogspot.ru |
|
|
В контакте: |
vk.com/id185471101 |
|
|
Фейсбук: |
facebook.com/100008480927503 |
|
|
Страница книги: |
http://av-assembler.ru/asm/afd/assembler-for-dummy.htm |
ВНИМАНИЕ!
Все права на данную книгу принадлежат Полякову Андрею Валерьевичу. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без согласования с автором.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых автором как надёжные. Тем не менее, имея в виду возможные человеческие или технические ошибки, автор не может гарантировать абсолютную точность и полноту приводимых сведений и не несёт ответственности за возможные ошибки и ущерб, связанные с использованием этого документа.
1. РАЗРЕШЕНИЯ
Разрешается использование книги в ознакомительных и образовательных целях (только для личного использования). Разрешается бесплатное распространение книги.
2. ОГРАНИЧЕНИЯ
Запрещается использование книги в коммерческих целях (продажа, размещение на ресурсах с платным доступом и т.п.). Запрещается вносить изменения в текст книги. Запрещается присваивать авторство.
См. также ЛИЦЕНЗИОННОЕ СОГЛАШЕНИЕ.
|
Поляков А.В. Ассемблер для чайников. |
2 |
Поляков А.В.
Ассемблер для чайников
2015 г.

|
Поляков А.В. Ассемблер для чайников. |
3 |
|
СОДЕРЖАНИЕ |
|
|
СОДЕРЖАНИЕ……………………………………………………………………………………………………………………………………………… |
3 |
|
ПРЕДИСЛОВИЕ ……………………………………………………………………………………………………………………………………………. |
4 |
|
ВВЕДЕНИЕ ………………………………………………………………………………………………………………………………………………….. |
5 |
|
НЕМНОГО О ПРОЦЕССОРАХ ……………………………………………………………………………………………………………………………………. |
6 |
|
1. БЫСТРЫЙ СТАРТ ……………………………………………………………………………………………………………………………………… |
8 |
|
1.1. ПЕРВАЯ ПРОГРАММА……………………………………………………………………………………………………………………………………… |
8 |
|
1.1.1. Emu8086……………………………………………………………………………………………………………………………………………. |
8 |
|
1.1.2. Debug ……………………………………………………………………………………………………………………………………………… |
12 |
|
1.1.3. MASM, TASM и WASM………………………………………………………………………………………………………………………. |
17 |
|
1.1.3.1. Ассемблирование в TASM …………………………………………………………………………………………………………………………… |
18 |
|
1.1.3.2. Ассемблирование в MASM………………………………………………………………………………………………………………………….. |
19 |
|
1.1.3.3. Ассемблирование в WASM………………………………………………………………………………………………………………………….. |
19 |
|
1.1.3.4. Выполнение программы …………………………………………………………………………………………………………………………….. |
19 |
|
1.1.3.5. Использование BAT-файлов ………………………………………………………………………………………………………………………… |
20 |
|
1.1.4. Шестнадцатеричный редактор …………………………………………………………………………………………………….. |
22 |
|
Резюме…………………………………………………………………………………………………………………………………………………….. |
25 |
|
2. ВВЕДЕНИЕ В АССЕМБЛЕР ………………………………………………………………………………………………………………………… |
26 |
|
2.1. КАК УСТРОЕН КОМПЬЮТЕР …………………………………………………………………………………………………………………………….. |
26 |
|
2.1.1. Структура процессора …………………………………………………………………………………………………………………… |
27 |
|
2.1.2. Регистры процессора ……………………………………………………………………………………………………………………… |
29 |
|
2.1.3. Цикл выполнения команды ……………………………………………………………………………………………………………… |
31 |
|
2.1.4. Организация памяти………………………………………………………………………………………………………………………. |
32 |
|
2.1.5. Реальный режим …………………………………………………………………………………………………………………………….. |
33 |
|
2.1.6. Защищённый режим ……………………………………………………………………………………………………………………….. |
34 |
|
2.2. СИСТЕМЫ СЧИСЛЕНИЯ ………………………………………………………………………………………………………………………………….. |
34 |
|
2.2.1. Двоичная система счисления ………………………………………………………………………………………………………….. |
34 |
|
2.2.2. Шестнадцатеричная система счисления ……………………………………………………………………………………….. |
36 |
|
2.2.3. Другие системы ……………………………………………………………………………………………………………………………… |
37 |
|
2.3. ПРЕДСТАВЛЕНИЕ ДАННЫХ В ПАМЯТИ КОМПЬЮТЕРА………………………………………………………………………………………………. |
38 |
|
2.3.1. Положительные числа ……………………………………………………………………………………………………………………. |
38 |
|
2.3.2. Отрицательные числа……………………………………………………………………………………………………………………. |
39 |
|
2.3.3. Что такое переполнение………………………………………………………………………………………………………………… |
40 |
|
2.3.4. Регистр флагов ………………………………………………………………………………………………………………………………. |
42 |
|
2.3.5. Коды символов………………………………………………………………………………………………………………………………… |
43 |
|
2.3.6. Вещественные числа………………………………………………………………………………………………………………………. |
44 |
|
2.3.6.1. Первая попытка………………………………………………………………………………………………………………………………………….. |
44 |
|
2.3.6.2. Нормализованная запись числа…………………………………………………………………………………………………………………… |
45 |
|
2.3.6.3. Преобразование дробной части в двоичную форму …………………………………………………………………………………….. |
47 |
|
2.3.6.4. Представление вещественных чисел в памяти компьютера ………………………………………………………………………….. |
47 |
|
2.3.6.5. Числа с фиксированной точкой……………………………………………………………………………………………………………………. |
49 |
|
2.3.6.6. Числа с плавающей точкой………………………………………………………………………………………………………………………….. |
49 |
|
ЛИЦЕНЗИОННОЕ СОГЛАШЕНИЕ ………………………………………………………………………………………………………………….. |
52 |
|
Поляков А.В. Ассемблер для чайников. |
4 |
ПРЕДИСЛОВИЕ
Ассемблер – это магическое слово взывает благоговейный трепет у начинающих программистов. Общаясь между собой, они обязательно говорят о том, что где-то у кого-то есть знакомый «чувак», который может читать исходные коды на языке ассемблера как книжный текст. При этом, как правило, язык ассемблера воспринимается как нечто недоступное простым смертным.
Отчасти это действительно так. Можно выучить несколько простых команд и даже написать какую-нибудь программку, но настоящим гуру (в любом деле) можно стать только в том случае, когда человек очень хорошо знает теоретические основы и понимает, что и зачем он делает.
Есть другая крайность – бывалые программисты на языках высокого уровня убеждены, что язык ассемблера – это пережиток прошлого. Да, средства разработки за последние 20 лет шагнули далеко вперёд. Теперь можно написать простенькую программу вообще не зная ни одного языка программирования. Однако не стоит забывать о таких вещах, как, например, микроконтроллеры. Да и в компьютерном программировании некоторые задачи проще и быстрее решить с помощью языка ассемблера.
Данная книга предназначена для тех, кто уже имеет навыки программирования на языке высокого уровня, но хотел бы перейти «ближе к железу» и разобраться с тем, как выполняются команды процессора, как происходит распределение памяти, как управляются разные «железяки» типа дисководов и т.п.
Книга разбита на несколько разделов. Первый раздел – быстрый старт. Здесь очень кратко описаны основные принципы программирования на языке Ассемблера, сами ассемблеры (компиляторы) и методы работы с ассемблерами. Если вы уверенно себя чувствуете в программировании на высоком уровне, но хотели бы освоить азы низкоуровневого программирования, то, быть может, вам будет достаточно прочитать только этот раздел.
Второй раздел описывает такие вещи, как системы исчисления, представления данных в памяти компьютера и т.п., то есть вещи, которые непосредственно к программированию не относятся, но без которых профессиональное программирование невозможно. Также во втором разделе более подробно рассматриваются общие принципы программирования на языке Ассемблера.
Остальные разделы описывают некоторые конкретные примеры программирования на языке Ассемблера, содержат справочные материалы и т.п.
Основы программирования вообще в этой книге не описаны, поэтому для начинающих настоятельно рекомендую ознакомиться с книгой Как стать программистом, где разъяснены «на пальцах» общие принципы программирования и подробно рассмотрены примеры создания простых программ от программ для компьютеров до программ для станков с ЧПУ.

|
Поляков А.В. Ассемблер для чайников. |
5 |
ВВЕДЕНИЕ
Для начала разберёмся с терминологией.
Машинный код – система команд конкретной вычислительной машины (процессора), которая интерпретируется непосредственно процессором. Команда, как правило, представляет собой целое число, которое записывается в регистр процессора. Процессор читает это число и выполняет операцию, которая соответствует этой команде. Популярно это описано в книге Как стать программистом.
Язык программирования низкого уровня (низкоуровневый язык программирования) – это язык программирования, максимально приближённый к программированию в машинных кодах. В отличие от машинных кодов, в языке низкого уровня каждой команде соответствует не число, а сокращённое название команды (мнемоника). Например, команда ADD – это сокращение от слова ADDITION (сложение). Поэтому использование языка низкого уровня существенно упрощает написание и чтение программ (по сравнению с программированием в машинных кодах). Язык низкого уровня привязан к конкретному процессору. Например, если вы написали программу на языке низкого уровня для процессора PIC, то можете быть уверены, что она не будет работать с процессором AVR.
Язык программирования высокого уровня – это язык программирования, максимально приближённый к человеческому языку (обычно к английскому, но есть языки программирования на национальных языках, например, язык 1С основан на русском языке). Язык высокого уровня практически не привязан ни к конкретному процессору, ни к операционной системе (если не используются специфические директивы).
Язык ассемблера – это низкоуровневый язык программирования, на котором вы пишите свои программы. Для каждого процессора существует свой язык ассемблера.
Ассемблер – это специальная программа, которая преобразует (ассемблирует, то есть собирает) исходные тексты вашей программы, написанной на языке ассемблера, в исполняемый файл (файл с расширением EXE или COM). Если быть точным, то для создания исполняемого файла требуются дополнительные программы, а не только ассемблер. Но об этом позже…
В большинстве случаев говорят «ассемблер», а подразумевают «язык ассемблера». Теперь вы знаете, что это разные вещи и так говорить не совсем правильно. Хотя все программисты вас поймут.
ВАЖНО!
В отличие от языков высокого уровня, таких, как Паскаль, Бейсик и т.п., для КАЖДОГО АССЕМБЛЕРА существует СВОЙ ЯЗЫК АССЕМБЛЕРА. Это правило в корне отличает язык ассемблера от языков высокого уровня. Исходные тексты программы (или просто «исходники»), написанной на языке высокого уровня, вы в большинстве случаев можете откомпилировать разными компиляторами для разных процессоров и разных операционных систем. С ассемблерными исходниками это сделать будет намного сложнее. Конечно, эта разница почти не ощутима для разных ассемблеров, которые предназначены для одинаковых процессоров. Но в том то и дело, что для КАЖДОГО ПРОЦЕССОРА существует СВОЙ АССЕМБЛЕР и СВОЙ ЯЗЫК АССЕМБЛЕРА. В этом смысле программировать на языках высокого уровня гораздо проще. Однако за все удовольствия надо платить. В случае с языками высокого уровня мы можем столкнуться с такими вещами как больший размер исполняемого файла, худшее быстродействие и т.п.
|
Поляков А.В. Ассемблер для чайников. |
6 |
В этой книге мы будем говорить только о программировании для компьютеров с процессорами Intel (или совместимыми). Для того чтобы на практике проверить приведённые
вкниге примеры, вам потребуются следующие программы (или хотя бы некоторые из них):
1.Emu8086. Хорошая программа, особенно для новичков. Включает в себя редактор исходного кода и некоторые другие полезные вещи. Работает в Windows, хотя программы пишутся под DOS. К сожалению, программа стоит денег (но оно того стоит))). Подробности см. на сайте http://www.emu8086.com.
2.TASM – Турбо Ассемблер от фирмы Borland. Можно создавать программы как для DOS так и для Windows. Тоже стоит денег и в данный момент уже не поддерживается (да и фирмы Borland уже не существует). А вообще вещь хорошая.
3.MASM – Ассемблер от компании Microsoft (расшифровывается как МАКРО ассемблер, а не Microsoft Assembler, как думают многие непосвящённые). Пожалуй, самый популярный ассемблер для процессоров Intel. Поддерживается до сих пор. Условно бесплатная программа. То есть, если вы будете покупать её отдельно, то она будет стоить денег. Но она доступна бесплатно подписчикам MSDN и входит в пакет программ Visual Studio от Microsoft.
4.WASM – ассемблер от компании Watcom. Как и все другие, обладает преимуществами и недостатками.
5.Debug — обладает скромными возможностями, но имеет большой плюс — входит в стандартный набор Windows. Поищите ее в папке WINDOWS\COMMAND или WINDOWS\SYSTEM32. Если не найдете, тогда в других папках каталога WINDOWS.
6.Желательно также иметь какой-нибудь шестнадцатеричный редактор. Не помешает и досовский файловый менеджер, например Волков Коммандер (VC) или Нортон Коммандер (NC). С их помощью можно также посмотреть шестнадцатеричные коды файла, но редактировать нельзя. Бесплатных шестнадцатеричных редакторов в Интернете довольно много. Вот один из них: McAfee FileInsight v2.1. Этот же редактор можно использовать для работы с исходными текстами программ. Однако мне больше нравится делать это с помощью следующего редактора:
7.Текстовый редактор. Необходим для написания исходных текстов ваших программ. Могу порекомендовать бесплатный редактор PSPad, который поддерживает множество языков программирования, в том числе и язык Ассемблера.
Все представленные в этой книге программы (и примеры программ) проверены на работоспособность. И именно эти программы используются для реализации примеров программ, приведённых в данной книге.
И еще – исходный код, написанный, например для Emu8086, будет немного отличаться от кода, написанного, например, для TASM. Эти отличия будут оговорены.
Большая часть программ, приведённых в книге, написана для MASM. Во-первых, потому что этот ассемблер наиболее популярен и до сих пор поддерживается. Во-вторых, потому что он поставляется с MSDN и с пакетом программ Visual Studio от Microsoft. Ну и в третьих, потому что я являюсь счастливым обладателем лицензионной копии MASM.
Если же у вас уже есть какой-либо ассемблер, не вошедший в перечисленный выше список, то вам придётся самостоятельно разобраться с его синтаксисом и почитать руководство пользователя, чтобы научиться правильно с ним работать. Но общие рекомендации, приведённые в данной книге, будут справедливы для любых (ну или почти для любых) ассемблеров.
Немного о процессорах
Процессор – это мозг компьютера. Физически это специальная микросхема с несколькими сотнями выводов, которая вставляется в материнскую плату. Если вы с трудом представляете себе, что это такое, рекомендую ознакомиться со статьёй Чайникам о компьютерах.
|
Поляков А.В. Ассемблер для чайников. |
7 |
Процессоров существует довольно много даже в мире компьютеров. Но кроме компьютеров ещё есть телевизоры, стиральные машины, кондиционеры, системы управления двигателями внутреннего сгорания и т.п., где также очень широко используются процессоры (микропроцессоры, микроконтроллеры).
Каждый процессор обладает своим набором регистров. Регистры процессора – это такие специальные ячейки памяти, которые находятся непосредственно в микросхеме процессора. Регистры используются для разных целей (более подробно о регистрах будет написано ниже).
Каждый процессор имеет свой набор команд. Команда процессора записывается в определённый регистр, и тогда процессор выполняет эту команду. О командах процессора и регистрах мы будем говорить много и часто на протяжении всей книги. Для начинающих рекомендую книгу Как стать программистом, где в самых общих чертах, но зато понятным языком рассказано о принципах выполнения программы компьютером.
Что такое команда с точки зрения процессора? Это просто число. Однако современные процессоры могут иметь несколько сотен команд. Запомнить все их будет сложно. Как же тогда писать программы? Для упрощения работы программиста был придуман язык Ассемблера, где каждой команде соответствует мнемонический код. Например, число 4 соответствует мнемонике ADD. Иногда язык ассемблера ещё называют языком мнемонических команд.
|
Поляков А.В. Ассемблер для чайников. |
8 |
1. БЫСТРЫЙ СТАРТ
1.1. Первая программа
Обычно в качестве первого примера приводят программу, которая выводит на экран строку «Hello World!». Однако для человека, который только начал изучать Ассемблер, такая программа будет слишком сложной (вы будете смеяться, но это действительно так – особенно в условиях отсутствия доходчивой информации). Поэтому наша первая программа будет еще проще – мы выведем на экран только один символ – английскую букву «A». И вообще – если вы уж решили стать программистом – срочно установите по умолчанию английскую раскладку клавиатуры. Тем более что некоторые ассемблеры и компиляторы не воспринимают русские буквы. Итак, наша первая программа будет выводить на экран английскую букву «А». Далее мы рассмотрим создание такой программы с использованием различных ассемблеров.
1.1.1. Emu8086
Если вы скачали и установили эмулятор процессора 8086 (см. раздел «ВВЕДЕНИЕ»), то вы можете использовать его для создания ваших первых программ на языке ассемблера. На текущий момент (ноябрь 2011 г) доступна версия программы 4.08. Справку на русском языке вы можете найти здесь: http://www.avprog.narod.ru/progs/emu8086/help.html.
Программа Emu8086 платная. Однако в течение 30 дней вы можете использовать её для ознакомления бесплатно.
Итак, вы скачали и установили программу Emu8086 на свой компьютер. Запускаем её и создаём новый файл через меню FILE – NEW – COM TEMPLATE (Файл – Новый – Шаблон файла COM). В редакторе исходного кода после этого мы увидим следующее:
Рис. 1.1. Создание нового файла в Emu8086.
|
Поляков А.В. Ассемблер для чайников. |
9 |
Здесь надо отметить, что программы, создаваемые с помощью Ассемблеров для компьютеров под управлением Windows, бывают двух типов: COM и EXE. Отличия между этими файлами мы рассмотрим позже, а пока вам достаточно знать, что на первое время мы будем создавать исполняемые файлы с расширением COM, так как они более простые.
После создания файла в Emu8086 описанным выше способом в редакторе исходного кода вы увидите строку «add your code hear» — «добавьте ваш код здесь» (рис. 1.1). Эту строку мы удаляем и вставляем вместо неё следующий текст:
MOV AH, 02h
MOV DL, 41h
INT 21h
INT 20h
Таким образом, полный текст программы будет выглядеть так:
ORG 100h
MOV AH, 02h
MOV DL, 41h
INT 21h
INT 20h
RET
Кроме этого в верхней части ещё имеются комментарии (на рис. 1.1 – это текст зелёного цвета). Комментарий в языке Ассемблера начинается с символа ; (точка с запятой) и продолжается до конца строки. Если вы не знаете, что такое комментарии и зачем они нужны, см. книгу Как стать программистом. Как я уже говорил, здесь мы не будем растолковать азы программирования, так как книга, которую вы сейчас читаете, рассчитана на людей, знакомых с основами программирования.
Также отметим, что регистр символов в языке ассемблера роли не играет. Вы можете написать RET, ret или Ret – это будет одна и та же команда.
Вы можете сохранить этот файл куда-нибудь на диск. Но можете и не сохранять. Чтобы выполнить программу, нажмите кнопку EMULATE (с зелёным треугольником) или клавишу F5. Откроется два окна: окно эмулятора и окно исходного кода (рис. 1.2).
Вокне эмулятора отображаются регистры и находятся кнопки управления программой. В окне исходного кода отображается исходный текст вашей программы, где подсвечивается строка, которая выполняется в данный момент. Всё это очень удобно для изучения и отладки программ. Но нам это пока не надо.
Вокне эмулятора вы можете запустить вашу программу на выполнение целиком (кнопка RUN) либо в пошаговом режиме (кнопка SINGLE STEP). Пошаговый режим удобен для отладки. Ну а мы сейчас запустим программу на выполнение кнопкой RUN. После этого (если вы не сделали ошибок в тексте программы) вы увидите сообщение о завершении программы (рис. 1.3). Здесь вам сообщают о том, что программа передала управление операционной системе, то есть программа была успешно завершена. Нажмите кнопку ОК в этом окне и вы увидите, наконец, результат работы вашей первой программы на языке ассемблера (рис.
1.4).
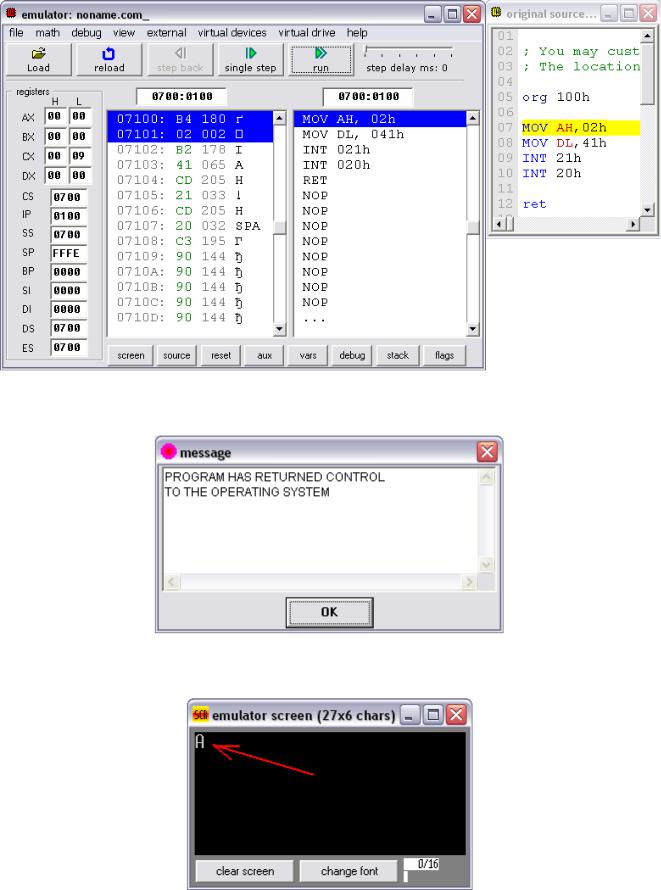
|
Поляков А.В. Ассемблер для чайников. |
10 |
Рис. 1.2. Окно эмулятора Emu8086.
Рис. 1.3. Сообщение о завершении программы.
Рис. 1.4. Ваша первая программа выполнена.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #